-
Notifications
You must be signed in to change notification settings - Fork 12
/
Copy path06_semi_structured_data.Rmd
873 lines (555 loc) · 28.2 KB
/
06_semi_structured_data.Rmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
# Semi-structured data {#semi_structured_data}
```{r include = FALSE}
# Caching this markdown file
#knitr::opts_chunk$set(cache = TRUE)
```
## Setup
```{r}
# Install packages
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, # tidyverse pkgs including purrr
furrr, # parallel processing
tictoc, # performance test
tcltk, # GUI for choosing a dir path
tidyjson, # tidying JSON files
XML, # parsing XML
rvest, # parsing HTML
jsonlite, # downloading JSON file from web
glue, # pasting string and objects
xopen, # opepn URLs in browser
urltools, # regex and url parsing
here) # computational reproducibility
## Install the current development version from GitHub
devtools::install_github("jaeyk/tidytweetjson", dependencies = TRUE) ; library(tidytweetjson)
```
## The Big Picture
- Automating the process of turning semi-structured data (input) into structured data (output)
## What is semi-structured data?
> Semi-structured data is a form of structured data that does not obey the tabular structure of data models associated with relational databases or other forms of data tables, but nonetheless contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields within the data. Therefore, it is also known as a self-describing structure. - [Wikipedia](https://en.wikipedia.org/wiki/Semi-structured_data#:~:text=Semi%2Dstructured%20data%20is%20a,and%20fields%20within%20the%20data.)
- Examples: HTML (e.g., websites), XML (e.g., government data), JSON (e.g., social media API)
Below is how JSON (tweet) looks like.
- A tree-like structure
- Keys and values (key: value)
{
"created_at": "Thu Apr 06 15:24:15 +0000 2017",
"id_str": "850006245121695744",
"text": "1\/ Today we\u2019re sharing our vision for the future of the Twitter API platform!\nhttps:\/\/t.co\/XweGngmxlP",
"user": {
"id": 2244994945,
"name": "Twitter Dev",
"screen_name": "TwitterDev",
"location": "Internet",
"url": "https:\/\/dev.twitter.com\/",
"description": "Your official source for Twitter Platform news, updates & events. Need technical help? Visit https:\/\/twittercommunity.com\/ \u2328\ufe0f #TapIntoTwitter"
}
}
- Why should we care about semi-structured data?
- Because this is what the data frontier looks like: \# of unstructured data \> \# of semi-structured data \> \# of structured data
- There are easy and fast ways to turn semi-structured data into structured data (ideally in a tidy format) using R, Python, and command-line tools. See my own examples ([tidyethnicnews](https://github.com/jaeyk/tidyethnicnews) and [tidytweetjson](https://github.com/jaeyk/tidytweetjson)).
## Workflow
1. Import/connect to a semi-structured file using `rvest,` `jsonlite,` `xml2,` `pdftools,` `tidyjson`, etc.
2. Define target elements in a single file and extract them
- [`readr`](https://readr.tidyverse.org/) package providers `parse_` functions that are useful for vector parsing.
- [`stringr`](https://stringr.tidyverse.org/) package for string manipulations (e.g., using regular expressions in a tidy way). Quite useful for parsing PDF files (see [this example](https://themockup.blog/posts/2020-04-03-beer-and-pdftools-a-vignette/)).
- [`rvest`](https://github.com/tidyverse/rvest) package for parsing HTML (R equivalent to `beautiful soup` in Python)
- [`tidyjson`](https://github.com/sailthru/tidyjson) package for parsing JSON data
3. Create a list of files (in this case URLs) to parse
4. Write a parsing function
5. Automate parsing process
## HTML/CSS: web scraping
Let's go back to the example we covered in the earlier chapter of the book.
```{r}
url_list <- c(
"https://en.wikipedia.org/wiki/University_of_California,_Berkeley",
"https://en.wikipedia.org/wiki/Stanford_University",
"https://en.wikipedia.org/wiki/Carnegie_Mellon_University",
"https://DLAB"
)
```
* Step 1: Inspection
Examine the Berkeley website so that we could identify a node that indicates the school's motto. Then, if you're using Chrome, draw your interest elements, then `right click > inspect > copy full xpath.`
```{r, eval = FALSE}
url <- "https://en.wikipedia.org/wiki/University_of_California,_Berkeley"
download.file(url, destfile = "scraped_page.html", quiet = TRUE)
target <- read_html("scraped_page.html")
# If you want character vector output
target %>%
html_nodes(xpath = "/html/body/div[3]/div[3]/div[5]/div[1]/table[1]") %>%
html_text()
# If you want table output
target %>%
html_nodes(xpath = "/html/body/div[3]/div[3]/div[5]/div[1]/table[1]") %>%
html_table()
```
* Step 2: Write a function
I highly recommend writing your function working slowly by wrapping the function with [`slowly()`](https://purrr.tidyverse.org/reference/insistently.html).
```{r}
get_table_from_wiki <- function(url){
download.file(url, destfile = "scraped_page.html", quiet = TRUE)
target <- read_html("scraped_page.html")
table <- target %>%
html_nodes(xpath = "/html/body/div[3]/div[3]/div[5]/div[1]/table[1]") %>%
html_table()
return(table)
}
```
* Step 3: Test
```{r, eval = FALSE}
get_table_from_wiki(url_list[[2]])
```
* Step 4: Automation
```{r, eval=FALSE}
map(url_list, get_table_from_wiki)
```
* Step 5: Error handling
```{r, eval = FALSE}
map(url_lists, safely(get_table_from_wiki)) %>%
map("result") %>%
# = map(function(x) x[["result"]]) = map(~.x[["name"]])
purrr::compact() # Remove empty elements
```
```{r, eval = FALSE}
# If error occurred, "The URL is broken." will be stored in that element(s).
out <- map(
url_list,
possibly(get_table_from_wiki,
otherwise = "The URL is broken."
)
)
```
## XML/JSON: government database/social media scraping
### Governemnt database (XML)
The following tax return data example comes from the U.S. Internal Revenue Service (IRS) Amazon database. [This PDf file](https://www.irs.gov/pub/irs-pdf/f990.pdf) shows what the original document looks like.
**Workflow**
1. Get the XML link and parse it
2. Go to the root of the XML document
3. Identify a specific node you care about
4. Get values related to that node
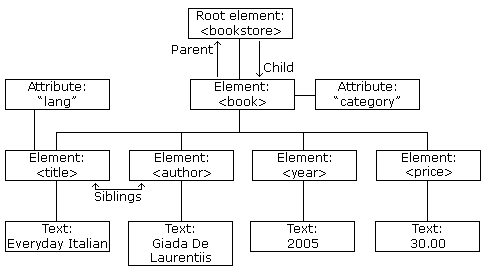
Step1: Get an XML document link
```{r echo = FALSE}
# Unfortunately, the link doesn't work as of March 29, 2023 as IRS discontinues its AWS service. But the code should work.
xml_link <- c("http://s3.amazonaws.com/irs-form-990/201910919349301206_public.xml")
```
Step 2: Get the page and parse the XML document.
```{r eval=FALSE}
xml_root <- xml_link %>%
# Get page and parse xml
xmlTreeParse() %>%
# Get root
xmlRoot()
# Data output: list
typeof(xml_root)
# Two elements. Our target is the second one.
summary(xml_root)
```
Step 3: Get nodes
We grab the mission statement of this org from its tax report (990). `//` is an [XPath syntax](https://www.w3schools.com/xml/xpath_syntax.asp) that helps to "select nodes in the document from the current node that matches the selection no matter where they are."
```{r eval=FALSE}
xml_root %>%
purrr::pluck(2) %>% # Second element (Return Data)
getNodeSet("//MissionDesc") # Mission statement
```
Step 4: Get values
```{r eval=FALSE}
xml_root %>%
purrr::pluck(2) %>% # Second element (Return Data)
getNodeSet("//MissionDesc") %>% # Mission statement
xmlValue()
```
### Social media API (JSON)
#### Objectives
- Learning what kind of social media data are accessible through application programming interfaces (APIs)
**Review question**
In the previous session, we learned the difference between semi-structured data and structured data. Can anyone tell us the difference between them?
#### The big picture for digital data collection
1. Input: semi-structured data
2. Output: structured data
3. Process:
- Getting **target data** from a remote server
- The target data is usually massive (\>10 G.B.) by the traditional social science standard.
- Parsing the target data your laptop/database
- Laptop (sample-parse): Downsamle the large target data and parse it on your laptop. This is just one option to [deal with big data in R](https://rviews.rstudio.com/2019/07/17/3-big-data-strategies-for-r/). It's a simple strategy that doesn't require storing target data in your database.
- Database (push-parse): Push the large target data to a database, then explore, select, and filter it. If you are interested in using this option, check out my [SQL for R Users](https://github.com/dlab-berkeley/sql-for-r-users) workshop.
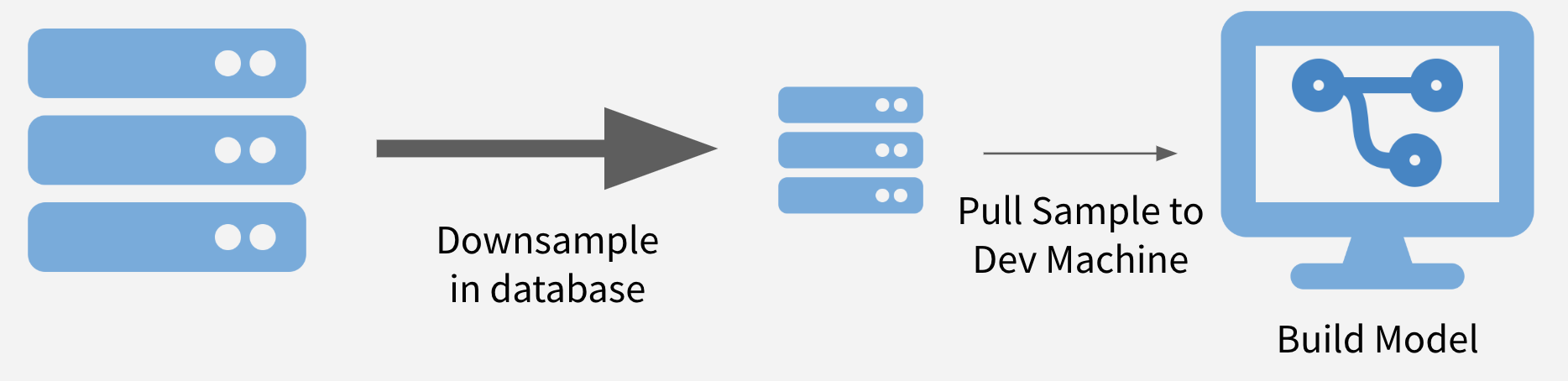
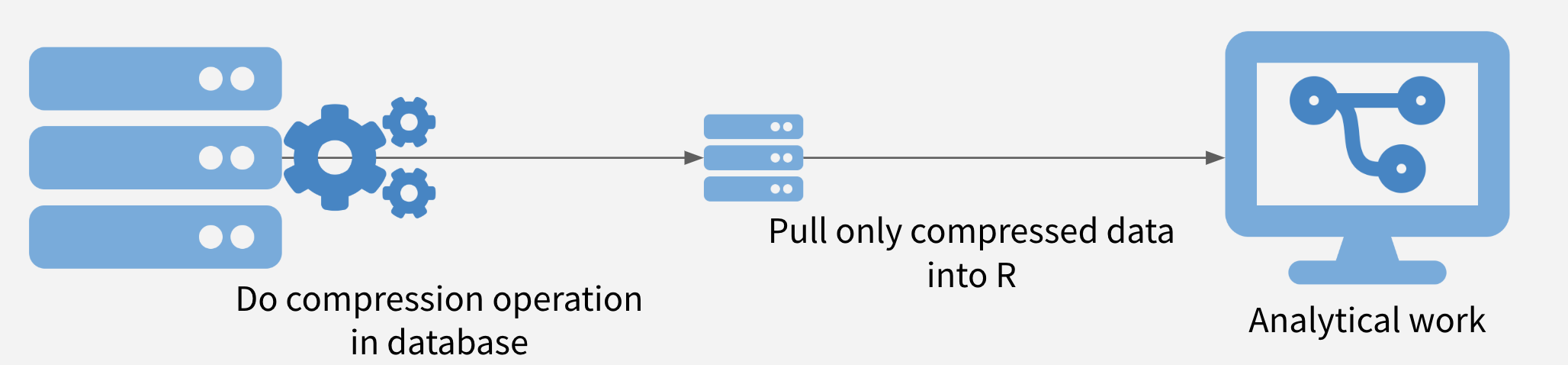
- But what exactly is this target data?
- When you scrape websites, you mostly deal with HTML (defines a structure of a website), CSS (its style), and JavaScript (its dynamic interactions).
- When you access social media data through API, you deal with either XML or JSON (major formats for storing and transporting data; they are light and flexible).
- XML and JSON have tree-like (nested; a root and branches) structures and keys and values (or elements and attributes).
- If HTML, CSS, and JavaScript are storefronts, then XML and JSON are warehouses.

#### Opportunities and challenges for parsing social media data
This explanation draws on Pablo Barbara's [LSE social media workshop slides](http://pablobarbera.com/social-media-workshop/social-media-slides.pdf).
**Basic information**
- What is an API?: An interface (you can think of it as something akin to a restaurant menu. API parameters are API menu items.)
- [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) (Representational state transfer) API: static information (e.g., user profiles, list of followers and friends)
- [Streaming](https://blog.axway.com/amplify/api-management/streaming-apis#:~:text=Streaming%20APIs%20are%20used%20to,a%20subset%20of%20Streaming%20APIS.) API: dynamic information (e.g, new tweets)
**Why should we care?**
- API is the new data frontier. [ProgrammableWeb](https://www.programmableweb.com/apis/directory) shows that there are more than 24,046 APIs as of April 1, 2021.
- Big and streaming (real-time) data
- High-dimensional data (e.g., text, image, video, etc.)
- Lots of analytic opportunities (e.g., time-series, network, spatial analysis)
- Also, this type of data has many limitations (external validity, algorithmic bias, etc).
- Think about taking the API + approach (i.e., API not replacing but augmenting traditional data collection)
**How API works**
Request (you form a request URL) <-> Response (API responses to your request by sending you data usually in JSON format)

**API Statuses**
1. Twitter
- Twitter API is still widely accessible ([v2](https://developer.twitter.com/en/docs/twitter-api/early-access)
- In January 2021, Twitter introduced the [academic Twitter API](https://developer.twitter.com/en/solutions/academic-research) that allows generous access to Twitter's historical data for academic researchers
- Many R packages exist for the Twitter API: [rtweet](https://cran.r-project.org/web/packages/rtweet/rtweet.pdf) (REST + streaming), [tweetscores](https://github.com/pablobarbera/twitter_ideology/tree/master/pkg/tweetscores) (REST), [streamR](https://github.com/pablobarbera/streamR) (streaming)
- Some notable limitations. If Twitter users don't share their tweets' locations (e.g., GPS), you can't collect them.
> Twitter data is unique from data shared by most other social platforms because it reflects information that users *choose* to share publicly. Our API platform provides broad access to public Twitter data that users have chosen to share with the world. - Twitter Help Center
- What does this policy mean? If Twitter users don't share their tweets' locations (e.g., GPS), you can't collect them. However, you can get around this problem to identify a user's location based on their self-reported profile.
2. Other APIs
The following comments draw on Alexandra Siegel's talk on "Collecting and Analyzing Social Media Data" given at Montréal Methods Workshops.
- [Facebook API](https://developers.facebook.com/) access has become constrained since the 2016 U.S. election.
- Exception: [Social Science One](https://socialscience.one/blog/unprecedented-facebook-urls-dataset-now-available-research-through-social-science-one).
- Also, check out [Crowdtangle](https://www.crowdtangle.com/) for collecting public FB page data
- Using FB ads is still a popular method, especially among scholars studying developing countries.
- [YouTube API](https://developers.google.com/youtube/v3): generous access + (computer-generated) transcript in many languages
- Documentation on [captions](https://developers.google.com/youtube/v3/docs/captions) from YouTube
- [Instragram API](https://www.instagram.com/developer/): Data from public accounts are available.
- [Reddit API](https://www.reddit.com/dev/api/): Well-annotated text data suitable for machine learning
**Upside**
- Legal and well-documented.
Web scraping (Wild Wild West) \<\> API (Big Gated Garden)
- You have legal but limited access to (growing) big data that can be divided into text, image, and video and transformed into cross-sectional (geocodes), longitudinal (timestamps), and historical event data (hashtags). See Zachary C. Steinert-Threlkeld's [2020 APSA Short Course Generating Event Data From Social Media](https://github.com/ZacharyST/APSA2020_EventDataFromSocialMedia).
- Social media data are also well-organized, managed, and curated data. It's easy to navigate because XML and JSON have keys and values. If you find keys, you will find observations you look for.
**Downside**
1. Rate-limited.
2. If you want to access more and various data than those available, you need to pay for premium access.
### Next steps
We will learn how to access and collect data using Twitter and New York Times API. We are going to learn this in two ways: (1) using plug-and-play packages (both using RStudio and the terminal) and (2) getting API data from scratch (`httr,` `jsonlite`).
First, sign up for the Twitter developer account before everything else. If you want to know how to sign up for a new Twitter developer account and access Twitter API, see Steinert-Threlkeld's [APSA workshop slides](https://github.com/ZacharyST/APSA2020_EventDataFromSocialMedia/blob/master/Presentation/02_AccessTwitter.pdf).
### rtweet
The `rtweet` examples come from [Chris Bail's tutorial](https://cbail.github.io/SICSS_APIs_markdown.html).
#### Setup
The first thing you need to do is set up.
Assuming that you already signed up for a Twitter developer account
```{r eval = FALSE}
app_name <- "YOUR APP NAME"
consumer_key <- "YOUR CONSUMER KEY"
consumer_secret <- "YOUR CONSUMER SECRET"
rtweet::create_token(app = app_name,
consumer_key = consumer_key,
consumer_secret = consumer_secret)
```
#### Search API
Using **search API**; This API returns a collection of Tweets mentioning a particular query.
```{r}
# Install and load rtweet
if (!require(pacman)) {install.packages("pacman")}
pacman::p_load(rtweet)
```
```{r eval = FALSE}
# The past 6-9 days
rt <- search_tweets(q = "#stopasianhate", n = 1000, include_rts = FALSE)
# The longer term
# search_fullarchive() premium service
head(rt$text)
```
Can you guess what would be the class type of rt?
```{r eval = FALSE}
class(rt)
```
What would be the number of rows?
```{r eval = FALSE}
nrow(rt)
```
#### Time series analysis
- Time series analysis
```{r eval = FALSE}
pacman::p_load(ggplot2, ggthemes, rtweet)
ts_plot(rt, "3 hours") +
ggthemes::theme_fivethirtyeight() +
labs(title = "Frequency of Tweets about StopAsianHate from the Past Day",
subtitle = "Tweet counts aggregated using three-hour intervals",
source = "Twitter's Search API via rtweet")
```
#### Geographical analysis
- Geographical analysis
```{r eval = FALSE}
pacman::p_load(maps)
geocoded <- lat_lng(rt)
maps::map("state", lwd = .25) # lwd = line type
with(geocoded, points(lng, lat))
```
### Hydrating
#### Objectives
- Learning how hydrating works
- Learning how to use [Twarc](https://github.com/DocNow/twarc) to communicate with Twitter's API
**Review question**
What are the main two types of Twitter's API?
#### Hydrating: An Alternative Way to Collect Historical Twitter Data
- You can collect Twitter data using Twitter's API, or you can hydrate Tweet IDs collected by other researchers. This is an excellent resource to collect historical Twitter data.
- [Covid-19 Twitter chatter dataset for scientific use](http://www.panacealab.org/covid19/) by Panacealab
- [Women's March Dataset](https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/5ZVMOR) by Littman and Park
- Harvard Dataverse has many dehydrated Tweet IDs that could be of interest to social scientists.

#### Twarc: one solution to (almost) all Twitter's API problems
- Why Twarc?
- A command-line tool and Python library that works for almost every Twitter API-related problem.
- It's really well-documented, tested, and maintained.
- [Twarc documentation](https://scholarslab.github.io/learn-twarc/06-twarc-command-basics) covers basic commands.
- [Tward-cloud documentation](https://twarc-cloud.readthedocs.io/_/downloads/en/stable/pdf/) explains how to collect data from Twitter's API using Twarc running in [Amazon Web Services](https://aws.amazon.com/) (AWS).
- Twarc was developed as part of the [Documenting the Now](https://www.docnow.io/) project, which the Mellon Foundation funded.

- There's no reason to be afraid of using a command-line tool and Python library, even though you primarily use R. It's easy to embed [Python code](https://bookdown.org/yihui/rmarkdown/language-engines.html#python) and [shell scripts](https://bookdown.org/yihui/rmarkdown/language-engines.html#shell-scripts) in R Markdown.
- Even though you don't know how to write Python code or shell scripts, it's handy to learn how to integrate them into your R workflow.
- I assume that you have already installed [Python 3](https://www.python.org/download/releases/3.0/).
```{bash eval = FALSE}
pip3 install twarc
```
##### Applications
The following examples are created by [the University of Virginia library](http://digitalcollecting.lib.virginia.edu/toolkit/docs/social-media/twarc-commands/).
###### Search
- Download pre-existing tweets (7-day window) matching certain conditions
- In command-line, `>` = Create a file
- I recommend running the following commands in the terminal because it's more stable than in R Markdown.

```{bash eval=FALSE}
# Key word
twarc search blacklivesmatter > blm_tweets.jsonl
```
```{bash eval=FALSE}
# Hashtag
twarc search '#blacklivesmatter' > blm_tweets_hash.jsonl
```
```{bash eval=FALSE}
# Hashtag + Language
twarc search '#blacklivesmatter' --lang en > blm_tweets_hash.jsonl
```
- It is really important to **save these tweets into a `jsonl` format;** `jsonl` extension refers to JSON **Lines** files. This structure is useful for splitting JSON data into smaller chunks if it is too large.
###### Filter
- Download tweets meeting certain conditions as they happen.
```{bash eval=FALSE}
# Key word
twarc filter blacklivesmatter > blm_tweets.jsonl
```
###### Sample
- Use Twitter's random sample of recent tweets.
```{bash eval=FALSE}
twarc sample > tweets.jsonl
```
###### Hydrate
- Tweet I.D.s -\> Tweets
```{bash eval=FALSE}
twarc hydrate tweet_ids.txt > tweets.jsonl
```
###### Dehydrate
- Hydrate \<\> Dehydrate
- Tweets -\> Tweet I.D.s
```{bash eval=FALSE}
twarc dehydrate tweets.jsonl > tweet_ids.txt
```
**Challenge**
1. Collect tweets containing keywords of your choice using `twarc search` and save them as `tweets.jsonl`.
2. Using `less` command in the terminal, inspect `twarc.log.`
3. Using `less` command in the terminal, inspect `tweets.json.`
### Parsing JSON
#### Objectives
- Learning chunk and pull strategy
- Learning how `tidyjson` works
- Learning how to apply `tidyjson` to tweets
#### Chunk and Pull
##### Problem
- What if the size of the Twitter data you downloaded is too big (e.g., \>10 GB) to do complex wrangling in R?
##### Solution
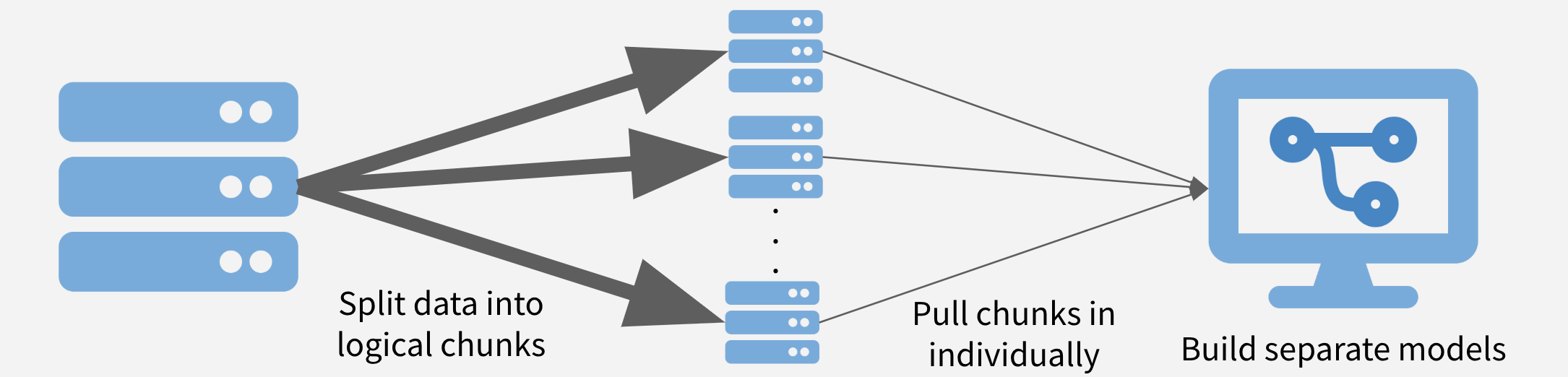
Step1: Split the large JSON file in small chunks.
```{bash eval = FALSE}
#Divide the JSON file by 100 lines (tweets)
# Linux and Windows (in Bash)
$ split -100 search.jsonl
# macOS
$ gsplit -100 search.jsonl
```
- After that, you will see several files appear in the directory. Each of these files should have 100 tweets or fewer. All of these file names **should start with "x," as in "xaa."**
Step 2: Apply the parsing function to each chunk and pull all of these chunks together.
```{r eval = FALSE}
# You need to choose a Tweet JSON file
filepath <- file.choose()
# Assign the parsed result to the `df` object
# 11.28 sec elapsed to parse 17,928 tweets
tic()
df <- jsonl_to_df(filepath)
toc()
```
```{r eval = FALSE}
# Setup
n_cores <- availableCores() - 1
n_cores # This number depends on your computer spec.
plan(multiprocess, # multicore, if supported, otherwise multisession
workers = n_cores) # the maximum number of workers
# You need to designate a directory path where you saved the list of JSON files.
# 9.385 sec elapsed to parse 17,928 tweets
dirpath <- tcltk::tk_choose.dir()
tic()
df_all <- tidytweetjson::jsonl_to_df_all(dirpath)
toc()
```
##### tidyjson
The [`tidyjson`](https://cran.r-project.org/web/packages/tidyjson/vignettes/introduction-to-tidyjson.html) package helps to use tidyverse framework to JSON data.
- toy example
```{r}
# JSON collection; nested structure + keys and values
worldbank[1]
# Check out keys (objects)
worldbank %>%
as.tbl_json() %>%
gather_object() %>%
filter(document.id == 1)
```
```{r}
# Get the values associated with the keys
worldbank %>%
as.tbl_json() %>% # Turn JSON into tbl_json object
enter_object("project_name") %>% # Enter the objects
append_values_string() %>% # Append the values
as_tibble() # To reduce the size of the file
```
- The following example draws on my [tidytweetjson](https://github.com/jaeyk/tidytweetjson) R package. The package applies `tidyjson` to Tweets.
###### Individual file
```{r}
jsonl_to_df <- function(file_path){
# Save file name
file_name <- strsplit(x = file_path,
split = "[/]")
file_name <- file_name[[1]][length(file_name[[1]])]
# Import a Tweet JSON file
listed <- read_json(file_path, format = c("jsonl"))
# IDs of the tweets with country codes
ccodes <- listed %>%
enter_object("place") %>%
enter_object("country_code") %>%
append_values_string() %>%
as_tibble() %>%
rename("country_code" = "string")
# IDs of the tweets with location
locations <- listed %>%
enter_object("user") %>%
enter_object("location") %>%
append_values_string() %>%
as_tibble() %>%
rename(location = "string")
# Extract other key elements from the JSON file
df <- listed %>%
spread_values(
id = jnumber("id"),
created_at = jstring("created_at"),
full_text = jstring("full_text"),
retweet_count = jnumber("retweet_count"),
favorite_count = jnumber("favorite_count"),
user.followers_count = jnumber("user.followers_count"),
user.friends_count = jnumber("user.friends_count")
) %>%
as_tibble
message(paste("Parsing", file_name, "done."))
# Full join
outcome <- full_join(ccodes, df) %>% full_join(locations)
# Or you can write this way: outcome <- reduce(list(df, ccodes, locations), full_join)
# Select
outcome %>% select(-c("document.id"))}
```
###### Many files
- Set up parallel processing.
```{r eval = FALSE}
n_cores <- availableCores() - 1
n_cores # This number depends on your computer spec.
plan(multiprocess, # multicore, if supported, otherwise multisession
workers = n_cores) # the maximum number of workers
```
- Parsing in parallel.
**Review**
There are, at least, three ways you can use function + `purrr::map().`
```{r eval = FALSE}
squared <- function(x){
x*2
}
# Named function
map(1:3, squared)
# Anonymous function
map(1:3, function(x){ x *2 })
# Using formula; ~ = formula, .x = input
map(1:3,~.x*2)
```
```{r, eval = FALSE}
# Create a list of file paths
filename <- list.files(dir_path,
pattern = '^x',
full.names = TRUE)
df <- filename %>%
# Apply jsonl_to_df function to items on the list
future_map(~jsonl_to_df(.)) %>%
# Full join the list of dataframes
reduce(full_join,
by = c("id",
"location",
"country_code",
"created_at",
"full_text",
"retweet_count",
"favorite_count",
"user.followers_count",
"user.friends_count"))
# Output
df
```
**rtweet and twarc**
- The main difference is using RStudio vs. the terminal.
- The difference matters when your data size is large. For example, suppose the size of the Twitter data you downloaded is 10 GB. R/RStudio might have a hard time dealing with this size of data. Then, how can you wrangle this data size in a complex way using R?
### Getting API data from scratch
Load packages. For the connection interface, don't use `RCurl,` but I strongly recommend using `httr.` The following code examples draw from my R interface for the New York Times API called [`rnytapi`](https://jaeyk.github.io/rnytapi/).
```{r eval = FALSE}
pacman::p_load(httr, jsonlite, purrr, glue)
```
#### Form REQUEST
```{r eval = FALSE}
get_request <- function(term, begin_date, end_date, key, page = 1) {
out <- GET("http://api.nytimes.com/svc/search/v2/articlesearch.json",
query = list('q' = term,
'begin_date' = begin_date,
'end_date' = end_date,
'api-key' = key,
'page' = page))
return(out)
}
```
#### Extract data
```{r eval = FALSE}
get_content <- function(term, begin_date, end_date, key, page = 1) {
message(glue("Scraping page {page}"))
fromJSON(content(get_request(term, begin_date, end_date, key, page),
"text",
encoding = "UTF-8"),
simplifyDataFrame = TRUE, flatten = TRUE) %>% as.data.frame()
}
```
#### Automating iterations
```{r eval = FALSE}
extract_all <- function(term, begin_date, end_date, key) {
request <- GET("http://api.nytimes.com/svc/search/v2/articlesearch.json",
query = list('q' = term,
'begin_date' = begin_date,
'end_date' = end_date,
'api-key' = key))
max_pages <- (round(content(request)$response$meta$hits[1] / 10) - 1)
message(glue("The total number of pages is {max_pages}"))
iter <- 0:max_pages
arg_list <- list(rep(term, times = length(iter)),
rep(begin_date, times = length(iter)),
rep(end_date, times = length(iter)),
rep(key, times = length(iter)),
iter
)
out <- pmap_dfr(arg_list, slowly(get_content,
# 6 seconds sleep is the default requirement.
rate = rate_delay(
pause = 6,
max_times = 4000)))
return(out)
}
```