Framework to generate augmented datasets with multiple subjects using existing datasets as input.

The paper describing this framework is available here and sample code in the following Google Colab.
Gait recognition is being employed as an effective approach to identify people without requiring subject collaboration. Nowadays, developed techniques for this task are obtaining high performance on current datasets (usually more than 90% of accuracy). However, those datasets are simple as they only contain one subject in the scene at the same time. This fact limits the extrapolation of the results to real world conditions where, usually, multiple subjects are simultaneously present at the scene, generating different types of occlusions and requiring better tracking methods and models trained to deal with those situations. Thus, with the aim of evaluating more realistic and challenging situations appearing in scenarios with multiple subjects, we release a new framework (MuPeG) that generates augmented datasets with multiple subjects using existing datasets as input. By this way, it is not necessary to record and label new videos, since it is automatically done by our framework. In addition, based on the use of datasets generated by our framework, we propose an experimental methodology that describes how to use datasets with multiple subjects and the recommended experiments that are necessary to perform. Moreover, we release the first experimental results using datasets with multiple subjects. In our case, we use an augmented version of TUM-GAID and CASIA-B datasets obtained with our framework. In these augmented datasets the obtained accuracies are 54.8% and 42.3% whereas in the original datasets (single subject), the same model achieved 99.7% and 98.0% for TUM-GAID and CASIA-B, respectively. The performance drop shows clearly that the difficulty of datasets with multiple subjects in the scene is much higher than the ones reported in the literature for a single subject. Thus, our proposed framework is able to generate useful datasets with multiple subjects which are more similar to real life situations.
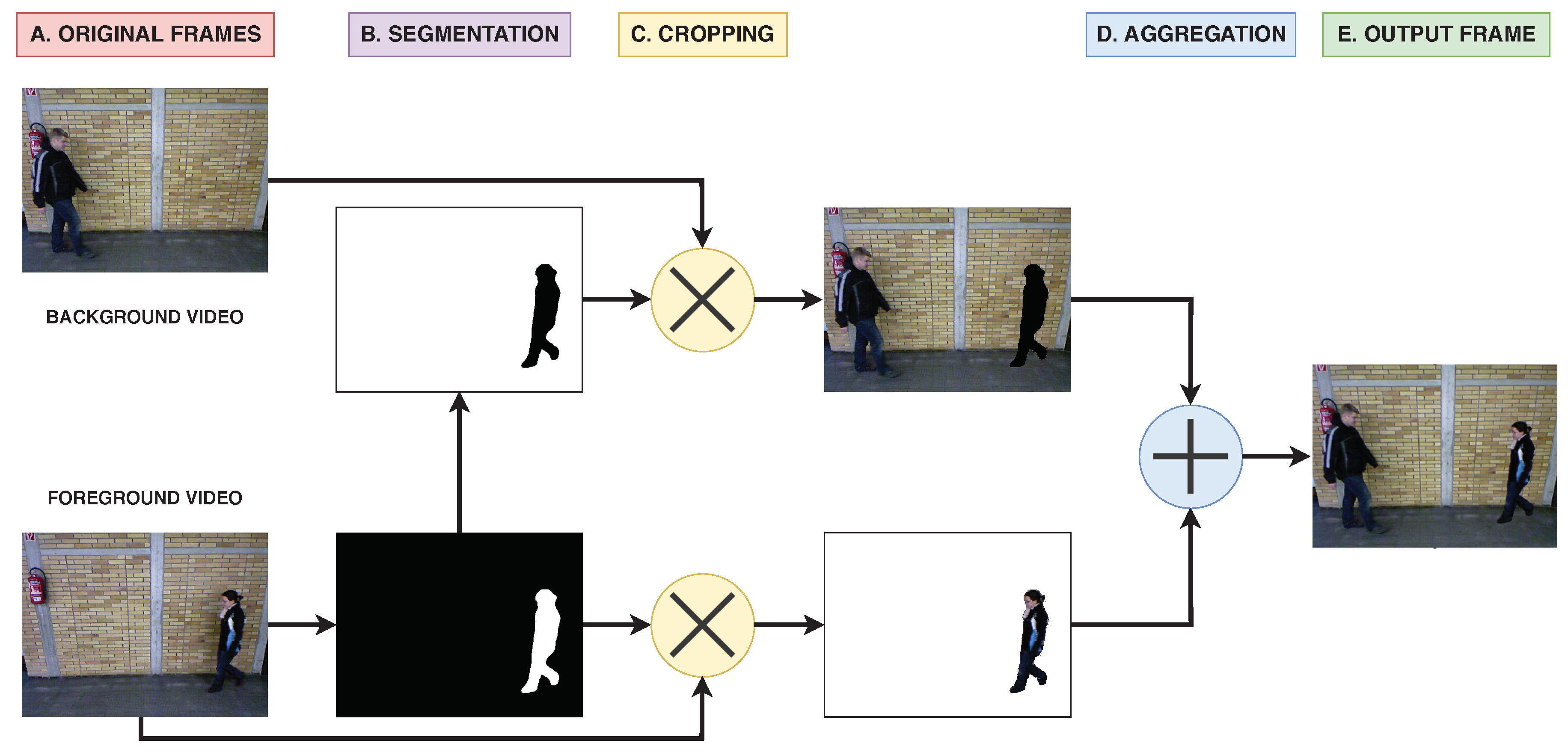
Examples with TUM-GAID and CASIA-B datasets:

MuPeG depends on the following libraries:
- OpenCV
- NumPy
- Tensorflow 1.x (we recommend tensorflow-gpu)
- Tensorflow Object Detection API
- Keras
- SciPy
- six
If tensorflow-gpu is installed, we recommend that you refer to the GPU support installation guide
Most dependencies can be installed using the requiments.txt file contained in this repository:
pip install -r requirements.txt
To install Tensorflow Object Detection API follow the steps indicated here
To use the MuPeG framework clone this repository with git:
git clone https://github.com/rubende/cnngait_tf
Check our .
Please, check our wiki (under construction).
This project is licensed under the MIT License - see the LICENSE.md file for details
If you use this framework in your research, please cite:
@Article{delgado2020mupeg,
AUTHOR = {Delgado-Escaño, Rubén and Castro, Francisco M. and Cózar, Julián R. and Marín-Jiménez, Manuel J. and Guil, Nicolás},
TITLE = {MuPeG—The Multiple Person Gait Framework},
JOURNAL = {Sensors},
VOLUME = {20},
YEAR = {2020},
NUMBER = {5},
ARTICLE-NUMBER = {1358},
URL = {https://www.mdpi.com/1424-8220/20/5/1358},
ISSN = {1424-8220},
DOI = {10.3390/s20051358}
}
- We thank the reviewers for their helpful comments.