

无需数据库即可部署
监控和报警都插件化
./conf/plugin.yml 可以用相对路径引用外部插件
监控有很多复杂的逻辑 , 比如配置 orchestrator 自动切换主从的 mysql 高可用 , 那么应该监控 mysql 主从拓扑是不是正确 , 有没有脑裂 。
监控和自愈应该是一体的 , 比如发现 IP 挂了 , 应该去屏蔽 cloudflare 上解析的 ip , 发现恢复了 , 应该去启用 ip 。
现在有的方案想实现我的这些需求 , 都太重了。
干脆自己写一个 , 所有的监控都插件化 , 按需启用
用下面的方案可以免费部署
默认会启动两个后端 , 只保留一个即可 , 比如 :
fly machine list
fly machine destroy d8d9999b292058 --force
推送代码到 github 的 main 分支 , 会自动触发 cloudflare page 的 webhooks 来部署
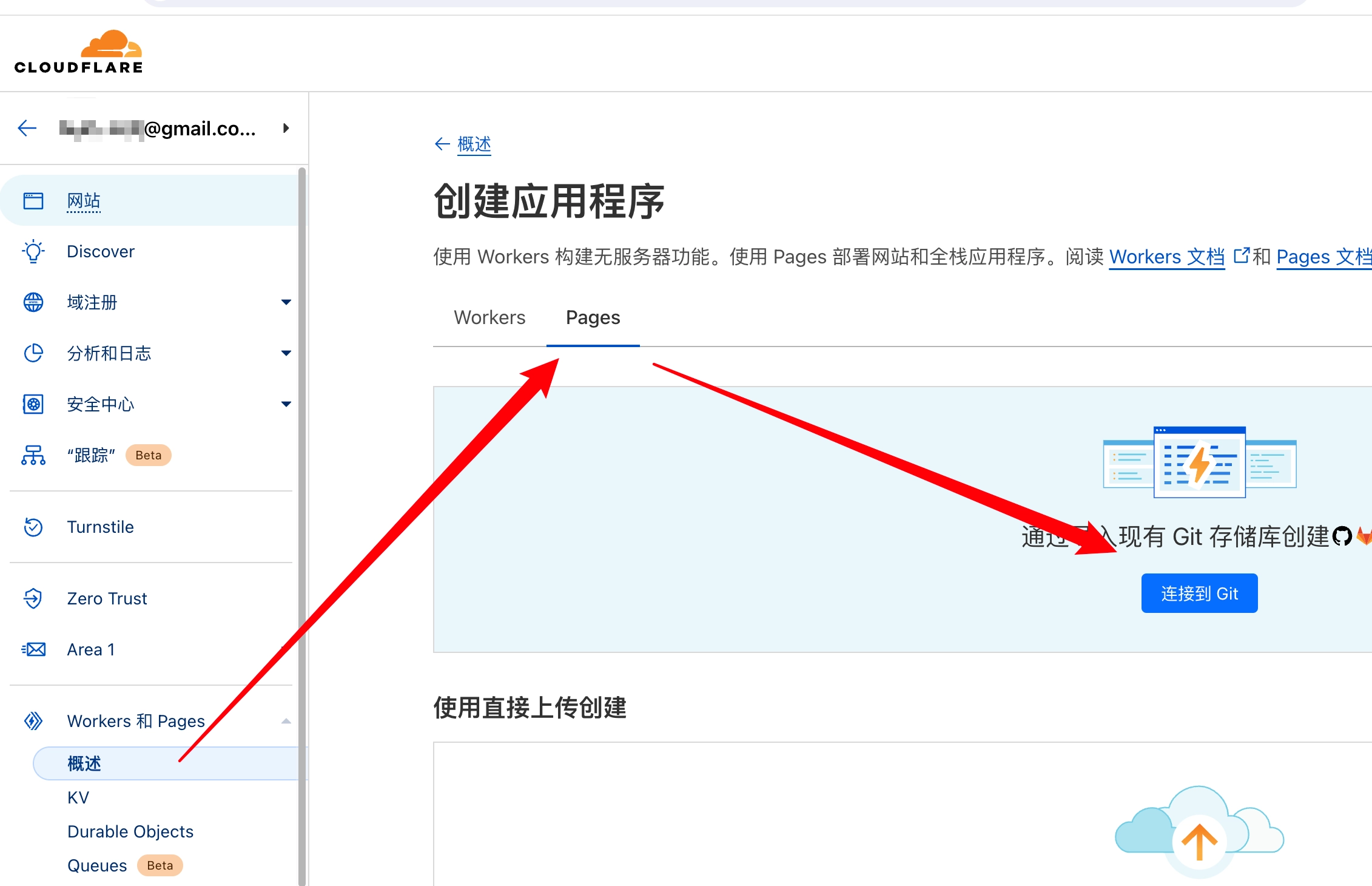
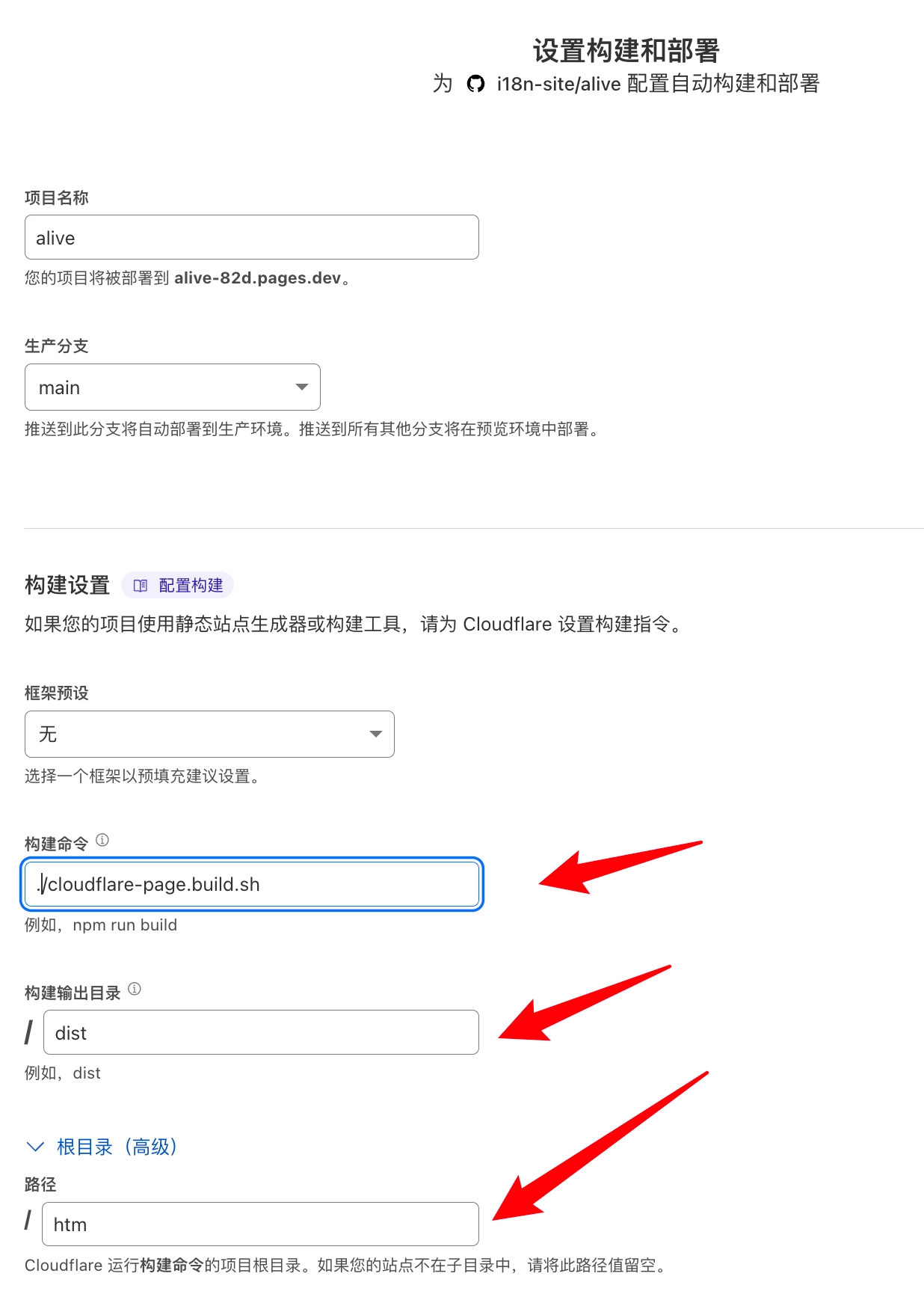
运行 ./sh/conf_init.sh 初始化配置
修改 ./conf/plugin.yml 启用插件
运行 ./plugin.sh 生成 rust 代码
./dev.sh srv 启动后端 , ./srv/ssl/up.sh 启动本地 https 代理
./htm/dev.sh 启动前端
./doc.sh生成文档 (比如 ,./doc.sh alive_api)./htm前端./alive_api/api.proto后端返回数据是 protobuf 格式./srv后端./srv/ssl/up.sh后端的本地 https 代理 (开了才能配合前端调试)./watch监控插件./new.watch.sh xxx新建监控插件./alter报警插件./new.alter.sh xxx新建报警插件./sh/conf_example.sh从实际的配置导出演示的配置文件
可以用 cron-job.org 监控

后续计划暂无排期 , 只是备忘
- 基于报警插件 , 可以对接后端数据库 , 持久化报警日志
- 现在后端返回的数据有
runed,cost_sum,avg10, 可以用展示监控服务访问延时的变化 , 但是前端没做展示 (可以在服务延时异常的时候显示前端警告)