2조 물리적 데이터베이스 미션
B-tree란
- 정렬된 데이터를 유지하고, 로그 시간 내 search, sequential access, insertion, deletion을 수행하는 self-balancing tree 자료구조
- 리프 노드를 제외한 트리의 모든 노드에 값을 저장함
B-tree 정의
- 모든 노드는 최대 m개의 자식을 가짐
- 루트와 리프를 제외한 노드에는 최소 m/2개 하위 노드가 있음
- 루트 노드는 리프가 아닌 한 최소 두 개의 하위 노드를 가짐
- 모든 잎은 같은 수준에 나타남
- k개의 자식을 갖는 리프가 아닌 노드에는 k-1개 키가 포함됨
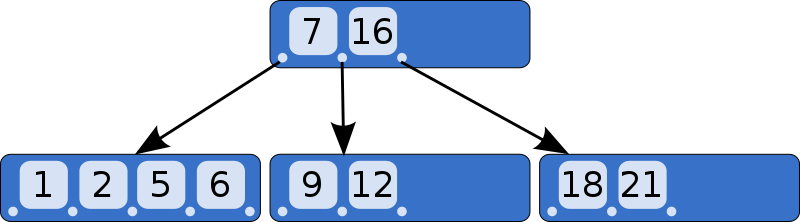
B-tree 의 등장 배경
- Rudolf Bayer와 Edward M. McCreight가 Boeing Research Labs에서 근무하는 동안 대규모 무작위 액세스 파일의 색인 페이지를 효율적으로 관리할 목적으로 발명
- 1970년 7월 Organization and Maintenance of Large Ordered Index 논문 발표
B-tree 의 동작 방식
- Search
- 루트에서 시작하여 위에서 아래로 재귀 탐색
- Insertion
- 트리를 검색하여 새 요소를 추가해야 하는 리프 노드를 찾음
- 노드에 허용되는 최대 요소 수보다 적은 수 요소가 포함되어 있다면, 자리가 있으므로 노드 요소 순서를 유지하며 새 요소를 삽입
- 만약 노드가 다 찼다면, 노드를 분리함
- 단일 중앙값 선택: 리프 요소와 새 요소 중 선택
- 중앙값보다 작은 값을 새 왼쪽 노드에, 중앙값보다 큰 값은 새 오른쪽 노드에 사용됨, 중앙값은 분리값으로 사용됨
- Deletion
- 삭제할 키 위치를 찾음
- leaf 노드라면 그냥 삭제
- 내부 노드라면
- 왼쪽 자식의 최대 키 값 또는 오른쪽 자식의 최소 키 값으로 대체한 후, 그 키 값을 해당 자식 노드에서 삭제합니다.
- 삭제 후 리프 노드가 필요한 노드 수보다 적어지는 경우, 리프 노드부터 트리 균형을 재조정함
- 삭제할 키 위치를 찾음
B-tree와 B+ tree의 차이점
- B-tree는 모든 노드에 키와 데이터가 저장되나, B+tree는 내부 노드는 키 값만, 데이터를 리프 노드에 저장
- B-tree는 리프 노드 간 링크가 없으나 B+tree는 링크드 리스트처럼 링크가 존재

References
Clustered Index는 테이블의 실제 데이터를 인덱스의 리프 페이지에 저장하는 특별한 유형의 인덱스입니다. 테이블당 하나의 Clustered Index만 가질 수 있으며, 이는 테이블의 데이터가 물리적으로 정렬되는 방식을 결정합니다. MySQL 의 경우 PK 가 기본적으로 clustered index 의 key 가 되기 때문에 PK 를 무엇으로 정하느냐에 따라 성능에 차이가 나게 됩니다.
편의성도 있지만 클러스터링 인덱스와 관련이 있습니다. 만약에 PK 가 랜덤인데 클러스터링 인덱스를 사용해야 된다면 정렬을 유지하면서 이곳 저곳에서 insert 가 일어나게 되고 그 과정 속에서 데이터를 한칸씩 뒤로 미루는 작업이 필요합니다. 대규모 트래픽에서는 이것이 부하로 이어지기 때문에 랜덤으로 하는 것 보다는 순서대로 쌓일 수 있는 auto_increment 가 선호됩니다.
데이터 정렬: Clustered Index는 인덱스 키를 기준으로 테이블의 데이터를 물리적으로 정렬합니다. 데이터 저장: 정렬된 데이터는 B-tree 구조의 리프 노드에 직접 저장됩니다. 빠른 검색: 키 값을 기준으로 데이터를 빠르게 검색할 수 있습니다. 범위 쿼리 최적화: 연속된 데이터에 대한 접근이 효율적입니다.
Non-Clustered Index Only: 테이블의 모든 열을 포함하는 Non-Clustered Index를 생성하여 데이터를 저장할 수 있습니다. 이를 "Covering Index"라고도 합니다.
 출처 https://hudi.blog/db-clustered-and-non-clustered-index/
출처 https://hudi.blog/db-clustered-and-non-clustered-index/
- 인덱스 페이지 : 루트 페이지와 리프 페이지로 나뉜다. 루트 페이지는 어떤 리프페이지로 가야되는지에 대한 데이터를 갖고있다. 그리고 리프페이지는 데이터를 직접 갖지 않는 대신 위치에 대한 정보를 갖는다. 데이터 페이지 번호와 오프셋이 포함된다.
- 인덱스 페이지는 정렬되어 있음!
- 데이터 페이지: 인덱스 페이지에서 얻은 포인터 정보로 접근하는 공간으로 실제로 데이터가 저장되는 공간
- 실제 데이터가 저장되는 공간은 데이터가 정렬되어 있지 않음
 language 칼럼에 대해 비클러스터형 인덱스, rank 칼럼을 PK 로 지정했을 경우
language 칼럼에 대해 비클러스터형 인덱스, rank 칼럼을 PK 로 지정했을 경우
- 비클러스터형 인덱스를 통해 pk 값을 얻어냄
- 그 다음에 클러스터링 인덱스를 탐색하여 실제 데이터 접근
a. Row-Oriented Storage:
전통적인 방식으로, 데이터를 행 단위로 저장합니다. OLTP(Online Transaction Processing) 시스템에 적합합니다.
b. Column-Oriented Storage:
데이터를 열 단위로 저장합니다. OLAP(Online Analytical Processing) 시스템에서 자주 사용됩니다. 특정 열에 대한 집계 연산이 빠릅니다.
c. Partitioned Tables:
큰 테이블을 더 작은 물리적 부분으로 나누어 저장합니다. 데이터 관리와 쿼리 성능을 향상시킬 수 있습니다.
d. Compressed Tables:
데이터를 압축하여 저장공간을 절약합니다. I/O 작업을 줄여 성능을 향상시킬 수 있습니다.
e. In-Memory Tables:
데이터를 디스크가 아닌 메모리에 저장합니다. 매우 빠른 데이터 접근이 가능합니다.
InnoDB는 MySQL 8.0의 기본 스토리지 엔진으로, 고성능과 신뢰성을 제공하는 트랜잭션 지원 스토리지 엔진입니다. MySQL 공식 문서에 따르면, InnoDB는 다음과 같은 특징을 가지고 있습니다:
- ACID 준수: 트랜잭션의 원자성(Atomicity), 일관성(Consistency), 고립성(Isolation), 지속성(Durability)을 보장합니다.
-
행 수준 잠금: 동시성 처리 성능을 향상시킵니다.
- 왜 행 수준 잠금이 동시성 처리 성능을 향상시키나요?
- 일단 잠금은 동시에 여러 트랜잭션이 동일한 데이터에 접근할 때 데이터의 일관성과 무결성을 보호하기 위해 사용합니다.
- 주로 사용되는 잠금의 종류로는 테이블 수준 잠금, 행 수준 잠금이 있습니다.
- InnoDB의 경우에는 트랜잭션이 특정 행을 수행할 때, 해당 행에만 잠금을 설정합니다. 다른 트랜잭션은 잠긴 행을 제외한 나머지 행에 자유롭게 접근할 수 있습니다.
- 왜 행 수준 잠금이 동시성 처리 성능을 향상시키나요?
- 외래 키 지원: 데이터 무결성을 강화합니다.
- 버퍼 풀: 자주 접근하는 데이터를 메모리에 캐시하여 I/O 성능을 개선합니다.
InnoDB의 동작 원리
- 스토리지 엔진으로서의 역할
InnoDB는 MySQL 서버의 핵심 컴포넌트로, 쿼리 실행 엔진과 스토리지 계층 사이에서 작동합니다. 주요 역할은 다음과 같습니다:
- SQL 쿼리의 실제 실행
- 데이터 저장 및 검색
- 인덱스 관리
- 트랜잭션 처리
- 트랜잭션 처리
InnoDB의 트랜잭션 처리는 MVCC(Multi-Version Concurrency Control) 메커니즘을 기반으로 합니다. 이를 통해:
- MVCC 메커니즘이 무엇인가요?
- MVCC는 데이터베이스 관리시스템에서 동시성을 제어하는 방법으로, 데이터의 여러 버전을 유지하여 읽기 작업과 쓰기 작업이 서로를 차단하지 않고 동시에 수행될 수 있도록 하는 기술입니다.
- 버전관리
- 각 행은 여러 버전으로 존재할 수 있습니다.
- 각 버전에는 트랜잭션 ID와 같은 메타데이터가 포함됩니다.
- 읽기 작업
- 트랜잭션은 자신의 트랜잭션 ID보다 작거나 같은 ID를 가진 버전의 데이터만 읽습니다.
- 이를 통해 Consistent Read가 가능해집니다.
- InnoDB는 다음과 같은 방식으로 MVCC를 구현합니다.
- 시스템 테이블스페이스: 트랜잭션 정보와 언두 로그를 저장합니다.
- 언두 로그
- 데이터 변경 이전의 상태를 저장
- 롤백 및 일관된 읽기에 사용합니다.
- 트랜잭션 ID
- 각 트랜잭션에 고유한 ID를 할당합니다.
- 데이터 버전 관리에 사용
- ReadView
- 트랜잭션이 시작될 때 생성된다.
- 해당 시섬의 활성 트랜잭션 목록을 포함
- 어떤 버전의 데이터를 읽을지 결정하는 데 사용
- 읽기 작업이 쓰기 작업을 차단하지 않음
- 동시성 향상
- 일관된 읽기 보장
-
데이터 저장 구조
-
InnoDB는 테이블스페이스라는 논리적 저장 구조를 사용합니다:
- 시스템 테이블스페이스: 데이터 사전 정보, 언두 로그 등 저장
- 파일-퍼-테이블(file-per-table) 테이블스페이스: 개별 테이블 데이터, 인덱스 저장
- 일반 테이블스페이스: 여러 테이블의 데이터를 그룹화하여 저장
- 세그먼트는 테이블스페이스 내에서 특정 객체(예: 테이블)의 데이터를 저장하는 논리적 컨테이너입니다.
- 익스텐트는 연속된 페이지들의 집합입니다. InnoDB에서의 기본 크기는 1MB입니다.
- 페이지는 InnoDB의 가장 작은 I/O 단위입니다. 기본 크기는 16KB입니다.
실제 데이터 저장 과정
- 새 테이블 생성 시
- 기본적으로 새로운 파일-퍼-테이블 테이블 스페이스가 생성됩니다.
- 데이터 세그먼트와 인덱스 세그먼트(있는 경우)가 할당됩니다.
- 데이터 삽입 시
- 적절한 데이터 페이지를 찾거나 새 페이지를 할당합니다.
- 페이지 내의 빈 공간에 데이터를 저장합니다.
- 필요시 새 익스텐트를 할당합니다.
- 인덱스 갱신
- 관련 인덱스 페이지를 갱신합니다.
-
CREATE DATABASE 실행 시
CREATE DATABASE example_db;
- 디렉토리 생성
- MySQL 데이터 디렉토리 내에 example_db라는 이름의 새 디렉토리가 생성됩니다.
- 기본 위치: /var/lib/mysql/example_db
- 메타데이터 업데이트
- MySQL의 데이터 딕셔너리에 새 데이터베이스 정보가 기록됩니다.
- 권한 설정
- 새 데이터베이스에 대한 권한이 설정됩니다.
- 디렉토리 생성
-
CREATE TABLE 실행 시
USE example_db; CREATE TABLE users ( id INT PRIMAY KEY AUTO_INCREMENT, name VARCHAR(100), email VARCHAR(100) ) ENGINE=InooDB;
- 테이블스페이스 생성
- 기본적으로 file-per-table 설정에 따라 users.idb 파일이 생성
- 위치: /var/lib/mysql/example_db/users.ibd
- 테이블 구조 정의
- InnoDB 데이터 딕셔너리 테이블 구조 정보가 저장됩니다.
- 컬럼 정보, 데이터 타입, 제약 조건 등이 기록됩니다.
- 인덱스 생성
- PRIMARY KEY를 위한 클러스터드 인덱스가 생성됩니다.
- 이 인덱스는 테이블의 실제 데이터를 구성합니다.
- 초기 세그먼트 할당
- 데이터 세그먼트: 테이블 데이터를 저장할 공간
- 인덱스 세그먼트: PRIMAY KEY 인덱스를 저장할 공간
- 초기 페이지 할당
- 루트 페이지: 인덱스의 최상위 노드
- 데이터 페이지: 실제 레코드를 저장할 첫 번쨰 페이지
- 메타데이터 업데이트
- information_schema와 performance_scheam의 관련 테이블들이 업데이트
- 트랜잭션 로그 기록
- 테이블 생성 작업이 redo 로그에 기록
- 권한 검사 및 설정
- 사용자의 테이블 생성 권한이 확인
- 새 테이블에 대한 기본 권한이 설정
- 테이블스페이스 생성
-
시스템 테이블스페이스 업데이트
- idbata1 파일(시스템 테이블스페이스)에 새 테이블 관련 메타데이터 추가
-
버퍼 풀 초기화
- 새 테이블을 위한 버퍼 풀 페이지가 필요에 따라 할당
InnoDB 외에도 MySQL은 여러 스토리지 엔진을 지원합니다. 주요 차이점은 다음과 같습니다:
-
MyISAM:
- 트랜잭션 미지원
- 테이블 수준 잠금
- 전체 텍스트 검색에 강점
-
Memory:
- 인메모리 저장
- 빠른 읽기 성능
- 서버 재시작 시 데이터 손실
-
Archive:
- 대량의 히스토리 데이터 저장에 적합
- 압축 저장으로 공간 효율성 높음
InnoDB가 기본 엔진으로 선택된 이유는 대부분의 사용 사례에서 최적의 성능과 안정성을 제공하기 때문입니다.
- B-Tree 인덱스(위에서 자세히 설명)
- 균형 잡힌 트리 구조로, 데이터를 정렬된 상태로 유지합니다.
- 리프 노드에 실제 데이터 또는 데이터에 대한 포인터를 저장합니다.
- 검색, 삽입, 삭제 연산의 시간 복잡도가 O(log n)으로 효율적입니다.
- 범위 검색에 매우 효과적이며, 정렬된 데이터 접근이 빠릅니다.
- 대부분의 RDBMS에서 기본 인덱스 유형으로 사용됩니다.
- R-Tree 인덱스(밑에서 자세히 설명)
- 다차원 공간 데이터를 인덱싱하기 위한 트리 구조입니다.
- 각 노드가 다차원 직사각형(Minimum Bounding Rectangle, MBR)을 나타냅니다.
- 공간 검색 연산(포함, 교차, 근접 등)을 효율적으로 수행할 수 있습니다.
- GIS(지리 정보 시스템) 애플리케이션에서 많이 사용됩니다.
- MySQL에서는 SPATIAL 인덱스 타입으로 구현되어 있습니다.
- Hash 인덱스
-
해시 함수를 사용하여 키를 해시 값으로 변환합니다.
-
해시 값을 기반으로 데이터의 위치를 직접 찾아갈 수 있어 매우 빠릅니다.
-
등호 비교에 최적화되어 있지만, 범위 검색이나 정렬, 부분 키 검색에는 사용할 수 없습니다.
-
충돌 해결을 위해 체이닝이나 개방 주소법 등의 기법을 사용합니다.
- a) 체이닝 (Chaining):
- 각 버킷에 연결 리스트를 사용하여 여러 엔트리를 저장합니다.
- 충돌이 발생하면 해당 버킷의 리스트에 새 엔트리를 추가합니다.
- 장점: 구현이 간단하고, 버킷 수에 제한 없이 데이터를 저장할 수 있습니다.
- 단점: 최악의 경우 검색 시간이 O(n)이 될 수 있습니다 (모든 키가 같은 버킷에 해시된 경우).
b) 개방 주소법 (Open Addressing):
- 충돌 발생 시 다른 버킷을 찾아 데이터를 저장합니다.
- 주요 방식:
- 선형 탐사 (Linear Probing): 충돌 시 다음 버킷을 순차적으로 확인합니다.
- 이차 탐사 (Quadratic Probing): 충돌 시 제곱수만큼 떨어진 버킷을 확인합니다.
- 이중 해싱 (Double Hashing): 두 번째 해시 함수를 사용하여 다음 위치를 결정합니다.
- 장점: 캐시 효율성이 좋고, 추가적인 포인터 저장이 필요 없습니다.
- 단점: 클러스터링 현상이 발생할 수 있고, 로드 팩터가 증가하면 성능이 저하됩니다.
-
메모리 기반 테이블에서 주로 사용되며, 디스크 기반 테이블에서는 제한적입니다.
-
사용 사례
- 캐시 시스템
- 정확한 일치 검색이 주로 필요한 인메모리 데이터베이스
- 임시 데이터를 위한 고속 조회 테이블
- Full-text 인덱스
- Full-text 인덱스는 대량의 텍스트 데이터에서 효율적인 검색을 위해 설계된 특수한 형태의 인덱스입니다.
- 전체 텍스트 인덱스는 InnoDB 또는 MyISAM 테이블에서만 사용할 수 있으며 CHAR, VARCHAR 또는 TEXT 열에 대해서만 생성할 수 있습니다.
- 일반적인 B-Tree 인덱스와는 달리, 텍스트 전체를 분석하여 개별 단어나 토큰에 대한 인덱스를 생성합니다.
- 텍스트를 단어 단위로 분리하고 각 단어에 대한 역인덱스를 생성합니다.
- 구조: {단어: [(문서ID, 위치), (문서ID, 위치), ...]}
- 문서ID는 인덱싱된 각 텍스트 항목(행 또는 문서)에 할당된 고유한 번호 또는 식별자입니다.
- 불용어(stopwords) 처리, 어간 추출(stemming) 등의 기능을 제공합니다.
- 불용어 제거: 'the', 'a', 'an' 등 검색에 큰 의미가 없는 일반적인 단어를 제거합니다.
- 어간 추출: 단어를 기본 형태로 축소합니다. 예: "running" -> "run”
- 자연어 검색, 불리언 모드 검색 등 다양한 검색 모드를 지원합니다.
- 자연어 검색: 사용자가 입력한 쿼리를 일반 문장처럼 처리합니다.
- 불리언 모드 검색: 예: "apple AND (pie OR tart) NOT cake”
- 대량의 텍스트 데이터에서 특정 단어나 구문을 빠르게 찾을 수 있습니다.
- 복합 인덱스 - B-Tree 사용
- 두 개 이상의 컬럼을 조합하여 생성한 인덱스입니다.
- 각 노드의 키는 복합 인덱스의 모든 컬럼 값을 포함합니다.
- 예: (A, B, C) 인덱스의 경우, 각 키는 (A값, B값, C값)의 형태를 가집니다.
- 인덱스 내에서 컬럼의 순서가 중요하며, 왼쪽에서 오른쪽으로 순서대로 사용됩니다.
- 선행 컬럼이 조건절에 있어야 인덱스가 효과적으로 작동합니다.
- 순서가 매우 중요합니다. 순서가 다르면 동작이 예상과는 다르게 동작할 수 있습니다.
- 여러 컬럼을 포함하는 WHERE 절, ORDER BY, GROUP BY 등에서 성능을 향상시킵니다.
- 추가적인 ORDER나 탐색을 줄일 수 있습니다.
- 단일 컬럼 인덱스보다 더 세밀한 쿼리 최적화가 가능합니다.
- 인덱스는 최대 16개의 열로 구성될 수 있습니다.
https://dev.mysql.com/doc/refman/8.0/en/index-btree-hash.html#hash-index-characteristics
https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html

| 타입 | 정의 | 예시 |
|---|---|---|
| Point | 좌표 공간의 한 지점 | POINT(10 10) |
| LineString | 다수의 Point를 연결해주는 선분 | LINESTRING(10 10, 20 20, 30 30) |
| Polygon | 다수의 선분들이 연결되어 닫혀있는 상태 | POLYGON((10 10, 10 20, 20 10, 10 10)) |
| Multi-Point | 다수의 Point 집합 | MULTIPOINT(10 10, 20 20) |
| Multi-LineString | 다수의 LineString 집합 | MULTILINESTRING((10 10, 20 20), (15 15, 25 25)) |
| Multi-Polygon | 다수의 Polygon 집합 | MULTIPOLYGON(((10 10, 10 20, 20 10, 10 10)), ((40 40, 30 30, 40 40))) |
| GeomCollection | 모든 공간 데이터들의 집합 | GEOMETRYCOLLECTION(POINT(10 10), LINESTRING(20 20, 30 30)) |
MySQL이 지원하는 공간 데이터의 종류이다.
단일 타입으로는 Point, LineString, Polygon이 있고, 나머진 이 세가지 타입의 조합이다.
공간 함수는 [MySQL Docs](https://dev.mysql.com/doc/refman/5.7/en/spatial-function-reference.html)를 참고하자 !
공간 데이터를 다루면 필히 인덱스를 적용하게 된다. 그럼 공간 데이터의 인덱스도 B-Tree로 다룰까?
아니다. 공간 인덱스 R-Tree 라는 자료 구조를 이용한다.
R-Tree 는 점, 선, 면(다각형)과 같은 다차원 정보를 효율적으로 저장하기 위한 트리 형태의 자료구조이다.
R-Tree는 MBR을 알아야 하는데, 그래서 MBR이 뭘까?
그림을 보면서 이해를 해보자.

위의 그림을 보면 점, 선, 어떤 도형을 기준으로 그 도형을 포함한 사각형이 만들어졌고, 이 모든 도형을 포함하는 사각형이 만들어졌다.
MBR 은 Minimun bounding rectangle로 특정 도형을 감싸는 최소 크기의 사각형을 의미한다.
그래서 이를 바탕으로 R-Tree를 구성하는데 아래의 그림을 보면 더 이해가 쉬울 것이다.

R-Tree 자료구조는 B-Tree 와 흡사한 형태로 구성되어있다.
각 노드에 저장할 수 있는 도형의 개수는 사전에 지정되는데, 최대 M개에서 최소 m(M/2)개 저장할 수 있다.
또한 B-Tree 처럼 리프 노드에 데이터(도형)를 저장하고, 리프 노드가 아닌 노드는 MBR 간의 포함관계를 표현한다.
탐색은 Top-down 방식으로 진행되며 루트 노드부터 리프 노드까지 내려간다.
이때 MBR 간에 중첩된 영역이 많을수록 탐색 성능은 떨어진다.
그 이유는 중첩된 영역이 이 많을수록 탐색할 노드가 많아지기 때문이다.
탐색 과정은 다음과 같다.
- 루트 노드부터 모든 하위 노드들을 순회하며 MBR 을 이용하여 검색 영역 내에 들어오는지 검사
- 리프 노드를 찾으면 포함된 도형들이 검색 영역에 포함되는지 확인
https://kong-dev.tistory.com/245#google_vignette
https://sparkdia.tistory.com/24?category=1114027
https://dev.mysql.com/doc/refman/8.0/en/spatial-index-optimization.html
Oracle, MS-SQL, PostgreSQL 에서 테이블과 레코드를 저장하는 방식은 어떤 것들이 있는가?
- Oracle
Oracle Database는 복잡하고 강력한 저장 구조를 가지고 있으며, 데이터를 저장하고 관리하는 다양한 방법을 제공합니다.
테이블 저장 구조:
Heap Organized Tables: Oracle에서 가장 일반적으로 사용되는 테이블 형식입니다. 레코드는 특정한 순서 없이 테이블에 삽입된 순서대로 저장됩니다. 인덱스를 사용하여 데이터를 빠르게 검색할 수 있습니다. Index Organized Tables (IOT): 레코드가 테이블에 저장될 때 기본 키를 기준으로 정렬되어 저장됩니다. 인덱스와 데이터가 함께 저장되므로, 데이터 검색 시 성능이 향상될 수 있습니다. Clustered Tables: 두 개 이상의 테이블이 같은 물리적 공간을 공유하며, 관련된 레코드가 물리적으로 인접해 저장됩니다. 이는 조인 연산의 성능을 높이는 데 도움을 줍니다. 레코드 저장 방식:
Block: Oracle은 데이터를 블록 단위로 저장합니다. 각 블록은 테이블의 여러 레코드를 포함할 수 있으며, 블록은 데이터베이스에서 I/O 작업의 기본 단위입니다. Extent: Extent는 연속된 블록의 집합으로, 테이블이나 인덱스가 확장될 때 새로운 Extent가 할당됩니다. Segment: 테이블이나 인덱스와 같은 논리적 저장 구조의 집합을 말하며, 하나 이상의 Extent로 구성됩니다.
- MS-SQL (Microsoft SQL Server)
MS-SQL은 데이터 저장을 위한 다양한 기능을 제공하며, 고성능과 확장성을 위한 여러 저장 옵션을 가지고 있습니다.
테이블 저장 구조:
Heap: 인덱스가 없는 테이블로, 레코드가 삽입되는 순서대로 페이지에 저장됩니다. 기본 키 또는 클러스터드 인덱스가 없는 테이블입니다. Clustered Index: 테이블에 클러스터드 인덱스가 있는 경우, 테이블의 데이터는 인덱스의 키 순서에 따라 정렬된 상태로 저장됩니다. 따라서 클러스터드 인덱스가 테이블의 물리적 저장 방식을 결정합니다. Partitioned Tables: 대용량 테이블을 여러 파티션으로 나누어 저장할 수 있으며, 각 파티션은 독립적으로 관리됩니다. 레코드 저장 방식:
Page: MS-SQL은 데이터를 8KB 크기의 페이지 단위로 저장합니다. 하나의 페이지에는 여러 레코드가 포함될 수 있습니다. Extent: Extent는 8개의 연속된 페이지(64KB)로 구성됩니다. 이 Extent는 테이블이나 인덱스가 확장될 때 할당됩니다. Filegroup: Filegroup은 데이터 파일을 논리적으로 그룹화한 것이며, 각 Filegroup은 여러 파일로 구성될 수 있습니다.
- PostgreSQL
PostgreSQL은 오픈 소스 관계형 데이터베이스로, 유연하고 확장 가능한 저장 방식을 가지고 있습니다.
테이블 저장 구조: Heap: PostgreSQL의 기본 테이블 저장 방식은 Heap 구조입니다. 레코드는 테이블에 삽입되는 순서대로 저장되며, MVCC(Multi-Version Concurrency Control)를 통해 트랜잭션이 발생한 다양한 상태의 레코드를 관리합니다. Partitioned Tables: 대용량 테이블을 관리하기 위해 파티셔닝을 사용하여 테이블을 여러 파티션으로 나눌 수 있습니다. 레코드 저장 방식: Page: PostgreSQL은 데이터를 페이지 단위로 저장합니다. 각 페이지는 보통 8KB 크기이며, 여러 레코드가 포함될 수 있습니다. Block: 페이지는 다시 블록 단위로 관리되며, 블록은 PostgreSQL의 물리적 저장 단위입니다. Tablespace: Tablespace는 데이터베이스 객체(예: 테이블, 인덱스)를 저장할 수 있는 물리적 저장소를 논리적으로 구분하는 방법입니다. 이를 통해 데이터베이스 파일의 물리적 위치를 제어할 수 있습니다.