ML Approach to identify characteristics associated with income level of people (those earning >$50,000 vs <$50,000).
We use the publicly available Adult Income Dataset from the 1994 US Census Board Database for this task. The census_income_metadata file contains information on data/datatypes. We have ~200,000 records in training set and XXX in testing.
The notebook adult_income.ipynb contains end-to-end code for
-
Programmatically load data and check sanity against metadata file
-
Exploratory Data Analysis
-
Feature Engineering and Feature Encoding
-
Model Comparison and Selection (ROC AUC, PR AUC etc.)
- Logistic Regression
- RandomForest Classifier
- XGBoost Classifier
- CatBoost Classifier
-
Hyperparameter Tuning and Model Validation (Precision, Recall, Accuracy etc.)
-
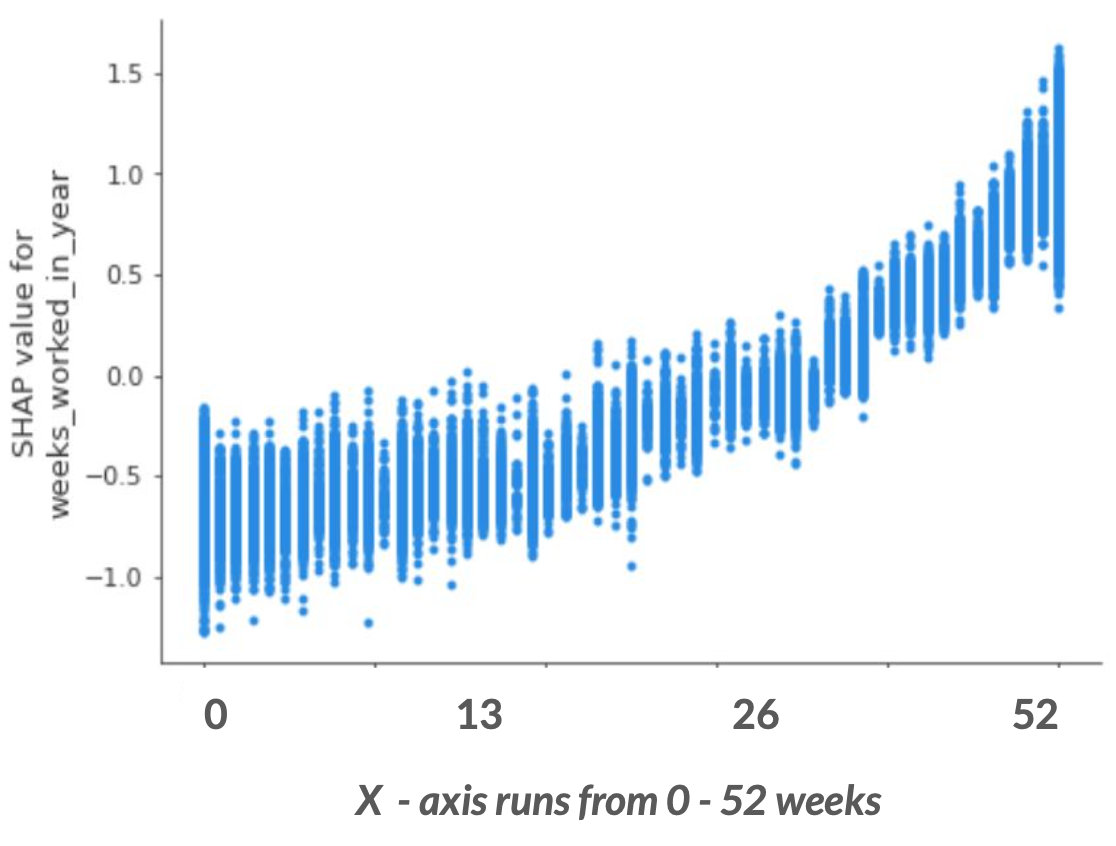
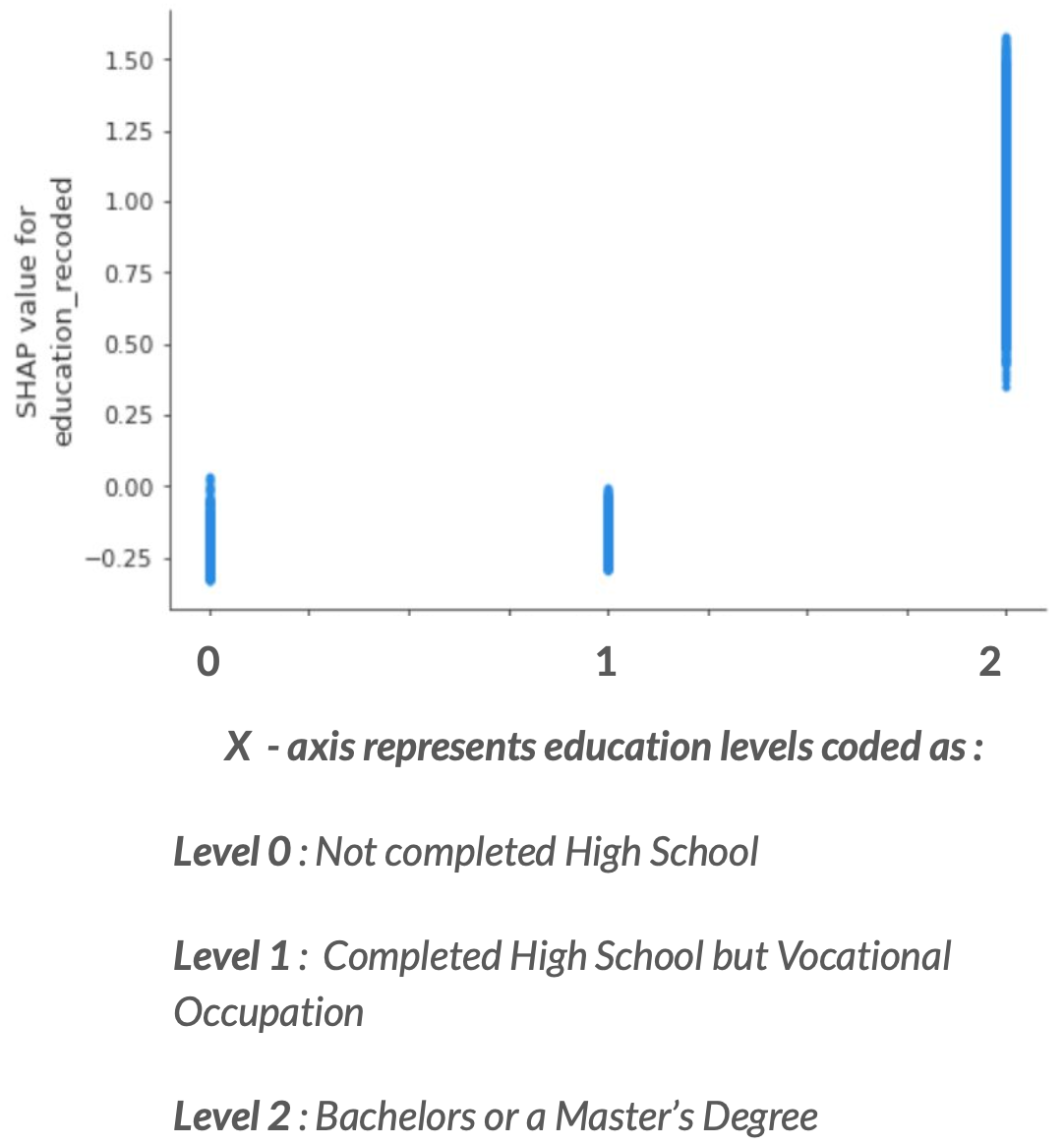
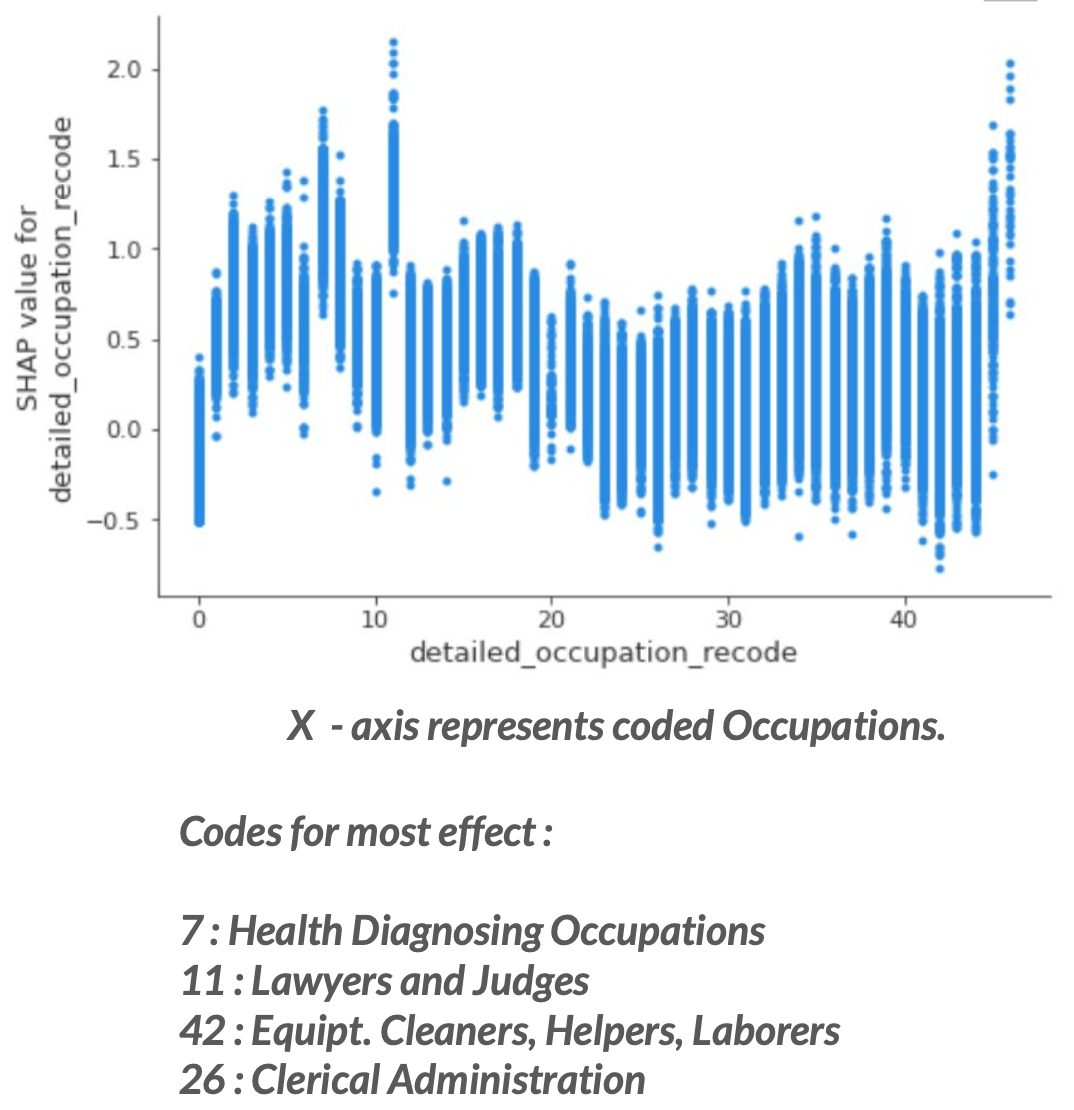
Model Interpretation (Feature Importances, SHAP scores, Partial Dependency Plots etc.)
-
Imputation Techniques to handle imbalanced dataset (SMOTE, Oversampling, Undersampling etc.)
All the analysis, observation and comments are documented within the Python notebook itself.
We observe that the top 8 most important characteristics associated with income are :

We then look at Partial Dependency plots for the top features.