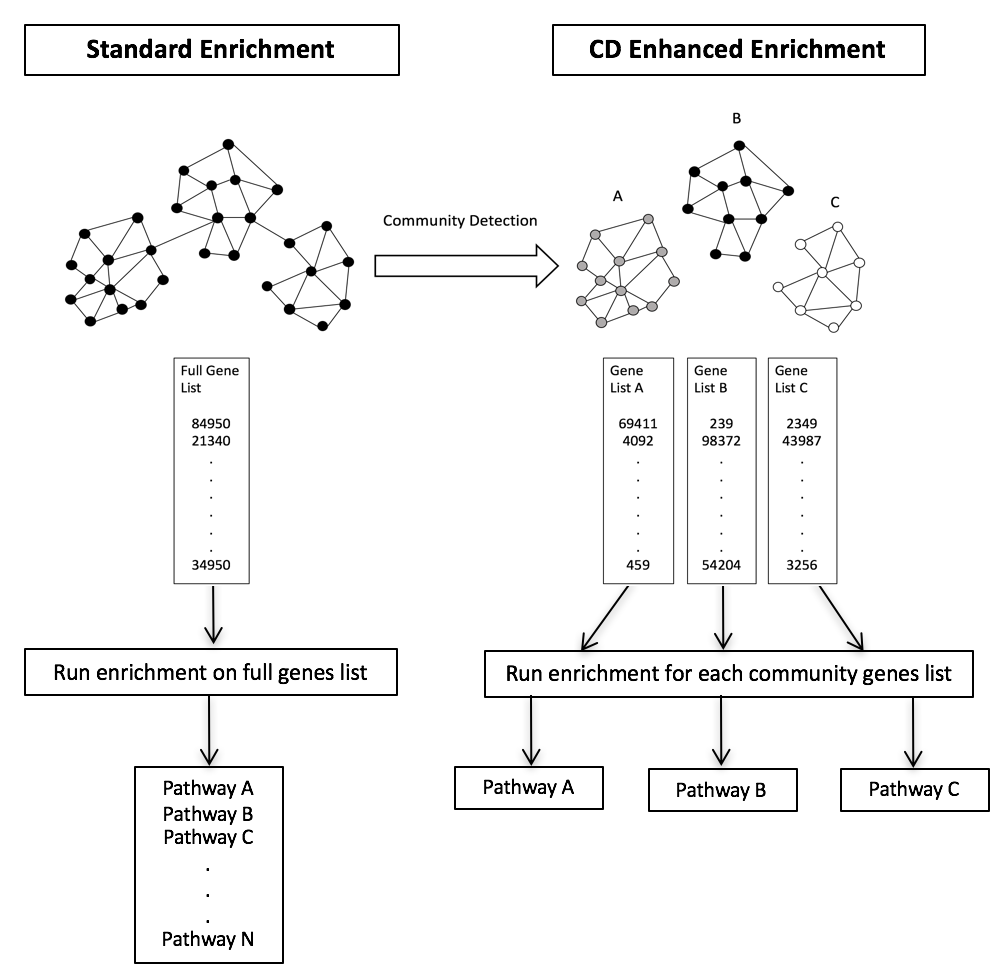
This repository performs gene enrichment analysis using either the KEGG, or PID databases. The experiment is set up to contain both a control and experimental arm where the control arm is enrichment of a gene list of m pathways using only p% of the genes in each pathway with a% additional random genes from the ontology. This gene list is then subjected to enrichment analysis and the relevant enriched pathways are determined. The experimental condition is just like the control except that community detection is performed before enrichment analysis. In particular, one can select Fastgreedy, Walktrap, Infomap, or Multilevel as the possible grouping method. For all methods, the F1-score, false positive ratio, and false negative ratio are returned.
All figures from the simulations are included in the Paper_Figs folder and results from the simulations are included in the Data folder as all_iterations_data.csv.
To reproduce all analyses including simulations and HGSC applications:
# Create and activate reproducible conda environment
conda env create --force --file environment.yml
source activate gea_community_detection
# Data for this project can be downloaded using the script and URL text file
# located in the Data folder. This is required before running the pipeline.
bash Data/data_files.sh
# Reproduce all results
bash Scripts/gea_pipeline.sh-
About the code: Lia Harrington ([email protected])
-
About the project or collaboration: Jennifer Doherty ([email protected]) or Casey Greene at ([email protected]).