Data
Introduction to what airflow is and how it is being used for DLME

- Enable/Disable DAG: A DAG will not run (even manually) unless enabled
- DAG name & tags: Clicking on the label will display the DAG
- Runs: Displayed in Successful/Running/Failed order. Clicking each will display a list of dag runs
- Schedule: How is this DAG scheduled - following cron syntax and special commands (i.e.
@yearly,@once) - Last Run: Links to DAG view from the most recent DAG run
- Play: Manually trigger the DAG
- Reload: Refresh the DAG definition
- Delete: Delete the DAG
NOTE: This is the default display when navigating into a DAG. As a DAG grows in complexity, the task display can become hard to understand in the tree view - though the grid view of DAG runs can be helpful when debugging.

This DAG view is generally more appealing and understanding. It displays and updates as a DAG runs, therefore the visual representation of where in the task list a particular DAG run is can be very helpful.
Here we see a simple DAG with five (5) tasks:
- configure_git
- validate_metadata_folder
- clone_metadata
- pull_metadata
- finished_pulling
The graph display makes it clear that validate_metadata_folder results in a branch between clone_metadata and pull_metadata and runs after configure_git. The final task, finished_pulling is a DummyOperator - a place holder task used for control flow.

The border color of the tasks in this display is important, and a key is provided at the top of the display. Here we see that configure_git, validate_metadata_folder, clone_metadata, and finished_pulling each have a dark green border indicating SUCCESS. The pull_metadata task has a pink border, indicating SKIPPED.
This indicates that:
-
configure_gitran and completed with aSUCCESSstate. -
validate_metadata_folderthen ran and completed with aSUCCESSstate. It also returned a value that forced triggering ofclone_metadataand skipping ofpull_metadata. -
finished_pullingcaptured the flow betweenclone_metadataandpull_metadataand ended in aSUCCESSstate.
When displaying a DAG run, hovering over a task will display information about the task run:

Clicking on a task in graph view opens a modal to dive deeper into a task run instance. Most helpful features are:
- Log: Any log output from the individual task instance. This is very helpful as individual task logs are not lost in a full DAG or application log.
- Run: Run an individual task.



Here we see a DAG run display for a DAG that includes TaskGroups. TaskGroups represent a reusable task structure that can be included in many DAGS without code duplication.
Here we see the validate_metadata DAG from above included as a task within this DAG as a TaskGroup. This allows us to reuse this set of tasks in any DAG without code duplication.

TaskGroups are a very useful tool for complex sets of tasks, as well as generating tasks to make writing DAGs easier. Here we see a complex set of 20 harvest tasks that were generated based on the provider configuration and run in parallel.

Airflow is used to manage Extract, Transform, and Load (ETL) automation for DLME. It manages the execution and reporting around sequences of tasks called DAGs. A diagram of a DLME ETL DAGs for one provider will make this clear:
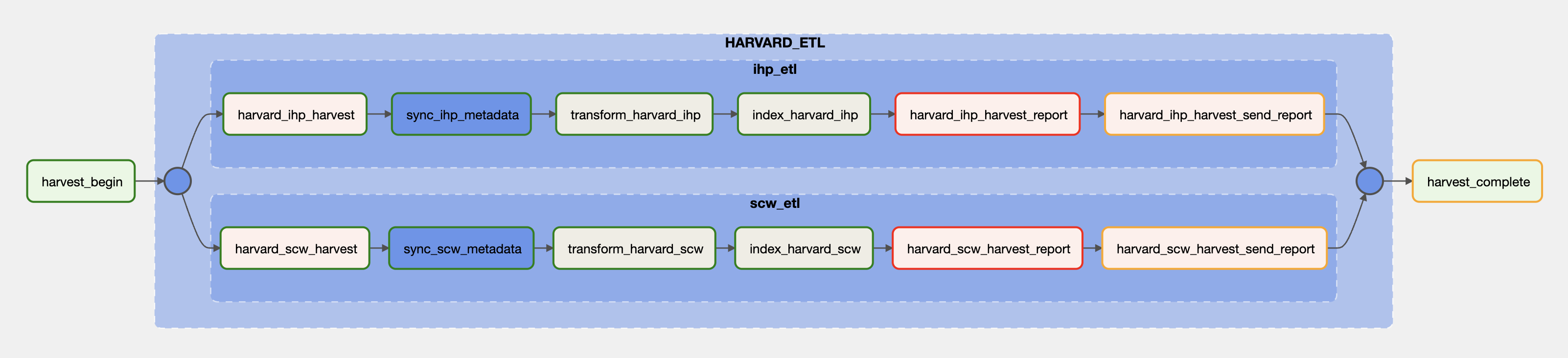
The above diagram shows the DAGs for Harvard University, which has two collections. Each box represents a task that is executed if and when the prior task succeeds. The tasks and descriptions are:
- provider_collection_harvest: triggers a harvest task to harvest metadata from the data provider and converts it to a csv file.
- sync_collection_metadata: syncs the metadata in Amazon S3; this is where the data is stored.
- transform_provider_collection: triggers a traject config to transform the csv file into a jsonnd file conforming to the DLME application profile.
- index_provider_collection: indexes the ndjson file in the DLME dev environment
- provider_collection_harvest_report: generates a coverage and data quality report that can be used by DLME data providers to understand how we transformed their data, and surface data coverage, quality issues.
- provider_collection_harvest_send_report: sends the above report to a number of pre configured email addresses.
DLME currently maintains the following intake drivers:
-
hathi_trust: Used for harvesting metadata from Hathi Trust collections. -
iiif_json: Used for harvesting IIIF v2 collections. -
iiif_json_v3: Used for harvesting IIIF v3 collections. -
json: Used for harvesting collections from custom json APIs. -
oai_xml: Used for harvesting OAI-PMH collections. -
sequential_csv: Used for harvesting csv files. -
xml: Used for harvesting collections from custom xml APIs.
To add a new catalog, first add an entry in the catalog.yaml file, then create a new catalog file (make sure the file name matches the entry in catalog.yaml). Find another catalog entry that uses that same driver to use as a template for filling out the catalog.
Warning: The xml and json drivers are generic drivers, which means the harvest fields have to be explicitly mapped in the catalog. The other drivers are expected to harvest all fields without the need for explicitly adding them in the catalog.
To harvest data locally for the purpose of mapping, you have two options:
From the Airflow directory:
- run
docker build . -f Dockerfile --tag suldlss/dlme-airflow:latest - run
docker compose up - navigate to
https://localhost:8080/ - login username=airflow, password=airflow
- manually trigger the DAG and look for the data in the
dlme-airflow/workingdirectory. You can use the csv file for easy exploration but the data will be mapped from the json file.
From the Airflow directory:
run: uv run bin/get loc wdl --limit 10 > data.json change or omit the --limit flag as you like. There are also bin/post-harvest and bin/filter-data tasks that will allow you to get the data to the state it needs to be in before being passed to the Traject config.
The DLME application profile is the canonical and formal reference for all fields in the DLME data model. This documentation can be used as an authority describing mapping strategies and techniques for specific fields and for linking these to affordances in the web application.
In general, traject configs should be written at the highest level of generalization/abstraction possible. When a data provider has multiple sets of records–e.g. some Arabic manuscripts and some travel books–it is best to write a single config file for both collections, if possible. When this is not possible, the generalizable patterns should be included in a ‘provider_common_config.rb’ file and the patterns specific to each set can be captured in specific configs ‘privider_arabic_manuscripts.rb’ and ‘provider_travel_books.rb’. In this way, duplication of code is avoided as much as possible.
DLME uses the following strategy for controlling vocabularies.
- Add the values to the settings file. Currently, we are controlling the vocabulary used for
cho_edm_type,cho_has_type, and the allowable language codes we tag metadata values with. - Add a macro in the contracts file that makes sure the field in question is only allowing values from the above list.
- The above will ensure that no extraneous values are found in the controlled field. However, it will not guarantee that every value in the harvested data gets mapped to a value in our controlled vocabulary. To do this, use a normalization macro like normalize_has_type where "not found" gets mapped for any values not found in one of the translation maps. Then exclude "NOT FOUND" in the contracts file. This will cause an error to be raised during mapping when any value is found that is not in one of the translation maps. Add the missing value to the appropriate translation map.
- In some cases, it will be best to map a value from the harvested data (e.g.
type>cho_has_type) but this will prove challenging in some cases if the data quality is bad or too broad/narrower for our vocabulary. Sometimescho_has_typecan be mapped at the collection level. Make sure the mapping you choose will be safe for all collections, including future possibilities not currently aggregated in DLME. For example, the AUC Voice of America collection has "speech", "interview", "song & music", and "report". The values "speech", "interview", and "report" could mean different things in different collections. In this collection, they refer to types of audio files but in another collection they might refer to transcripts of audio. We cautiously mapped all items in this collection tocho_has_type= "Radio Program" and also mapped "song & music" to "Music". It is okay to map the same value in multiple times as duplicates will be removed. In some cases, you may wish to map one harvested value to more than one value in the controlled vocabulary.
cho_aat_material (controlled vocabulary, normalized, translated): This field maps incoming metadata mapped to the ‘cho_medium’ field. Values are mapped to a controlled vocabulary of the Getty Art & Architecture Thesaurus ‘Materials’ facet. Values from the data contributor must be searched for in the Getty AAT web application and the appropriate preferred term is then added to the getty_att_material_from_contributor.yaml file and translated into Arabic in the ‘getty_aat_material_ar_from_en.yaml’. DLME should consider contributing the Arabic translations back to the Getty AAT Thesaurus. This field is particularly important for improving discoverability of pre-Islmic objects.
cho_edm_type (controlled vocabulary, normalized, translated): The original intent was for this field to capture Europeana types, however, it has not been used in that way. European types are essentially media types; they are useful for machines to determine what can be done with a file but not very useful for end users. Instead we have currently implemented this field as a generic type field.
cho_description As a practice more granular metadata fields that do not have a direct mapping in the DLME application profile are mapped to cho_description and prepended with a contextual description (e.g. manuscripts often have a ‘hand’ field which can be mapped to cho_description and prepended with the string: ‘Hand: ‘).
cho_has_type (controlled vocabulary, normalized, translated): This field is implemented as a narrower category of cho_edm_type. It does not use an external controlled vocabulary. Values change over time based on intuitions of what might be useful to end users and what data is available from data contributors. It works fairly well for ‘Text’ but is becoming unwieldy for ‘Object’ and ‘Image’ and is currently not useful for ‘Video’, ‘Dataset’, or ‘Sound’; there simply isn’t enough records to warrant use of narrower categories for these cho_edm_types.
cho_is_part_of This field should always display in the record view in the production site. agg_data_provider_colelction should also always display. Given that these fields will often, but not always, have the same data, cho_is_part_of should not be mapped when the value is effectively the same as that of agg_data_provider_colelction.
cho_language (controlled vocabulary, normalized, translated): The normalize_language handles language normalization by down casing the values and passing them to a series of translation maps.
cho_spatial Minimal effort has been made to normalize spelling, case, and language. No effort has been made to map values to a controlled vocabulary other than that provided in the ‘spatial.yaml’ translation map (which controls spelling, case, and language only; consult this file for examples). The minimal normalization improves performance of the ‘Geographic region’ facet which is used to build browse groups/categories. This field is particularly important for improving discoverability of pre-Islamic objects.
cho_temporal Minimal effort has been made to normalize spelling, case, and language. No effort has been made to map values to a controlled vocabulary other than that provided in the ‘temporal.yaml’ translation map (which controls spelling, case, and language only; consult this file for examples). When the cho_temporal value is found in the ‘periodo.yaml’ file (a translation map used to fetch PeriodO uris from PeriodO labels) PeriodO labels are stored in the ‘cho_periodo_period’ field. The minimal normalization improves performance of the ‘Time period’ facet which is used to build browse groups/categories. The PeriodO labels are displayed in the record view in the DLME web application to provide context for end users. This field is particularly important for improving discoverability of pre-Islmic objects.
cho_title Since this is a required field, truncated descriptions may be used in cases of records without titles.Highly generic values in the title field should be supplemented with a truncated description, if appropriate, or an identifier.
cho_type This is an unmodified type value harvested from the data contributor.
agg_data_provider_collection Add the agg_data_provider_collection_id as a key in the agg_collection_from_provider_id translation map with a human-readable collection name as the value.
agg_data_provider_collection_id This field is usually built from the file path of the collection to_field 'agg_data_provider_collection_id', path_to_file, split('/'), at_index(-2), dlme_gsub('_', '-'), dlme_prepend('gottingen-')
Some fields can be quite complex to normalize. Below are some techniques for dealing with these fields:
Type fields There are three DLME type fields: cho_edm_type, cho_has_type, and cho_type. Its easiest to map cho_type first as this is the raw value from the data contributor. Then map cho_has_type, since cho_edm_type is derived from cho_has_type. Use the normalize_has_type macro and the normalize_edm_type macro to get values.
In order to display multilingual metadata in the DLME web application, fields in the intermediate representation are converted to a hash (with the convert_to_language_hash macro), where the key is a language code. When all records that a given config file operates on have metadata in the same language for a given field (or when the partner data has language tags), use the lang macro to assign a BCP-47 language code. When the values are mixed language use the arabic_lang_or_default or the hebrew_lang_or_default where the first parameter is the value you want if Arabic script is found in the field (or Hebrew script for hebrew_lang_or_default) and the second parameter is the language tag you want if Arabic script is not found. Depending on the collection, values can be specific e.g. ar-Arab or not e.g. und-Arab (for an unknown language in Arabic script). Be careful not so assign a more specific value than is warranted. Also look out for multilingual values that need to be split into two separate monolingual values before assigning language codes. All fields (except cho_date_range_norm, cho_date_range_hijri, cho_identifier, collection, and id) require a language key and transform will fail if one is not provided.
All BCP-47 language tags used in DLME are part of a controlled vocabulary to prevent mistyping. Any language code used that is not in the controlled vocabulary will raise an error.
These language keys enable the display of language specific metadata on the web application. In the English view, English metadata is displayed first, when available, followed by other metadata in Latin script. In the Arabic view, Arabic metadata is displayed first, when available, followed by other metadata in Arabic script. The sort order is controlled here.
This quality assurance workflow starts with the harvested data. It will not surface errors that come about during harvest. You should compare the partner metadata directly with the harvested data to make sure everything was harvested correctly. This is especially important for collections that use the xml and json drivers. These are generic drivers, which means the harvest fields have to be explicitly mapped in the catalog.
As you work through your Traject config, transform the collection with the -w flag so that any errors cause the transform to stop:
docker run --rm -e SKIP_FETCH_DATA=true \
-v $(pwd)/.:/opt/traject \
-v $(pwd)/../dlme-airflow/working:/opt/airflow/working \
-v $(pwd)/output:/opt/traject/output \
suldlss/dlme-transform:latest \
bodleian \
-w
Once the collection fully transforms without any errors...
There is a utility for ensuring all fields in the source data get mapped in the Traject config and checking that the fields called in the Traject config actually exist in the source data. From the dlme-airflow directory run:
uv run bin/validate-traject aub
This will create a file called traject-validation.txt that looks something like the following:
Fields present in the input files that are not mapped:
- descriptions
- thumbnail
- homepage
- authors
- subjects
Fields mapped in the traject config that are not present in the input data:
- creator
- source
- contributor
- description
From the dlme-airflow directory:
uv run bin/report aub travelbooks
Inspect the mapping report.
bundle exec rubocop
bundle exec rspec
Once the dlme-airflow and dlme-transform pull requests have been merged and dlme-airflow has been deployed, you can trigger the DAG in the Airflow dev server. The index task will cause the data to be indexed in the review environment where you can manually inspect it.
The airflow DAGs should be scheduled to refresh data at least every three months. The DLME data manager will receive an email when DAG runs complete which contains a mapping report. The report should be reviewed and then the data can be manually inspected in the review environment. If this environment is regularly cleared, it will be easy to see which collections need manual review. If everything looks good, move the data to the production environment.
You can get data back from the dlme website. Just add the .json after the "catalog" portion of any url:
https://dlmenetwork.org/library/catalog.json?f%5Bagg_data_provider_collection_id%5D%5B%5D=cambridge-genizah
