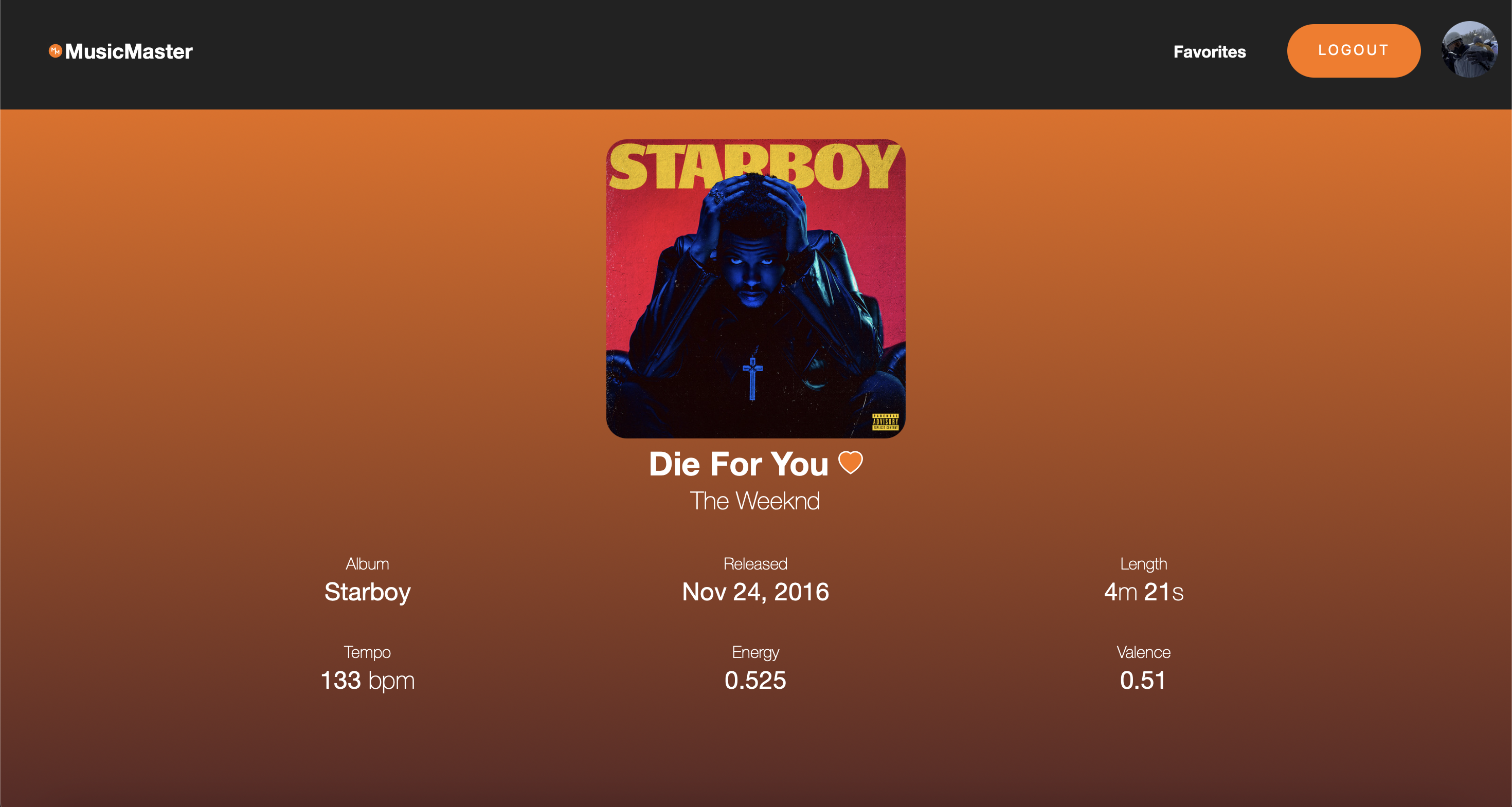
MusicMaster is a music recommendation engine built on the Spotify API and song dataset which utilizes machine learning and content-based filtering to recommend songs. Users can log in with their Spotify account through the OAuth framework to search for song information, audio features, and save their favorite songs and artists. MusicMaster will then come up with personalized song recommendations based on the saved information, allowing the user to directly add playlists and songs to their Spotify account for viewing and listening.
- Ensure you have the latest version of
Node,npm,Python, andPostgreSQLinstalled on your machine - Clone the repo from GitHub
- In your terminal,
cdinto themusicmasterdirectory - Run
npm install - Run
npm startto launch the frontend - Open a new terminal instance,
cdinto themusicmaster/src/backenddirectory - Run
pip install -r requirements.txt - Create a new database in Postgre called
musicmaster - Create a
.envfile within the same directory with variablesDB_USERandDB_PASSWORD, corresponding to the username and password to the musicmaster database you created in the previous step - Run
python init.py - Run
python server.py
MusicMaster's front-end was built in React, which is used to authenticate the user with Spotify's OAuth 2.0 framework, fetch song and artist information and features, and display the song information and saved content to the user.
MusicMaster's back-end was built in Flask and is connected to a PostgreSQL database. Within the MusicMaster database, there are a users, songs, and artists datatables with association tables to handle the one-to-many relationships between users and saved songs/artists. The front-end queries the back-end to fetch the saved content for a user, which will then return the content for the front-end to display.
Through the Spotify API, MusicMaster can fetch information about songs and artists and allow the user to add recommended songs to their personal Spotify accounts.
MusicMaster uses a content-based filtering system utilizing cosine similarity on the normalized dataset to recommend songs to the user. The dataset consists of Spotify song information and audio features from 2017.