diff --git a/ci/bundle_custom_data.py b/ci/bundle_custom_data.py
index f3b75589..711bce3f 100644
--- a/ci/bundle_custom_data.py
+++ b/ci/bundle_custom_data.py
@@ -49,6 +49,9 @@
"spleen_ct_segmentation": {},
"endoscopic_tool_segmentation": {},
"pathology_tumor_detection": {},
+ "pathology_nuclei_classification": {},
+ "pathology_nuclick_annotation": {"use_trace": True},
+ "wholeBody_ct_segmentation": {"use_trace": True},
"pancreas_ct_dints_segmentation": {
"use_trace": True,
"converter_kwargs": {"truncate_long_and_double": True, "torch_executed_ops": ["aten::upsample_trilinear3d"]},
diff --git a/models/pancreas_ct_dints_segmentation/configs/metadata.json b/models/pancreas_ct_dints_segmentation/configs/metadata.json
index 2fd6955f..6c4f02b5 100644
--- a/models/pancreas_ct_dints_segmentation/configs/metadata.json
+++ b/models/pancreas_ct_dints_segmentation/configs/metadata.json
@@ -1,7 +1,8 @@
{
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
- "version": "0.4.3",
+ "version": "0.4.4",
"changelog": {
+ "0.4.4": "update the benchmark results of TensorRT",
"0.4.3": "add support for TensorRT conversion and inference",
"0.4.2": "update search function to match monai 1.2",
"0.4.1": "fix the wrong GPU index issue of multi-node",
diff --git a/models/pancreas_ct_dints_segmentation/docs/README.md b/models/pancreas_ct_dints_segmentation/docs/README.md
index 8ef4d171..ce11419f 100644
--- a/models/pancreas_ct_dints_segmentation/docs/README.md
+++ b/models/pancreas_ct_dints_segmentation/docs/README.md
@@ -84,8 +84,8 @@ This bundle supports acceleration with TensorRT. The table below displays the sp
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
-| model computation | 54611.72 | 19240.66 | 16104.8 | 11443.57 | 2.84 | 3.39 | 4.77 | 1.68 |
-| end2end | 133.93 | 43.41 | 35.65 | 26.63 | 3.09 | 3.76 | 5.03 | 1.63 |
+| model computation | 133.93 | 43.41 | 35.65 | 26.63 | 3.09 | 3.76 | 5.03 | 1.63 |
+| end2end | 54611.72 | 19240.66 | 16104.8 | 11443.57 | 2.84 | 3.39 | 4.77 | 1.68 |
Where:
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
diff --git a/models/pathology_nuclei_classification/configs/inference_trt.json b/models/pathology_nuclei_classification/configs/inference_trt.json
new file mode 100644
index 00000000..e484f27a
--- /dev/null
+++ b/models/pathology_nuclei_classification/configs/inference_trt.json
@@ -0,0 +1,12 @@
+{
+ "imports": [
+ "$import glob",
+ "$import os",
+ "$import pathlib",
+ "$import json",
+ "$import torch_tensorrt"
+ ],
+ "handlers#0#_disabled_": true,
+ "network_def": "$torch.jit.load(@bundle_root + '/models/model_trt.ts')",
+ "evaluator#amp": false
+}
diff --git a/models/pathology_nuclei_classification/configs/metadata.json b/models/pathology_nuclei_classification/configs/metadata.json
index 487b45b3..55ff958e 100644
--- a/models/pathology_nuclei_classification/configs/metadata.json
+++ b/models/pathology_nuclei_classification/configs/metadata.json
@@ -1,7 +1,8 @@
{
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
- "version": "0.1.4",
+ "version": "0.1.5",
"changelog": {
+ "0.1.5": "add support for TensorRT conversion and inference",
"0.1.4": "fix the wrong GPU index issue of multi-node",
"0.1.3": "remove error dollar symbol in readme",
"0.1.2": "add RAM warning",
diff --git a/models/pathology_nuclei_classification/docs/README.md b/models/pathology_nuclei_classification/docs/README.md
index 60f54c52..125c875a 100644
--- a/models/pathology_nuclei_classification/docs/README.md
+++ b/models/pathology_nuclei_classification/docs/README.md
@@ -139,6 +139,31 @@ A graph showing the validation F1-score over 100 epochs.
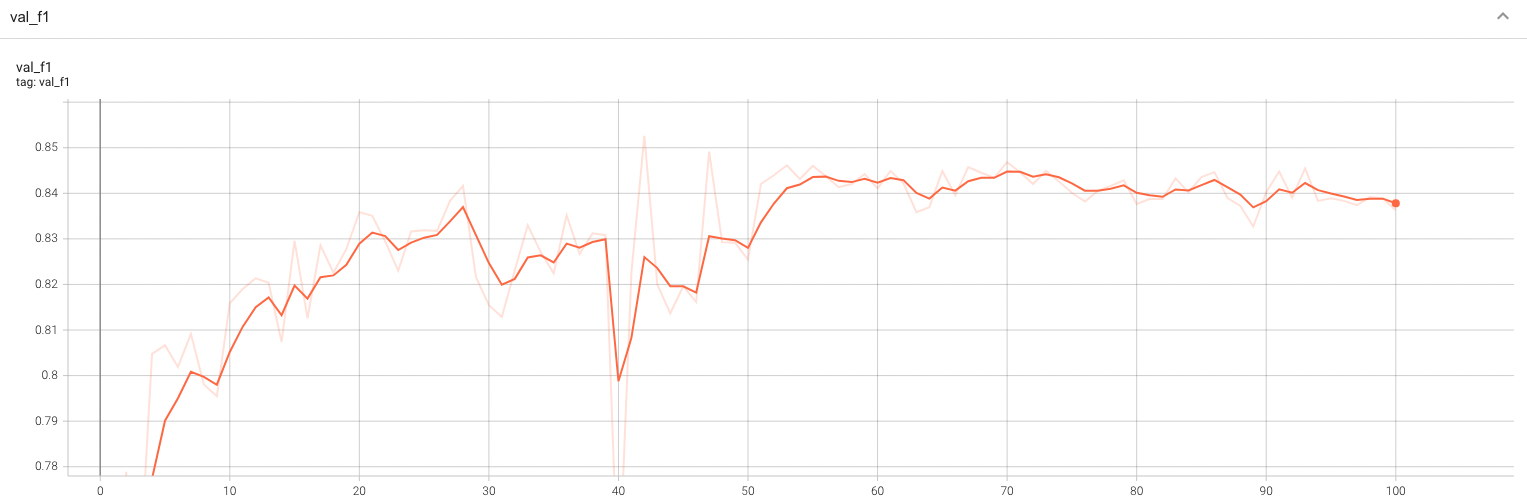 <br>
+#### TensorRT speedup
+This bundle supports acceleration with TensorRT. The table below displays the speedup ratios observed on an A100 80G GPU.
+
+| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
+| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+| model computation | 9.99 | 14.14 | 4.62 | 2.37 | 0.71 | 2.16 | 4.22 | 5.97 |
+| end2end | 412.95 | 408.88 | 351.64 | 286.85 | 1.01 | 1.17 | 1.44 | 1.43 |
+
+Where:
+- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
+- `end2end` means run the bundle end-to-end with the TensorRT based model.
+- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
+- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
+- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
+- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
+
+This result is benchmarked under:
+ - TensorRT: 8.6.1+cuda12.0
+ - Torch-TensorRT Version: 1.4.0
+ - CPU Architecture: x86-64
+ - OS: ubuntu 20.04
+ - Python version:3.8.10
+ - CUDA version: 12.1
+ - GPU models and configuration: A100 80G
+
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
@@ -182,6 +207,18 @@ torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config
python -m monai.bundle run --config_file configs/inference.json
```
+#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
+
+```
+python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16>
+```
+
+#### Execute inference with the TensorRT model:
+
+```
+python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
+```
+
# References
[1] S. Graham, Q. D. Vu, S. E. A. Raza, A. Azam, Y-W. Tsang, J. T. Kwak and N. Rajpoot. "HoVer-Net: Simultaneous Segmentation and Classification of Nuclei in Multi-Tissue Histology Images." Medical Image Analysis, Sept. 2019. [[doi](https://doi.org/10.1016/j.media.2019.101563)]
diff --git a/models/pathology_nuclick_annotation/configs/inference_trt.json b/models/pathology_nuclick_annotation/configs/inference_trt.json
new file mode 100644
index 00000000..23c2c168
--- /dev/null
+++ b/models/pathology_nuclick_annotation/configs/inference_trt.json
@@ -0,0 +1,12 @@
+{
+ "imports": [
+ "$import glob",
+ "$import json",
+ "$import pathlib",
+ "$import os",
+ "$import torch_tensorrt"
+ ],
+ "handlers#0#_disabled_": true,
+ "network_def": "$torch.jit.load(@bundle_root + '/models/model_trt.ts')",
+ "evaluator#amp": false
+}
diff --git a/models/pathology_nuclick_annotation/configs/metadata.json b/models/pathology_nuclick_annotation/configs/metadata.json
index 381840a3..a4d30da1 100644
--- a/models/pathology_nuclick_annotation/configs/metadata.json
+++ b/models/pathology_nuclick_annotation/configs/metadata.json
@@ -1,7 +1,8 @@
{
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
- "version": "0.1.4",
+ "version": "0.1.5",
"changelog": {
+ "0.1.5": "add support for TensorRT conversion and inference",
"0.1.4": "fix the wrong GPU index issue of multi-node",
"0.1.3": "remove error dollar symbol in readme",
"0.1.2": "add RAM usage with CachDataset",
diff --git a/models/pathology_nuclick_annotation/docs/README.md b/models/pathology_nuclick_annotation/docs/README.md
index a04d48d0..38336cb3 100644
--- a/models/pathology_nuclick_annotation/docs/README.md
+++ b/models/pathology_nuclick_annotation/docs/README.md
@@ -125,6 +125,31 @@ A graph showing the validation mean Dice over 50 epochs.
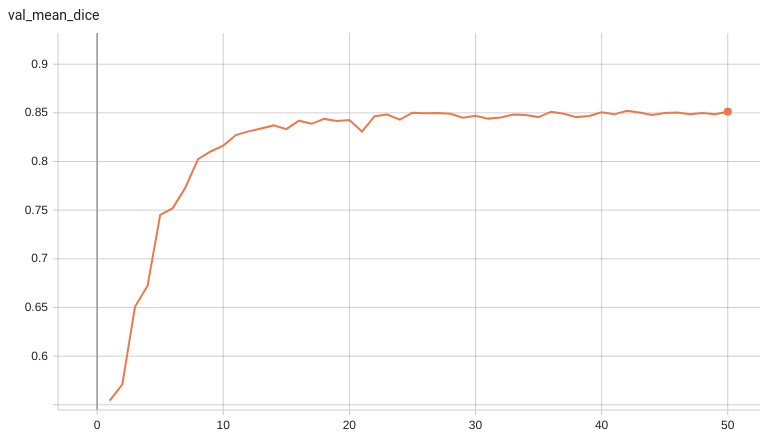 <br>
+#### TensorRT speedup
+This bundle supports acceleration with TensorRT. The table below displays the speedup ratios observed on an A100 80G GPU.
+
+| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
+| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+| model computation | 3.27 | 4.31 | 2.12 | 1.73 | 0.76 | 1.54 | 1.89 | 2.49 |
+| end2end | 705.32 | 752.64 | 290.45 | 347.07 | 0.94 | 2.43 | 2.03 | 2.17 |
+
+Where:
+- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
+- `end2end` means run the bundle end-to-end with the TensorRT based model.
+- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
+- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
+- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
+- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
+
+This result is benchmarked under:
+ - TensorRT: 8.6.1+cuda12.0
+ - Torch-TensorRT Version: 1.4.0
+ - CPU Architecture: x86-64
+ - OS: ubuntu 20.04
+ - Python version:3.8.10
+ - CUDA version: 12.1
+ - GPU models and configuration: A100 80G
+
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
@@ -168,6 +193,18 @@ torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config
python -m monai.bundle run --config_file configs/inference.json
```
+#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
+
+```
+python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16> --use_trace "True"
+```
+
+#### Execute inference with the TensorRT model:
+
+```
+python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
+```
+
# References
[1] Koohbanani, Navid Alemi, et al. "NuClick: a deep learning framework for interactive segmentation of microscopic images." Medical Image Analysis 65 (2020): 101771. https://arxiv.org/abs/2005.14511.
diff --git a/models/wholeBody_ct_segmentation/configs/inference_trt.json b/models/wholeBody_ct_segmentation/configs/inference_trt.json
new file mode 100644
index 00000000..adfbca41
--- /dev/null
+++ b/models/wholeBody_ct_segmentation/configs/inference_trt.json
@@ -0,0 +1,10 @@
+{
+ "imports": [
+ "$import glob",
+ "$import os",
+ "$import torch_tensorrt"
+ ],
+ "handlers#0#_disabled_": true,
+ "network_def": "$torch.jit.load(@bundle_root + '/models/model_trt.ts')",
+ "evaluator#amp": false
+}
diff --git a/models/wholeBody_ct_segmentation/configs/metadata.json b/models/wholeBody_ct_segmentation/configs/metadata.json
index 1e4f7745..0a5d8e1a 100644
--- a/models/wholeBody_ct_segmentation/configs/metadata.json
+++ b/models/wholeBody_ct_segmentation/configs/metadata.json
@@ -1,7 +1,8 @@
{
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
- "version": "0.1.9",
+ "version": "0.2.0",
"changelog": {
+ "0.2.0": "add support for TensorRT conversion and inference",
"0.1.9": "fix the wrong GPU index issue of multi-node",
"0.1.8": "Update evalaute doc, GPU usage details, and dataset preparation instructions",
"0.1.7": "remove error dollar symbol in readme",
diff --git a/models/wholeBody_ct_segmentation/docs/README.md b/models/wholeBody_ct_segmentation/docs/README.md
index 1006e960..3227726e 100644
--- a/models/wholeBody_ct_segmentation/docs/README.md
+++ b/models/wholeBody_ct_segmentation/docs/README.md
@@ -151,6 +151,31 @@ CPU: Memory: **2.3G**
Please note that this bundle is non-deterministic because of the trilinear interpolation used in the network. Therefore, reproducing the training process may not get exactly the same performance.
Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducibility for more details about reproducibility.
+#### TensorRT speedup
+This bundle supports acceleration with TensorRT. The table below displays the speedup ratios observed on an A100 80G GPU.
+
+| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
+| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
+| model computation | 88.20 | 37.1 | 39.2 | 36.9 | 2.38 | 2.25 | 2.39 | 1.01 |
+| end2end | 3717.14 | 2596.77 | 2517.29 | 2501.37 | 1.43 | 1.48 | 1.49 | 1.04 |
+
+Where:
+- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
+- `end2end` means run the bundle end-to-end with the TensorRT based model.
+- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
+- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
+- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
+- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
+
+This result is benchmarked under:
+ - TensorRT: 8.6.1+cuda12.0
+ - Torch-TensorRT Version: 1.4.0
+ - CPU Architecture: x86-64
+ - OS: ubuntu 20.04
+ - Python version:3.8.10
+ - CUDA version: 12.1
+ - GPU models and configuration: A100 80G
+
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
@@ -199,6 +224,18 @@ python -m monai.bundle run --config_file configs/inference.json
python -m monai.bundle run --config_file configs/inference.json --datalist "['sampledata/imagesTr/s0037.nii.gz','sampledata/imagesTr/s0038.nii.gz']"
```
+#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
+
+```
+python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16> --use_trace "True"
+```
+
+#### Execute inference with the TensorRT model:
+
+```
+python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
+```
+
# References