<div align="center">
<img src="./images/logo.png" alt="VideoCaptioner Logo" width="100">
<p>卡卡字幕助手</p>
<h1>VideoCaptioner</h1>
<p>一款基於大語言模型(LLM)的視頻字幕處理助手,支持語音識別、字幕斷句、優化、翻譯全流程處理</p>
簡體中文 / [正體中文](./docs/README_TW.md) / [English](./docs/README_EN.md) / [日本語](./docs/README_JA.md)
</div>
## 📖 項目介紹
卡卡字幕助手(VideoCaptioner)操作簡單且無需高配置,支持網絡調用和本地離線(支持調用 GPU)兩種方式進行語音識別,利用大語言模型進行字幕智能斷句、校正、翻譯,全流程一鍵處理字幕視頻!為視頻配上效果驚艷的字幕。
最新版本已經支持 VAD、人聲分離、字級時間戳、批量字幕等實用功能
- 🎯 無需 GPU 即可使用強大的語音識別引擎,生成精準字幕
- ✂️ 基於 LLM 的智能分割與斷句,字幕閱讀更自然流暢
- 🔄 AI 字幕多線程優化與翻譯,調整字幕格式、表達更地道專業
- 🎬 支持批量視頻字幕合成,提升處理效率
- 📝 直觀的字幕編輯查看介面,支持即時預覽和快捷編輯
- 🤖 消耗模型 Token 少,且內置基礎 LLM 模型,保證開箱即用
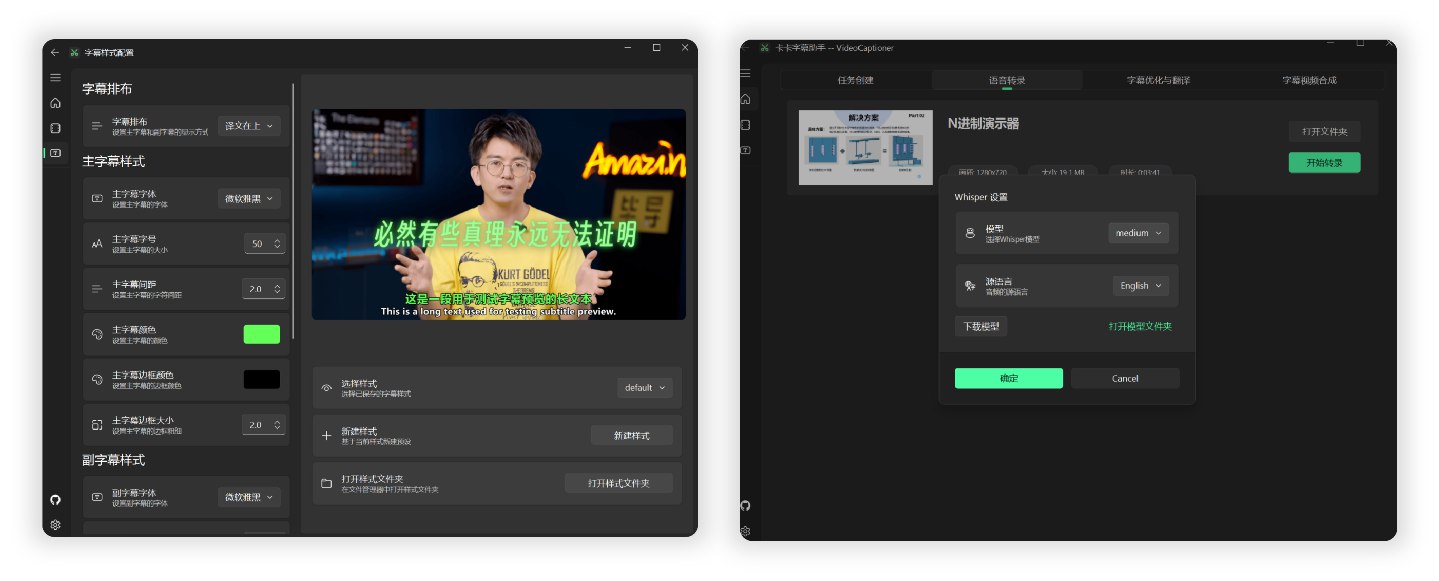
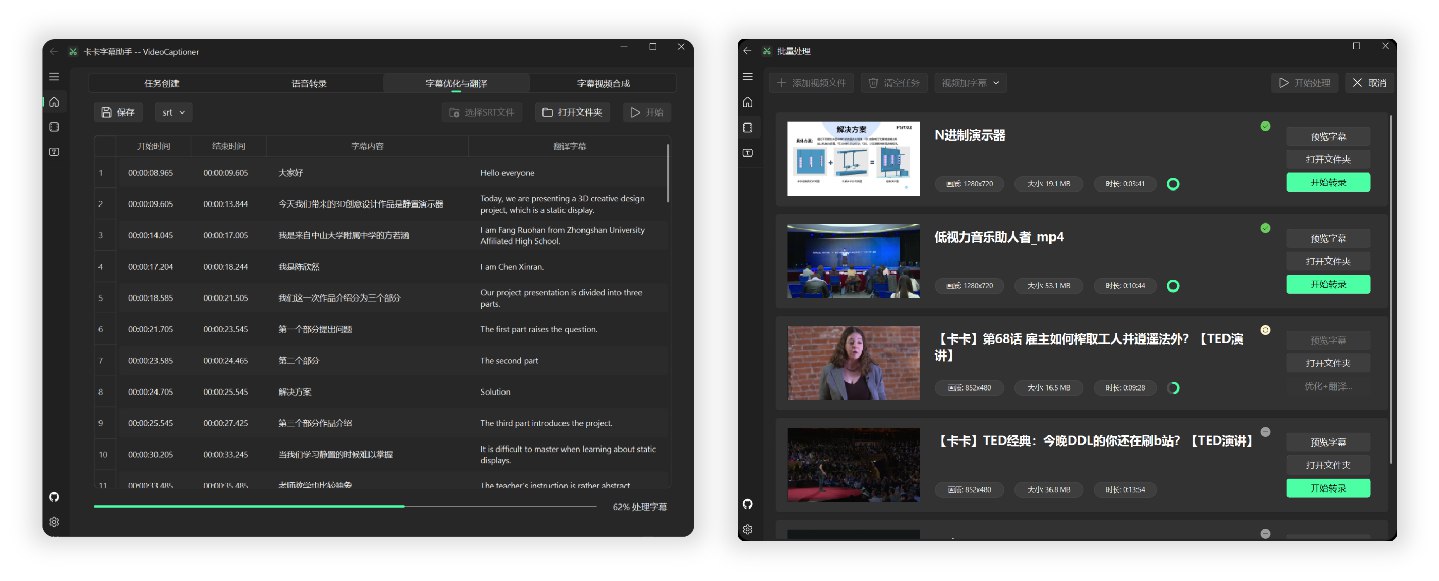
## 📸 介面預覽
<div align="center">
<img src="https://h1.appinn.me/file/1731487405884_main.png" alt="軟體介面預覽" width="90%" style="border-radius: 5px;">
</div>
## 🧪 測試
全流程處理一個 14 分鐘 1080P 的 [B站英文 TED 視頻](https://www.bilibili.com/video/BV1jT411X7Dz),調用本地 Whisper 模型進行語音識別,使用 `gpt-4o-mini` 模型優化和翻譯為中文,總共消耗時間約 **3 分鐘**。
根據後台計算,模型優化和翻譯消耗費用不足 ¥0.01(以 OpenAI 官方價格計算)
具體字幕和視頻合成效果的測試結果圖片,請參考 [TED 視頻測試](./docs/test.md)
## 🚀 快速開始
### Windows 用戶
軟體較為輕量,打包大小不足 60M,已集成所有必要環境,下載後可直接運行。
1. 從 [Release](https://github.com/WEIFENG2333/VideoCaptioner/releases) 頁面下載最新版本的可執行程式。或者:[藍奏盤下載](https://wwwm.lanzoue.com/ixsFn2n14bzc)
2. 打開安裝包進行安裝
3. (可選)LLM API 配置,選擇是否啟用字幕優化或者字幕翻譯
4. 拖拽視頻檔案到軟體窗口,即可全自動處理
提示:每個步驟均支持單獨處理,均支持檔案拖拽。
<details>
<summary>MacOS 用戶</summary>
由於本人缺少 Mac,所以無法測試和打包,暫時無法提供 MacOS 的可執行程式。
Mac 用戶請自行使用下載源碼並安裝 python 依賴運行。(本地 Whisper 功能暫不支持 MacOS)
1. 安裝 ffmpeg 和 Aria2 下載工具
```bash
brew install ffmpeg
brew install aria2
brew install python@3.**- 克隆項目
git clone https://github.com/WEIFENG2333/VideoCaptioner.git
cd VideoCaptioner- 安裝依賴
python3.** -m venv venv
source venv/bin/activate
pip install -r requirements.txt- 運行程式
python main.pyDocker 部署(beta)
目前應用較為簡略,歡迎各位 PR 貢獻。
git clone https://github.com/WEIFENG2333/VideoCaptioner.git
cd VideoCaptionerdocker build -t video-captioner .使用自定義 API 配置運行:
docker run -d \
-p 8501:8501 \
-v $(pwd)/temp:/app/temp \
-e OPENAI_BASE_URL="你的API地址" \
-e OPENAI_API_KEY="你的API密鑰" \
--name video-captioner \
video-captioner打開瀏覽器訪問:http://localhost:8501
- 容器內已預裝 ffmpeg 等必要依賴
- 如需使用其他模型,請透過環境變數配置
軟體充分利用大語言模型(LLM)在理解上下文方面的優勢,對語音識別生成的字幕進行進一步處理。有效修正錯別字、統一專業術語,讓字幕內容更加準確連貫,為使用者帶來出色的觀賞體驗!
- 支持國內外主流視頻平台(B站、Youtube 等)
- 自動提取視頻原有字幕進行處理
- 提供多種介面線上識別,效果媲美剪映(免費、高速)
- 支持本地 Whisper 模型(保護隱私、可離線)
- 自動優化專業術語、程式碼片段和數學公式格式
- 利用上下文進行斷句優化,提升閱讀體驗
- 支持文稿提示,使用原有文稿或者相關提示優化字幕斷句
- 結合上下文的智能翻譯,確保譯文兼顧全文
- 透過 Prompt 指導大模型反思翻譯,提升翻譯質量
- 使用序列模糊匹配算法,保證時間軸完全一致
- 豐富的字幕樣式模板(科普風、新聞風、番劇風等等)
- 多種格式字幕視頻(SRT、ASS、VTT、TXT)
| 配置項 | 說明 |
|---|---|
| 內置模型 | 軟體內置基礎大語言模型(gpt-4o-mini),無需配置即可使用(公益服務不穩定) |
| API 支持 | 支持標準 OpenAI API 格式。兼容 SiliconCloud、DeepSeek 、 Ollama 等。 配置方法請參考配置文檔 |
推薦模型:追求更高質量可選用 Claude-3.5-sonnet 或 gpt-4o
Whisper 版本有 WhisperCpp 和 fasterWhisper(推薦)兩種,後者效果更好,都需要自行在軟體內下載模型。
| 模型 | 磁碟空間 | 記憶體佔用 | 說明 |
|---|---|---|---|
| Tiny | 75 MiB | ~273 MB | 轉錄效果一般,僅用於測試 |
| Small | 466 MiB | ~852 MB | 英文識別效果已經不錯 |
| Medium | 1.5 GiB | ~2.1 GB | 中文識別建議至少使用此版本 |
| Large-v1/v2 👍 | 2.9 GiB | ~3.9 GB | 效果好,配置允許情況下推薦使用 |
| Large-v3 | 2.9 GiB | ~3.9 GB | 社群回饋可能會出現幻覺/字幕重複問題 |
推薦模型:Large-v1 穩定且質量較好。
註:以上模型國內網路可直接在軟體內下載;支持 GPU 也支持核顯調用。
- 在「字幕優化與翻譯」頁面,包含「文稿匹配」選項,支持以下 一種或者多種 內容,輔助校正字幕和翻譯:
| 類型 | 說明 | 填寫示例 |
|---|---|---|
| 術語表 | 專業術語、人名、特定詞語的修正對照表 | 機器學習->Machine Learning 馬斯克->Elon Musk 打call -> 應援 圖靈斑圖 公車悖論 |
| 原字幕文稿 | 視頻的原有文稿或相關內容 | 完整的演講稿、課程講義等 |
| 修正要求 | 內容相關的具體修正要求 | 統一人稱代詞、規範專業術語等 填寫 內容相關 的要求即可,示例參考 |
- 如果需要文稿進行字幕優化輔助,全流程處理時,先填寫文稿資訊,再開始任務處理
- 注意:使用上下文參數量不高的小型 LLM 模型時,建議控制文稿內容在 1 千字內;如果使用上下文較大的模型,則可以適當增加文稿內容。
| 接口名稱 | 支持語言 | 運行方式 | 說明 |
|---|---|---|---|
| B 接口 | 僅支持中文、英文 | 線上 | 免費、速度較快 |
| J 接口 | 僅支持中文、英文 | 線上 | 免費、速度較快 |
| WhisperCpp | 中文、日語、韓語、英文等 99 種語言,外語效果較好 | 本地 | (實際使用不穩定)需要下載轉錄模型 中文建議 medium 以上模型 英文等使用較小模型即可達到不錯效果。 |
| fasterWhisper 👍 | 中文、英文等多 99 種語言,外語效果優秀,時間軸更準確 | 本地 | (🌟極力推薦🌟)需要下載程式和轉錄模型 支持 CUDA,速度更快,轉錄準確。 超級準確的時間戳字幕。 建議優先使用。 |
如果使用 URL 下載功能時,若遇到以下情況:
- 下載視頻網站需要登入資訊才可下載;
- 只能下載較低解析度的視頻;
- 網路條件較差時需要驗證;
- 請參考 Cookie 配置說明 獲取 Cookie 資訊,並將 cookies.txt 檔案放置到軟體安裝目錄的
AppData目錄下,即可正常下載高品質視頻。
程式簡單的處理流程如下:
語音識別 -> 字幕斷句(可選) -> 字幕優化翻譯(可選) -> 字幕視頻合成
安裝軟體的主要目錄結構說明如下:
VideoCaptioner/
├── runtime/ # 運行環境目錄(不用更改)
├── resources/ # 軟體資源檔案目錄(二進位程式、圖示等,以及下載的 faster-whisper 程式)
├── work-dir/ # 工作目錄,處理完成的視頻和字幕檔案保存在這裡
├── AppData/ # 應用資料目錄
│ ├── cache/ # 快取目錄,快取轉錄、大模型請求的資料
│ ├── models/ # 存放 Whisper 模型檔案
│ ├── logs/ # 日誌目錄,記錄軟體運行狀態
│ ├── settings.json # 存儲使用者設置
│ └── cookies.txt # 視頻平台的 cookie 資訊(下載高清視頻時需要)
└── VideoCaptioner.exe # 主程式執行檔
-
字幕斷句的質量對觀賞體驗至關重要。為此我開發了 SubtitleSpliter,它能將逐字字幕智能重組為符合自然語言習慣的段落,並與視頻畫面完美同步。
-
在處理過程中,僅向大語言模型發送文本內容,不包含時間軸資訊,這大大降低了處理開銷。
-
在翻譯環節,我們採用了吳恩達提出的「翻譯-反思-翻譯」方法論。這種迭代優化的方式不僅確保了翻譯的準確性。
作者是一名大三學生,個人能力和專案都還有許多不足,專案也在不斷完善中,如果在使用過程中遇到 Bug,歡迎提交 Issue 與 Pull Request 以幫助改進專案。
2024.1.22
- 完整重構程式碼架構,優化整體效能
- 字幕優化與翻譯功能模組分離,提供更靈活的處理選項
- 新增批量處理功能:支持批量字幕、批量轉錄、批量字幕視頻合成
- 全面優化 UI 介面與交互細節
- 擴展 LLM 支持:新增 SiliconCloud、DeepSeek、Ollama、Gemini、ChatGLM 等模型
- 集成多種翻譯服務:DeepLx、Bing、Google、LLM
- 新增 faster-whisper-large-v3-turbo 模型支持
- 新增多種 VAD(語音活動檢測)方法
- 支持自定義反思翻譯開關
- 字幕斷句支持語義/句子兩種模式
- 字幕斷句、優化、翻譯提示詞的優化
- 字幕、轉錄快取機制的優化
- 優化中文字幕自動換行功能
- 新增豎屏字幕樣式
- 改進字幕時間軸切換機制,消除閃爍問題
- 修復 Whisper API 無法使用問題
- 新增多種字幕視頻格式支持
- 修復部分情況轉錄錯誤的問題
- 優化視頻工作目錄結構
- 新增日誌查看功能
- 新增泰語、德語等語言的字幕優化
- 修復諸多 Bug...
2024.12.07
- 新增 Faster-whisper 支持,音頻轉字幕質量更優
- 支持 VAD 語音斷點檢測,大大減少幻覺現象
- 支持人聲分離,分離視頻背景噪音
- 支持關閉視頻合成
- 新增字幕最大長度設定
- 新增字幕末尾標點去除設定
- 優化和翻譯的提示詞優化
- 優化 LLM 字幕斷句錯誤的情況
- 修復音頻轉換格式不一致問題
2024.11.23
- 新增 Whisper-v3 模型支持,大幅提升語音識別準確率
- 優化字幕斷句算法,提供更自然的閱讀體驗
- 修復檢測模型可用性時的穩定性問題
2024.11.20
- 支持自定義調節字幕位置和樣式
- 新增字幕優化和翻譯過程的即時日誌查看
- 修復使用 API 時的自動翻譯問題
- 優化視頻工作目錄結構,提升檔案管理效率
2024.11.17
- 支持雙語/單語字幕靈活導出
- 新增文稿匹配提示對齊功能
- 修復字幕導入時的穩定性問題
- 修復非中文路徑下載模型的相容性問題
2024.11.13
- 新增 Whisper API 調用支持
- 支持導入 cookie.txt 下載各大視頻平台資源
- 字幕檔名自動與視頻保持一致
- 軟體首頁新增運行日誌即時查看
- 統一和完善軟體內部功能
如果覺得專案對你有幫助,可以給專案點個 Star,這將是對我最大的鼓勵和支持!

