ORPO (Odds Ratio Preference Optimization) is a novel fine-tuning technique that combines fine-tuning and preference alignment into a single unified process. This combined approach offers advantages in efficiency and performance compared to traditional methods like RLHF or DPO.
Traditional alignment methods typically involve two separate steps: supervised fine-tuning to adapt the model to a domain, followed by preference alignment to align with human preferences. While SFT effectively adapts models to target domains, it can inadvertently increase the probability of generating both desirable and undesirable responses, as shown in the graph below:

ORPO addresses this limitation by integrating both steps into a single process, as illustrated in the comparison below:
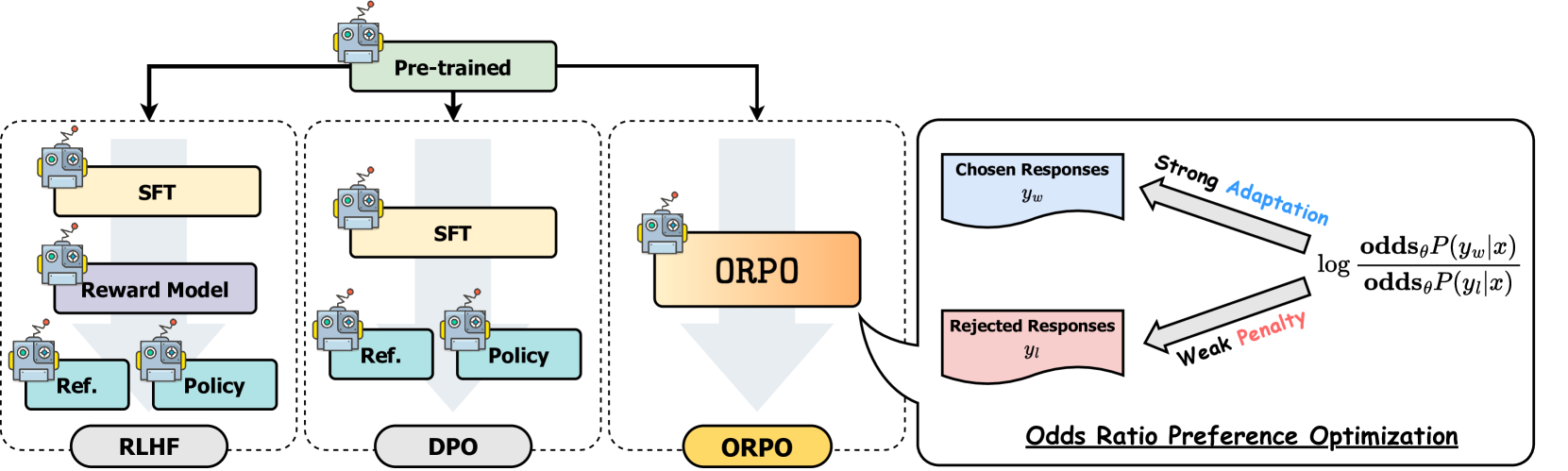
ORPO creates a new objective by combining two main components:
-
SFT Loss: The standard negative log-likelihood loss used in language modeling, which maximizes the probability of generating reference tokens. This helps maintain the model's general language capabilities.
-
Odds Ratio Loss: A novel component that penalizes undesirable responses while rewarding preferred ones. This loss function uses odds ratios to effectively contrast between favored and disfavored responses at the token level.
Together, these components guide the model to adapt to desired generations for the specific domain while actively discouraging generations from the set of rejected responses. The odds ratio mechanism provides a natural way to measure and optimize the model's preference between chosen and rejected outputs.
The training process uses a preference dataset containing:
- Input prompts
- Chosen (preferred) responses
- Rejected (disfavored) responses
Unlike traditional methods that require separate stages and reference models, ORPO integrates preference alignment directly into the supervised fine-tuning process. This monolithic approach makes it:
- Reference model-free
- Computationally more efficient
- Memory efficient (fewer FLOPs)
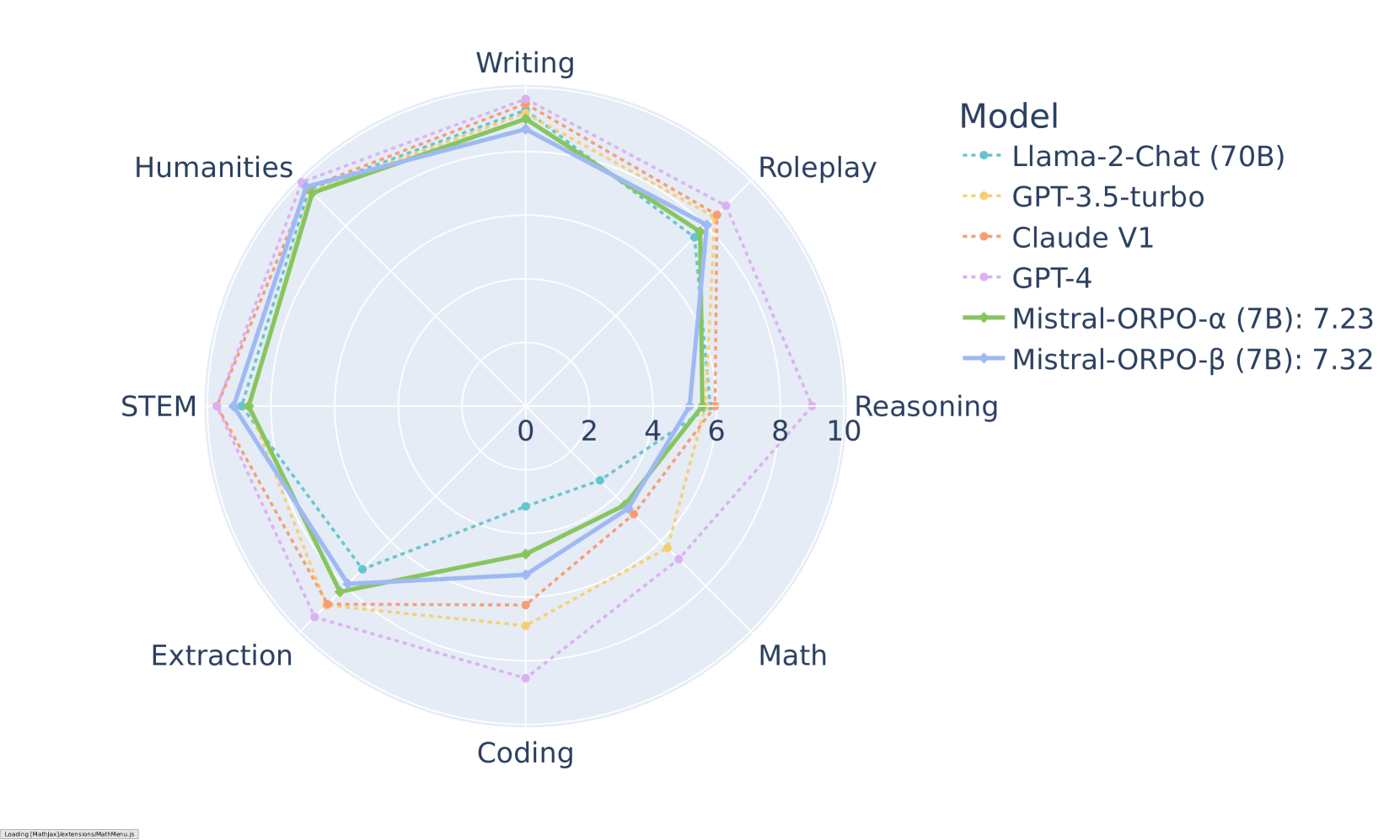
ORPO has demonstrated impressive results across various benchmarks. On MT-Bench, it achieves competitive scores across different categories:
When compared to other alignment methods, ORPO shows superior performance on AlpacaEval 2.0:
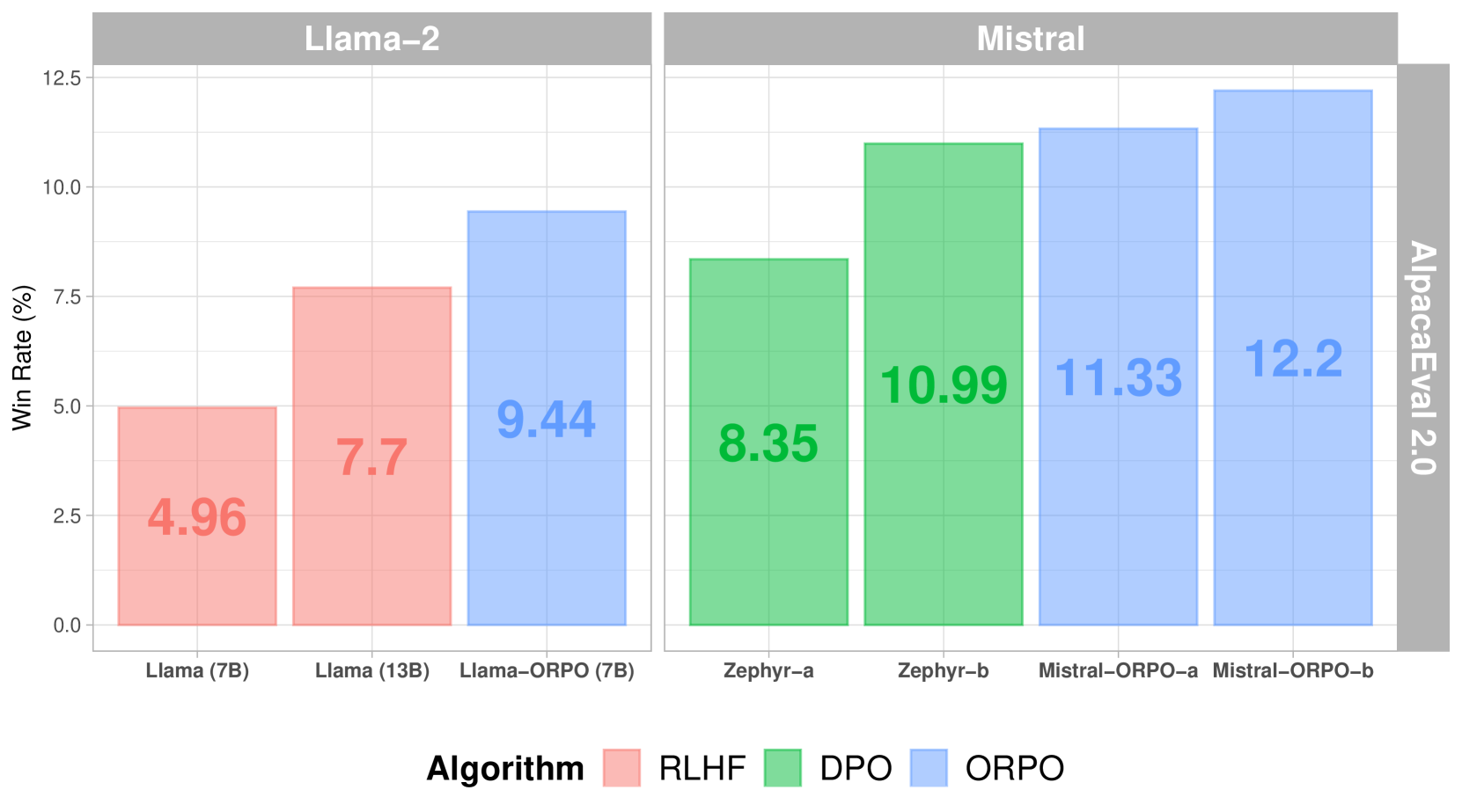
Compared to SFT+DPO, ORPO reduces computational requirements by eliminating the need for a reference model and halving the number of forward passes per batch. Also, the training process is more stable across different model sizes and datasets, requiring fewer hyperparameters to tune. Performance-wise, ORPO matches larger models while showing better alignment with human preferences.
Successful implementation of ORPO depends heavily on high-quality preference data. The training data should follow clear annotation guidelines and provide a balanced representation of preferred and rejected responses across diverse scenarios. During training, it's crucial to carefully balance the OR loss weighting and monitor gradient behavior to prevent overfitting while maintaining effective preference learning.
ORPO can be implemented using the Transformers Reinforcement Learning (TRL) library. Here's a basic example:
from trl import ORPOConfig, ORPOTrainer
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained("your_base_model")
tokenizer = AutoTokenizer.from_pretrained("your_base_model")
# Configure ORPO training
orpo_config = ORPOConfig(
learning_rate=1e-5,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
orpo_alpha=1.0, # Controls strength of preference optimization
orpo_beta=0.1, # Temperature parameter for odds ratio
)
# Initialize trainer
trainer = ORPOTrainer(
model=model,
args=orpo_config,
train_dataset=your_dataset,
tokenizer=tokenizer,
)
# Start training
trainer.train()The training data should be formatted as pairs of chosen and rejected responses for each prompt:
dataset = [
{
"prompt": "What is machine learning?",
"chosen": "Machine learning is a field of AI...",
"rejected": "Machine learning is when computers..."
},
# More examples...
]Key parameters to consider:
orpo_alpha: Controls the strength of preference optimizationorpo_beta: Temperature parameter for the odds ratio calculationlearning_rate: Should be relatively small to prevent catastrophic forgettinggradient_accumulation_steps: Helps with training stability
ORPO's current limitations primarily relate to scale and specificity. The method is less explored for models larger than 7B parameters and may require careful validation for specialized domains. High OR loss weights can lead to overfitting, necessitating careful monitoring of the balance between preference learning and general capabilities.
Try the ORPO Tutorial to implement this unified approach to preference alignment.