-
Notifications
You must be signed in to change notification settings - Fork 2.1k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Update requirements and README.md of lstm_tacotron2
- Loading branch information
Showing
10 changed files
with
111 additions
and
93 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,102 @@ | ||
| ```shell | ||
| $ hub install lstm_tacotron2==1.0.0 | ||
| ``` | ||
|
|
||
| ## 概述 | ||
|
|
||
| 声音克隆是指使用特定的音色,结合文字的读音合成音频,使得合成后的音频具有目标说话人的特征,从而达到克隆的目的。 | ||
|
|
||
| 在训练语音克隆模型时,目标音色作为Speaker Encoder的输入,模型会提取这段语音的说话人特征(音色)作为Speaker Embedding。接着,在训练模型重新合成此类音色的语音时,除了输入的目标文本外,说话人的特征也将成为额外条件加入模型的训练。 | ||
|
|
||
| 在预测时,选取一段新的目标音色作为Speaker Encoder的输入,并提取其说话人特征,最终实现输入为一段文本和一段目标音色,模型生成目标音色说出此段文本的语音片段。 | ||
|
|
||
| 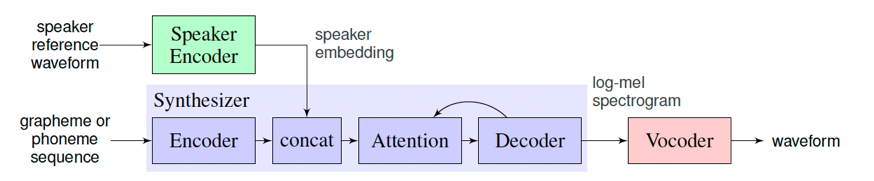 | ||
|
|
||
| `lstm_tacotron2`是一个支持中文的语音克隆模型,分别使用了LSTMSpeakerEncoder、Tacotron2和WaveFlow模型分别用于语音特征提取、目标音频特征合成和语音波形转换。 | ||
|
|
||
| 关于模型的详请可参考[Parakeet](https://github.com/PaddlePaddle/Parakeet/tree/release/v0.3/parakeet/models)。 | ||
|
|
||
|
|
||
| ## API | ||
|
|
||
| ```python | ||
| def __init__(speaker_audio: str = None, | ||
| output_dir: str = './') | ||
| ``` | ||
| 初始化module,可配置模型的目标音色的音频文件和输出的路径。 | ||
|
|
||
| **参数** | ||
| - `speaker_audio`(str): 目标说话人语音音频文件(*.wav)的路径,默认为None(使用默认的女声作为目标音色)。 | ||
| - `output_dir`(str): 合成音频的输出文件,默认为当前目录。 | ||
|
|
||
|
|
||
| ```python | ||
| def get_speaker_embedding() | ||
| ``` | ||
| 获取模型的目标说话人特征。 | ||
|
|
||
| **返回** | ||
| * `results`(numpy.ndarray): 长度为256的numpy数组,代表目标说话人的特征。 | ||
|
|
||
| ```python | ||
| def set_speaker_embedding(speaker_audio: str) | ||
| ``` | ||
| 设置模型的目标说话人特征。 | ||
|
|
||
| **参数** | ||
| - `speaker_audio`(str): 必填,目标说话人语音音频文件(*.wav)的路径。 | ||
|
|
||
| ```python | ||
| def generate(data: List[str], batch_size: int = 1, use_gpu: bool = False): | ||
| ``` | ||
| 根据输入文字,合成目标说话人的语音音频文件。 | ||
|
|
||
| **参数** | ||
| - `data`(List[str]): 必填,目标音频的内容文本列表,目前只支持中文,不支持添加标点符号。 | ||
| - `batch_size`(int): 可选,模型合成语音时的batch_size,默认为1。 | ||
| - `use_gpu`(bool): 是否使用gpu执行计算,默认为False。 | ||
|
|
||
|
|
||
| **代码示例** | ||
|
|
||
| ```python | ||
| import paddlehub as hub | ||
|
|
||
| model = hub.Module(name='lstm_tacotron2', output_dir='./', speaker_audio='/data/man.wav') # 指定目标音色音频文件 | ||
| texts = [ | ||
| '语音的表现形式在未来将变得越来越重要$', | ||
| '今天的天气怎么样$', ] | ||
| wavs = model.generate(texts, use_gpu=True) | ||
|
|
||
| for text, wav in zip(texts, wavs): | ||
| print('='*30) | ||
| print(f'Text: {text}') | ||
| print(f'Wav: {wav}') | ||
| ``` | ||
|
|
||
| 输出 | ||
| ``` | ||
| ============================== | ||
| Text: 语音的表现形式在未来将变得越来越重要$ | ||
| Wav: /data/1.wav | ||
| ============================== | ||
| Text: 今天的天气怎么样$ | ||
| Wav: /data/2.wav | ||
| ``` | ||
|
|
||
|
|
||
| ## 查看代码 | ||
|
|
||
| https://github.com/PaddlePaddle/Parakeet | ||
|
|
||
| ## 依赖 | ||
|
|
||
| paddlepaddle >= 2.0.0 | ||
|
|
||
| paddlehub >= 2.1.0 | ||
|
|
||
| ## 更新历史 | ||
|
|
||
| * 1.0.0 | ||
|
|
||
| 初始发布 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,7 +1 @@ | ||
| librosa | ||
| nltk | ||
| pypinyin | ||
| scipy | ||
| soundfile | ||
| webrtcvad | ||
| yaml | ||
| paddle-parakeet |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters