{kind=link}
{kind=link}
This is how I understand about attention mechanism.
-
The Background of Attention. Why the attention has been made? For training model with sequential data, researchers naturally think RNN(LSTM, GRU) structure. And it worked well. There is no doubt about the structure since sequential data has recurrence relation. But the problem of RNN architecture is that it precludes parallelization so that computation takes some times. Also RNN has limit of keeping long memory. So the researchers came up with the transformer model which use self-attention(Dense, Linear layer). There is no recurrence relation in attention, also no order. They put positional encoding for order and residual connection for long memory.
-
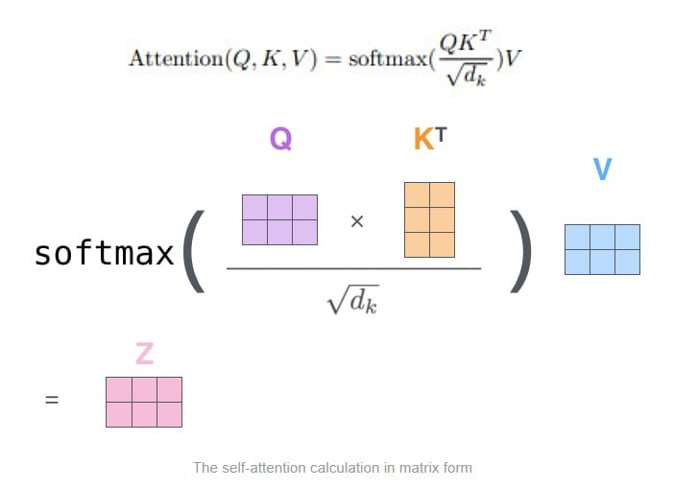
How the self-attention works? The goal is to identify and attend to most important features in input.
- Encode position information
- Extract Query, Key, Value for search
- Compute attention weighting
- Extract features with high attention
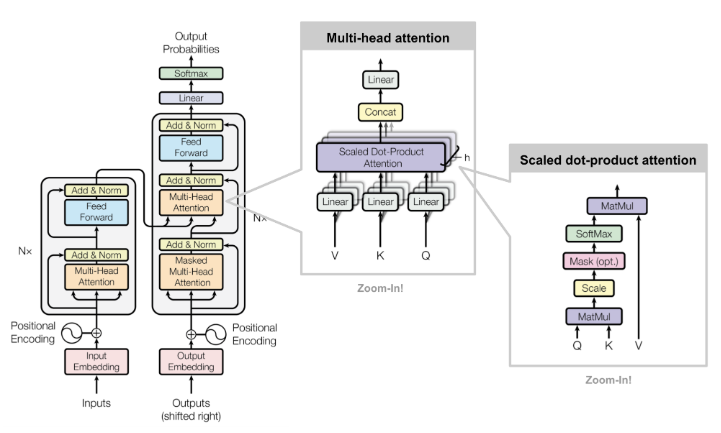
- FYI, Muti-head attention is just Concat(# of heads with self-attention). Also implys that input of attention splits into multiple parts of it.
-
How does Transformer look?
-
Behind Philosophy
-
Unsolved Questions
- Does the Embedding of input learn from data like CBOW, Skip-gram, or does it just fixed random vector?