@TOC
人工智能(AI)长远以来的目标:希望机器可以和人一样聪明。
机器学习的三要素:
- 确定一个函数
- 选择一个度量值用于衡量一个方法
- 一个好的算法从中选择最好的结果
什么是人工智能的学习呢? 并不是那种已经计划好的使用判语句进行处理的内容,那种“人工智能”就类似于我们说的“人工智障”,只能够处理预期的内容,其他的一概不会。到最后啼笑皆非。
- 真正的人工智能需要经过模型的定义通过大量数据的学习后认知和了解有关的特征,最后可以对没有见过的数据进行预测。
- 原理:人类认知事物是有一个时间的,通过不断的摸索才能够获得有关的知识与认知。而人工智能就是模仿人类对事物的认知来进行训练的。
- 举例:第一个吃螃蟹的人,在观察事物中不断的探索,最后经过大家的不断尝试 确认螃蟹是可以吃的,但是不是每个人都可以吃,有些 人会过敏! 而人工智能就是把大量的数据存入模型让模型去训练,一遍遍的探索,最后获得一个比较好的认知结果。有可能把数据放进模型经过几千轮的迭代就类似于人类数百年的学习和探索。 注: 以上内容源于个人理解!
不同的内容学习办法、学习方式、获得结果也不尽相同。 回归: 通过以前的一些数据对未来的数据进行预测,得到的输出是一个结果。 最经典的:波士顿房价预测
分类: 通过输出可以分为:二分类和多分类。 二分类:得到两个输出,类似于yes or no。 多分类:需要一个列表,输出的是列表中每个数据的可能性。
除了上面属于监督式学习还有半监式、非监督式、迁移学习、强化学习……
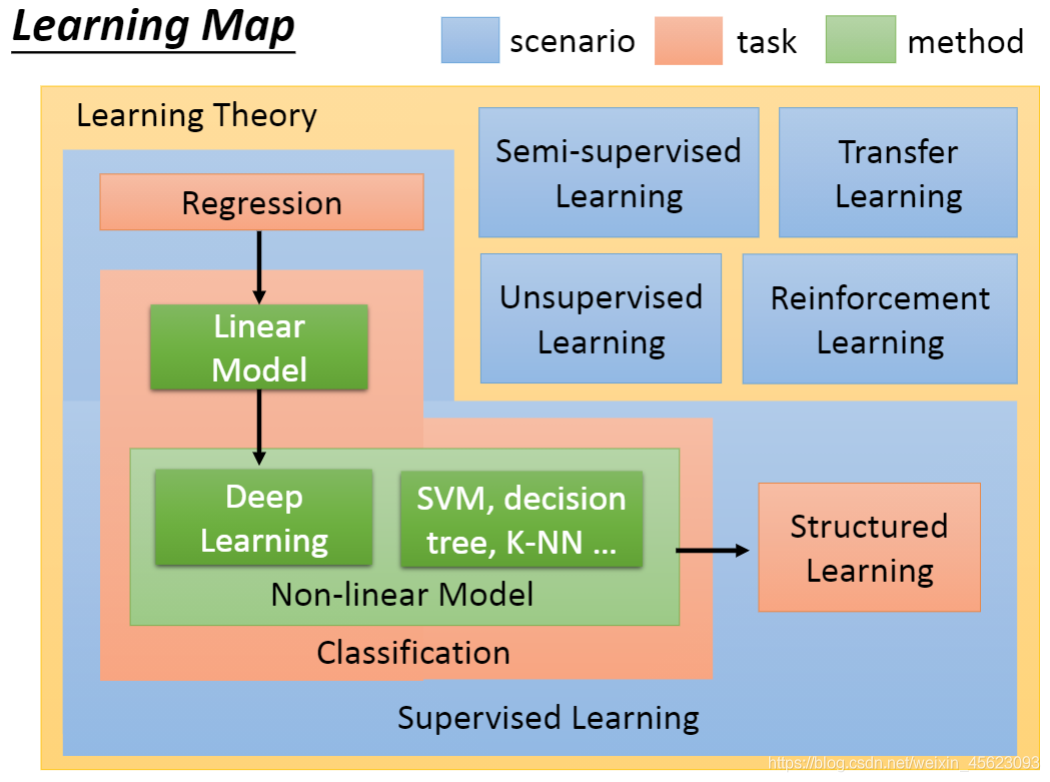
model才能够有更加优秀的人工智能产品。
(小期许:期待李老师早日回归 (私货))

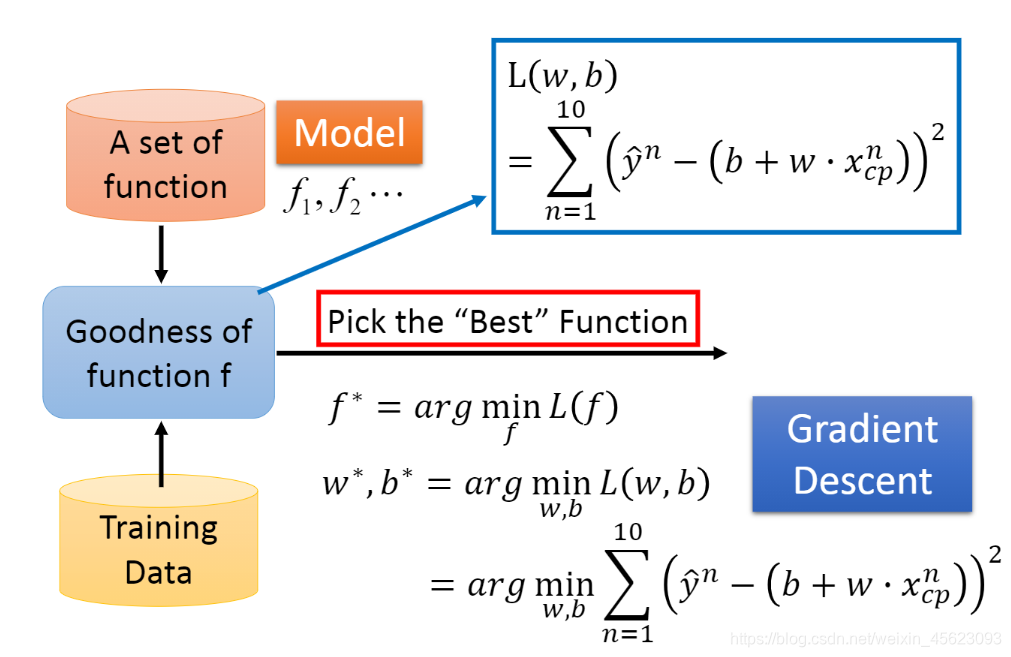
w和b是未知的需要我们的模型进行一个列举然后获得对应的结果。
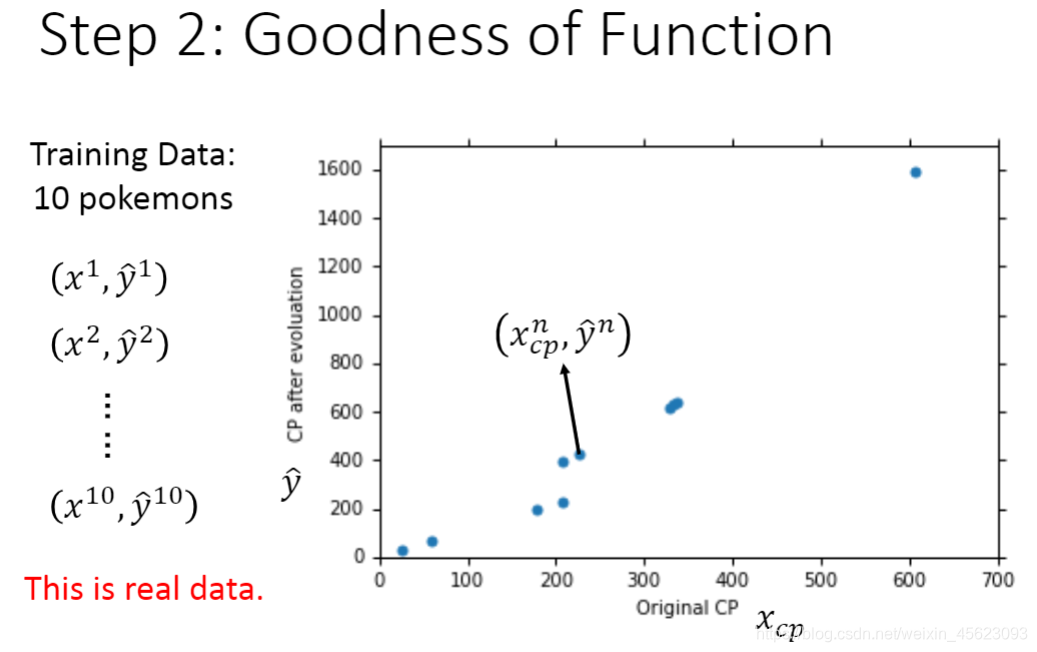

通过数据处理与查看,进一步了解我们所需要的内容,对数据进行处理和对模型的完善。
- 一个未知数的loss变化:
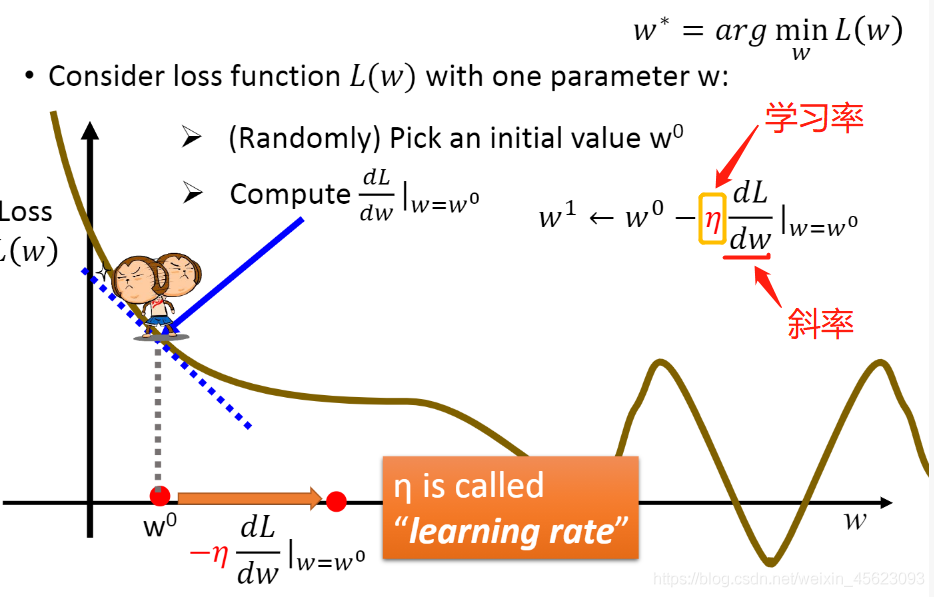
我们通过学习率和所在的切线dL/dw(微分)的乘积得到我们需要“走”(移动)的距离然后和原数据的差距就可以到下一个点然后继续之前的步骤,直到到达最低点

wT点时数据就会停下来。因为无论学习率和斜率的乘积都是0就不会运动了,这个就是目前的一个结果。
- 两个未知数的loss

先初始化两值w0、b0
接着计算:
w = w0 ; b = b0时w对loss的偏微分,b对loss的偏微分。
更新参数:
w1 = w0 - 学习率 * w对loss的偏微分
b1 = b0 - 学习率 * b对loss的偏微分
通过不断的更新就可以找到loss相对比较小的值。

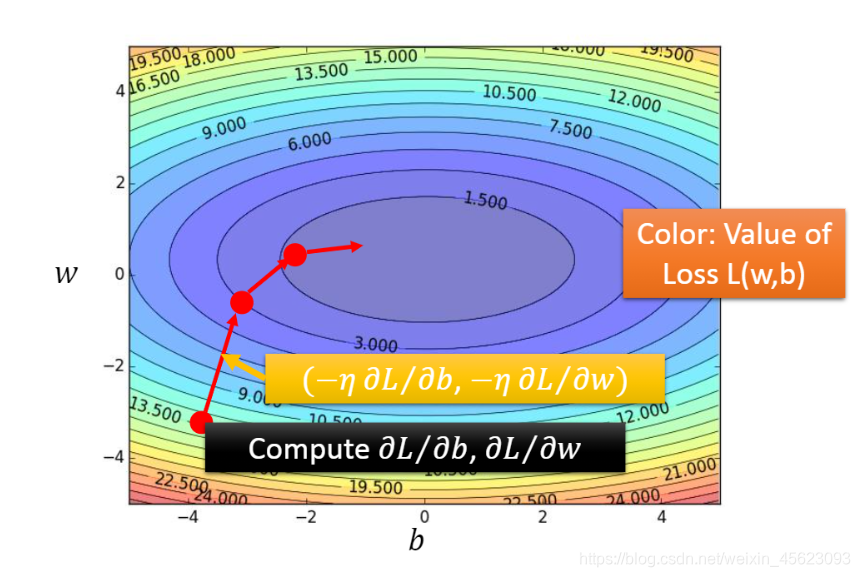
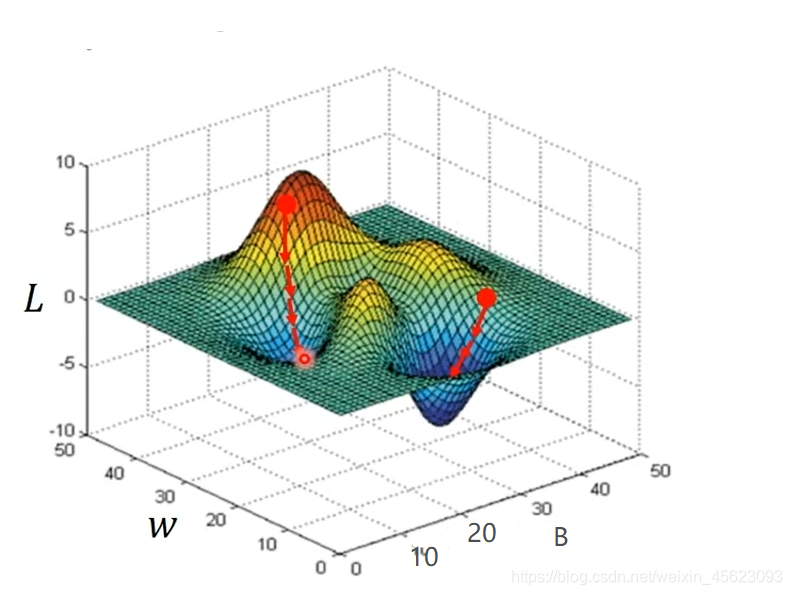
- 如果数据和下图那么就会出现两个不一样的"最优值"。
我们通过
𝜕𝐿/𝜕𝑤 and Τ𝜕/𝜕𝑏来进行查看通过微分的计算可以得到我们想要的结果。
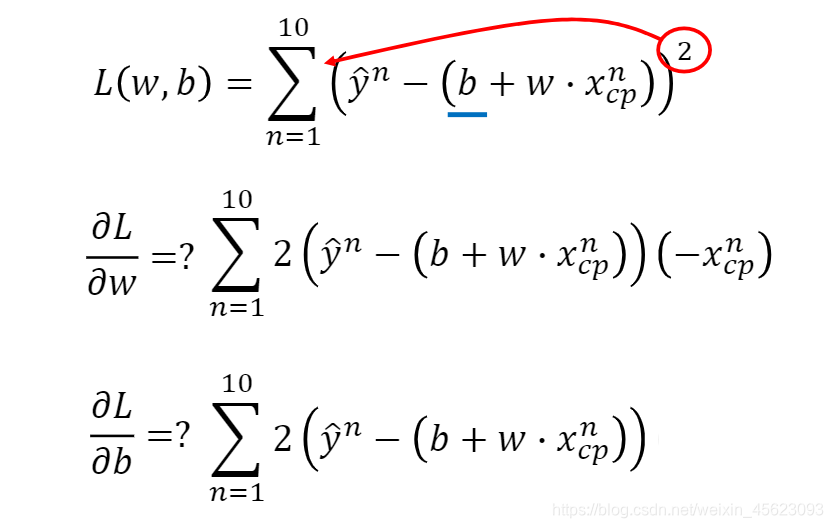
通过loss获取最好的结果得到数据然后进行还原以后得到了下图:
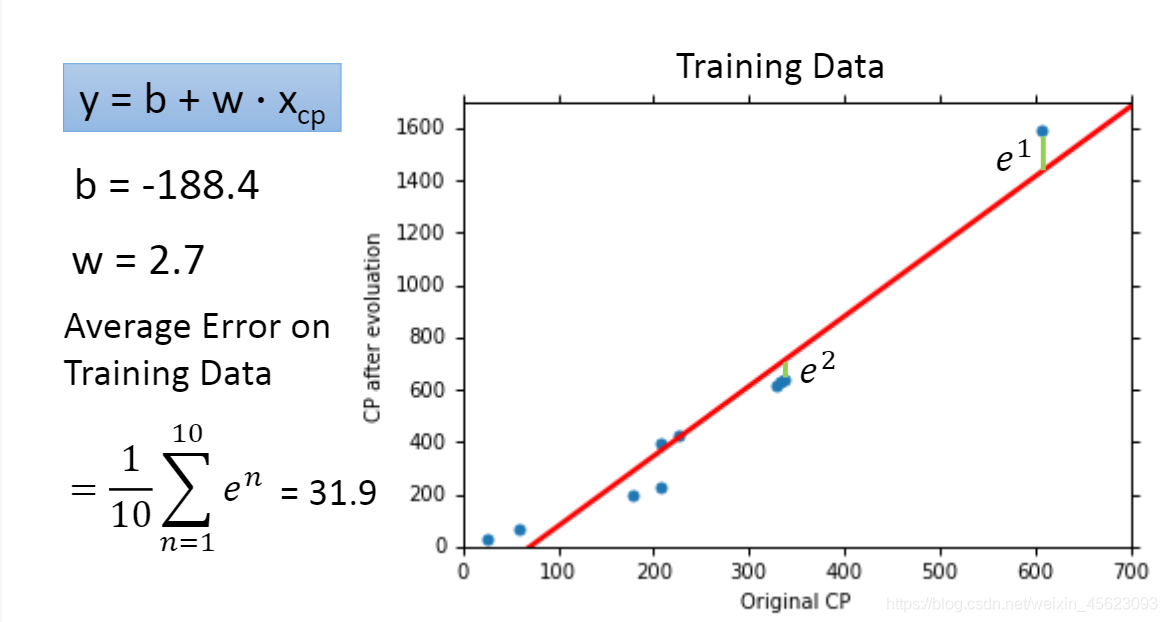
y = 2.7 * x -188.4
以上结果可以看出来数据没有完全预测得到我们想要的结果。
我们可以计算error的值来对计算的优劣成果进行评价
error的值等于每个点到预测线的距离的平均值
我们这个误差值是否具有代表性?结果是不一定!
我们需要找到其他的未经过测试的结果来进一步的预测。
通过比较两个error之间的值来比较模型的优劣。
上面的数据对最后的结果并不满意需要进一步的提高 就要对原本的模型进行调整。
-
改成二元二次方程。
y = b + w1 * xcp + w2 * (xcp) ^2通过新的模型进行学习实际的结果可以证明新的模型效果比旧的好。
error 的值也进一步得到了提高
-
改成二元三次方程。
y = b + w1 * xcp + w2 * (xcp) ^2 + w3 * (xcp)^3结果虽然和第二个模型相差不大,但是也是有一定的效果的。
-
改成二元四次方程。
y = b + w1 * xcp + w2 * (xcp) ^2 + w3 * (xcp)^3 + w4 * (xcp)^4 -
继续使用更复杂的模型。



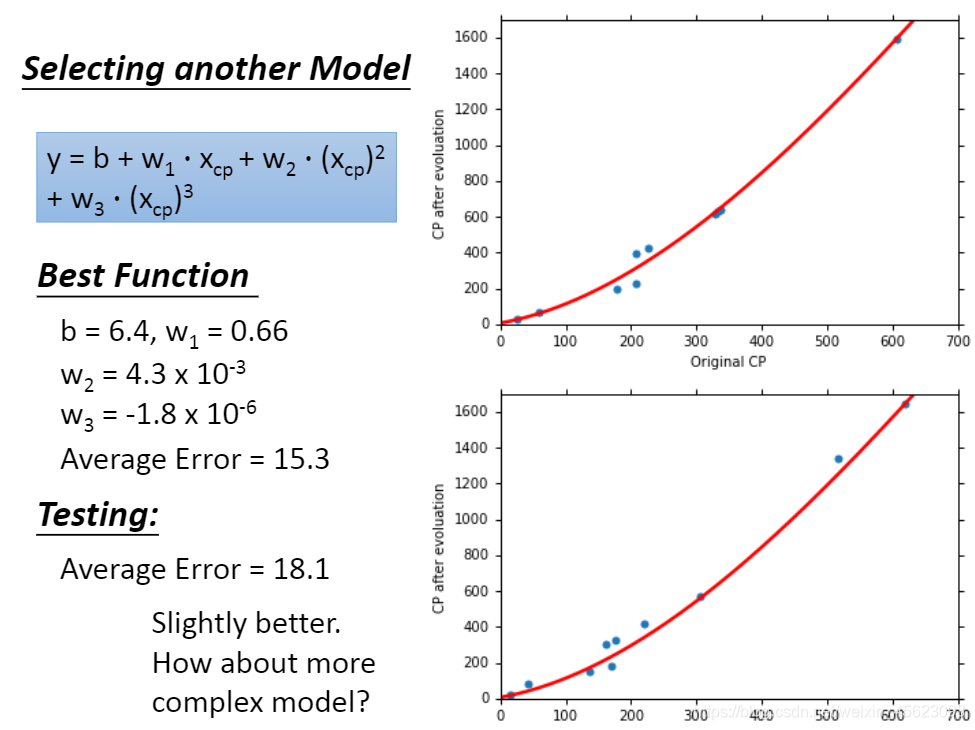

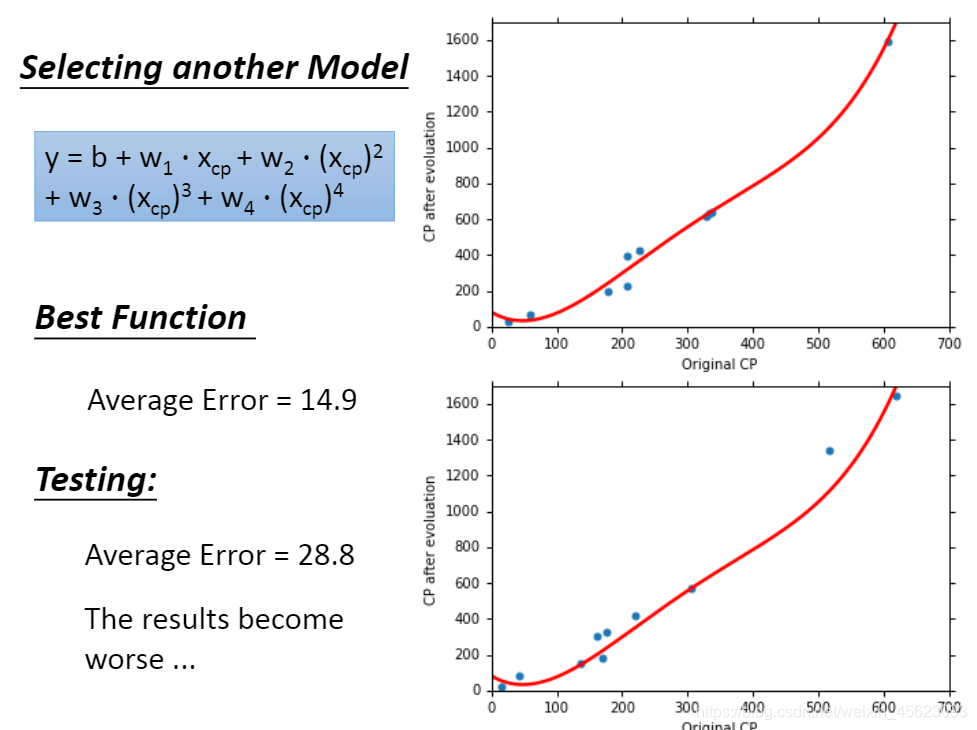
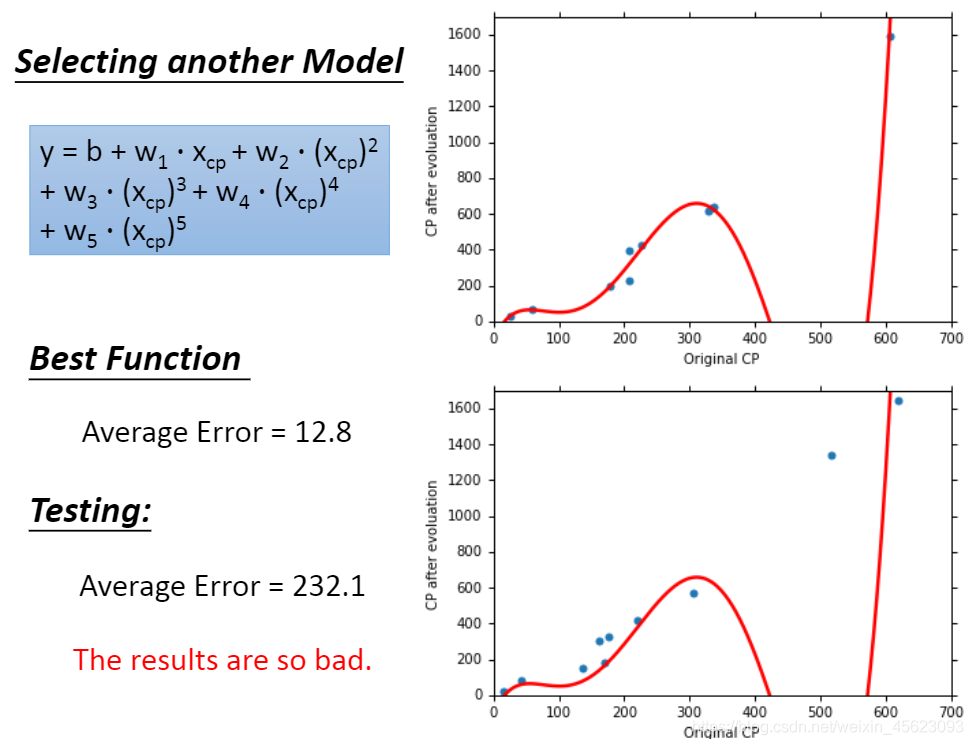


过拟合:就是类似于老师上课把期末考试的卷子一直重复,你可以把试卷倒背如流,期末考试考的一定是满分或者非常高的分数,但是不巧,试卷换了,最后用的卷子和你平时背的完全不一样,最后成绩特别差,这种情况就是过拟合。
模型过于复杂并不是一件好事情,说不定效果会更差。需要找一个合适的模型。
当模型比较复杂时loss的计算方式会影响最后取的最优解的值。如果让loss稍微平滑一点,没有那么大的波动,说不定就不会跳过那个属于他的 真命天子了。
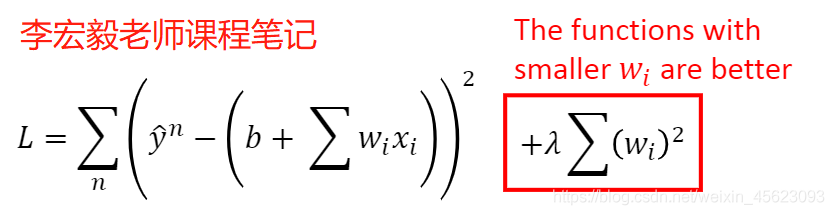
莽撞的性格,使得他更加的平滑和委婉。
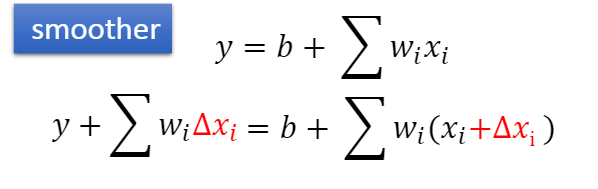
平滑器当wi越小越接近于0,他减缓的速度就会越慢。越来越平滑。
这样子的数据相对来说受到的干扰会更小,不会因为一些没有用的内容而受到较大的干扰。

error的值。不利于接下去对其他数据的预测。
# 导入第三方库
import numpy as np
import matplotlib.pyplot as plt# 定义初始数据
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
# ydata = b+w * xdatax = np.arange(-200,-100,1) # 偏差
y = np.arange(-5, 5, 0.1) # 权重
# print(x[:10],y[:10]) # 查看数据
z = np.zeros((len(x), len(y))) # 创建空数组,大小是(len(x),len(y))
X, Y = np.meshgrid(x, y)
# print(x.shape)x, y = np.meshgrid(x, y):两组数值生成相同的维度。 看下图自己理解一下

a = np.array([0, 1, 2])
b = np.array([0, 1])
A, B = np.meshgrid(a, b)
print(A)
print(B)[[0 1 2] [0 1 2]] [[0 0 0] [1 1 1]]
for i in range(len(x)): # 循环len(x)次
for j in range(len(y)):
b = x[i] # b = 遍历的x
w = y[j]
z[j][i] = 0
for n in range(len(x_data)):
z[j][i] = z[j][i] + (y_data[n] - b - w*x_data[n])**2
z[j][i] = z[j][i]/len(x_data)
# print(z.shape)b = -120 # 初始值
w = -4 # 初始值
lr = 0.0000001 # 学习率
itration = 100000 # 学习次数
# 存储绘图的初始化
b_history = [b]
w_history = [w]
# 计算各点b和w的偏微分
for i in range(itration):
b_grad = 0.0
w_grad = 0.0
for n in range(len(x_data)):
b_grad = b_grad - 0.2*(y_data[n] - b - w*x_data[n])*1.0
w_grad = w_grad - 0.2*(y_data[n] - b - w*x_data[n])*x_data[n]
# 更新参数
b = b - lr * b_grad
w = w - lr * w_grad
# 存储绘图参数
b_history.append(b)
w_history.append(w)plt.contourf(x,y,z,50,alpha=0.5, cmap=plt.get_cmap('jet'))
#坐标:[-188.4],[2.67],color:线条颜色
plt.plot([-188.4],[2.67],'x', ms=12, markeredgewidth=3, color='orange')
plt.plot(b_history,w_history,'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200,-100)
plt.ylim(-5,5)
#设置横纵坐标的名称以及对应字体格式
plt.xlabel(r'$b$', fontsize =16)
plt.ylabel(r'$w$', fontsize =16)Text(0,0.5,'$w$')
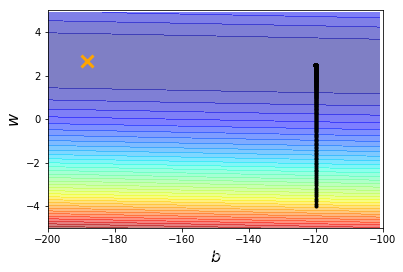
在上面的学习中,我们已经知道了并不是模型越好效果就越好,还是要在一定的程度上才可以。
我们预测的值和实际的预期的值是有差距的。
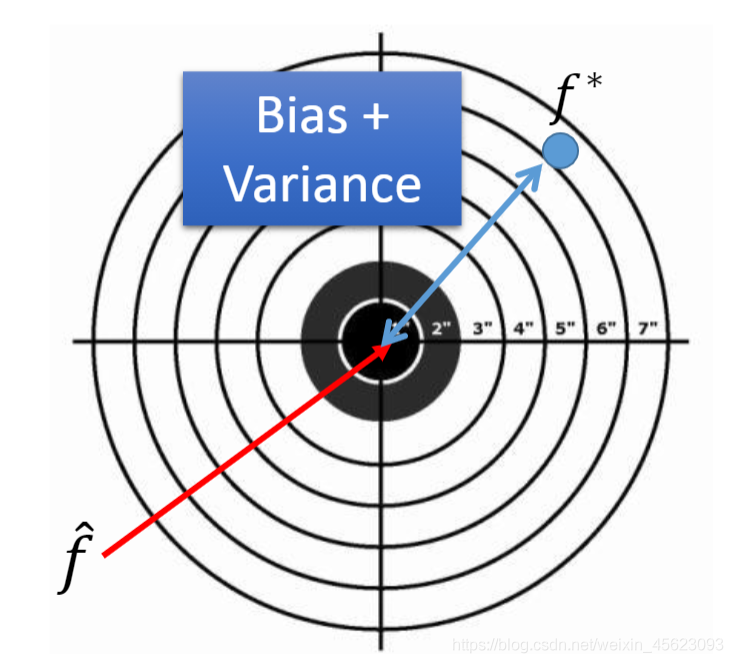
f^但是预测结束以后得到的结果却是f*,里面有一定的距离差。
这个差距的由来可能来自两个原因:bias和varance
最后的结果不一定与预期值相同,但是会散落在预期值周围。

bias(偏差)进行计算以后可以 得到离散的程度。
他和数据的样本量有关系。样本量越多离散程度越低,样本量越高离散程度越高。
然后对varance (方差)进行计算。
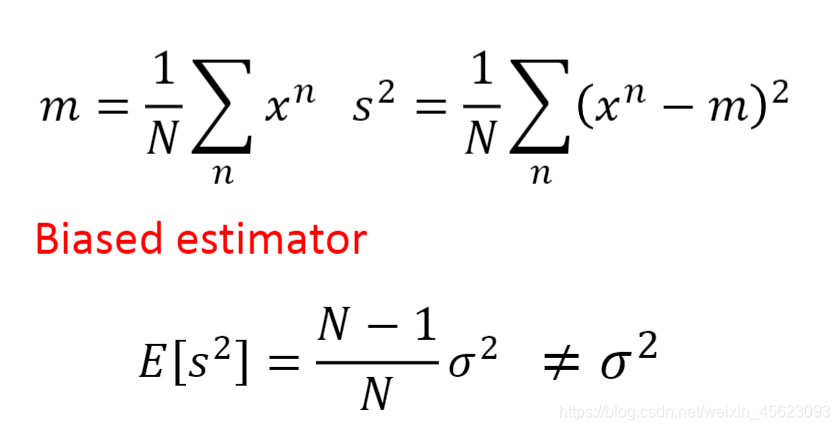
他的误差可能是结果没有取好,类似于打靶没有瞄准靶心,也就是效果 不是非常的模型,还有可能就是模型的方差很大,比较离散,没有聚拢。
当模型比较简单是varance值是比较小的,当模型复杂以后varance会散布的更加的开。
模型越复杂都到data的影响就越多,最后的结果也越多。
类似于在室内打靶收到的影响只有自己的发挥和器械的精度,相对应只有两个变量。但是在室外,涉及到风速、空气湿度,光线 折射度、距离……因素影响,最后的效果偏差肯定也是比较大的。
bias越小说明离散程度越高,当模型简单时bais是比较大的。当模型复杂以后最后的bais会比较小。
bias类似于套圈圈的游戏,你的模型比较简单,谁然比较集中的投掷某一个物品,但是由于各种偏差,能够投中的概率还是很低的,如果力道不对偏差的位置多那么输入集中但是距离既定目标还是很远的。 如果大量的数据分开来会散落在既定目标周边,那么大家平均以后的结果就会越接近我们的目标值,说不定还会有意外收获。
- 如果你的模型甚至不能适应训练的例子,那么你就有很大的偏差(欠拟合)
- 如果你能拟合训练数据,但测试数据误差很大,那么你可能有很大的方差(过拟合)
对于欠拟合,重新设计你的模型: • 添加更多的功能作为输入 • 一个更复杂的模型
对于过拟合,增加我们的data
方法一:这个办法不是万能的,但是是一个不错的选择。
如果data数量有限,可以适当的使用数据增强(增广)
方法二:使用正则化,使得数据 更加的平滑。
对应的bias会受到影响。
回归的内容就到这里了!
参考资料:
李宏毅老师课程-机器学习
李宏毅课程笔记(一)——回归演示demo(super松·著)
机器学习回归之路项目
作者:三岁
经历:自学python,现在混迹于paddle社区,希望和大家一起从基础走起,一起学习Paddle
csdn地址:https://blog.csdn.net/weixin_45623093/article/list/3
我在AI Studio上获得钻石等级,点亮7个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/284366
传说中的飞桨社区最菜代码人,让我们一起努力!
记住:三岁出品必是精品 (不要脸系列)