To analyze the reviews of some products on amazon we need the ASIN of the product.
The URL of a search list after giving the search keyword (query) has the form:
url=f"https://www.amazon.com/s?k={query}&page={page}"
The URL of every product will have the form:
url = f"https://www.amazon.com/{Optional_part}/dp/{asin}/"
And the URL of the reviews is
url = f"https://www.amazon.com/product-reviews/{asin}/"
So we need the asin of an object to scrap its review.
We will have 3 search queries to test the search results of those products.
The scraper for the search results is in scrap_search.py
(Its explanation and commented in the Jupiter notebook scrap_search.ipynb)
The scraper of the reviews is in the file scrap_reviews.py it scrapes the reviews of one product and is explained in the notebook.
In the main.py file we connect them together to scrape the reviews of all possible products that appear when searching by keyword.
The results data can be found in the data folder.
the aim is to get reviews from amazon, it is interesting to analyze such with NLP.\n This is a student project within the ReDI School Data Circle program.
you need to create and activate your virtual environment and inside it, you need to run
pip install -r requirements.txt- Add the search keyword in the main scope.
- run the code
- A popup will ask you to enter the number of the file in which your results will be saved.
- Check the results in the Data directory
- Enter the product asin
- run the code
- when the popup asks you enter the file number
- check the results in the data directory
- Enter the search keyword.
- Run the code
- Wait for a while (could take more than 10 minutes)
- Enter the file number
- check the results in the Data directory
This part needs just to be run (but it is still under examination)
Please open an issue first to discuss what you would like to change.
You can model the data from the resulted json file by following this approach Or use the Pandas framework to create an SQL database as explained here
Further
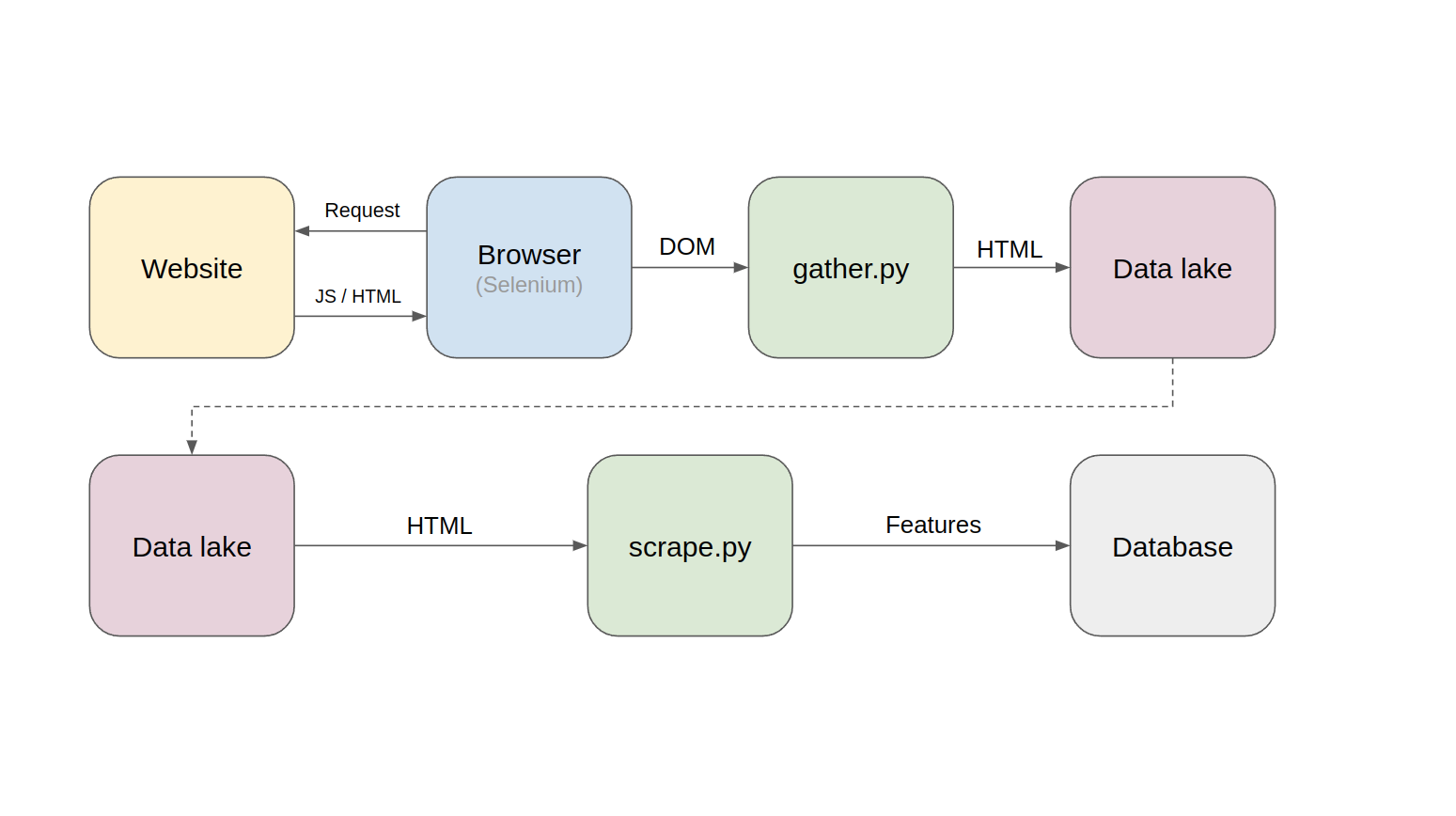
We can create a ml model which crawls the data daily as an html and gathers it as an archive in a data lake (using AWS s3 or Azure cloud) and scrape it later. This link describes the benefits of this approach to build a dynamic pipeline.
One can also combine the scraper with django to create a new websites listing specific items and some analysis on them.