Kokkos Runtime Auto Tuning with APEX
Kokkos has an API that can be used to construct a tuning context around a computational kernel, declare input variables that define the context state, declare output variables to be tuned, and request output variables when the kernel is executed. APEX includes support to use this API to tune Kokkos kernel parameters running in any execution space, and even switch between execution spaces (i.e. choose between serial or OpenMP depending on the problem size, etc.) or execution policies. For an overview of APEX usage with Kokkos, see Using APEX with Kokkos. For brief overview of tuning support in Kokkos, see the Kokkos 4.5 release briefing slides.
Kokkos can be thought of as an abstraction layer above hardware-specific or model-specific implementations for a given system. In order to provide performance portability, internal parameters are empirically or heuristically hand-tuned to provide "one size fits most" performance, with the goal of minimizing the effect of the abstraction overhead and approximating the performance of an optimized, lower-level implementation. In some cases these hand-tuned parameter choices can be improved upon for different input data sizes or microarchitecture differences. Some kernels may also be written as "generic" solvers that are reused within a library or application, and the same kernel can have different performance behavior depending on where in the code it is called, which execution space architecture it is run on (CUDA, HIP, SYCL, OpenMP, OpenMP Offload, etc.), and with what inputs. In addition, some assumptions (i.e. 100% occupancy is always ideal) are not true for some cases, and sometimes the best performing settings don't make intuitive sense. By modifying the internal parametric settings at runtime, we can explore the search space and hopefully find settings yielding better performance.
Can Kokkos auto-tuning be done by just tuning parameters of the specific Kokkos execution spaces, e.g., CUDA performance parameters of chunks, OpenMP parameters of chunks per thread, schedule type? The answer to this could be “Yes, but there are downsides to this in terms of portability to new unknown /non-existing platforms". This article focuses specifically on tuning of Kokkos parameters in a way that is portable across different Kokkos backends. The contribution is not simply that parameter values can be reused across Kokkos backends but the process of doing the tuning is also portable.
"Auto-tuning" can be performed either offline or online. In offline tuning, the parameter space is explored outside of a full application context, and the program runs to completion with a given combination of parametric settings. After executing the application multiple times with values from the parameter space (either a sampled set or exhaustively), the "best performing" parameter combination is cached for later use for the full application. In online tuning, the parameter space is explored inside a full application context, and the settings are constantly updated until convergence or the end of execution. In either case, if the search space has been sufficiently explored by the search algorithm (i.e. the search has converged on a solution), those results can be cached and subsequently used for future executions with the same experiment configuration. The benefit of online tuning is that the overhead of offline searching is avoided. The downsides of online tuning include being limited to parameters that can only be changed at runtime (i.e. GPU block tiling factors but not launch bounds) and the inclusion of runtime overhead (exploring parameter combinations with worse performance than the default) which can potentially slow down the application - but at least the tuning time itself is yielding productive results, and the settings are tuned to the specific problem at hand. Our experiments have shown that in most cases the actively tuning case still performs faster than the default, untuned configuration despite the search overhead.
Several examples of online and offline tuning have been demonstrated, including [Bari2016, Beckingsale2017, Balaprakash2018, Wagle2019, Wood2019, Liu2021] as just a few recent examples. Even just the subset of CUDA auto-tuning is fairly rich. This work is similar to those ideas. The APEX library [Huck2015, Huck2022] used in these examples has included runtime parameter optimization since its initial design [Huck2013]. While initially designed for the HPX runtime system, it has since been extended to tune OpenMP and Kokkos parameters, as well as any arbitrary library or application parameters (small message network coalescing parameters, for example). Why is Kokkos-specific (performance portable) auto-tuning using a combination of online auto-tuning and offline auto-tuning beneficial? Unlike tuning CUDA programs, which are focused on parameters of an NVIDIA GPU, we need online tuning even more for Kokkos because Kokkos is a heterogeneous programming library for a CPU+GPU – different Kokkos backends interoperate differently and heterogeneous processing means optimal parameters may change during application execution due to unpredictable OS events.
In addition to the Kokkos internal tuning support, any arbitrary runtime parameter can be tuned with the Kokkos tuning API and the APEX search strategies. Some rudimentary examples are described in this article, but theoretically using this interface we can (and plan to) reproduce the offline tuning result from Automatic performance tuning for Albany Land Ice [2023: Carlson, Watkins and Tezaur] using this support. The variables tuned in that example include:
- Smoother Type: {Multi-threaded (MT) Gauss-Seidel, Two-stage Gauss-Seidel, Chebyshev}
- Number of sweeps: {1, 2} [MT Gauss-Seidel, Two-stage Gauss-Seidel]
- Damping factor: [0.8, 1.2] [MT Gauss-Seidel]
- Inner damping factor: [0.8, 1.2] [Two-stage Gauss-Seidel]
- Chebyshev degree: {1, 2, 3, 4, 5, 6} [Chebyshev]
- Eigenvalue ratio: [10.0, 50.0] [Chebyshev]
- Maximum chebyshev iterations: {5, 6, ..., 100} [Chebyshev]
In that paper, the authors used offline tuning with GPTune to find parametric settings that resulted in up to 1.5x speedup over manually tuned smoothers for some corner cases, and a 1.2x speedup on average. We believe we can find a similar result with runtime auto tuning...we shall see. This particular use case is very interesting and challenging, in that it is a nested search problem. In some particular order, the search has to find optimal settings for each of the three smoothers, and the fastest implementation of the three tuned smoothers is found. This search involves an unsortable set of smoother names, continuous variables and discrete sets of integer variables. In addition, we should be able to optionally tune the launch parameters of the Kokkos kernels used by each of the solvers.
After APEX has converged on a search result, the results are cached for future runs with the same problem configuration (Kokkos kernel labels, loop sizes, code locations). In that way, APEX can also replicate the behavior of an offline search.
The Kokkos execution spaces (*exceptions noted) have support for tuning internal Kokkos parameters for:
- Range policy occupancy (*CUDA only)
- MDRange policy tiling factors (translates to block x,y,z dimensions) and occupancy (*CUDA only for occupancy)
- Team policy team size and vector length
To enable the internal tuning support, configure Kokkos with the -DKokkos_ENABLE_TUNING=ON CMake variable and use the --kokkos-tune-internals runtime flag for your executable.
To build and run the examples in this article, do the following (your compilers and Kokkos architectures/options may vary - These examples were built and run on a 32 core Intel(R) Xeon(R) Gold 6226R CPU @ 2.90GHz with 2 HW threads per core, and three NVIDIA GPUs, including a Tesla P100-PCIE-16GB, Tesla V100-PCIE-16GB, and an A100 80GB PCIe):
git clone https://github.com/khuck/apex-kokkos-tuning.git
cd apex-kokkos-tuning
cmake -B build \
-DCMAKE_BUILD_TYPE=RelWithDebInfo \
-DCMAKE_CXX_COMPILER=g++ \
-DCMAKE_C_COMPILER=gcc \
-DCMAKE_INSTALL_PREFIX=`pwd`/install \
-DKokkos_ENABLE_TUNING=ON \
-DKokkos_ENABLE_OPENMP=ON \
-DKokkos_ENABLE_SERIAL=ON \
-DKokkos_ENABLE_CUDA=ON \
-DKokkos_ENABLE_CUDA_LAMBDA=ON \
-DKokkos_ARCH_NATIVE=ON \
-DAPEX_WITH_CUDA=TRUE \
-DCUDAToolkit_ROOT=${CUDA} \
.
cmake --build build --parallel 16
cmake --build build --parallel --target install
The only APEX-specific CMake variables are the -DAPEX_WITH_CUDA=TRUE and -DCUDAToolkit_ROOT=${CUDA} options, where ${CUDA} is assumed to be the path to a CUDA installation.
There are dozens of APEX runtime options, however there are only a few needed to enable Kokkos support and the runtime auto tuning. For convenience, we will set the $PATH environment variable to include the installation bin directory and the directory with the test examples:
export PATH=`pwd`/install/bin:`pwd`/build/tests:${PATH}
at runtime, we will use the apex_exec wrapper script to configure APEX, and a handful of options (only those discussed in the article are listed below):
[khuck@voltar apex-kokkos-tuning]$ apex_exec
Usage:
apex_exec <APEX options> executable <executable options>
where APEX options are zero or more of:
--apex:help show this usage message
--apex:csv enable csv text output
--apex:tasktree enable tasktree output
(python3 with Pandas required for post-processing)
--apex:gtrace enable Google Trace Events output
--apex:kokkos enable Kokkos support
--apex:kokkos-tuning enable Kokkos runtime autotuning support
--apex:kokkos-fence enable Kokkos fences for async kernels
--apex:kokkos-counters enable Kokkos counters for allocations, deep copies, and marker events
--apex:cuda enable CUDA/CUPTI measurement (default: off)
--apex:cuda-counters enable CUDA/CUPTI counter support (default: off)
--apex:cuda-details enable per-kernel statistics where available (default: off)
The --apex:kokkos-fence option will control whether Kokkos returns from an asynchronous kernel launch immediately (default behavior) or will wait until the asynchronous execution has finished to return (typical behavior when profiling is enabled). Without this option, APEX only measures how long it takes to launch a kernel. With this option enabled, the measurement includes the time spent executing the kernel. However, this fence can change the asynchronous behavior of the application. By default, Kokkos does not fence after a kernel launch. Fencing makes for simpler measurement, but enabling APEX support for measuring the specific execution space (OpenMP target offload, OpenACC, CUDA, HIP, SYCL, HPX) also enables the measurement of asynchronous execution. It comes down to user preference and what the user is trying to measure.
In order to enable Kokkos internal tuning for some examples, we will use the --kokkos-tune-internals runtime flag, but keep in mind that this is only needed to tune Kokkos internals - some examples will tune explicitly. The difference will hopefully become obvious as we go along.
Other environment variables are helpful or even necessary when performing the runtime auto tuning:
| Variable | Values | Description |
|---|---|---|
APEX_KOKKOS_VERBOSE |
0,1 | enable verbose output - useful for debugging purposes, default is 0 |
APEX_KOKKOS_TUNING_WINDOW |
non-zero positive integer | how many times to evaluate each configuration (minimum time is chosen as representative), default is 5 |
APEX_KOKKOS_TUNING_POLICY |
simulated_annealing, genetic_search, exhaustive, random, nelder_mead, automatic
|
search strategy option, automatic is the default. |
For Kokkos runtime auto tuning, simulated_annealing seems to provide a good compromise between faster convergence and avoiding a local minima. genetic_search can be faster to converge when dealing with many different output variables to tune (i.e. 6D View Deep Copy). nelder_mead is the best search strategy to use for continuous variables. The automatic setting will use a heuristic to choose an appropriate search strategy based on variable types. The basic logic for automatic is:
- if there is one variable, and it is a set of categoricals, use exhaustive.
- if there is one variable and it is an integer range, use simulated annealing.
- if there is one variable and it is a continuous range, use nelder mead.
- if there are more than one variable, and any of them are categorical sets, then use genetic search
- if any of them are integer ranges, use simulated annealing
- if all variables are continuous ranges, use nelder mead.
There are other OpenMP environment variables that are requested by the Kokkos runtime:
| Variable | Values | Description |
|---|---|---|
OMP_NUM_THREADS |
1-N | the number of OpenMP CPU threads to use, where N is the number of hardware threads available on the machine. For more information, see https://www.openmp.org/spec-html/5.1/openmpse59.html#x325-5000006.2 |
OMP_PROC_BIND |
true, false, primary, close, spread
|
For details, see https://www.openmp.org/spec-html/5.1/openmpse61.html#x327-5020006.4 |
OMP_PLACES |
threads, cores, ll_caches, numa_domains, sockets, processor list |
For details, see https://www.openmp.org/spec-html/5.1/openmpse62.html#x328-5030006.5 |
The examples in this section are from https://github.com/khuck/apex-kokkos-tuning. In all of the examples, we are executing the kernels at least Impl::max_iterations times (set to 1000) to allow the longer search strategies (like exhaustive) to converge. Keep in mind that some examples will not converge when tuned exhaustively - for example, the deep_copy_6.cpp example has to search 11^6 == 1,771,561 tiling factor combinations to converge an exhaustive search.
This example demonstrates how the internal tuning can be used to set the desired occupancy for a kernel. Refer to the example https://github.com/khuck/apex-kokkos-tuning/blob/main/tests/occupancy.cpp for the following code. In this example, we are constructing a standard Kokkos::RangePolicy, then creating a new Policy with traits, requesting an auto tuned occupancy. This example will explore the occupancy (some fraction of cudaDeviceProp.maxThreadsPerMultiProcessor, although slightly more complicated than that) from 0.05 to 1.0 in step sizes of 0.05. To make a fair test, if tuning is enabled at runtime we use the Kokkos::Experimental::DesiredOccupancy policy, otherwise we use the default RangePolicy.
see lines 60-62 of occupancy.cpp
Kokkos::RangePolicy<> p(0, left.extent(0));
auto const p_occ = Kokkos::Experimental::prefer(
p, Kokkos::Experimental::DesiredOccupancy{Kokkos::AUTO});To run the example without tuning, we do (--apex:kokkos-fence is optional, but by enabling it we measure the total time for the kernel and not just the time to launch the kernel):
apex_exec --apex:kokkos --apex:kokkos-fence occupancy
and get output something like the following:
[khuck@voltar apex-kokkos-tuning]$ apex_exec --apex:kokkos --apex:kokkos-fence occupancy
___ ______ _______ __
/ _ \ | ___ \ ___\ \ / /
/ /_\ \| |_/ / |__ \ V /
| _ || __/| __| / \
| | | || | | |___/ /^\ \
\_| |_/\_| \____/\/ \/
APEX Version: v2.6.5-e44221a3-develop
Built on: 15:35:38 Sep 10 2024 (RelWithDebInfo)
C++ Language Standard version : 201703
GCC Compiler version : 8.5.0 20210514 (Red Hat 8.5.0-20)
Configured features: Pthread, CUDA, PLUGINS
Executing command line: occupancy
Kokkos Version: 4.4.99
Compiler:
KOKKOS_COMPILER_GNU: 850
KOKKOS_COMPILER_NVCC: 1170
Architecture:
CPU architecture: none
Default Device: N6Kokkos4CudaE
GPU architecture: AMPERE80
platform: 64bit
Atomics:
Vectorization:
KOKKOS_ENABLE_PRAGMA_IVDEP: no
KOKKOS_ENABLE_PRAGMA_LOOPCOUNT: no
KOKKOS_ENABLE_PRAGMA_UNROLL: no
KOKKOS_ENABLE_PRAGMA_VECTOR: no
Memory:
Options:
KOKKOS_ENABLE_ASM: yes
KOKKOS_ENABLE_CXX17: yes
KOKKOS_ENABLE_CXX20: no
KOKKOS_ENABLE_CXX23: no
KOKKOS_ENABLE_CXX26: no
KOKKOS_ENABLE_DEBUG_BOUNDS_CHECK: no
KOKKOS_ENABLE_HWLOC: no
KOKKOS_ENABLE_LIBDL: yes
Host Parallel Execution Space:
KOKKOS_ENABLE_OPENMP: yes
OpenMP Runtime Configuration:
Kokkos::OpenMP thread_pool_topology[ 1 x 8 x 1 ]
Device Execution Space:
KOKKOS_ENABLE_CUDA: yes
Cuda Options:
KOKKOS_ENABLE_CUDA_LAMBDA: yes
KOKKOS_ENABLE_CUDA_LDG_INTRINSIC: yes
KOKKOS_ENABLE_CUDA_RELOCATABLE_DEVICE_CODE: no
KOKKOS_ENABLE_CUDA_UVM: no
KOKKOS_ENABLE_IMPL_CUDA_MALLOC_ASYNC: yes
Cuda Runtime Configuration:
macro KOKKOS_ENABLE_CUDA : defined
macro CUDA_VERSION = 11070 = version 11.7
Kokkos::Cuda[ 0 ] NVIDIA A100 80GB PCIe capability 8.0, Total Global Memory: 79.15 GiB, Shared Memory per Block: 48 KiB : Selected
Kokkos::Cuda[ 1 ] Tesla V100-PCIE-16GB capability 7.0, Total Global Memory: 15.77 GiB, Shared Memory per Block: 48 KiB
Kokkos::Cuda[ 2 ] Tesla P100-PCIE-16GB capability 6.0, Total Global Memory: 15.89 GiB, Shared Memory per Block: 48 KiB
Not Tuning!
No Kokkos allocation Leaks on rank 0!
Command line: occupancy
Start Date/Time: 10/09/2024 15:39:13
Elapsed time: 6.87937 seconds
Total processes detected: 1
HW Threads detected on rank 0: 1
Worker Threads observed on rank 0: 1
Available CPU time on rank 0: 6.87937 seconds
Available CPU time on all ranks: 6.87937 seconds
Counter : #samp | mean | max
--------------------------------------------------------------------------------
1 Minute Load average : 7 2.00 2.00
CPU Guest % : 6 0.00 0.00
CPU I/O Wait % : 6 1.53 1.69
CPU IRQ % : 6 0.15 0.16
CPU Idle % : 6 69.22 70.62
CPU Nice % : 6 0.00 0.00
CPU Steal % : 6 0.00 0.00
CPU System % : 6 1.92 2.80
CPU User % : 6 27.12 28.10
CPU soft IRQ % : 6 0.07 0.08
DRAM Energy : 6 11.50 13.00
Package-0 Energy : 6 124.67 126.00
status:Threads : 7 10.71 11.00
status:VmData kB : 7 1.08e+05 1.15e+05
status:VmExe kB : 7 864.00 864.00
status:VmHWM kB : 7 1.18e+05 1.37e+05
status:VmLck kB : 7 0.00 0.00
status:VmLib kB : 7 1.27e+04 1.27e+04
status:VmPTE kB : 7 421.71 464.00
status:VmPeak kB : 7 1.54e+08 1.80e+08
status:VmPin kB : 7 0.00 0.00
status:VmRSS kB : 7 1.18e+05 1.37e+05
status:VmSize kB : 7 1.54e+08 1.80e+08
status:VmStk kB : 7 136.00 136.00
status:VmSwap kB : 7 0.00 0.00
status:nonvoluntary_ctxt_switches : 7 45.71 90.00
status:voluntary_ctxt_switches : 7 16.14 18.00
--------------------------------------------------------------------------------
CPU Timers : #calls| mean | total
--------------------------------------------------------------------------------
APEX MAIN : 1 6.88 6.88
int apex_preload_main(int, char**, char**) : 1 6.88 6.88
Kokkos::parallel_for [Cuda, Dev:0] Bench : 1000 0.01 6.58
Kokkos::parallel_for [Cuda, Dev:0] Kokkos::View::in… : 1 0.00 0.00
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Total timers : 1002
...so we had a runtime of 6.87 seconds. If we run again with tuning enabled:
export APEX_KOKKOS_TUNING_WINDOW=2
export APEX_KOKKOS_TUNING_POLICY=simulated_annealing
apex_exec --apex:kokkos-tuning --apex:kokkos --apex:kokkos-fence --apex:tasktree occupancy --kokkos-tune-internals
we should get output like this (most of the superfluous noise removed):
[khuck@voltar apex-kokkos-tuning]$ apex_exec --apex:kokkos-tuning --apex:kokkos --apex:kokkos-fence --apex:tasktree occupancy --kokkos-tune-internals
...
Tuning!
New best! 1.9649e+06 k: 1 kmax: 400 temp: 0.0025, Bench: 40
New best! 1.95618e+06 k: 2 kmax: 400 temp: 0.005, Bench: 40
New best! 1.93264e+06 k: 3 kmax: 400 temp: 0.0075, Bench: 30
New best! 1.93043e+06 k: 6 kmax: 400 temp: 0.015, Bench: 30
New best! 1.92966e+06 k: 14 kmax: 400 temp: 0.035, Bench: 35
New best! 1.92404e+06 k: 17 kmax: 400 temp: 0.0425, Bench: 20
New best! 1.91874e+06 k: 31 kmax: 400 temp: 0.0775, Bench: 20
New best! 1.91457e+06 k: 50 kmax: 400 temp: 0.125, Bench: 20
APEX: Tuning has converged for session 1.
[20]
No Kokkos allocation Leaks on rank 0!
Command line: occupancy --kokkos-tune-internals
Start Date/Time: 10/09/2024 15:43:01
Elapsed time: 2.21315 seconds
Total processes detected: 1
HW Threads detected on rank 0: 1
Worker Threads observed on rank 0: 1
Available CPU time on rank 0: 2.21315 seconds
Available CPU time on all ranks: 2.21315 seconds
Counter : #samp | mean | max
--------------------------------------------------------------------------------
1 Minute Load average : 3 14.67 21.00
CPU Guest % : 2 0.00 0.00
CPU I/O Wait % : 2 1.51 1.58
CPU IRQ % : 2 0.16 0.16
CPU Idle % : 2 68.90 69.38
CPU Nice % : 2 0.00 0.00
CPU Steal % : 2 0.00 0.00
CPU System % : 2 1.58 1.78
CPU User % : 2 27.75 28.39
CPU soft IRQ % : 2 0.12 0.14
DRAM Energy : 2 12.50 13.00
Package-0 Energy : 2 134.50 136.00
[kokkos.kernel_name:Bench,kokkos.kernel_type:parall… : 1 0.00 0.00
[kokkos.kernel_name:Bench,kokkos.kernel_type:parall… : 1000 20.37 45.00
status:Threads : 3 10.33 11.00
status:VmData kB : 3 9.94e+04 1.15e+05
status:VmExe kB : 3 864.00 864.00
status:VmHWM kB : 3 9.34e+04 1.37e+05
status:VmLck kB : 3 0.00 0.00
status:VmLib kB : 3 1.27e+04 1.27e+04
status:VmPTE kB : 3 354.67 452.00
status:VmPeak kB : 3 1.20e+08 1.80e+08
status:VmPin kB : 3 0.00 0.00
status:VmRSS kB : 3 9.34e+04 1.37e+05
status:VmSize kB : 3 1.20e+08 1.80e+08
status:VmStk kB : 3 136.00 136.00
status:VmSwap kB : 3 0.00 0.00
status:nonvoluntary_ctxt_switches : 3 18.00 34.00
status:voluntary_ctxt_switches : 3 13.67 18.00
--------------------------------------------------------------------------------
CPU Timers : #calls| mean | total
--------------------------------------------------------------------------------
APEX MAIN : 1 2.21 2.21
int apex_preload_main(int, char**, char**) : 1 2.21 2.21
Kokkos::parallel_for [Cuda, Dev:0] Bench : 1000 0.00 2.00
Kokkos::parallel_for [Cuda, Dev:0] Kokkos::View::in… : 1 0.00 0.00
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Total timers : 1002
...giving us a runtime of 2.21 seconds! So what is happening here? We can see some verbose tuning output from the tuner, giving us progress on different occupancy settings and their resulting runtime, as we converge:
New best! 1.9649e+06 k: 1 kmax: 400 temp: 0.0025, Bench: 40
New best! 1.95618e+06 k: 2 kmax: 400 temp: 0.005, Bench: 40
New best! 1.93264e+06 k: 3 kmax: 400 temp: 0.0075, Bench: 30
New best! 1.93043e+06 k: 6 kmax: 400 temp: 0.015, Bench: 30
New best! 1.92966e+06 k: 14 kmax: 400 temp: 0.035, Bench: 35
New best! 1.92404e+06 k: 17 kmax: 400 temp: 0.0425, Bench: 20
New best! 1.91874e+06 k: 31 kmax: 400 temp: 0.0775, Bench: 20
New best! 1.91457e+06 k: 50 kmax: 400 temp: 0.125, Bench: 20
APEX: Tuning has converged for session 1.
So after 50 tuning steps, the internal occupancy setting converged to 20. The search continued for 400 total steps, but a better setting was not discovered. Note also that the convergence settings are written out to a YAML file for future executions, and can be used as cached results. If we execute a third time without deleting those cached results, we should in our output Reading cache of Kokkos tuning results from: './apex_converged_tuning.yaml', and the runtime is slightly faster: 2.15 seconds in this case. That is because the overhead of runtime searching has been removed:
...
Reading cache of Kokkos tuning results from: './apex_converged_tuning.yaml'
...
Command line: occupancy --kokkos-tune-internals
Start Date/Time: 10/09/2024 15:47:36
Elapsed time: 2.14919 seconds
Total processes detected: 1
HW Threads detected on rank 0: 1
Worker Threads observed on rank 0: 1
Available CPU time on rank 0: 2.14919 seconds
Available CPU time on all ranks: 2.14919 seconds
...
Obviously this is a contrived example, with a simple kernel. However, some applications (the ArborX DBScan algorithm, for example) have found that occupancy values less than the maximum do provide a 10-20% speedup on some CUDA architectures.
For completeness, we can try the tuning with an exhaustive search strategy:
rm apex_converged_tuning.yaml
export APEX_KOKKOS_TUNING_WINDOW=2
export APEX_KOKKOS_TUNING_POLICY=exhaustive
apex_exec --apex:kokkos-tuning --apex:kokkos --apex:kokkos-fence --apex:tasktree occupancy --kokkos-tune-internals
which gives output similar to:
New best! 2.98381e+06 k: 1 kmax: 20, Bench: 5
New best! 2.98066e+06 k: 2 kmax: 20, Bench: 10
New best! 2.04213e+06 k: 3 kmax: 20, Bench: 15
New best! 1.94301e+06 k: 4 kmax: 20, Bench: 20
New best! 1.93743e+06 k: 5 kmax: 20, Bench: 25
APEX: Tuning has converged for session 1.
...a slightly different convergence value of 25, but close in performance to the simulated annealing search convergence execution time of 1.91457e+06 nanoseconds, showing that with small kernels on noisy systems, tuning can be somewhat inexact although within statistical error bounds. If we add the --apex:gtrace flag and collect a trace, we can load it into Perfetto and see what is happening in the search:

Once the occupancy value increases to 85 (testing all values from 5 to 100), the execution time for the kernel jumps from 2ms to 6.5ms. In this case, any occupancy value between 20 and 80 would provide a better execution time than the default occupancy of 100.
The --apex:tasktree option will generate an output CSV file called apex_tasktree.csv. That file can be post-processed with the apex-treesummary.py script, for example:
[khuck@voltar apex-kokkos-tuning]$ apex-treesummary.py --ascii
building common tree...
1-> 2.146 - 100.000% [1] {min=2.146 (2), max=2.146 (2), median=2.146, mean=2.146, threads=1} APEX MAIN
1 |-> 2.146 - 99.993% [1] {min=2.146 (2), max=2.146 (2), median=2.146, mean=2.146, threads=1} int apex_preload_main(int, char**, char**)
1 | |-> 1.934 - 90.099% [1000] {min=1.934 (1), max=1.934 (1), median=1.934, mean=0.002, threads=1} Kokkos::parallel_for [Cuda, Dev:0] Bench
1 | |-> 0.000 - 0.006% [1] {min=0.000 (0), max=0.000 (0), median=0.000, mean=0.000, threads=1} Kokkos::parallel_for [Cuda, Dev:0] Kokkos::View::initialization [process_this] via memset
5 total graph nodes
Task tree also written to tasktree.txt.
The second and third examples demonstrate how to set up an explicit tuning situation using the helper functions in the tuning_playground.hpp header file. The first example, 1d_stencil.cpp will choose between three different execution spaces: Serial, OpenMP with dynamic schedule, and OpenMP with static schedule. The example uses the same lambda for all three calls to the Kokkos::parallel_for loops. The fastest_of() function will take a label for the context, the count of lambda/function instances, and a variable number of Implementations (assumed to be the same number as the count parameter passed in). This example does not require the --kokkos-tune-internals flag, because this is an explicitly tuned example - using the search strategy, APEX will evaluate all three Implementations and converge on the one that takes the least amount of time.
Let's look at the fastest_of helper function in the header. The important lines to point out are making the input and output variable values, constructing the context, setting the input values, requesting the next output value to test, and ending the context.
Running the 1D example without tuning results in rotating between the three Implementations. With tuning, and with only 3 values to test, it should converge quickly. The output should include something like this (converging to the static OpenMP Implementation):
New best! 69790 k: 1 kmax: 3, choose_one: 0
New best! 41681 k: 2 kmax: 3, choose_one: 1
New best! 23844 k: 3 kmax: 3, choose_one: 2
APEX: Tuning has converged for session 1.
The 2D stencil example is more interesting. The 2D case only choses between two different Implementations, Serial and OpenMP. It also uses an MDRange policy, because the View is 2 dimensional. If we run with a larger window and with exhaustive tuning, we'll see that the search quickly converges to the OpenMP Implementation:
[khuck@voltar apex-kokkos-tuning]$ rm apex_converged_tuning.yaml
[khuck@voltar apex-kokkos-tuning]$ APEX_KOKKOS_TUNING_POLICY=exhaustive
[khuck@voltar apex-kokkos-tuning]$ APEX_KOKKOS_TUNING_WINDOW=10
[khuck@voltar apex-kokkos-tuning]$ apex_exec --apex:kokkos-tuning --apex:kokkos --apex:kokkos-fence 2d_stencil
...
New best! 27798 k: 1 kmax: 2, choose_one: 0
New best! 13565 k: 2 kmax: 2, choose_one: 1
APEX: Tuning has converged for session 1.
...
CPU Timers : #calls| mean | total
--------------------------------------------------------------------------------
APEX MAIN : 1 0.22 0.22
int apex_preload_main(int, char**, char**) : 1 0.22 0.22
Kokkos::parallel_for [OpenMP] openmp 2D heat_transf… : 990 0.00 0.01
Kokkos::parallel_for [Serial] serial 2D heat_transf… : 10 0.00 0.00
Kokkos::parallel_for [OpenMP] Kokkos::View::initial… : 1 0.00 0.00
Kokkos::parallel_for [OpenMP] Kokkos::View::initial… : 1 0.00 0.00
Kokkos deep copy: Host left stencil -> Host right s… : 1 0.00 0.00
--------------------------------------------------------------------------------
We can see that the search converged after 20 iterations, then used the faster OpenMP Implementation for the remainder of the iterations.
However, if we add the --kokkos-tune-internals flag, shrink the tuning window, and use the genetic search, APEX will not only choose between the two Implementations but it will also tune the tiling factors for the MDRange policy for each implementation. We should get output like this:
[khuck@voltar apex-kokkos-tuning]$ export APEX_KOKKOS_TUNING_WINDOW=1
[khuck@voltar apex-kokkos-tuning]$ APEX_KOKKOS_TUNING_POLICY=genetic_search
[khuck@voltar apex-kokkos-tuning]$ rm apex_converged_tuning.yaml
[khuck@voltar apex-kokkos-tuning]$ apex_exec --apex:kokkos-tuning --apex:kokkos --apex:kokkos-fence 2d_stencil --kokkos-tune-internals
...
New best! 659620 k: 1 kmax: 196, serial 2D heat_transfer_tile_size_0: 0.466200, serial 2D heat_transfer_tile_size_1: 0.932400
New best! 790730 k: 1 kmax: 16, choose_one: 0
New best! 304839 k: 1 kmax: 196, openmp 2D heat_transfer_tile_size_0: 0.466200, openmp 2D heat_transfer_tile_size_1: 0.932400
New best! 339354 k: 2 kmax: 16, choose_one: 1
New best! 173227 k: 2 kmax: 196, openmp 2D heat_transfer_tile_size_0: 0.066600, openmp 2D heat_transfer_tile_size_1: 0.666000
New best! 190214 k: 3 kmax: 16, choose_one: 1
New best! 105518 k: 9 kmax: 196, openmp 2D heat_transfer_tile_size_0: 0.333000, openmp 2D heat_transfer_tile_size_1: 0.865800
New best! 119521 k: 17 kmax: 16, choose_one: 1
New best! 654784 k: 15 kmax: 196, serial 2D heat_transfer_tile_size_0: 0.799200, serial 2D heat_transfer_tile_size_1: 0.732600
New best! 115930 k: 42 kmax: 16, choose_one: 1
New best! 620102 k: 27 kmax: 196, serial 2D heat_transfer_tile_size_0: 0.865800, serial 2D heat_transfer_tile_size_1: 0.666000
New best! 616592 k: 32 kmax: 196, serial 2D heat_transfer_tile_size_0: 0.333000, serial 2D heat_transfer_tile_size_1: 0.865800
New best! 595983 k: 35 kmax: 196, serial 2D heat_transfer_tile_size_0: 0.333000, serial 2D heat_transfer_tile_size_1: 0.666000
New best! 594326 k: 39 kmax: 196, serial 2D heat_transfer_tile_size_0: 0.333000, serial 2D heat_transfer_tile_size_1: 0.865800
APEX: Tuning has converged for session 3.
[0.333000,0.865800]
New best! 115013 k: 181 kmax: 16, choose_one: 1
New best! 112880 k: 182 kmax: 16, choose_one: 1
New best! 112041 k: 185 kmax: 16, choose_one: 1
New best! 111905 k: 192 kmax: 16, choose_one: 1
New best! 594212 k: 101 kmax: 196, serial 2D heat_transfer_tile_size_0: 0.333000, serial 2D heat_transfer_tile_size_1: 0.666000
New best! 589661 k: 104 kmax: 196, serial 2D heat_transfer_tile_size_0: 0.466200, serial 2D heat_transfer_tile_size_1: 0.666000
New best! 109093 k: 228 kmax: 16, choose_one: 1
New best! 108569 k: 229 kmax: 16, choose_one: 1
New best! 108458 k: 231 kmax: 16, choose_one: 1
APEX: Tuning has converged for session 2.
[0.466200,0.666000]
APEX: Tuning has converged for session 1.
[1]
What's happening? The search first converges on the best tiling factors for the OpenMP Implementation. Then the tiling factors for the Serial Implementation are found. Finally, once those two searches have concluded the choice of the OpenMP implementation is made, and the example uses OpenMP with tuned tiling factors for the remainder of the run.
The "I don't know, just matrix multiply" example is similar to the 2D stencil example, but rather than search for the best between two execution space implementations, it searches between two different policies for the default execution space (CUDA in this configuration) - either the MDRange or Team policy. Each policy is also tuned internally when the --kokkos-tune-internals flag is used, so the final converged search result should be the MDRange policy tuned with tuned tiling factors. To see what the tiling factors are with the cached converged tuning results, use the --apex:cuda --apex:cuda-details --apex:cuda-counters flags (see the Deep Copy example, next). Here's what a trace of this example looks like:
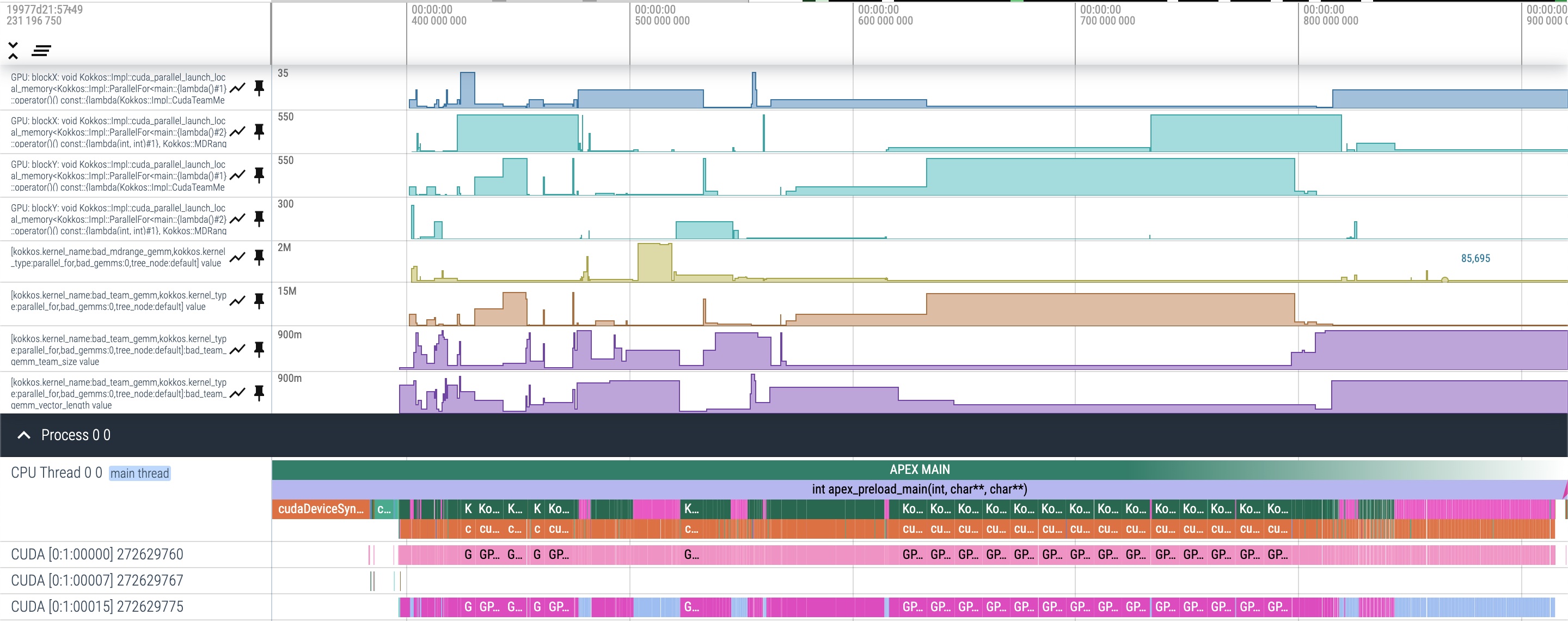
While it is a little difficult to see what is happening, the pinned metrics in the top half of the trace show the Team block.X, MDRange block.X, Team block.Y, MDRange block.Y, MDRange time, Team time, Team size, and Team vector length values. Below that, a timeline shows the kernel execution call stacks on the CPU and the resulting device times on three different streams, including some very bad choices in the middle third of the runtime. Once the search converges, the kernel runtimes are relatively short.
The deep copy examples exclusively use internal tuning. Kokkos implements deep copy operations as a Kokkos::parallel_for loop with an Kokkos::MDRange policy. Which means those copies can be tuned as well! There are 5 deep copy examples, from 2D through 6D Kokkos::View objects. For example, tuning the 2D example will result in tiling factors of [0.399600,0.799200]. But what does that mean? Those values translate to CUDA block X,Y dimensions. We can capture those with additional APEX flags, --apex:cuda --apex:cuda-details --apex:cuda-counters. In the APEX output, we can see that APEX explored different block X,Y values (the Z values stay constant at 1):
Counter : #samp | mean | max
--------------------------------------------------------------------------------
GPU: blockX: void Kokkos::Impl::cuda_parallel_launc… : 2000 12.13 512.00
GPU: blockY: void Kokkos::Impl::cuda_parallel_launc… : 2000 31.42 128.00
GPU: blockZ: void Kokkos::Impl::cuda_parallel_launc… : 2000 1.00 1.00
...resulting in different grid values:
GPU: gridX: void Kokkos::Impl::cuda_parallel_launch… : 2000 13.74 100.00
GPU: gridY: void Kokkos::Impl::cuda_parallel_launch… : 2000 6.14 100.00
GPU: gridZ: void Kokkos::Impl::cuda_parallel_launch… : 2000 1.00 1.00
If we re-run with the cached values, we will see what those converged values were:
GPU: blockX: void Kokkos::Impl::cuda_parallel_launc… : 2000 8.00 8.00
GPU: blockY: void Kokkos::Impl::cuda_parallel_launc… : 2000 32.00 32.00
GPU: blockZ: void Kokkos::Impl::cuda_parallel_launc… : 2000 1.00 1.00
GPU: gridX: void Kokkos::Impl::cuda_parallel_launch… : 2000 13.00 13.00
GPU: gridY: void Kokkos::Impl::cuda_parallel_launch… : 2000 4.00 4.00
GPU: gridZ: void Kokkos::Impl::cuda_parallel_launch… : 2000 1.00 1.00
If we re-run without the --kokkos-tune-internals flag, we see what the default heuristic values would have been:
GPU: blockX: void Kokkos::Impl::cuda_parallel_launc… : 2000 2.00 2.00
GPU: blockY: void Kokkos::Impl::cuda_parallel_launc… : 2000 16.00 16.00
GPU: blockZ: void Kokkos::Impl::cuda_parallel_launc… : 2000 1.00 1.00
GPU: gridX: void Kokkos::Impl::cuda_parallel_launch… : 2000 50.00 50.00
GPU: gridY: void Kokkos::Impl::cuda_parallel_launch… : 2000 7.00 7.00
GPU: gridZ: void Kokkos::Impl::cuda_parallel_launch… : 2000 1.00 1.00
The 3D, 4D, 5D and 6D examples show similar results, but also include tuning for the Z dimensions. For MDRange policies greater than 3 dimensions, the tiling factors are combined to generate the block X,Y,Z values.
The MDRange GEMM example is similar to the deep copy examples, but using a user-provided matrix-multiply kernel and not an internal data copy kernel. In this case, two square 2D Views are multiplied together and the result is assigned to the output View.
The Matrix Multiply 2D Tiling example uses exclusively explicit tuning of tiling factors, thread count and scheduler for an OpenMP MDRange policy. This example doesn't use the helper functions from the tuning_playground.hpp header file, but explicitly defines the input variables, output variables, and context boundaries.