At retrieval time, we want to be fast! 🏃
We possibly want to compare the user's query against a large collection of documents (millions and even more) in a very short time. So we choose efficient and rapid techniques, both for sparse retrieval (BM25) and dense retrieval, and avoid large inference efforts at query time.
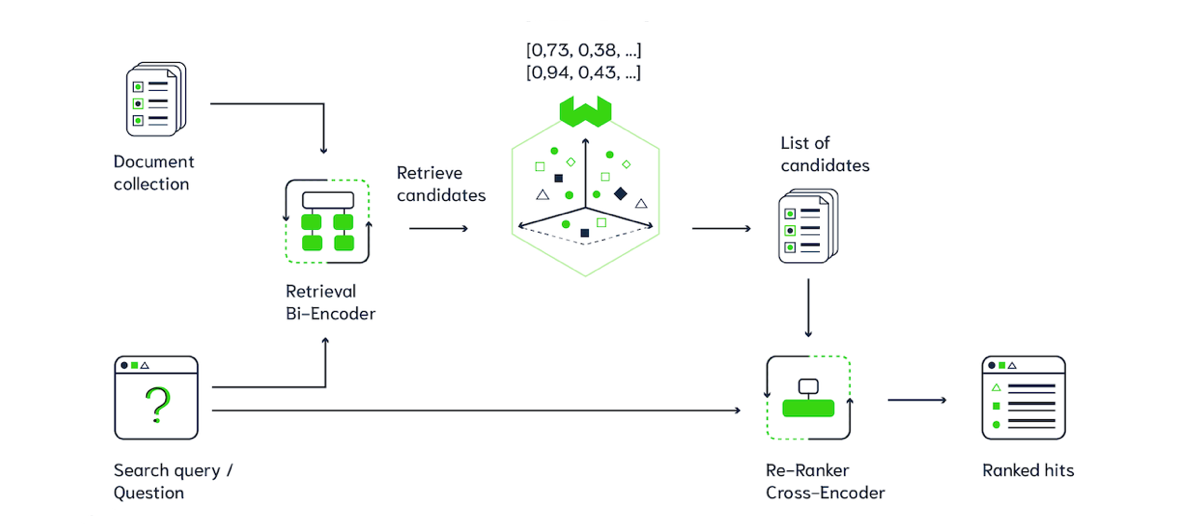
For example, if we choose the dense retrieval (SentenceTransformers), in the indexing phase we adopt a Bi-Encoder, based on BERT, which associates each document to a vector. These vectors are then saved in a Document store. At query time the same Bi-Encoder is used to represent the query. We then quickly search for the document vectors closest to the query vector.
Common retrieval approaches favor speed and may return some irrelevant candidates.
Once we have some possibly relevant documents, we can use a Cross-Encoder to refine the ranking of these documents.
The query and each document are passed to the Cross-Encoder transformer network which produces an output value between 0 and 1, indicating the similarity of the input pair.
By performing attention across the query and the document, we get a better indication of the similarity, so the quality of the ranking can be improved. Because Cross-Encoder inference is slow 🐌, at query time we can re-rank only a limited number of documents.
A Cross-Encoder Re-Ranker can also be combined with a BM25 sparse retriever!
(Image by Weaviate and Laura Ham)
- we have a collection of indexed documents saved in a Document store
- when the user enters a query, it is represented using a (sparse or dense) retriever
- the K nearest documents are retrieved
- the retrieved candidate documents are passed to the Cross-Encoder Re-Ranker together with the query
- we get an improved ranking! 🥇🥈🥉
- Using Cross-Encoders as reranker in multistage vector search: Very intuitive blogpost by Laura Ham from Weaviate blog
- Retrieve & Re-Rank - SentenceTransformers docs
- Bi-Encoder vs. Cross-Encoder - SentenceTransformers docs: simple comparison between Bi-Encoders and Cross-Encoders