
 +
+
+
+
+
+
+ 
 +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
-
-
-
-- ### 模型介绍
-
- - 本模块采用一个像素风格迁移网络 Pix2PixHD,能够根据输入的语义分割标签生成照片风格的图片。为了解决模型归一化层导致标签语义信息丢失的问题,向 Pix2PixHD 的生成器网络中添加了 SPADE(Spatially-Adaptive
- Normalization)空间自适应归一化模块,通过两个卷积层保留了归一化时训练的缩放与偏置参数的空间维度,以增强生成图片的质量。语义风格标签图像可以参考[coco_stuff数据集](https://github.com/nightrome/cocostuff)获取, 也可以通过[PaddleGAN repo中的该项目](https://github.com/PaddlePaddle/PaddleGAN/blob/87537ad9d4eeda17eaa5916c6a585534ab989ea8/docs/zh_CN/tutorials/photopen.md)来自定义生成图像进行体验。
-
-
-
-## 二、安装
-
-- ### 1、环境依赖
- - ppgan
-
-- ### 2、安装
-
- - ```shell
- $ hub install photopen
- ```
- - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
- | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-
-## 三、模型API预测
-
-- ### 1、命令行预测
-
- - ```shell
- # Read from a file
- $ hub run photopen --input_path "/PATH/TO/IMAGE"
- ```
- - 通过命令行方式实现图像生成模型的调用,更多请见 [PaddleHub命令行指令](../../../../docs/docs_ch/tutorial/cmd_usage.rst)
-
-- ### 2、预测代码示例
-
- - ```python
- import paddlehub as hub
-
- module = hub.Module(name="photopen")
- input_path = ["/PATH/TO/IMAGE"]
- # Read from a file
- module.photo_transfer(paths=input_path, output_dir='./transfer_result/', use_gpu=True)
- ```
-
-- ### 3、API
-
- - ```python
- photo_transfer(images=None, paths=None, output_dir='./transfer_result/', use_gpu=False, visualization=True):
- ```
- - 图像转换生成API。
-
- - **参数**
-
- - images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];
- - paths (list\[str\]): 图片的路径;
- - output\_dir (str): 结果保存的路径;
- - use\_gpu (bool): 是否使用 GPU;
- - visualization(bool): 是否保存结果到本地文件夹
-
-
-## 四、服务部署
-
-- PaddleHub Serving可以部署一个在线图像转换生成服务。
-
-- ### 第一步:启动PaddleHub Serving
-
- - 运行启动命令:
- - ```shell
- $ hub serving start -m photopen
- ```
-
- - 这样就完成了一个图像转换生成的在线服务API的部署,默认端口号为8866。
-
- - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-
-- ### 第二步:发送预测请求
-
- - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
- - ```python
- import requests
- import json
- import cv2
- import base64
-
-
- def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-
- # 发送HTTP请求
- data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
- headers = {"Content-type": "application/json"}
- url = "http://127.0.0.1:8866/predict/photopen"
- r = requests.post(url=url, headers=headers, data=json.dumps(data))
-
- # 打印预测结果
- print(r.json()["results"])
-
-## 五、更新历史
-
-* 1.0.0
-
- 初始发布
-
- - ```shell
- $ hub install ernie_tiny==1.1.0
- ```
diff --git a/modules/text/text_generation/ernie_tiny/README_en.md b/modules/text/text_generation/ernie_tiny/README_en.md
deleted file mode 100644
index 373348799..000000000
--- a/modules/text/text_generation/ernie_tiny/README_en.md
+++ /dev/null
@@ -1,171 +0,0 @@
-# ernie_tiny
-
-|Module Name|ernie_tiny|
-| :--- | :---: |
-|Category|object detection|
-|Network|faster_rcnn|
-|Dataset|COCO2017|
-|Fine-tuning supported or not|No|
-|Module Size|161MB|
-|Latest update date|2021-03-15|
-|Data indicators|-|
-
-
-## I.Basic Information
-
-- ### Application Effect Display
- - Sample results:
-
-  -
-
-
+
+
+
+
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
-
+
+
-
-
+
@@ -22,14 +21,14 @@ English | [简体中文](README_ch.md)
## ⭐Features
- **📦400+ AI Models**: Rich, high-quality AI models, including CV, NLP, Speech, Video and Cross-Modal.
-- **🧒Easy to Use**: 3 lines of code to predict the 400+ AI models.
-- **💁Model As Service**: Easy to build a service with only one line of command.
+- **🧒Easy to Use**: 3 lines of code to predict 400+ AI models.
+- **💁Model As Service**: Easy to serve model with only one line of command.
- **💻Cross-platform**: Support Linux, Windows and MacOS.
### 💥Recent Updates
- **🔥2022.08.19:** The v2.3.0 version is released 🎉
- - supports [**ERNIE_ViLG**](./modules/image/text_to_image/ernie_vilg)([Hugging Face Space Demo](https://huggingface.co/spaces/PaddlePaddle/ERNIE-ViLG))
- - supports [**Disco Diffusion(DD)**](./modules/image/text_to_image/disco_diffusion_clip_vitb32) and [**Stable Diffusion(SD)**](./modules/image/text_to_image/stable_diffusion)
+ - Supports [**ERNIE-ViLG**](./modules/image/text_to_image/ernie_vilg)([HuggingFace Space Demo](https://huggingface.co/spaces/PaddlePaddle/ERNIE-ViLG))
+ - Supports [**Disco Diffusion (DD)**](./modules/image/text_to_image/disco_diffusion_clip_vitb32) and [**Stable Diffusion (SD)**](./modules/image/text_to_image/stable_diffusion)
- **2022.02.18:** Release models to HuggingFace [PaddlePaddle Space](https://huggingface.co/PaddlePaddle)
@@ -40,7 +39,7 @@ English | [简体中文](README_ch.md)
## 🌈Visualization Demo
#### 🏜️ [Text-to-Image Models](https://www.paddlepaddle.org.cn/hubdetail?name=ernie_vilg&en_category=TextToImage)
-- Include ERNIE-ViL, ERNIE 3.0 Zeus, supports applications such as text-to-image, writing essays, summarization, couplets, question answering, writing novels and completing text.
+- Include ERNIE-ViLG, ERNIE-ViL, ERNIE 3.0 Zeus, supports applications such as text-to-image, writing essays, summarization, couplets, question answering, writing novels and completing text.
From 2e727825a3b2ee45358b42ee5c12967d7fdb4595 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Wed, 14 Sep 2022 14:23:29 +0800
Subject: [PATCH 050/117] fix typo
---
docs/docs_ch/get_start/linux_quickstart.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/docs_ch/get_start/linux_quickstart.md b/docs/docs_ch/get_start/linux_quickstart.md
index ebebaa448..c6f08573d 100755
--- a/docs/docs_ch/get_start/linux_quickstart.md
+++ b/docs/docs_ch/get_start/linux_quickstart.md
@@ -206,5 +206,5 @@
-
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出图像
+
+- ### 模型介绍
+
+ - PP-TinyPose是PaddleDetecion针对移动端设备优化的实时关键点检测模型,可流畅地在移动端设备上执行多人姿态估计任务。借助PaddleDetecion自研的优秀轻量级检测模型PicoDet以及轻量级姿态估计任务骨干网络HRNet, 结合多种策略有效平衡了模型的速度和精度表现。
+
+ - 更多详情参考:[PP-TinyPose](https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.4/configs/keypoint/tiny_pose)。
+
+
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.2
+
+ - paddlehub >= 2.2 | [如何安装paddlehub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install pp-tinypose
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run pp-tinypose --input_path "/PATH/TO/IMAGE" --visualization True --use_gpu
+ ```
+ - 通过命令行方式实现关键点检测模型的调用,更多请见 [PaddleHub命令行指令](../../../../docs/docs_ch/tutorial/cmd_usage.rst)
+
+- ### 2、代码示例
+
+ - ```python
+ import paddlehub as hub
+ import cv2
+
+ model = hub.Module(name="pp-tinypose")
+ result = model.predict('/PATH/TO/IMAGE', save_path='pp_tinypose_output', visualization=True, use_gpu=True)
+ ```
+
+- ### 3、API
+
+
+ - ```python
+ def predict(self, img: Union[str, np.ndarray], save_path: str = "pp_tinypose_output", visualization: bool = True, use_gpu = False)
+ ```
+
+ - 预测API,识别输入图片中的所有人肢体关键点。
+
+ - **参数**
+
+ - img (numpy.ndarray|str): 图片数据,使用图片路径或者输入numpy.ndarray,BGR格式;
+ - save_path (str): 图片保存路径, 默认为'pp_tinypose_output';
+ - visualization (bool): 是否将识别结果保存为图片文件;
+ - use_gpu: 是否使用gpu;
+ - **返回**
+
+ - res (list\[dict\]): 识别结果的列表,列表元素依然为列表,存的内容为[图像名称,检测框,关键点]。
+
+
+## 四、服务部署
+
+- PaddleHub Serving 可以部署一个关键点检测的在线服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+ - ```shell
+ $ hub serving start -m pp-tinypose
+ ```
+
+ - 这样就完成了一个关键点检测的服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ # 发送HTTP请求
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/pp-tinypose"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ ```
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ - ```shell
+ $ hub install pp-tinypose==1.0.0
+ ```
diff --git a/modules/image/keypoint_detection/pp-tinypose/__init__.py b/modules/image/keypoint_detection/pp-tinypose/__init__.py
new file mode 100644
index 000000000..55916b319
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/__init__.py
@@ -0,0 +1,5 @@
+import os
+import sys
+
+CUR_DIR = os.path.dirname(os.path.abspath(__file__))
+sys.path.append(CUR_DIR)
diff --git a/modules/image/keypoint_detection/pp-tinypose/benchmark_utils.py b/modules/image/keypoint_detection/pp-tinypose/benchmark_utils.py
new file mode 100644
index 000000000..e1dd4ec35
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/benchmark_utils.py
@@ -0,0 +1,262 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import logging
+import os
+from pathlib import Path
+
+import paddle
+import paddle.inference as paddle_infer
+
+CUR_DIR = os.path.dirname(os.path.abspath(__file__))
+LOG_PATH_ROOT = f"{CUR_DIR}/../../output"
+
+
+class PaddleInferBenchmark(object):
+
+ def __init__(self,
+ config,
+ model_info: dict = {},
+ data_info: dict = {},
+ perf_info: dict = {},
+ resource_info: dict = {},
+ **kwargs):
+ """
+ Construct PaddleInferBenchmark Class to format logs.
+ args:
+ config(paddle.inference.Config): paddle inference config
+ model_info(dict): basic model info
+ {'model_name': 'resnet50'
+ 'precision': 'fp32'}
+ data_info(dict): input data info
+ {'batch_size': 1
+ 'shape': '3,224,224'
+ 'data_num': 1000}
+ perf_info(dict): performance result
+ {'preprocess_time_s': 1.0
+ 'inference_time_s': 2.0
+ 'postprocess_time_s': 1.0
+ 'total_time_s': 4.0}
+ resource_info(dict):
+ cpu and gpu resources
+ {'cpu_rss': 100
+ 'gpu_rss': 100
+ 'gpu_util': 60}
+ """
+ # PaddleInferBenchmark Log Version
+ self.log_version = "1.0.3"
+
+ # Paddle Version
+ self.paddle_version = paddle.__version__
+ self.paddle_commit = paddle.__git_commit__
+ paddle_infer_info = paddle_infer.get_version()
+ self.paddle_branch = paddle_infer_info.strip().split(': ')[-1]
+
+ # model info
+ self.model_info = model_info
+
+ # data info
+ self.data_info = data_info
+
+ # perf info
+ self.perf_info = perf_info
+
+ try:
+ # required value
+ self.model_name = model_info['model_name']
+ self.precision = model_info['precision']
+
+ self.batch_size = data_info['batch_size']
+ self.shape = data_info['shape']
+ self.data_num = data_info['data_num']
+
+ self.inference_time_s = round(perf_info['inference_time_s'], 4)
+ except:
+ self.print_help()
+ raise ValueError("Set argument wrong, please check input argument and its type")
+
+ self.preprocess_time_s = perf_info.get('preprocess_time_s', 0)
+ self.postprocess_time_s = perf_info.get('postprocess_time_s', 0)
+ self.with_tracker = True if 'tracking_time_s' in perf_info else False
+ self.tracking_time_s = perf_info.get('tracking_time_s', 0)
+ self.total_time_s = perf_info.get('total_time_s', 0)
+
+ self.inference_time_s_90 = perf_info.get("inference_time_s_90", "")
+ self.inference_time_s_99 = perf_info.get("inference_time_s_99", "")
+ self.succ_rate = perf_info.get("succ_rate", "")
+ self.qps = perf_info.get("qps", "")
+
+ # conf info
+ self.config_status = self.parse_config(config)
+
+ # mem info
+ if isinstance(resource_info, dict):
+ self.cpu_rss_mb = int(resource_info.get('cpu_rss_mb', 0))
+ self.cpu_vms_mb = int(resource_info.get('cpu_vms_mb', 0))
+ self.cpu_shared_mb = int(resource_info.get('cpu_shared_mb', 0))
+ self.cpu_dirty_mb = int(resource_info.get('cpu_dirty_mb', 0))
+ self.cpu_util = round(resource_info.get('cpu_util', 0), 2)
+
+ self.gpu_rss_mb = int(resource_info.get('gpu_rss_mb', 0))
+ self.gpu_util = round(resource_info.get('gpu_util', 0), 2)
+ self.gpu_mem_util = round(resource_info.get('gpu_mem_util', 0), 2)
+ else:
+ self.cpu_rss_mb = 0
+ self.cpu_vms_mb = 0
+ self.cpu_shared_mb = 0
+ self.cpu_dirty_mb = 0
+ self.cpu_util = 0
+
+ self.gpu_rss_mb = 0
+ self.gpu_util = 0
+ self.gpu_mem_util = 0
+
+ # init benchmark logger
+ self.benchmark_logger()
+
+ def benchmark_logger(self):
+ """
+ benchmark logger
+ """
+ # remove other logging handler
+ for handler in logging.root.handlers[:]:
+ logging.root.removeHandler(handler)
+
+ # Init logger
+ FORMAT = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'
+ log_output = f"{LOG_PATH_ROOT}/{self.model_name}.log"
+ Path(f"{LOG_PATH_ROOT}").mkdir(parents=True, exist_ok=True)
+ logging.basicConfig(level=logging.INFO,
+ format=FORMAT,
+ handlers=[
+ logging.FileHandler(filename=log_output, mode='w'),
+ logging.StreamHandler(),
+ ])
+ self.logger = logging.getLogger(__name__)
+ self.logger.info(f"Paddle Inference benchmark log will be saved to {log_output}")
+
+ def parse_config(self, config) -> dict:
+ """
+ parse paddle predictor config
+ args:
+ config(paddle.inference.Config): paddle inference config
+ return:
+ config_status(dict): dict style config info
+ """
+ if isinstance(config, paddle_infer.Config):
+ config_status = {}
+ config_status['runtime_device'] = "gpu" if config.use_gpu() else "cpu"
+ config_status['ir_optim'] = config.ir_optim()
+ config_status['enable_tensorrt'] = config.tensorrt_engine_enabled()
+ config_status['precision'] = self.precision
+ config_status['enable_mkldnn'] = config.mkldnn_enabled()
+ config_status['cpu_math_library_num_threads'] = config.cpu_math_library_num_threads()
+ elif isinstance(config, dict):
+ config_status['runtime_device'] = config.get('runtime_device', "")
+ config_status['ir_optim'] = config.get('ir_optim', "")
+ config_status['enable_tensorrt'] = config.get('enable_tensorrt', "")
+ config_status['precision'] = config.get('precision', "")
+ config_status['enable_mkldnn'] = config.get('enable_mkldnn', "")
+ config_status['cpu_math_library_num_threads'] = config.get('cpu_math_library_num_threads', "")
+ else:
+ self.print_help()
+ raise ValueError("Set argument config wrong, please check input argument and its type")
+ return config_status
+
+ def report(self, identifier=None):
+ """
+ print log report
+ args:
+ identifier(string): identify log
+ """
+ if identifier:
+ identifier = f"[{identifier}]"
+ else:
+ identifier = ""
+
+ self.logger.info("\n")
+ self.logger.info("---------------------- Paddle info ----------------------")
+ self.logger.info(f"{identifier} paddle_version: {self.paddle_version}")
+ self.logger.info(f"{identifier} paddle_commit: {self.paddle_commit}")
+ self.logger.info(f"{identifier} paddle_branch: {self.paddle_branch}")
+ self.logger.info(f"{identifier} log_api_version: {self.log_version}")
+ self.logger.info("----------------------- Conf info -----------------------")
+ self.logger.info(f"{identifier} runtime_device: {self.config_status['runtime_device']}")
+ self.logger.info(f"{identifier} ir_optim: {self.config_status['ir_optim']}")
+ self.logger.info(f"{identifier} enable_memory_optim: {True}")
+ self.logger.info(f"{identifier} enable_tensorrt: {self.config_status['enable_tensorrt']}")
+ self.logger.info(f"{identifier} enable_mkldnn: {self.config_status['enable_mkldnn']}")
+ self.logger.info(
+ f"{identifier} cpu_math_library_num_threads: {self.config_status['cpu_math_library_num_threads']}")
+ self.logger.info("----------------------- Model info ----------------------")
+ self.logger.info(f"{identifier} model_name: {self.model_name}")
+ self.logger.info(f"{identifier} precision: {self.precision}")
+ self.logger.info("----------------------- Data info -----------------------")
+ self.logger.info(f"{identifier} batch_size: {self.batch_size}")
+ self.logger.info(f"{identifier} input_shape: {self.shape}")
+ self.logger.info(f"{identifier} data_num: {self.data_num}")
+ self.logger.info("----------------------- Perf info -----------------------")
+ self.logger.info(
+ f"{identifier} cpu_rss(MB): {self.cpu_rss_mb}, cpu_vms: {self.cpu_vms_mb}, cpu_shared_mb: {self.cpu_shared_mb}, cpu_dirty_mb: {self.cpu_dirty_mb}, cpu_util: {self.cpu_util}%"
+ )
+ self.logger.info(
+ f"{identifier} gpu_rss(MB): {self.gpu_rss_mb}, gpu_util: {self.gpu_util}%, gpu_mem_util: {self.gpu_mem_util}%"
+ )
+ self.logger.info(f"{identifier} total time spent(s): {self.total_time_s}")
+
+ if self.with_tracker:
+ self.logger.info(f"{identifier} preprocess_time(ms): {round(self.preprocess_time_s*1000, 1)}, "
+ f"inference_time(ms): {round(self.inference_time_s*1000, 1)}, "
+ f"postprocess_time(ms): {round(self.postprocess_time_s*1000, 1)}, "
+ f"tracking_time(ms): {round(self.tracking_time_s*1000, 1)}")
+ else:
+ self.logger.info(f"{identifier} preprocess_time(ms): {round(self.preprocess_time_s*1000, 1)}, "
+ f"inference_time(ms): {round(self.inference_time_s*1000, 1)}, "
+ f"postprocess_time(ms): {round(self.postprocess_time_s*1000, 1)}")
+ if self.inference_time_s_90:
+ self.looger.info(
+ f"{identifier} 90%_cost: {self.inference_time_s_90}, 99%_cost: {self.inference_time_s_99}, succ_rate: {self.succ_rate}"
+ )
+ if self.qps:
+ self.logger.info(f"{identifier} QPS: {self.qps}")
+
+ def print_help(self):
+ """
+ print function help
+ """
+ print("""Usage:
+ ==== Print inference benchmark logs. ====
+ config = paddle.inference.Config()
+ model_info = {'model_name': 'resnet50'
+ 'precision': 'fp32'}
+ data_info = {'batch_size': 1
+ 'shape': '3,224,224'
+ 'data_num': 1000}
+ perf_info = {'preprocess_time_s': 1.0
+ 'inference_time_s': 2.0
+ 'postprocess_time_s': 1.0
+ 'total_time_s': 4.0}
+ resource_info = {'cpu_rss_mb': 100
+ 'gpu_rss_mb': 100
+ 'gpu_util': 60}
+ log = PaddleInferBenchmark(config, model_info, data_info, perf_info, resource_info)
+ log('Test')
+ """)
+
+ def __call__(self, identifier=None):
+ """
+ __call__
+ args:
+ identifier(string): identify log
+ """
+ self.report(identifier)
diff --git a/modules/image/keypoint_detection/pp-tinypose/det_keypoint_unite_infer.py b/modules/image/keypoint_detection/pp-tinypose/det_keypoint_unite_infer.py
new file mode 100644
index 000000000..612f6dd51
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/det_keypoint_unite_infer.py
@@ -0,0 +1,230 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import json
+import math
+import os
+
+import cv2
+import numpy as np
+import paddle
+import yaml
+from benchmark_utils import PaddleInferBenchmark
+from det_keypoint_unite_utils import argsparser
+from infer import bench_log
+from infer import Detector
+from infer import get_test_images
+from infer import PredictConfig
+from infer import print_arguments
+from keypoint_infer import KeyPointDetector
+from keypoint_infer import PredictConfig_KeyPoint
+from keypoint_postprocess import translate_to_ori_images
+from preprocess import decode_image
+from utils import get_current_memory_mb
+from visualize import visualize_pose
+
+KEYPOINT_SUPPORT_MODELS = {'HigherHRNet': 'keypoint_bottomup', 'HRNet': 'keypoint_topdown'}
+
+
+def predict_with_given_det(image, det_res, keypoint_detector, keypoint_batch_size, run_benchmark):
+ rec_images, records, det_rects = keypoint_detector.get_person_from_rect(image, det_res)
+ keypoint_vector = []
+ score_vector = []
+
+ rect_vector = det_rects
+ keypoint_results = keypoint_detector.predict_image(rec_images, run_benchmark, repeats=10, visual=False)
+ keypoint_vector, score_vector = translate_to_ori_images(keypoint_results, np.array(records))
+ keypoint_res = {}
+ keypoint_res['keypoint'] = [keypoint_vector.tolist(), score_vector.tolist()] if len(keypoint_vector) > 0 else [[],
+ []]
+ keypoint_res['bbox'] = rect_vector
+ return keypoint_res
+
+
+def topdown_unite_predict(detector, topdown_keypoint_detector, image_list, keypoint_batch_size=1, save_res=False):
+ det_timer = detector.get_timer()
+ store_res = []
+ for i, img_file in enumerate(image_list):
+ # Decode image in advance in det + pose prediction
+ det_timer.preprocess_time_s.start()
+ image, _ = decode_image(img_file, {})
+ det_timer.preprocess_time_s.end()
+
+ if FLAGS.run_benchmark:
+ results = detector.predict_image([image], run_benchmark=True, repeats=10)
+
+ cm, gm, gu = get_current_memory_mb()
+ detector.cpu_mem += cm
+ detector.gpu_mem += gm
+ detector.gpu_util += gu
+ else:
+ results = detector.predict_image([image], visual=False)
+ results = detector.filter_box(results, FLAGS.det_threshold)
+ if results['boxes_num'] > 0:
+ keypoint_res = predict_with_given_det(image, results, topdown_keypoint_detector, keypoint_batch_size,
+ FLAGS.run_benchmark)
+
+ if save_res:
+ save_name = img_file if isinstance(img_file, str) else i
+ store_res.append(
+ [save_name, keypoint_res['bbox'], [keypoint_res['keypoint'][0], keypoint_res['keypoint'][1]]])
+ else:
+ results["keypoint"] = [[], []]
+ keypoint_res = results
+ if FLAGS.run_benchmark:
+ cm, gm, gu = get_current_memory_mb()
+ topdown_keypoint_detector.cpu_mem += cm
+ topdown_keypoint_detector.gpu_mem += gm
+ topdown_keypoint_detector.gpu_util += gu
+ else:
+ if not os.path.exists(FLAGS.output_dir):
+ os.makedirs(FLAGS.output_dir)
+ visualize_pose(img_file, keypoint_res, visual_thresh=FLAGS.keypoint_threshold, save_dir=FLAGS.output_dir)
+ if save_res:
+ """
+ 1) store_res: a list of image_data
+ 2) image_data: [imageid, rects, [keypoints, scores]]
+ 3) rects: list of rect [xmin, ymin, xmax, ymax]
+ 4) keypoints: 17(joint numbers)*[x, y, conf], total 51 data in list
+ 5) scores: mean of all joint conf
+ """
+ with open("det_keypoint_unite_image_results.json", 'w') as wf:
+ json.dump(store_res, wf, indent=4)
+
+
+def topdown_unite_predict_video(detector, topdown_keypoint_detector, camera_id, keypoint_batch_size=1, save_res=False):
+ video_name = 'output.mp4'
+ if camera_id != -1:
+ capture = cv2.VideoCapture(camera_id)
+ else:
+ capture = cv2.VideoCapture(FLAGS.video_file)
+ video_name = os.path.split(FLAGS.video_file)[-1]
+ # Get Video info : resolution, fps, frame count
+ width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ fps = int(capture.get(cv2.CAP_PROP_FPS))
+ frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))
+ print("fps: %d, frame_count: %d" % (fps, frame_count))
+
+ if not os.path.exists(FLAGS.output_dir):
+ os.makedirs(FLAGS.output_dir)
+ out_path = os.path.join(FLAGS.output_dir, video_name)
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ writer = cv2.VideoWriter(out_path, fourcc, fps, (width, height))
+ index = 0
+ store_res = []
+ while (1):
+ ret, frame = capture.read()
+ if not ret:
+ break
+ index += 1
+ print('detect frame: %d' % (index))
+
+ frame2 = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
+
+ results = detector.predict_image([frame2], visual=False)
+ results = detector.filter_box(results, FLAGS.det_threshold)
+ if results['boxes_num'] == 0:
+ writer.write(frame)
+ continue
+
+ keypoint_res = predict_with_given_det(frame2, results, topdown_keypoint_detector, keypoint_batch_size,
+ FLAGS.run_benchmark)
+
+ im = visualize_pose(frame, keypoint_res, visual_thresh=FLAGS.keypoint_threshold, returnimg=True)
+ if save_res:
+ store_res.append([index, keypoint_res['bbox'], [keypoint_res['keypoint'][0], keypoint_res['keypoint'][1]]])
+
+ writer.write(im)
+ if camera_id != -1:
+ cv2.imshow('Mask Detection', im)
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+ writer.release()
+ print('output_video saved to: {}'.format(out_path))
+ if save_res:
+ """
+ 1) store_res: a list of frame_data
+ 2) frame_data: [frameid, rects, [keypoints, scores]]
+ 3) rects: list of rect [xmin, ymin, xmax, ymax]
+ 4) keypoints: 17(joint numbers)*[x, y, conf], total 51 data in list
+ 5) scores: mean of all joint conf
+ """
+ with open("det_keypoint_unite_video_results.json", 'w') as wf:
+ json.dump(store_res, wf, indent=4)
+
+
+def main():
+ deploy_file = os.path.join(FLAGS.det_model_dir, 'infer_cfg.yml')
+ with open(deploy_file) as f:
+ yml_conf = yaml.safe_load(f)
+ arch = yml_conf['arch']
+ detector = Detector(FLAGS.det_model_dir,
+ device=FLAGS.device,
+ run_mode=FLAGS.run_mode,
+ trt_min_shape=FLAGS.trt_min_shape,
+ trt_max_shape=FLAGS.trt_max_shape,
+ trt_opt_shape=FLAGS.trt_opt_shape,
+ trt_calib_mode=FLAGS.trt_calib_mode,
+ cpu_threads=FLAGS.cpu_threads,
+ enable_mkldnn=FLAGS.enable_mkldnn,
+ threshold=FLAGS.det_threshold)
+
+ topdown_keypoint_detector = KeyPointDetector(FLAGS.keypoint_model_dir,
+ device=FLAGS.device,
+ run_mode=FLAGS.run_mode,
+ batch_size=FLAGS.keypoint_batch_size,
+ trt_min_shape=FLAGS.trt_min_shape,
+ trt_max_shape=FLAGS.trt_max_shape,
+ trt_opt_shape=FLAGS.trt_opt_shape,
+ trt_calib_mode=FLAGS.trt_calib_mode,
+ cpu_threads=FLAGS.cpu_threads,
+ enable_mkldnn=FLAGS.enable_mkldnn,
+ use_dark=FLAGS.use_dark)
+ keypoint_arch = topdown_keypoint_detector.pred_config.arch
+ assert KEYPOINT_SUPPORT_MODELS[
+ keypoint_arch] == 'keypoint_topdown', 'Detection-Keypoint unite inference only supports topdown models.'
+
+ # predict from video file or camera video stream
+ if FLAGS.video_file is not None or FLAGS.camera_id != -1:
+ topdown_unite_predict_video(detector, topdown_keypoint_detector, FLAGS.camera_id, FLAGS.keypoint_batch_size,
+ FLAGS.save_res)
+ else:
+ # predict from image
+ img_list = get_test_images(FLAGS.image_dir, FLAGS.image_file)
+ topdown_unite_predict(detector, topdown_keypoint_detector, img_list, FLAGS.keypoint_batch_size, FLAGS.save_res)
+ if not FLAGS.run_benchmark:
+ detector.det_times.info(average=True)
+ topdown_keypoint_detector.det_times.info(average=True)
+ else:
+ mode = FLAGS.run_mode
+ det_model_dir = FLAGS.det_model_dir
+ det_model_info = {'model_name': det_model_dir.strip('/').split('/')[-1], 'precision': mode.split('_')[-1]}
+ bench_log(detector, img_list, det_model_info, name='Det')
+ keypoint_model_dir = FLAGS.keypoint_model_dir
+ keypoint_model_info = {
+ 'model_name': keypoint_model_dir.strip('/').split('/')[-1],
+ 'precision': mode.split('_')[-1]
+ }
+ bench_log(topdown_keypoint_detector, img_list, keypoint_model_info, FLAGS.keypoint_batch_size, 'KeyPoint')
+
+
+if __name__ == '__main__':
+ paddle.enable_static()
+ parser = argsparser()
+ FLAGS = parser.parse_args()
+ print_arguments(FLAGS)
+ FLAGS.device = FLAGS.device.upper()
+ assert FLAGS.device in ['CPU', 'GPU', 'XPU'], "device should be CPU, GPU or XPU"
+
+ main()
diff --git a/modules/image/keypoint_detection/pp-tinypose/det_keypoint_unite_utils.py b/modules/image/keypoint_detection/pp-tinypose/det_keypoint_unite_utils.py
new file mode 100644
index 000000000..309c80814
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/det_keypoint_unite_utils.py
@@ -0,0 +1,86 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import ast
+
+
+def argsparser():
+ parser = argparse.ArgumentParser(description=__doc__)
+ parser.add_argument("--det_model_dir",
+ type=str,
+ default=None,
+ help=("Directory include:'model.pdiparams', 'model.pdmodel', "
+ "'infer_cfg.yml', created by tools/export_model.py."),
+ required=True)
+ parser.add_argument("--keypoint_model_dir",
+ type=str,
+ default=None,
+ help=("Directory include:'model.pdiparams', 'model.pdmodel', "
+ "'infer_cfg.yml', created by tools/export_model.py."),
+ required=True)
+ parser.add_argument("--image_file", type=str, default=None, help="Path of image file.")
+ parser.add_argument("--image_dir",
+ type=str,
+ default=None,
+ help="Dir of image file, `image_file` has a higher priority.")
+ parser.add_argument("--keypoint_batch_size",
+ type=int,
+ default=8,
+ help=("batch_size for keypoint inference. In detection-keypoint unit"
+ "inference, the batch size in detection is 1. Then collate det "
+ "result in batch for keypoint inference."))
+ parser.add_argument("--video_file",
+ type=str,
+ default=None,
+ help="Path of video file, `video_file` or `camera_id` has a highest priority.")
+ parser.add_argument("--camera_id", type=int, default=-1, help="device id of camera to predict.")
+ parser.add_argument("--det_threshold", type=float, default=0.5, help="Threshold of score.")
+ parser.add_argument("--keypoint_threshold", type=float, default=0.5, help="Threshold of score.")
+ parser.add_argument("--output_dir", type=str, default="output", help="Directory of output visualization files.")
+ parser.add_argument("--run_mode",
+ type=str,
+ default='paddle',
+ help="mode of running(paddle/trt_fp32/trt_fp16/trt_int8)")
+ parser.add_argument("--device",
+ type=str,
+ default='cpu',
+ help="Choose the device you want to run, it can be: CPU/GPU/XPU, default is CPU.")
+ parser.add_argument("--run_benchmark",
+ type=ast.literal_eval,
+ default=False,
+ help="Whether to predict a image_file repeatedly for benchmark")
+ parser.add_argument("--enable_mkldnn", type=ast.literal_eval, default=False, help="Whether use mkldnn with CPU.")
+ parser.add_argument("--cpu_threads", type=int, default=1, help="Num of threads with CPU.")
+ parser.add_argument("--trt_min_shape", type=int, default=1, help="min_shape for TensorRT.")
+ parser.add_argument("--trt_max_shape", type=int, default=1280, help="max_shape for TensorRT.")
+ parser.add_argument("--trt_opt_shape", type=int, default=640, help="opt_shape for TensorRT.")
+ parser.add_argument("--trt_calib_mode",
+ type=bool,
+ default=False,
+ help="If the model is produced by TRT offline quantitative "
+ "calibration, trt_calib_mode need to set True.")
+ parser.add_argument('--use_dark',
+ type=ast.literal_eval,
+ default=True,
+ help='whether to use darkpose to get better keypoint position predict ')
+ parser.add_argument('--save_res',
+ type=bool,
+ default=False,
+ help=("whether to save predict results to json file"
+ "1) store_res: a list of image_data"
+ "2) image_data: [imageid, rects, [keypoints, scores]]"
+ "3) rects: list of rect [xmin, ymin, xmax, ymax]"
+ "4) keypoints: 17(joint numbers)*[x, y, conf], total 51 data in list"
+ "5) scores: mean of all joint conf"))
+ return parser
diff --git a/modules/image/keypoint_detection/pp-tinypose/infer.py b/modules/image/keypoint_detection/pp-tinypose/infer.py
new file mode 100644
index 000000000..fe0764e97
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/infer.py
@@ -0,0 +1,694 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import glob
+import json
+import math
+import os
+import sys
+from functools import reduce
+from pathlib import Path
+
+import cv2
+import numpy as np
+import paddle
+import yaml
+from benchmark_utils import PaddleInferBenchmark
+from keypoint_preprocess import EvalAffine
+from keypoint_preprocess import expand_crop
+from keypoint_preprocess import TopDownEvalAffine
+from paddle.inference import Config
+from paddle.inference import create_predictor
+from preprocess import decode_image
+from preprocess import LetterBoxResize
+from preprocess import NormalizeImage
+from preprocess import Pad
+from preprocess import PadStride
+from preprocess import Permute
+from preprocess import preprocess
+from preprocess import Resize
+from preprocess import WarpAffine
+from utils import argsparser
+from utils import get_current_memory_mb
+from utils import Timer
+from visualize import visualize_box
+
+# Global dictionary
+SUPPORT_MODELS = {
+ 'YOLO',
+ 'RCNN',
+ 'SSD',
+ 'Face',
+ 'FCOS',
+ 'SOLOv2',
+ 'TTFNet',
+ 'S2ANet',
+ 'JDE',
+ 'FairMOT',
+ 'DeepSORT',
+ 'GFL',
+ 'PicoDet',
+ 'CenterNet',
+ 'TOOD',
+ 'RetinaNet',
+ 'StrongBaseline',
+ 'STGCN',
+ 'YOLOX',
+}
+
+
+def bench_log(detector, img_list, model_info, batch_size=1, name=None):
+ mems = {
+ 'cpu_rss_mb': detector.cpu_mem / len(img_list),
+ 'gpu_rss_mb': detector.gpu_mem / len(img_list),
+ 'gpu_util': detector.gpu_util * 100 / len(img_list)
+ }
+ perf_info = detector.det_times.report(average=True)
+ data_info = {'batch_size': batch_size, 'shape': "dynamic_shape", 'data_num': perf_info['img_num']}
+ log = PaddleInferBenchmark(detector.config, model_info, data_info, perf_info, mems)
+ log(name)
+
+
+class Detector(object):
+ """
+ Args:
+ pred_config (object): config of model, defined by `Config(model_dir)`
+ model_dir (str): root path of model.pdiparams, model.pdmodel and infer_cfg.yml
+ device (str): Choose the device you want to run, it can be: CPU/GPU/XPU, default is CPU
+ run_mode (str): mode of running(paddle/trt_fp32/trt_fp16)
+ batch_size (int): size of pre batch in inference
+ trt_min_shape (int): min shape for dynamic shape in trt
+ trt_max_shape (int): max shape for dynamic shape in trt
+ trt_opt_shape (int): opt shape for dynamic shape in trt
+ trt_calib_mode (bool): If the model is produced by TRT offline quantitative
+ calibration, trt_calib_mode need to set True
+ cpu_threads (int): cpu threads
+ enable_mkldnn (bool): whether to open MKLDNN
+ enable_mkldnn_bfloat16 (bool): whether to turn on mkldnn bfloat16
+ output_dir (str): The path of output
+ threshold (float): The threshold of score for visualization
+ delete_shuffle_pass (bool): whether to remove shuffle_channel_detect_pass in TensorRT.
+ Used by action model.
+ """
+
+ def __init__(self,
+ model_dir,
+ device='CPU',
+ run_mode='paddle',
+ batch_size=1,
+ trt_min_shape=1,
+ trt_max_shape=1280,
+ trt_opt_shape=640,
+ trt_calib_mode=False,
+ cpu_threads=1,
+ enable_mkldnn=False,
+ enable_mkldnn_bfloat16=False,
+ output_dir='output',
+ threshold=0.5,
+ delete_shuffle_pass=False):
+ self.pred_config = self.set_config(model_dir)
+ self.device = device
+ self.predictor, self.config = load_predictor(model_dir,
+ run_mode=run_mode,
+ batch_size=batch_size,
+ min_subgraph_size=self.pred_config.min_subgraph_size,
+ device=device,
+ use_dynamic_shape=self.pred_config.use_dynamic_shape,
+ trt_min_shape=trt_min_shape,
+ trt_max_shape=trt_max_shape,
+ trt_opt_shape=trt_opt_shape,
+ trt_calib_mode=trt_calib_mode,
+ cpu_threads=cpu_threads,
+ enable_mkldnn=enable_mkldnn,
+ enable_mkldnn_bfloat16=enable_mkldnn_bfloat16,
+ delete_shuffle_pass=delete_shuffle_pass)
+ self.det_times = Timer()
+ self.cpu_mem, self.gpu_mem, self.gpu_util = 0, 0, 0
+ self.batch_size = batch_size
+ self.output_dir = output_dir
+ self.threshold = threshold
+
+ def set_config(self, model_dir):
+ return PredictConfig(model_dir)
+
+ def preprocess(self, image_list):
+ preprocess_ops = []
+ for op_info in self.pred_config.preprocess_infos:
+ new_op_info = op_info.copy()
+ op_type = new_op_info.pop('type')
+ preprocess_ops.append(eval(op_type)(**new_op_info))
+
+ input_im_lst = []
+ input_im_info_lst = []
+ for im_path in image_list:
+ im, im_info = preprocess(im_path, preprocess_ops)
+ input_im_lst.append(im)
+ input_im_info_lst.append(im_info)
+ inputs = create_inputs(input_im_lst, input_im_info_lst)
+ input_names = self.predictor.get_input_names()
+ for i in range(len(input_names)):
+ input_tensor = self.predictor.get_input_handle(input_names[i])
+ input_tensor.copy_from_cpu(inputs[input_names[i]])
+
+ return inputs
+
+ def postprocess(self, inputs, result):
+ # postprocess output of predictor
+ np_boxes_num = result['boxes_num']
+ if np_boxes_num[0] <= 0:
+ print('[WARNNING] No object detected.')
+ result = {'boxes': np.zeros([0, 6]), 'boxes_num': [0]}
+ result = {k: v for k, v in result.items() if v is not None}
+ return result
+
+ def filter_box(self, result, threshold):
+ np_boxes_num = result['boxes_num']
+ boxes = result['boxes']
+ start_idx = 0
+ filter_boxes = []
+ filter_num = []
+ for i in range(len(np_boxes_num)):
+ boxes_num = np_boxes_num[i]
+ boxes_i = boxes[start_idx:start_idx + boxes_num, :]
+ idx = boxes_i[:, 1] > threshold
+ filter_boxes_i = boxes_i[idx, :]
+ filter_boxes.append(filter_boxes_i)
+ filter_num.append(filter_boxes_i.shape[0])
+ start_idx += boxes_num
+ boxes = np.concatenate(filter_boxes)
+ filter_num = np.array(filter_num)
+ filter_res = {'boxes': boxes, 'boxes_num': filter_num}
+ return filter_res
+
+ def predict(self, repeats=1):
+ '''
+ Args:
+ repeats (int): repeats number for prediction
+ Returns:
+ result (dict): include 'boxes': np.ndarray: shape:[N,6], N: number of box,
+ matix element:[class, score, x_min, y_min, x_max, y_max]
+ MaskRCNN's result include 'masks': np.ndarray:
+ shape: [N, im_h, im_w]
+ '''
+ # model prediction
+ np_boxes, np_masks = None, None
+ for i in range(repeats):
+ self.predictor.run()
+ output_names = self.predictor.get_output_names()
+ boxes_tensor = self.predictor.get_output_handle(output_names[0])
+ np_boxes = boxes_tensor.copy_to_cpu()
+ boxes_num = self.predictor.get_output_handle(output_names[1])
+ np_boxes_num = boxes_num.copy_to_cpu()
+ if self.pred_config.mask:
+ masks_tensor = self.predictor.get_output_handle(output_names[2])
+ np_masks = masks_tensor.copy_to_cpu()
+ result = dict(boxes=np_boxes, masks=np_masks, boxes_num=np_boxes_num)
+ return result
+
+ def merge_batch_result(self, batch_result):
+ if len(batch_result) == 1:
+ return batch_result[0]
+ res_key = batch_result[0].keys()
+ results = {k: [] for k in res_key}
+ for res in batch_result:
+ for k, v in res.items():
+ results[k].append(v)
+ for k, v in results.items():
+ if k != 'masks':
+ results[k] = np.concatenate(v)
+ return results
+
+ def get_timer(self):
+ return self.det_times
+
+ def predict_image(self, image_list, run_benchmark=False, repeats=1, visual=True, save_file=None):
+ batch_loop_cnt = math.ceil(float(len(image_list)) / self.batch_size)
+ results = []
+ for i in range(batch_loop_cnt):
+ start_index = i * self.batch_size
+ end_index = min((i + 1) * self.batch_size, len(image_list))
+ batch_image_list = image_list[start_index:end_index]
+ if run_benchmark:
+ # preprocess
+ inputs = self.preprocess(batch_image_list) # warmup
+ self.det_times.preprocess_time_s.start()
+ inputs = self.preprocess(batch_image_list)
+ self.det_times.preprocess_time_s.end()
+
+ # model prediction
+ result = self.predict(repeats=50) # warmup
+ self.det_times.inference_time_s.start()
+ result = self.predict(repeats=repeats)
+ self.det_times.inference_time_s.end(repeats=repeats)
+
+ # postprocess
+ result_warmup = self.postprocess(inputs, result) # warmup
+ self.det_times.postprocess_time_s.start()
+ result = self.postprocess(inputs, result)
+ self.det_times.postprocess_time_s.end()
+ self.det_times.img_num += len(batch_image_list)
+
+ cm, gm, gu = get_current_memory_mb()
+ self.cpu_mem += cm
+ self.gpu_mem += gm
+ self.gpu_util += gu
+ else:
+ # preprocess
+ self.det_times.preprocess_time_s.start()
+ inputs = self.preprocess(batch_image_list)
+ self.det_times.preprocess_time_s.end()
+
+ # model prediction
+ self.det_times.inference_time_s.start()
+ result = self.predict()
+ self.det_times.inference_time_s.end()
+
+ # postprocess
+ self.det_times.postprocess_time_s.start()
+ result = self.postprocess(inputs, result)
+ self.det_times.postprocess_time_s.end()
+ self.det_times.img_num += len(batch_image_list)
+
+ if visual:
+ visualize(batch_image_list,
+ result,
+ self.pred_config.labels,
+ output_dir=self.output_dir,
+ threshold=self.threshold)
+
+ results.append(result)
+ if visual:
+ print('Test iter {}'.format(i))
+
+ if save_file is not None:
+ Path(self.output_dir).mkdir(exist_ok=True)
+ self.format_coco_results(image_list, results, save_file=save_file)
+
+ results = self.merge_batch_result(results)
+ return results
+
+ def predict_video(self, video_file, camera_id):
+ video_out_name = 'output.mp4'
+ if camera_id != -1:
+ capture = cv2.VideoCapture(camera_id)
+ else:
+ capture = cv2.VideoCapture(video_file)
+ video_out_name = os.path.split(video_file)[-1]
+ # Get Video info : resolution, fps, frame count
+ width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ fps = int(capture.get(cv2.CAP_PROP_FPS))
+ frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))
+ print("fps: %d, frame_count: %d" % (fps, frame_count))
+
+ if not os.path.exists(self.output_dir):
+ os.makedirs(self.output_dir)
+ out_path = os.path.join(self.output_dir, video_out_name)
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ writer = cv2.VideoWriter(out_path, fourcc, fps, (width, height))
+ index = 1
+ while (1):
+ ret, frame = capture.read()
+ if not ret:
+ break
+ print('detect frame: %d' % (index))
+ index += 1
+ results = self.predict_image([frame[:, :, ::-1]], visual=False)
+
+ im = visualize_box(frame, results, self.pred_config.labels, threshold=self.threshold)
+ im = np.array(im)
+ writer.write(im)
+ if camera_id != -1:
+ cv2.imshow('Mask Detection', im)
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+ writer.release()
+
+ @staticmethod
+ def format_coco_results(image_list, results, save_file=None):
+ coco_results = []
+ image_id = 0
+
+ for result in results:
+ start_idx = 0
+ for box_num in result['boxes_num']:
+ idx_slice = slice(start_idx, start_idx + box_num)
+ start_idx += box_num
+
+ image_file = image_list[image_id]
+ image_id += 1
+
+ if 'boxes' in result:
+ boxes = result['boxes'][idx_slice, :]
+ per_result = [
+ {
+ 'image_file': image_file,
+ 'bbox': [box[2], box[3], box[4] - box[2], box[5] - box[3]], # xyxy -> xywh
+ 'score': box[1],
+ 'category_id': int(box[0]),
+ } for k, box in enumerate(boxes.tolist())
+ ]
+
+ elif 'segm' in result:
+ import pycocotools.mask as mask_util
+
+ scores = result['score'][idx_slice].tolist()
+ category_ids = result['label'][idx_slice].tolist()
+ segms = result['segm'][idx_slice, :]
+ rles = [
+ mask_util.encode(np.array(mask[:, :, np.newaxis], dtype=np.uint8, order='F'))[0]
+ for mask in segms
+ ]
+ for rle in rles:
+ rle['counts'] = rle['counts'].decode('utf-8')
+
+ per_result = [{
+ 'image_file': image_file,
+ 'segmentation': rle,
+ 'score': scores[k],
+ 'category_id': category_ids[k],
+ } for k, rle in enumerate(rles)]
+
+ else:
+ raise RuntimeError('')
+
+ # per_result = [item for item in per_result if item['score'] > threshold]
+ coco_results.extend(per_result)
+
+ if save_file:
+ with open(os.path.join(save_file), 'w') as f:
+ json.dump(coco_results, f)
+
+ return coco_results
+
+
+def create_inputs(imgs, im_info):
+ """generate input for different model type
+ Args:
+ imgs (list(numpy)): list of images (np.ndarray)
+ im_info (list(dict)): list of image info
+ Returns:
+ inputs (dict): input of model
+ """
+ inputs = {}
+
+ im_shape = []
+ scale_factor = []
+ if len(imgs) == 1:
+ inputs['image'] = np.array((imgs[0], )).astype('float32')
+ inputs['im_shape'] = np.array((im_info[0]['im_shape'], )).astype('float32')
+ inputs['scale_factor'] = np.array((im_info[0]['scale_factor'], )).astype('float32')
+ return inputs
+
+ for e in im_info:
+ im_shape.append(np.array((e['im_shape'], )).astype('float32'))
+ scale_factor.append(np.array((e['scale_factor'], )).astype('float32'))
+
+ inputs['im_shape'] = np.concatenate(im_shape, axis=0)
+ inputs['scale_factor'] = np.concatenate(scale_factor, axis=0)
+
+ imgs_shape = [[e.shape[1], e.shape[2]] for e in imgs]
+ max_shape_h = max([e[0] for e in imgs_shape])
+ max_shape_w = max([e[1] for e in imgs_shape])
+ padding_imgs = []
+ for img in imgs:
+ im_c, im_h, im_w = img.shape[:]
+ padding_im = np.zeros((im_c, max_shape_h, max_shape_w), dtype=np.float32)
+ padding_im[:, :im_h, :im_w] = img
+ padding_imgs.append(padding_im)
+ inputs['image'] = np.stack(padding_imgs, axis=0)
+ return inputs
+
+
+class PredictConfig():
+ """set config of preprocess, postprocess and visualize
+ Args:
+ model_dir (str): root path of model.yml
+ """
+
+ def __init__(self, model_dir):
+ # parsing Yaml config for Preprocess
+ deploy_file = os.path.join(model_dir, 'infer_cfg.yml')
+ with open(deploy_file) as f:
+ yml_conf = yaml.safe_load(f)
+ self.check_model(yml_conf)
+ self.arch = yml_conf['arch']
+ self.preprocess_infos = yml_conf['Preprocess']
+ self.min_subgraph_size = yml_conf['min_subgraph_size']
+ self.labels = yml_conf['label_list']
+ self.mask = False
+ self.use_dynamic_shape = yml_conf['use_dynamic_shape']
+ if 'mask' in yml_conf:
+ self.mask = yml_conf['mask']
+ self.tracker = None
+ if 'tracker' in yml_conf:
+ self.tracker = yml_conf['tracker']
+ if 'NMS' in yml_conf:
+ self.nms = yml_conf['NMS']
+ if 'fpn_stride' in yml_conf:
+ self.fpn_stride = yml_conf['fpn_stride']
+ if self.arch == 'RCNN' and yml_conf.get('export_onnx', False):
+ print('The RCNN export model is used for ONNX and it only supports batch_size = 1')
+ self.print_config()
+
+ def check_model(self, yml_conf):
+ """
+ Raises:
+ ValueError: loaded model not in supported model type
+ """
+ for support_model in SUPPORT_MODELS:
+ if support_model in yml_conf['arch']:
+ return True
+ raise ValueError("Unsupported arch: {}, expect {}".format(yml_conf['arch'], SUPPORT_MODELS))
+
+ def print_config(self):
+ print('----------- Model Configuration -----------')
+ print('%s: %s' % ('Model Arch', self.arch))
+ print('%s: ' % ('Transform Order'))
+ for op_info in self.preprocess_infos:
+ print('--%s: %s' % ('transform op', op_info['type']))
+ print('--------------------------------------------')
+
+
+def load_predictor(model_dir,
+ run_mode='paddle',
+ batch_size=1,
+ device='CPU',
+ min_subgraph_size=3,
+ use_dynamic_shape=False,
+ trt_min_shape=1,
+ trt_max_shape=1280,
+ trt_opt_shape=640,
+ trt_calib_mode=False,
+ cpu_threads=1,
+ enable_mkldnn=False,
+ enable_mkldnn_bfloat16=False,
+ delete_shuffle_pass=False):
+ """set AnalysisConfig, generate AnalysisPredictor
+ Args:
+ model_dir (str): root path of __model__ and __params__
+ device (str): Choose the device you want to run, it can be: CPU/GPU/XPU, default is CPU
+ run_mode (str): mode of running(paddle/trt_fp32/trt_fp16/trt_int8)
+ use_dynamic_shape (bool): use dynamic shape or not
+ trt_min_shape (int): min shape for dynamic shape in trt
+ trt_max_shape (int): max shape for dynamic shape in trt
+ trt_opt_shape (int): opt shape for dynamic shape in trt
+ trt_calib_mode (bool): If the model is produced by TRT offline quantitative
+ calibration, trt_calib_mode need to set True
+ delete_shuffle_pass (bool): whether to remove shuffle_channel_detect_pass in TensorRT.
+ Used by action model.
+ Returns:
+ predictor (PaddlePredictor): AnalysisPredictor
+ Raises:
+ ValueError: predict by TensorRT need device == 'GPU'.
+ """
+ if device != 'GPU' and run_mode != 'paddle':
+ raise ValueError("Predict by TensorRT mode: {}, expect device=='GPU', but device == {}".format(
+ run_mode, device))
+ config = Config(os.path.join(model_dir, 'model.pdmodel'), os.path.join(model_dir, 'model.pdiparams'))
+ if device == 'GPU':
+ # initial GPU memory(M), device ID
+ config.enable_use_gpu(200, 0)
+ # optimize graph and fuse op
+ config.switch_ir_optim(True)
+ elif device == 'XPU':
+ config.enable_lite_engine()
+ config.enable_xpu(10 * 1024 * 1024)
+ else:
+ config.disable_gpu()
+ config.set_cpu_math_library_num_threads(cpu_threads)
+ if enable_mkldnn:
+ try:
+ # cache 10 different shapes for mkldnn to avoid memory leak
+ config.set_mkldnn_cache_capacity(10)
+ config.enable_mkldnn()
+ if enable_mkldnn_bfloat16:
+ config.enable_mkldnn_bfloat16()
+ except Exception as e:
+ print("The current environment does not support `mkldnn`, so disable mkldnn.")
+ pass
+
+ precision_map = {
+ 'trt_int8': Config.Precision.Int8,
+ 'trt_fp32': Config.Precision.Float32,
+ 'trt_fp16': Config.Precision.Half
+ }
+ if run_mode in precision_map.keys():
+ config.enable_tensorrt_engine(workspace_size=(1 << 25) * batch_size,
+ max_batch_size=batch_size,
+ min_subgraph_size=min_subgraph_size,
+ precision_mode=precision_map[run_mode],
+ use_static=False,
+ use_calib_mode=trt_calib_mode)
+
+ if use_dynamic_shape:
+ min_input_shape = {'image': [batch_size, 3, trt_min_shape, trt_min_shape]}
+ max_input_shape = {'image': [batch_size, 3, trt_max_shape, trt_max_shape]}
+ opt_input_shape = {'image': [batch_size, 3, trt_opt_shape, trt_opt_shape]}
+ config.set_trt_dynamic_shape_info(min_input_shape, max_input_shape, opt_input_shape)
+ print('trt set dynamic shape done!')
+
+ # disable print log when predict
+ config.disable_glog_info()
+ # enable shared memory
+ config.enable_memory_optim()
+ # disable feed, fetch OP, needed by zero_copy_run
+ config.switch_use_feed_fetch_ops(False)
+ if delete_shuffle_pass:
+ config.delete_pass("shuffle_channel_detect_pass")
+ predictor = create_predictor(config)
+ return predictor, config
+
+
+def get_test_images(infer_dir, infer_img):
+ """
+ Get image path list in TEST mode
+ """
+ assert infer_img is not None or infer_dir is not None, \
+ "--image_file or --image_dir should be set"
+ assert infer_img is None or os.path.isfile(infer_img), \
+ "{} is not a file".format(infer_img)
+ assert infer_dir is None or os.path.isdir(infer_dir), \
+ "{} is not a directory".format(infer_dir)
+
+ # infer_img has a higher priority
+ if infer_img and os.path.isfile(infer_img):
+ return [infer_img]
+
+ images = set()
+ infer_dir = os.path.abspath(infer_dir)
+ assert os.path.isdir(infer_dir), \
+ "infer_dir {} is not a directory".format(infer_dir)
+ exts = ['jpg', 'jpeg', 'png', 'bmp']
+ exts += [ext.upper() for ext in exts]
+ for ext in exts:
+ images.update(glob.glob('{}/*.{}'.format(infer_dir, ext)))
+ images = list(images)
+
+ assert len(images) > 0, "no image found in {}".format(infer_dir)
+ print("Found {} inference images in total.".format(len(images)))
+
+ return images
+
+
+def visualize(image_list, result, labels, output_dir='output/', threshold=0.5):
+ # visualize the predict result
+ start_idx = 0
+ for idx, image_file in enumerate(image_list):
+ im_bboxes_num = result['boxes_num'][idx]
+ im_results = {}
+ if 'boxes' in result:
+ im_results['boxes'] = result['boxes'][start_idx:start_idx + im_bboxes_num, :]
+ if 'masks' in result:
+ im_results['masks'] = result['masks'][start_idx:start_idx + im_bboxes_num, :]
+ if 'segm' in result:
+ im_results['segm'] = result['segm'][start_idx:start_idx + im_bboxes_num, :]
+ if 'label' in result:
+ im_results['label'] = result['label'][start_idx:start_idx + im_bboxes_num]
+ if 'score' in result:
+ im_results['score'] = result['score'][start_idx:start_idx + im_bboxes_num]
+
+ start_idx += im_bboxes_num
+ im = visualize_box(image_file, im_results, labels, threshold=threshold)
+ img_name = os.path.split(image_file)[-1]
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir)
+ out_path = os.path.join(output_dir, img_name)
+ im.save(out_path, quality=95)
+ print("save result to: " + out_path)
+
+
+def print_arguments(args):
+ print('----------- Running Arguments -----------')
+ for arg, value in sorted(vars(args).items()):
+ print('%s: %s' % (arg, value))
+ print('------------------------------------------')
+
+
+def main():
+ deploy_file = os.path.join(FLAGS.model_dir, 'infer_cfg.yml')
+ with open(deploy_file) as f:
+ yml_conf = yaml.safe_load(f)
+ arch = yml_conf['arch']
+ detector_func = 'Detector'
+ if arch == 'SOLOv2':
+ detector_func = 'DetectorSOLOv2'
+ elif arch == 'PicoDet':
+ detector_func = 'DetectorPicoDet'
+
+ detector = eval(detector_func)(FLAGS.model_dir,
+ device=FLAGS.device,
+ run_mode=FLAGS.run_mode,
+ batch_size=FLAGS.batch_size,
+ trt_min_shape=FLAGS.trt_min_shape,
+ trt_max_shape=FLAGS.trt_max_shape,
+ trt_opt_shape=FLAGS.trt_opt_shape,
+ trt_calib_mode=FLAGS.trt_calib_mode,
+ cpu_threads=FLAGS.cpu_threads,
+ enable_mkldnn=FLAGS.enable_mkldnn,
+ enable_mkldnn_bfloat16=FLAGS.enable_mkldnn_bfloat16,
+ threshold=FLAGS.threshold,
+ output_dir=FLAGS.output_dir)
+
+ # predict from video file or camera video stream
+ if FLAGS.video_file is not None or FLAGS.camera_id != -1:
+ detector.predict_video(FLAGS.video_file, FLAGS.camera_id)
+ else:
+ # predict from image
+ if FLAGS.image_dir is None and FLAGS.image_file is not None:
+ assert FLAGS.batch_size == 1, "batch_size should be 1, when image_file is not None"
+ img_list = get_test_images(FLAGS.image_dir, FLAGS.image_file)
+ save_file = os.path.join(FLAGS.output_dir, 'results.json') if FLAGS.save_results else None
+ detector.predict_image(img_list, FLAGS.run_benchmark, repeats=100, save_file=save_file)
+ if not FLAGS.run_benchmark:
+ detector.det_times.info(average=True)
+ else:
+ mode = FLAGS.run_mode
+ model_dir = FLAGS.model_dir
+ model_info = {'model_name': model_dir.strip('/').split('/')[-1], 'precision': mode.split('_')[-1]}
+ bench_log(detector, img_list, model_info, name='DET')
+
+
+if __name__ == '__main__':
+ paddle.enable_static()
+ parser = argsparser()
+ FLAGS = parser.parse_args()
+ print_arguments(FLAGS)
+ FLAGS.device = FLAGS.device.upper()
+ assert FLAGS.device in ['CPU', 'GPU', 'XPU'], "device should be CPU, GPU or XPU"
+ assert not FLAGS.use_gpu, "use_gpu has been deprecated, please use --device"
+
+ assert not (FLAGS.enable_mkldnn == False and FLAGS.enable_mkldnn_bfloat16
+ == True), 'To enable mkldnn bfloat, please turn on both enable_mkldnn and enable_mkldnn_bfloat16'
+
+ main()
diff --git a/modules/image/keypoint_detection/pp-tinypose/keypoint_infer.py b/modules/image/keypoint_detection/pp-tinypose/keypoint_infer.py
new file mode 100644
index 000000000..e782ac1be
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/keypoint_infer.py
@@ -0,0 +1,381 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import glob
+import math
+import os
+import sys
+import time
+from functools import reduce
+
+import cv2
+import numpy as np
+import paddle
+import yaml
+from PIL import Image
+# add deploy path of PadleDetection to sys.path
+parent_path = os.path.abspath(os.path.join(__file__, *(['..'])))
+sys.path.insert(0, parent_path)
+
+from preprocess import preprocess, NormalizeImage, Permute
+from keypoint_preprocess import EvalAffine, TopDownEvalAffine, expand_crop
+from keypoint_postprocess import HRNetPostProcess
+from visualize import visualize_pose
+from paddle.inference import Config
+from paddle.inference import create_predictor
+from utils import argsparser, Timer, get_current_memory_mb
+from benchmark_utils import PaddleInferBenchmark
+from infer import Detector, get_test_images, print_arguments
+
+# Global dictionary
+KEYPOINT_SUPPORT_MODELS = {'HigherHRNet': 'keypoint_bottomup', 'HRNet': 'keypoint_topdown'}
+
+
+class KeyPointDetector(Detector):
+ """
+ Args:
+ model_dir (str): root path of model.pdiparams, model.pdmodel and infer_cfg.yml
+ device (str): Choose the device you want to run, it can be: CPU/GPU/XPU, default is CPU
+ run_mode (str): mode of running(paddle/trt_fp32/trt_fp16)
+ batch_size (int): size of pre batch in inference
+ trt_min_shape (int): min shape for dynamic shape in trt
+ trt_max_shape (int): max shape for dynamic shape in trt
+ trt_opt_shape (int): opt shape for dynamic shape in trt
+ trt_calib_mode (bool): If the model is produced by TRT offline quantitative
+ calibration, trt_calib_mode need to set True
+ cpu_threads (int): cpu threads
+ enable_mkldnn (bool): whether to open MKLDNN
+ use_dark(bool): whether to use postprocess in DarkPose
+ """
+
+ def __init__(self,
+ model_dir,
+ device='CPU',
+ run_mode='paddle',
+ batch_size=1,
+ trt_min_shape=1,
+ trt_max_shape=1280,
+ trt_opt_shape=640,
+ trt_calib_mode=False,
+ cpu_threads=1,
+ enable_mkldnn=False,
+ output_dir='output',
+ threshold=0.5,
+ use_dark=True):
+ super(KeyPointDetector, self).__init__(
+ model_dir=model_dir,
+ device=device,
+ run_mode=run_mode,
+ batch_size=batch_size,
+ trt_min_shape=trt_min_shape,
+ trt_max_shape=trt_max_shape,
+ trt_opt_shape=trt_opt_shape,
+ trt_calib_mode=trt_calib_mode,
+ cpu_threads=cpu_threads,
+ enable_mkldnn=enable_mkldnn,
+ output_dir=output_dir,
+ threshold=threshold,
+ )
+ self.use_dark = use_dark
+
+ def set_config(self, model_dir):
+ return PredictConfig_KeyPoint(model_dir)
+
+ def get_person_from_rect(self, image, results):
+ # crop the person result from image
+ self.det_times.preprocess_time_s.start()
+ valid_rects = results['boxes']
+ rect_images = []
+ new_rects = []
+ org_rects = []
+ for rect in valid_rects:
+ rect_image, new_rect, org_rect = expand_crop(image, rect)
+ if rect_image is None or rect_image.size == 0:
+ continue
+ rect_images.append(rect_image)
+ new_rects.append(new_rect)
+ org_rects.append(org_rect)
+ self.det_times.preprocess_time_s.end()
+ return rect_images, new_rects, org_rects
+
+ def postprocess(self, inputs, result):
+ np_heatmap = result['heatmap']
+ np_masks = result['masks']
+ # postprocess output of predictor
+ if KEYPOINT_SUPPORT_MODELS[self.pred_config.arch] == 'keypoint_bottomup':
+ results = {}
+ h, w = inputs['im_shape'][0]
+ preds = [np_heatmap]
+ if np_masks is not None:
+ preds += np_masks
+ preds += [h, w]
+ keypoint_postprocess = HRNetPostProcess()
+ kpts, scores = keypoint_postprocess(*preds)
+ results['keypoint'] = kpts
+ results['score'] = scores
+ return results
+ elif KEYPOINT_SUPPORT_MODELS[self.pred_config.arch] == 'keypoint_topdown':
+ results = {}
+ imshape = inputs['im_shape'][:, ::-1]
+ center = np.round(imshape / 2.)
+ scale = imshape / 200.
+ keypoint_postprocess = HRNetPostProcess(use_dark=self.use_dark)
+ kpts, scores = keypoint_postprocess(np_heatmap, center, scale)
+ results['keypoint'] = kpts
+ results['score'] = scores
+ return results
+ else:
+ raise ValueError("Unsupported arch: {}, expect {}".format(self.pred_config.arch, KEYPOINT_SUPPORT_MODELS))
+
+ def predict(self, repeats=1):
+ '''
+ Args:
+ repeats (int): repeat number for prediction
+ Returns:
+ results (dict): include 'boxes': np.ndarray: shape:[N,6], N: number of box,
+ matix element:[class, score, x_min, y_min, x_max, y_max]
+ MaskRCNN's results include 'masks': np.ndarray:
+ shape: [N, im_h, im_w]
+ '''
+ # model prediction
+ np_heatmap, np_masks = None, None
+ for i in range(repeats):
+ self.predictor.run()
+ output_names = self.predictor.get_output_names()
+ heatmap_tensor = self.predictor.get_output_handle(output_names[0])
+ np_heatmap = heatmap_tensor.copy_to_cpu()
+ if self.pred_config.tagmap:
+ masks_tensor = self.predictor.get_output_handle(output_names[1])
+ heat_k = self.predictor.get_output_handle(output_names[2])
+ inds_k = self.predictor.get_output_handle(output_names[3])
+ np_masks = [masks_tensor.copy_to_cpu(), heat_k.copy_to_cpu(), inds_k.copy_to_cpu()]
+ result = dict(heatmap=np_heatmap, masks=np_masks)
+ return result
+
+ def predict_image(self, image_list, run_benchmark=False, repeats=1, visual=True):
+ results = []
+ batch_loop_cnt = math.ceil(float(len(image_list)) / self.batch_size)
+ for i in range(batch_loop_cnt):
+ start_index = i * self.batch_size
+ end_index = min((i + 1) * self.batch_size, len(image_list))
+ batch_image_list = image_list[start_index:end_index]
+ if run_benchmark:
+ # preprocess
+ inputs = self.preprocess(batch_image_list) # warmup
+ self.det_times.preprocess_time_s.start()
+ inputs = self.preprocess(batch_image_list)
+ self.det_times.preprocess_time_s.end()
+
+ # model prediction
+ result_warmup = self.predict(repeats=repeats) # warmup
+ self.det_times.inference_time_s.start()
+ result = self.predict(repeats=repeats)
+ self.det_times.inference_time_s.end(repeats=repeats)
+
+ # postprocess
+ result_warmup = self.postprocess(inputs, result) # warmup
+ self.det_times.postprocess_time_s.start()
+ result = self.postprocess(inputs, result)
+ self.det_times.postprocess_time_s.end()
+ self.det_times.img_num += len(batch_image_list)
+
+ cm, gm, gu = get_current_memory_mb()
+ self.cpu_mem += cm
+ self.gpu_mem += gm
+ self.gpu_util += gu
+
+ else:
+ # preprocess
+ self.det_times.preprocess_time_s.start()
+ inputs = self.preprocess(batch_image_list)
+ self.det_times.preprocess_time_s.end()
+
+ # model prediction
+ self.det_times.inference_time_s.start()
+ result = self.predict()
+ self.det_times.inference_time_s.end()
+
+ # postprocess
+ self.det_times.postprocess_time_s.start()
+ result = self.postprocess(inputs, result)
+ self.det_times.postprocess_time_s.end()
+ self.det_times.img_num += len(batch_image_list)
+
+ if visual:
+ if not os.path.exists(self.output_dir):
+ os.makedirs(self.output_dir)
+ visualize(batch_image_list, result, visual_thresh=self.threshold, save_dir=self.output_dir)
+
+ results.append(result)
+ if visual:
+ print('Test iter {}'.format(i))
+ results = self.merge_batch_result(results)
+ return results
+
+ def predict_video(self, video_file, camera_id):
+ video_name = 'output.mp4'
+ if camera_id != -1:
+ capture = cv2.VideoCapture(camera_id)
+ else:
+ capture = cv2.VideoCapture(video_file)
+ video_name = os.path.split(video_file)[-1]
+ # Get Video info : resolution, fps, frame count
+ width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ fps = int(capture.get(cv2.CAP_PROP_FPS))
+ frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))
+ print("fps: %d, frame_count: %d" % (fps, frame_count))
+
+ if not os.path.exists(self.output_dir):
+ os.makedirs(self.output_dir)
+ out_path = os.path.join(self.output_dir, video_name)
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ writer = cv2.VideoWriter(out_path, fourcc, fps, (width, height))
+ index = 1
+ while (1):
+ ret, frame = capture.read()
+ if not ret:
+ break
+ print('detect frame: %d' % (index))
+ index += 1
+ results = self.predict_image([frame[:, :, ::-1]], visual=False)
+ im_results = {}
+ im_results['keypoint'] = [results['keypoint'], results['score']]
+ im = visualize_pose(frame, im_results, visual_thresh=self.threshold, returnimg=True)
+ writer.write(im)
+ if camera_id != -1:
+ cv2.imshow('Mask Detection', im)
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+ writer.release()
+
+
+def create_inputs(imgs, im_info):
+ """generate input for different model type
+ Args:
+ imgs (list(numpy)): list of image (np.ndarray)
+ im_info (list(dict)): list of image info
+ Returns:
+ inputs (dict): input of model
+ """
+ inputs = {}
+ inputs['image'] = np.stack(imgs, axis=0).astype('float32')
+ im_shape = []
+ for e in im_info:
+ im_shape.append(np.array((e['im_shape'])).astype('float32'))
+ inputs['im_shape'] = np.stack(im_shape, axis=0)
+ return inputs
+
+
+class PredictConfig_KeyPoint():
+ """set config of preprocess, postprocess and visualize
+ Args:
+ model_dir (str): root path of model.yml
+ """
+
+ def __init__(self, model_dir):
+ # parsing Yaml config for Preprocess
+ deploy_file = os.path.join(model_dir, 'infer_cfg.yml')
+ with open(deploy_file) as f:
+ yml_conf = yaml.safe_load(f)
+ self.check_model(yml_conf)
+ self.arch = yml_conf['arch']
+ self.archcls = KEYPOINT_SUPPORT_MODELS[yml_conf['arch']]
+ self.preprocess_infos = yml_conf['Preprocess']
+ self.min_subgraph_size = yml_conf['min_subgraph_size']
+ self.labels = yml_conf['label_list']
+ self.tagmap = False
+ self.use_dynamic_shape = yml_conf['use_dynamic_shape']
+ if 'keypoint_bottomup' == self.archcls:
+ self.tagmap = True
+ self.print_config()
+
+ def check_model(self, yml_conf):
+ """
+ Raises:
+ ValueError: loaded model not in supported model type
+ """
+ for support_model in KEYPOINT_SUPPORT_MODELS:
+ if support_model in yml_conf['arch']:
+ return True
+ raise ValueError("Unsupported arch: {}, expect {}".format(yml_conf['arch'], KEYPOINT_SUPPORT_MODELS))
+
+ def print_config(self):
+ print('----------- Model Configuration -----------')
+ print('%s: %s' % ('Model Arch', self.arch))
+ print('%s: ' % ('Transform Order'))
+ for op_info in self.preprocess_infos:
+ print('--%s: %s' % ('transform op', op_info['type']))
+ print('--------------------------------------------')
+
+
+def visualize(image_list, results, visual_thresh=0.6, save_dir='output'):
+ im_results = {}
+ for i, image_file in enumerate(image_list):
+ skeletons = results['keypoint']
+ scores = results['score']
+ skeleton = skeletons[i:i + 1]
+ score = scores[i:i + 1]
+ im_results['keypoint'] = [skeleton, score]
+ visualize_pose(image_file, im_results, visual_thresh=visual_thresh, save_dir=save_dir)
+
+
+def main():
+ detector = KeyPointDetector(FLAGS.model_dir,
+ device=FLAGS.device,
+ run_mode=FLAGS.run_mode,
+ batch_size=FLAGS.batch_size,
+ trt_min_shape=FLAGS.trt_min_shape,
+ trt_max_shape=FLAGS.trt_max_shape,
+ trt_opt_shape=FLAGS.trt_opt_shape,
+ trt_calib_mode=FLAGS.trt_calib_mode,
+ cpu_threads=FLAGS.cpu_threads,
+ enable_mkldnn=FLAGS.enable_mkldnn,
+ threshold=FLAGS.threshold,
+ output_dir=FLAGS.output_dir,
+ use_dark=FLAGS.use_dark)
+
+ # predict from video file or camera video stream
+ if FLAGS.video_file is not None or FLAGS.camera_id != -1:
+ detector.predict_video(FLAGS.video_file, FLAGS.camera_id)
+ else:
+ # predict from image
+ img_list = get_test_images(FLAGS.image_dir, FLAGS.image_file)
+ detector.predict_image(img_list, FLAGS.run_benchmark, repeats=10)
+ if not FLAGS.run_benchmark:
+ detector.det_times.info(average=True)
+ else:
+ mems = {
+ 'cpu_rss_mb': detector.cpu_mem / len(img_list),
+ 'gpu_rss_mb': detector.gpu_mem / len(img_list),
+ 'gpu_util': detector.gpu_util * 100 / len(img_list)
+ }
+ perf_info = detector.det_times.report(average=True)
+ model_dir = FLAGS.model_dir
+ mode = FLAGS.run_mode
+ model_info = {'model_name': model_dir.strip('/').split('/')[-1], 'precision': mode.split('_')[-1]}
+ data_info = {'batch_size': 1, 'shape': "dynamic_shape", 'data_num': perf_info['img_num']}
+ det_log = PaddleInferBenchmark(detector.config, model_info, data_info, perf_info, mems)
+ det_log('KeyPoint')
+
+
+if __name__ == '__main__':
+ paddle.enable_static()
+ parser = argsparser()
+ FLAGS = parser.parse_args()
+ print_arguments(FLAGS)
+ FLAGS.device = FLAGS.device.upper()
+ assert FLAGS.device in ['CPU', 'GPU', 'XPU'], "device should be CPU, GPU or XPU"
+ assert not FLAGS.use_gpu, "use_gpu has been deprecated, please use --device"
+
+ main()
diff --git a/modules/image/keypoint_detection/pp-tinypose/keypoint_postprocess.py b/modules/image/keypoint_detection/pp-tinypose/keypoint_postprocess.py
new file mode 100644
index 000000000..64d479f61
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/keypoint_postprocess.py
@@ -0,0 +1,192 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+from collections import abc
+from collections import defaultdict
+
+import cv2
+import numpy as np
+import paddle
+import paddle.nn as nn
+from keypoint_preprocess import get_affine_mat_kernel
+from keypoint_preprocess import get_affine_transform
+from scipy.optimize import linear_sum_assignment
+
+
+class HRNetPostProcess(object):
+
+ def __init__(self, use_dark=True):
+ self.use_dark = use_dark
+
+ def flip_back(self, output_flipped, matched_parts):
+ assert output_flipped.ndim == 4,\
+ 'output_flipped should be [batch_size, num_joints, height, width]'
+
+ output_flipped = output_flipped[:, :, :, ::-1]
+
+ for pair in matched_parts:
+ tmp = output_flipped[:, pair[0], :, :].copy()
+ output_flipped[:, pair[0], :, :] = output_flipped[:, pair[1], :, :]
+ output_flipped[:, pair[1], :, :] = tmp
+
+ return output_flipped
+
+ def get_max_preds(self, heatmaps):
+ """get predictions from score maps
+
+ Args:
+ heatmaps: numpy.ndarray([batch_size, num_joints, height, width])
+
+ Returns:
+ preds: numpy.ndarray([batch_size, num_joints, 2]), keypoints coords
+ maxvals: numpy.ndarray([batch_size, num_joints, 2]), the maximum confidence of the keypoints
+ """
+ assert isinstance(heatmaps, np.ndarray), 'heatmaps should be numpy.ndarray'
+ assert heatmaps.ndim == 4, 'batch_images should be 4-ndim'
+
+ batch_size = heatmaps.shape[0]
+ num_joints = heatmaps.shape[1]
+ width = heatmaps.shape[3]
+ heatmaps_reshaped = heatmaps.reshape((batch_size, num_joints, -1))
+ idx = np.argmax(heatmaps_reshaped, 2)
+ maxvals = np.amax(heatmaps_reshaped, 2)
+
+ maxvals = maxvals.reshape((batch_size, num_joints, 1))
+ idx = idx.reshape((batch_size, num_joints, 1))
+
+ preds = np.tile(idx, (1, 1, 2)).astype(np.float32)
+
+ preds[:, :, 0] = (preds[:, :, 0]) % width
+ preds[:, :, 1] = np.floor((preds[:, :, 1]) / width)
+
+ pred_mask = np.tile(np.greater(maxvals, 0.0), (1, 1, 2))
+ pred_mask = pred_mask.astype(np.float32)
+
+ preds *= pred_mask
+
+ return preds, maxvals
+
+ def gaussian_blur(self, heatmap, kernel):
+ border = (kernel - 1) // 2
+ batch_size = heatmap.shape[0]
+ num_joints = heatmap.shape[1]
+ height = heatmap.shape[2]
+ width = heatmap.shape[3]
+ for i in range(batch_size):
+ for j in range(num_joints):
+ origin_max = np.max(heatmap[i, j])
+ dr = np.zeros((height + 2 * border, width + 2 * border))
+ dr[border:-border, border:-border] = heatmap[i, j].copy()
+ dr = cv2.GaussianBlur(dr, (kernel, kernel), 0)
+ heatmap[i, j] = dr[border:-border, border:-border].copy()
+ heatmap[i, j] *= origin_max / np.max(heatmap[i, j])
+ return heatmap
+
+ def dark_parse(self, hm, coord):
+ heatmap_height = hm.shape[0]
+ heatmap_width = hm.shape[1]
+ px = int(coord[0])
+ py = int(coord[1])
+ if 1 < px < heatmap_width - 2 and 1 < py < heatmap_height - 2:
+ dx = 0.5 * (hm[py][px + 1] - hm[py][px - 1])
+ dy = 0.5 * (hm[py + 1][px] - hm[py - 1][px])
+ dxx = 0.25 * (hm[py][px + 2] - 2 * hm[py][px] + hm[py][px - 2])
+ dxy = 0.25 * (hm[py+1][px+1] - hm[py-1][px+1] - hm[py+1][px-1] \
+ + hm[py-1][px-1])
+ dyy = 0.25 * (hm[py + 2 * 1][px] - 2 * hm[py][px] + hm[py - 2 * 1][px])
+ derivative = np.matrix([[dx], [dy]])
+ hessian = np.matrix([[dxx, dxy], [dxy, dyy]])
+ if dxx * dyy - dxy**2 != 0:
+ hessianinv = hessian.I
+ offset = -hessianinv * derivative
+ offset = np.squeeze(np.array(offset.T), axis=0)
+ coord += offset
+ return coord
+
+ def dark_postprocess(self, hm, coords, kernelsize):
+ """
+ refer to https://github.com/ilovepose/DarkPose/lib/core/inference.py
+
+ """
+ hm = self.gaussian_blur(hm, kernelsize)
+ hm = np.maximum(hm, 1e-10)
+ hm = np.log(hm)
+ for n in range(coords.shape[0]):
+ for p in range(coords.shape[1]):
+ coords[n, p] = self.dark_parse(hm[n][p], coords[n][p])
+ return coords
+
+ def get_final_preds(self, heatmaps, center, scale, kernelsize=3):
+ """the highest heatvalue location with a quarter offset in the
+ direction from the highest response to the second highest response.
+
+ Args:
+ heatmaps (numpy.ndarray): The predicted heatmaps
+ center (numpy.ndarray): The boxes center
+ scale (numpy.ndarray): The scale factor
+
+ Returns:
+ preds: numpy.ndarray([batch_size, num_joints, 2]), keypoints coords
+ maxvals: numpy.ndarray([batch_size, num_joints, 1]), the maximum confidence of the keypoints
+ """
+
+ coords, maxvals = self.get_max_preds(heatmaps)
+
+ heatmap_height = heatmaps.shape[2]
+ heatmap_width = heatmaps.shape[3]
+
+ if self.use_dark:
+ coords = self.dark_postprocess(heatmaps, coords, kernelsize)
+ else:
+ for n in range(coords.shape[0]):
+ for p in range(coords.shape[1]):
+ hm = heatmaps[n][p]
+ px = int(math.floor(coords[n][p][0] + 0.5))
+ py = int(math.floor(coords[n][p][1] + 0.5))
+ if 1 < px < heatmap_width - 1 and 1 < py < heatmap_height - 1:
+ diff = np.array([hm[py][px + 1] - hm[py][px - 1], hm[py + 1][px] - hm[py - 1][px]])
+ coords[n][p] += np.sign(diff) * .25
+ preds = coords.copy()
+
+ # Transform back
+ for i in range(coords.shape[0]):
+ preds[i] = transform_preds(coords[i], center[i], scale[i], [heatmap_width, heatmap_height])
+
+ return preds, maxvals
+
+ def __call__(self, output, center, scale):
+ preds, maxvals = self.get_final_preds(output, center, scale)
+ return np.concatenate((preds, maxvals), axis=-1), np.mean(maxvals, axis=1)
+
+
+def transform_preds(coords, center, scale, output_size):
+ target_coords = np.zeros(coords.shape)
+ trans = get_affine_transform(center, scale * 200, 0, output_size, inv=1)
+ for p in range(coords.shape[0]):
+ target_coords[p, 0:2] = affine_transform(coords[p, 0:2], trans)
+ return target_coords
+
+
+def affine_transform(pt, t):
+ new_pt = np.array([pt[0], pt[1], 1.]).T
+ new_pt = np.dot(t, new_pt)
+ return new_pt[:2]
+
+
+def translate_to_ori_images(keypoint_result, batch_records):
+ kpts = keypoint_result['keypoint']
+ scores = keypoint_result['score']
+ kpts[..., 0] += batch_records[:, 0:1]
+ kpts[..., 1] += batch_records[:, 1:2]
+ return kpts, scores
diff --git a/modules/image/keypoint_detection/pp-tinypose/keypoint_preprocess.py b/modules/image/keypoint_detection/pp-tinypose/keypoint_preprocess.py
new file mode 100644
index 000000000..9e4eb3fd4
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/keypoint_preprocess.py
@@ -0,0 +1,232 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+this code is based on https://github.com/open-mmlab/mmpose/mmpose/core/post_processing/post_transforms.py
+"""
+import cv2
+import numpy as np
+
+
+class EvalAffine(object):
+
+ def __init__(self, size, stride=64):
+ super(EvalAffine, self).__init__()
+ self.size = size
+ self.stride = stride
+
+ def __call__(self, image, im_info):
+ s = self.size
+ h, w, _ = image.shape
+ trans, size_resized = get_affine_mat_kernel(h, w, s, inv=False)
+ image_resized = cv2.warpAffine(image, trans, size_resized)
+ return image_resized, im_info
+
+
+def get_affine_mat_kernel(h, w, s, inv=False):
+ if w < h:
+ w_ = s
+ h_ = int(np.ceil((s / w * h) / 64.) * 64)
+ scale_w = w
+ scale_h = h_ / w_ * w
+
+ else:
+ h_ = s
+ w_ = int(np.ceil((s / h * w) / 64.) * 64)
+ scale_h = h
+ scale_w = w_ / h_ * h
+
+ center = np.array([np.round(w / 2.), np.round(h / 2.)])
+
+ size_resized = (w_, h_)
+ trans = get_affine_transform(center, np.array([scale_w, scale_h]), 0, size_resized, inv=inv)
+
+ return trans, size_resized
+
+
+def get_affine_transform(center, input_size, rot, output_size, shift=(0., 0.), inv=False):
+ """Get the affine transform matrix, given the center/scale/rot/output_size.
+
+ Args:
+ center (np.ndarray[2, ]): Center of the bounding box (x, y).
+ scale (np.ndarray[2, ]): Scale of the bounding box
+ wrt [width, height].
+ rot (float): Rotation angle (degree).
+ output_size (np.ndarray[2, ]): Size of the destination heatmaps.
+ shift (0-100%): Shift translation ratio wrt the width/height.
+ Default (0., 0.).
+ inv (bool): Option to inverse the affine transform direction.
+ (inv=False: src->dst or inv=True: dst->src)
+
+ Returns:
+ np.ndarray: The transform matrix.
+ """
+ assert len(center) == 2
+ assert len(output_size) == 2
+ assert len(shift) == 2
+ if not isinstance(input_size, (np.ndarray, list)):
+ input_size = np.array([input_size, input_size], dtype=np.float32)
+ scale_tmp = input_size
+
+ shift = np.array(shift)
+ src_w = scale_tmp[0]
+ dst_w = output_size[0]
+ dst_h = output_size[1]
+
+ rot_rad = np.pi * rot / 180
+ src_dir = rotate_point([0., src_w * -0.5], rot_rad)
+ dst_dir = np.array([0., dst_w * -0.5])
+
+ src = np.zeros((3, 2), dtype=np.float32)
+ src[0, :] = center + scale_tmp * shift
+ src[1, :] = center + src_dir + scale_tmp * shift
+ src[2, :] = _get_3rd_point(src[0, :], src[1, :])
+
+ dst = np.zeros((3, 2), dtype=np.float32)
+ dst[0, :] = [dst_w * 0.5, dst_h * 0.5]
+ dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5]) + dst_dir
+ dst[2, :] = _get_3rd_point(dst[0, :], dst[1, :])
+
+ if inv:
+ trans = cv2.getAffineTransform(np.float32(dst), np.float32(src))
+ else:
+ trans = cv2.getAffineTransform(np.float32(src), np.float32(dst))
+
+ return trans
+
+
+def get_warp_matrix(theta, size_input, size_dst, size_target):
+ """This code is based on
+ https://github.com/open-mmlab/mmpose/blob/master/mmpose/core/post_processing/post_transforms.py
+
+ Calculate the transformation matrix under the constraint of unbiased.
+ Paper ref: Huang et al. The Devil is in the Details: Delving into Unbiased
+ Data Processing for Human Pose Estimation (CVPR 2020).
+
+ Args:
+ theta (float): Rotation angle in degrees.
+ size_input (np.ndarray): Size of input image [w, h].
+ size_dst (np.ndarray): Size of output image [w, h].
+ size_target (np.ndarray): Size of ROI in input plane [w, h].
+
+ Returns:
+ matrix (np.ndarray): A matrix for transformation.
+ """
+ theta = np.deg2rad(theta)
+ matrix = np.zeros((2, 3), dtype=np.float32)
+ scale_x = size_dst[0] / size_target[0]
+ scale_y = size_dst[1] / size_target[1]
+ matrix[0, 0] = np.cos(theta) * scale_x
+ matrix[0, 1] = -np.sin(theta) * scale_x
+ matrix[0, 2] = scale_x * (-0.5 * size_input[0] * np.cos(theta) + 0.5 * size_input[1] * np.sin(theta) +
+ 0.5 * size_target[0])
+ matrix[1, 0] = np.sin(theta) * scale_y
+ matrix[1, 1] = np.cos(theta) * scale_y
+ matrix[1, 2] = scale_y * (-0.5 * size_input[0] * np.sin(theta) - 0.5 * size_input[1] * np.cos(theta) +
+ 0.5 * size_target[1])
+ return matrix
+
+
+def rotate_point(pt, angle_rad):
+ """Rotate a point by an angle.
+
+ Args:
+ pt (list[float]): 2 dimensional point to be rotated
+ angle_rad (float): rotation angle by radian
+
+ Returns:
+ list[float]: Rotated point.
+ """
+ assert len(pt) == 2
+ sn, cs = np.sin(angle_rad), np.cos(angle_rad)
+ new_x = pt[0] * cs - pt[1] * sn
+ new_y = pt[0] * sn + pt[1] * cs
+ rotated_pt = [new_x, new_y]
+
+ return rotated_pt
+
+
+def _get_3rd_point(a, b):
+ """To calculate the affine matrix, three pairs of points are required. This
+ function is used to get the 3rd point, given 2D points a & b.
+
+ The 3rd point is defined by rotating vector `a - b` by 90 degrees
+ anticlockwise, using b as the rotation center.
+
+ Args:
+ a (np.ndarray): point(x,y)
+ b (np.ndarray): point(x,y)
+
+ Returns:
+ np.ndarray: The 3rd point.
+ """
+ assert len(a) == 2
+ assert len(b) == 2
+ direction = a - b
+ third_pt = b + np.array([-direction[1], direction[0]], dtype=np.float32)
+
+ return third_pt
+
+
+class TopDownEvalAffine(object):
+ """apply affine transform to image and coords
+
+ Args:
+ trainsize (list): [w, h], the standard size used to train
+ use_udp (bool): whether to use Unbiased Data Processing.
+ records(dict): the dict contained the image and coords
+
+ Returns:
+ records (dict): contain the image and coords after tranformed
+
+ """
+
+ def __init__(self, trainsize, use_udp=False):
+ self.trainsize = trainsize
+ self.use_udp = use_udp
+
+ def __call__(self, image, im_info):
+ rot = 0
+ imshape = im_info['im_shape'][::-1]
+ center = im_info['center'] if 'center' in im_info else imshape / 2.
+ scale = im_info['scale'] if 'scale' in im_info else imshape
+ if self.use_udp:
+ trans = get_warp_matrix(rot, center * 2.0, [self.trainsize[0] - 1.0, self.trainsize[1] - 1.0], scale)
+ image = cv2.warpAffine(image,
+ trans, (int(self.trainsize[0]), int(self.trainsize[1])),
+ flags=cv2.INTER_LINEAR)
+ else:
+ trans = get_affine_transform(center, scale, rot, self.trainsize)
+ image = cv2.warpAffine(image,
+ trans, (int(self.trainsize[0]), int(self.trainsize[1])),
+ flags=cv2.INTER_LINEAR)
+
+ return image, im_info
+
+
+def expand_crop(images, rect, expand_ratio=0.3):
+ imgh, imgw, c = images.shape
+ label, conf, xmin, ymin, xmax, ymax = [int(x) for x in rect.tolist()]
+ if label != 0:
+ return None, None, None
+ org_rect = [xmin, ymin, xmax, ymax]
+ h_half = (ymax - ymin) * (1 + expand_ratio) / 2.
+ w_half = (xmax - xmin) * (1 + expand_ratio) / 2.
+ if h_half > w_half * 4 / 3:
+ w_half = h_half * 0.75
+ center = [(ymin + ymax) / 2., (xmin + xmax) / 2.]
+ ymin = max(0, int(center[0] - h_half))
+ ymax = min(imgh - 1, int(center[0] + h_half))
+ xmin = max(0, int(center[1] - w_half))
+ xmax = min(imgw - 1, int(center[1] + w_half))
+ return images[ymin:ymax, xmin:xmax, :], [xmin, ymin, xmax, ymax], org_rect
diff --git a/modules/image/keypoint_detection/pp-tinypose/logger.py b/modules/image/keypoint_detection/pp-tinypose/logger.py
new file mode 100644
index 000000000..f7a5c5bea
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/logger.py
@@ -0,0 +1,68 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import functools
+import logging
+import os
+import sys
+
+import paddle.distributed as dist
+
+__all__ = ['setup_logger']
+
+logger_initialized = []
+
+
+def setup_logger(name="ppdet", output=None):
+ """
+ Initialize logger and set its verbosity level to INFO.
+ Args:
+ output (str): a file name or a directory to save log. If None, will not save log file.
+ If ends with ".txt" or ".log", assumed to be a file name.
+ Otherwise, logs will be saved to `output/log.txt`.
+ name (str): the root module name of this logger
+
+ Returns:
+ logging.Logger: a logger
+ """
+ logger = logging.getLogger(name)
+ if name in logger_initialized:
+ return logger
+
+ logger.setLevel(logging.INFO)
+ logger.propagate = False
+
+ formatter = logging.Formatter("[%(asctime)s] %(name)s %(levelname)s: %(message)s", datefmt="%m/%d %H:%M:%S")
+ # stdout logging: master only
+ local_rank = dist.get_rank()
+ if local_rank == 0:
+ ch = logging.StreamHandler(stream=sys.stdout)
+ ch.setLevel(logging.DEBUG)
+ ch.setFormatter(formatter)
+ logger.addHandler(ch)
+
+ # file logging: all workers
+ if output is not None:
+ if output.endswith(".txt") or output.endswith(".log"):
+ filename = output
+ else:
+ filename = os.path.join(output, "log.txt")
+ if local_rank > 0:
+ filename = filename + ".rank{}".format(local_rank)
+ os.makedirs(os.path.dirname(filename))
+ fh = logging.FileHandler(filename, mode='a')
+ fh.setLevel(logging.DEBUG)
+ fh.setFormatter(logging.Formatter())
+ logger.addHandler(fh)
+ logger_initialized.append(name)
+ return logger
diff --git a/modules/image/keypoint_detection/pp-tinypose/module.py b/modules/image/keypoint_detection/pp-tinypose/module.py
new file mode 100644
index 000000000..4c9e920ee
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/module.py
@@ -0,0 +1,148 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import json
+import math
+import os
+import time
+from typing import Union
+
+import cv2
+import numpy as np
+import paddle
+import yaml
+from det_keypoint_unite_infer import predict_with_given_det
+from infer import bench_log
+from infer import Detector
+from infer import get_test_images
+from infer import PredictConfig
+from infer import print_arguments
+from keypoint_infer import KeyPointDetector
+from keypoint_infer import PredictConfig_KeyPoint
+from keypoint_postprocess import translate_to_ori_images
+from preprocess import base64_to_cv2
+from preprocess import decode_image
+from visualize import visualize_pose
+
+import paddlehub.vision.transforms as T
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+@moduleinfo(name="pp-tinypose",
+ type="CV/image_editing",
+ author="paddlepaddle",
+ author_email="",
+ summary="Openpose_body_estimation is a body pose estimation model based on Realtime Multi-Person 2D Pose \
+ Estimation using Part Affinity Fields.",
+ version="1.0.0")
+class PP_TinyPose:
+ """
+ PP-TinyPose Model.
+
+ Args:
+ load_checkpoint(str): Checkpoint save path, default is None.
+ """
+
+ def __init__(self):
+ self.det_model_dir = os.path.join(self.directory, 'model/picodet_s_320_coco_lcnet/')
+ self.keypoint_model_dir = os.path.join(self.directory, 'model/dark_hrnet_w32_256x192/')
+ self.detector = Detector(self.det_model_dir)
+ self.topdown_keypoint_detector = KeyPointDetector(self.keypoint_model_dir)
+
+ def predict(self,
+ img: Union[str, np.ndarray],
+ save_path: str = "pp_tinypose_output",
+ visualization: bool = False,
+ use_gpu=False):
+ if use_gpu:
+ device = 'GPU'
+ else:
+ device = 'CPU'
+ if self.detector.device != device:
+ self.detector = Detector(self.det_model_dir, device=device)
+ self.topdown_keypoint_detector = KeyPointDetector(self.keypoint_model_dir, device=device)
+
+ self.visualization = visualization
+ store_res = []
+
+ # Decode image in advance in det + pose prediction
+ image, _ = decode_image(img, {})
+ results = self.detector.predict_image([image], visual=False)
+ results = self.detector.filter_box(results, 0.5)
+ if results['boxes_num'] > 0:
+ keypoint_res = predict_with_given_det(image, results, self.topdown_keypoint_detector, 1, False)
+ save_name = img if isinstance(img, str) else (str(time.time()) + '.png')
+ store_res.append(
+ [save_name, keypoint_res['bbox'], [keypoint_res['keypoint'][0], keypoint_res['keypoint'][1]]])
+ if not os.path.exists(save_path):
+ os.makedirs(save_path)
+ if self.visualization:
+ visualize_pose(save_name, keypoint_res, visual_thresh=0.5, save_dir=save_path)
+ return store_res
+
+ @serving
+ def serving_method(self, images: list, **kwargs):
+ """
+ Run as a service.
+ """
+ images_decode = [base64_to_cv2(image) for image in images]
+ results = self.predict(img=images_decode[0], **kwargs)
+ results = json.dumps(results)
+ return results
+
+ @runnable
+ def run_cmd(self, argvs: list):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options", description="Run configuration for controlling module behavior, not required.")
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ results = self.predict(img=args.input_path,
+ save_path=args.output_dir,
+ visualization=args.visualization,
+ use_gpu=args.use_gpu)
+
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options.
+ """
+
+ self.arg_config_group.add_argument('--output_dir',
+ type=str,
+ default='pp_tinypose_output',
+ help="The directory to save output images.")
+ self.arg_config_group.add_argument('--visualization',
+ type=bool,
+ default=True,
+ help="whether to save output as images.")
+
+ self.arg_config_group.add_argument('--use_gpu', action='store_true', help="use GPU or not")
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument('--input_path', type=str, help="path to image.")
diff --git a/modules/image/keypoint_detection/pp-tinypose/preprocess.py b/modules/image/keypoint_detection/pp-tinypose/preprocess.py
new file mode 100644
index 000000000..a0d44c45d
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/preprocess.py
@@ -0,0 +1,332 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import base64
+
+import cv2
+import numpy as np
+from keypoint_preprocess import get_affine_transform
+
+
+def decode_image(im_file, im_info):
+ """read rgb image
+ Args:
+ im_file (str|np.ndarray): input can be image path or np.ndarray
+ im_info (dict): info of image
+ Returns:
+ im (np.ndarray): processed image (np.ndarray)
+ im_info (dict): info of processed image
+ """
+ if isinstance(im_file, str):
+ with open(im_file, 'rb') as f:
+ im_read = f.read()
+ data = np.frombuffer(im_read, dtype='uint8')
+ im = cv2.imdecode(data, 1) # BGR mode, but need RGB mode
+ im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
+ else:
+ im = cv2.cvtColor(im_file, cv2.COLOR_BGR2RGB)
+ im_info['im_shape'] = np.array(im.shape[:2], dtype=np.float32)
+ im_info['scale_factor'] = np.array([1., 1.], dtype=np.float32)
+ return im, im_info
+
+
+class Resize(object):
+ """resize image by target_size and max_size
+ Args:
+ target_size (int): the target size of image
+ keep_ratio (bool): whether keep_ratio or not, default true
+ interp (int): method of resize
+ """
+
+ def __init__(self, target_size, keep_ratio=True, interp=cv2.INTER_LINEAR):
+ if isinstance(target_size, int):
+ target_size = [target_size, target_size]
+ self.target_size = target_size
+ self.keep_ratio = keep_ratio
+ self.interp = interp
+
+ def __call__(self, im, im_info):
+ """
+ Args:
+ im (np.ndarray): image (np.ndarray)
+ im_info (dict): info of image
+ Returns:
+ im (np.ndarray): processed image (np.ndarray)
+ im_info (dict): info of processed image
+ """
+ assert len(self.target_size) == 2
+ assert self.target_size[0] > 0 and self.target_size[1] > 0
+ im_channel = im.shape[2]
+ im_scale_y, im_scale_x = self.generate_scale(im)
+ im = cv2.resize(im, None, None, fx=im_scale_x, fy=im_scale_y, interpolation=self.interp)
+ im_info['im_shape'] = np.array(im.shape[:2]).astype('float32')
+ im_info['scale_factor'] = np.array([im_scale_y, im_scale_x]).astype('float32')
+ return im, im_info
+
+ def generate_scale(self, im):
+ """
+ Args:
+ im (np.ndarray): image (np.ndarray)
+ Returns:
+ im_scale_x: the resize ratio of X
+ im_scale_y: the resize ratio of Y
+ """
+ origin_shape = im.shape[:2]
+ im_c = im.shape[2]
+ if self.keep_ratio:
+ im_size_min = np.min(origin_shape)
+ im_size_max = np.max(origin_shape)
+ target_size_min = np.min(self.target_size)
+ target_size_max = np.max(self.target_size)
+ im_scale = float(target_size_min) / float(im_size_min)
+ if np.round(im_scale * im_size_max) > target_size_max:
+ im_scale = float(target_size_max) / float(im_size_max)
+ im_scale_x = im_scale
+ im_scale_y = im_scale
+ else:
+ resize_h, resize_w = self.target_size
+ im_scale_y = resize_h / float(origin_shape[0])
+ im_scale_x = resize_w / float(origin_shape[1])
+ return im_scale_y, im_scale_x
+
+
+class NormalizeImage(object):
+ """normalize image
+ Args:
+ mean (list): im - mean
+ std (list): im / std
+ is_scale (bool): whether need im / 255
+ is_channel_first (bool): if True: image shape is CHW, else: HWC
+ """
+
+ def __init__(self, mean, std, is_scale=True):
+ self.mean = mean
+ self.std = std
+ self.is_scale = is_scale
+
+ def __call__(self, im, im_info):
+ """
+ Args:
+ im (np.ndarray): image (np.ndarray)
+ im_info (dict): info of image
+ Returns:
+ im (np.ndarray): processed image (np.ndarray)
+ im_info (dict): info of processed image
+ """
+ im = im.astype(np.float32, copy=False)
+ mean = np.array(self.mean)[np.newaxis, np.newaxis, :]
+ std = np.array(self.std)[np.newaxis, np.newaxis, :]
+
+ if self.is_scale:
+ im = im / 255.0
+ im -= mean
+ im /= std
+ return im, im_info
+
+
+class Permute(object):
+ """permute image
+ Args:
+ to_bgr (bool): whether convert RGB to BGR
+ channel_first (bool): whether convert HWC to CHW
+ """
+
+ def __init__(self, ):
+ super(Permute, self).__init__()
+
+ def __call__(self, im, im_info):
+ """
+ Args:
+ im (np.ndarray): image (np.ndarray)
+ im_info (dict): info of image
+ Returns:
+ im (np.ndarray): processed image (np.ndarray)
+ im_info (dict): info of processed image
+ """
+ im = im.transpose((2, 0, 1)).copy()
+ return im, im_info
+
+
+class PadStride(object):
+ """ padding image for model with FPN, instead PadBatch(pad_to_stride) in original config
+ Args:
+ stride (bool): model with FPN need image shape % stride == 0
+ """
+
+ def __init__(self, stride=0):
+ self.coarsest_stride = stride
+
+ def __call__(self, im, im_info):
+ """
+ Args:
+ im (np.ndarray): image (np.ndarray)
+ im_info (dict): info of image
+ Returns:
+ im (np.ndarray): processed image (np.ndarray)
+ im_info (dict): info of processed image
+ """
+ coarsest_stride = self.coarsest_stride
+ if coarsest_stride <= 0:
+ return im, im_info
+ im_c, im_h, im_w = im.shape
+ pad_h = int(np.ceil(float(im_h) / coarsest_stride) * coarsest_stride)
+ pad_w = int(np.ceil(float(im_w) / coarsest_stride) * coarsest_stride)
+ padding_im = np.zeros((im_c, pad_h, pad_w), dtype=np.float32)
+ padding_im[:, :im_h, :im_w] = im
+ return padding_im, im_info
+
+
+class LetterBoxResize(object):
+
+ def __init__(self, target_size):
+ """
+ Resize image to target size, convert normalized xywh to pixel xyxy
+ format ([x_center, y_center, width, height] -> [x0, y0, x1, y1]).
+ Args:
+ target_size (int|list): image target size.
+ """
+ super(LetterBoxResize, self).__init__()
+ if isinstance(target_size, int):
+ target_size = [target_size, target_size]
+ self.target_size = target_size
+
+ def letterbox(self, img, height, width, color=(127.5, 127.5, 127.5)):
+ # letterbox: resize a rectangular image to a padded rectangular
+ shape = img.shape[:2] # [height, width]
+ ratio_h = float(height) / shape[0]
+ ratio_w = float(width) / shape[1]
+ ratio = min(ratio_h, ratio_w)
+ new_shape = (round(shape[1] * ratio), round(shape[0] * ratio)) # [width, height]
+ padw = (width - new_shape[0]) / 2
+ padh = (height - new_shape[1]) / 2
+ top, bottom = round(padh - 0.1), round(padh + 0.1)
+ left, right = round(padw - 0.1), round(padw + 0.1)
+
+ img = cv2.resize(img, new_shape, interpolation=cv2.INTER_AREA) # resized, no border
+ img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # padded rectangular
+ return img, ratio, padw, padh
+
+ def __call__(self, im, im_info):
+ """
+ Args:
+ im (np.ndarray): image (np.ndarray)
+ im_info (dict): info of image
+ Returns:
+ im (np.ndarray): processed image (np.ndarray)
+ im_info (dict): info of processed image
+ """
+ assert len(self.target_size) == 2
+ assert self.target_size[0] > 0 and self.target_size[1] > 0
+ height, width = self.target_size
+ h, w = im.shape[:2]
+ im, ratio, padw, padh = self.letterbox(im, height=height, width=width)
+
+ new_shape = [round(h * ratio), round(w * ratio)]
+ im_info['im_shape'] = np.array(new_shape, dtype=np.float32)
+ im_info['scale_factor'] = np.array([ratio, ratio], dtype=np.float32)
+ return im, im_info
+
+
+class Pad(object):
+
+ def __init__(self, size, fill_value=[114.0, 114.0, 114.0]):
+ """
+ Pad image to a specified size.
+ Args:
+ size (list[int]): image target size
+ fill_value (list[float]): rgb value of pad area, default (114.0, 114.0, 114.0)
+ """
+ super(Pad, self).__init__()
+ if isinstance(size, int):
+ size = [size, size]
+ self.size = size
+ self.fill_value = fill_value
+
+ def __call__(self, im, im_info):
+ im_h, im_w = im.shape[:2]
+ h, w = self.size
+ if h == im_h and w == im_w:
+ im = im.astype(np.float32)
+ return im, im_info
+
+ canvas = np.ones((h, w, 3), dtype=np.float32)
+ canvas *= np.array(self.fill_value, dtype=np.float32)
+ canvas[0:im_h, 0:im_w, :] = im.astype(np.float32)
+ im = canvas
+ return im, im_info
+
+
+class WarpAffine(object):
+ """Warp affine the image
+ """
+
+ def __init__(self, keep_res=False, pad=31, input_h=512, input_w=512, scale=0.4, shift=0.1):
+ self.keep_res = keep_res
+ self.pad = pad
+ self.input_h = input_h
+ self.input_w = input_w
+ self.scale = scale
+ self.shift = shift
+
+ def __call__(self, im, im_info):
+ """
+ Args:
+ im (np.ndarray): image (np.ndarray)
+ im_info (dict): info of image
+ Returns:
+ im (np.ndarray): processed image (np.ndarray)
+ im_info (dict): info of processed image
+ """
+ img = cv2.cvtColor(im, cv2.COLOR_RGB2BGR)
+
+ h, w = img.shape[:2]
+
+ if self.keep_res:
+ input_h = (h | self.pad) + 1
+ input_w = (w | self.pad) + 1
+ s = np.array([input_w, input_h], dtype=np.float32)
+ c = np.array([w // 2, h // 2], dtype=np.float32)
+
+ else:
+ s = max(h, w) * 1.0
+ input_h, input_w = self.input_h, self.input_w
+ c = np.array([w / 2., h / 2.], dtype=np.float32)
+
+ trans_input = get_affine_transform(c, s, 0, [input_w, input_h])
+ img = cv2.resize(img, (w, h))
+ inp = cv2.warpAffine(img, trans_input, (input_w, input_h), flags=cv2.INTER_LINEAR)
+ return inp, im_info
+
+
+def preprocess(im, preprocess_ops):
+ # process image by preprocess_ops
+ im_info = {
+ 'scale_factor': np.array([1., 1.], dtype=np.float32),
+ 'im_shape': None,
+ }
+ im, im_info = decode_image(im, im_info)
+ for operator in preprocess_ops:
+ im, im_info = operator(im, im_info)
+ return im, im_info
+
+
+def cv2_to_base64(image: np.ndarray):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+
+def base64_to_cv2(b64str: str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
diff --git a/modules/image/keypoint_detection/pp-tinypose/utils.py b/modules/image/keypoint_detection/pp-tinypose/utils.py
new file mode 100644
index 000000000..4e0b46b77
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/utils.py
@@ -0,0 +1,217 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import ast
+import os
+import time
+
+
+def argsparser():
+ parser = argparse.ArgumentParser(description=__doc__)
+ parser.add_argument("--model_dir",
+ type=str,
+ default=None,
+ help=("Directory include:'model.pdiparams', 'model.pdmodel', "
+ "'infer_cfg.yml', created by tools/export_model.py."),
+ required=True)
+ parser.add_argument("--image_file", type=str, default=None, help="Path of image file.")
+ parser.add_argument("--image_dir",
+ type=str,
+ default=None,
+ help="Dir of image file, `image_file` has a higher priority.")
+ parser.add_argument("--batch_size", type=int, default=1, help="batch_size for inference.")
+ parser.add_argument("--video_file",
+ type=str,
+ default=None,
+ help="Path of video file, `video_file` or `camera_id` has a highest priority.")
+ parser.add_argument("--camera_id", type=int, default=-1, help="device id of camera to predict.")
+ parser.add_argument("--threshold", type=float, default=0.5, help="Threshold of score.")
+ parser.add_argument("--output_dir", type=str, default="output", help="Directory of output visualization files.")
+ parser.add_argument("--run_mode",
+ type=str,
+ default='paddle',
+ help="mode of running(paddle/trt_fp32/trt_fp16/trt_int8)")
+ parser.add_argument("--device",
+ type=str,
+ default='cpu',
+ help="Choose the device you want to run, it can be: CPU/GPU/XPU, default is CPU.")
+ parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Deprecated, please use `--device`.")
+ parser.add_argument("--run_benchmark",
+ type=ast.literal_eval,
+ default=False,
+ help="Whether to predict a image_file repeatedly for benchmark")
+ parser.add_argument("--enable_mkldnn", type=ast.literal_eval, default=False, help="Whether use mkldnn with CPU.")
+ parser.add_argument("--enable_mkldnn_bfloat16",
+ type=ast.literal_eval,
+ default=False,
+ help="Whether use mkldnn bfloat16 inference with CPU.")
+ parser.add_argument("--cpu_threads", type=int, default=1, help="Num of threads with CPU.")
+ parser.add_argument("--trt_min_shape", type=int, default=1, help="min_shape for TensorRT.")
+ parser.add_argument("--trt_max_shape", type=int, default=1280, help="max_shape for TensorRT.")
+ parser.add_argument("--trt_opt_shape", type=int, default=640, help="opt_shape for TensorRT.")
+ parser.add_argument("--trt_calib_mode",
+ type=bool,
+ default=False,
+ help="If the model is produced by TRT offline quantitative "
+ "calibration, trt_calib_mode need to set True.")
+ parser.add_argument('--save_images', action='store_true', help='Save visualization image results.')
+ parser.add_argument('--save_mot_txts', action='store_true', help='Save tracking results (txt).')
+ parser.add_argument('--save_mot_txt_per_img',
+ action='store_true',
+ help='Save tracking results (txt) for each image.')
+ parser.add_argument('--scaled',
+ type=bool,
+ default=False,
+ help="Whether coords after detector outputs are scaled, False in JDE YOLOv3 "
+ "True in general detector.")
+ parser.add_argument("--tracker_config", type=str, default=None, help=("tracker donfig"))
+ parser.add_argument("--reid_model_dir",
+ type=str,
+ default=None,
+ help=("Directory include:'model.pdiparams', 'model.pdmodel', "
+ "'infer_cfg.yml', created by tools/export_model.py."))
+ parser.add_argument("--reid_batch_size", type=int, default=50, help="max batch_size for reid model inference.")
+ parser.add_argument('--use_dark',
+ type=ast.literal_eval,
+ default=True,
+ help='whether to use darkpose to get better keypoint position predict ')
+ parser.add_argument("--action_file", type=str, default=None, help="Path of input file for action recognition.")
+ parser.add_argument("--window_size",
+ type=int,
+ default=50,
+ help="Temporal size of skeleton feature for action recognition.")
+ parser.add_argument("--random_pad",
+ type=ast.literal_eval,
+ default=False,
+ help="Whether do random padding for action recognition.")
+ parser.add_argument("--save_results",
+ type=bool,
+ default=False,
+ help="Whether save detection result to file using coco format")
+
+ return parser
+
+
+class Times(object):
+
+ def __init__(self):
+ self.time = 0.
+ # start time
+ self.st = 0.
+ # end time
+ self.et = 0.
+
+ def start(self):
+ self.st = time.time()
+
+ def end(self, repeats=1, accumulative=True):
+ self.et = time.time()
+ if accumulative:
+ self.time += (self.et - self.st) / repeats
+ else:
+ self.time = (self.et - self.st) / repeats
+
+ def reset(self):
+ self.time = 0.
+ self.st = 0.
+ self.et = 0.
+
+ def value(self):
+ return round(self.time, 4)
+
+
+class Timer(Times):
+
+ def __init__(self, with_tracker=False):
+ super(Timer, self).__init__()
+ self.with_tracker = with_tracker
+ self.preprocess_time_s = Times()
+ self.inference_time_s = Times()
+ self.postprocess_time_s = Times()
+ self.tracking_time_s = Times()
+ self.img_num = 0
+
+ def info(self, average=False):
+ pre_time = self.preprocess_time_s.value()
+ infer_time = self.inference_time_s.value()
+ post_time = self.postprocess_time_s.value()
+ track_time = self.tracking_time_s.value()
+
+ total_time = pre_time + infer_time + post_time
+ if self.with_tracker:
+ total_time = total_time + track_time
+ total_time = round(total_time, 4)
+ print("------------------ Inference Time Info ----------------------")
+ print("total_time(ms): {}, img_num: {}".format(total_time * 1000, self.img_num))
+ preprocess_time = round(pre_time / max(1, self.img_num), 4) if average else pre_time
+ postprocess_time = round(post_time / max(1, self.img_num), 4) if average else post_time
+ inference_time = round(infer_time / max(1, self.img_num), 4) if average else infer_time
+ tracking_time = round(track_time / max(1, self.img_num), 4) if average else track_time
+
+ average_latency = total_time / max(1, self.img_num)
+ qps = 0
+ if total_time > 0:
+ qps = 1 / average_latency
+ print("average latency time(ms): {:.2f}, QPS: {:2f}".format(average_latency * 1000, qps))
+ if self.with_tracker:
+ print(
+ "preprocess_time(ms): {:.2f}, inference_time(ms): {:.2f}, postprocess_time(ms): {:.2f}, tracking_time(ms): {:.2f}"
+ .format(preprocess_time * 1000, inference_time * 1000, postprocess_time * 1000, tracking_time * 1000))
+ else:
+ print("preprocess_time(ms): {:.2f}, inference_time(ms): {:.2f}, postprocess_time(ms): {:.2f}".format(
+ preprocess_time * 1000, inference_time * 1000, postprocess_time * 1000))
+
+ def report(self, average=False):
+ dic = {}
+ pre_time = self.preprocess_time_s.value()
+ infer_time = self.inference_time_s.value()
+ post_time = self.postprocess_time_s.value()
+ track_time = self.tracking_time_s.value()
+
+ dic['preprocess_time_s'] = round(pre_time / max(1, self.img_num), 4) if average else pre_time
+ dic['inference_time_s'] = round(infer_time / max(1, self.img_num), 4) if average else infer_time
+ dic['postprocess_time_s'] = round(post_time / max(1, self.img_num), 4) if average else post_time
+ dic['img_num'] = self.img_num
+ total_time = pre_time + infer_time + post_time
+ if self.with_tracker:
+ dic['tracking_time_s'] = round(track_time / max(1, self.img_num), 4) if average else track_time
+ total_time = total_time + track_time
+ dic['total_time_s'] = round(total_time, 4)
+ return dic
+
+
+def get_current_memory_mb():
+ """
+ It is used to Obtain the memory usage of the CPU and GPU during the running of the program.
+ And this function Current program is time-consuming.
+ """
+ import pynvml
+ import psutil
+ import GPUtil
+ gpu_id = int(os.environ.get('CUDA_VISIBLE_DEVICES', 0))
+
+ pid = os.getpid()
+ p = psutil.Process(pid)
+ info = p.memory_full_info()
+ cpu_mem = info.uss / 1024. / 1024.
+ gpu_mem = 0
+ gpu_percent = 0
+ gpus = GPUtil.getGPUs()
+ if gpu_id is not None and len(gpus) > 0:
+ gpu_percent = gpus[gpu_id].load
+ pynvml.nvmlInit()
+ handle = pynvml.nvmlDeviceGetHandleByIndex(0)
+ meminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)
+ gpu_mem = meminfo.used / 1024. / 1024.
+ return round(cpu_mem, 4), round(gpu_mem, 4), round(gpu_percent, 4)
diff --git a/modules/image/keypoint_detection/pp-tinypose/visualize.py b/modules/image/keypoint_detection/pp-tinypose/visualize.py
new file mode 100644
index 000000000..18da3cbf6
--- /dev/null
+++ b/modules/image/keypoint_detection/pp-tinypose/visualize.py
@@ -0,0 +1,208 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import division
+
+import os
+
+import cv2
+import numpy as np
+from PIL import Image
+from PIL import ImageDraw
+from PIL import ImageFile
+
+ImageFile.LOAD_TRUNCATED_IMAGES = True
+import math
+
+
+def visualize_box(im, results, labels, threshold=0.5):
+ """
+ Args:
+ im (str/np.ndarray): path of image/np.ndarray read by cv2
+ results (dict): include 'boxes': np.ndarray: shape:[N,6], N: number of box,
+ matix element:[class, score, x_min, y_min, x_max, y_max]
+ MaskRCNN's results include 'masks': np.ndarray:
+ shape:[N, im_h, im_w]
+ labels (list): labels:['class1', ..., 'classn']
+ threshold (float): Threshold of score.
+ Returns:
+ im (PIL.Image.Image): visualized image
+ """
+ if isinstance(im, str):
+ im = Image.open(im).convert('RGB')
+ elif isinstance(im, np.ndarray):
+ im = Image.fromarray(im)
+ if 'boxes' in results and len(results['boxes']) > 0:
+ im = draw_box(im, results['boxes'], labels, threshold=threshold)
+ return im
+
+
+def get_color_map_list(num_classes):
+ """
+ Args:
+ num_classes (int): number of class
+ Returns:
+ color_map (list): RGB color list
+ """
+ color_map = num_classes * [0, 0, 0]
+ for i in range(0, num_classes):
+ j = 0
+ lab = i
+ while lab:
+ color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
+ color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
+ color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
+ j += 1
+ lab >>= 3
+ color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
+ return color_map
+
+
+def draw_box(im, np_boxes, labels, threshold=0.5):
+ """
+ Args:
+ im (PIL.Image.Image): PIL image
+ np_boxes (np.ndarray): shape:[N,6], N: number of box,
+ matix element:[class, score, x_min, y_min, x_max, y_max]
+ labels (list): labels:['class1', ..., 'classn']
+ threshold (float): threshold of box
+ Returns:
+ im (PIL.Image.Image): visualized image
+ """
+ draw_thickness = min(im.size) // 320
+ draw = ImageDraw.Draw(im)
+ clsid2color = {}
+ color_list = get_color_map_list(len(labels))
+ expect_boxes = (np_boxes[:, 1] > threshold) & (np_boxes[:, 0] > -1)
+ np_boxes = np_boxes[expect_boxes, :]
+
+ for dt in np_boxes:
+ clsid, bbox, score = int(dt[0]), dt[2:], dt[1]
+ if clsid not in clsid2color:
+ clsid2color[clsid] = color_list[clsid]
+ color = tuple(clsid2color[clsid])
+
+ if len(bbox) == 4:
+ xmin, ymin, xmax, ymax = bbox
+ print('class_id:{:d}, confidence:{:.4f}, left_top:[{:.2f},{:.2f}],'
+ 'right_bottom:[{:.2f},{:.2f}]'.format(int(clsid), score, xmin, ymin, xmax, ymax))
+ # draw bbox
+ draw.line([(xmin, ymin), (xmin, ymax), (xmax, ymax), (xmax, ymin), (xmin, ymin)],
+ width=draw_thickness,
+ fill=color)
+ elif len(bbox) == 8:
+ x1, y1, x2, y2, x3, y3, x4, y4 = bbox
+ draw.line([(x1, y1), (x2, y2), (x3, y3), (x4, y4), (x1, y1)], width=2, fill=color)
+ xmin = min(x1, x2, x3, x4)
+ ymin = min(y1, y2, y3, y4)
+
+ # draw label
+ text = "{} {:.4f}".format(labels[clsid], score)
+ tw, th = draw.textsize(text)
+ draw.rectangle([(xmin + 1, ymin - th), (xmin + tw + 1, ymin)], fill=color)
+ draw.text((xmin + 1, ymin - th), text, fill=(255, 255, 255))
+ return im
+
+
+def get_color(idx):
+ idx = idx * 3
+ color = ((37 * idx) % 255, (17 * idx) % 255, (29 * idx) % 255)
+ return color
+
+
+def visualize_pose(imgfile,
+ results,
+ visual_thresh=0.6,
+ save_name='pose.jpg',
+ save_dir='output',
+ returnimg=False,
+ ids=None):
+ try:
+ import matplotlib.pyplot as plt
+ import matplotlib
+ plt.switch_backend('agg')
+ except Exception as e:
+ raise e
+ skeletons, scores = results['keypoint']
+ skeletons = np.array(skeletons)
+ kpt_nums = 17
+ if len(skeletons) > 0:
+ kpt_nums = skeletons.shape[1]
+ if kpt_nums == 17: #plot coco keypoint
+ EDGES = [(0, 1), (0, 2), (1, 3), (2, 4), (3, 5), (4, 6), (5, 7), (6, 8), (7, 9), (8, 10), (5, 11), (6, 12),
+ (11, 13), (12, 14), (13, 15), (14, 16), (11, 12)]
+ else: #plot mpii keypoint
+ EDGES = [(0, 1), (1, 2), (3, 4), (4, 5), (2, 6), (3, 6), (6, 7), (7, 8), (8, 9), (10, 11), (11, 12), (13, 14),
+ (14, 15), (8, 12), (8, 13)]
+ NUM_EDGES = len(EDGES)
+
+ colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
+ [0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], \
+ [170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
+ cmap = matplotlib.cm.get_cmap('hsv')
+ plt.figure()
+
+ img = cv2.imread(imgfile) if type(imgfile) == str else imgfile
+
+ color_set = results['colors'] if 'colors' in results else None
+
+ if 'bbox' in results and ids is None:
+ bboxs = results['bbox']
+ for j, rect in enumerate(bboxs):
+ xmin, ymin, xmax, ymax = rect
+ color = colors[0] if color_set is None else colors[color_set[j] % len(colors)]
+ cv2.rectangle(img, (xmin, ymin), (xmax, ymax), color, 1)
+
+ canvas = img.copy()
+ for i in range(kpt_nums):
+ for j in range(len(skeletons)):
+ if skeletons[j][i, 2] < visual_thresh:
+ continue
+ if ids is None:
+ color = colors[i] if color_set is None else colors[color_set[j] % len(colors)]
+ else:
+ color = get_color(ids[j])
+
+ cv2.circle(canvas, tuple(skeletons[j][i, 0:2].astype('int32')), 2, color, thickness=-1)
+
+ to_plot = cv2.addWeighted(img, 0.3, canvas, 0.7, 0)
+ fig = matplotlib.pyplot.gcf()
+
+ stickwidth = 2
+
+ for i in range(NUM_EDGES):
+ for j in range(len(skeletons)):
+ edge = EDGES[i]
+ if skeletons[j][edge[0], 2] < visual_thresh or skeletons[j][edge[1], 2] < visual_thresh:
+ continue
+
+ cur_canvas = canvas.copy()
+ X = [skeletons[j][edge[0], 1], skeletons[j][edge[1], 1]]
+ Y = [skeletons[j][edge[0], 0], skeletons[j][edge[1], 0]]
+ mX = np.mean(X)
+ mY = np.mean(Y)
+ length = ((X[0] - X[1])**2 + (Y[0] - Y[1])**2)**0.5
+ angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1]))
+ polygon = cv2.ellipse2Poly((int(mY), int(mX)), (int(length / 2), stickwidth), int(angle), 0, 360, 1)
+ if ids is None:
+ color = colors[i] if color_set is None else colors[color_set[j] % len(colors)]
+ else:
+ color = get_color(ids[j])
+ cv2.fillConvexPoly(cur_canvas, polygon, color)
+ canvas = cv2.addWeighted(canvas, 0.4, cur_canvas, 0.6, 0)
+ if returnimg:
+ return canvas
+ save_name = os.path.join(save_dir, os.path.splitext(os.path.basename(imgfile))[0] + '_vis.jpg')
+ plt.imsave(save_name, canvas[:, :, ::-1])
+ print("keypoint visualize image saved to: " + save_name)
+ plt.close()
From 6667867155ce8d05f48ad4e9a2247eedf81c3e4b Mon Sep 17 00:00:00 2001
From: chenjian
输入图像
-
+ 
输出图像
diff --git a/modules/image/keypoint_detection/pp-tinypose/module.py b/modules/image/keypoint_detection/pp-tinypose/module.py
index 4d1efc82f..c0aa6fd88 100644
--- a/modules/image/keypoint_detection/pp-tinypose/module.py
+++ b/modules/image/keypoint_detection/pp-tinypose/module.py
@@ -48,7 +48,7 @@ class PP_TinyPose:
def __init__(self):
self.det_model_dir = os.path.join(self.directory, 'model/picodet_s_320_coco_lcnet/')
- self.keypoint_model_dir = os.path.join(self.directory, 'model/dark_hrnet_w32_256x192/')
+ self.keypoint_model_dir = os.path.join(self.directory, 'model/tinypose_256x192/')
self.detector = Detector(self.det_model_dir)
self.topdown_keypoint_detector = KeyPointDetector(self.keypoint_model_dir)
From b4931eaf28c3e9662bc64cfd2f62e9fa10008ad0 Mon Sep 17 00:00:00 2001
From: chenjian 


@@ -8,71 +19,26 @@ $ hub install chinese-electra-base==2.0.1
更多详情请参考[ELECTRA论文](https://openreview.net/pdf?id=r1xMH1BtvB)
-## API
-```python
-def __init__(
- task=None,
- load_checkpoint=None,
- label_map=None,
- num_classes=2,
- suffix=False,
- **kwargs,
-)
-```
-
-创建Module对象(动态图组网版本)。
+## 二、安装
-**参数**
-
-* `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
-* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
-* `label_map`:预测时的类别映射表。
-* `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
-* `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
-* `**kwargs`:用户额外指定的关键字字典类型的参数。
-
-```python
-def predict(
- data,
- max_seq_len=128,
- batch_size=1,
- use_gpu=False
-)
-```
-
-**参数**
-
-* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
-* `max_seq_len`:模型处理文本的最大长度
-* `batch_size`:模型批处理大小
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-
-**返回**
-
-* `results`:list类型,不同任务类型的返回结果如下
- * 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
- * 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-
-```python
-def get_embedding(
- data,
- use_gpu=False
-)
-```
+- ### 1、环境依赖
-用于获取输入文本的句子粒度特征与字粒度特征
+ - paddlepaddle >= 2.0.0
-**参数**
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-* `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+- ### 2、安装
-**返回**
+ - ```shell
+ $ hub install chinese-electra-base==2.0.2
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+## 三、模型API预测
-**代码示例**
+- ### 1、预测代码示例
```python
import paddlehub as hub
@@ -96,59 +62,110 @@ for idx, text in enumerate(data):
```
详情可参考PaddleHub示例:
-- [文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classification)
-- [序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/sequence_labeling)
+- [文本分类](../../../../demo/text_classification)
+- [序列标注](../../../../demo/sequence_labeling)
-## 服务部署
+- ### 2、API
+ - ```python
+ def __init__(
+ task=None,
+ load_checkpoint=None,
+ label_map=None,
+ num_classes=2,
+ suffix=False,
+ **kwargs,
+ )
+ ```
-PaddleHub Serving可以部署一个在线获取预训练词向量。
+ - 创建Module对象(动态图组网版本)。
-### Step1: 启动PaddleHub Serving
+ - **参数**
-运行启动命令:
+ - `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
+ - `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
+ - `label_map`:预测时的类别映射表。
+ - `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
+ - `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
+ - `**kwargs`:用户额外指定的关键字字典类型的参数。
-```shell
-$ hub serving start -m chinese-electra-base
-```
+ - ```python
+ def predict(
+ data,
+ max_seq_len=128,
+ batch_size=1,
+ use_gpu=False
+ )
+ ```
-这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+ - **参数**
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
+ - `max_seq_len`:模型处理文本的最大长度
+ - `batch_size`:模型批处理大小
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-### Step2: 发送预测请求
+ - **返回**
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - `results`:list类型,不同任务类型的返回结果如下
+ - 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
+ - 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-```python
-import requests
-import json
-
-# 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
-text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
-# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
-# 对应本地部署,则为module.get_embedding(data=text)
-data = {"data": text}
-# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
-url = "http://127.0.0.1:8866/predict/chinese-electra-base"
-# 指定post请求的headers为application/json方式
-headers = {"Content-Type": "application/json"}
-
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-print(r.json())
-```
+ - ```python
+ def get_embedding(
+ data,
+ use_gpu=False
+ )
+ ```
+
+ - 用于获取输入文本的句子粒度特征与字粒度特征
+
+ - **参数**
-## 查看代码
+ - `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-https://github.com/ymcui/Chinese-ELECTRA
+ - **返回**
+ - `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
-## 依赖
-paddlepaddle >= 2.0.0
+## 四、服务部署
-paddlehub >= 2.0.0
+- PaddleHub Serving可以部署一个在线获取预训练词向量。
-## 更新历史
+- ### 第一步:启动PaddleHub Serving
+
+ - ```shell
+ $ hub serving start -m chinese-electra-base
+ ```
+
+ - 这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ # 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
+ text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"data"
+ # 对应本地部署,则为module.get_embedding(data=text)
+ data = {"data": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://127.0.0.1:8866/predict/chinese-electra-base"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+## 五、更新历史
* 1.0.0
@@ -161,3 +178,7 @@ paddlehub >= 2.0.0
* 2.0.1
增加文本匹配任务`text-matching`
+
+* 2.0.2
+
+ 修复词嵌入模型预测的问题
diff --git a/modules/text/language_model/chinese_electra_base/module.py b/modules/text/language_model/chinese_electra_base/module.py
index 52a9a9fd2..db66dba10 100644
--- a/modules/text/language_model/chinese_electra_base/module.py
+++ b/modules/text/language_model/chinese_electra_base/module.py
@@ -28,7 +28,7 @@
@moduleinfo(
name="chinese-electra-base",
- version="2.0.1",
+ version="2.0.2",
summary=
"chinese-electra-base, 12-layer, 768-hidden, 12-heads, 102M parameters. The module is executed as paddle.dygraph.",
author="ymcui",
@@ -163,8 +163,7 @@ def forward(self,
return probs, loss, {'acc': acc}
return probs
else:
- sequence_output, pooled_output = result
- return sequence_output, pooled_output
+ return result
@staticmethod
def get_tokenizer(*args, **kwargs):
diff --git a/modules/text/language_model/chinese_electra_small/README.md b/modules/text/language_model/chinese_electra_small/README.md
index e4d49d10a..e6ed73dd5 100644
--- a/modules/text/language_model/chinese_electra_small/README.md
+++ b/modules/text/language_model/chinese_electra_small/README.md
@@ -1,78 +1,42 @@
-```shell
-$ hub install chinese-electra-small==2.0.1
-```
+# chinese-electra-small
+|模型名称|chinese-electra-small|
+| :--- | :---: |
+|类别|文本-语义模型|
+|网络|ELECTRA|
+|数据集|中文维基+通用数据|
+|是否支持Fine-tuning|是|
+|模型大小|47MB|
+|最新更新日期|2022-02-08|
+|数据指标|-|
+
+
+## 一、模型基本信息
+- ### 模型介绍
@@ -8,71 +19,25 @@ $ hub install electra-base==1.0.1
更多详情请参考[ELECTRA论文](https://openreview.net/pdf?id=r1xMH1BtvB)
-## API
-```python
-def __init__(
- task=None,
- load_checkpoint=None,
- label_map=None,
- num_classes=2,
- suffix=False,
- **kwargs,
-)
-```
-
-创建Module对象(动态图组网版本)。
-
-**参数**
-
-* `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
-* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
-* `label_map`:预测时的类别映射表。
-* `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
-* `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
-* `**kwargs`:用户额外指定的关键字字典类型的参数。
-
-```python
-def predict(
- data,
- max_seq_len=128,
- batch_size=1,
- use_gpu=False
-)
-```
-
-**参数**
-
-* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
-* `max_seq_len`:模型处理文本的最大长度
-* `batch_size`:模型批处理大小
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-
-**返回**
-
-* `results`:list类型,不同任务类型的返回结果如下
- * 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
- * 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-
-```python
-def get_embedding(
- data,
- use_gpu=False
-)
-```
+## 二、安装
-用于获取输入文本的句子粒度特征与字粒度特征
+- ### 1、环境依赖
-**参数**
+ - paddlepaddle >= 2.0.0
-* `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**返回**
+- ### 2、安装
-* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+ - ```shell
+ $ hub install electra-base==1.0.2
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+## 三、模型API预测
-**代码示例**
+- ### 1、预测代码示例
```python
import paddlehub as hub
@@ -99,56 +64,108 @@ for idx, text in enumerate(data):
- [文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classification)
- [序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/sequence_labeling)
-## 服务部署
+- ### 2、API
+ - ```python
+ def __init__(
+ task=None,
+ load_checkpoint=None,
+ label_map=None,
+ num_classes=2,
+ suffix=False,
+ **kwargs,
+ )
+ ```
-PaddleHub Serving可以部署一个在线获取预训练词向量。
+ - 创建Module对象(动态图组网版本)。
-### Step1: 启动PaddleHub Serving
+ - **参数**
-运行启动命令:
+ - `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
+ - `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
+ - `label_map`:预测时的类别映射表。
+ - `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
+ - `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
+ *- `**kwargs`:用户额外指定的关键字字典类型的参数。
-```shell
-$ hub serving start -m electra-base
-```
+ - ```python
+ def predict(
+ data,
+ max_seq_len=128,
+ batch_size=1,
+ use_gpu=False
+ )
+ ```
-这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+ - **参数**
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
+ - `max_seq_len`:模型处理文本的最大长度
+ - `batch_size`:模型批处理大小
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-### Step2: 发送预测请求
+ - **返回**
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - `results`:list类型,不同任务类型的返回结果如下
+ - 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
+ - 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
+
+ - ```python
+ def get_embedding(
+ data,
+ use_gpu=False
+ )
+ ```
+
+ - 用于获取输入文本的句子粒度特征与字粒度特征
+
+ - **参数**
+
+ - `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+
+ - **返回**
+
+ - `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
-```python
-import requests
-import json
-
-# 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
-text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
-# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
-# 对应本地部署,则为module.get_embedding(data=text)
-data = {"data": text}
-# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
-url = "http://127.0.0.1:8866/predict/electra-base"
-# 指定post请求的headers为application/json方式
-headers = {"Content-Type": "application/json"}
-
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-print(r.json())
-```
-## 查看代码
+## 四、服务部署
-https://github.com/google-research/electra
+- PaddleHub Serving可以部署一个在线获取预训练词向量。
+- ### 第一步:启动PaddleHub Serving
-## 依赖
+ - ```shell
+ $ hub serving start -m electra-base
+ ```
-paddlepaddle >= 2.0.0
+ - 这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
-paddlehub >= 2.0.0
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-## 更新历史
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ # 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
+ text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"data"
+ # 对应本地部署,则为module.get_embedding(data=text)
+ data = {"data": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://127.0.0.1:8866/predict/electra-base"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+
+## 五、更新历史
* 1.0.0
@@ -157,3 +174,7 @@ paddlehub >= 2.0.0
* 1.0.1
增加文本匹配任务`text-matching`
+
+* 1.0.2
+
+ 修复词嵌入模型预测的问题
diff --git a/modules/text/language_model/electra_base/module.py b/modules/text/language_model/electra_base/module.py
index 9f4c473c7..97ea3a9ed 100644
--- a/modules/text/language_model/electra_base/module.py
+++ b/modules/text/language_model/electra_base/module.py
@@ -28,7 +28,7 @@
@moduleinfo(
name="electra-base",
- version="1.0.1",
+ version="1.0.2",
summary="electra-base, 12-layer, 768-hidden, 12-heads, 110M parameters. The module is executed as paddle.dygraph.",
author="paddlepaddle",
author_email="",
@@ -162,8 +162,7 @@ def forward(self,
return probs, loss, {'acc': acc}
return probs
else:
- sequence_output, pooled_output = result
- return sequence_output, pooled_output
+ return result
@staticmethod
def get_tokenizer(*args, **kwargs):
diff --git a/modules/text/language_model/electra_large/README.md b/modules/text/language_model/electra_large/README.md
index 0eae56097..05e7e28f3 100644
--- a/modules/text/language_model/electra_large/README.md
+++ b/modules/text/language_model/electra_large/README.md
@@ -1,6 +1,17 @@
-```shell
-$ hub install electra-large==1.0.1
-```
+# electra-large
+|模型名称|electra-large|
+| :--- | :---: |
+|类别|文本-语义模型|
+|网络|ELECTRA|
+|数据集|英文维基百科|
+|是否支持Fine-tuning|是|
+|模型大小|1.9GB|
+|最新更新日期|2022-02-08|
+|数据指标|-|
+
+## 一、模型基本信息
+
+- ### 模型介绍
@@ -8,72 +19,25 @@ $ hub install electra-large==1.0.1
更多详情请参考[ELECTRA论文](https://openreview.net/pdf?id=r1xMH1BtvB)
-## API
-```python
-def __init__(
- task=None,
- load_checkpoint=None,
- label_map=None,
- num_classes=2,
- suffix=False,
- **kwargs,
-)
-```
-
-创建Module对象(动态图组网版本)。
-
-**参数**
-
-* `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
-* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
-* `label_map`:预测时的类别映射表。
-* `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
-* `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
-* `**kwargs`:用户额外指定的关键字字典类型的参数。
-
-```python
-def predict(
- data,
- max_seq_len=128,
- batch_size=1,
- use_gpu=False
-)
-```
-
-**参数**
-
-* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
-* `max_seq_len`:模型处理文本的最大长度
-* `batch_size`:模型批处理大小
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-
-**返回**
-
-* `results`:list类型,不同任务类型的返回结果如下
- * 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
- * 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-
-```python
-def get_embedding(
- data,
- use_gpu=False
-)
-```
-
-用于获取输入文本的句子粒度特征与字粒度特征
-
-**参数**
+## 二、安装
-* `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
-**返回**
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+- ### 2、安装
+ - ```shell
+ $ hub install electra-large==1.0.2
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-**代码示例**
+## 三、模型API预测
+- ### 1、预测代码示例
```python
import paddlehub as hub
@@ -96,59 +60,110 @@ for idx, text in enumerate(data):
```
详情可参考PaddleHub示例:
-- [文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classification)
-- [序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/sequence_labeling)
+- [文本分类](../../../../demo/text_classification)
+- [序列标注](../../../../demo/sequence_labeling)
+
+- ### 2、API
+ - ```python
+ def __init__(
+ task=None,
+ load_checkpoint=None,
+ label_map=None,
+ num_classes=2,
+ suffix=False,
+ **kwargs,
+ )
+ ```
-## 服务部署
+ - 创建Module对象(动态图组网版本)。
-PaddleHub Serving可以部署一个在线获取预训练词向量。
+ - **参数**
-### Step1: 启动PaddleHub Serving
+ - `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
+ - `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
+ - `label_map`:预测时的类别映射表。
+ - `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
+ - `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
+ - `**kwargs`:用户额外指定的关键字字典类型的参数。
-运行启动命令:
+ - ```python
+ def predict(
+ data,
+ max_seq_len=128,
+ batch_size=1,
+ use_gpu=False
+ )
+ ```
-```shell
-$ hub serving start -m electra-large
-```
+ - **参数**
-这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+ - `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
+ - `max_seq_len`:模型处理文本的最大长度
+ - `batch_size`:模型批处理大小
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - **返回**
-### Step2: 发送预测请求
+ - `results`:list类型,不同任务类型的返回结果如下
+ - 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
+ - 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - ```python
+ def get_embedding(
+ data,
+ use_gpu=False
+ )
+ ```
-```python
-import requests
-import json
-
-# 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
-text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
-# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
-# 对应本地部署,则为module.get_embedding(data=text)
-data = {"data": text}
-# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
-url = "http://127.0.0.1:8866/predict/electra-large"
-# 指定post请求的headers为application/json方式
-headers = {"Content-Type": "application/json"}
-
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-print(r.json())
-```
+ - 用于获取输入文本的句子粒度特征与字粒度特征
-## 查看代码
+ - **参数**
-https://github.com/google-research/electra
+ - `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+ - **返回**
-## 依赖
+ - `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
-paddlepaddle >= 2.0.0
-paddlehub >= 2.0.0
+## 四、服务部署
-## 更新历史
+- PaddleHub Serving可以部署一个在线获取预训练词向量。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - ```shell
+ $ hub serving start -m electra-large
+ ```
+
+ - 这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ # 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
+ text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"data"
+ # 对应本地部署,则为module.get_embedding(data=text)
+ data = {"data": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://127.0.0.1:8866/predict/electra-large"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+## 五、更新历史
* 1.0.0
@@ -157,3 +172,7 @@ paddlehub >= 2.0.0
* 1.0.1
增加文本匹配任务`text-matching`
+
+* 1.0.2
+
+ 修复词嵌入模型预测的问题
diff --git a/modules/text/language_model/electra_large/module.py b/modules/text/language_model/electra_large/module.py
index 8360f30f7..16d08b59f 100644
--- a/modules/text/language_model/electra_large/module.py
+++ b/modules/text/language_model/electra_large/module.py
@@ -28,7 +28,7 @@
@moduleinfo(
name="electra-large",
- version="1.0.1",
+ version="1.0.2",
summary="electra-large, 24-layer, 1024-hidden, 16-heads, 335M parameters. The module is executed as paddle.dygraph.",
author="paddlepaddle",
author_email="",
@@ -162,8 +162,7 @@ def forward(self,
return probs, loss, {'acc': acc}
return probs
else:
- sequence_output, pooled_output = result
- return sequence_output, pooled_output
+ return result
@staticmethod
def get_tokenizer(*args, **kwargs):
diff --git a/modules/text/language_model/electra_small/README.md b/modules/text/language_model/electra_small/README.md
index bb2adb75f..32ed69058 100644
--- a/modules/text/language_model/electra_small/README.md
+++ b/modules/text/language_model/electra_small/README.md
@@ -1,78 +1,42 @@
-```shell
-$ hub install electra-small==1.0.1
-```
-
+# electra-small
+|模型名称|electra-small|
+| :--- | :---: |
+|类别|文本-语义模型|
+|网络|ELECTRA|
+|数据集|英文维基百科|
+|是否支持Fine-tuning|是|
+|模型大小|78MB|
+|最新更新日期|2022-02-08|
+|数据指标|-|
+
+## 一、模型基本信息
+
+- ### 模型介绍
 +
+
+
+ - 生成过程
+  +
+
+
+### 模型介绍
+
+disco_diffusion_cnclip_vitb16 是一个文图生成模型,可以通过输入一段文字来生成符合该句子语义的图像。该模型由两部分组成,一部分是扩散模型,是一种生成模型,可以从噪声输入中重建出原始图像。另一部分是多模态预训练模型(CLIP), 可以将文本和图像表示在同一个特征空间,相近语义的文本和图像在该特征空间里距离会更相近。在该文图生成模型中,扩散模型负责从初始噪声或者指定初始图像中来生成目标图像,CLIP负责引导生成图像的语义和输入的文本的语义尽可能接近,随着扩散模型在CLIP的引导下不断的迭代生成新图像,最终能够生成文本所描述内容的图像。该模块中使用的CLIP模型结构为ViTB16。
+
+更多详情请参考论文:[Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233) 以及 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install disco_diffusion_cnclip_vitb16
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run disco_diffusion_cnclip_vitb16 --text_prompts "孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作。" --output_dir disco_diffusion_cnclip_vitb16_out
+ ```
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_cnclip_vitb16")
+ text_prompts = ["孤舟蓑笠翁,独钓寒江雪。"]
+ # 生成图像, 默认会在disco_diffusion_cnclip_vitb16_out目录保存图像
+ # 返回的da是一个DocumentArray对象,保存了所有的结果,包括最终结果和迭代过程的中间结果
+ # 可以通过操作DocumentArray对象对生成的图像做后处理,保存或者分析
+ da = module.generate_image(text_prompts=text_prompts, artist='齐白石', output_dir='./disco_diffusion_cnclip_vitb16_out/')
+ # 手动将最终生成的图像保存到指定路径
+ da[0].save_uri_to_file('disco_diffusion_cnclip_vitb16_out-result.png')
+ # 展示所有的中间结果
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # 将整个生成过程保存为一个动态图gif
+ da[0].chunks.save_gif('disco_diffusion_cnclip_vitb16_out-result.gif', show_index=True, inline_display=True, size_ratio=0.5)
+ ```
+
+- ### 3、API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_cnclip_vitb16_out'):
+ ```
+
+ - 文图生成API,生成文本描述内容的图像。
+
+ - **参数**
+
+ - text_prompts(str): 输入的语句,描述想要生成的图像的内容。通常比较有效的构造方式为 "一段描述性的文字内容" + "指定艺术家的名字",如"孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作"。
+ - style(Optional[str]): 指定绘画的风格,如水墨画、油画、水彩画等。当不指定时,风格完全由您所填写的prompt决定。
+ - artist(Optional[str]): 指定特定的艺术家,如齐白石、Greg Rutkowsk,将会生成所指定艺术家的绘画风格。当不指定时,风格完全由您所填写的prompt决定。各种艺术家的风格可以参考[网站](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/)。
+ - width_height(Optional[List[int]]): 指定最终输出图像的宽高,宽和高都需要是64的倍数,生成的图像越大,所需要的计算时间越长。
+ - seed(Optional[int]): 随机种子,由于输入默认是随机高斯噪声,设置不同的随机种子会由不同的初始输入,从而最终生成不同的结果,可以设置该参数来获得不同的输出图像。
+ - output_dir(Optional[str]): 保存输出图像的目录,默认为"disco_diffusion_cnclip_vitb16_out"。
+
+
+ - **返回**
+ - ra(DocumentArray): DocumentArray对象, 包含`n_batches`个Documents,其中每个Document都保存了迭代过程的所有中间结果。详细可参考[DocumentArray使用文档](https://docarray.jina.ai/fundamentals/documentarray/index.html)。
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install disco_diffusion_cnclip_vitb16 == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/README.md b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/README.md
new file mode 100644
index 000000000..61cbe4ac5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/README.md
@@ -0,0 +1,3 @@
+# Chinese-CLIP (Paddle)
+Chinese-CLIP implemented by Paddle.
+This module is based on [billjie1/Chinese-CLIP](https://github.com/billjie1/Chinese-CLIP).
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/__init__.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/__init__.py
new file mode 100755
index 000000000..2e17bd07f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/__init__.py
@@ -0,0 +1,4 @@
+from .bert_tokenizer import FullTokenizer
+
+_tokenizer = FullTokenizer()
+from .utils import tokenize, create_model
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/bert_tokenizer.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/bert_tokenizer.py
new file mode 100755
index 000000000..ab4ec678b
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/bert_tokenizer.py
@@ -0,0 +1,426 @@
+# coding=utf-8
+# Copyright 2018 The Google AI Language Team Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization classes."""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import collections
+import os
+import re
+import unicodedata
+from functools import lru_cache
+
+import six
+
+
+@lru_cache()
+def default_vocab():
+ return os.path.join(os.path.dirname(os.path.abspath(__file__)), "vocab.txt")
+
+
+def validate_case_matches_checkpoint(do_lower_case, init_checkpoint):
+ """Checks whether the casing config is consistent with the checkpoint name."""
+
+ # The casing has to be passed in by the user and there is no explicit check
+ # as to whether it matches the checkpoint. The casing information probably
+ # should have been stored in the bert_config.json file, but it's not, so
+ # we have to heuristically detect it to validate.
+
+ if not init_checkpoint:
+ return
+
+ m = re.match("^.*?([A-Za-z0-9_-]+)/bert_model.ckpt", init_checkpoint)
+ if m is None:
+ return
+
+ model_name = m.group(1)
+
+ lower_models = [
+ "uncased_L-24_H-1024_A-16", "uncased_L-12_H-768_A-12", "multilingual_L-12_H-768_A-12", "chinese_L-12_H-768_A-12"
+ ]
+
+ cased_models = ["cased_L-12_H-768_A-12", "cased_L-24_H-1024_A-16", "multi_cased_L-12_H-768_A-12"]
+
+ is_bad_config = False
+ if model_name in lower_models and not do_lower_case:
+ is_bad_config = True
+ actual_flag = "False"
+ case_name = "lowercased"
+ opposite_flag = "True"
+
+ if model_name in cased_models and do_lower_case:
+ is_bad_config = True
+ actual_flag = "True"
+ case_name = "cased"
+ opposite_flag = "False"
+
+ if is_bad_config:
+ raise ValueError("You passed in `--do_lower_case=%s` with `--init_checkpoint=%s`. "
+ "However, `%s` seems to be a %s model, so you "
+ "should pass in `--do_lower_case=%s` so that the fine-tuning matches "
+ "how the model was pre-training. If this error is wrong, please "
+ "just comment out this check." %
+ (actual_flag, init_checkpoint, model_name, case_name, opposite_flag))
+
+
+def convert_to_unicode(text):
+ """Converts `text` to Unicode (if it's not already), assuming utf-8 input."""
+ if six.PY3:
+ if isinstance(text, str):
+ return text
+ elif isinstance(text, bytes):
+ return text.decode("utf-8", "ignore")
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ elif six.PY2:
+ if isinstance(text, str):
+ return text.decode("utf-8", "ignore")
+ elif isinstance(text, unicode):
+ return text
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ else:
+ raise ValueError("Not running on Python2 or Python 3?")
+
+
+def printable_text(text):
+ """Returns text encoded in a way suitable for print or `tf.logging`."""
+
+ # These functions want `str` for both Python2 and Python3, but in one case
+ # it's a Unicode string and in the other it's a byte string.
+ if six.PY3:
+ if isinstance(text, str):
+ return text
+ elif isinstance(text, bytes):
+ return text.decode("utf-8", "ignore")
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ elif six.PY2:
+ if isinstance(text, str):
+ return text
+ elif isinstance(text, unicode):
+ return text.encode("utf-8")
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ else:
+ raise ValueError("Not running on Python2 or Python 3?")
+
+
+def load_vocab(vocab_file):
+ """Loads a vocabulary file into a dictionary."""
+ vocab = collections.OrderedDict()
+ index = 0
+ with open(vocab_file, "r") as reader:
+ while True:
+ token = convert_to_unicode(reader.readline())
+ if not token:
+ break
+ token = token.strip()
+ vocab[token] = index
+ index += 1
+ return vocab
+
+
+def convert_by_vocab(vocab, items):
+ """Converts a sequence of [tokens|ids] using the vocab."""
+ output = []
+ for item in items:
+ output.append(vocab[item])
+ return output
+
+
+def convert_tokens_to_ids(vocab, tokens):
+ return convert_by_vocab(vocab, tokens)
+
+
+def convert_ids_to_tokens(inv_vocab, ids):
+ return convert_by_vocab(inv_vocab, ids)
+
+
+def whitespace_tokenize(text):
+ """Runs basic whitespace cleaning and splitting on a piece of text."""
+ text = text.strip()
+ if not text:
+ return []
+ tokens = text.split()
+ return tokens
+
+
+class FullTokenizer(object):
+ """Runs end-to-end tokenziation."""
+
+ def __init__(self, vocab_file=default_vocab(), do_lower_case=True):
+ self.vocab = load_vocab(vocab_file)
+ self.inv_vocab = {v: k for k, v in self.vocab.items()}
+ self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case)
+ self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
+
+ def tokenize(self, text):
+ split_tokens = []
+ for token in self.basic_tokenizer.tokenize(text):
+ for sub_token in self.wordpiece_tokenizer.tokenize(token):
+ split_tokens.append(sub_token)
+
+ return split_tokens
+
+ def convert_tokens_to_ids(self, tokens):
+ return convert_by_vocab(self.vocab, tokens)
+
+ def convert_ids_to_tokens(self, ids):
+ return convert_by_vocab(self.inv_vocab, ids)
+
+ @staticmethod
+ def convert_tokens_to_string(tokens, clean_up_tokenization_spaces=True):
+ """ Converts a sequence of tokens (string) in a single string. """
+
+ def clean_up_tokenization(out_string):
+ """ Clean up a list of simple English tokenization artifacts
+ like spaces before punctuations and abreviated forms.
+ """
+ out_string = (out_string.replace(" .", ".").replace(" ?", "?").replace(" !", "!").replace(
+ " ,",
+ ",").replace(" ' ",
+ "'").replace(" n't",
+ "n't").replace(" 'm",
+ "'m").replace(" 's",
+ "'s").replace(" 've",
+ "'ve").replace(" 're", "'re"))
+ return out_string
+
+ text = ' '.join(tokens).replace(' ##', '').strip()
+ if clean_up_tokenization_spaces:
+ clean_text = clean_up_tokenization(text)
+ return clean_text
+ else:
+ return text
+
+ def vocab_size(self):
+ return len(self.vocab)
+
+
+class BasicTokenizer(object):
+ """Runs basic tokenization (punctuation splitting, lower casing, etc.)."""
+
+ def __init__(self, do_lower_case=True):
+ """Constructs a BasicTokenizer.
+
+ Args:
+ do_lower_case: Whether to lower case the input.
+ """
+ self.do_lower_case = do_lower_case
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text."""
+ text = convert_to_unicode(text)
+ text = self._clean_text(text)
+
+ # This was added on November 1st, 2018 for the multilingual and Chinese
+ # models. This is also applied to the English models now, but it doesn't
+ # matter since the English models were not trained on any Chinese data
+ # and generally don't have any Chinese data in them (there are Chinese
+ # characters in the vocabulary because Wikipedia does have some Chinese
+ # words in the English Wikipedia.).
+ text = self._tokenize_chinese_chars(text)
+
+ orig_tokens = whitespace_tokenize(text)
+ split_tokens = []
+ for token in orig_tokens:
+ if self.do_lower_case:
+ token = token.lower()
+ token = self._run_strip_accents(token)
+ split_tokens.extend(self._run_split_on_punc(token))
+
+ output_tokens = whitespace_tokenize(" ".join(split_tokens))
+ return output_tokens
+
+ def _run_strip_accents(self, text):
+ """Strips accents from a piece of text."""
+ text = unicodedata.normalize("NFD", text)
+ output = []
+ for char in text:
+ cat = unicodedata.category(char)
+ if cat == "Mn":
+ continue
+ output.append(char)
+ return "".join(output)
+
+ def _run_split_on_punc(self, text):
+ """Splits punctuation on a piece of text."""
+ chars = list(text)
+ i = 0
+ start_new_word = True
+ output = []
+ while i < len(chars):
+ char = chars[i]
+ if _is_punctuation(char):
+ output.append([char])
+ start_new_word = True
+ else:
+ if start_new_word:
+ output.append([])
+ start_new_word = False
+ output[-1].append(char)
+ i += 1
+
+ return ["".join(x) for x in output]
+
+ def _tokenize_chinese_chars(self, text):
+ """Adds whitespace around any CJK character."""
+ output = []
+ for char in text:
+ cp = ord(char)
+ if self._is_chinese_char(cp):
+ output.append(" ")
+ output.append(char)
+ output.append(" ")
+ else:
+ output.append(char)
+ return "".join(output)
+
+ def _is_chinese_char(self, cp):
+ """Checks whether CP is the codepoint of a CJK character."""
+ # This defines a "chinese character" as anything in the CJK Unicode block:
+ # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
+ #
+ # Note that the CJK Unicode block is NOT all Japanese and Korean characters,
+ # despite its name. The modern Korean Hangul alphabet is a different block,
+ # as is Japanese Hiragana and Katakana. Those alphabets are used to write
+ # space-separated words, so they are not treated specially and handled
+ # like the all of the other languages.
+ if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
+ (cp >= 0x3400 and cp <= 0x4DBF) or #
+ (cp >= 0x20000 and cp <= 0x2A6DF) or #
+ (cp >= 0x2A700 and cp <= 0x2B73F) or #
+ (cp >= 0x2B740 and cp <= 0x2B81F) or #
+ (cp >= 0x2B820 and cp <= 0x2CEAF) or (cp >= 0xF900 and cp <= 0xFAFF) or #
+ (cp >= 0x2F800 and cp <= 0x2FA1F)): #
+ return True
+
+ return False
+
+ def _clean_text(self, text):
+ """Performs invalid character removal and whitespace cleanup on text."""
+ output = []
+ for char in text:
+ cp = ord(char)
+ if cp == 0 or cp == 0xfffd or _is_control(char):
+ continue
+ if _is_whitespace(char):
+ output.append(" ")
+ else:
+ output.append(char)
+ return "".join(output)
+
+
+class WordpieceTokenizer(object):
+ """Runs WordPiece tokenziation."""
+
+ def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200):
+ self.vocab = vocab
+ self.unk_token = unk_token
+ self.max_input_chars_per_word = max_input_chars_per_word
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text into its word pieces.
+
+ This uses a greedy longest-match-first algorithm to perform tokenization
+ using the given vocabulary.
+
+ For example:
+ input = "unaffable"
+ output = ["un", "##aff", "##able"]
+
+ Args:
+ text: A single token or whitespace separated tokens. This should have
+ already been passed through `BasicTokenizer.
+
+ Returns:
+ A list of wordpiece tokens.
+ """
+
+ text = convert_to_unicode(text)
+
+ output_tokens = []
+ for token in whitespace_tokenize(text):
+ chars = list(token)
+ if len(chars) > self.max_input_chars_per_word:
+ output_tokens.append(self.unk_token)
+ continue
+
+ is_bad = False
+ start = 0
+ sub_tokens = []
+ while start < len(chars):
+ end = len(chars)
+ cur_substr = None
+ while start < end:
+ substr = "".join(chars[start:end])
+ if start > 0:
+ substr = "##" + substr
+ if substr in self.vocab:
+ cur_substr = substr
+ break
+ end -= 1
+ if cur_substr is None:
+ is_bad = True
+ break
+ sub_tokens.append(cur_substr)
+ start = end
+
+ if is_bad:
+ output_tokens.append(self.unk_token)
+ else:
+ output_tokens.extend(sub_tokens)
+ return output_tokens
+
+
+def _is_whitespace(char):
+ """Checks whether `chars` is a whitespace character."""
+ # \t, \n, and \r are technically contorl characters but we treat them
+ # as whitespace since they are generally considered as such.
+ if char == " " or char == "\t" or char == "\n" or char == "\r":
+ return True
+ cat = unicodedata.category(char)
+ if cat == "Zs":
+ return True
+ return False
+
+
+def _is_control(char):
+ """Checks whether `chars` is a control character."""
+ # These are technically control characters but we count them as whitespace
+ # characters.
+ if char == "\t" or char == "\n" or char == "\r":
+ return False
+ cat = unicodedata.category(char)
+ if cat in ("Cc", "Cf"):
+ return True
+ return False
+
+
+def _is_punctuation(char):
+ """Checks whether `chars` is a punctuation character."""
+ cp = ord(char)
+ # We treat all non-letter/number ASCII as punctuation.
+ # Characters such as "^", "$", and "`" are not in the Unicode
+ # Punctuation class but we treat them as punctuation anyways, for
+ # consistency.
+ if ((cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or (cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126)):
+ return True
+ cat = unicodedata.category(char)
+ if cat.startswith("P"):
+ return True
+ return False
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/configuration_bert.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/configuration_bert.py
new file mode 100755
index 000000000..323193192
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/configuration_bert.py
@@ -0,0 +1,85 @@
+# coding=utf-8
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" BERT model configuration """
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import logging
+
+logger = logging.getLogger(__name__)
+
+
+class BertConfig(object):
+ r"""
+ :class:`~transformers.BertConfig` is the configuration class to store the configuration of a
+ `BertModel`.
+
+
+ Arguments:
+ vocab_size_or_config_json_file: Vocabulary size of `inputs_ids` in `BertModel`.
+ hidden_size: Size of the encoder layers and the pooler layer.
+ num_hidden_layers: Number of hidden layers in the Transformer encoder.
+ num_attention_heads: Number of attention heads for each attention layer in
+ the Transformer encoder.
+ intermediate_size: The size of the "intermediate" (i.e., feed-forward)
+ layer in the Transformer encoder.
+ hidden_act: The non-linear activation function (function or string) in the
+ encoder and pooler. If string, "gelu", "relu", "swish" and "gelu_new" are supported.
+ hidden_dropout_prob: The dropout probabilitiy for all fully connected
+ layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob: The dropout ratio for the attention
+ probabilities.
+ max_position_embeddings: The maximum sequence length that this model might
+ ever be used with. Typically set this to something large just in case
+ (e.g., 512 or 1024 or 2048).
+ type_vocab_size: The vocabulary size of the `token_type_ids` passed into
+ `BertModel`.
+ initializer_range: The sttdev of the truncated_normal_initializer for
+ initializing all weight matrices.
+ layer_norm_eps: The epsilon used by LayerNorm.
+ """
+
+ def __init__(self,
+ vocab_size_or_config_json_file=30522,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=2,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ output_attentions=False,
+ output_hidden_states=False):
+ self.vocab_size = vocab_size_or_config_json_file
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_act = hidden_act
+ self.intermediate_size = intermediate_size
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.output_attentions = output_attentions
+ self.output_hidden_states = output_hidden_states
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model.py
new file mode 100644
index 000000000..cc352e475
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model.py
@@ -0,0 +1,247 @@
+from collections import OrderedDict
+from typing import Tuple
+from typing import Union
+
+import numpy as np
+import paddle
+import paddle.nn.functional as F
+from disco_diffusion_cnclip_vitb16.cn_clip.clip import _tokenizer
+from disco_diffusion_cnclip_vitb16.cn_clip.clip.configuration_bert import BertConfig
+from disco_diffusion_cnclip_vitb16.cn_clip.clip.modeling_bert import BertModel
+from paddle import nn
+from paddle.nn import MultiHeadAttention
+
+
+class Bottleneck(nn.Layer):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1):
+ super().__init__()
+
+ # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
+ self.conv1 = nn.Conv2D(inplanes, planes, 1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(planes)
+
+ self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(planes)
+
+ self.avgpool = nn.AvgPool2D(stride) if stride > 1 else nn.Identity()
+
+ self.conv3 = nn.Conv2D(planes, planes * self.expansion, 1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(planes * self.expansion)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = None
+ self.stride = stride
+
+ if stride > 1 or inplanes != planes * Bottleneck.expansion:
+ # downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
+ self.downsample = nn.Sequential(
+ OrderedDict([("-1", nn.AvgPool2D(stride)),
+ ("0", nn.Conv2D(inplanes, planes * self.expansion, 1, stride=1, bias_attr=False)),
+ ("1", nn.BatchNorm2D(planes * self.expansion))]))
+
+ def forward(self, x: paddle.Tensor):
+ identity = x
+
+ out = self.relu(self.bn1(self.conv1(x)))
+ out = self.relu(self.bn2(self.conv2(out)))
+ out = self.avgpool(out)
+ out = self.bn3(self.conv3(out))
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.relu(out)
+ return out
+
+
+class QuickGELU(nn.Layer):
+
+ def forward(self, x: paddle.Tensor):
+ return x * paddle.nn.functional.sigmoid(1.702 * x)
+
+
+class ResidualAttentionBlock(nn.Layer):
+
+ def __init__(self, d_model: int, n_head: int, attn_mask: paddle.Tensor = None):
+ super().__init__()
+ self.attn = MultiHeadAttention(d_model, n_head)
+ self.ln_1 = nn.LayerNorm(d_model)
+ self.mlp = nn.Sequential(*[("c_fc", nn.Linear(d_model, d_model * 4)), (
+ "gelu", QuickGELU()), ("c_proj", nn.Linear(d_model * 4, d_model))])
+ self.ln_2 = nn.LayerNorm(d_model)
+ self.attn_mask = attn_mask
+
+ def attention(self, x: paddle.Tensor):
+ self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
+ return self.attn(x, x, x, attn_mask=self.attn_mask)
+
+ def forward(self, x: paddle.Tensor):
+ x = x + self.attention(self.ln_1(x))
+ x = x + self.mlp(self.ln_2(x))
+ return x
+
+
+class Transformer(nn.Layer):
+
+ def __init__(self, width: int, layers: int, heads: int, attn_mask: paddle.Tensor = None):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
+
+ def forward(self, x: paddle.Tensor):
+ return self.resblocks(x)
+
+
+class VisualTransformer(nn.Layer):
+
+ def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.output_dim = output_dim
+ self.conv1 = nn.Conv2D(in_channels=3,
+ out_channels=width,
+ kernel_size=patch_size,
+ stride=patch_size,
+ bias_attr=False)
+
+ scale = width**-0.5
+ # self.class_embedding = nn.Parameter(scale * paddle.randn(width))
+ class_embedding = self.create_parameter([width])
+ self.add_parameter("class_embedding", class_embedding)
+ # self.positional_embedding = nn.Parameter(scale * paddle.randn([(input_resolution // patch_size) ** 2 + 1, width)])
+ positional_embedding = self.create_parameter([(input_resolution // patch_size)**2 + 1, width])
+ self.add_parameter("positional_embedding", positional_embedding)
+ self.ln_pre = nn.LayerNorm(width)
+
+ self.transformer = Transformer(width, layers, heads)
+
+ self.ln_post = nn.LayerNorm(width)
+ # self.proj = nn.Parameter(scale * paddle.randn([width, output_dim]))
+ proj = self.create_parameter([width, output_dim])
+ self.add_parameter("proj", proj)
+
+ def forward(self, x: paddle.Tensor):
+ x = self.conv1(x) # shape = [*, width, grid, grid]
+ x = x.reshape([x.shape[0], x.shape[1], -1]) # shape = [*, width, grid ** 2]
+ x = x.transpose([0, 2, 1]) # shape = [*, grid ** 2, width]
+ x = paddle.concat([self.class_embedding + paddle.zeros([x.shape[0], 1, x.shape[-1]], dtype=x.dtype), x],
+ axis=1) # shape = [*, grid ** 2 + 1, width]
+ x = x + paddle.cast(self.positional_embedding, x.dtype)
+ x = self.ln_pre(x)
+
+ x = self.transformer(x)
+
+ x = self.ln_post(x[:, 0, :])
+
+ if self.proj is not None:
+ x = x @ self.proj
+
+ return x
+
+
+class CLIP(nn.Layer):
+
+ def __init__(
+ self,
+ embed_dim: int,
+ # vision
+ image_resolution: int,
+ vision_layers: Union[Tuple[int, int, int, int], int],
+ vision_width: int,
+ vision_patch_size: int,
+ # text
+ vocab_size: int,
+ text_attention_probs_dropout_prob: float,
+ text_hidden_act: str,
+ text_hidden_dropout_prob: float,
+ text_hidden_size: int,
+ text_initializer_range: float,
+ text_intermediate_size: int,
+ text_max_position_embeddings: int,
+ text_num_attention_heads: int,
+ text_num_hidden_layers: int,
+ text_type_vocab_size: int,
+ tokenizer=_tokenizer,
+ ):
+ super().__init__()
+
+ vision_heads = vision_width // 64
+ self.visual = VisualTransformer(input_resolution=image_resolution,
+ patch_size=vision_patch_size,
+ width=vision_width,
+ layers=vision_layers,
+ heads=vision_heads,
+ output_dim=embed_dim)
+
+ self.bert_config = BertConfig(
+ vocab_size_or_config_json_file=vocab_size,
+ hidden_size=text_hidden_size,
+ num_hidden_layers=text_num_hidden_layers,
+ num_attention_heads=text_num_attention_heads,
+ intermediate_size=text_intermediate_size,
+ hidden_act=text_hidden_act,
+ hidden_dropout_prob=text_hidden_dropout_prob,
+ attention_probs_dropout_prob=text_attention_probs_dropout_prob,
+ max_position_embeddings=text_max_position_embeddings,
+ type_vocab_size=text_type_vocab_size,
+ initializer_range=text_initializer_range,
+ layer_norm_eps=1e-12,
+ )
+ self.bert = BertModel(self.bert_config)
+
+ text_projection = self.create_parameter([text_hidden_size, embed_dim])
+ self.add_parameter("text_projection", text_projection)
+ logit_scale = self.create_parameter([1])
+ self.add_parameter("logit_scale", logit_scale)
+
+ self.tokenizer = tokenizer
+
+ @property
+ def dtype(self):
+ return self.visual.conv1.weight.dtype
+
+ def encode_image(self, image):
+ return self.visual(image.cast(self.dtype))
+
+ def encode_text(self, text):
+ pad_index = self.tokenizer.vocab['[PAD]']
+
+ attn_mask = text.not_equal(paddle.to_tensor(pad_index)).cast(self.dtype)
+
+ x = self.bert(text, attention_mask=attn_mask)[0].cast(self.dtype) # [batch_size, seq_length, hidden_size]
+ return x[:, 0, :] @ self.text_projection
+
+ def forward(self, image, text):
+ assert image is not None or text is not None, "text and image cannot both be None!"
+
+ if image is None:
+ return self.encode_text(text)
+ elif text is None:
+ return self.encode_image(image)
+ image_features = self.encode_image(image)
+ text_features = self.encode_text(text)
+
+ image_features = image_features / image_features.norm(axis=-1, keepdim=True)
+ text_features = text_features / text_features.norm(axis=-1, keepdim=True)
+
+ return image_features, text_features, self.logit_scale.exp()
+
+ def get_similarity(self, image, text):
+ image_features = self.encode_image(image)
+ text_features = self.encode_text(text)
+
+ # normalized features
+ image_features = image_features / image_features.norm(axis=1, keepdim=True)
+ text_features = text_features / text_features.norm(axis=1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_image = logit_scale * image_features @ text_features.t()
+ logits_per_text = logits_per_image.t()
+
+ # shape = [global_batch_size, global_batch_size]
+ return logits_per_image, logits_per_text
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/RoBERTa-wwm-ext-base-chinese.json b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/RoBERTa-wwm-ext-base-chinese.json
new file mode 100755
index 000000000..fdd5bce81
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/RoBERTa-wwm-ext-base-chinese.json
@@ -0,0 +1,13 @@
+{
+ "vocab_size": 21128,
+ "text_attention_probs_dropout_prob": 0.1,
+ "text_hidden_act": "gelu",
+ "text_hidden_dropout_prob": 0.1,
+ "text_hidden_size": 768,
+ "text_initializer_range": 0.02,
+ "text_intermediate_size": 3072,
+ "text_max_position_embeddings": 512,
+ "text_num_attention_heads": 12,
+ "text_num_hidden_layers": 12,
+ "text_type_vocab_size": 2
+}
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/RoBERTa-wwm-ext-large-chinese.json b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/RoBERTa-wwm-ext-large-chinese.json
new file mode 100755
index 000000000..b4ef28998
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/RoBERTa-wwm-ext-large-chinese.json
@@ -0,0 +1,13 @@
+{
+ "vocab_size": 21128,
+ "text_attention_probs_dropout_prob": 0.1,
+ "text_hidden_act": "gelu",
+ "text_hidden_dropout_prob": 0.1,
+ "text_hidden_size": 1024,
+ "text_initializer_range": 0.02,
+ "text_intermediate_size": 4096,
+ "text_max_position_embeddings": 512,
+ "text_num_attention_heads": 16,
+ "text_num_hidden_layers": 24,
+ "text_type_vocab_size": 2
+}
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/ViT-B-16.json b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/ViT-B-16.json
new file mode 100755
index 000000000..4adcbeca7
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/ViT-B-16.json
@@ -0,0 +1,7 @@
+{
+ "embed_dim": 512,
+ "image_resolution": 224,
+ "vision_layers": 12,
+ "vision_width": 768,
+ "vision_patch_size": 16
+}
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/ViT-B-32.json b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/ViT-B-32.json
new file mode 100755
index 000000000..75c98937a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/ViT-B-32.json
@@ -0,0 +1,7 @@
+{
+ "embed_dim": 512,
+ "image_resolution": 224,
+ "vision_layers": 12,
+ "vision_width": 768,
+ "vision_patch_size": 32
+}
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/ViT-L-14.json b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/ViT-L-14.json
new file mode 100755
index 000000000..d731eef46
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/model_configs/ViT-L-14.json
@@ -0,0 +1,7 @@
+{
+ "embed_dim": 768,
+ "image_resolution": 224,
+ "vision_layers": 24,
+ "vision_width": 1024,
+ "vision_patch_size": 14
+}
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/modeling_bert.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/modeling_bert.py
new file mode 100755
index 000000000..881352974
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/modeling_bert.py
@@ -0,0 +1,450 @@
+# coding=utf-8
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch BERT model. """
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import json
+import logging
+import math
+import os
+import sys
+from io import open
+
+import paddle
+from paddle import nn
+
+from .configuration_bert import BertConfig
+
+logger = logging.getLogger(__name__)
+
+
+def gelu(x):
+ """ Original Implementation of the gelu activation function in Google Bert repo when initially created.
+ For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
+ 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
+ Also see https://arxiv.org/abs/1606.08415
+ """
+ return x * 0.5 * (1.0 + paddle.erf(x / math.sqrt(2.0)))
+
+
+def gelu_new(x):
+ """ Implementation of the gelu activation function currently in Google Bert repo (identical to OpenAI GPT).
+ Also see https://arxiv.org/abs/1606.08415
+ """
+ return 0.5 * x * (1 + paddle.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * paddle.pow(x, 3))))
+
+
+def swish(x):
+ return x * paddle.nn.functional.sigmoid(x)
+
+
+ACT2FN = {"gelu": gelu, "relu": paddle.nn.functional.relu, "swish": swish, "gelu_new": gelu_new}
+
+BertLayerNorm = paddle.nn.LayerNorm
+
+
+class BertEmbeddings(nn.Layer):
+ """Construct the embeddings from word, position and token_type embeddings.
+ """
+
+ def __init__(self, config):
+ super(BertEmbeddings, self).__init__()
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size) #, padding_idx=0)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = BertLayerNorm(config.hidden_size, epsilon=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, input_ids, token_type_ids=None, position_ids=None):
+ seq_length = input_ids.shape[1]
+ if position_ids is None:
+ position_ids = paddle.arange(seq_length, dtype='int64')
+ position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
+ if token_type_ids is None:
+ token_type_ids = paddle.zeros_like(input_ids)
+
+ words_embeddings = self.word_embeddings(input_ids)
+ position_embeddings = self.position_embeddings(position_ids)
+
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = words_embeddings + position_embeddings + token_type_embeddings
+ embeddings = self.LayerNorm(embeddings)
+
+ embeddings = self.dropout(embeddings)
+
+ return embeddings
+
+
+class BertSelfAttention(nn.Layer):
+
+ def __init__(self, config):
+ super(BertSelfAttention, self).__init__()
+ if config.hidden_size % config.num_attention_heads != 0:
+ raise ValueError("The hidden size (%d) is not a multiple of the number of attention "
+ "heads (%d)" % (config.hidden_size, config.num_attention_heads))
+ self.output_attentions = config.output_attentions
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x):
+ new_x_shape = x.shape[:-1] + [self.num_attention_heads, self.attention_head_size]
+ x = x.reshape(new_x_shape)
+ return x.transpose([0, 2, 1, 3])
+
+ def forward(self, hidden_states, attention_mask=None, head_mask=None):
+ mixed_query_layer = self.query(hidden_states)
+ mixed_key_layer = self.key(hidden_states)
+ mixed_value_layer = self.value(hidden_states)
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+ key_layer = self.transpose_for_scores(mixed_key_layer)
+ value_layer = self.transpose_for_scores(mixed_value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = paddle.matmul(query_layer, key_layer.transpose([0, 1, 3, 2]))
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.Softmax(axis=-1)(attention_scores)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = paddle.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.transpose([0, 2, 1, 3])
+ new_context_layer_shape = context_layer.shape[:-2] + [self.all_head_size]
+ context_layer = context_layer.reshape(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer, )
+ return outputs
+
+
+class BertSelfOutput(nn.Layer):
+
+ def __init__(self, config):
+ super(BertSelfOutput, self).__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = BertLayerNorm(config.hidden_size, epsilon=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states, input_tensor):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class BertAttention(nn.Layer):
+
+ def __init__(self, config):
+ super(BertAttention, self).__init__()
+ self.self = BertSelfAttention(config)
+ self.output = BertSelfOutput(config)
+ self.pruned_heads = set()
+
+ def forward(self, input_tensor, attention_mask=None, head_mask=None):
+ self_outputs = self.self(input_tensor, attention_mask, head_mask)
+ attention_output = self.output(self_outputs[0], input_tensor)
+ outputs = (attention_output, ) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+class BertIntermediate(nn.Layer):
+
+ def __init__(self, config):
+ super(BertIntermediate, self).__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str) or (sys.version_info[0] == 2 and isinstance(config.hidden_act, unicode)):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+class BertOutput(nn.Layer):
+
+ def __init__(self, config):
+ super(BertOutput, self).__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = BertLayerNorm(config.hidden_size, epsilon=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states, input_tensor):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class BertLayer(nn.Layer):
+
+ def __init__(self, config):
+ super(BertLayer, self).__init__()
+ self.attention = BertAttention(config)
+ self.intermediate = BertIntermediate(config)
+ self.output = BertOutput(config)
+
+ def forward(self, hidden_states, attention_mask=None, head_mask=None):
+ attention_outputs = self.attention(hidden_states, attention_mask, head_mask)
+ attention_output = attention_outputs[0]
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ outputs = (layer_output, ) + attention_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+class BertEncoder(nn.Layer):
+
+ def __init__(self, config):
+ super(BertEncoder, self).__init__()
+ self.output_attentions = config.output_attentions
+ self.output_hidden_states = config.output_hidden_states
+ self.layer = nn.LayerList([BertLayer(config) for _ in range(config.num_hidden_layers)])
+
+ def forward(self, hidden_states, attention_mask=None, head_mask=None):
+ all_hidden_states = ()
+ all_attentions = ()
+ for i, layer_module in enumerate(self.layer):
+ if self.output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])
+ hidden_states = layer_outputs[0]
+
+ if self.output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1], )
+ # Add last layer
+ if self.output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ outputs = (hidden_states, )
+ if self.output_hidden_states:
+ outputs = outputs + (all_hidden_states, )
+ if self.output_attentions:
+ outputs = outputs + (all_attentions, )
+ return outputs # last-layer hidden state, (all hidden states), (all attentions)
+
+
+class BertPooler(nn.Layer):
+
+ def __init__(self, config):
+ super(BertPooler, self).__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states):
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+class BertPredictionHeadTransform(nn.Layer):
+
+ def __init__(self, config):
+ super(BertPredictionHeadTransform, self).__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ if isinstance(config.hidden_act, str) or (sys.version_info[0] == 2 and isinstance(config.hidden_act, unicode)):
+ self.transform_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.transform_act_fn = config.hidden_act
+ self.LayerNorm = BertLayerNorm(config.hidden_size, epsilon=config.layer_norm_eps)
+
+ def forward(self, hidden_states):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.transform_act_fn(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+
+class BertLMPredictionHead(nn.Layer):
+
+ def __init__(self, config):
+ super(BertLMPredictionHead, self).__init__()
+ self.transform = BertPredictionHeadTransform(config)
+
+ # The output weights are the same as the input embeddings, but there is
+ # an output-only bias for each token.
+ self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ self.bias = nn.Parameter(paddle.zeros(config.vocab_size))
+
+ def forward(self, hidden_states):
+ hidden_states = self.transform(hidden_states)
+ hidden_states = self.decoder(hidden_states) + self.bias
+ return hidden_states
+
+
+class BertOnlyMLMHead(nn.Layer):
+
+ def __init__(self, config):
+ super(BertOnlyMLMHead, self).__init__()
+ self.predictions = BertLMPredictionHead(config)
+
+ def forward(self, sequence_output):
+ prediction_scores = self.predictions(sequence_output)
+ return prediction_scores
+
+
+class BertOnlyNSPHead(nn.Layer):
+
+ def __init__(self, config):
+ super(BertOnlyNSPHead, self).__init__()
+ self.seq_relationship = nn.Linear(config.hidden_size, 2)
+
+ def forward(self, pooled_output):
+ seq_relationship_score = self.seq_relationship(pooled_output)
+ return seq_relationship_score
+
+
+class BertPreTrainingHeads(nn.Layer):
+
+ def __init__(self, config):
+ super(BertPreTrainingHeads, self).__init__()
+ self.predictions = BertLMPredictionHead(config)
+ self.seq_relationship = nn.Linear(config.hidden_size, 2)
+
+ def forward(self, sequence_output, pooled_output):
+ prediction_scores = self.predictions(sequence_output)
+ seq_relationship_score = self.seq_relationship(pooled_output)
+ return prediction_scores, seq_relationship_score
+
+
+class BertPreTrainedModel(nn.Layer):
+ config_class = BertConfig
+ base_model_prefix = "bert"
+
+ def __init__(self, config):
+ super(BertPreTrainedModel, self).__init__()
+ self.config = config
+
+
+class BertModel(BertPreTrainedModel):
+ r"""
+ Outputs: `Tuple` comprising various elements depending on the configuration (config) and inputs:
+ **last_hidden_state**: ``torch.FloatTensor`` of shape ``(batch_size, sequence_length, hidden_size)``
+ Sequence of hidden-states at the output of the last layer of the model.
+ **pooler_output**: ``torch.FloatTensor`` of shape ``(batch_size, hidden_size)``
+ Last layer hidden-state of the first token of the sequence (classification token)
+ further processed by a Linear layer and a Tanh activation function. The Linear
+ layer weights are trained from the next sentence prediction (classification)
+ objective during Bert pretraining. This output is usually *not* a good summary
+ of the semantic content of the input, you're often better with averaging or pooling
+ the sequence of hidden-states for the whole input sequence.
+ **hidden_states**: (`optional`, returned when ``config.output_hidden_states=True``)
+ list of ``torch.FloatTensor`` (one for the output of each layer + the output of the embeddings)
+ of shape ``(batch_size, sequence_length, hidden_size)``:
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ **attentions**: (`optional`, returned when ``config.output_attentions=True``)
+ list of ``torch.FloatTensor`` (one for each layer) of shape ``(batch_size, num_heads, sequence_length, sequence_length)``:
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
+
+ Examples::
+
+ tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
+ model = BertModel.from_pretrained('bert-base-uncased')
+ input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
+ outputs = model(input_ids)
+ last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
+
+ """
+
+ def __init__(self, config):
+ super(BertModel, self).__init__(config)
+
+ self.embeddings = BertEmbeddings(config)
+ self.encoder = BertEncoder(config)
+ self.pooler = BertPooler(config)
+
+ def forward(self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None):
+ if attention_mask is None:
+ attention_mask = paddle.ones_like(input_ids)
+ if token_type_ids is None:
+ token_type_ids = paddle.zeros_like(input_ids)
+
+ # We create a 3D attention mask from a 2D tensor mask.
+ # Sizes are [batch_size, 1, 1, to_seq_length]
+ # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
+ # this attention mask is more simple than the triangular masking of causal attention
+ # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
+ extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and -10000.0 for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ extended_attention_mask = extended_attention_mask.cast(dtype=self.parameters()[0].dtype) # fp16 compatibility
+ extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ if head_mask is not None:
+ if head_mask.rank() == 1:
+ head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
+ head_mask = head_mask.expand(self.config.num_hidden_layers, -1, -1, -1, -1)
+ elif head_mask.rank() == 2:
+ head_mask = head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(
+ -1) # We can specify head_mask for each layer
+ head_mask = head_mask.cast(dtype=self.parameters()[0].dtype) # switch to fload if need + fp16 compatibility
+ else:
+ head_mask = [None] * self.config.num_hidden_layers
+
+ embedding_output = self.embeddings(input_ids, position_ids=position_ids, token_type_ids=token_type_ids)
+
+ encoder_outputs = self.encoder(embedding_output, extended_attention_mask, head_mask=head_mask)
+
+ sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(sequence_output)
+
+ outputs = (
+ sequence_output,
+ pooled_output,
+ ) + encoder_outputs[1:] # add hidden_states and attentions if they are here
+ return outputs # sequence_output, pooled_output, (hidden_states), (attentions)
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/utils.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/utils.py
new file mode 100755
index 000000000..06607c51f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/cn_clip/clip/utils.py
@@ -0,0 +1,74 @@
+# Code modified from https://github.com/openai/CLIP
+import json
+import os
+from pathlib import Path
+from typing import List
+from typing import Union
+
+import paddle
+from disco_diffusion_cnclip_vitb16.cn_clip.clip import _tokenizer
+from disco_diffusion_cnclip_vitb16.cn_clip.clip.model import CLIP
+from tqdm import tqdm
+
+__all__ = ["tokenize", "create_model", "available_models"]
+
+_MODEL_INFO = {"ViTB16": {"struct": "ViT-B-16@RoBERTa-wwm-ext-base-chinese", "input_resolution": 224}}
+
+
+def available_models() -> List[str]:
+ """Returns the names of available CLIP models"""
+ return list(_MODEL_INFO.keys())
+
+
+def tokenize(texts: Union[str, List[str]], context_length: int = 64):
+ """
+ Returns the tokenized representation of given input string(s)
+ Parameters
+ ----------
+ texts : Union[str, List[str]]
+ An input string or a list of input strings to tokenize
+ context_length : int
+ The context length to use; all baseline models use 24 as the context length
+ Returns
+ -------
+ A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
+ """
+ if isinstance(texts, str):
+ texts = [texts]
+
+ all_tokens = []
+ for text in texts:
+ all_tokens.append([_tokenizer.vocab['[CLS]']] +
+ _tokenizer.convert_tokens_to_ids(_tokenizer.tokenize(text))[:context_length - 2] +
+ [_tokenizer.vocab['[SEP]']])
+
+ result = paddle.zeros([len(all_tokens), context_length], dtype='int64')
+
+ for i, tokens in enumerate(all_tokens):
+ assert len(tokens) <= context_length
+ result[i, :len(tokens)] = paddle.to_tensor(tokens)
+
+ return result
+
+
+def create_model(name):
+ checkpoint = paddle.load(os.path.join(os.path.dirname(__file__), 'pre_trained', '{}.pdparams'.format(name)))
+ model_name = _MODEL_INFO[name]['struct']
+ vision_model, text_model = model_name.split('@')
+ # Initialize the model.
+ vision_model_config_file = Path(__file__).parent / f"model_configs/{vision_model.replace('/', '-')}.json"
+ print('Loading vision model config from', vision_model_config_file)
+ assert os.path.exists(vision_model_config_file)
+
+ text_model_config_file = Path(__file__).parent / f"model_configs/{text_model.replace('/', '-')}.json"
+ print('Loading text model config from', text_model_config_file)
+ assert os.path.exists(text_model_config_file)
+
+ with open(vision_model_config_file, 'r') as fv, open(text_model_config_file, 'r') as ft:
+ model_info = json.load(fv)
+ for k, v in json.load(ft).items():
+ model_info[k] = v
+
+ model = CLIP(**model_info)
+ model.set_state_dict(checkpoint)
+ return model
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/module.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/module.py
new file mode 100755
index 000000000..806135c16
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/module.py
@@ -0,0 +1,435 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import ast
+import os
+import sys
+from functools import partial
+from typing import List
+from typing import Optional
+
+import paddle
+from disco_diffusion_cnclip_vitb16 import resize_right
+from disco_diffusion_cnclip_vitb16.reverse_diffusion import create
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+@moduleinfo(name="disco_diffusion_cnclip_vitb16",
+ version="1.0.0",
+ type="image/text_to_image",
+ summary="",
+ author="paddlepaddle",
+ author_email="paddle-dev@baidu.com")
+class DiscoDiffusionClip:
+
+ def generate_image(self,
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 0,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 0,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 1,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ use_gpu: Optional[bool] = True,
+ output_dir: Optional[str] = 'disco_diffusion_cnclip_vitb16_out'):
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+ :param style: Image style, such as oil paintings, if specified, style will be used to construct prompts.
+ :param artist: Artist style, if specified, style will be used to construct prompts.
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param use_gpu: whether to use gpu or not.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+ if use_gpu:
+ try:
+ _places = os.environ.get("CUDA_VISIBLE_DEVICES", None)
+ if _places:
+ paddle.device.set_device("gpu:{}".format(0))
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
+ )
+ else:
+ paddle.device.set_device("cpu")
+ paddle.disable_static()
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir, exist_ok=True)
+
+ if isinstance(text_prompts, str):
+ text_prompts = text_prompts.rstrip(',.,。')
+ if style is not None:
+ text_prompts += ",{}".format(style)
+ if artist is not None:
+ text_prompts += ",由{}所作".format(artist)
+ elif isinstance(text_prompts, list):
+ text_prompts[0] = text_prompts[0].rstrip(',.,。')
+ if style is not None:
+ text_prompts[0] += ",{}".format(style)
+ if artist is not None:
+ text_prompts[0] += ",由{}所作".format(artist)
+
+ return create(text_prompts=text_prompts,
+ init_image=init_image,
+ width_height=width_height,
+ skip_steps=skip_steps,
+ steps=steps,
+ cut_ic_pow=cut_ic_pow,
+ init_scale=init_scale,
+ clip_guidance_scale=clip_guidance_scale,
+ tv_scale=tv_scale,
+ range_scale=range_scale,
+ sat_scale=sat_scale,
+ cutn_batches=cutn_batches,
+ diffusion_sampling_mode=diffusion_sampling_mode,
+ perlin_init=perlin_init,
+ perlin_mode=perlin_mode,
+ seed=seed,
+ eta=eta,
+ clamp_grad=clamp_grad,
+ clamp_max=clamp_max,
+ randomize_class=randomize_class,
+ clip_denoised=clip_denoised,
+ fuzzy_prompt=fuzzy_prompt,
+ rand_mag=rand_mag,
+ cut_overview=cut_overview,
+ cut_innercut=cut_innercut,
+ cut_icgray_p=cut_icgray_p,
+ display_rate=display_rate,
+ n_batches=n_batches,
+ batch_size=batch_size,
+ batch_name=batch_name,
+ clip_models=['ViTB16'],
+ output_dir=output_dir)
+
+ @serving
+ def serving_method(self, text_prompts, **kwargs):
+ """
+ Run as a service.
+ """
+ results = []
+ for text_prompt in text_prompts:
+ result = self.generate_image(text_prompts=text_prompt, **kwargs)[0].to_base64()
+ results.append(result)
+ return results
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options", description="Run configuration for controlling module behavior, not required.")
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ results = self.generate_image(text_prompts=args.text_prompts,
+ style=args.style,
+ artist=args.artist,
+ init_image=args.init_image,
+ width_height=args.width_height,
+ skip_steps=args.skip_steps,
+ steps=args.steps,
+ cut_ic_pow=args.cut_ic_pow,
+ init_scale=args.init_scale,
+ clip_guidance_scale=args.clip_guidance_scale,
+ tv_scale=args.tv_scale,
+ range_scale=args.range_scale,
+ sat_scale=args.sat_scale,
+ cutn_batches=args.cutn_batches,
+ diffusion_sampling_mode=args.diffusion_sampling_mode,
+ perlin_init=args.perlin_init,
+ perlin_mode=args.perlin_mode,
+ seed=args.seed,
+ eta=args.eta,
+ clamp_grad=args.clamp_grad,
+ clamp_max=args.clamp_max,
+ randomize_class=args.randomize_class,
+ clip_denoised=args.clip_denoised,
+ fuzzy_prompt=args.fuzzy_prompt,
+ rand_mag=args.rand_mag,
+ cut_overview=args.cut_overview,
+ cut_innercut=args.cut_innercut,
+ cut_icgray_p=args.cut_icgray_p,
+ display_rate=args.display_rate,
+ n_batches=args.n_batches,
+ batch_size=args.batch_size,
+ batch_name=args.batch_name,
+ output_dir=args.output_dir)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options.
+ """
+ self.arg_input_group.add_argument(
+ '--skip_steps',
+ type=int,
+ default=0,
+ help=
+ 'Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15%% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50%% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture'
+ )
+ self.arg_input_group.add_argument(
+ '--steps',
+ type=int,
+ default=250,
+ help=
+ "When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time."
+ )
+ self.arg_input_group.add_argument(
+ '--cut_ic_pow',
+ type=int,
+ default=1,
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--init_scale',
+ type=int,
+ default=1000,
+ help=
+ "This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost."
+ )
+ self.arg_input_group.add_argument(
+ '--clip_guidance_scale',
+ type=int,
+ default=5000,
+ help=
+ "CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well."
+ )
+ self.arg_input_group.add_argument(
+ '--tv_scale',
+ type=int,
+ default=0,
+ help=
+ "Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising"
+ )
+ self.arg_input_group.add_argument(
+ '--range_scale',
+ type=int,
+ default=0,
+ help=
+ "Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images."
+ )
+ self.arg_input_group.add_argument(
+ '--sat_scale',
+ type=int,
+ default=0,
+ help=
+ "Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation."
+ )
+ self.arg_input_group.add_argument(
+ '--cutn_batches',
+ type=int,
+ default=4,
+ help=
+ "Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below."
+ )
+ self.arg_input_group.add_argument(
+ '--diffusion_sampling_mode',
+ type=str,
+ default='ddim',
+ help=
+ "Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_init',
+ type=bool,
+ default=False,
+ help=
+ "Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_mode',
+ type=str,
+ default='mixed',
+ help=
+ "sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--seed',
+ type=int,
+ default=None,
+ help=
+ "Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical."
+ )
+ self.arg_input_group.add_argument(
+ '--eta',
+ type=float,
+ default=0.8,
+ help=
+ "eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_grad',
+ type=bool,
+ default=True,
+ help=
+ "As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_max',
+ type=float,
+ default=0.05,
+ help=
+ "Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy."
+ )
+ self.arg_input_group.add_argument('--randomize_class', type=bool, default=True, help="Random class.")
+ self.arg_input_group.add_argument('--clip_denoised', type=bool, default=False, help="Clip denoised.")
+ self.arg_input_group.add_argument(
+ '--fuzzy_prompt',
+ type=bool,
+ default=False,
+ help=
+ "Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this."
+ )
+ self.arg_input_group.add_argument(
+ '--rand_mag',
+ type=float,
+ default=0.5,
+ help="Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.")
+ self.arg_input_group.add_argument('--cut_overview',
+ type=str,
+ default='[12]*400+[4]*600',
+ help="The schedule of overview cuts")
+ self.arg_input_group.add_argument('--cut_innercut',
+ type=str,
+ default='[4]*400+[12]*600',
+ help="The schedule of inner cuts")
+ self.arg_input_group.add_argument(
+ '--cut_icgray_p',
+ type=str,
+ default='[0.2]*400+[0]*600',
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--display_rate',
+ type=int,
+ default=10,
+ help=
+ "During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly."
+ )
+ self.arg_config_group.add_argument('--use_gpu',
+ type=ast.literal_eval,
+ default=True,
+ help="whether use GPU or not")
+ self.arg_config_group.add_argument('--output_dir',
+ type=str,
+ default='disco_diffusion_cnclip_vitb16',
+ help='Output directory.')
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument('--text_prompts', type=str)
+ self.arg_input_group.add_argument(
+ '--style',
+ type=str,
+ default=None,
+ help='Image style, such as oil paintings, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument('--artist',
+ type=str,
+ default=None,
+ help='Artist style, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument(
+ '--init_image',
+ type=str,
+ default=None,
+ help=
+ "Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion."
+ )
+ self.arg_input_group.add_argument(
+ '--width_height',
+ type=ast.literal_eval,
+ default=[1280, 768],
+ help=
+ "Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so."
+ )
+ self.arg_input_group.add_argument(
+ '--n_batches',
+ type=int,
+ default=1,
+ help=
+ "This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings."
+ )
+ self.arg_input_group.add_argument('--batch_size', type=int, default=1, help="Batch size.")
+ self.arg_input_group.add_argument(
+ '--batch_name',
+ type=str,
+ default='',
+ help=
+ 'The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.'
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/requirements.txt b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/requirements.txt
new file mode 100755
index 000000000..8b4bc0ea4
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/requirements.txt
@@ -0,0 +1,8 @@
+numpy
+paddle_lpips==0.1.2
+ftfy
+docarray>=0.13.29
+pyyaml
+regex
+tqdm
+ipywidgets
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/README.md b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/README.md
new file mode 100755
index 000000000..1f8d0bb0a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/README.md
@@ -0,0 +1,3 @@
+# ResizeRight (Paddle)
+Fully differentiable resize function implemented by Paddle.
+This module is based on [assafshocher/ResizeRight](https://github.com/assafshocher/ResizeRight).
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/__init__.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/__init__.py
new file mode 100755
index 000000000..e69de29bb
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/interp_methods.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/interp_methods.py
new file mode 100755
index 000000000..276eb055a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/interp_methods.py
@@ -0,0 +1,70 @@
+from math import pi
+
+try:
+ import paddle
+except ImportError:
+ paddle = None
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def set_framework_dependencies(x):
+ if type(x) is numpy.ndarray:
+ to_dtype = lambda a: a
+ fw = numpy
+ else:
+ to_dtype = lambda a: paddle.cast(a, x.dtype)
+ fw = paddle
+ # eps = fw.finfo(fw.float32).eps
+ eps = paddle.to_tensor(np.finfo(np.float32).eps)
+ return fw, to_dtype, eps
+
+
+def support_sz(sz):
+
+ def wrapper(f):
+ f.support_sz = sz
+ return f
+
+ return wrapper
+
+
+@support_sz(4)
+def cubic(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ absx = fw.abs(x)
+ absx2 = absx**2
+ absx3 = absx**3
+ return ((1.5 * absx3 - 2.5 * absx2 + 1.) * to_dtype(absx <= 1.) +
+ (-0.5 * absx3 + 2.5 * absx2 - 4. * absx + 2.) * to_dtype((1. < absx) & (absx <= 2.)))
+
+
+@support_sz(4)
+def lanczos2(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 2) + eps) / ((pi**2 * x**2 / 2) + eps)) * to_dtype(abs(x) < 2))
+
+
+@support_sz(6)
+def lanczos3(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 3) + eps) / ((pi**2 * x**2 / 3) + eps)) * to_dtype(abs(x) < 3))
+
+
+@support_sz(2)
+def linear(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return ((x + 1) * to_dtype((-1 <= x) & (x < 0)) + (1 - x) * to_dtype((0 <= x) & (x <= 1)))
+
+
+@support_sz(1)
+def box(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return to_dtype((-1 <= x) & (x < 0)) + to_dtype((0 <= x) & (x <= 1))
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/resize_right.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/resize_right.py
new file mode 100755
index 000000000..d8bab5b81
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/resize_right/resize_right.py
@@ -0,0 +1,403 @@
+import warnings
+from fractions import Fraction
+from math import ceil
+from typing import Tuple
+
+import disco_diffusion_cnclip_vitb16.resize_right.interp_methods as interp_methods
+
+
+class NoneClass:
+ pass
+
+
+try:
+ import paddle
+ from paddle import nn
+ nnModuleWrapped = nn.Layer
+except ImportError:
+ warnings.warn('No PyTorch found, will work only with Numpy')
+ paddle = None
+ nnModuleWrapped = NoneClass
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ warnings.warn('No Numpy found, will work only with PyTorch')
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def resize(input,
+ scale_factors=None,
+ out_shape=None,
+ interp_method=interp_methods.cubic,
+ support_sz=None,
+ antialiasing=True,
+ by_convs=False,
+ scale_tolerance=None,
+ max_numerator=10,
+ pad_mode='constant'):
+ # get properties of the input tensor
+ in_shape, n_dims = input.shape, input.ndim
+
+ # fw stands for framework that can be either numpy or paddle,
+ # determined by the input type
+ fw = numpy if type(input) is numpy.ndarray else paddle
+ eps = np.finfo(np.float32).eps if fw == numpy else paddle.to_tensor(np.finfo(np.float32).eps)
+ device = input.place if fw is paddle else None
+
+ # set missing scale factors or output shapem one according to another,
+ # scream if both missing. this is also where all the defults policies
+ # take place. also handling the by_convs attribute carefully.
+ scale_factors, out_shape, by_convs = set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs,
+ scale_tolerance, max_numerator, eps, fw)
+
+ # sort indices of dimensions according to scale of each dimension.
+ # since we are going dim by dim this is efficient
+ sorted_filtered_dims_and_scales = [(dim, scale_factors[dim], by_convs[dim], in_shape[dim], out_shape[dim])
+ for dim in sorted(range(n_dims), key=lambda ind: scale_factors[ind])
+ if scale_factors[dim] != 1.]
+ # unless support size is specified by the user, it is an attribute
+ # of the interpolation method
+ if support_sz is None:
+ support_sz = interp_method.support_sz
+
+ # output begins identical to input and changes with each iteration
+ output = input
+
+ # iterate over dims
+ for (dim, scale_factor, dim_by_convs, in_sz, out_sz) in sorted_filtered_dims_and_scales:
+ # STEP 1- PROJECTED GRID: The non-integer locations of the projection
+ # of output pixel locations to the input tensor
+ projected_grid = get_projected_grid(in_sz, out_sz, scale_factor, fw, dim_by_convs, device)
+
+ # STEP 1.5: ANTIALIASING- If antialiasing is taking place, we modify
+ # the window size and the interpolation method (see inside function)
+ cur_interp_method, cur_support_sz = apply_antialiasing_if_needed(interp_method, support_sz, scale_factor,
+ antialiasing)
+
+ # STEP 2- FIELDS OF VIEW: for each output pixels, map the input pixels
+ # that influence it. Also calculate needed padding and update grid
+ # accoedingly
+ field_of_view = get_field_of_view(projected_grid, cur_support_sz, fw, eps, device)
+
+ # STEP 2.5- CALCULATE PAD AND UPDATE: according to the field of view,
+ # the input should be padded to handle the boundaries, coordinates
+ # should be updated. actual padding only occurs when weights are
+ # aplied (step 4). if using by_convs for this dim, then we need to
+ # calc right and left boundaries for each filter instead.
+ pad_sz, projected_grid, field_of_view = calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor,
+ dim_by_convs, fw, device)
+ # STEP 3- CALCULATE WEIGHTS: Match a set of weights to the pixels in
+ # the field of view for each output pixel
+ weights = get_weights(cur_interp_method, projected_grid, field_of_view)
+
+ # STEP 4- APPLY WEIGHTS: Each output pixel is calculated by multiplying
+ # its set of weights with the pixel values in its field of view.
+ # We now multiply the fields of view with their matching weights.
+ # We do this by tensor multiplication and broadcasting.
+ # if by_convs is true for this dim, then we do this action by
+ # convolutions. this is equivalent but faster.
+ if not dim_by_convs:
+ output = apply_weights(output, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw)
+ else:
+ output = apply_convs(output, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw)
+ return output
+
+
+def get_projected_grid(in_sz, out_sz, scale_factor, fw, by_convs, device=None):
+ # we start by having the ouput coordinates which are just integer locations
+ # in the special case when usin by_convs, we only need two cycles of grid
+ # points. the first and last.
+ grid_sz = out_sz if not by_convs else scale_factor.numerator
+ out_coordinates = fw_arange(grid_sz, fw, device)
+
+ # This is projecting the ouput pixel locations in 1d to the input tensor,
+ # as non-integer locations.
+ # the following fomrula is derived in the paper
+ # "From Discrete to Continuous Convolutions" by Shocher et al.
+ return (out_coordinates / float(scale_factor) + (in_sz - 1) / 2 - (out_sz - 1) / (2 * float(scale_factor)))
+
+
+def get_field_of_view(projected_grid, cur_support_sz, fw, eps, device):
+ # for each output pixel, map which input pixels influence it, in 1d.
+ # we start by calculating the leftmost neighbor, using half of the window
+ # size (eps is for when boundary is exact int)
+ left_boundaries = fw_ceil(projected_grid - cur_support_sz / 2 - eps, fw)
+
+ # then we simply take all the pixel centers in the field by counting
+ # window size pixels from the left boundary
+ ordinal_numbers = fw_arange(ceil(cur_support_sz - eps), fw, device)
+ return left_boundaries[:, None] + ordinal_numbers
+
+
+def calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor, dim_by_convs, fw, device):
+ if not dim_by_convs:
+ # determine padding according to neighbor coords out of bound.
+ # this is a generalized notion of padding, when pad<0 it means crop
+ pad_sz = [-field_of_view[0, 0].item(), field_of_view[-1, -1].item() - in_sz + 1]
+
+ # since input image will be changed by padding, coordinates of both
+ # field_of_view and projected_grid need to be updated
+ field_of_view += pad_sz[0]
+ projected_grid += pad_sz[0]
+
+ else:
+ # only used for by_convs, to calc the boundaries of each filter the
+ # number of distinct convolutions is the numerator of the scale factor
+ num_convs, stride = scale_factor.numerator, scale_factor.denominator
+
+ # calculate left and right boundaries for each conv. left can also be
+ # negative right can be bigger than in_sz. such cases imply padding if
+ # needed. however if# both are in-bounds, it means we need to crop,
+ # practically apply the conv only on part of the image.
+ left_pads = -field_of_view[:, 0]
+
+ # next calc is tricky, explanation by rows:
+ # 1) counting output pixels between the first position of each filter
+ # to the right boundary of the input
+ # 2) dividing it by number of filters to count how many 'jumps'
+ # each filter does
+ # 3) multiplying by the stride gives us the distance over the input
+ # coords done by all these jumps for each filter
+ # 4) to this distance we add the right boundary of the filter when
+ # placed in its leftmost position. so now we get the right boundary
+ # of that filter in input coord.
+ # 5) the padding size needed is obtained by subtracting the rightmost
+ # input coordinate. if the result is positive padding is needed. if
+ # negative then negative padding means shaving off pixel columns.
+ right_pads = (((out_sz - fw_arange(num_convs, fw, device) - 1) # (1)
+ // num_convs) # (2)
+ * stride # (3)
+ + field_of_view[:, -1] # (4)
+ - in_sz + 1) # (5)
+
+ # in the by_convs case pad_sz is a list of left-right pairs. one per
+ # each filter
+
+ pad_sz = list(zip(left_pads, right_pads))
+
+ return pad_sz, projected_grid, field_of_view
+
+
+def get_weights(interp_method, projected_grid, field_of_view):
+ # the set of weights per each output pixels is the result of the chosen
+ # interpolation method applied to the distances between projected grid
+ # locations and the pixel-centers in the field of view (distances are
+ # directed, can be positive or negative)
+ weights = interp_method(projected_grid[:, None] - field_of_view)
+
+ # we now carefully normalize the weights to sum to 1 per each output pixel
+ sum_weights = weights.sum(1, keepdim=True)
+ sum_weights[sum_weights == 0] = 1
+ return weights / sum_weights
+
+
+def apply_weights(input, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw):
+ # for this operation we assume the resized dim is the first one.
+ # so we transpose and will transpose back after multiplying
+ tmp_input = fw_swapaxes(input, dim, 0, fw)
+
+ # apply padding
+ tmp_input = fw_pad(tmp_input, fw, pad_sz, pad_mode)
+
+ # field_of_view is a tensor of order 2: for each output (1d location
+ # along cur dim)- a list of 1d neighbors locations.
+ # note that this whole operations is applied to each dim separately,
+ # this is why it is all in 1d.
+ # neighbors = tmp_input[field_of_view] is a tensor of order image_dims+1:
+ # for each output pixel (this time indicated in all dims), these are the
+ # values of the neighbors in the 1d field of view. note that we only
+ # consider neighbors along the current dim, but such set exists for every
+ # multi-dim location, hence the final tensor order is image_dims+1.
+ paddle.device.cuda.empty_cache()
+ neighbors = tmp_input[field_of_view]
+
+ # weights is an order 2 tensor: for each output location along 1d- a list
+ # of weights matching the field of view. we augment it with ones, for
+ # broadcasting, so that when multiplies some tensor the weights affect
+ # only its first dim.
+ tmp_weights = fw.reshape(weights, (*weights.shape, *[1] * (n_dims - 1)))
+
+ # now we simply multiply the weights with the neighbors, and then sum
+ # along the field of view, to get a single value per out pixel
+ tmp_output = (neighbors * tmp_weights).sum(1)
+ # we transpose back the resized dim to its original position
+ return fw_swapaxes(tmp_output, 0, dim, fw)
+
+
+def apply_convs(input, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw):
+ # for this operations we assume the resized dim is the last one.
+ # so we transpose and will transpose back after multiplying
+ input = fw_swapaxes(input, dim, -1, fw)
+
+ # the stride for all convs is the denominator of the scale factor
+ stride, num_convs = scale_factor.denominator, scale_factor.numerator
+
+ # prepare an empty tensor for the output
+ tmp_out_shape = list(input.shape)
+ tmp_out_shape[-1] = out_sz
+ tmp_output = fw_empty(tuple(tmp_out_shape), fw, input.device)
+
+ # iterate over the conv operations. we have as many as the numerator
+ # of the scale-factor. for each we need boundaries and a filter.
+ for conv_ind, (pad_sz, filt) in enumerate(zip(pad_sz, weights)):
+ # apply padding (we pad last dim, padding can be negative)
+ pad_dim = input.ndim - 1
+ tmp_input = fw_pad(input, fw, pad_sz, pad_mode, dim=pad_dim)
+
+ # apply convolution over last dim. store in the output tensor with
+ # positional strides so that when the loop is comlete conv results are
+ # interwind
+ tmp_output[..., conv_ind::num_convs] = fw_conv(tmp_input, filt, stride)
+
+ return fw_swapaxes(tmp_output, -1, dim, fw)
+
+
+def set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs, scale_tolerance, max_numerator, eps, fw):
+ # eventually we must have both scale-factors and out-sizes for all in/out
+ # dims. however, we support many possible partial arguments
+ if scale_factors is None and out_shape is None:
+ raise ValueError("either scale_factors or out_shape should be "
+ "provided")
+ if out_shape is not None:
+ # if out_shape has less dims than in_shape, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ out_shape = (list(out_shape) +
+ list(in_shape[len(out_shape):]) if fw is numpy else list(in_shape[:-len(out_shape)]) +
+ list(out_shape))
+ if scale_factors is None:
+ # if no scale given, we calculate it as the out to in ratio
+ # (not recomended)
+ scale_factors = [out_sz / in_sz for out_sz, in_sz in zip(out_shape, in_shape)]
+ if scale_factors is not None:
+ # by default, if a single number is given as scale, we assume resizing
+ # two dims (most common are images with 2 spatial dims)
+ scale_factors = (scale_factors if isinstance(scale_factors, (list, tuple)) else [scale_factors, scale_factors])
+ # if less scale_factors than in_shape dims, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ scale_factors = (list(scale_factors) + [1] * (len(in_shape) - len(scale_factors)) if fw is numpy else [1] *
+ (len(in_shape) - len(scale_factors)) + list(scale_factors))
+ if out_shape is None:
+ # when no out_shape given, it is calculated by multiplying the
+ # scale by the in_shape (not recomended)
+ out_shape = [ceil(scale_factor * in_sz) for scale_factor, in_sz in zip(scale_factors, in_shape)]
+ # next part intentionally after out_shape determined for stability
+ # we fix by_convs to be a list of truth values in case it is not
+ if not isinstance(by_convs, (list, tuple)):
+ by_convs = [by_convs] * len(out_shape)
+
+ # next loop fixes the scale for each dim to be either frac or float.
+ # this is determined by by_convs and by tolerance for scale accuracy.
+ for ind, (sf, dim_by_convs) in enumerate(zip(scale_factors, by_convs)):
+ # first we fractionaize
+ if dim_by_convs:
+ frac = Fraction(1 / sf).limit_denominator(max_numerator)
+ frac = Fraction(numerator=frac.denominator, denominator=frac.numerator)
+
+ # if accuracy is within tolerance scale will be frac. if not, then
+ # it will be float and the by_convs attr will be set false for
+ # this dim
+ if scale_tolerance is None:
+ scale_tolerance = eps
+ if dim_by_convs and abs(frac - sf) < scale_tolerance:
+ scale_factors[ind] = frac
+ else:
+ scale_factors[ind] = float(sf)
+ by_convs[ind] = False
+
+ return scale_factors, out_shape, by_convs
+
+
+def apply_antialiasing_if_needed(interp_method, support_sz, scale_factor, antialiasing):
+ # antialiasing is "stretching" the field of view according to the scale
+ # factor (only for downscaling). this is low-pass filtering. this
+ # requires modifying both the interpolation (stretching the 1d
+ # function and multiplying by the scale-factor) and the window size.
+ scale_factor = float(scale_factor)
+ if scale_factor >= 1.0 or not antialiasing:
+ return interp_method, support_sz
+ cur_interp_method = (lambda arg: scale_factor * interp_method(scale_factor * arg))
+ cur_support_sz = support_sz / scale_factor
+ return cur_interp_method, cur_support_sz
+
+
+def fw_ceil(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.ceil(x))
+ else:
+ return paddle.cast(x.ceil(), dtype='int64')
+
+
+def fw_floor(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.floor(x))
+ else:
+ return paddle.cast(x.floor(), dtype='int64')
+
+
+def fw_cat(x, fw):
+ if fw is numpy:
+ return fw.concatenate(x)
+ else:
+ return fw.concat(x)
+
+
+def fw_swapaxes(x, ax_1, ax_2, fw):
+ if fw is numpy:
+ return fw.swapaxes(x, ax_1, ax_2)
+ else:
+ if ax_1 == -1:
+ ax_1 = len(x.shape) - 1
+ if ax_2 == -1:
+ ax_2 = len(x.shape) - 1
+ perm0 = list(range(len(x.shape)))
+ temp = ax_1
+ perm0[temp] = ax_2
+ perm0[ax_2] = temp
+ return fw.transpose(x, perm0)
+
+
+def fw_pad(x, fw, pad_sz, pad_mode, dim=0):
+ if pad_sz == (0, 0):
+ return x
+ if fw is numpy:
+ pad_vec = [(0, 0)] * x.ndim
+ pad_vec[dim] = pad_sz
+ return fw.pad(x, pad_width=pad_vec, mode=pad_mode)
+ else:
+ if x.ndim < 3:
+ x = x[None, None, ...]
+
+ pad_vec = [0] * ((x.ndim - 2) * 2)
+ pad_vec[0:2] = pad_sz
+ return fw_swapaxes(fw.nn.functional.pad(fw_swapaxes(x, dim, -1, fw), pad=pad_vec, mode=pad_mode), dim, -1, fw)
+
+
+def fw_conv(input, filter, stride):
+ # we want to apply 1d conv to any nd array. the way to do it is to reshape
+ # the input to a 4D tensor. first two dims are singeletons, 3rd dim stores
+ # all the spatial dims that we are not convolving along now. then we can
+ # apply conv2d with a 1xK filter. This convolves the same way all the other
+ # dims stored in the 3d dim. like depthwise conv over these.
+ # TODO: numpy support
+ reshaped_input = input.reshape(1, 1, -1, input.shape[-1])
+ reshaped_output = paddle.nn.functional.conv2d(reshaped_input, filter.view(1, 1, 1, -1), stride=(1, stride))
+ return reshaped_output.reshape(*input.shape[:-1], -1)
+
+
+def fw_arange(upper_bound, fw, device):
+ if fw is numpy:
+ return fw.arange(upper_bound)
+ else:
+ return fw.arange(upper_bound)
+
+
+def fw_empty(shape, fw, device):
+ if fw is numpy:
+ return fw.empty(shape)
+ else:
+ return fw.empty(shape=shape)
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/README.md b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/README.md
new file mode 100644
index 000000000..711671bad
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/README.md
@@ -0,0 +1,2 @@
+# Diffusion model (Paddle)
+This module implements diffusion model which accepts a text prompt and outputs images semantically close to the text. The code is rewritten by Paddle, and mainly refer to two projects: jina-ai/discoart[https://github.com/jina-ai/discoart] and openai/guided-diffusion[https://github.com/openai/guided-diffusion]. Thanks for their wonderful work.
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/__init__.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/__init__.py
new file mode 100755
index 000000000..39fc908dc
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/__init__.py
@@ -0,0 +1,156 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/__init__.py
+'''
+import os
+import warnings
+
+os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
+
+__all__ = ['create']
+
+import sys
+
+__resources_path__ = os.path.join(
+ os.path.dirname(sys.modules.get(__package__).__file__ if __package__ in sys.modules else __file__),
+ 'resources',
+)
+
+import gc
+
+# check if GPU is available
+import paddle
+
+# download and load models, this will take some time on the first load
+
+from .helper import load_all_models, load_diffusion_model, load_clip_models
+
+model_config, secondary_model = load_all_models('512x512_diffusion_uncond_finetune_008100', use_secondary_model=True)
+
+from typing import TYPE_CHECKING, overload, List, Optional
+
+if TYPE_CHECKING:
+ from docarray import DocumentArray, Document
+
+_clip_models_cache = {}
+
+# begin_create_overload
+
+
+@overload
+def create(text_prompts: Optional[List[str]] = [
+ 'A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.',
+ 'yellow color scheme',
+],
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 10,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 150,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_model: Optional[str] = '512x512_diffusion_uncond_finetune_008100',
+ use_secondary_model: Optional[bool] = True,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 4,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ clip_models: Optional[list] = ['ViTB32', 'ViTB16', 'RN50'],
+ output_dir: Optional[str] = 'discoart_output') -> 'DocumentArray':
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_model: Diffusion_model of choice.
+ :param use_secondary_model: Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param clip_models: CLIP Model selectors. ViTB32, ViTB16, ViTL14, RN101, RN50, RN50x4, RN50x16, RN50x64.These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around. You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.The rough order of speed/mem usage is (smallest/fastest to largest/slowest):VitB32RN50RN101VitB16RN50x4RN50x16RN50x64ViTL14For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+# end_create_overload
+
+
+@overload
+def create(init_document: 'Document') -> 'DocumentArray':
+ """
+ Create an artwork using a DocArray ``Document`` object as initial state.
+ :param init_document: its ``.tags`` will be used as parameters, ``.uri`` (if present) will be used as init image.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+def create(**kwargs) -> 'DocumentArray':
+ from .config import load_config
+ from .runner import do_run
+
+ if 'init_document' in kwargs:
+ d = kwargs['init_document']
+ _kwargs = d.tags
+ if not _kwargs:
+ warnings.warn('init_document has no .tags, fallback to default config')
+ if d.uri:
+ _kwargs['init_image'] = kwargs['init_document'].uri
+ else:
+ warnings.warn('init_document has no .uri, fallback to no init image')
+ kwargs.pop('init_document')
+ if kwargs:
+ warnings.warn('init_document has .tags and .uri, but kwargs are also present, will override .tags')
+ _kwargs.update(kwargs)
+ _args = load_config(user_config=_kwargs)
+ else:
+ _args = load_config(user_config=kwargs)
+
+ model, diffusion = load_diffusion_model(model_config, _args.diffusion_model, steps=_args.steps)
+
+ clip_models = load_clip_models(enabled=_args.clip_models, clip_models=_clip_models_cache)
+
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+ try:
+ return do_run(_args, (model, diffusion, clip_models, secondary_model))
+ except KeyboardInterrupt:
+ pass
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/config.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/config.py
new file mode 100755
index 000000000..0cbc71e6f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/config.py
@@ -0,0 +1,77 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/config.py
+'''
+import copy
+import random
+import warnings
+from types import SimpleNamespace
+from typing import Dict
+
+import yaml
+from yaml import Loader
+
+from . import __resources_path__
+
+with open(f'{__resources_path__}/default.yml') as ymlfile:
+ default_args = yaml.load(ymlfile, Loader=Loader)
+
+
+def load_config(user_config: Dict, ):
+ cfg = copy.deepcopy(default_args)
+
+ if user_config:
+ cfg.update(**user_config)
+
+ for k in user_config.keys():
+ if k not in cfg:
+ warnings.warn(f'unknown argument {k}, ignored')
+
+ for k, v in cfg.items():
+ if k in ('batch_size', 'display_rate', 'seed', 'skip_steps', 'steps', 'n_batches',
+ 'cutn_batches') and isinstance(v, float):
+ cfg[k] = int(v)
+ if k == 'width_height':
+ cfg[k] = [int(vv) for vv in v]
+
+ cfg.update(**{
+ 'seed': cfg['seed'] or random.randint(0, 2**32),
+ })
+
+ if cfg['batch_name']:
+ da_name = f'{__package__}-{cfg["batch_name"]}-{cfg["seed"]}'
+ else:
+ da_name = f'{__package__}-{cfg["seed"]}'
+ warnings.warn('you did not set `batch_name`, set it to have unique session ID')
+
+ cfg.update(**{'name_docarray': da_name})
+
+ print_args_table(cfg)
+
+ return SimpleNamespace(**cfg)
+
+
+def print_args_table(cfg):
+ from rich.table import Table
+ from rich import box
+ from rich.console import Console
+
+ console = Console()
+
+ param_str = Table(
+ title=cfg['name_docarray'],
+ box=box.ROUNDED,
+ highlight=True,
+ title_justify='left',
+ )
+ param_str.add_column('Argument', justify='right')
+ param_str.add_column('Value', justify='left')
+
+ for k, v in sorted(cfg.items()):
+ value = str(v)
+
+ if not default_args.get(k, None) == v:
+ value = f'[b]{value}[/]'
+
+ param_str.add_row(k, value)
+
+ console.print(param_str)
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/helper.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/helper.py
new file mode 100755
index 000000000..b291b9b1d
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/helper.py
@@ -0,0 +1,138 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/helper.py
+'''
+import hashlib
+import logging
+import os
+import subprocess
+import sys
+from os.path import expanduser
+from pathlib import Path
+from typing import Any
+from typing import Dict
+from typing import List
+
+import paddle
+
+
+def _get_logger():
+ logger = logging.getLogger(__package__)
+ _log_level = os.environ.get('DISCOART_LOG_LEVEL', 'INFO')
+ logger.setLevel(_log_level)
+ ch = logging.StreamHandler()
+ ch.setLevel(_log_level)
+ formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
+ ch.setFormatter(formatter)
+ logger.addHandler(ch)
+ return logger
+
+
+logger = _get_logger()
+
+
+def load_clip_models(enabled: List[str], clip_models: Dict[str, Any] = {}):
+
+ import disco_diffusion_cnclip_vitb16.cn_clip as cn_clip
+ from disco_diffusion_cnclip_vitb16.cn_clip.clip.utils import create_model
+
+ # load enabled models
+ for k in enabled:
+ if k not in clip_models:
+ clip_models[k] = create_model(name=k)
+ clip_models[k].eval()
+ for parameter in clip_models[k].parameters():
+ parameter.stop_gradient = True
+
+ # disable not enabled models to save memory
+ for k in clip_models:
+ if k not in enabled:
+ clip_models.pop(k)
+
+ return list(clip_models.values())
+
+
+def load_all_models(diffusion_model, use_secondary_model):
+ from .model.script_util import (
+ model_and_diffusion_defaults, )
+
+ model_config = model_and_diffusion_defaults()
+
+ if diffusion_model == '512x512_diffusion_uncond_finetune_008100':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 512,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+ elif diffusion_model == '256x256_diffusion_uncond':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 256,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+
+ secondary_model = None
+ if use_secondary_model:
+ from .model.sec_diff import SecondaryDiffusionImageNet2
+ secondary_model = SecondaryDiffusionImageNet2()
+ model_dict = paddle.load(
+ os.path.join(os.path.dirname(__file__), 'pre_trained', 'secondary_model_imagenet_2.pdparams'))
+ secondary_model.set_state_dict(model_dict)
+ secondary_model.eval()
+ for parameter in secondary_model.parameters():
+ parameter.stop_gradient = True
+
+ return model_config, secondary_model
+
+
+def load_diffusion_model(model_config, diffusion_model, steps):
+ from .model.script_util import (
+ create_model_and_diffusion, )
+
+ timestep_respacing = f'ddim{steps}'
+ diffusion_steps = (1000 // steps) * steps if steps < 1000 else steps
+ model_config.update({
+ 'timestep_respacing': timestep_respacing,
+ 'diffusion_steps': diffusion_steps,
+ })
+
+ model, diffusion = create_model_and_diffusion(**model_config)
+ model.set_state_dict(
+ paddle.load(os.path.join(os.path.dirname(__file__), 'pre_trained', f'{diffusion_model}.pdparams')))
+ model.eval()
+ for name, param in model.named_parameters():
+ param.stop_gradient = True
+
+ return model, diffusion
+
+
+def parse_prompt(prompt):
+ if prompt.startswith('http://') or prompt.startswith('https://'):
+ vals = prompt.rsplit(':', 2)
+ vals = [vals[0] + ':' + vals[1], *vals[2:]]
+ else:
+ vals = prompt.rsplit(':', 1)
+ vals = vals + ['', '1'][len(vals):]
+ return vals[0], float(vals[1])
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/__init__.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/__init__.py
new file mode 100755
index 000000000..466800666
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/__init__.py
@@ -0,0 +1,3 @@
+"""
+Codebase for "Improved Denoising Diffusion Probabilistic Models" implemented by Paddle.
+"""
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/gaussian_diffusion.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/gaussian_diffusion.py
new file mode 100755
index 000000000..86cd2c650
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/gaussian_diffusion.py
@@ -0,0 +1,1214 @@
+"""
+Diffusion model implemented by Paddle.
+This code is rewritten based on Pytorch version of of Ho et al's diffusion models:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py
+"""
+import enum
+import math
+
+import numpy as np
+import paddle
+
+from .losses import discretized_gaussian_log_likelihood
+from .losses import normal_kl
+from .nn import mean_flat
+
+
+def get_named_beta_schedule(schedule_name, num_diffusion_timesteps):
+ """
+ Get a pre-defined beta schedule for the given name.
+
+ The beta schedule library consists of beta schedules which remain similar
+ in the limit of num_diffusion_timesteps.
+ Beta schedules may be added, but should not be removed or changed once
+ they are committed to maintain backwards compatibility.
+ """
+ if schedule_name == "linear":
+ # Linear schedule from Ho et al, extended to work for any number of
+ # diffusion steps.
+ scale = 1000 / num_diffusion_timesteps
+ beta_start = scale * 0.0001
+ beta_end = scale * 0.02
+ return np.linspace(beta_start, beta_end, num_diffusion_timesteps, dtype=np.float64)
+ elif schedule_name == "cosine":
+ return betas_for_alpha_bar(
+ num_diffusion_timesteps,
+ lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2)**2,
+ )
+ else:
+ raise NotImplementedError(f"unknown beta schedule: {schedule_name}")
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function,
+ which defines the cumulative product of (1-beta) over time from t = [0,1].
+
+ :param num_diffusion_timesteps: the number of betas to produce.
+ :param alpha_bar: a lambda that takes an argument t from 0 to 1 and
+ produces the cumulative product of (1-beta) up to that
+ part of the diffusion process.
+ :param max_beta: the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+ """
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return np.array(betas)
+
+
+class ModelMeanType(enum.Enum):
+ """
+ Which type of output the model predicts.
+ """
+
+ PREVIOUS_X = enum.auto() # the model predicts x_{t-1}
+ START_X = enum.auto() # the model predicts x_0
+ EPSILON = enum.auto() # the model predicts epsilon
+
+
+class ModelVarType(enum.Enum):
+ """
+ What is used as the model's output variance.
+
+ The LEARNED_RANGE option has been added to allow the model to predict
+ values between FIXED_SMALL and FIXED_LARGE, making its job easier.
+ """
+
+ LEARNED = enum.auto()
+ FIXED_SMALL = enum.auto()
+ FIXED_LARGE = enum.auto()
+ LEARNED_RANGE = enum.auto()
+
+
+class LossType(enum.Enum):
+ MSE = enum.auto() # use raw MSE loss (and KL when learning variances)
+ RESCALED_MSE = (enum.auto()) # use raw MSE loss (with RESCALED_KL when learning variances)
+ KL = enum.auto() # use the variational lower-bound
+ RESCALED_KL = enum.auto() # like KL, but rescale to estimate the full VLB
+
+ def is_vb(self):
+ return self == LossType.KL or self == LossType.RESCALED_KL
+
+
+class GaussianDiffusion:
+ """
+ Utilities for training and sampling diffusion models.
+
+ Ported directly from here, and then adapted over time to further experimentation.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py#L42
+
+ :param betas: a 1-D numpy array of betas for each diffusion timestep,
+ starting at T and going to 1.
+ :param model_mean_type: a ModelMeanType determining what the model outputs.
+ :param model_var_type: a ModelVarType determining how variance is output.
+ :param loss_type: a LossType determining the loss function to use.
+ :param rescale_timesteps: if True, pass floating point timesteps into the
+ model so that they are always scaled like in the
+ original paper (0 to 1000).
+ """
+
+ def __init__(
+ self,
+ *,
+ betas,
+ model_mean_type,
+ model_var_type,
+ loss_type,
+ rescale_timesteps=False,
+ ):
+ self.model_mean_type = model_mean_type
+ self.model_var_type = model_var_type
+ self.loss_type = loss_type
+ self.rescale_timesteps = rescale_timesteps
+
+ # Use float64 for accuracy.
+ betas = np.array(betas, dtype=np.float64)
+ self.betas = betas
+ assert len(betas.shape) == 1, "betas must be 1-D"
+ assert (betas > 0).all() and (betas <= 1).all()
+
+ self.num_timesteps = int(betas.shape[0])
+
+ alphas = 1.0 - betas
+ self.alphas_cumprod = np.cumprod(alphas, axis=0)
+ self.alphas_cumprod_prev = np.append(1.0, self.alphas_cumprod[:-1])
+ self.alphas_cumprod_next = np.append(self.alphas_cumprod[1:], 0.0)
+ assert self.alphas_cumprod_prev.shape == (self.num_timesteps, )
+
+ # calculations for diffusion q(x_t | x_{t-1}) and others
+ self.sqrt_alphas_cumprod = np.sqrt(self.alphas_cumprod)
+ self.sqrt_one_minus_alphas_cumprod = np.sqrt(1.0 - self.alphas_cumprod)
+ self.log_one_minus_alphas_cumprod = np.log(1.0 - self.alphas_cumprod)
+ self.sqrt_recip_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod)
+ self.sqrt_recipm1_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod - 1)
+
+ # calculations for posterior q(x_{t-1} | x_t, x_0)
+ self.posterior_variance = (betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ # log calculation clipped because the posterior variance is 0 at the
+ # beginning of the diffusion chain.
+ self.posterior_log_variance_clipped = np.log(np.append(self.posterior_variance[1], self.posterior_variance[1:]))
+ self.posterior_mean_coef1 = (betas * np.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ self.posterior_mean_coef2 = ((1.0 - self.alphas_cumprod_prev) * np.sqrt(alphas) / (1.0 - self.alphas_cumprod))
+
+ def q_mean_variance(self, x_start, t):
+ """
+ Get the distribution q(x_t | x_0).
+
+ :param x_start: the [N x C x ...] tensor of noiseless inputs.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :return: A tuple (mean, variance, log_variance), all of x_start's shape.
+ """
+ mean = (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start)
+ variance = _extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
+ log_variance = _extract_into_tensor(self.log_one_minus_alphas_cumprod, t, x_start.shape)
+ return mean, variance, log_variance
+
+ def q_sample(self, x_start, t, noise=None):
+ """
+ Diffuse the data for a given number of diffusion steps.
+
+ In other words, sample from q(x_t | x_0).
+
+ :param x_start: the initial data batch.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :param noise: if specified, the split-out normal noise.
+ :return: A noisy version of x_start.
+ """
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ assert noise.shape == x_start.shape
+ return (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
+ _extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
+
+ def q_posterior_mean_variance(self, x_start, x_t, t):
+ """
+ Compute the mean and variance of the diffusion posterior:
+
+ q(x_{t-1} | x_t, x_0)
+
+ """
+ assert x_start.shape == x_t.shape
+ posterior_mean = (_extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start +
+ _extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t)
+ posterior_variance = _extract_into_tensor(self.posterior_variance, t, x_t.shape)
+ posterior_log_variance_clipped = _extract_into_tensor(self.posterior_log_variance_clipped, t, x_t.shape)
+ assert (posterior_mean.shape[0] == posterior_variance.shape[0] == posterior_log_variance_clipped.shape[0] ==
+ x_start.shape[0])
+ return posterior_mean, posterior_variance, posterior_log_variance_clipped
+
+ def p_mean_variance(self, model, x, t, clip_denoised=True, denoised_fn=None, model_kwargs=None):
+ """
+ Apply the model to get p(x_{t-1} | x_t), as well as a prediction of
+ the initial x, x_0.
+
+ :param model: the model, which takes a signal and a batch of timesteps
+ as input.
+ :param x: the [N x C x ...] tensor at time t.
+ :param t: a 1-D Tensor of timesteps.
+ :param clip_denoised: if True, clip the denoised signal into [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample. Applies before
+ clip_denoised.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict with the following keys:
+ - 'mean': the model mean output.
+ - 'variance': the model variance output.
+ - 'log_variance': the log of 'variance'.
+ - 'pred_xstart': the prediction for x_0.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+
+ B, C = x.shape[:2]
+ assert t.shape == [B]
+ model_output = model(x, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [ModelVarType.LEARNED, ModelVarType.LEARNED_RANGE]:
+ assert model_output.shape == [B, C * 2, *x.shape[2:]]
+ model_output, model_var_values = paddle.split(model_output, 2, axis=1)
+ if self.model_var_type == ModelVarType.LEARNED:
+ model_log_variance = model_var_values
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ min_log = _extract_into_tensor(self.posterior_log_variance_clipped, t, x.shape)
+ max_log = _extract_into_tensor(np.log(self.betas), t, x.shape)
+ # The model_var_values is [-1, 1] for [min_var, max_var].
+ frac = (model_var_values + 1) / 2
+ model_log_variance = frac * max_log + (1 - frac) * min_log
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ model_variance, model_log_variance = {
+ # for fixedlarge, we set the initial (log-)variance like so
+ # to get a better decoder log likelihood.
+ ModelVarType.FIXED_LARGE: (
+ np.append(self.posterior_variance[1], self.betas[1:]),
+ np.log(np.append(self.posterior_variance[1], self.betas[1:])),
+ ),
+ ModelVarType.FIXED_SMALL: (
+ self.posterior_variance,
+ self.posterior_log_variance_clipped,
+ ),
+ }[self.model_var_type]
+ model_variance = _extract_into_tensor(model_variance, t, x.shape)
+ model_log_variance = _extract_into_tensor(model_log_variance, t, x.shape)
+
+ def process_xstart(x):
+ if denoised_fn is not None:
+ x = denoised_fn(x)
+ if clip_denoised:
+ return x.clamp(-1, 1)
+ return x
+
+ if self.model_mean_type == ModelMeanType.PREVIOUS_X:
+ pred_xstart = process_xstart(self._predict_xstart_from_xprev(x_t=x, t=t, xprev=model_output))
+ model_mean = model_output
+ elif self.model_mean_type in [ModelMeanType.START_X, ModelMeanType.EPSILON]:
+ if self.model_mean_type == ModelMeanType.START_X:
+ pred_xstart = process_xstart(model_output)
+ else:
+ pred_xstart = process_xstart(self._predict_xstart_from_eps(x_t=x, t=t, eps=model_output))
+ model_mean, _, _ = self.q_posterior_mean_variance(x_start=pred_xstart, x_t=x, t=t)
+ else:
+ raise NotImplementedError(self.model_mean_type)
+
+ assert (model_mean.shape == model_log_variance.shape == pred_xstart.shape == x.shape)
+ return {
+ "mean": model_mean,
+ "variance": model_variance,
+ "log_variance": model_log_variance,
+ "pred_xstart": pred_xstart,
+ }
+
+ def _predict_xstart_from_eps(self, x_t, t, eps):
+ assert x_t.shape == eps.shape
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * eps)
+
+ def _predict_xstart_from_xprev(self, x_t, t, xprev):
+ assert x_t.shape == xprev.shape
+ return ( # (xprev - coef2*x_t) / coef1
+ _extract_into_tensor(1.0 / self.posterior_mean_coef1, t, x_t.shape) * xprev -
+ _extract_into_tensor(self.posterior_mean_coef2 / self.posterior_mean_coef1, t, x_t.shape) * x_t)
+
+ def _predict_eps_from_xstart(self, x_t, t, pred_xstart):
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ pred_xstart) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
+
+ def _scale_timesteps(self, t):
+ if self.rescale_timesteps:
+ return paddle.cast((t), 'float32') * (1000.0 / self.num_timesteps)
+ return t
+
+ def condition_mean(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_mean_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, t, p_mean_var, **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_score(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def condition_score_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, t, p_mean_var, **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def p_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"]}
+
+ def p_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean_with_grad(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"].detach()}
+
+ def p_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model.
+
+ :param model: the model module.
+ :param shape: the shape of the samples, (N, C, H, W).
+ :param noise: if specified, the noise from the encoder to sample.
+ Should be of the same shape as `shape`.
+ :param clip_denoised: if True, clip x_start predictions to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param device: if specified, the device to create the samples on.
+ If not specified, use a model parameter's device.
+ :param progress: if True, show a tqdm progress bar.
+ :return: a non-differentiable batch of samples.
+ """
+ final = None
+ for sample in self.p_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def p_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model and yield intermediate samples from
+ each timestep of diffusion.
+
+ Arguments are the same as p_sample_loop().
+ Returns a generator over dicts, where each dict is the return value of
+ p_sample().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ sample_fn = self.p_sample_with_grad if cond_fn_with_grad else self.p_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ )
+ yield out
+ img = out["sample"]
+
+ def ddim_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"]}
+
+ def ddim_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ out["pred_xstart"] = out["pred_xstart"].detach()
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"].detach()}
+
+ def ddim_reverse_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t+1} from the model using DDIM reverse ODE.
+ """
+ assert eta == 0.0, "Reverse ODE only for deterministic path"
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x.shape) * x -
+ out["pred_xstart"]) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x.shape)
+ alpha_bar_next = _extract_into_tensor(self.alphas_cumprod_next, t, x.shape)
+
+ # Equation 12. reversed
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_next) + paddle.sqrt(1 - alpha_bar_next) * eps)
+
+ return {"sample": mean_pred, "pred_xstart": out["pred_xstart"]}
+
+ def ddim_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model using DDIM.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.ddim_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ eta=eta,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def ddim_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Use DDIM to sample from the model and yield intermediate samples from
+ each timestep of DDIM.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ # if device is None:
+ # device = next(model.parameters()).device
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0])
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(
+ low=0,
+ high=model.num_classes,
+ shape=model_kwargs['y'].shape,
+ )
+ sample_fn = self.ddim_sample_with_grad if cond_fn_with_grad else self.ddim_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ eta=eta,
+ )
+ yield out
+ img = out["sample"]
+
+ def plms_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ cond_fn_with_grad=False,
+ order=2,
+ old_out=None,
+ ):
+ """
+ Sample x_{t-1} from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample().
+ """
+ if not int(order) or not 1 <= order <= 4:
+ raise ValueError('order is invalid (should be int from 1-4).')
+
+ def get_model_output(x, t):
+ with paddle.set_grad_enabled(cond_fn_with_grad and cond_fn is not None):
+ x = x.detach().requires_grad_() if cond_fn_with_grad else x
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ if cond_fn_with_grad:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ x = x.detach()
+ else:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+ return eps, out, out_orig
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ eps, out, out_orig = get_model_output(x, t)
+
+ if order > 1 and old_out is None:
+ # Pseudo Improved Euler
+ old_eps = [eps]
+ mean_pred = out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps
+ eps_2, _, _ = get_model_output(mean_pred, t - 1)
+ eps_prime = (eps + eps_2) / 2
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+ else:
+ # Pseudo Linear Multistep (Adams-Bashforth)
+ old_eps = old_out["old_eps"]
+ old_eps.append(eps)
+ cur_order = min(order, len(old_eps))
+ if cur_order == 1:
+ eps_prime = old_eps[-1]
+ elif cur_order == 2:
+ eps_prime = (3 * old_eps[-1] - old_eps[-2]) / 2
+ elif cur_order == 3:
+ eps_prime = (23 * old_eps[-1] - 16 * old_eps[-2] + 5 * old_eps[-3]) / 12
+ elif cur_order == 4:
+ eps_prime = (55 * old_eps[-1] - 59 * old_eps[-2] + 37 * old_eps[-3] - 9 * old_eps[-4]) / 24
+ else:
+ raise RuntimeError('cur_order is invalid.')
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+
+ if len(old_eps) >= order:
+ old_eps.pop(0)
+
+ nonzero_mask = paddle.cast((t != 0), 'float32').reshape([-1, *([1] * (len(x.shape) - 1))])
+ sample = mean_pred * nonzero_mask + out["pred_xstart"] * (1 - nonzero_mask)
+
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"], "old_eps": old_eps}
+
+ def plms_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Generate samples from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.plms_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ ):
+ final = sample
+ return final["sample"]
+
+ def plms_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Use PLMS to sample from the model and yield intermediate samples from each
+ timestep of PLMS.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ old_out = None
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ out = self.plms_sample(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ old_out=old_out,
+ )
+ yield out
+ old_out = out
+ img = out["sample"]
+
+ def _vb_terms_bpd(self, model, x_start, x_t, t, clip_denoised=True, model_kwargs=None):
+ """
+ Get a term for the variational lower-bound.
+
+ The resulting units are bits (rather than nats, as one might expect).
+ This allows for comparison to other papers.
+
+ :return: a dict with the following keys:
+ - 'output': a shape [N] tensor of NLLs or KLs.
+ - 'pred_xstart': the x_0 predictions.
+ """
+ true_mean, _, true_log_variance_clipped = self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)
+ out = self.p_mean_variance(model, x_t, t, clip_denoised=clip_denoised, model_kwargs=model_kwargs)
+ kl = normal_kl(true_mean, true_log_variance_clipped, out["mean"], out["log_variance"])
+ kl = mean_flat(kl) / np.log(2.0)
+
+ decoder_nll = -discretized_gaussian_log_likelihood(
+ x_start, means=out["mean"], log_scales=0.5 * out["log_variance"])
+ assert decoder_nll.shape == x_start.shape
+ decoder_nll = mean_flat(decoder_nll) / np.log(2.0)
+
+ # At the first timestep return the decoder NLL,
+ # otherwise return KL(q(x_{t-1}|x_t,x_0) || p(x_{t-1}|x_t))
+ output = paddle.where((t == 0), decoder_nll, kl)
+ return {"output": output, "pred_xstart": out["pred_xstart"]}
+
+ def training_losses(self, model, x_start, t, model_kwargs=None, noise=None):
+ """
+ Compute training losses for a single timestep.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param t: a batch of timestep indices.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param noise: if specified, the specific Gaussian noise to try to remove.
+ :return: a dict with the key "loss" containing a tensor of shape [N].
+ Some mean or variance settings may also have other keys.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start, t, noise=noise)
+
+ terms = {}
+
+ if self.loss_type == LossType.KL or self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] = self._vb_terms_bpd(
+ model=model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ model_kwargs=model_kwargs,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] *= self.num_timesteps
+ elif self.loss_type == LossType.MSE or self.loss_type == LossType.RESCALED_MSE:
+ model_output = model(x_t, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [
+ ModelVarType.LEARNED,
+ ModelVarType.LEARNED_RANGE,
+ ]:
+ B, C = x_t.shape[:2]
+ assert model_output.shape == (B, C * 2, *x_t.shape[2:])
+ model_output, model_var_values = paddle.split(model_output, 2, dim=1)
+ # Learn the variance using the variational bound, but don't let
+ # it affect our mean prediction.
+ frozen_out = paddle.concat([model_output.detach(), model_var_values], axis=1)
+ terms["vb"] = self._vb_terms_bpd(
+ model=lambda *args, r=frozen_out: r,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_MSE:
+ # Divide by 1000 for equivalence with initial implementation.
+ # Without a factor of 1/1000, the VB term hurts the MSE term.
+ terms["vb"] *= self.num_timesteps / 1000.0
+
+ target = {
+ ModelMeanType.PREVIOUS_X: self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)[0],
+ ModelMeanType.START_X: x_start,
+ ModelMeanType.EPSILON: noise,
+ }[self.model_mean_type]
+ assert model_output.shape == target.shape == x_start.shape
+ terms["mse"] = mean_flat((target - model_output)**2)
+ if "vb" in terms:
+ terms["loss"] = terms["mse"] + terms["vb"]
+ else:
+ terms["loss"] = terms["mse"]
+ else:
+ raise NotImplementedError(self.loss_type)
+
+ return terms
+
+ def _prior_bpd(self, x_start):
+ """
+ Get the prior KL term for the variational lower-bound, measured in
+ bits-per-dim.
+
+ This term can't be optimized, as it only depends on the encoder.
+
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :return: a batch of [N] KL values (in bits), one per batch element.
+ """
+ batch_size = x_start.shape[0]
+ t = paddle.to_tensor([self.num_timesteps - 1] * batch_size, place=x_start.place)
+ qt_mean, _, qt_log_variance = self.q_mean_variance(x_start, t)
+ kl_prior = normal_kl(mean1=qt_mean, logvar1=qt_log_variance, mean2=0.0, logvar2=0.0)
+ return mean_flat(kl_prior) / np.log(2.0)
+
+ def calc_bpd_loop(self, model, x_start, clip_denoised=True, model_kwargs=None):
+ """
+ Compute the entire variational lower-bound, measured in bits-per-dim,
+ as well as other related quantities.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param clip_denoised: if True, clip denoised samples.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+
+ :return: a dict containing the following keys:
+ - total_bpd: the total variational lower-bound, per batch element.
+ - prior_bpd: the prior term in the lower-bound.
+ - vb: an [N x T] tensor of terms in the lower-bound.
+ - xstart_mse: an [N x T] tensor of x_0 MSEs for each timestep.
+ - mse: an [N x T] tensor of epsilon MSEs for each timestep.
+ """
+ device = x_start.place
+ batch_size = x_start.shape[0]
+
+ vb = []
+ xstart_mse = []
+ mse = []
+ for t in list(range(self.num_timesteps))[::-1]:
+ t_batch = paddle.to_tensor([t] * batch_size, place=device)
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start=x_start, t=t_batch, noise=noise)
+ # Calculate VLB term at the current timestep
+ # with paddle.no_grad():
+ out = self._vb_terms_bpd(
+ model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t_batch,
+ clip_denoised=clip_denoised,
+ model_kwargs=model_kwargs,
+ )
+ vb.append(out["output"])
+ xstart_mse.append(mean_flat((out["pred_xstart"] - x_start)**2))
+ eps = self._predict_eps_from_xstart(x_t, t_batch, out["pred_xstart"])
+ mse.append(mean_flat((eps - noise)**2))
+
+ vb = paddle.stack(vb, axis=1)
+ xstart_mse = paddle.stack(xstart_mse, axis=1)
+ mse = paddle.stack(mse, axis=1)
+
+ prior_bpd = self._prior_bpd(x_start)
+ total_bpd = vb.sum(axis=1) + prior_bpd
+ return {
+ "total_bpd": total_bpd,
+ "prior_bpd": prior_bpd,
+ "vb": vb,
+ "xstart_mse": xstart_mse,
+ "mse": mse,
+ }
+
+
+def _extract_into_tensor(arr, timesteps, broadcast_shape):
+ """
+ Extract values from a 1-D numpy array for a batch of indices.
+
+ :param arr: the 1-D numpy array.
+ :param timesteps: a tensor of indices into the array to extract.
+ :param broadcast_shape: a larger shape of K dimensions with the batch
+ dimension equal to the length of timesteps.
+ :return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
+ """
+ res = paddle.to_tensor(arr, place=timesteps.place)[timesteps]
+ while len(res.shape) < len(broadcast_shape):
+ res = res[..., None]
+ return res.expand(broadcast_shape)
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/losses.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/losses.py
new file mode 100755
index 000000000..5c3970de5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/losses.py
@@ -0,0 +1,86 @@
+"""
+Helpers for various likelihood-based losses implemented by Paddle. These are ported from the original
+Ho et al. diffusion models codebase:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/utils.py
+"""
+import numpy as np
+import paddle
+import paddle.nn.functional as F
+
+
+def normal_kl(mean1, logvar1, mean2, logvar2):
+ """
+ Compute the KL divergence between two gaussians.
+
+ Shapes are automatically broadcasted, so batches can be compared to
+ scalars, among other use cases.
+ """
+ tensor = None
+ for obj in (mean1, logvar1, mean2, logvar2):
+ if isinstance(obj, paddle.Tensor):
+ tensor = obj
+ break
+ assert tensor is not None, "at least one argument must be a Tensor"
+
+ # Force variances to be Tensors. Broadcasting helps convert scalars to
+ # Tensors, but it does not work for th.exp().
+ logvar1, logvar2 = [x if isinstance(x, paddle.Tensor) else paddle.to_tensor(x) for x in (logvar1, logvar2)]
+
+ return 0.5 * (-1.0 + logvar2 - logvar1 + paddle.exp(logvar1 - logvar2) +
+ ((mean1 - mean2)**2) * paddle.exp(-logvar2))
+
+
+def approx_standard_normal_cdf(x):
+ """
+ A fast approximation of the cumulative distribution function of the
+ standard normal.
+ """
+ return 0.5 * (1.0 + paddle.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * paddle.pow(x, 3))))
+
+
+def discretized_gaussian_log_likelihood(x, *, means, log_scales):
+ """
+ Compute the log-likelihood of a Gaussian distribution discretizing to a
+ given image.
+
+ :param x: the target images. It is assumed that this was uint8 values,
+ rescaled to the range [-1, 1].
+ :param means: the Gaussian mean Tensor.
+ :param log_scales: the Gaussian log stddev Tensor.
+ :return: a tensor like x of log probabilities (in nats).
+ """
+ assert x.shape == means.shape == log_scales.shape
+ centered_x = x - means
+ inv_stdv = paddle.exp(-log_scales)
+ plus_in = inv_stdv * (centered_x + 1.0 / 255.0)
+ cdf_plus = approx_standard_normal_cdf(plus_in)
+ min_in = inv_stdv * (centered_x - 1.0 / 255.0)
+ cdf_min = approx_standard_normal_cdf(min_in)
+ log_cdf_plus = paddle.log(cdf_plus.clip(min=1e-12))
+ log_one_minus_cdf_min = paddle.log((1.0 - cdf_min).clip(min=1e-12))
+ cdf_delta = cdf_plus - cdf_min
+ log_probs = paddle.where(
+ x < -0.999,
+ log_cdf_plus,
+ paddle.where(x > 0.999, log_one_minus_cdf_min, paddle.log(cdf_delta.clip(min=1e-12))),
+ )
+ assert log_probs.shape == x.shape
+ return log_probs
+
+
+def spherical_dist_loss(x, y):
+ x = F.normalize(x, axis=-1)
+ y = F.normalize(y, axis=-1)
+ return (x - y).norm(axis=-1).divide(paddle.to_tensor(2.0)).asin().pow(2).multiply(paddle.to_tensor(2.0))
+
+
+def tv_loss(input):
+ """L2 total variation loss, as in Mahendran et al."""
+ input = F.pad(input, (0, 1, 0, 1), 'replicate')
+ x_diff = input[..., :-1, 1:] - input[..., :-1, :-1]
+ y_diff = input[..., 1:, :-1] - input[..., :-1, :-1]
+ return (x_diff**2 + y_diff**2).mean([1, 2, 3])
+
+
+def range_loss(input):
+ return (input - input.clip(-1, 1)).pow(2).mean([1, 2, 3])
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/make_cutouts.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/make_cutouts.py
new file mode 100755
index 000000000..cba46edc9
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/make_cutouts.py
@@ -0,0 +1,177 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/make_cutouts.py
+'''
+import math
+
+import paddle
+import paddle.nn as nn
+from disco_diffusion_cnclip_vitb16.resize_right.resize_right import resize
+from paddle.nn import functional as F
+
+from . import transforms as T
+
+skip_augs = False # @param{type: 'boolean'}
+
+
+def sinc(x):
+ return paddle.where(x != 0, paddle.sin(math.pi * x) / (math.pi * x), x.new_ones([]))
+
+
+def lanczos(x, a):
+ cond = paddle.logical_and(-a < x, x < a)
+ out = paddle.where(cond, sinc(x) * sinc(x / a), x.new_zeros([]))
+ return out / out.sum()
+
+
+def ramp(ratio, width):
+ n = math.ceil(width / ratio + 1)
+ out = paddle.empty([n])
+ cur = 0
+ for i in range(out.shape[0]):
+ out[i] = cur
+ cur += ratio
+ return paddle.concat([-out[1:].flip([0]), out])[1:-1]
+
+
+class MakeCutouts(nn.Layer):
+
+ def __init__(self, cut_size, cutn, skip_augs=False):
+ super().__init__()
+ self.cut_size = cut_size
+ self.cutn = cutn
+ self.skip_augs = skip_augs
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(degrees=15, translate=(0.1, 0.1)),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomPerspective(distortion_scale=0.4, p=0.7),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.15),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ input = T.Pad(input.shape[2] // 4, fill=0)(input)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+
+ cutouts = []
+ for ch in range(self.cutn):
+ if ch > self.cutn - self.cutn // 4:
+ cutout = input.clone()
+ else:
+ size = int(max_size *
+ paddle.zeros(1, ).normal_(mean=0.8, std=0.3).clip(float(self.cut_size / max_size), 1.0))
+ offsetx = paddle.randint(0, abs(sideX - size + 1), ())
+ offsety = paddle.randint(0, abs(sideY - size + 1), ())
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+
+ if not self.skip_augs:
+ cutout = self.augs(cutout)
+ cutouts.append(resample(cutout, (self.cut_size, self.cut_size)))
+ del cutout
+
+ cutouts = paddle.concat(cutouts, axis=0)
+ return cutouts
+
+
+class MakeCutoutsDango(nn.Layer):
+
+ def __init__(self, cut_size, Overview=4, InnerCrop=0, IC_Size_Pow=0.5, IC_Grey_P=0.2):
+ super().__init__()
+ self.cut_size = cut_size
+ self.Overview = Overview
+ self.InnerCrop = InnerCrop
+ self.IC_Size_Pow = IC_Size_Pow
+ self.IC_Grey_P = IC_Grey_P
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(
+ degrees=10,
+ translate=(0.05, 0.05),
+ interpolation=T.InterpolationMode.BILINEAR,
+ ),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.1),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ cutouts = []
+ gray = T.Grayscale(3)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+ min_size = min(sideX, sideY, self.cut_size)
+ output_shape = [1, 3, self.cut_size, self.cut_size]
+ pad_input = F.pad(
+ input,
+ (
+ (sideY - max_size) // 2,
+ (sideY - max_size) // 2,
+ (sideX - max_size) // 2,
+ (sideX - max_size) // 2,
+ ),
+ **padargs,
+ )
+ cutout = resize(pad_input, out_shape=output_shape)
+
+ if self.Overview > 0:
+ if self.Overview <= 4:
+ if self.Overview >= 1:
+ cutouts.append(cutout)
+ if self.Overview >= 2:
+ cutouts.append(gray(cutout))
+ if self.Overview >= 3:
+ cutouts.append(cutout[:, :, :, ::-1])
+ if self.Overview == 4:
+ cutouts.append(gray(cutout[:, :, :, ::-1]))
+ else:
+ cutout = resize(pad_input, out_shape=output_shape)
+ for _ in range(self.Overview):
+ cutouts.append(cutout)
+
+ if self.InnerCrop > 0:
+ for i in range(self.InnerCrop):
+ size = int(paddle.rand([1])**self.IC_Size_Pow * (max_size - min_size) + min_size)
+ offsetx = paddle.randint(0, sideX - size + 1)
+ offsety = paddle.randint(0, sideY - size + 1)
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+ if i <= int(self.IC_Grey_P * self.InnerCrop):
+ cutout = gray(cutout)
+ cutout = resize(cutout, out_shape=output_shape)
+ cutouts.append(cutout)
+
+ cutouts = paddle.concat(cutouts)
+ if skip_augs is not True:
+ cutouts = self.augs(cutouts)
+ return cutouts
+
+
+def resample(input, size, align_corners=True):
+ n, c, h, w = input.shape
+ dh, dw = size
+
+ input = input.reshape([n * c, 1, h, w])
+
+ if dh < h:
+ kernel_h = lanczos(ramp(dh / h, 2), 2).to(input.device, input.dtype)
+ pad_h = (kernel_h.shape[0] - 1) // 2
+ input = F.pad(input, (0, 0, pad_h, pad_h), 'reflect')
+ input = F.conv2d(input, kernel_h[None, None, :, None])
+
+ if dw < w:
+ kernel_w = lanczos(ramp(dw / w, 2), 2).to(input.device, input.dtype)
+ pad_w = (kernel_w.shape[0] - 1) // 2
+ input = F.pad(input, (pad_w, pad_w, 0, 0), 'reflect')
+ input = F.conv2d(input, kernel_w[None, None, None, :])
+
+ input = input.reshape([n, c, h, w])
+ return F.interpolate(input, size, mode='bicubic', align_corners=align_corners)
+
+
+padargs = {}
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/nn.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/nn.py
new file mode 100755
index 000000000..d618183e2
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/nn.py
@@ -0,0 +1,127 @@
+"""
+Various utilities for neural networks implemented by Paddle. This code is rewritten based on:
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/nn.py
+"""
+import math
+
+import paddle
+import paddle.nn as nn
+
+
+class SiLU(nn.Layer):
+
+ def forward(self, x):
+ return x * nn.functional.sigmoid(x)
+
+
+class GroupNorm32(nn.GroupNorm):
+
+ def forward(self, x):
+ return super().forward(x)
+
+
+def conv_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D convolution module.
+ """
+ if dims == 1:
+ return nn.Conv1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.Conv2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.Conv3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def linear(*args, **kwargs):
+ """
+ Create a linear module.
+ """
+ return nn.Linear(*args, **kwargs)
+
+
+def avg_pool_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D average pooling module.
+ """
+ if dims == 1:
+ return nn.AvgPool1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.AvgPool2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.AvgPool3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def update_ema(target_params, source_params, rate=0.99):
+ """
+ Update target parameters to be closer to those of source parameters using
+ an exponential moving average.
+
+ :param target_params: the target parameter sequence.
+ :param source_params: the source parameter sequence.
+ :param rate: the EMA rate (closer to 1 means slower).
+ """
+ for targ, src in zip(target_params, source_params):
+ targ.detach().mul_(rate).add_(src, alpha=1 - rate)
+
+
+def zero_module(module):
+ """
+ Zero out the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().zero_()
+ return module
+
+
+def scale_module(module, scale):
+ """
+ Scale the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().mul_(scale)
+ return module
+
+
+def mean_flat(tensor):
+ """
+ Take the mean over all non-batch dimensions.
+ """
+ return tensor.mean(axis=list(range(1, len(tensor.shape))))
+
+
+def normalization(channels):
+ """
+ Make a standard normalization layer.
+
+ :param channels: number of input channels.
+ :return: an nn.Module for normalization.
+ """
+ return GroupNorm32(32, channels)
+
+
+def timestep_embedding(timesteps, dim, max_period=10000):
+ """
+ Create sinusoidal timestep embeddings.
+
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param dim: the dimension of the output.
+ :param max_period: controls the minimum frequency of the embeddings.
+ :return: an [N x dim] Tensor of positional embeddings.
+ """
+ half = dim // 2
+ freqs = paddle.exp(-math.log(max_period) * paddle.arange(start=0, end=half, dtype=paddle.float32) / half)
+ args = paddle.cast(timesteps[:, None], 'float32') * freqs[None]
+ embedding = paddle.concat([paddle.cos(args), paddle.sin(args)], axis=-1)
+ if dim % 2:
+ embedding = paddle.concat([embedding, paddle.zeros_like(embedding[:, :1])], axis=-1)
+ return embedding
+
+
+def checkpoint(func, inputs, params, flag):
+ """
+ This function is disabled. And now just forward.
+ """
+ return func(*inputs)
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/perlin_noises.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/perlin_noises.py
new file mode 100755
index 000000000..6dacb331b
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/perlin_noises.py
@@ -0,0 +1,78 @@
+'''
+Perlin noise implementation by Paddle.
+This code is rewritten based on:
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/perlin_noises.py
+'''
+import numpy as np
+import paddle
+import paddle.vision.transforms as TF
+from PIL import Image
+from PIL import ImageOps
+
+
+def interp(t):
+ return 3 * t**2 - 2 * t**3
+
+
+def perlin(width, height, scale=10):
+ gx, gy = paddle.randn([2, width + 1, height + 1, 1, 1])
+ xs = paddle.linspace(0, 1, scale + 1)[:-1, None]
+ ys = paddle.linspace(0, 1, scale + 1)[None, :-1]
+ wx = 1 - interp(xs)
+ wy = 1 - interp(ys)
+ dots = 0
+ dots += wx * wy * (gx[:-1, :-1] * xs + gy[:-1, :-1] * ys)
+ dots += (1 - wx) * wy * (-gx[1:, :-1] * (1 - xs) + gy[1:, :-1] * ys)
+ dots += wx * (1 - wy) * (gx[:-1, 1:] * xs - gy[:-1, 1:] * (1 - ys))
+ dots += (1 - wx) * (1 - wy) * (-gx[1:, 1:] * (1 - xs) - gy[1:, 1:] * (1 - ys))
+ return dots.transpose([0, 2, 1, 3]).reshape([width * scale, height * scale])
+
+
+def perlin_ms(octaves, width, height, grayscale):
+ out_array = [0.5] if grayscale else [0.5, 0.5, 0.5]
+ # out_array = [0.0] if grayscale else [0.0, 0.0, 0.0]
+ for i in range(1 if grayscale else 3):
+ scale = 2**len(octaves)
+ oct_width = width
+ oct_height = height
+ for oct in octaves:
+ p = perlin(oct_width, oct_height, scale)
+ out_array[i] += p * oct
+ scale //= 2
+ oct_width *= 2
+ oct_height *= 2
+ return paddle.concat(out_array)
+
+
+def create_perlin_noise(octaves, width, height, grayscale, side_y, side_x):
+ out = perlin_ms(octaves, width, height, grayscale)
+ if grayscale:
+ out = TF.resize(size=(side_y, side_x), img=out.numpy())
+ out = np.uint8(out)
+ out = Image.fromarray(out).convert('RGB')
+ else:
+ out = out.reshape([-1, 3, out.shape[0] // 3, out.shape[1]])
+ out = out.squeeze().transpose([1, 2, 0]).numpy()
+ out = TF.resize(size=(side_y, side_x), img=out)
+ out = out.clip(0, 1) * 255
+ out = np.uint8(out)
+ out = Image.fromarray(out)
+
+ out = ImageOps.autocontrast(out)
+ return out
+
+
+def regen_perlin(perlin_mode, side_y, side_x, batch_size):
+ if perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+
+ init = (TF.to_tensor(init).add(TF.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+ return init.expand([batch_size, -1, -1, -1])
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/respace.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/respace.py
new file mode 100755
index 000000000..c001c70d0
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/respace.py
@@ -0,0 +1,123 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/respace.py
+'''
+import numpy as np
+import paddle
+
+from .gaussian_diffusion import GaussianDiffusion
+
+
+def space_timesteps(num_timesteps, section_counts):
+ """
+ Create a list of timesteps to use from an original diffusion process,
+ given the number of timesteps we want to take from equally-sized portions
+ of the original process.
+
+ For example, if there's 300 timesteps and the section counts are [10,15,20]
+ then the first 100 timesteps are strided to be 10 timesteps, the second 100
+ are strided to be 15 timesteps, and the final 100 are strided to be 20.
+
+ If the stride is a string starting with "ddim", then the fixed striding
+ from the DDIM paper is used, and only one section is allowed.
+
+ :param num_timesteps: the number of diffusion steps in the original
+ process to divide up.
+ :param section_counts: either a list of numbers, or a string containing
+ comma-separated numbers, indicating the step count
+ per section. As a special case, use "ddimN" where N
+ is a number of steps to use the striding from the
+ DDIM paper.
+ :return: a set of diffusion steps from the original process to use.
+ """
+ if isinstance(section_counts, str):
+ if section_counts.startswith("ddim"):
+ desired_count = int(section_counts[len("ddim"):])
+ for i in range(1, num_timesteps):
+ if len(range(0, num_timesteps, i)) == desired_count:
+ return set(range(0, num_timesteps, i))
+ raise ValueError(f"cannot create exactly {num_timesteps} steps with an integer stride")
+ section_counts = [int(x) for x in section_counts.split(",")]
+ size_per = num_timesteps // len(section_counts)
+ extra = num_timesteps % len(section_counts)
+ start_idx = 0
+ all_steps = []
+ for i, section_count in enumerate(section_counts):
+ size = size_per + (1 if i < extra else 0)
+ if size < section_count:
+ raise ValueError(f"cannot divide section of {size} steps into {section_count}")
+ if section_count <= 1:
+ frac_stride = 1
+ else:
+ frac_stride = (size - 1) / (section_count - 1)
+ cur_idx = 0.0
+ taken_steps = []
+ for _ in range(section_count):
+ taken_steps.append(start_idx + round(cur_idx))
+ cur_idx += frac_stride
+ all_steps += taken_steps
+ start_idx += size
+ return set(all_steps)
+
+
+class SpacedDiffusion(GaussianDiffusion):
+ """
+ A diffusion process which can skip steps in a base diffusion process.
+
+ :param use_timesteps: a collection (sequence or set) of timesteps from the
+ original diffusion process to retain.
+ :param kwargs: the kwargs to create the base diffusion process.
+ """
+
+ def __init__(self, use_timesteps, **kwargs):
+ self.use_timesteps = set(use_timesteps)
+ self.timestep_map = []
+ self.original_num_steps = len(kwargs["betas"])
+
+ base_diffusion = GaussianDiffusion(**kwargs) # pylint: disable=missing-kwoa
+ last_alpha_cumprod = 1.0
+ new_betas = []
+ for i, alpha_cumprod in enumerate(base_diffusion.alphas_cumprod):
+ if i in self.use_timesteps:
+ new_betas.append(1 - alpha_cumprod / last_alpha_cumprod)
+ last_alpha_cumprod = alpha_cumprod
+ self.timestep_map.append(i)
+ kwargs["betas"] = np.array(new_betas)
+ super().__init__(**kwargs)
+
+ def p_mean_variance(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().p_mean_variance(self._wrap_model(model), *args, **kwargs)
+
+ def training_losses(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().training_losses(self._wrap_model(model), *args, **kwargs)
+
+ def condition_mean(self, cond_fn, *args, **kwargs):
+ return super().condition_mean(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def condition_score(self, cond_fn, *args, **kwargs):
+ return super().condition_score(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def _wrap_model(self, model):
+ if isinstance(model, _WrappedModel):
+ return model
+ return _WrappedModel(model, self.timestep_map, self.rescale_timesteps, self.original_num_steps)
+
+ def _scale_timesteps(self, t):
+ # Scaling is done by the wrapped model.
+ return t
+
+
+class _WrappedModel:
+
+ def __init__(self, model, timestep_map, rescale_timesteps, original_num_steps):
+ self.model = model
+ self.timestep_map = timestep_map
+ self.rescale_timesteps = rescale_timesteps
+ self.original_num_steps = original_num_steps
+
+ def __call__(self, x, ts, **kwargs):
+ map_tensor = paddle.to_tensor(self.timestep_map, place=ts.place, dtype=ts.dtype)
+ new_ts = map_tensor[ts]
+ if self.rescale_timesteps:
+ new_ts = paddle.cast(new_ts, 'float32') * (1000.0 / self.original_num_steps)
+ return self.model(x, new_ts, **kwargs)
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/script_util.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/script_util.py
new file mode 100755
index 000000000..d728a5430
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/script_util.py
@@ -0,0 +1,201 @@
+'''
+This code is based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/script_util.py
+'''
+import argparse
+import inspect
+
+from . import gaussian_diffusion as gd
+from .respace import space_timesteps
+from .respace import SpacedDiffusion
+from .unet import EncoderUNetModel
+from .unet import SuperResModel
+from .unet import UNetModel
+
+NUM_CLASSES = 1000
+
+
+def diffusion_defaults():
+ """
+ Defaults for image and classifier training.
+ """
+ return dict(
+ learn_sigma=False,
+ diffusion_steps=1000,
+ noise_schedule="linear",
+ timestep_respacing="",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ )
+
+
+def model_and_diffusion_defaults():
+ """
+ Defaults for image training.
+ """
+ res = dict(
+ image_size=64,
+ num_channels=128,
+ num_res_blocks=2,
+ num_heads=4,
+ num_heads_upsample=-1,
+ num_head_channels=-1,
+ attention_resolutions="16,8",
+ channel_mult="",
+ dropout=0.0,
+ class_cond=False,
+ use_checkpoint=False,
+ use_scale_shift_norm=True,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+ )
+ res.update(diffusion_defaults())
+ return res
+
+
+def create_model_and_diffusion(
+ image_size,
+ class_cond,
+ learn_sigma,
+ num_channels,
+ num_res_blocks,
+ channel_mult,
+ num_heads,
+ num_head_channels,
+ num_heads_upsample,
+ attention_resolutions,
+ dropout,
+ diffusion_steps,
+ noise_schedule,
+ timestep_respacing,
+ use_kl,
+ predict_xstart,
+ rescale_timesteps,
+ rescale_learned_sigmas,
+ use_checkpoint,
+ use_scale_shift_norm,
+ resblock_updown,
+ use_fp16,
+ use_new_attention_order,
+):
+ model = create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult=channel_mult,
+ learn_sigma=learn_sigma,
+ class_cond=class_cond,
+ use_checkpoint=use_checkpoint,
+ attention_resolutions=attention_resolutions,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ dropout=dropout,
+ resblock_updown=resblock_updown,
+ use_fp16=use_fp16,
+ use_new_attention_order=use_new_attention_order,
+ )
+ diffusion = create_gaussian_diffusion(
+ steps=diffusion_steps,
+ learn_sigma=learn_sigma,
+ noise_schedule=noise_schedule,
+ use_kl=use_kl,
+ predict_xstart=predict_xstart,
+ rescale_timesteps=rescale_timesteps,
+ rescale_learned_sigmas=rescale_learned_sigmas,
+ timestep_respacing=timestep_respacing,
+ )
+ return model, diffusion
+
+
+def create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult="",
+ learn_sigma=False,
+ class_cond=False,
+ use_checkpoint=False,
+ attention_resolutions="16",
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ dropout=0,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+):
+ if channel_mult == "":
+ if image_size == 512:
+ channel_mult = (0.5, 1, 1, 2, 2, 4, 4)
+ elif image_size == 256:
+ channel_mult = (1, 1, 2, 2, 4, 4)
+ elif image_size == 128:
+ channel_mult = (1, 1, 2, 3, 4)
+ elif image_size == 64:
+ channel_mult = (1, 2, 3, 4)
+ else:
+ raise ValueError(f"unsupported image size: {image_size}")
+ else:
+ channel_mult = tuple(int(ch_mult) for ch_mult in channel_mult.split(","))
+
+ attention_ds = []
+ for res in attention_resolutions.split(","):
+ attention_ds.append(image_size // int(res))
+
+ return UNetModel(
+ image_size=image_size,
+ in_channels=3,
+ model_channels=num_channels,
+ out_channels=(3 if not learn_sigma else 6),
+ num_res_blocks=num_res_blocks,
+ attention_resolutions=tuple(attention_ds),
+ dropout=dropout,
+ channel_mult=channel_mult,
+ num_classes=(NUM_CLASSES if class_cond else None),
+ use_checkpoint=use_checkpoint,
+ use_fp16=use_fp16,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ resblock_updown=resblock_updown,
+ use_new_attention_order=use_new_attention_order,
+ )
+
+
+def create_gaussian_diffusion(
+ *,
+ steps=1000,
+ learn_sigma=False,
+ sigma_small=False,
+ noise_schedule="linear",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ timestep_respacing="",
+):
+ betas = gd.get_named_beta_schedule(noise_schedule, steps)
+ if use_kl:
+ loss_type = gd.LossType.RESCALED_KL
+ elif rescale_learned_sigmas:
+ loss_type = gd.LossType.RESCALED_MSE
+ else:
+ loss_type = gd.LossType.MSE
+ if not timestep_respacing:
+ timestep_respacing = [steps]
+ return SpacedDiffusion(
+ use_timesteps=space_timesteps(steps, timestep_respacing),
+ betas=betas,
+ model_mean_type=(gd.ModelMeanType.EPSILON if not predict_xstart else gd.ModelMeanType.START_X),
+ model_var_type=((gd.ModelVarType.FIXED_LARGE if not sigma_small else gd.ModelVarType.FIXED_SMALL)
+ if not learn_sigma else gd.ModelVarType.LEARNED_RANGE),
+ loss_type=loss_type,
+ rescale_timesteps=rescale_timesteps,
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/sec_diff.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/sec_diff.py
new file mode 100755
index 000000000..1e361f18f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/sec_diff.py
@@ -0,0 +1,135 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/sec_diff.py
+'''
+import math
+from dataclasses import dataclass
+from functools import partial
+
+import paddle
+import paddle.nn as nn
+
+
+@dataclass
+class DiffusionOutput:
+ v: paddle.Tensor
+ pred: paddle.Tensor
+ eps: paddle.Tensor
+
+
+class SkipBlock(nn.Layer):
+
+ def __init__(self, main, skip=None):
+ super().__init__()
+ self.main = nn.Sequential(*main)
+ self.skip = skip if skip else nn.Identity()
+
+ def forward(self, input):
+ return paddle.concat([self.main(input), self.skip(input)], axis=1)
+
+
+def append_dims(x, n):
+ return x[(Ellipsis, *(None, ) * (n - x.ndim))]
+
+
+def expand_to_planes(x, shape):
+ return paddle.tile(append_dims(x, len(shape)), [1, 1, *shape[2:]])
+
+
+def alpha_sigma_to_t(alpha, sigma):
+ return paddle.atan2(sigma, alpha) * 2 / math.pi
+
+
+def t_to_alpha_sigma(t):
+ return paddle.cos(t * math.pi / 2), paddle.sin(t * math.pi / 2)
+
+
+class SecondaryDiffusionImageNet2(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+ c = 64 # The base channel count
+ cs = [c, c * 2, c * 2, c * 4, c * 4, c * 8]
+
+ self.timestep_embed = FourierFeatures(1, 16)
+ self.down = nn.AvgPool2D(2)
+ self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
+
+ self.net = nn.Sequential(
+ ConvBlock(3 + 16, cs[0]),
+ ConvBlock(cs[0], cs[0]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[0], cs[1]),
+ ConvBlock(cs[1], cs[1]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[1], cs[2]),
+ ConvBlock(cs[2], cs[2]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[2], cs[3]),
+ ConvBlock(cs[3], cs[3]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[3], cs[4]),
+ ConvBlock(cs[4], cs[4]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[4], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[4]),
+ self.up,
+ ]),
+ ConvBlock(cs[4] * 2, cs[4]),
+ ConvBlock(cs[4], cs[3]),
+ self.up,
+ ]),
+ ConvBlock(cs[3] * 2, cs[3]),
+ ConvBlock(cs[3], cs[2]),
+ self.up,
+ ]),
+ ConvBlock(cs[2] * 2, cs[2]),
+ ConvBlock(cs[2], cs[1]),
+ self.up,
+ ]),
+ ConvBlock(cs[1] * 2, cs[1]),
+ ConvBlock(cs[1], cs[0]),
+ self.up,
+ ]),
+ ConvBlock(cs[0] * 2, cs[0]),
+ nn.Conv2D(cs[0], 3, 3, padding=1),
+ )
+
+ def forward(self, input, t):
+ timestep_embed = expand_to_planes(self.timestep_embed(t[:, None]), input.shape)
+ v = self.net(paddle.concat([input, timestep_embed], axis=1))
+ alphas, sigmas = map(partial(append_dims, n=v.ndim), t_to_alpha_sigma(t))
+ pred = input * alphas - v * sigmas
+ eps = input * sigmas + v * alphas
+ return DiffusionOutput(v, pred, eps)
+
+
+class FourierFeatures(nn.Layer):
+
+ def __init__(self, in_features, out_features, std=1.0):
+ super().__init__()
+ assert out_features % 2 == 0
+ # self.weight = nn.Parameter(paddle.randn([out_features // 2, in_features]) * std)
+ self.weight = paddle.create_parameter([out_features // 2, in_features],
+ dtype='float32',
+ default_initializer=nn.initializer.Normal(mean=0.0, std=std))
+
+ def forward(self, input):
+ f = 2 * math.pi * input @ self.weight.T
+ return paddle.concat([f.cos(), f.sin()], axis=-1)
+
+
+class ConvBlock(nn.Sequential):
+
+ def __init__(self, c_in, c_out):
+ super().__init__(
+ nn.Conv2D(c_in, c_out, 3, padding=1),
+ nn.ReLU(),
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/transforms.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/transforms.py
new file mode 100755
index 000000000..e0b620b01
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/transforms.py
@@ -0,0 +1,757 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/pytorch/vision/blob/main/torchvision/transforms/transforms.py
+'''
+import math
+import numbers
+import warnings
+from enum import Enum
+from typing import Any
+from typing import Dict
+from typing import List
+from typing import Optional
+from typing import Sequence
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn.functional import grid_sample
+from paddle.vision import transforms as T
+
+
+class Normalize(nn.Layer):
+
+ def __init__(self, mean, std):
+ super(Normalize, self).__init__()
+ self.mean = paddle.to_tensor(mean)
+ self.std = paddle.to_tensor(std)
+
+ def forward(self, tensor: Tensor):
+ dtype = tensor.dtype
+ mean = paddle.to_tensor(self.mean, dtype=dtype)
+ std = paddle.to_tensor(self.std, dtype=dtype)
+ mean = mean.reshape([1, -1, 1, 1])
+ std = std.reshape([1, -1, 1, 1])
+ result = tensor.subtract(mean).divide(std)
+ return result
+
+
+class InterpolationMode(Enum):
+ """Interpolation modes
+ Available interpolation methods are ``nearest``, ``bilinear``, ``bicubic``, ``box``, ``hamming``, and ``lanczos``.
+ """
+
+ NEAREST = "nearest"
+ BILINEAR = "bilinear"
+ BICUBIC = "bicubic"
+ # For PIL compatibility
+ BOX = "box"
+ HAMMING = "hamming"
+ LANCZOS = "lanczos"
+
+
+class Grayscale(nn.Layer):
+
+ def __init__(self, num_output_channels):
+ super(Grayscale, self).__init__()
+ self.num_output_channels = num_output_channels
+
+ def forward(self, x):
+ output = (0.2989 * x[:, 0:1, :, :] + 0.587 * x[:, 1:2, :, :] + 0.114 * x[:, 2:3, :, :])
+ if self.num_output_channels == 3:
+ return output.expand(x.shape)
+
+ return output
+
+
+class Lambda(nn.Layer):
+
+ def __init__(self, func):
+ super(Lambda, self).__init__()
+ self.transform = func
+
+ def forward(self, x):
+ return self.transform(x)
+
+
+class RandomGrayscale(nn.Layer):
+
+ def __init__(self, p):
+ super(RandomGrayscale, self).__init__()
+ self.prob = p
+ self.transform = Grayscale(3)
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return self.transform(x)
+ else:
+ return x
+
+
+class RandomHorizontalFlip(nn.Layer):
+
+ def __init__(self, prob):
+ super(RandomHorizontalFlip, self).__init__()
+ self.prob = prob
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return x[:, :, :, ::-1]
+ else:
+ return x
+
+
+def _blend(img1: Tensor, img2: Tensor, ratio: float) -> Tensor:
+ ratio = float(ratio)
+ bound = 1.0
+ return (ratio * img1 + (1.0 - ratio) * img2).clip(0, bound)
+
+
+def trunc_div(a, b):
+ ipt = paddle.divide(a, b)
+ sign_ipt = paddle.sign(ipt)
+ abs_ipt = paddle.abs(ipt)
+ abs_ipt = paddle.floor(abs_ipt)
+ out = paddle.multiply(sign_ipt, abs_ipt)
+ return out
+
+
+def fmod(a, b):
+ return a - trunc_div(a, b) * b
+
+
+def _rgb2hsv(img: Tensor) -> Tensor:
+ r, g, b = img.unbind(axis=-3)
+
+ # Implementation is based on https://github.com/python-pillow/Pillow/blob/4174d4267616897df3746d315d5a2d0f82c656ee/
+ # src/libImaging/Convert.c#L330
+ maxc = paddle.max(img, axis=-3)
+ minc = paddle.min(img, axis=-3)
+
+ # The algorithm erases S and H channel where `maxc = minc`. This avoids NaN
+ # from happening in the results, because
+ # + S channel has division by `maxc`, which is zero only if `maxc = minc`
+ # + H channel has division by `(maxc - minc)`.
+ #
+ # Instead of overwriting NaN afterwards, we just prevent it from occuring so
+ # we don't need to deal with it in case we save the NaN in a buffer in
+ # backprop, if it is ever supported, but it doesn't hurt to do so.
+ eqc = maxc == minc
+
+ cr = maxc - minc
+ # Since `eqc => cr = 0`, replacing denominator with 1 when `eqc` is fine.
+ ones = paddle.ones_like(maxc)
+ s = cr / paddle.where(eqc, ones, maxc)
+ # Note that `eqc => maxc = minc = r = g = b`. So the following calculation
+ # of `h` would reduce to `bc - gc + 2 + rc - bc + 4 + rc - bc = 6` so it
+ # would not matter what values `rc`, `gc`, and `bc` have here, and thus
+ # replacing denominator with 1 when `eqc` is fine.
+ cr_divisor = paddle.where(eqc, ones, cr)
+ rc = (maxc - r) / cr_divisor
+ gc = (maxc - g) / cr_divisor
+ bc = (maxc - b) / cr_divisor
+
+ hr = (maxc == r).cast('float32') * (bc - gc)
+ hg = ((maxc == g) & (maxc != r)).cast('float32') * (2.0 + rc - bc)
+ hb = ((maxc != g) & (maxc != r)).cast('float32') * (4.0 + gc - rc)
+ h = hr + hg + hb
+ h = fmod((h / 6.0 + 1.0), paddle.to_tensor(1.0))
+ return paddle.stack((h, s, maxc), axis=-3)
+
+
+def _hsv2rgb(img: Tensor) -> Tensor:
+ h, s, v = img.unbind(axis=-3)
+ i = paddle.floor(h * 6.0)
+ f = (h * 6.0) - i
+ i = i.cast(dtype='int32')
+
+ p = paddle.clip((v * (1.0 - s)), 0.0, 1.0)
+ q = paddle.clip((v * (1.0 - s * f)), 0.0, 1.0)
+ t = paddle.clip((v * (1.0 - s * (1.0 - f))), 0.0, 1.0)
+ i = i % 6
+
+ mask = i.unsqueeze(axis=-3) == paddle.arange(6).reshape([-1, 1, 1])
+
+ a1 = paddle.stack((v, q, p, p, t, v), axis=-3)
+ a2 = paddle.stack((t, v, v, q, p, p), axis=-3)
+ a3 = paddle.stack((p, p, t, v, v, q), axis=-3)
+ a4 = paddle.stack((a1, a2, a3), axis=-4)
+
+ return paddle.einsum("...ijk, ...xijk -> ...xjk", mask.cast(dtype=img.dtype), a4)
+
+
+def adjust_brightness(img: Tensor, brightness_factor: float) -> Tensor:
+ if brightness_factor < 0:
+ raise ValueError(f"brightness_factor ({brightness_factor}) is not non-negative.")
+
+ return _blend(img, paddle.zeros_like(img), brightness_factor)
+
+
+def adjust_contrast(img: Tensor, contrast_factor: float) -> Tensor:
+ if contrast_factor < 0:
+ raise ValueError(f"contrast_factor ({contrast_factor}) is not non-negative.")
+
+ c = img.shape[1]
+
+ if c == 3:
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+ mean = paddle.mean(output, axis=(-3, -2, -1), keepdim=True)
+
+ else:
+ mean = paddle.mean(img, axis=(-3, -2, -1), keepdim=True)
+
+ return _blend(img, mean, contrast_factor)
+
+
+def adjust_hue(img: Tensor, hue_factor: float) -> Tensor:
+ if not (-0.5 <= hue_factor <= 0.5):
+ raise ValueError(f"hue_factor ({hue_factor}) is not in [-0.5, 0.5].")
+
+ img = _rgb2hsv(img)
+ h, s, v = img.unbind(axis=-3)
+ h = fmod(h + hue_factor, paddle.to_tensor(1.0))
+ img = paddle.stack((h, s, v), axis=-3)
+ img_hue_adj = _hsv2rgb(img)
+ return img_hue_adj
+
+
+def adjust_saturation(img: Tensor, saturation_factor: float) -> Tensor:
+ if saturation_factor < 0:
+ raise ValueError(f"saturation_factor ({saturation_factor}) is not non-negative.")
+
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+
+ return _blend(img, output, saturation_factor)
+
+
+class ColorJitter(nn.Layer):
+
+ def __init__(self, brightness=0, contrast=0, saturation=0, hue=0):
+ super(ColorJitter, self).__init__()
+ self.brightness = self._check_input(brightness, "brightness")
+ self.contrast = self._check_input(contrast, "contrast")
+ self.saturation = self._check_input(saturation, "saturation")
+ self.hue = self._check_input(hue, "hue", center=0, bound=(-0.5, 0.5), clip_first_on_zero=False)
+
+ def _check_input(self, value, name, center=1, bound=(0, float("inf")), clip_first_on_zero=True):
+ if isinstance(value, numbers.Number):
+ if value < 0:
+ raise ValueError(f"If {name} is a single number, it must be non negative.")
+ value = [center - float(value), center + float(value)]
+ if clip_first_on_zero:
+ value[0] = max(value[0], 0.0)
+ elif isinstance(value, (tuple, list)) and len(value) == 2:
+ if not bound[0] <= value[0] <= value[1] <= bound[1]:
+ raise ValueError(f"{name} values should be between {bound}")
+ else:
+ raise TypeError(f"{name} should be a single number or a list/tuple with length 2.")
+
+ # if value is 0 or (1., 1.) for brightness/contrast/saturation
+ # or (0., 0.) for hue, do nothing
+ if value[0] == value[1] == center:
+ value = None
+ return value
+
+ @staticmethod
+ def get_params(
+ brightness: Optional[List[float]],
+ contrast: Optional[List[float]],
+ saturation: Optional[List[float]],
+ hue: Optional[List[float]],
+ ) -> Tuple[Tensor, Optional[float], Optional[float], Optional[float], Optional[float]]:
+ """Get the parameters for the randomized transform to be applied on image.
+
+ Args:
+ brightness (tuple of float (min, max), optional): The range from which the brightness_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ contrast (tuple of float (min, max), optional): The range from which the contrast_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ saturation (tuple of float (min, max), optional): The range from which the saturation_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ hue (tuple of float (min, max), optional): The range from which the hue_factor is chosen uniformly.
+ Pass None to turn off the transformation.
+
+ Returns:
+ tuple: The parameters used to apply the randomized transform
+ along with their random order.
+ """
+ fn_idx = paddle.randperm(4)
+
+ b = None if brightness is None else paddle.empty([1]).uniform_(brightness[0], brightness[1])
+ c = None if contrast is None else paddle.empty([1]).uniform_(contrast[0], contrast[1])
+ s = None if saturation is None else paddle.empty([1]).uniform_(saturation[0], saturation[1])
+ h = None if hue is None else paddle.empty([1]).uniform_(hue[0], hue[1])
+
+ return fn_idx, b, c, s, h
+
+ def forward(self, img):
+ """
+ Args:
+ img (PIL Image or Tensor): Input image.
+
+ Returns:
+ PIL Image or Tensor: Color jittered image.
+ """
+ fn_idx, brightness_factor, contrast_factor, saturation_factor, hue_factor = self.get_params(
+ self.brightness, self.contrast, self.saturation, self.hue)
+
+ for fn_id in fn_idx:
+ if fn_id == 0 and brightness_factor is not None:
+ img = adjust_brightness(img, brightness_factor)
+ elif fn_id == 1 and contrast_factor is not None:
+ img = adjust_contrast(img, contrast_factor)
+ elif fn_id == 2 and saturation_factor is not None:
+ img = adjust_saturation(img, saturation_factor)
+ elif fn_id == 3 and hue_factor is not None:
+ img = adjust_hue(img, hue_factor)
+
+ return img
+
+ def __repr__(self) -> str:
+ s = (f"{self.__class__.__name__}("
+ f"brightness={self.brightness}"
+ f", contrast={self.contrast}"
+ f", saturation={self.saturation}"
+ f", hue={self.hue})")
+ return s
+
+
+def _apply_grid_transform(img: Tensor, grid: Tensor, mode: str, fill: Optional[List[float]]) -> Tensor:
+
+ if img.shape[0] > 1:
+ # Apply same grid to a batch of images
+ grid = grid.expand([img.shape[0], grid.shape[1], grid.shape[2], grid.shape[3]])
+
+ # Append a dummy mask for customized fill colors, should be faster than grid_sample() twice
+ if fill is not None:
+ dummy = paddle.ones((img.shape[0], 1, img.shape[2], img.shape[3]), dtype=img.dtype)
+ img = paddle.concat((img, dummy), axis=1)
+
+ img = grid_sample(img, grid, mode=mode, padding_mode="zeros", align_corners=False)
+
+ # Fill with required color
+ if fill is not None:
+ mask = img[:, -1:, :, :] # N * 1 * H * W
+ img = img[:, :-1, :, :] # N * C * H * W
+ mask = mask.expand_as(img)
+ len_fill = len(fill) if isinstance(fill, (tuple, list)) else 1
+ fill_img = paddle.to_tensor(fill, dtype=img.dtype).reshape([1, len_fill, 1, 1]).expand_as(img)
+ if mode == "nearest":
+ mask = mask < 0.5
+ img[mask] = fill_img[mask]
+ else: # 'bilinear'
+ img = img * mask + (1.0 - mask) * fill_img
+ return img
+
+
+def _gen_affine_grid(
+ theta: Tensor,
+ w: int,
+ h: int,
+ ow: int,
+ oh: int,
+) -> Tensor:
+ # https://github.com/pytorch/pytorch/blob/74b65c32be68b15dc7c9e8bb62459efbfbde33d8/aten/src/ATen/native/
+ # AffineGridGenerator.cpp#L18
+ # Difference with AffineGridGenerator is that:
+ # 1) we normalize grid values after applying theta
+ # 2) we can normalize by other image size, such that it covers "extend" option like in PIL.Image.rotate
+
+ d = 0.5
+ base_grid = paddle.empty([1, oh, ow, 3], dtype=theta.dtype)
+ x_grid = paddle.linspace(-ow * 0.5 + d, ow * 0.5 + d - 1, num=ow)
+ base_grid[..., 0] = (x_grid)
+ y_grid = paddle.linspace(-oh * 0.5 + d, oh * 0.5 + d - 1, num=oh).unsqueeze_(-1)
+ base_grid[..., 1] = (y_grid)
+ base_grid[..., 2] = 1.0
+ rescaled_theta = theta.transpose([0, 2, 1]) / paddle.to_tensor([0.5 * w, 0.5 * h], dtype=theta.dtype)
+ output_grid = base_grid.reshape([1, oh * ow, 3]).bmm(rescaled_theta)
+ return output_grid.reshape([1, oh, ow, 2])
+
+
+def affine_impl(img: Tensor,
+ matrix: List[float],
+ interpolation: str = "nearest",
+ fill: Optional[List[float]] = None) -> Tensor:
+ theta = paddle.to_tensor(matrix, dtype=img.dtype).reshape([1, 2, 3])
+ shape = img.shape
+ # grid will be generated on the same device as theta and img
+ grid = _gen_affine_grid(theta, w=shape[-1], h=shape[-2], ow=shape[-1], oh=shape[-2])
+ return _apply_grid_transform(img, grid, interpolation, fill=fill)
+
+
+def _get_inverse_affine_matrix(center: List[float],
+ angle: float,
+ translate: List[float],
+ scale: float,
+ shear: List[float],
+ inverted: bool = True) -> List[float]:
+ # Helper method to compute inverse matrix for affine transformation
+
+ # Pillow requires inverse affine transformation matrix:
+ # Affine matrix is : M = T * C * RotateScaleShear * C^-1
+ #
+ # where T is translation matrix: [1, 0, tx | 0, 1, ty | 0, 0, 1]
+ # C is translation matrix to keep center: [1, 0, cx | 0, 1, cy | 0, 0, 1]
+ # RotateScaleShear is rotation with scale and shear matrix
+ #
+ # RotateScaleShear(a, s, (sx, sy)) =
+ # = R(a) * S(s) * SHy(sy) * SHx(sx)
+ # = [ s*cos(a - sy)/cos(sy), s*(-cos(a - sy)*tan(sx)/cos(sy) - sin(a)), 0 ]
+ # [ s*sin(a + sy)/cos(sy), s*(-sin(a - sy)*tan(sx)/cos(sy) + cos(a)), 0 ]
+ # [ 0 , 0 , 1 ]
+ # where R is a rotation matrix, S is a scaling matrix, and SHx and SHy are the shears:
+ # SHx(s) = [1, -tan(s)] and SHy(s) = [1 , 0]
+ # [0, 1 ] [-tan(s), 1]
+ #
+ # Thus, the inverse is M^-1 = C * RotateScaleShear^-1 * C^-1 * T^-1
+
+ rot = math.radians(angle)
+ sx = math.radians(shear[0])
+ sy = math.radians(shear[1])
+
+ cx, cy = center
+ tx, ty = translate
+
+ # RSS without scaling
+ a = math.cos(rot - sy) / math.cos(sy)
+ b = -math.cos(rot - sy) * math.tan(sx) / math.cos(sy) - math.sin(rot)
+ c = math.sin(rot - sy) / math.cos(sy)
+ d = -math.sin(rot - sy) * math.tan(sx) / math.cos(sy) + math.cos(rot)
+
+ if inverted:
+ # Inverted rotation matrix with scale and shear
+ # det([[a, b], [c, d]]) == 1, since det(rotation) = 1 and det(shear) = 1
+ matrix = [d, -b, 0.0, -c, a, 0.0]
+ matrix = [x / scale for x in matrix]
+ # Apply inverse of translation and of center translation: RSS^-1 * C^-1 * T^-1
+ matrix[2] += matrix[0] * (-cx - tx) + matrix[1] * (-cy - ty)
+ matrix[5] += matrix[3] * (-cx - tx) + matrix[4] * (-cy - ty)
+ # Apply center translation: C * RSS^-1 * C^-1 * T^-1
+ matrix[2] += cx
+ matrix[5] += cy
+ else:
+ matrix = [a, b, 0.0, c, d, 0.0]
+ matrix = [x * scale for x in matrix]
+ # Apply inverse of center translation: RSS * C^-1
+ matrix[2] += matrix[0] * (-cx) + matrix[1] * (-cy)
+ matrix[5] += matrix[3] * (-cx) + matrix[4] * (-cy)
+ # Apply translation and center : T * C * RSS * C^-1
+ matrix[2] += cx + tx
+ matrix[5] += cy + ty
+
+ return matrix
+
+
+def affine(
+ img: Tensor,
+ angle: float,
+ translate: List[int],
+ scale: float,
+ shear: List[float],
+ interpolation: InterpolationMode = InterpolationMode.NEAREST,
+ fill: Optional[List[float]] = None,
+ resample: Optional[int] = None,
+ fillcolor: Optional[List[float]] = None,
+ center: Optional[List[int]] = None,
+) -> Tensor:
+ """Apply affine transformation on the image keeping image center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ img (PIL Image or Tensor): image to transform.
+ angle (number): rotation angle in degrees between -180 and 180, clockwise direction.
+ translate (sequence of integers): horizontal and vertical translations (post-rotation translation)
+ scale (float): overall scale
+ shear (float or sequence): shear angle value in degrees between -180 to 180, clockwise direction.
+ If a sequence is specified, the first value corresponds to a shear parallel to the x axis, while
+ the second value corresponds to a shear parallel to the y axis.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number, optional): Pixel fill value for the area outside the transformed
+ image. If given a number, the value is used for all bands respectively.
+
+ .. note::
+ In torchscript mode single int/float value is not supported, please use a sequence
+ of length 1: ``[value, ]``.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation. Origin is the upper left corner.
+ Default is the center of the image.
+
+ Returns:
+ PIL Image or Tensor: Transformed image.
+ """
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ if not isinstance(angle, (int, float)):
+ raise TypeError("Argument angle should be int or float")
+
+ if not isinstance(translate, (list, tuple)):
+ raise TypeError("Argument translate should be a sequence")
+
+ if len(translate) != 2:
+ raise ValueError("Argument translate should be a sequence of length 2")
+
+ if scale <= 0.0:
+ raise ValueError("Argument scale should be positive")
+
+ if not isinstance(shear, (numbers.Number, (list, tuple))):
+ raise TypeError("Shear should be either a single value or a sequence of two values")
+
+ if not isinstance(interpolation, InterpolationMode):
+ raise TypeError("Argument interpolation should be a InterpolationMode")
+
+ if isinstance(angle, int):
+ angle = float(angle)
+
+ if isinstance(translate, tuple):
+ translate = list(translate)
+
+ if isinstance(shear, numbers.Number):
+ shear = [shear, 0.0]
+
+ if isinstance(shear, tuple):
+ shear = list(shear)
+
+ if len(shear) == 1:
+ shear = [shear[0], shear[0]]
+
+ if len(shear) != 2:
+ raise ValueError(f"Shear should be a sequence containing two values. Got {shear}")
+
+ if center is not None and not isinstance(center, (list, tuple)):
+ raise TypeError("Argument center should be a sequence")
+ center_f = [0.0, 0.0]
+ if center is not None:
+ _, height, width = img.shape[0], img.shape[1], img.shape[2]
+ # Center values should be in pixel coordinates but translated such that (0, 0) corresponds to image center.
+ center_f = [1.0 * (c - s * 0.5) for c, s in zip(center, [width, height])]
+
+ translate_f = [1.0 * t for t in translate]
+ matrix = _get_inverse_affine_matrix(center_f, angle, translate_f, scale, shear)
+ return affine_impl(img, matrix=matrix, interpolation=interpolation.value, fill=fill)
+
+
+def _interpolation_modes_from_int(i: int) -> InterpolationMode:
+ inverse_modes_mapping = {
+ 0: InterpolationMode.NEAREST,
+ 2: InterpolationMode.BILINEAR,
+ 3: InterpolationMode.BICUBIC,
+ 4: InterpolationMode.BOX,
+ 5: InterpolationMode.HAMMING,
+ 1: InterpolationMode.LANCZOS,
+ }
+ return inverse_modes_mapping[i]
+
+
+def _check_sequence_input(x, name, req_sizes):
+ msg = req_sizes[0] if len(req_sizes) < 2 else " or ".join([str(s) for s in req_sizes])
+ if not isinstance(x, Sequence):
+ raise TypeError(f"{name} should be a sequence of length {msg}.")
+ if len(x) not in req_sizes:
+ raise ValueError(f"{name} should be sequence of length {msg}.")
+
+
+def _setup_angle(x, name, req_sizes=(2, )):
+ if isinstance(x, numbers.Number):
+ if x < 0:
+ raise ValueError(f"If {name} is a single number, it must be positive.")
+ x = [-x, x]
+ else:
+ _check_sequence_input(x, name, req_sizes)
+
+ return [float(d) for d in x]
+
+
+class RandomAffine(nn.Layer):
+ """Random affine transformation of the image keeping center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ degrees (sequence or number): Range of degrees to select from.
+ If degrees is a number instead of sequence like (min, max), the range of degrees
+ will be (-degrees, +degrees). Set to 0 to deactivate rotations.
+ translate (tuple, optional): tuple of maximum absolute fraction for horizontal
+ and vertical translations. For example translate=(a, b), then horizontal shift
+ is randomly sampled in the range -img_width * a < dx < img_width * a and vertical shift is
+ randomly sampled in the range -img_height * b < dy < img_height * b. Will not translate by default.
+ scale (tuple, optional): scaling factor interval, e.g (a, b), then scale is
+ randomly sampled from the range a <= scale <= b. Will keep original scale by default.
+ shear (sequence or number, optional): Range of degrees to select from.
+ If shear is a number, a shear parallel to the x axis in the range (-shear, +shear)
+ will be applied. Else if shear is a sequence of 2 values a shear parallel to the x axis in the
+ range (shear[0], shear[1]) will be applied. Else if shear is a sequence of 4 values,
+ a x-axis shear in (shear[0], shear[1]) and y-axis shear in (shear[2], shear[3]) will be applied.
+ Will not apply shear by default.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number): Pixel fill value for the area outside the transformed
+ image. Default is ``0``. If given a number, the value is used for all bands respectively.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation, (x, y). Origin is the upper left corner.
+ Default is the center of the image.
+
+ .. _filters: https://pillow.readthedocs.io/en/latest/handbook/concepts.html#filters
+
+ """
+
+ def __init__(
+ self,
+ degrees,
+ translate=None,
+ scale=None,
+ shear=None,
+ interpolation=InterpolationMode.NEAREST,
+ fill=0,
+ fillcolor=None,
+ resample=None,
+ center=None,
+ ):
+ super(RandomAffine, self).__init__()
+ if resample is not None:
+ warnings.warn("The parameter 'resample' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'interpolation' instead.")
+ interpolation = _interpolation_modes_from_int(resample)
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ self.degrees = _setup_angle(degrees, name="degrees", req_sizes=(2, ))
+
+ if translate is not None:
+ _check_sequence_input(translate, "translate", req_sizes=(2, ))
+ for t in translate:
+ if not (0.0 <= t <= 1.0):
+ raise ValueError("translation values should be between 0 and 1")
+ self.translate = translate
+
+ if scale is not None:
+ _check_sequence_input(scale, "scale", req_sizes=(2, ))
+ for s in scale:
+ if s <= 0:
+ raise ValueError("scale values should be positive")
+ self.scale = scale
+
+ if shear is not None:
+ self.shear = _setup_angle(shear, name="shear", req_sizes=(2, 4))
+ else:
+ self.shear = shear
+
+ self.resample = self.interpolation = interpolation
+
+ if fill is None:
+ fill = 0
+ elif not isinstance(fill, (Sequence, numbers.Number)):
+ raise TypeError("Fill should be either a sequence or a number.")
+
+ self.fillcolor = self.fill = fill
+
+ if center is not None:
+ _check_sequence_input(center, "center", req_sizes=(2, ))
+
+ self.center = center
+
+ @staticmethod
+ def get_params(
+ degrees: List[float],
+ translate: Optional[List[float]],
+ scale_ranges: Optional[List[float]],
+ shears: Optional[List[float]],
+ img_size: List[int],
+ ) -> Tuple[float, Tuple[int, int], float, Tuple[float, float]]:
+ """Get parameters for affine transformation
+
+ Returns:
+ params to be passed to the affine transformation
+ """
+ angle = float(paddle.empty([1]).uniform_(float(degrees[0]), float(degrees[1])))
+ if translate is not None:
+ max_dx = float(translate[0] * img_size[0])
+ max_dy = float(translate[1] * img_size[1])
+ tx = int(float(paddle.empty([1]).uniform_(-max_dx, max_dx)))
+ ty = int(float(paddle.empty([1]).uniform_(-max_dy, max_dy)))
+ translations = (tx, ty)
+ else:
+ translations = (0, 0)
+
+ if scale_ranges is not None:
+ scale = float(paddle.empty([1]).uniform_(scale_ranges[0], scale_ranges[1]))
+ else:
+ scale = 1.0
+
+ shear_x = shear_y = 0.0
+ if shears is not None:
+ shear_x = float(paddle.empty([1]).uniform_(shears[0], shears[1]))
+ if len(shears) == 4:
+ shear_y = float(paddle.empty([1]).uniform_(shears[2], shears[3]))
+
+ shear = (shear_x, shear_y)
+
+ return angle, translations, scale, shear
+
+ def forward(self, img):
+ fill = self.fill
+ channels, height, width = img.shape[1], img.shape[2], img.shape[3]
+ if isinstance(fill, (int, float)):
+ fill = [float(fill)] * channels
+ else:
+ fill = [float(f) for f in fill]
+
+ img_size = [width, height] # flip for keeping BC on get_params call
+
+ ret = self.get_params(self.degrees, self.translate, self.scale, self.shear, img_size)
+
+ return affine(img, *ret, interpolation=self.interpolation, fill=fill, center=self.center)
+
+ def __repr__(self) -> str:
+ s = f"{self.__class__.__name__}(degrees={self.degrees}"
+ s += f", translate={self.translate}" if self.translate is not None else ""
+ s += f", scale={self.scale}" if self.scale is not None else ""
+ s += f", shear={self.shear}" if self.shear is not None else ""
+ s += f", interpolation={self.interpolation.value}" if self.interpolation != InterpolationMode.NEAREST else ""
+ s += f", fill={self.fill}" if self.fill != 0 else ""
+ s += f", center={self.center}" if self.center is not None else ""
+ s += ")"
+
+ return s
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/unet.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/unet.py
new file mode 100755
index 000000000..56f3ad61e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/model/unet.py
@@ -0,0 +1,838 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/unet.py
+'''
+import math
+from abc import abstractmethod
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+from .nn import avg_pool_nd
+from .nn import checkpoint
+from .nn import conv_nd
+from .nn import linear
+from .nn import normalization
+from .nn import SiLU
+from .nn import timestep_embedding
+from .nn import zero_module
+
+
+class AttentionPool2d(nn.Layer):
+ """
+ Adapted from CLIP: https://github.com/openai/CLIP/blob/main/clip/model.py
+ """
+
+ def __init__(
+ self,
+ spacial_dim: int,
+ embed_dim: int,
+ num_heads_channels: int,
+ output_dim: int = None,
+ ):
+ super().__init__()
+ # self.positional_embedding = nn.Parameter(
+ # th.randn(embed_dim, spacial_dim ** 2 + 1) / embed_dim ** 0.5
+ # )
+ positional_embedding = self.create_parameter(paddle.randn(embed_dim, spacial_dim**2 + 1) / embed_dim**0.5)
+ self.add_parameter("positional_embedding", positional_embedding)
+ self.qkv_proj = conv_nd(1, embed_dim, 3 * embed_dim, 1)
+ self.c_proj = conv_nd(1, embed_dim, output_dim or embed_dim, 1)
+ self.num_heads = embed_dim // num_heads_channels
+ self.attention = QKVAttention(self.num_heads)
+
+ def forward(self, x):
+ b, c, *_spatial = x.shape
+ # x = x.reshape(b, c, -1) # NC(HW)
+ x = paddle.reshape(x, [b, c, -1])
+ x = paddle.concat([x.mean(dim=-1, keepdim=True), x], axis=-1) # NC(HW+1)
+ x = x + paddle.cast(self.positional_embedding[None, :, :], x.dtype) # NC(HW+1)
+ x = self.qkv_proj(x)
+ x = self.attention(x)
+ x = self.c_proj(x)
+ return x[:, :, 0]
+
+
+class TimestepBlock(nn.Layer):
+ """
+ Any module where forward() takes timestep embeddings as a second argument.
+ """
+
+ @abstractmethod
+ def forward(self, x, emb):
+ """
+ Apply the module to `x` given `emb` timestep embeddings.
+ """
+
+
+class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
+ """
+ A sequential module that passes timestep embeddings to the children that
+ support it as an extra input.
+ """
+
+ def forward(self, x, emb):
+ for layer in self:
+ if isinstance(layer, TimestepBlock):
+ x = layer(x, emb)
+ else:
+ x = layer(x)
+ return x
+
+
+class Upsample(nn.Layer):
+ """
+ An upsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ if use_conv:
+ self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=1)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.dims == 3:
+ x = F.interpolate(x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest")
+ else:
+ x = F.interpolate(x, scale_factor=2, mode="nearest")
+ if self.use_conv:
+ x = self.conv(x)
+ return x
+
+
+class Downsample(nn.Layer):
+ """
+ A downsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ stride = 2 if dims != 3 else (1, 2, 2)
+ if use_conv:
+ self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=1)
+ else:
+ assert self.channels == self.out_channels
+ self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ return self.op(x)
+
+
+class ResBlock(TimestepBlock):
+ """
+ A residual block that can optionally change the number of channels.
+
+ :param channels: the number of input channels.
+ :param emb_channels: the number of timestep embedding channels.
+ :param dropout: the rate of dropout.
+ :param out_channels: if specified, the number of out channels.
+ :param use_conv: if True and out_channels is specified, use a spatial
+ convolution instead of a smaller 1x1 convolution to change the
+ channels in the skip connection.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param use_checkpoint: if True, use gradient checkpointing on this module.
+ :param up: if True, use this block for upsampling.
+ :param down: if True, use this block for downsampling.
+ """
+
+ def __init__(
+ self,
+ channels,
+ emb_channels,
+ dropout,
+ out_channels=None,
+ use_conv=False,
+ use_scale_shift_norm=False,
+ dims=2,
+ use_checkpoint=False,
+ up=False,
+ down=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ self.emb_channels = emb_channels
+ self.dropout = dropout
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_checkpoint = use_checkpoint
+ self.use_scale_shift_norm = use_scale_shift_norm
+
+ self.in_layers = nn.Sequential(
+ normalization(channels),
+ SiLU(),
+ conv_nd(dims, channels, self.out_channels, 3, padding=1),
+ )
+
+ self.updown = up or down
+
+ if up:
+ self.h_upd = Upsample(channels, False, dims)
+ self.x_upd = Upsample(channels, False, dims)
+ elif down:
+ self.h_upd = Downsample(channels, False, dims)
+ self.x_upd = Downsample(channels, False, dims)
+ else:
+ self.h_upd = self.x_upd = nn.Identity()
+
+ self.emb_layers = nn.Sequential(
+ SiLU(),
+ linear(
+ emb_channels,
+ 2 * self.out_channels if use_scale_shift_norm else self.out_channels,
+ ),
+ )
+ self.out_layers = nn.Sequential(
+ normalization(self.out_channels),
+ SiLU(),
+ nn.Dropout(p=dropout),
+ zero_module(conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)),
+ )
+
+ if self.out_channels == channels:
+ self.skip_connection = nn.Identity()
+ elif use_conv:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 3, padding=1)
+ else:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
+
+ def forward(self, x, emb):
+ """
+ Apply the block to a Tensor, conditioned on a timestep embedding.
+
+ :param x: an [N x C x ...] Tensor of features.
+ :param emb: an [N x emb_channels] Tensor of timestep embeddings.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ return checkpoint(self._forward, (x, emb), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x, emb):
+ if self.updown:
+ in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
+ h = in_rest(x)
+ h = self.h_upd(h)
+ x = self.x_upd(x)
+ h = in_conv(h)
+ else:
+ h = self.in_layers(x)
+ emb_out = self.emb_layers(emb)
+ emb_out = paddle.cast(emb_out, h.dtype)
+ while len(emb_out.shape) < len(h.shape):
+ emb_out = emb_out[..., None]
+ if self.use_scale_shift_norm:
+ out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
+ scale, shift = paddle.chunk(emb_out, 2, axis=1)
+ h = out_norm(h) * (1 + scale) + shift
+ h = out_rest(h)
+ else:
+ h = h + emb_out
+ h = self.out_layers(h)
+ return self.skip_connection(x) + h
+
+
+class AttentionBlock(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other.
+
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_heads=1,
+ num_head_channels=-1,
+ use_checkpoint=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels == -1:
+ self.num_heads = num_heads
+ else:
+ assert (channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+ self.use_checkpoint = use_checkpoint
+ self.norm = normalization(channels)
+ self.qkv = conv_nd(1, channels, channels * 3, 1)
+ if use_new_attention_order:
+ # split qkv before split heads
+ self.attention = QKVAttention(self.num_heads)
+ else:
+ # split heads before split qkv
+ self.attention = QKVAttentionLegacy(self.num_heads)
+
+ self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
+
+ def forward(self, x):
+ return checkpoint(self._forward, (x, ), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x):
+ b, c, *spatial = x.shape
+ # x = x.reshape(b, c, -1)
+ x = paddle.reshape(x, [b, c, -1])
+ qkv = self.qkv(self.norm(x))
+ h = self.attention(qkv)
+ h = self.proj_out(h)
+ # return (x + h).reshape(b, c, *spatial)
+ return paddle.reshape(x + h, [b, c, *spatial])
+
+
+def count_flops_attn(model, _x, y):
+ """
+ A counter for the `thop` package to count the operations in an
+ attention operation.
+ Meant to be used like:
+ macs, params = thop.profile(
+ model,
+ inputs=(inputs, timestamps),
+ custom_ops={QKVAttention: QKVAttention.count_flops},
+ )
+ """
+ b, c, *spatial = y[0].shape
+ num_spatial = int(np.prod(spatial))
+ # We perform two matmuls with the same number of ops.
+ # The first computes the weight matrix, the second computes
+ # the combination of the value vectors.
+ matmul_ops = 2 * b * (num_spatial**2) * c
+ model.total_ops += paddle.to_tensor([matmul_ops], dtype='float64')
+
+
+class QKVAttentionLegacy(nn.Layer):
+ """
+ A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ # q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
+ q, k, v = paddle.reshape(qkv, [bs * self.n_heads, ch * 3, length]).split(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v)
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class QKVAttention(nn.Layer):
+ """
+ A module which performs QKV attention and splits in a different order.
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (3 * H * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.chunk(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum(
+ "bct,bcs->bts",
+ (q * scale).view(bs * self.n_heads, ch, length),
+ (k * scale).view(bs * self.n_heads, ch, length),
+ ) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v.reshape(bs * self.n_heads, ch, length))
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class UNetModel(nn.Layer):
+ """
+ The full UNet model with attention and timestep embedding.
+
+ :param in_channels: channels in the input Tensor.
+ :param model_channels: base channel count for the model.
+ :param out_channels: channels in the output Tensor.
+ :param num_res_blocks: number of residual blocks per downsample.
+ :param attention_resolutions: a collection of downsample rates at which
+ attention will take place. May be a set, list, or tuple.
+ For example, if this contains 4, then at 4x downsampling, attention
+ will be used.
+ :param dropout: the dropout probability.
+ :param channel_mult: channel multiplier for each level of the UNet.
+ :param conv_resample: if True, use learned convolutions for upsampling and
+ downsampling.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param num_classes: if specified (as an int), then this model will be
+ class-conditional with `num_classes` classes.
+ :param use_checkpoint: use gradient checkpointing to reduce memory usage.
+ :param num_heads: the number of attention heads in each attention layer.
+ :param num_heads_channels: if specified, ignore num_heads and instead use
+ a fixed channel width per attention head.
+ :param num_heads_upsample: works with num_heads to set a different number
+ of heads for upsampling. Deprecated.
+ :param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
+ :param resblock_updown: use residual blocks for up/downsampling.
+ :param use_new_attention_order: use a different attention pattern for potentially
+ increased efficiency.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ num_classes=None,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.image_size = image_size
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.num_classes = num_classes
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ if self.num_classes is not None:
+ self.label_emb = nn.Embedding(num_classes, time_embed_dim)
+
+ ch = input_ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+
+ self.output_blocks = nn.LayerList([])
+ for level, mult in list(enumerate(channel_mult))[::-1]:
+ for i in range(num_res_blocks + 1):
+ ich = input_block_chans.pop()
+ layers = [
+ ResBlock(
+ ch + ich,
+ time_embed_dim,
+ dropout,
+ out_channels=int(model_channels * mult),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(model_channels * mult)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads_upsample,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ if level and i == num_res_blocks:
+ out_ch = ch
+ layers.append(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ up=True,
+ ) if resblock_updown else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch))
+ ds //= 2
+ self.output_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ zero_module(conv_nd(dims, input_ch, out_channels, 3, padding=1)),
+ )
+
+ def forward(self, x, timesteps, y=None):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :param y: an [N] Tensor of labels, if class-conditional.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ assert (y is not None) == (self.num_classes
+ is not None), "must specify y if and only if the model is class-conditional"
+
+ hs = []
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+ if self.num_classes is not None:
+ assert y.shape == (x.shape[0], )
+ emb = emb + self.label_emb(y)
+
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ hs.append(h)
+ h = self.middle_block(h, emb)
+ for module in self.output_blocks:
+ h = paddle.concat([h, hs.pop()], axis=1)
+ h = module(h, emb)
+ # h = paddle.cast(h, x.dtype)
+ return self.out(h)
+
+
+class SuperResModel(UNetModel):
+ """
+ A UNetModel that performs super-resolution.
+
+ Expects an extra kwarg `low_res` to condition on a low-resolution image.
+ """
+
+ def __init__(self, image_size, in_channels, *args, **kwargs):
+ super().__init__(image_size, in_channels * 2, *args, **kwargs)
+
+ def forward(self, x, timesteps, low_res=None, **kwargs):
+ _, _, new_height, new_width = x.shape
+ upsampled = F.interpolate(low_res, (new_height, new_width), mode="bilinear")
+ x = paddle.concat([x, upsampled], axis=1)
+ return super().forward(x, timesteps, **kwargs)
+
+
+class EncoderUNetModel(nn.Layer):
+ """
+ The half UNet model with attention and timestep embedding.
+
+ For usage, see UNet.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ pool="adaptive",
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+ self.pool = pool
+ if pool == "adaptive":
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ nn.AdaptiveAvgPool2D((1, 1)),
+ zero_module(conv_nd(dims, ch, out_channels, 1)),
+ nn.Flatten(),
+ )
+ elif pool == "attention":
+ assert num_head_channels != -1
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ AttentionPool2d((image_size // ds), ch, num_head_channels, out_channels),
+ )
+ elif pool == "spatial":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ nn.ReLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ elif pool == "spatial_v2":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ normalization(2048),
+ SiLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ else:
+ raise NotImplementedError(f"Unexpected {pool} pooling")
+
+ def forward(self, x, timesteps):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :return: an [N x K] Tensor of outputs.
+ """
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+
+ results = []
+ # h = x.type(self.dtype)
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ if self.pool.startswith("spatial"):
+ # results.append(h.type(x.dtype).mean(axis=(2, 3)))
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = self.middle_block(h, emb)
+ if self.pool.startswith("spatial"):
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = paddle.concat(results, axis=-1)
+ return self.out(h)
+ else:
+ # h = h.type(x.dtype)
+ h = paddle.cast(h, x.dtype)
+ return self.out(h)
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/resources/default.yml b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/resources/default.yml
new file mode 100755
index 000000000..3a161f169
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/resources/default.yml
@@ -0,0 +1,45 @@
+text_prompts:
+ - greg rutkowski和thomas kinkade在artstation上的一幅美丽的画,一个独特的灯塔,照耀着它的光穿过喧嚣的血海。
+
+init_image:
+width_height: [ 1280, 768]
+
+skip_steps: 10
+steps: 250
+
+cut_ic_pow: 1
+init_scale: 1000
+clip_guidance_scale: 5000
+
+tv_scale: 0
+range_scale: 150
+sat_scale: 0
+cutn_batches: 4
+
+diffusion_model: 512x512_diffusion_uncond_finetune_008100
+use_secondary_model: True
+diffusion_sampling_mode: ddim
+
+perlin_init: False
+perlin_mode: mixed
+seed: 445467575
+eta: 0.8
+clamp_grad: True
+clamp_max: 0.05
+
+randomize_class: True
+clip_denoised: False
+fuzzy_prompt: False
+rand_mag: 0.05
+
+cut_overview: "[12]*400+[4]*600"
+cut_innercut: "[4]*400+[12]*600"
+cut_icgray_p: "[0.2]*400+[0]*600"
+
+display_rate: 10
+n_batches: 1
+batch_size: 1
+batch_name: ''
+clip_models:
+ - ViTB16
+output_dir: "./"
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/resources/docstrings.yml b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/resources/docstrings.yml
new file mode 100755
index 000000000..702015e1c
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/resources/docstrings.yml
@@ -0,0 +1,103 @@
+text_prompts: |
+ Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."
+ Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments.
+ Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+init_image: |
+ Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here.
+ If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+width_height: |
+ Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+
+skip_steps: |
+ Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.
+ As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.
+ The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.
+ If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.
+ Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.
+ Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image.
+ However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+
+steps: |
+ When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.
+ Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user.
+ Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+
+cut_ic_pow: |
+ This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+init_scale: |
+ This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+clip_guidance_scale: |
+ CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS.
+ Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500.
+ Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+tv_scale: |
+ Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+range_scale: |
+ Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+
+sat_scale: |
+ Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+cutn_batches: |
+ Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep.
+ Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage.
+ At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep.
+ However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.
+ So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+
+diffusion_model: Diffusion_model of choice.
+
+use_secondary_model: |
+ Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+
+diffusion_sampling_mode: |
+ Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+
+perlin_init: |
+ Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps).
+ Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+
+perlin_mode: |
+ sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+seed: |
+ Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar.
+ After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+eta: |
+ eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results.
+ The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+clamp_grad: |
+ As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+clamp_max: |
+ Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+
+randomize_class:
+clip_denoised: False
+fuzzy_prompt: |
+ Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+rand_mag: |
+ Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+
+cut_overview: The schedule of overview cuts
+cut_innercut: The schedule of inner cuts
+cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+display_rate: |
+ During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+n_batches: |
+ This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+batch_name: |
+ The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+clip_models: |
+ CLIP Model selectors. ViT-B/32, ViT-B/16, ViT-L/14, RN101, RN50, RN50x4, RN50x16, RN50x64.
+ These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around.
+ You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.
+ The rough order of speed/mem usage is (smallest/fastest to largest/slowest):
+ ViT-B/32
+ RN50
+ RN101
+ ViT-B/16
+ RN50x4
+ RN50x16
+ RN50x64
+ ViT-L/14
+ For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/runner.py b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/runner.py
new file mode 100755
index 000000000..58a0c23a0
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/reverse_diffusion/runner.py
@@ -0,0 +1,285 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/runner.py
+'''
+import gc
+import os
+import random
+from threading import Thread
+
+import disco_diffusion_cnclip_vitb16.cn_clip.clip as clip
+import numpy as np
+import paddle
+import paddle.vision.transforms as T
+import paddle_lpips as lpips
+from docarray import Document
+from docarray import DocumentArray
+from IPython import display
+from ipywidgets import Output
+from PIL import Image
+
+from .helper import logger
+from .helper import parse_prompt
+from .model.losses import range_loss
+from .model.losses import spherical_dist_loss
+from .model.losses import tv_loss
+from .model.make_cutouts import MakeCutoutsDango
+from .model.sec_diff import alpha_sigma_to_t
+from .model.sec_diff import SecondaryDiffusionImageNet2
+from .model.transforms import Normalize
+
+
+def do_run(args, models) -> 'DocumentArray':
+ logger.info('preparing models...')
+ model, diffusion, clip_models, secondary_model = models
+ normalize = Normalize(
+ mean=[0.48145466, 0.4578275, 0.40821073],
+ std=[0.26862954, 0.26130258, 0.27577711],
+ )
+ lpips_model = lpips.LPIPS(net='vgg')
+ for parameter in lpips_model.parameters():
+ parameter.stop_gradient = True
+ side_x = (args.width_height[0] // 64) * 64
+ side_y = (args.width_height[1] // 64) * 64
+ cut_overview = eval(args.cut_overview)
+ cut_innercut = eval(args.cut_innercut)
+ cut_icgray_p = eval(args.cut_icgray_p)
+
+ from .model.perlin_noises import create_perlin_noise, regen_perlin
+
+ seed = args.seed
+
+ skip_steps = args.skip_steps
+
+ loss_values = []
+
+ if seed is not None:
+ np.random.seed(seed)
+ random.seed(seed)
+ paddle.seed(seed)
+
+ model_stats = []
+ for clip_model in clip_models:
+ model_stat = {
+ 'clip_model': None,
+ 'target_embeds': [],
+ 'make_cutouts': None,
+ 'weights': [],
+ }
+ model_stat['clip_model'] = clip_model
+
+ if isinstance(args.text_prompts, str):
+ args.text_prompts = [args.text_prompts]
+
+ for prompt in args.text_prompts:
+ txt, weight = parse_prompt(prompt)
+ txt = clip_model.encode_text(clip.tokenize(prompt))
+ if args.fuzzy_prompt:
+ for i in range(25):
+ model_stat['target_embeds'].append((txt + paddle.randn(txt.shape) * args.rand_mag).clip(0, 1))
+ model_stat['weights'].append(weight)
+ else:
+ model_stat['target_embeds'].append(txt)
+ model_stat['weights'].append(weight)
+
+ model_stat['target_embeds'] = paddle.concat(model_stat['target_embeds'])
+ model_stat['weights'] = paddle.to_tensor(model_stat['weights'])
+ if model_stat['weights'].sum().abs() < 1e-3:
+ raise RuntimeError('The weights must not sum to 0.')
+ model_stat['weights'] /= model_stat['weights'].sum().abs()
+ model_stats.append(model_stat)
+
+ init = None
+ if args.init_image:
+ d = Document(uri=args.init_image).load_uri_to_image_tensor(side_x, side_y)
+ init = T.to_tensor(d.tensor).unsqueeze(0) * 2 - 1
+
+ if args.perlin_init:
+ if args.perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif args.perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ init = (T.to_tensor(init).add(T.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+
+ cur_t = None
+
+ def cond_fn(x, t, y=None):
+ x_is_NaN = False
+ n = x.shape[0]
+ if secondary_model:
+ alpha = paddle.to_tensor(diffusion.sqrt_alphas_cumprod[cur_t], dtype='float32')
+ sigma = paddle.to_tensor(diffusion.sqrt_one_minus_alphas_cumprod[cur_t], dtype='float32')
+ cosine_t = alpha_sigma_to_t(alpha, sigma)
+ x = paddle.to_tensor(x.detach(), dtype='float32')
+ x.stop_gradient = False
+ cosine_t = paddle.tile(paddle.to_tensor(cosine_t.detach().cpu().numpy()), [n])
+ cosine_t.stop_gradient = False
+ out = secondary_model(x, cosine_t).pred
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ else:
+ t = paddle.ones([n], dtype='int64') * cur_t
+ out = diffusion.p_mean_variance(model, x, t, clip_denoised=False, model_kwargs={'y': y})
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out['pred_xstart'] * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ for model_stat in model_stats:
+ for i in range(args.cutn_batches):
+ t_int = (int(t.item()) + 1) # errors on last step without +1, need to find source
+ # when using SLIP Base model the dimensions need to be hard coded to avoid AttributeError: 'VisionTransformer' object has no attribute 'input_resolution'
+ try:
+ input_resolution = model_stat['clip_model'].visual.input_resolution
+ except:
+ input_resolution = 224
+
+ cuts = MakeCutoutsDango(
+ input_resolution,
+ Overview=cut_overview[1000 - t_int],
+ InnerCrop=cut_innercut[1000 - t_int],
+ IC_Size_Pow=args.cut_ic_pow,
+ IC_Grey_P=cut_icgray_p[1000 - t_int],
+ )
+ clip_in = normalize(cuts(x_in.add(paddle.to_tensor(1.0)).divide(paddle.to_tensor(2.0))))
+ image_embeds = (model_stat['clip_model'].encode_image(clip_in))
+
+ dists = spherical_dist_loss(
+ image_embeds.unsqueeze(1),
+ model_stat['target_embeds'].unsqueeze(0),
+ )
+
+ dists = dists.reshape([
+ cut_overview[1000 - t_int] + cut_innercut[1000 - t_int],
+ n,
+ -1,
+ ])
+ losses = dists.multiply(model_stat['weights']).sum(2).mean(0)
+ loss_values.append(losses.sum().item()) # log loss, probably shouldn't do per cutn_batch
+
+ x_in_grad += (paddle.grad(losses.sum() * args.clip_guidance_scale, x_in)[0] / args.cutn_batches)
+ tv_losses = tv_loss(x_in)
+ range_losses = range_loss(x_in)
+ sat_losses = paddle.abs(x_in - x_in.clip(min=-1, max=1)).mean()
+ loss = (tv_losses.sum() * args.tv_scale + range_losses.sum() * args.range_scale +
+ sat_losses.sum() * args.sat_scale)
+ if init is not None and args.init_scale:
+ init_losses = lpips_model(x_in, init)
+ loss = loss + init_losses.sum() * args.init_scale
+ x_in_grad += paddle.grad(loss, x_in)[0]
+ if not paddle.isnan(x_in_grad).any():
+ grad = -paddle.grad(x_in_d, x, x_in_grad)[0]
+ else:
+ x_is_NaN = True
+ grad = paddle.zeros_like(x)
+ if args.clamp_grad and not x_is_NaN:
+ magnitude = grad.square().mean().sqrt()
+ return (grad * magnitude.clip(max=args.clamp_max) / magnitude)
+ return grad
+
+ if args.diffusion_sampling_mode == 'ddim':
+ sample_fn = diffusion.ddim_sample_loop_progressive
+ else:
+ sample_fn = diffusion.plms_sample_loop_progressive
+
+ logger.info('creating artwork...')
+
+ image_display = Output()
+ da_batches = DocumentArray()
+
+ for _nb in range(args.n_batches):
+ display.clear_output(wait=True)
+ display.display(args.name_docarray, image_display)
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+
+ d = Document(tags=vars(args))
+ da_batches.append(d)
+
+ cur_t = diffusion.num_timesteps - skip_steps - 1
+
+ if args.perlin_init:
+ init = regen_perlin(args.perlin_mode, side_y, side_x, args.batch_size)
+
+ if args.diffusion_sampling_mode == 'ddim':
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ eta=args.eta,
+ )
+ else:
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ order=2,
+ )
+
+ threads = []
+ for j, sample in enumerate(samples):
+ cur_t -= 1
+ with image_display:
+ if j % args.display_rate == 0 or cur_t == -1:
+ for _, image in enumerate(sample['pred_xstart']):
+ image = (image + 1) / 2
+ image = image.clip(0, 1).squeeze().transpose([1, 2, 0]).numpy() * 255
+ image = np.uint8(image)
+ image = Image.fromarray(image)
+
+ image.save(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb)))
+ c = Document(tags={'cur_t': cur_t})
+ c.load_pil_image_to_datauri(image)
+ d.chunks.append(c)
+ display.clear_output(wait=True)
+ display.display(display.Image(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb))))
+ d.chunks.plot_image_sprites(os.path.join(args.output_dir,
+ f'{args.name_docarray}-progress-{_nb}.png'),
+ show_index=True)
+ t = Thread(
+ target=_silent_push,
+ args=(
+ da_batches,
+ args.name_docarray,
+ ),
+ )
+ threads.append(t)
+ t.start()
+
+ if cur_t == -1:
+ d.load_pil_image_to_datauri(image)
+
+ for t in threads:
+ t.join()
+ display.clear_output(wait=True)
+ logger.info(f'done! {args.name_docarray}')
+ da_batches.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ return da_batches
+
+
+def _silent_push(da_batches: DocumentArray, name: str) -> None:
+ try:
+ da_batches.push(name)
+ except Exception as ex:
+ logger.debug(f'push failed: {ex}')
From fc35d0c8c2cbd9cad5cbd79cd201b6e324302f5f Mon Sep 17 00:00:00 2001
From: chenjian  +
+
+
+ - 生成过程
+  +
+
+
+### 模型介绍
+
+disco_diffusion_clip_vitb32 是一个文图生成模型,可以通过输入一段文字来生成符合该句子语义的图像。该模型由两部分组成,一部分是扩散模型,是一种生成模型,可以从噪声输入中重建出原始图像。另一部分是多模态预训练模型(CLIP), 可以将文本和图像表示在同一个特征空间,相近语义的文本和图像在该特征空间里距离会更相近。在该文图生成模型中,扩散模型负责从初始噪声或者指定初始图像中来生成目标图像,CLIP负责引导生成图像的语义和输入的文本的语义尽可能接近,随着扩散模型在CLIP的引导下不断的迭代生成新图像,最终能够生成文本所描述内容的图像。该模块中使用的CLIP模型结构为ViTB32。
+
+更多详情请参考论文:[Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233) 以及 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install disco_diffusion_clip_vitb32
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run disco_diffusion_clip_vitb32 --text_prompts "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation." --output_dir disco_diffusion_clip_vitb32_out
+ ```
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_clip_vitb32")
+ text_prompts = ["A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."]
+ # 生成图像, 默认会在disco_diffusion_clip_vitb32_out目录保存图像
+ # 返回的da是一个DocumentArray对象,保存了所有的结果,包括最终结果和迭代过程的中间结果
+ # 可以通过操作DocumentArray对象对生成的图像做后处理,保存或者分析
+ da = module.generate_image(text_prompts=text_prompts, output_dir='./disco_diffusion_clip_vitb32_out/')
+ # 手动将最终生成的图像保存到指定路径
+ da[0].save_uri_to_file('disco_diffusion_clip_vitb32_out-result.png')
+ # 展示所有的中间结果
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # 将整个生成过程保存为一个动态图gif
+ da[0].chunks.save_gif('disco_diffusion_clip_vitb32_out-result.gif', show_index=True, inline_display=True, size_ratio=0.5)
+ ```
+
+- ### 3、API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_clip_vitb32_out'):
+ ```
+
+ - 文图生成API,生成文本描述内容的图像。
+
+ - **参数**
+
+ - text_prompts(str): 输入的语句,描述想要生成的图像的内容。通常比较有效的构造方式为 "一段描述性的文字内容" + "指定艺术家的名字",如"a beautiful painting of Chinese architecture, by krenz, sunny, super wide angle, artstation."。prompt的构造可以参考[网站](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#)。
+ - style(Optional[str]): 指定绘画的风格,如'watercolor','Chinese painting'等。当不指定时,风格完全由您所填写的prompt决定。
+ - artist(Optional[str]): 指定特定的艺术家,如Greg Rutkowsk、krenz,将会生成所指定艺术家的绘画风格。当不指定时,风格完全由您所填写的prompt决定。各种艺术家的风格可以参考[网站](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/)。
+ - width_height(Optional[List[int]]): 指定最终输出图像的宽高,宽和高都需要是64的倍数,生成的图像越大,所需要的计算时间越长。
+ - seed(Optional[int]): 随机种子,由于输入默认是随机高斯噪声,设置不同的随机种子会由不同的初始输入,从而最终生成不同的结果,可以设置该参数来获得不同的输出图像。
+ - output_dir(Optional[str]): 保存输出图像的目录,默认为"disco_diffusion_clip_vitb32_out"。
+
+
+ - **返回**
+ - ra(DocumentArray): DocumentArray对象, 包含`n_batches`个Documents,其中每个Document都保存了迭代过程的所有中间结果。详细可参考[DocumentArray使用文档](https://docarray.jina.ai/fundamentals/documentarray/index.html)。
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install disco_diffusion_clip_vitb32 == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/README.md b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/README.md
new file mode 100644
index 000000000..317214d80
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/README.md
@@ -0,0 +1,2 @@
+# OpenAI CLIP implemented in Paddle.
+The original implementation repo is [ranchlai/clip.paddle](https://github.com/ranchlai/clip.paddle). We copy this repo here for guided diffusion.
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/__init__.py
new file mode 100755
index 000000000..5657b56e6
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/__init__.py
@@ -0,0 +1 @@
+from .utils import *
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/layers.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/layers.py
new file mode 100755
index 000000000..286f35ab4
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/layers.py
@@ -0,0 +1,182 @@
+from typing import Optional
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn import Linear
+
+__all__ = ['ResidualAttentionBlock', 'AttentionPool2d', 'multi_head_attention_forward', 'MultiHeadAttention']
+
+
+def multi_head_attention_forward(x: Tensor,
+ num_heads: int,
+ q_proj: Linear,
+ k_proj: Linear,
+ v_proj: Linear,
+ c_proj: Linear,
+ attn_mask: Optional[Tensor] = None):
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = emb_dim // num_heads
+ scaling = float(head_dim)**-0.5
+ q = q_proj(x) # L, N, E
+ k = k_proj(x) # L, N, E
+ v = v_proj(x) # L, N, E
+ #k = k.con
+ v = v.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ k = k.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ q = q.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+
+ q = q * scaling
+ qk = paddle.bmm(q, k.transpose((0, 2, 1)))
+ if attn_mask is not None:
+ if attn_mask.ndim == 2:
+ attn_mask.unsqueeze_(0)
+ #assert str(attn_mask.dtype) == 'VarType.FP32' and attn_mask.ndim == 3
+ assert attn_mask.shape[0] == 1 and attn_mask.shape[1] == max_len and attn_mask.shape[2] == max_len
+ qk += attn_mask
+
+ qk = paddle.nn.functional.softmax(qk, axis=-1)
+ atten = paddle.bmm(qk, v)
+ atten = atten.transpose((1, 0, 2))
+ atten = atten.reshape((max_len, batch_size, emb_dim))
+ atten = c_proj(atten)
+ return atten
+
+
+class MultiHeadAttention(nn.Layer): # without attention mask
+
+ def __init__(self, emb_dim: int, num_heads: int):
+ super().__init__()
+ self.q_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.k_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.v_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.c_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.head_dim = emb_dim // num_heads
+ self.emb_dim = emb_dim
+ self.num_heads = num_heads
+ assert self.head_dim * num_heads == emb_dim, "embed_dim must be divisible by num_heads"
+ #self.scaling = float(self.head_dim) ** -0.5
+
+ def forward(self, x, attn_mask=None): # x is in shape[max_len,batch_size,emb_dim]
+
+ atten = multi_head_attention_forward(x,
+ self.num_heads,
+ self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.c_proj,
+ attn_mask=attn_mask)
+
+ return atten
+
+
+class Identity(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return x
+
+
+class Bottleneck(nn.Layer):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1):
+ super().__init__()
+
+ # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
+ self.conv1 = nn.Conv2D(inplanes, planes, 1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(planes)
+
+ self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(planes)
+
+ self.avgpool = nn.AvgPool2D(stride) if stride > 1 else Identity()
+
+ self.conv3 = nn.Conv2D(planes, planes * self.expansion, 1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(planes * self.expansion)
+
+ self.relu = nn.ReLU()
+ self.downsample = None
+ self.stride = stride
+
+ if stride > 1 or inplanes != planes * Bottleneck.expansion:
+ self.downsample = nn.Sequential(
+ ("-1", nn.AvgPool2D(stride)),
+ ("0", nn.Conv2D(inplanes, planes * self.expansion, 1, stride=1, bias_attr=False)),
+ ("1", nn.BatchNorm2D(planes * self.expansion)))
+
+ def forward(self, x):
+ identity = x
+
+ out = self.relu(self.bn1(self.conv1(x)))
+ out = self.relu(self.bn2(self.conv2(out)))
+ out = self.avgpool(out)
+ out = self.bn3(self.conv3(out))
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.relu(out)
+ return out
+
+
+class AttentionPool2d(nn.Layer):
+
+ def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
+ super().__init__()
+
+ self.positional_embedding = paddle.create_parameter((spacial_dim**2 + 1, embed_dim), dtype='float32')
+
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim, bias_attr=True)
+ self.num_heads = num_heads
+
+ self.head_dim = embed_dim // num_heads
+ assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
+
+ def forward(self, x):
+
+ x = x.reshape((x.shape[0], x.shape[1], x.shape[2] * x.shape[3])).transpose((2, 0, 1)) # NCHW -> (HW)NC
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = self.head_dim
+ x = paddle.concat([paddle.mean(x, axis=0, keepdim=True), x], axis=0)
+ x = x + paddle.unsqueeze(self.positional_embedding, 1)
+ out = multi_head_attention_forward(x, self.num_heads, self.q_proj, self.k_proj, self.v_proj, self.c_proj)
+
+ return out[0]
+
+
+class QuickGELU(nn.Layer):
+
+ def forward(self, x):
+ return x * paddle.nn.functional.sigmoid(1.702 * x)
+
+
+class ResidualAttentionBlock(nn.Layer):
+
+ def __init__(self, d_model: int, n_head: int, attn_mask=None):
+ super().__init__()
+
+ self.attn = MultiHeadAttention(d_model, n_head)
+ self.ln_1 = nn.LayerNorm(d_model)
+ self.mlp = nn.Sequential(("c_fc", nn.Linear(d_model, d_model * 4)), ("gelu", QuickGELU()),
+ ("c_proj", nn.Linear(d_model * 4, d_model)))
+ self.ln_2 = nn.LayerNorm(d_model)
+ self.attn_mask = attn_mask
+
+ def attention(self, x):
+ x = self.attn(x, self.attn_mask)
+ assert isinstance(x, paddle.Tensor) # not tuble here
+ return x
+
+ def forward(self, x):
+
+ x = x + self.attention(self.ln_1(x))
+ x = x + self.mlp(self.ln_2(x))
+ return x
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/model.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/model.py
new file mode 100755
index 000000000..63d1835c5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/model.py
@@ -0,0 +1,227 @@
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import nn
+
+from .layers import AttentionPool2d
+from .layers import Bottleneck
+from .layers import MultiHeadAttention
+from .layers import ResidualAttentionBlock
+
+
+class ModifiedResNet(nn.Layer):
+ """
+ A ResNet class that is similar to torchvision's but contains the following changes:
+ - There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
+ - Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
+ - The final pooling layer is a QKV attention instead of an average pool
+ """
+
+ def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
+ super().__init__()
+ self.output_dim = output_dim
+ self.input_resolution = input_resolution
+
+ # the 3-layer stem
+ self.conv1 = nn.Conv2D(3, width // 2, kernel_size=3, stride=2, padding=1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(width // 2)
+ self.conv2 = nn.Conv2D(width // 2, width // 2, kernel_size=3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(width // 2)
+ self.conv3 = nn.Conv2D(width // 2, width, kernel_size=3, padding=1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(width)
+ self.avgpool = nn.AvgPool2D(2)
+ self.relu = nn.ReLU()
+
+ # residual layers
+ self._inplanes = width # this is a *mutable* variable used during construction
+ self.layer1 = self._make_layer(width, layers[0])
+ self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
+ self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
+ self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
+
+ embed_dim = width * 32 # the ResNet feature dimension
+ self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
+
+ def _make_layer(self, planes, blocks, stride=1):
+ layers = [Bottleneck(self._inplanes, planes, stride)]
+
+ self._inplanes = planes * Bottleneck.expansion
+ for _ in range(1, blocks):
+ layers.append(Bottleneck(self._inplanes, planes))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ def stem(x):
+ for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
+ x = self.relu(bn(conv(x)))
+ x = self.avgpool(x)
+ return x
+
+ #x = x.type(self.conv1.weight.dtype)
+ x = stem(x)
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+ x = self.attnpool(x)
+
+ return x
+
+
+class Transformer(nn.Layer):
+
+ def __init__(self, width: int, layers: int, heads: int, attn_mask=None):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
+
+ def forward(self, x):
+ return self.resblocks(x)
+
+
+class VisualTransformer(nn.Layer):
+
+ def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.output_dim = output_dim
+ # used patch_size x patch_size, stride patch_size to do linear projection
+ self.conv1 = nn.Conv2D(in_channels=3,
+ out_channels=width,
+ kernel_size=patch_size,
+ stride=patch_size,
+ bias_attr=False)
+
+ # scale = width ** -0.5
+ self.class_embedding = paddle.create_parameter((width, ), 'float32')
+
+ self.positional_embedding = paddle.create_parameter(((input_resolution // patch_size)**2 + 1, width), 'float32')
+
+ self.ln_pre = nn.LayerNorm(width)
+
+ self.transformer = Transformer(width, layers, heads)
+
+ self.ln_post = nn.LayerNorm(width)
+ self.proj = paddle.create_parameter((width, output_dim), 'float32')
+
+ def forward(self, x):
+
+ x = self.conv1(x)
+ x = x.reshape((x.shape[0], x.shape[1], -1))
+ x = x.transpose((0, 2, 1))
+ x = paddle.concat([self.class_embedding + paddle.zeros((x.shape[0], 1, x.shape[-1]), dtype=x.dtype), x], axis=1)
+
+ x = x + self.positional_embedding
+ x = self.ln_pre(x)
+ x = x.transpose((1, 0, 2))
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2))
+ x = self.ln_post(x[:, 0, :])
+ if self.proj is not None:
+ x = paddle.matmul(x, self.proj)
+
+ return x
+
+
+class CLIP(nn.Layer):
+
+ def __init__(
+ self,
+ embed_dim: int,
+ # vision
+ image_resolution: int,
+ vision_layers: Union[Tuple[int, int, int, int], int],
+ vision_width: int,
+ vision_patch_size: int,
+ # text
+ context_length: int,
+ vocab_size: int,
+ transformer_width: int,
+ transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+
+ self.context_length = context_length
+ if isinstance(vision_layers, (tuple, list)):
+ vision_heads = vision_width * 32 // 64
+ self.visual = ModifiedResNet(layers=vision_layers,
+ output_dim=embed_dim,
+ heads=vision_heads,
+ input_resolution=image_resolution,
+ width=vision_width)
+ else:
+ vision_heads = vision_width // 64
+ self.visual = VisualTransformer(input_resolution=image_resolution,
+ patch_size=vision_patch_size,
+ width=vision_width,
+ layers=vision_layers,
+ heads=vision_heads,
+ output_dim=embed_dim)
+
+ self.transformer = Transformer(width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+
+ self.vocab_size = vocab_size
+ self.token_embedding = nn.Embedding(vocab_size, transformer_width)
+ self.positional_embedding = paddle.create_parameter((self.context_length, transformer_width), 'float32')
+ self.ln_final = nn.LayerNorm(transformer_width)
+
+ self.text_projection = paddle.create_parameter((transformer_width, embed_dim), 'float32')
+ self.logit_scale = paddle.create_parameter((1, ), 'float32')
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # mask = paddle.empty((self.context_length, self.context_length),dtype='float32')
+ # mask.fill_(float("-inf"))
+ #mask.triu_(1) # zero out the lower diagonal
+
+ mask = paddle.ones((self.context_length, self.context_length)) * float("-inf")
+ mask = paddle.triu(mask, diagonal=1)
+
+ return mask
+
+ def encode_image(self, image):
+ return self.visual(image)
+
+ def encode_text(self, text):
+ x = self.token_embedding(text) # [batch_size, n_ctx, d_model]
+ # print(x.shape)
+
+ x = x + self.positional_embedding
+ #print(x.shape)
+
+ x = x.transpose((1, 0, 2)) # NLD -> LND
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2)) # LND -> NLD
+ x = self.ln_final(x)
+
+ idx = text.numpy().argmax(-1)
+ idx = list(idx)
+ x = [x[i:i + 1, int(j), :] for i, j in enumerate(idx)]
+ x = paddle.concat(x, 0)
+ x = paddle.matmul(x, self.text_projection)
+ return x
+
+ def forward(self, image, text):
+ image_features = self.encode_image(image)
+ text_features = self.encode_text(text)
+
+ # normalized features
+ image_features = image_features / image_features.norm(dim=-1, keepdim=True)
+ text_features = text_features / text_features.norm(dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_image = paddle.matmul(logit_scale * image_features, text_features.t())
+ logits_per_text = paddle.matmul(logit_scale * text_features, image_features.t())
+
+ # shape = [global_batch_size, global_batch_size]
+ return logits_per_image, logits_per_text
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/simple_tokenizer.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/simple_tokenizer.py
new file mode 100755
index 000000000..4eaf82e9e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/simple_tokenizer.py
@@ -0,0 +1,135 @@
+import gzip
+import html
+import os
+from functools import lru_cache
+
+import ftfy
+import regex as re
+
+
+@lru_cache()
+def default_bpe():
+ return os.path.join(os.path.dirname(os.path.abspath(__file__)), "../assets/bpe_simple_vocab_16e6.txt.gz")
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a corresponding list of unicode strings.
+ The reversible bpe codes work on unicode strings.
+ This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
+ When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
+ This is a signficant percentage of your normal, say, 32K bpe vocab.
+ To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ And avoids mapping to whitespace/control characters the bpe code barfs on.
+ """
+ bs = list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """Return set of symbol pairs in a word.
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+def basic_clean(text):
+ text = ftfy.fix_text(text)
+ text = html.unescape(html.unescape(text))
+ return text.strip()
+
+
+def whitespace_clean(text):
+ text = re.sub(r'\s+', ' ', text)
+ text = text.strip()
+ return text
+
+
+class SimpleTokenizer(object):
+
+ def __init__(self, bpe_path: str = default_bpe()):
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
+ merges = merges[1:49152 - 256 - 2 + 1]
+ merges = [tuple(merge.split()) for merge in merges]
+ vocab = list(bytes_to_unicode().values())
+ vocab = vocab + [v + '' for v in vocab]
+ for merge in merges:
+ vocab.append(''.join(merge))
+ vocab.extend(['<|startoftext|>', '<|endoftext|>'])
+ self.encoder = dict(zip(vocab, range(len(vocab))))
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.bpe_ranks = dict(zip(merges, range(len(merges))))
+ self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
+ self.pat = re.compile(
+ r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
+ re.IGNORECASE)
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token[:-1]) + (token[-1] + '', )
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token + ''
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ new_word.extend(word[i:j])
+ i = j
+ except:
+ new_word.extend(word[i:])
+ break
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = ' '.join(word)
+ self.cache[token] = word
+ return word
+
+ def encode(self, text):
+ bpe_tokens = []
+ text = whitespace_clean(basic_clean(text)).lower()
+ for token in re.findall(self.pat, text):
+ token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
+ bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
+ return bpe_tokens
+
+ def decode(self, tokens):
+ text = ''.join([self.decoder[token] for token in tokens])
+ text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('', ' ')
+ return text
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/utils.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/utils.py
new file mode 100755
index 000000000..8ea909142
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/clip/clip/utils.py
@@ -0,0 +1,122 @@
+import os
+from typing import List
+from typing import Union
+
+import numpy as np
+import paddle
+from paddle.utils import download
+from paddle.vision.transforms import CenterCrop
+from paddle.vision.transforms import Compose
+from paddle.vision.transforms import Normalize
+from paddle.vision.transforms import Resize
+from paddle.vision.transforms import ToTensor
+
+from .model import CLIP
+from .simple_tokenizer import SimpleTokenizer
+
+__all__ = ['transform', 'tokenize', 'build_model']
+
+MODEL_NAMES = ['RN50', 'RN101', 'VIT32']
+
+URL = {
+ 'RN50': os.path.join(os.path.dirname(__file__), 'pre_trained', 'RN50.pdparams'),
+ 'RN101': os.path.join(os.path.dirname(__file__), 'pre_trained', 'RN101.pdparams'),
+ 'VIT32': os.path.join(os.path.dirname(__file__), 'pre_trained', 'ViT-B-32.pdparams')
+}
+
+MEAN, STD = (0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)
+_tokenizer = SimpleTokenizer()
+
+transform = Compose([
+ Resize(224, interpolation='bicubic'),
+ CenterCrop(224), lambda image: image.convert('RGB'),
+ ToTensor(),
+ Normalize(mean=MEAN, std=STD), lambda t: t.unsqueeze_(0)
+])
+
+
+def tokenize(texts: Union[str, List[str]], context_length: int = 77):
+ """
+ Returns the tokenized representation of given input string(s)
+
+ Parameters
+ ----------
+ texts : Union[str, List[str]]
+ An input string or a list of input strings to tokenize
+
+ context_length : int
+ The context length to use; all CLIP models use 77 as the context length
+
+ Returns
+ -------
+ A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
+ """
+ if isinstance(texts, str):
+ texts = [texts]
+
+ sot_token = _tokenizer.encoder["<|startoftext|>"]
+ eot_token = _tokenizer.encoder["<|endoftext|>"]
+ all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
+ result = paddle.zeros((len(all_tokens), context_length), dtype='int64')
+
+ for i, tokens in enumerate(all_tokens):
+ if len(tokens) > context_length:
+ raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
+ result[i, :len(tokens)] = paddle.Tensor(np.array(tokens))
+
+ return result
+
+
+def build_model(name='VIT32'):
+ assert name in MODEL_NAMES, f"model name must be one of {MODEL_NAMES}"
+ name2model = {'RN101': build_rn101_model, 'VIT32': build_vit_model, 'RN50': build_rn50_model}
+ model = name2model[name]()
+ weight = URL[name]
+ sd = paddle.load(weight)
+ model.load_dict(sd)
+ model.eval()
+ return model
+
+
+def build_vit_model():
+
+ model = CLIP(embed_dim=512,
+ image_resolution=224,
+ vision_layers=12,
+ vision_width=768,
+ vision_patch_size=32,
+ context_length=77,
+ vocab_size=49408,
+ transformer_width=512,
+ transformer_heads=8,
+ transformer_layers=12)
+ return model
+
+
+def build_rn101_model():
+ model = CLIP(
+ embed_dim=512,
+ image_resolution=224,
+ vision_layers=(3, 4, 23, 3),
+ vision_width=64,
+ vision_patch_size=0, #Not used in resnet
+ context_length=77,
+ vocab_size=49408,
+ transformer_width=512,
+ transformer_heads=8,
+ transformer_layers=12)
+ return model
+
+
+def build_rn50_model():
+ model = CLIP(embed_dim=1024,
+ image_resolution=224,
+ vision_layers=(3, 4, 6, 3),
+ vision_width=64,
+ vision_patch_size=None,
+ context_length=77,
+ vocab_size=49408,
+ transformer_width=512,
+ transformer_heads=8,
+ transformer_layers=12)
+ return model
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/module.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/module.py
new file mode 100755
index 000000000..fb025bfc9
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/module.py
@@ -0,0 +1,441 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import ast
+import os
+import sys
+from functools import partial
+from typing import List
+from typing import Optional
+
+import disco_diffusion_clip_vitb32.clip as clip
+import disco_diffusion_clip_vitb32.resize_right as resize_right
+import paddle
+from disco_diffusion_clip_vitb32.reverse_diffusion import create
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+@moduleinfo(name="disco_diffusion_clip_vitb32",
+ version="1.0.0",
+ type="image/text_to_image",
+ summary="",
+ author="paddlepaddle",
+ author_email="paddle-dev@baidu.com")
+class DiscoDiffusionClip:
+
+ def generate_image(self,
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 0,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 0,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 1,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ use_gpu: Optional[bool] = True,
+ output_dir: Optional[str] = 'disco_diffusion_clip_vitb32_out'):
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+ :param style: Image style, such as oil paintings, if specified, style will be used to construct prompts.
+ :param artist: Artist style, if specified, style will be used to construct prompts.
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param use_gpu: whether to use gpu or not.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+ if use_gpu:
+ try:
+ _places = os.environ.get("CUDA_VISIBLE_DEVICES", None)
+ if _places:
+ paddle.device.set_device("gpu:{}".format(0))
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
+ )
+ else:
+ paddle.device.set_device("cpu")
+ paddle.disable_static()
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir, exist_ok=True)
+
+ if isinstance(text_prompts, str):
+ text_prompts = text_prompts.rstrip(',.,。')
+ if style is not None:
+ text_prompts += ",{}".format(style)
+ if artist is not None:
+ text_prompts += ",{},trending on artstation".format(artist)
+ elif isinstance(text_prompts, list):
+ text_prompts[0] = text_prompts[0].rstrip(',.,。')
+ if style is not None:
+ text_prompts[0] += ",{}".format(style)
+ if artist is not None:
+ text_prompts[0] += ",{},trending on artstation".format(artist)
+
+ return create(text_prompts=text_prompts,
+ init_image=init_image,
+ width_height=width_height,
+ skip_steps=skip_steps,
+ steps=steps,
+ cut_ic_pow=cut_ic_pow,
+ init_scale=init_scale,
+ clip_guidance_scale=clip_guidance_scale,
+ tv_scale=tv_scale,
+ range_scale=range_scale,
+ sat_scale=sat_scale,
+ cutn_batches=cutn_batches,
+ diffusion_sampling_mode=diffusion_sampling_mode,
+ perlin_init=perlin_init,
+ perlin_mode=perlin_mode,
+ seed=seed,
+ eta=eta,
+ clamp_grad=clamp_grad,
+ clamp_max=clamp_max,
+ randomize_class=randomize_class,
+ clip_denoised=clip_denoised,
+ fuzzy_prompt=fuzzy_prompt,
+ rand_mag=rand_mag,
+ cut_overview=cut_overview,
+ cut_innercut=cut_innercut,
+ cut_icgray_p=cut_icgray_p,
+ display_rate=display_rate,
+ n_batches=n_batches,
+ batch_size=batch_size,
+ batch_name=batch_name,
+ clip_models=['VIT32'],
+ output_dir=output_dir)
+
+ @serving
+ def serving_method(self, text_prompts, **kwargs):
+ """
+ Run as a service.
+ """
+ results = []
+ for text_prompt in text_prompts:
+ result = self.generate_image(text_prompts=text_prompt, **kwargs)[0].to_base64()
+ results.append(result)
+ return results
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options", description="Run configuration for controlling module behavior, not required.")
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ results = self.generate_image(text_prompts=args.text_prompts,
+ style=args.style,
+ artist=args.artist,
+ init_image=args.init_image,
+ width_height=args.width_height,
+ skip_steps=args.skip_steps,
+ steps=args.steps,
+ cut_ic_pow=args.cut_ic_pow,
+ init_scale=args.init_scale,
+ clip_guidance_scale=args.clip_guidance_scale,
+ tv_scale=args.tv_scale,
+ range_scale=args.range_scale,
+ sat_scale=args.sat_scale,
+ cutn_batches=args.cutn_batches,
+ diffusion_sampling_mode=args.diffusion_sampling_mode,
+ perlin_init=args.perlin_init,
+ perlin_mode=args.perlin_mode,
+ seed=args.seed,
+ eta=args.eta,
+ clamp_grad=args.clamp_grad,
+ clamp_max=args.clamp_max,
+ randomize_class=args.randomize_class,
+ clip_denoised=args.clip_denoised,
+ fuzzy_prompt=args.fuzzy_prompt,
+ rand_mag=args.rand_mag,
+ cut_overview=args.cut_overview,
+ cut_innercut=args.cut_innercut,
+ cut_icgray_p=args.cut_icgray_p,
+ display_rate=args.display_rate,
+ n_batches=args.n_batches,
+ batch_size=args.batch_size,
+ batch_name=args.batch_name,
+ output_dir=args.output_dir)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options.
+ """
+ self.arg_input_group.add_argument(
+ '--skip_steps',
+ type=int,
+ default=0,
+ help=
+ 'Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15%% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50%% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture'
+ )
+ self.arg_input_group.add_argument(
+ '--steps',
+ type=int,
+ default=250,
+ help=
+ "When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time."
+ )
+ self.arg_input_group.add_argument(
+ '--cut_ic_pow',
+ type=int,
+ default=1,
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--init_scale',
+ type=int,
+ default=1000,
+ help=
+ "This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost."
+ )
+ self.arg_input_group.add_argument(
+ '--clip_guidance_scale',
+ type=int,
+ default=5000,
+ help=
+ "CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well."
+ )
+ self.arg_input_group.add_argument(
+ '--tv_scale',
+ type=int,
+ default=0,
+ help=
+ "Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising"
+ )
+ self.arg_input_group.add_argument(
+ '--range_scale',
+ type=int,
+ default=0,
+ help=
+ "Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images."
+ )
+ self.arg_input_group.add_argument(
+ '--sat_scale',
+ type=int,
+ default=0,
+ help=
+ "Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation."
+ )
+ self.arg_input_group.add_argument(
+ '--cutn_batches',
+ type=int,
+ default=4,
+ help=
+ "Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below."
+ )
+ self.arg_input_group.add_argument(
+ '--diffusion_sampling_mode',
+ type=str,
+ default='ddim',
+ help=
+ "Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_init',
+ type=bool,
+ default=False,
+ help=
+ "Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_mode',
+ type=str,
+ default='mixed',
+ help=
+ "sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--seed',
+ type=int,
+ default=None,
+ help=
+ "Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical."
+ )
+ self.arg_input_group.add_argument(
+ '--eta',
+ type=float,
+ default=0.8,
+ help=
+ "eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_grad',
+ type=bool,
+ default=True,
+ help=
+ "As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_max',
+ type=float,
+ default=0.05,
+ help=
+ "Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy."
+ )
+ self.arg_input_group.add_argument('--randomize_class', type=bool, default=True, help="Random class.")
+ self.arg_input_group.add_argument('--clip_denoised', type=bool, default=False, help="Clip denoised.")
+ self.arg_input_group.add_argument(
+ '--fuzzy_prompt',
+ type=bool,
+ default=False,
+ help=
+ "Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this."
+ )
+ self.arg_input_group.add_argument(
+ '--rand_mag',
+ type=float,
+ default=0.5,
+ help="Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.")
+ self.arg_input_group.add_argument('--cut_overview',
+ type=str,
+ default='[12]*400+[4]*600',
+ help="The schedule of overview cuts")
+ self.arg_input_group.add_argument('--cut_innercut',
+ type=str,
+ default='[4]*400+[12]*600',
+ help="The schedule of inner cuts")
+ self.arg_input_group.add_argument(
+ '--cut_icgray_p',
+ type=str,
+ default='[0.2]*400+[0]*600',
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--display_rate',
+ type=int,
+ default=10,
+ help=
+ "During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly."
+ )
+ self.arg_config_group.add_argument('--use_gpu',
+ type=ast.literal_eval,
+ default=True,
+ help="whether use GPU or not")
+ self.arg_config_group.add_argument('--output_dir',
+ type=str,
+ default='disco_diffusion_clip_vitb32_out',
+ help='Output directory.')
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument(
+ '--text_prompts',
+ type=str,
+ help=
+ 'Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.'
+ )
+ self.arg_input_group.add_argument(
+ '--style',
+ type=str,
+ default=None,
+ help='Image style, such as oil paintings, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument('--artist',
+ type=str,
+ default=None,
+ help='Artist style, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument(
+ '--init_image',
+ type=str,
+ default=None,
+ help=
+ "Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion."
+ )
+ self.arg_input_group.add_argument(
+ '--width_height',
+ type=ast.literal_eval,
+ default=[1280, 768],
+ help=
+ "Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so."
+ )
+ self.arg_input_group.add_argument(
+ '--n_batches',
+ type=int,
+ default=1,
+ help=
+ "This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings."
+ )
+ self.arg_input_group.add_argument('--batch_size', type=int, default=1, help="Batch size.")
+ self.arg_input_group.add_argument(
+ '--batch_name',
+ type=str,
+ default='',
+ help=
+ 'The name of the batch, the batch id will be named as "reverse_diffusion-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.'
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/requirements.txt b/modules/image/text_to_image/disco_diffusion_clip_vitb32/requirements.txt
new file mode 100755
index 000000000..8b4bc0ea4
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/requirements.txt
@@ -0,0 +1,8 @@
+numpy
+paddle_lpips==0.1.2
+ftfy
+docarray>=0.13.29
+pyyaml
+regex
+tqdm
+ipywidgets
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/README.md b/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/README.md
new file mode 100644
index 000000000..1f8d0bb0a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/README.md
@@ -0,0 +1,3 @@
+# ResizeRight (Paddle)
+Fully differentiable resize function implemented by Paddle.
+This module is based on [assafshocher/ResizeRight](https://github.com/assafshocher/ResizeRight).
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/__init__.py
new file mode 100755
index 000000000..e69de29bb
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/interp_methods.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/interp_methods.py
new file mode 100755
index 000000000..276eb055a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/interp_methods.py
@@ -0,0 +1,70 @@
+from math import pi
+
+try:
+ import paddle
+except ImportError:
+ paddle = None
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def set_framework_dependencies(x):
+ if type(x) is numpy.ndarray:
+ to_dtype = lambda a: a
+ fw = numpy
+ else:
+ to_dtype = lambda a: paddle.cast(a, x.dtype)
+ fw = paddle
+ # eps = fw.finfo(fw.float32).eps
+ eps = paddle.to_tensor(np.finfo(np.float32).eps)
+ return fw, to_dtype, eps
+
+
+def support_sz(sz):
+
+ def wrapper(f):
+ f.support_sz = sz
+ return f
+
+ return wrapper
+
+
+@support_sz(4)
+def cubic(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ absx = fw.abs(x)
+ absx2 = absx**2
+ absx3 = absx**3
+ return ((1.5 * absx3 - 2.5 * absx2 + 1.) * to_dtype(absx <= 1.) +
+ (-0.5 * absx3 + 2.5 * absx2 - 4. * absx + 2.) * to_dtype((1. < absx) & (absx <= 2.)))
+
+
+@support_sz(4)
+def lanczos2(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 2) + eps) / ((pi**2 * x**2 / 2) + eps)) * to_dtype(abs(x) < 2))
+
+
+@support_sz(6)
+def lanczos3(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 3) + eps) / ((pi**2 * x**2 / 3) + eps)) * to_dtype(abs(x) < 3))
+
+
+@support_sz(2)
+def linear(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return ((x + 1) * to_dtype((-1 <= x) & (x < 0)) + (1 - x) * to_dtype((0 <= x) & (x <= 1)))
+
+
+@support_sz(1)
+def box(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return to_dtype((-1 <= x) & (x < 0)) + to_dtype((0 <= x) & (x <= 1))
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/resize_right.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/resize_right.py
new file mode 100755
index 000000000..77ea95640
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/resize_right/resize_right.py
@@ -0,0 +1,403 @@
+import warnings
+from fractions import Fraction
+from math import ceil
+from typing import Tuple
+
+import disco_diffusion_clip_vitb32.resize_right.interp_methods as interp_methods
+
+
+class NoneClass:
+ pass
+
+
+try:
+ import paddle
+ from paddle import nn
+ nnModuleWrapped = nn.Layer
+except ImportError:
+ warnings.warn('No PyTorch found, will work only with Numpy')
+ paddle = None
+ nnModuleWrapped = NoneClass
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ warnings.warn('No Numpy found, will work only with PyTorch')
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def resize(input,
+ scale_factors=None,
+ out_shape=None,
+ interp_method=interp_methods.cubic,
+ support_sz=None,
+ antialiasing=True,
+ by_convs=False,
+ scale_tolerance=None,
+ max_numerator=10,
+ pad_mode='constant'):
+ # get properties of the input tensor
+ in_shape, n_dims = input.shape, input.ndim
+
+ # fw stands for framework that can be either numpy or paddle,
+ # determined by the input type
+ fw = numpy if type(input) is numpy.ndarray else paddle
+ eps = np.finfo(np.float32).eps if fw == numpy else paddle.to_tensor(np.finfo(np.float32).eps)
+ device = input.place if fw is paddle else None
+
+ # set missing scale factors or output shapem one according to another,
+ # scream if both missing. this is also where all the defults policies
+ # take place. also handling the by_convs attribute carefully.
+ scale_factors, out_shape, by_convs = set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs,
+ scale_tolerance, max_numerator, eps, fw)
+
+ # sort indices of dimensions according to scale of each dimension.
+ # since we are going dim by dim this is efficient
+ sorted_filtered_dims_and_scales = [(dim, scale_factors[dim], by_convs[dim], in_shape[dim], out_shape[dim])
+ for dim in sorted(range(n_dims), key=lambda ind: scale_factors[ind])
+ if scale_factors[dim] != 1.]
+ # unless support size is specified by the user, it is an attribute
+ # of the interpolation method
+ if support_sz is None:
+ support_sz = interp_method.support_sz
+
+ # output begins identical to input and changes with each iteration
+ output = input
+
+ # iterate over dims
+ for (dim, scale_factor, dim_by_convs, in_sz, out_sz) in sorted_filtered_dims_and_scales:
+ # STEP 1- PROJECTED GRID: The non-integer locations of the projection
+ # of output pixel locations to the input tensor
+ projected_grid = get_projected_grid(in_sz, out_sz, scale_factor, fw, dim_by_convs, device)
+
+ # STEP 1.5: ANTIALIASING- If antialiasing is taking place, we modify
+ # the window size and the interpolation method (see inside function)
+ cur_interp_method, cur_support_sz = apply_antialiasing_if_needed(interp_method, support_sz, scale_factor,
+ antialiasing)
+
+ # STEP 2- FIELDS OF VIEW: for each output pixels, map the input pixels
+ # that influence it. Also calculate needed padding and update grid
+ # accoedingly
+ field_of_view = get_field_of_view(projected_grid, cur_support_sz, fw, eps, device)
+
+ # STEP 2.5- CALCULATE PAD AND UPDATE: according to the field of view,
+ # the input should be padded to handle the boundaries, coordinates
+ # should be updated. actual padding only occurs when weights are
+ # aplied (step 4). if using by_convs for this dim, then we need to
+ # calc right and left boundaries for each filter instead.
+ pad_sz, projected_grid, field_of_view = calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor,
+ dim_by_convs, fw, device)
+ # STEP 3- CALCULATE WEIGHTS: Match a set of weights to the pixels in
+ # the field of view for each output pixel
+ weights = get_weights(cur_interp_method, projected_grid, field_of_view)
+
+ # STEP 4- APPLY WEIGHTS: Each output pixel is calculated by multiplying
+ # its set of weights with the pixel values in its field of view.
+ # We now multiply the fields of view with their matching weights.
+ # We do this by tensor multiplication and broadcasting.
+ # if by_convs is true for this dim, then we do this action by
+ # convolutions. this is equivalent but faster.
+ if not dim_by_convs:
+ output = apply_weights(output, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw)
+ else:
+ output = apply_convs(output, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw)
+ return output
+
+
+def get_projected_grid(in_sz, out_sz, scale_factor, fw, by_convs, device=None):
+ # we start by having the ouput coordinates which are just integer locations
+ # in the special case when usin by_convs, we only need two cycles of grid
+ # points. the first and last.
+ grid_sz = out_sz if not by_convs else scale_factor.numerator
+ out_coordinates = fw_arange(grid_sz, fw, device)
+
+ # This is projecting the ouput pixel locations in 1d to the input tensor,
+ # as non-integer locations.
+ # the following fomrula is derived in the paper
+ # "From Discrete to Continuous Convolutions" by Shocher et al.
+ return (out_coordinates / float(scale_factor) + (in_sz - 1) / 2 - (out_sz - 1) / (2 * float(scale_factor)))
+
+
+def get_field_of_view(projected_grid, cur_support_sz, fw, eps, device):
+ # for each output pixel, map which input pixels influence it, in 1d.
+ # we start by calculating the leftmost neighbor, using half of the window
+ # size (eps is for when boundary is exact int)
+ left_boundaries = fw_ceil(projected_grid - cur_support_sz / 2 - eps, fw)
+
+ # then we simply take all the pixel centers in the field by counting
+ # window size pixels from the left boundary
+ ordinal_numbers = fw_arange(ceil(cur_support_sz - eps), fw, device)
+ return left_boundaries[:, None] + ordinal_numbers
+
+
+def calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor, dim_by_convs, fw, device):
+ if not dim_by_convs:
+ # determine padding according to neighbor coords out of bound.
+ # this is a generalized notion of padding, when pad<0 it means crop
+ pad_sz = [-field_of_view[0, 0].item(), field_of_view[-1, -1].item() - in_sz + 1]
+
+ # since input image will be changed by padding, coordinates of both
+ # field_of_view and projected_grid need to be updated
+ field_of_view += pad_sz[0]
+ projected_grid += pad_sz[0]
+
+ else:
+ # only used for by_convs, to calc the boundaries of each filter the
+ # number of distinct convolutions is the numerator of the scale factor
+ num_convs, stride = scale_factor.numerator, scale_factor.denominator
+
+ # calculate left and right boundaries for each conv. left can also be
+ # negative right can be bigger than in_sz. such cases imply padding if
+ # needed. however if# both are in-bounds, it means we need to crop,
+ # practically apply the conv only on part of the image.
+ left_pads = -field_of_view[:, 0]
+
+ # next calc is tricky, explanation by rows:
+ # 1) counting output pixels between the first position of each filter
+ # to the right boundary of the input
+ # 2) dividing it by number of filters to count how many 'jumps'
+ # each filter does
+ # 3) multiplying by the stride gives us the distance over the input
+ # coords done by all these jumps for each filter
+ # 4) to this distance we add the right boundary of the filter when
+ # placed in its leftmost position. so now we get the right boundary
+ # of that filter in input coord.
+ # 5) the padding size needed is obtained by subtracting the rightmost
+ # input coordinate. if the result is positive padding is needed. if
+ # negative then negative padding means shaving off pixel columns.
+ right_pads = (((out_sz - fw_arange(num_convs, fw, device) - 1) # (1)
+ // num_convs) # (2)
+ * stride # (3)
+ + field_of_view[:, -1] # (4)
+ - in_sz + 1) # (5)
+
+ # in the by_convs case pad_sz is a list of left-right pairs. one per
+ # each filter
+
+ pad_sz = list(zip(left_pads, right_pads))
+
+ return pad_sz, projected_grid, field_of_view
+
+
+def get_weights(interp_method, projected_grid, field_of_view):
+ # the set of weights per each output pixels is the result of the chosen
+ # interpolation method applied to the distances between projected grid
+ # locations and the pixel-centers in the field of view (distances are
+ # directed, can be positive or negative)
+ weights = interp_method(projected_grid[:, None] - field_of_view)
+
+ # we now carefully normalize the weights to sum to 1 per each output pixel
+ sum_weights = weights.sum(1, keepdim=True)
+ sum_weights[sum_weights == 0] = 1
+ return weights / sum_weights
+
+
+def apply_weights(input, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw):
+ # for this operation we assume the resized dim is the first one.
+ # so we transpose and will transpose back after multiplying
+ tmp_input = fw_swapaxes(input, dim, 0, fw)
+
+ # apply padding
+ tmp_input = fw_pad(tmp_input, fw, pad_sz, pad_mode)
+
+ # field_of_view is a tensor of order 2: for each output (1d location
+ # along cur dim)- a list of 1d neighbors locations.
+ # note that this whole operations is applied to each dim separately,
+ # this is why it is all in 1d.
+ # neighbors = tmp_input[field_of_view] is a tensor of order image_dims+1:
+ # for each output pixel (this time indicated in all dims), these are the
+ # values of the neighbors in the 1d field of view. note that we only
+ # consider neighbors along the current dim, but such set exists for every
+ # multi-dim location, hence the final tensor order is image_dims+1.
+ paddle.device.cuda.empty_cache()
+ neighbors = tmp_input[field_of_view]
+
+ # weights is an order 2 tensor: for each output location along 1d- a list
+ # of weights matching the field of view. we augment it with ones, for
+ # broadcasting, so that when multiplies some tensor the weights affect
+ # only its first dim.
+ tmp_weights = fw.reshape(weights, (*weights.shape, *[1] * (n_dims - 1)))
+
+ # now we simply multiply the weights with the neighbors, and then sum
+ # along the field of view, to get a single value per out pixel
+ tmp_output = (neighbors * tmp_weights).sum(1)
+ # we transpose back the resized dim to its original position
+ return fw_swapaxes(tmp_output, 0, dim, fw)
+
+
+def apply_convs(input, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw):
+ # for this operations we assume the resized dim is the last one.
+ # so we transpose and will transpose back after multiplying
+ input = fw_swapaxes(input, dim, -1, fw)
+
+ # the stride for all convs is the denominator of the scale factor
+ stride, num_convs = scale_factor.denominator, scale_factor.numerator
+
+ # prepare an empty tensor for the output
+ tmp_out_shape = list(input.shape)
+ tmp_out_shape[-1] = out_sz
+ tmp_output = fw_empty(tuple(tmp_out_shape), fw, input.device)
+
+ # iterate over the conv operations. we have as many as the numerator
+ # of the scale-factor. for each we need boundaries and a filter.
+ for conv_ind, (pad_sz, filt) in enumerate(zip(pad_sz, weights)):
+ # apply padding (we pad last dim, padding can be negative)
+ pad_dim = input.ndim - 1
+ tmp_input = fw_pad(input, fw, pad_sz, pad_mode, dim=pad_dim)
+
+ # apply convolution over last dim. store in the output tensor with
+ # positional strides so that when the loop is comlete conv results are
+ # interwind
+ tmp_output[..., conv_ind::num_convs] = fw_conv(tmp_input, filt, stride)
+
+ return fw_swapaxes(tmp_output, -1, dim, fw)
+
+
+def set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs, scale_tolerance, max_numerator, eps, fw):
+ # eventually we must have both scale-factors and out-sizes for all in/out
+ # dims. however, we support many possible partial arguments
+ if scale_factors is None and out_shape is None:
+ raise ValueError("either scale_factors or out_shape should be "
+ "provided")
+ if out_shape is not None:
+ # if out_shape has less dims than in_shape, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ out_shape = (list(out_shape) +
+ list(in_shape[len(out_shape):]) if fw is numpy else list(in_shape[:-len(out_shape)]) +
+ list(out_shape))
+ if scale_factors is None:
+ # if no scale given, we calculate it as the out to in ratio
+ # (not recomended)
+ scale_factors = [out_sz / in_sz for out_sz, in_sz in zip(out_shape, in_shape)]
+ if scale_factors is not None:
+ # by default, if a single number is given as scale, we assume resizing
+ # two dims (most common are images with 2 spatial dims)
+ scale_factors = (scale_factors if isinstance(scale_factors, (list, tuple)) else [scale_factors, scale_factors])
+ # if less scale_factors than in_shape dims, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ scale_factors = (list(scale_factors) + [1] * (len(in_shape) - len(scale_factors)) if fw is numpy else [1] *
+ (len(in_shape) - len(scale_factors)) + list(scale_factors))
+ if out_shape is None:
+ # when no out_shape given, it is calculated by multiplying the
+ # scale by the in_shape (not recomended)
+ out_shape = [ceil(scale_factor * in_sz) for scale_factor, in_sz in zip(scale_factors, in_shape)]
+ # next part intentionally after out_shape determined for stability
+ # we fix by_convs to be a list of truth values in case it is not
+ if not isinstance(by_convs, (list, tuple)):
+ by_convs = [by_convs] * len(out_shape)
+
+ # next loop fixes the scale for each dim to be either frac or float.
+ # this is determined by by_convs and by tolerance for scale accuracy.
+ for ind, (sf, dim_by_convs) in enumerate(zip(scale_factors, by_convs)):
+ # first we fractionaize
+ if dim_by_convs:
+ frac = Fraction(1 / sf).limit_denominator(max_numerator)
+ frac = Fraction(numerator=frac.denominator, denominator=frac.numerator)
+
+ # if accuracy is within tolerance scale will be frac. if not, then
+ # it will be float and the by_convs attr will be set false for
+ # this dim
+ if scale_tolerance is None:
+ scale_tolerance = eps
+ if dim_by_convs and abs(frac - sf) < scale_tolerance:
+ scale_factors[ind] = frac
+ else:
+ scale_factors[ind] = float(sf)
+ by_convs[ind] = False
+
+ return scale_factors, out_shape, by_convs
+
+
+def apply_antialiasing_if_needed(interp_method, support_sz, scale_factor, antialiasing):
+ # antialiasing is "stretching" the field of view according to the scale
+ # factor (only for downscaling). this is low-pass filtering. this
+ # requires modifying both the interpolation (stretching the 1d
+ # function and multiplying by the scale-factor) and the window size.
+ scale_factor = float(scale_factor)
+ if scale_factor >= 1.0 or not antialiasing:
+ return interp_method, support_sz
+ cur_interp_method = (lambda arg: scale_factor * interp_method(scale_factor * arg))
+ cur_support_sz = support_sz / scale_factor
+ return cur_interp_method, cur_support_sz
+
+
+def fw_ceil(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.ceil(x))
+ else:
+ return paddle.cast(x.ceil(), dtype='int64')
+
+
+def fw_floor(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.floor(x))
+ else:
+ return paddle.cast(x.floor(), dtype='int64')
+
+
+def fw_cat(x, fw):
+ if fw is numpy:
+ return fw.concatenate(x)
+ else:
+ return fw.concat(x)
+
+
+def fw_swapaxes(x, ax_1, ax_2, fw):
+ if fw is numpy:
+ return fw.swapaxes(x, ax_1, ax_2)
+ else:
+ if ax_1 == -1:
+ ax_1 = len(x.shape) - 1
+ if ax_2 == -1:
+ ax_2 = len(x.shape) - 1
+ perm0 = list(range(len(x.shape)))
+ temp = ax_1
+ perm0[temp] = ax_2
+ perm0[ax_2] = temp
+ return fw.transpose(x, perm0)
+
+
+def fw_pad(x, fw, pad_sz, pad_mode, dim=0):
+ if pad_sz == (0, 0):
+ return x
+ if fw is numpy:
+ pad_vec = [(0, 0)] * x.ndim
+ pad_vec[dim] = pad_sz
+ return fw.pad(x, pad_width=pad_vec, mode=pad_mode)
+ else:
+ if x.ndim < 3:
+ x = x[None, None, ...]
+
+ pad_vec = [0] * ((x.ndim - 2) * 2)
+ pad_vec[0:2] = pad_sz
+ return fw_swapaxes(fw.nn.functional.pad(fw_swapaxes(x, dim, -1, fw), pad=pad_vec, mode=pad_mode), dim, -1, fw)
+
+
+def fw_conv(input, filter, stride):
+ # we want to apply 1d conv to any nd array. the way to do it is to reshape
+ # the input to a 4D tensor. first two dims are singeletons, 3rd dim stores
+ # all the spatial dims that we are not convolving along now. then we can
+ # apply conv2d with a 1xK filter. This convolves the same way all the other
+ # dims stored in the 3d dim. like depthwise conv over these.
+ # TODO: numpy support
+ reshaped_input = input.reshape(1, 1, -1, input.shape[-1])
+ reshaped_output = paddle.nn.functional.conv2d(reshaped_input, filter.view(1, 1, 1, -1), stride=(1, stride))
+ return reshaped_output.reshape(*input.shape[:-1], -1)
+
+
+def fw_arange(upper_bound, fw, device):
+ if fw is numpy:
+ return fw.arange(upper_bound)
+ else:
+ return fw.arange(upper_bound)
+
+
+def fw_empty(shape, fw, device):
+ if fw is numpy:
+ return fw.empty(shape)
+ else:
+ return fw.empty(shape=shape)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/README.md b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/README.md
new file mode 100644
index 000000000..711671bad
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/README.md
@@ -0,0 +1,2 @@
+# Diffusion model (Paddle)
+This module implements diffusion model which accepts a text prompt and outputs images semantically close to the text. The code is rewritten by Paddle, and mainly refer to two projects: jina-ai/discoart[https://github.com/jina-ai/discoart] and openai/guided-diffusion[https://github.com/openai/guided-diffusion]. Thanks for their wonderful work.
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/__init__.py
new file mode 100755
index 000000000..39fc908dc
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/__init__.py
@@ -0,0 +1,156 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/__init__.py
+'''
+import os
+import warnings
+
+os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
+
+__all__ = ['create']
+
+import sys
+
+__resources_path__ = os.path.join(
+ os.path.dirname(sys.modules.get(__package__).__file__ if __package__ in sys.modules else __file__),
+ 'resources',
+)
+
+import gc
+
+# check if GPU is available
+import paddle
+
+# download and load models, this will take some time on the first load
+
+from .helper import load_all_models, load_diffusion_model, load_clip_models
+
+model_config, secondary_model = load_all_models('512x512_diffusion_uncond_finetune_008100', use_secondary_model=True)
+
+from typing import TYPE_CHECKING, overload, List, Optional
+
+if TYPE_CHECKING:
+ from docarray import DocumentArray, Document
+
+_clip_models_cache = {}
+
+# begin_create_overload
+
+
+@overload
+def create(text_prompts: Optional[List[str]] = [
+ 'A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.',
+ 'yellow color scheme',
+],
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 10,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 150,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_model: Optional[str] = '512x512_diffusion_uncond_finetune_008100',
+ use_secondary_model: Optional[bool] = True,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 4,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ clip_models: Optional[list] = ['ViTB32', 'ViTB16', 'RN50'],
+ output_dir: Optional[str] = 'discoart_output') -> 'DocumentArray':
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_model: Diffusion_model of choice.
+ :param use_secondary_model: Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param clip_models: CLIP Model selectors. ViTB32, ViTB16, ViTL14, RN101, RN50, RN50x4, RN50x16, RN50x64.These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around. You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.The rough order of speed/mem usage is (smallest/fastest to largest/slowest):VitB32RN50RN101VitB16RN50x4RN50x16RN50x64ViTL14For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+# end_create_overload
+
+
+@overload
+def create(init_document: 'Document') -> 'DocumentArray':
+ """
+ Create an artwork using a DocArray ``Document`` object as initial state.
+ :param init_document: its ``.tags`` will be used as parameters, ``.uri`` (if present) will be used as init image.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+def create(**kwargs) -> 'DocumentArray':
+ from .config import load_config
+ from .runner import do_run
+
+ if 'init_document' in kwargs:
+ d = kwargs['init_document']
+ _kwargs = d.tags
+ if not _kwargs:
+ warnings.warn('init_document has no .tags, fallback to default config')
+ if d.uri:
+ _kwargs['init_image'] = kwargs['init_document'].uri
+ else:
+ warnings.warn('init_document has no .uri, fallback to no init image')
+ kwargs.pop('init_document')
+ if kwargs:
+ warnings.warn('init_document has .tags and .uri, but kwargs are also present, will override .tags')
+ _kwargs.update(kwargs)
+ _args = load_config(user_config=_kwargs)
+ else:
+ _args = load_config(user_config=kwargs)
+
+ model, diffusion = load_diffusion_model(model_config, _args.diffusion_model, steps=_args.steps)
+
+ clip_models = load_clip_models(enabled=_args.clip_models, clip_models=_clip_models_cache)
+
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+ try:
+ return do_run(_args, (model, diffusion, clip_models, secondary_model))
+ except KeyboardInterrupt:
+ pass
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/config.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/config.py
new file mode 100755
index 000000000..0cbc71e6f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/config.py
@@ -0,0 +1,77 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/config.py
+'''
+import copy
+import random
+import warnings
+from types import SimpleNamespace
+from typing import Dict
+
+import yaml
+from yaml import Loader
+
+from . import __resources_path__
+
+with open(f'{__resources_path__}/default.yml') as ymlfile:
+ default_args = yaml.load(ymlfile, Loader=Loader)
+
+
+def load_config(user_config: Dict, ):
+ cfg = copy.deepcopy(default_args)
+
+ if user_config:
+ cfg.update(**user_config)
+
+ for k in user_config.keys():
+ if k not in cfg:
+ warnings.warn(f'unknown argument {k}, ignored')
+
+ for k, v in cfg.items():
+ if k in ('batch_size', 'display_rate', 'seed', 'skip_steps', 'steps', 'n_batches',
+ 'cutn_batches') and isinstance(v, float):
+ cfg[k] = int(v)
+ if k == 'width_height':
+ cfg[k] = [int(vv) for vv in v]
+
+ cfg.update(**{
+ 'seed': cfg['seed'] or random.randint(0, 2**32),
+ })
+
+ if cfg['batch_name']:
+ da_name = f'{__package__}-{cfg["batch_name"]}-{cfg["seed"]}'
+ else:
+ da_name = f'{__package__}-{cfg["seed"]}'
+ warnings.warn('you did not set `batch_name`, set it to have unique session ID')
+
+ cfg.update(**{'name_docarray': da_name})
+
+ print_args_table(cfg)
+
+ return SimpleNamespace(**cfg)
+
+
+def print_args_table(cfg):
+ from rich.table import Table
+ from rich import box
+ from rich.console import Console
+
+ console = Console()
+
+ param_str = Table(
+ title=cfg['name_docarray'],
+ box=box.ROUNDED,
+ highlight=True,
+ title_justify='left',
+ )
+ param_str.add_column('Argument', justify='right')
+ param_str.add_column('Value', justify='left')
+
+ for k, v in sorted(cfg.items()):
+ value = str(v)
+
+ if not default_args.get(k, None) == v:
+ value = f'[b]{value}[/]'
+
+ param_str.add_row(k, value)
+
+ console.print(param_str)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/helper.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/helper.py
new file mode 100755
index 000000000..6fc4196be
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/helper.py
@@ -0,0 +1,137 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/helper.py
+'''
+import hashlib
+import logging
+import os
+import subprocess
+import sys
+from os.path import expanduser
+from pathlib import Path
+from typing import Any
+from typing import Dict
+from typing import List
+
+import paddle
+
+
+def _get_logger():
+ logger = logging.getLogger(__package__)
+ logger.setLevel("INFO")
+ ch = logging.StreamHandler()
+ ch.setLevel("INFO")
+ formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
+ ch.setFormatter(formatter)
+ logger.addHandler(ch)
+ return logger
+
+
+logger = _get_logger()
+
+
+def load_clip_models(enabled: List[str], clip_models: Dict[str, Any] = {}):
+
+ import disco_diffusion_clip_vitb32.clip.clip as clip
+ from disco_diffusion_clip_vitb32.clip.clip import build_model, tokenize, transform
+
+ # load enabled models
+ for k in enabled:
+ if k not in clip_models:
+ clip_models[k] = build_model(name=k)
+ clip_models[k].eval()
+ for parameter in clip_models[k].parameters():
+ parameter.stop_gradient = True
+
+ # disable not enabled models to save memory
+ for k in clip_models:
+ if k not in enabled:
+ clip_models.pop(k)
+
+ return list(clip_models.values())
+
+
+def load_all_models(diffusion_model, use_secondary_model):
+ from .model.script_util import (
+ model_and_diffusion_defaults, )
+
+ model_config = model_and_diffusion_defaults()
+
+ if diffusion_model == '512x512_diffusion_uncond_finetune_008100':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 512,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+ elif diffusion_model == '256x256_diffusion_uncond':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 256,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+
+ secondary_model = None
+ if use_secondary_model:
+ from .model.sec_diff import SecondaryDiffusionImageNet2
+ secondary_model = SecondaryDiffusionImageNet2()
+ model_dict = paddle.load(
+ os.path.join(os.path.dirname(__file__), 'pre_trained', 'secondary_model_imagenet_2.pdparams'))
+ secondary_model.set_state_dict(model_dict)
+ secondary_model.eval()
+ for parameter in secondary_model.parameters():
+ parameter.stop_gradient = True
+
+ return model_config, secondary_model
+
+
+def load_diffusion_model(model_config, diffusion_model, steps):
+ from .model.script_util import (
+ create_model_and_diffusion, )
+
+ timestep_respacing = f'ddim{steps}'
+ diffusion_steps = (1000 // steps) * steps if steps < 1000 else steps
+ model_config.update({
+ 'timestep_respacing': timestep_respacing,
+ 'diffusion_steps': diffusion_steps,
+ })
+
+ model, diffusion = create_model_and_diffusion(**model_config)
+ model.set_state_dict(
+ paddle.load(os.path.join(os.path.dirname(__file__), 'pre_trained', f'{diffusion_model}.pdparams')))
+ model.eval()
+ for name, param in model.named_parameters():
+ param.stop_gradient = True
+
+ return model, diffusion
+
+
+def parse_prompt(prompt):
+ if prompt.startswith('http://') or prompt.startswith('https://'):
+ vals = prompt.rsplit(':', 2)
+ vals = [vals[0] + ':' + vals[1], *vals[2:]]
+ else:
+ vals = prompt.rsplit(':', 1)
+ vals = vals + ['', '1'][len(vals):]
+ return vals[0], float(vals[1])
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/__init__.py
new file mode 100755
index 000000000..466800666
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/__init__.py
@@ -0,0 +1,3 @@
+"""
+Codebase for "Improved Denoising Diffusion Probabilistic Models" implemented by Paddle.
+"""
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/gaussian_diffusion.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/gaussian_diffusion.py
new file mode 100755
index 000000000..86cd2c650
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/gaussian_diffusion.py
@@ -0,0 +1,1214 @@
+"""
+Diffusion model implemented by Paddle.
+This code is rewritten based on Pytorch version of of Ho et al's diffusion models:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py
+"""
+import enum
+import math
+
+import numpy as np
+import paddle
+
+from .losses import discretized_gaussian_log_likelihood
+from .losses import normal_kl
+from .nn import mean_flat
+
+
+def get_named_beta_schedule(schedule_name, num_diffusion_timesteps):
+ """
+ Get a pre-defined beta schedule for the given name.
+
+ The beta schedule library consists of beta schedules which remain similar
+ in the limit of num_diffusion_timesteps.
+ Beta schedules may be added, but should not be removed or changed once
+ they are committed to maintain backwards compatibility.
+ """
+ if schedule_name == "linear":
+ # Linear schedule from Ho et al, extended to work for any number of
+ # diffusion steps.
+ scale = 1000 / num_diffusion_timesteps
+ beta_start = scale * 0.0001
+ beta_end = scale * 0.02
+ return np.linspace(beta_start, beta_end, num_diffusion_timesteps, dtype=np.float64)
+ elif schedule_name == "cosine":
+ return betas_for_alpha_bar(
+ num_diffusion_timesteps,
+ lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2)**2,
+ )
+ else:
+ raise NotImplementedError(f"unknown beta schedule: {schedule_name}")
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function,
+ which defines the cumulative product of (1-beta) over time from t = [0,1].
+
+ :param num_diffusion_timesteps: the number of betas to produce.
+ :param alpha_bar: a lambda that takes an argument t from 0 to 1 and
+ produces the cumulative product of (1-beta) up to that
+ part of the diffusion process.
+ :param max_beta: the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+ """
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return np.array(betas)
+
+
+class ModelMeanType(enum.Enum):
+ """
+ Which type of output the model predicts.
+ """
+
+ PREVIOUS_X = enum.auto() # the model predicts x_{t-1}
+ START_X = enum.auto() # the model predicts x_0
+ EPSILON = enum.auto() # the model predicts epsilon
+
+
+class ModelVarType(enum.Enum):
+ """
+ What is used as the model's output variance.
+
+ The LEARNED_RANGE option has been added to allow the model to predict
+ values between FIXED_SMALL and FIXED_LARGE, making its job easier.
+ """
+
+ LEARNED = enum.auto()
+ FIXED_SMALL = enum.auto()
+ FIXED_LARGE = enum.auto()
+ LEARNED_RANGE = enum.auto()
+
+
+class LossType(enum.Enum):
+ MSE = enum.auto() # use raw MSE loss (and KL when learning variances)
+ RESCALED_MSE = (enum.auto()) # use raw MSE loss (with RESCALED_KL when learning variances)
+ KL = enum.auto() # use the variational lower-bound
+ RESCALED_KL = enum.auto() # like KL, but rescale to estimate the full VLB
+
+ def is_vb(self):
+ return self == LossType.KL or self == LossType.RESCALED_KL
+
+
+class GaussianDiffusion:
+ """
+ Utilities for training and sampling diffusion models.
+
+ Ported directly from here, and then adapted over time to further experimentation.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py#L42
+
+ :param betas: a 1-D numpy array of betas for each diffusion timestep,
+ starting at T and going to 1.
+ :param model_mean_type: a ModelMeanType determining what the model outputs.
+ :param model_var_type: a ModelVarType determining how variance is output.
+ :param loss_type: a LossType determining the loss function to use.
+ :param rescale_timesteps: if True, pass floating point timesteps into the
+ model so that they are always scaled like in the
+ original paper (0 to 1000).
+ """
+
+ def __init__(
+ self,
+ *,
+ betas,
+ model_mean_type,
+ model_var_type,
+ loss_type,
+ rescale_timesteps=False,
+ ):
+ self.model_mean_type = model_mean_type
+ self.model_var_type = model_var_type
+ self.loss_type = loss_type
+ self.rescale_timesteps = rescale_timesteps
+
+ # Use float64 for accuracy.
+ betas = np.array(betas, dtype=np.float64)
+ self.betas = betas
+ assert len(betas.shape) == 1, "betas must be 1-D"
+ assert (betas > 0).all() and (betas <= 1).all()
+
+ self.num_timesteps = int(betas.shape[0])
+
+ alphas = 1.0 - betas
+ self.alphas_cumprod = np.cumprod(alphas, axis=0)
+ self.alphas_cumprod_prev = np.append(1.0, self.alphas_cumprod[:-1])
+ self.alphas_cumprod_next = np.append(self.alphas_cumprod[1:], 0.0)
+ assert self.alphas_cumprod_prev.shape == (self.num_timesteps, )
+
+ # calculations for diffusion q(x_t | x_{t-1}) and others
+ self.sqrt_alphas_cumprod = np.sqrt(self.alphas_cumprod)
+ self.sqrt_one_minus_alphas_cumprod = np.sqrt(1.0 - self.alphas_cumprod)
+ self.log_one_minus_alphas_cumprod = np.log(1.0 - self.alphas_cumprod)
+ self.sqrt_recip_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod)
+ self.sqrt_recipm1_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod - 1)
+
+ # calculations for posterior q(x_{t-1} | x_t, x_0)
+ self.posterior_variance = (betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ # log calculation clipped because the posterior variance is 0 at the
+ # beginning of the diffusion chain.
+ self.posterior_log_variance_clipped = np.log(np.append(self.posterior_variance[1], self.posterior_variance[1:]))
+ self.posterior_mean_coef1 = (betas * np.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ self.posterior_mean_coef2 = ((1.0 - self.alphas_cumprod_prev) * np.sqrt(alphas) / (1.0 - self.alphas_cumprod))
+
+ def q_mean_variance(self, x_start, t):
+ """
+ Get the distribution q(x_t | x_0).
+
+ :param x_start: the [N x C x ...] tensor of noiseless inputs.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :return: A tuple (mean, variance, log_variance), all of x_start's shape.
+ """
+ mean = (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start)
+ variance = _extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
+ log_variance = _extract_into_tensor(self.log_one_minus_alphas_cumprod, t, x_start.shape)
+ return mean, variance, log_variance
+
+ def q_sample(self, x_start, t, noise=None):
+ """
+ Diffuse the data for a given number of diffusion steps.
+
+ In other words, sample from q(x_t | x_0).
+
+ :param x_start: the initial data batch.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :param noise: if specified, the split-out normal noise.
+ :return: A noisy version of x_start.
+ """
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ assert noise.shape == x_start.shape
+ return (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
+ _extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
+
+ def q_posterior_mean_variance(self, x_start, x_t, t):
+ """
+ Compute the mean and variance of the diffusion posterior:
+
+ q(x_{t-1} | x_t, x_0)
+
+ """
+ assert x_start.shape == x_t.shape
+ posterior_mean = (_extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start +
+ _extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t)
+ posterior_variance = _extract_into_tensor(self.posterior_variance, t, x_t.shape)
+ posterior_log_variance_clipped = _extract_into_tensor(self.posterior_log_variance_clipped, t, x_t.shape)
+ assert (posterior_mean.shape[0] == posterior_variance.shape[0] == posterior_log_variance_clipped.shape[0] ==
+ x_start.shape[0])
+ return posterior_mean, posterior_variance, posterior_log_variance_clipped
+
+ def p_mean_variance(self, model, x, t, clip_denoised=True, denoised_fn=None, model_kwargs=None):
+ """
+ Apply the model to get p(x_{t-1} | x_t), as well as a prediction of
+ the initial x, x_0.
+
+ :param model: the model, which takes a signal and a batch of timesteps
+ as input.
+ :param x: the [N x C x ...] tensor at time t.
+ :param t: a 1-D Tensor of timesteps.
+ :param clip_denoised: if True, clip the denoised signal into [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample. Applies before
+ clip_denoised.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict with the following keys:
+ - 'mean': the model mean output.
+ - 'variance': the model variance output.
+ - 'log_variance': the log of 'variance'.
+ - 'pred_xstart': the prediction for x_0.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+
+ B, C = x.shape[:2]
+ assert t.shape == [B]
+ model_output = model(x, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [ModelVarType.LEARNED, ModelVarType.LEARNED_RANGE]:
+ assert model_output.shape == [B, C * 2, *x.shape[2:]]
+ model_output, model_var_values = paddle.split(model_output, 2, axis=1)
+ if self.model_var_type == ModelVarType.LEARNED:
+ model_log_variance = model_var_values
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ min_log = _extract_into_tensor(self.posterior_log_variance_clipped, t, x.shape)
+ max_log = _extract_into_tensor(np.log(self.betas), t, x.shape)
+ # The model_var_values is [-1, 1] for [min_var, max_var].
+ frac = (model_var_values + 1) / 2
+ model_log_variance = frac * max_log + (1 - frac) * min_log
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ model_variance, model_log_variance = {
+ # for fixedlarge, we set the initial (log-)variance like so
+ # to get a better decoder log likelihood.
+ ModelVarType.FIXED_LARGE: (
+ np.append(self.posterior_variance[1], self.betas[1:]),
+ np.log(np.append(self.posterior_variance[1], self.betas[1:])),
+ ),
+ ModelVarType.FIXED_SMALL: (
+ self.posterior_variance,
+ self.posterior_log_variance_clipped,
+ ),
+ }[self.model_var_type]
+ model_variance = _extract_into_tensor(model_variance, t, x.shape)
+ model_log_variance = _extract_into_tensor(model_log_variance, t, x.shape)
+
+ def process_xstart(x):
+ if denoised_fn is not None:
+ x = denoised_fn(x)
+ if clip_denoised:
+ return x.clamp(-1, 1)
+ return x
+
+ if self.model_mean_type == ModelMeanType.PREVIOUS_X:
+ pred_xstart = process_xstart(self._predict_xstart_from_xprev(x_t=x, t=t, xprev=model_output))
+ model_mean = model_output
+ elif self.model_mean_type in [ModelMeanType.START_X, ModelMeanType.EPSILON]:
+ if self.model_mean_type == ModelMeanType.START_X:
+ pred_xstart = process_xstart(model_output)
+ else:
+ pred_xstart = process_xstart(self._predict_xstart_from_eps(x_t=x, t=t, eps=model_output))
+ model_mean, _, _ = self.q_posterior_mean_variance(x_start=pred_xstart, x_t=x, t=t)
+ else:
+ raise NotImplementedError(self.model_mean_type)
+
+ assert (model_mean.shape == model_log_variance.shape == pred_xstart.shape == x.shape)
+ return {
+ "mean": model_mean,
+ "variance": model_variance,
+ "log_variance": model_log_variance,
+ "pred_xstart": pred_xstart,
+ }
+
+ def _predict_xstart_from_eps(self, x_t, t, eps):
+ assert x_t.shape == eps.shape
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * eps)
+
+ def _predict_xstart_from_xprev(self, x_t, t, xprev):
+ assert x_t.shape == xprev.shape
+ return ( # (xprev - coef2*x_t) / coef1
+ _extract_into_tensor(1.0 / self.posterior_mean_coef1, t, x_t.shape) * xprev -
+ _extract_into_tensor(self.posterior_mean_coef2 / self.posterior_mean_coef1, t, x_t.shape) * x_t)
+
+ def _predict_eps_from_xstart(self, x_t, t, pred_xstart):
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ pred_xstart) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
+
+ def _scale_timesteps(self, t):
+ if self.rescale_timesteps:
+ return paddle.cast((t), 'float32') * (1000.0 / self.num_timesteps)
+ return t
+
+ def condition_mean(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_mean_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, t, p_mean_var, **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_score(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def condition_score_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, t, p_mean_var, **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def p_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"]}
+
+ def p_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean_with_grad(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"].detach()}
+
+ def p_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model.
+
+ :param model: the model module.
+ :param shape: the shape of the samples, (N, C, H, W).
+ :param noise: if specified, the noise from the encoder to sample.
+ Should be of the same shape as `shape`.
+ :param clip_denoised: if True, clip x_start predictions to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param device: if specified, the device to create the samples on.
+ If not specified, use a model parameter's device.
+ :param progress: if True, show a tqdm progress bar.
+ :return: a non-differentiable batch of samples.
+ """
+ final = None
+ for sample in self.p_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def p_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model and yield intermediate samples from
+ each timestep of diffusion.
+
+ Arguments are the same as p_sample_loop().
+ Returns a generator over dicts, where each dict is the return value of
+ p_sample().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ sample_fn = self.p_sample_with_grad if cond_fn_with_grad else self.p_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ )
+ yield out
+ img = out["sample"]
+
+ def ddim_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"]}
+
+ def ddim_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ out["pred_xstart"] = out["pred_xstart"].detach()
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"].detach()}
+
+ def ddim_reverse_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t+1} from the model using DDIM reverse ODE.
+ """
+ assert eta == 0.0, "Reverse ODE only for deterministic path"
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x.shape) * x -
+ out["pred_xstart"]) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x.shape)
+ alpha_bar_next = _extract_into_tensor(self.alphas_cumprod_next, t, x.shape)
+
+ # Equation 12. reversed
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_next) + paddle.sqrt(1 - alpha_bar_next) * eps)
+
+ return {"sample": mean_pred, "pred_xstart": out["pred_xstart"]}
+
+ def ddim_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model using DDIM.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.ddim_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ eta=eta,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def ddim_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Use DDIM to sample from the model and yield intermediate samples from
+ each timestep of DDIM.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ # if device is None:
+ # device = next(model.parameters()).device
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0])
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(
+ low=0,
+ high=model.num_classes,
+ shape=model_kwargs['y'].shape,
+ )
+ sample_fn = self.ddim_sample_with_grad if cond_fn_with_grad else self.ddim_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ eta=eta,
+ )
+ yield out
+ img = out["sample"]
+
+ def plms_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ cond_fn_with_grad=False,
+ order=2,
+ old_out=None,
+ ):
+ """
+ Sample x_{t-1} from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample().
+ """
+ if not int(order) or not 1 <= order <= 4:
+ raise ValueError('order is invalid (should be int from 1-4).')
+
+ def get_model_output(x, t):
+ with paddle.set_grad_enabled(cond_fn_with_grad and cond_fn is not None):
+ x = x.detach().requires_grad_() if cond_fn_with_grad else x
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ if cond_fn_with_grad:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ x = x.detach()
+ else:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+ return eps, out, out_orig
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ eps, out, out_orig = get_model_output(x, t)
+
+ if order > 1 and old_out is None:
+ # Pseudo Improved Euler
+ old_eps = [eps]
+ mean_pred = out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps
+ eps_2, _, _ = get_model_output(mean_pred, t - 1)
+ eps_prime = (eps + eps_2) / 2
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+ else:
+ # Pseudo Linear Multistep (Adams-Bashforth)
+ old_eps = old_out["old_eps"]
+ old_eps.append(eps)
+ cur_order = min(order, len(old_eps))
+ if cur_order == 1:
+ eps_prime = old_eps[-1]
+ elif cur_order == 2:
+ eps_prime = (3 * old_eps[-1] - old_eps[-2]) / 2
+ elif cur_order == 3:
+ eps_prime = (23 * old_eps[-1] - 16 * old_eps[-2] + 5 * old_eps[-3]) / 12
+ elif cur_order == 4:
+ eps_prime = (55 * old_eps[-1] - 59 * old_eps[-2] + 37 * old_eps[-3] - 9 * old_eps[-4]) / 24
+ else:
+ raise RuntimeError('cur_order is invalid.')
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+
+ if len(old_eps) >= order:
+ old_eps.pop(0)
+
+ nonzero_mask = paddle.cast((t != 0), 'float32').reshape([-1, *([1] * (len(x.shape) - 1))])
+ sample = mean_pred * nonzero_mask + out["pred_xstart"] * (1 - nonzero_mask)
+
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"], "old_eps": old_eps}
+
+ def plms_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Generate samples from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.plms_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ ):
+ final = sample
+ return final["sample"]
+
+ def plms_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Use PLMS to sample from the model and yield intermediate samples from each
+ timestep of PLMS.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ old_out = None
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ out = self.plms_sample(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ old_out=old_out,
+ )
+ yield out
+ old_out = out
+ img = out["sample"]
+
+ def _vb_terms_bpd(self, model, x_start, x_t, t, clip_denoised=True, model_kwargs=None):
+ """
+ Get a term for the variational lower-bound.
+
+ The resulting units are bits (rather than nats, as one might expect).
+ This allows for comparison to other papers.
+
+ :return: a dict with the following keys:
+ - 'output': a shape [N] tensor of NLLs or KLs.
+ - 'pred_xstart': the x_0 predictions.
+ """
+ true_mean, _, true_log_variance_clipped = self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)
+ out = self.p_mean_variance(model, x_t, t, clip_denoised=clip_denoised, model_kwargs=model_kwargs)
+ kl = normal_kl(true_mean, true_log_variance_clipped, out["mean"], out["log_variance"])
+ kl = mean_flat(kl) / np.log(2.0)
+
+ decoder_nll = -discretized_gaussian_log_likelihood(
+ x_start, means=out["mean"], log_scales=0.5 * out["log_variance"])
+ assert decoder_nll.shape == x_start.shape
+ decoder_nll = mean_flat(decoder_nll) / np.log(2.0)
+
+ # At the first timestep return the decoder NLL,
+ # otherwise return KL(q(x_{t-1}|x_t,x_0) || p(x_{t-1}|x_t))
+ output = paddle.where((t == 0), decoder_nll, kl)
+ return {"output": output, "pred_xstart": out["pred_xstart"]}
+
+ def training_losses(self, model, x_start, t, model_kwargs=None, noise=None):
+ """
+ Compute training losses for a single timestep.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param t: a batch of timestep indices.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param noise: if specified, the specific Gaussian noise to try to remove.
+ :return: a dict with the key "loss" containing a tensor of shape [N].
+ Some mean or variance settings may also have other keys.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start, t, noise=noise)
+
+ terms = {}
+
+ if self.loss_type == LossType.KL or self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] = self._vb_terms_bpd(
+ model=model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ model_kwargs=model_kwargs,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] *= self.num_timesteps
+ elif self.loss_type == LossType.MSE or self.loss_type == LossType.RESCALED_MSE:
+ model_output = model(x_t, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [
+ ModelVarType.LEARNED,
+ ModelVarType.LEARNED_RANGE,
+ ]:
+ B, C = x_t.shape[:2]
+ assert model_output.shape == (B, C * 2, *x_t.shape[2:])
+ model_output, model_var_values = paddle.split(model_output, 2, dim=1)
+ # Learn the variance using the variational bound, but don't let
+ # it affect our mean prediction.
+ frozen_out = paddle.concat([model_output.detach(), model_var_values], axis=1)
+ terms["vb"] = self._vb_terms_bpd(
+ model=lambda *args, r=frozen_out: r,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_MSE:
+ # Divide by 1000 for equivalence with initial implementation.
+ # Without a factor of 1/1000, the VB term hurts the MSE term.
+ terms["vb"] *= self.num_timesteps / 1000.0
+
+ target = {
+ ModelMeanType.PREVIOUS_X: self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)[0],
+ ModelMeanType.START_X: x_start,
+ ModelMeanType.EPSILON: noise,
+ }[self.model_mean_type]
+ assert model_output.shape == target.shape == x_start.shape
+ terms["mse"] = mean_flat((target - model_output)**2)
+ if "vb" in terms:
+ terms["loss"] = terms["mse"] + terms["vb"]
+ else:
+ terms["loss"] = terms["mse"]
+ else:
+ raise NotImplementedError(self.loss_type)
+
+ return terms
+
+ def _prior_bpd(self, x_start):
+ """
+ Get the prior KL term for the variational lower-bound, measured in
+ bits-per-dim.
+
+ This term can't be optimized, as it only depends on the encoder.
+
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :return: a batch of [N] KL values (in bits), one per batch element.
+ """
+ batch_size = x_start.shape[0]
+ t = paddle.to_tensor([self.num_timesteps - 1] * batch_size, place=x_start.place)
+ qt_mean, _, qt_log_variance = self.q_mean_variance(x_start, t)
+ kl_prior = normal_kl(mean1=qt_mean, logvar1=qt_log_variance, mean2=0.0, logvar2=0.0)
+ return mean_flat(kl_prior) / np.log(2.0)
+
+ def calc_bpd_loop(self, model, x_start, clip_denoised=True, model_kwargs=None):
+ """
+ Compute the entire variational lower-bound, measured in bits-per-dim,
+ as well as other related quantities.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param clip_denoised: if True, clip denoised samples.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+
+ :return: a dict containing the following keys:
+ - total_bpd: the total variational lower-bound, per batch element.
+ - prior_bpd: the prior term in the lower-bound.
+ - vb: an [N x T] tensor of terms in the lower-bound.
+ - xstart_mse: an [N x T] tensor of x_0 MSEs for each timestep.
+ - mse: an [N x T] tensor of epsilon MSEs for each timestep.
+ """
+ device = x_start.place
+ batch_size = x_start.shape[0]
+
+ vb = []
+ xstart_mse = []
+ mse = []
+ for t in list(range(self.num_timesteps))[::-1]:
+ t_batch = paddle.to_tensor([t] * batch_size, place=device)
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start=x_start, t=t_batch, noise=noise)
+ # Calculate VLB term at the current timestep
+ # with paddle.no_grad():
+ out = self._vb_terms_bpd(
+ model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t_batch,
+ clip_denoised=clip_denoised,
+ model_kwargs=model_kwargs,
+ )
+ vb.append(out["output"])
+ xstart_mse.append(mean_flat((out["pred_xstart"] - x_start)**2))
+ eps = self._predict_eps_from_xstart(x_t, t_batch, out["pred_xstart"])
+ mse.append(mean_flat((eps - noise)**2))
+
+ vb = paddle.stack(vb, axis=1)
+ xstart_mse = paddle.stack(xstart_mse, axis=1)
+ mse = paddle.stack(mse, axis=1)
+
+ prior_bpd = self._prior_bpd(x_start)
+ total_bpd = vb.sum(axis=1) + prior_bpd
+ return {
+ "total_bpd": total_bpd,
+ "prior_bpd": prior_bpd,
+ "vb": vb,
+ "xstart_mse": xstart_mse,
+ "mse": mse,
+ }
+
+
+def _extract_into_tensor(arr, timesteps, broadcast_shape):
+ """
+ Extract values from a 1-D numpy array for a batch of indices.
+
+ :param arr: the 1-D numpy array.
+ :param timesteps: a tensor of indices into the array to extract.
+ :param broadcast_shape: a larger shape of K dimensions with the batch
+ dimension equal to the length of timesteps.
+ :return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
+ """
+ res = paddle.to_tensor(arr, place=timesteps.place)[timesteps]
+ while len(res.shape) < len(broadcast_shape):
+ res = res[..., None]
+ return res.expand(broadcast_shape)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/losses.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/losses.py
new file mode 100755
index 000000000..5c3970de5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/losses.py
@@ -0,0 +1,86 @@
+"""
+Helpers for various likelihood-based losses implemented by Paddle. These are ported from the original
+Ho et al. diffusion models codebase:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/utils.py
+"""
+import numpy as np
+import paddle
+import paddle.nn.functional as F
+
+
+def normal_kl(mean1, logvar1, mean2, logvar2):
+ """
+ Compute the KL divergence between two gaussians.
+
+ Shapes are automatically broadcasted, so batches can be compared to
+ scalars, among other use cases.
+ """
+ tensor = None
+ for obj in (mean1, logvar1, mean2, logvar2):
+ if isinstance(obj, paddle.Tensor):
+ tensor = obj
+ break
+ assert tensor is not None, "at least one argument must be a Tensor"
+
+ # Force variances to be Tensors. Broadcasting helps convert scalars to
+ # Tensors, but it does not work for th.exp().
+ logvar1, logvar2 = [x if isinstance(x, paddle.Tensor) else paddle.to_tensor(x) for x in (logvar1, logvar2)]
+
+ return 0.5 * (-1.0 + logvar2 - logvar1 + paddle.exp(logvar1 - logvar2) +
+ ((mean1 - mean2)**2) * paddle.exp(-logvar2))
+
+
+def approx_standard_normal_cdf(x):
+ """
+ A fast approximation of the cumulative distribution function of the
+ standard normal.
+ """
+ return 0.5 * (1.0 + paddle.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * paddle.pow(x, 3))))
+
+
+def discretized_gaussian_log_likelihood(x, *, means, log_scales):
+ """
+ Compute the log-likelihood of a Gaussian distribution discretizing to a
+ given image.
+
+ :param x: the target images. It is assumed that this was uint8 values,
+ rescaled to the range [-1, 1].
+ :param means: the Gaussian mean Tensor.
+ :param log_scales: the Gaussian log stddev Tensor.
+ :return: a tensor like x of log probabilities (in nats).
+ """
+ assert x.shape == means.shape == log_scales.shape
+ centered_x = x - means
+ inv_stdv = paddle.exp(-log_scales)
+ plus_in = inv_stdv * (centered_x + 1.0 / 255.0)
+ cdf_plus = approx_standard_normal_cdf(plus_in)
+ min_in = inv_stdv * (centered_x - 1.0 / 255.0)
+ cdf_min = approx_standard_normal_cdf(min_in)
+ log_cdf_plus = paddle.log(cdf_plus.clip(min=1e-12))
+ log_one_minus_cdf_min = paddle.log((1.0 - cdf_min).clip(min=1e-12))
+ cdf_delta = cdf_plus - cdf_min
+ log_probs = paddle.where(
+ x < -0.999,
+ log_cdf_plus,
+ paddle.where(x > 0.999, log_one_minus_cdf_min, paddle.log(cdf_delta.clip(min=1e-12))),
+ )
+ assert log_probs.shape == x.shape
+ return log_probs
+
+
+def spherical_dist_loss(x, y):
+ x = F.normalize(x, axis=-1)
+ y = F.normalize(y, axis=-1)
+ return (x - y).norm(axis=-1).divide(paddle.to_tensor(2.0)).asin().pow(2).multiply(paddle.to_tensor(2.0))
+
+
+def tv_loss(input):
+ """L2 total variation loss, as in Mahendran et al."""
+ input = F.pad(input, (0, 1, 0, 1), 'replicate')
+ x_diff = input[..., :-1, 1:] - input[..., :-1, :-1]
+ y_diff = input[..., 1:, :-1] - input[..., :-1, :-1]
+ return (x_diff**2 + y_diff**2).mean([1, 2, 3])
+
+
+def range_loss(input):
+ return (input - input.clip(-1, 1)).pow(2).mean([1, 2, 3])
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/make_cutouts.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/make_cutouts.py
new file mode 100755
index 000000000..cd46e4bd5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/make_cutouts.py
@@ -0,0 +1,177 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/make_cutouts.py
+'''
+import math
+
+import paddle
+import paddle.nn as nn
+from disco_diffusion_clip_vitb32.resize_right.resize_right import resize
+from paddle.nn import functional as F
+
+from . import transforms as T
+
+skip_augs = False # @param{type: 'boolean'}
+
+
+def sinc(x):
+ return paddle.where(x != 0, paddle.sin(math.pi * x) / (math.pi * x), x.new_ones([]))
+
+
+def lanczos(x, a):
+ cond = paddle.logical_and(-a < x, x < a)
+ out = paddle.where(cond, sinc(x) * sinc(x / a), x.new_zeros([]))
+ return out / out.sum()
+
+
+def ramp(ratio, width):
+ n = math.ceil(width / ratio + 1)
+ out = paddle.empty([n])
+ cur = 0
+ for i in range(out.shape[0]):
+ out[i] = cur
+ cur += ratio
+ return paddle.concat([-out[1:].flip([0]), out])[1:-1]
+
+
+class MakeCutouts(nn.Layer):
+
+ def __init__(self, cut_size, cutn, skip_augs=False):
+ super().__init__()
+ self.cut_size = cut_size
+ self.cutn = cutn
+ self.skip_augs = skip_augs
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(degrees=15, translate=(0.1, 0.1)),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomPerspective(distortion_scale=0.4, p=0.7),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.15),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ input = T.Pad(input.shape[2] // 4, fill=0)(input)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+
+ cutouts = []
+ for ch in range(self.cutn):
+ if ch > self.cutn - self.cutn // 4:
+ cutout = input.clone()
+ else:
+ size = int(max_size *
+ paddle.zeros(1, ).normal_(mean=0.8, std=0.3).clip(float(self.cut_size / max_size), 1.0))
+ offsetx = paddle.randint(0, abs(sideX - size + 1), ())
+ offsety = paddle.randint(0, abs(sideY - size + 1), ())
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+
+ if not self.skip_augs:
+ cutout = self.augs(cutout)
+ cutouts.append(resample(cutout, (self.cut_size, self.cut_size)))
+ del cutout
+
+ cutouts = paddle.concat(cutouts, axis=0)
+ return cutouts
+
+
+class MakeCutoutsDango(nn.Layer):
+
+ def __init__(self, cut_size, Overview=4, InnerCrop=0, IC_Size_Pow=0.5, IC_Grey_P=0.2):
+ super().__init__()
+ self.cut_size = cut_size
+ self.Overview = Overview
+ self.InnerCrop = InnerCrop
+ self.IC_Size_Pow = IC_Size_Pow
+ self.IC_Grey_P = IC_Grey_P
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(
+ degrees=10,
+ translate=(0.05, 0.05),
+ interpolation=T.InterpolationMode.BILINEAR,
+ ),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.1),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ cutouts = []
+ gray = T.Grayscale(3)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+ min_size = min(sideX, sideY, self.cut_size)
+ output_shape = [1, 3, self.cut_size, self.cut_size]
+ pad_input = F.pad(
+ input,
+ (
+ (sideY - max_size) // 2,
+ (sideY - max_size) // 2,
+ (sideX - max_size) // 2,
+ (sideX - max_size) // 2,
+ ),
+ **padargs,
+ )
+ cutout = resize(pad_input, out_shape=output_shape)
+
+ if self.Overview > 0:
+ if self.Overview <= 4:
+ if self.Overview >= 1:
+ cutouts.append(cutout)
+ if self.Overview >= 2:
+ cutouts.append(gray(cutout))
+ if self.Overview >= 3:
+ cutouts.append(cutout[:, :, :, ::-1])
+ if self.Overview == 4:
+ cutouts.append(gray(cutout[:, :, :, ::-1]))
+ else:
+ cutout = resize(pad_input, out_shape=output_shape)
+ for _ in range(self.Overview):
+ cutouts.append(cutout)
+
+ if self.InnerCrop > 0:
+ for i in range(self.InnerCrop):
+ size = int(paddle.rand([1])**self.IC_Size_Pow * (max_size - min_size) + min_size)
+ offsetx = paddle.randint(0, sideX - size + 1)
+ offsety = paddle.randint(0, sideY - size + 1)
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+ if i <= int(self.IC_Grey_P * self.InnerCrop):
+ cutout = gray(cutout)
+ cutout = resize(cutout, out_shape=output_shape)
+ cutouts.append(cutout)
+
+ cutouts = paddle.concat(cutouts)
+ if skip_augs is not True:
+ cutouts = self.augs(cutouts)
+ return cutouts
+
+
+def resample(input, size, align_corners=True):
+ n, c, h, w = input.shape
+ dh, dw = size
+
+ input = input.reshape([n * c, 1, h, w])
+
+ if dh < h:
+ kernel_h = lanczos(ramp(dh / h, 2), 2).to(input.device, input.dtype)
+ pad_h = (kernel_h.shape[0] - 1) // 2
+ input = F.pad(input, (0, 0, pad_h, pad_h), 'reflect')
+ input = F.conv2d(input, kernel_h[None, None, :, None])
+
+ if dw < w:
+ kernel_w = lanczos(ramp(dw / w, 2), 2).to(input.device, input.dtype)
+ pad_w = (kernel_w.shape[0] - 1) // 2
+ input = F.pad(input, (pad_w, pad_w, 0, 0), 'reflect')
+ input = F.conv2d(input, kernel_w[None, None, None, :])
+
+ input = input.reshape([n, c, h, w])
+ return F.interpolate(input, size, mode='bicubic', align_corners=align_corners)
+
+
+padargs = {}
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/nn.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/nn.py
new file mode 100755
index 000000000..d618183e2
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/nn.py
@@ -0,0 +1,127 @@
+"""
+Various utilities for neural networks implemented by Paddle. This code is rewritten based on:
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/nn.py
+"""
+import math
+
+import paddle
+import paddle.nn as nn
+
+
+class SiLU(nn.Layer):
+
+ def forward(self, x):
+ return x * nn.functional.sigmoid(x)
+
+
+class GroupNorm32(nn.GroupNorm):
+
+ def forward(self, x):
+ return super().forward(x)
+
+
+def conv_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D convolution module.
+ """
+ if dims == 1:
+ return nn.Conv1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.Conv2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.Conv3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def linear(*args, **kwargs):
+ """
+ Create a linear module.
+ """
+ return nn.Linear(*args, **kwargs)
+
+
+def avg_pool_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D average pooling module.
+ """
+ if dims == 1:
+ return nn.AvgPool1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.AvgPool2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.AvgPool3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def update_ema(target_params, source_params, rate=0.99):
+ """
+ Update target parameters to be closer to those of source parameters using
+ an exponential moving average.
+
+ :param target_params: the target parameter sequence.
+ :param source_params: the source parameter sequence.
+ :param rate: the EMA rate (closer to 1 means slower).
+ """
+ for targ, src in zip(target_params, source_params):
+ targ.detach().mul_(rate).add_(src, alpha=1 - rate)
+
+
+def zero_module(module):
+ """
+ Zero out the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().zero_()
+ return module
+
+
+def scale_module(module, scale):
+ """
+ Scale the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().mul_(scale)
+ return module
+
+
+def mean_flat(tensor):
+ """
+ Take the mean over all non-batch dimensions.
+ """
+ return tensor.mean(axis=list(range(1, len(tensor.shape))))
+
+
+def normalization(channels):
+ """
+ Make a standard normalization layer.
+
+ :param channels: number of input channels.
+ :return: an nn.Module for normalization.
+ """
+ return GroupNorm32(32, channels)
+
+
+def timestep_embedding(timesteps, dim, max_period=10000):
+ """
+ Create sinusoidal timestep embeddings.
+
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param dim: the dimension of the output.
+ :param max_period: controls the minimum frequency of the embeddings.
+ :return: an [N x dim] Tensor of positional embeddings.
+ """
+ half = dim // 2
+ freqs = paddle.exp(-math.log(max_period) * paddle.arange(start=0, end=half, dtype=paddle.float32) / half)
+ args = paddle.cast(timesteps[:, None], 'float32') * freqs[None]
+ embedding = paddle.concat([paddle.cos(args), paddle.sin(args)], axis=-1)
+ if dim % 2:
+ embedding = paddle.concat([embedding, paddle.zeros_like(embedding[:, :1])], axis=-1)
+ return embedding
+
+
+def checkpoint(func, inputs, params, flag):
+ """
+ This function is disabled. And now just forward.
+ """
+ return func(*inputs)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/perlin_noises.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/perlin_noises.py
new file mode 100755
index 000000000..6dacb331b
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/perlin_noises.py
@@ -0,0 +1,78 @@
+'''
+Perlin noise implementation by Paddle.
+This code is rewritten based on:
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/perlin_noises.py
+'''
+import numpy as np
+import paddle
+import paddle.vision.transforms as TF
+from PIL import Image
+from PIL import ImageOps
+
+
+def interp(t):
+ return 3 * t**2 - 2 * t**3
+
+
+def perlin(width, height, scale=10):
+ gx, gy = paddle.randn([2, width + 1, height + 1, 1, 1])
+ xs = paddle.linspace(0, 1, scale + 1)[:-1, None]
+ ys = paddle.linspace(0, 1, scale + 1)[None, :-1]
+ wx = 1 - interp(xs)
+ wy = 1 - interp(ys)
+ dots = 0
+ dots += wx * wy * (gx[:-1, :-1] * xs + gy[:-1, :-1] * ys)
+ dots += (1 - wx) * wy * (-gx[1:, :-1] * (1 - xs) + gy[1:, :-1] * ys)
+ dots += wx * (1 - wy) * (gx[:-1, 1:] * xs - gy[:-1, 1:] * (1 - ys))
+ dots += (1 - wx) * (1 - wy) * (-gx[1:, 1:] * (1 - xs) - gy[1:, 1:] * (1 - ys))
+ return dots.transpose([0, 2, 1, 3]).reshape([width * scale, height * scale])
+
+
+def perlin_ms(octaves, width, height, grayscale):
+ out_array = [0.5] if grayscale else [0.5, 0.5, 0.5]
+ # out_array = [0.0] if grayscale else [0.0, 0.0, 0.0]
+ for i in range(1 if grayscale else 3):
+ scale = 2**len(octaves)
+ oct_width = width
+ oct_height = height
+ for oct in octaves:
+ p = perlin(oct_width, oct_height, scale)
+ out_array[i] += p * oct
+ scale //= 2
+ oct_width *= 2
+ oct_height *= 2
+ return paddle.concat(out_array)
+
+
+def create_perlin_noise(octaves, width, height, grayscale, side_y, side_x):
+ out = perlin_ms(octaves, width, height, grayscale)
+ if grayscale:
+ out = TF.resize(size=(side_y, side_x), img=out.numpy())
+ out = np.uint8(out)
+ out = Image.fromarray(out).convert('RGB')
+ else:
+ out = out.reshape([-1, 3, out.shape[0] // 3, out.shape[1]])
+ out = out.squeeze().transpose([1, 2, 0]).numpy()
+ out = TF.resize(size=(side_y, side_x), img=out)
+ out = out.clip(0, 1) * 255
+ out = np.uint8(out)
+ out = Image.fromarray(out)
+
+ out = ImageOps.autocontrast(out)
+ return out
+
+
+def regen_perlin(perlin_mode, side_y, side_x, batch_size):
+ if perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+
+ init = (TF.to_tensor(init).add(TF.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+ return init.expand([batch_size, -1, -1, -1])
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/respace.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/respace.py
new file mode 100755
index 000000000..c001c70d0
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/respace.py
@@ -0,0 +1,123 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/respace.py
+'''
+import numpy as np
+import paddle
+
+from .gaussian_diffusion import GaussianDiffusion
+
+
+def space_timesteps(num_timesteps, section_counts):
+ """
+ Create a list of timesteps to use from an original diffusion process,
+ given the number of timesteps we want to take from equally-sized portions
+ of the original process.
+
+ For example, if there's 300 timesteps and the section counts are [10,15,20]
+ then the first 100 timesteps are strided to be 10 timesteps, the second 100
+ are strided to be 15 timesteps, and the final 100 are strided to be 20.
+
+ If the stride is a string starting with "ddim", then the fixed striding
+ from the DDIM paper is used, and only one section is allowed.
+
+ :param num_timesteps: the number of diffusion steps in the original
+ process to divide up.
+ :param section_counts: either a list of numbers, or a string containing
+ comma-separated numbers, indicating the step count
+ per section. As a special case, use "ddimN" where N
+ is a number of steps to use the striding from the
+ DDIM paper.
+ :return: a set of diffusion steps from the original process to use.
+ """
+ if isinstance(section_counts, str):
+ if section_counts.startswith("ddim"):
+ desired_count = int(section_counts[len("ddim"):])
+ for i in range(1, num_timesteps):
+ if len(range(0, num_timesteps, i)) == desired_count:
+ return set(range(0, num_timesteps, i))
+ raise ValueError(f"cannot create exactly {num_timesteps} steps with an integer stride")
+ section_counts = [int(x) for x in section_counts.split(",")]
+ size_per = num_timesteps // len(section_counts)
+ extra = num_timesteps % len(section_counts)
+ start_idx = 0
+ all_steps = []
+ for i, section_count in enumerate(section_counts):
+ size = size_per + (1 if i < extra else 0)
+ if size < section_count:
+ raise ValueError(f"cannot divide section of {size} steps into {section_count}")
+ if section_count <= 1:
+ frac_stride = 1
+ else:
+ frac_stride = (size - 1) / (section_count - 1)
+ cur_idx = 0.0
+ taken_steps = []
+ for _ in range(section_count):
+ taken_steps.append(start_idx + round(cur_idx))
+ cur_idx += frac_stride
+ all_steps += taken_steps
+ start_idx += size
+ return set(all_steps)
+
+
+class SpacedDiffusion(GaussianDiffusion):
+ """
+ A diffusion process which can skip steps in a base diffusion process.
+
+ :param use_timesteps: a collection (sequence or set) of timesteps from the
+ original diffusion process to retain.
+ :param kwargs: the kwargs to create the base diffusion process.
+ """
+
+ def __init__(self, use_timesteps, **kwargs):
+ self.use_timesteps = set(use_timesteps)
+ self.timestep_map = []
+ self.original_num_steps = len(kwargs["betas"])
+
+ base_diffusion = GaussianDiffusion(**kwargs) # pylint: disable=missing-kwoa
+ last_alpha_cumprod = 1.0
+ new_betas = []
+ for i, alpha_cumprod in enumerate(base_diffusion.alphas_cumprod):
+ if i in self.use_timesteps:
+ new_betas.append(1 - alpha_cumprod / last_alpha_cumprod)
+ last_alpha_cumprod = alpha_cumprod
+ self.timestep_map.append(i)
+ kwargs["betas"] = np.array(new_betas)
+ super().__init__(**kwargs)
+
+ def p_mean_variance(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().p_mean_variance(self._wrap_model(model), *args, **kwargs)
+
+ def training_losses(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().training_losses(self._wrap_model(model), *args, **kwargs)
+
+ def condition_mean(self, cond_fn, *args, **kwargs):
+ return super().condition_mean(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def condition_score(self, cond_fn, *args, **kwargs):
+ return super().condition_score(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def _wrap_model(self, model):
+ if isinstance(model, _WrappedModel):
+ return model
+ return _WrappedModel(model, self.timestep_map, self.rescale_timesteps, self.original_num_steps)
+
+ def _scale_timesteps(self, t):
+ # Scaling is done by the wrapped model.
+ return t
+
+
+class _WrappedModel:
+
+ def __init__(self, model, timestep_map, rescale_timesteps, original_num_steps):
+ self.model = model
+ self.timestep_map = timestep_map
+ self.rescale_timesteps = rescale_timesteps
+ self.original_num_steps = original_num_steps
+
+ def __call__(self, x, ts, **kwargs):
+ map_tensor = paddle.to_tensor(self.timestep_map, place=ts.place, dtype=ts.dtype)
+ new_ts = map_tensor[ts]
+ if self.rescale_timesteps:
+ new_ts = paddle.cast(new_ts, 'float32') * (1000.0 / self.original_num_steps)
+ return self.model(x, new_ts, **kwargs)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/script_util.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/script_util.py
new file mode 100755
index 000000000..d728a5430
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/script_util.py
@@ -0,0 +1,201 @@
+'''
+This code is based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/script_util.py
+'''
+import argparse
+import inspect
+
+from . import gaussian_diffusion as gd
+from .respace import space_timesteps
+from .respace import SpacedDiffusion
+from .unet import EncoderUNetModel
+from .unet import SuperResModel
+from .unet import UNetModel
+
+NUM_CLASSES = 1000
+
+
+def diffusion_defaults():
+ """
+ Defaults for image and classifier training.
+ """
+ return dict(
+ learn_sigma=False,
+ diffusion_steps=1000,
+ noise_schedule="linear",
+ timestep_respacing="",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ )
+
+
+def model_and_diffusion_defaults():
+ """
+ Defaults for image training.
+ """
+ res = dict(
+ image_size=64,
+ num_channels=128,
+ num_res_blocks=2,
+ num_heads=4,
+ num_heads_upsample=-1,
+ num_head_channels=-1,
+ attention_resolutions="16,8",
+ channel_mult="",
+ dropout=0.0,
+ class_cond=False,
+ use_checkpoint=False,
+ use_scale_shift_norm=True,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+ )
+ res.update(diffusion_defaults())
+ return res
+
+
+def create_model_and_diffusion(
+ image_size,
+ class_cond,
+ learn_sigma,
+ num_channels,
+ num_res_blocks,
+ channel_mult,
+ num_heads,
+ num_head_channels,
+ num_heads_upsample,
+ attention_resolutions,
+ dropout,
+ diffusion_steps,
+ noise_schedule,
+ timestep_respacing,
+ use_kl,
+ predict_xstart,
+ rescale_timesteps,
+ rescale_learned_sigmas,
+ use_checkpoint,
+ use_scale_shift_norm,
+ resblock_updown,
+ use_fp16,
+ use_new_attention_order,
+):
+ model = create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult=channel_mult,
+ learn_sigma=learn_sigma,
+ class_cond=class_cond,
+ use_checkpoint=use_checkpoint,
+ attention_resolutions=attention_resolutions,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ dropout=dropout,
+ resblock_updown=resblock_updown,
+ use_fp16=use_fp16,
+ use_new_attention_order=use_new_attention_order,
+ )
+ diffusion = create_gaussian_diffusion(
+ steps=diffusion_steps,
+ learn_sigma=learn_sigma,
+ noise_schedule=noise_schedule,
+ use_kl=use_kl,
+ predict_xstart=predict_xstart,
+ rescale_timesteps=rescale_timesteps,
+ rescale_learned_sigmas=rescale_learned_sigmas,
+ timestep_respacing=timestep_respacing,
+ )
+ return model, diffusion
+
+
+def create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult="",
+ learn_sigma=False,
+ class_cond=False,
+ use_checkpoint=False,
+ attention_resolutions="16",
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ dropout=0,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+):
+ if channel_mult == "":
+ if image_size == 512:
+ channel_mult = (0.5, 1, 1, 2, 2, 4, 4)
+ elif image_size == 256:
+ channel_mult = (1, 1, 2, 2, 4, 4)
+ elif image_size == 128:
+ channel_mult = (1, 1, 2, 3, 4)
+ elif image_size == 64:
+ channel_mult = (1, 2, 3, 4)
+ else:
+ raise ValueError(f"unsupported image size: {image_size}")
+ else:
+ channel_mult = tuple(int(ch_mult) for ch_mult in channel_mult.split(","))
+
+ attention_ds = []
+ for res in attention_resolutions.split(","):
+ attention_ds.append(image_size // int(res))
+
+ return UNetModel(
+ image_size=image_size,
+ in_channels=3,
+ model_channels=num_channels,
+ out_channels=(3 if not learn_sigma else 6),
+ num_res_blocks=num_res_blocks,
+ attention_resolutions=tuple(attention_ds),
+ dropout=dropout,
+ channel_mult=channel_mult,
+ num_classes=(NUM_CLASSES if class_cond else None),
+ use_checkpoint=use_checkpoint,
+ use_fp16=use_fp16,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ resblock_updown=resblock_updown,
+ use_new_attention_order=use_new_attention_order,
+ )
+
+
+def create_gaussian_diffusion(
+ *,
+ steps=1000,
+ learn_sigma=False,
+ sigma_small=False,
+ noise_schedule="linear",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ timestep_respacing="",
+):
+ betas = gd.get_named_beta_schedule(noise_schedule, steps)
+ if use_kl:
+ loss_type = gd.LossType.RESCALED_KL
+ elif rescale_learned_sigmas:
+ loss_type = gd.LossType.RESCALED_MSE
+ else:
+ loss_type = gd.LossType.MSE
+ if not timestep_respacing:
+ timestep_respacing = [steps]
+ return SpacedDiffusion(
+ use_timesteps=space_timesteps(steps, timestep_respacing),
+ betas=betas,
+ model_mean_type=(gd.ModelMeanType.EPSILON if not predict_xstart else gd.ModelMeanType.START_X),
+ model_var_type=((gd.ModelVarType.FIXED_LARGE if not sigma_small else gd.ModelVarType.FIXED_SMALL)
+ if not learn_sigma else gd.ModelVarType.LEARNED_RANGE),
+ loss_type=loss_type,
+ rescale_timesteps=rescale_timesteps,
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/sec_diff.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/sec_diff.py
new file mode 100755
index 000000000..1e361f18f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/sec_diff.py
@@ -0,0 +1,135 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/sec_diff.py
+'''
+import math
+from dataclasses import dataclass
+from functools import partial
+
+import paddle
+import paddle.nn as nn
+
+
+@dataclass
+class DiffusionOutput:
+ v: paddle.Tensor
+ pred: paddle.Tensor
+ eps: paddle.Tensor
+
+
+class SkipBlock(nn.Layer):
+
+ def __init__(self, main, skip=None):
+ super().__init__()
+ self.main = nn.Sequential(*main)
+ self.skip = skip if skip else nn.Identity()
+
+ def forward(self, input):
+ return paddle.concat([self.main(input), self.skip(input)], axis=1)
+
+
+def append_dims(x, n):
+ return x[(Ellipsis, *(None, ) * (n - x.ndim))]
+
+
+def expand_to_planes(x, shape):
+ return paddle.tile(append_dims(x, len(shape)), [1, 1, *shape[2:]])
+
+
+def alpha_sigma_to_t(alpha, sigma):
+ return paddle.atan2(sigma, alpha) * 2 / math.pi
+
+
+def t_to_alpha_sigma(t):
+ return paddle.cos(t * math.pi / 2), paddle.sin(t * math.pi / 2)
+
+
+class SecondaryDiffusionImageNet2(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+ c = 64 # The base channel count
+ cs = [c, c * 2, c * 2, c * 4, c * 4, c * 8]
+
+ self.timestep_embed = FourierFeatures(1, 16)
+ self.down = nn.AvgPool2D(2)
+ self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
+
+ self.net = nn.Sequential(
+ ConvBlock(3 + 16, cs[0]),
+ ConvBlock(cs[0], cs[0]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[0], cs[1]),
+ ConvBlock(cs[1], cs[1]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[1], cs[2]),
+ ConvBlock(cs[2], cs[2]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[2], cs[3]),
+ ConvBlock(cs[3], cs[3]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[3], cs[4]),
+ ConvBlock(cs[4], cs[4]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[4], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[4]),
+ self.up,
+ ]),
+ ConvBlock(cs[4] * 2, cs[4]),
+ ConvBlock(cs[4], cs[3]),
+ self.up,
+ ]),
+ ConvBlock(cs[3] * 2, cs[3]),
+ ConvBlock(cs[3], cs[2]),
+ self.up,
+ ]),
+ ConvBlock(cs[2] * 2, cs[2]),
+ ConvBlock(cs[2], cs[1]),
+ self.up,
+ ]),
+ ConvBlock(cs[1] * 2, cs[1]),
+ ConvBlock(cs[1], cs[0]),
+ self.up,
+ ]),
+ ConvBlock(cs[0] * 2, cs[0]),
+ nn.Conv2D(cs[0], 3, 3, padding=1),
+ )
+
+ def forward(self, input, t):
+ timestep_embed = expand_to_planes(self.timestep_embed(t[:, None]), input.shape)
+ v = self.net(paddle.concat([input, timestep_embed], axis=1))
+ alphas, sigmas = map(partial(append_dims, n=v.ndim), t_to_alpha_sigma(t))
+ pred = input * alphas - v * sigmas
+ eps = input * sigmas + v * alphas
+ return DiffusionOutput(v, pred, eps)
+
+
+class FourierFeatures(nn.Layer):
+
+ def __init__(self, in_features, out_features, std=1.0):
+ super().__init__()
+ assert out_features % 2 == 0
+ # self.weight = nn.Parameter(paddle.randn([out_features // 2, in_features]) * std)
+ self.weight = paddle.create_parameter([out_features // 2, in_features],
+ dtype='float32',
+ default_initializer=nn.initializer.Normal(mean=0.0, std=std))
+
+ def forward(self, input):
+ f = 2 * math.pi * input @ self.weight.T
+ return paddle.concat([f.cos(), f.sin()], axis=-1)
+
+
+class ConvBlock(nn.Sequential):
+
+ def __init__(self, c_in, c_out):
+ super().__init__(
+ nn.Conv2D(c_in, c_out, 3, padding=1),
+ nn.ReLU(),
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/transforms.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/transforms.py
new file mode 100755
index 000000000..e0b620b01
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/transforms.py
@@ -0,0 +1,757 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/pytorch/vision/blob/main/torchvision/transforms/transforms.py
+'''
+import math
+import numbers
+import warnings
+from enum import Enum
+from typing import Any
+from typing import Dict
+from typing import List
+from typing import Optional
+from typing import Sequence
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn.functional import grid_sample
+from paddle.vision import transforms as T
+
+
+class Normalize(nn.Layer):
+
+ def __init__(self, mean, std):
+ super(Normalize, self).__init__()
+ self.mean = paddle.to_tensor(mean)
+ self.std = paddle.to_tensor(std)
+
+ def forward(self, tensor: Tensor):
+ dtype = tensor.dtype
+ mean = paddle.to_tensor(self.mean, dtype=dtype)
+ std = paddle.to_tensor(self.std, dtype=dtype)
+ mean = mean.reshape([1, -1, 1, 1])
+ std = std.reshape([1, -1, 1, 1])
+ result = tensor.subtract(mean).divide(std)
+ return result
+
+
+class InterpolationMode(Enum):
+ """Interpolation modes
+ Available interpolation methods are ``nearest``, ``bilinear``, ``bicubic``, ``box``, ``hamming``, and ``lanczos``.
+ """
+
+ NEAREST = "nearest"
+ BILINEAR = "bilinear"
+ BICUBIC = "bicubic"
+ # For PIL compatibility
+ BOX = "box"
+ HAMMING = "hamming"
+ LANCZOS = "lanczos"
+
+
+class Grayscale(nn.Layer):
+
+ def __init__(self, num_output_channels):
+ super(Grayscale, self).__init__()
+ self.num_output_channels = num_output_channels
+
+ def forward(self, x):
+ output = (0.2989 * x[:, 0:1, :, :] + 0.587 * x[:, 1:2, :, :] + 0.114 * x[:, 2:3, :, :])
+ if self.num_output_channels == 3:
+ return output.expand(x.shape)
+
+ return output
+
+
+class Lambda(nn.Layer):
+
+ def __init__(self, func):
+ super(Lambda, self).__init__()
+ self.transform = func
+
+ def forward(self, x):
+ return self.transform(x)
+
+
+class RandomGrayscale(nn.Layer):
+
+ def __init__(self, p):
+ super(RandomGrayscale, self).__init__()
+ self.prob = p
+ self.transform = Grayscale(3)
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return self.transform(x)
+ else:
+ return x
+
+
+class RandomHorizontalFlip(nn.Layer):
+
+ def __init__(self, prob):
+ super(RandomHorizontalFlip, self).__init__()
+ self.prob = prob
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return x[:, :, :, ::-1]
+ else:
+ return x
+
+
+def _blend(img1: Tensor, img2: Tensor, ratio: float) -> Tensor:
+ ratio = float(ratio)
+ bound = 1.0
+ return (ratio * img1 + (1.0 - ratio) * img2).clip(0, bound)
+
+
+def trunc_div(a, b):
+ ipt = paddle.divide(a, b)
+ sign_ipt = paddle.sign(ipt)
+ abs_ipt = paddle.abs(ipt)
+ abs_ipt = paddle.floor(abs_ipt)
+ out = paddle.multiply(sign_ipt, abs_ipt)
+ return out
+
+
+def fmod(a, b):
+ return a - trunc_div(a, b) * b
+
+
+def _rgb2hsv(img: Tensor) -> Tensor:
+ r, g, b = img.unbind(axis=-3)
+
+ # Implementation is based on https://github.com/python-pillow/Pillow/blob/4174d4267616897df3746d315d5a2d0f82c656ee/
+ # src/libImaging/Convert.c#L330
+ maxc = paddle.max(img, axis=-3)
+ minc = paddle.min(img, axis=-3)
+
+ # The algorithm erases S and H channel where `maxc = minc`. This avoids NaN
+ # from happening in the results, because
+ # + S channel has division by `maxc`, which is zero only if `maxc = minc`
+ # + H channel has division by `(maxc - minc)`.
+ #
+ # Instead of overwriting NaN afterwards, we just prevent it from occuring so
+ # we don't need to deal with it in case we save the NaN in a buffer in
+ # backprop, if it is ever supported, but it doesn't hurt to do so.
+ eqc = maxc == minc
+
+ cr = maxc - minc
+ # Since `eqc => cr = 0`, replacing denominator with 1 when `eqc` is fine.
+ ones = paddle.ones_like(maxc)
+ s = cr / paddle.where(eqc, ones, maxc)
+ # Note that `eqc => maxc = minc = r = g = b`. So the following calculation
+ # of `h` would reduce to `bc - gc + 2 + rc - bc + 4 + rc - bc = 6` so it
+ # would not matter what values `rc`, `gc`, and `bc` have here, and thus
+ # replacing denominator with 1 when `eqc` is fine.
+ cr_divisor = paddle.where(eqc, ones, cr)
+ rc = (maxc - r) / cr_divisor
+ gc = (maxc - g) / cr_divisor
+ bc = (maxc - b) / cr_divisor
+
+ hr = (maxc == r).cast('float32') * (bc - gc)
+ hg = ((maxc == g) & (maxc != r)).cast('float32') * (2.0 + rc - bc)
+ hb = ((maxc != g) & (maxc != r)).cast('float32') * (4.0 + gc - rc)
+ h = hr + hg + hb
+ h = fmod((h / 6.0 + 1.0), paddle.to_tensor(1.0))
+ return paddle.stack((h, s, maxc), axis=-3)
+
+
+def _hsv2rgb(img: Tensor) -> Tensor:
+ h, s, v = img.unbind(axis=-3)
+ i = paddle.floor(h * 6.0)
+ f = (h * 6.0) - i
+ i = i.cast(dtype='int32')
+
+ p = paddle.clip((v * (1.0 - s)), 0.0, 1.0)
+ q = paddle.clip((v * (1.0 - s * f)), 0.0, 1.0)
+ t = paddle.clip((v * (1.0 - s * (1.0 - f))), 0.0, 1.0)
+ i = i % 6
+
+ mask = i.unsqueeze(axis=-3) == paddle.arange(6).reshape([-1, 1, 1])
+
+ a1 = paddle.stack((v, q, p, p, t, v), axis=-3)
+ a2 = paddle.stack((t, v, v, q, p, p), axis=-3)
+ a3 = paddle.stack((p, p, t, v, v, q), axis=-3)
+ a4 = paddle.stack((a1, a2, a3), axis=-4)
+
+ return paddle.einsum("...ijk, ...xijk -> ...xjk", mask.cast(dtype=img.dtype), a4)
+
+
+def adjust_brightness(img: Tensor, brightness_factor: float) -> Tensor:
+ if brightness_factor < 0:
+ raise ValueError(f"brightness_factor ({brightness_factor}) is not non-negative.")
+
+ return _blend(img, paddle.zeros_like(img), brightness_factor)
+
+
+def adjust_contrast(img: Tensor, contrast_factor: float) -> Tensor:
+ if contrast_factor < 0:
+ raise ValueError(f"contrast_factor ({contrast_factor}) is not non-negative.")
+
+ c = img.shape[1]
+
+ if c == 3:
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+ mean = paddle.mean(output, axis=(-3, -2, -1), keepdim=True)
+
+ else:
+ mean = paddle.mean(img, axis=(-3, -2, -1), keepdim=True)
+
+ return _blend(img, mean, contrast_factor)
+
+
+def adjust_hue(img: Tensor, hue_factor: float) -> Tensor:
+ if not (-0.5 <= hue_factor <= 0.5):
+ raise ValueError(f"hue_factor ({hue_factor}) is not in [-0.5, 0.5].")
+
+ img = _rgb2hsv(img)
+ h, s, v = img.unbind(axis=-3)
+ h = fmod(h + hue_factor, paddle.to_tensor(1.0))
+ img = paddle.stack((h, s, v), axis=-3)
+ img_hue_adj = _hsv2rgb(img)
+ return img_hue_adj
+
+
+def adjust_saturation(img: Tensor, saturation_factor: float) -> Tensor:
+ if saturation_factor < 0:
+ raise ValueError(f"saturation_factor ({saturation_factor}) is not non-negative.")
+
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+
+ return _blend(img, output, saturation_factor)
+
+
+class ColorJitter(nn.Layer):
+
+ def __init__(self, brightness=0, contrast=0, saturation=0, hue=0):
+ super(ColorJitter, self).__init__()
+ self.brightness = self._check_input(brightness, "brightness")
+ self.contrast = self._check_input(contrast, "contrast")
+ self.saturation = self._check_input(saturation, "saturation")
+ self.hue = self._check_input(hue, "hue", center=0, bound=(-0.5, 0.5), clip_first_on_zero=False)
+
+ def _check_input(self, value, name, center=1, bound=(0, float("inf")), clip_first_on_zero=True):
+ if isinstance(value, numbers.Number):
+ if value < 0:
+ raise ValueError(f"If {name} is a single number, it must be non negative.")
+ value = [center - float(value), center + float(value)]
+ if clip_first_on_zero:
+ value[0] = max(value[0], 0.0)
+ elif isinstance(value, (tuple, list)) and len(value) == 2:
+ if not bound[0] <= value[0] <= value[1] <= bound[1]:
+ raise ValueError(f"{name} values should be between {bound}")
+ else:
+ raise TypeError(f"{name} should be a single number or a list/tuple with length 2.")
+
+ # if value is 0 or (1., 1.) for brightness/contrast/saturation
+ # or (0., 0.) for hue, do nothing
+ if value[0] == value[1] == center:
+ value = None
+ return value
+
+ @staticmethod
+ def get_params(
+ brightness: Optional[List[float]],
+ contrast: Optional[List[float]],
+ saturation: Optional[List[float]],
+ hue: Optional[List[float]],
+ ) -> Tuple[Tensor, Optional[float], Optional[float], Optional[float], Optional[float]]:
+ """Get the parameters for the randomized transform to be applied on image.
+
+ Args:
+ brightness (tuple of float (min, max), optional): The range from which the brightness_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ contrast (tuple of float (min, max), optional): The range from which the contrast_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ saturation (tuple of float (min, max), optional): The range from which the saturation_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ hue (tuple of float (min, max), optional): The range from which the hue_factor is chosen uniformly.
+ Pass None to turn off the transformation.
+
+ Returns:
+ tuple: The parameters used to apply the randomized transform
+ along with their random order.
+ """
+ fn_idx = paddle.randperm(4)
+
+ b = None if brightness is None else paddle.empty([1]).uniform_(brightness[0], brightness[1])
+ c = None if contrast is None else paddle.empty([1]).uniform_(contrast[0], contrast[1])
+ s = None if saturation is None else paddle.empty([1]).uniform_(saturation[0], saturation[1])
+ h = None if hue is None else paddle.empty([1]).uniform_(hue[0], hue[1])
+
+ return fn_idx, b, c, s, h
+
+ def forward(self, img):
+ """
+ Args:
+ img (PIL Image or Tensor): Input image.
+
+ Returns:
+ PIL Image or Tensor: Color jittered image.
+ """
+ fn_idx, brightness_factor, contrast_factor, saturation_factor, hue_factor = self.get_params(
+ self.brightness, self.contrast, self.saturation, self.hue)
+
+ for fn_id in fn_idx:
+ if fn_id == 0 and brightness_factor is not None:
+ img = adjust_brightness(img, brightness_factor)
+ elif fn_id == 1 and contrast_factor is not None:
+ img = adjust_contrast(img, contrast_factor)
+ elif fn_id == 2 and saturation_factor is not None:
+ img = adjust_saturation(img, saturation_factor)
+ elif fn_id == 3 and hue_factor is not None:
+ img = adjust_hue(img, hue_factor)
+
+ return img
+
+ def __repr__(self) -> str:
+ s = (f"{self.__class__.__name__}("
+ f"brightness={self.brightness}"
+ f", contrast={self.contrast}"
+ f", saturation={self.saturation}"
+ f", hue={self.hue})")
+ return s
+
+
+def _apply_grid_transform(img: Tensor, grid: Tensor, mode: str, fill: Optional[List[float]]) -> Tensor:
+
+ if img.shape[0] > 1:
+ # Apply same grid to a batch of images
+ grid = grid.expand([img.shape[0], grid.shape[1], grid.shape[2], grid.shape[3]])
+
+ # Append a dummy mask for customized fill colors, should be faster than grid_sample() twice
+ if fill is not None:
+ dummy = paddle.ones((img.shape[0], 1, img.shape[2], img.shape[3]), dtype=img.dtype)
+ img = paddle.concat((img, dummy), axis=1)
+
+ img = grid_sample(img, grid, mode=mode, padding_mode="zeros", align_corners=False)
+
+ # Fill with required color
+ if fill is not None:
+ mask = img[:, -1:, :, :] # N * 1 * H * W
+ img = img[:, :-1, :, :] # N * C * H * W
+ mask = mask.expand_as(img)
+ len_fill = len(fill) if isinstance(fill, (tuple, list)) else 1
+ fill_img = paddle.to_tensor(fill, dtype=img.dtype).reshape([1, len_fill, 1, 1]).expand_as(img)
+ if mode == "nearest":
+ mask = mask < 0.5
+ img[mask] = fill_img[mask]
+ else: # 'bilinear'
+ img = img * mask + (1.0 - mask) * fill_img
+ return img
+
+
+def _gen_affine_grid(
+ theta: Tensor,
+ w: int,
+ h: int,
+ ow: int,
+ oh: int,
+) -> Tensor:
+ # https://github.com/pytorch/pytorch/blob/74b65c32be68b15dc7c9e8bb62459efbfbde33d8/aten/src/ATen/native/
+ # AffineGridGenerator.cpp#L18
+ # Difference with AffineGridGenerator is that:
+ # 1) we normalize grid values after applying theta
+ # 2) we can normalize by other image size, such that it covers "extend" option like in PIL.Image.rotate
+
+ d = 0.5
+ base_grid = paddle.empty([1, oh, ow, 3], dtype=theta.dtype)
+ x_grid = paddle.linspace(-ow * 0.5 + d, ow * 0.5 + d - 1, num=ow)
+ base_grid[..., 0] = (x_grid)
+ y_grid = paddle.linspace(-oh * 0.5 + d, oh * 0.5 + d - 1, num=oh).unsqueeze_(-1)
+ base_grid[..., 1] = (y_grid)
+ base_grid[..., 2] = 1.0
+ rescaled_theta = theta.transpose([0, 2, 1]) / paddle.to_tensor([0.5 * w, 0.5 * h], dtype=theta.dtype)
+ output_grid = base_grid.reshape([1, oh * ow, 3]).bmm(rescaled_theta)
+ return output_grid.reshape([1, oh, ow, 2])
+
+
+def affine_impl(img: Tensor,
+ matrix: List[float],
+ interpolation: str = "nearest",
+ fill: Optional[List[float]] = None) -> Tensor:
+ theta = paddle.to_tensor(matrix, dtype=img.dtype).reshape([1, 2, 3])
+ shape = img.shape
+ # grid will be generated on the same device as theta and img
+ grid = _gen_affine_grid(theta, w=shape[-1], h=shape[-2], ow=shape[-1], oh=shape[-2])
+ return _apply_grid_transform(img, grid, interpolation, fill=fill)
+
+
+def _get_inverse_affine_matrix(center: List[float],
+ angle: float,
+ translate: List[float],
+ scale: float,
+ shear: List[float],
+ inverted: bool = True) -> List[float]:
+ # Helper method to compute inverse matrix for affine transformation
+
+ # Pillow requires inverse affine transformation matrix:
+ # Affine matrix is : M = T * C * RotateScaleShear * C^-1
+ #
+ # where T is translation matrix: [1, 0, tx | 0, 1, ty | 0, 0, 1]
+ # C is translation matrix to keep center: [1, 0, cx | 0, 1, cy | 0, 0, 1]
+ # RotateScaleShear is rotation with scale and shear matrix
+ #
+ # RotateScaleShear(a, s, (sx, sy)) =
+ # = R(a) * S(s) * SHy(sy) * SHx(sx)
+ # = [ s*cos(a - sy)/cos(sy), s*(-cos(a - sy)*tan(sx)/cos(sy) - sin(a)), 0 ]
+ # [ s*sin(a + sy)/cos(sy), s*(-sin(a - sy)*tan(sx)/cos(sy) + cos(a)), 0 ]
+ # [ 0 , 0 , 1 ]
+ # where R is a rotation matrix, S is a scaling matrix, and SHx and SHy are the shears:
+ # SHx(s) = [1, -tan(s)] and SHy(s) = [1 , 0]
+ # [0, 1 ] [-tan(s), 1]
+ #
+ # Thus, the inverse is M^-1 = C * RotateScaleShear^-1 * C^-1 * T^-1
+
+ rot = math.radians(angle)
+ sx = math.radians(shear[0])
+ sy = math.radians(shear[1])
+
+ cx, cy = center
+ tx, ty = translate
+
+ # RSS without scaling
+ a = math.cos(rot - sy) / math.cos(sy)
+ b = -math.cos(rot - sy) * math.tan(sx) / math.cos(sy) - math.sin(rot)
+ c = math.sin(rot - sy) / math.cos(sy)
+ d = -math.sin(rot - sy) * math.tan(sx) / math.cos(sy) + math.cos(rot)
+
+ if inverted:
+ # Inverted rotation matrix with scale and shear
+ # det([[a, b], [c, d]]) == 1, since det(rotation) = 1 and det(shear) = 1
+ matrix = [d, -b, 0.0, -c, a, 0.0]
+ matrix = [x / scale for x in matrix]
+ # Apply inverse of translation and of center translation: RSS^-1 * C^-1 * T^-1
+ matrix[2] += matrix[0] * (-cx - tx) + matrix[1] * (-cy - ty)
+ matrix[5] += matrix[3] * (-cx - tx) + matrix[4] * (-cy - ty)
+ # Apply center translation: C * RSS^-1 * C^-1 * T^-1
+ matrix[2] += cx
+ matrix[5] += cy
+ else:
+ matrix = [a, b, 0.0, c, d, 0.0]
+ matrix = [x * scale for x in matrix]
+ # Apply inverse of center translation: RSS * C^-1
+ matrix[2] += matrix[0] * (-cx) + matrix[1] * (-cy)
+ matrix[5] += matrix[3] * (-cx) + matrix[4] * (-cy)
+ # Apply translation and center : T * C * RSS * C^-1
+ matrix[2] += cx + tx
+ matrix[5] += cy + ty
+
+ return matrix
+
+
+def affine(
+ img: Tensor,
+ angle: float,
+ translate: List[int],
+ scale: float,
+ shear: List[float],
+ interpolation: InterpolationMode = InterpolationMode.NEAREST,
+ fill: Optional[List[float]] = None,
+ resample: Optional[int] = None,
+ fillcolor: Optional[List[float]] = None,
+ center: Optional[List[int]] = None,
+) -> Tensor:
+ """Apply affine transformation on the image keeping image center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ img (PIL Image or Tensor): image to transform.
+ angle (number): rotation angle in degrees between -180 and 180, clockwise direction.
+ translate (sequence of integers): horizontal and vertical translations (post-rotation translation)
+ scale (float): overall scale
+ shear (float or sequence): shear angle value in degrees between -180 to 180, clockwise direction.
+ If a sequence is specified, the first value corresponds to a shear parallel to the x axis, while
+ the second value corresponds to a shear parallel to the y axis.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number, optional): Pixel fill value for the area outside the transformed
+ image. If given a number, the value is used for all bands respectively.
+
+ .. note::
+ In torchscript mode single int/float value is not supported, please use a sequence
+ of length 1: ``[value, ]``.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation. Origin is the upper left corner.
+ Default is the center of the image.
+
+ Returns:
+ PIL Image or Tensor: Transformed image.
+ """
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ if not isinstance(angle, (int, float)):
+ raise TypeError("Argument angle should be int or float")
+
+ if not isinstance(translate, (list, tuple)):
+ raise TypeError("Argument translate should be a sequence")
+
+ if len(translate) != 2:
+ raise ValueError("Argument translate should be a sequence of length 2")
+
+ if scale <= 0.0:
+ raise ValueError("Argument scale should be positive")
+
+ if not isinstance(shear, (numbers.Number, (list, tuple))):
+ raise TypeError("Shear should be either a single value or a sequence of two values")
+
+ if not isinstance(interpolation, InterpolationMode):
+ raise TypeError("Argument interpolation should be a InterpolationMode")
+
+ if isinstance(angle, int):
+ angle = float(angle)
+
+ if isinstance(translate, tuple):
+ translate = list(translate)
+
+ if isinstance(shear, numbers.Number):
+ shear = [shear, 0.0]
+
+ if isinstance(shear, tuple):
+ shear = list(shear)
+
+ if len(shear) == 1:
+ shear = [shear[0], shear[0]]
+
+ if len(shear) != 2:
+ raise ValueError(f"Shear should be a sequence containing two values. Got {shear}")
+
+ if center is not None and not isinstance(center, (list, tuple)):
+ raise TypeError("Argument center should be a sequence")
+ center_f = [0.0, 0.0]
+ if center is not None:
+ _, height, width = img.shape[0], img.shape[1], img.shape[2]
+ # Center values should be in pixel coordinates but translated such that (0, 0) corresponds to image center.
+ center_f = [1.0 * (c - s * 0.5) for c, s in zip(center, [width, height])]
+
+ translate_f = [1.0 * t for t in translate]
+ matrix = _get_inverse_affine_matrix(center_f, angle, translate_f, scale, shear)
+ return affine_impl(img, matrix=matrix, interpolation=interpolation.value, fill=fill)
+
+
+def _interpolation_modes_from_int(i: int) -> InterpolationMode:
+ inverse_modes_mapping = {
+ 0: InterpolationMode.NEAREST,
+ 2: InterpolationMode.BILINEAR,
+ 3: InterpolationMode.BICUBIC,
+ 4: InterpolationMode.BOX,
+ 5: InterpolationMode.HAMMING,
+ 1: InterpolationMode.LANCZOS,
+ }
+ return inverse_modes_mapping[i]
+
+
+def _check_sequence_input(x, name, req_sizes):
+ msg = req_sizes[0] if len(req_sizes) < 2 else " or ".join([str(s) for s in req_sizes])
+ if not isinstance(x, Sequence):
+ raise TypeError(f"{name} should be a sequence of length {msg}.")
+ if len(x) not in req_sizes:
+ raise ValueError(f"{name} should be sequence of length {msg}.")
+
+
+def _setup_angle(x, name, req_sizes=(2, )):
+ if isinstance(x, numbers.Number):
+ if x < 0:
+ raise ValueError(f"If {name} is a single number, it must be positive.")
+ x = [-x, x]
+ else:
+ _check_sequence_input(x, name, req_sizes)
+
+ return [float(d) for d in x]
+
+
+class RandomAffine(nn.Layer):
+ """Random affine transformation of the image keeping center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ degrees (sequence or number): Range of degrees to select from.
+ If degrees is a number instead of sequence like (min, max), the range of degrees
+ will be (-degrees, +degrees). Set to 0 to deactivate rotations.
+ translate (tuple, optional): tuple of maximum absolute fraction for horizontal
+ and vertical translations. For example translate=(a, b), then horizontal shift
+ is randomly sampled in the range -img_width * a < dx < img_width * a and vertical shift is
+ randomly sampled in the range -img_height * b < dy < img_height * b. Will not translate by default.
+ scale (tuple, optional): scaling factor interval, e.g (a, b), then scale is
+ randomly sampled from the range a <= scale <= b. Will keep original scale by default.
+ shear (sequence or number, optional): Range of degrees to select from.
+ If shear is a number, a shear parallel to the x axis in the range (-shear, +shear)
+ will be applied. Else if shear is a sequence of 2 values a shear parallel to the x axis in the
+ range (shear[0], shear[1]) will be applied. Else if shear is a sequence of 4 values,
+ a x-axis shear in (shear[0], shear[1]) and y-axis shear in (shear[2], shear[3]) will be applied.
+ Will not apply shear by default.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number): Pixel fill value for the area outside the transformed
+ image. Default is ``0``. If given a number, the value is used for all bands respectively.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation, (x, y). Origin is the upper left corner.
+ Default is the center of the image.
+
+ .. _filters: https://pillow.readthedocs.io/en/latest/handbook/concepts.html#filters
+
+ """
+
+ def __init__(
+ self,
+ degrees,
+ translate=None,
+ scale=None,
+ shear=None,
+ interpolation=InterpolationMode.NEAREST,
+ fill=0,
+ fillcolor=None,
+ resample=None,
+ center=None,
+ ):
+ super(RandomAffine, self).__init__()
+ if resample is not None:
+ warnings.warn("The parameter 'resample' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'interpolation' instead.")
+ interpolation = _interpolation_modes_from_int(resample)
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ self.degrees = _setup_angle(degrees, name="degrees", req_sizes=(2, ))
+
+ if translate is not None:
+ _check_sequence_input(translate, "translate", req_sizes=(2, ))
+ for t in translate:
+ if not (0.0 <= t <= 1.0):
+ raise ValueError("translation values should be between 0 and 1")
+ self.translate = translate
+
+ if scale is not None:
+ _check_sequence_input(scale, "scale", req_sizes=(2, ))
+ for s in scale:
+ if s <= 0:
+ raise ValueError("scale values should be positive")
+ self.scale = scale
+
+ if shear is not None:
+ self.shear = _setup_angle(shear, name="shear", req_sizes=(2, 4))
+ else:
+ self.shear = shear
+
+ self.resample = self.interpolation = interpolation
+
+ if fill is None:
+ fill = 0
+ elif not isinstance(fill, (Sequence, numbers.Number)):
+ raise TypeError("Fill should be either a sequence or a number.")
+
+ self.fillcolor = self.fill = fill
+
+ if center is not None:
+ _check_sequence_input(center, "center", req_sizes=(2, ))
+
+ self.center = center
+
+ @staticmethod
+ def get_params(
+ degrees: List[float],
+ translate: Optional[List[float]],
+ scale_ranges: Optional[List[float]],
+ shears: Optional[List[float]],
+ img_size: List[int],
+ ) -> Tuple[float, Tuple[int, int], float, Tuple[float, float]]:
+ """Get parameters for affine transformation
+
+ Returns:
+ params to be passed to the affine transformation
+ """
+ angle = float(paddle.empty([1]).uniform_(float(degrees[0]), float(degrees[1])))
+ if translate is not None:
+ max_dx = float(translate[0] * img_size[0])
+ max_dy = float(translate[1] * img_size[1])
+ tx = int(float(paddle.empty([1]).uniform_(-max_dx, max_dx)))
+ ty = int(float(paddle.empty([1]).uniform_(-max_dy, max_dy)))
+ translations = (tx, ty)
+ else:
+ translations = (0, 0)
+
+ if scale_ranges is not None:
+ scale = float(paddle.empty([1]).uniform_(scale_ranges[0], scale_ranges[1]))
+ else:
+ scale = 1.0
+
+ shear_x = shear_y = 0.0
+ if shears is not None:
+ shear_x = float(paddle.empty([1]).uniform_(shears[0], shears[1]))
+ if len(shears) == 4:
+ shear_y = float(paddle.empty([1]).uniform_(shears[2], shears[3]))
+
+ shear = (shear_x, shear_y)
+
+ return angle, translations, scale, shear
+
+ def forward(self, img):
+ fill = self.fill
+ channels, height, width = img.shape[1], img.shape[2], img.shape[3]
+ if isinstance(fill, (int, float)):
+ fill = [float(fill)] * channels
+ else:
+ fill = [float(f) for f in fill]
+
+ img_size = [width, height] # flip for keeping BC on get_params call
+
+ ret = self.get_params(self.degrees, self.translate, self.scale, self.shear, img_size)
+
+ return affine(img, *ret, interpolation=self.interpolation, fill=fill, center=self.center)
+
+ def __repr__(self) -> str:
+ s = f"{self.__class__.__name__}(degrees={self.degrees}"
+ s += f", translate={self.translate}" if self.translate is not None else ""
+ s += f", scale={self.scale}" if self.scale is not None else ""
+ s += f", shear={self.shear}" if self.shear is not None else ""
+ s += f", interpolation={self.interpolation.value}" if self.interpolation != InterpolationMode.NEAREST else ""
+ s += f", fill={self.fill}" if self.fill != 0 else ""
+ s += f", center={self.center}" if self.center is not None else ""
+ s += ")"
+
+ return s
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/unet.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/unet.py
new file mode 100755
index 000000000..56f3ad61e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/model/unet.py
@@ -0,0 +1,838 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/unet.py
+'''
+import math
+from abc import abstractmethod
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+from .nn import avg_pool_nd
+from .nn import checkpoint
+from .nn import conv_nd
+from .nn import linear
+from .nn import normalization
+from .nn import SiLU
+from .nn import timestep_embedding
+from .nn import zero_module
+
+
+class AttentionPool2d(nn.Layer):
+ """
+ Adapted from CLIP: https://github.com/openai/CLIP/blob/main/clip/model.py
+ """
+
+ def __init__(
+ self,
+ spacial_dim: int,
+ embed_dim: int,
+ num_heads_channels: int,
+ output_dim: int = None,
+ ):
+ super().__init__()
+ # self.positional_embedding = nn.Parameter(
+ # th.randn(embed_dim, spacial_dim ** 2 + 1) / embed_dim ** 0.5
+ # )
+ positional_embedding = self.create_parameter(paddle.randn(embed_dim, spacial_dim**2 + 1) / embed_dim**0.5)
+ self.add_parameter("positional_embedding", positional_embedding)
+ self.qkv_proj = conv_nd(1, embed_dim, 3 * embed_dim, 1)
+ self.c_proj = conv_nd(1, embed_dim, output_dim or embed_dim, 1)
+ self.num_heads = embed_dim // num_heads_channels
+ self.attention = QKVAttention(self.num_heads)
+
+ def forward(self, x):
+ b, c, *_spatial = x.shape
+ # x = x.reshape(b, c, -1) # NC(HW)
+ x = paddle.reshape(x, [b, c, -1])
+ x = paddle.concat([x.mean(dim=-1, keepdim=True), x], axis=-1) # NC(HW+1)
+ x = x + paddle.cast(self.positional_embedding[None, :, :], x.dtype) # NC(HW+1)
+ x = self.qkv_proj(x)
+ x = self.attention(x)
+ x = self.c_proj(x)
+ return x[:, :, 0]
+
+
+class TimestepBlock(nn.Layer):
+ """
+ Any module where forward() takes timestep embeddings as a second argument.
+ """
+
+ @abstractmethod
+ def forward(self, x, emb):
+ """
+ Apply the module to `x` given `emb` timestep embeddings.
+ """
+
+
+class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
+ """
+ A sequential module that passes timestep embeddings to the children that
+ support it as an extra input.
+ """
+
+ def forward(self, x, emb):
+ for layer in self:
+ if isinstance(layer, TimestepBlock):
+ x = layer(x, emb)
+ else:
+ x = layer(x)
+ return x
+
+
+class Upsample(nn.Layer):
+ """
+ An upsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ if use_conv:
+ self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=1)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.dims == 3:
+ x = F.interpolate(x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest")
+ else:
+ x = F.interpolate(x, scale_factor=2, mode="nearest")
+ if self.use_conv:
+ x = self.conv(x)
+ return x
+
+
+class Downsample(nn.Layer):
+ """
+ A downsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ stride = 2 if dims != 3 else (1, 2, 2)
+ if use_conv:
+ self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=1)
+ else:
+ assert self.channels == self.out_channels
+ self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ return self.op(x)
+
+
+class ResBlock(TimestepBlock):
+ """
+ A residual block that can optionally change the number of channels.
+
+ :param channels: the number of input channels.
+ :param emb_channels: the number of timestep embedding channels.
+ :param dropout: the rate of dropout.
+ :param out_channels: if specified, the number of out channels.
+ :param use_conv: if True and out_channels is specified, use a spatial
+ convolution instead of a smaller 1x1 convolution to change the
+ channels in the skip connection.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param use_checkpoint: if True, use gradient checkpointing on this module.
+ :param up: if True, use this block for upsampling.
+ :param down: if True, use this block for downsampling.
+ """
+
+ def __init__(
+ self,
+ channels,
+ emb_channels,
+ dropout,
+ out_channels=None,
+ use_conv=False,
+ use_scale_shift_norm=False,
+ dims=2,
+ use_checkpoint=False,
+ up=False,
+ down=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ self.emb_channels = emb_channels
+ self.dropout = dropout
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_checkpoint = use_checkpoint
+ self.use_scale_shift_norm = use_scale_shift_norm
+
+ self.in_layers = nn.Sequential(
+ normalization(channels),
+ SiLU(),
+ conv_nd(dims, channels, self.out_channels, 3, padding=1),
+ )
+
+ self.updown = up or down
+
+ if up:
+ self.h_upd = Upsample(channels, False, dims)
+ self.x_upd = Upsample(channels, False, dims)
+ elif down:
+ self.h_upd = Downsample(channels, False, dims)
+ self.x_upd = Downsample(channels, False, dims)
+ else:
+ self.h_upd = self.x_upd = nn.Identity()
+
+ self.emb_layers = nn.Sequential(
+ SiLU(),
+ linear(
+ emb_channels,
+ 2 * self.out_channels if use_scale_shift_norm else self.out_channels,
+ ),
+ )
+ self.out_layers = nn.Sequential(
+ normalization(self.out_channels),
+ SiLU(),
+ nn.Dropout(p=dropout),
+ zero_module(conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)),
+ )
+
+ if self.out_channels == channels:
+ self.skip_connection = nn.Identity()
+ elif use_conv:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 3, padding=1)
+ else:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
+
+ def forward(self, x, emb):
+ """
+ Apply the block to a Tensor, conditioned on a timestep embedding.
+
+ :param x: an [N x C x ...] Tensor of features.
+ :param emb: an [N x emb_channels] Tensor of timestep embeddings.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ return checkpoint(self._forward, (x, emb), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x, emb):
+ if self.updown:
+ in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
+ h = in_rest(x)
+ h = self.h_upd(h)
+ x = self.x_upd(x)
+ h = in_conv(h)
+ else:
+ h = self.in_layers(x)
+ emb_out = self.emb_layers(emb)
+ emb_out = paddle.cast(emb_out, h.dtype)
+ while len(emb_out.shape) < len(h.shape):
+ emb_out = emb_out[..., None]
+ if self.use_scale_shift_norm:
+ out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
+ scale, shift = paddle.chunk(emb_out, 2, axis=1)
+ h = out_norm(h) * (1 + scale) + shift
+ h = out_rest(h)
+ else:
+ h = h + emb_out
+ h = self.out_layers(h)
+ return self.skip_connection(x) + h
+
+
+class AttentionBlock(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other.
+
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_heads=1,
+ num_head_channels=-1,
+ use_checkpoint=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels == -1:
+ self.num_heads = num_heads
+ else:
+ assert (channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+ self.use_checkpoint = use_checkpoint
+ self.norm = normalization(channels)
+ self.qkv = conv_nd(1, channels, channels * 3, 1)
+ if use_new_attention_order:
+ # split qkv before split heads
+ self.attention = QKVAttention(self.num_heads)
+ else:
+ # split heads before split qkv
+ self.attention = QKVAttentionLegacy(self.num_heads)
+
+ self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
+
+ def forward(self, x):
+ return checkpoint(self._forward, (x, ), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x):
+ b, c, *spatial = x.shape
+ # x = x.reshape(b, c, -1)
+ x = paddle.reshape(x, [b, c, -1])
+ qkv = self.qkv(self.norm(x))
+ h = self.attention(qkv)
+ h = self.proj_out(h)
+ # return (x + h).reshape(b, c, *spatial)
+ return paddle.reshape(x + h, [b, c, *spatial])
+
+
+def count_flops_attn(model, _x, y):
+ """
+ A counter for the `thop` package to count the operations in an
+ attention operation.
+ Meant to be used like:
+ macs, params = thop.profile(
+ model,
+ inputs=(inputs, timestamps),
+ custom_ops={QKVAttention: QKVAttention.count_flops},
+ )
+ """
+ b, c, *spatial = y[0].shape
+ num_spatial = int(np.prod(spatial))
+ # We perform two matmuls with the same number of ops.
+ # The first computes the weight matrix, the second computes
+ # the combination of the value vectors.
+ matmul_ops = 2 * b * (num_spatial**2) * c
+ model.total_ops += paddle.to_tensor([matmul_ops], dtype='float64')
+
+
+class QKVAttentionLegacy(nn.Layer):
+ """
+ A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ # q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
+ q, k, v = paddle.reshape(qkv, [bs * self.n_heads, ch * 3, length]).split(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v)
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class QKVAttention(nn.Layer):
+ """
+ A module which performs QKV attention and splits in a different order.
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (3 * H * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.chunk(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum(
+ "bct,bcs->bts",
+ (q * scale).view(bs * self.n_heads, ch, length),
+ (k * scale).view(bs * self.n_heads, ch, length),
+ ) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v.reshape(bs * self.n_heads, ch, length))
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class UNetModel(nn.Layer):
+ """
+ The full UNet model with attention and timestep embedding.
+
+ :param in_channels: channels in the input Tensor.
+ :param model_channels: base channel count for the model.
+ :param out_channels: channels in the output Tensor.
+ :param num_res_blocks: number of residual blocks per downsample.
+ :param attention_resolutions: a collection of downsample rates at which
+ attention will take place. May be a set, list, or tuple.
+ For example, if this contains 4, then at 4x downsampling, attention
+ will be used.
+ :param dropout: the dropout probability.
+ :param channel_mult: channel multiplier for each level of the UNet.
+ :param conv_resample: if True, use learned convolutions for upsampling and
+ downsampling.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param num_classes: if specified (as an int), then this model will be
+ class-conditional with `num_classes` classes.
+ :param use_checkpoint: use gradient checkpointing to reduce memory usage.
+ :param num_heads: the number of attention heads in each attention layer.
+ :param num_heads_channels: if specified, ignore num_heads and instead use
+ a fixed channel width per attention head.
+ :param num_heads_upsample: works with num_heads to set a different number
+ of heads for upsampling. Deprecated.
+ :param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
+ :param resblock_updown: use residual blocks for up/downsampling.
+ :param use_new_attention_order: use a different attention pattern for potentially
+ increased efficiency.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ num_classes=None,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.image_size = image_size
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.num_classes = num_classes
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ if self.num_classes is not None:
+ self.label_emb = nn.Embedding(num_classes, time_embed_dim)
+
+ ch = input_ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+
+ self.output_blocks = nn.LayerList([])
+ for level, mult in list(enumerate(channel_mult))[::-1]:
+ for i in range(num_res_blocks + 1):
+ ich = input_block_chans.pop()
+ layers = [
+ ResBlock(
+ ch + ich,
+ time_embed_dim,
+ dropout,
+ out_channels=int(model_channels * mult),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(model_channels * mult)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads_upsample,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ if level and i == num_res_blocks:
+ out_ch = ch
+ layers.append(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ up=True,
+ ) if resblock_updown else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch))
+ ds //= 2
+ self.output_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ zero_module(conv_nd(dims, input_ch, out_channels, 3, padding=1)),
+ )
+
+ def forward(self, x, timesteps, y=None):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :param y: an [N] Tensor of labels, if class-conditional.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ assert (y is not None) == (self.num_classes
+ is not None), "must specify y if and only if the model is class-conditional"
+
+ hs = []
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+ if self.num_classes is not None:
+ assert y.shape == (x.shape[0], )
+ emb = emb + self.label_emb(y)
+
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ hs.append(h)
+ h = self.middle_block(h, emb)
+ for module in self.output_blocks:
+ h = paddle.concat([h, hs.pop()], axis=1)
+ h = module(h, emb)
+ # h = paddle.cast(h, x.dtype)
+ return self.out(h)
+
+
+class SuperResModel(UNetModel):
+ """
+ A UNetModel that performs super-resolution.
+
+ Expects an extra kwarg `low_res` to condition on a low-resolution image.
+ """
+
+ def __init__(self, image_size, in_channels, *args, **kwargs):
+ super().__init__(image_size, in_channels * 2, *args, **kwargs)
+
+ def forward(self, x, timesteps, low_res=None, **kwargs):
+ _, _, new_height, new_width = x.shape
+ upsampled = F.interpolate(low_res, (new_height, new_width), mode="bilinear")
+ x = paddle.concat([x, upsampled], axis=1)
+ return super().forward(x, timesteps, **kwargs)
+
+
+class EncoderUNetModel(nn.Layer):
+ """
+ The half UNet model with attention and timestep embedding.
+
+ For usage, see UNet.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ pool="adaptive",
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+ self.pool = pool
+ if pool == "adaptive":
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ nn.AdaptiveAvgPool2D((1, 1)),
+ zero_module(conv_nd(dims, ch, out_channels, 1)),
+ nn.Flatten(),
+ )
+ elif pool == "attention":
+ assert num_head_channels != -1
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ AttentionPool2d((image_size // ds), ch, num_head_channels, out_channels),
+ )
+ elif pool == "spatial":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ nn.ReLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ elif pool == "spatial_v2":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ normalization(2048),
+ SiLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ else:
+ raise NotImplementedError(f"Unexpected {pool} pooling")
+
+ def forward(self, x, timesteps):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :return: an [N x K] Tensor of outputs.
+ """
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+
+ results = []
+ # h = x.type(self.dtype)
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ if self.pool.startswith("spatial"):
+ # results.append(h.type(x.dtype).mean(axis=(2, 3)))
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = self.middle_block(h, emb)
+ if self.pool.startswith("spatial"):
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = paddle.concat(results, axis=-1)
+ return self.out(h)
+ else:
+ # h = h.type(x.dtype)
+ h = paddle.cast(h, x.dtype)
+ return self.out(h)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/resources/default.yml b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/resources/default.yml
new file mode 100755
index 000000000..97c3c1b98
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/resources/default.yml
@@ -0,0 +1,47 @@
+text_prompts:
+ - A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.
+
+init_image:
+
+width_height: [ 1280, 768]
+
+skip_steps: 10
+steps: 250
+
+cut_ic_pow: 1
+init_scale: 1000
+clip_guidance_scale: 5000
+
+tv_scale: 0
+range_scale: 150
+sat_scale: 0
+cutn_batches: 4
+
+diffusion_model: 512x512_diffusion_uncond_finetune_008100
+use_secondary_model: True
+diffusion_sampling_mode: ddim
+
+perlin_init: False
+perlin_mode: mixed
+seed: 445467575
+eta: 0.8
+clamp_grad: True
+clamp_max: 0.05
+
+randomize_class: True
+clip_denoised: False
+fuzzy_prompt: False
+rand_mag: 0.05
+
+cut_overview: "[12]*400+[4]*600"
+cut_innercut: "[4]*400+[12]*600"
+cut_icgray_p: "[0.2]*400+[0]*600"
+
+display_rate: 10
+n_batches: 1
+batch_size: 1
+batch_name: ''
+clip_models:
+ - VIT
+ - RN50
+ - RN101
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/resources/docstrings.yml b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/resources/docstrings.yml
new file mode 100755
index 000000000..702015e1c
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/resources/docstrings.yml
@@ -0,0 +1,103 @@
+text_prompts: |
+ Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."
+ Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments.
+ Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+init_image: |
+ Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here.
+ If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+width_height: |
+ Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+
+skip_steps: |
+ Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.
+ As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.
+ The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.
+ If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.
+ Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.
+ Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image.
+ However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+
+steps: |
+ When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.
+ Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user.
+ Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+
+cut_ic_pow: |
+ This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+init_scale: |
+ This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+clip_guidance_scale: |
+ CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS.
+ Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500.
+ Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+tv_scale: |
+ Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+range_scale: |
+ Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+
+sat_scale: |
+ Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+cutn_batches: |
+ Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep.
+ Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage.
+ At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep.
+ However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.
+ So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+
+diffusion_model: Diffusion_model of choice.
+
+use_secondary_model: |
+ Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+
+diffusion_sampling_mode: |
+ Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+
+perlin_init: |
+ Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps).
+ Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+
+perlin_mode: |
+ sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+seed: |
+ Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar.
+ After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+eta: |
+ eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results.
+ The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+clamp_grad: |
+ As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+clamp_max: |
+ Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+
+randomize_class:
+clip_denoised: False
+fuzzy_prompt: |
+ Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+rand_mag: |
+ Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+
+cut_overview: The schedule of overview cuts
+cut_innercut: The schedule of inner cuts
+cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+display_rate: |
+ During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+n_batches: |
+ This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+batch_name: |
+ The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+clip_models: |
+ CLIP Model selectors. ViT-B/32, ViT-B/16, ViT-L/14, RN101, RN50, RN50x4, RN50x16, RN50x64.
+ These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around.
+ You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.
+ The rough order of speed/mem usage is (smallest/fastest to largest/slowest):
+ ViT-B/32
+ RN50
+ RN101
+ ViT-B/16
+ RN50x4
+ RN50x16
+ RN50x64
+ ViT-L/14
+ For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/runner.py b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/runner.py
new file mode 100755
index 000000000..b1e155b06
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/reverse_diffusion/runner.py
@@ -0,0 +1,285 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/runner.py
+'''
+import gc
+import os
+import random
+from threading import Thread
+
+import disco_diffusion_clip_vitb32.clip.clip as clip
+import numpy as np
+import paddle
+import paddle.vision.transforms as T
+import paddle_lpips as lpips
+from docarray import Document
+from docarray import DocumentArray
+from IPython import display
+from ipywidgets import Output
+from PIL import Image
+
+from .helper import logger
+from .helper import parse_prompt
+from .model.losses import range_loss
+from .model.losses import spherical_dist_loss
+from .model.losses import tv_loss
+from .model.make_cutouts import MakeCutoutsDango
+from .model.sec_diff import alpha_sigma_to_t
+from .model.sec_diff import SecondaryDiffusionImageNet2
+from .model.transforms import Normalize
+
+
+def do_run(args, models) -> 'DocumentArray':
+ logger.info('preparing models...')
+ model, diffusion, clip_models, secondary_model = models
+ normalize = Normalize(
+ mean=[0.48145466, 0.4578275, 0.40821073],
+ std=[0.26862954, 0.26130258, 0.27577711],
+ )
+ lpips_model = lpips.LPIPS(net='vgg')
+ for parameter in lpips_model.parameters():
+ parameter.stop_gradient = True
+ side_x = (args.width_height[0] // 64) * 64
+ side_y = (args.width_height[1] // 64) * 64
+ cut_overview = eval(args.cut_overview)
+ cut_innercut = eval(args.cut_innercut)
+ cut_icgray_p = eval(args.cut_icgray_p)
+
+ from .model.perlin_noises import create_perlin_noise, regen_perlin
+
+ seed = args.seed
+
+ skip_steps = args.skip_steps
+
+ loss_values = []
+
+ if seed is not None:
+ np.random.seed(seed)
+ random.seed(seed)
+ paddle.seed(seed)
+
+ model_stats = []
+ for clip_model in clip_models:
+ model_stat = {
+ 'clip_model': None,
+ 'target_embeds': [],
+ 'make_cutouts': None,
+ 'weights': [],
+ }
+ model_stat['clip_model'] = clip_model
+
+ if isinstance(args.text_prompts, str):
+ args.text_prompts = [args.text_prompts]
+
+ for prompt in args.text_prompts:
+ txt, weight = parse_prompt(prompt)
+ txt = clip_model.encode_text(clip.tokenize(prompt))
+ if args.fuzzy_prompt:
+ for i in range(25):
+ model_stat['target_embeds'].append((txt + paddle.randn(txt.shape) * args.rand_mag).clip(0, 1))
+ model_stat['weights'].append(weight)
+ else:
+ model_stat['target_embeds'].append(txt)
+ model_stat['weights'].append(weight)
+
+ model_stat['target_embeds'] = paddle.concat(model_stat['target_embeds'])
+ model_stat['weights'] = paddle.to_tensor(model_stat['weights'])
+ if model_stat['weights'].sum().abs() < 1e-3:
+ raise RuntimeError('The weights must not sum to 0.')
+ model_stat['weights'] /= model_stat['weights'].sum().abs()
+ model_stats.append(model_stat)
+
+ init = None
+ if args.init_image:
+ d = Document(uri=args.init_image).load_uri_to_image_tensor(side_x, side_y)
+ init = T.to_tensor(d.tensor).unsqueeze(0) * 2 - 1
+
+ if args.perlin_init:
+ if args.perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif args.perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ init = (T.to_tensor(init).add(T.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+
+ cur_t = None
+
+ def cond_fn(x, t, y=None):
+ x_is_NaN = False
+ n = x.shape[0]
+ if secondary_model:
+ alpha = paddle.to_tensor(diffusion.sqrt_alphas_cumprod[cur_t], dtype='float32')
+ sigma = paddle.to_tensor(diffusion.sqrt_one_minus_alphas_cumprod[cur_t], dtype='float32')
+ cosine_t = alpha_sigma_to_t(alpha, sigma)
+ x = paddle.to_tensor(x.detach(), dtype='float32')
+ x.stop_gradient = False
+ cosine_t = paddle.tile(paddle.to_tensor(cosine_t.detach().cpu().numpy()), [n])
+ cosine_t.stop_gradient = False
+ out = secondary_model(x, cosine_t).pred
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ else:
+ t = paddle.ones([n], dtype='int64') * cur_t
+ out = diffusion.p_mean_variance(model, x, t, clip_denoised=False, model_kwargs={'y': y})
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out['pred_xstart'] * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ for model_stat in model_stats:
+ for i in range(args.cutn_batches):
+ t_int = (int(t.item()) + 1) # errors on last step without +1, need to find source
+ # when using SLIP Base model the dimensions need to be hard coded to avoid AttributeError: 'VisionTransformer' object has no attribute 'input_resolution'
+ try:
+ input_resolution = model_stat['clip_model'].visual.input_resolution
+ except:
+ input_resolution = 224
+
+ cuts = MakeCutoutsDango(
+ input_resolution,
+ Overview=cut_overview[1000 - t_int],
+ InnerCrop=cut_innercut[1000 - t_int],
+ IC_Size_Pow=args.cut_ic_pow,
+ IC_Grey_P=cut_icgray_p[1000 - t_int],
+ )
+ clip_in = normalize(cuts(x_in.add(paddle.to_tensor(1.0)).divide(paddle.to_tensor(2.0))))
+ image_embeds = (model_stat['clip_model'].encode_image(clip_in))
+
+ dists = spherical_dist_loss(
+ image_embeds.unsqueeze(1),
+ model_stat['target_embeds'].unsqueeze(0),
+ )
+
+ dists = dists.reshape([
+ cut_overview[1000 - t_int] + cut_innercut[1000 - t_int],
+ n,
+ -1,
+ ])
+ losses = dists.multiply(model_stat['weights']).sum(2).mean(0)
+ loss_values.append(losses.sum().item()) # log loss, probably shouldn't do per cutn_batch
+
+ x_in_grad += (paddle.grad(losses.sum() * args.clip_guidance_scale, x_in)[0] / args.cutn_batches)
+ tv_losses = tv_loss(x_in)
+ range_losses = range_loss(x_in)
+ sat_losses = paddle.abs(x_in - x_in.clip(min=-1, max=1)).mean()
+ loss = (tv_losses.sum() * args.tv_scale + range_losses.sum() * args.range_scale +
+ sat_losses.sum() * args.sat_scale)
+ if init is not None and args.init_scale:
+ init_losses = lpips_model(x_in, init)
+ loss = loss + init_losses.sum() * args.init_scale
+ x_in_grad += paddle.grad(loss, x_in)[0]
+ if not paddle.isnan(x_in_grad).any():
+ grad = -paddle.grad(x_in_d, x, x_in_grad)[0]
+ else:
+ x_is_NaN = True
+ grad = paddle.zeros_like(x)
+ if args.clamp_grad and not x_is_NaN:
+ magnitude = grad.square().mean().sqrt()
+ return (grad * magnitude.clip(max=args.clamp_max) / magnitude)
+ return grad
+
+ if args.diffusion_sampling_mode == 'ddim':
+ sample_fn = diffusion.ddim_sample_loop_progressive
+ else:
+ sample_fn = diffusion.plms_sample_loop_progressive
+
+ logger.info('creating artwork...')
+
+ image_display = Output()
+ da_batches = DocumentArray()
+
+ for _nb in range(args.n_batches):
+ display.clear_output(wait=True)
+ display.display(args.name_docarray, image_display)
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+
+ d = Document(tags=vars(args))
+ da_batches.append(d)
+
+ cur_t = diffusion.num_timesteps - skip_steps - 1
+
+ if args.perlin_init:
+ init = regen_perlin(args.perlin_mode, side_y, side_x, args.batch_size)
+
+ if args.diffusion_sampling_mode == 'ddim':
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ eta=args.eta,
+ )
+ else:
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ order=2,
+ )
+
+ threads = []
+ for j, sample in enumerate(samples):
+ cur_t -= 1
+ with image_display:
+ if j % args.display_rate == 0 or cur_t == -1:
+ for _, image in enumerate(sample['pred_xstart']):
+ image = (image + 1) / 2
+ image = image.clip(0, 1).squeeze().transpose([1, 2, 0]).numpy() * 255
+ image = np.uint8(image)
+ image = Image.fromarray(image)
+
+ image.save(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb)))
+ c = Document(tags={'cur_t': cur_t})
+ c.load_pil_image_to_datauri(image)
+ d.chunks.append(c)
+ display.clear_output(wait=True)
+ display.display(display.Image(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb))))
+ d.chunks.plot_image_sprites(os.path.join(args.output_dir,
+ f'{args.name_docarray}-progress-{_nb}.png'),
+ show_index=True)
+ t = Thread(
+ target=_silent_push,
+ args=(
+ da_batches,
+ args.name_docarray,
+ ),
+ )
+ threads.append(t)
+ t.start()
+
+ if cur_t == -1:
+ d.load_pil_image_to_datauri(image)
+
+ for t in threads:
+ t.join()
+ display.clear_output(wait=True)
+ logger.info(f'done! {args.name_docarray}')
+ da_batches.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ return da_batches
+
+
+def _silent_push(da_batches: DocumentArray, name: str) -> None:
+ try:
+ da_batches.push(name)
+ except Exception as ex:
+ logger.debug(f'push failed: {ex}')
From ffcde21305c61d950a9f93e57e6180c9a9665b87 Mon Sep 17 00:00:00 2001
From: chenjian  +
+
+
+ - 生成过程
+  +
+
+
+
+### 模型介绍
+
+disco_diffusion_ernievil_base 是一个文图生成模型,可以通过输入一段文字来生成符合该句子语义的图像。该模型由两部分组成,一部分是扩散模型,是一种生成模型,可以从噪声输入中重建出原始图像。另一部分是多模态预训练模型(ERNIE-ViL), 可以将文本和图像表示在同一个特征空间,相近语义的文本和图像在该特征空间里距离会更相近。在该文图生成模型中,扩散模型负责从初始噪声或者指定初始图像中来生成目标图像,ERNIE-ViL负责引导生成图像的语义和输入的文本的语义尽可能接近,随着扩散模型在ERNIE-ViL的引导下不断的迭代生成新图像,最终能够生成文本所描述内容的图像。该模块中使用的模型为ERNIE-ViL,由ERNIE 3.0+ViT构成。
+
+更多详情请参考论文:[Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install disco_diffusion_ernievil_base
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run disco_diffusion_ernievil_base --text_prompts "孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作。" --output_dir disco_diffusion_ernievil_base_out
+ ```
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_ernievil_base")
+ text_prompts = ["孤舟蓑笠翁,独钓寒江雪。"]
+ # 生成图像, 默认会在disco_diffusion_ernievil_base_out目录保存图像
+ # 返回的da是一个DocumentArray对象,保存了所有的结果,包括最终结果和迭代过程的中间结果
+ # 可以通过操作DocumentArray对象对生成的图像做后处理,保存或者分析
+ da = module.generate_image(text_prompts=text_prompts, artist='齐白石', output_dir='./disco_diffusion_ernievil_base_out/')
+ # 手动将最终生成的图像保存到指定路径
+ da[0].save_uri_to_file('disco_diffusion_ernievil_base_out-result.png')
+ # 展示所有的中间结果
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # 将整个生成过程保存为一个动态图gif
+ da[0].chunks.save_gif('disco_diffusion_ernievil_base_out-result.gif', show_index=True, inline_display=True, size_ratio=0.5)
+ ```
+
+- ### 3、API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_ernievil_base_out'):
+ ```
+
+ - 文图生成API,生成文本描述内容的图像。
+
+ - **参数**
+
+ - text_prompts(str): 输入的语句,描述想要生成的图像的内容。通常比较有效的构造方式为 "一段描述性的文字内容" + "指定艺术家的名字",如"孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作"。
+ - style(Optional[str]): 指定绘画的风格,如水墨画、油画、水彩画等。当不指定时,风格完全由您所填写的prompt决定。
+ - artist(Optional[str]): 指定特定的艺术家,如齐白石、Greg Rutkowsk,将会生成所指定艺术家的绘画风格。当不指定时,风格完全由您所填写的prompt决定。各种艺术家的风格可以参考[网站](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/)。
+ - width_height(Optional[List[int]]): 指定最终输出图像的宽高,宽和高都需要是64的倍数,生成的图像越大,所需要的计算时间越长。
+ - seed(Optional[int]): 随机种子,由于输入默认是随机高斯噪声,设置不同的随机种子会由不同的初始输入,从而最终生成不同的结果,可以设置该参数来获得不同的输出图像。
+ - output_dir(Optional[str]): 保存输出图像的目录,默认为"disco_diffusion_ernievil_base_out"。
+
+
+ - **返回**
+ - ra(DocumentArray): DocumentArray对象, 包含`n_batches`个Documents,其中每个Document都保存了迭代过程的所有中间结果。详细可参考[DocumentArray使用文档](https://docarray.jina.ai/fundamentals/documentarray/index.html)。
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install disco_diffusion_ernievil_base == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/module.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/module.py
new file mode 100755
index 000000000..a4159ee0f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/module.py
@@ -0,0 +1,437 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import ast
+import os
+import sys
+from functools import partial
+from typing import List
+from typing import Optional
+
+import paddle
+from disco_diffusion_ernievil_base import resize_right
+from disco_diffusion_ernievil_base.reverse_diffusion import create
+from disco_diffusion_ernievil_base.vit_b_16x import ernievil2
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+@moduleinfo(name="disco_diffusion_ernievil_base",
+ version="1.0.0",
+ type="image/text_to_image",
+ summary="",
+ author="paddlepaddle",
+ author_email="paddle-dev@baidu.com")
+class DiscoDiffusionClip:
+
+ def generate_image(self,
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 0,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 0,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 1,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ use_gpu: Optional[bool] = True,
+ output_dir: Optional[str] = 'disco_diffusion_ernievil_base_out'):
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param style: Image style, such as oil paintings, if specified, style will be used to construct prompts.
+ :param artist: Artist style, if specified, style will be used to construct prompts.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param use_gpu: whether to use gpu or not.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+ if use_gpu:
+ try:
+ _places = os.environ.get("CUDA_VISIBLE_DEVICES", None)
+ if _places:
+ paddle.device.set_device("gpu:{}".format(0))
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
+ )
+ else:
+ paddle.device.set_device("cpu")
+ paddle.disable_static()
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir, exist_ok=True)
+
+ if isinstance(text_prompts, str):
+ text_prompts = text_prompts.rstrip(',.,。')
+ if style is not None:
+ text_prompts += ",{}".format(style)
+ if artist is not None:
+ text_prompts += ",由{}所作".format(artist)
+ elif isinstance(text_prompts, list):
+ text_prompts[0] = text_prompts[0].rstrip(',.,。')
+ if style is not None:
+ text_prompts[0] += ",{}".format(style)
+ if artist is not None:
+ text_prompts[0] += ",由{}所作".format(artist)
+
+ return create(text_prompts=text_prompts,
+ init_image=init_image,
+ width_height=width_height,
+ skip_steps=skip_steps,
+ steps=steps,
+ cut_ic_pow=cut_ic_pow,
+ init_scale=init_scale,
+ clip_guidance_scale=clip_guidance_scale,
+ tv_scale=tv_scale,
+ range_scale=range_scale,
+ sat_scale=sat_scale,
+ cutn_batches=cutn_batches,
+ diffusion_sampling_mode=diffusion_sampling_mode,
+ perlin_init=perlin_init,
+ perlin_mode=perlin_mode,
+ seed=seed,
+ eta=eta,
+ clamp_grad=clamp_grad,
+ clamp_max=clamp_max,
+ randomize_class=randomize_class,
+ clip_denoised=clip_denoised,
+ fuzzy_prompt=fuzzy_prompt,
+ rand_mag=rand_mag,
+ cut_overview=cut_overview,
+ cut_innercut=cut_innercut,
+ cut_icgray_p=cut_icgray_p,
+ display_rate=display_rate,
+ n_batches=n_batches,
+ batch_size=batch_size,
+ batch_name=batch_name,
+ clip_models=['vit_b_16x'],
+ output_dir=output_dir)
+
+ @serving
+ def serving_method(self, text_prompts, **kwargs):
+ """
+ Run as a service.
+ """
+ results = []
+ for text_prompt in text_prompts:
+ result = self.generate_image(text_prompts=text_prompt, **kwargs)[0].to_base64()
+ results.append(result)
+ return results
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options", description="Run configuration for controlling module behavior, not required.")
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ results = self.generate_image(text_prompts=args.text_prompts,
+ style=args.style,
+ artist=args.artist,
+ init_image=args.init_image,
+ width_height=args.width_height,
+ skip_steps=args.skip_steps,
+ steps=args.steps,
+ cut_ic_pow=args.cut_ic_pow,
+ init_scale=args.init_scale,
+ clip_guidance_scale=args.clip_guidance_scale,
+ tv_scale=args.tv_scale,
+ range_scale=args.range_scale,
+ sat_scale=args.sat_scale,
+ cutn_batches=args.cutn_batches,
+ diffusion_sampling_mode=args.diffusion_sampling_mode,
+ perlin_init=args.perlin_init,
+ perlin_mode=args.perlin_mode,
+ seed=args.seed,
+ eta=args.eta,
+ clamp_grad=args.clamp_grad,
+ clamp_max=args.clamp_max,
+ randomize_class=args.randomize_class,
+ clip_denoised=args.clip_denoised,
+ fuzzy_prompt=args.fuzzy_prompt,
+ rand_mag=args.rand_mag,
+ cut_overview=args.cut_overview,
+ cut_innercut=args.cut_innercut,
+ cut_icgray_p=args.cut_icgray_p,
+ display_rate=args.display_rate,
+ n_batches=args.n_batches,
+ batch_size=args.batch_size,
+ batch_name=args.batch_name,
+ output_dir=args.output_dir)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options.
+ """
+ self.arg_input_group.add_argument(
+ '--skip_steps',
+ type=int,
+ default=0,
+ help=
+ 'Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15%% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50%% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture'
+ )
+ self.arg_input_group.add_argument(
+ '--steps',
+ type=int,
+ default=250,
+ help=
+ "When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time."
+ )
+ self.arg_input_group.add_argument(
+ '--cut_ic_pow',
+ type=int,
+ default=1,
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--init_scale',
+ type=int,
+ default=1000,
+ help=
+ "This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost."
+ )
+ self.arg_input_group.add_argument(
+ '--clip_guidance_scale',
+ type=int,
+ default=5000,
+ help=
+ "CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well."
+ )
+ self.arg_input_group.add_argument(
+ '--tv_scale',
+ type=int,
+ default=0,
+ help=
+ "Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising"
+ )
+ self.arg_input_group.add_argument(
+ '--range_scale',
+ type=int,
+ default=0,
+ help=
+ "Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images."
+ )
+ self.arg_input_group.add_argument(
+ '--sat_scale',
+ type=int,
+ default=0,
+ help=
+ "Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation."
+ )
+ self.arg_input_group.add_argument(
+ '--cutn_batches',
+ type=int,
+ default=4,
+ help=
+ "Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below."
+ )
+ self.arg_input_group.add_argument(
+ '--diffusion_sampling_mode',
+ type=str,
+ default='ddim',
+ help=
+ "Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_init',
+ type=bool,
+ default=False,
+ help=
+ "Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_mode',
+ type=str,
+ default='mixed',
+ help=
+ "sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--seed',
+ type=int,
+ default=None,
+ help=
+ "Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical."
+ )
+ self.arg_input_group.add_argument(
+ '--eta',
+ type=float,
+ default=0.8,
+ help=
+ "eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_grad',
+ type=bool,
+ default=True,
+ help=
+ "As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_max',
+ type=float,
+ default=0.05,
+ help=
+ "Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy."
+ )
+ self.arg_input_group.add_argument('--randomize_class', type=bool, default=True, help="Random class.")
+ self.arg_input_group.add_argument('--clip_denoised', type=bool, default=False, help="Clip denoised.")
+ self.arg_input_group.add_argument(
+ '--fuzzy_prompt',
+ type=bool,
+ default=False,
+ help=
+ "Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this."
+ )
+ self.arg_input_group.add_argument(
+ '--rand_mag',
+ type=float,
+ default=0.5,
+ help="Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.")
+ self.arg_input_group.add_argument('--cut_overview',
+ type=str,
+ default='[12]*400+[4]*600',
+ help="The schedule of overview cuts")
+ self.arg_input_group.add_argument('--cut_innercut',
+ type=str,
+ default='[4]*400+[12]*600',
+ help="The schedule of inner cuts")
+ self.arg_input_group.add_argument(
+ '--cut_icgray_p',
+ type=str,
+ default='[0.2]*400+[0]*600',
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--display_rate',
+ type=int,
+ default=10,
+ help=
+ "During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly."
+ )
+ self.arg_config_group.add_argument('--use_gpu',
+ type=ast.literal_eval,
+ default=True,
+ help="whether use GPU or not")
+ self.arg_config_group.add_argument('--output_dir',
+ type=str,
+ default='disco_diffusion_ernievil_base_out',
+ help='Output directory.')
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument('--text_prompts', type=str)
+ self.arg_input_group.add_argument(
+ '--style',
+ type=str,
+ default=None,
+ help='Image style, such as oil paintings, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument('--artist',
+ type=str,
+ default=None,
+ help='Artist style, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument(
+ '--init_image',
+ type=str,
+ default=None,
+ help=
+ "Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion."
+ )
+ self.arg_input_group.add_argument(
+ '--width_height',
+ type=ast.literal_eval,
+ default=[1280, 768],
+ help=
+ "Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so."
+ )
+ self.arg_input_group.add_argument(
+ '--n_batches',
+ type=int,
+ default=1,
+ help=
+ "This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings."
+ )
+ self.arg_input_group.add_argument('--batch_size', type=int, default=1, help="Batch size.")
+ self.arg_input_group.add_argument(
+ '--batch_name',
+ type=str,
+ default='',
+ help=
+ 'The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.'
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/requirements.txt b/modules/image/text_to_image/disco_diffusion_ernievil_base/requirements.txt
new file mode 100755
index 000000000..8b4bc0ea4
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/requirements.txt
@@ -0,0 +1,8 @@
+numpy
+paddle_lpips==0.1.2
+ftfy
+docarray>=0.13.29
+pyyaml
+regex
+tqdm
+ipywidgets
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/README.md b/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/README.md
new file mode 100755
index 000000000..1f8d0bb0a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/README.md
@@ -0,0 +1,3 @@
+# ResizeRight (Paddle)
+Fully differentiable resize function implemented by Paddle.
+This module is based on [assafshocher/ResizeRight](https://github.com/assafshocher/ResizeRight).
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/__init__.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/__init__.py
new file mode 100755
index 000000000..e69de29bb
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/interp_methods.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/interp_methods.py
new file mode 100755
index 000000000..276eb055a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/interp_methods.py
@@ -0,0 +1,70 @@
+from math import pi
+
+try:
+ import paddle
+except ImportError:
+ paddle = None
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def set_framework_dependencies(x):
+ if type(x) is numpy.ndarray:
+ to_dtype = lambda a: a
+ fw = numpy
+ else:
+ to_dtype = lambda a: paddle.cast(a, x.dtype)
+ fw = paddle
+ # eps = fw.finfo(fw.float32).eps
+ eps = paddle.to_tensor(np.finfo(np.float32).eps)
+ return fw, to_dtype, eps
+
+
+def support_sz(sz):
+
+ def wrapper(f):
+ f.support_sz = sz
+ return f
+
+ return wrapper
+
+
+@support_sz(4)
+def cubic(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ absx = fw.abs(x)
+ absx2 = absx**2
+ absx3 = absx**3
+ return ((1.5 * absx3 - 2.5 * absx2 + 1.) * to_dtype(absx <= 1.) +
+ (-0.5 * absx3 + 2.5 * absx2 - 4. * absx + 2.) * to_dtype((1. < absx) & (absx <= 2.)))
+
+
+@support_sz(4)
+def lanczos2(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 2) + eps) / ((pi**2 * x**2 / 2) + eps)) * to_dtype(abs(x) < 2))
+
+
+@support_sz(6)
+def lanczos3(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 3) + eps) / ((pi**2 * x**2 / 3) + eps)) * to_dtype(abs(x) < 3))
+
+
+@support_sz(2)
+def linear(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return ((x + 1) * to_dtype((-1 <= x) & (x < 0)) + (1 - x) * to_dtype((0 <= x) & (x <= 1)))
+
+
+@support_sz(1)
+def box(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return to_dtype((-1 <= x) & (x < 0)) + to_dtype((0 <= x) & (x <= 1))
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/resize_right.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/resize_right.py
new file mode 100755
index 000000000..b63c61718
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/resize_right/resize_right.py
@@ -0,0 +1,403 @@
+import warnings
+from fractions import Fraction
+from math import ceil
+from typing import Tuple
+
+import disco_diffusion_ernievil_base.resize_right.interp_methods as interp_methods
+
+
+class NoneClass:
+ pass
+
+
+try:
+ import paddle
+ from paddle import nn
+ nnModuleWrapped = nn.Layer
+except ImportError:
+ warnings.warn('No PyTorch found, will work only with Numpy')
+ paddle = None
+ nnModuleWrapped = NoneClass
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ warnings.warn('No Numpy found, will work only with PyTorch')
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def resize(input,
+ scale_factors=None,
+ out_shape=None,
+ interp_method=interp_methods.cubic,
+ support_sz=None,
+ antialiasing=True,
+ by_convs=False,
+ scale_tolerance=None,
+ max_numerator=10,
+ pad_mode='constant'):
+ # get properties of the input tensor
+ in_shape, n_dims = input.shape, input.ndim
+
+ # fw stands for framework that can be either numpy or paddle,
+ # determined by the input type
+ fw = numpy if type(input) is numpy.ndarray else paddle
+ eps = np.finfo(np.float32).eps if fw == numpy else paddle.to_tensor(np.finfo(np.float32).eps)
+ device = input.place if fw is paddle else None
+
+ # set missing scale factors or output shapem one according to another,
+ # scream if both missing. this is also where all the defults policies
+ # take place. also handling the by_convs attribute carefully.
+ scale_factors, out_shape, by_convs = set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs,
+ scale_tolerance, max_numerator, eps, fw)
+
+ # sort indices of dimensions according to scale of each dimension.
+ # since we are going dim by dim this is efficient
+ sorted_filtered_dims_and_scales = [(dim, scale_factors[dim], by_convs[dim], in_shape[dim], out_shape[dim])
+ for dim in sorted(range(n_dims), key=lambda ind: scale_factors[ind])
+ if scale_factors[dim] != 1.]
+ # unless support size is specified by the user, it is an attribute
+ # of the interpolation method
+ if support_sz is None:
+ support_sz = interp_method.support_sz
+
+ # output begins identical to input and changes with each iteration
+ output = input
+
+ # iterate over dims
+ for (dim, scale_factor, dim_by_convs, in_sz, out_sz) in sorted_filtered_dims_and_scales:
+ # STEP 1- PROJECTED GRID: The non-integer locations of the projection
+ # of output pixel locations to the input tensor
+ projected_grid = get_projected_grid(in_sz, out_sz, scale_factor, fw, dim_by_convs, device)
+
+ # STEP 1.5: ANTIALIASING- If antialiasing is taking place, we modify
+ # the window size and the interpolation method (see inside function)
+ cur_interp_method, cur_support_sz = apply_antialiasing_if_needed(interp_method, support_sz, scale_factor,
+ antialiasing)
+
+ # STEP 2- FIELDS OF VIEW: for each output pixels, map the input pixels
+ # that influence it. Also calculate needed padding and update grid
+ # accoedingly
+ field_of_view = get_field_of_view(projected_grid, cur_support_sz, fw, eps, device)
+
+ # STEP 2.5- CALCULATE PAD AND UPDATE: according to the field of view,
+ # the input should be padded to handle the boundaries, coordinates
+ # should be updated. actual padding only occurs when weights are
+ # aplied (step 4). if using by_convs for this dim, then we need to
+ # calc right and left boundaries for each filter instead.
+ pad_sz, projected_grid, field_of_view = calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor,
+ dim_by_convs, fw, device)
+ # STEP 3- CALCULATE WEIGHTS: Match a set of weights to the pixels in
+ # the field of view for each output pixel
+ weights = get_weights(cur_interp_method, projected_grid, field_of_view)
+
+ # STEP 4- APPLY WEIGHTS: Each output pixel is calculated by multiplying
+ # its set of weights with the pixel values in its field of view.
+ # We now multiply the fields of view with their matching weights.
+ # We do this by tensor multiplication and broadcasting.
+ # if by_convs is true for this dim, then we do this action by
+ # convolutions. this is equivalent but faster.
+ if not dim_by_convs:
+ output = apply_weights(output, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw)
+ else:
+ output = apply_convs(output, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw)
+ return output
+
+
+def get_projected_grid(in_sz, out_sz, scale_factor, fw, by_convs, device=None):
+ # we start by having the ouput coordinates which are just integer locations
+ # in the special case when usin by_convs, we only need two cycles of grid
+ # points. the first and last.
+ grid_sz = out_sz if not by_convs else scale_factor.numerator
+ out_coordinates = fw_arange(grid_sz, fw, device)
+
+ # This is projecting the ouput pixel locations in 1d to the input tensor,
+ # as non-integer locations.
+ # the following fomrula is derived in the paper
+ # "From Discrete to Continuous Convolutions" by Shocher et al.
+ return (out_coordinates / float(scale_factor) + (in_sz - 1) / 2 - (out_sz - 1) / (2 * float(scale_factor)))
+
+
+def get_field_of_view(projected_grid, cur_support_sz, fw, eps, device):
+ # for each output pixel, map which input pixels influence it, in 1d.
+ # we start by calculating the leftmost neighbor, using half of the window
+ # size (eps is for when boundary is exact int)
+ left_boundaries = fw_ceil(projected_grid - cur_support_sz / 2 - eps, fw)
+
+ # then we simply take all the pixel centers in the field by counting
+ # window size pixels from the left boundary
+ ordinal_numbers = fw_arange(ceil(cur_support_sz - eps), fw, device)
+ return left_boundaries[:, None] + ordinal_numbers
+
+
+def calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor, dim_by_convs, fw, device):
+ if not dim_by_convs:
+ # determine padding according to neighbor coords out of bound.
+ # this is a generalized notion of padding, when pad<0 it means crop
+ pad_sz = [-field_of_view[0, 0].item(), field_of_view[-1, -1].item() - in_sz + 1]
+
+ # since input image will be changed by padding, coordinates of both
+ # field_of_view and projected_grid need to be updated
+ field_of_view += pad_sz[0]
+ projected_grid += pad_sz[0]
+
+ else:
+ # only used for by_convs, to calc the boundaries of each filter the
+ # number of distinct convolutions is the numerator of the scale factor
+ num_convs, stride = scale_factor.numerator, scale_factor.denominator
+
+ # calculate left and right boundaries for each conv. left can also be
+ # negative right can be bigger than in_sz. such cases imply padding if
+ # needed. however if# both are in-bounds, it means we need to crop,
+ # practically apply the conv only on part of the image.
+ left_pads = -field_of_view[:, 0]
+
+ # next calc is tricky, explanation by rows:
+ # 1) counting output pixels between the first position of each filter
+ # to the right boundary of the input
+ # 2) dividing it by number of filters to count how many 'jumps'
+ # each filter does
+ # 3) multiplying by the stride gives us the distance over the input
+ # coords done by all these jumps for each filter
+ # 4) to this distance we add the right boundary of the filter when
+ # placed in its leftmost position. so now we get the right boundary
+ # of that filter in input coord.
+ # 5) the padding size needed is obtained by subtracting the rightmost
+ # input coordinate. if the result is positive padding is needed. if
+ # negative then negative padding means shaving off pixel columns.
+ right_pads = (((out_sz - fw_arange(num_convs, fw, device) - 1) # (1)
+ // num_convs) # (2)
+ * stride # (3)
+ + field_of_view[:, -1] # (4)
+ - in_sz + 1) # (5)
+
+ # in the by_convs case pad_sz is a list of left-right pairs. one per
+ # each filter
+
+ pad_sz = list(zip(left_pads, right_pads))
+
+ return pad_sz, projected_grid, field_of_view
+
+
+def get_weights(interp_method, projected_grid, field_of_view):
+ # the set of weights per each output pixels is the result of the chosen
+ # interpolation method applied to the distances between projected grid
+ # locations and the pixel-centers in the field of view (distances are
+ # directed, can be positive or negative)
+ weights = interp_method(projected_grid[:, None] - field_of_view)
+
+ # we now carefully normalize the weights to sum to 1 per each output pixel
+ sum_weights = weights.sum(1, keepdim=True)
+ sum_weights[sum_weights == 0] = 1
+ return weights / sum_weights
+
+
+def apply_weights(input, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw):
+ # for this operation we assume the resized dim is the first one.
+ # so we transpose and will transpose back after multiplying
+ tmp_input = fw_swapaxes(input, dim, 0, fw)
+
+ # apply padding
+ tmp_input = fw_pad(tmp_input, fw, pad_sz, pad_mode)
+
+ # field_of_view is a tensor of order 2: for each output (1d location
+ # along cur dim)- a list of 1d neighbors locations.
+ # note that this whole operations is applied to each dim separately,
+ # this is why it is all in 1d.
+ # neighbors = tmp_input[field_of_view] is a tensor of order image_dims+1:
+ # for each output pixel (this time indicated in all dims), these are the
+ # values of the neighbors in the 1d field of view. note that we only
+ # consider neighbors along the current dim, but such set exists for every
+ # multi-dim location, hence the final tensor order is image_dims+1.
+ paddle.device.cuda.empty_cache()
+ neighbors = tmp_input[field_of_view]
+
+ # weights is an order 2 tensor: for each output location along 1d- a list
+ # of weights matching the field of view. we augment it with ones, for
+ # broadcasting, so that when multiplies some tensor the weights affect
+ # only its first dim.
+ tmp_weights = fw.reshape(weights, (*weights.shape, *[1] * (n_dims - 1)))
+
+ # now we simply multiply the weights with the neighbors, and then sum
+ # along the field of view, to get a single value per out pixel
+ tmp_output = (neighbors * tmp_weights).sum(1)
+ # we transpose back the resized dim to its original position
+ return fw_swapaxes(tmp_output, 0, dim, fw)
+
+
+def apply_convs(input, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw):
+ # for this operations we assume the resized dim is the last one.
+ # so we transpose and will transpose back after multiplying
+ input = fw_swapaxes(input, dim, -1, fw)
+
+ # the stride for all convs is the denominator of the scale factor
+ stride, num_convs = scale_factor.denominator, scale_factor.numerator
+
+ # prepare an empty tensor for the output
+ tmp_out_shape = list(input.shape)
+ tmp_out_shape[-1] = out_sz
+ tmp_output = fw_empty(tuple(tmp_out_shape), fw, input.device)
+
+ # iterate over the conv operations. we have as many as the numerator
+ # of the scale-factor. for each we need boundaries and a filter.
+ for conv_ind, (pad_sz, filt) in enumerate(zip(pad_sz, weights)):
+ # apply padding (we pad last dim, padding can be negative)
+ pad_dim = input.ndim - 1
+ tmp_input = fw_pad(input, fw, pad_sz, pad_mode, dim=pad_dim)
+
+ # apply convolution over last dim. store in the output tensor with
+ # positional strides so that when the loop is comlete conv results are
+ # interwind
+ tmp_output[..., conv_ind::num_convs] = fw_conv(tmp_input, filt, stride)
+
+ return fw_swapaxes(tmp_output, -1, dim, fw)
+
+
+def set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs, scale_tolerance, max_numerator, eps, fw):
+ # eventually we must have both scale-factors and out-sizes for all in/out
+ # dims. however, we support many possible partial arguments
+ if scale_factors is None and out_shape is None:
+ raise ValueError("either scale_factors or out_shape should be "
+ "provided")
+ if out_shape is not None:
+ # if out_shape has less dims than in_shape, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ out_shape = (list(out_shape) +
+ list(in_shape[len(out_shape):]) if fw is numpy else list(in_shape[:-len(out_shape)]) +
+ list(out_shape))
+ if scale_factors is None:
+ # if no scale given, we calculate it as the out to in ratio
+ # (not recomended)
+ scale_factors = [out_sz / in_sz for out_sz, in_sz in zip(out_shape, in_shape)]
+ if scale_factors is not None:
+ # by default, if a single number is given as scale, we assume resizing
+ # two dims (most common are images with 2 spatial dims)
+ scale_factors = (scale_factors if isinstance(scale_factors, (list, tuple)) else [scale_factors, scale_factors])
+ # if less scale_factors than in_shape dims, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ scale_factors = (list(scale_factors) + [1] * (len(in_shape) - len(scale_factors)) if fw is numpy else [1] *
+ (len(in_shape) - len(scale_factors)) + list(scale_factors))
+ if out_shape is None:
+ # when no out_shape given, it is calculated by multiplying the
+ # scale by the in_shape (not recomended)
+ out_shape = [ceil(scale_factor * in_sz) for scale_factor, in_sz in zip(scale_factors, in_shape)]
+ # next part intentionally after out_shape determined for stability
+ # we fix by_convs to be a list of truth values in case it is not
+ if not isinstance(by_convs, (list, tuple)):
+ by_convs = [by_convs] * len(out_shape)
+
+ # next loop fixes the scale for each dim to be either frac or float.
+ # this is determined by by_convs and by tolerance for scale accuracy.
+ for ind, (sf, dim_by_convs) in enumerate(zip(scale_factors, by_convs)):
+ # first we fractionaize
+ if dim_by_convs:
+ frac = Fraction(1 / sf).limit_denominator(max_numerator)
+ frac = Fraction(numerator=frac.denominator, denominator=frac.numerator)
+
+ # if accuracy is within tolerance scale will be frac. if not, then
+ # it will be float and the by_convs attr will be set false for
+ # this dim
+ if scale_tolerance is None:
+ scale_tolerance = eps
+ if dim_by_convs and abs(frac - sf) < scale_tolerance:
+ scale_factors[ind] = frac
+ else:
+ scale_factors[ind] = float(sf)
+ by_convs[ind] = False
+
+ return scale_factors, out_shape, by_convs
+
+
+def apply_antialiasing_if_needed(interp_method, support_sz, scale_factor, antialiasing):
+ # antialiasing is "stretching" the field of view according to the scale
+ # factor (only for downscaling). this is low-pass filtering. this
+ # requires modifying both the interpolation (stretching the 1d
+ # function and multiplying by the scale-factor) and the window size.
+ scale_factor = float(scale_factor)
+ if scale_factor >= 1.0 or not antialiasing:
+ return interp_method, support_sz
+ cur_interp_method = (lambda arg: scale_factor * interp_method(scale_factor * arg))
+ cur_support_sz = support_sz / scale_factor
+ return cur_interp_method, cur_support_sz
+
+
+def fw_ceil(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.ceil(x))
+ else:
+ return paddle.cast(x.ceil(), dtype='int64')
+
+
+def fw_floor(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.floor(x))
+ else:
+ return paddle.cast(x.floor(), dtype='int64')
+
+
+def fw_cat(x, fw):
+ if fw is numpy:
+ return fw.concatenate(x)
+ else:
+ return fw.concat(x)
+
+
+def fw_swapaxes(x, ax_1, ax_2, fw):
+ if fw is numpy:
+ return fw.swapaxes(x, ax_1, ax_2)
+ else:
+ if ax_1 == -1:
+ ax_1 = len(x.shape) - 1
+ if ax_2 == -1:
+ ax_2 = len(x.shape) - 1
+ perm0 = list(range(len(x.shape)))
+ temp = ax_1
+ perm0[temp] = ax_2
+ perm0[ax_2] = temp
+ return fw.transpose(x, perm0)
+
+
+def fw_pad(x, fw, pad_sz, pad_mode, dim=0):
+ if pad_sz == (0, 0):
+ return x
+ if fw is numpy:
+ pad_vec = [(0, 0)] * x.ndim
+ pad_vec[dim] = pad_sz
+ return fw.pad(x, pad_width=pad_vec, mode=pad_mode)
+ else:
+ if x.ndim < 3:
+ x = x[None, None, ...]
+
+ pad_vec = [0] * ((x.ndim - 2) * 2)
+ pad_vec[0:2] = pad_sz
+ return fw_swapaxes(fw.nn.functional.pad(fw_swapaxes(x, dim, -1, fw), pad=pad_vec, mode=pad_mode), dim, -1, fw)
+
+
+def fw_conv(input, filter, stride):
+ # we want to apply 1d conv to any nd array. the way to do it is to reshape
+ # the input to a 4D tensor. first two dims are singeletons, 3rd dim stores
+ # all the spatial dims that we are not convolving along now. then we can
+ # apply conv2d with a 1xK filter. This convolves the same way all the other
+ # dims stored in the 3d dim. like depthwise conv over these.
+ # TODO: numpy support
+ reshaped_input = input.reshape(1, 1, -1, input.shape[-1])
+ reshaped_output = paddle.nn.functional.conv2d(reshaped_input, filter.view(1, 1, 1, -1), stride=(1, stride))
+ return reshaped_output.reshape(*input.shape[:-1], -1)
+
+
+def fw_arange(upper_bound, fw, device):
+ if fw is numpy:
+ return fw.arange(upper_bound)
+ else:
+ return fw.arange(upper_bound)
+
+
+def fw_empty(shape, fw, device):
+ if fw is numpy:
+ return fw.empty(shape)
+ else:
+ return fw.empty(shape=shape)
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/README.md b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/README.md
new file mode 100755
index 000000000..711671bad
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/README.md
@@ -0,0 +1,2 @@
+# Diffusion model (Paddle)
+This module implements diffusion model which accepts a text prompt and outputs images semantically close to the text. The code is rewritten by Paddle, and mainly refer to two projects: jina-ai/discoart[https://github.com/jina-ai/discoart] and openai/guided-diffusion[https://github.com/openai/guided-diffusion]. Thanks for their wonderful work.
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/__init__.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/__init__.py
new file mode 100755
index 000000000..39fc908dc
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/__init__.py
@@ -0,0 +1,156 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/__init__.py
+'''
+import os
+import warnings
+
+os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
+
+__all__ = ['create']
+
+import sys
+
+__resources_path__ = os.path.join(
+ os.path.dirname(sys.modules.get(__package__).__file__ if __package__ in sys.modules else __file__),
+ 'resources',
+)
+
+import gc
+
+# check if GPU is available
+import paddle
+
+# download and load models, this will take some time on the first load
+
+from .helper import load_all_models, load_diffusion_model, load_clip_models
+
+model_config, secondary_model = load_all_models('512x512_diffusion_uncond_finetune_008100', use_secondary_model=True)
+
+from typing import TYPE_CHECKING, overload, List, Optional
+
+if TYPE_CHECKING:
+ from docarray import DocumentArray, Document
+
+_clip_models_cache = {}
+
+# begin_create_overload
+
+
+@overload
+def create(text_prompts: Optional[List[str]] = [
+ 'A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.',
+ 'yellow color scheme',
+],
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 10,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 150,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_model: Optional[str] = '512x512_diffusion_uncond_finetune_008100',
+ use_secondary_model: Optional[bool] = True,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 4,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ clip_models: Optional[list] = ['ViTB32', 'ViTB16', 'RN50'],
+ output_dir: Optional[str] = 'discoart_output') -> 'DocumentArray':
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_model: Diffusion_model of choice.
+ :param use_secondary_model: Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param clip_models: CLIP Model selectors. ViTB32, ViTB16, ViTL14, RN101, RN50, RN50x4, RN50x16, RN50x64.These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around. You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.The rough order of speed/mem usage is (smallest/fastest to largest/slowest):VitB32RN50RN101VitB16RN50x4RN50x16RN50x64ViTL14For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+# end_create_overload
+
+
+@overload
+def create(init_document: 'Document') -> 'DocumentArray':
+ """
+ Create an artwork using a DocArray ``Document`` object as initial state.
+ :param init_document: its ``.tags`` will be used as parameters, ``.uri`` (if present) will be used as init image.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+def create(**kwargs) -> 'DocumentArray':
+ from .config import load_config
+ from .runner import do_run
+
+ if 'init_document' in kwargs:
+ d = kwargs['init_document']
+ _kwargs = d.tags
+ if not _kwargs:
+ warnings.warn('init_document has no .tags, fallback to default config')
+ if d.uri:
+ _kwargs['init_image'] = kwargs['init_document'].uri
+ else:
+ warnings.warn('init_document has no .uri, fallback to no init image')
+ kwargs.pop('init_document')
+ if kwargs:
+ warnings.warn('init_document has .tags and .uri, but kwargs are also present, will override .tags')
+ _kwargs.update(kwargs)
+ _args = load_config(user_config=_kwargs)
+ else:
+ _args = load_config(user_config=kwargs)
+
+ model, diffusion = load_diffusion_model(model_config, _args.diffusion_model, steps=_args.steps)
+
+ clip_models = load_clip_models(enabled=_args.clip_models, clip_models=_clip_models_cache)
+
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+ try:
+ return do_run(_args, (model, diffusion, clip_models, secondary_model))
+ except KeyboardInterrupt:
+ pass
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/config.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/config.py
new file mode 100755
index 000000000..0cbc71e6f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/config.py
@@ -0,0 +1,77 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/config.py
+'''
+import copy
+import random
+import warnings
+from types import SimpleNamespace
+from typing import Dict
+
+import yaml
+from yaml import Loader
+
+from . import __resources_path__
+
+with open(f'{__resources_path__}/default.yml') as ymlfile:
+ default_args = yaml.load(ymlfile, Loader=Loader)
+
+
+def load_config(user_config: Dict, ):
+ cfg = copy.deepcopy(default_args)
+
+ if user_config:
+ cfg.update(**user_config)
+
+ for k in user_config.keys():
+ if k not in cfg:
+ warnings.warn(f'unknown argument {k}, ignored')
+
+ for k, v in cfg.items():
+ if k in ('batch_size', 'display_rate', 'seed', 'skip_steps', 'steps', 'n_batches',
+ 'cutn_batches') and isinstance(v, float):
+ cfg[k] = int(v)
+ if k == 'width_height':
+ cfg[k] = [int(vv) for vv in v]
+
+ cfg.update(**{
+ 'seed': cfg['seed'] or random.randint(0, 2**32),
+ })
+
+ if cfg['batch_name']:
+ da_name = f'{__package__}-{cfg["batch_name"]}-{cfg["seed"]}'
+ else:
+ da_name = f'{__package__}-{cfg["seed"]}'
+ warnings.warn('you did not set `batch_name`, set it to have unique session ID')
+
+ cfg.update(**{'name_docarray': da_name})
+
+ print_args_table(cfg)
+
+ return SimpleNamespace(**cfg)
+
+
+def print_args_table(cfg):
+ from rich.table import Table
+ from rich import box
+ from rich.console import Console
+
+ console = Console()
+
+ param_str = Table(
+ title=cfg['name_docarray'],
+ box=box.ROUNDED,
+ highlight=True,
+ title_justify='left',
+ )
+ param_str.add_column('Argument', justify='right')
+ param_str.add_column('Value', justify='left')
+
+ for k, v in sorted(cfg.items()):
+ value = str(v)
+
+ if not default_args.get(k, None) == v:
+ value = f'[b]{value}[/]'
+
+ param_str.add_row(k, value)
+
+ console.print(param_str)
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/helper.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/helper.py
new file mode 100755
index 000000000..ef72e68bf
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/helper.py
@@ -0,0 +1,138 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/helper.py
+'''
+import hashlib
+import logging
+import os
+import subprocess
+import sys
+from os.path import expanduser
+from pathlib import Path
+from typing import Any
+from typing import Dict
+from typing import List
+
+import paddle
+
+
+def _get_logger():
+ logger = logging.getLogger(__package__)
+ _log_level = os.environ.get('DISCOART_LOG_LEVEL', 'INFO')
+ logger.setLevel(_log_level)
+ ch = logging.StreamHandler()
+ ch.setLevel(_log_level)
+ formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
+ ch.setFormatter(formatter)
+ logger.addHandler(ch)
+ return logger
+
+
+logger = _get_logger()
+
+
+def load_clip_models(enabled: List[str], clip_models: Dict[str, Any] = {}):
+
+ import disco_diffusion_ernievil_base.vit_b_16x.ernievil2 as ernievil2
+ from disco_diffusion_ernievil_base.vit_b_16x.ernievil2.utils.utils import build_model
+
+ # load enabled models
+ for k in enabled:
+ if k not in clip_models:
+ clip_models[k] = build_model(name=k)
+ clip_models[k].eval()
+ for parameter in clip_models[k].parameters():
+ parameter.stop_gradient = True
+
+ # disable not enabled models to save memory
+ for k in clip_models:
+ if k not in enabled:
+ clip_models.pop(k)
+
+ return list(clip_models.values())
+
+
+def load_all_models(diffusion_model, use_secondary_model):
+ from .model.script_util import (
+ model_and_diffusion_defaults, )
+
+ model_config = model_and_diffusion_defaults()
+
+ if diffusion_model == '512x512_diffusion_uncond_finetune_008100':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 512,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+ elif diffusion_model == '256x256_diffusion_uncond':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 256,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+
+ secondary_model = None
+ if use_secondary_model:
+ from .model.sec_diff import SecondaryDiffusionImageNet2
+ secondary_model = SecondaryDiffusionImageNet2()
+ model_dict = paddle.load(
+ os.path.join(os.path.dirname(__file__), 'pre_trained', 'secondary_model_imagenet_2.pdparams'))
+ secondary_model.set_state_dict(model_dict)
+ secondary_model.eval()
+ for parameter in secondary_model.parameters():
+ parameter.stop_gradient = True
+
+ return model_config, secondary_model
+
+
+def load_diffusion_model(model_config, diffusion_model, steps):
+ from .model.script_util import (
+ create_model_and_diffusion, )
+
+ timestep_respacing = f'ddim{steps}'
+ diffusion_steps = (1000 // steps) * steps if steps < 1000 else steps
+ model_config.update({
+ 'timestep_respacing': timestep_respacing,
+ 'diffusion_steps': diffusion_steps,
+ })
+
+ model, diffusion = create_model_and_diffusion(**model_config)
+ model.set_state_dict(
+ paddle.load(os.path.join(os.path.dirname(__file__), 'pre_trained', f'{diffusion_model}.pdparams')))
+ model.eval()
+ for name, param in model.named_parameters():
+ param.stop_gradient = True
+
+ return model, diffusion
+
+
+def parse_prompt(prompt):
+ if prompt.startswith('http://') or prompt.startswith('https://'):
+ vals = prompt.rsplit(':', 2)
+ vals = [vals[0] + ':' + vals[1], *vals[2:]]
+ else:
+ vals = prompt.rsplit(':', 1)
+ vals = vals + ['', '1'][len(vals):]
+ return vals[0], float(vals[1])
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/__init__.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/__init__.py
new file mode 100755
index 000000000..466800666
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/__init__.py
@@ -0,0 +1,3 @@
+"""
+Codebase for "Improved Denoising Diffusion Probabilistic Models" implemented by Paddle.
+"""
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/gaussian_diffusion.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/gaussian_diffusion.py
new file mode 100755
index 000000000..86cd2c650
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/gaussian_diffusion.py
@@ -0,0 +1,1214 @@
+"""
+Diffusion model implemented by Paddle.
+This code is rewritten based on Pytorch version of of Ho et al's diffusion models:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py
+"""
+import enum
+import math
+
+import numpy as np
+import paddle
+
+from .losses import discretized_gaussian_log_likelihood
+from .losses import normal_kl
+from .nn import mean_flat
+
+
+def get_named_beta_schedule(schedule_name, num_diffusion_timesteps):
+ """
+ Get a pre-defined beta schedule for the given name.
+
+ The beta schedule library consists of beta schedules which remain similar
+ in the limit of num_diffusion_timesteps.
+ Beta schedules may be added, but should not be removed or changed once
+ they are committed to maintain backwards compatibility.
+ """
+ if schedule_name == "linear":
+ # Linear schedule from Ho et al, extended to work for any number of
+ # diffusion steps.
+ scale = 1000 / num_diffusion_timesteps
+ beta_start = scale * 0.0001
+ beta_end = scale * 0.02
+ return np.linspace(beta_start, beta_end, num_diffusion_timesteps, dtype=np.float64)
+ elif schedule_name == "cosine":
+ return betas_for_alpha_bar(
+ num_diffusion_timesteps,
+ lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2)**2,
+ )
+ else:
+ raise NotImplementedError(f"unknown beta schedule: {schedule_name}")
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function,
+ which defines the cumulative product of (1-beta) over time from t = [0,1].
+
+ :param num_diffusion_timesteps: the number of betas to produce.
+ :param alpha_bar: a lambda that takes an argument t from 0 to 1 and
+ produces the cumulative product of (1-beta) up to that
+ part of the diffusion process.
+ :param max_beta: the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+ """
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return np.array(betas)
+
+
+class ModelMeanType(enum.Enum):
+ """
+ Which type of output the model predicts.
+ """
+
+ PREVIOUS_X = enum.auto() # the model predicts x_{t-1}
+ START_X = enum.auto() # the model predicts x_0
+ EPSILON = enum.auto() # the model predicts epsilon
+
+
+class ModelVarType(enum.Enum):
+ """
+ What is used as the model's output variance.
+
+ The LEARNED_RANGE option has been added to allow the model to predict
+ values between FIXED_SMALL and FIXED_LARGE, making its job easier.
+ """
+
+ LEARNED = enum.auto()
+ FIXED_SMALL = enum.auto()
+ FIXED_LARGE = enum.auto()
+ LEARNED_RANGE = enum.auto()
+
+
+class LossType(enum.Enum):
+ MSE = enum.auto() # use raw MSE loss (and KL when learning variances)
+ RESCALED_MSE = (enum.auto()) # use raw MSE loss (with RESCALED_KL when learning variances)
+ KL = enum.auto() # use the variational lower-bound
+ RESCALED_KL = enum.auto() # like KL, but rescale to estimate the full VLB
+
+ def is_vb(self):
+ return self == LossType.KL or self == LossType.RESCALED_KL
+
+
+class GaussianDiffusion:
+ """
+ Utilities for training and sampling diffusion models.
+
+ Ported directly from here, and then adapted over time to further experimentation.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py#L42
+
+ :param betas: a 1-D numpy array of betas for each diffusion timestep,
+ starting at T and going to 1.
+ :param model_mean_type: a ModelMeanType determining what the model outputs.
+ :param model_var_type: a ModelVarType determining how variance is output.
+ :param loss_type: a LossType determining the loss function to use.
+ :param rescale_timesteps: if True, pass floating point timesteps into the
+ model so that they are always scaled like in the
+ original paper (0 to 1000).
+ """
+
+ def __init__(
+ self,
+ *,
+ betas,
+ model_mean_type,
+ model_var_type,
+ loss_type,
+ rescale_timesteps=False,
+ ):
+ self.model_mean_type = model_mean_type
+ self.model_var_type = model_var_type
+ self.loss_type = loss_type
+ self.rescale_timesteps = rescale_timesteps
+
+ # Use float64 for accuracy.
+ betas = np.array(betas, dtype=np.float64)
+ self.betas = betas
+ assert len(betas.shape) == 1, "betas must be 1-D"
+ assert (betas > 0).all() and (betas <= 1).all()
+
+ self.num_timesteps = int(betas.shape[0])
+
+ alphas = 1.0 - betas
+ self.alphas_cumprod = np.cumprod(alphas, axis=0)
+ self.alphas_cumprod_prev = np.append(1.0, self.alphas_cumprod[:-1])
+ self.alphas_cumprod_next = np.append(self.alphas_cumprod[1:], 0.0)
+ assert self.alphas_cumprod_prev.shape == (self.num_timesteps, )
+
+ # calculations for diffusion q(x_t | x_{t-1}) and others
+ self.sqrt_alphas_cumprod = np.sqrt(self.alphas_cumprod)
+ self.sqrt_one_minus_alphas_cumprod = np.sqrt(1.0 - self.alphas_cumprod)
+ self.log_one_minus_alphas_cumprod = np.log(1.0 - self.alphas_cumprod)
+ self.sqrt_recip_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod)
+ self.sqrt_recipm1_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod - 1)
+
+ # calculations for posterior q(x_{t-1} | x_t, x_0)
+ self.posterior_variance = (betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ # log calculation clipped because the posterior variance is 0 at the
+ # beginning of the diffusion chain.
+ self.posterior_log_variance_clipped = np.log(np.append(self.posterior_variance[1], self.posterior_variance[1:]))
+ self.posterior_mean_coef1 = (betas * np.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ self.posterior_mean_coef2 = ((1.0 - self.alphas_cumprod_prev) * np.sqrt(alphas) / (1.0 - self.alphas_cumprod))
+
+ def q_mean_variance(self, x_start, t):
+ """
+ Get the distribution q(x_t | x_0).
+
+ :param x_start: the [N x C x ...] tensor of noiseless inputs.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :return: A tuple (mean, variance, log_variance), all of x_start's shape.
+ """
+ mean = (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start)
+ variance = _extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
+ log_variance = _extract_into_tensor(self.log_one_minus_alphas_cumprod, t, x_start.shape)
+ return mean, variance, log_variance
+
+ def q_sample(self, x_start, t, noise=None):
+ """
+ Diffuse the data for a given number of diffusion steps.
+
+ In other words, sample from q(x_t | x_0).
+
+ :param x_start: the initial data batch.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :param noise: if specified, the split-out normal noise.
+ :return: A noisy version of x_start.
+ """
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ assert noise.shape == x_start.shape
+ return (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
+ _extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
+
+ def q_posterior_mean_variance(self, x_start, x_t, t):
+ """
+ Compute the mean and variance of the diffusion posterior:
+
+ q(x_{t-1} | x_t, x_0)
+
+ """
+ assert x_start.shape == x_t.shape
+ posterior_mean = (_extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start +
+ _extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t)
+ posterior_variance = _extract_into_tensor(self.posterior_variance, t, x_t.shape)
+ posterior_log_variance_clipped = _extract_into_tensor(self.posterior_log_variance_clipped, t, x_t.shape)
+ assert (posterior_mean.shape[0] == posterior_variance.shape[0] == posterior_log_variance_clipped.shape[0] ==
+ x_start.shape[0])
+ return posterior_mean, posterior_variance, posterior_log_variance_clipped
+
+ def p_mean_variance(self, model, x, t, clip_denoised=True, denoised_fn=None, model_kwargs=None):
+ """
+ Apply the model to get p(x_{t-1} | x_t), as well as a prediction of
+ the initial x, x_0.
+
+ :param model: the model, which takes a signal and a batch of timesteps
+ as input.
+ :param x: the [N x C x ...] tensor at time t.
+ :param t: a 1-D Tensor of timesteps.
+ :param clip_denoised: if True, clip the denoised signal into [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample. Applies before
+ clip_denoised.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict with the following keys:
+ - 'mean': the model mean output.
+ - 'variance': the model variance output.
+ - 'log_variance': the log of 'variance'.
+ - 'pred_xstart': the prediction for x_0.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+
+ B, C = x.shape[:2]
+ assert t.shape == [B]
+ model_output = model(x, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [ModelVarType.LEARNED, ModelVarType.LEARNED_RANGE]:
+ assert model_output.shape == [B, C * 2, *x.shape[2:]]
+ model_output, model_var_values = paddle.split(model_output, 2, axis=1)
+ if self.model_var_type == ModelVarType.LEARNED:
+ model_log_variance = model_var_values
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ min_log = _extract_into_tensor(self.posterior_log_variance_clipped, t, x.shape)
+ max_log = _extract_into_tensor(np.log(self.betas), t, x.shape)
+ # The model_var_values is [-1, 1] for [min_var, max_var].
+ frac = (model_var_values + 1) / 2
+ model_log_variance = frac * max_log + (1 - frac) * min_log
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ model_variance, model_log_variance = {
+ # for fixedlarge, we set the initial (log-)variance like so
+ # to get a better decoder log likelihood.
+ ModelVarType.FIXED_LARGE: (
+ np.append(self.posterior_variance[1], self.betas[1:]),
+ np.log(np.append(self.posterior_variance[1], self.betas[1:])),
+ ),
+ ModelVarType.FIXED_SMALL: (
+ self.posterior_variance,
+ self.posterior_log_variance_clipped,
+ ),
+ }[self.model_var_type]
+ model_variance = _extract_into_tensor(model_variance, t, x.shape)
+ model_log_variance = _extract_into_tensor(model_log_variance, t, x.shape)
+
+ def process_xstart(x):
+ if denoised_fn is not None:
+ x = denoised_fn(x)
+ if clip_denoised:
+ return x.clamp(-1, 1)
+ return x
+
+ if self.model_mean_type == ModelMeanType.PREVIOUS_X:
+ pred_xstart = process_xstart(self._predict_xstart_from_xprev(x_t=x, t=t, xprev=model_output))
+ model_mean = model_output
+ elif self.model_mean_type in [ModelMeanType.START_X, ModelMeanType.EPSILON]:
+ if self.model_mean_type == ModelMeanType.START_X:
+ pred_xstart = process_xstart(model_output)
+ else:
+ pred_xstart = process_xstart(self._predict_xstart_from_eps(x_t=x, t=t, eps=model_output))
+ model_mean, _, _ = self.q_posterior_mean_variance(x_start=pred_xstart, x_t=x, t=t)
+ else:
+ raise NotImplementedError(self.model_mean_type)
+
+ assert (model_mean.shape == model_log_variance.shape == pred_xstart.shape == x.shape)
+ return {
+ "mean": model_mean,
+ "variance": model_variance,
+ "log_variance": model_log_variance,
+ "pred_xstart": pred_xstart,
+ }
+
+ def _predict_xstart_from_eps(self, x_t, t, eps):
+ assert x_t.shape == eps.shape
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * eps)
+
+ def _predict_xstart_from_xprev(self, x_t, t, xprev):
+ assert x_t.shape == xprev.shape
+ return ( # (xprev - coef2*x_t) / coef1
+ _extract_into_tensor(1.0 / self.posterior_mean_coef1, t, x_t.shape) * xprev -
+ _extract_into_tensor(self.posterior_mean_coef2 / self.posterior_mean_coef1, t, x_t.shape) * x_t)
+
+ def _predict_eps_from_xstart(self, x_t, t, pred_xstart):
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ pred_xstart) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
+
+ def _scale_timesteps(self, t):
+ if self.rescale_timesteps:
+ return paddle.cast((t), 'float32') * (1000.0 / self.num_timesteps)
+ return t
+
+ def condition_mean(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_mean_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, t, p_mean_var, **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_score(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def condition_score_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, t, p_mean_var, **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def p_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"]}
+
+ def p_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean_with_grad(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"].detach()}
+
+ def p_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model.
+
+ :param model: the model module.
+ :param shape: the shape of the samples, (N, C, H, W).
+ :param noise: if specified, the noise from the encoder to sample.
+ Should be of the same shape as `shape`.
+ :param clip_denoised: if True, clip x_start predictions to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param device: if specified, the device to create the samples on.
+ If not specified, use a model parameter's device.
+ :param progress: if True, show a tqdm progress bar.
+ :return: a non-differentiable batch of samples.
+ """
+ final = None
+ for sample in self.p_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def p_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model and yield intermediate samples from
+ each timestep of diffusion.
+
+ Arguments are the same as p_sample_loop().
+ Returns a generator over dicts, where each dict is the return value of
+ p_sample().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ sample_fn = self.p_sample_with_grad if cond_fn_with_grad else self.p_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ )
+ yield out
+ img = out["sample"]
+
+ def ddim_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"]}
+
+ def ddim_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ out["pred_xstart"] = out["pred_xstart"].detach()
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"].detach()}
+
+ def ddim_reverse_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t+1} from the model using DDIM reverse ODE.
+ """
+ assert eta == 0.0, "Reverse ODE only for deterministic path"
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x.shape) * x -
+ out["pred_xstart"]) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x.shape)
+ alpha_bar_next = _extract_into_tensor(self.alphas_cumprod_next, t, x.shape)
+
+ # Equation 12. reversed
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_next) + paddle.sqrt(1 - alpha_bar_next) * eps)
+
+ return {"sample": mean_pred, "pred_xstart": out["pred_xstart"]}
+
+ def ddim_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model using DDIM.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.ddim_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ eta=eta,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def ddim_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Use DDIM to sample from the model and yield intermediate samples from
+ each timestep of DDIM.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ # if device is None:
+ # device = next(model.parameters()).device
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0])
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(
+ low=0,
+ high=model.num_classes,
+ shape=model_kwargs['y'].shape,
+ )
+ sample_fn = self.ddim_sample_with_grad if cond_fn_with_grad else self.ddim_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ eta=eta,
+ )
+ yield out
+ img = out["sample"]
+
+ def plms_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ cond_fn_with_grad=False,
+ order=2,
+ old_out=None,
+ ):
+ """
+ Sample x_{t-1} from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample().
+ """
+ if not int(order) or not 1 <= order <= 4:
+ raise ValueError('order is invalid (should be int from 1-4).')
+
+ def get_model_output(x, t):
+ with paddle.set_grad_enabled(cond_fn_with_grad and cond_fn is not None):
+ x = x.detach().requires_grad_() if cond_fn_with_grad else x
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ if cond_fn_with_grad:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ x = x.detach()
+ else:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+ return eps, out, out_orig
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ eps, out, out_orig = get_model_output(x, t)
+
+ if order > 1 and old_out is None:
+ # Pseudo Improved Euler
+ old_eps = [eps]
+ mean_pred = out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps
+ eps_2, _, _ = get_model_output(mean_pred, t - 1)
+ eps_prime = (eps + eps_2) / 2
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+ else:
+ # Pseudo Linear Multistep (Adams-Bashforth)
+ old_eps = old_out["old_eps"]
+ old_eps.append(eps)
+ cur_order = min(order, len(old_eps))
+ if cur_order == 1:
+ eps_prime = old_eps[-1]
+ elif cur_order == 2:
+ eps_prime = (3 * old_eps[-1] - old_eps[-2]) / 2
+ elif cur_order == 3:
+ eps_prime = (23 * old_eps[-1] - 16 * old_eps[-2] + 5 * old_eps[-3]) / 12
+ elif cur_order == 4:
+ eps_prime = (55 * old_eps[-1] - 59 * old_eps[-2] + 37 * old_eps[-3] - 9 * old_eps[-4]) / 24
+ else:
+ raise RuntimeError('cur_order is invalid.')
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+
+ if len(old_eps) >= order:
+ old_eps.pop(0)
+
+ nonzero_mask = paddle.cast((t != 0), 'float32').reshape([-1, *([1] * (len(x.shape) - 1))])
+ sample = mean_pred * nonzero_mask + out["pred_xstart"] * (1 - nonzero_mask)
+
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"], "old_eps": old_eps}
+
+ def plms_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Generate samples from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.plms_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ ):
+ final = sample
+ return final["sample"]
+
+ def plms_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Use PLMS to sample from the model and yield intermediate samples from each
+ timestep of PLMS.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ old_out = None
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ out = self.plms_sample(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ old_out=old_out,
+ )
+ yield out
+ old_out = out
+ img = out["sample"]
+
+ def _vb_terms_bpd(self, model, x_start, x_t, t, clip_denoised=True, model_kwargs=None):
+ """
+ Get a term for the variational lower-bound.
+
+ The resulting units are bits (rather than nats, as one might expect).
+ This allows for comparison to other papers.
+
+ :return: a dict with the following keys:
+ - 'output': a shape [N] tensor of NLLs or KLs.
+ - 'pred_xstart': the x_0 predictions.
+ """
+ true_mean, _, true_log_variance_clipped = self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)
+ out = self.p_mean_variance(model, x_t, t, clip_denoised=clip_denoised, model_kwargs=model_kwargs)
+ kl = normal_kl(true_mean, true_log_variance_clipped, out["mean"], out["log_variance"])
+ kl = mean_flat(kl) / np.log(2.0)
+
+ decoder_nll = -discretized_gaussian_log_likelihood(
+ x_start, means=out["mean"], log_scales=0.5 * out["log_variance"])
+ assert decoder_nll.shape == x_start.shape
+ decoder_nll = mean_flat(decoder_nll) / np.log(2.0)
+
+ # At the first timestep return the decoder NLL,
+ # otherwise return KL(q(x_{t-1}|x_t,x_0) || p(x_{t-1}|x_t))
+ output = paddle.where((t == 0), decoder_nll, kl)
+ return {"output": output, "pred_xstart": out["pred_xstart"]}
+
+ def training_losses(self, model, x_start, t, model_kwargs=None, noise=None):
+ """
+ Compute training losses for a single timestep.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param t: a batch of timestep indices.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param noise: if specified, the specific Gaussian noise to try to remove.
+ :return: a dict with the key "loss" containing a tensor of shape [N].
+ Some mean or variance settings may also have other keys.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start, t, noise=noise)
+
+ terms = {}
+
+ if self.loss_type == LossType.KL or self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] = self._vb_terms_bpd(
+ model=model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ model_kwargs=model_kwargs,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] *= self.num_timesteps
+ elif self.loss_type == LossType.MSE or self.loss_type == LossType.RESCALED_MSE:
+ model_output = model(x_t, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [
+ ModelVarType.LEARNED,
+ ModelVarType.LEARNED_RANGE,
+ ]:
+ B, C = x_t.shape[:2]
+ assert model_output.shape == (B, C * 2, *x_t.shape[2:])
+ model_output, model_var_values = paddle.split(model_output, 2, dim=1)
+ # Learn the variance using the variational bound, but don't let
+ # it affect our mean prediction.
+ frozen_out = paddle.concat([model_output.detach(), model_var_values], axis=1)
+ terms["vb"] = self._vb_terms_bpd(
+ model=lambda *args, r=frozen_out: r,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_MSE:
+ # Divide by 1000 for equivalence with initial implementation.
+ # Without a factor of 1/1000, the VB term hurts the MSE term.
+ terms["vb"] *= self.num_timesteps / 1000.0
+
+ target = {
+ ModelMeanType.PREVIOUS_X: self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)[0],
+ ModelMeanType.START_X: x_start,
+ ModelMeanType.EPSILON: noise,
+ }[self.model_mean_type]
+ assert model_output.shape == target.shape == x_start.shape
+ terms["mse"] = mean_flat((target - model_output)**2)
+ if "vb" in terms:
+ terms["loss"] = terms["mse"] + terms["vb"]
+ else:
+ terms["loss"] = terms["mse"]
+ else:
+ raise NotImplementedError(self.loss_type)
+
+ return terms
+
+ def _prior_bpd(self, x_start):
+ """
+ Get the prior KL term for the variational lower-bound, measured in
+ bits-per-dim.
+
+ This term can't be optimized, as it only depends on the encoder.
+
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :return: a batch of [N] KL values (in bits), one per batch element.
+ """
+ batch_size = x_start.shape[0]
+ t = paddle.to_tensor([self.num_timesteps - 1] * batch_size, place=x_start.place)
+ qt_mean, _, qt_log_variance = self.q_mean_variance(x_start, t)
+ kl_prior = normal_kl(mean1=qt_mean, logvar1=qt_log_variance, mean2=0.0, logvar2=0.0)
+ return mean_flat(kl_prior) / np.log(2.0)
+
+ def calc_bpd_loop(self, model, x_start, clip_denoised=True, model_kwargs=None):
+ """
+ Compute the entire variational lower-bound, measured in bits-per-dim,
+ as well as other related quantities.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param clip_denoised: if True, clip denoised samples.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+
+ :return: a dict containing the following keys:
+ - total_bpd: the total variational lower-bound, per batch element.
+ - prior_bpd: the prior term in the lower-bound.
+ - vb: an [N x T] tensor of terms in the lower-bound.
+ - xstart_mse: an [N x T] tensor of x_0 MSEs for each timestep.
+ - mse: an [N x T] tensor of epsilon MSEs for each timestep.
+ """
+ device = x_start.place
+ batch_size = x_start.shape[0]
+
+ vb = []
+ xstart_mse = []
+ mse = []
+ for t in list(range(self.num_timesteps))[::-1]:
+ t_batch = paddle.to_tensor([t] * batch_size, place=device)
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start=x_start, t=t_batch, noise=noise)
+ # Calculate VLB term at the current timestep
+ # with paddle.no_grad():
+ out = self._vb_terms_bpd(
+ model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t_batch,
+ clip_denoised=clip_denoised,
+ model_kwargs=model_kwargs,
+ )
+ vb.append(out["output"])
+ xstart_mse.append(mean_flat((out["pred_xstart"] - x_start)**2))
+ eps = self._predict_eps_from_xstart(x_t, t_batch, out["pred_xstart"])
+ mse.append(mean_flat((eps - noise)**2))
+
+ vb = paddle.stack(vb, axis=1)
+ xstart_mse = paddle.stack(xstart_mse, axis=1)
+ mse = paddle.stack(mse, axis=1)
+
+ prior_bpd = self._prior_bpd(x_start)
+ total_bpd = vb.sum(axis=1) + prior_bpd
+ return {
+ "total_bpd": total_bpd,
+ "prior_bpd": prior_bpd,
+ "vb": vb,
+ "xstart_mse": xstart_mse,
+ "mse": mse,
+ }
+
+
+def _extract_into_tensor(arr, timesteps, broadcast_shape):
+ """
+ Extract values from a 1-D numpy array for a batch of indices.
+
+ :param arr: the 1-D numpy array.
+ :param timesteps: a tensor of indices into the array to extract.
+ :param broadcast_shape: a larger shape of K dimensions with the batch
+ dimension equal to the length of timesteps.
+ :return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
+ """
+ res = paddle.to_tensor(arr, place=timesteps.place)[timesteps]
+ while len(res.shape) < len(broadcast_shape):
+ res = res[..., None]
+ return res.expand(broadcast_shape)
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/losses.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/losses.py
new file mode 100755
index 000000000..5c3970de5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/losses.py
@@ -0,0 +1,86 @@
+"""
+Helpers for various likelihood-based losses implemented by Paddle. These are ported from the original
+Ho et al. diffusion models codebase:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/utils.py
+"""
+import numpy as np
+import paddle
+import paddle.nn.functional as F
+
+
+def normal_kl(mean1, logvar1, mean2, logvar2):
+ """
+ Compute the KL divergence between two gaussians.
+
+ Shapes are automatically broadcasted, so batches can be compared to
+ scalars, among other use cases.
+ """
+ tensor = None
+ for obj in (mean1, logvar1, mean2, logvar2):
+ if isinstance(obj, paddle.Tensor):
+ tensor = obj
+ break
+ assert tensor is not None, "at least one argument must be a Tensor"
+
+ # Force variances to be Tensors. Broadcasting helps convert scalars to
+ # Tensors, but it does not work for th.exp().
+ logvar1, logvar2 = [x if isinstance(x, paddle.Tensor) else paddle.to_tensor(x) for x in (logvar1, logvar2)]
+
+ return 0.5 * (-1.0 + logvar2 - logvar1 + paddle.exp(logvar1 - logvar2) +
+ ((mean1 - mean2)**2) * paddle.exp(-logvar2))
+
+
+def approx_standard_normal_cdf(x):
+ """
+ A fast approximation of the cumulative distribution function of the
+ standard normal.
+ """
+ return 0.5 * (1.0 + paddle.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * paddle.pow(x, 3))))
+
+
+def discretized_gaussian_log_likelihood(x, *, means, log_scales):
+ """
+ Compute the log-likelihood of a Gaussian distribution discretizing to a
+ given image.
+
+ :param x: the target images. It is assumed that this was uint8 values,
+ rescaled to the range [-1, 1].
+ :param means: the Gaussian mean Tensor.
+ :param log_scales: the Gaussian log stddev Tensor.
+ :return: a tensor like x of log probabilities (in nats).
+ """
+ assert x.shape == means.shape == log_scales.shape
+ centered_x = x - means
+ inv_stdv = paddle.exp(-log_scales)
+ plus_in = inv_stdv * (centered_x + 1.0 / 255.0)
+ cdf_plus = approx_standard_normal_cdf(plus_in)
+ min_in = inv_stdv * (centered_x - 1.0 / 255.0)
+ cdf_min = approx_standard_normal_cdf(min_in)
+ log_cdf_plus = paddle.log(cdf_plus.clip(min=1e-12))
+ log_one_minus_cdf_min = paddle.log((1.0 - cdf_min).clip(min=1e-12))
+ cdf_delta = cdf_plus - cdf_min
+ log_probs = paddle.where(
+ x < -0.999,
+ log_cdf_plus,
+ paddle.where(x > 0.999, log_one_minus_cdf_min, paddle.log(cdf_delta.clip(min=1e-12))),
+ )
+ assert log_probs.shape == x.shape
+ return log_probs
+
+
+def spherical_dist_loss(x, y):
+ x = F.normalize(x, axis=-1)
+ y = F.normalize(y, axis=-1)
+ return (x - y).norm(axis=-1).divide(paddle.to_tensor(2.0)).asin().pow(2).multiply(paddle.to_tensor(2.0))
+
+
+def tv_loss(input):
+ """L2 total variation loss, as in Mahendran et al."""
+ input = F.pad(input, (0, 1, 0, 1), 'replicate')
+ x_diff = input[..., :-1, 1:] - input[..., :-1, :-1]
+ y_diff = input[..., 1:, :-1] - input[..., :-1, :-1]
+ return (x_diff**2 + y_diff**2).mean([1, 2, 3])
+
+
+def range_loss(input):
+ return (input - input.clip(-1, 1)).pow(2).mean([1, 2, 3])
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/make_cutouts.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/make_cutouts.py
new file mode 100755
index 000000000..babaedfb9
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/make_cutouts.py
@@ -0,0 +1,177 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/make_cutouts.py
+'''
+import math
+
+import paddle
+import paddle.nn as nn
+from disco_diffusion_ernievil_base.resize_right.resize_right import resize
+from paddle.nn import functional as F
+
+from . import transforms as T
+
+skip_augs = False # @param{type: 'boolean'}
+
+
+def sinc(x):
+ return paddle.where(x != 0, paddle.sin(math.pi * x) / (math.pi * x), x.new_ones([]))
+
+
+def lanczos(x, a):
+ cond = paddle.logical_and(-a < x, x < a)
+ out = paddle.where(cond, sinc(x) * sinc(x / a), x.new_zeros([]))
+ return out / out.sum()
+
+
+def ramp(ratio, width):
+ n = math.ceil(width / ratio + 1)
+ out = paddle.empty([n])
+ cur = 0
+ for i in range(out.shape[0]):
+ out[i] = cur
+ cur += ratio
+ return paddle.concat([-out[1:].flip([0]), out])[1:-1]
+
+
+class MakeCutouts(nn.Layer):
+
+ def __init__(self, cut_size, cutn, skip_augs=False):
+ super().__init__()
+ self.cut_size = cut_size
+ self.cutn = cutn
+ self.skip_augs = skip_augs
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(degrees=15, translate=(0.1, 0.1)),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomPerspective(distortion_scale=0.4, p=0.7),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.15),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ input = T.Pad(input.shape[2] // 4, fill=0)(input)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+
+ cutouts = []
+ for ch in range(self.cutn):
+ if ch > self.cutn - self.cutn // 4:
+ cutout = input.clone()
+ else:
+ size = int(max_size *
+ paddle.zeros(1, ).normal_(mean=0.8, std=0.3).clip(float(self.cut_size / max_size), 1.0))
+ offsetx = paddle.randint(0, abs(sideX - size + 1), ())
+ offsety = paddle.randint(0, abs(sideY - size + 1), ())
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+
+ if not self.skip_augs:
+ cutout = self.augs(cutout)
+ cutouts.append(resample(cutout, (self.cut_size, self.cut_size)))
+ del cutout
+
+ cutouts = paddle.concat(cutouts, axis=0)
+ return cutouts
+
+
+class MakeCutoutsDango(nn.Layer):
+
+ def __init__(self, cut_size, Overview=4, InnerCrop=0, IC_Size_Pow=0.5, IC_Grey_P=0.2):
+ super().__init__()
+ self.cut_size = cut_size
+ self.Overview = Overview
+ self.InnerCrop = InnerCrop
+ self.IC_Size_Pow = IC_Size_Pow
+ self.IC_Grey_P = IC_Grey_P
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(
+ degrees=10,
+ translate=(0.05, 0.05),
+ interpolation=T.InterpolationMode.BILINEAR,
+ ),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.1),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ cutouts = []
+ gray = T.Grayscale(3)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+ min_size = min(sideX, sideY, self.cut_size)
+ output_shape = [1, 3, self.cut_size, self.cut_size]
+ pad_input = F.pad(
+ input,
+ (
+ (sideY - max_size) // 2,
+ (sideY - max_size) // 2,
+ (sideX - max_size) // 2,
+ (sideX - max_size) // 2,
+ ),
+ **padargs,
+ )
+ cutout = resize(pad_input, out_shape=output_shape)
+
+ if self.Overview > 0:
+ if self.Overview <= 4:
+ if self.Overview >= 1:
+ cutouts.append(cutout)
+ if self.Overview >= 2:
+ cutouts.append(gray(cutout))
+ if self.Overview >= 3:
+ cutouts.append(cutout[:, :, :, ::-1])
+ if self.Overview == 4:
+ cutouts.append(gray(cutout[:, :, :, ::-1]))
+ else:
+ cutout = resize(pad_input, out_shape=output_shape)
+ for _ in range(self.Overview):
+ cutouts.append(cutout)
+
+ if self.InnerCrop > 0:
+ for i in range(self.InnerCrop):
+ size = int(paddle.rand([1])**self.IC_Size_Pow * (max_size - min_size) + min_size)
+ offsetx = paddle.randint(0, sideX - size + 1)
+ offsety = paddle.randint(0, sideY - size + 1)
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+ if i <= int(self.IC_Grey_P * self.InnerCrop):
+ cutout = gray(cutout)
+ cutout = resize(cutout, out_shape=output_shape)
+ cutouts.append(cutout)
+
+ cutouts = paddle.concat(cutouts)
+ if skip_augs is not True:
+ cutouts = self.augs(cutouts)
+ return cutouts
+
+
+def resample(input, size, align_corners=True):
+ n, c, h, w = input.shape
+ dh, dw = size
+
+ input = input.reshape([n * c, 1, h, w])
+
+ if dh < h:
+ kernel_h = lanczos(ramp(dh / h, 2), 2).to(input.device, input.dtype)
+ pad_h = (kernel_h.shape[0] - 1) // 2
+ input = F.pad(input, (0, 0, pad_h, pad_h), 'reflect')
+ input = F.conv2d(input, kernel_h[None, None, :, None])
+
+ if dw < w:
+ kernel_w = lanczos(ramp(dw / w, 2), 2).to(input.device, input.dtype)
+ pad_w = (kernel_w.shape[0] - 1) // 2
+ input = F.pad(input, (pad_w, pad_w, 0, 0), 'reflect')
+ input = F.conv2d(input, kernel_w[None, None, None, :])
+
+ input = input.reshape([n, c, h, w])
+ return F.interpolate(input, size, mode='bicubic', align_corners=align_corners)
+
+
+padargs = {}
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/nn.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/nn.py
new file mode 100755
index 000000000..d618183e2
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/nn.py
@@ -0,0 +1,127 @@
+"""
+Various utilities for neural networks implemented by Paddle. This code is rewritten based on:
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/nn.py
+"""
+import math
+
+import paddle
+import paddle.nn as nn
+
+
+class SiLU(nn.Layer):
+
+ def forward(self, x):
+ return x * nn.functional.sigmoid(x)
+
+
+class GroupNorm32(nn.GroupNorm):
+
+ def forward(self, x):
+ return super().forward(x)
+
+
+def conv_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D convolution module.
+ """
+ if dims == 1:
+ return nn.Conv1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.Conv2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.Conv3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def linear(*args, **kwargs):
+ """
+ Create a linear module.
+ """
+ return nn.Linear(*args, **kwargs)
+
+
+def avg_pool_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D average pooling module.
+ """
+ if dims == 1:
+ return nn.AvgPool1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.AvgPool2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.AvgPool3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def update_ema(target_params, source_params, rate=0.99):
+ """
+ Update target parameters to be closer to those of source parameters using
+ an exponential moving average.
+
+ :param target_params: the target parameter sequence.
+ :param source_params: the source parameter sequence.
+ :param rate: the EMA rate (closer to 1 means slower).
+ """
+ for targ, src in zip(target_params, source_params):
+ targ.detach().mul_(rate).add_(src, alpha=1 - rate)
+
+
+def zero_module(module):
+ """
+ Zero out the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().zero_()
+ return module
+
+
+def scale_module(module, scale):
+ """
+ Scale the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().mul_(scale)
+ return module
+
+
+def mean_flat(tensor):
+ """
+ Take the mean over all non-batch dimensions.
+ """
+ return tensor.mean(axis=list(range(1, len(tensor.shape))))
+
+
+def normalization(channels):
+ """
+ Make a standard normalization layer.
+
+ :param channels: number of input channels.
+ :return: an nn.Module for normalization.
+ """
+ return GroupNorm32(32, channels)
+
+
+def timestep_embedding(timesteps, dim, max_period=10000):
+ """
+ Create sinusoidal timestep embeddings.
+
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param dim: the dimension of the output.
+ :param max_period: controls the minimum frequency of the embeddings.
+ :return: an [N x dim] Tensor of positional embeddings.
+ """
+ half = dim // 2
+ freqs = paddle.exp(-math.log(max_period) * paddle.arange(start=0, end=half, dtype=paddle.float32) / half)
+ args = paddle.cast(timesteps[:, None], 'float32') * freqs[None]
+ embedding = paddle.concat([paddle.cos(args), paddle.sin(args)], axis=-1)
+ if dim % 2:
+ embedding = paddle.concat([embedding, paddle.zeros_like(embedding[:, :1])], axis=-1)
+ return embedding
+
+
+def checkpoint(func, inputs, params, flag):
+ """
+ This function is disabled. And now just forward.
+ """
+ return func(*inputs)
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/perlin_noises.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/perlin_noises.py
new file mode 100755
index 000000000..6dacb331b
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/perlin_noises.py
@@ -0,0 +1,78 @@
+'''
+Perlin noise implementation by Paddle.
+This code is rewritten based on:
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/perlin_noises.py
+'''
+import numpy as np
+import paddle
+import paddle.vision.transforms as TF
+from PIL import Image
+from PIL import ImageOps
+
+
+def interp(t):
+ return 3 * t**2 - 2 * t**3
+
+
+def perlin(width, height, scale=10):
+ gx, gy = paddle.randn([2, width + 1, height + 1, 1, 1])
+ xs = paddle.linspace(0, 1, scale + 1)[:-1, None]
+ ys = paddle.linspace(0, 1, scale + 1)[None, :-1]
+ wx = 1 - interp(xs)
+ wy = 1 - interp(ys)
+ dots = 0
+ dots += wx * wy * (gx[:-1, :-1] * xs + gy[:-1, :-1] * ys)
+ dots += (1 - wx) * wy * (-gx[1:, :-1] * (1 - xs) + gy[1:, :-1] * ys)
+ dots += wx * (1 - wy) * (gx[:-1, 1:] * xs - gy[:-1, 1:] * (1 - ys))
+ dots += (1 - wx) * (1 - wy) * (-gx[1:, 1:] * (1 - xs) - gy[1:, 1:] * (1 - ys))
+ return dots.transpose([0, 2, 1, 3]).reshape([width * scale, height * scale])
+
+
+def perlin_ms(octaves, width, height, grayscale):
+ out_array = [0.5] if grayscale else [0.5, 0.5, 0.5]
+ # out_array = [0.0] if grayscale else [0.0, 0.0, 0.0]
+ for i in range(1 if grayscale else 3):
+ scale = 2**len(octaves)
+ oct_width = width
+ oct_height = height
+ for oct in octaves:
+ p = perlin(oct_width, oct_height, scale)
+ out_array[i] += p * oct
+ scale //= 2
+ oct_width *= 2
+ oct_height *= 2
+ return paddle.concat(out_array)
+
+
+def create_perlin_noise(octaves, width, height, grayscale, side_y, side_x):
+ out = perlin_ms(octaves, width, height, grayscale)
+ if grayscale:
+ out = TF.resize(size=(side_y, side_x), img=out.numpy())
+ out = np.uint8(out)
+ out = Image.fromarray(out).convert('RGB')
+ else:
+ out = out.reshape([-1, 3, out.shape[0] // 3, out.shape[1]])
+ out = out.squeeze().transpose([1, 2, 0]).numpy()
+ out = TF.resize(size=(side_y, side_x), img=out)
+ out = out.clip(0, 1) * 255
+ out = np.uint8(out)
+ out = Image.fromarray(out)
+
+ out = ImageOps.autocontrast(out)
+ return out
+
+
+def regen_perlin(perlin_mode, side_y, side_x, batch_size):
+ if perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+
+ init = (TF.to_tensor(init).add(TF.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+ return init.expand([batch_size, -1, -1, -1])
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/respace.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/respace.py
new file mode 100755
index 000000000..c001c70d0
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/respace.py
@@ -0,0 +1,123 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/respace.py
+'''
+import numpy as np
+import paddle
+
+from .gaussian_diffusion import GaussianDiffusion
+
+
+def space_timesteps(num_timesteps, section_counts):
+ """
+ Create a list of timesteps to use from an original diffusion process,
+ given the number of timesteps we want to take from equally-sized portions
+ of the original process.
+
+ For example, if there's 300 timesteps and the section counts are [10,15,20]
+ then the first 100 timesteps are strided to be 10 timesteps, the second 100
+ are strided to be 15 timesteps, and the final 100 are strided to be 20.
+
+ If the stride is a string starting with "ddim", then the fixed striding
+ from the DDIM paper is used, and only one section is allowed.
+
+ :param num_timesteps: the number of diffusion steps in the original
+ process to divide up.
+ :param section_counts: either a list of numbers, or a string containing
+ comma-separated numbers, indicating the step count
+ per section. As a special case, use "ddimN" where N
+ is a number of steps to use the striding from the
+ DDIM paper.
+ :return: a set of diffusion steps from the original process to use.
+ """
+ if isinstance(section_counts, str):
+ if section_counts.startswith("ddim"):
+ desired_count = int(section_counts[len("ddim"):])
+ for i in range(1, num_timesteps):
+ if len(range(0, num_timesteps, i)) == desired_count:
+ return set(range(0, num_timesteps, i))
+ raise ValueError(f"cannot create exactly {num_timesteps} steps with an integer stride")
+ section_counts = [int(x) for x in section_counts.split(",")]
+ size_per = num_timesteps // len(section_counts)
+ extra = num_timesteps % len(section_counts)
+ start_idx = 0
+ all_steps = []
+ for i, section_count in enumerate(section_counts):
+ size = size_per + (1 if i < extra else 0)
+ if size < section_count:
+ raise ValueError(f"cannot divide section of {size} steps into {section_count}")
+ if section_count <= 1:
+ frac_stride = 1
+ else:
+ frac_stride = (size - 1) / (section_count - 1)
+ cur_idx = 0.0
+ taken_steps = []
+ for _ in range(section_count):
+ taken_steps.append(start_idx + round(cur_idx))
+ cur_idx += frac_stride
+ all_steps += taken_steps
+ start_idx += size
+ return set(all_steps)
+
+
+class SpacedDiffusion(GaussianDiffusion):
+ """
+ A diffusion process which can skip steps in a base diffusion process.
+
+ :param use_timesteps: a collection (sequence or set) of timesteps from the
+ original diffusion process to retain.
+ :param kwargs: the kwargs to create the base diffusion process.
+ """
+
+ def __init__(self, use_timesteps, **kwargs):
+ self.use_timesteps = set(use_timesteps)
+ self.timestep_map = []
+ self.original_num_steps = len(kwargs["betas"])
+
+ base_diffusion = GaussianDiffusion(**kwargs) # pylint: disable=missing-kwoa
+ last_alpha_cumprod = 1.0
+ new_betas = []
+ for i, alpha_cumprod in enumerate(base_diffusion.alphas_cumprod):
+ if i in self.use_timesteps:
+ new_betas.append(1 - alpha_cumprod / last_alpha_cumprod)
+ last_alpha_cumprod = alpha_cumprod
+ self.timestep_map.append(i)
+ kwargs["betas"] = np.array(new_betas)
+ super().__init__(**kwargs)
+
+ def p_mean_variance(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().p_mean_variance(self._wrap_model(model), *args, **kwargs)
+
+ def training_losses(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().training_losses(self._wrap_model(model), *args, **kwargs)
+
+ def condition_mean(self, cond_fn, *args, **kwargs):
+ return super().condition_mean(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def condition_score(self, cond_fn, *args, **kwargs):
+ return super().condition_score(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def _wrap_model(self, model):
+ if isinstance(model, _WrappedModel):
+ return model
+ return _WrappedModel(model, self.timestep_map, self.rescale_timesteps, self.original_num_steps)
+
+ def _scale_timesteps(self, t):
+ # Scaling is done by the wrapped model.
+ return t
+
+
+class _WrappedModel:
+
+ def __init__(self, model, timestep_map, rescale_timesteps, original_num_steps):
+ self.model = model
+ self.timestep_map = timestep_map
+ self.rescale_timesteps = rescale_timesteps
+ self.original_num_steps = original_num_steps
+
+ def __call__(self, x, ts, **kwargs):
+ map_tensor = paddle.to_tensor(self.timestep_map, place=ts.place, dtype=ts.dtype)
+ new_ts = map_tensor[ts]
+ if self.rescale_timesteps:
+ new_ts = paddle.cast(new_ts, 'float32') * (1000.0 / self.original_num_steps)
+ return self.model(x, new_ts, **kwargs)
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/script_util.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/script_util.py
new file mode 100755
index 000000000..d728a5430
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/script_util.py
@@ -0,0 +1,201 @@
+'''
+This code is based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/script_util.py
+'''
+import argparse
+import inspect
+
+from . import gaussian_diffusion as gd
+from .respace import space_timesteps
+from .respace import SpacedDiffusion
+from .unet import EncoderUNetModel
+from .unet import SuperResModel
+from .unet import UNetModel
+
+NUM_CLASSES = 1000
+
+
+def diffusion_defaults():
+ """
+ Defaults for image and classifier training.
+ """
+ return dict(
+ learn_sigma=False,
+ diffusion_steps=1000,
+ noise_schedule="linear",
+ timestep_respacing="",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ )
+
+
+def model_and_diffusion_defaults():
+ """
+ Defaults for image training.
+ """
+ res = dict(
+ image_size=64,
+ num_channels=128,
+ num_res_blocks=2,
+ num_heads=4,
+ num_heads_upsample=-1,
+ num_head_channels=-1,
+ attention_resolutions="16,8",
+ channel_mult="",
+ dropout=0.0,
+ class_cond=False,
+ use_checkpoint=False,
+ use_scale_shift_norm=True,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+ )
+ res.update(diffusion_defaults())
+ return res
+
+
+def create_model_and_diffusion(
+ image_size,
+ class_cond,
+ learn_sigma,
+ num_channels,
+ num_res_blocks,
+ channel_mult,
+ num_heads,
+ num_head_channels,
+ num_heads_upsample,
+ attention_resolutions,
+ dropout,
+ diffusion_steps,
+ noise_schedule,
+ timestep_respacing,
+ use_kl,
+ predict_xstart,
+ rescale_timesteps,
+ rescale_learned_sigmas,
+ use_checkpoint,
+ use_scale_shift_norm,
+ resblock_updown,
+ use_fp16,
+ use_new_attention_order,
+):
+ model = create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult=channel_mult,
+ learn_sigma=learn_sigma,
+ class_cond=class_cond,
+ use_checkpoint=use_checkpoint,
+ attention_resolutions=attention_resolutions,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ dropout=dropout,
+ resblock_updown=resblock_updown,
+ use_fp16=use_fp16,
+ use_new_attention_order=use_new_attention_order,
+ )
+ diffusion = create_gaussian_diffusion(
+ steps=diffusion_steps,
+ learn_sigma=learn_sigma,
+ noise_schedule=noise_schedule,
+ use_kl=use_kl,
+ predict_xstart=predict_xstart,
+ rescale_timesteps=rescale_timesteps,
+ rescale_learned_sigmas=rescale_learned_sigmas,
+ timestep_respacing=timestep_respacing,
+ )
+ return model, diffusion
+
+
+def create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult="",
+ learn_sigma=False,
+ class_cond=False,
+ use_checkpoint=False,
+ attention_resolutions="16",
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ dropout=0,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+):
+ if channel_mult == "":
+ if image_size == 512:
+ channel_mult = (0.5, 1, 1, 2, 2, 4, 4)
+ elif image_size == 256:
+ channel_mult = (1, 1, 2, 2, 4, 4)
+ elif image_size == 128:
+ channel_mult = (1, 1, 2, 3, 4)
+ elif image_size == 64:
+ channel_mult = (1, 2, 3, 4)
+ else:
+ raise ValueError(f"unsupported image size: {image_size}")
+ else:
+ channel_mult = tuple(int(ch_mult) for ch_mult in channel_mult.split(","))
+
+ attention_ds = []
+ for res in attention_resolutions.split(","):
+ attention_ds.append(image_size // int(res))
+
+ return UNetModel(
+ image_size=image_size,
+ in_channels=3,
+ model_channels=num_channels,
+ out_channels=(3 if not learn_sigma else 6),
+ num_res_blocks=num_res_blocks,
+ attention_resolutions=tuple(attention_ds),
+ dropout=dropout,
+ channel_mult=channel_mult,
+ num_classes=(NUM_CLASSES if class_cond else None),
+ use_checkpoint=use_checkpoint,
+ use_fp16=use_fp16,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ resblock_updown=resblock_updown,
+ use_new_attention_order=use_new_attention_order,
+ )
+
+
+def create_gaussian_diffusion(
+ *,
+ steps=1000,
+ learn_sigma=False,
+ sigma_small=False,
+ noise_schedule="linear",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ timestep_respacing="",
+):
+ betas = gd.get_named_beta_schedule(noise_schedule, steps)
+ if use_kl:
+ loss_type = gd.LossType.RESCALED_KL
+ elif rescale_learned_sigmas:
+ loss_type = gd.LossType.RESCALED_MSE
+ else:
+ loss_type = gd.LossType.MSE
+ if not timestep_respacing:
+ timestep_respacing = [steps]
+ return SpacedDiffusion(
+ use_timesteps=space_timesteps(steps, timestep_respacing),
+ betas=betas,
+ model_mean_type=(gd.ModelMeanType.EPSILON if not predict_xstart else gd.ModelMeanType.START_X),
+ model_var_type=((gd.ModelVarType.FIXED_LARGE if not sigma_small else gd.ModelVarType.FIXED_SMALL)
+ if not learn_sigma else gd.ModelVarType.LEARNED_RANGE),
+ loss_type=loss_type,
+ rescale_timesteps=rescale_timesteps,
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/sec_diff.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/sec_diff.py
new file mode 100755
index 000000000..1e361f18f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/sec_diff.py
@@ -0,0 +1,135 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/sec_diff.py
+'''
+import math
+from dataclasses import dataclass
+from functools import partial
+
+import paddle
+import paddle.nn as nn
+
+
+@dataclass
+class DiffusionOutput:
+ v: paddle.Tensor
+ pred: paddle.Tensor
+ eps: paddle.Tensor
+
+
+class SkipBlock(nn.Layer):
+
+ def __init__(self, main, skip=None):
+ super().__init__()
+ self.main = nn.Sequential(*main)
+ self.skip = skip if skip else nn.Identity()
+
+ def forward(self, input):
+ return paddle.concat([self.main(input), self.skip(input)], axis=1)
+
+
+def append_dims(x, n):
+ return x[(Ellipsis, *(None, ) * (n - x.ndim))]
+
+
+def expand_to_planes(x, shape):
+ return paddle.tile(append_dims(x, len(shape)), [1, 1, *shape[2:]])
+
+
+def alpha_sigma_to_t(alpha, sigma):
+ return paddle.atan2(sigma, alpha) * 2 / math.pi
+
+
+def t_to_alpha_sigma(t):
+ return paddle.cos(t * math.pi / 2), paddle.sin(t * math.pi / 2)
+
+
+class SecondaryDiffusionImageNet2(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+ c = 64 # The base channel count
+ cs = [c, c * 2, c * 2, c * 4, c * 4, c * 8]
+
+ self.timestep_embed = FourierFeatures(1, 16)
+ self.down = nn.AvgPool2D(2)
+ self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
+
+ self.net = nn.Sequential(
+ ConvBlock(3 + 16, cs[0]),
+ ConvBlock(cs[0], cs[0]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[0], cs[1]),
+ ConvBlock(cs[1], cs[1]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[1], cs[2]),
+ ConvBlock(cs[2], cs[2]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[2], cs[3]),
+ ConvBlock(cs[3], cs[3]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[3], cs[4]),
+ ConvBlock(cs[4], cs[4]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[4], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[4]),
+ self.up,
+ ]),
+ ConvBlock(cs[4] * 2, cs[4]),
+ ConvBlock(cs[4], cs[3]),
+ self.up,
+ ]),
+ ConvBlock(cs[3] * 2, cs[3]),
+ ConvBlock(cs[3], cs[2]),
+ self.up,
+ ]),
+ ConvBlock(cs[2] * 2, cs[2]),
+ ConvBlock(cs[2], cs[1]),
+ self.up,
+ ]),
+ ConvBlock(cs[1] * 2, cs[1]),
+ ConvBlock(cs[1], cs[0]),
+ self.up,
+ ]),
+ ConvBlock(cs[0] * 2, cs[0]),
+ nn.Conv2D(cs[0], 3, 3, padding=1),
+ )
+
+ def forward(self, input, t):
+ timestep_embed = expand_to_planes(self.timestep_embed(t[:, None]), input.shape)
+ v = self.net(paddle.concat([input, timestep_embed], axis=1))
+ alphas, sigmas = map(partial(append_dims, n=v.ndim), t_to_alpha_sigma(t))
+ pred = input * alphas - v * sigmas
+ eps = input * sigmas + v * alphas
+ return DiffusionOutput(v, pred, eps)
+
+
+class FourierFeatures(nn.Layer):
+
+ def __init__(self, in_features, out_features, std=1.0):
+ super().__init__()
+ assert out_features % 2 == 0
+ # self.weight = nn.Parameter(paddle.randn([out_features // 2, in_features]) * std)
+ self.weight = paddle.create_parameter([out_features // 2, in_features],
+ dtype='float32',
+ default_initializer=nn.initializer.Normal(mean=0.0, std=std))
+
+ def forward(self, input):
+ f = 2 * math.pi * input @ self.weight.T
+ return paddle.concat([f.cos(), f.sin()], axis=-1)
+
+
+class ConvBlock(nn.Sequential):
+
+ def __init__(self, c_in, c_out):
+ super().__init__(
+ nn.Conv2D(c_in, c_out, 3, padding=1),
+ nn.ReLU(),
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/transforms.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/transforms.py
new file mode 100755
index 000000000..e0b620b01
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/transforms.py
@@ -0,0 +1,757 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/pytorch/vision/blob/main/torchvision/transforms/transforms.py
+'''
+import math
+import numbers
+import warnings
+from enum import Enum
+from typing import Any
+from typing import Dict
+from typing import List
+from typing import Optional
+from typing import Sequence
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn.functional import grid_sample
+from paddle.vision import transforms as T
+
+
+class Normalize(nn.Layer):
+
+ def __init__(self, mean, std):
+ super(Normalize, self).__init__()
+ self.mean = paddle.to_tensor(mean)
+ self.std = paddle.to_tensor(std)
+
+ def forward(self, tensor: Tensor):
+ dtype = tensor.dtype
+ mean = paddle.to_tensor(self.mean, dtype=dtype)
+ std = paddle.to_tensor(self.std, dtype=dtype)
+ mean = mean.reshape([1, -1, 1, 1])
+ std = std.reshape([1, -1, 1, 1])
+ result = tensor.subtract(mean).divide(std)
+ return result
+
+
+class InterpolationMode(Enum):
+ """Interpolation modes
+ Available interpolation methods are ``nearest``, ``bilinear``, ``bicubic``, ``box``, ``hamming``, and ``lanczos``.
+ """
+
+ NEAREST = "nearest"
+ BILINEAR = "bilinear"
+ BICUBIC = "bicubic"
+ # For PIL compatibility
+ BOX = "box"
+ HAMMING = "hamming"
+ LANCZOS = "lanczos"
+
+
+class Grayscale(nn.Layer):
+
+ def __init__(self, num_output_channels):
+ super(Grayscale, self).__init__()
+ self.num_output_channels = num_output_channels
+
+ def forward(self, x):
+ output = (0.2989 * x[:, 0:1, :, :] + 0.587 * x[:, 1:2, :, :] + 0.114 * x[:, 2:3, :, :])
+ if self.num_output_channels == 3:
+ return output.expand(x.shape)
+
+ return output
+
+
+class Lambda(nn.Layer):
+
+ def __init__(self, func):
+ super(Lambda, self).__init__()
+ self.transform = func
+
+ def forward(self, x):
+ return self.transform(x)
+
+
+class RandomGrayscale(nn.Layer):
+
+ def __init__(self, p):
+ super(RandomGrayscale, self).__init__()
+ self.prob = p
+ self.transform = Grayscale(3)
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return self.transform(x)
+ else:
+ return x
+
+
+class RandomHorizontalFlip(nn.Layer):
+
+ def __init__(self, prob):
+ super(RandomHorizontalFlip, self).__init__()
+ self.prob = prob
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return x[:, :, :, ::-1]
+ else:
+ return x
+
+
+def _blend(img1: Tensor, img2: Tensor, ratio: float) -> Tensor:
+ ratio = float(ratio)
+ bound = 1.0
+ return (ratio * img1 + (1.0 - ratio) * img2).clip(0, bound)
+
+
+def trunc_div(a, b):
+ ipt = paddle.divide(a, b)
+ sign_ipt = paddle.sign(ipt)
+ abs_ipt = paddle.abs(ipt)
+ abs_ipt = paddle.floor(abs_ipt)
+ out = paddle.multiply(sign_ipt, abs_ipt)
+ return out
+
+
+def fmod(a, b):
+ return a - trunc_div(a, b) * b
+
+
+def _rgb2hsv(img: Tensor) -> Tensor:
+ r, g, b = img.unbind(axis=-3)
+
+ # Implementation is based on https://github.com/python-pillow/Pillow/blob/4174d4267616897df3746d315d5a2d0f82c656ee/
+ # src/libImaging/Convert.c#L330
+ maxc = paddle.max(img, axis=-3)
+ minc = paddle.min(img, axis=-3)
+
+ # The algorithm erases S and H channel where `maxc = minc`. This avoids NaN
+ # from happening in the results, because
+ # + S channel has division by `maxc`, which is zero only if `maxc = minc`
+ # + H channel has division by `(maxc - minc)`.
+ #
+ # Instead of overwriting NaN afterwards, we just prevent it from occuring so
+ # we don't need to deal with it in case we save the NaN in a buffer in
+ # backprop, if it is ever supported, but it doesn't hurt to do so.
+ eqc = maxc == minc
+
+ cr = maxc - minc
+ # Since `eqc => cr = 0`, replacing denominator with 1 when `eqc` is fine.
+ ones = paddle.ones_like(maxc)
+ s = cr / paddle.where(eqc, ones, maxc)
+ # Note that `eqc => maxc = minc = r = g = b`. So the following calculation
+ # of `h` would reduce to `bc - gc + 2 + rc - bc + 4 + rc - bc = 6` so it
+ # would not matter what values `rc`, `gc`, and `bc` have here, and thus
+ # replacing denominator with 1 when `eqc` is fine.
+ cr_divisor = paddle.where(eqc, ones, cr)
+ rc = (maxc - r) / cr_divisor
+ gc = (maxc - g) / cr_divisor
+ bc = (maxc - b) / cr_divisor
+
+ hr = (maxc == r).cast('float32') * (bc - gc)
+ hg = ((maxc == g) & (maxc != r)).cast('float32') * (2.0 + rc - bc)
+ hb = ((maxc != g) & (maxc != r)).cast('float32') * (4.0 + gc - rc)
+ h = hr + hg + hb
+ h = fmod((h / 6.0 + 1.0), paddle.to_tensor(1.0))
+ return paddle.stack((h, s, maxc), axis=-3)
+
+
+def _hsv2rgb(img: Tensor) -> Tensor:
+ h, s, v = img.unbind(axis=-3)
+ i = paddle.floor(h * 6.0)
+ f = (h * 6.0) - i
+ i = i.cast(dtype='int32')
+
+ p = paddle.clip((v * (1.0 - s)), 0.0, 1.0)
+ q = paddle.clip((v * (1.0 - s * f)), 0.0, 1.0)
+ t = paddle.clip((v * (1.0 - s * (1.0 - f))), 0.0, 1.0)
+ i = i % 6
+
+ mask = i.unsqueeze(axis=-3) == paddle.arange(6).reshape([-1, 1, 1])
+
+ a1 = paddle.stack((v, q, p, p, t, v), axis=-3)
+ a2 = paddle.stack((t, v, v, q, p, p), axis=-3)
+ a3 = paddle.stack((p, p, t, v, v, q), axis=-3)
+ a4 = paddle.stack((a1, a2, a3), axis=-4)
+
+ return paddle.einsum("...ijk, ...xijk -> ...xjk", mask.cast(dtype=img.dtype), a4)
+
+
+def adjust_brightness(img: Tensor, brightness_factor: float) -> Tensor:
+ if brightness_factor < 0:
+ raise ValueError(f"brightness_factor ({brightness_factor}) is not non-negative.")
+
+ return _blend(img, paddle.zeros_like(img), brightness_factor)
+
+
+def adjust_contrast(img: Tensor, contrast_factor: float) -> Tensor:
+ if contrast_factor < 0:
+ raise ValueError(f"contrast_factor ({contrast_factor}) is not non-negative.")
+
+ c = img.shape[1]
+
+ if c == 3:
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+ mean = paddle.mean(output, axis=(-3, -2, -1), keepdim=True)
+
+ else:
+ mean = paddle.mean(img, axis=(-3, -2, -1), keepdim=True)
+
+ return _blend(img, mean, contrast_factor)
+
+
+def adjust_hue(img: Tensor, hue_factor: float) -> Tensor:
+ if not (-0.5 <= hue_factor <= 0.5):
+ raise ValueError(f"hue_factor ({hue_factor}) is not in [-0.5, 0.5].")
+
+ img = _rgb2hsv(img)
+ h, s, v = img.unbind(axis=-3)
+ h = fmod(h + hue_factor, paddle.to_tensor(1.0))
+ img = paddle.stack((h, s, v), axis=-3)
+ img_hue_adj = _hsv2rgb(img)
+ return img_hue_adj
+
+
+def adjust_saturation(img: Tensor, saturation_factor: float) -> Tensor:
+ if saturation_factor < 0:
+ raise ValueError(f"saturation_factor ({saturation_factor}) is not non-negative.")
+
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+
+ return _blend(img, output, saturation_factor)
+
+
+class ColorJitter(nn.Layer):
+
+ def __init__(self, brightness=0, contrast=0, saturation=0, hue=0):
+ super(ColorJitter, self).__init__()
+ self.brightness = self._check_input(brightness, "brightness")
+ self.contrast = self._check_input(contrast, "contrast")
+ self.saturation = self._check_input(saturation, "saturation")
+ self.hue = self._check_input(hue, "hue", center=0, bound=(-0.5, 0.5), clip_first_on_zero=False)
+
+ def _check_input(self, value, name, center=1, bound=(0, float("inf")), clip_first_on_zero=True):
+ if isinstance(value, numbers.Number):
+ if value < 0:
+ raise ValueError(f"If {name} is a single number, it must be non negative.")
+ value = [center - float(value), center + float(value)]
+ if clip_first_on_zero:
+ value[0] = max(value[0], 0.0)
+ elif isinstance(value, (tuple, list)) and len(value) == 2:
+ if not bound[0] <= value[0] <= value[1] <= bound[1]:
+ raise ValueError(f"{name} values should be between {bound}")
+ else:
+ raise TypeError(f"{name} should be a single number or a list/tuple with length 2.")
+
+ # if value is 0 or (1., 1.) for brightness/contrast/saturation
+ # or (0., 0.) for hue, do nothing
+ if value[0] == value[1] == center:
+ value = None
+ return value
+
+ @staticmethod
+ def get_params(
+ brightness: Optional[List[float]],
+ contrast: Optional[List[float]],
+ saturation: Optional[List[float]],
+ hue: Optional[List[float]],
+ ) -> Tuple[Tensor, Optional[float], Optional[float], Optional[float], Optional[float]]:
+ """Get the parameters for the randomized transform to be applied on image.
+
+ Args:
+ brightness (tuple of float (min, max), optional): The range from which the brightness_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ contrast (tuple of float (min, max), optional): The range from which the contrast_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ saturation (tuple of float (min, max), optional): The range from which the saturation_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ hue (tuple of float (min, max), optional): The range from which the hue_factor is chosen uniformly.
+ Pass None to turn off the transformation.
+
+ Returns:
+ tuple: The parameters used to apply the randomized transform
+ along with their random order.
+ """
+ fn_idx = paddle.randperm(4)
+
+ b = None if brightness is None else paddle.empty([1]).uniform_(brightness[0], brightness[1])
+ c = None if contrast is None else paddle.empty([1]).uniform_(contrast[0], contrast[1])
+ s = None if saturation is None else paddle.empty([1]).uniform_(saturation[0], saturation[1])
+ h = None if hue is None else paddle.empty([1]).uniform_(hue[0], hue[1])
+
+ return fn_idx, b, c, s, h
+
+ def forward(self, img):
+ """
+ Args:
+ img (PIL Image or Tensor): Input image.
+
+ Returns:
+ PIL Image or Tensor: Color jittered image.
+ """
+ fn_idx, brightness_factor, contrast_factor, saturation_factor, hue_factor = self.get_params(
+ self.brightness, self.contrast, self.saturation, self.hue)
+
+ for fn_id in fn_idx:
+ if fn_id == 0 and brightness_factor is not None:
+ img = adjust_brightness(img, brightness_factor)
+ elif fn_id == 1 and contrast_factor is not None:
+ img = adjust_contrast(img, contrast_factor)
+ elif fn_id == 2 and saturation_factor is not None:
+ img = adjust_saturation(img, saturation_factor)
+ elif fn_id == 3 and hue_factor is not None:
+ img = adjust_hue(img, hue_factor)
+
+ return img
+
+ def __repr__(self) -> str:
+ s = (f"{self.__class__.__name__}("
+ f"brightness={self.brightness}"
+ f", contrast={self.contrast}"
+ f", saturation={self.saturation}"
+ f", hue={self.hue})")
+ return s
+
+
+def _apply_grid_transform(img: Tensor, grid: Tensor, mode: str, fill: Optional[List[float]]) -> Tensor:
+
+ if img.shape[0] > 1:
+ # Apply same grid to a batch of images
+ grid = grid.expand([img.shape[0], grid.shape[1], grid.shape[2], grid.shape[3]])
+
+ # Append a dummy mask for customized fill colors, should be faster than grid_sample() twice
+ if fill is not None:
+ dummy = paddle.ones((img.shape[0], 1, img.shape[2], img.shape[3]), dtype=img.dtype)
+ img = paddle.concat((img, dummy), axis=1)
+
+ img = grid_sample(img, grid, mode=mode, padding_mode="zeros", align_corners=False)
+
+ # Fill with required color
+ if fill is not None:
+ mask = img[:, -1:, :, :] # N * 1 * H * W
+ img = img[:, :-1, :, :] # N * C * H * W
+ mask = mask.expand_as(img)
+ len_fill = len(fill) if isinstance(fill, (tuple, list)) else 1
+ fill_img = paddle.to_tensor(fill, dtype=img.dtype).reshape([1, len_fill, 1, 1]).expand_as(img)
+ if mode == "nearest":
+ mask = mask < 0.5
+ img[mask] = fill_img[mask]
+ else: # 'bilinear'
+ img = img * mask + (1.0 - mask) * fill_img
+ return img
+
+
+def _gen_affine_grid(
+ theta: Tensor,
+ w: int,
+ h: int,
+ ow: int,
+ oh: int,
+) -> Tensor:
+ # https://github.com/pytorch/pytorch/blob/74b65c32be68b15dc7c9e8bb62459efbfbde33d8/aten/src/ATen/native/
+ # AffineGridGenerator.cpp#L18
+ # Difference with AffineGridGenerator is that:
+ # 1) we normalize grid values after applying theta
+ # 2) we can normalize by other image size, such that it covers "extend" option like in PIL.Image.rotate
+
+ d = 0.5
+ base_grid = paddle.empty([1, oh, ow, 3], dtype=theta.dtype)
+ x_grid = paddle.linspace(-ow * 0.5 + d, ow * 0.5 + d - 1, num=ow)
+ base_grid[..., 0] = (x_grid)
+ y_grid = paddle.linspace(-oh * 0.5 + d, oh * 0.5 + d - 1, num=oh).unsqueeze_(-1)
+ base_grid[..., 1] = (y_grid)
+ base_grid[..., 2] = 1.0
+ rescaled_theta = theta.transpose([0, 2, 1]) / paddle.to_tensor([0.5 * w, 0.5 * h], dtype=theta.dtype)
+ output_grid = base_grid.reshape([1, oh * ow, 3]).bmm(rescaled_theta)
+ return output_grid.reshape([1, oh, ow, 2])
+
+
+def affine_impl(img: Tensor,
+ matrix: List[float],
+ interpolation: str = "nearest",
+ fill: Optional[List[float]] = None) -> Tensor:
+ theta = paddle.to_tensor(matrix, dtype=img.dtype).reshape([1, 2, 3])
+ shape = img.shape
+ # grid will be generated on the same device as theta and img
+ grid = _gen_affine_grid(theta, w=shape[-1], h=shape[-2], ow=shape[-1], oh=shape[-2])
+ return _apply_grid_transform(img, grid, interpolation, fill=fill)
+
+
+def _get_inverse_affine_matrix(center: List[float],
+ angle: float,
+ translate: List[float],
+ scale: float,
+ shear: List[float],
+ inverted: bool = True) -> List[float]:
+ # Helper method to compute inverse matrix for affine transformation
+
+ # Pillow requires inverse affine transformation matrix:
+ # Affine matrix is : M = T * C * RotateScaleShear * C^-1
+ #
+ # where T is translation matrix: [1, 0, tx | 0, 1, ty | 0, 0, 1]
+ # C is translation matrix to keep center: [1, 0, cx | 0, 1, cy | 0, 0, 1]
+ # RotateScaleShear is rotation with scale and shear matrix
+ #
+ # RotateScaleShear(a, s, (sx, sy)) =
+ # = R(a) * S(s) * SHy(sy) * SHx(sx)
+ # = [ s*cos(a - sy)/cos(sy), s*(-cos(a - sy)*tan(sx)/cos(sy) - sin(a)), 0 ]
+ # [ s*sin(a + sy)/cos(sy), s*(-sin(a - sy)*tan(sx)/cos(sy) + cos(a)), 0 ]
+ # [ 0 , 0 , 1 ]
+ # where R is a rotation matrix, S is a scaling matrix, and SHx and SHy are the shears:
+ # SHx(s) = [1, -tan(s)] and SHy(s) = [1 , 0]
+ # [0, 1 ] [-tan(s), 1]
+ #
+ # Thus, the inverse is M^-1 = C * RotateScaleShear^-1 * C^-1 * T^-1
+
+ rot = math.radians(angle)
+ sx = math.radians(shear[0])
+ sy = math.radians(shear[1])
+
+ cx, cy = center
+ tx, ty = translate
+
+ # RSS without scaling
+ a = math.cos(rot - sy) / math.cos(sy)
+ b = -math.cos(rot - sy) * math.tan(sx) / math.cos(sy) - math.sin(rot)
+ c = math.sin(rot - sy) / math.cos(sy)
+ d = -math.sin(rot - sy) * math.tan(sx) / math.cos(sy) + math.cos(rot)
+
+ if inverted:
+ # Inverted rotation matrix with scale and shear
+ # det([[a, b], [c, d]]) == 1, since det(rotation) = 1 and det(shear) = 1
+ matrix = [d, -b, 0.0, -c, a, 0.0]
+ matrix = [x / scale for x in matrix]
+ # Apply inverse of translation and of center translation: RSS^-1 * C^-1 * T^-1
+ matrix[2] += matrix[0] * (-cx - tx) + matrix[1] * (-cy - ty)
+ matrix[5] += matrix[3] * (-cx - tx) + matrix[4] * (-cy - ty)
+ # Apply center translation: C * RSS^-1 * C^-1 * T^-1
+ matrix[2] += cx
+ matrix[5] += cy
+ else:
+ matrix = [a, b, 0.0, c, d, 0.0]
+ matrix = [x * scale for x in matrix]
+ # Apply inverse of center translation: RSS * C^-1
+ matrix[2] += matrix[0] * (-cx) + matrix[1] * (-cy)
+ matrix[5] += matrix[3] * (-cx) + matrix[4] * (-cy)
+ # Apply translation and center : T * C * RSS * C^-1
+ matrix[2] += cx + tx
+ matrix[5] += cy + ty
+
+ return matrix
+
+
+def affine(
+ img: Tensor,
+ angle: float,
+ translate: List[int],
+ scale: float,
+ shear: List[float],
+ interpolation: InterpolationMode = InterpolationMode.NEAREST,
+ fill: Optional[List[float]] = None,
+ resample: Optional[int] = None,
+ fillcolor: Optional[List[float]] = None,
+ center: Optional[List[int]] = None,
+) -> Tensor:
+ """Apply affine transformation on the image keeping image center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ img (PIL Image or Tensor): image to transform.
+ angle (number): rotation angle in degrees between -180 and 180, clockwise direction.
+ translate (sequence of integers): horizontal and vertical translations (post-rotation translation)
+ scale (float): overall scale
+ shear (float or sequence): shear angle value in degrees between -180 to 180, clockwise direction.
+ If a sequence is specified, the first value corresponds to a shear parallel to the x axis, while
+ the second value corresponds to a shear parallel to the y axis.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number, optional): Pixel fill value for the area outside the transformed
+ image. If given a number, the value is used for all bands respectively.
+
+ .. note::
+ In torchscript mode single int/float value is not supported, please use a sequence
+ of length 1: ``[value, ]``.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation. Origin is the upper left corner.
+ Default is the center of the image.
+
+ Returns:
+ PIL Image or Tensor: Transformed image.
+ """
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ if not isinstance(angle, (int, float)):
+ raise TypeError("Argument angle should be int or float")
+
+ if not isinstance(translate, (list, tuple)):
+ raise TypeError("Argument translate should be a sequence")
+
+ if len(translate) != 2:
+ raise ValueError("Argument translate should be a sequence of length 2")
+
+ if scale <= 0.0:
+ raise ValueError("Argument scale should be positive")
+
+ if not isinstance(shear, (numbers.Number, (list, tuple))):
+ raise TypeError("Shear should be either a single value or a sequence of two values")
+
+ if not isinstance(interpolation, InterpolationMode):
+ raise TypeError("Argument interpolation should be a InterpolationMode")
+
+ if isinstance(angle, int):
+ angle = float(angle)
+
+ if isinstance(translate, tuple):
+ translate = list(translate)
+
+ if isinstance(shear, numbers.Number):
+ shear = [shear, 0.0]
+
+ if isinstance(shear, tuple):
+ shear = list(shear)
+
+ if len(shear) == 1:
+ shear = [shear[0], shear[0]]
+
+ if len(shear) != 2:
+ raise ValueError(f"Shear should be a sequence containing two values. Got {shear}")
+
+ if center is not None and not isinstance(center, (list, tuple)):
+ raise TypeError("Argument center should be a sequence")
+ center_f = [0.0, 0.0]
+ if center is not None:
+ _, height, width = img.shape[0], img.shape[1], img.shape[2]
+ # Center values should be in pixel coordinates but translated such that (0, 0) corresponds to image center.
+ center_f = [1.0 * (c - s * 0.5) for c, s in zip(center, [width, height])]
+
+ translate_f = [1.0 * t for t in translate]
+ matrix = _get_inverse_affine_matrix(center_f, angle, translate_f, scale, shear)
+ return affine_impl(img, matrix=matrix, interpolation=interpolation.value, fill=fill)
+
+
+def _interpolation_modes_from_int(i: int) -> InterpolationMode:
+ inverse_modes_mapping = {
+ 0: InterpolationMode.NEAREST,
+ 2: InterpolationMode.BILINEAR,
+ 3: InterpolationMode.BICUBIC,
+ 4: InterpolationMode.BOX,
+ 5: InterpolationMode.HAMMING,
+ 1: InterpolationMode.LANCZOS,
+ }
+ return inverse_modes_mapping[i]
+
+
+def _check_sequence_input(x, name, req_sizes):
+ msg = req_sizes[0] if len(req_sizes) < 2 else " or ".join([str(s) for s in req_sizes])
+ if not isinstance(x, Sequence):
+ raise TypeError(f"{name} should be a sequence of length {msg}.")
+ if len(x) not in req_sizes:
+ raise ValueError(f"{name} should be sequence of length {msg}.")
+
+
+def _setup_angle(x, name, req_sizes=(2, )):
+ if isinstance(x, numbers.Number):
+ if x < 0:
+ raise ValueError(f"If {name} is a single number, it must be positive.")
+ x = [-x, x]
+ else:
+ _check_sequence_input(x, name, req_sizes)
+
+ return [float(d) for d in x]
+
+
+class RandomAffine(nn.Layer):
+ """Random affine transformation of the image keeping center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ degrees (sequence or number): Range of degrees to select from.
+ If degrees is a number instead of sequence like (min, max), the range of degrees
+ will be (-degrees, +degrees). Set to 0 to deactivate rotations.
+ translate (tuple, optional): tuple of maximum absolute fraction for horizontal
+ and vertical translations. For example translate=(a, b), then horizontal shift
+ is randomly sampled in the range -img_width * a < dx < img_width * a and vertical shift is
+ randomly sampled in the range -img_height * b < dy < img_height * b. Will not translate by default.
+ scale (tuple, optional): scaling factor interval, e.g (a, b), then scale is
+ randomly sampled from the range a <= scale <= b. Will keep original scale by default.
+ shear (sequence or number, optional): Range of degrees to select from.
+ If shear is a number, a shear parallel to the x axis in the range (-shear, +shear)
+ will be applied. Else if shear is a sequence of 2 values a shear parallel to the x axis in the
+ range (shear[0], shear[1]) will be applied. Else if shear is a sequence of 4 values,
+ a x-axis shear in (shear[0], shear[1]) and y-axis shear in (shear[2], shear[3]) will be applied.
+ Will not apply shear by default.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number): Pixel fill value for the area outside the transformed
+ image. Default is ``0``. If given a number, the value is used for all bands respectively.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation, (x, y). Origin is the upper left corner.
+ Default is the center of the image.
+
+ .. _filters: https://pillow.readthedocs.io/en/latest/handbook/concepts.html#filters
+
+ """
+
+ def __init__(
+ self,
+ degrees,
+ translate=None,
+ scale=None,
+ shear=None,
+ interpolation=InterpolationMode.NEAREST,
+ fill=0,
+ fillcolor=None,
+ resample=None,
+ center=None,
+ ):
+ super(RandomAffine, self).__init__()
+ if resample is not None:
+ warnings.warn("The parameter 'resample' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'interpolation' instead.")
+ interpolation = _interpolation_modes_from_int(resample)
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ self.degrees = _setup_angle(degrees, name="degrees", req_sizes=(2, ))
+
+ if translate is not None:
+ _check_sequence_input(translate, "translate", req_sizes=(2, ))
+ for t in translate:
+ if not (0.0 <= t <= 1.0):
+ raise ValueError("translation values should be between 0 and 1")
+ self.translate = translate
+
+ if scale is not None:
+ _check_sequence_input(scale, "scale", req_sizes=(2, ))
+ for s in scale:
+ if s <= 0:
+ raise ValueError("scale values should be positive")
+ self.scale = scale
+
+ if shear is not None:
+ self.shear = _setup_angle(shear, name="shear", req_sizes=(2, 4))
+ else:
+ self.shear = shear
+
+ self.resample = self.interpolation = interpolation
+
+ if fill is None:
+ fill = 0
+ elif not isinstance(fill, (Sequence, numbers.Number)):
+ raise TypeError("Fill should be either a sequence or a number.")
+
+ self.fillcolor = self.fill = fill
+
+ if center is not None:
+ _check_sequence_input(center, "center", req_sizes=(2, ))
+
+ self.center = center
+
+ @staticmethod
+ def get_params(
+ degrees: List[float],
+ translate: Optional[List[float]],
+ scale_ranges: Optional[List[float]],
+ shears: Optional[List[float]],
+ img_size: List[int],
+ ) -> Tuple[float, Tuple[int, int], float, Tuple[float, float]]:
+ """Get parameters for affine transformation
+
+ Returns:
+ params to be passed to the affine transformation
+ """
+ angle = float(paddle.empty([1]).uniform_(float(degrees[0]), float(degrees[1])))
+ if translate is not None:
+ max_dx = float(translate[0] * img_size[0])
+ max_dy = float(translate[1] * img_size[1])
+ tx = int(float(paddle.empty([1]).uniform_(-max_dx, max_dx)))
+ ty = int(float(paddle.empty([1]).uniform_(-max_dy, max_dy)))
+ translations = (tx, ty)
+ else:
+ translations = (0, 0)
+
+ if scale_ranges is not None:
+ scale = float(paddle.empty([1]).uniform_(scale_ranges[0], scale_ranges[1]))
+ else:
+ scale = 1.0
+
+ shear_x = shear_y = 0.0
+ if shears is not None:
+ shear_x = float(paddle.empty([1]).uniform_(shears[0], shears[1]))
+ if len(shears) == 4:
+ shear_y = float(paddle.empty([1]).uniform_(shears[2], shears[3]))
+
+ shear = (shear_x, shear_y)
+
+ return angle, translations, scale, shear
+
+ def forward(self, img):
+ fill = self.fill
+ channels, height, width = img.shape[1], img.shape[2], img.shape[3]
+ if isinstance(fill, (int, float)):
+ fill = [float(fill)] * channels
+ else:
+ fill = [float(f) for f in fill]
+
+ img_size = [width, height] # flip for keeping BC on get_params call
+
+ ret = self.get_params(self.degrees, self.translate, self.scale, self.shear, img_size)
+
+ return affine(img, *ret, interpolation=self.interpolation, fill=fill, center=self.center)
+
+ def __repr__(self) -> str:
+ s = f"{self.__class__.__name__}(degrees={self.degrees}"
+ s += f", translate={self.translate}" if self.translate is not None else ""
+ s += f", scale={self.scale}" if self.scale is not None else ""
+ s += f", shear={self.shear}" if self.shear is not None else ""
+ s += f", interpolation={self.interpolation.value}" if self.interpolation != InterpolationMode.NEAREST else ""
+ s += f", fill={self.fill}" if self.fill != 0 else ""
+ s += f", center={self.center}" if self.center is not None else ""
+ s += ")"
+
+ return s
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/unet.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/unet.py
new file mode 100755
index 000000000..56f3ad61e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/model/unet.py
@@ -0,0 +1,838 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/unet.py
+'''
+import math
+from abc import abstractmethod
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+from .nn import avg_pool_nd
+from .nn import checkpoint
+from .nn import conv_nd
+from .nn import linear
+from .nn import normalization
+from .nn import SiLU
+from .nn import timestep_embedding
+from .nn import zero_module
+
+
+class AttentionPool2d(nn.Layer):
+ """
+ Adapted from CLIP: https://github.com/openai/CLIP/blob/main/clip/model.py
+ """
+
+ def __init__(
+ self,
+ spacial_dim: int,
+ embed_dim: int,
+ num_heads_channels: int,
+ output_dim: int = None,
+ ):
+ super().__init__()
+ # self.positional_embedding = nn.Parameter(
+ # th.randn(embed_dim, spacial_dim ** 2 + 1) / embed_dim ** 0.5
+ # )
+ positional_embedding = self.create_parameter(paddle.randn(embed_dim, spacial_dim**2 + 1) / embed_dim**0.5)
+ self.add_parameter("positional_embedding", positional_embedding)
+ self.qkv_proj = conv_nd(1, embed_dim, 3 * embed_dim, 1)
+ self.c_proj = conv_nd(1, embed_dim, output_dim or embed_dim, 1)
+ self.num_heads = embed_dim // num_heads_channels
+ self.attention = QKVAttention(self.num_heads)
+
+ def forward(self, x):
+ b, c, *_spatial = x.shape
+ # x = x.reshape(b, c, -1) # NC(HW)
+ x = paddle.reshape(x, [b, c, -1])
+ x = paddle.concat([x.mean(dim=-1, keepdim=True), x], axis=-1) # NC(HW+1)
+ x = x + paddle.cast(self.positional_embedding[None, :, :], x.dtype) # NC(HW+1)
+ x = self.qkv_proj(x)
+ x = self.attention(x)
+ x = self.c_proj(x)
+ return x[:, :, 0]
+
+
+class TimestepBlock(nn.Layer):
+ """
+ Any module where forward() takes timestep embeddings as a second argument.
+ """
+
+ @abstractmethod
+ def forward(self, x, emb):
+ """
+ Apply the module to `x` given `emb` timestep embeddings.
+ """
+
+
+class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
+ """
+ A sequential module that passes timestep embeddings to the children that
+ support it as an extra input.
+ """
+
+ def forward(self, x, emb):
+ for layer in self:
+ if isinstance(layer, TimestepBlock):
+ x = layer(x, emb)
+ else:
+ x = layer(x)
+ return x
+
+
+class Upsample(nn.Layer):
+ """
+ An upsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ if use_conv:
+ self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=1)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.dims == 3:
+ x = F.interpolate(x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest")
+ else:
+ x = F.interpolate(x, scale_factor=2, mode="nearest")
+ if self.use_conv:
+ x = self.conv(x)
+ return x
+
+
+class Downsample(nn.Layer):
+ """
+ A downsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ stride = 2 if dims != 3 else (1, 2, 2)
+ if use_conv:
+ self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=1)
+ else:
+ assert self.channels == self.out_channels
+ self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ return self.op(x)
+
+
+class ResBlock(TimestepBlock):
+ """
+ A residual block that can optionally change the number of channels.
+
+ :param channels: the number of input channels.
+ :param emb_channels: the number of timestep embedding channels.
+ :param dropout: the rate of dropout.
+ :param out_channels: if specified, the number of out channels.
+ :param use_conv: if True and out_channels is specified, use a spatial
+ convolution instead of a smaller 1x1 convolution to change the
+ channels in the skip connection.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param use_checkpoint: if True, use gradient checkpointing on this module.
+ :param up: if True, use this block for upsampling.
+ :param down: if True, use this block for downsampling.
+ """
+
+ def __init__(
+ self,
+ channels,
+ emb_channels,
+ dropout,
+ out_channels=None,
+ use_conv=False,
+ use_scale_shift_norm=False,
+ dims=2,
+ use_checkpoint=False,
+ up=False,
+ down=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ self.emb_channels = emb_channels
+ self.dropout = dropout
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_checkpoint = use_checkpoint
+ self.use_scale_shift_norm = use_scale_shift_norm
+
+ self.in_layers = nn.Sequential(
+ normalization(channels),
+ SiLU(),
+ conv_nd(dims, channels, self.out_channels, 3, padding=1),
+ )
+
+ self.updown = up or down
+
+ if up:
+ self.h_upd = Upsample(channels, False, dims)
+ self.x_upd = Upsample(channels, False, dims)
+ elif down:
+ self.h_upd = Downsample(channels, False, dims)
+ self.x_upd = Downsample(channels, False, dims)
+ else:
+ self.h_upd = self.x_upd = nn.Identity()
+
+ self.emb_layers = nn.Sequential(
+ SiLU(),
+ linear(
+ emb_channels,
+ 2 * self.out_channels if use_scale_shift_norm else self.out_channels,
+ ),
+ )
+ self.out_layers = nn.Sequential(
+ normalization(self.out_channels),
+ SiLU(),
+ nn.Dropout(p=dropout),
+ zero_module(conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)),
+ )
+
+ if self.out_channels == channels:
+ self.skip_connection = nn.Identity()
+ elif use_conv:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 3, padding=1)
+ else:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
+
+ def forward(self, x, emb):
+ """
+ Apply the block to a Tensor, conditioned on a timestep embedding.
+
+ :param x: an [N x C x ...] Tensor of features.
+ :param emb: an [N x emb_channels] Tensor of timestep embeddings.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ return checkpoint(self._forward, (x, emb), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x, emb):
+ if self.updown:
+ in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
+ h = in_rest(x)
+ h = self.h_upd(h)
+ x = self.x_upd(x)
+ h = in_conv(h)
+ else:
+ h = self.in_layers(x)
+ emb_out = self.emb_layers(emb)
+ emb_out = paddle.cast(emb_out, h.dtype)
+ while len(emb_out.shape) < len(h.shape):
+ emb_out = emb_out[..., None]
+ if self.use_scale_shift_norm:
+ out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
+ scale, shift = paddle.chunk(emb_out, 2, axis=1)
+ h = out_norm(h) * (1 + scale) + shift
+ h = out_rest(h)
+ else:
+ h = h + emb_out
+ h = self.out_layers(h)
+ return self.skip_connection(x) + h
+
+
+class AttentionBlock(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other.
+
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_heads=1,
+ num_head_channels=-1,
+ use_checkpoint=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels == -1:
+ self.num_heads = num_heads
+ else:
+ assert (channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+ self.use_checkpoint = use_checkpoint
+ self.norm = normalization(channels)
+ self.qkv = conv_nd(1, channels, channels * 3, 1)
+ if use_new_attention_order:
+ # split qkv before split heads
+ self.attention = QKVAttention(self.num_heads)
+ else:
+ # split heads before split qkv
+ self.attention = QKVAttentionLegacy(self.num_heads)
+
+ self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
+
+ def forward(self, x):
+ return checkpoint(self._forward, (x, ), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x):
+ b, c, *spatial = x.shape
+ # x = x.reshape(b, c, -1)
+ x = paddle.reshape(x, [b, c, -1])
+ qkv = self.qkv(self.norm(x))
+ h = self.attention(qkv)
+ h = self.proj_out(h)
+ # return (x + h).reshape(b, c, *spatial)
+ return paddle.reshape(x + h, [b, c, *spatial])
+
+
+def count_flops_attn(model, _x, y):
+ """
+ A counter for the `thop` package to count the operations in an
+ attention operation.
+ Meant to be used like:
+ macs, params = thop.profile(
+ model,
+ inputs=(inputs, timestamps),
+ custom_ops={QKVAttention: QKVAttention.count_flops},
+ )
+ """
+ b, c, *spatial = y[0].shape
+ num_spatial = int(np.prod(spatial))
+ # We perform two matmuls with the same number of ops.
+ # The first computes the weight matrix, the second computes
+ # the combination of the value vectors.
+ matmul_ops = 2 * b * (num_spatial**2) * c
+ model.total_ops += paddle.to_tensor([matmul_ops], dtype='float64')
+
+
+class QKVAttentionLegacy(nn.Layer):
+ """
+ A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ # q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
+ q, k, v = paddle.reshape(qkv, [bs * self.n_heads, ch * 3, length]).split(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v)
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class QKVAttention(nn.Layer):
+ """
+ A module which performs QKV attention and splits in a different order.
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (3 * H * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.chunk(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum(
+ "bct,bcs->bts",
+ (q * scale).view(bs * self.n_heads, ch, length),
+ (k * scale).view(bs * self.n_heads, ch, length),
+ ) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v.reshape(bs * self.n_heads, ch, length))
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class UNetModel(nn.Layer):
+ """
+ The full UNet model with attention and timestep embedding.
+
+ :param in_channels: channels in the input Tensor.
+ :param model_channels: base channel count for the model.
+ :param out_channels: channels in the output Tensor.
+ :param num_res_blocks: number of residual blocks per downsample.
+ :param attention_resolutions: a collection of downsample rates at which
+ attention will take place. May be a set, list, or tuple.
+ For example, if this contains 4, then at 4x downsampling, attention
+ will be used.
+ :param dropout: the dropout probability.
+ :param channel_mult: channel multiplier for each level of the UNet.
+ :param conv_resample: if True, use learned convolutions for upsampling and
+ downsampling.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param num_classes: if specified (as an int), then this model will be
+ class-conditional with `num_classes` classes.
+ :param use_checkpoint: use gradient checkpointing to reduce memory usage.
+ :param num_heads: the number of attention heads in each attention layer.
+ :param num_heads_channels: if specified, ignore num_heads and instead use
+ a fixed channel width per attention head.
+ :param num_heads_upsample: works with num_heads to set a different number
+ of heads for upsampling. Deprecated.
+ :param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
+ :param resblock_updown: use residual blocks for up/downsampling.
+ :param use_new_attention_order: use a different attention pattern for potentially
+ increased efficiency.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ num_classes=None,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.image_size = image_size
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.num_classes = num_classes
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ if self.num_classes is not None:
+ self.label_emb = nn.Embedding(num_classes, time_embed_dim)
+
+ ch = input_ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+
+ self.output_blocks = nn.LayerList([])
+ for level, mult in list(enumerate(channel_mult))[::-1]:
+ for i in range(num_res_blocks + 1):
+ ich = input_block_chans.pop()
+ layers = [
+ ResBlock(
+ ch + ich,
+ time_embed_dim,
+ dropout,
+ out_channels=int(model_channels * mult),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(model_channels * mult)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads_upsample,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ if level and i == num_res_blocks:
+ out_ch = ch
+ layers.append(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ up=True,
+ ) if resblock_updown else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch))
+ ds //= 2
+ self.output_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ zero_module(conv_nd(dims, input_ch, out_channels, 3, padding=1)),
+ )
+
+ def forward(self, x, timesteps, y=None):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :param y: an [N] Tensor of labels, if class-conditional.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ assert (y is not None) == (self.num_classes
+ is not None), "must specify y if and only if the model is class-conditional"
+
+ hs = []
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+ if self.num_classes is not None:
+ assert y.shape == (x.shape[0], )
+ emb = emb + self.label_emb(y)
+
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ hs.append(h)
+ h = self.middle_block(h, emb)
+ for module in self.output_blocks:
+ h = paddle.concat([h, hs.pop()], axis=1)
+ h = module(h, emb)
+ # h = paddle.cast(h, x.dtype)
+ return self.out(h)
+
+
+class SuperResModel(UNetModel):
+ """
+ A UNetModel that performs super-resolution.
+
+ Expects an extra kwarg `low_res` to condition on a low-resolution image.
+ """
+
+ def __init__(self, image_size, in_channels, *args, **kwargs):
+ super().__init__(image_size, in_channels * 2, *args, **kwargs)
+
+ def forward(self, x, timesteps, low_res=None, **kwargs):
+ _, _, new_height, new_width = x.shape
+ upsampled = F.interpolate(low_res, (new_height, new_width), mode="bilinear")
+ x = paddle.concat([x, upsampled], axis=1)
+ return super().forward(x, timesteps, **kwargs)
+
+
+class EncoderUNetModel(nn.Layer):
+ """
+ The half UNet model with attention and timestep embedding.
+
+ For usage, see UNet.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ pool="adaptive",
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+ self.pool = pool
+ if pool == "adaptive":
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ nn.AdaptiveAvgPool2D((1, 1)),
+ zero_module(conv_nd(dims, ch, out_channels, 1)),
+ nn.Flatten(),
+ )
+ elif pool == "attention":
+ assert num_head_channels != -1
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ AttentionPool2d((image_size // ds), ch, num_head_channels, out_channels),
+ )
+ elif pool == "spatial":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ nn.ReLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ elif pool == "spatial_v2":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ normalization(2048),
+ SiLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ else:
+ raise NotImplementedError(f"Unexpected {pool} pooling")
+
+ def forward(self, x, timesteps):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :return: an [N x K] Tensor of outputs.
+ """
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+
+ results = []
+ # h = x.type(self.dtype)
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ if self.pool.startswith("spatial"):
+ # results.append(h.type(x.dtype).mean(axis=(2, 3)))
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = self.middle_block(h, emb)
+ if self.pool.startswith("spatial"):
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = paddle.concat(results, axis=-1)
+ return self.out(h)
+ else:
+ # h = h.type(x.dtype)
+ h = paddle.cast(h, x.dtype)
+ return self.out(h)
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/resources/default.yml b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/resources/default.yml
new file mode 100755
index 000000000..3a161f169
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/resources/default.yml
@@ -0,0 +1,45 @@
+text_prompts:
+ - greg rutkowski和thomas kinkade在artstation上的一幅美丽的画,一个独特的灯塔,照耀着它的光穿过喧嚣的血海。
+
+init_image:
+width_height: [ 1280, 768]
+
+skip_steps: 10
+steps: 250
+
+cut_ic_pow: 1
+init_scale: 1000
+clip_guidance_scale: 5000
+
+tv_scale: 0
+range_scale: 150
+sat_scale: 0
+cutn_batches: 4
+
+diffusion_model: 512x512_diffusion_uncond_finetune_008100
+use_secondary_model: True
+diffusion_sampling_mode: ddim
+
+perlin_init: False
+perlin_mode: mixed
+seed: 445467575
+eta: 0.8
+clamp_grad: True
+clamp_max: 0.05
+
+randomize_class: True
+clip_denoised: False
+fuzzy_prompt: False
+rand_mag: 0.05
+
+cut_overview: "[12]*400+[4]*600"
+cut_innercut: "[4]*400+[12]*600"
+cut_icgray_p: "[0.2]*400+[0]*600"
+
+display_rate: 10
+n_batches: 1
+batch_size: 1
+batch_name: ''
+clip_models:
+ - ViTB16
+output_dir: "./"
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/resources/docstrings.yml b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/resources/docstrings.yml
new file mode 100755
index 000000000..702015e1c
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/resources/docstrings.yml
@@ -0,0 +1,103 @@
+text_prompts: |
+ Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."
+ Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments.
+ Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+init_image: |
+ Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here.
+ If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+width_height: |
+ Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+
+skip_steps: |
+ Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.
+ As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.
+ The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.
+ If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.
+ Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.
+ Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image.
+ However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+
+steps: |
+ When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.
+ Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user.
+ Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+
+cut_ic_pow: |
+ This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+init_scale: |
+ This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+clip_guidance_scale: |
+ CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS.
+ Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500.
+ Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+tv_scale: |
+ Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+range_scale: |
+ Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+
+sat_scale: |
+ Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+cutn_batches: |
+ Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep.
+ Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage.
+ At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep.
+ However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.
+ So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+
+diffusion_model: Diffusion_model of choice.
+
+use_secondary_model: |
+ Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+
+diffusion_sampling_mode: |
+ Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+
+perlin_init: |
+ Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps).
+ Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+
+perlin_mode: |
+ sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+seed: |
+ Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar.
+ After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+eta: |
+ eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results.
+ The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+clamp_grad: |
+ As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+clamp_max: |
+ Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+
+randomize_class:
+clip_denoised: False
+fuzzy_prompt: |
+ Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+rand_mag: |
+ Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+
+cut_overview: The schedule of overview cuts
+cut_innercut: The schedule of inner cuts
+cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+display_rate: |
+ During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+n_batches: |
+ This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+batch_name: |
+ The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+clip_models: |
+ CLIP Model selectors. ViT-B/32, ViT-B/16, ViT-L/14, RN101, RN50, RN50x4, RN50x16, RN50x64.
+ These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around.
+ You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.
+ The rough order of speed/mem usage is (smallest/fastest to largest/slowest):
+ ViT-B/32
+ RN50
+ RN101
+ ViT-B/16
+ RN50x4
+ RN50x16
+ RN50x64
+ ViT-L/14
+ For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/runner.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/runner.py
new file mode 100755
index 000000000..c3fa9e757
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/reverse_diffusion/runner.py
@@ -0,0 +1,285 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/runner.py
+'''
+import gc
+import os
+import random
+from threading import Thread
+
+import numpy as np
+import paddle
+import paddle.vision.transforms as T
+import paddle_lpips as lpips
+from disco_diffusion_ernievil_base.vit_b_16x.ernievil2.utils.utils import tokenize
+from docarray import Document
+from docarray import DocumentArray
+from IPython import display
+from ipywidgets import Output
+from PIL import Image
+
+from .helper import logger
+from .helper import parse_prompt
+from .model.losses import range_loss
+from .model.losses import spherical_dist_loss
+from .model.losses import tv_loss
+from .model.make_cutouts import MakeCutoutsDango
+from .model.sec_diff import alpha_sigma_to_t
+from .model.sec_diff import SecondaryDiffusionImageNet2
+from .model.transforms import Normalize
+
+
+def do_run(args, models) -> 'DocumentArray':
+ logger.info('preparing models...')
+ model, diffusion, clip_models, secondary_model = models
+ normalize = Normalize(
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225],
+ )
+ lpips_model = lpips.LPIPS(net='vgg')
+ for parameter in lpips_model.parameters():
+ parameter.stop_gradient = True
+ side_x = (args.width_height[0] // 64) * 64
+ side_y = (args.width_height[1] // 64) * 64
+ cut_overview = eval(args.cut_overview)
+ cut_innercut = eval(args.cut_innercut)
+ cut_icgray_p = eval(args.cut_icgray_p)
+
+ from .model.perlin_noises import create_perlin_noise, regen_perlin
+
+ seed = args.seed
+
+ skip_steps = args.skip_steps
+
+ loss_values = []
+
+ if seed is not None:
+ np.random.seed(seed)
+ random.seed(seed)
+ paddle.seed(seed)
+
+ model_stats = []
+ for clip_model in clip_models:
+ model_stat = {
+ 'clip_model': None,
+ 'target_embeds': [],
+ 'make_cutouts': None,
+ 'weights': [],
+ }
+ model_stat['clip_model'] = clip_model
+
+ if isinstance(args.text_prompts, str):
+ args.text_prompts = [args.text_prompts]
+
+ for prompt in args.text_prompts:
+ txt, weight = parse_prompt(prompt)
+ txt = clip_model.encode_text(tokenize(prompt))
+ if args.fuzzy_prompt:
+ for i in range(25):
+ model_stat['target_embeds'].append((txt + paddle.randn(txt.shape) * args.rand_mag).clip(0, 1))
+ model_stat['weights'].append(weight)
+ else:
+ model_stat['target_embeds'].append(txt)
+ model_stat['weights'].append(weight)
+
+ model_stat['target_embeds'] = paddle.concat(model_stat['target_embeds'])
+ model_stat['weights'] = paddle.to_tensor(model_stat['weights'])
+ if model_stat['weights'].sum().abs() < 1e-3:
+ raise RuntimeError('The weights must not sum to 0.')
+ model_stat['weights'] /= model_stat['weights'].sum().abs()
+ model_stats.append(model_stat)
+
+ init = None
+ if args.init_image:
+ d = Document(uri=args.init_image).load_uri_to_image_tensor(side_x, side_y)
+ init = T.to_tensor(d.tensor).unsqueeze(0) * 2 - 1
+
+ if args.perlin_init:
+ if args.perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif args.perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ init = (T.to_tensor(init).add(T.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+
+ cur_t = None
+
+ def cond_fn(x, t, y=None):
+ x_is_NaN = False
+ n = x.shape[0]
+ if secondary_model:
+ alpha = paddle.to_tensor(diffusion.sqrt_alphas_cumprod[cur_t], dtype='float32')
+ sigma = paddle.to_tensor(diffusion.sqrt_one_minus_alphas_cumprod[cur_t], dtype='float32')
+ cosine_t = alpha_sigma_to_t(alpha, sigma)
+ x = paddle.to_tensor(x.detach(), dtype='float32')
+ x.stop_gradient = False
+ cosine_t = paddle.tile(paddle.to_tensor(cosine_t.detach().cpu().numpy()), [n])
+ cosine_t.stop_gradient = False
+ out = secondary_model(x, cosine_t).pred
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ else:
+ t = paddle.ones([n], dtype='int64') * cur_t
+ out = diffusion.p_mean_variance(model, x, t, clip_denoised=False, model_kwargs={'y': y})
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out['pred_xstart'] * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ for model_stat in model_stats:
+ for i in range(args.cutn_batches):
+ t_int = (int(t.item()) + 1) # errors on last step without +1, need to find source
+ # when using SLIP Base model the dimensions need to be hard coded to avoid AttributeError: 'VisionTransformer' object has no attribute 'input_resolution'
+ try:
+ input_resolution = model_stat['clip_model'].visual.input_resolution
+ except:
+ input_resolution = 224
+
+ cuts = MakeCutoutsDango(
+ input_resolution,
+ Overview=cut_overview[1000 - t_int],
+ InnerCrop=cut_innercut[1000 - t_int],
+ IC_Size_Pow=args.cut_ic_pow,
+ IC_Grey_P=cut_icgray_p[1000 - t_int],
+ )
+ clip_in = normalize(cuts(x_in.add(paddle.to_tensor(1.0)).divide(paddle.to_tensor(2.0))))
+ image_embeds = (model_stat['clip_model'].encode_image(clip_in))
+
+ dists = spherical_dist_loss(
+ image_embeds.unsqueeze(1),
+ model_stat['target_embeds'].unsqueeze(0),
+ )
+
+ dists = dists.reshape([
+ cut_overview[1000 - t_int] + cut_innercut[1000 - t_int],
+ n,
+ -1,
+ ])
+ losses = dists.multiply(model_stat['weights']).sum(2).mean(0)
+ loss_values.append(losses.sum().item()) # log loss, probably shouldn't do per cutn_batch
+
+ x_in_grad += ((paddle.grad(losses.sum() * args.clip_guidance_scale, x_in)[0]) / args.cutn_batches)
+ tv_losses = tv_loss(x_in)
+ range_losses = range_loss(x_in)
+ sat_losses = paddle.abs(x_in - x_in.clip(min=-1, max=1)).mean()
+ loss = (tv_losses.sum() * args.tv_scale + range_losses.sum() * args.range_scale +
+ sat_losses.sum() * args.sat_scale)
+ if init is not None and args.init_scale:
+ init_losses = lpips_model(x_in, init)
+ loss = loss + init_losses.sum() * args.init_scale
+ x_in_grad += paddle.grad(loss, x_in)[0]
+ if not paddle.isnan(x_in_grad).any():
+ grad = -paddle.grad(x_in_d, x, x_in_grad)[0]
+ else:
+ x_is_NaN = True
+ grad = paddle.zeros_like(x)
+ if args.clamp_grad and not x_is_NaN:
+ magnitude = grad.square().mean().sqrt()
+ return (grad * magnitude.clip(max=args.clamp_max) / magnitude)
+ return grad
+
+ if args.diffusion_sampling_mode == 'ddim':
+ sample_fn = diffusion.ddim_sample_loop_progressive
+ else:
+ sample_fn = diffusion.plms_sample_loop_progressive
+
+ logger.info('creating artwork...')
+
+ image_display = Output()
+ da_batches = DocumentArray()
+
+ for _nb in range(args.n_batches):
+ display.clear_output(wait=True)
+ display.display(args.name_docarray, image_display)
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+
+ d = Document(tags=vars(args))
+ da_batches.append(d)
+
+ cur_t = diffusion.num_timesteps - skip_steps - 1
+
+ if args.perlin_init:
+ init = regen_perlin(args.perlin_mode, side_y, side_x, args.batch_size)
+
+ if args.diffusion_sampling_mode == 'ddim':
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ eta=args.eta,
+ )
+ else:
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ order=2,
+ )
+
+ threads = []
+ for j, sample in enumerate(samples):
+ cur_t -= 1
+ with image_display:
+ if j % args.display_rate == 0 or cur_t == -1:
+ for _, image in enumerate(sample['pred_xstart']):
+ image = (image + 1) / 2
+ image = image.clip(0, 1).squeeze().transpose([1, 2, 0]).numpy() * 255
+ image = np.uint8(image)
+ image = Image.fromarray(image)
+
+ image.save(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb)))
+ c = Document(tags={'cur_t': cur_t})
+ c.load_pil_image_to_datauri(image)
+ d.chunks.append(c)
+ display.clear_output(wait=True)
+ display.display(display.Image(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb))))
+ d.chunks.plot_image_sprites(os.path.join(args.output_dir,
+ f'{args.name_docarray}-progress-{_nb}.png'),
+ show_index=True)
+ t = Thread(
+ target=_silent_push,
+ args=(
+ da_batches,
+ args.name_docarray,
+ ),
+ )
+ threads.append(t)
+ t.start()
+
+ if cur_t == -1:
+ d.load_pil_image_to_datauri(image)
+
+ for t in threads:
+ t.join()
+ display.clear_output(wait=True)
+ logger.info(f'done! {args.name_docarray}')
+ da_batches.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ return da_batches
+
+
+def _silent_push(da_batches: DocumentArray, name: str) -> None:
+ try:
+ da_batches.push(name)
+ except Exception as ex:
+ logger.debug(f'push failed: {ex}')
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/vit_b_16x/ernievil2/__init__.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/vit_b_16x/ernievil2/__init__.py
new file mode 100755
index 000000000..5c75b1c83
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/vit_b_16x/ernievil2/__init__.py
@@ -0,0 +1,18 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+__version__ = '2.0.0' # Maybe dev is better
+
+from . import transformers
+from . import utils
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/vit_b_16x/ernievil2/transformers/__init__.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/vit_b_16x/ernievil2/transformers/__init__.py
new file mode 100755
index 000000000..e69de29bb
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/vit_b_16x/ernievil2/transformers/beam.py b/modules/image/text_to_image/disco_diffusion_ernievil_base/vit_b_16x/ernievil2/transformers/beam.py
new file mode 100755
index 000000000..d316ec9bb
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/vit_b_16x/ernievil2/transformers/beam.py
@@ -0,0 +1,1602 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import print_function
+
+import sys
+import warnings
+from functools import partial
+from functools import reduce
+
+import paddle
+from paddle.fluid import core
+from paddle.fluid.data_feeder import check_dtype
+from paddle.fluid.data_feeder import check_type
+from paddle.fluid.data_feeder import check_variable_and_dtype
+from paddle.fluid.data_feeder import convert_dtype
+from paddle.fluid.framework import default_main_program
+from paddle.fluid.framework import in_dygraph_mode
+from paddle.fluid.layer_helper import LayerHelper
+from paddle.fluid.layers import control_flow
+from paddle.fluid.layers import nn
+from paddle.fluid.layers import sequence_lod
+from paddle.fluid.layers import tensor
+from paddle.fluid.layers import utils
+from paddle.fluid.layers.utils import *
+from paddle.fluid.param_attr import ParamAttr
+from paddle.utils import deprecated
+#import paddle.nn as nn
+
+
+class ArrayWrapper(object):
+
+ def __init__(self, x):
+ self.array = [x]
+
+ def append(self, x):
+ self.array.append(x)
+ return self
+
+ def __getitem__(self, item):
+ return self.array.__getitem__(item)
+
+
+def _maybe_copy(state, new_state, step_mask):
+ """update rnn state or just pass the old state through"""
+ new_state = nn.elementwise_mul(new_state, step_mask, axis=0) \
+ + nn.elementwise_mul(state, (1 - step_mask), axis=0)
+ return new_state
+
+
+def _transpose_batch_time(x):
+ perm = [1, 0] + list(range(2, len(x.shape)))
+ return nn.transpose(x, perm)
+
+
+class Decoder(object):
+ """
+ :api_attr: Static Graph
+
+ Decoder is the base class for any decoder instance used in `dynamic_decode`.
+ It provides interface for output generation for one time step, which can be
+ used to generate sequences.
+
+ The key abstraction provided by Decoder is:
+
+ 1. :code:`(initial_input, initial_state, finished) = initialize(inits)` ,
+ which generates the input and state for the first decoding step, and gives the
+ initial status telling whether each sequence in the batch is finished.
+ It would be called once before the decoding iterations.
+
+ 2. :code:`(output, next_state, next_input, finished) = step(time, input, state)` ,
+ which transforms the input and state to the output and new state, generates
+ input for the next decoding step, and emits the flag indicating finished status.
+ It is the main part for each decoding iteration.
+
+ 3. :code:`(final_outputs, final_state) = finalize(outputs, final_state, sequence_lengths)` ,
+ which revises the outputs(stack of all time steps' output) and final state(state from the
+ last decoding step) to get the counterpart for special usage.
+ Not necessary to be implemented if no need to revise the stacked outputs and
+ state from the last decoding step. If implemented, it would be called after
+ the decoding iterations.
+
+ Decoder is more general compared to RNNCell, since the returned `next_input`
+ and `finished` make it can determine the input and when to finish by itself
+ when used in dynamic decoding. Decoder always wraps a RNNCell instance though
+ not necessary.
+ """
+
+ def initialize(self, inits):
+ r"""
+ Called once before the decoding iterations.
+
+ Parameters:
+ inits: Argument provided by the caller.
+
+ Returns:
+ tuple: A tuple( :code:`(initial_inputs, initial_states, finished)` ). \
+ `initial_inputs` and `initial_states` both are a (possibly nested \
+ structure of) tensor variable[s], and `finished` is a tensor with \
+ bool data type.
+ """
+ raise NotImplementedError
+
+ def step(self, time, inputs, states, **kwargs):
+ r"""
+ Called per step of decoding.
+
+ Parameters:
+ time(Variable): A Tensor with shape :math:`[1]` provided by the caller.
+ The data type is int64.
+ inputs(Variable): A (possibly nested structure of) tensor variable[s].
+ states(Variable): A (possibly nested structure of) tensor variable[s].
+ **kwargs: Additional keyword arguments, provided by the caller.
+
+ Returns:
+ tuple: A tuple( :code:(outputs, next_states, next_inputs, finished)` ). \
+ `next_inputs` and `next_states` both are a (possibly nested \
+ structure of) tensor variable[s], and the structure, shape and \
+ data type must be same as the counterpart from input arguments. \
+ `outputs` is a (possibly nested structure of) tensor variable[s]. \
+ `finished` is a Tensor with bool data type.
+ """
+ raise NotImplementedError
+
+ def finalize(self, outputs, final_states, sequence_lengths):
+ r"""
+ Called once after the decoding iterations if implemented.
+
+ Parameters:
+ outputs(Variable): A (possibly nested structure of) tensor variable[s].
+ The structure and data type is same as `output_dtype`.
+ The tensor stacks all time steps' output thus has shape
+ :math:`[time\_step, batch\_size, ...]` , which is done by the caller.
+ final_states(Variable): A (possibly nested structure of) tensor variable[s].
+ It is the `next_states` returned by `decoder.step` at last decoding step,
+ thus has the same structure, shape and data type with states at any time
+ step.
+
+ Returns:
+ tuple: A tuple( :code:`(final_outputs, final_states)` ). \
+ `final_outputs` and `final_states` both are a (possibly nested \
+ structure of) tensor variable[s].
+ """
+ raise NotImplementedError
+
+ @property
+ def tracks_own_finished(self):
+ """
+ Describes whether the Decoder keeps track of finished states by itself.
+
+ `decoder.step()` would emit a bool `finished` value at each decoding
+ step. The emited `finished` can be used to determine whether every
+ batch entries is finished directly, or it can be combined with the
+ finished tracker keeped in `dynamic_decode` by performing a logical OR
+ to take the already finished into account.
+
+ If `False`, the latter would be took when performing `dynamic_decode`,
+ which is the default. Otherwise, the former would be took, which uses
+ the finished value emited by the decoder as all batch entry finished
+ status directly, and it is the case when batch entries might be
+ reordered such as beams in BeamSearchDecoder.
+
+ Returns:
+ bool: A python bool `False`.
+ """
+ return False
+
+
+class BeamSearchDecoder(Decoder):
+ """
+ Decoder with beam search decoding strategy. It wraps a cell to get probabilities,
+ and follows a beam search step to calculate scores and select candidate
+ token ids for each decoding step.
+
+ Please refer to `Beam search  +
+
+
+
+### 模型介绍
+
+文心ERNIE-ViLG参数规模达到100亿,是目前为止全球最大规模中文跨模态生成模型,在文本生成图像、图像描述等跨模态生成任务上效果全球领先,在图文生成领域MS-COCO、COCO-CN、AIC-ICC等数据集上取得最好效果。你可以输入一段文本描述以及生成风格,模型就会根据输入的内容自动创作出符合要求的图像。
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install ernie_vilg
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run ernie_vilg --text_prompts "宁静的小镇" --output_dir ernie_vilg_out
+ ```
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="ernie_vilg")
+ text_prompts = ["宁静的小镇"]
+ images = module.generate_image(text_prompts=text_prompts, output_dir='./ernie_vilg_out/')
+ ```
+
+- ### 3、API
+
+ - ```python
+ def __init__(ak: Optional[str]=None, sk: Optional[str]=None)
+ ```
+ - 初始化模块,可自定义用于申请访问文心API的ak和sk。
+
+ - **参数**
+ - ak:(Optional[str]): 用于申请文心api使用token的ak,可不填。
+ - sk:(Optional[str]): 用于申请文心api使用token的sk,可不填。
+
+ - ```python
+ def generate_image(
+ text_prompts:str,
+ style: Optional[str] = "油画",
+ topk: Optional[int] = 10,
+ output_dir: Optional[str] = 'ernievilg_output')
+ ```
+
+ - 文图生成API,生成文本描述内容的图像。
+
+ - **参数**
+
+ - text_prompts(str): 输入的语句,描述想要生成的图像的内容。
+ - style(Optional[str]): 生成图像的风格,当前支持'油画','水彩','粉笔画','卡通','儿童画','蜡笔画'。
+ - topk(Optional[int]): 保存前多少张图,最多保存10张。
+ - output_dir(Optional[str]): 保存输出图像的目录,默认为"ernievilg_output"。
+
+
+ - **返回**
+ - images(List(PIL.Image)): 返回生成的所有图像列表,PIL的Image格式。
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install ernie_vilg == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/ernie_vilg/module.py b/modules/image/text_to_image/ernie_vilg/module.py
new file mode 100644
index 000000000..7af5abb0c
--- /dev/null
+++ b/modules/image/text_to_image/ernie_vilg/module.py
@@ -0,0 +1,230 @@
+import argparse
+import ast
+import os
+import re
+import sys
+import time
+from functools import partial
+from io import BytesIO
+from typing import List
+from typing import Optional
+
+import requests
+from PIL import Image
+from tqdm.auto import tqdm
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+@moduleinfo(name="ernie_vilg",
+ version="1.0.0",
+ type="image/text_to_image",
+ summary="",
+ author="baidu-nlp",
+ author_email="paddle-dev@baidu.com")
+class ErnieVilG:
+
+ def __init__(self, ak=None, sk=None):
+ """
+ :param ak: ak for applying token to request wenxin api.
+ :param sk: sk for applying token to request wenxin api.
+ """
+ if ak is None or sk is None:
+ self.ak = 'G26BfAOLpGIRBN5XrOV2eyPA25CE01lE'
+ self.sk = 'txLZOWIjEqXYMU3lSm05ViW4p9DWGOWs'
+ else:
+ self.ak = ak
+ self.sk = sk
+ self.token_host = 'https://wenxin.baidu.com/younger/portal/api/oauth/token'
+ self.token = self._apply_token(self.ak, self.sk)
+
+ def _apply_token(self, ak, sk):
+ if ak is None or sk is None:
+ ak = self.ak
+ sk = self.sk
+ response = requests.get(self.token_host,
+ params={
+ 'grant_type': 'client_credentials',
+ 'client_id': ak,
+ 'client_secret': sk
+ })
+ if response:
+ res = response.json()
+ if res['code'] != 0:
+ print('Request access token error.')
+ raise RuntimeError("Request access token error.")
+ else:
+ print('Request access token error.')
+ raise RuntimeError("Request access token error.")
+ return res['data']
+
+ def generate_image(self,
+ text_prompts,
+ style: Optional[str] = "油画",
+ topk: Optional[int] = 10,
+ output_dir: Optional[str] = 'ernievilg_output'):
+ """
+ Create image by text prompts using ErnieVilG model.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like.
+ :param style: Image stype, currently supported 油画、水彩、粉笔画、卡通、儿童画、蜡笔画
+ :param topk: Top k images to save.
+ :output_dir: Output directory
+ """
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir, exist_ok=True)
+ token = self.token
+ create_url = 'https://wenxin.baidu.com/younger/portal/api/rest/1.0/ernievilg/v1/txt2img?from=paddlehub'
+ get_url = 'https://wenxin.baidu.com/younger/portal/api/rest/1.0/ernievilg/v1/getImg?from=paddlehub'
+ if isinstance(text_prompts, str):
+ text_prompts = [text_prompts]
+ taskids = []
+ for text_prompt in text_prompts:
+ res = requests.post(create_url,
+ headers={'Content-Type': 'application/x-www-form-urlencoded'},
+ data={
+ 'access_token': token,
+ "text": text_prompt,
+ "style": style
+ })
+ res = res.json()
+ if res['code'] == 4001:
+ print('请求参数错误')
+ raise RuntimeError("请求参数错误")
+ elif res['code'] == 4002:
+ print('请求参数格式错误,请检查必传参数是否齐全,参数类型等')
+ raise RuntimeError("请求参数格式错误,请检查必传参数是否齐全,参数类型等")
+ elif res['code'] == 4003:
+ print('请求参数中,图片风格不在可选范围内')
+ raise RuntimeError("请求参数中,图片风格不在可选范围内")
+ elif res['code'] == 4004:
+ print('API服务内部错误,可能引起原因有请求超时、模型推理错误等')
+ raise RuntimeError("API服务内部错误,可能引起原因有请求超时、模型推理错误等")
+ elif res['code'] == 100 or res['code'] == 110 or res['code'] == 111:
+ token = self._apply_token(self.ak, self.sk)
+ res = requests.post(create_url,
+ headers={'Content-Type': 'application/x-www-form-urlencoded'},
+ data={
+ 'access_token': token,
+ "text": text_prompt,
+ "style": style
+ })
+ res = res.json()
+ if res['code'] != 0:
+ print("Token失效重新请求后依然发生错误,请检查输入的参数")
+ raise RuntimeError("Token失效重新请求后依然发生错误,请检查输入的参数")
+
+ taskids.append(res['data']["taskId"])
+
+ start_time = time.time()
+ process_bar = tqdm(total=100, unit='%')
+ results = {}
+ first_iter = True
+ while True:
+ if not taskids:
+ break
+ total_time = 0
+ has_done = []
+ for taskid in taskids:
+ res = requests.post(get_url,
+ headers={'Content-Type': 'application/x-www-form-urlencoded'},
+ data={
+ 'access_token': token,
+ 'taskId': {taskid}
+ })
+ res = res.json()
+ if res['code'] == 4001:
+ print('请求参数错误')
+ raise RuntimeError("请求参数错误")
+ elif res['code'] == 4002:
+ print('请求参数格式错误,请检查必传参数是否齐全,参数类型等')
+ raise RuntimeError("请求参数格式错误,请检查必传参数是否齐全,参数类型等")
+ elif res['code'] == 4003:
+ print('请求参数中,图片风格不在可选范围内')
+ raise RuntimeError("请求参数中,图片风格不在可选范围内")
+ elif res['code'] == 4004:
+ print('API服务内部错误,可能引起原因有请求超时、模型推理错误等')
+ raise RuntimeError("API服务内部错误,可能引起原因有请求超时、模型推理错误等")
+ elif res['code'] == 100 or res['code'] == 110 or res['code'] == 111:
+ token = self._apply_token(self.ak, self.sk)
+ res = requests.post(get_url,
+ headers={'Content-Type': 'application/x-www-form-urlencoded'},
+ data={
+ 'access_token': token,
+ 'taskId': {taskid}
+ })
+ res = res.json()
+ if res['code'] != 0:
+ print("Token失效重新请求后依然发生错误,请检查输入的参数")
+ raise RuntimeError("Token失效重新请求后依然发生错误,请检查输入的参数")
+ if res['data']['status'] == 1:
+ has_done.append(res['data']['taskId'])
+ results[res['data']['text']] = {
+ 'imgUrls': res['data']['imgUrls'],
+ 'waiting': res['data']['waiting'],
+ 'taskId': res['data']['taskId']
+ }
+ total_time = int(re.match('[0-9]+', str(res['data']['waiting'])).group(0)) * 60
+ end_time = time.time()
+ progress_rate = int(((end_time - start_time) / total_time * 100)) if total_time != 0 else 100
+ if progress_rate > process_bar.n:
+ increase_rate = progress_rate - process_bar.n
+ if progress_rate >= 100:
+ increase_rate = 100 - process_bar.n
+ else:
+ increase_rate = 0
+ process_bar.update(increase_rate)
+ time.sleep(5)
+ for taskid in has_done:
+ taskids.remove(taskid)
+ print('Saving Images...')
+ result_images = []
+ for text, data in results.items():
+ for idx, imgdata in enumerate(data['imgUrls']):
+ image = Image.open(BytesIO(requests.get(imgdata['image']).content))
+ image.save(os.path.join(output_dir, '{}_{}.png'.format(text, idx)))
+ result_images.append(image)
+ if idx + 1 >= topk:
+ break
+ print('Done')
+ return result_images
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ if args.ak is not None and args.sk is not None:
+ self.ak = args.ak
+ self.sk = args.sk
+ self.token = self._apply_token(self.ak, self.sk)
+ results = self.generate_image(text_prompts=args.text_prompts,
+ style=args.style,
+ topk=args.topk,
+ output_dir=args.output_dir)
+ return results
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument('--text_prompts', type=str)
+ self.arg_input_group.add_argument('--style',
+ type=str,
+ default='油画',
+ choices=['油画', '水彩', '粉笔画', '卡通', '儿童画', '蜡笔画'],
+ help="绘画风格")
+ self.arg_input_group.add_argument('--topk', type=int, default=10, help="选取保存前多少张图,最多10张")
+ self.arg_input_group.add_argument('--ak', type=str, default=None, help="申请文心api使用token的ak")
+ self.arg_input_group.add_argument('--sk', type=str, default=None, help="申请文心api使用token的sk")
+ self.arg_input_group.add_argument('--output_dir', type=str, default='ernievilg_output')
diff --git a/modules/image/text_to_image/ernie_vilg/requirements.txt b/modules/image/text_to_image/ernie_vilg/requirements.txt
new file mode 100644
index 000000000..5bb8c66c6
--- /dev/null
+++ b/modules/image/text_to_image/ernie_vilg/requirements.txt
@@ -0,0 +1,2 @@
+requests
+tqdm
From c1cd06b233c805b44e23170906ea8ea1c90baeda Mon Sep 17 00:00:00 2001
From: chenjian  +
+
+
+ - 生成过程
+  +
+
+
+### 模型介绍
+
+disco_diffusion_clip_rn50 是一个文图生成模型,可以通过输入一段文字来生成符合该句子语义的图像。该模型由两部分组成,一部分是扩散模型,是一种生成模型,可以从噪声输入中重建出原始图像。另一部分是多模态预训练模型(CLIP), 可以将文本和图像表示在同一个特征空间,相近语义的文本和图像在该特征空间里距离会更相近。在该文图生成模型中,扩散模型负责从初始噪声或者指定初始图像中来生成目标图像,CLIP负责引导生成图像的语义和输入的文本的语义尽可能接近,随着扩散模型在CLIP的引导下不断的迭代生成新图像,最终能够生成文本所描述内容的图像。该模块中使用的CLIP模型结构为ResNet50。
+
+更多详情请参考论文:[Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233) 以及 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install disco_diffusion_clip_rn50
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run disco_diffusion_clip_rn50 --text_prompts "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation." --output_dir disco_diffusion_clip_rn50_out
+ ```
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_clip_rn50")
+ text_prompts = ["A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."]
+ # 生成图像, 默认会在disco_diffusion_clip_rn50_out目录保存图像
+ # 返回的da是一个DocumentArray对象,保存了所有的结果,包括最终结果和迭代过程的中间结果
+ # 可以通过操作DocumentArray对象对生成的图像做后处理,保存或者分析
+ da = module.generate_image(text_prompts=text_prompts, output_dir='./disco_diffusion_clip_rn50_out/')
+ # 手动将最终生成的图像保存到指定路径
+ da[0].save_uri_to_file('disco_diffusion_clip_rn50_out-result.png')
+ # 展示所有的中间结果
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # 将整个生成过程保存为一个动态图gif
+ da[0].chunks.save_gif('disco_diffusion_clip_rn50_out-result.gif', show_index=True, inline_display=True, size_ratio=0.5)
+ ```
+
+- ### 3、API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_clip_rn50_out'):
+ ```
+
+ - 文图生成API,生成文本描述内容的图像。
+
+ - **参数**
+
+ - text_prompts(str): 输入的语句,描述想要生成的图像的内容。通常比较有效的构造方式为 "一段描述性的文字内容" + "指定艺术家的名字",如"a beautiful painting of Chinese architecture, by krenz, sunny, super wide angle, artstation."。prompt的构造可以参考[网站](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#)。
+ - style(Optional[str]): 指定绘画的风格,如'watercolor','Chinese painting'等。当不指定时,风格完全由您所填写的prompt决定。
+ - artist(Optional[str]): 指定特定的艺术家,如Greg Rutkowsk、krenz,将会生成所指定艺术家的绘画风格。当不指定时,风格完全由您所填写的prompt决定。各种艺术家的风格可以参考[网站](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/)。
+ - width_height(Optional[List[int]]): 指定最终输出图像的宽高,宽和高都需要是64的倍数,生成的图像越大,所需要的计算时间越长。
+ - seed(Optional[int]): 随机种子,由于输入默认是随机高斯噪声,设置不同的随机种子会由不同的初始输入,从而最终生成不同的结果,可以设置该参数来获得不同的输出图像。
+ - output_dir(Optional[str]): 保存输出图像的目录,默认为"disco_diffusion_clip_rn50_out"。
+
+
+ - **返回**
+ - ra(DocumentArray): DocumentArray对象, 包含`n_batches`个Documents,其中每个Document都保存了迭代过程的所有中间结果。详细可参考[DocumentArray使用文档](https://docarray.jina.ai/fundamentals/documentarray/index.html)。
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install disco_diffusion_clip_rn50 == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/README.md b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/README.md
new file mode 100644
index 000000000..317214d80
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/README.md
@@ -0,0 +1,2 @@
+# OpenAI CLIP implemented in Paddle.
+The original implementation repo is [ranchlai/clip.paddle](https://github.com/ranchlai/clip.paddle). We copy this repo here for guided diffusion.
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/__init__.py
new file mode 100755
index 000000000..5657b56e6
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/__init__.py
@@ -0,0 +1 @@
+from .utils import *
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/layers.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/layers.py
new file mode 100755
index 000000000..286f35ab4
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/layers.py
@@ -0,0 +1,182 @@
+from typing import Optional
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn import Linear
+
+__all__ = ['ResidualAttentionBlock', 'AttentionPool2d', 'multi_head_attention_forward', 'MultiHeadAttention']
+
+
+def multi_head_attention_forward(x: Tensor,
+ num_heads: int,
+ q_proj: Linear,
+ k_proj: Linear,
+ v_proj: Linear,
+ c_proj: Linear,
+ attn_mask: Optional[Tensor] = None):
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = emb_dim // num_heads
+ scaling = float(head_dim)**-0.5
+ q = q_proj(x) # L, N, E
+ k = k_proj(x) # L, N, E
+ v = v_proj(x) # L, N, E
+ #k = k.con
+ v = v.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ k = k.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ q = q.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+
+ q = q * scaling
+ qk = paddle.bmm(q, k.transpose((0, 2, 1)))
+ if attn_mask is not None:
+ if attn_mask.ndim == 2:
+ attn_mask.unsqueeze_(0)
+ #assert str(attn_mask.dtype) == 'VarType.FP32' and attn_mask.ndim == 3
+ assert attn_mask.shape[0] == 1 and attn_mask.shape[1] == max_len and attn_mask.shape[2] == max_len
+ qk += attn_mask
+
+ qk = paddle.nn.functional.softmax(qk, axis=-1)
+ atten = paddle.bmm(qk, v)
+ atten = atten.transpose((1, 0, 2))
+ atten = atten.reshape((max_len, batch_size, emb_dim))
+ atten = c_proj(atten)
+ return atten
+
+
+class MultiHeadAttention(nn.Layer): # without attention mask
+
+ def __init__(self, emb_dim: int, num_heads: int):
+ super().__init__()
+ self.q_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.k_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.v_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.c_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.head_dim = emb_dim // num_heads
+ self.emb_dim = emb_dim
+ self.num_heads = num_heads
+ assert self.head_dim * num_heads == emb_dim, "embed_dim must be divisible by num_heads"
+ #self.scaling = float(self.head_dim) ** -0.5
+
+ def forward(self, x, attn_mask=None): # x is in shape[max_len,batch_size,emb_dim]
+
+ atten = multi_head_attention_forward(x,
+ self.num_heads,
+ self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.c_proj,
+ attn_mask=attn_mask)
+
+ return atten
+
+
+class Identity(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return x
+
+
+class Bottleneck(nn.Layer):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1):
+ super().__init__()
+
+ # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
+ self.conv1 = nn.Conv2D(inplanes, planes, 1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(planes)
+
+ self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(planes)
+
+ self.avgpool = nn.AvgPool2D(stride) if stride > 1 else Identity()
+
+ self.conv3 = nn.Conv2D(planes, planes * self.expansion, 1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(planes * self.expansion)
+
+ self.relu = nn.ReLU()
+ self.downsample = None
+ self.stride = stride
+
+ if stride > 1 or inplanes != planes * Bottleneck.expansion:
+ self.downsample = nn.Sequential(
+ ("-1", nn.AvgPool2D(stride)),
+ ("0", nn.Conv2D(inplanes, planes * self.expansion, 1, stride=1, bias_attr=False)),
+ ("1", nn.BatchNorm2D(planes * self.expansion)))
+
+ def forward(self, x):
+ identity = x
+
+ out = self.relu(self.bn1(self.conv1(x)))
+ out = self.relu(self.bn2(self.conv2(out)))
+ out = self.avgpool(out)
+ out = self.bn3(self.conv3(out))
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.relu(out)
+ return out
+
+
+class AttentionPool2d(nn.Layer):
+
+ def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
+ super().__init__()
+
+ self.positional_embedding = paddle.create_parameter((spacial_dim**2 + 1, embed_dim), dtype='float32')
+
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim, bias_attr=True)
+ self.num_heads = num_heads
+
+ self.head_dim = embed_dim // num_heads
+ assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
+
+ def forward(self, x):
+
+ x = x.reshape((x.shape[0], x.shape[1], x.shape[2] * x.shape[3])).transpose((2, 0, 1)) # NCHW -> (HW)NC
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = self.head_dim
+ x = paddle.concat([paddle.mean(x, axis=0, keepdim=True), x], axis=0)
+ x = x + paddle.unsqueeze(self.positional_embedding, 1)
+ out = multi_head_attention_forward(x, self.num_heads, self.q_proj, self.k_proj, self.v_proj, self.c_proj)
+
+ return out[0]
+
+
+class QuickGELU(nn.Layer):
+
+ def forward(self, x):
+ return x * paddle.nn.functional.sigmoid(1.702 * x)
+
+
+class ResidualAttentionBlock(nn.Layer):
+
+ def __init__(self, d_model: int, n_head: int, attn_mask=None):
+ super().__init__()
+
+ self.attn = MultiHeadAttention(d_model, n_head)
+ self.ln_1 = nn.LayerNorm(d_model)
+ self.mlp = nn.Sequential(("c_fc", nn.Linear(d_model, d_model * 4)), ("gelu", QuickGELU()),
+ ("c_proj", nn.Linear(d_model * 4, d_model)))
+ self.ln_2 = nn.LayerNorm(d_model)
+ self.attn_mask = attn_mask
+
+ def attention(self, x):
+ x = self.attn(x, self.attn_mask)
+ assert isinstance(x, paddle.Tensor) # not tuble here
+ return x
+
+ def forward(self, x):
+
+ x = x + self.attention(self.ln_1(x))
+ x = x + self.mlp(self.ln_2(x))
+ return x
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/model.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/model.py
new file mode 100755
index 000000000..63d1835c5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/model.py
@@ -0,0 +1,227 @@
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import nn
+
+from .layers import AttentionPool2d
+from .layers import Bottleneck
+from .layers import MultiHeadAttention
+from .layers import ResidualAttentionBlock
+
+
+class ModifiedResNet(nn.Layer):
+ """
+ A ResNet class that is similar to torchvision's but contains the following changes:
+ - There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
+ - Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
+ - The final pooling layer is a QKV attention instead of an average pool
+ """
+
+ def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
+ super().__init__()
+ self.output_dim = output_dim
+ self.input_resolution = input_resolution
+
+ # the 3-layer stem
+ self.conv1 = nn.Conv2D(3, width // 2, kernel_size=3, stride=2, padding=1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(width // 2)
+ self.conv2 = nn.Conv2D(width // 2, width // 2, kernel_size=3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(width // 2)
+ self.conv3 = nn.Conv2D(width // 2, width, kernel_size=3, padding=1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(width)
+ self.avgpool = nn.AvgPool2D(2)
+ self.relu = nn.ReLU()
+
+ # residual layers
+ self._inplanes = width # this is a *mutable* variable used during construction
+ self.layer1 = self._make_layer(width, layers[0])
+ self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
+ self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
+ self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
+
+ embed_dim = width * 32 # the ResNet feature dimension
+ self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
+
+ def _make_layer(self, planes, blocks, stride=1):
+ layers = [Bottleneck(self._inplanes, planes, stride)]
+
+ self._inplanes = planes * Bottleneck.expansion
+ for _ in range(1, blocks):
+ layers.append(Bottleneck(self._inplanes, planes))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ def stem(x):
+ for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
+ x = self.relu(bn(conv(x)))
+ x = self.avgpool(x)
+ return x
+
+ #x = x.type(self.conv1.weight.dtype)
+ x = stem(x)
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+ x = self.attnpool(x)
+
+ return x
+
+
+class Transformer(nn.Layer):
+
+ def __init__(self, width: int, layers: int, heads: int, attn_mask=None):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
+
+ def forward(self, x):
+ return self.resblocks(x)
+
+
+class VisualTransformer(nn.Layer):
+
+ def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.output_dim = output_dim
+ # used patch_size x patch_size, stride patch_size to do linear projection
+ self.conv1 = nn.Conv2D(in_channels=3,
+ out_channels=width,
+ kernel_size=patch_size,
+ stride=patch_size,
+ bias_attr=False)
+
+ # scale = width ** -0.5
+ self.class_embedding = paddle.create_parameter((width, ), 'float32')
+
+ self.positional_embedding = paddle.create_parameter(((input_resolution // patch_size)**2 + 1, width), 'float32')
+
+ self.ln_pre = nn.LayerNorm(width)
+
+ self.transformer = Transformer(width, layers, heads)
+
+ self.ln_post = nn.LayerNorm(width)
+ self.proj = paddle.create_parameter((width, output_dim), 'float32')
+
+ def forward(self, x):
+
+ x = self.conv1(x)
+ x = x.reshape((x.shape[0], x.shape[1], -1))
+ x = x.transpose((0, 2, 1))
+ x = paddle.concat([self.class_embedding + paddle.zeros((x.shape[0], 1, x.shape[-1]), dtype=x.dtype), x], axis=1)
+
+ x = x + self.positional_embedding
+ x = self.ln_pre(x)
+ x = x.transpose((1, 0, 2))
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2))
+ x = self.ln_post(x[:, 0, :])
+ if self.proj is not None:
+ x = paddle.matmul(x, self.proj)
+
+ return x
+
+
+class CLIP(nn.Layer):
+
+ def __init__(
+ self,
+ embed_dim: int,
+ # vision
+ image_resolution: int,
+ vision_layers: Union[Tuple[int, int, int, int], int],
+ vision_width: int,
+ vision_patch_size: int,
+ # text
+ context_length: int,
+ vocab_size: int,
+ transformer_width: int,
+ transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+
+ self.context_length = context_length
+ if isinstance(vision_layers, (tuple, list)):
+ vision_heads = vision_width * 32 // 64
+ self.visual = ModifiedResNet(layers=vision_layers,
+ output_dim=embed_dim,
+ heads=vision_heads,
+ input_resolution=image_resolution,
+ width=vision_width)
+ else:
+ vision_heads = vision_width // 64
+ self.visual = VisualTransformer(input_resolution=image_resolution,
+ patch_size=vision_patch_size,
+ width=vision_width,
+ layers=vision_layers,
+ heads=vision_heads,
+ output_dim=embed_dim)
+
+ self.transformer = Transformer(width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+
+ self.vocab_size = vocab_size
+ self.token_embedding = nn.Embedding(vocab_size, transformer_width)
+ self.positional_embedding = paddle.create_parameter((self.context_length, transformer_width), 'float32')
+ self.ln_final = nn.LayerNorm(transformer_width)
+
+ self.text_projection = paddle.create_parameter((transformer_width, embed_dim), 'float32')
+ self.logit_scale = paddle.create_parameter((1, ), 'float32')
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # mask = paddle.empty((self.context_length, self.context_length),dtype='float32')
+ # mask.fill_(float("-inf"))
+ #mask.triu_(1) # zero out the lower diagonal
+
+ mask = paddle.ones((self.context_length, self.context_length)) * float("-inf")
+ mask = paddle.triu(mask, diagonal=1)
+
+ return mask
+
+ def encode_image(self, image):
+ return self.visual(image)
+
+ def encode_text(self, text):
+ x = self.token_embedding(text) # [batch_size, n_ctx, d_model]
+ # print(x.shape)
+
+ x = x + self.positional_embedding
+ #print(x.shape)
+
+ x = x.transpose((1, 0, 2)) # NLD -> LND
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2)) # LND -> NLD
+ x = self.ln_final(x)
+
+ idx = text.numpy().argmax(-1)
+ idx = list(idx)
+ x = [x[i:i + 1, int(j), :] for i, j in enumerate(idx)]
+ x = paddle.concat(x, 0)
+ x = paddle.matmul(x, self.text_projection)
+ return x
+
+ def forward(self, image, text):
+ image_features = self.encode_image(image)
+ text_features = self.encode_text(text)
+
+ # normalized features
+ image_features = image_features / image_features.norm(dim=-1, keepdim=True)
+ text_features = text_features / text_features.norm(dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_image = paddle.matmul(logit_scale * image_features, text_features.t())
+ logits_per_text = paddle.matmul(logit_scale * text_features, image_features.t())
+
+ # shape = [global_batch_size, global_batch_size]
+ return logits_per_image, logits_per_text
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/simple_tokenizer.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/simple_tokenizer.py
new file mode 100755
index 000000000..4eaf82e9e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/simple_tokenizer.py
@@ -0,0 +1,135 @@
+import gzip
+import html
+import os
+from functools import lru_cache
+
+import ftfy
+import regex as re
+
+
+@lru_cache()
+def default_bpe():
+ return os.path.join(os.path.dirname(os.path.abspath(__file__)), "../assets/bpe_simple_vocab_16e6.txt.gz")
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a corresponding list of unicode strings.
+ The reversible bpe codes work on unicode strings.
+ This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
+ When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
+ This is a signficant percentage of your normal, say, 32K bpe vocab.
+ To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ And avoids mapping to whitespace/control characters the bpe code barfs on.
+ """
+ bs = list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """Return set of symbol pairs in a word.
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+def basic_clean(text):
+ text = ftfy.fix_text(text)
+ text = html.unescape(html.unescape(text))
+ return text.strip()
+
+
+def whitespace_clean(text):
+ text = re.sub(r'\s+', ' ', text)
+ text = text.strip()
+ return text
+
+
+class SimpleTokenizer(object):
+
+ def __init__(self, bpe_path: str = default_bpe()):
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
+ merges = merges[1:49152 - 256 - 2 + 1]
+ merges = [tuple(merge.split()) for merge in merges]
+ vocab = list(bytes_to_unicode().values())
+ vocab = vocab + [v + '' for v in vocab]
+ for merge in merges:
+ vocab.append(''.join(merge))
+ vocab.extend(['<|startoftext|>', '<|endoftext|>'])
+ self.encoder = dict(zip(vocab, range(len(vocab))))
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.bpe_ranks = dict(zip(merges, range(len(merges))))
+ self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
+ self.pat = re.compile(
+ r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
+ re.IGNORECASE)
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token[:-1]) + (token[-1] + '', )
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token + ''
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ new_word.extend(word[i:j])
+ i = j
+ except:
+ new_word.extend(word[i:])
+ break
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = ' '.join(word)
+ self.cache[token] = word
+ return word
+
+ def encode(self, text):
+ bpe_tokens = []
+ text = whitespace_clean(basic_clean(text)).lower()
+ for token in re.findall(self.pat, text):
+ token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
+ bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
+ return bpe_tokens
+
+ def decode(self, tokens):
+ text = ''.join([self.decoder[token] for token in tokens])
+ text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('', ' ')
+ return text
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/utils.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/utils.py
new file mode 100755
index 000000000..979784682
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/clip/clip/utils.py
@@ -0,0 +1,122 @@
+import os
+from typing import List
+from typing import Union
+
+import numpy as np
+import paddle
+from paddle.utils import download
+from paddle.vision.transforms import CenterCrop
+from paddle.vision.transforms import Compose
+from paddle.vision.transforms import Normalize
+from paddle.vision.transforms import Resize
+from paddle.vision.transforms import ToTensor
+
+from .model import CLIP
+from .simple_tokenizer import SimpleTokenizer
+
+__all__ = ['transform', 'tokenize', 'build_model']
+
+MODEL_NAMES = ['RN50', 'RN101', 'VIT32']
+
+URL = {
+ 'RN50': os.path.join(os.path.dirname(__file__), 'pre_trained', 'RN50.pdparams'),
+ 'RN101': os.path.join(os.path.dirname(__file__), 'pre_trained', 'RN101.pdparams'),
+ 'VIT32': os.path.join(os.path.dirname(__file__), 'pre_trained', 'ViT-B-32.pdparams')
+}
+
+MEAN, STD = (0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)
+_tokenizer = SimpleTokenizer()
+
+transform = Compose([
+ Resize(224, interpolation='bicubic'),
+ CenterCrop(224), lambda image: image.convert('RGB'),
+ ToTensor(),
+ Normalize(mean=MEAN, std=STD), lambda t: t.unsqueeze_(0)
+])
+
+
+def tokenize(texts: Union[str, List[str]], context_length: int = 77):
+ """
+ Returns the tokenized representation of given input string(s)
+
+ Parameters
+ ----------
+ texts : Union[str, List[str]]
+ An input string or a list of input strings to tokenize
+
+ context_length : int
+ The context length to use; all CLIP models use 77 as the context length
+
+ Returns
+ -------
+ A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
+ """
+ if isinstance(texts, str):
+ texts = [texts]
+
+ sot_token = _tokenizer.encoder["<|startoftext|>"]
+ eot_token = _tokenizer.encoder["<|endoftext|>"]
+ all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
+ result = paddle.zeros((len(all_tokens), context_length), dtype='int64')
+
+ for i, tokens in enumerate(all_tokens):
+ if len(tokens) > context_length:
+ raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
+ result[i, :len(tokens)] = paddle.Tensor(np.array(tokens))
+
+ return result
+
+
+def build_model(name='RN50'):
+ assert name in MODEL_NAMES, f"model name must be one of {MODEL_NAMES}"
+ name2model = {'RN101': build_rn101_model, 'VIT32': build_vit_model, 'RN50': build_rn50_model}
+ model = name2model[name]()
+ weight = URL[name]
+ sd = paddle.load(weight)
+ model.load_dict(sd)
+ model.eval()
+ return model
+
+
+def build_vit_model():
+
+ model = CLIP(embed_dim=512,
+ image_resolution=224,
+ vision_layers=12,
+ vision_width=768,
+ vision_patch_size=32,
+ context_length=77,
+ vocab_size=49408,
+ transformer_width=512,
+ transformer_heads=8,
+ transformer_layers=12)
+ return model
+
+
+def build_rn101_model():
+ model = CLIP(
+ embed_dim=512,
+ image_resolution=224,
+ vision_layers=(3, 4, 23, 3),
+ vision_width=64,
+ vision_patch_size=0, #Not used in resnet
+ context_length=77,
+ vocab_size=49408,
+ transformer_width=512,
+ transformer_heads=8,
+ transformer_layers=12)
+ return model
+
+
+def build_rn50_model():
+ model = CLIP(embed_dim=1024,
+ image_resolution=224,
+ vision_layers=(3, 4, 6, 3),
+ vision_width=64,
+ vision_patch_size=None,
+ context_length=77,
+ vocab_size=49408,
+ transformer_width=512,
+ transformer_heads=8,
+ transformer_layers=12)
+ return model
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/module.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/module.py
new file mode 100755
index 000000000..4b681525b
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/module.py
@@ -0,0 +1,441 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import ast
+import os
+import sys
+from functools import partial
+from typing import List
+from typing import Optional
+
+import disco_diffusion_clip_rn50.clip as clip
+import disco_diffusion_clip_rn50.resize_right as resize_right
+import paddle
+from disco_diffusion_clip_rn50.reverse_diffusion import create
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+@moduleinfo(name="disco_diffusion_clip_rn50",
+ version="1.0.0",
+ type="image/text_to_image",
+ summary="",
+ author="paddlepaddle",
+ author_email="paddle-dev@baidu.com")
+class DiscoDiffusionClip:
+
+ def generate_image(self,
+ text_prompts: [str],
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 0,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 0,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 1,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ use_gpu: Optional[bool] = True,
+ output_dir: Optional[str] = 'disco_diffusion_clip_rn50_out'):
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+ :param style: Image style, such as oil paintings, if specified, style will be used to construct prompts.
+ :param artist: Artist style, if specified, style will be used to construct prompts.
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param use_gpu: whether to use gpu or not.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+ if use_gpu:
+ try:
+ _places = os.environ.get("CUDA_VISIBLE_DEVICES", None)
+ if _places:
+ paddle.device.set_device("gpu:{}".format(0))
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
+ )
+ else:
+ paddle.device.set_device("cpu")
+ paddle.disable_static()
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir, exist_ok=True)
+
+ if isinstance(text_prompts, str):
+ text_prompts = text_prompts.rstrip(',.,。')
+ if style is not None:
+ text_prompts += ",{}".format(style)
+ if artist is not None:
+ text_prompts += ",{},trending on artstation".format(artist)
+ elif isinstance(text_prompts, list):
+ text_prompts[0] = text_prompts[0].rstrip(',.,。')
+ if style is not None:
+ text_prompts[0] += ",{}".format(style)
+ if artist is not None:
+ text_prompts[0] += ",{},trending on artstation".format(artist)
+
+ return create(text_prompts=text_prompts,
+ init_image=init_image,
+ width_height=width_height,
+ skip_steps=skip_steps,
+ steps=steps,
+ cut_ic_pow=cut_ic_pow,
+ init_scale=init_scale,
+ clip_guidance_scale=clip_guidance_scale,
+ tv_scale=tv_scale,
+ range_scale=range_scale,
+ sat_scale=sat_scale,
+ cutn_batches=cutn_batches,
+ diffusion_sampling_mode=diffusion_sampling_mode,
+ perlin_init=perlin_init,
+ perlin_mode=perlin_mode,
+ seed=seed,
+ eta=eta,
+ clamp_grad=clamp_grad,
+ clamp_max=clamp_max,
+ randomize_class=randomize_class,
+ clip_denoised=clip_denoised,
+ fuzzy_prompt=fuzzy_prompt,
+ rand_mag=rand_mag,
+ cut_overview=cut_overview,
+ cut_innercut=cut_innercut,
+ cut_icgray_p=cut_icgray_p,
+ display_rate=display_rate,
+ n_batches=n_batches,
+ batch_size=batch_size,
+ batch_name=batch_name,
+ clip_models=['RN50'],
+ output_dir=output_dir)
+
+ @serving
+ def serving_method(self, text_prompts, **kwargs):
+ """
+ Run as a service.
+ """
+ results = []
+ for text_prompt in text_prompts:
+ result = self.generate_image(text_prompts=text_prompt, **kwargs)[0].to_base64()
+ results.append(result)
+ return results
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options", description="Run configuration for controlling module behavior, not required.")
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ results = self.generate_image(text_prompts=args.text_prompts,
+ style=args.style,
+ artist=args.artist,
+ init_image=args.init_image,
+ width_height=args.width_height,
+ skip_steps=args.skip_steps,
+ steps=args.steps,
+ cut_ic_pow=args.cut_ic_pow,
+ init_scale=args.init_scale,
+ clip_guidance_scale=args.clip_guidance_scale,
+ tv_scale=args.tv_scale,
+ range_scale=args.range_scale,
+ sat_scale=args.sat_scale,
+ cutn_batches=args.cutn_batches,
+ diffusion_sampling_mode=args.diffusion_sampling_mode,
+ perlin_init=args.perlin_init,
+ perlin_mode=args.perlin_mode,
+ seed=args.seed,
+ eta=args.eta,
+ clamp_grad=args.clamp_grad,
+ clamp_max=args.clamp_max,
+ randomize_class=args.randomize_class,
+ clip_denoised=args.clip_denoised,
+ fuzzy_prompt=args.fuzzy_prompt,
+ rand_mag=args.rand_mag,
+ cut_overview=args.cut_overview,
+ cut_innercut=args.cut_innercut,
+ cut_icgray_p=args.cut_icgray_p,
+ display_rate=args.display_rate,
+ n_batches=args.n_batches,
+ batch_size=args.batch_size,
+ batch_name=args.batch_name,
+ output_dir=args.output_dir)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options.
+ """
+ self.arg_input_group.add_argument(
+ '--skip_steps',
+ type=int,
+ default=0,
+ help=
+ 'Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15%% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50%% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture'
+ )
+ self.arg_input_group.add_argument(
+ '--steps',
+ type=int,
+ default=250,
+ help=
+ "When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time."
+ )
+ self.arg_input_group.add_argument(
+ '--cut_ic_pow',
+ type=int,
+ default=1,
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--init_scale',
+ type=int,
+ default=1000,
+ help=
+ "This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost."
+ )
+ self.arg_input_group.add_argument(
+ '--clip_guidance_scale',
+ type=int,
+ default=5000,
+ help=
+ "CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well."
+ )
+ self.arg_input_group.add_argument(
+ '--tv_scale',
+ type=int,
+ default=0,
+ help=
+ "Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising"
+ )
+ self.arg_input_group.add_argument(
+ '--range_scale',
+ type=int,
+ default=0,
+ help=
+ "Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images."
+ )
+ self.arg_input_group.add_argument(
+ '--sat_scale',
+ type=int,
+ default=0,
+ help=
+ "Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation."
+ )
+ self.arg_input_group.add_argument(
+ '--cutn_batches',
+ type=int,
+ default=4,
+ help=
+ "Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below."
+ )
+ self.arg_input_group.add_argument(
+ '--diffusion_sampling_mode',
+ type=str,
+ default='ddim',
+ help=
+ "Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_init',
+ type=bool,
+ default=False,
+ help=
+ "Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_mode',
+ type=str,
+ default='mixed',
+ help=
+ "sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--seed',
+ type=int,
+ default=None,
+ help=
+ "Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical."
+ )
+ self.arg_input_group.add_argument(
+ '--eta',
+ type=float,
+ default=0.8,
+ help=
+ "eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_grad',
+ type=bool,
+ default=True,
+ help=
+ "As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_max',
+ type=float,
+ default=0.05,
+ help=
+ "Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy."
+ )
+ self.arg_input_group.add_argument('--randomize_class', type=bool, default=True, help="Random class.")
+ self.arg_input_group.add_argument('--clip_denoised', type=bool, default=False, help="Clip denoised.")
+ self.arg_input_group.add_argument(
+ '--fuzzy_prompt',
+ type=bool,
+ default=False,
+ help=
+ "Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this."
+ )
+ self.arg_input_group.add_argument(
+ '--rand_mag',
+ type=float,
+ default=0.5,
+ help="Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.")
+ self.arg_input_group.add_argument('--cut_overview',
+ type=str,
+ default='[12]*400+[4]*600',
+ help="The schedule of overview cuts")
+ self.arg_input_group.add_argument('--cut_innercut',
+ type=str,
+ default='[4]*400+[12]*600',
+ help="The schedule of inner cuts")
+ self.arg_input_group.add_argument(
+ '--cut_icgray_p',
+ type=str,
+ default='[0.2]*400+[0]*600',
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--display_rate',
+ type=int,
+ default=10,
+ help=
+ "During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly."
+ )
+ self.arg_config_group.add_argument('--use_gpu',
+ type=ast.literal_eval,
+ default=True,
+ help="whether use GPU or not")
+ self.arg_config_group.add_argument('--output_dir',
+ type=str,
+ default='disco_diffusion_clip_rn50_out',
+ help='Output directory.')
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument(
+ '--text_prompts',
+ type=str,
+ help=
+ 'Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.'
+ )
+ self.arg_input_group.add_argument(
+ '--style',
+ type=str,
+ default=None,
+ help='Image style, such as oil paintings, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument('--artist',
+ type=str,
+ default=None,
+ help='Artist style, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument(
+ '--init_image',
+ type=str,
+ default=None,
+ help=
+ "Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion."
+ )
+ self.arg_input_group.add_argument(
+ '--width_height',
+ type=ast.literal_eval,
+ default=[1280, 768],
+ help=
+ "Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so."
+ )
+ self.arg_input_group.add_argument(
+ '--n_batches',
+ type=int,
+ default=1,
+ help=
+ "This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings."
+ )
+ self.arg_input_group.add_argument('--batch_size', type=int, default=1, help="Batch size.")
+ self.arg_input_group.add_argument(
+ '--batch_name',
+ type=str,
+ default='',
+ help=
+ 'The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.'
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/requirements.txt b/modules/image/text_to_image/disco_diffusion_clip_rn50/requirements.txt
new file mode 100755
index 000000000..8b4bc0ea4
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/requirements.txt
@@ -0,0 +1,8 @@
+numpy
+paddle_lpips==0.1.2
+ftfy
+docarray>=0.13.29
+pyyaml
+regex
+tqdm
+ipywidgets
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/README.md b/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/README.md
new file mode 100644
index 000000000..1f8d0bb0a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/README.md
@@ -0,0 +1,3 @@
+# ResizeRight (Paddle)
+Fully differentiable resize function implemented by Paddle.
+This module is based on [assafshocher/ResizeRight](https://github.com/assafshocher/ResizeRight).
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/__init__.py
new file mode 100755
index 000000000..e69de29bb
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/interp_methods.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/interp_methods.py
new file mode 100755
index 000000000..276eb055a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/interp_methods.py
@@ -0,0 +1,70 @@
+from math import pi
+
+try:
+ import paddle
+except ImportError:
+ paddle = None
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def set_framework_dependencies(x):
+ if type(x) is numpy.ndarray:
+ to_dtype = lambda a: a
+ fw = numpy
+ else:
+ to_dtype = lambda a: paddle.cast(a, x.dtype)
+ fw = paddle
+ # eps = fw.finfo(fw.float32).eps
+ eps = paddle.to_tensor(np.finfo(np.float32).eps)
+ return fw, to_dtype, eps
+
+
+def support_sz(sz):
+
+ def wrapper(f):
+ f.support_sz = sz
+ return f
+
+ return wrapper
+
+
+@support_sz(4)
+def cubic(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ absx = fw.abs(x)
+ absx2 = absx**2
+ absx3 = absx**3
+ return ((1.5 * absx3 - 2.5 * absx2 + 1.) * to_dtype(absx <= 1.) +
+ (-0.5 * absx3 + 2.5 * absx2 - 4. * absx + 2.) * to_dtype((1. < absx) & (absx <= 2.)))
+
+
+@support_sz(4)
+def lanczos2(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 2) + eps) / ((pi**2 * x**2 / 2) + eps)) * to_dtype(abs(x) < 2))
+
+
+@support_sz(6)
+def lanczos3(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 3) + eps) / ((pi**2 * x**2 / 3) + eps)) * to_dtype(abs(x) < 3))
+
+
+@support_sz(2)
+def linear(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return ((x + 1) * to_dtype((-1 <= x) & (x < 0)) + (1 - x) * to_dtype((0 <= x) & (x <= 1)))
+
+
+@support_sz(1)
+def box(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return to_dtype((-1 <= x) & (x < 0)) + to_dtype((0 <= x) & (x <= 1))
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/resize_right.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/resize_right.py
new file mode 100755
index 000000000..4f6cb94a8
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/resize_right/resize_right.py
@@ -0,0 +1,403 @@
+import warnings
+from fractions import Fraction
+from math import ceil
+from typing import Tuple
+
+import disco_diffusion_clip_rn50.resize_right.interp_methods as interp_methods
+
+
+class NoneClass:
+ pass
+
+
+try:
+ import paddle
+ from paddle import nn
+ nnModuleWrapped = nn.Layer
+except ImportError:
+ warnings.warn('No PyTorch found, will work only with Numpy')
+ paddle = None
+ nnModuleWrapped = NoneClass
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ warnings.warn('No Numpy found, will work only with PyTorch')
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def resize(input,
+ scale_factors=None,
+ out_shape=None,
+ interp_method=interp_methods.cubic,
+ support_sz=None,
+ antialiasing=True,
+ by_convs=False,
+ scale_tolerance=None,
+ max_numerator=10,
+ pad_mode='constant'):
+ # get properties of the input tensor
+ in_shape, n_dims = input.shape, input.ndim
+
+ # fw stands for framework that can be either numpy or paddle,
+ # determined by the input type
+ fw = numpy if type(input) is numpy.ndarray else paddle
+ eps = np.finfo(np.float32).eps if fw == numpy else paddle.to_tensor(np.finfo(np.float32).eps)
+ device = input.place if fw is paddle else None
+
+ # set missing scale factors or output shapem one according to another,
+ # scream if both missing. this is also where all the defults policies
+ # take place. also handling the by_convs attribute carefully.
+ scale_factors, out_shape, by_convs = set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs,
+ scale_tolerance, max_numerator, eps, fw)
+
+ # sort indices of dimensions according to scale of each dimension.
+ # since we are going dim by dim this is efficient
+ sorted_filtered_dims_and_scales = [(dim, scale_factors[dim], by_convs[dim], in_shape[dim], out_shape[dim])
+ for dim in sorted(range(n_dims), key=lambda ind: scale_factors[ind])
+ if scale_factors[dim] != 1.]
+ # unless support size is specified by the user, it is an attribute
+ # of the interpolation method
+ if support_sz is None:
+ support_sz = interp_method.support_sz
+
+ # output begins identical to input and changes with each iteration
+ output = input
+
+ # iterate over dims
+ for (dim, scale_factor, dim_by_convs, in_sz, out_sz) in sorted_filtered_dims_and_scales:
+ # STEP 1- PROJECTED GRID: The non-integer locations of the projection
+ # of output pixel locations to the input tensor
+ projected_grid = get_projected_grid(in_sz, out_sz, scale_factor, fw, dim_by_convs, device)
+
+ # STEP 1.5: ANTIALIASING- If antialiasing is taking place, we modify
+ # the window size and the interpolation method (see inside function)
+ cur_interp_method, cur_support_sz = apply_antialiasing_if_needed(interp_method, support_sz, scale_factor,
+ antialiasing)
+
+ # STEP 2- FIELDS OF VIEW: for each output pixels, map the input pixels
+ # that influence it. Also calculate needed padding and update grid
+ # accoedingly
+ field_of_view = get_field_of_view(projected_grid, cur_support_sz, fw, eps, device)
+
+ # STEP 2.5- CALCULATE PAD AND UPDATE: according to the field of view,
+ # the input should be padded to handle the boundaries, coordinates
+ # should be updated. actual padding only occurs when weights are
+ # aplied (step 4). if using by_convs for this dim, then we need to
+ # calc right and left boundaries for each filter instead.
+ pad_sz, projected_grid, field_of_view = calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor,
+ dim_by_convs, fw, device)
+ # STEP 3- CALCULATE WEIGHTS: Match a set of weights to the pixels in
+ # the field of view for each output pixel
+ weights = get_weights(cur_interp_method, projected_grid, field_of_view)
+
+ # STEP 4- APPLY WEIGHTS: Each output pixel is calculated by multiplying
+ # its set of weights with the pixel values in its field of view.
+ # We now multiply the fields of view with their matching weights.
+ # We do this by tensor multiplication and broadcasting.
+ # if by_convs is true for this dim, then we do this action by
+ # convolutions. this is equivalent but faster.
+ if not dim_by_convs:
+ output = apply_weights(output, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw)
+ else:
+ output = apply_convs(output, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw)
+ return output
+
+
+def get_projected_grid(in_sz, out_sz, scale_factor, fw, by_convs, device=None):
+ # we start by having the ouput coordinates which are just integer locations
+ # in the special case when usin by_convs, we only need two cycles of grid
+ # points. the first and last.
+ grid_sz = out_sz if not by_convs else scale_factor.numerator
+ out_coordinates = fw_arange(grid_sz, fw, device)
+
+ # This is projecting the ouput pixel locations in 1d to the input tensor,
+ # as non-integer locations.
+ # the following fomrula is derived in the paper
+ # "From Discrete to Continuous Convolutions" by Shocher et al.
+ return (out_coordinates / float(scale_factor) + (in_sz - 1) / 2 - (out_sz - 1) / (2 * float(scale_factor)))
+
+
+def get_field_of_view(projected_grid, cur_support_sz, fw, eps, device):
+ # for each output pixel, map which input pixels influence it, in 1d.
+ # we start by calculating the leftmost neighbor, using half of the window
+ # size (eps is for when boundary is exact int)
+ left_boundaries = fw_ceil(projected_grid - cur_support_sz / 2 - eps, fw)
+
+ # then we simply take all the pixel centers in the field by counting
+ # window size pixels from the left boundary
+ ordinal_numbers = fw_arange(ceil(cur_support_sz - eps), fw, device)
+ return left_boundaries[:, None] + ordinal_numbers
+
+
+def calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor, dim_by_convs, fw, device):
+ if not dim_by_convs:
+ # determine padding according to neighbor coords out of bound.
+ # this is a generalized notion of padding, when pad<0 it means crop
+ pad_sz = [-field_of_view[0, 0].item(), field_of_view[-1, -1].item() - in_sz + 1]
+
+ # since input image will be changed by padding, coordinates of both
+ # field_of_view and projected_grid need to be updated
+ field_of_view += pad_sz[0]
+ projected_grid += pad_sz[0]
+
+ else:
+ # only used for by_convs, to calc the boundaries of each filter the
+ # number of distinct convolutions is the numerator of the scale factor
+ num_convs, stride = scale_factor.numerator, scale_factor.denominator
+
+ # calculate left and right boundaries for each conv. left can also be
+ # negative right can be bigger than in_sz. such cases imply padding if
+ # needed. however if# both are in-bounds, it means we need to crop,
+ # practically apply the conv only on part of the image.
+ left_pads = -field_of_view[:, 0]
+
+ # next calc is tricky, explanation by rows:
+ # 1) counting output pixels between the first position of each filter
+ # to the right boundary of the input
+ # 2) dividing it by number of filters to count how many 'jumps'
+ # each filter does
+ # 3) multiplying by the stride gives us the distance over the input
+ # coords done by all these jumps for each filter
+ # 4) to this distance we add the right boundary of the filter when
+ # placed in its leftmost position. so now we get the right boundary
+ # of that filter in input coord.
+ # 5) the padding size needed is obtained by subtracting the rightmost
+ # input coordinate. if the result is positive padding is needed. if
+ # negative then negative padding means shaving off pixel columns.
+ right_pads = (((out_sz - fw_arange(num_convs, fw, device) - 1) # (1)
+ // num_convs) # (2)
+ * stride # (3)
+ + field_of_view[:, -1] # (4)
+ - in_sz + 1) # (5)
+
+ # in the by_convs case pad_sz is a list of left-right pairs. one per
+ # each filter
+
+ pad_sz = list(zip(left_pads, right_pads))
+
+ return pad_sz, projected_grid, field_of_view
+
+
+def get_weights(interp_method, projected_grid, field_of_view):
+ # the set of weights per each output pixels is the result of the chosen
+ # interpolation method applied to the distances between projected grid
+ # locations and the pixel-centers in the field of view (distances are
+ # directed, can be positive or negative)
+ weights = interp_method(projected_grid[:, None] - field_of_view)
+
+ # we now carefully normalize the weights to sum to 1 per each output pixel
+ sum_weights = weights.sum(1, keepdim=True)
+ sum_weights[sum_weights == 0] = 1
+ return weights / sum_weights
+
+
+def apply_weights(input, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw):
+ # for this operation we assume the resized dim is the first one.
+ # so we transpose and will transpose back after multiplying
+ tmp_input = fw_swapaxes(input, dim, 0, fw)
+
+ # apply padding
+ tmp_input = fw_pad(tmp_input, fw, pad_sz, pad_mode)
+
+ # field_of_view is a tensor of order 2: for each output (1d location
+ # along cur dim)- a list of 1d neighbors locations.
+ # note that this whole operations is applied to each dim separately,
+ # this is why it is all in 1d.
+ # neighbors = tmp_input[field_of_view] is a tensor of order image_dims+1:
+ # for each output pixel (this time indicated in all dims), these are the
+ # values of the neighbors in the 1d field of view. note that we only
+ # consider neighbors along the current dim, but such set exists for every
+ # multi-dim location, hence the final tensor order is image_dims+1.
+ paddle.device.cuda.empty_cache()
+ neighbors = tmp_input[field_of_view]
+
+ # weights is an order 2 tensor: for each output location along 1d- a list
+ # of weights matching the field of view. we augment it with ones, for
+ # broadcasting, so that when multiplies some tensor the weights affect
+ # only its first dim.
+ tmp_weights = fw.reshape(weights, (*weights.shape, *[1] * (n_dims - 1)))
+
+ # now we simply multiply the weights with the neighbors, and then sum
+ # along the field of view, to get a single value per out pixel
+ tmp_output = (neighbors * tmp_weights).sum(1)
+ # we transpose back the resized dim to its original position
+ return fw_swapaxes(tmp_output, 0, dim, fw)
+
+
+def apply_convs(input, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw):
+ # for this operations we assume the resized dim is the last one.
+ # so we transpose and will transpose back after multiplying
+ input = fw_swapaxes(input, dim, -1, fw)
+
+ # the stride for all convs is the denominator of the scale factor
+ stride, num_convs = scale_factor.denominator, scale_factor.numerator
+
+ # prepare an empty tensor for the output
+ tmp_out_shape = list(input.shape)
+ tmp_out_shape[-1] = out_sz
+ tmp_output = fw_empty(tuple(tmp_out_shape), fw, input.device)
+
+ # iterate over the conv operations. we have as many as the numerator
+ # of the scale-factor. for each we need boundaries and a filter.
+ for conv_ind, (pad_sz, filt) in enumerate(zip(pad_sz, weights)):
+ # apply padding (we pad last dim, padding can be negative)
+ pad_dim = input.ndim - 1
+ tmp_input = fw_pad(input, fw, pad_sz, pad_mode, dim=pad_dim)
+
+ # apply convolution over last dim. store in the output tensor with
+ # positional strides so that when the loop is comlete conv results are
+ # interwind
+ tmp_output[..., conv_ind::num_convs] = fw_conv(tmp_input, filt, stride)
+
+ return fw_swapaxes(tmp_output, -1, dim, fw)
+
+
+def set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs, scale_tolerance, max_numerator, eps, fw):
+ # eventually we must have both scale-factors and out-sizes for all in/out
+ # dims. however, we support many possible partial arguments
+ if scale_factors is None and out_shape is None:
+ raise ValueError("either scale_factors or out_shape should be "
+ "provided")
+ if out_shape is not None:
+ # if out_shape has less dims than in_shape, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ out_shape = (list(out_shape) +
+ list(in_shape[len(out_shape):]) if fw is numpy else list(in_shape[:-len(out_shape)]) +
+ list(out_shape))
+ if scale_factors is None:
+ # if no scale given, we calculate it as the out to in ratio
+ # (not recomended)
+ scale_factors = [out_sz / in_sz for out_sz, in_sz in zip(out_shape, in_shape)]
+ if scale_factors is not None:
+ # by default, if a single number is given as scale, we assume resizing
+ # two dims (most common are images with 2 spatial dims)
+ scale_factors = (scale_factors if isinstance(scale_factors, (list, tuple)) else [scale_factors, scale_factors])
+ # if less scale_factors than in_shape dims, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ scale_factors = (list(scale_factors) + [1] * (len(in_shape) - len(scale_factors)) if fw is numpy else [1] *
+ (len(in_shape) - len(scale_factors)) + list(scale_factors))
+ if out_shape is None:
+ # when no out_shape given, it is calculated by multiplying the
+ # scale by the in_shape (not recomended)
+ out_shape = [ceil(scale_factor * in_sz) for scale_factor, in_sz in zip(scale_factors, in_shape)]
+ # next part intentionally after out_shape determined for stability
+ # we fix by_convs to be a list of truth values in case it is not
+ if not isinstance(by_convs, (list, tuple)):
+ by_convs = [by_convs] * len(out_shape)
+
+ # next loop fixes the scale for each dim to be either frac or float.
+ # this is determined by by_convs and by tolerance for scale accuracy.
+ for ind, (sf, dim_by_convs) in enumerate(zip(scale_factors, by_convs)):
+ # first we fractionaize
+ if dim_by_convs:
+ frac = Fraction(1 / sf).limit_denominator(max_numerator)
+ frac = Fraction(numerator=frac.denominator, denominator=frac.numerator)
+
+ # if accuracy is within tolerance scale will be frac. if not, then
+ # it will be float and the by_convs attr will be set false for
+ # this dim
+ if scale_tolerance is None:
+ scale_tolerance = eps
+ if dim_by_convs and abs(frac - sf) < scale_tolerance:
+ scale_factors[ind] = frac
+ else:
+ scale_factors[ind] = float(sf)
+ by_convs[ind] = False
+
+ return scale_factors, out_shape, by_convs
+
+
+def apply_antialiasing_if_needed(interp_method, support_sz, scale_factor, antialiasing):
+ # antialiasing is "stretching" the field of view according to the scale
+ # factor (only for downscaling). this is low-pass filtering. this
+ # requires modifying both the interpolation (stretching the 1d
+ # function and multiplying by the scale-factor) and the window size.
+ scale_factor = float(scale_factor)
+ if scale_factor >= 1.0 or not antialiasing:
+ return interp_method, support_sz
+ cur_interp_method = (lambda arg: scale_factor * interp_method(scale_factor * arg))
+ cur_support_sz = support_sz / scale_factor
+ return cur_interp_method, cur_support_sz
+
+
+def fw_ceil(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.ceil(x))
+ else:
+ return paddle.cast(x.ceil(), dtype='int64')
+
+
+def fw_floor(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.floor(x))
+ else:
+ return paddle.cast(x.floor(), dtype='int64')
+
+
+def fw_cat(x, fw):
+ if fw is numpy:
+ return fw.concatenate(x)
+ else:
+ return fw.concat(x)
+
+
+def fw_swapaxes(x, ax_1, ax_2, fw):
+ if fw is numpy:
+ return fw.swapaxes(x, ax_1, ax_2)
+ else:
+ if ax_1 == -1:
+ ax_1 = len(x.shape) - 1
+ if ax_2 == -1:
+ ax_2 = len(x.shape) - 1
+ perm0 = list(range(len(x.shape)))
+ temp = ax_1
+ perm0[temp] = ax_2
+ perm0[ax_2] = temp
+ return fw.transpose(x, perm0)
+
+
+def fw_pad(x, fw, pad_sz, pad_mode, dim=0):
+ if pad_sz == (0, 0):
+ return x
+ if fw is numpy:
+ pad_vec = [(0, 0)] * x.ndim
+ pad_vec[dim] = pad_sz
+ return fw.pad(x, pad_width=pad_vec, mode=pad_mode)
+ else:
+ if x.ndim < 3:
+ x = x[None, None, ...]
+
+ pad_vec = [0] * ((x.ndim - 2) * 2)
+ pad_vec[0:2] = pad_sz
+ return fw_swapaxes(fw.nn.functional.pad(fw_swapaxes(x, dim, -1, fw), pad=pad_vec, mode=pad_mode), dim, -1, fw)
+
+
+def fw_conv(input, filter, stride):
+ # we want to apply 1d conv to any nd array. the way to do it is to reshape
+ # the input to a 4D tensor. first two dims are singeletons, 3rd dim stores
+ # all the spatial dims that we are not convolving along now. then we can
+ # apply conv2d with a 1xK filter. This convolves the same way all the other
+ # dims stored in the 3d dim. like depthwise conv over these.
+ # TODO: numpy support
+ reshaped_input = input.reshape(1, 1, -1, input.shape[-1])
+ reshaped_output = paddle.nn.functional.conv2d(reshaped_input, filter.view(1, 1, 1, -1), stride=(1, stride))
+ return reshaped_output.reshape(*input.shape[:-1], -1)
+
+
+def fw_arange(upper_bound, fw, device):
+ if fw is numpy:
+ return fw.arange(upper_bound)
+ else:
+ return fw.arange(upper_bound)
+
+
+def fw_empty(shape, fw, device):
+ if fw is numpy:
+ return fw.empty(shape)
+ else:
+ return fw.empty(shape=shape)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/README.md b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/README.md
new file mode 100644
index 000000000..711671bad
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/README.md
@@ -0,0 +1,2 @@
+# Diffusion model (Paddle)
+This module implements diffusion model which accepts a text prompt and outputs images semantically close to the text. The code is rewritten by Paddle, and mainly refer to two projects: jina-ai/discoart[https://github.com/jina-ai/discoart] and openai/guided-diffusion[https://github.com/openai/guided-diffusion]. Thanks for their wonderful work.
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/__init__.py
new file mode 100755
index 000000000..39fc908dc
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/__init__.py
@@ -0,0 +1,156 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/__init__.py
+'''
+import os
+import warnings
+
+os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
+
+__all__ = ['create']
+
+import sys
+
+__resources_path__ = os.path.join(
+ os.path.dirname(sys.modules.get(__package__).__file__ if __package__ in sys.modules else __file__),
+ 'resources',
+)
+
+import gc
+
+# check if GPU is available
+import paddle
+
+# download and load models, this will take some time on the first load
+
+from .helper import load_all_models, load_diffusion_model, load_clip_models
+
+model_config, secondary_model = load_all_models('512x512_diffusion_uncond_finetune_008100', use_secondary_model=True)
+
+from typing import TYPE_CHECKING, overload, List, Optional
+
+if TYPE_CHECKING:
+ from docarray import DocumentArray, Document
+
+_clip_models_cache = {}
+
+# begin_create_overload
+
+
+@overload
+def create(text_prompts: Optional[List[str]] = [
+ 'A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.',
+ 'yellow color scheme',
+],
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 10,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 150,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_model: Optional[str] = '512x512_diffusion_uncond_finetune_008100',
+ use_secondary_model: Optional[bool] = True,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 4,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ clip_models: Optional[list] = ['ViTB32', 'ViTB16', 'RN50'],
+ output_dir: Optional[str] = 'discoart_output') -> 'DocumentArray':
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_model: Diffusion_model of choice.
+ :param use_secondary_model: Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param clip_models: CLIP Model selectors. ViTB32, ViTB16, ViTL14, RN101, RN50, RN50x4, RN50x16, RN50x64.These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around. You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.The rough order of speed/mem usage is (smallest/fastest to largest/slowest):VitB32RN50RN101VitB16RN50x4RN50x16RN50x64ViTL14For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+# end_create_overload
+
+
+@overload
+def create(init_document: 'Document') -> 'DocumentArray':
+ """
+ Create an artwork using a DocArray ``Document`` object as initial state.
+ :param init_document: its ``.tags`` will be used as parameters, ``.uri`` (if present) will be used as init image.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+def create(**kwargs) -> 'DocumentArray':
+ from .config import load_config
+ from .runner import do_run
+
+ if 'init_document' in kwargs:
+ d = kwargs['init_document']
+ _kwargs = d.tags
+ if not _kwargs:
+ warnings.warn('init_document has no .tags, fallback to default config')
+ if d.uri:
+ _kwargs['init_image'] = kwargs['init_document'].uri
+ else:
+ warnings.warn('init_document has no .uri, fallback to no init image')
+ kwargs.pop('init_document')
+ if kwargs:
+ warnings.warn('init_document has .tags and .uri, but kwargs are also present, will override .tags')
+ _kwargs.update(kwargs)
+ _args = load_config(user_config=_kwargs)
+ else:
+ _args = load_config(user_config=kwargs)
+
+ model, diffusion = load_diffusion_model(model_config, _args.diffusion_model, steps=_args.steps)
+
+ clip_models = load_clip_models(enabled=_args.clip_models, clip_models=_clip_models_cache)
+
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+ try:
+ return do_run(_args, (model, diffusion, clip_models, secondary_model))
+ except KeyboardInterrupt:
+ pass
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/config.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/config.py
new file mode 100755
index 000000000..0cbc71e6f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/config.py
@@ -0,0 +1,77 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/config.py
+'''
+import copy
+import random
+import warnings
+from types import SimpleNamespace
+from typing import Dict
+
+import yaml
+from yaml import Loader
+
+from . import __resources_path__
+
+with open(f'{__resources_path__}/default.yml') as ymlfile:
+ default_args = yaml.load(ymlfile, Loader=Loader)
+
+
+def load_config(user_config: Dict, ):
+ cfg = copy.deepcopy(default_args)
+
+ if user_config:
+ cfg.update(**user_config)
+
+ for k in user_config.keys():
+ if k not in cfg:
+ warnings.warn(f'unknown argument {k}, ignored')
+
+ for k, v in cfg.items():
+ if k in ('batch_size', 'display_rate', 'seed', 'skip_steps', 'steps', 'n_batches',
+ 'cutn_batches') and isinstance(v, float):
+ cfg[k] = int(v)
+ if k == 'width_height':
+ cfg[k] = [int(vv) for vv in v]
+
+ cfg.update(**{
+ 'seed': cfg['seed'] or random.randint(0, 2**32),
+ })
+
+ if cfg['batch_name']:
+ da_name = f'{__package__}-{cfg["batch_name"]}-{cfg["seed"]}'
+ else:
+ da_name = f'{__package__}-{cfg["seed"]}'
+ warnings.warn('you did not set `batch_name`, set it to have unique session ID')
+
+ cfg.update(**{'name_docarray': da_name})
+
+ print_args_table(cfg)
+
+ return SimpleNamespace(**cfg)
+
+
+def print_args_table(cfg):
+ from rich.table import Table
+ from rich import box
+ from rich.console import Console
+
+ console = Console()
+
+ param_str = Table(
+ title=cfg['name_docarray'],
+ box=box.ROUNDED,
+ highlight=True,
+ title_justify='left',
+ )
+ param_str.add_column('Argument', justify='right')
+ param_str.add_column('Value', justify='left')
+
+ for k, v in sorted(cfg.items()):
+ value = str(v)
+
+ if not default_args.get(k, None) == v:
+ value = f'[b]{value}[/]'
+
+ param_str.add_row(k, value)
+
+ console.print(param_str)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/helper.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/helper.py
new file mode 100755
index 000000000..2a4fa163e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/helper.py
@@ -0,0 +1,137 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/helper.py
+'''
+import hashlib
+import logging
+import os
+import subprocess
+import sys
+from os.path import expanduser
+from pathlib import Path
+from typing import Any
+from typing import Dict
+from typing import List
+
+import paddle
+
+
+def _get_logger():
+ logger = logging.getLogger(__package__)
+ logger.setLevel("INFO")
+ ch = logging.StreamHandler()
+ ch.setLevel("INFO")
+ formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
+ ch.setFormatter(formatter)
+ logger.addHandler(ch)
+ return logger
+
+
+logger = _get_logger()
+
+
+def load_clip_models(enabled: List[str], clip_models: Dict[str, Any] = {}):
+
+ import disco_diffusion_clip_rn50.clip.clip as clip
+ from disco_diffusion_clip_rn50.clip.clip import build_model, tokenize, transform
+
+ # load enabled models
+ for k in enabled:
+ if k not in clip_models:
+ clip_models[k] = build_model(name=k)
+ clip_models[k].eval()
+ for parameter in clip_models[k].parameters():
+ parameter.stop_gradient = True
+
+ # disable not enabled models to save memory
+ for k in clip_models:
+ if k not in enabled:
+ clip_models.pop(k)
+
+ return list(clip_models.values())
+
+
+def load_all_models(diffusion_model, use_secondary_model):
+ from .model.script_util import (
+ model_and_diffusion_defaults, )
+
+ model_config = model_and_diffusion_defaults()
+
+ if diffusion_model == '512x512_diffusion_uncond_finetune_008100':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 512,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+ elif diffusion_model == '256x256_diffusion_uncond':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 256,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+
+ secondary_model = None
+ if use_secondary_model:
+ from .model.sec_diff import SecondaryDiffusionImageNet2
+ secondary_model = SecondaryDiffusionImageNet2()
+ model_dict = paddle.load(
+ os.path.join(os.path.dirname(__file__), 'pre_trained', 'secondary_model_imagenet_2.pdparams'))
+ secondary_model.set_state_dict(model_dict)
+ secondary_model.eval()
+ for parameter in secondary_model.parameters():
+ parameter.stop_gradient = True
+
+ return model_config, secondary_model
+
+
+def load_diffusion_model(model_config, diffusion_model, steps):
+ from .model.script_util import (
+ create_model_and_diffusion, )
+
+ timestep_respacing = f'ddim{steps}'
+ diffusion_steps = (1000 // steps) * steps if steps < 1000 else steps
+ model_config.update({
+ 'timestep_respacing': timestep_respacing,
+ 'diffusion_steps': diffusion_steps,
+ })
+
+ model, diffusion = create_model_and_diffusion(**model_config)
+ model.set_state_dict(
+ paddle.load(os.path.join(os.path.dirname(__file__), 'pre_trained', f'{diffusion_model}.pdparams')))
+ model.eval()
+ for name, param in model.named_parameters():
+ param.stop_gradient = True
+
+ return model, diffusion
+
+
+def parse_prompt(prompt):
+ if prompt.startswith('http://') or prompt.startswith('https://'):
+ vals = prompt.rsplit(':', 2)
+ vals = [vals[0] + ':' + vals[1], *vals[2:]]
+ else:
+ vals = prompt.rsplit(':', 1)
+ vals = vals + ['', '1'][len(vals):]
+ return vals[0], float(vals[1])
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/__init__.py
new file mode 100755
index 000000000..466800666
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/__init__.py
@@ -0,0 +1,3 @@
+"""
+Codebase for "Improved Denoising Diffusion Probabilistic Models" implemented by Paddle.
+"""
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/gaussian_diffusion.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/gaussian_diffusion.py
new file mode 100755
index 000000000..86cd2c650
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/gaussian_diffusion.py
@@ -0,0 +1,1214 @@
+"""
+Diffusion model implemented by Paddle.
+This code is rewritten based on Pytorch version of of Ho et al's diffusion models:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py
+"""
+import enum
+import math
+
+import numpy as np
+import paddle
+
+from .losses import discretized_gaussian_log_likelihood
+from .losses import normal_kl
+from .nn import mean_flat
+
+
+def get_named_beta_schedule(schedule_name, num_diffusion_timesteps):
+ """
+ Get a pre-defined beta schedule for the given name.
+
+ The beta schedule library consists of beta schedules which remain similar
+ in the limit of num_diffusion_timesteps.
+ Beta schedules may be added, but should not be removed or changed once
+ they are committed to maintain backwards compatibility.
+ """
+ if schedule_name == "linear":
+ # Linear schedule from Ho et al, extended to work for any number of
+ # diffusion steps.
+ scale = 1000 / num_diffusion_timesteps
+ beta_start = scale * 0.0001
+ beta_end = scale * 0.02
+ return np.linspace(beta_start, beta_end, num_diffusion_timesteps, dtype=np.float64)
+ elif schedule_name == "cosine":
+ return betas_for_alpha_bar(
+ num_diffusion_timesteps,
+ lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2)**2,
+ )
+ else:
+ raise NotImplementedError(f"unknown beta schedule: {schedule_name}")
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function,
+ which defines the cumulative product of (1-beta) over time from t = [0,1].
+
+ :param num_diffusion_timesteps: the number of betas to produce.
+ :param alpha_bar: a lambda that takes an argument t from 0 to 1 and
+ produces the cumulative product of (1-beta) up to that
+ part of the diffusion process.
+ :param max_beta: the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+ """
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return np.array(betas)
+
+
+class ModelMeanType(enum.Enum):
+ """
+ Which type of output the model predicts.
+ """
+
+ PREVIOUS_X = enum.auto() # the model predicts x_{t-1}
+ START_X = enum.auto() # the model predicts x_0
+ EPSILON = enum.auto() # the model predicts epsilon
+
+
+class ModelVarType(enum.Enum):
+ """
+ What is used as the model's output variance.
+
+ The LEARNED_RANGE option has been added to allow the model to predict
+ values between FIXED_SMALL and FIXED_LARGE, making its job easier.
+ """
+
+ LEARNED = enum.auto()
+ FIXED_SMALL = enum.auto()
+ FIXED_LARGE = enum.auto()
+ LEARNED_RANGE = enum.auto()
+
+
+class LossType(enum.Enum):
+ MSE = enum.auto() # use raw MSE loss (and KL when learning variances)
+ RESCALED_MSE = (enum.auto()) # use raw MSE loss (with RESCALED_KL when learning variances)
+ KL = enum.auto() # use the variational lower-bound
+ RESCALED_KL = enum.auto() # like KL, but rescale to estimate the full VLB
+
+ def is_vb(self):
+ return self == LossType.KL or self == LossType.RESCALED_KL
+
+
+class GaussianDiffusion:
+ """
+ Utilities for training and sampling diffusion models.
+
+ Ported directly from here, and then adapted over time to further experimentation.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py#L42
+
+ :param betas: a 1-D numpy array of betas for each diffusion timestep,
+ starting at T and going to 1.
+ :param model_mean_type: a ModelMeanType determining what the model outputs.
+ :param model_var_type: a ModelVarType determining how variance is output.
+ :param loss_type: a LossType determining the loss function to use.
+ :param rescale_timesteps: if True, pass floating point timesteps into the
+ model so that they are always scaled like in the
+ original paper (0 to 1000).
+ """
+
+ def __init__(
+ self,
+ *,
+ betas,
+ model_mean_type,
+ model_var_type,
+ loss_type,
+ rescale_timesteps=False,
+ ):
+ self.model_mean_type = model_mean_type
+ self.model_var_type = model_var_type
+ self.loss_type = loss_type
+ self.rescale_timesteps = rescale_timesteps
+
+ # Use float64 for accuracy.
+ betas = np.array(betas, dtype=np.float64)
+ self.betas = betas
+ assert len(betas.shape) == 1, "betas must be 1-D"
+ assert (betas > 0).all() and (betas <= 1).all()
+
+ self.num_timesteps = int(betas.shape[0])
+
+ alphas = 1.0 - betas
+ self.alphas_cumprod = np.cumprod(alphas, axis=0)
+ self.alphas_cumprod_prev = np.append(1.0, self.alphas_cumprod[:-1])
+ self.alphas_cumprod_next = np.append(self.alphas_cumprod[1:], 0.0)
+ assert self.alphas_cumprod_prev.shape == (self.num_timesteps, )
+
+ # calculations for diffusion q(x_t | x_{t-1}) and others
+ self.sqrt_alphas_cumprod = np.sqrt(self.alphas_cumprod)
+ self.sqrt_one_minus_alphas_cumprod = np.sqrt(1.0 - self.alphas_cumprod)
+ self.log_one_minus_alphas_cumprod = np.log(1.0 - self.alphas_cumprod)
+ self.sqrt_recip_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod)
+ self.sqrt_recipm1_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod - 1)
+
+ # calculations for posterior q(x_{t-1} | x_t, x_0)
+ self.posterior_variance = (betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ # log calculation clipped because the posterior variance is 0 at the
+ # beginning of the diffusion chain.
+ self.posterior_log_variance_clipped = np.log(np.append(self.posterior_variance[1], self.posterior_variance[1:]))
+ self.posterior_mean_coef1 = (betas * np.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ self.posterior_mean_coef2 = ((1.0 - self.alphas_cumprod_prev) * np.sqrt(alphas) / (1.0 - self.alphas_cumprod))
+
+ def q_mean_variance(self, x_start, t):
+ """
+ Get the distribution q(x_t | x_0).
+
+ :param x_start: the [N x C x ...] tensor of noiseless inputs.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :return: A tuple (mean, variance, log_variance), all of x_start's shape.
+ """
+ mean = (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start)
+ variance = _extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
+ log_variance = _extract_into_tensor(self.log_one_minus_alphas_cumprod, t, x_start.shape)
+ return mean, variance, log_variance
+
+ def q_sample(self, x_start, t, noise=None):
+ """
+ Diffuse the data for a given number of diffusion steps.
+
+ In other words, sample from q(x_t | x_0).
+
+ :param x_start: the initial data batch.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :param noise: if specified, the split-out normal noise.
+ :return: A noisy version of x_start.
+ """
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ assert noise.shape == x_start.shape
+ return (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
+ _extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
+
+ def q_posterior_mean_variance(self, x_start, x_t, t):
+ """
+ Compute the mean and variance of the diffusion posterior:
+
+ q(x_{t-1} | x_t, x_0)
+
+ """
+ assert x_start.shape == x_t.shape
+ posterior_mean = (_extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start +
+ _extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t)
+ posterior_variance = _extract_into_tensor(self.posterior_variance, t, x_t.shape)
+ posterior_log_variance_clipped = _extract_into_tensor(self.posterior_log_variance_clipped, t, x_t.shape)
+ assert (posterior_mean.shape[0] == posterior_variance.shape[0] == posterior_log_variance_clipped.shape[0] ==
+ x_start.shape[0])
+ return posterior_mean, posterior_variance, posterior_log_variance_clipped
+
+ def p_mean_variance(self, model, x, t, clip_denoised=True, denoised_fn=None, model_kwargs=None):
+ """
+ Apply the model to get p(x_{t-1} | x_t), as well as a prediction of
+ the initial x, x_0.
+
+ :param model: the model, which takes a signal and a batch of timesteps
+ as input.
+ :param x: the [N x C x ...] tensor at time t.
+ :param t: a 1-D Tensor of timesteps.
+ :param clip_denoised: if True, clip the denoised signal into [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample. Applies before
+ clip_denoised.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict with the following keys:
+ - 'mean': the model mean output.
+ - 'variance': the model variance output.
+ - 'log_variance': the log of 'variance'.
+ - 'pred_xstart': the prediction for x_0.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+
+ B, C = x.shape[:2]
+ assert t.shape == [B]
+ model_output = model(x, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [ModelVarType.LEARNED, ModelVarType.LEARNED_RANGE]:
+ assert model_output.shape == [B, C * 2, *x.shape[2:]]
+ model_output, model_var_values = paddle.split(model_output, 2, axis=1)
+ if self.model_var_type == ModelVarType.LEARNED:
+ model_log_variance = model_var_values
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ min_log = _extract_into_tensor(self.posterior_log_variance_clipped, t, x.shape)
+ max_log = _extract_into_tensor(np.log(self.betas), t, x.shape)
+ # The model_var_values is [-1, 1] for [min_var, max_var].
+ frac = (model_var_values + 1) / 2
+ model_log_variance = frac * max_log + (1 - frac) * min_log
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ model_variance, model_log_variance = {
+ # for fixedlarge, we set the initial (log-)variance like so
+ # to get a better decoder log likelihood.
+ ModelVarType.FIXED_LARGE: (
+ np.append(self.posterior_variance[1], self.betas[1:]),
+ np.log(np.append(self.posterior_variance[1], self.betas[1:])),
+ ),
+ ModelVarType.FIXED_SMALL: (
+ self.posterior_variance,
+ self.posterior_log_variance_clipped,
+ ),
+ }[self.model_var_type]
+ model_variance = _extract_into_tensor(model_variance, t, x.shape)
+ model_log_variance = _extract_into_tensor(model_log_variance, t, x.shape)
+
+ def process_xstart(x):
+ if denoised_fn is not None:
+ x = denoised_fn(x)
+ if clip_denoised:
+ return x.clamp(-1, 1)
+ return x
+
+ if self.model_mean_type == ModelMeanType.PREVIOUS_X:
+ pred_xstart = process_xstart(self._predict_xstart_from_xprev(x_t=x, t=t, xprev=model_output))
+ model_mean = model_output
+ elif self.model_mean_type in [ModelMeanType.START_X, ModelMeanType.EPSILON]:
+ if self.model_mean_type == ModelMeanType.START_X:
+ pred_xstart = process_xstart(model_output)
+ else:
+ pred_xstart = process_xstart(self._predict_xstart_from_eps(x_t=x, t=t, eps=model_output))
+ model_mean, _, _ = self.q_posterior_mean_variance(x_start=pred_xstart, x_t=x, t=t)
+ else:
+ raise NotImplementedError(self.model_mean_type)
+
+ assert (model_mean.shape == model_log_variance.shape == pred_xstart.shape == x.shape)
+ return {
+ "mean": model_mean,
+ "variance": model_variance,
+ "log_variance": model_log_variance,
+ "pred_xstart": pred_xstart,
+ }
+
+ def _predict_xstart_from_eps(self, x_t, t, eps):
+ assert x_t.shape == eps.shape
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * eps)
+
+ def _predict_xstart_from_xprev(self, x_t, t, xprev):
+ assert x_t.shape == xprev.shape
+ return ( # (xprev - coef2*x_t) / coef1
+ _extract_into_tensor(1.0 / self.posterior_mean_coef1, t, x_t.shape) * xprev -
+ _extract_into_tensor(self.posterior_mean_coef2 / self.posterior_mean_coef1, t, x_t.shape) * x_t)
+
+ def _predict_eps_from_xstart(self, x_t, t, pred_xstart):
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ pred_xstart) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
+
+ def _scale_timesteps(self, t):
+ if self.rescale_timesteps:
+ return paddle.cast((t), 'float32') * (1000.0 / self.num_timesteps)
+ return t
+
+ def condition_mean(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_mean_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, t, p_mean_var, **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_score(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def condition_score_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, t, p_mean_var, **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def p_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"]}
+
+ def p_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean_with_grad(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"].detach()}
+
+ def p_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model.
+
+ :param model: the model module.
+ :param shape: the shape of the samples, (N, C, H, W).
+ :param noise: if specified, the noise from the encoder to sample.
+ Should be of the same shape as `shape`.
+ :param clip_denoised: if True, clip x_start predictions to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param device: if specified, the device to create the samples on.
+ If not specified, use a model parameter's device.
+ :param progress: if True, show a tqdm progress bar.
+ :return: a non-differentiable batch of samples.
+ """
+ final = None
+ for sample in self.p_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def p_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model and yield intermediate samples from
+ each timestep of diffusion.
+
+ Arguments are the same as p_sample_loop().
+ Returns a generator over dicts, where each dict is the return value of
+ p_sample().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ sample_fn = self.p_sample_with_grad if cond_fn_with_grad else self.p_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ )
+ yield out
+ img = out["sample"]
+
+ def ddim_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"]}
+
+ def ddim_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ out["pred_xstart"] = out["pred_xstart"].detach()
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"].detach()}
+
+ def ddim_reverse_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t+1} from the model using DDIM reverse ODE.
+ """
+ assert eta == 0.0, "Reverse ODE only for deterministic path"
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x.shape) * x -
+ out["pred_xstart"]) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x.shape)
+ alpha_bar_next = _extract_into_tensor(self.alphas_cumprod_next, t, x.shape)
+
+ # Equation 12. reversed
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_next) + paddle.sqrt(1 - alpha_bar_next) * eps)
+
+ return {"sample": mean_pred, "pred_xstart": out["pred_xstart"]}
+
+ def ddim_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model using DDIM.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.ddim_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ eta=eta,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def ddim_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Use DDIM to sample from the model and yield intermediate samples from
+ each timestep of DDIM.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ # if device is None:
+ # device = next(model.parameters()).device
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0])
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(
+ low=0,
+ high=model.num_classes,
+ shape=model_kwargs['y'].shape,
+ )
+ sample_fn = self.ddim_sample_with_grad if cond_fn_with_grad else self.ddim_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ eta=eta,
+ )
+ yield out
+ img = out["sample"]
+
+ def plms_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ cond_fn_with_grad=False,
+ order=2,
+ old_out=None,
+ ):
+ """
+ Sample x_{t-1} from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample().
+ """
+ if not int(order) or not 1 <= order <= 4:
+ raise ValueError('order is invalid (should be int from 1-4).')
+
+ def get_model_output(x, t):
+ with paddle.set_grad_enabled(cond_fn_with_grad and cond_fn is not None):
+ x = x.detach().requires_grad_() if cond_fn_with_grad else x
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ if cond_fn_with_grad:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ x = x.detach()
+ else:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+ return eps, out, out_orig
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ eps, out, out_orig = get_model_output(x, t)
+
+ if order > 1 and old_out is None:
+ # Pseudo Improved Euler
+ old_eps = [eps]
+ mean_pred = out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps
+ eps_2, _, _ = get_model_output(mean_pred, t - 1)
+ eps_prime = (eps + eps_2) / 2
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+ else:
+ # Pseudo Linear Multistep (Adams-Bashforth)
+ old_eps = old_out["old_eps"]
+ old_eps.append(eps)
+ cur_order = min(order, len(old_eps))
+ if cur_order == 1:
+ eps_prime = old_eps[-1]
+ elif cur_order == 2:
+ eps_prime = (3 * old_eps[-1] - old_eps[-2]) / 2
+ elif cur_order == 3:
+ eps_prime = (23 * old_eps[-1] - 16 * old_eps[-2] + 5 * old_eps[-3]) / 12
+ elif cur_order == 4:
+ eps_prime = (55 * old_eps[-1] - 59 * old_eps[-2] + 37 * old_eps[-3] - 9 * old_eps[-4]) / 24
+ else:
+ raise RuntimeError('cur_order is invalid.')
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+
+ if len(old_eps) >= order:
+ old_eps.pop(0)
+
+ nonzero_mask = paddle.cast((t != 0), 'float32').reshape([-1, *([1] * (len(x.shape) - 1))])
+ sample = mean_pred * nonzero_mask + out["pred_xstart"] * (1 - nonzero_mask)
+
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"], "old_eps": old_eps}
+
+ def plms_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Generate samples from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.plms_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ ):
+ final = sample
+ return final["sample"]
+
+ def plms_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Use PLMS to sample from the model and yield intermediate samples from each
+ timestep of PLMS.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ old_out = None
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ out = self.plms_sample(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ old_out=old_out,
+ )
+ yield out
+ old_out = out
+ img = out["sample"]
+
+ def _vb_terms_bpd(self, model, x_start, x_t, t, clip_denoised=True, model_kwargs=None):
+ """
+ Get a term for the variational lower-bound.
+
+ The resulting units are bits (rather than nats, as one might expect).
+ This allows for comparison to other papers.
+
+ :return: a dict with the following keys:
+ - 'output': a shape [N] tensor of NLLs or KLs.
+ - 'pred_xstart': the x_0 predictions.
+ """
+ true_mean, _, true_log_variance_clipped = self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)
+ out = self.p_mean_variance(model, x_t, t, clip_denoised=clip_denoised, model_kwargs=model_kwargs)
+ kl = normal_kl(true_mean, true_log_variance_clipped, out["mean"], out["log_variance"])
+ kl = mean_flat(kl) / np.log(2.0)
+
+ decoder_nll = -discretized_gaussian_log_likelihood(
+ x_start, means=out["mean"], log_scales=0.5 * out["log_variance"])
+ assert decoder_nll.shape == x_start.shape
+ decoder_nll = mean_flat(decoder_nll) / np.log(2.0)
+
+ # At the first timestep return the decoder NLL,
+ # otherwise return KL(q(x_{t-1}|x_t,x_0) || p(x_{t-1}|x_t))
+ output = paddle.where((t == 0), decoder_nll, kl)
+ return {"output": output, "pred_xstart": out["pred_xstart"]}
+
+ def training_losses(self, model, x_start, t, model_kwargs=None, noise=None):
+ """
+ Compute training losses for a single timestep.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param t: a batch of timestep indices.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param noise: if specified, the specific Gaussian noise to try to remove.
+ :return: a dict with the key "loss" containing a tensor of shape [N].
+ Some mean or variance settings may also have other keys.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start, t, noise=noise)
+
+ terms = {}
+
+ if self.loss_type == LossType.KL or self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] = self._vb_terms_bpd(
+ model=model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ model_kwargs=model_kwargs,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] *= self.num_timesteps
+ elif self.loss_type == LossType.MSE or self.loss_type == LossType.RESCALED_MSE:
+ model_output = model(x_t, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [
+ ModelVarType.LEARNED,
+ ModelVarType.LEARNED_RANGE,
+ ]:
+ B, C = x_t.shape[:2]
+ assert model_output.shape == (B, C * 2, *x_t.shape[2:])
+ model_output, model_var_values = paddle.split(model_output, 2, dim=1)
+ # Learn the variance using the variational bound, but don't let
+ # it affect our mean prediction.
+ frozen_out = paddle.concat([model_output.detach(), model_var_values], axis=1)
+ terms["vb"] = self._vb_terms_bpd(
+ model=lambda *args, r=frozen_out: r,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_MSE:
+ # Divide by 1000 for equivalence with initial implementation.
+ # Without a factor of 1/1000, the VB term hurts the MSE term.
+ terms["vb"] *= self.num_timesteps / 1000.0
+
+ target = {
+ ModelMeanType.PREVIOUS_X: self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)[0],
+ ModelMeanType.START_X: x_start,
+ ModelMeanType.EPSILON: noise,
+ }[self.model_mean_type]
+ assert model_output.shape == target.shape == x_start.shape
+ terms["mse"] = mean_flat((target - model_output)**2)
+ if "vb" in terms:
+ terms["loss"] = terms["mse"] + terms["vb"]
+ else:
+ terms["loss"] = terms["mse"]
+ else:
+ raise NotImplementedError(self.loss_type)
+
+ return terms
+
+ def _prior_bpd(self, x_start):
+ """
+ Get the prior KL term for the variational lower-bound, measured in
+ bits-per-dim.
+
+ This term can't be optimized, as it only depends on the encoder.
+
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :return: a batch of [N] KL values (in bits), one per batch element.
+ """
+ batch_size = x_start.shape[0]
+ t = paddle.to_tensor([self.num_timesteps - 1] * batch_size, place=x_start.place)
+ qt_mean, _, qt_log_variance = self.q_mean_variance(x_start, t)
+ kl_prior = normal_kl(mean1=qt_mean, logvar1=qt_log_variance, mean2=0.0, logvar2=0.0)
+ return mean_flat(kl_prior) / np.log(2.0)
+
+ def calc_bpd_loop(self, model, x_start, clip_denoised=True, model_kwargs=None):
+ """
+ Compute the entire variational lower-bound, measured in bits-per-dim,
+ as well as other related quantities.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param clip_denoised: if True, clip denoised samples.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+
+ :return: a dict containing the following keys:
+ - total_bpd: the total variational lower-bound, per batch element.
+ - prior_bpd: the prior term in the lower-bound.
+ - vb: an [N x T] tensor of terms in the lower-bound.
+ - xstart_mse: an [N x T] tensor of x_0 MSEs for each timestep.
+ - mse: an [N x T] tensor of epsilon MSEs for each timestep.
+ """
+ device = x_start.place
+ batch_size = x_start.shape[0]
+
+ vb = []
+ xstart_mse = []
+ mse = []
+ for t in list(range(self.num_timesteps))[::-1]:
+ t_batch = paddle.to_tensor([t] * batch_size, place=device)
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start=x_start, t=t_batch, noise=noise)
+ # Calculate VLB term at the current timestep
+ # with paddle.no_grad():
+ out = self._vb_terms_bpd(
+ model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t_batch,
+ clip_denoised=clip_denoised,
+ model_kwargs=model_kwargs,
+ )
+ vb.append(out["output"])
+ xstart_mse.append(mean_flat((out["pred_xstart"] - x_start)**2))
+ eps = self._predict_eps_from_xstart(x_t, t_batch, out["pred_xstart"])
+ mse.append(mean_flat((eps - noise)**2))
+
+ vb = paddle.stack(vb, axis=1)
+ xstart_mse = paddle.stack(xstart_mse, axis=1)
+ mse = paddle.stack(mse, axis=1)
+
+ prior_bpd = self._prior_bpd(x_start)
+ total_bpd = vb.sum(axis=1) + prior_bpd
+ return {
+ "total_bpd": total_bpd,
+ "prior_bpd": prior_bpd,
+ "vb": vb,
+ "xstart_mse": xstart_mse,
+ "mse": mse,
+ }
+
+
+def _extract_into_tensor(arr, timesteps, broadcast_shape):
+ """
+ Extract values from a 1-D numpy array for a batch of indices.
+
+ :param arr: the 1-D numpy array.
+ :param timesteps: a tensor of indices into the array to extract.
+ :param broadcast_shape: a larger shape of K dimensions with the batch
+ dimension equal to the length of timesteps.
+ :return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
+ """
+ res = paddle.to_tensor(arr, place=timesteps.place)[timesteps]
+ while len(res.shape) < len(broadcast_shape):
+ res = res[..., None]
+ return res.expand(broadcast_shape)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/losses.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/losses.py
new file mode 100755
index 000000000..5c3970de5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/losses.py
@@ -0,0 +1,86 @@
+"""
+Helpers for various likelihood-based losses implemented by Paddle. These are ported from the original
+Ho et al. diffusion models codebase:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/utils.py
+"""
+import numpy as np
+import paddle
+import paddle.nn.functional as F
+
+
+def normal_kl(mean1, logvar1, mean2, logvar2):
+ """
+ Compute the KL divergence between two gaussians.
+
+ Shapes are automatically broadcasted, so batches can be compared to
+ scalars, among other use cases.
+ """
+ tensor = None
+ for obj in (mean1, logvar1, mean2, logvar2):
+ if isinstance(obj, paddle.Tensor):
+ tensor = obj
+ break
+ assert tensor is not None, "at least one argument must be a Tensor"
+
+ # Force variances to be Tensors. Broadcasting helps convert scalars to
+ # Tensors, but it does not work for th.exp().
+ logvar1, logvar2 = [x if isinstance(x, paddle.Tensor) else paddle.to_tensor(x) for x in (logvar1, logvar2)]
+
+ return 0.5 * (-1.0 + logvar2 - logvar1 + paddle.exp(logvar1 - logvar2) +
+ ((mean1 - mean2)**2) * paddle.exp(-logvar2))
+
+
+def approx_standard_normal_cdf(x):
+ """
+ A fast approximation of the cumulative distribution function of the
+ standard normal.
+ """
+ return 0.5 * (1.0 + paddle.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * paddle.pow(x, 3))))
+
+
+def discretized_gaussian_log_likelihood(x, *, means, log_scales):
+ """
+ Compute the log-likelihood of a Gaussian distribution discretizing to a
+ given image.
+
+ :param x: the target images. It is assumed that this was uint8 values,
+ rescaled to the range [-1, 1].
+ :param means: the Gaussian mean Tensor.
+ :param log_scales: the Gaussian log stddev Tensor.
+ :return: a tensor like x of log probabilities (in nats).
+ """
+ assert x.shape == means.shape == log_scales.shape
+ centered_x = x - means
+ inv_stdv = paddle.exp(-log_scales)
+ plus_in = inv_stdv * (centered_x + 1.0 / 255.0)
+ cdf_plus = approx_standard_normal_cdf(plus_in)
+ min_in = inv_stdv * (centered_x - 1.0 / 255.0)
+ cdf_min = approx_standard_normal_cdf(min_in)
+ log_cdf_plus = paddle.log(cdf_plus.clip(min=1e-12))
+ log_one_minus_cdf_min = paddle.log((1.0 - cdf_min).clip(min=1e-12))
+ cdf_delta = cdf_plus - cdf_min
+ log_probs = paddle.where(
+ x < -0.999,
+ log_cdf_plus,
+ paddle.where(x > 0.999, log_one_minus_cdf_min, paddle.log(cdf_delta.clip(min=1e-12))),
+ )
+ assert log_probs.shape == x.shape
+ return log_probs
+
+
+def spherical_dist_loss(x, y):
+ x = F.normalize(x, axis=-1)
+ y = F.normalize(y, axis=-1)
+ return (x - y).norm(axis=-1).divide(paddle.to_tensor(2.0)).asin().pow(2).multiply(paddle.to_tensor(2.0))
+
+
+def tv_loss(input):
+ """L2 total variation loss, as in Mahendran et al."""
+ input = F.pad(input, (0, 1, 0, 1), 'replicate')
+ x_diff = input[..., :-1, 1:] - input[..., :-1, :-1]
+ y_diff = input[..., 1:, :-1] - input[..., :-1, :-1]
+ return (x_diff**2 + y_diff**2).mean([1, 2, 3])
+
+
+def range_loss(input):
+ return (input - input.clip(-1, 1)).pow(2).mean([1, 2, 3])
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/make_cutouts.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/make_cutouts.py
new file mode 100755
index 000000000..392c7877e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/make_cutouts.py
@@ -0,0 +1,177 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/make_cutouts.py
+'''
+import math
+
+import paddle
+import paddle.nn as nn
+from disco_diffusion_clip_rn50.resize_right.resize_right import resize
+from paddle.nn import functional as F
+
+from . import transforms as T
+
+skip_augs = False # @param{type: 'boolean'}
+
+
+def sinc(x):
+ return paddle.where(x != 0, paddle.sin(math.pi * x) / (math.pi * x), x.new_ones([]))
+
+
+def lanczos(x, a):
+ cond = paddle.logical_and(-a < x, x < a)
+ out = paddle.where(cond, sinc(x) * sinc(x / a), x.new_zeros([]))
+ return out / out.sum()
+
+
+def ramp(ratio, width):
+ n = math.ceil(width / ratio + 1)
+ out = paddle.empty([n])
+ cur = 0
+ for i in range(out.shape[0]):
+ out[i] = cur
+ cur += ratio
+ return paddle.concat([-out[1:].flip([0]), out])[1:-1]
+
+
+class MakeCutouts(nn.Layer):
+
+ def __init__(self, cut_size, cutn, skip_augs=False):
+ super().__init__()
+ self.cut_size = cut_size
+ self.cutn = cutn
+ self.skip_augs = skip_augs
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(degrees=15, translate=(0.1, 0.1)),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomPerspective(distortion_scale=0.4, p=0.7),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.15),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ input = T.Pad(input.shape[2] // 4, fill=0)(input)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+
+ cutouts = []
+ for ch in range(self.cutn):
+ if ch > self.cutn - self.cutn // 4:
+ cutout = input.clone()
+ else:
+ size = int(max_size *
+ paddle.zeros(1, ).normal_(mean=0.8, std=0.3).clip(float(self.cut_size / max_size), 1.0))
+ offsetx = paddle.randint(0, abs(sideX - size + 1), ())
+ offsety = paddle.randint(0, abs(sideY - size + 1), ())
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+
+ if not self.skip_augs:
+ cutout = self.augs(cutout)
+ cutouts.append(resample(cutout, (self.cut_size, self.cut_size)))
+ del cutout
+
+ cutouts = paddle.concat(cutouts, axis=0)
+ return cutouts
+
+
+class MakeCutoutsDango(nn.Layer):
+
+ def __init__(self, cut_size, Overview=4, InnerCrop=0, IC_Size_Pow=0.5, IC_Grey_P=0.2):
+ super().__init__()
+ self.cut_size = cut_size
+ self.Overview = Overview
+ self.InnerCrop = InnerCrop
+ self.IC_Size_Pow = IC_Size_Pow
+ self.IC_Grey_P = IC_Grey_P
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(
+ degrees=10,
+ translate=(0.05, 0.05),
+ interpolation=T.InterpolationMode.BILINEAR,
+ ),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.1),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ cutouts = []
+ gray = T.Grayscale(3)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+ min_size = min(sideX, sideY, self.cut_size)
+ output_shape = [1, 3, self.cut_size, self.cut_size]
+ pad_input = F.pad(
+ input,
+ (
+ (sideY - max_size) // 2,
+ (sideY - max_size) // 2,
+ (sideX - max_size) // 2,
+ (sideX - max_size) // 2,
+ ),
+ **padargs,
+ )
+ cutout = resize(pad_input, out_shape=output_shape)
+
+ if self.Overview > 0:
+ if self.Overview <= 4:
+ if self.Overview >= 1:
+ cutouts.append(cutout)
+ if self.Overview >= 2:
+ cutouts.append(gray(cutout))
+ if self.Overview >= 3:
+ cutouts.append(cutout[:, :, :, ::-1])
+ if self.Overview == 4:
+ cutouts.append(gray(cutout[:, :, :, ::-1]))
+ else:
+ cutout = resize(pad_input, out_shape=output_shape)
+ for _ in range(self.Overview):
+ cutouts.append(cutout)
+
+ if self.InnerCrop > 0:
+ for i in range(self.InnerCrop):
+ size = int(paddle.rand([1])**self.IC_Size_Pow * (max_size - min_size) + min_size)
+ offsetx = paddle.randint(0, sideX - size + 1)
+ offsety = paddle.randint(0, sideY - size + 1)
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+ if i <= int(self.IC_Grey_P * self.InnerCrop):
+ cutout = gray(cutout)
+ cutout = resize(cutout, out_shape=output_shape)
+ cutouts.append(cutout)
+
+ cutouts = paddle.concat(cutouts)
+ if skip_augs is not True:
+ cutouts = self.augs(cutouts)
+ return cutouts
+
+
+def resample(input, size, align_corners=True):
+ n, c, h, w = input.shape
+ dh, dw = size
+
+ input = input.reshape([n * c, 1, h, w])
+
+ if dh < h:
+ kernel_h = lanczos(ramp(dh / h, 2), 2).to(input.device, input.dtype)
+ pad_h = (kernel_h.shape[0] - 1) // 2
+ input = F.pad(input, (0, 0, pad_h, pad_h), 'reflect')
+ input = F.conv2d(input, kernel_h[None, None, :, None])
+
+ if dw < w:
+ kernel_w = lanczos(ramp(dw / w, 2), 2).to(input.device, input.dtype)
+ pad_w = (kernel_w.shape[0] - 1) // 2
+ input = F.pad(input, (pad_w, pad_w, 0, 0), 'reflect')
+ input = F.conv2d(input, kernel_w[None, None, None, :])
+
+ input = input.reshape([n, c, h, w])
+ return F.interpolate(input, size, mode='bicubic', align_corners=align_corners)
+
+
+padargs = {}
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/nn.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/nn.py
new file mode 100755
index 000000000..d618183e2
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/nn.py
@@ -0,0 +1,127 @@
+"""
+Various utilities for neural networks implemented by Paddle. This code is rewritten based on:
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/nn.py
+"""
+import math
+
+import paddle
+import paddle.nn as nn
+
+
+class SiLU(nn.Layer):
+
+ def forward(self, x):
+ return x * nn.functional.sigmoid(x)
+
+
+class GroupNorm32(nn.GroupNorm):
+
+ def forward(self, x):
+ return super().forward(x)
+
+
+def conv_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D convolution module.
+ """
+ if dims == 1:
+ return nn.Conv1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.Conv2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.Conv3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def linear(*args, **kwargs):
+ """
+ Create a linear module.
+ """
+ return nn.Linear(*args, **kwargs)
+
+
+def avg_pool_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D average pooling module.
+ """
+ if dims == 1:
+ return nn.AvgPool1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.AvgPool2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.AvgPool3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def update_ema(target_params, source_params, rate=0.99):
+ """
+ Update target parameters to be closer to those of source parameters using
+ an exponential moving average.
+
+ :param target_params: the target parameter sequence.
+ :param source_params: the source parameter sequence.
+ :param rate: the EMA rate (closer to 1 means slower).
+ """
+ for targ, src in zip(target_params, source_params):
+ targ.detach().mul_(rate).add_(src, alpha=1 - rate)
+
+
+def zero_module(module):
+ """
+ Zero out the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().zero_()
+ return module
+
+
+def scale_module(module, scale):
+ """
+ Scale the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().mul_(scale)
+ return module
+
+
+def mean_flat(tensor):
+ """
+ Take the mean over all non-batch dimensions.
+ """
+ return tensor.mean(axis=list(range(1, len(tensor.shape))))
+
+
+def normalization(channels):
+ """
+ Make a standard normalization layer.
+
+ :param channels: number of input channels.
+ :return: an nn.Module for normalization.
+ """
+ return GroupNorm32(32, channels)
+
+
+def timestep_embedding(timesteps, dim, max_period=10000):
+ """
+ Create sinusoidal timestep embeddings.
+
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param dim: the dimension of the output.
+ :param max_period: controls the minimum frequency of the embeddings.
+ :return: an [N x dim] Tensor of positional embeddings.
+ """
+ half = dim // 2
+ freqs = paddle.exp(-math.log(max_period) * paddle.arange(start=0, end=half, dtype=paddle.float32) / half)
+ args = paddle.cast(timesteps[:, None], 'float32') * freqs[None]
+ embedding = paddle.concat([paddle.cos(args), paddle.sin(args)], axis=-1)
+ if dim % 2:
+ embedding = paddle.concat([embedding, paddle.zeros_like(embedding[:, :1])], axis=-1)
+ return embedding
+
+
+def checkpoint(func, inputs, params, flag):
+ """
+ This function is disabled. And now just forward.
+ """
+ return func(*inputs)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/perlin_noises.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/perlin_noises.py
new file mode 100755
index 000000000..6dacb331b
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/perlin_noises.py
@@ -0,0 +1,78 @@
+'''
+Perlin noise implementation by Paddle.
+This code is rewritten based on:
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/perlin_noises.py
+'''
+import numpy as np
+import paddle
+import paddle.vision.transforms as TF
+from PIL import Image
+from PIL import ImageOps
+
+
+def interp(t):
+ return 3 * t**2 - 2 * t**3
+
+
+def perlin(width, height, scale=10):
+ gx, gy = paddle.randn([2, width + 1, height + 1, 1, 1])
+ xs = paddle.linspace(0, 1, scale + 1)[:-1, None]
+ ys = paddle.linspace(0, 1, scale + 1)[None, :-1]
+ wx = 1 - interp(xs)
+ wy = 1 - interp(ys)
+ dots = 0
+ dots += wx * wy * (gx[:-1, :-1] * xs + gy[:-1, :-1] * ys)
+ dots += (1 - wx) * wy * (-gx[1:, :-1] * (1 - xs) + gy[1:, :-1] * ys)
+ dots += wx * (1 - wy) * (gx[:-1, 1:] * xs - gy[:-1, 1:] * (1 - ys))
+ dots += (1 - wx) * (1 - wy) * (-gx[1:, 1:] * (1 - xs) - gy[1:, 1:] * (1 - ys))
+ return dots.transpose([0, 2, 1, 3]).reshape([width * scale, height * scale])
+
+
+def perlin_ms(octaves, width, height, grayscale):
+ out_array = [0.5] if grayscale else [0.5, 0.5, 0.5]
+ # out_array = [0.0] if grayscale else [0.0, 0.0, 0.0]
+ for i in range(1 if grayscale else 3):
+ scale = 2**len(octaves)
+ oct_width = width
+ oct_height = height
+ for oct in octaves:
+ p = perlin(oct_width, oct_height, scale)
+ out_array[i] += p * oct
+ scale //= 2
+ oct_width *= 2
+ oct_height *= 2
+ return paddle.concat(out_array)
+
+
+def create_perlin_noise(octaves, width, height, grayscale, side_y, side_x):
+ out = perlin_ms(octaves, width, height, grayscale)
+ if grayscale:
+ out = TF.resize(size=(side_y, side_x), img=out.numpy())
+ out = np.uint8(out)
+ out = Image.fromarray(out).convert('RGB')
+ else:
+ out = out.reshape([-1, 3, out.shape[0] // 3, out.shape[1]])
+ out = out.squeeze().transpose([1, 2, 0]).numpy()
+ out = TF.resize(size=(side_y, side_x), img=out)
+ out = out.clip(0, 1) * 255
+ out = np.uint8(out)
+ out = Image.fromarray(out)
+
+ out = ImageOps.autocontrast(out)
+ return out
+
+
+def regen_perlin(perlin_mode, side_y, side_x, batch_size):
+ if perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+
+ init = (TF.to_tensor(init).add(TF.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+ return init.expand([batch_size, -1, -1, -1])
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/respace.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/respace.py
new file mode 100755
index 000000000..c001c70d0
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/respace.py
@@ -0,0 +1,123 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/respace.py
+'''
+import numpy as np
+import paddle
+
+from .gaussian_diffusion import GaussianDiffusion
+
+
+def space_timesteps(num_timesteps, section_counts):
+ """
+ Create a list of timesteps to use from an original diffusion process,
+ given the number of timesteps we want to take from equally-sized portions
+ of the original process.
+
+ For example, if there's 300 timesteps and the section counts are [10,15,20]
+ then the first 100 timesteps are strided to be 10 timesteps, the second 100
+ are strided to be 15 timesteps, and the final 100 are strided to be 20.
+
+ If the stride is a string starting with "ddim", then the fixed striding
+ from the DDIM paper is used, and only one section is allowed.
+
+ :param num_timesteps: the number of diffusion steps in the original
+ process to divide up.
+ :param section_counts: either a list of numbers, or a string containing
+ comma-separated numbers, indicating the step count
+ per section. As a special case, use "ddimN" where N
+ is a number of steps to use the striding from the
+ DDIM paper.
+ :return: a set of diffusion steps from the original process to use.
+ """
+ if isinstance(section_counts, str):
+ if section_counts.startswith("ddim"):
+ desired_count = int(section_counts[len("ddim"):])
+ for i in range(1, num_timesteps):
+ if len(range(0, num_timesteps, i)) == desired_count:
+ return set(range(0, num_timesteps, i))
+ raise ValueError(f"cannot create exactly {num_timesteps} steps with an integer stride")
+ section_counts = [int(x) for x in section_counts.split(",")]
+ size_per = num_timesteps // len(section_counts)
+ extra = num_timesteps % len(section_counts)
+ start_idx = 0
+ all_steps = []
+ for i, section_count in enumerate(section_counts):
+ size = size_per + (1 if i < extra else 0)
+ if size < section_count:
+ raise ValueError(f"cannot divide section of {size} steps into {section_count}")
+ if section_count <= 1:
+ frac_stride = 1
+ else:
+ frac_stride = (size - 1) / (section_count - 1)
+ cur_idx = 0.0
+ taken_steps = []
+ for _ in range(section_count):
+ taken_steps.append(start_idx + round(cur_idx))
+ cur_idx += frac_stride
+ all_steps += taken_steps
+ start_idx += size
+ return set(all_steps)
+
+
+class SpacedDiffusion(GaussianDiffusion):
+ """
+ A diffusion process which can skip steps in a base diffusion process.
+
+ :param use_timesteps: a collection (sequence or set) of timesteps from the
+ original diffusion process to retain.
+ :param kwargs: the kwargs to create the base diffusion process.
+ """
+
+ def __init__(self, use_timesteps, **kwargs):
+ self.use_timesteps = set(use_timesteps)
+ self.timestep_map = []
+ self.original_num_steps = len(kwargs["betas"])
+
+ base_diffusion = GaussianDiffusion(**kwargs) # pylint: disable=missing-kwoa
+ last_alpha_cumprod = 1.0
+ new_betas = []
+ for i, alpha_cumprod in enumerate(base_diffusion.alphas_cumprod):
+ if i in self.use_timesteps:
+ new_betas.append(1 - alpha_cumprod / last_alpha_cumprod)
+ last_alpha_cumprod = alpha_cumprod
+ self.timestep_map.append(i)
+ kwargs["betas"] = np.array(new_betas)
+ super().__init__(**kwargs)
+
+ def p_mean_variance(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().p_mean_variance(self._wrap_model(model), *args, **kwargs)
+
+ def training_losses(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().training_losses(self._wrap_model(model), *args, **kwargs)
+
+ def condition_mean(self, cond_fn, *args, **kwargs):
+ return super().condition_mean(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def condition_score(self, cond_fn, *args, **kwargs):
+ return super().condition_score(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def _wrap_model(self, model):
+ if isinstance(model, _WrappedModel):
+ return model
+ return _WrappedModel(model, self.timestep_map, self.rescale_timesteps, self.original_num_steps)
+
+ def _scale_timesteps(self, t):
+ # Scaling is done by the wrapped model.
+ return t
+
+
+class _WrappedModel:
+
+ def __init__(self, model, timestep_map, rescale_timesteps, original_num_steps):
+ self.model = model
+ self.timestep_map = timestep_map
+ self.rescale_timesteps = rescale_timesteps
+ self.original_num_steps = original_num_steps
+
+ def __call__(self, x, ts, **kwargs):
+ map_tensor = paddle.to_tensor(self.timestep_map, place=ts.place, dtype=ts.dtype)
+ new_ts = map_tensor[ts]
+ if self.rescale_timesteps:
+ new_ts = paddle.cast(new_ts, 'float32') * (1000.0 / self.original_num_steps)
+ return self.model(x, new_ts, **kwargs)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/script_util.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/script_util.py
new file mode 100755
index 000000000..d728a5430
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/script_util.py
@@ -0,0 +1,201 @@
+'''
+This code is based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/script_util.py
+'''
+import argparse
+import inspect
+
+from . import gaussian_diffusion as gd
+from .respace import space_timesteps
+from .respace import SpacedDiffusion
+from .unet import EncoderUNetModel
+from .unet import SuperResModel
+from .unet import UNetModel
+
+NUM_CLASSES = 1000
+
+
+def diffusion_defaults():
+ """
+ Defaults for image and classifier training.
+ """
+ return dict(
+ learn_sigma=False,
+ diffusion_steps=1000,
+ noise_schedule="linear",
+ timestep_respacing="",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ )
+
+
+def model_and_diffusion_defaults():
+ """
+ Defaults for image training.
+ """
+ res = dict(
+ image_size=64,
+ num_channels=128,
+ num_res_blocks=2,
+ num_heads=4,
+ num_heads_upsample=-1,
+ num_head_channels=-1,
+ attention_resolutions="16,8",
+ channel_mult="",
+ dropout=0.0,
+ class_cond=False,
+ use_checkpoint=False,
+ use_scale_shift_norm=True,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+ )
+ res.update(diffusion_defaults())
+ return res
+
+
+def create_model_and_diffusion(
+ image_size,
+ class_cond,
+ learn_sigma,
+ num_channels,
+ num_res_blocks,
+ channel_mult,
+ num_heads,
+ num_head_channels,
+ num_heads_upsample,
+ attention_resolutions,
+ dropout,
+ diffusion_steps,
+ noise_schedule,
+ timestep_respacing,
+ use_kl,
+ predict_xstart,
+ rescale_timesteps,
+ rescale_learned_sigmas,
+ use_checkpoint,
+ use_scale_shift_norm,
+ resblock_updown,
+ use_fp16,
+ use_new_attention_order,
+):
+ model = create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult=channel_mult,
+ learn_sigma=learn_sigma,
+ class_cond=class_cond,
+ use_checkpoint=use_checkpoint,
+ attention_resolutions=attention_resolutions,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ dropout=dropout,
+ resblock_updown=resblock_updown,
+ use_fp16=use_fp16,
+ use_new_attention_order=use_new_attention_order,
+ )
+ diffusion = create_gaussian_diffusion(
+ steps=diffusion_steps,
+ learn_sigma=learn_sigma,
+ noise_schedule=noise_schedule,
+ use_kl=use_kl,
+ predict_xstart=predict_xstart,
+ rescale_timesteps=rescale_timesteps,
+ rescale_learned_sigmas=rescale_learned_sigmas,
+ timestep_respacing=timestep_respacing,
+ )
+ return model, diffusion
+
+
+def create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult="",
+ learn_sigma=False,
+ class_cond=False,
+ use_checkpoint=False,
+ attention_resolutions="16",
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ dropout=0,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+):
+ if channel_mult == "":
+ if image_size == 512:
+ channel_mult = (0.5, 1, 1, 2, 2, 4, 4)
+ elif image_size == 256:
+ channel_mult = (1, 1, 2, 2, 4, 4)
+ elif image_size == 128:
+ channel_mult = (1, 1, 2, 3, 4)
+ elif image_size == 64:
+ channel_mult = (1, 2, 3, 4)
+ else:
+ raise ValueError(f"unsupported image size: {image_size}")
+ else:
+ channel_mult = tuple(int(ch_mult) for ch_mult in channel_mult.split(","))
+
+ attention_ds = []
+ for res in attention_resolutions.split(","):
+ attention_ds.append(image_size // int(res))
+
+ return UNetModel(
+ image_size=image_size,
+ in_channels=3,
+ model_channels=num_channels,
+ out_channels=(3 if not learn_sigma else 6),
+ num_res_blocks=num_res_blocks,
+ attention_resolutions=tuple(attention_ds),
+ dropout=dropout,
+ channel_mult=channel_mult,
+ num_classes=(NUM_CLASSES if class_cond else None),
+ use_checkpoint=use_checkpoint,
+ use_fp16=use_fp16,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ resblock_updown=resblock_updown,
+ use_new_attention_order=use_new_attention_order,
+ )
+
+
+def create_gaussian_diffusion(
+ *,
+ steps=1000,
+ learn_sigma=False,
+ sigma_small=False,
+ noise_schedule="linear",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ timestep_respacing="",
+):
+ betas = gd.get_named_beta_schedule(noise_schedule, steps)
+ if use_kl:
+ loss_type = gd.LossType.RESCALED_KL
+ elif rescale_learned_sigmas:
+ loss_type = gd.LossType.RESCALED_MSE
+ else:
+ loss_type = gd.LossType.MSE
+ if not timestep_respacing:
+ timestep_respacing = [steps]
+ return SpacedDiffusion(
+ use_timesteps=space_timesteps(steps, timestep_respacing),
+ betas=betas,
+ model_mean_type=(gd.ModelMeanType.EPSILON if not predict_xstart else gd.ModelMeanType.START_X),
+ model_var_type=((gd.ModelVarType.FIXED_LARGE if not sigma_small else gd.ModelVarType.FIXED_SMALL)
+ if not learn_sigma else gd.ModelVarType.LEARNED_RANGE),
+ loss_type=loss_type,
+ rescale_timesteps=rescale_timesteps,
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/sec_diff.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/sec_diff.py
new file mode 100755
index 000000000..1e361f18f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/sec_diff.py
@@ -0,0 +1,135 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/sec_diff.py
+'''
+import math
+from dataclasses import dataclass
+from functools import partial
+
+import paddle
+import paddle.nn as nn
+
+
+@dataclass
+class DiffusionOutput:
+ v: paddle.Tensor
+ pred: paddle.Tensor
+ eps: paddle.Tensor
+
+
+class SkipBlock(nn.Layer):
+
+ def __init__(self, main, skip=None):
+ super().__init__()
+ self.main = nn.Sequential(*main)
+ self.skip = skip if skip else nn.Identity()
+
+ def forward(self, input):
+ return paddle.concat([self.main(input), self.skip(input)], axis=1)
+
+
+def append_dims(x, n):
+ return x[(Ellipsis, *(None, ) * (n - x.ndim))]
+
+
+def expand_to_planes(x, shape):
+ return paddle.tile(append_dims(x, len(shape)), [1, 1, *shape[2:]])
+
+
+def alpha_sigma_to_t(alpha, sigma):
+ return paddle.atan2(sigma, alpha) * 2 / math.pi
+
+
+def t_to_alpha_sigma(t):
+ return paddle.cos(t * math.pi / 2), paddle.sin(t * math.pi / 2)
+
+
+class SecondaryDiffusionImageNet2(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+ c = 64 # The base channel count
+ cs = [c, c * 2, c * 2, c * 4, c * 4, c * 8]
+
+ self.timestep_embed = FourierFeatures(1, 16)
+ self.down = nn.AvgPool2D(2)
+ self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
+
+ self.net = nn.Sequential(
+ ConvBlock(3 + 16, cs[0]),
+ ConvBlock(cs[0], cs[0]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[0], cs[1]),
+ ConvBlock(cs[1], cs[1]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[1], cs[2]),
+ ConvBlock(cs[2], cs[2]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[2], cs[3]),
+ ConvBlock(cs[3], cs[3]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[3], cs[4]),
+ ConvBlock(cs[4], cs[4]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[4], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[4]),
+ self.up,
+ ]),
+ ConvBlock(cs[4] * 2, cs[4]),
+ ConvBlock(cs[4], cs[3]),
+ self.up,
+ ]),
+ ConvBlock(cs[3] * 2, cs[3]),
+ ConvBlock(cs[3], cs[2]),
+ self.up,
+ ]),
+ ConvBlock(cs[2] * 2, cs[2]),
+ ConvBlock(cs[2], cs[1]),
+ self.up,
+ ]),
+ ConvBlock(cs[1] * 2, cs[1]),
+ ConvBlock(cs[1], cs[0]),
+ self.up,
+ ]),
+ ConvBlock(cs[0] * 2, cs[0]),
+ nn.Conv2D(cs[0], 3, 3, padding=1),
+ )
+
+ def forward(self, input, t):
+ timestep_embed = expand_to_planes(self.timestep_embed(t[:, None]), input.shape)
+ v = self.net(paddle.concat([input, timestep_embed], axis=1))
+ alphas, sigmas = map(partial(append_dims, n=v.ndim), t_to_alpha_sigma(t))
+ pred = input * alphas - v * sigmas
+ eps = input * sigmas + v * alphas
+ return DiffusionOutput(v, pred, eps)
+
+
+class FourierFeatures(nn.Layer):
+
+ def __init__(self, in_features, out_features, std=1.0):
+ super().__init__()
+ assert out_features % 2 == 0
+ # self.weight = nn.Parameter(paddle.randn([out_features // 2, in_features]) * std)
+ self.weight = paddle.create_parameter([out_features // 2, in_features],
+ dtype='float32',
+ default_initializer=nn.initializer.Normal(mean=0.0, std=std))
+
+ def forward(self, input):
+ f = 2 * math.pi * input @ self.weight.T
+ return paddle.concat([f.cos(), f.sin()], axis=-1)
+
+
+class ConvBlock(nn.Sequential):
+
+ def __init__(self, c_in, c_out):
+ super().__init__(
+ nn.Conv2D(c_in, c_out, 3, padding=1),
+ nn.ReLU(),
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/transforms.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/transforms.py
new file mode 100755
index 000000000..e0b620b01
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/transforms.py
@@ -0,0 +1,757 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/pytorch/vision/blob/main/torchvision/transforms/transforms.py
+'''
+import math
+import numbers
+import warnings
+from enum import Enum
+from typing import Any
+from typing import Dict
+from typing import List
+from typing import Optional
+from typing import Sequence
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn.functional import grid_sample
+from paddle.vision import transforms as T
+
+
+class Normalize(nn.Layer):
+
+ def __init__(self, mean, std):
+ super(Normalize, self).__init__()
+ self.mean = paddle.to_tensor(mean)
+ self.std = paddle.to_tensor(std)
+
+ def forward(self, tensor: Tensor):
+ dtype = tensor.dtype
+ mean = paddle.to_tensor(self.mean, dtype=dtype)
+ std = paddle.to_tensor(self.std, dtype=dtype)
+ mean = mean.reshape([1, -1, 1, 1])
+ std = std.reshape([1, -1, 1, 1])
+ result = tensor.subtract(mean).divide(std)
+ return result
+
+
+class InterpolationMode(Enum):
+ """Interpolation modes
+ Available interpolation methods are ``nearest``, ``bilinear``, ``bicubic``, ``box``, ``hamming``, and ``lanczos``.
+ """
+
+ NEAREST = "nearest"
+ BILINEAR = "bilinear"
+ BICUBIC = "bicubic"
+ # For PIL compatibility
+ BOX = "box"
+ HAMMING = "hamming"
+ LANCZOS = "lanczos"
+
+
+class Grayscale(nn.Layer):
+
+ def __init__(self, num_output_channels):
+ super(Grayscale, self).__init__()
+ self.num_output_channels = num_output_channels
+
+ def forward(self, x):
+ output = (0.2989 * x[:, 0:1, :, :] + 0.587 * x[:, 1:2, :, :] + 0.114 * x[:, 2:3, :, :])
+ if self.num_output_channels == 3:
+ return output.expand(x.shape)
+
+ return output
+
+
+class Lambda(nn.Layer):
+
+ def __init__(self, func):
+ super(Lambda, self).__init__()
+ self.transform = func
+
+ def forward(self, x):
+ return self.transform(x)
+
+
+class RandomGrayscale(nn.Layer):
+
+ def __init__(self, p):
+ super(RandomGrayscale, self).__init__()
+ self.prob = p
+ self.transform = Grayscale(3)
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return self.transform(x)
+ else:
+ return x
+
+
+class RandomHorizontalFlip(nn.Layer):
+
+ def __init__(self, prob):
+ super(RandomHorizontalFlip, self).__init__()
+ self.prob = prob
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return x[:, :, :, ::-1]
+ else:
+ return x
+
+
+def _blend(img1: Tensor, img2: Tensor, ratio: float) -> Tensor:
+ ratio = float(ratio)
+ bound = 1.0
+ return (ratio * img1 + (1.0 - ratio) * img2).clip(0, bound)
+
+
+def trunc_div(a, b):
+ ipt = paddle.divide(a, b)
+ sign_ipt = paddle.sign(ipt)
+ abs_ipt = paddle.abs(ipt)
+ abs_ipt = paddle.floor(abs_ipt)
+ out = paddle.multiply(sign_ipt, abs_ipt)
+ return out
+
+
+def fmod(a, b):
+ return a - trunc_div(a, b) * b
+
+
+def _rgb2hsv(img: Tensor) -> Tensor:
+ r, g, b = img.unbind(axis=-3)
+
+ # Implementation is based on https://github.com/python-pillow/Pillow/blob/4174d4267616897df3746d315d5a2d0f82c656ee/
+ # src/libImaging/Convert.c#L330
+ maxc = paddle.max(img, axis=-3)
+ minc = paddle.min(img, axis=-3)
+
+ # The algorithm erases S and H channel where `maxc = minc`. This avoids NaN
+ # from happening in the results, because
+ # + S channel has division by `maxc`, which is zero only if `maxc = minc`
+ # + H channel has division by `(maxc - minc)`.
+ #
+ # Instead of overwriting NaN afterwards, we just prevent it from occuring so
+ # we don't need to deal with it in case we save the NaN in a buffer in
+ # backprop, if it is ever supported, but it doesn't hurt to do so.
+ eqc = maxc == minc
+
+ cr = maxc - minc
+ # Since `eqc => cr = 0`, replacing denominator with 1 when `eqc` is fine.
+ ones = paddle.ones_like(maxc)
+ s = cr / paddle.where(eqc, ones, maxc)
+ # Note that `eqc => maxc = minc = r = g = b`. So the following calculation
+ # of `h` would reduce to `bc - gc + 2 + rc - bc + 4 + rc - bc = 6` so it
+ # would not matter what values `rc`, `gc`, and `bc` have here, and thus
+ # replacing denominator with 1 when `eqc` is fine.
+ cr_divisor = paddle.where(eqc, ones, cr)
+ rc = (maxc - r) / cr_divisor
+ gc = (maxc - g) / cr_divisor
+ bc = (maxc - b) / cr_divisor
+
+ hr = (maxc == r).cast('float32') * (bc - gc)
+ hg = ((maxc == g) & (maxc != r)).cast('float32') * (2.0 + rc - bc)
+ hb = ((maxc != g) & (maxc != r)).cast('float32') * (4.0 + gc - rc)
+ h = hr + hg + hb
+ h = fmod((h / 6.0 + 1.0), paddle.to_tensor(1.0))
+ return paddle.stack((h, s, maxc), axis=-3)
+
+
+def _hsv2rgb(img: Tensor) -> Tensor:
+ h, s, v = img.unbind(axis=-3)
+ i = paddle.floor(h * 6.0)
+ f = (h * 6.0) - i
+ i = i.cast(dtype='int32')
+
+ p = paddle.clip((v * (1.0 - s)), 0.0, 1.0)
+ q = paddle.clip((v * (1.0 - s * f)), 0.0, 1.0)
+ t = paddle.clip((v * (1.0 - s * (1.0 - f))), 0.0, 1.0)
+ i = i % 6
+
+ mask = i.unsqueeze(axis=-3) == paddle.arange(6).reshape([-1, 1, 1])
+
+ a1 = paddle.stack((v, q, p, p, t, v), axis=-3)
+ a2 = paddle.stack((t, v, v, q, p, p), axis=-3)
+ a3 = paddle.stack((p, p, t, v, v, q), axis=-3)
+ a4 = paddle.stack((a1, a2, a3), axis=-4)
+
+ return paddle.einsum("...ijk, ...xijk -> ...xjk", mask.cast(dtype=img.dtype), a4)
+
+
+def adjust_brightness(img: Tensor, brightness_factor: float) -> Tensor:
+ if brightness_factor < 0:
+ raise ValueError(f"brightness_factor ({brightness_factor}) is not non-negative.")
+
+ return _blend(img, paddle.zeros_like(img), brightness_factor)
+
+
+def adjust_contrast(img: Tensor, contrast_factor: float) -> Tensor:
+ if contrast_factor < 0:
+ raise ValueError(f"contrast_factor ({contrast_factor}) is not non-negative.")
+
+ c = img.shape[1]
+
+ if c == 3:
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+ mean = paddle.mean(output, axis=(-3, -2, -1), keepdim=True)
+
+ else:
+ mean = paddle.mean(img, axis=(-3, -2, -1), keepdim=True)
+
+ return _blend(img, mean, contrast_factor)
+
+
+def adjust_hue(img: Tensor, hue_factor: float) -> Tensor:
+ if not (-0.5 <= hue_factor <= 0.5):
+ raise ValueError(f"hue_factor ({hue_factor}) is not in [-0.5, 0.5].")
+
+ img = _rgb2hsv(img)
+ h, s, v = img.unbind(axis=-3)
+ h = fmod(h + hue_factor, paddle.to_tensor(1.0))
+ img = paddle.stack((h, s, v), axis=-3)
+ img_hue_adj = _hsv2rgb(img)
+ return img_hue_adj
+
+
+def adjust_saturation(img: Tensor, saturation_factor: float) -> Tensor:
+ if saturation_factor < 0:
+ raise ValueError(f"saturation_factor ({saturation_factor}) is not non-negative.")
+
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+
+ return _blend(img, output, saturation_factor)
+
+
+class ColorJitter(nn.Layer):
+
+ def __init__(self, brightness=0, contrast=0, saturation=0, hue=0):
+ super(ColorJitter, self).__init__()
+ self.brightness = self._check_input(brightness, "brightness")
+ self.contrast = self._check_input(contrast, "contrast")
+ self.saturation = self._check_input(saturation, "saturation")
+ self.hue = self._check_input(hue, "hue", center=0, bound=(-0.5, 0.5), clip_first_on_zero=False)
+
+ def _check_input(self, value, name, center=1, bound=(0, float("inf")), clip_first_on_zero=True):
+ if isinstance(value, numbers.Number):
+ if value < 0:
+ raise ValueError(f"If {name} is a single number, it must be non negative.")
+ value = [center - float(value), center + float(value)]
+ if clip_first_on_zero:
+ value[0] = max(value[0], 0.0)
+ elif isinstance(value, (tuple, list)) and len(value) == 2:
+ if not bound[0] <= value[0] <= value[1] <= bound[1]:
+ raise ValueError(f"{name} values should be between {bound}")
+ else:
+ raise TypeError(f"{name} should be a single number or a list/tuple with length 2.")
+
+ # if value is 0 or (1., 1.) for brightness/contrast/saturation
+ # or (0., 0.) for hue, do nothing
+ if value[0] == value[1] == center:
+ value = None
+ return value
+
+ @staticmethod
+ def get_params(
+ brightness: Optional[List[float]],
+ contrast: Optional[List[float]],
+ saturation: Optional[List[float]],
+ hue: Optional[List[float]],
+ ) -> Tuple[Tensor, Optional[float], Optional[float], Optional[float], Optional[float]]:
+ """Get the parameters for the randomized transform to be applied on image.
+
+ Args:
+ brightness (tuple of float (min, max), optional): The range from which the brightness_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ contrast (tuple of float (min, max), optional): The range from which the contrast_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ saturation (tuple of float (min, max), optional): The range from which the saturation_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ hue (tuple of float (min, max), optional): The range from which the hue_factor is chosen uniformly.
+ Pass None to turn off the transformation.
+
+ Returns:
+ tuple: The parameters used to apply the randomized transform
+ along with their random order.
+ """
+ fn_idx = paddle.randperm(4)
+
+ b = None if brightness is None else paddle.empty([1]).uniform_(brightness[0], brightness[1])
+ c = None if contrast is None else paddle.empty([1]).uniform_(contrast[0], contrast[1])
+ s = None if saturation is None else paddle.empty([1]).uniform_(saturation[0], saturation[1])
+ h = None if hue is None else paddle.empty([1]).uniform_(hue[0], hue[1])
+
+ return fn_idx, b, c, s, h
+
+ def forward(self, img):
+ """
+ Args:
+ img (PIL Image or Tensor): Input image.
+
+ Returns:
+ PIL Image or Tensor: Color jittered image.
+ """
+ fn_idx, brightness_factor, contrast_factor, saturation_factor, hue_factor = self.get_params(
+ self.brightness, self.contrast, self.saturation, self.hue)
+
+ for fn_id in fn_idx:
+ if fn_id == 0 and brightness_factor is not None:
+ img = adjust_brightness(img, brightness_factor)
+ elif fn_id == 1 and contrast_factor is not None:
+ img = adjust_contrast(img, contrast_factor)
+ elif fn_id == 2 and saturation_factor is not None:
+ img = adjust_saturation(img, saturation_factor)
+ elif fn_id == 3 and hue_factor is not None:
+ img = adjust_hue(img, hue_factor)
+
+ return img
+
+ def __repr__(self) -> str:
+ s = (f"{self.__class__.__name__}("
+ f"brightness={self.brightness}"
+ f", contrast={self.contrast}"
+ f", saturation={self.saturation}"
+ f", hue={self.hue})")
+ return s
+
+
+def _apply_grid_transform(img: Tensor, grid: Tensor, mode: str, fill: Optional[List[float]]) -> Tensor:
+
+ if img.shape[0] > 1:
+ # Apply same grid to a batch of images
+ grid = grid.expand([img.shape[0], grid.shape[1], grid.shape[2], grid.shape[3]])
+
+ # Append a dummy mask for customized fill colors, should be faster than grid_sample() twice
+ if fill is not None:
+ dummy = paddle.ones((img.shape[0], 1, img.shape[2], img.shape[3]), dtype=img.dtype)
+ img = paddle.concat((img, dummy), axis=1)
+
+ img = grid_sample(img, grid, mode=mode, padding_mode="zeros", align_corners=False)
+
+ # Fill with required color
+ if fill is not None:
+ mask = img[:, -1:, :, :] # N * 1 * H * W
+ img = img[:, :-1, :, :] # N * C * H * W
+ mask = mask.expand_as(img)
+ len_fill = len(fill) if isinstance(fill, (tuple, list)) else 1
+ fill_img = paddle.to_tensor(fill, dtype=img.dtype).reshape([1, len_fill, 1, 1]).expand_as(img)
+ if mode == "nearest":
+ mask = mask < 0.5
+ img[mask] = fill_img[mask]
+ else: # 'bilinear'
+ img = img * mask + (1.0 - mask) * fill_img
+ return img
+
+
+def _gen_affine_grid(
+ theta: Tensor,
+ w: int,
+ h: int,
+ ow: int,
+ oh: int,
+) -> Tensor:
+ # https://github.com/pytorch/pytorch/blob/74b65c32be68b15dc7c9e8bb62459efbfbde33d8/aten/src/ATen/native/
+ # AffineGridGenerator.cpp#L18
+ # Difference with AffineGridGenerator is that:
+ # 1) we normalize grid values after applying theta
+ # 2) we can normalize by other image size, such that it covers "extend" option like in PIL.Image.rotate
+
+ d = 0.5
+ base_grid = paddle.empty([1, oh, ow, 3], dtype=theta.dtype)
+ x_grid = paddle.linspace(-ow * 0.5 + d, ow * 0.5 + d - 1, num=ow)
+ base_grid[..., 0] = (x_grid)
+ y_grid = paddle.linspace(-oh * 0.5 + d, oh * 0.5 + d - 1, num=oh).unsqueeze_(-1)
+ base_grid[..., 1] = (y_grid)
+ base_grid[..., 2] = 1.0
+ rescaled_theta = theta.transpose([0, 2, 1]) / paddle.to_tensor([0.5 * w, 0.5 * h], dtype=theta.dtype)
+ output_grid = base_grid.reshape([1, oh * ow, 3]).bmm(rescaled_theta)
+ return output_grid.reshape([1, oh, ow, 2])
+
+
+def affine_impl(img: Tensor,
+ matrix: List[float],
+ interpolation: str = "nearest",
+ fill: Optional[List[float]] = None) -> Tensor:
+ theta = paddle.to_tensor(matrix, dtype=img.dtype).reshape([1, 2, 3])
+ shape = img.shape
+ # grid will be generated on the same device as theta and img
+ grid = _gen_affine_grid(theta, w=shape[-1], h=shape[-2], ow=shape[-1], oh=shape[-2])
+ return _apply_grid_transform(img, grid, interpolation, fill=fill)
+
+
+def _get_inverse_affine_matrix(center: List[float],
+ angle: float,
+ translate: List[float],
+ scale: float,
+ shear: List[float],
+ inverted: bool = True) -> List[float]:
+ # Helper method to compute inverse matrix for affine transformation
+
+ # Pillow requires inverse affine transformation matrix:
+ # Affine matrix is : M = T * C * RotateScaleShear * C^-1
+ #
+ # where T is translation matrix: [1, 0, tx | 0, 1, ty | 0, 0, 1]
+ # C is translation matrix to keep center: [1, 0, cx | 0, 1, cy | 0, 0, 1]
+ # RotateScaleShear is rotation with scale and shear matrix
+ #
+ # RotateScaleShear(a, s, (sx, sy)) =
+ # = R(a) * S(s) * SHy(sy) * SHx(sx)
+ # = [ s*cos(a - sy)/cos(sy), s*(-cos(a - sy)*tan(sx)/cos(sy) - sin(a)), 0 ]
+ # [ s*sin(a + sy)/cos(sy), s*(-sin(a - sy)*tan(sx)/cos(sy) + cos(a)), 0 ]
+ # [ 0 , 0 , 1 ]
+ # where R is a rotation matrix, S is a scaling matrix, and SHx and SHy are the shears:
+ # SHx(s) = [1, -tan(s)] and SHy(s) = [1 , 0]
+ # [0, 1 ] [-tan(s), 1]
+ #
+ # Thus, the inverse is M^-1 = C * RotateScaleShear^-1 * C^-1 * T^-1
+
+ rot = math.radians(angle)
+ sx = math.radians(shear[0])
+ sy = math.radians(shear[1])
+
+ cx, cy = center
+ tx, ty = translate
+
+ # RSS without scaling
+ a = math.cos(rot - sy) / math.cos(sy)
+ b = -math.cos(rot - sy) * math.tan(sx) / math.cos(sy) - math.sin(rot)
+ c = math.sin(rot - sy) / math.cos(sy)
+ d = -math.sin(rot - sy) * math.tan(sx) / math.cos(sy) + math.cos(rot)
+
+ if inverted:
+ # Inverted rotation matrix with scale and shear
+ # det([[a, b], [c, d]]) == 1, since det(rotation) = 1 and det(shear) = 1
+ matrix = [d, -b, 0.0, -c, a, 0.0]
+ matrix = [x / scale for x in matrix]
+ # Apply inverse of translation and of center translation: RSS^-1 * C^-1 * T^-1
+ matrix[2] += matrix[0] * (-cx - tx) + matrix[1] * (-cy - ty)
+ matrix[5] += matrix[3] * (-cx - tx) + matrix[4] * (-cy - ty)
+ # Apply center translation: C * RSS^-1 * C^-1 * T^-1
+ matrix[2] += cx
+ matrix[5] += cy
+ else:
+ matrix = [a, b, 0.0, c, d, 0.0]
+ matrix = [x * scale for x in matrix]
+ # Apply inverse of center translation: RSS * C^-1
+ matrix[2] += matrix[0] * (-cx) + matrix[1] * (-cy)
+ matrix[5] += matrix[3] * (-cx) + matrix[4] * (-cy)
+ # Apply translation and center : T * C * RSS * C^-1
+ matrix[2] += cx + tx
+ matrix[5] += cy + ty
+
+ return matrix
+
+
+def affine(
+ img: Tensor,
+ angle: float,
+ translate: List[int],
+ scale: float,
+ shear: List[float],
+ interpolation: InterpolationMode = InterpolationMode.NEAREST,
+ fill: Optional[List[float]] = None,
+ resample: Optional[int] = None,
+ fillcolor: Optional[List[float]] = None,
+ center: Optional[List[int]] = None,
+) -> Tensor:
+ """Apply affine transformation on the image keeping image center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ img (PIL Image or Tensor): image to transform.
+ angle (number): rotation angle in degrees between -180 and 180, clockwise direction.
+ translate (sequence of integers): horizontal and vertical translations (post-rotation translation)
+ scale (float): overall scale
+ shear (float or sequence): shear angle value in degrees between -180 to 180, clockwise direction.
+ If a sequence is specified, the first value corresponds to a shear parallel to the x axis, while
+ the second value corresponds to a shear parallel to the y axis.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number, optional): Pixel fill value for the area outside the transformed
+ image. If given a number, the value is used for all bands respectively.
+
+ .. note::
+ In torchscript mode single int/float value is not supported, please use a sequence
+ of length 1: ``[value, ]``.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation. Origin is the upper left corner.
+ Default is the center of the image.
+
+ Returns:
+ PIL Image or Tensor: Transformed image.
+ """
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ if not isinstance(angle, (int, float)):
+ raise TypeError("Argument angle should be int or float")
+
+ if not isinstance(translate, (list, tuple)):
+ raise TypeError("Argument translate should be a sequence")
+
+ if len(translate) != 2:
+ raise ValueError("Argument translate should be a sequence of length 2")
+
+ if scale <= 0.0:
+ raise ValueError("Argument scale should be positive")
+
+ if not isinstance(shear, (numbers.Number, (list, tuple))):
+ raise TypeError("Shear should be either a single value or a sequence of two values")
+
+ if not isinstance(interpolation, InterpolationMode):
+ raise TypeError("Argument interpolation should be a InterpolationMode")
+
+ if isinstance(angle, int):
+ angle = float(angle)
+
+ if isinstance(translate, tuple):
+ translate = list(translate)
+
+ if isinstance(shear, numbers.Number):
+ shear = [shear, 0.0]
+
+ if isinstance(shear, tuple):
+ shear = list(shear)
+
+ if len(shear) == 1:
+ shear = [shear[0], shear[0]]
+
+ if len(shear) != 2:
+ raise ValueError(f"Shear should be a sequence containing two values. Got {shear}")
+
+ if center is not None and not isinstance(center, (list, tuple)):
+ raise TypeError("Argument center should be a sequence")
+ center_f = [0.0, 0.0]
+ if center is not None:
+ _, height, width = img.shape[0], img.shape[1], img.shape[2]
+ # Center values should be in pixel coordinates but translated such that (0, 0) corresponds to image center.
+ center_f = [1.0 * (c - s * 0.5) for c, s in zip(center, [width, height])]
+
+ translate_f = [1.0 * t for t in translate]
+ matrix = _get_inverse_affine_matrix(center_f, angle, translate_f, scale, shear)
+ return affine_impl(img, matrix=matrix, interpolation=interpolation.value, fill=fill)
+
+
+def _interpolation_modes_from_int(i: int) -> InterpolationMode:
+ inverse_modes_mapping = {
+ 0: InterpolationMode.NEAREST,
+ 2: InterpolationMode.BILINEAR,
+ 3: InterpolationMode.BICUBIC,
+ 4: InterpolationMode.BOX,
+ 5: InterpolationMode.HAMMING,
+ 1: InterpolationMode.LANCZOS,
+ }
+ return inverse_modes_mapping[i]
+
+
+def _check_sequence_input(x, name, req_sizes):
+ msg = req_sizes[0] if len(req_sizes) < 2 else " or ".join([str(s) for s in req_sizes])
+ if not isinstance(x, Sequence):
+ raise TypeError(f"{name} should be a sequence of length {msg}.")
+ if len(x) not in req_sizes:
+ raise ValueError(f"{name} should be sequence of length {msg}.")
+
+
+def _setup_angle(x, name, req_sizes=(2, )):
+ if isinstance(x, numbers.Number):
+ if x < 0:
+ raise ValueError(f"If {name} is a single number, it must be positive.")
+ x = [-x, x]
+ else:
+ _check_sequence_input(x, name, req_sizes)
+
+ return [float(d) for d in x]
+
+
+class RandomAffine(nn.Layer):
+ """Random affine transformation of the image keeping center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ degrees (sequence or number): Range of degrees to select from.
+ If degrees is a number instead of sequence like (min, max), the range of degrees
+ will be (-degrees, +degrees). Set to 0 to deactivate rotations.
+ translate (tuple, optional): tuple of maximum absolute fraction for horizontal
+ and vertical translations. For example translate=(a, b), then horizontal shift
+ is randomly sampled in the range -img_width * a < dx < img_width * a and vertical shift is
+ randomly sampled in the range -img_height * b < dy < img_height * b. Will not translate by default.
+ scale (tuple, optional): scaling factor interval, e.g (a, b), then scale is
+ randomly sampled from the range a <= scale <= b. Will keep original scale by default.
+ shear (sequence or number, optional): Range of degrees to select from.
+ If shear is a number, a shear parallel to the x axis in the range (-shear, +shear)
+ will be applied. Else if shear is a sequence of 2 values a shear parallel to the x axis in the
+ range (shear[0], shear[1]) will be applied. Else if shear is a sequence of 4 values,
+ a x-axis shear in (shear[0], shear[1]) and y-axis shear in (shear[2], shear[3]) will be applied.
+ Will not apply shear by default.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number): Pixel fill value for the area outside the transformed
+ image. Default is ``0``. If given a number, the value is used for all bands respectively.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation, (x, y). Origin is the upper left corner.
+ Default is the center of the image.
+
+ .. _filters: https://pillow.readthedocs.io/en/latest/handbook/concepts.html#filters
+
+ """
+
+ def __init__(
+ self,
+ degrees,
+ translate=None,
+ scale=None,
+ shear=None,
+ interpolation=InterpolationMode.NEAREST,
+ fill=0,
+ fillcolor=None,
+ resample=None,
+ center=None,
+ ):
+ super(RandomAffine, self).__init__()
+ if resample is not None:
+ warnings.warn("The parameter 'resample' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'interpolation' instead.")
+ interpolation = _interpolation_modes_from_int(resample)
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ self.degrees = _setup_angle(degrees, name="degrees", req_sizes=(2, ))
+
+ if translate is not None:
+ _check_sequence_input(translate, "translate", req_sizes=(2, ))
+ for t in translate:
+ if not (0.0 <= t <= 1.0):
+ raise ValueError("translation values should be between 0 and 1")
+ self.translate = translate
+
+ if scale is not None:
+ _check_sequence_input(scale, "scale", req_sizes=(2, ))
+ for s in scale:
+ if s <= 0:
+ raise ValueError("scale values should be positive")
+ self.scale = scale
+
+ if shear is not None:
+ self.shear = _setup_angle(shear, name="shear", req_sizes=(2, 4))
+ else:
+ self.shear = shear
+
+ self.resample = self.interpolation = interpolation
+
+ if fill is None:
+ fill = 0
+ elif not isinstance(fill, (Sequence, numbers.Number)):
+ raise TypeError("Fill should be either a sequence or a number.")
+
+ self.fillcolor = self.fill = fill
+
+ if center is not None:
+ _check_sequence_input(center, "center", req_sizes=(2, ))
+
+ self.center = center
+
+ @staticmethod
+ def get_params(
+ degrees: List[float],
+ translate: Optional[List[float]],
+ scale_ranges: Optional[List[float]],
+ shears: Optional[List[float]],
+ img_size: List[int],
+ ) -> Tuple[float, Tuple[int, int], float, Tuple[float, float]]:
+ """Get parameters for affine transformation
+
+ Returns:
+ params to be passed to the affine transformation
+ """
+ angle = float(paddle.empty([1]).uniform_(float(degrees[0]), float(degrees[1])))
+ if translate is not None:
+ max_dx = float(translate[0] * img_size[0])
+ max_dy = float(translate[1] * img_size[1])
+ tx = int(float(paddle.empty([1]).uniform_(-max_dx, max_dx)))
+ ty = int(float(paddle.empty([1]).uniform_(-max_dy, max_dy)))
+ translations = (tx, ty)
+ else:
+ translations = (0, 0)
+
+ if scale_ranges is not None:
+ scale = float(paddle.empty([1]).uniform_(scale_ranges[0], scale_ranges[1]))
+ else:
+ scale = 1.0
+
+ shear_x = shear_y = 0.0
+ if shears is not None:
+ shear_x = float(paddle.empty([1]).uniform_(shears[0], shears[1]))
+ if len(shears) == 4:
+ shear_y = float(paddle.empty([1]).uniform_(shears[2], shears[3]))
+
+ shear = (shear_x, shear_y)
+
+ return angle, translations, scale, shear
+
+ def forward(self, img):
+ fill = self.fill
+ channels, height, width = img.shape[1], img.shape[2], img.shape[3]
+ if isinstance(fill, (int, float)):
+ fill = [float(fill)] * channels
+ else:
+ fill = [float(f) for f in fill]
+
+ img_size = [width, height] # flip for keeping BC on get_params call
+
+ ret = self.get_params(self.degrees, self.translate, self.scale, self.shear, img_size)
+
+ return affine(img, *ret, interpolation=self.interpolation, fill=fill, center=self.center)
+
+ def __repr__(self) -> str:
+ s = f"{self.__class__.__name__}(degrees={self.degrees}"
+ s += f", translate={self.translate}" if self.translate is not None else ""
+ s += f", scale={self.scale}" if self.scale is not None else ""
+ s += f", shear={self.shear}" if self.shear is not None else ""
+ s += f", interpolation={self.interpolation.value}" if self.interpolation != InterpolationMode.NEAREST else ""
+ s += f", fill={self.fill}" if self.fill != 0 else ""
+ s += f", center={self.center}" if self.center is not None else ""
+ s += ")"
+
+ return s
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/unet.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/unet.py
new file mode 100755
index 000000000..56f3ad61e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/model/unet.py
@@ -0,0 +1,838 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/unet.py
+'''
+import math
+from abc import abstractmethod
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+from .nn import avg_pool_nd
+from .nn import checkpoint
+from .nn import conv_nd
+from .nn import linear
+from .nn import normalization
+from .nn import SiLU
+from .nn import timestep_embedding
+from .nn import zero_module
+
+
+class AttentionPool2d(nn.Layer):
+ """
+ Adapted from CLIP: https://github.com/openai/CLIP/blob/main/clip/model.py
+ """
+
+ def __init__(
+ self,
+ spacial_dim: int,
+ embed_dim: int,
+ num_heads_channels: int,
+ output_dim: int = None,
+ ):
+ super().__init__()
+ # self.positional_embedding = nn.Parameter(
+ # th.randn(embed_dim, spacial_dim ** 2 + 1) / embed_dim ** 0.5
+ # )
+ positional_embedding = self.create_parameter(paddle.randn(embed_dim, spacial_dim**2 + 1) / embed_dim**0.5)
+ self.add_parameter("positional_embedding", positional_embedding)
+ self.qkv_proj = conv_nd(1, embed_dim, 3 * embed_dim, 1)
+ self.c_proj = conv_nd(1, embed_dim, output_dim or embed_dim, 1)
+ self.num_heads = embed_dim // num_heads_channels
+ self.attention = QKVAttention(self.num_heads)
+
+ def forward(self, x):
+ b, c, *_spatial = x.shape
+ # x = x.reshape(b, c, -1) # NC(HW)
+ x = paddle.reshape(x, [b, c, -1])
+ x = paddle.concat([x.mean(dim=-1, keepdim=True), x], axis=-1) # NC(HW+1)
+ x = x + paddle.cast(self.positional_embedding[None, :, :], x.dtype) # NC(HW+1)
+ x = self.qkv_proj(x)
+ x = self.attention(x)
+ x = self.c_proj(x)
+ return x[:, :, 0]
+
+
+class TimestepBlock(nn.Layer):
+ """
+ Any module where forward() takes timestep embeddings as a second argument.
+ """
+
+ @abstractmethod
+ def forward(self, x, emb):
+ """
+ Apply the module to `x` given `emb` timestep embeddings.
+ """
+
+
+class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
+ """
+ A sequential module that passes timestep embeddings to the children that
+ support it as an extra input.
+ """
+
+ def forward(self, x, emb):
+ for layer in self:
+ if isinstance(layer, TimestepBlock):
+ x = layer(x, emb)
+ else:
+ x = layer(x)
+ return x
+
+
+class Upsample(nn.Layer):
+ """
+ An upsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ if use_conv:
+ self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=1)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.dims == 3:
+ x = F.interpolate(x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest")
+ else:
+ x = F.interpolate(x, scale_factor=2, mode="nearest")
+ if self.use_conv:
+ x = self.conv(x)
+ return x
+
+
+class Downsample(nn.Layer):
+ """
+ A downsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ stride = 2 if dims != 3 else (1, 2, 2)
+ if use_conv:
+ self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=1)
+ else:
+ assert self.channels == self.out_channels
+ self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ return self.op(x)
+
+
+class ResBlock(TimestepBlock):
+ """
+ A residual block that can optionally change the number of channels.
+
+ :param channels: the number of input channels.
+ :param emb_channels: the number of timestep embedding channels.
+ :param dropout: the rate of dropout.
+ :param out_channels: if specified, the number of out channels.
+ :param use_conv: if True and out_channels is specified, use a spatial
+ convolution instead of a smaller 1x1 convolution to change the
+ channels in the skip connection.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param use_checkpoint: if True, use gradient checkpointing on this module.
+ :param up: if True, use this block for upsampling.
+ :param down: if True, use this block for downsampling.
+ """
+
+ def __init__(
+ self,
+ channels,
+ emb_channels,
+ dropout,
+ out_channels=None,
+ use_conv=False,
+ use_scale_shift_norm=False,
+ dims=2,
+ use_checkpoint=False,
+ up=False,
+ down=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ self.emb_channels = emb_channels
+ self.dropout = dropout
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_checkpoint = use_checkpoint
+ self.use_scale_shift_norm = use_scale_shift_norm
+
+ self.in_layers = nn.Sequential(
+ normalization(channels),
+ SiLU(),
+ conv_nd(dims, channels, self.out_channels, 3, padding=1),
+ )
+
+ self.updown = up or down
+
+ if up:
+ self.h_upd = Upsample(channels, False, dims)
+ self.x_upd = Upsample(channels, False, dims)
+ elif down:
+ self.h_upd = Downsample(channels, False, dims)
+ self.x_upd = Downsample(channels, False, dims)
+ else:
+ self.h_upd = self.x_upd = nn.Identity()
+
+ self.emb_layers = nn.Sequential(
+ SiLU(),
+ linear(
+ emb_channels,
+ 2 * self.out_channels if use_scale_shift_norm else self.out_channels,
+ ),
+ )
+ self.out_layers = nn.Sequential(
+ normalization(self.out_channels),
+ SiLU(),
+ nn.Dropout(p=dropout),
+ zero_module(conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)),
+ )
+
+ if self.out_channels == channels:
+ self.skip_connection = nn.Identity()
+ elif use_conv:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 3, padding=1)
+ else:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
+
+ def forward(self, x, emb):
+ """
+ Apply the block to a Tensor, conditioned on a timestep embedding.
+
+ :param x: an [N x C x ...] Tensor of features.
+ :param emb: an [N x emb_channels] Tensor of timestep embeddings.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ return checkpoint(self._forward, (x, emb), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x, emb):
+ if self.updown:
+ in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
+ h = in_rest(x)
+ h = self.h_upd(h)
+ x = self.x_upd(x)
+ h = in_conv(h)
+ else:
+ h = self.in_layers(x)
+ emb_out = self.emb_layers(emb)
+ emb_out = paddle.cast(emb_out, h.dtype)
+ while len(emb_out.shape) < len(h.shape):
+ emb_out = emb_out[..., None]
+ if self.use_scale_shift_norm:
+ out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
+ scale, shift = paddle.chunk(emb_out, 2, axis=1)
+ h = out_norm(h) * (1 + scale) + shift
+ h = out_rest(h)
+ else:
+ h = h + emb_out
+ h = self.out_layers(h)
+ return self.skip_connection(x) + h
+
+
+class AttentionBlock(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other.
+
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_heads=1,
+ num_head_channels=-1,
+ use_checkpoint=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels == -1:
+ self.num_heads = num_heads
+ else:
+ assert (channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+ self.use_checkpoint = use_checkpoint
+ self.norm = normalization(channels)
+ self.qkv = conv_nd(1, channels, channels * 3, 1)
+ if use_new_attention_order:
+ # split qkv before split heads
+ self.attention = QKVAttention(self.num_heads)
+ else:
+ # split heads before split qkv
+ self.attention = QKVAttentionLegacy(self.num_heads)
+
+ self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
+
+ def forward(self, x):
+ return checkpoint(self._forward, (x, ), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x):
+ b, c, *spatial = x.shape
+ # x = x.reshape(b, c, -1)
+ x = paddle.reshape(x, [b, c, -1])
+ qkv = self.qkv(self.norm(x))
+ h = self.attention(qkv)
+ h = self.proj_out(h)
+ # return (x + h).reshape(b, c, *spatial)
+ return paddle.reshape(x + h, [b, c, *spatial])
+
+
+def count_flops_attn(model, _x, y):
+ """
+ A counter for the `thop` package to count the operations in an
+ attention operation.
+ Meant to be used like:
+ macs, params = thop.profile(
+ model,
+ inputs=(inputs, timestamps),
+ custom_ops={QKVAttention: QKVAttention.count_flops},
+ )
+ """
+ b, c, *spatial = y[0].shape
+ num_spatial = int(np.prod(spatial))
+ # We perform two matmuls with the same number of ops.
+ # The first computes the weight matrix, the second computes
+ # the combination of the value vectors.
+ matmul_ops = 2 * b * (num_spatial**2) * c
+ model.total_ops += paddle.to_tensor([matmul_ops], dtype='float64')
+
+
+class QKVAttentionLegacy(nn.Layer):
+ """
+ A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ # q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
+ q, k, v = paddle.reshape(qkv, [bs * self.n_heads, ch * 3, length]).split(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v)
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class QKVAttention(nn.Layer):
+ """
+ A module which performs QKV attention and splits in a different order.
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (3 * H * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.chunk(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum(
+ "bct,bcs->bts",
+ (q * scale).view(bs * self.n_heads, ch, length),
+ (k * scale).view(bs * self.n_heads, ch, length),
+ ) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v.reshape(bs * self.n_heads, ch, length))
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class UNetModel(nn.Layer):
+ """
+ The full UNet model with attention and timestep embedding.
+
+ :param in_channels: channels in the input Tensor.
+ :param model_channels: base channel count for the model.
+ :param out_channels: channels in the output Tensor.
+ :param num_res_blocks: number of residual blocks per downsample.
+ :param attention_resolutions: a collection of downsample rates at which
+ attention will take place. May be a set, list, or tuple.
+ For example, if this contains 4, then at 4x downsampling, attention
+ will be used.
+ :param dropout: the dropout probability.
+ :param channel_mult: channel multiplier for each level of the UNet.
+ :param conv_resample: if True, use learned convolutions for upsampling and
+ downsampling.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param num_classes: if specified (as an int), then this model will be
+ class-conditional with `num_classes` classes.
+ :param use_checkpoint: use gradient checkpointing to reduce memory usage.
+ :param num_heads: the number of attention heads in each attention layer.
+ :param num_heads_channels: if specified, ignore num_heads and instead use
+ a fixed channel width per attention head.
+ :param num_heads_upsample: works with num_heads to set a different number
+ of heads for upsampling. Deprecated.
+ :param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
+ :param resblock_updown: use residual blocks for up/downsampling.
+ :param use_new_attention_order: use a different attention pattern for potentially
+ increased efficiency.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ num_classes=None,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.image_size = image_size
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.num_classes = num_classes
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ if self.num_classes is not None:
+ self.label_emb = nn.Embedding(num_classes, time_embed_dim)
+
+ ch = input_ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+
+ self.output_blocks = nn.LayerList([])
+ for level, mult in list(enumerate(channel_mult))[::-1]:
+ for i in range(num_res_blocks + 1):
+ ich = input_block_chans.pop()
+ layers = [
+ ResBlock(
+ ch + ich,
+ time_embed_dim,
+ dropout,
+ out_channels=int(model_channels * mult),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(model_channels * mult)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads_upsample,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ if level and i == num_res_blocks:
+ out_ch = ch
+ layers.append(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ up=True,
+ ) if resblock_updown else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch))
+ ds //= 2
+ self.output_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ zero_module(conv_nd(dims, input_ch, out_channels, 3, padding=1)),
+ )
+
+ def forward(self, x, timesteps, y=None):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :param y: an [N] Tensor of labels, if class-conditional.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ assert (y is not None) == (self.num_classes
+ is not None), "must specify y if and only if the model is class-conditional"
+
+ hs = []
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+ if self.num_classes is not None:
+ assert y.shape == (x.shape[0], )
+ emb = emb + self.label_emb(y)
+
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ hs.append(h)
+ h = self.middle_block(h, emb)
+ for module in self.output_blocks:
+ h = paddle.concat([h, hs.pop()], axis=1)
+ h = module(h, emb)
+ # h = paddle.cast(h, x.dtype)
+ return self.out(h)
+
+
+class SuperResModel(UNetModel):
+ """
+ A UNetModel that performs super-resolution.
+
+ Expects an extra kwarg `low_res` to condition on a low-resolution image.
+ """
+
+ def __init__(self, image_size, in_channels, *args, **kwargs):
+ super().__init__(image_size, in_channels * 2, *args, **kwargs)
+
+ def forward(self, x, timesteps, low_res=None, **kwargs):
+ _, _, new_height, new_width = x.shape
+ upsampled = F.interpolate(low_res, (new_height, new_width), mode="bilinear")
+ x = paddle.concat([x, upsampled], axis=1)
+ return super().forward(x, timesteps, **kwargs)
+
+
+class EncoderUNetModel(nn.Layer):
+ """
+ The half UNet model with attention and timestep embedding.
+
+ For usage, see UNet.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ pool="adaptive",
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+ self.pool = pool
+ if pool == "adaptive":
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ nn.AdaptiveAvgPool2D((1, 1)),
+ zero_module(conv_nd(dims, ch, out_channels, 1)),
+ nn.Flatten(),
+ )
+ elif pool == "attention":
+ assert num_head_channels != -1
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ AttentionPool2d((image_size // ds), ch, num_head_channels, out_channels),
+ )
+ elif pool == "spatial":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ nn.ReLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ elif pool == "spatial_v2":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ normalization(2048),
+ SiLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ else:
+ raise NotImplementedError(f"Unexpected {pool} pooling")
+
+ def forward(self, x, timesteps):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :return: an [N x K] Tensor of outputs.
+ """
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+
+ results = []
+ # h = x.type(self.dtype)
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ if self.pool.startswith("spatial"):
+ # results.append(h.type(x.dtype).mean(axis=(2, 3)))
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = self.middle_block(h, emb)
+ if self.pool.startswith("spatial"):
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = paddle.concat(results, axis=-1)
+ return self.out(h)
+ else:
+ # h = h.type(x.dtype)
+ h = paddle.cast(h, x.dtype)
+ return self.out(h)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/resources/default.yml b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/resources/default.yml
new file mode 100755
index 000000000..97c3c1b98
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/resources/default.yml
@@ -0,0 +1,47 @@
+text_prompts:
+ - A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.
+
+init_image:
+
+width_height: [ 1280, 768]
+
+skip_steps: 10
+steps: 250
+
+cut_ic_pow: 1
+init_scale: 1000
+clip_guidance_scale: 5000
+
+tv_scale: 0
+range_scale: 150
+sat_scale: 0
+cutn_batches: 4
+
+diffusion_model: 512x512_diffusion_uncond_finetune_008100
+use_secondary_model: True
+diffusion_sampling_mode: ddim
+
+perlin_init: False
+perlin_mode: mixed
+seed: 445467575
+eta: 0.8
+clamp_grad: True
+clamp_max: 0.05
+
+randomize_class: True
+clip_denoised: False
+fuzzy_prompt: False
+rand_mag: 0.05
+
+cut_overview: "[12]*400+[4]*600"
+cut_innercut: "[4]*400+[12]*600"
+cut_icgray_p: "[0.2]*400+[0]*600"
+
+display_rate: 10
+n_batches: 1
+batch_size: 1
+batch_name: ''
+clip_models:
+ - VIT
+ - RN50
+ - RN101
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/resources/docstrings.yml b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/resources/docstrings.yml
new file mode 100755
index 000000000..702015e1c
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/resources/docstrings.yml
@@ -0,0 +1,103 @@
+text_prompts: |
+ Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."
+ Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments.
+ Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+init_image: |
+ Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here.
+ If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+width_height: |
+ Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+
+skip_steps: |
+ Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.
+ As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.
+ The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.
+ If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.
+ Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.
+ Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image.
+ However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+
+steps: |
+ When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.
+ Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user.
+ Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+
+cut_ic_pow: |
+ This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+init_scale: |
+ This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+clip_guidance_scale: |
+ CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS.
+ Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500.
+ Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+tv_scale: |
+ Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+range_scale: |
+ Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+
+sat_scale: |
+ Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+cutn_batches: |
+ Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep.
+ Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage.
+ At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep.
+ However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.
+ So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+
+diffusion_model: Diffusion_model of choice.
+
+use_secondary_model: |
+ Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+
+diffusion_sampling_mode: |
+ Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+
+perlin_init: |
+ Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps).
+ Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+
+perlin_mode: |
+ sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+seed: |
+ Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar.
+ After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+eta: |
+ eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results.
+ The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+clamp_grad: |
+ As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+clamp_max: |
+ Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+
+randomize_class:
+clip_denoised: False
+fuzzy_prompt: |
+ Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+rand_mag: |
+ Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+
+cut_overview: The schedule of overview cuts
+cut_innercut: The schedule of inner cuts
+cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+display_rate: |
+ During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+n_batches: |
+ This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+batch_name: |
+ The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+clip_models: |
+ CLIP Model selectors. ViT-B/32, ViT-B/16, ViT-L/14, RN101, RN50, RN50x4, RN50x16, RN50x64.
+ These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around.
+ You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.
+ The rough order of speed/mem usage is (smallest/fastest to largest/slowest):
+ ViT-B/32
+ RN50
+ RN101
+ ViT-B/16
+ RN50x4
+ RN50x16
+ RN50x64
+ ViT-L/14
+ For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/runner.py b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/runner.py
new file mode 100755
index 000000000..9645d93cf
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/reverse_diffusion/runner.py
@@ -0,0 +1,285 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/runner.py
+'''
+import gc
+import os
+import random
+from threading import Thread
+
+import disco_diffusion_clip_rn50.clip.clip as clip
+import numpy as np
+import paddle
+import paddle.vision.transforms as T
+import paddle_lpips as lpips
+from docarray import Document
+from docarray import DocumentArray
+from IPython import display
+from ipywidgets import Output
+from PIL import Image
+
+from .helper import logger
+from .helper import parse_prompt
+from .model.losses import range_loss
+from .model.losses import spherical_dist_loss
+from .model.losses import tv_loss
+from .model.make_cutouts import MakeCutoutsDango
+from .model.sec_diff import alpha_sigma_to_t
+from .model.sec_diff import SecondaryDiffusionImageNet2
+from .model.transforms import Normalize
+
+
+def do_run(args, models) -> 'DocumentArray':
+ logger.info('preparing models...')
+ model, diffusion, clip_models, secondary_model = models
+ normalize = Normalize(
+ mean=[0.48145466, 0.4578275, 0.40821073],
+ std=[0.26862954, 0.26130258, 0.27577711],
+ )
+ lpips_model = lpips.LPIPS(net='vgg')
+ for parameter in lpips_model.parameters():
+ parameter.stop_gradient = True
+ side_x = (args.width_height[0] // 64) * 64
+ side_y = (args.width_height[1] // 64) * 64
+ cut_overview = eval(args.cut_overview)
+ cut_innercut = eval(args.cut_innercut)
+ cut_icgray_p = eval(args.cut_icgray_p)
+
+ from .model.perlin_noises import create_perlin_noise, regen_perlin
+
+ seed = args.seed
+
+ skip_steps = args.skip_steps
+
+ loss_values = []
+
+ if seed is not None:
+ np.random.seed(seed)
+ random.seed(seed)
+ paddle.seed(seed)
+
+ model_stats = []
+ for clip_model in clip_models:
+ model_stat = {
+ 'clip_model': None,
+ 'target_embeds': [],
+ 'make_cutouts': None,
+ 'weights': [],
+ }
+ model_stat['clip_model'] = clip_model
+
+ if isinstance(args.text_prompts, str):
+ args.text_prompts = [args.text_prompts]
+
+ for prompt in args.text_prompts:
+ txt, weight = parse_prompt(prompt)
+ txt = clip_model.encode_text(clip.tokenize(prompt))
+ if args.fuzzy_prompt:
+ for i in range(25):
+ model_stat['target_embeds'].append((txt + paddle.randn(txt.shape) * args.rand_mag).clip(0, 1))
+ model_stat['weights'].append(weight)
+ else:
+ model_stat['target_embeds'].append(txt)
+ model_stat['weights'].append(weight)
+
+ model_stat['target_embeds'] = paddle.concat(model_stat['target_embeds'])
+ model_stat['weights'] = paddle.to_tensor(model_stat['weights'])
+ if model_stat['weights'].sum().abs() < 1e-3:
+ raise RuntimeError('The weights must not sum to 0.')
+ model_stat['weights'] /= model_stat['weights'].sum().abs()
+ model_stats.append(model_stat)
+
+ init = None
+ if args.init_image:
+ d = Document(uri=args.init_image).load_uri_to_image_tensor(side_x, side_y)
+ init = T.to_tensor(d.tensor).unsqueeze(0) * 2 - 1
+
+ if args.perlin_init:
+ if args.perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif args.perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ init = (T.to_tensor(init).add(T.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+
+ cur_t = None
+
+ def cond_fn(x, t, y=None):
+ x_is_NaN = False
+ n = x.shape[0]
+ if secondary_model:
+ alpha = paddle.to_tensor(diffusion.sqrt_alphas_cumprod[cur_t], dtype='float32')
+ sigma = paddle.to_tensor(diffusion.sqrt_one_minus_alphas_cumprod[cur_t], dtype='float32')
+ cosine_t = alpha_sigma_to_t(alpha, sigma)
+ x = paddle.to_tensor(x.detach(), dtype='float32')
+ x.stop_gradient = False
+ cosine_t = paddle.tile(paddle.to_tensor(cosine_t.detach().cpu().numpy()), [n])
+ cosine_t.stop_gradient = False
+ out = secondary_model(x, cosine_t).pred
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ else:
+ t = paddle.ones([n], dtype='int64') * cur_t
+ out = diffusion.p_mean_variance(model, x, t, clip_denoised=False, model_kwargs={'y': y})
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out['pred_xstart'] * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ for model_stat in model_stats:
+ for i in range(args.cutn_batches):
+ t_int = (int(t.item()) + 1) # errors on last step without +1, need to find source
+ # when using SLIP Base model the dimensions need to be hard coded to avoid AttributeError: 'VisionTransformer' object has no attribute 'input_resolution'
+ try:
+ input_resolution = model_stat['clip_model'].visual.input_resolution
+ except:
+ input_resolution = 224
+
+ cuts = MakeCutoutsDango(
+ input_resolution,
+ Overview=cut_overview[1000 - t_int],
+ InnerCrop=cut_innercut[1000 - t_int],
+ IC_Size_Pow=args.cut_ic_pow,
+ IC_Grey_P=cut_icgray_p[1000 - t_int],
+ )
+ clip_in = normalize(cuts(x_in.add(paddle.to_tensor(1.0)).divide(paddle.to_tensor(2.0))))
+ image_embeds = (model_stat['clip_model'].encode_image(clip_in))
+
+ dists = spherical_dist_loss(
+ image_embeds.unsqueeze(1),
+ model_stat['target_embeds'].unsqueeze(0),
+ )
+
+ dists = dists.reshape([
+ cut_overview[1000 - t_int] + cut_innercut[1000 - t_int],
+ n,
+ -1,
+ ])
+ losses = dists.multiply(model_stat['weights']).sum(2).mean(0)
+ loss_values.append(losses.sum().item()) # log loss, probably shouldn't do per cutn_batch
+
+ x_in_grad += (paddle.grad(losses.sum() * args.clip_guidance_scale, x_in)[0] / args.cutn_batches)
+ tv_losses = tv_loss(x_in)
+ range_losses = range_loss(x_in)
+ sat_losses = paddle.abs(x_in - x_in.clip(min=-1, max=1)).mean()
+ loss = (tv_losses.sum() * args.tv_scale + range_losses.sum() * args.range_scale +
+ sat_losses.sum() * args.sat_scale)
+ if init is not None and args.init_scale:
+ init_losses = lpips_model(x_in, init)
+ loss = loss + init_losses.sum() * args.init_scale
+ x_in_grad += paddle.grad(loss, x_in)[0]
+ if not paddle.isnan(x_in_grad).any():
+ grad = -paddle.grad(x_in_d, x, x_in_grad)[0]
+ else:
+ x_is_NaN = True
+ grad = paddle.zeros_like(x)
+ if args.clamp_grad and not x_is_NaN:
+ magnitude = grad.square().mean().sqrt()
+ return (grad * magnitude.clip(max=args.clamp_max) / magnitude)
+ return grad
+
+ if args.diffusion_sampling_mode == 'ddim':
+ sample_fn = diffusion.ddim_sample_loop_progressive
+ else:
+ sample_fn = diffusion.plms_sample_loop_progressive
+
+ logger.info('creating artwork...')
+
+ image_display = Output()
+ da_batches = DocumentArray()
+
+ for _nb in range(args.n_batches):
+ display.clear_output(wait=True)
+ display.display(args.name_docarray, image_display)
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+
+ d = Document(tags=vars(args))
+ da_batches.append(d)
+
+ cur_t = diffusion.num_timesteps - skip_steps - 1
+
+ if args.perlin_init:
+ init = regen_perlin(args.perlin_mode, side_y, side_x, args.batch_size)
+
+ if args.diffusion_sampling_mode == 'ddim':
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ eta=args.eta,
+ )
+ else:
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ order=2,
+ )
+
+ threads = []
+ for j, sample in enumerate(samples):
+ cur_t -= 1
+ with image_display:
+ if j % args.display_rate == 0 or cur_t == -1:
+ for _, image in enumerate(sample['pred_xstart']):
+ image = (image + 1) / 2
+ image = image.clip(0, 1).squeeze().transpose([1, 2, 0]).numpy() * 255
+ image = np.uint8(image)
+ image = Image.fromarray(image)
+
+ image.save(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb)))
+ c = Document(tags={'cur_t': cur_t})
+ c.load_pil_image_to_datauri(image)
+ d.chunks.append(c)
+ display.clear_output(wait=True)
+ display.display(display.Image(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb))))
+ d.chunks.plot_image_sprites(os.path.join(args.output_dir,
+ f'{args.name_docarray}-progress-{_nb}.png'),
+ show_index=True)
+ t = Thread(
+ target=_silent_push,
+ args=(
+ da_batches,
+ args.name_docarray,
+ ),
+ )
+ threads.append(t)
+ t.start()
+
+ if cur_t == -1:
+ d.load_pil_image_to_datauri(image)
+
+ for t in threads:
+ t.join()
+ display.clear_output(wait=True)
+ logger.info(f'done! {args.name_docarray}')
+ da_batches.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ return da_batches
+
+
+def _silent_push(da_batches: DocumentArray, name: str) -> None:
+ try:
+ da_batches.push(name)
+ except Exception as ex:
+ logger.debug(f'push failed: {ex}')
From aeebde7562da044c8c768ea613b4bbcd3ce93b5b Mon Sep 17 00:00:00 2001
From: chenjian  +
+
+
+ - 生成过程
+  +
+
+
+### 模型介绍
+
+disco_diffusion_clip_rn101 是一个文图生成模型,可以通过输入一段文字来生成符合该句子语义的图像。该模型由两部分组成,一部分是扩散模型,是一种生成模型,可以从噪声输入中重建出原始图像。另一部分是多模态预训练模型(CLIP), 可以将文本和图像表示在同一个特征空间,相近语义的文本和图像在该特征空间里距离会更相近。在该文图生成模型中,扩散模型负责从初始噪声或者指定初始图像中来生成目标图像,CLIP负责引导生成图像的语义和输入的文本的语义尽可能接近,随着扩散模型在CLIP的引导下不断的迭代生成新图像,最终能够生成文本所描述内容的图像。该模块中使用的CLIP模型结构为ResNet101。
+
+更多详情请参考论文:[Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233) 以及 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install disco_diffusion_clip_rn101
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run disco_diffusion_clip_rn101 --text_prompts "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation." --output_dir disco_diffusion_clip_rn101_out
+ ```
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_clip_rn101")
+ text_prompts = ["A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."]
+ # 生成图像, 默认会在disco_diffusion_clip_rn101_out目录保存图像
+ # 返回的da是一个DocumentArray对象,保存了所有的结果,包括最终结果和迭代过程的中间结果
+ # 可以通过操作DocumentArray对象对生成的图像做后处理,保存或者分析
+ da = module.generate_image(text_prompts=text_prompts, output_dir='./disco_diffusion_clip_rn101_out/')
+ # 手动将最终生成的图像保存到指定路径
+ da[0].save_uri_to_file('disco_diffusion_clip_rn101_out-result.png')
+ # 展示所有的中间结果
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # 将整个生成过程保存为一个动态图gif
+ da[0].chunks.save_gif('disco_diffusion_clip_rn101_out-result.gif', show_index=True, inline_display=True, size_ratio=0.5)
+ ```
+
+- ### 3、API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_clip_rn101_out'):
+ ```
+
+ - 文图生成API,生成文本描述内容的图像。
+
+ - **参数**
+
+ - text_prompts(str): 输入的语句,描述想要生成的图像的内容。通常比较有效的构造方式为 "一段描述性的文字内容" + "指定艺术家的名字",如"a beautiful painting of Chinese architecture, by krenz, sunny, super wide angle, artstation."。prompt的构造可以参考[网站](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#)。
+ - style(Optional[str]): 指定绘画的风格,如'watercolor','Chinese painting'等。当不指定时,风格完全由您所填写的prompt决定。
+ - artist(Optional[str]): 指定特定的艺术家,如Greg Rutkowsk、krenz,将会生成所指定艺术家的绘画风格。当不指定时,风格完全由您所填写的prompt决定。各种艺术家的风格可以参考[网站](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/)。
+ - width_height(Optional[List[int]]): 指定最终输出图像的宽高,宽和高都需要是64的倍数,生成的图像越大,所需要的计算时间越长。
+ - seed(Optional[int]): 随机种子,由于输入默认是随机高斯噪声,设置不同的随机种子会由不同的初始输入,从而最终生成不同的结果,可以设置该参数来获得不同的输出图像。
+ - output_dir(Optional[str]): 保存输出图像的目录,默认为"disco_diffusion_clip_rn101_out"。
+
+
+ - **返回**
+ - ra(DocumentArray): DocumentArray对象, 包含`n_batches`个Documents,其中每个Document都保存了迭代过程的所有中间结果。详细可参考[DocumentArray使用文档](https://docarray.jina.ai/fundamentals/documentarray/index.html)。
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install disco_diffusion_clip_rn101 == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/README.md b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/README.md
new file mode 100644
index 000000000..317214d80
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/README.md
@@ -0,0 +1,2 @@
+# OpenAI CLIP implemented in Paddle.
+The original implementation repo is [ranchlai/clip.paddle](https://github.com/ranchlai/clip.paddle). We copy this repo here for guided diffusion.
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/__init__.py
new file mode 100755
index 000000000..5657b56e6
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/__init__.py
@@ -0,0 +1 @@
+from .utils import *
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/layers.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/layers.py
new file mode 100755
index 000000000..286f35ab4
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/layers.py
@@ -0,0 +1,182 @@
+from typing import Optional
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn import Linear
+
+__all__ = ['ResidualAttentionBlock', 'AttentionPool2d', 'multi_head_attention_forward', 'MultiHeadAttention']
+
+
+def multi_head_attention_forward(x: Tensor,
+ num_heads: int,
+ q_proj: Linear,
+ k_proj: Linear,
+ v_proj: Linear,
+ c_proj: Linear,
+ attn_mask: Optional[Tensor] = None):
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = emb_dim // num_heads
+ scaling = float(head_dim)**-0.5
+ q = q_proj(x) # L, N, E
+ k = k_proj(x) # L, N, E
+ v = v_proj(x) # L, N, E
+ #k = k.con
+ v = v.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ k = k.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ q = q.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+
+ q = q * scaling
+ qk = paddle.bmm(q, k.transpose((0, 2, 1)))
+ if attn_mask is not None:
+ if attn_mask.ndim == 2:
+ attn_mask.unsqueeze_(0)
+ #assert str(attn_mask.dtype) == 'VarType.FP32' and attn_mask.ndim == 3
+ assert attn_mask.shape[0] == 1 and attn_mask.shape[1] == max_len and attn_mask.shape[2] == max_len
+ qk += attn_mask
+
+ qk = paddle.nn.functional.softmax(qk, axis=-1)
+ atten = paddle.bmm(qk, v)
+ atten = atten.transpose((1, 0, 2))
+ atten = atten.reshape((max_len, batch_size, emb_dim))
+ atten = c_proj(atten)
+ return atten
+
+
+class MultiHeadAttention(nn.Layer): # without attention mask
+
+ def __init__(self, emb_dim: int, num_heads: int):
+ super().__init__()
+ self.q_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.k_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.v_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.c_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.head_dim = emb_dim // num_heads
+ self.emb_dim = emb_dim
+ self.num_heads = num_heads
+ assert self.head_dim * num_heads == emb_dim, "embed_dim must be divisible by num_heads"
+ #self.scaling = float(self.head_dim) ** -0.5
+
+ def forward(self, x, attn_mask=None): # x is in shape[max_len,batch_size,emb_dim]
+
+ atten = multi_head_attention_forward(x,
+ self.num_heads,
+ self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.c_proj,
+ attn_mask=attn_mask)
+
+ return atten
+
+
+class Identity(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return x
+
+
+class Bottleneck(nn.Layer):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1):
+ super().__init__()
+
+ # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
+ self.conv1 = nn.Conv2D(inplanes, planes, 1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(planes)
+
+ self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(planes)
+
+ self.avgpool = nn.AvgPool2D(stride) if stride > 1 else Identity()
+
+ self.conv3 = nn.Conv2D(planes, planes * self.expansion, 1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(planes * self.expansion)
+
+ self.relu = nn.ReLU()
+ self.downsample = None
+ self.stride = stride
+
+ if stride > 1 or inplanes != planes * Bottleneck.expansion:
+ self.downsample = nn.Sequential(
+ ("-1", nn.AvgPool2D(stride)),
+ ("0", nn.Conv2D(inplanes, planes * self.expansion, 1, stride=1, bias_attr=False)),
+ ("1", nn.BatchNorm2D(planes * self.expansion)))
+
+ def forward(self, x):
+ identity = x
+
+ out = self.relu(self.bn1(self.conv1(x)))
+ out = self.relu(self.bn2(self.conv2(out)))
+ out = self.avgpool(out)
+ out = self.bn3(self.conv3(out))
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.relu(out)
+ return out
+
+
+class AttentionPool2d(nn.Layer):
+
+ def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
+ super().__init__()
+
+ self.positional_embedding = paddle.create_parameter((spacial_dim**2 + 1, embed_dim), dtype='float32')
+
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim, bias_attr=True)
+ self.num_heads = num_heads
+
+ self.head_dim = embed_dim // num_heads
+ assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
+
+ def forward(self, x):
+
+ x = x.reshape((x.shape[0], x.shape[1], x.shape[2] * x.shape[3])).transpose((2, 0, 1)) # NCHW -> (HW)NC
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = self.head_dim
+ x = paddle.concat([paddle.mean(x, axis=0, keepdim=True), x], axis=0)
+ x = x + paddle.unsqueeze(self.positional_embedding, 1)
+ out = multi_head_attention_forward(x, self.num_heads, self.q_proj, self.k_proj, self.v_proj, self.c_proj)
+
+ return out[0]
+
+
+class QuickGELU(nn.Layer):
+
+ def forward(self, x):
+ return x * paddle.nn.functional.sigmoid(1.702 * x)
+
+
+class ResidualAttentionBlock(nn.Layer):
+
+ def __init__(self, d_model: int, n_head: int, attn_mask=None):
+ super().__init__()
+
+ self.attn = MultiHeadAttention(d_model, n_head)
+ self.ln_1 = nn.LayerNorm(d_model)
+ self.mlp = nn.Sequential(("c_fc", nn.Linear(d_model, d_model * 4)), ("gelu", QuickGELU()),
+ ("c_proj", nn.Linear(d_model * 4, d_model)))
+ self.ln_2 = nn.LayerNorm(d_model)
+ self.attn_mask = attn_mask
+
+ def attention(self, x):
+ x = self.attn(x, self.attn_mask)
+ assert isinstance(x, paddle.Tensor) # not tuble here
+ return x
+
+ def forward(self, x):
+
+ x = x + self.attention(self.ln_1(x))
+ x = x + self.mlp(self.ln_2(x))
+ return x
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/model.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/model.py
new file mode 100755
index 000000000..63d1835c5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/model.py
@@ -0,0 +1,227 @@
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import nn
+
+from .layers import AttentionPool2d
+from .layers import Bottleneck
+from .layers import MultiHeadAttention
+from .layers import ResidualAttentionBlock
+
+
+class ModifiedResNet(nn.Layer):
+ """
+ A ResNet class that is similar to torchvision's but contains the following changes:
+ - There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
+ - Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
+ - The final pooling layer is a QKV attention instead of an average pool
+ """
+
+ def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
+ super().__init__()
+ self.output_dim = output_dim
+ self.input_resolution = input_resolution
+
+ # the 3-layer stem
+ self.conv1 = nn.Conv2D(3, width // 2, kernel_size=3, stride=2, padding=1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(width // 2)
+ self.conv2 = nn.Conv2D(width // 2, width // 2, kernel_size=3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(width // 2)
+ self.conv3 = nn.Conv2D(width // 2, width, kernel_size=3, padding=1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(width)
+ self.avgpool = nn.AvgPool2D(2)
+ self.relu = nn.ReLU()
+
+ # residual layers
+ self._inplanes = width # this is a *mutable* variable used during construction
+ self.layer1 = self._make_layer(width, layers[0])
+ self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
+ self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
+ self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
+
+ embed_dim = width * 32 # the ResNet feature dimension
+ self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
+
+ def _make_layer(self, planes, blocks, stride=1):
+ layers = [Bottleneck(self._inplanes, planes, stride)]
+
+ self._inplanes = planes * Bottleneck.expansion
+ for _ in range(1, blocks):
+ layers.append(Bottleneck(self._inplanes, planes))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ def stem(x):
+ for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
+ x = self.relu(bn(conv(x)))
+ x = self.avgpool(x)
+ return x
+
+ #x = x.type(self.conv1.weight.dtype)
+ x = stem(x)
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+ x = self.attnpool(x)
+
+ return x
+
+
+class Transformer(nn.Layer):
+
+ def __init__(self, width: int, layers: int, heads: int, attn_mask=None):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
+
+ def forward(self, x):
+ return self.resblocks(x)
+
+
+class VisualTransformer(nn.Layer):
+
+ def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.output_dim = output_dim
+ # used patch_size x patch_size, stride patch_size to do linear projection
+ self.conv1 = nn.Conv2D(in_channels=3,
+ out_channels=width,
+ kernel_size=patch_size,
+ stride=patch_size,
+ bias_attr=False)
+
+ # scale = width ** -0.5
+ self.class_embedding = paddle.create_parameter((width, ), 'float32')
+
+ self.positional_embedding = paddle.create_parameter(((input_resolution // patch_size)**2 + 1, width), 'float32')
+
+ self.ln_pre = nn.LayerNorm(width)
+
+ self.transformer = Transformer(width, layers, heads)
+
+ self.ln_post = nn.LayerNorm(width)
+ self.proj = paddle.create_parameter((width, output_dim), 'float32')
+
+ def forward(self, x):
+
+ x = self.conv1(x)
+ x = x.reshape((x.shape[0], x.shape[1], -1))
+ x = x.transpose((0, 2, 1))
+ x = paddle.concat([self.class_embedding + paddle.zeros((x.shape[0], 1, x.shape[-1]), dtype=x.dtype), x], axis=1)
+
+ x = x + self.positional_embedding
+ x = self.ln_pre(x)
+ x = x.transpose((1, 0, 2))
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2))
+ x = self.ln_post(x[:, 0, :])
+ if self.proj is not None:
+ x = paddle.matmul(x, self.proj)
+
+ return x
+
+
+class CLIP(nn.Layer):
+
+ def __init__(
+ self,
+ embed_dim: int,
+ # vision
+ image_resolution: int,
+ vision_layers: Union[Tuple[int, int, int, int], int],
+ vision_width: int,
+ vision_patch_size: int,
+ # text
+ context_length: int,
+ vocab_size: int,
+ transformer_width: int,
+ transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+
+ self.context_length = context_length
+ if isinstance(vision_layers, (tuple, list)):
+ vision_heads = vision_width * 32 // 64
+ self.visual = ModifiedResNet(layers=vision_layers,
+ output_dim=embed_dim,
+ heads=vision_heads,
+ input_resolution=image_resolution,
+ width=vision_width)
+ else:
+ vision_heads = vision_width // 64
+ self.visual = VisualTransformer(input_resolution=image_resolution,
+ patch_size=vision_patch_size,
+ width=vision_width,
+ layers=vision_layers,
+ heads=vision_heads,
+ output_dim=embed_dim)
+
+ self.transformer = Transformer(width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+
+ self.vocab_size = vocab_size
+ self.token_embedding = nn.Embedding(vocab_size, transformer_width)
+ self.positional_embedding = paddle.create_parameter((self.context_length, transformer_width), 'float32')
+ self.ln_final = nn.LayerNorm(transformer_width)
+
+ self.text_projection = paddle.create_parameter((transformer_width, embed_dim), 'float32')
+ self.logit_scale = paddle.create_parameter((1, ), 'float32')
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # mask = paddle.empty((self.context_length, self.context_length),dtype='float32')
+ # mask.fill_(float("-inf"))
+ #mask.triu_(1) # zero out the lower diagonal
+
+ mask = paddle.ones((self.context_length, self.context_length)) * float("-inf")
+ mask = paddle.triu(mask, diagonal=1)
+
+ return mask
+
+ def encode_image(self, image):
+ return self.visual(image)
+
+ def encode_text(self, text):
+ x = self.token_embedding(text) # [batch_size, n_ctx, d_model]
+ # print(x.shape)
+
+ x = x + self.positional_embedding
+ #print(x.shape)
+
+ x = x.transpose((1, 0, 2)) # NLD -> LND
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2)) # LND -> NLD
+ x = self.ln_final(x)
+
+ idx = text.numpy().argmax(-1)
+ idx = list(idx)
+ x = [x[i:i + 1, int(j), :] for i, j in enumerate(idx)]
+ x = paddle.concat(x, 0)
+ x = paddle.matmul(x, self.text_projection)
+ return x
+
+ def forward(self, image, text):
+ image_features = self.encode_image(image)
+ text_features = self.encode_text(text)
+
+ # normalized features
+ image_features = image_features / image_features.norm(dim=-1, keepdim=True)
+ text_features = text_features / text_features.norm(dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_image = paddle.matmul(logit_scale * image_features, text_features.t())
+ logits_per_text = paddle.matmul(logit_scale * text_features, image_features.t())
+
+ # shape = [global_batch_size, global_batch_size]
+ return logits_per_image, logits_per_text
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/simple_tokenizer.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/simple_tokenizer.py
new file mode 100755
index 000000000..4eaf82e9e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/simple_tokenizer.py
@@ -0,0 +1,135 @@
+import gzip
+import html
+import os
+from functools import lru_cache
+
+import ftfy
+import regex as re
+
+
+@lru_cache()
+def default_bpe():
+ return os.path.join(os.path.dirname(os.path.abspath(__file__)), "../assets/bpe_simple_vocab_16e6.txt.gz")
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a corresponding list of unicode strings.
+ The reversible bpe codes work on unicode strings.
+ This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
+ When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
+ This is a signficant percentage of your normal, say, 32K bpe vocab.
+ To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ And avoids mapping to whitespace/control characters the bpe code barfs on.
+ """
+ bs = list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """Return set of symbol pairs in a word.
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+def basic_clean(text):
+ text = ftfy.fix_text(text)
+ text = html.unescape(html.unescape(text))
+ return text.strip()
+
+
+def whitespace_clean(text):
+ text = re.sub(r'\s+', ' ', text)
+ text = text.strip()
+ return text
+
+
+class SimpleTokenizer(object):
+
+ def __init__(self, bpe_path: str = default_bpe()):
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
+ merges = merges[1:49152 - 256 - 2 + 1]
+ merges = [tuple(merge.split()) for merge in merges]
+ vocab = list(bytes_to_unicode().values())
+ vocab = vocab + [v + '' for v in vocab]
+ for merge in merges:
+ vocab.append(''.join(merge))
+ vocab.extend(['<|startoftext|>', '<|endoftext|>'])
+ self.encoder = dict(zip(vocab, range(len(vocab))))
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.bpe_ranks = dict(zip(merges, range(len(merges))))
+ self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
+ self.pat = re.compile(
+ r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
+ re.IGNORECASE)
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token[:-1]) + (token[-1] + '', )
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token + ''
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ new_word.extend(word[i:j])
+ i = j
+ except:
+ new_word.extend(word[i:])
+ break
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = ' '.join(word)
+ self.cache[token] = word
+ return word
+
+ def encode(self, text):
+ bpe_tokens = []
+ text = whitespace_clean(basic_clean(text)).lower()
+ for token in re.findall(self.pat, text):
+ token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
+ bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
+ return bpe_tokens
+
+ def decode(self, tokens):
+ text = ''.join([self.decoder[token] for token in tokens])
+ text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('', ' ')
+ return text
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/utils.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/utils.py
new file mode 100755
index 000000000..53d5c4440
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/clip/clip/utils.py
@@ -0,0 +1,122 @@
+import os
+from typing import List
+from typing import Union
+
+import numpy as np
+import paddle
+from paddle.utils import download
+from paddle.vision.transforms import CenterCrop
+from paddle.vision.transforms import Compose
+from paddle.vision.transforms import Normalize
+from paddle.vision.transforms import Resize
+from paddle.vision.transforms import ToTensor
+
+from .model import CLIP
+from .simple_tokenizer import SimpleTokenizer
+
+__all__ = ['transform', 'tokenize', 'build_model']
+
+MODEL_NAMES = ['RN50', 'RN101', 'VIT32']
+
+URL = {
+ 'RN50': os.path.join(os.path.dirname(__file__), 'pre_trained', 'RN50.pdparams'),
+ 'RN101': os.path.join(os.path.dirname(__file__), 'pre_trained', 'RN101.pdparams'),
+ 'VIT32': os.path.join(os.path.dirname(__file__), 'pre_trained', 'ViT-B-32.pdparams')
+}
+
+MEAN, STD = (0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)
+_tokenizer = SimpleTokenizer()
+
+transform = Compose([
+ Resize(224, interpolation='bicubic'),
+ CenterCrop(224), lambda image: image.convert('RGB'),
+ ToTensor(),
+ Normalize(mean=MEAN, std=STD), lambda t: t.unsqueeze_(0)
+])
+
+
+def tokenize(texts: Union[str, List[str]], context_length: int = 77):
+ """
+ Returns the tokenized representation of given input string(s)
+
+ Parameters
+ ----------
+ texts : Union[str, List[str]]
+ An input string or a list of input strings to tokenize
+
+ context_length : int
+ The context length to use; all CLIP models use 77 as the context length
+
+ Returns
+ -------
+ A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
+ """
+ if isinstance(texts, str):
+ texts = [texts]
+
+ sot_token = _tokenizer.encoder["<|startoftext|>"]
+ eot_token = _tokenizer.encoder["<|endoftext|>"]
+ all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
+ result = paddle.zeros((len(all_tokens), context_length), dtype='int64')
+
+ for i, tokens in enumerate(all_tokens):
+ if len(tokens) > context_length:
+ raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
+ result[i, :len(tokens)] = paddle.Tensor(np.array(tokens))
+
+ return result
+
+
+def build_model(name='RN101'):
+ assert name in MODEL_NAMES, f"model name must be one of {MODEL_NAMES}"
+ name2model = {'RN101': build_rn101_model, 'VIT32': build_vit_model, 'RN50': build_rn50_model}
+ model = name2model[name]()
+ weight = URL[name]
+ sd = paddle.load(weight)
+ model.load_dict(sd)
+ model.eval()
+ return model
+
+
+def build_vit_model():
+
+ model = CLIP(embed_dim=512,
+ image_resolution=224,
+ vision_layers=12,
+ vision_width=768,
+ vision_patch_size=32,
+ context_length=77,
+ vocab_size=49408,
+ transformer_width=512,
+ transformer_heads=8,
+ transformer_layers=12)
+ return model
+
+
+def build_rn101_model():
+ model = CLIP(
+ embed_dim=512,
+ image_resolution=224,
+ vision_layers=(3, 4, 23, 3),
+ vision_width=64,
+ vision_patch_size=0, #Not used in resnet
+ context_length=77,
+ vocab_size=49408,
+ transformer_width=512,
+ transformer_heads=8,
+ transformer_layers=12)
+ return model
+
+
+def build_rn50_model():
+ model = CLIP(embed_dim=1024,
+ image_resolution=224,
+ vision_layers=(3, 4, 6, 3),
+ vision_width=64,
+ vision_patch_size=None,
+ context_length=77,
+ vocab_size=49408,
+ transformer_width=512,
+ transformer_heads=8,
+ transformer_layers=12)
+ return model
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/module.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/module.py
new file mode 100755
index 000000000..c59b2f5ff
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/module.py
@@ -0,0 +1,441 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import ast
+import os
+import sys
+from functools import partial
+from typing import List
+from typing import Optional
+
+import disco_diffusion_clip_rn101.clip as clip
+import disco_diffusion_clip_rn101.resize_right as resize_right
+import paddle
+from disco_diffusion_clip_rn101.reverse_diffusion import create
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+@moduleinfo(name="disco_diffusion_clip_rn101",
+ version="1.0.0",
+ type="image/text_to_image",
+ summary="",
+ author="paddlepaddle",
+ author_email="paddle-dev@baidu.com")
+class DiscoDiffusionClip:
+
+ def generate_image(self,
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 0,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 0,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 1,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ use_gpu: Optional[bool] = True,
+ output_dir: Optional[str] = 'disco_diffusion_clip_rn101_out'):
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+ :param style: Image style, such as oil paintings, if specified, style will be used to construct prompts.
+ :param artist: Artist style, if specified, style will be used to construct prompts.
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param use_gpu: whether to use gpu or not.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+ if use_gpu:
+ try:
+ _places = os.environ.get("CUDA_VISIBLE_DEVICES", None)
+ if _places:
+ paddle.device.set_device("gpu:{}".format(0))
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
+ )
+ else:
+ paddle.device.set_device("cpu")
+ paddle.disable_static()
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir, exist_ok=True)
+
+ if isinstance(text_prompts, str):
+ text_prompts = text_prompts.rstrip(',.,。')
+ if style is not None:
+ text_prompts += ",{}".format(style)
+ if artist is not None:
+ text_prompts += ",{},trending on artstation".format(artist)
+ elif isinstance(text_prompts, list):
+ text_prompts[0] = text_prompts[0].rstrip(',.,。')
+ if style is not None:
+ text_prompts[0] += ",{}".format(style)
+ if artist is not None:
+ text_prompts[0] += ",{},trending on artstation".format(artist)
+
+ return create(text_prompts=text_prompts,
+ init_image=init_image,
+ width_height=width_height,
+ skip_steps=skip_steps,
+ steps=steps,
+ cut_ic_pow=cut_ic_pow,
+ init_scale=init_scale,
+ clip_guidance_scale=clip_guidance_scale,
+ tv_scale=tv_scale,
+ range_scale=range_scale,
+ sat_scale=sat_scale,
+ cutn_batches=cutn_batches,
+ diffusion_sampling_mode=diffusion_sampling_mode,
+ perlin_init=perlin_init,
+ perlin_mode=perlin_mode,
+ seed=seed,
+ eta=eta,
+ clamp_grad=clamp_grad,
+ clamp_max=clamp_max,
+ randomize_class=randomize_class,
+ clip_denoised=clip_denoised,
+ fuzzy_prompt=fuzzy_prompt,
+ rand_mag=rand_mag,
+ cut_overview=cut_overview,
+ cut_innercut=cut_innercut,
+ cut_icgray_p=cut_icgray_p,
+ display_rate=display_rate,
+ n_batches=n_batches,
+ batch_size=batch_size,
+ batch_name=batch_name,
+ clip_models=['RN101'],
+ output_dir=output_dir)
+
+ @serving
+ def serving_method(self, text_prompts, **kwargs):
+ """
+ Run as a service.
+ """
+ results = []
+ for text_prompt in text_prompts:
+ result = self.generate_image(text_prompts=text_prompt, **kwargs)[0].to_base64()
+ results.append(result)
+ return results
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options", description="Run configuration for controlling module behavior, not required.")
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ results = self.generate_image(text_prompts=args.text_prompts,
+ style=args.style,
+ artist=args.artist,
+ init_image=args.init_image,
+ width_height=args.width_height,
+ skip_steps=args.skip_steps,
+ steps=args.steps,
+ cut_ic_pow=args.cut_ic_pow,
+ init_scale=args.init_scale,
+ clip_guidance_scale=args.clip_guidance_scale,
+ tv_scale=args.tv_scale,
+ range_scale=args.range_scale,
+ sat_scale=args.sat_scale,
+ cutn_batches=args.cutn_batches,
+ diffusion_sampling_mode=args.diffusion_sampling_mode,
+ perlin_init=args.perlin_init,
+ perlin_mode=args.perlin_mode,
+ seed=args.seed,
+ eta=args.eta,
+ clamp_grad=args.clamp_grad,
+ clamp_max=args.clamp_max,
+ randomize_class=args.randomize_class,
+ clip_denoised=args.clip_denoised,
+ fuzzy_prompt=args.fuzzy_prompt,
+ rand_mag=args.rand_mag,
+ cut_overview=args.cut_overview,
+ cut_innercut=args.cut_innercut,
+ cut_icgray_p=args.cut_icgray_p,
+ display_rate=args.display_rate,
+ n_batches=args.n_batches,
+ batch_size=args.batch_size,
+ batch_name=args.batch_name,
+ output_dir=args.output_dir)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options.
+ """
+ self.arg_input_group.add_argument(
+ '--skip_steps',
+ type=int,
+ default=0,
+ help=
+ 'Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15%% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50%% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture'
+ )
+ self.arg_input_group.add_argument(
+ '--steps',
+ type=int,
+ default=250,
+ help=
+ "When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time."
+ )
+ self.arg_input_group.add_argument(
+ '--cut_ic_pow',
+ type=int,
+ default=1,
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--init_scale',
+ type=int,
+ default=1000,
+ help=
+ "This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost."
+ )
+ self.arg_input_group.add_argument(
+ '--clip_guidance_scale',
+ type=int,
+ default=5000,
+ help=
+ "CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well."
+ )
+ self.arg_input_group.add_argument(
+ '--tv_scale',
+ type=int,
+ default=0,
+ help=
+ "Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising"
+ )
+ self.arg_input_group.add_argument(
+ '--range_scale',
+ type=int,
+ default=0,
+ help=
+ "Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images."
+ )
+ self.arg_input_group.add_argument(
+ '--sat_scale',
+ type=int,
+ default=0,
+ help=
+ "Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation."
+ )
+ self.arg_input_group.add_argument(
+ '--cutn_batches',
+ type=int,
+ default=4,
+ help=
+ "Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below."
+ )
+ self.arg_input_group.add_argument(
+ '--diffusion_sampling_mode',
+ type=str,
+ default='ddim',
+ help=
+ "Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_init',
+ type=bool,
+ default=False,
+ help=
+ "Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively."
+ )
+ self.arg_input_group.add_argument(
+ '--perlin_mode',
+ type=str,
+ default='mixed',
+ help=
+ "sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--seed',
+ type=int,
+ default=None,
+ help=
+ "Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical."
+ )
+ self.arg_input_group.add_argument(
+ '--eta',
+ type=float,
+ default=0.8,
+ help=
+ "eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_grad',
+ type=bool,
+ default=True,
+ help=
+ "As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced."
+ )
+ self.arg_input_group.add_argument(
+ '--clamp_max',
+ type=float,
+ default=0.05,
+ help=
+ "Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy."
+ )
+ self.arg_input_group.add_argument('--randomize_class', type=bool, default=True, help="Random class.")
+ self.arg_input_group.add_argument('--clip_denoised', type=bool, default=False, help="Clip denoised.")
+ self.arg_input_group.add_argument(
+ '--fuzzy_prompt',
+ type=bool,
+ default=False,
+ help=
+ "Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this."
+ )
+ self.arg_input_group.add_argument(
+ '--rand_mag',
+ type=float,
+ default=0.5,
+ help="Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.")
+ self.arg_input_group.add_argument('--cut_overview',
+ type=str,
+ default='[12]*400+[4]*600',
+ help="The schedule of overview cuts")
+ self.arg_input_group.add_argument('--cut_innercut',
+ type=str,
+ default='[4]*400+[12]*600',
+ help="The schedule of inner cuts")
+ self.arg_input_group.add_argument(
+ '--cut_icgray_p',
+ type=str,
+ default='[0.2]*400+[0]*600',
+ help=
+ "This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details."
+ )
+ self.arg_input_group.add_argument(
+ '--display_rate',
+ type=int,
+ default=10,
+ help=
+ "During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly."
+ )
+ self.arg_config_group.add_argument('--use_gpu',
+ type=ast.literal_eval,
+ default=True,
+ help="whether use GPU or not")
+ self.arg_config_group.add_argument('--output_dir',
+ type=str,
+ default='disco_diffusion_clip_rn101_out',
+ help='Output directory.')
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument(
+ '--text_prompts',
+ type=str,
+ help=
+ 'Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.'
+ )
+ self.arg_input_group.add_argument(
+ '--style',
+ type=str,
+ default=None,
+ help='Image style, such as oil paintings, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument('--artist',
+ type=str,
+ default=None,
+ help='Artist style, if specified, style will be used to construct prompts.')
+ self.arg_input_group.add_argument(
+ '--init_image',
+ type=str,
+ default=None,
+ help=
+ "Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion."
+ )
+ self.arg_input_group.add_argument(
+ '--width_height',
+ type=ast.literal_eval,
+ default=[1280, 768],
+ help=
+ "Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so."
+ )
+ self.arg_input_group.add_argument(
+ '--n_batches',
+ type=int,
+ default=1,
+ help=
+ "This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings."
+ )
+ self.arg_input_group.add_argument('--batch_size', type=int, default=1, help="Batch size.")
+ self.arg_input_group.add_argument(
+ '--batch_name',
+ type=str,
+ default='',
+ help=
+ 'The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.'
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/requirements.txt b/modules/image/text_to_image/disco_diffusion_clip_rn101/requirements.txt
new file mode 100755
index 000000000..8b4bc0ea4
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/requirements.txt
@@ -0,0 +1,8 @@
+numpy
+paddle_lpips==0.1.2
+ftfy
+docarray>=0.13.29
+pyyaml
+regex
+tqdm
+ipywidgets
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/README.md b/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/README.md
new file mode 100644
index 000000000..1f8d0bb0a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/README.md
@@ -0,0 +1,3 @@
+# ResizeRight (Paddle)
+Fully differentiable resize function implemented by Paddle.
+This module is based on [assafshocher/ResizeRight](https://github.com/assafshocher/ResizeRight).
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/__init__.py
new file mode 100755
index 000000000..e69de29bb
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/interp_methods.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/interp_methods.py
new file mode 100755
index 000000000..276eb055a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/interp_methods.py
@@ -0,0 +1,70 @@
+from math import pi
+
+try:
+ import paddle
+except ImportError:
+ paddle = None
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def set_framework_dependencies(x):
+ if type(x) is numpy.ndarray:
+ to_dtype = lambda a: a
+ fw = numpy
+ else:
+ to_dtype = lambda a: paddle.cast(a, x.dtype)
+ fw = paddle
+ # eps = fw.finfo(fw.float32).eps
+ eps = paddle.to_tensor(np.finfo(np.float32).eps)
+ return fw, to_dtype, eps
+
+
+def support_sz(sz):
+
+ def wrapper(f):
+ f.support_sz = sz
+ return f
+
+ return wrapper
+
+
+@support_sz(4)
+def cubic(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ absx = fw.abs(x)
+ absx2 = absx**2
+ absx3 = absx**3
+ return ((1.5 * absx3 - 2.5 * absx2 + 1.) * to_dtype(absx <= 1.) +
+ (-0.5 * absx3 + 2.5 * absx2 - 4. * absx + 2.) * to_dtype((1. < absx) & (absx <= 2.)))
+
+
+@support_sz(4)
+def lanczos2(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 2) + eps) / ((pi**2 * x**2 / 2) + eps)) * to_dtype(abs(x) < 2))
+
+
+@support_sz(6)
+def lanczos3(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return (((fw.sin(pi * x) * fw.sin(pi * x / 3) + eps) / ((pi**2 * x**2 / 3) + eps)) * to_dtype(abs(x) < 3))
+
+
+@support_sz(2)
+def linear(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return ((x + 1) * to_dtype((-1 <= x) & (x < 0)) + (1 - x) * to_dtype((0 <= x) & (x <= 1)))
+
+
+@support_sz(1)
+def box(x):
+ fw, to_dtype, eps = set_framework_dependencies(x)
+ return to_dtype((-1 <= x) & (x < 0)) + to_dtype((0 <= x) & (x <= 1))
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/resize_right.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/resize_right.py
new file mode 100755
index 000000000..6a92c828c
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/resize_right/resize_right.py
@@ -0,0 +1,403 @@
+import warnings
+from fractions import Fraction
+from math import ceil
+from typing import Tuple
+
+import disco_diffusion_clip_rn101.resize_right.interp_methods as interp_methods
+
+
+class NoneClass:
+ pass
+
+
+try:
+ import paddle
+ from paddle import nn
+ nnModuleWrapped = nn.Layer
+except ImportError:
+ warnings.warn('No PyTorch found, will work only with Numpy')
+ paddle = None
+ nnModuleWrapped = NoneClass
+
+try:
+ import numpy
+ import numpy as np
+except ImportError:
+ warnings.warn('No Numpy found, will work only with PyTorch')
+ numpy = None
+
+if numpy is None and paddle is None:
+ raise ImportError("Must have either Numpy or PyTorch but both not found")
+
+
+def resize(input,
+ scale_factors=None,
+ out_shape=None,
+ interp_method=interp_methods.cubic,
+ support_sz=None,
+ antialiasing=True,
+ by_convs=False,
+ scale_tolerance=None,
+ max_numerator=10,
+ pad_mode='constant'):
+ # get properties of the input tensor
+ in_shape, n_dims = input.shape, input.ndim
+
+ # fw stands for framework that can be either numpy or paddle,
+ # determined by the input type
+ fw = numpy if type(input) is numpy.ndarray else paddle
+ eps = np.finfo(np.float32).eps if fw == numpy else paddle.to_tensor(np.finfo(np.float32).eps)
+ device = input.place if fw is paddle else None
+
+ # set missing scale factors or output shapem one according to another,
+ # scream if both missing. this is also where all the defults policies
+ # take place. also handling the by_convs attribute carefully.
+ scale_factors, out_shape, by_convs = set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs,
+ scale_tolerance, max_numerator, eps, fw)
+
+ # sort indices of dimensions according to scale of each dimension.
+ # since we are going dim by dim this is efficient
+ sorted_filtered_dims_and_scales = [(dim, scale_factors[dim], by_convs[dim], in_shape[dim], out_shape[dim])
+ for dim in sorted(range(n_dims), key=lambda ind: scale_factors[ind])
+ if scale_factors[dim] != 1.]
+ # unless support size is specified by the user, it is an attribute
+ # of the interpolation method
+ if support_sz is None:
+ support_sz = interp_method.support_sz
+
+ # output begins identical to input and changes with each iteration
+ output = input
+
+ # iterate over dims
+ for (dim, scale_factor, dim_by_convs, in_sz, out_sz) in sorted_filtered_dims_and_scales:
+ # STEP 1- PROJECTED GRID: The non-integer locations of the projection
+ # of output pixel locations to the input tensor
+ projected_grid = get_projected_grid(in_sz, out_sz, scale_factor, fw, dim_by_convs, device)
+
+ # STEP 1.5: ANTIALIASING- If antialiasing is taking place, we modify
+ # the window size and the interpolation method (see inside function)
+ cur_interp_method, cur_support_sz = apply_antialiasing_if_needed(interp_method, support_sz, scale_factor,
+ antialiasing)
+
+ # STEP 2- FIELDS OF VIEW: for each output pixels, map the input pixels
+ # that influence it. Also calculate needed padding and update grid
+ # accoedingly
+ field_of_view = get_field_of_view(projected_grid, cur_support_sz, fw, eps, device)
+
+ # STEP 2.5- CALCULATE PAD AND UPDATE: according to the field of view,
+ # the input should be padded to handle the boundaries, coordinates
+ # should be updated. actual padding only occurs when weights are
+ # aplied (step 4). if using by_convs for this dim, then we need to
+ # calc right and left boundaries for each filter instead.
+ pad_sz, projected_grid, field_of_view = calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor,
+ dim_by_convs, fw, device)
+ # STEP 3- CALCULATE WEIGHTS: Match a set of weights to the pixels in
+ # the field of view for each output pixel
+ weights = get_weights(cur_interp_method, projected_grid, field_of_view)
+
+ # STEP 4- APPLY WEIGHTS: Each output pixel is calculated by multiplying
+ # its set of weights with the pixel values in its field of view.
+ # We now multiply the fields of view with their matching weights.
+ # We do this by tensor multiplication and broadcasting.
+ # if by_convs is true for this dim, then we do this action by
+ # convolutions. this is equivalent but faster.
+ if not dim_by_convs:
+ output = apply_weights(output, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw)
+ else:
+ output = apply_convs(output, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw)
+ return output
+
+
+def get_projected_grid(in_sz, out_sz, scale_factor, fw, by_convs, device=None):
+ # we start by having the ouput coordinates which are just integer locations
+ # in the special case when usin by_convs, we only need two cycles of grid
+ # points. the first and last.
+ grid_sz = out_sz if not by_convs else scale_factor.numerator
+ out_coordinates = fw_arange(grid_sz, fw, device)
+
+ # This is projecting the ouput pixel locations in 1d to the input tensor,
+ # as non-integer locations.
+ # the following fomrula is derived in the paper
+ # "From Discrete to Continuous Convolutions" by Shocher et al.
+ return (out_coordinates / float(scale_factor) + (in_sz - 1) / 2 - (out_sz - 1) / (2 * float(scale_factor)))
+
+
+def get_field_of_view(projected_grid, cur_support_sz, fw, eps, device):
+ # for each output pixel, map which input pixels influence it, in 1d.
+ # we start by calculating the leftmost neighbor, using half of the window
+ # size (eps is for when boundary is exact int)
+ left_boundaries = fw_ceil(projected_grid - cur_support_sz / 2 - eps, fw)
+
+ # then we simply take all the pixel centers in the field by counting
+ # window size pixels from the left boundary
+ ordinal_numbers = fw_arange(ceil(cur_support_sz - eps), fw, device)
+ return left_boundaries[:, None] + ordinal_numbers
+
+
+def calc_pad_sz(in_sz, out_sz, field_of_view, projected_grid, scale_factor, dim_by_convs, fw, device):
+ if not dim_by_convs:
+ # determine padding according to neighbor coords out of bound.
+ # this is a generalized notion of padding, when pad<0 it means crop
+ pad_sz = [-field_of_view[0, 0].item(), field_of_view[-1, -1].item() - in_sz + 1]
+
+ # since input image will be changed by padding, coordinates of both
+ # field_of_view and projected_grid need to be updated
+ field_of_view += pad_sz[0]
+ projected_grid += pad_sz[0]
+
+ else:
+ # only used for by_convs, to calc the boundaries of each filter the
+ # number of distinct convolutions is the numerator of the scale factor
+ num_convs, stride = scale_factor.numerator, scale_factor.denominator
+
+ # calculate left and right boundaries for each conv. left can also be
+ # negative right can be bigger than in_sz. such cases imply padding if
+ # needed. however if# both are in-bounds, it means we need to crop,
+ # practically apply the conv only on part of the image.
+ left_pads = -field_of_view[:, 0]
+
+ # next calc is tricky, explanation by rows:
+ # 1) counting output pixels between the first position of each filter
+ # to the right boundary of the input
+ # 2) dividing it by number of filters to count how many 'jumps'
+ # each filter does
+ # 3) multiplying by the stride gives us the distance over the input
+ # coords done by all these jumps for each filter
+ # 4) to this distance we add the right boundary of the filter when
+ # placed in its leftmost position. so now we get the right boundary
+ # of that filter in input coord.
+ # 5) the padding size needed is obtained by subtracting the rightmost
+ # input coordinate. if the result is positive padding is needed. if
+ # negative then negative padding means shaving off pixel columns.
+ right_pads = (((out_sz - fw_arange(num_convs, fw, device) - 1) # (1)
+ // num_convs) # (2)
+ * stride # (3)
+ + field_of_view[:, -1] # (4)
+ - in_sz + 1) # (5)
+
+ # in the by_convs case pad_sz is a list of left-right pairs. one per
+ # each filter
+
+ pad_sz = list(zip(left_pads, right_pads))
+
+ return pad_sz, projected_grid, field_of_view
+
+
+def get_weights(interp_method, projected_grid, field_of_view):
+ # the set of weights per each output pixels is the result of the chosen
+ # interpolation method applied to the distances between projected grid
+ # locations and the pixel-centers in the field of view (distances are
+ # directed, can be positive or negative)
+ weights = interp_method(projected_grid[:, None] - field_of_view)
+
+ # we now carefully normalize the weights to sum to 1 per each output pixel
+ sum_weights = weights.sum(1, keepdim=True)
+ sum_weights[sum_weights == 0] = 1
+ return weights / sum_weights
+
+
+def apply_weights(input, field_of_view, weights, dim, n_dims, pad_sz, pad_mode, fw):
+ # for this operation we assume the resized dim is the first one.
+ # so we transpose and will transpose back after multiplying
+ tmp_input = fw_swapaxes(input, dim, 0, fw)
+
+ # apply padding
+ tmp_input = fw_pad(tmp_input, fw, pad_sz, pad_mode)
+
+ # field_of_view is a tensor of order 2: for each output (1d location
+ # along cur dim)- a list of 1d neighbors locations.
+ # note that this whole operations is applied to each dim separately,
+ # this is why it is all in 1d.
+ # neighbors = tmp_input[field_of_view] is a tensor of order image_dims+1:
+ # for each output pixel (this time indicated in all dims), these are the
+ # values of the neighbors in the 1d field of view. note that we only
+ # consider neighbors along the current dim, but such set exists for every
+ # multi-dim location, hence the final tensor order is image_dims+1.
+ paddle.device.cuda.empty_cache()
+ neighbors = tmp_input[field_of_view]
+
+ # weights is an order 2 tensor: for each output location along 1d- a list
+ # of weights matching the field of view. we augment it with ones, for
+ # broadcasting, so that when multiplies some tensor the weights affect
+ # only its first dim.
+ tmp_weights = fw.reshape(weights, (*weights.shape, *[1] * (n_dims - 1)))
+
+ # now we simply multiply the weights with the neighbors, and then sum
+ # along the field of view, to get a single value per out pixel
+ tmp_output = (neighbors * tmp_weights).sum(1)
+ # we transpose back the resized dim to its original position
+ return fw_swapaxes(tmp_output, 0, dim, fw)
+
+
+def apply_convs(input, scale_factor, in_sz, out_sz, weights, dim, pad_sz, pad_mode, fw):
+ # for this operations we assume the resized dim is the last one.
+ # so we transpose and will transpose back after multiplying
+ input = fw_swapaxes(input, dim, -1, fw)
+
+ # the stride for all convs is the denominator of the scale factor
+ stride, num_convs = scale_factor.denominator, scale_factor.numerator
+
+ # prepare an empty tensor for the output
+ tmp_out_shape = list(input.shape)
+ tmp_out_shape[-1] = out_sz
+ tmp_output = fw_empty(tuple(tmp_out_shape), fw, input.device)
+
+ # iterate over the conv operations. we have as many as the numerator
+ # of the scale-factor. for each we need boundaries and a filter.
+ for conv_ind, (pad_sz, filt) in enumerate(zip(pad_sz, weights)):
+ # apply padding (we pad last dim, padding can be negative)
+ pad_dim = input.ndim - 1
+ tmp_input = fw_pad(input, fw, pad_sz, pad_mode, dim=pad_dim)
+
+ # apply convolution over last dim. store in the output tensor with
+ # positional strides so that when the loop is comlete conv results are
+ # interwind
+ tmp_output[..., conv_ind::num_convs] = fw_conv(tmp_input, filt, stride)
+
+ return fw_swapaxes(tmp_output, -1, dim, fw)
+
+
+def set_scale_and_out_sz(in_shape, out_shape, scale_factors, by_convs, scale_tolerance, max_numerator, eps, fw):
+ # eventually we must have both scale-factors and out-sizes for all in/out
+ # dims. however, we support many possible partial arguments
+ if scale_factors is None and out_shape is None:
+ raise ValueError("either scale_factors or out_shape should be "
+ "provided")
+ if out_shape is not None:
+ # if out_shape has less dims than in_shape, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ out_shape = (list(out_shape) +
+ list(in_shape[len(out_shape):]) if fw is numpy else list(in_shape[:-len(out_shape)]) +
+ list(out_shape))
+ if scale_factors is None:
+ # if no scale given, we calculate it as the out to in ratio
+ # (not recomended)
+ scale_factors = [out_sz / in_sz for out_sz, in_sz in zip(out_shape, in_shape)]
+ if scale_factors is not None:
+ # by default, if a single number is given as scale, we assume resizing
+ # two dims (most common are images with 2 spatial dims)
+ scale_factors = (scale_factors if isinstance(scale_factors, (list, tuple)) else [scale_factors, scale_factors])
+ # if less scale_factors than in_shape dims, we defaultly resize the
+ # first dims for numpy and last dims for paddle
+ scale_factors = (list(scale_factors) + [1] * (len(in_shape) - len(scale_factors)) if fw is numpy else [1] *
+ (len(in_shape) - len(scale_factors)) + list(scale_factors))
+ if out_shape is None:
+ # when no out_shape given, it is calculated by multiplying the
+ # scale by the in_shape (not recomended)
+ out_shape = [ceil(scale_factor * in_sz) for scale_factor, in_sz in zip(scale_factors, in_shape)]
+ # next part intentionally after out_shape determined for stability
+ # we fix by_convs to be a list of truth values in case it is not
+ if not isinstance(by_convs, (list, tuple)):
+ by_convs = [by_convs] * len(out_shape)
+
+ # next loop fixes the scale for each dim to be either frac or float.
+ # this is determined by by_convs and by tolerance for scale accuracy.
+ for ind, (sf, dim_by_convs) in enumerate(zip(scale_factors, by_convs)):
+ # first we fractionaize
+ if dim_by_convs:
+ frac = Fraction(1 / sf).limit_denominator(max_numerator)
+ frac = Fraction(numerator=frac.denominator, denominator=frac.numerator)
+
+ # if accuracy is within tolerance scale will be frac. if not, then
+ # it will be float and the by_convs attr will be set false for
+ # this dim
+ if scale_tolerance is None:
+ scale_tolerance = eps
+ if dim_by_convs and abs(frac - sf) < scale_tolerance:
+ scale_factors[ind] = frac
+ else:
+ scale_factors[ind] = float(sf)
+ by_convs[ind] = False
+
+ return scale_factors, out_shape, by_convs
+
+
+def apply_antialiasing_if_needed(interp_method, support_sz, scale_factor, antialiasing):
+ # antialiasing is "stretching" the field of view according to the scale
+ # factor (only for downscaling). this is low-pass filtering. this
+ # requires modifying both the interpolation (stretching the 1d
+ # function and multiplying by the scale-factor) and the window size.
+ scale_factor = float(scale_factor)
+ if scale_factor >= 1.0 or not antialiasing:
+ return interp_method, support_sz
+ cur_interp_method = (lambda arg: scale_factor * interp_method(scale_factor * arg))
+ cur_support_sz = support_sz / scale_factor
+ return cur_interp_method, cur_support_sz
+
+
+def fw_ceil(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.ceil(x))
+ else:
+ return paddle.cast(x.ceil(), dtype='int64')
+
+
+def fw_floor(x, fw):
+ if fw is numpy:
+ return fw.int_(fw.floor(x))
+ else:
+ return paddle.cast(x.floor(), dtype='int64')
+
+
+def fw_cat(x, fw):
+ if fw is numpy:
+ return fw.concatenate(x)
+ else:
+ return fw.concat(x)
+
+
+def fw_swapaxes(x, ax_1, ax_2, fw):
+ if fw is numpy:
+ return fw.swapaxes(x, ax_1, ax_2)
+ else:
+ if ax_1 == -1:
+ ax_1 = len(x.shape) - 1
+ if ax_2 == -1:
+ ax_2 = len(x.shape) - 1
+ perm0 = list(range(len(x.shape)))
+ temp = ax_1
+ perm0[temp] = ax_2
+ perm0[ax_2] = temp
+ return fw.transpose(x, perm0)
+
+
+def fw_pad(x, fw, pad_sz, pad_mode, dim=0):
+ if pad_sz == (0, 0):
+ return x
+ if fw is numpy:
+ pad_vec = [(0, 0)] * x.ndim
+ pad_vec[dim] = pad_sz
+ return fw.pad(x, pad_width=pad_vec, mode=pad_mode)
+ else:
+ if x.ndim < 3:
+ x = x[None, None, ...]
+
+ pad_vec = [0] * ((x.ndim - 2) * 2)
+ pad_vec[0:2] = pad_sz
+ return fw_swapaxes(fw.nn.functional.pad(fw_swapaxes(x, dim, -1, fw), pad=pad_vec, mode=pad_mode), dim, -1, fw)
+
+
+def fw_conv(input, filter, stride):
+ # we want to apply 1d conv to any nd array. the way to do it is to reshape
+ # the input to a 4D tensor. first two dims are singeletons, 3rd dim stores
+ # all the spatial dims that we are not convolving along now. then we can
+ # apply conv2d with a 1xK filter. This convolves the same way all the other
+ # dims stored in the 3d dim. like depthwise conv over these.
+ # TODO: numpy support
+ reshaped_input = input.reshape(1, 1, -1, input.shape[-1])
+ reshaped_output = paddle.nn.functional.conv2d(reshaped_input, filter.view(1, 1, 1, -1), stride=(1, stride))
+ return reshaped_output.reshape(*input.shape[:-1], -1)
+
+
+def fw_arange(upper_bound, fw, device):
+ if fw is numpy:
+ return fw.arange(upper_bound)
+ else:
+ return fw.arange(upper_bound)
+
+
+def fw_empty(shape, fw, device):
+ if fw is numpy:
+ return fw.empty(shape)
+ else:
+ return fw.empty(shape=shape)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/README.md b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/README.md
new file mode 100644
index 000000000..711671bad
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/README.md
@@ -0,0 +1,2 @@
+# Diffusion model (Paddle)
+This module implements diffusion model which accepts a text prompt and outputs images semantically close to the text. The code is rewritten by Paddle, and mainly refer to two projects: jina-ai/discoart[https://github.com/jina-ai/discoart] and openai/guided-diffusion[https://github.com/openai/guided-diffusion]. Thanks for their wonderful work.
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/__init__.py
new file mode 100755
index 000000000..39fc908dc
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/__init__.py
@@ -0,0 +1,156 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/__init__.py
+'''
+import os
+import warnings
+
+os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
+
+__all__ = ['create']
+
+import sys
+
+__resources_path__ = os.path.join(
+ os.path.dirname(sys.modules.get(__package__).__file__ if __package__ in sys.modules else __file__),
+ 'resources',
+)
+
+import gc
+
+# check if GPU is available
+import paddle
+
+# download and load models, this will take some time on the first load
+
+from .helper import load_all_models, load_diffusion_model, load_clip_models
+
+model_config, secondary_model = load_all_models('512x512_diffusion_uncond_finetune_008100', use_secondary_model=True)
+
+from typing import TYPE_CHECKING, overload, List, Optional
+
+if TYPE_CHECKING:
+ from docarray import DocumentArray, Document
+
+_clip_models_cache = {}
+
+# begin_create_overload
+
+
+@overload
+def create(text_prompts: Optional[List[str]] = [
+ 'A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.',
+ 'yellow color scheme',
+],
+ init_image: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ skip_steps: Optional[int] = 10,
+ steps: Optional[int] = 250,
+ cut_ic_pow: Optional[int] = 1,
+ init_scale: Optional[int] = 1000,
+ clip_guidance_scale: Optional[int] = 5000,
+ tv_scale: Optional[int] = 0,
+ range_scale: Optional[int] = 150,
+ sat_scale: Optional[int] = 0,
+ cutn_batches: Optional[int] = 4,
+ diffusion_model: Optional[str] = '512x512_diffusion_uncond_finetune_008100',
+ use_secondary_model: Optional[bool] = True,
+ diffusion_sampling_mode: Optional[str] = 'ddim',
+ perlin_init: Optional[bool] = False,
+ perlin_mode: Optional[str] = 'mixed',
+ seed: Optional[int] = None,
+ eta: Optional[float] = 0.8,
+ clamp_grad: Optional[bool] = True,
+ clamp_max: Optional[float] = 0.05,
+ randomize_class: Optional[bool] = True,
+ clip_denoised: Optional[bool] = False,
+ fuzzy_prompt: Optional[bool] = False,
+ rand_mag: Optional[float] = 0.05,
+ cut_overview: Optional[str] = '[12]*400+[4]*600',
+ cut_innercut: Optional[str] = '[4]*400+[12]*600',
+ cut_icgray_p: Optional[str] = '[0.2]*400+[0]*600',
+ display_rate: Optional[int] = 10,
+ n_batches: Optional[int] = 4,
+ batch_size: Optional[int] = 1,
+ batch_name: Optional[str] = '',
+ clip_models: Optional[list] = ['ViTB32', 'ViTB16', 'RN50'],
+ output_dir: Optional[str] = 'discoart_output') -> 'DocumentArray':
+ """
+ Create Disco Diffusion artworks and save the result into a DocumentArray.
+
+ :param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments. Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+ :param init_image: Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here. If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+ :param width_height: Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+ :param skip_steps: Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image. However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+ :param steps: When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user. Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+ :param cut_ic_pow: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param init_scale: This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+ :param clip_guidance_scale: CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS. Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500. Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+ :param tv_scale: Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+ :param range_scale: Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+ :param sat_scale: Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+ :param cutn_batches: Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep. Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage. At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep. However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+ :param diffusion_model: Diffusion_model of choice.
+ :param use_secondary_model: Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+ :param diffusion_sampling_mode: Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+ :param perlin_init: Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps). Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+ :param perlin_mode: sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+ :param seed: Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar. After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+ :param eta: eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results. The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+ :param clamp_grad: As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+ :param clamp_max: Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+ :param fuzzy_prompt: Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+ :param rand_mag: Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+ :param cut_overview: The schedule of overview cuts
+ :param cut_innercut: The schedule of inner cuts
+ :param cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+ :param display_rate: During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+ :param n_batches: This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+ :param batch_name: The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+ :param clip_models: CLIP Model selectors. ViTB32, ViTB16, ViTL14, RN101, RN50, RN50x4, RN50x16, RN50x64.These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around. You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.The rough order of speed/mem usage is (smallest/fastest to largest/slowest):VitB32RN50RN101VitB16RN50x4RN50x16RN50x64ViTL14For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+# end_create_overload
+
+
+@overload
+def create(init_document: 'Document') -> 'DocumentArray':
+ """
+ Create an artwork using a DocArray ``Document`` object as initial state.
+ :param init_document: its ``.tags`` will be used as parameters, ``.uri`` (if present) will be used as init image.
+ :return: a DocumentArray object that has `n_batches` Documents
+ """
+
+
+def create(**kwargs) -> 'DocumentArray':
+ from .config import load_config
+ from .runner import do_run
+
+ if 'init_document' in kwargs:
+ d = kwargs['init_document']
+ _kwargs = d.tags
+ if not _kwargs:
+ warnings.warn('init_document has no .tags, fallback to default config')
+ if d.uri:
+ _kwargs['init_image'] = kwargs['init_document'].uri
+ else:
+ warnings.warn('init_document has no .uri, fallback to no init image')
+ kwargs.pop('init_document')
+ if kwargs:
+ warnings.warn('init_document has .tags and .uri, but kwargs are also present, will override .tags')
+ _kwargs.update(kwargs)
+ _args = load_config(user_config=_kwargs)
+ else:
+ _args = load_config(user_config=kwargs)
+
+ model, diffusion = load_diffusion_model(model_config, _args.diffusion_model, steps=_args.steps)
+
+ clip_models = load_clip_models(enabled=_args.clip_models, clip_models=_clip_models_cache)
+
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+ try:
+ return do_run(_args, (model, diffusion, clip_models, secondary_model))
+ except KeyboardInterrupt:
+ pass
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/config.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/config.py
new file mode 100755
index 000000000..0cbc71e6f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/config.py
@@ -0,0 +1,77 @@
+'''
+https://github.com/jina-ai/discoart/blob/main/discoart/config.py
+'''
+import copy
+import random
+import warnings
+from types import SimpleNamespace
+from typing import Dict
+
+import yaml
+from yaml import Loader
+
+from . import __resources_path__
+
+with open(f'{__resources_path__}/default.yml') as ymlfile:
+ default_args = yaml.load(ymlfile, Loader=Loader)
+
+
+def load_config(user_config: Dict, ):
+ cfg = copy.deepcopy(default_args)
+
+ if user_config:
+ cfg.update(**user_config)
+
+ for k in user_config.keys():
+ if k not in cfg:
+ warnings.warn(f'unknown argument {k}, ignored')
+
+ for k, v in cfg.items():
+ if k in ('batch_size', 'display_rate', 'seed', 'skip_steps', 'steps', 'n_batches',
+ 'cutn_batches') and isinstance(v, float):
+ cfg[k] = int(v)
+ if k == 'width_height':
+ cfg[k] = [int(vv) for vv in v]
+
+ cfg.update(**{
+ 'seed': cfg['seed'] or random.randint(0, 2**32),
+ })
+
+ if cfg['batch_name']:
+ da_name = f'{__package__}-{cfg["batch_name"]}-{cfg["seed"]}'
+ else:
+ da_name = f'{__package__}-{cfg["seed"]}'
+ warnings.warn('you did not set `batch_name`, set it to have unique session ID')
+
+ cfg.update(**{'name_docarray': da_name})
+
+ print_args_table(cfg)
+
+ return SimpleNamespace(**cfg)
+
+
+def print_args_table(cfg):
+ from rich.table import Table
+ from rich import box
+ from rich.console import Console
+
+ console = Console()
+
+ param_str = Table(
+ title=cfg['name_docarray'],
+ box=box.ROUNDED,
+ highlight=True,
+ title_justify='left',
+ )
+ param_str.add_column('Argument', justify='right')
+ param_str.add_column('Value', justify='left')
+
+ for k, v in sorted(cfg.items()):
+ value = str(v)
+
+ if not default_args.get(k, None) == v:
+ value = f'[b]{value}[/]'
+
+ param_str.add_row(k, value)
+
+ console.print(param_str)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/helper.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/helper.py
new file mode 100755
index 000000000..4a1bc6685
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/helper.py
@@ -0,0 +1,137 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/helper.py
+'''
+import hashlib
+import logging
+import os
+import subprocess
+import sys
+from os.path import expanduser
+from pathlib import Path
+from typing import Any
+from typing import Dict
+from typing import List
+
+import paddle
+
+
+def _get_logger():
+ logger = logging.getLogger(__package__)
+ logger.setLevel("INFO")
+ ch = logging.StreamHandler()
+ ch.setLevel("INFO")
+ formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
+ ch.setFormatter(formatter)
+ logger.addHandler(ch)
+ return logger
+
+
+logger = _get_logger()
+
+
+def load_clip_models(enabled: List[str], clip_models: Dict[str, Any] = {}):
+
+ import disco_diffusion_clip_rn101.clip.clip as clip
+ from disco_diffusion_clip_rn101.clip.clip import build_model, tokenize, transform
+
+ # load enabled models
+ for k in enabled:
+ if k not in clip_models:
+ clip_models[k] = build_model(name=k)
+ clip_models[k].eval()
+ for parameter in clip_models[k].parameters():
+ parameter.stop_gradient = True
+
+ # disable not enabled models to save memory
+ for k in clip_models:
+ if k not in enabled:
+ clip_models.pop(k)
+
+ return list(clip_models.values())
+
+
+def load_all_models(diffusion_model, use_secondary_model):
+ from .model.script_util import (
+ model_and_diffusion_defaults, )
+
+ model_config = model_and_diffusion_defaults()
+
+ if diffusion_model == '512x512_diffusion_uncond_finetune_008100':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 512,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+ elif diffusion_model == '256x256_diffusion_uncond':
+ model_config.update({
+ 'attention_resolutions': '32, 16, 8',
+ 'class_cond': False,
+ 'diffusion_steps': 1000, # No need to edit this, it is taken care of later.
+ 'rescale_timesteps': True,
+ 'timestep_respacing': 250, # No need to edit this, it is taken care of later.
+ 'image_size': 256,
+ 'learn_sigma': True,
+ 'noise_schedule': 'linear',
+ 'num_channels': 256,
+ 'num_head_channels': 64,
+ 'num_res_blocks': 2,
+ 'resblock_updown': True,
+ 'use_fp16': False,
+ 'use_scale_shift_norm': True,
+ })
+
+ secondary_model = None
+ if use_secondary_model:
+ from .model.sec_diff import SecondaryDiffusionImageNet2
+ secondary_model = SecondaryDiffusionImageNet2()
+ model_dict = paddle.load(
+ os.path.join(os.path.dirname(__file__), 'pre_trained', 'secondary_model_imagenet_2.pdparams'))
+ secondary_model.set_state_dict(model_dict)
+ secondary_model.eval()
+ for parameter in secondary_model.parameters():
+ parameter.stop_gradient = True
+
+ return model_config, secondary_model
+
+
+def load_diffusion_model(model_config, diffusion_model, steps):
+ from .model.script_util import (
+ create_model_and_diffusion, )
+
+ timestep_respacing = f'ddim{steps}'
+ diffusion_steps = (1000 // steps) * steps if steps < 1000 else steps
+ model_config.update({
+ 'timestep_respacing': timestep_respacing,
+ 'diffusion_steps': diffusion_steps,
+ })
+
+ model, diffusion = create_model_and_diffusion(**model_config)
+ model.set_state_dict(
+ paddle.load(os.path.join(os.path.dirname(__file__), 'pre_trained', f'{diffusion_model}.pdparams')))
+ model.eval()
+ for name, param in model.named_parameters():
+ param.stop_gradient = True
+
+ return model, diffusion
+
+
+def parse_prompt(prompt):
+ if prompt.startswith('http://') or prompt.startswith('https://'):
+ vals = prompt.rsplit(':', 2)
+ vals = [vals[0] + ':' + vals[1], *vals[2:]]
+ else:
+ vals = prompt.rsplit(':', 1)
+ vals = vals + ['', '1'][len(vals):]
+ return vals[0], float(vals[1])
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/__init__.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/__init__.py
new file mode 100755
index 000000000..466800666
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/__init__.py
@@ -0,0 +1,3 @@
+"""
+Codebase for "Improved Denoising Diffusion Probabilistic Models" implemented by Paddle.
+"""
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/gaussian_diffusion.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/gaussian_diffusion.py
new file mode 100755
index 000000000..86cd2c650
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/gaussian_diffusion.py
@@ -0,0 +1,1214 @@
+"""
+Diffusion model implemented by Paddle.
+This code is rewritten based on Pytorch version of of Ho et al's diffusion models:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py
+"""
+import enum
+import math
+
+import numpy as np
+import paddle
+
+from .losses import discretized_gaussian_log_likelihood
+from .losses import normal_kl
+from .nn import mean_flat
+
+
+def get_named_beta_schedule(schedule_name, num_diffusion_timesteps):
+ """
+ Get a pre-defined beta schedule for the given name.
+
+ The beta schedule library consists of beta schedules which remain similar
+ in the limit of num_diffusion_timesteps.
+ Beta schedules may be added, but should not be removed or changed once
+ they are committed to maintain backwards compatibility.
+ """
+ if schedule_name == "linear":
+ # Linear schedule from Ho et al, extended to work for any number of
+ # diffusion steps.
+ scale = 1000 / num_diffusion_timesteps
+ beta_start = scale * 0.0001
+ beta_end = scale * 0.02
+ return np.linspace(beta_start, beta_end, num_diffusion_timesteps, dtype=np.float64)
+ elif schedule_name == "cosine":
+ return betas_for_alpha_bar(
+ num_diffusion_timesteps,
+ lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2)**2,
+ )
+ else:
+ raise NotImplementedError(f"unknown beta schedule: {schedule_name}")
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function,
+ which defines the cumulative product of (1-beta) over time from t = [0,1].
+
+ :param num_diffusion_timesteps: the number of betas to produce.
+ :param alpha_bar: a lambda that takes an argument t from 0 to 1 and
+ produces the cumulative product of (1-beta) up to that
+ part of the diffusion process.
+ :param max_beta: the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+ """
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return np.array(betas)
+
+
+class ModelMeanType(enum.Enum):
+ """
+ Which type of output the model predicts.
+ """
+
+ PREVIOUS_X = enum.auto() # the model predicts x_{t-1}
+ START_X = enum.auto() # the model predicts x_0
+ EPSILON = enum.auto() # the model predicts epsilon
+
+
+class ModelVarType(enum.Enum):
+ """
+ What is used as the model's output variance.
+
+ The LEARNED_RANGE option has been added to allow the model to predict
+ values between FIXED_SMALL and FIXED_LARGE, making its job easier.
+ """
+
+ LEARNED = enum.auto()
+ FIXED_SMALL = enum.auto()
+ FIXED_LARGE = enum.auto()
+ LEARNED_RANGE = enum.auto()
+
+
+class LossType(enum.Enum):
+ MSE = enum.auto() # use raw MSE loss (and KL when learning variances)
+ RESCALED_MSE = (enum.auto()) # use raw MSE loss (with RESCALED_KL when learning variances)
+ KL = enum.auto() # use the variational lower-bound
+ RESCALED_KL = enum.auto() # like KL, but rescale to estimate the full VLB
+
+ def is_vb(self):
+ return self == LossType.KL or self == LossType.RESCALED_KL
+
+
+class GaussianDiffusion:
+ """
+ Utilities for training and sampling diffusion models.
+
+ Ported directly from here, and then adapted over time to further experimentation.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py#L42
+
+ :param betas: a 1-D numpy array of betas for each diffusion timestep,
+ starting at T and going to 1.
+ :param model_mean_type: a ModelMeanType determining what the model outputs.
+ :param model_var_type: a ModelVarType determining how variance is output.
+ :param loss_type: a LossType determining the loss function to use.
+ :param rescale_timesteps: if True, pass floating point timesteps into the
+ model so that they are always scaled like in the
+ original paper (0 to 1000).
+ """
+
+ def __init__(
+ self,
+ *,
+ betas,
+ model_mean_type,
+ model_var_type,
+ loss_type,
+ rescale_timesteps=False,
+ ):
+ self.model_mean_type = model_mean_type
+ self.model_var_type = model_var_type
+ self.loss_type = loss_type
+ self.rescale_timesteps = rescale_timesteps
+
+ # Use float64 for accuracy.
+ betas = np.array(betas, dtype=np.float64)
+ self.betas = betas
+ assert len(betas.shape) == 1, "betas must be 1-D"
+ assert (betas > 0).all() and (betas <= 1).all()
+
+ self.num_timesteps = int(betas.shape[0])
+
+ alphas = 1.0 - betas
+ self.alphas_cumprod = np.cumprod(alphas, axis=0)
+ self.alphas_cumprod_prev = np.append(1.0, self.alphas_cumprod[:-1])
+ self.alphas_cumprod_next = np.append(self.alphas_cumprod[1:], 0.0)
+ assert self.alphas_cumprod_prev.shape == (self.num_timesteps, )
+
+ # calculations for diffusion q(x_t | x_{t-1}) and others
+ self.sqrt_alphas_cumprod = np.sqrt(self.alphas_cumprod)
+ self.sqrt_one_minus_alphas_cumprod = np.sqrt(1.0 - self.alphas_cumprod)
+ self.log_one_minus_alphas_cumprod = np.log(1.0 - self.alphas_cumprod)
+ self.sqrt_recip_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod)
+ self.sqrt_recipm1_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod - 1)
+
+ # calculations for posterior q(x_{t-1} | x_t, x_0)
+ self.posterior_variance = (betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ # log calculation clipped because the posterior variance is 0 at the
+ # beginning of the diffusion chain.
+ self.posterior_log_variance_clipped = np.log(np.append(self.posterior_variance[1], self.posterior_variance[1:]))
+ self.posterior_mean_coef1 = (betas * np.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))
+ self.posterior_mean_coef2 = ((1.0 - self.alphas_cumprod_prev) * np.sqrt(alphas) / (1.0 - self.alphas_cumprod))
+
+ def q_mean_variance(self, x_start, t):
+ """
+ Get the distribution q(x_t | x_0).
+
+ :param x_start: the [N x C x ...] tensor of noiseless inputs.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :return: A tuple (mean, variance, log_variance), all of x_start's shape.
+ """
+ mean = (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start)
+ variance = _extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
+ log_variance = _extract_into_tensor(self.log_one_minus_alphas_cumprod, t, x_start.shape)
+ return mean, variance, log_variance
+
+ def q_sample(self, x_start, t, noise=None):
+ """
+ Diffuse the data for a given number of diffusion steps.
+
+ In other words, sample from q(x_t | x_0).
+
+ :param x_start: the initial data batch.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :param noise: if specified, the split-out normal noise.
+ :return: A noisy version of x_start.
+ """
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ assert noise.shape == x_start.shape
+ return (_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
+ _extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
+
+ def q_posterior_mean_variance(self, x_start, x_t, t):
+ """
+ Compute the mean and variance of the diffusion posterior:
+
+ q(x_{t-1} | x_t, x_0)
+
+ """
+ assert x_start.shape == x_t.shape
+ posterior_mean = (_extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start +
+ _extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t)
+ posterior_variance = _extract_into_tensor(self.posterior_variance, t, x_t.shape)
+ posterior_log_variance_clipped = _extract_into_tensor(self.posterior_log_variance_clipped, t, x_t.shape)
+ assert (posterior_mean.shape[0] == posterior_variance.shape[0] == posterior_log_variance_clipped.shape[0] ==
+ x_start.shape[0])
+ return posterior_mean, posterior_variance, posterior_log_variance_clipped
+
+ def p_mean_variance(self, model, x, t, clip_denoised=True, denoised_fn=None, model_kwargs=None):
+ """
+ Apply the model to get p(x_{t-1} | x_t), as well as a prediction of
+ the initial x, x_0.
+
+ :param model: the model, which takes a signal and a batch of timesteps
+ as input.
+ :param x: the [N x C x ...] tensor at time t.
+ :param t: a 1-D Tensor of timesteps.
+ :param clip_denoised: if True, clip the denoised signal into [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample. Applies before
+ clip_denoised.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict with the following keys:
+ - 'mean': the model mean output.
+ - 'variance': the model variance output.
+ - 'log_variance': the log of 'variance'.
+ - 'pred_xstart': the prediction for x_0.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+
+ B, C = x.shape[:2]
+ assert t.shape == [B]
+ model_output = model(x, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [ModelVarType.LEARNED, ModelVarType.LEARNED_RANGE]:
+ assert model_output.shape == [B, C * 2, *x.shape[2:]]
+ model_output, model_var_values = paddle.split(model_output, 2, axis=1)
+ if self.model_var_type == ModelVarType.LEARNED:
+ model_log_variance = model_var_values
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ min_log = _extract_into_tensor(self.posterior_log_variance_clipped, t, x.shape)
+ max_log = _extract_into_tensor(np.log(self.betas), t, x.shape)
+ # The model_var_values is [-1, 1] for [min_var, max_var].
+ frac = (model_var_values + 1) / 2
+ model_log_variance = frac * max_log + (1 - frac) * min_log
+ model_variance = paddle.exp(model_log_variance)
+ else:
+ model_variance, model_log_variance = {
+ # for fixedlarge, we set the initial (log-)variance like so
+ # to get a better decoder log likelihood.
+ ModelVarType.FIXED_LARGE: (
+ np.append(self.posterior_variance[1], self.betas[1:]),
+ np.log(np.append(self.posterior_variance[1], self.betas[1:])),
+ ),
+ ModelVarType.FIXED_SMALL: (
+ self.posterior_variance,
+ self.posterior_log_variance_clipped,
+ ),
+ }[self.model_var_type]
+ model_variance = _extract_into_tensor(model_variance, t, x.shape)
+ model_log_variance = _extract_into_tensor(model_log_variance, t, x.shape)
+
+ def process_xstart(x):
+ if denoised_fn is not None:
+ x = denoised_fn(x)
+ if clip_denoised:
+ return x.clamp(-1, 1)
+ return x
+
+ if self.model_mean_type == ModelMeanType.PREVIOUS_X:
+ pred_xstart = process_xstart(self._predict_xstart_from_xprev(x_t=x, t=t, xprev=model_output))
+ model_mean = model_output
+ elif self.model_mean_type in [ModelMeanType.START_X, ModelMeanType.EPSILON]:
+ if self.model_mean_type == ModelMeanType.START_X:
+ pred_xstart = process_xstart(model_output)
+ else:
+ pred_xstart = process_xstart(self._predict_xstart_from_eps(x_t=x, t=t, eps=model_output))
+ model_mean, _, _ = self.q_posterior_mean_variance(x_start=pred_xstart, x_t=x, t=t)
+ else:
+ raise NotImplementedError(self.model_mean_type)
+
+ assert (model_mean.shape == model_log_variance.shape == pred_xstart.shape == x.shape)
+ return {
+ "mean": model_mean,
+ "variance": model_variance,
+ "log_variance": model_log_variance,
+ "pred_xstart": pred_xstart,
+ }
+
+ def _predict_xstart_from_eps(self, x_t, t, eps):
+ assert x_t.shape == eps.shape
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * eps)
+
+ def _predict_xstart_from_xprev(self, x_t, t, xprev):
+ assert x_t.shape == xprev.shape
+ return ( # (xprev - coef2*x_t) / coef1
+ _extract_into_tensor(1.0 / self.posterior_mean_coef1, t, x_t.shape) * xprev -
+ _extract_into_tensor(self.posterior_mean_coef2 / self.posterior_mean_coef1, t, x_t.shape) * x_t)
+
+ def _predict_eps_from_xstart(self, x_t, t, pred_xstart):
+ return (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
+ pred_xstart) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
+
+ def _scale_timesteps(self, t):
+ if self.rescale_timesteps:
+ return paddle.cast((t), 'float32') * (1000.0 / self.num_timesteps)
+ return t
+
+ def condition_mean(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_mean_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute the mean for the previous step, given a function cond_fn that
+ computes the gradient of a conditional log probability with respect to
+ x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
+ condition on y.
+
+ This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
+ """
+ gradient = cond_fn(x, t, p_mean_var, **model_kwargs)
+ new_mean = (paddle.cast((p_mean_var["mean"]), 'float32') + p_mean_var["variance"] * paddle.cast(
+ (gradient), 'float32'))
+ return new_mean
+
+ def condition_score(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, self._scale_timesteps(t), **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def condition_score_with_grad(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
+ """
+ Compute what the p_mean_variance output would have been, should the
+ model's score function be conditioned by cond_fn.
+
+ See condition_mean() for details on cond_fn.
+
+ Unlike condition_mean(), this instead uses the conditioning strategy
+ from Song et al (2020).
+ """
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+
+ eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
+ eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, t, p_mean_var, **model_kwargs)
+
+ out = p_mean_var.copy()
+ out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
+ out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
+ return out
+
+ def p_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"]}
+
+ def p_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ ):
+ """
+ Sample x_{t-1} from the model at the given timestep.
+
+ :param model: the model to sample from.
+ :param x: the current tensor at x_{t-1}.
+ :param t: the value of t, starting at 0 for the first diffusion step.
+ :param clip_denoised: if True, clip the x_start prediction to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :return: a dict containing the following keys:
+ - 'sample': a random sample from the model.
+ - 'pred_xstart': a prediction of x_0.
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ if cond_fn is not None:
+ out["mean"] = self.condition_mean_with_grad(cond_fn, out, x, t, model_kwargs=model_kwargs)
+ sample = out["mean"] + nonzero_mask * paddle.exp(0.5 * out["log_variance"]) * noise
+ return {"sample": sample, "pred_xstart": out["pred_xstart"].detach()}
+
+ def p_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model.
+
+ :param model: the model module.
+ :param shape: the shape of the samples, (N, C, H, W).
+ :param noise: if specified, the noise from the encoder to sample.
+ Should be of the same shape as `shape`.
+ :param clip_denoised: if True, clip x_start predictions to [-1, 1].
+ :param denoised_fn: if not None, a function which applies to the
+ x_start prediction before it is used to sample.
+ :param cond_fn: if not None, this is a gradient function that acts
+ similarly to the model.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param device: if specified, the device to create the samples on.
+ If not specified, use a model parameter's device.
+ :param progress: if True, show a tqdm progress bar.
+ :return: a non-differentiable batch of samples.
+ """
+ final = None
+ for sample in self.p_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def p_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model and yield intermediate samples from
+ each timestep of diffusion.
+
+ Arguments are the same as p_sample_loop().
+ Returns a generator over dicts, where each dict is the return value of
+ p_sample().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ sample_fn = self.p_sample_with_grad if cond_fn_with_grad else self.p_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ )
+ yield out
+ img = out["sample"]
+
+ def ddim_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"]}
+
+ def ddim_sample_with_grad(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t-1} from the model using DDIM.
+
+ Same usage as p_sample().
+ """
+ # with th.enable_grad():
+ # x = x.detach().requires_grad_()
+ x = x.detach()
+ # x.stop_gradient = False
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ out["pred_xstart"] = out["pred_xstart"].detach()
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ sigma = (eta * paddle.sqrt(
+ (1 - alpha_bar_prev) / (1 - alpha_bar)) * paddle.sqrt(1 - alpha_bar / alpha_bar_prev))
+ # Equation 12.
+ # noise = th.randn_like(x)
+ noise = paddle.randn(x.shape, x.dtype)
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) +
+ paddle.sqrt(1 - alpha_bar_prev - sigma**2) * eps)
+ nonzero_mask = (paddle.cast((t != 0), 'float32').reshape([-1,
+ *([1] * (len(x.shape) - 1))])) # no noise when t == 0
+ sample = mean_pred + nonzero_mask * sigma * noise
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"].detach()}
+
+ def ddim_reverse_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ model_kwargs=None,
+ eta=0.0,
+ ):
+ """
+ Sample x_{t+1} from the model using DDIM reverse ODE.
+ """
+ assert eta == 0.0, "Reverse ODE only for deterministic path"
+ out = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = (_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x.shape) * x -
+ out["pred_xstart"]) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x.shape)
+ alpha_bar_next = _extract_into_tensor(self.alphas_cumprod_next, t, x.shape)
+
+ # Equation 12. reversed
+ mean_pred = (out["pred_xstart"] * paddle.sqrt(alpha_bar_next) + paddle.sqrt(1 - alpha_bar_next) * eps)
+
+ return {"sample": mean_pred, "pred_xstart": out["pred_xstart"]}
+
+ def ddim_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Generate samples from the model using DDIM.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.ddim_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ eta=eta,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ ):
+ final = sample
+ return final["sample"]
+
+ def ddim_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ eta=0.0,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ ):
+ """
+ Use DDIM to sample from the model and yield intermediate samples from
+ each timestep of DDIM.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ # if device is None:
+ # device = next(model.parameters()).device
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0])
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(
+ low=0,
+ high=model.num_classes,
+ shape=model_kwargs['y'].shape,
+ )
+ sample_fn = self.ddim_sample_with_grad if cond_fn_with_grad else self.ddim_sample
+ out = sample_fn(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ eta=eta,
+ )
+ yield out
+ img = out["sample"]
+
+ def plms_sample(
+ self,
+ model,
+ x,
+ t,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ cond_fn_with_grad=False,
+ order=2,
+ old_out=None,
+ ):
+ """
+ Sample x_{t-1} from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample().
+ """
+ if not int(order) or not 1 <= order <= 4:
+ raise ValueError('order is invalid (should be int from 1-4).')
+
+ def get_model_output(x, t):
+ with paddle.set_grad_enabled(cond_fn_with_grad and cond_fn is not None):
+ x = x.detach().requires_grad_() if cond_fn_with_grad else x
+ out_orig = self.p_mean_variance(
+ model,
+ x,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ model_kwargs=model_kwargs,
+ )
+ if cond_fn is not None:
+ if cond_fn_with_grad:
+ out = self.condition_score_with_grad(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ x = x.detach()
+ else:
+ out = self.condition_score(cond_fn, out_orig, x, t, model_kwargs=model_kwargs)
+ else:
+ out = out_orig
+
+ # Usually our model outputs epsilon, but we re-derive it
+ # in case we used x_start or x_prev prediction.
+ eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
+ return eps, out, out_orig
+
+ alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
+ alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
+ eps, out, out_orig = get_model_output(x, t)
+
+ if order > 1 and old_out is None:
+ # Pseudo Improved Euler
+ old_eps = [eps]
+ mean_pred = out["pred_xstart"] * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps
+ eps_2, _, _ = get_model_output(mean_pred, t - 1)
+ eps_prime = (eps + eps_2) / 2
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+ else:
+ # Pseudo Linear Multistep (Adams-Bashforth)
+ old_eps = old_out["old_eps"]
+ old_eps.append(eps)
+ cur_order = min(order, len(old_eps))
+ if cur_order == 1:
+ eps_prime = old_eps[-1]
+ elif cur_order == 2:
+ eps_prime = (3 * old_eps[-1] - old_eps[-2]) / 2
+ elif cur_order == 3:
+ eps_prime = (23 * old_eps[-1] - 16 * old_eps[-2] + 5 * old_eps[-3]) / 12
+ elif cur_order == 4:
+ eps_prime = (55 * old_eps[-1] - 59 * old_eps[-2] + 37 * old_eps[-3] - 9 * old_eps[-4]) / 24
+ else:
+ raise RuntimeError('cur_order is invalid.')
+ pred_prime = self._predict_xstart_from_eps(x, t, eps_prime)
+ mean_pred = pred_prime * paddle.sqrt(alpha_bar_prev) + paddle.sqrt(1 - alpha_bar_prev) * eps_prime
+
+ if len(old_eps) >= order:
+ old_eps.pop(0)
+
+ nonzero_mask = paddle.cast((t != 0), 'float32').reshape([-1, *([1] * (len(x.shape) - 1))])
+ sample = mean_pred * nonzero_mask + out["pred_xstart"] * (1 - nonzero_mask)
+
+ return {"sample": sample, "pred_xstart": out_orig["pred_xstart"], "old_eps": old_eps}
+
+ def plms_sample_loop(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Generate samples from the model using Pseudo Linear Multistep.
+
+ Same usage as p_sample_loop().
+ """
+ final = None
+ for sample in self.plms_sample_loop_progressive(
+ model,
+ shape,
+ noise=noise,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ device=device,
+ progress=progress,
+ skip_timesteps=skip_timesteps,
+ init_image=init_image,
+ randomize_class=randomize_class,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ ):
+ final = sample
+ return final["sample"]
+
+ def plms_sample_loop_progressive(
+ self,
+ model,
+ shape,
+ noise=None,
+ clip_denoised=True,
+ denoised_fn=None,
+ cond_fn=None,
+ model_kwargs=None,
+ device=None,
+ progress=False,
+ skip_timesteps=0,
+ init_image=None,
+ randomize_class=False,
+ cond_fn_with_grad=False,
+ order=2,
+ ):
+ """
+ Use PLMS to sample from the model and yield intermediate samples from each
+ timestep of PLMS.
+
+ Same usage as p_sample_loop_progressive().
+ """
+ if device is None:
+ device = model.parameters()[0].place
+ assert isinstance(shape, (tuple, list))
+ if noise is not None:
+ img = noise
+ else:
+ img = paddle.randn(shape)
+
+ if skip_timesteps and init_image is None:
+ init_image = paddle.zeros_like(img)
+
+ indices = list(range(self.num_timesteps - skip_timesteps))[::-1]
+
+ if init_image is not None:
+ my_t = paddle.ones([shape[0]], dtype='int64') * indices[0]
+ img = self.q_sample(init_image, my_t, img)
+
+ if progress:
+ # Lazy import so that we don't depend on tqdm.
+ from tqdm.auto import tqdm
+
+ indices = tqdm(indices)
+
+ old_out = None
+
+ for i in indices:
+ t = paddle.to_tensor([i] * shape[0], place=device)
+ if randomize_class and 'y' in model_kwargs:
+ model_kwargs['y'] = paddle.randint(low=0, high=model.num_classes, shape=model_kwargs['y'].shape)
+ # with paddle.no_grad():
+ out = self.plms_sample(
+ model,
+ img,
+ t,
+ clip_denoised=clip_denoised,
+ denoised_fn=denoised_fn,
+ cond_fn=cond_fn,
+ model_kwargs=model_kwargs,
+ cond_fn_with_grad=cond_fn_with_grad,
+ order=order,
+ old_out=old_out,
+ )
+ yield out
+ old_out = out
+ img = out["sample"]
+
+ def _vb_terms_bpd(self, model, x_start, x_t, t, clip_denoised=True, model_kwargs=None):
+ """
+ Get a term for the variational lower-bound.
+
+ The resulting units are bits (rather than nats, as one might expect).
+ This allows for comparison to other papers.
+
+ :return: a dict with the following keys:
+ - 'output': a shape [N] tensor of NLLs or KLs.
+ - 'pred_xstart': the x_0 predictions.
+ """
+ true_mean, _, true_log_variance_clipped = self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)
+ out = self.p_mean_variance(model, x_t, t, clip_denoised=clip_denoised, model_kwargs=model_kwargs)
+ kl = normal_kl(true_mean, true_log_variance_clipped, out["mean"], out["log_variance"])
+ kl = mean_flat(kl) / np.log(2.0)
+
+ decoder_nll = -discretized_gaussian_log_likelihood(
+ x_start, means=out["mean"], log_scales=0.5 * out["log_variance"])
+ assert decoder_nll.shape == x_start.shape
+ decoder_nll = mean_flat(decoder_nll) / np.log(2.0)
+
+ # At the first timestep return the decoder NLL,
+ # otherwise return KL(q(x_{t-1}|x_t,x_0) || p(x_{t-1}|x_t))
+ output = paddle.where((t == 0), decoder_nll, kl)
+ return {"output": output, "pred_xstart": out["pred_xstart"]}
+
+ def training_losses(self, model, x_start, t, model_kwargs=None, noise=None):
+ """
+ Compute training losses for a single timestep.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param t: a batch of timestep indices.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+ :param noise: if specified, the specific Gaussian noise to try to remove.
+ :return: a dict with the key "loss" containing a tensor of shape [N].
+ Some mean or variance settings may also have other keys.
+ """
+ if model_kwargs is None:
+ model_kwargs = {}
+ if noise is None:
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start, t, noise=noise)
+
+ terms = {}
+
+ if self.loss_type == LossType.KL or self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] = self._vb_terms_bpd(
+ model=model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ model_kwargs=model_kwargs,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_KL:
+ terms["loss"] *= self.num_timesteps
+ elif self.loss_type == LossType.MSE or self.loss_type == LossType.RESCALED_MSE:
+ model_output = model(x_t, self._scale_timesteps(t), **model_kwargs)
+
+ if self.model_var_type in [
+ ModelVarType.LEARNED,
+ ModelVarType.LEARNED_RANGE,
+ ]:
+ B, C = x_t.shape[:2]
+ assert model_output.shape == (B, C * 2, *x_t.shape[2:])
+ model_output, model_var_values = paddle.split(model_output, 2, dim=1)
+ # Learn the variance using the variational bound, but don't let
+ # it affect our mean prediction.
+ frozen_out = paddle.concat([model_output.detach(), model_var_values], axis=1)
+ terms["vb"] = self._vb_terms_bpd(
+ model=lambda *args, r=frozen_out: r,
+ x_start=x_start,
+ x_t=x_t,
+ t=t,
+ clip_denoised=False,
+ )["output"]
+ if self.loss_type == LossType.RESCALED_MSE:
+ # Divide by 1000 for equivalence with initial implementation.
+ # Without a factor of 1/1000, the VB term hurts the MSE term.
+ terms["vb"] *= self.num_timesteps / 1000.0
+
+ target = {
+ ModelMeanType.PREVIOUS_X: self.q_posterior_mean_variance(x_start=x_start, x_t=x_t, t=t)[0],
+ ModelMeanType.START_X: x_start,
+ ModelMeanType.EPSILON: noise,
+ }[self.model_mean_type]
+ assert model_output.shape == target.shape == x_start.shape
+ terms["mse"] = mean_flat((target - model_output)**2)
+ if "vb" in terms:
+ terms["loss"] = terms["mse"] + terms["vb"]
+ else:
+ terms["loss"] = terms["mse"]
+ else:
+ raise NotImplementedError(self.loss_type)
+
+ return terms
+
+ def _prior_bpd(self, x_start):
+ """
+ Get the prior KL term for the variational lower-bound, measured in
+ bits-per-dim.
+
+ This term can't be optimized, as it only depends on the encoder.
+
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :return: a batch of [N] KL values (in bits), one per batch element.
+ """
+ batch_size = x_start.shape[0]
+ t = paddle.to_tensor([self.num_timesteps - 1] * batch_size, place=x_start.place)
+ qt_mean, _, qt_log_variance = self.q_mean_variance(x_start, t)
+ kl_prior = normal_kl(mean1=qt_mean, logvar1=qt_log_variance, mean2=0.0, logvar2=0.0)
+ return mean_flat(kl_prior) / np.log(2.0)
+
+ def calc_bpd_loop(self, model, x_start, clip_denoised=True, model_kwargs=None):
+ """
+ Compute the entire variational lower-bound, measured in bits-per-dim,
+ as well as other related quantities.
+
+ :param model: the model to evaluate loss on.
+ :param x_start: the [N x C x ...] tensor of inputs.
+ :param clip_denoised: if True, clip denoised samples.
+ :param model_kwargs: if not None, a dict of extra keyword arguments to
+ pass to the model. This can be used for conditioning.
+
+ :return: a dict containing the following keys:
+ - total_bpd: the total variational lower-bound, per batch element.
+ - prior_bpd: the prior term in the lower-bound.
+ - vb: an [N x T] tensor of terms in the lower-bound.
+ - xstart_mse: an [N x T] tensor of x_0 MSEs for each timestep.
+ - mse: an [N x T] tensor of epsilon MSEs for each timestep.
+ """
+ device = x_start.place
+ batch_size = x_start.shape[0]
+
+ vb = []
+ xstart_mse = []
+ mse = []
+ for t in list(range(self.num_timesteps))[::-1]:
+ t_batch = paddle.to_tensor([t] * batch_size, place=device)
+ # noise = th.randn_like(x_start)
+ noise = paddle.randn(x_start.shape, x_start.dtype)
+ x_t = self.q_sample(x_start=x_start, t=t_batch, noise=noise)
+ # Calculate VLB term at the current timestep
+ # with paddle.no_grad():
+ out = self._vb_terms_bpd(
+ model,
+ x_start=x_start,
+ x_t=x_t,
+ t=t_batch,
+ clip_denoised=clip_denoised,
+ model_kwargs=model_kwargs,
+ )
+ vb.append(out["output"])
+ xstart_mse.append(mean_flat((out["pred_xstart"] - x_start)**2))
+ eps = self._predict_eps_from_xstart(x_t, t_batch, out["pred_xstart"])
+ mse.append(mean_flat((eps - noise)**2))
+
+ vb = paddle.stack(vb, axis=1)
+ xstart_mse = paddle.stack(xstart_mse, axis=1)
+ mse = paddle.stack(mse, axis=1)
+
+ prior_bpd = self._prior_bpd(x_start)
+ total_bpd = vb.sum(axis=1) + prior_bpd
+ return {
+ "total_bpd": total_bpd,
+ "prior_bpd": prior_bpd,
+ "vb": vb,
+ "xstart_mse": xstart_mse,
+ "mse": mse,
+ }
+
+
+def _extract_into_tensor(arr, timesteps, broadcast_shape):
+ """
+ Extract values from a 1-D numpy array for a batch of indices.
+
+ :param arr: the 1-D numpy array.
+ :param timesteps: a tensor of indices into the array to extract.
+ :param broadcast_shape: a larger shape of K dimensions with the batch
+ dimension equal to the length of timesteps.
+ :return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
+ """
+ res = paddle.to_tensor(arr, place=timesteps.place)[timesteps]
+ while len(res.shape) < len(broadcast_shape):
+ res = res[..., None]
+ return res.expand(broadcast_shape)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/losses.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/losses.py
new file mode 100755
index 000000000..5c3970de5
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/losses.py
@@ -0,0 +1,86 @@
+"""
+Helpers for various likelihood-based losses implemented by Paddle. These are ported from the original
+Ho et al. diffusion models codebase:
+https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/utils.py
+"""
+import numpy as np
+import paddle
+import paddle.nn.functional as F
+
+
+def normal_kl(mean1, logvar1, mean2, logvar2):
+ """
+ Compute the KL divergence between two gaussians.
+
+ Shapes are automatically broadcasted, so batches can be compared to
+ scalars, among other use cases.
+ """
+ tensor = None
+ for obj in (mean1, logvar1, mean2, logvar2):
+ if isinstance(obj, paddle.Tensor):
+ tensor = obj
+ break
+ assert tensor is not None, "at least one argument must be a Tensor"
+
+ # Force variances to be Tensors. Broadcasting helps convert scalars to
+ # Tensors, but it does not work for th.exp().
+ logvar1, logvar2 = [x if isinstance(x, paddle.Tensor) else paddle.to_tensor(x) for x in (logvar1, logvar2)]
+
+ return 0.5 * (-1.0 + logvar2 - logvar1 + paddle.exp(logvar1 - logvar2) +
+ ((mean1 - mean2)**2) * paddle.exp(-logvar2))
+
+
+def approx_standard_normal_cdf(x):
+ """
+ A fast approximation of the cumulative distribution function of the
+ standard normal.
+ """
+ return 0.5 * (1.0 + paddle.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * paddle.pow(x, 3))))
+
+
+def discretized_gaussian_log_likelihood(x, *, means, log_scales):
+ """
+ Compute the log-likelihood of a Gaussian distribution discretizing to a
+ given image.
+
+ :param x: the target images. It is assumed that this was uint8 values,
+ rescaled to the range [-1, 1].
+ :param means: the Gaussian mean Tensor.
+ :param log_scales: the Gaussian log stddev Tensor.
+ :return: a tensor like x of log probabilities (in nats).
+ """
+ assert x.shape == means.shape == log_scales.shape
+ centered_x = x - means
+ inv_stdv = paddle.exp(-log_scales)
+ plus_in = inv_stdv * (centered_x + 1.0 / 255.0)
+ cdf_plus = approx_standard_normal_cdf(plus_in)
+ min_in = inv_stdv * (centered_x - 1.0 / 255.0)
+ cdf_min = approx_standard_normal_cdf(min_in)
+ log_cdf_plus = paddle.log(cdf_plus.clip(min=1e-12))
+ log_one_minus_cdf_min = paddle.log((1.0 - cdf_min).clip(min=1e-12))
+ cdf_delta = cdf_plus - cdf_min
+ log_probs = paddle.where(
+ x < -0.999,
+ log_cdf_plus,
+ paddle.where(x > 0.999, log_one_minus_cdf_min, paddle.log(cdf_delta.clip(min=1e-12))),
+ )
+ assert log_probs.shape == x.shape
+ return log_probs
+
+
+def spherical_dist_loss(x, y):
+ x = F.normalize(x, axis=-1)
+ y = F.normalize(y, axis=-1)
+ return (x - y).norm(axis=-1).divide(paddle.to_tensor(2.0)).asin().pow(2).multiply(paddle.to_tensor(2.0))
+
+
+def tv_loss(input):
+ """L2 total variation loss, as in Mahendran et al."""
+ input = F.pad(input, (0, 1, 0, 1), 'replicate')
+ x_diff = input[..., :-1, 1:] - input[..., :-1, :-1]
+ y_diff = input[..., 1:, :-1] - input[..., :-1, :-1]
+ return (x_diff**2 + y_diff**2).mean([1, 2, 3])
+
+
+def range_loss(input):
+ return (input - input.clip(-1, 1)).pow(2).mean([1, 2, 3])
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/make_cutouts.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/make_cutouts.py
new file mode 100755
index 000000000..f92953c3f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/make_cutouts.py
@@ -0,0 +1,177 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/make_cutouts.py
+'''
+import math
+
+import paddle
+import paddle.nn as nn
+from disco_diffusion_clip_rn101.resize_right.resize_right import resize
+from paddle.nn import functional as F
+
+from . import transforms as T
+
+skip_augs = False # @param{type: 'boolean'}
+
+
+def sinc(x):
+ return paddle.where(x != 0, paddle.sin(math.pi * x) / (math.pi * x), x.new_ones([]))
+
+
+def lanczos(x, a):
+ cond = paddle.logical_and(-a < x, x < a)
+ out = paddle.where(cond, sinc(x) * sinc(x / a), x.new_zeros([]))
+ return out / out.sum()
+
+
+def ramp(ratio, width):
+ n = math.ceil(width / ratio + 1)
+ out = paddle.empty([n])
+ cur = 0
+ for i in range(out.shape[0]):
+ out[i] = cur
+ cur += ratio
+ return paddle.concat([-out[1:].flip([0]), out])[1:-1]
+
+
+class MakeCutouts(nn.Layer):
+
+ def __init__(self, cut_size, cutn, skip_augs=False):
+ super().__init__()
+ self.cut_size = cut_size
+ self.cutn = cutn
+ self.skip_augs = skip_augs
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(degrees=15, translate=(0.1, 0.1)),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomPerspective(distortion_scale=0.4, p=0.7),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.15),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ input = T.Pad(input.shape[2] // 4, fill=0)(input)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+
+ cutouts = []
+ for ch in range(self.cutn):
+ if ch > self.cutn - self.cutn // 4:
+ cutout = input.clone()
+ else:
+ size = int(max_size *
+ paddle.zeros(1, ).normal_(mean=0.8, std=0.3).clip(float(self.cut_size / max_size), 1.0))
+ offsetx = paddle.randint(0, abs(sideX - size + 1), ())
+ offsety = paddle.randint(0, abs(sideY - size + 1), ())
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+
+ if not self.skip_augs:
+ cutout = self.augs(cutout)
+ cutouts.append(resample(cutout, (self.cut_size, self.cut_size)))
+ del cutout
+
+ cutouts = paddle.concat(cutouts, axis=0)
+ return cutouts
+
+
+class MakeCutoutsDango(nn.Layer):
+
+ def __init__(self, cut_size, Overview=4, InnerCrop=0, IC_Size_Pow=0.5, IC_Grey_P=0.2):
+ super().__init__()
+ self.cut_size = cut_size
+ self.Overview = Overview
+ self.InnerCrop = InnerCrop
+ self.IC_Size_Pow = IC_Size_Pow
+ self.IC_Grey_P = IC_Grey_P
+ self.augs = nn.Sequential(*[
+ T.RandomHorizontalFlip(prob=0.5),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomAffine(
+ degrees=10,
+ translate=(0.05, 0.05),
+ interpolation=T.InterpolationMode.BILINEAR,
+ ),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.RandomGrayscale(p=0.1),
+ T.Lambda(lambda x: x + paddle.randn(x.shape) * 0.01),
+ T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1),
+ ])
+
+ def forward(self, input):
+ cutouts = []
+ gray = T.Grayscale(3)
+ sideY, sideX = input.shape[2:4]
+ max_size = min(sideX, sideY)
+ min_size = min(sideX, sideY, self.cut_size)
+ output_shape = [1, 3, self.cut_size, self.cut_size]
+ pad_input = F.pad(
+ input,
+ (
+ (sideY - max_size) // 2,
+ (sideY - max_size) // 2,
+ (sideX - max_size) // 2,
+ (sideX - max_size) // 2,
+ ),
+ **padargs,
+ )
+ cutout = resize(pad_input, out_shape=output_shape)
+
+ if self.Overview > 0:
+ if self.Overview <= 4:
+ if self.Overview >= 1:
+ cutouts.append(cutout)
+ if self.Overview >= 2:
+ cutouts.append(gray(cutout))
+ if self.Overview >= 3:
+ cutouts.append(cutout[:, :, :, ::-1])
+ if self.Overview == 4:
+ cutouts.append(gray(cutout[:, :, :, ::-1]))
+ else:
+ cutout = resize(pad_input, out_shape=output_shape)
+ for _ in range(self.Overview):
+ cutouts.append(cutout)
+
+ if self.InnerCrop > 0:
+ for i in range(self.InnerCrop):
+ size = int(paddle.rand([1])**self.IC_Size_Pow * (max_size - min_size) + min_size)
+ offsetx = paddle.randint(0, sideX - size + 1)
+ offsety = paddle.randint(0, sideY - size + 1)
+ cutout = input[:, :, offsety:offsety + size, offsetx:offsetx + size]
+ if i <= int(self.IC_Grey_P * self.InnerCrop):
+ cutout = gray(cutout)
+ cutout = resize(cutout, out_shape=output_shape)
+ cutouts.append(cutout)
+
+ cutouts = paddle.concat(cutouts)
+ if skip_augs is not True:
+ cutouts = self.augs(cutouts)
+ return cutouts
+
+
+def resample(input, size, align_corners=True):
+ n, c, h, w = input.shape
+ dh, dw = size
+
+ input = input.reshape([n * c, 1, h, w])
+
+ if dh < h:
+ kernel_h = lanczos(ramp(dh / h, 2), 2).to(input.device, input.dtype)
+ pad_h = (kernel_h.shape[0] - 1) // 2
+ input = F.pad(input, (0, 0, pad_h, pad_h), 'reflect')
+ input = F.conv2d(input, kernel_h[None, None, :, None])
+
+ if dw < w:
+ kernel_w = lanczos(ramp(dw / w, 2), 2).to(input.device, input.dtype)
+ pad_w = (kernel_w.shape[0] - 1) // 2
+ input = F.pad(input, (pad_w, pad_w, 0, 0), 'reflect')
+ input = F.conv2d(input, kernel_w[None, None, None, :])
+
+ input = input.reshape([n, c, h, w])
+ return F.interpolate(input, size, mode='bicubic', align_corners=align_corners)
+
+
+padargs = {}
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/nn.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/nn.py
new file mode 100755
index 000000000..d618183e2
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/nn.py
@@ -0,0 +1,127 @@
+"""
+Various utilities for neural networks implemented by Paddle. This code is rewritten based on:
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/nn.py
+"""
+import math
+
+import paddle
+import paddle.nn as nn
+
+
+class SiLU(nn.Layer):
+
+ def forward(self, x):
+ return x * nn.functional.sigmoid(x)
+
+
+class GroupNorm32(nn.GroupNorm):
+
+ def forward(self, x):
+ return super().forward(x)
+
+
+def conv_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D convolution module.
+ """
+ if dims == 1:
+ return nn.Conv1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.Conv2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.Conv3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def linear(*args, **kwargs):
+ """
+ Create a linear module.
+ """
+ return nn.Linear(*args, **kwargs)
+
+
+def avg_pool_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D average pooling module.
+ """
+ if dims == 1:
+ return nn.AvgPool1D(*args, **kwargs)
+ elif dims == 2:
+ return nn.AvgPool2D(*args, **kwargs)
+ elif dims == 3:
+ return nn.AvgPool3D(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def update_ema(target_params, source_params, rate=0.99):
+ """
+ Update target parameters to be closer to those of source parameters using
+ an exponential moving average.
+
+ :param target_params: the target parameter sequence.
+ :param source_params: the source parameter sequence.
+ :param rate: the EMA rate (closer to 1 means slower).
+ """
+ for targ, src in zip(target_params, source_params):
+ targ.detach().mul_(rate).add_(src, alpha=1 - rate)
+
+
+def zero_module(module):
+ """
+ Zero out the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().zero_()
+ return module
+
+
+def scale_module(module, scale):
+ """
+ Scale the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().mul_(scale)
+ return module
+
+
+def mean_flat(tensor):
+ """
+ Take the mean over all non-batch dimensions.
+ """
+ return tensor.mean(axis=list(range(1, len(tensor.shape))))
+
+
+def normalization(channels):
+ """
+ Make a standard normalization layer.
+
+ :param channels: number of input channels.
+ :return: an nn.Module for normalization.
+ """
+ return GroupNorm32(32, channels)
+
+
+def timestep_embedding(timesteps, dim, max_period=10000):
+ """
+ Create sinusoidal timestep embeddings.
+
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param dim: the dimension of the output.
+ :param max_period: controls the minimum frequency of the embeddings.
+ :return: an [N x dim] Tensor of positional embeddings.
+ """
+ half = dim // 2
+ freqs = paddle.exp(-math.log(max_period) * paddle.arange(start=0, end=half, dtype=paddle.float32) / half)
+ args = paddle.cast(timesteps[:, None], 'float32') * freqs[None]
+ embedding = paddle.concat([paddle.cos(args), paddle.sin(args)], axis=-1)
+ if dim % 2:
+ embedding = paddle.concat([embedding, paddle.zeros_like(embedding[:, :1])], axis=-1)
+ return embedding
+
+
+def checkpoint(func, inputs, params, flag):
+ """
+ This function is disabled. And now just forward.
+ """
+ return func(*inputs)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/perlin_noises.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/perlin_noises.py
new file mode 100755
index 000000000..6dacb331b
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/perlin_noises.py
@@ -0,0 +1,78 @@
+'''
+Perlin noise implementation by Paddle.
+This code is rewritten based on:
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/perlin_noises.py
+'''
+import numpy as np
+import paddle
+import paddle.vision.transforms as TF
+from PIL import Image
+from PIL import ImageOps
+
+
+def interp(t):
+ return 3 * t**2 - 2 * t**3
+
+
+def perlin(width, height, scale=10):
+ gx, gy = paddle.randn([2, width + 1, height + 1, 1, 1])
+ xs = paddle.linspace(0, 1, scale + 1)[:-1, None]
+ ys = paddle.linspace(0, 1, scale + 1)[None, :-1]
+ wx = 1 - interp(xs)
+ wy = 1 - interp(ys)
+ dots = 0
+ dots += wx * wy * (gx[:-1, :-1] * xs + gy[:-1, :-1] * ys)
+ dots += (1 - wx) * wy * (-gx[1:, :-1] * (1 - xs) + gy[1:, :-1] * ys)
+ dots += wx * (1 - wy) * (gx[:-1, 1:] * xs - gy[:-1, 1:] * (1 - ys))
+ dots += (1 - wx) * (1 - wy) * (-gx[1:, 1:] * (1 - xs) - gy[1:, 1:] * (1 - ys))
+ return dots.transpose([0, 2, 1, 3]).reshape([width * scale, height * scale])
+
+
+def perlin_ms(octaves, width, height, grayscale):
+ out_array = [0.5] if grayscale else [0.5, 0.5, 0.5]
+ # out_array = [0.0] if grayscale else [0.0, 0.0, 0.0]
+ for i in range(1 if grayscale else 3):
+ scale = 2**len(octaves)
+ oct_width = width
+ oct_height = height
+ for oct in octaves:
+ p = perlin(oct_width, oct_height, scale)
+ out_array[i] += p * oct
+ scale //= 2
+ oct_width *= 2
+ oct_height *= 2
+ return paddle.concat(out_array)
+
+
+def create_perlin_noise(octaves, width, height, grayscale, side_y, side_x):
+ out = perlin_ms(octaves, width, height, grayscale)
+ if grayscale:
+ out = TF.resize(size=(side_y, side_x), img=out.numpy())
+ out = np.uint8(out)
+ out = Image.fromarray(out).convert('RGB')
+ else:
+ out = out.reshape([-1, 3, out.shape[0] // 3, out.shape[1]])
+ out = out.squeeze().transpose([1, 2, 0]).numpy()
+ out = TF.resize(size=(side_y, side_x), img=out)
+ out = out.clip(0, 1) * 255
+ out = np.uint8(out)
+ out = Image.fromarray(out)
+
+ out = ImageOps.autocontrast(out)
+ return out
+
+
+def regen_perlin(perlin_mode, side_y, side_x, batch_size):
+ if perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+
+ init = (TF.to_tensor(init).add(TF.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+ return init.expand([batch_size, -1, -1, -1])
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/respace.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/respace.py
new file mode 100755
index 000000000..c001c70d0
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/respace.py
@@ -0,0 +1,123 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/respace.py
+'''
+import numpy as np
+import paddle
+
+from .gaussian_diffusion import GaussianDiffusion
+
+
+def space_timesteps(num_timesteps, section_counts):
+ """
+ Create a list of timesteps to use from an original diffusion process,
+ given the number of timesteps we want to take from equally-sized portions
+ of the original process.
+
+ For example, if there's 300 timesteps and the section counts are [10,15,20]
+ then the first 100 timesteps are strided to be 10 timesteps, the second 100
+ are strided to be 15 timesteps, and the final 100 are strided to be 20.
+
+ If the stride is a string starting with "ddim", then the fixed striding
+ from the DDIM paper is used, and only one section is allowed.
+
+ :param num_timesteps: the number of diffusion steps in the original
+ process to divide up.
+ :param section_counts: either a list of numbers, or a string containing
+ comma-separated numbers, indicating the step count
+ per section. As a special case, use "ddimN" where N
+ is a number of steps to use the striding from the
+ DDIM paper.
+ :return: a set of diffusion steps from the original process to use.
+ """
+ if isinstance(section_counts, str):
+ if section_counts.startswith("ddim"):
+ desired_count = int(section_counts[len("ddim"):])
+ for i in range(1, num_timesteps):
+ if len(range(0, num_timesteps, i)) == desired_count:
+ return set(range(0, num_timesteps, i))
+ raise ValueError(f"cannot create exactly {num_timesteps} steps with an integer stride")
+ section_counts = [int(x) for x in section_counts.split(",")]
+ size_per = num_timesteps // len(section_counts)
+ extra = num_timesteps % len(section_counts)
+ start_idx = 0
+ all_steps = []
+ for i, section_count in enumerate(section_counts):
+ size = size_per + (1 if i < extra else 0)
+ if size < section_count:
+ raise ValueError(f"cannot divide section of {size} steps into {section_count}")
+ if section_count <= 1:
+ frac_stride = 1
+ else:
+ frac_stride = (size - 1) / (section_count - 1)
+ cur_idx = 0.0
+ taken_steps = []
+ for _ in range(section_count):
+ taken_steps.append(start_idx + round(cur_idx))
+ cur_idx += frac_stride
+ all_steps += taken_steps
+ start_idx += size
+ return set(all_steps)
+
+
+class SpacedDiffusion(GaussianDiffusion):
+ """
+ A diffusion process which can skip steps in a base diffusion process.
+
+ :param use_timesteps: a collection (sequence or set) of timesteps from the
+ original diffusion process to retain.
+ :param kwargs: the kwargs to create the base diffusion process.
+ """
+
+ def __init__(self, use_timesteps, **kwargs):
+ self.use_timesteps = set(use_timesteps)
+ self.timestep_map = []
+ self.original_num_steps = len(kwargs["betas"])
+
+ base_diffusion = GaussianDiffusion(**kwargs) # pylint: disable=missing-kwoa
+ last_alpha_cumprod = 1.0
+ new_betas = []
+ for i, alpha_cumprod in enumerate(base_diffusion.alphas_cumprod):
+ if i in self.use_timesteps:
+ new_betas.append(1 - alpha_cumprod / last_alpha_cumprod)
+ last_alpha_cumprod = alpha_cumprod
+ self.timestep_map.append(i)
+ kwargs["betas"] = np.array(new_betas)
+ super().__init__(**kwargs)
+
+ def p_mean_variance(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().p_mean_variance(self._wrap_model(model), *args, **kwargs)
+
+ def training_losses(self, model, *args, **kwargs): # pylint: disable=signature-differs
+ return super().training_losses(self._wrap_model(model), *args, **kwargs)
+
+ def condition_mean(self, cond_fn, *args, **kwargs):
+ return super().condition_mean(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def condition_score(self, cond_fn, *args, **kwargs):
+ return super().condition_score(self._wrap_model(cond_fn), *args, **kwargs)
+
+ def _wrap_model(self, model):
+ if isinstance(model, _WrappedModel):
+ return model
+ return _WrappedModel(model, self.timestep_map, self.rescale_timesteps, self.original_num_steps)
+
+ def _scale_timesteps(self, t):
+ # Scaling is done by the wrapped model.
+ return t
+
+
+class _WrappedModel:
+
+ def __init__(self, model, timestep_map, rescale_timesteps, original_num_steps):
+ self.model = model
+ self.timestep_map = timestep_map
+ self.rescale_timesteps = rescale_timesteps
+ self.original_num_steps = original_num_steps
+
+ def __call__(self, x, ts, **kwargs):
+ map_tensor = paddle.to_tensor(self.timestep_map, place=ts.place, dtype=ts.dtype)
+ new_ts = map_tensor[ts]
+ if self.rescale_timesteps:
+ new_ts = paddle.cast(new_ts, 'float32') * (1000.0 / self.original_num_steps)
+ return self.model(x, new_ts, **kwargs)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/script_util.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/script_util.py
new file mode 100755
index 000000000..d728a5430
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/script_util.py
@@ -0,0 +1,201 @@
+'''
+This code is based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/script_util.py
+'''
+import argparse
+import inspect
+
+from . import gaussian_diffusion as gd
+from .respace import space_timesteps
+from .respace import SpacedDiffusion
+from .unet import EncoderUNetModel
+from .unet import SuperResModel
+from .unet import UNetModel
+
+NUM_CLASSES = 1000
+
+
+def diffusion_defaults():
+ """
+ Defaults for image and classifier training.
+ """
+ return dict(
+ learn_sigma=False,
+ diffusion_steps=1000,
+ noise_schedule="linear",
+ timestep_respacing="",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ )
+
+
+def model_and_diffusion_defaults():
+ """
+ Defaults for image training.
+ """
+ res = dict(
+ image_size=64,
+ num_channels=128,
+ num_res_blocks=2,
+ num_heads=4,
+ num_heads_upsample=-1,
+ num_head_channels=-1,
+ attention_resolutions="16,8",
+ channel_mult="",
+ dropout=0.0,
+ class_cond=False,
+ use_checkpoint=False,
+ use_scale_shift_norm=True,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+ )
+ res.update(diffusion_defaults())
+ return res
+
+
+def create_model_and_diffusion(
+ image_size,
+ class_cond,
+ learn_sigma,
+ num_channels,
+ num_res_blocks,
+ channel_mult,
+ num_heads,
+ num_head_channels,
+ num_heads_upsample,
+ attention_resolutions,
+ dropout,
+ diffusion_steps,
+ noise_schedule,
+ timestep_respacing,
+ use_kl,
+ predict_xstart,
+ rescale_timesteps,
+ rescale_learned_sigmas,
+ use_checkpoint,
+ use_scale_shift_norm,
+ resblock_updown,
+ use_fp16,
+ use_new_attention_order,
+):
+ model = create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult=channel_mult,
+ learn_sigma=learn_sigma,
+ class_cond=class_cond,
+ use_checkpoint=use_checkpoint,
+ attention_resolutions=attention_resolutions,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ dropout=dropout,
+ resblock_updown=resblock_updown,
+ use_fp16=use_fp16,
+ use_new_attention_order=use_new_attention_order,
+ )
+ diffusion = create_gaussian_diffusion(
+ steps=diffusion_steps,
+ learn_sigma=learn_sigma,
+ noise_schedule=noise_schedule,
+ use_kl=use_kl,
+ predict_xstart=predict_xstart,
+ rescale_timesteps=rescale_timesteps,
+ rescale_learned_sigmas=rescale_learned_sigmas,
+ timestep_respacing=timestep_respacing,
+ )
+ return model, diffusion
+
+
+def create_model(
+ image_size,
+ num_channels,
+ num_res_blocks,
+ channel_mult="",
+ learn_sigma=False,
+ class_cond=False,
+ use_checkpoint=False,
+ attention_resolutions="16",
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ dropout=0,
+ resblock_updown=False,
+ use_fp16=False,
+ use_new_attention_order=False,
+):
+ if channel_mult == "":
+ if image_size == 512:
+ channel_mult = (0.5, 1, 1, 2, 2, 4, 4)
+ elif image_size == 256:
+ channel_mult = (1, 1, 2, 2, 4, 4)
+ elif image_size == 128:
+ channel_mult = (1, 1, 2, 3, 4)
+ elif image_size == 64:
+ channel_mult = (1, 2, 3, 4)
+ else:
+ raise ValueError(f"unsupported image size: {image_size}")
+ else:
+ channel_mult = tuple(int(ch_mult) for ch_mult in channel_mult.split(","))
+
+ attention_ds = []
+ for res in attention_resolutions.split(","):
+ attention_ds.append(image_size // int(res))
+
+ return UNetModel(
+ image_size=image_size,
+ in_channels=3,
+ model_channels=num_channels,
+ out_channels=(3 if not learn_sigma else 6),
+ num_res_blocks=num_res_blocks,
+ attention_resolutions=tuple(attention_ds),
+ dropout=dropout,
+ channel_mult=channel_mult,
+ num_classes=(NUM_CLASSES if class_cond else None),
+ use_checkpoint=use_checkpoint,
+ use_fp16=use_fp16,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ num_heads_upsample=num_heads_upsample,
+ use_scale_shift_norm=use_scale_shift_norm,
+ resblock_updown=resblock_updown,
+ use_new_attention_order=use_new_attention_order,
+ )
+
+
+def create_gaussian_diffusion(
+ *,
+ steps=1000,
+ learn_sigma=False,
+ sigma_small=False,
+ noise_schedule="linear",
+ use_kl=False,
+ predict_xstart=False,
+ rescale_timesteps=False,
+ rescale_learned_sigmas=False,
+ timestep_respacing="",
+):
+ betas = gd.get_named_beta_schedule(noise_schedule, steps)
+ if use_kl:
+ loss_type = gd.LossType.RESCALED_KL
+ elif rescale_learned_sigmas:
+ loss_type = gd.LossType.RESCALED_MSE
+ else:
+ loss_type = gd.LossType.MSE
+ if not timestep_respacing:
+ timestep_respacing = [steps]
+ return SpacedDiffusion(
+ use_timesteps=space_timesteps(steps, timestep_respacing),
+ betas=betas,
+ model_mean_type=(gd.ModelMeanType.EPSILON if not predict_xstart else gd.ModelMeanType.START_X),
+ model_var_type=((gd.ModelVarType.FIXED_LARGE if not sigma_small else gd.ModelVarType.FIXED_SMALL)
+ if not learn_sigma else gd.ModelVarType.LEARNED_RANGE),
+ loss_type=loss_type,
+ rescale_timesteps=rescale_timesteps,
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/sec_diff.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/sec_diff.py
new file mode 100755
index 000000000..1e361f18f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/sec_diff.py
@@ -0,0 +1,135 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/jina-ai/discoart/blob/main/discoart/nn/sec_diff.py
+'''
+import math
+from dataclasses import dataclass
+from functools import partial
+
+import paddle
+import paddle.nn as nn
+
+
+@dataclass
+class DiffusionOutput:
+ v: paddle.Tensor
+ pred: paddle.Tensor
+ eps: paddle.Tensor
+
+
+class SkipBlock(nn.Layer):
+
+ def __init__(self, main, skip=None):
+ super().__init__()
+ self.main = nn.Sequential(*main)
+ self.skip = skip if skip else nn.Identity()
+
+ def forward(self, input):
+ return paddle.concat([self.main(input), self.skip(input)], axis=1)
+
+
+def append_dims(x, n):
+ return x[(Ellipsis, *(None, ) * (n - x.ndim))]
+
+
+def expand_to_planes(x, shape):
+ return paddle.tile(append_dims(x, len(shape)), [1, 1, *shape[2:]])
+
+
+def alpha_sigma_to_t(alpha, sigma):
+ return paddle.atan2(sigma, alpha) * 2 / math.pi
+
+
+def t_to_alpha_sigma(t):
+ return paddle.cos(t * math.pi / 2), paddle.sin(t * math.pi / 2)
+
+
+class SecondaryDiffusionImageNet2(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+ c = 64 # The base channel count
+ cs = [c, c * 2, c * 2, c * 4, c * 4, c * 8]
+
+ self.timestep_embed = FourierFeatures(1, 16)
+ self.down = nn.AvgPool2D(2)
+ self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
+
+ self.net = nn.Sequential(
+ ConvBlock(3 + 16, cs[0]),
+ ConvBlock(cs[0], cs[0]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[0], cs[1]),
+ ConvBlock(cs[1], cs[1]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[1], cs[2]),
+ ConvBlock(cs[2], cs[2]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[2], cs[3]),
+ ConvBlock(cs[3], cs[3]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[3], cs[4]),
+ ConvBlock(cs[4], cs[4]),
+ SkipBlock([
+ self.down,
+ ConvBlock(cs[4], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[5]),
+ ConvBlock(cs[5], cs[4]),
+ self.up,
+ ]),
+ ConvBlock(cs[4] * 2, cs[4]),
+ ConvBlock(cs[4], cs[3]),
+ self.up,
+ ]),
+ ConvBlock(cs[3] * 2, cs[3]),
+ ConvBlock(cs[3], cs[2]),
+ self.up,
+ ]),
+ ConvBlock(cs[2] * 2, cs[2]),
+ ConvBlock(cs[2], cs[1]),
+ self.up,
+ ]),
+ ConvBlock(cs[1] * 2, cs[1]),
+ ConvBlock(cs[1], cs[0]),
+ self.up,
+ ]),
+ ConvBlock(cs[0] * 2, cs[0]),
+ nn.Conv2D(cs[0], 3, 3, padding=1),
+ )
+
+ def forward(self, input, t):
+ timestep_embed = expand_to_planes(self.timestep_embed(t[:, None]), input.shape)
+ v = self.net(paddle.concat([input, timestep_embed], axis=1))
+ alphas, sigmas = map(partial(append_dims, n=v.ndim), t_to_alpha_sigma(t))
+ pred = input * alphas - v * sigmas
+ eps = input * sigmas + v * alphas
+ return DiffusionOutput(v, pred, eps)
+
+
+class FourierFeatures(nn.Layer):
+
+ def __init__(self, in_features, out_features, std=1.0):
+ super().__init__()
+ assert out_features % 2 == 0
+ # self.weight = nn.Parameter(paddle.randn([out_features // 2, in_features]) * std)
+ self.weight = paddle.create_parameter([out_features // 2, in_features],
+ dtype='float32',
+ default_initializer=nn.initializer.Normal(mean=0.0, std=std))
+
+ def forward(self, input):
+ f = 2 * math.pi * input @ self.weight.T
+ return paddle.concat([f.cos(), f.sin()], axis=-1)
+
+
+class ConvBlock(nn.Sequential):
+
+ def __init__(self, c_in, c_out):
+ super().__init__(
+ nn.Conv2D(c_in, c_out, 3, padding=1),
+ nn.ReLU(),
+ )
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/transforms.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/transforms.py
new file mode 100755
index 000000000..e0b620b01
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/transforms.py
@@ -0,0 +1,757 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/pytorch/vision/blob/main/torchvision/transforms/transforms.py
+'''
+import math
+import numbers
+import warnings
+from enum import Enum
+from typing import Any
+from typing import Dict
+from typing import List
+from typing import Optional
+from typing import Sequence
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn.functional import grid_sample
+from paddle.vision import transforms as T
+
+
+class Normalize(nn.Layer):
+
+ def __init__(self, mean, std):
+ super(Normalize, self).__init__()
+ self.mean = paddle.to_tensor(mean)
+ self.std = paddle.to_tensor(std)
+
+ def forward(self, tensor: Tensor):
+ dtype = tensor.dtype
+ mean = paddle.to_tensor(self.mean, dtype=dtype)
+ std = paddle.to_tensor(self.std, dtype=dtype)
+ mean = mean.reshape([1, -1, 1, 1])
+ std = std.reshape([1, -1, 1, 1])
+ result = tensor.subtract(mean).divide(std)
+ return result
+
+
+class InterpolationMode(Enum):
+ """Interpolation modes
+ Available interpolation methods are ``nearest``, ``bilinear``, ``bicubic``, ``box``, ``hamming``, and ``lanczos``.
+ """
+
+ NEAREST = "nearest"
+ BILINEAR = "bilinear"
+ BICUBIC = "bicubic"
+ # For PIL compatibility
+ BOX = "box"
+ HAMMING = "hamming"
+ LANCZOS = "lanczos"
+
+
+class Grayscale(nn.Layer):
+
+ def __init__(self, num_output_channels):
+ super(Grayscale, self).__init__()
+ self.num_output_channels = num_output_channels
+
+ def forward(self, x):
+ output = (0.2989 * x[:, 0:1, :, :] + 0.587 * x[:, 1:2, :, :] + 0.114 * x[:, 2:3, :, :])
+ if self.num_output_channels == 3:
+ return output.expand(x.shape)
+
+ return output
+
+
+class Lambda(nn.Layer):
+
+ def __init__(self, func):
+ super(Lambda, self).__init__()
+ self.transform = func
+
+ def forward(self, x):
+ return self.transform(x)
+
+
+class RandomGrayscale(nn.Layer):
+
+ def __init__(self, p):
+ super(RandomGrayscale, self).__init__()
+ self.prob = p
+ self.transform = Grayscale(3)
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return self.transform(x)
+ else:
+ return x
+
+
+class RandomHorizontalFlip(nn.Layer):
+
+ def __init__(self, prob):
+ super(RandomHorizontalFlip, self).__init__()
+ self.prob = prob
+
+ def forward(self, x):
+ if paddle.rand([1]) < self.prob:
+ return x[:, :, :, ::-1]
+ else:
+ return x
+
+
+def _blend(img1: Tensor, img2: Tensor, ratio: float) -> Tensor:
+ ratio = float(ratio)
+ bound = 1.0
+ return (ratio * img1 + (1.0 - ratio) * img2).clip(0, bound)
+
+
+def trunc_div(a, b):
+ ipt = paddle.divide(a, b)
+ sign_ipt = paddle.sign(ipt)
+ abs_ipt = paddle.abs(ipt)
+ abs_ipt = paddle.floor(abs_ipt)
+ out = paddle.multiply(sign_ipt, abs_ipt)
+ return out
+
+
+def fmod(a, b):
+ return a - trunc_div(a, b) * b
+
+
+def _rgb2hsv(img: Tensor) -> Tensor:
+ r, g, b = img.unbind(axis=-3)
+
+ # Implementation is based on https://github.com/python-pillow/Pillow/blob/4174d4267616897df3746d315d5a2d0f82c656ee/
+ # src/libImaging/Convert.c#L330
+ maxc = paddle.max(img, axis=-3)
+ minc = paddle.min(img, axis=-3)
+
+ # The algorithm erases S and H channel where `maxc = minc`. This avoids NaN
+ # from happening in the results, because
+ # + S channel has division by `maxc`, which is zero only if `maxc = minc`
+ # + H channel has division by `(maxc - minc)`.
+ #
+ # Instead of overwriting NaN afterwards, we just prevent it from occuring so
+ # we don't need to deal with it in case we save the NaN in a buffer in
+ # backprop, if it is ever supported, but it doesn't hurt to do so.
+ eqc = maxc == minc
+
+ cr = maxc - minc
+ # Since `eqc => cr = 0`, replacing denominator with 1 when `eqc` is fine.
+ ones = paddle.ones_like(maxc)
+ s = cr / paddle.where(eqc, ones, maxc)
+ # Note that `eqc => maxc = minc = r = g = b`. So the following calculation
+ # of `h` would reduce to `bc - gc + 2 + rc - bc + 4 + rc - bc = 6` so it
+ # would not matter what values `rc`, `gc`, and `bc` have here, and thus
+ # replacing denominator with 1 when `eqc` is fine.
+ cr_divisor = paddle.where(eqc, ones, cr)
+ rc = (maxc - r) / cr_divisor
+ gc = (maxc - g) / cr_divisor
+ bc = (maxc - b) / cr_divisor
+
+ hr = (maxc == r).cast('float32') * (bc - gc)
+ hg = ((maxc == g) & (maxc != r)).cast('float32') * (2.0 + rc - bc)
+ hb = ((maxc != g) & (maxc != r)).cast('float32') * (4.0 + gc - rc)
+ h = hr + hg + hb
+ h = fmod((h / 6.0 + 1.0), paddle.to_tensor(1.0))
+ return paddle.stack((h, s, maxc), axis=-3)
+
+
+def _hsv2rgb(img: Tensor) -> Tensor:
+ h, s, v = img.unbind(axis=-3)
+ i = paddle.floor(h * 6.0)
+ f = (h * 6.0) - i
+ i = i.cast(dtype='int32')
+
+ p = paddle.clip((v * (1.0 - s)), 0.0, 1.0)
+ q = paddle.clip((v * (1.0 - s * f)), 0.0, 1.0)
+ t = paddle.clip((v * (1.0 - s * (1.0 - f))), 0.0, 1.0)
+ i = i % 6
+
+ mask = i.unsqueeze(axis=-3) == paddle.arange(6).reshape([-1, 1, 1])
+
+ a1 = paddle.stack((v, q, p, p, t, v), axis=-3)
+ a2 = paddle.stack((t, v, v, q, p, p), axis=-3)
+ a3 = paddle.stack((p, p, t, v, v, q), axis=-3)
+ a4 = paddle.stack((a1, a2, a3), axis=-4)
+
+ return paddle.einsum("...ijk, ...xijk -> ...xjk", mask.cast(dtype=img.dtype), a4)
+
+
+def adjust_brightness(img: Tensor, brightness_factor: float) -> Tensor:
+ if brightness_factor < 0:
+ raise ValueError(f"brightness_factor ({brightness_factor}) is not non-negative.")
+
+ return _blend(img, paddle.zeros_like(img), brightness_factor)
+
+
+def adjust_contrast(img: Tensor, contrast_factor: float) -> Tensor:
+ if contrast_factor < 0:
+ raise ValueError(f"contrast_factor ({contrast_factor}) is not non-negative.")
+
+ c = img.shape[1]
+
+ if c == 3:
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+ mean = paddle.mean(output, axis=(-3, -2, -1), keepdim=True)
+
+ else:
+ mean = paddle.mean(img, axis=(-3, -2, -1), keepdim=True)
+
+ return _blend(img, mean, contrast_factor)
+
+
+def adjust_hue(img: Tensor, hue_factor: float) -> Tensor:
+ if not (-0.5 <= hue_factor <= 0.5):
+ raise ValueError(f"hue_factor ({hue_factor}) is not in [-0.5, 0.5].")
+
+ img = _rgb2hsv(img)
+ h, s, v = img.unbind(axis=-3)
+ h = fmod(h + hue_factor, paddle.to_tensor(1.0))
+ img = paddle.stack((h, s, v), axis=-3)
+ img_hue_adj = _hsv2rgb(img)
+ return img_hue_adj
+
+
+def adjust_saturation(img: Tensor, saturation_factor: float) -> Tensor:
+ if saturation_factor < 0:
+ raise ValueError(f"saturation_factor ({saturation_factor}) is not non-negative.")
+
+ output = (0.2989 * img[:, 0:1, :, :] + 0.587 * img[:, 1:2, :, :] + 0.114 * img[:, 2:3, :, :])
+
+ return _blend(img, output, saturation_factor)
+
+
+class ColorJitter(nn.Layer):
+
+ def __init__(self, brightness=0, contrast=0, saturation=0, hue=0):
+ super(ColorJitter, self).__init__()
+ self.brightness = self._check_input(brightness, "brightness")
+ self.contrast = self._check_input(contrast, "contrast")
+ self.saturation = self._check_input(saturation, "saturation")
+ self.hue = self._check_input(hue, "hue", center=0, bound=(-0.5, 0.5), clip_first_on_zero=False)
+
+ def _check_input(self, value, name, center=1, bound=(0, float("inf")), clip_first_on_zero=True):
+ if isinstance(value, numbers.Number):
+ if value < 0:
+ raise ValueError(f"If {name} is a single number, it must be non negative.")
+ value = [center - float(value), center + float(value)]
+ if clip_first_on_zero:
+ value[0] = max(value[0], 0.0)
+ elif isinstance(value, (tuple, list)) and len(value) == 2:
+ if not bound[0] <= value[0] <= value[1] <= bound[1]:
+ raise ValueError(f"{name} values should be between {bound}")
+ else:
+ raise TypeError(f"{name} should be a single number or a list/tuple with length 2.")
+
+ # if value is 0 or (1., 1.) for brightness/contrast/saturation
+ # or (0., 0.) for hue, do nothing
+ if value[0] == value[1] == center:
+ value = None
+ return value
+
+ @staticmethod
+ def get_params(
+ brightness: Optional[List[float]],
+ contrast: Optional[List[float]],
+ saturation: Optional[List[float]],
+ hue: Optional[List[float]],
+ ) -> Tuple[Tensor, Optional[float], Optional[float], Optional[float], Optional[float]]:
+ """Get the parameters for the randomized transform to be applied on image.
+
+ Args:
+ brightness (tuple of float (min, max), optional): The range from which the brightness_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ contrast (tuple of float (min, max), optional): The range from which the contrast_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ saturation (tuple of float (min, max), optional): The range from which the saturation_factor is chosen
+ uniformly. Pass None to turn off the transformation.
+ hue (tuple of float (min, max), optional): The range from which the hue_factor is chosen uniformly.
+ Pass None to turn off the transformation.
+
+ Returns:
+ tuple: The parameters used to apply the randomized transform
+ along with their random order.
+ """
+ fn_idx = paddle.randperm(4)
+
+ b = None if brightness is None else paddle.empty([1]).uniform_(brightness[0], brightness[1])
+ c = None if contrast is None else paddle.empty([1]).uniform_(contrast[0], contrast[1])
+ s = None if saturation is None else paddle.empty([1]).uniform_(saturation[0], saturation[1])
+ h = None if hue is None else paddle.empty([1]).uniform_(hue[0], hue[1])
+
+ return fn_idx, b, c, s, h
+
+ def forward(self, img):
+ """
+ Args:
+ img (PIL Image or Tensor): Input image.
+
+ Returns:
+ PIL Image or Tensor: Color jittered image.
+ """
+ fn_idx, brightness_factor, contrast_factor, saturation_factor, hue_factor = self.get_params(
+ self.brightness, self.contrast, self.saturation, self.hue)
+
+ for fn_id in fn_idx:
+ if fn_id == 0 and brightness_factor is not None:
+ img = adjust_brightness(img, brightness_factor)
+ elif fn_id == 1 and contrast_factor is not None:
+ img = adjust_contrast(img, contrast_factor)
+ elif fn_id == 2 and saturation_factor is not None:
+ img = adjust_saturation(img, saturation_factor)
+ elif fn_id == 3 and hue_factor is not None:
+ img = adjust_hue(img, hue_factor)
+
+ return img
+
+ def __repr__(self) -> str:
+ s = (f"{self.__class__.__name__}("
+ f"brightness={self.brightness}"
+ f", contrast={self.contrast}"
+ f", saturation={self.saturation}"
+ f", hue={self.hue})")
+ return s
+
+
+def _apply_grid_transform(img: Tensor, grid: Tensor, mode: str, fill: Optional[List[float]]) -> Tensor:
+
+ if img.shape[0] > 1:
+ # Apply same grid to a batch of images
+ grid = grid.expand([img.shape[0], grid.shape[1], grid.shape[2], grid.shape[3]])
+
+ # Append a dummy mask for customized fill colors, should be faster than grid_sample() twice
+ if fill is not None:
+ dummy = paddle.ones((img.shape[0], 1, img.shape[2], img.shape[3]), dtype=img.dtype)
+ img = paddle.concat((img, dummy), axis=1)
+
+ img = grid_sample(img, grid, mode=mode, padding_mode="zeros", align_corners=False)
+
+ # Fill with required color
+ if fill is not None:
+ mask = img[:, -1:, :, :] # N * 1 * H * W
+ img = img[:, :-1, :, :] # N * C * H * W
+ mask = mask.expand_as(img)
+ len_fill = len(fill) if isinstance(fill, (tuple, list)) else 1
+ fill_img = paddle.to_tensor(fill, dtype=img.dtype).reshape([1, len_fill, 1, 1]).expand_as(img)
+ if mode == "nearest":
+ mask = mask < 0.5
+ img[mask] = fill_img[mask]
+ else: # 'bilinear'
+ img = img * mask + (1.0 - mask) * fill_img
+ return img
+
+
+def _gen_affine_grid(
+ theta: Tensor,
+ w: int,
+ h: int,
+ ow: int,
+ oh: int,
+) -> Tensor:
+ # https://github.com/pytorch/pytorch/blob/74b65c32be68b15dc7c9e8bb62459efbfbde33d8/aten/src/ATen/native/
+ # AffineGridGenerator.cpp#L18
+ # Difference with AffineGridGenerator is that:
+ # 1) we normalize grid values after applying theta
+ # 2) we can normalize by other image size, such that it covers "extend" option like in PIL.Image.rotate
+
+ d = 0.5
+ base_grid = paddle.empty([1, oh, ow, 3], dtype=theta.dtype)
+ x_grid = paddle.linspace(-ow * 0.5 + d, ow * 0.5 + d - 1, num=ow)
+ base_grid[..., 0] = (x_grid)
+ y_grid = paddle.linspace(-oh * 0.5 + d, oh * 0.5 + d - 1, num=oh).unsqueeze_(-1)
+ base_grid[..., 1] = (y_grid)
+ base_grid[..., 2] = 1.0
+ rescaled_theta = theta.transpose([0, 2, 1]) / paddle.to_tensor([0.5 * w, 0.5 * h], dtype=theta.dtype)
+ output_grid = base_grid.reshape([1, oh * ow, 3]).bmm(rescaled_theta)
+ return output_grid.reshape([1, oh, ow, 2])
+
+
+def affine_impl(img: Tensor,
+ matrix: List[float],
+ interpolation: str = "nearest",
+ fill: Optional[List[float]] = None) -> Tensor:
+ theta = paddle.to_tensor(matrix, dtype=img.dtype).reshape([1, 2, 3])
+ shape = img.shape
+ # grid will be generated on the same device as theta and img
+ grid = _gen_affine_grid(theta, w=shape[-1], h=shape[-2], ow=shape[-1], oh=shape[-2])
+ return _apply_grid_transform(img, grid, interpolation, fill=fill)
+
+
+def _get_inverse_affine_matrix(center: List[float],
+ angle: float,
+ translate: List[float],
+ scale: float,
+ shear: List[float],
+ inverted: bool = True) -> List[float]:
+ # Helper method to compute inverse matrix for affine transformation
+
+ # Pillow requires inverse affine transformation matrix:
+ # Affine matrix is : M = T * C * RotateScaleShear * C^-1
+ #
+ # where T is translation matrix: [1, 0, tx | 0, 1, ty | 0, 0, 1]
+ # C is translation matrix to keep center: [1, 0, cx | 0, 1, cy | 0, 0, 1]
+ # RotateScaleShear is rotation with scale and shear matrix
+ #
+ # RotateScaleShear(a, s, (sx, sy)) =
+ # = R(a) * S(s) * SHy(sy) * SHx(sx)
+ # = [ s*cos(a - sy)/cos(sy), s*(-cos(a - sy)*tan(sx)/cos(sy) - sin(a)), 0 ]
+ # [ s*sin(a + sy)/cos(sy), s*(-sin(a - sy)*tan(sx)/cos(sy) + cos(a)), 0 ]
+ # [ 0 , 0 , 1 ]
+ # where R is a rotation matrix, S is a scaling matrix, and SHx and SHy are the shears:
+ # SHx(s) = [1, -tan(s)] and SHy(s) = [1 , 0]
+ # [0, 1 ] [-tan(s), 1]
+ #
+ # Thus, the inverse is M^-1 = C * RotateScaleShear^-1 * C^-1 * T^-1
+
+ rot = math.radians(angle)
+ sx = math.radians(shear[0])
+ sy = math.radians(shear[1])
+
+ cx, cy = center
+ tx, ty = translate
+
+ # RSS without scaling
+ a = math.cos(rot - sy) / math.cos(sy)
+ b = -math.cos(rot - sy) * math.tan(sx) / math.cos(sy) - math.sin(rot)
+ c = math.sin(rot - sy) / math.cos(sy)
+ d = -math.sin(rot - sy) * math.tan(sx) / math.cos(sy) + math.cos(rot)
+
+ if inverted:
+ # Inverted rotation matrix with scale and shear
+ # det([[a, b], [c, d]]) == 1, since det(rotation) = 1 and det(shear) = 1
+ matrix = [d, -b, 0.0, -c, a, 0.0]
+ matrix = [x / scale for x in matrix]
+ # Apply inverse of translation and of center translation: RSS^-1 * C^-1 * T^-1
+ matrix[2] += matrix[0] * (-cx - tx) + matrix[1] * (-cy - ty)
+ matrix[5] += matrix[3] * (-cx - tx) + matrix[4] * (-cy - ty)
+ # Apply center translation: C * RSS^-1 * C^-1 * T^-1
+ matrix[2] += cx
+ matrix[5] += cy
+ else:
+ matrix = [a, b, 0.0, c, d, 0.0]
+ matrix = [x * scale for x in matrix]
+ # Apply inverse of center translation: RSS * C^-1
+ matrix[2] += matrix[0] * (-cx) + matrix[1] * (-cy)
+ matrix[5] += matrix[3] * (-cx) + matrix[4] * (-cy)
+ # Apply translation and center : T * C * RSS * C^-1
+ matrix[2] += cx + tx
+ matrix[5] += cy + ty
+
+ return matrix
+
+
+def affine(
+ img: Tensor,
+ angle: float,
+ translate: List[int],
+ scale: float,
+ shear: List[float],
+ interpolation: InterpolationMode = InterpolationMode.NEAREST,
+ fill: Optional[List[float]] = None,
+ resample: Optional[int] = None,
+ fillcolor: Optional[List[float]] = None,
+ center: Optional[List[int]] = None,
+) -> Tensor:
+ """Apply affine transformation on the image keeping image center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ img (PIL Image or Tensor): image to transform.
+ angle (number): rotation angle in degrees between -180 and 180, clockwise direction.
+ translate (sequence of integers): horizontal and vertical translations (post-rotation translation)
+ scale (float): overall scale
+ shear (float or sequence): shear angle value in degrees between -180 to 180, clockwise direction.
+ If a sequence is specified, the first value corresponds to a shear parallel to the x axis, while
+ the second value corresponds to a shear parallel to the y axis.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number, optional): Pixel fill value for the area outside the transformed
+ image. If given a number, the value is used for all bands respectively.
+
+ .. note::
+ In torchscript mode single int/float value is not supported, please use a sequence
+ of length 1: ``[value, ]``.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation. Origin is the upper left corner.
+ Default is the center of the image.
+
+ Returns:
+ PIL Image or Tensor: Transformed image.
+ """
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ if not isinstance(angle, (int, float)):
+ raise TypeError("Argument angle should be int or float")
+
+ if not isinstance(translate, (list, tuple)):
+ raise TypeError("Argument translate should be a sequence")
+
+ if len(translate) != 2:
+ raise ValueError("Argument translate should be a sequence of length 2")
+
+ if scale <= 0.0:
+ raise ValueError("Argument scale should be positive")
+
+ if not isinstance(shear, (numbers.Number, (list, tuple))):
+ raise TypeError("Shear should be either a single value or a sequence of two values")
+
+ if not isinstance(interpolation, InterpolationMode):
+ raise TypeError("Argument interpolation should be a InterpolationMode")
+
+ if isinstance(angle, int):
+ angle = float(angle)
+
+ if isinstance(translate, tuple):
+ translate = list(translate)
+
+ if isinstance(shear, numbers.Number):
+ shear = [shear, 0.0]
+
+ if isinstance(shear, tuple):
+ shear = list(shear)
+
+ if len(shear) == 1:
+ shear = [shear[0], shear[0]]
+
+ if len(shear) != 2:
+ raise ValueError(f"Shear should be a sequence containing two values. Got {shear}")
+
+ if center is not None and not isinstance(center, (list, tuple)):
+ raise TypeError("Argument center should be a sequence")
+ center_f = [0.0, 0.0]
+ if center is not None:
+ _, height, width = img.shape[0], img.shape[1], img.shape[2]
+ # Center values should be in pixel coordinates but translated such that (0, 0) corresponds to image center.
+ center_f = [1.0 * (c - s * 0.5) for c, s in zip(center, [width, height])]
+
+ translate_f = [1.0 * t for t in translate]
+ matrix = _get_inverse_affine_matrix(center_f, angle, translate_f, scale, shear)
+ return affine_impl(img, matrix=matrix, interpolation=interpolation.value, fill=fill)
+
+
+def _interpolation_modes_from_int(i: int) -> InterpolationMode:
+ inverse_modes_mapping = {
+ 0: InterpolationMode.NEAREST,
+ 2: InterpolationMode.BILINEAR,
+ 3: InterpolationMode.BICUBIC,
+ 4: InterpolationMode.BOX,
+ 5: InterpolationMode.HAMMING,
+ 1: InterpolationMode.LANCZOS,
+ }
+ return inverse_modes_mapping[i]
+
+
+def _check_sequence_input(x, name, req_sizes):
+ msg = req_sizes[0] if len(req_sizes) < 2 else " or ".join([str(s) for s in req_sizes])
+ if not isinstance(x, Sequence):
+ raise TypeError(f"{name} should be a sequence of length {msg}.")
+ if len(x) not in req_sizes:
+ raise ValueError(f"{name} should be sequence of length {msg}.")
+
+
+def _setup_angle(x, name, req_sizes=(2, )):
+ if isinstance(x, numbers.Number):
+ if x < 0:
+ raise ValueError(f"If {name} is a single number, it must be positive.")
+ x = [-x, x]
+ else:
+ _check_sequence_input(x, name, req_sizes)
+
+ return [float(d) for d in x]
+
+
+class RandomAffine(nn.Layer):
+ """Random affine transformation of the image keeping center invariant.
+ If the image is paddle Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+
+ Args:
+ degrees (sequence or number): Range of degrees to select from.
+ If degrees is a number instead of sequence like (min, max), the range of degrees
+ will be (-degrees, +degrees). Set to 0 to deactivate rotations.
+ translate (tuple, optional): tuple of maximum absolute fraction for horizontal
+ and vertical translations. For example translate=(a, b), then horizontal shift
+ is randomly sampled in the range -img_width * a < dx < img_width * a and vertical shift is
+ randomly sampled in the range -img_height * b < dy < img_height * b. Will not translate by default.
+ scale (tuple, optional): scaling factor interval, e.g (a, b), then scale is
+ randomly sampled from the range a <= scale <= b. Will keep original scale by default.
+ shear (sequence or number, optional): Range of degrees to select from.
+ If shear is a number, a shear parallel to the x axis in the range (-shear, +shear)
+ will be applied. Else if shear is a sequence of 2 values a shear parallel to the x axis in the
+ range (shear[0], shear[1]) will be applied. Else if shear is a sequence of 4 values,
+ a x-axis shear in (shear[0], shear[1]) and y-axis shear in (shear[2], shear[3]) will be applied.
+ Will not apply shear by default.
+ interpolation (InterpolationMode): Desired interpolation enum defined by
+ :class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.NEAREST``.
+ If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.BILINEAR`` are supported.
+ For backward compatibility integer values (e.g. ``PIL.Image[.Resampling].NEAREST``) are still accepted,
+ but deprecated since 0.13 and will be removed in 0.15. Please use InterpolationMode enum.
+ fill (sequence or number): Pixel fill value for the area outside the transformed
+ image. Default is ``0``. If given a number, the value is used for all bands respectively.
+ fillcolor (sequence or number, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``fill`` instead.
+ resample (int, optional):
+ .. warning::
+ This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``interpolation``
+ instead.
+ center (sequence, optional): Optional center of rotation, (x, y). Origin is the upper left corner.
+ Default is the center of the image.
+
+ .. _filters: https://pillow.readthedocs.io/en/latest/handbook/concepts.html#filters
+
+ """
+
+ def __init__(
+ self,
+ degrees,
+ translate=None,
+ scale=None,
+ shear=None,
+ interpolation=InterpolationMode.NEAREST,
+ fill=0,
+ fillcolor=None,
+ resample=None,
+ center=None,
+ ):
+ super(RandomAffine, self).__init__()
+ if resample is not None:
+ warnings.warn("The parameter 'resample' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'interpolation' instead.")
+ interpolation = _interpolation_modes_from_int(resample)
+
+ # Backward compatibility with integer value
+ if isinstance(interpolation, int):
+ warnings.warn("Argument 'interpolation' of type int is deprecated since 0.13 and will be removed in 0.15. "
+ "Please use InterpolationMode enum.")
+ interpolation = _interpolation_modes_from_int(interpolation)
+
+ if fillcolor is not None:
+ warnings.warn("The parameter 'fillcolor' is deprecated since 0.12 and will be removed in 0.14. "
+ "Please use 'fill' instead.")
+ fill = fillcolor
+
+ self.degrees = _setup_angle(degrees, name="degrees", req_sizes=(2, ))
+
+ if translate is not None:
+ _check_sequence_input(translate, "translate", req_sizes=(2, ))
+ for t in translate:
+ if not (0.0 <= t <= 1.0):
+ raise ValueError("translation values should be between 0 and 1")
+ self.translate = translate
+
+ if scale is not None:
+ _check_sequence_input(scale, "scale", req_sizes=(2, ))
+ for s in scale:
+ if s <= 0:
+ raise ValueError("scale values should be positive")
+ self.scale = scale
+
+ if shear is not None:
+ self.shear = _setup_angle(shear, name="shear", req_sizes=(2, 4))
+ else:
+ self.shear = shear
+
+ self.resample = self.interpolation = interpolation
+
+ if fill is None:
+ fill = 0
+ elif not isinstance(fill, (Sequence, numbers.Number)):
+ raise TypeError("Fill should be either a sequence or a number.")
+
+ self.fillcolor = self.fill = fill
+
+ if center is not None:
+ _check_sequence_input(center, "center", req_sizes=(2, ))
+
+ self.center = center
+
+ @staticmethod
+ def get_params(
+ degrees: List[float],
+ translate: Optional[List[float]],
+ scale_ranges: Optional[List[float]],
+ shears: Optional[List[float]],
+ img_size: List[int],
+ ) -> Tuple[float, Tuple[int, int], float, Tuple[float, float]]:
+ """Get parameters for affine transformation
+
+ Returns:
+ params to be passed to the affine transformation
+ """
+ angle = float(paddle.empty([1]).uniform_(float(degrees[0]), float(degrees[1])))
+ if translate is not None:
+ max_dx = float(translate[0] * img_size[0])
+ max_dy = float(translate[1] * img_size[1])
+ tx = int(float(paddle.empty([1]).uniform_(-max_dx, max_dx)))
+ ty = int(float(paddle.empty([1]).uniform_(-max_dy, max_dy)))
+ translations = (tx, ty)
+ else:
+ translations = (0, 0)
+
+ if scale_ranges is not None:
+ scale = float(paddle.empty([1]).uniform_(scale_ranges[0], scale_ranges[1]))
+ else:
+ scale = 1.0
+
+ shear_x = shear_y = 0.0
+ if shears is not None:
+ shear_x = float(paddle.empty([1]).uniform_(shears[0], shears[1]))
+ if len(shears) == 4:
+ shear_y = float(paddle.empty([1]).uniform_(shears[2], shears[3]))
+
+ shear = (shear_x, shear_y)
+
+ return angle, translations, scale, shear
+
+ def forward(self, img):
+ fill = self.fill
+ channels, height, width = img.shape[1], img.shape[2], img.shape[3]
+ if isinstance(fill, (int, float)):
+ fill = [float(fill)] * channels
+ else:
+ fill = [float(f) for f in fill]
+
+ img_size = [width, height] # flip for keeping BC on get_params call
+
+ ret = self.get_params(self.degrees, self.translate, self.scale, self.shear, img_size)
+
+ return affine(img, *ret, interpolation=self.interpolation, fill=fill, center=self.center)
+
+ def __repr__(self) -> str:
+ s = f"{self.__class__.__name__}(degrees={self.degrees}"
+ s += f", translate={self.translate}" if self.translate is not None else ""
+ s += f", scale={self.scale}" if self.scale is not None else ""
+ s += f", shear={self.shear}" if self.shear is not None else ""
+ s += f", interpolation={self.interpolation.value}" if self.interpolation != InterpolationMode.NEAREST else ""
+ s += f", fill={self.fill}" if self.fill != 0 else ""
+ s += f", center={self.center}" if self.center is not None else ""
+ s += ")"
+
+ return s
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/unet.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/unet.py
new file mode 100755
index 000000000..56f3ad61e
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/model/unet.py
@@ -0,0 +1,838 @@
+'''
+This code is rewritten by Paddle based on
+https://github.com/openai/guided-diffusion/blob/main/guided_diffusion/unet.py
+'''
+import math
+from abc import abstractmethod
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+from .nn import avg_pool_nd
+from .nn import checkpoint
+from .nn import conv_nd
+from .nn import linear
+from .nn import normalization
+from .nn import SiLU
+from .nn import timestep_embedding
+from .nn import zero_module
+
+
+class AttentionPool2d(nn.Layer):
+ """
+ Adapted from CLIP: https://github.com/openai/CLIP/blob/main/clip/model.py
+ """
+
+ def __init__(
+ self,
+ spacial_dim: int,
+ embed_dim: int,
+ num_heads_channels: int,
+ output_dim: int = None,
+ ):
+ super().__init__()
+ # self.positional_embedding = nn.Parameter(
+ # th.randn(embed_dim, spacial_dim ** 2 + 1) / embed_dim ** 0.5
+ # )
+ positional_embedding = self.create_parameter(paddle.randn(embed_dim, spacial_dim**2 + 1) / embed_dim**0.5)
+ self.add_parameter("positional_embedding", positional_embedding)
+ self.qkv_proj = conv_nd(1, embed_dim, 3 * embed_dim, 1)
+ self.c_proj = conv_nd(1, embed_dim, output_dim or embed_dim, 1)
+ self.num_heads = embed_dim // num_heads_channels
+ self.attention = QKVAttention(self.num_heads)
+
+ def forward(self, x):
+ b, c, *_spatial = x.shape
+ # x = x.reshape(b, c, -1) # NC(HW)
+ x = paddle.reshape(x, [b, c, -1])
+ x = paddle.concat([x.mean(dim=-1, keepdim=True), x], axis=-1) # NC(HW+1)
+ x = x + paddle.cast(self.positional_embedding[None, :, :], x.dtype) # NC(HW+1)
+ x = self.qkv_proj(x)
+ x = self.attention(x)
+ x = self.c_proj(x)
+ return x[:, :, 0]
+
+
+class TimestepBlock(nn.Layer):
+ """
+ Any module where forward() takes timestep embeddings as a second argument.
+ """
+
+ @abstractmethod
+ def forward(self, x, emb):
+ """
+ Apply the module to `x` given `emb` timestep embeddings.
+ """
+
+
+class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
+ """
+ A sequential module that passes timestep embeddings to the children that
+ support it as an extra input.
+ """
+
+ def forward(self, x, emb):
+ for layer in self:
+ if isinstance(layer, TimestepBlock):
+ x = layer(x, emb)
+ else:
+ x = layer(x)
+ return x
+
+
+class Upsample(nn.Layer):
+ """
+ An upsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ if use_conv:
+ self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=1)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.dims == 3:
+ x = F.interpolate(x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest")
+ else:
+ x = F.interpolate(x, scale_factor=2, mode="nearest")
+ if self.use_conv:
+ x = self.conv(x)
+ return x
+
+
+class Downsample(nn.Layer):
+ """
+ A downsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ stride = 2 if dims != 3 else (1, 2, 2)
+ if use_conv:
+ self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=1)
+ else:
+ assert self.channels == self.out_channels
+ self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ return self.op(x)
+
+
+class ResBlock(TimestepBlock):
+ """
+ A residual block that can optionally change the number of channels.
+
+ :param channels: the number of input channels.
+ :param emb_channels: the number of timestep embedding channels.
+ :param dropout: the rate of dropout.
+ :param out_channels: if specified, the number of out channels.
+ :param use_conv: if True and out_channels is specified, use a spatial
+ convolution instead of a smaller 1x1 convolution to change the
+ channels in the skip connection.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param use_checkpoint: if True, use gradient checkpointing on this module.
+ :param up: if True, use this block for upsampling.
+ :param down: if True, use this block for downsampling.
+ """
+
+ def __init__(
+ self,
+ channels,
+ emb_channels,
+ dropout,
+ out_channels=None,
+ use_conv=False,
+ use_scale_shift_norm=False,
+ dims=2,
+ use_checkpoint=False,
+ up=False,
+ down=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ self.emb_channels = emb_channels
+ self.dropout = dropout
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_checkpoint = use_checkpoint
+ self.use_scale_shift_norm = use_scale_shift_norm
+
+ self.in_layers = nn.Sequential(
+ normalization(channels),
+ SiLU(),
+ conv_nd(dims, channels, self.out_channels, 3, padding=1),
+ )
+
+ self.updown = up or down
+
+ if up:
+ self.h_upd = Upsample(channels, False, dims)
+ self.x_upd = Upsample(channels, False, dims)
+ elif down:
+ self.h_upd = Downsample(channels, False, dims)
+ self.x_upd = Downsample(channels, False, dims)
+ else:
+ self.h_upd = self.x_upd = nn.Identity()
+
+ self.emb_layers = nn.Sequential(
+ SiLU(),
+ linear(
+ emb_channels,
+ 2 * self.out_channels if use_scale_shift_norm else self.out_channels,
+ ),
+ )
+ self.out_layers = nn.Sequential(
+ normalization(self.out_channels),
+ SiLU(),
+ nn.Dropout(p=dropout),
+ zero_module(conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)),
+ )
+
+ if self.out_channels == channels:
+ self.skip_connection = nn.Identity()
+ elif use_conv:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 3, padding=1)
+ else:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
+
+ def forward(self, x, emb):
+ """
+ Apply the block to a Tensor, conditioned on a timestep embedding.
+
+ :param x: an [N x C x ...] Tensor of features.
+ :param emb: an [N x emb_channels] Tensor of timestep embeddings.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ return checkpoint(self._forward, (x, emb), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x, emb):
+ if self.updown:
+ in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
+ h = in_rest(x)
+ h = self.h_upd(h)
+ x = self.x_upd(x)
+ h = in_conv(h)
+ else:
+ h = self.in_layers(x)
+ emb_out = self.emb_layers(emb)
+ emb_out = paddle.cast(emb_out, h.dtype)
+ while len(emb_out.shape) < len(h.shape):
+ emb_out = emb_out[..., None]
+ if self.use_scale_shift_norm:
+ out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
+ scale, shift = paddle.chunk(emb_out, 2, axis=1)
+ h = out_norm(h) * (1 + scale) + shift
+ h = out_rest(h)
+ else:
+ h = h + emb_out
+ h = self.out_layers(h)
+ return self.skip_connection(x) + h
+
+
+class AttentionBlock(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other.
+
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_heads=1,
+ num_head_channels=-1,
+ use_checkpoint=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels == -1:
+ self.num_heads = num_heads
+ else:
+ assert (channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+ self.use_checkpoint = use_checkpoint
+ self.norm = normalization(channels)
+ self.qkv = conv_nd(1, channels, channels * 3, 1)
+ if use_new_attention_order:
+ # split qkv before split heads
+ self.attention = QKVAttention(self.num_heads)
+ else:
+ # split heads before split qkv
+ self.attention = QKVAttentionLegacy(self.num_heads)
+
+ self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
+
+ def forward(self, x):
+ return checkpoint(self._forward, (x, ), self.parameters(), self.use_checkpoint)
+
+ def _forward(self, x):
+ b, c, *spatial = x.shape
+ # x = x.reshape(b, c, -1)
+ x = paddle.reshape(x, [b, c, -1])
+ qkv = self.qkv(self.norm(x))
+ h = self.attention(qkv)
+ h = self.proj_out(h)
+ # return (x + h).reshape(b, c, *spatial)
+ return paddle.reshape(x + h, [b, c, *spatial])
+
+
+def count_flops_attn(model, _x, y):
+ """
+ A counter for the `thop` package to count the operations in an
+ attention operation.
+ Meant to be used like:
+ macs, params = thop.profile(
+ model,
+ inputs=(inputs, timestamps),
+ custom_ops={QKVAttention: QKVAttention.count_flops},
+ )
+ """
+ b, c, *spatial = y[0].shape
+ num_spatial = int(np.prod(spatial))
+ # We perform two matmuls with the same number of ops.
+ # The first computes the weight matrix, the second computes
+ # the combination of the value vectors.
+ matmul_ops = 2 * b * (num_spatial**2) * c
+ model.total_ops += paddle.to_tensor([matmul_ops], dtype='float64')
+
+
+class QKVAttentionLegacy(nn.Layer):
+ """
+ A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ # q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
+ q, k, v = paddle.reshape(qkv, [bs * self.n_heads, ch * 3, length]).split(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v)
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class QKVAttention(nn.Layer):
+ """
+ A module which performs QKV attention and splits in a different order.
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+
+ :param qkv: an [N x (3 * H * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.chunk(3, axis=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum(
+ "bct,bcs->bts",
+ (q * scale).view(bs * self.n_heads, ch, length),
+ (k * scale).view(bs * self.n_heads, ch, length),
+ ) # More stable with f16 than dividing afterwards
+ weight = paddle.cast(nn.functional.softmax(paddle.cast(weight, 'float32'), axis=-1), weight.dtype)
+ a = paddle.einsum("bts,bcs->bct", weight, v.reshape(bs * self.n_heads, ch, length))
+ # return a.reshape(bs, -1, length)
+ return paddle.reshape(a, [bs, -1, length])
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class UNetModel(nn.Layer):
+ """
+ The full UNet model with attention and timestep embedding.
+
+ :param in_channels: channels in the input Tensor.
+ :param model_channels: base channel count for the model.
+ :param out_channels: channels in the output Tensor.
+ :param num_res_blocks: number of residual blocks per downsample.
+ :param attention_resolutions: a collection of downsample rates at which
+ attention will take place. May be a set, list, or tuple.
+ For example, if this contains 4, then at 4x downsampling, attention
+ will be used.
+ :param dropout: the dropout probability.
+ :param channel_mult: channel multiplier for each level of the UNet.
+ :param conv_resample: if True, use learned convolutions for upsampling and
+ downsampling.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param num_classes: if specified (as an int), then this model will be
+ class-conditional with `num_classes` classes.
+ :param use_checkpoint: use gradient checkpointing to reduce memory usage.
+ :param num_heads: the number of attention heads in each attention layer.
+ :param num_heads_channels: if specified, ignore num_heads and instead use
+ a fixed channel width per attention head.
+ :param num_heads_upsample: works with num_heads to set a different number
+ of heads for upsampling. Deprecated.
+ :param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
+ :param resblock_updown: use residual blocks for up/downsampling.
+ :param use_new_attention_order: use a different attention pattern for potentially
+ increased efficiency.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ num_classes=None,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.image_size = image_size
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.num_classes = num_classes
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ if self.num_classes is not None:
+ self.label_emb = nn.Embedding(num_classes, time_embed_dim)
+
+ ch = input_ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+
+ self.output_blocks = nn.LayerList([])
+ for level, mult in list(enumerate(channel_mult))[::-1]:
+ for i in range(num_res_blocks + 1):
+ ich = input_block_chans.pop()
+ layers = [
+ ResBlock(
+ ch + ich,
+ time_embed_dim,
+ dropout,
+ out_channels=int(model_channels * mult),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(model_channels * mult)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads_upsample,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ if level and i == num_res_blocks:
+ out_ch = ch
+ layers.append(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ up=True,
+ ) if resblock_updown else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch))
+ ds //= 2
+ self.output_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ zero_module(conv_nd(dims, input_ch, out_channels, 3, padding=1)),
+ )
+
+ def forward(self, x, timesteps, y=None):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :param y: an [N] Tensor of labels, if class-conditional.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ assert (y is not None) == (self.num_classes
+ is not None), "must specify y if and only if the model is class-conditional"
+
+ hs = []
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+ if self.num_classes is not None:
+ assert y.shape == (x.shape[0], )
+ emb = emb + self.label_emb(y)
+
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ hs.append(h)
+ h = self.middle_block(h, emb)
+ for module in self.output_blocks:
+ h = paddle.concat([h, hs.pop()], axis=1)
+ h = module(h, emb)
+ # h = paddle.cast(h, x.dtype)
+ return self.out(h)
+
+
+class SuperResModel(UNetModel):
+ """
+ A UNetModel that performs super-resolution.
+
+ Expects an extra kwarg `low_res` to condition on a low-resolution image.
+ """
+
+ def __init__(self, image_size, in_channels, *args, **kwargs):
+ super().__init__(image_size, in_channels * 2, *args, **kwargs)
+
+ def forward(self, x, timesteps, low_res=None, **kwargs):
+ _, _, new_height, new_width = x.shape
+ upsampled = F.interpolate(low_res, (new_height, new_width), mode="bilinear")
+ x = paddle.concat([x, upsampled], axis=1)
+ return super().forward(x, timesteps, **kwargs)
+
+
+class EncoderUNetModel(nn.Layer):
+ """
+ The half UNet model with attention and timestep embedding.
+
+ For usage, see UNet.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ pool="adaptive",
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.use_checkpoint = use_checkpoint
+ self.dtype = paddle.float16 if use_fp16 else paddle.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ ch = int(channel_mult[0] * model_channels)
+ self.input_blocks = nn.LayerList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
+ self._feature_size = ch
+ input_block_chans = [ch]
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=int(mult * model_channels),
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = int(mult * model_channels)
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ))
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ ) if resblock_updown else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+ self.pool = pool
+ if pool == "adaptive":
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ nn.AdaptiveAvgPool2D((1, 1)),
+ zero_module(conv_nd(dims, ch, out_channels, 1)),
+ nn.Flatten(),
+ )
+ elif pool == "attention":
+ assert num_head_channels != -1
+ self.out = nn.Sequential(
+ normalization(ch),
+ SiLU(),
+ AttentionPool2d((image_size // ds), ch, num_head_channels, out_channels),
+ )
+ elif pool == "spatial":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ nn.ReLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ elif pool == "spatial_v2":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ normalization(2048),
+ SiLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ else:
+ raise NotImplementedError(f"Unexpected {pool} pooling")
+
+ def forward(self, x, timesteps):
+ """
+ Apply the model to an input batch.
+
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :return: an [N x K] Tensor of outputs.
+ """
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+
+ results = []
+ # h = x.type(self.dtype)
+ h = paddle.cast(x, self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ if self.pool.startswith("spatial"):
+ # results.append(h.type(x.dtype).mean(axis=(2, 3)))
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = self.middle_block(h, emb)
+ if self.pool.startswith("spatial"):
+ results.append(paddle.cast(h, x.dtype).mean(axis=(2, 3)))
+ h = paddle.concat(results, axis=-1)
+ return self.out(h)
+ else:
+ # h = h.type(x.dtype)
+ h = paddle.cast(h, x.dtype)
+ return self.out(h)
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/resources/default.yml b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/resources/default.yml
new file mode 100755
index 000000000..97c3c1b98
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/resources/default.yml
@@ -0,0 +1,47 @@
+text_prompts:
+ - A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.
+
+init_image:
+
+width_height: [ 1280, 768]
+
+skip_steps: 10
+steps: 250
+
+cut_ic_pow: 1
+init_scale: 1000
+clip_guidance_scale: 5000
+
+tv_scale: 0
+range_scale: 150
+sat_scale: 0
+cutn_batches: 4
+
+diffusion_model: 512x512_diffusion_uncond_finetune_008100
+use_secondary_model: True
+diffusion_sampling_mode: ddim
+
+perlin_init: False
+perlin_mode: mixed
+seed: 445467575
+eta: 0.8
+clamp_grad: True
+clamp_max: 0.05
+
+randomize_class: True
+clip_denoised: False
+fuzzy_prompt: False
+rand_mag: 0.05
+
+cut_overview: "[12]*400+[4]*600"
+cut_innercut: "[4]*400+[12]*600"
+cut_icgray_p: "[0.2]*400+[0]*600"
+
+display_rate: 10
+n_batches: 1
+batch_size: 1
+batch_name: ''
+clip_models:
+ - VIT
+ - RN50
+ - RN101
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/resources/docstrings.yml b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/resources/docstrings.yml
new file mode 100755
index 000000000..702015e1c
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/resources/docstrings.yml
@@ -0,0 +1,103 @@
+text_prompts: |
+ Phrase, sentence, or string of words and phrases describing what the image should look like. The words will be analyzed by the AI and will guide the diffusion process toward the image(s) you describe. These can include commas and weights to adjust the relative importance of each element. E.g. "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."
+ Notice that this prompt loosely follows a structure: [subject], [prepositional details], [setting], [meta modifiers and artist]; this is a good starting point for your experiments.
+ Developing text prompts takes practice and experience, and is not the subject of this guide. If you are a beginner to writing text prompts, a good place to start is on a simple AI art app like Night Cafe, starry ai or WOMBO prior to using DD, to get a feel for how text gets translated into images by GAN tools. These other apps use different technologies, but many of the same principles apply.
+init_image: |
+ Recall that in the image sequence above, the first image shown is just noise. If an init_image is provided, diffusion will replace the noise with the init_image as its starting state. To use an init_image, upload the image to the Colab instance or your Google Drive, and enter the full image path here.
+ If using an init_image, you may need to increase skip_steps to ~ 50% of total steps to retain the character of the init. See skip_steps above for further discussion.
+width_height: |
+ Desired final image size, in pixels. You can have a square, wide, or tall image, but each edge length should be set to a multiple of 64px, and a minimum of 512px on the default CLIP model setting. If you forget to use multiples of 64px in your dimensions, DD will adjust the dimensions of your image to make it so.
+
+skip_steps: |
+ Consider the chart shown here. Noise scheduling (denoise strength) starts very high and progressively gets lower and lower as diffusion steps progress. The noise levels in the first few steps are very high, so images change dramatically in early steps.
+ As DD moves along the curve, noise levels (and thus the amount an image changes per step) declines, and image coherence from one step to the next increases.
+ The first few steps of denoising are often so dramatic that some steps (maybe 10-15% of total) can be skipped without affecting the final image. You can experiment with this as a way to cut render times.
+ If you skip too many steps, however, the remaining noise may not be high enough to generate new content, and thus may not have ‘time left’ to finish an image satisfactorily.
+ Also, depending on your other settings, you may need to skip steps to prevent CLIP from overshooting your goal, resulting in ‘blown out’ colors (hyper saturated, solid white, or solid black regions) or otherwise poor image quality. Consider that the denoising process is at its strongest in the early steps, so skipping steps can sometimes mitigate other problems.
+ Lastly, if using an init_image, you will need to skip ~50% of the diffusion steps to retain the shapes in the original init image.
+ However, if you’re using an init_image, you can also adjust skip_steps up or down for creative reasons. With low skip_steps you can get a result "inspired by" the init_image which will retain the colors and rough layout and shapes but look quite different. With high skip_steps you can preserve most of the init_image contents and just do fine tuning of the texture.
+
+steps: |
+ When creating an image, the denoising curve is subdivided into steps for processing. Each step (or iteration) involves the AI looking at subsets of the image called ‘cuts’ and calculating the ‘direction’ the image should be guided to be more like the prompt. Then it adjusts the image with the help of the diffusion denoiser, and moves to the next step.
+ Increasing steps will provide more opportunities for the AI to adjust the image, and each adjustment will be smaller, and thus will yield a more precise, detailed image. Increasing steps comes at the expense of longer render times. Also, while increasing steps should generally increase image quality, there is a diminishing return on additional steps beyond 250 - 500 steps. However, some intricate images can take 1000, 2000, or more steps. It is really up to the user.
+ Just know that the render time is directly related to the number of steps, and many other parameters have a major impact on image quality, without costing additional time.
+
+cut_ic_pow: |
+ This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+init_scale: |
+ This controls how strongly CLIP will try to match the init_image provided. This is balanced against the clip_guidance_scale (CGS) above. Too much init scale, and the image won’t change much during diffusion. Too much CGS and the init image will be lost.
+clip_guidance_scale: |
+ CGS is one of the most important parameters you will use. It tells DD how strongly you want CLIP to move toward your prompt each timestep. Higher is generally better, but if CGS is too strong it will overshoot the goal and distort the image. So a happy medium is needed, and it takes experience to learn how to adjust CGS.
+ Note that this parameter generally scales with image dimensions. In other words, if you increase your total dimensions by 50% (e.g. a change from 512 x 512 to 512 x 768), then to maintain the same effect on the image, you’d want to increase clip_guidance_scale from 5000 to 7500.
+ Of the basic settings, clip_guidance_scale, steps and skip_steps are the most important contributors to image quality, so learn them well.
+tv_scale: |
+ Total variance denoising. Optional, set to zero to turn off. Controls ‘smoothness’ of final output. If used, tv_scale will try to smooth out your final image to reduce overall noise. If your image is too ‘crunchy’, increase tv_scale. TV denoising is good at preserving edges while smoothing away noise in flat regions. See https://en.wikipedia.org/wiki/Total_variation_denoising
+range_scale: |
+ Optional, set to zero to turn off. Used for adjustment of color contrast. Lower range_scale will increase contrast. Very low numbers create a reduced color palette, resulting in more vibrant or poster-like images. Higher range_scale will reduce contrast, for more muted images.
+
+sat_scale: |
+ Saturation scale. Optional, set to zero to turn off. If used, sat_scale will help mitigate oversaturation. If your image is too saturated, increase sat_scale to reduce the saturation.
+cutn_batches: |
+ Each iteration, the AI cuts the image into smaller pieces known as cuts, and compares each cut to the prompt to decide how to guide the next diffusion step. More cuts can generally lead to better images, since DD has more chances to fine-tune the image precision in each timestep.
+ Additional cuts are memory intensive, however, and if DD tries to evaluate too many cuts at once, it can run out of memory. You can use cutn_batches to increase cuts per timestep without increasing memory usage.
+ At the default settings, DD is scheduled to do 16 cuts per timestep. If cutn_batches is set to 1, there will indeed only be 16 cuts total per timestep.
+ However, if cutn_batches is increased to 4, DD will do 64 cuts total in each timestep, divided into 4 sequential batches of 16 cuts each. Because the cuts are being evaluated only 16 at a time, DD uses the memory required for only 16 cuts, but gives you the quality benefit of 64 cuts. The tradeoff, of course, is that this will take ~4 times as long to render each image.
+ So, (scheduled cuts) x (cutn_batches) = (total cuts per timestep). Increasing cutn_batches will increase render times, however, as the work is being done sequentially. DD’s default cut schedule is a good place to start, but the cut schedule can be adjusted in the Cutn Scheduling section, explained below.
+
+diffusion_model: Diffusion_model of choice.
+
+use_secondary_model: |
+ Option to use a secondary purpose-made diffusion model to clean up interim diffusion images for CLIP evaluation. If this option is turned off, DD will use the regular (large) diffusion model. Using the secondary model is faster - one user reported a 50% improvement in render speed! However, the secondary model is much smaller, and may reduce image quality and detail. I suggest you experiment with this.
+
+diffusion_sampling_mode: |
+ Two alternate diffusion denoising algorithms. ddim has been around longer, and is more established and tested. plms is a newly added alternate method that promises good diffusion results in fewer steps, but has not been as fully tested and may have side effects. This new plms mode is actively being researched in the #settings-and-techniques channel in the DD Discord.
+
+perlin_init: |
+ Normally, DD will use an image filled with random noise as a starting point for the diffusion curve. If perlin_init is selected, DD will instead use a Perlin noise model as an initial state. Perlin has very interesting characteristics, distinct from random noise, so it’s worth experimenting with this for your projects. Beyond perlin, you can, of course, generate your own noise images (such as with GIMP, etc) and use them as an init_image (without skipping steps).
+ Choosing perlin_init does not affect the actual diffusion process, just the starting point for the diffusion. Please note that selecting a perlin_init will replace and override any init_image you may have specified. Further, because the 2D, 3D and video animation systems all rely on the init_image system, if you enable Perlin while using animation modes, the perlin_init will jump in front of any previous image or video input, and DD will NOT give you the expected sequence of coherent images. All of that said, using Perlin and animation modes together do make a very colorful rainbow effect, which can be used creatively.
+
+perlin_mode: |
+ sets type of Perlin noise: colored, gray, or a mix of both, giving you additional options for noise types. Experiment to see what these do in your projects.
+seed: |
+ Deep in the diffusion code, there is a random number ‘seed’ which is used as the basis for determining the initial state of the diffusion. By default, this is random, but you can also specify your own seed. This is useful if you like a particular result and would like to run more iterations that will be similar.
+ After each run, the actual seed value used will be reported in the parameters report, and can be reused if desired by entering seed # here. If a specific numerical seed is used repeatedly, the resulting images will be quite similar but not identical.
+eta: |
+ eta (greek letter η) is a diffusion model variable that mixes in a random amount of scaled noise into each timestep. 0 is no noise, 1.0 is more noise. As with most DD parameters, you can go below zero for eta, but it may give you unpredictable results.
+ The steps parameter has a close relationship with the eta parameter. If you set eta to 0, then you can get decent output with only 50-75 steps. Setting eta to 1.0 favors higher step counts, ideally around 250 and up. eta has a subtle, unpredictable effect on image, so you’ll need to experiment to see how this affects your projects.
+clamp_grad: |
+ As I understand it, clamp_grad is an internal limiter that stops DD from producing extreme results. Try your images with and without clamp_grad. If the image changes drastically with clamp_grad turned off, it probably means your clip_guidance_scale is too high and should be reduced.
+clamp_max: |
+ Sets the value of the clamp_grad limitation. Default is 0.05, providing for smoother, more muted coloration in images, but setting higher values (0.15-0.3) can provide interesting contrast and vibrancy.
+
+randomize_class:
+clip_denoised: False
+fuzzy_prompt: |
+ Controls whether to add multiple noisy prompts to the prompt losses. If True, can increase variability of image output. Experiment with this.
+rand_mag: |
+ Affects only the fuzzy_prompt. Controls the magnitude of the random noise added by fuzzy_prompt.
+
+cut_overview: The schedule of overview cuts
+cut_innercut: The schedule of inner cuts
+cut_icgray_p: This sets the size of the border used for inner cuts. High cut_ic_pow values have larger borders, and therefore the cuts themselves will be smaller and provide finer details. If you have too many or too-small inner cuts, you may lose overall image coherency and/or it may cause an undesirable ‘mosaic’ effect. Low cut_ic_pow values will allow the inner cuts to be larger, helping image coherency while still helping with some details.
+
+display_rate: |
+ During a diffusion run, you can monitor the progress of each image being created with this variable. If display_rate is set to 50, DD will show you the in-progress image every 50 timesteps. Setting this to a lower value, like 5 or 10, is a good way to get an early peek at where your image is heading. If you don’t like the progression, just interrupt execution, change some settings, and re-run. If you are planning a long, unmonitored batch, it’s better to set display_rate equal to steps, because displaying interim images does slow Colab down slightly.
+n_batches: |
+ This variable sets the number of still images you want DD to create. If you are using an animation mode (see below for details) DD will ignore n_batches and create a single set of animated frames based on the animation settings.
+batch_name: |
+ The name of the batch, the batch id will be named as "discoart-[batch_name]-seed". To avoid your artworks be overridden by other users, please use a unique name.
+clip_models: |
+ CLIP Model selectors. ViT-B/32, ViT-B/16, ViT-L/14, RN101, RN50, RN50x4, RN50x16, RN50x64.
+ These various CLIP models are available for you to use during image generation. Models have different styles or ‘flavors,’ so look around.
+ You can mix in multiple models as well for different results. However, keep in mind that some models are extremely memory-hungry, and turning on additional models will take additional memory and may cause a crash.
+ The rough order of speed/mem usage is (smallest/fastest to largest/slowest):
+ ViT-B/32
+ RN50
+ RN101
+ ViT-B/16
+ RN50x4
+ RN50x16
+ RN50x64
+ ViT-L/14
+ For RN50x64 & ViTL14 you may need to use fewer cuts, depending on your VRAM.
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/runner.py b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/runner.py
new file mode 100755
index 000000000..7013c945a
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn101/reverse_diffusion/runner.py
@@ -0,0 +1,285 @@
+'''
+This code is rewritten by Paddle based on Jina-ai/discoart.
+https://github.com/jina-ai/discoart/blob/main/discoart/runner.py
+'''
+import gc
+import os
+import random
+from threading import Thread
+
+import disco_diffusion_clip_rn101.clip.clip as clip
+import numpy as np
+import paddle
+import paddle.vision.transforms as T
+import paddle_lpips as lpips
+from docarray import Document
+from docarray import DocumentArray
+from IPython import display
+from ipywidgets import Output
+from PIL import Image
+
+from .helper import logger
+from .helper import parse_prompt
+from .model.losses import range_loss
+from .model.losses import spherical_dist_loss
+from .model.losses import tv_loss
+from .model.make_cutouts import MakeCutoutsDango
+from .model.sec_diff import alpha_sigma_to_t
+from .model.sec_diff import SecondaryDiffusionImageNet2
+from .model.transforms import Normalize
+
+
+def do_run(args, models) -> 'DocumentArray':
+ logger.info('preparing models...')
+ model, diffusion, clip_models, secondary_model = models
+ normalize = Normalize(
+ mean=[0.48145466, 0.4578275, 0.40821073],
+ std=[0.26862954, 0.26130258, 0.27577711],
+ )
+ lpips_model = lpips.LPIPS(net='vgg')
+ for parameter in lpips_model.parameters():
+ parameter.stop_gradient = True
+ side_x = (args.width_height[0] // 64) * 64
+ side_y = (args.width_height[1] // 64) * 64
+ cut_overview = eval(args.cut_overview)
+ cut_innercut = eval(args.cut_innercut)
+ cut_icgray_p = eval(args.cut_icgray_p)
+
+ from .model.perlin_noises import create_perlin_noise, regen_perlin
+
+ seed = args.seed
+
+ skip_steps = args.skip_steps
+
+ loss_values = []
+
+ if seed is not None:
+ np.random.seed(seed)
+ random.seed(seed)
+ paddle.seed(seed)
+
+ model_stats = []
+ for clip_model in clip_models:
+ model_stat = {
+ 'clip_model': None,
+ 'target_embeds': [],
+ 'make_cutouts': None,
+ 'weights': [],
+ }
+ model_stat['clip_model'] = clip_model
+
+ if isinstance(args.text_prompts, str):
+ args.text_prompts = [args.text_prompts]
+
+ for prompt in args.text_prompts:
+ txt, weight = parse_prompt(prompt)
+ txt = clip_model.encode_text(clip.tokenize(prompt))
+ if args.fuzzy_prompt:
+ for i in range(25):
+ model_stat['target_embeds'].append((txt + paddle.randn(txt.shape) * args.rand_mag).clip(0, 1))
+ model_stat['weights'].append(weight)
+ else:
+ model_stat['target_embeds'].append(txt)
+ model_stat['weights'].append(weight)
+
+ model_stat['target_embeds'] = paddle.concat(model_stat['target_embeds'])
+ model_stat['weights'] = paddle.to_tensor(model_stat['weights'])
+ if model_stat['weights'].sum().abs() < 1e-3:
+ raise RuntimeError('The weights must not sum to 0.')
+ model_stat['weights'] /= model_stat['weights'].sum().abs()
+ model_stats.append(model_stat)
+
+ init = None
+ if args.init_image:
+ d = Document(uri=args.init_image).load_uri_to_image_tensor(side_x, side_y)
+ init = T.to_tensor(d.tensor).unsqueeze(0) * 2 - 1
+
+ if args.perlin_init:
+ if args.perlin_mode == 'color':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, False, side_y, side_x)
+ elif args.perlin_mode == 'gray':
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, True, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ else:
+ init = create_perlin_noise([1.5**-i * 0.5 for i in range(12)], 1, 1, False, side_y, side_x)
+ init2 = create_perlin_noise([1.5**-i * 0.5 for i in range(8)], 4, 4, True, side_y, side_x)
+ init = (T.to_tensor(init).add(T.to_tensor(init2)).divide(paddle.to_tensor(2.0)).unsqueeze(0) * 2 - 1)
+ del init2
+
+ cur_t = None
+
+ def cond_fn(x, t, y=None):
+ x_is_NaN = False
+ n = x.shape[0]
+ if secondary_model:
+ alpha = paddle.to_tensor(diffusion.sqrt_alphas_cumprod[cur_t], dtype='float32')
+ sigma = paddle.to_tensor(diffusion.sqrt_one_minus_alphas_cumprod[cur_t], dtype='float32')
+ cosine_t = alpha_sigma_to_t(alpha, sigma)
+ x = paddle.to_tensor(x.detach(), dtype='float32')
+ x.stop_gradient = False
+ cosine_t = paddle.tile(paddle.to_tensor(cosine_t.detach().cpu().numpy()), [n])
+ cosine_t.stop_gradient = False
+ out = secondary_model(x, cosine_t).pred
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ else:
+ t = paddle.ones([n], dtype='int64') * cur_t
+ out = diffusion.p_mean_variance(model, x, t, clip_denoised=False, model_kwargs={'y': y})
+ fac = diffusion.sqrt_one_minus_alphas_cumprod[cur_t]
+ x_in_d = out['pred_xstart'] * fac + x * (1 - fac)
+ x_in = x_in_d.detach()
+ x_in.stop_gradient = False
+ x_in_grad = paddle.zeros_like(x_in, dtype='float32')
+ for model_stat in model_stats:
+ for i in range(args.cutn_batches):
+ t_int = (int(t.item()) + 1) # errors on last step without +1, need to find source
+ # when using SLIP Base model the dimensions need to be hard coded to avoid AttributeError: 'VisionTransformer' object has no attribute 'input_resolution'
+ try:
+ input_resolution = model_stat['clip_model'].visual.input_resolution
+ except:
+ input_resolution = 224
+
+ cuts = MakeCutoutsDango(
+ input_resolution,
+ Overview=cut_overview[1000 - t_int],
+ InnerCrop=cut_innercut[1000 - t_int],
+ IC_Size_Pow=args.cut_ic_pow,
+ IC_Grey_P=cut_icgray_p[1000 - t_int],
+ )
+ clip_in = normalize(cuts(x_in.add(paddle.to_tensor(1.0)).divide(paddle.to_tensor(2.0))))
+ image_embeds = (model_stat['clip_model'].encode_image(clip_in))
+
+ dists = spherical_dist_loss(
+ image_embeds.unsqueeze(1),
+ model_stat['target_embeds'].unsqueeze(0),
+ )
+
+ dists = dists.reshape([
+ cut_overview[1000 - t_int] + cut_innercut[1000 - t_int],
+ n,
+ -1,
+ ])
+ losses = dists.multiply(model_stat['weights']).sum(2).mean(0)
+ loss_values.append(losses.sum().item()) # log loss, probably shouldn't do per cutn_batch
+
+ x_in_grad += (paddle.grad(losses.sum() * args.clip_guidance_scale, x_in)[0] / args.cutn_batches)
+ tv_losses = tv_loss(x_in)
+ range_losses = range_loss(x_in)
+ sat_losses = paddle.abs(x_in - x_in.clip(min=-1, max=1)).mean()
+ loss = (tv_losses.sum() * args.tv_scale + range_losses.sum() * args.range_scale +
+ sat_losses.sum() * args.sat_scale)
+ if init is not None and args.init_scale:
+ init_losses = lpips_model(x_in, init)
+ loss = loss + init_losses.sum() * args.init_scale
+ x_in_grad += paddle.grad(loss, x_in)[0]
+ if not paddle.isnan(x_in_grad).any():
+ grad = -paddle.grad(x_in_d, x, x_in_grad)[0]
+ else:
+ x_is_NaN = True
+ grad = paddle.zeros_like(x)
+ if args.clamp_grad and not x_is_NaN:
+ magnitude = grad.square().mean().sqrt()
+ return (grad * magnitude.clip(max=args.clamp_max) / magnitude)
+ return grad
+
+ if args.diffusion_sampling_mode == 'ddim':
+ sample_fn = diffusion.ddim_sample_loop_progressive
+ else:
+ sample_fn = diffusion.plms_sample_loop_progressive
+
+ logger.info('creating artwork...')
+
+ image_display = Output()
+ da_batches = DocumentArray()
+
+ for _nb in range(args.n_batches):
+ display.clear_output(wait=True)
+ display.display(args.name_docarray, image_display)
+ gc.collect()
+ paddle.device.cuda.empty_cache()
+
+ d = Document(tags=vars(args))
+ da_batches.append(d)
+
+ cur_t = diffusion.num_timesteps - skip_steps - 1
+
+ if args.perlin_init:
+ init = regen_perlin(args.perlin_mode, side_y, side_x, args.batch_size)
+
+ if args.diffusion_sampling_mode == 'ddim':
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ eta=args.eta,
+ )
+ else:
+ samples = sample_fn(
+ model,
+ (args.batch_size, 3, side_y, side_x),
+ clip_denoised=args.clip_denoised,
+ model_kwargs={},
+ cond_fn=cond_fn,
+ progress=True,
+ skip_timesteps=skip_steps,
+ init_image=init,
+ randomize_class=args.randomize_class,
+ order=2,
+ )
+
+ threads = []
+ for j, sample in enumerate(samples):
+ cur_t -= 1
+ with image_display:
+ if j % args.display_rate == 0 or cur_t == -1:
+ for _, image in enumerate(sample['pred_xstart']):
+ image = (image + 1) / 2
+ image = image.clip(0, 1).squeeze().transpose([1, 2, 0]).numpy() * 255
+ image = np.uint8(image)
+ image = Image.fromarray(image)
+
+ image.save(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb)))
+ c = Document(tags={'cur_t': cur_t})
+ c.load_pil_image_to_datauri(image)
+ d.chunks.append(c)
+ display.clear_output(wait=True)
+ display.display(display.Image(os.path.join(args.output_dir, 'progress-{}.png'.format(_nb))))
+ d.chunks.plot_image_sprites(os.path.join(args.output_dir,
+ f'{args.name_docarray}-progress-{_nb}.png'),
+ show_index=True)
+ t = Thread(
+ target=_silent_push,
+ args=(
+ da_batches,
+ args.name_docarray,
+ ),
+ )
+ threads.append(t)
+ t.start()
+
+ if cur_t == -1:
+ d.load_pil_image_to_datauri(image)
+
+ for t in threads:
+ t.join()
+ display.clear_output(wait=True)
+ logger.info(f'done! {args.name_docarray}')
+ da_batches.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ return da_batches
+
+
+def _silent_push(da_batches: DocumentArray, name: str) -> None:
+ try:
+ da_batches.push(name)
+ except Exception as ex:
+ logger.debug(f'push failed: {ex}')
From c52c4ed8f1a89faf7deae83fc72f453291b45cc1 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 19 Aug 2022 13:22:30 +0800
Subject: [PATCH 034/117] Add ERNIE 3.0 Zeus
---
.../text/text_generation/ernie_zeus/README.md | 297 ++++++++++++
.../text/text_generation/ernie_zeus/module.py | 451 ++++++++++++++++++
.../ernie_zeus/requirements.txt | 1 +
3 files changed, 749 insertions(+)
create mode 100644 modules/text/text_generation/ernie_zeus/README.md
create mode 100644 modules/text/text_generation/ernie_zeus/module.py
create mode 100644 modules/text/text_generation/ernie_zeus/requirements.txt
diff --git a/modules/text/text_generation/ernie_zeus/README.md b/modules/text/text_generation/ernie_zeus/README.md
new file mode 100644
index 000000000..920d55293
--- /dev/null
+++ b/modules/text/text_generation/ernie_zeus/README.md
@@ -0,0 +1,297 @@
+# ernie_zeus
+
+|模型名称|ernie_zeus|
+| :--- | :---: |
+|类别|文本-文本生成|
+|网络|-|
+|数据集|-|
+|是否支持Fine-tuning|否|
+|模型大小|-|
+|最新更新日期|2022-08-16|
+|数据指标|-|
+
+## 一、模型基本信息
+### 应用效果展示
+- 作文创作:
+ - 作文标题:诚以养德,信以修身
+
+ - 作文:翻开我的书橱,展现在眼前的就是《曾国藩家书》。每当读起这些充满哲理的内容时,心里总会不禁佩服他。他虽出生于官宦之家,但并没有因此而骄傲自大,从小养成了平淡做人、踏实肯干的好品质,最后更赢得了属下和朋友们对他的一致认同和赞赏。由此可见,只要平时注意锻炼自己,处事脚踏实地,定能收获一番丰硕的成果!记得有句话叫“以诚待人”。我觉得曾国藩就是始终把做到真诚与诚信作为修身立业的准则和美德。
+
+- 文案创作:
+ - 产品描述:芍药香氛的沐浴乳
+
+ - 文案:使用多种纯天然草本植物精华,泡沫细腻绵密,丰富的维他命及矿物质滋养皮肤。成分温和安全,适合干性、中性肌肤或敏感性肌肤使用!
+
+### 模型介绍
+ERNIE 3.0 Zeus 是 ERNIE 3.0 系列模型的最新升级。其除了对无标注数据和知识图谱的学习之外,还通过持续学习对百余种不同形式的任务数据学习。实现了任务知识增强,显著提升了模型的零样本/小样本学习能力。
+
+更多详情参考 [文心大模型官网](https://wenxin.baidu.com/wenxin) 及 [ERNIE 3.0 Zeus 项目主页](https://wenxin.baidu.com/wenxin/modelbasedetail/ernie3_zeus)。
+
+## 二、安装
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install ernie_zeus
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+- ### 3. 使用申请(可选)
+ - 请前往 [文心旸谷社区](https://wenxin.baidu.com/moduleApi/key) 申请使用本模型所需的 API key 和 Secret Key。
+
+
+## 三、模型 API 预测
+- ### 1. 命令行预测
+
+ - ```bash
+ # 作文创作
+ $ hub run ernie_zeus \
+ --task composition_generation \
+ --text '诚以养德,信以修身'
+ ```
+
+ - **参数**
+ - --task(str): 指定任务名称,与 API 名称保持一直
+ - --text(str): 根据不同的任务输入所需的文本。
+ - 其他参数请参考后续 API 章节。
+
+- ### 2. 预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ # 加载模型
+ model = hub.Module(name='ernie_zeus')
+
+ # 作文创作
+ result = model.composition_generation(
+ text='诚以养德,信以修身'
+ )
+
+ print(result)
+ ```
+
+- ### 3. API
+ - ```python
+ def __init__(
+ api_key: str = '',
+ secret_key: str = ''
+ ) -> None
+ ```
+
+ - 初始化 API
+
+ - **参数**
+
+ - api_key(str): API Key。(可选)
+ - secret_key(str): Secret Key。(可选)
+
+ - ```python
+ def custom_generation(
+ text: str,
+ min_dec_len: int = 1,
+ seq_len: int = 128,
+ topp: float = 1.0,
+ penalty_score: float = 1.0,
+ stop_token: str = '',
+ task_prompt: str = '',
+ penalty_text: str = '',
+ choice_text: str = '',
+ is_unidirectional: bool = False,
+ min_dec_penalty_text: str = '',
+ logits_bias: int = -10000,
+ mask_type: str = 'word',
+ api_key: str = '',
+ secret_key: str = ''
+ ) -> str
+ ```
+ - 自定义文本生成 API
+
+ - **参数**
+ - text(srt): 模型的输入文本, 为 prompt 形式的输入。文本长度 [1, 1000]。注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512。
+ - min_dec_len(int): 输出结果的最小长度, 避免因模型生成 END 或者遇到用户指定的 stop_token 而生成长度过短的情况,与 seq_len 结合使用来设置生成文本的长度范围 [1, seq_len]。
+ - seq_len(int): 输出结果的最大长度, 因模型生成 END 或者遇到用户指定的 stop_token, 实际返回结果可能会小于这个长度, 与 min_dec_len 结合使用来控制生成文本的长度范围 [1, 1000]。(注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512)
+ - topp(float): 影响输出文本的多样性, 取值越大, 生成文本的多样性越强。取值范围 [0.0, 1.0]。
+ - penalty_score(float): 通过对已生成的 token 增加惩罚, 减少重复生成的现象。值越大表示惩罚越大。取值范围 [1.0, 2.0]。
+ - stop_token(str): 预测结果解析时使用的结束字符串, 碰到对应字符串则直接截断并返回。可以通过设置该值, 过滤掉 few-shot 等场景下模型重复的 cases。
+ - task_prompt(str): 指定预置的任务模板, 效果更好。
+ PARAGRAPH: 引导模型生成一段文章; SENT: 引导模型生成一句话; ENTITY: 引导模型生成词组;
+ Summarization: 摘要; MT: 翻译; Text2Annotation: 抽取; Correction: 纠错;
+ QA_MRC: 阅读理解; Dialogue: 对话; QA_Closed_book: 闭卷问答; QA_Multi_Choice: 多选问答;
+ QuestionGeneration: 问题生成; Paraphrasing: 复述; NLI: 文本蕴含识别; SemanticMatching: 匹配;
+ Text2SQL: 文本描述转SQL; TextClassification: 文本分类; SentimentClassification: 情感分析;
+ zuowen: 写作文; adtext: 写文案; couplet: 对对联; novel: 写小说; cloze: 文本补全; Misc: 其它任务。
+ - penalty_text(str): 模型会惩罚该字符串中的 token。通过设置该值, 可以减少某些冗余与异常字符的生成。
+ - choice_text(str): 模型只能生成该字符串中的 token 的组合。通过设置该值, 可以对某些抽取式任务进行定向调优。
+ - is_unidirectional(bool): False 表示模型为双向生成, True 表示模型为单向生成。建议续写与 few-shot 等通用场景建议采用单向生成方式, 而完型填空等任务相关场景建议采用双向生成方式。
+ - min_dec_penalty_text(str): 与最小生成长度搭配使用, 可以在 min_dec_len 步前不让模型生成该字符串中的 tokens。
+ - logits_bias(int): 配合 penalty_text 使用, 对给定的 penalty_text 中的 token 增加一个 logits_bias, 可以通过设置该值屏蔽某些 token 生成的概率。
+ - mask_type(str): 设置该值可以控制模型生成粒度。可选参数为 word, sentence, paragraph。
+
+ - **返回**
+ - text(str): 生成的文本。
+
+ - ```python
+ def text_cloze(
+ text: str,
+ min_dec_len: int = 1,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.0
+ ) -> str
+ ```
+
+ - 完形填空 API
+
+ - **参数**
+ - text(str): 文字段落。使用 [MASK] 标记待补全文字。
+ - min_dec_len(int): 输出结果的最小长度, 避免因模型生成 END 或者遇到用户指定的 stop_token 而生成长度过短的情况,与 seq_len 结合使用来设置生成文本的长度范围 [1, seq_len]。
+ - seq_len(int): 输出结果的最大长度, 因模型生成 END 或者遇到用户指定的 stop_token, 实际返回结果可能会小于这个长度, 与 min_dec_len 结合使用来控制生成文本的长度范围 [1, 1000]。(注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512)
+ - topp(float): 影响输出文本的多样性, 取值越大, 生成文本的多样性越强。取值范围 [0.0, 1.0]。
+ - penalty_score(float): 通过对已生成的 token 增加惩罚, 减少重复生成的现象。值越大表示惩罚越大。取值范围 [1.0, 2.0]。
+
+ - **返回**
+ - text(str): 补全词语
+
+ - ```python
+ def composition_generation(
+ text: str,
+ min_dec_len: int = 128,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.2
+ ) -> str
+ ```
+ - 作文创作 API
+
+ - **参数**
+ - text(str): 作文题目。
+ - min_dec_len(int): 输出结果的最小长度, 避免因模型生成 END 或者遇到用户指定的 stop_token 而生成长度过短的情况,与 seq_len 结合使用来设置生成文本的长度范围 [1, seq_len]。
+ - seq_len(int): 输出结果的最大长度, 因模型生成 END 或者遇到用户指定的 stop_token, 实际返回结果可能会小于这个长度, 与 min_dec_len 结合使用来控制生成文本的长度范围 [1, 1000]。(注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512)
+ - topp(float): 影响输出文本的多样性, 取值越大, 生成文本的多样性越强。取值范围 [0.0, 1.0]。
+ - penalty_score(float): 通过对已生成的 token 增加惩罚, 减少重复生成的现象。值越大表示惩罚越大。取值范围 [1.0, 2.0]。
+
+ - **返回**
+ - text(str): 作文内容。
+
+ - ```python
+ def answer_generation(
+ text: str,
+ min_dec_len: int = 2,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.2
+ ) -> str
+ ```
+ - 自由问答 API
+
+ - **参数**
+ - text(str): 问题内容。
+ - min_dec_len(int): 输出结果的最小长度, 避免因模型生成 END 或者遇到用户指定的 stop_token 而生成长度过短的情况,与 seq_len 结合使用来设置生成文本的长度范围 [1, seq_len]。
+ - seq_len(int): 输出结果的最大长度, 因模型生成 END 或者遇到用户指定的 stop_token, 实际返回结果可能会小于这个长度, 与 min_dec_len 结合使用来控制生成文本的长度范围 [1, 1000]。(注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512)
+ - topp(float): 影响输出文本的多样性, 取值越大, 生成文本的多样性越强。取值范围 [0.0, 1.0]。
+ - penalty_score(float): 通过对已生成的 token 增加惩罚, 减少重复生成的现象。值越大表示惩罚越大。取值范围 [1.0, 2.0]。
+
+ - **返回**
+ - text(str): 问题答案。
+
+
+ - ```python
+ def couplet_continuation(
+ text: str,
+ min_dec_len: int = 2,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.0
+ ) -> str
+ ```
+ - 对联续写 API
+
+ - **参数**
+ - text(str): 对联上联。
+ - min_dec_len(int): 输出结果的最小长度, 避免因模型生成 END 或者遇到用户指定的 stop_token 而生成长度过短的情况,与 seq_len 结合使用来设置生成文本的长度范围 [1, seq_len]。
+ - seq_len(int): 输出结果的最大长度, 因模型生成 END 或者遇到用户指定的 stop_token, 实际返回结果可能会小于这个长度, 与 min_dec_len 结合使用来控制生成文本的长度范围 [1, 1000]。(注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512)
+ - topp(float): 影响输出文本的多样性, 取值越大, 生成文本的多样性越强。取值范围 [0.0, 1.0]。
+ - penalty_score(float): 通过对已生成的 token 增加惩罚, 减少重复生成的现象。值越大表示惩罚越大。取值范围 [1.0, 2.0]。
+
+ - **返回**
+ - text(str): 对联下联。
+
+ - ```python
+ def copywriting_generation(
+ text: str,
+ min_dec_len: int = 32,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.2
+ ) -> str
+ ```
+ - 文案创作 API
+
+ - **参数**
+ - text(str): 产品描述。
+ - min_dec_len(int): 输出结果的最小长度, 避免因模型生成 END 或者遇到用户指定的 stop_token 而生成长度过短的情况,与 seq_len 结合使用来设置生成文本的长度范围 [1, seq_len]。
+ - seq_len(int): 输出结果的最大长度, 因模型生成 END 或者遇到用户指定的 stop_token, 实际返回结果可能会小于这个长度, 与 min_dec_len 结合使用来控制生成文本的长度范围 [1, 1000]。(注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512)
+ - topp(float): 影响输出文本的多样性, 取值越大, 生成文本的多样性越强。取值范围 [0.0, 1.0]。
+ - penalty_score(float): 通过对已生成的 token 增加惩罚, 减少重复生成的现象。值越大表示惩罚越大。取值范围 [1.0, 2.0]。
+
+ - **返回**
+ - text(str): 产品文案。
+
+ - ```python
+ def novel_continuation(
+ text: str,
+ min_dec_len: int = 2,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.2
+ ) -> str
+ ```
+ - 小说续写 API
+
+ - **参数**
+ - text(str): 小说上文。
+ - min_dec_len(int): 输出结果的最小长度, 避免因模型生成 END 或者遇到用户指定的 stop_token 而生成长度过短的情况,与 seq_len 结合使用来设置生成文本的长度范围 [1, seq_len]。
+ - seq_len(int): 输出结果的最大长度, 因模型生成 END 或者遇到用户指定的 stop_token, 实际返回结果可能会小于这个长度, 与 min_dec_len 结合使用来控制生成文本的长度范围 [1, 1000]。(注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512)
+ - topp(float): 影响输出文本的多样性, 取值越大, 生成文本的多样性越强。取值范围 [0.0, 1.0]。
+ - penalty_score(float): 通过对已生成的 token 增加惩罚, 减少重复生成的现象。值越大表示惩罚越大。取值范围 [1.0, 2.0]。
+
+ - **返回**
+ - text(str): 小说下文。
+
+ - ```python
+ def text_summarization(
+ text: str,
+ min_dec_len: int = 4,
+ seq_len: int = 512,
+ topp: float = 0.0,
+ penalty_score: float = 1.0
+ ) -> str
+ ```
+ - 文本摘要 API
+
+ - **参数**
+ - text(str): 文本段落。
+ - min_dec_len(int): 输出结果的最小长度, 避免因模型生成 END 或者遇到用户指定的 stop_token 而生成长度过短的情况,与 seq_len 结合使用来设置生成文本的长度范围 [1, seq_len]。
+ - seq_len(int): 输出结果的最大长度, 因模型生成 END 或者遇到用户指定的 stop_token, 实际返回结果可能会小于这个长度, 与 min_dec_len 结合使用来控制生成文本的长度范围 [1, 1000]。(注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512)
+ - topp(float): 影响输出文本的多样性, 取值越大, 生成文本的多样性越强。取值范围 [0.0, 1.0]。
+ - penalty_score(float): 通过对已生成的 token 增加惩罚, 减少重复生成的现象。值越大表示惩罚越大。取值范围 [1.0, 2.0]。
+
+ - **返回**
+ - text(str): 段落摘要。
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install ernie_zeus == 1.0.0
+ ```
\ No newline at end of file
diff --git a/modules/text/text_generation/ernie_zeus/module.py b/modules/text/text_generation/ernie_zeus/module.py
new file mode 100644
index 000000000..169c6e811
--- /dev/null
+++ b/modules/text/text_generation/ernie_zeus/module.py
@@ -0,0 +1,451 @@
+import json
+import argparse
+
+import requests
+from paddlehub.module.module import moduleinfo, runnable
+
+
+def get_access_token(ak: str = '', sk: str = '') -> str:
+ '''
+ Get Access Token
+
+ Params:
+ ak(str): API Key
+ sk(str): Secret Key
+
+ Return:
+ access_token(str): Access Token
+ '''
+ url = 'https://wenxin.baidu.com/younger/portal/api/oauth/token'
+ headers = {
+ 'Content-Type': 'application/x-www-form-urlencoded'
+ }
+ datas = {
+ 'grant_type': 'client_credentials',
+ 'client_id': ak if ak != '' else 'G26BfAOLpGIRBN5XrOV2eyPA25CE01lE',
+ 'client_secret': sk if sk != '' else 'txLZOWIjEqXYMU3lSm05ViW4p9DWGOWs'
+ }
+
+ responses = requests.post(url, datas, headers=headers)
+
+ assert responses.status_code == 200, f"Network Error {responses.status_code}."
+
+ results = json.loads(responses.text)
+
+ assert results['msg'] == 'success', f"Error message: '{results['msg']}'. Please check the ak and sk."
+
+ return results['data']
+
+
+@moduleinfo(
+ name='ernie_zeus',
+ type='nlp/text_generation',
+ author='paddlepaddle',
+ author_email='',
+ summary='ernie_zeus',
+ version='1.0.0'
+)
+class ERNIEZeus:
+ def __init__(self, ak: str = '', sk: str = '') -> None:
+ self.access_token = get_access_token(ak, sk)
+
+ def custom_generation(self,
+ text: str,
+ min_dec_len: int = 1,
+ seq_len: int = 128,
+ topp: float = 1.0,
+ penalty_score: float = 1.0,
+ stop_token: str = '',
+ task_prompt: str = '',
+ penalty_text: str = '',
+ choice_text: str = '',
+ is_unidirectional: bool = False,
+ min_dec_penalty_text: str = '',
+ logits_bias: int = -10000,
+ mask_type: str = 'word') -> str:
+ '''
+ ERNIE 3.0 Zeus 自定义接口
+
+ Params:
+ text(srt): 模型的输入文本, 为 prompt 形式的输入。文本长度 [1, 1000]。注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512。
+ min_dec_len(int): 输出结果的最小长度, 避免因模型生成 END 或者遇到用户指定的 stop_token 而生成长度过短的情况,与 seq_len 结合使用来设置生成文本的长度范围 [1, seq_len]。
+ seq_len(int): 输出结果的最大长度, 因模型生成 END 或者遇到用户指定的 stop_token, 实际返回结果可能会小于这个长度, 与 min_dec_len 结合使用来控制生成文本的长度范围 [1, 1000]。(注: ERNIE 3.0-1.5B 模型取值范围 ≤ 512)
+ topp(float): 影响输出文本的多样性, 取值越大, 生成文本的多样性越强。取值范围 [0.0, 1.0]。
+ penalty_score(float): 通过对已生成的 token 增加惩罚, 减少重复生成的现象。值越大表示惩罚越大。取值范围 [1.0, 2.0]。
+ stop_token(str): 预测结果解析时使用的结束字符串, 碰到对应字符串则直接截断并返回。可以通过设置该值, 过滤掉 few-shot 等场景下模型重复的 cases。
+ task_prompt(str): 指定预置的任务模板, 效果更好。
+ PARAGRAPH: 引导模型生成一段文章; SENT: 引导模型生成一句话; ENTITY: 引导模型生成词组;
+ Summarization: 摘要; MT: 翻译; Text2Annotation: 抽取; Correction: 纠错;
+ QA_MRC: 阅读理解; Dialogue: 对话; QA_Closed_book: 闭卷问答; QA_Multi_Choice: 多选问答;
+ QuestionGeneration: 问题生成; Paraphrasing: 复述; NLI: 文本蕴含识别; SemanticMatching: 匹配;
+ Text2SQL: 文本描述转SQL; TextClassification: 文本分类; SentimentClassification: 情感分析;
+ zuowen: 写作文; adtext: 写文案; couplet: 对对联; novel: 写小说; cloze: 文本补全; Misc: 其它任务。
+ penalty_text(str): 模型会惩罚该字符串中的 token。通过设置该值, 可以减少某些冗余与异常字符的生成。
+ choice_text(str): 模型只能生成该字符串中的 token 的组合。通过设置该值, 可以对某些抽取式任务进行定向调优。
+ is_unidirectional(bool): False 表示模型为双向生成, True 表示模型为单向生成。建议续写与 few-shot 等通用场景建议采用单向生成方式, 而完型填空等任务相关场景建议采用双向生成方式。
+ min_dec_penalty_text(str): 与最小生成长度搭配使用, 可以在 min_dec_len 步前不让模型生成该字符串中的 tokens。
+ logits_bias(int): 配合 penalty_text 使用, 对给定的 penalty_text 中的 token 增加一个 logits_bias, 可以通过设置该值屏蔽某些 token 生成的概率。
+ mask_type(str): 设置该值可以控制模型生成粒度。可选参数为 word, sentence, paragraph。
+
+ Return:
+ text(str): 生成的文本
+ '''
+ url = 'https://wenxin.baidu.com/moduleApi/portal/api/rest/1.0/ernie/3.0.28/zeus?from=paddlehub'
+ access_token = self.access_token
+ headers = {
+ 'Content-Type': 'application/x-www-form-urlencoded'
+ }
+ datas = {
+ 'access_token': access_token,
+ 'text': text,
+ 'min_dec_len': min_dec_len,
+ 'seq_len': seq_len,
+ 'topp': topp,
+ 'penalty_score': penalty_score,
+ 'stop_token': stop_token,
+ 'task_prompt': task_prompt,
+ 'penalty_text': penalty_text,
+ 'choice_text': choice_text,
+ 'is_unidirectional': int(is_unidirectional),
+ 'min_dec_penalty_text': min_dec_penalty_text,
+ 'logits_bias': logits_bias,
+ 'mask_type': mask_type,
+ }
+
+ responses = requests.post(url, datas, headers=headers)
+
+ assert responses.status_code == 200, f"Network Error {responses.status_code}."
+
+ results = json.loads(responses.text)
+
+ assert results['code'] == 0, f"Error message: '{results['msg']}'."
+
+ return results['data']['result']
+
+ def text_generation(self,
+ text: str,
+ min_dec_len: int = 4,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.2) -> str:
+ '''
+ 文本生成
+ '''
+ return self.custom_generation(
+ text,
+ min_dec_len,
+ seq_len,
+ topp,
+ penalty_score,
+ stop_token='',
+ task_prompt='PARAGRAPH',
+ penalty_text='[{[gEND]',
+ choice_text='',
+ is_unidirectional=True,
+ min_dec_penalty_text='。?:![]',
+ logits_bias=-10,
+ mask_type='paragraph'
+ )
+
+ def text_summarization(self,
+ text: str,
+ min_dec_len: int = 4,
+ seq_len: int = 512,
+ topp: float = 0.0,
+ penalty_score: float = 1.0) -> str:
+ '''
+ 摘要生成
+ '''
+ text = "文章:{} 摘要:".format(text)
+ return self.custom_generation(
+ text,
+ min_dec_len,
+ seq_len,
+ topp,
+ penalty_score,
+ stop_token='',
+ task_prompt='Summarization',
+ penalty_text='',
+ choice_text='',
+ is_unidirectional=False,
+ min_dec_penalty_text='',
+ logits_bias=-10000,
+ mask_type='word'
+ )
+
+ def copywriting_generation(self,
+ text: str,
+ min_dec_len: int = 32,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.2) -> str:
+ '''
+ 文案生成
+ '''
+ text = "标题:{} 文案:".format(text)
+ return self.custom_generation(
+ text,
+ min_dec_len,
+ seq_len,
+ topp,
+ penalty_score,
+ stop_token='',
+ task_prompt='adtext',
+ penalty_text='',
+ choice_text='',
+ is_unidirectional=False,
+ min_dec_penalty_text='',
+ logits_bias=-10000,
+ mask_type='word'
+ )
+
+ def novel_continuation(self,
+ text: str,
+ min_dec_len: int = 2,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.2) -> str:
+ '''
+ 小说续写
+ '''
+ text = "上文:{} 下文:".format(text)
+ return self.custom_generation(
+ text,
+ min_dec_len,
+ seq_len,
+ topp,
+ penalty_score,
+ stop_token='',
+ task_prompt='gPARAGRAPH',
+ penalty_text='',
+ choice_text='',
+ is_unidirectional=True,
+ min_dec_penalty_text='。?:![]',
+ logits_bias=-5,
+ mask_type='paragraph'
+ )
+
+ def answer_generation(self,
+ text: str,
+ min_dec_len: int = 2,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.2) -> str:
+ '''
+ 自由问答
+ '''
+ text = "问题:{} 回答:".format(text)
+ return self.custom_generation(
+ text,
+ min_dec_len,
+ seq_len,
+ topp,
+ penalty_score,
+ stop_token='',
+ task_prompt='qa',
+ penalty_text='[gEND]',
+ choice_text='',
+ is_unidirectional=True,
+ min_dec_penalty_text='。?:![]',
+ logits_bias=-5,
+ mask_type='paragraph'
+ )
+
+ def couplet_continuation(self,
+ text: str,
+ min_dec_len: int = 2,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.0) -> str:
+ '''
+ 对联续写
+ '''
+ text = "上联:{} 下联:".format(text)
+ return self.custom_generation(
+ text,
+ min_dec_len,
+ seq_len,
+ topp,
+ penalty_score,
+ stop_token='',
+ task_prompt='couplet',
+ penalty_text='',
+ choice_text='',
+ is_unidirectional=False,
+ min_dec_penalty_text='',
+ logits_bias=-10000,
+ mask_type='word'
+ )
+
+ def composition_generation(self,
+ text: str,
+ min_dec_len: int = 128,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.2) -> str:
+ '''
+ 作文创作
+ '''
+ text = "作文题目:{} 正文:".format(text)
+ return self.custom_generation(
+ text,
+ min_dec_len,
+ seq_len,
+ topp,
+ penalty_score,
+ stop_token='',
+ task_prompt='zuowen',
+ penalty_text='',
+ choice_text='',
+ is_unidirectional=False,
+ min_dec_penalty_text='',
+ logits_bias=-10000,
+ mask_type='word'
+ )
+
+ def text_cloze(self,
+ text: str,
+ min_dec_len: int = 1,
+ seq_len: int = 512,
+ topp: float = 0.9,
+ penalty_score: float = 1.0) -> str:
+ '''
+ 完形填空
+ '''
+ return self.custom_generation(
+ text,
+ min_dec_len,
+ seq_len,
+ topp,
+ penalty_score,
+ stop_token='',
+ task_prompt='cloze',
+ penalty_text='',
+ choice_text='',
+ is_unidirectional=False,
+ min_dec_penalty_text='',
+ logits_bias=-10000,
+ mask_type='word'
+ )
+
+ @runnable
+ def cmd(self, argvs):
+ parser = argparse.ArgumentParser(
+ description="Run the {}".format(self.name),
+ prog="hub run {}".format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+
+ parser.add_argument('--text', type=str, required=True)
+ parser.add_argument('--min_dec_len', type=int, default=1)
+ parser.add_argument('--seq_len', type=int, default=128)
+ parser.add_argument('--topp', type=float, default=1.0)
+ parser.add_argument('--penalty_score', type=float, default=1.0)
+ parser.add_argument('--stop_token', type=str, default='')
+ parser.add_argument('--task_prompt', type=str, default='')
+ parser.add_argument('--penalty_text', type=str, default='')
+ parser.add_argument('--choice_text', type=str, default='')
+ parser.add_argument('--is_unidirectional', type=bool, default=False)
+ parser.add_argument('--min_dec_penalty_text', type=str, default='')
+ parser.add_argument('--logits_bias', type=int, default=-10000)
+ parser.add_argument('--mask_type', type=str, default='word')
+ parser.add_argument('--ak', type=str, default='')
+ parser.add_argument('--sk', type=str, default='')
+ parser.add_argument('--task', type=str, default='custom_generation')
+
+ args = parser.parse_args(argvs)
+
+ func = getattr(self, args.task)
+
+ if (args.ak != '') and (args.sk != ''):
+ self.access_token = get_access_token(args.ak, args.sk)
+
+ kwargs = vars(args)
+ if kwargs['task'] not in ['custom_generation']:
+ kwargs.pop('stop_token')
+ kwargs.pop('task_prompt')
+ kwargs.pop('penalty_text')
+ kwargs.pop('choice_text')
+ kwargs.pop('is_unidirectional')
+ kwargs.pop('min_dec_penalty_text')
+ kwargs.pop('logits_bias')
+ kwargs.pop('mask_type')
+ default_kwargs = {
+ 'min_dec_len': 1,
+ 'seq_len': 128,
+ 'topp': 1.0,
+ 'penalty_score': 1.0
+ }
+ else:
+ default_kwargs = {
+ 'min_dec_len': 1,
+ 'seq_len': 128,
+ 'topp': 1.0,
+ 'penalty_score': 1.0,
+ 'stop_token': '',
+ 'task_prompt': '',
+ 'penalty_text': '',
+ 'choice_text': '',
+ 'is_unidirectional': False,
+ 'min_dec_penalty_text': '',
+ 'logits_bias': -10000,
+ 'mask_type': 'word'
+ }
+ kwargs.pop('task')
+ kwargs.pop('ak')
+ kwargs.pop('sk')
+
+ for k in default_kwargs.keys():
+ if kwargs[k] == default_kwargs[k]:
+ kwargs.pop(k)
+
+ return func(**kwargs)
+
+
+if __name__ == '__main__':
+ ernie_zeus = ERNIEZeus()
+
+ result = ernie_zeus.custom_generation(
+ '你好,'
+ )
+ print(result)
+
+ result = ernie_zeus.text_generation(
+ '给宠物猫起一些可爱的名字。名字:'
+ )
+ print(result)
+
+ result = ernie_zeus.text_summarization(
+ '在芬兰、瑞典提交“入约”申请近一个月来,北约成员国内部尚未对此达成一致意见。与此同时,俄罗斯方面也多次对北约“第六轮扩张”发出警告。据北约官网显示,北约秘书长斯托尔滕贝格将于本月12日至13日出访瑞典和芬兰,并将分别与两国领导人进行会晤。'
+ )
+ print(result)
+
+ result = ernie_zeus.copywriting_generation(
+ '芍药香氛的沐浴乳'
+ )
+ print(result)
+
+ result = ernie_zeus.novel_continuation(
+ '昆仑山可以说是天下龙脉的根源,所有的山脉都可以看作是昆仑的分支。这些分出来的枝枝杈杈,都可以看作是一条条独立的龙脉。'
+ )
+ print(result)
+
+ result = ernie_zeus.answer_generation(
+ '交朋友的原则是什么?'
+ )
+ print(result)
+
+ result = ernie_zeus.couplet_continuation(
+ '五湖四海皆春色'
+ )
+ print(result)
+
+ result = ernie_zeus.composition_generation(
+ '诚以养德,信以修身'
+ )
+ print(result)
+
+ result = ernie_zeus.text_cloze(
+ '她有着一双[MASK]的眼眸。'
+ )
+ print(result)
diff --git a/modules/text/text_generation/ernie_zeus/requirements.txt b/modules/text/text_generation/ernie_zeus/requirements.txt
new file mode 100644
index 000000000..f2293605c
--- /dev/null
+++ b/modules/text/text_generation/ernie_zeus/requirements.txt
@@ -0,0 +1 @@
+requests
From 3dd26f86a850b704f20ffffff95ac5ac01c7d0af Mon Sep 17 00:00:00 2001
From: chenjian <1435317881@qq.com>
Date: Fri, 19 Aug 2022 19:31:57 +0800
Subject: [PATCH 035/117] Add release note v2.3.0
---
README.md | 20 +++++++++++++++-----
README_ch.md | 24 ++++++++++++++++++------
docs/docs_ch/release.md | 10 ++++++++++
docs/docs_en/release.md | 9 +++++++++
4 files changed, 52 insertions(+), 11 deletions(-)
diff --git a/README.md b/README.md
index 0fbb0bb87..fba466927 100644
--- a/README.md
+++ b/README.md
@@ -29,7 +29,7 @@ English | [简体中文](README_ch.md)
## Introduction and Features
- **PaddleHub** aims to provide developers with rich, high-quality, and directly usable pre-trained models.
-- **Abundant Pre-trained Models**: 360+ pre-trained models cover the 5 major categories, including Image, Text, Audio, Video, and Industrial application. All of them are free for download and offline usage.
+- **Abundant Pre-trained Models**: 360+ pre-trained models cover the 6 major categories, including Wenxin large models, Image, Text, Audio, Video, and Industrial application. All of them are free for download and offline usage.
- **No Need for Deep Learning Background**: you can use AI models quickly and enjoy the dividends of the artificial intelligence era.
- **Quick Model Prediction**: model prediction can be realized through a few lines of scripts to quickly experience the model effect.
- **Model As Service**: one-line command to build deep learning model API service deployment capabilities.
@@ -37,22 +37,32 @@ English | [简体中文](README_ch.md)
- **Cross-platform**: support Linux, Windows, MacOS and other operating systems.
### Recent updates
+- **🔥2022.08.19:** The v2.3.0 version is released, supports Wenxin large models and five text-to-image models based on disco diffusion(dd).
+ - Support [Wenxin large models API](https://wenxin.baidu.com/moduleApi) for Baidu ERNIE large-scale pre-trained model, including [**ERNIE-ViLG** model](https://aistudio.baidu.com/aistudio/projectdetail/4445016), which supports text-to-image task, and [**ERNIE 3.0 Zeus**](https://aistudio.baidu.com/aistudio/projectdetail/4445054) model, which supports applications such as writing essays, summarization, couplets, question answering, writing novels and completing text.
+ - Add five text-to-image domain models based on disco diffusion(dd), three for [English](https://aistudio.baidu.com/aistudio/projectdetail/4444984) and two for Chinese. Welcome to enjoy our **ERNIE-ViL**-based Chinese text-to-image module [disco_diffusion_ernievil_base](https://aistudio.baidu.com/aistudio/projectdetail/4444998) in aistudio.
- **2022.02.18:** Added Huggingface Org, add spaces and models to the org: [PaddlePaddle Huggingface](https://huggingface.co/PaddlePaddle)
-- **2021.12.22**,The v2.2.0 version is released. [1]More than 100 new models released,including dialog, speech, segmentation, OCR, text processing, GANs, and many other categories. The total number of pre-trained models reaches [**【360】**](https://www.paddlepaddle.org.cn/hublist). [2]Add an [indexed file](./modules/README.md) including useful information of pretrained models supported by PaddleHub. [3]Refactor README of pretrained models.
-- **2021.05.12:** Add an open-domain dialogue system, i.e., [plato-mini](https://www.paddlepaddle.org.cn/hubdetail?name=plato-mini&en_category=TextGeneration), to make it easy to build a chatbot in wechat with the help of the wechaty, [See Demo](https://github.com/KPatr1ck/paddlehub-wechaty-demo)
-- **2021.04.27:** The v2.1.0 version is released. [1] Add supports for five new models, including two high-precision semantic segmentation models based on VOC dataset and three voice classification models. [2] Enforce the transfer learning capabilities for image semantic segmentation, text semantic matching and voice classification on related datasets. [3] Add the export function APIs for two kinds of model formats, i.,e, ONNX and PaddleInference. [4] Add the support for [BentoML](https://github.com/bentoml/BentoML/), which is a cloud native framework for serving deployment. Users can easily serve pre-trained models from PaddleHub by following the [Tutorial notebooks](https://github.com/PaddlePaddle/PaddleHub/blob/release/v2.1/demo/serving/bentoml/cloud-native-model-serving-with-bentoml.ipynb). Also, see this announcement and [Release note](https://github.com/bentoml/BentoML/releases/tag/v0.12.1) from BentoML. (Many thanks to @[parano](https://github.com/parano) @[cqvu](https://github.com/cqvu) @[deehrlic](https://github.com/deehrlic) for contributing this feature in PaddleHub). [5] The total number of pre-trained models reaches **【300】**.
-- **2021.02.18:** The v2.0.0 version is released, making model development and debugging easier, and the finetune task is more flexible and easy to use.The ability to transfer learning for visual tasks is fully upgraded, supporting various tasks such as image classification, image coloring, and style transfer; Transformer models such as BERT, ERNIE, and RoBERTa are upgraded to dynamic graphs, supporting Fine-Tune capabilities for text classification and sequence labeling; Optimize the Serving capability, support multi-card prediction, automatic load balancing, and greatly improve performance; the new automatic data enhancement capability Auto Augment can efficiently search for data enhancement strategy combinations suitable for data sets. 61 new word vector models were added, including 51 Chinese models and 10 English models; add 4 image segmentation models, 2 depth models, 7 image generation models, and 3 text generation models, the total number of pre-trained models reaches **【274】**.
+- **🔥2021.12.22**,The v2.2.0 version is released. [1]More than 100 new models released,including dialog, speech, segmentation, OCR, text processing, GANs, and many other categories. The total number of pre-trained models reaches [**【360】**](https://www.paddlepaddle.org.cn/hublist). [2]Add an [indexed file](./modules/README.md) including useful information of pretrained models supported by PaddleHub. [3]Refactor README of pretrained models.
+
- [【more】](./docs/docs_en/release.md)
## Visualization Demo [[More]](./docs/docs_en/visualization.md) [[ModelList]](./modules)
+
+
+### **[Wenxin large models](https://www.paddlepaddle.org.cn/hubdetail?name=ernie_vilg&en_category=TextToImage)**
+- Include ERNIE-ViL、ERNIE 3.0 Zeus, supports applications such as text-to-image, writing essays, summarization, couplets, question answering, writing novels and completing text.
+
+
+
### **[Computer Vision (212 models)](./modules#Image)**
 +
+
- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
diff --git a/README_ch.md b/README_ch.md
index 7d6811b67..93018de64 100644
--- a/README_ch.md
+++ b/README_ch.md
@@ -30,7 +30,7 @@
## 简介与特性
- PaddleHub旨在为开发者提供丰富的、高质量的、直接可用的预训练模型
-- **【模型种类丰富】**: 涵盖CV、NLP、Audio、Video、工业应用主流五大品类的 **360+** 预训练模型,全部开源下载,离线可运行
+- **【模型种类丰富】**: 涵盖大模型、CV、NLP、Audio、Video、工业应用主流六大品类的 **360+** 预训练模型,全部开源下载,离线可运行
- **【超低使用门槛】**:无需深度学习背景、无需数据与训练过程,可快速使用AI模型
- **【一键模型快速预测】**:通过一行命令行或者极简的Python API实现模型调用,可快速体验模型效果
- **【一键模型转服务化】**:一行命令,搭建深度学习模型API服务化部署能力
@@ -38,18 +38,30 @@
- **【跨平台兼容性】**:可运行于Linux、Windows、MacOS等多种操作系统
## 近期更新
-- **2021.12.22**,发布v2.2.0版本。【1】新增100+高质量模型,涵盖对话、语音处理、语义分割、文字识别、文本处理、图像生成等多个领域,预训练模型总量达到[**【360+】**](https://www.paddlepaddle.org.cn/hublist);【2】新增模型[检索列表](./modules/README_ch.md),包含模型名称、网络、数据集和使用场景等信息,快速定位用户所需的模型;【3】模型文档排版优化,呈现数据集、指标、模型大小等更多实用信息。
-- **2021.05.12**,新增轻量级中文对话模型[plato-mini](https://www.paddlepaddle.org.cn/hubdetail?name=plato-mini&en_category=TextGeneration),可以配合使用wechaty实现微信闲聊机器人,[参考demo](https://github.com/KPatr1ck/paddlehub-wechaty-demo)
-- **2021.04.27**,发布v2.1.0版本。【1】新增基于VOC数据集的高精度语义分割模型2个,语音分类模型3个。【2】新增图像语义分割、文本语义匹配、语音分类等相关任务的Fine-Tune能力以及相关任务数据集;完善部署能力:【3】新增ONNX和PaddleInference等模型格式的导出功能。【4】新增[BentoML](https://github.com/bentoml/BentoML) 云原生服务化部署能力,可以支持统一的多框架模型管理和模型部署的工作流,[详细教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v2.1/demo/serving/bentoml/cloud-native-model-serving-with-bentoml.ipynb). 更多内容可以参考BentoML 最新 v0.12.1 [Releasenote](https://github.com/bentoml/BentoML/releases/tag/v0.12.1).(感谢@[parano](https://github.com/parano) @[cqvu](https://github.com/cqvu) @[deehrlic](https://github.com/deehrlic))的贡献与支持。【5】预训练模型总量达到[**【300】**](https://www.paddlepaddle.org.cn/hublist)个。
-- **2021.02.18**,发布v2.0.0版本,【1】模型开发调试更简单,finetune接口更加灵活易用。视觉类任务迁移学习能力全面升级,支持[图像分类](./demo/image_classification/README.md)、[图像着色](./demo/colorization/README.md)、[风格迁移](./demo/style_transfer/README.md)等多种任务;BERT、ERNIE、RoBERTa等Transformer类模型升级至动态图,支持[文本分类](./demo/text_classification/README.md)、[序列标注](./demo/sequence_labeling/README.md)的Fine-Tune能力;【2】优化服务化部署Serving能力,支持多卡预测、自动负载均衡,性能大幅度提升;【3】新增自动数据增强能力[Auto Augment](./demo/autoaug/README.md),能高效地搜索适合数据集的数据增强策略组合。【4】新增[词向量模型](./modules/text/embedding)61个,其中包含中文模型51个,英文模型10个;新增[图像分割](./modules/thirdparty/image/semantic_segmentation)模型4个、[深度模型](./modules/thirdparty/image/depth_estimation)2个、[图像生成](./modules/thirdparty/image/Image_gan/style_transfer)模型7个、[文本生成](./modules/thirdparty/text/text_generation)模型3个。【5】预训练模型总量达到[**【274】**](https://www.paddlepaddle.org.cn/hublist) 个。
-- [More](./docs/docs_ch/release.md)
+- **🔥2022.08.19:** 发布v2.3.0版本新增[文心大模型](https://wenxin.baidu.com/)和disco diffusion(dd)系列文图生成模型。
+ - 支持对[文心大模型API](https://wenxin.baidu.com/moduleApi)的调用, 包括 文图生成模型**ERNIE-ViLG**([体验Demo](https://aistudio.baidu.com/aistudio/projectdetail/4445016)), 以及支持写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等多个应用的语言模型**ERNIE 3.0 Zeus**([体验Demo](https://aistudio.baidu.com/aistudio/projectdetail/4445054))。
+ - 新增基于disco diffusion技术的文图生成dd系列模型5个,其中英文模型([体验Demo](https://aistudio.baidu.com/aistudio/projectdetail/4444984))3个,中文模型2个。欢迎点击链接在aistudio上进行体验基于**ERNIE-ViL**开发的中文文图生成模型disco_diffusion_ernievil_base([体验Demo](https://aistudio.baidu.com/aistudio/projectdetail/4444998))。
+- **2022.02.18:** 加入Huggingface,创建了PaddlePaddle的空间并上传了模型: [PaddlePaddle Huggingface](https://huggingface.co/PaddlePaddle)。
+
+- **🔥2021.12.22**,发布v2.2.0版本新增[预训练模型库官网](https://www.paddlepaddle.org.cn/hublist)。
+ - 新增100+高质量模型,涵盖对话、语音处理、语义分割、文字识别、文本处理、图像生成等多个领域,预训练模型总量达到【360+】;
+ - 新增模型[检索列表](./modules/README_ch.md),包含模型名称、网络、数据集和使用场景等信息,快速定位用户所需的模型;
+ - 模型文档排版优化,呈现数据集、指标、模型大小等更多实用信息。
+- [More](./docs/docs_ch/release.md)
## **精品模型效果展示[【更多】](./docs/docs_ch/visualization.md)[【模型库】](./modules/README_ch.md)**
+### **[文心大模型](https://www.paddlepaddle.org.cn/hubdetail?name=ernie_vilg&en_category=TextToImage)**
+- 包含大模型ERNIE-ViL、ERNIE 3.0 Zeus, 支持文图生成、写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等多个应用。
+
+
+
- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
diff --git a/README_ch.md b/README_ch.md
index 7d6811b67..93018de64 100644
--- a/README_ch.md
+++ b/README_ch.md
@@ -30,7 +30,7 @@
## 简介与特性
- PaddleHub旨在为开发者提供丰富的、高质量的、直接可用的预训练模型
-- **【模型种类丰富】**: 涵盖CV、NLP、Audio、Video、工业应用主流五大品类的 **360+** 预训练模型,全部开源下载,离线可运行
+- **【模型种类丰富】**: 涵盖大模型、CV、NLP、Audio、Video、工业应用主流六大品类的 **360+** 预训练模型,全部开源下载,离线可运行
- **【超低使用门槛】**:无需深度学习背景、无需数据与训练过程,可快速使用AI模型
- **【一键模型快速预测】**:通过一行命令行或者极简的Python API实现模型调用,可快速体验模型效果
- **【一键模型转服务化】**:一行命令,搭建深度学习模型API服务化部署能力
@@ -38,18 +38,30 @@
- **【跨平台兼容性】**:可运行于Linux、Windows、MacOS等多种操作系统
## 近期更新
-- **2021.12.22**,发布v2.2.0版本。【1】新增100+高质量模型,涵盖对话、语音处理、语义分割、文字识别、文本处理、图像生成等多个领域,预训练模型总量达到[**【360+】**](https://www.paddlepaddle.org.cn/hublist);【2】新增模型[检索列表](./modules/README_ch.md),包含模型名称、网络、数据集和使用场景等信息,快速定位用户所需的模型;【3】模型文档排版优化,呈现数据集、指标、模型大小等更多实用信息。
-- **2021.05.12**,新增轻量级中文对话模型[plato-mini](https://www.paddlepaddle.org.cn/hubdetail?name=plato-mini&en_category=TextGeneration),可以配合使用wechaty实现微信闲聊机器人,[参考demo](https://github.com/KPatr1ck/paddlehub-wechaty-demo)
-- **2021.04.27**,发布v2.1.0版本。【1】新增基于VOC数据集的高精度语义分割模型2个,语音分类模型3个。【2】新增图像语义分割、文本语义匹配、语音分类等相关任务的Fine-Tune能力以及相关任务数据集;完善部署能力:【3】新增ONNX和PaddleInference等模型格式的导出功能。【4】新增[BentoML](https://github.com/bentoml/BentoML) 云原生服务化部署能力,可以支持统一的多框架模型管理和模型部署的工作流,[详细教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v2.1/demo/serving/bentoml/cloud-native-model-serving-with-bentoml.ipynb). 更多内容可以参考BentoML 最新 v0.12.1 [Releasenote](https://github.com/bentoml/BentoML/releases/tag/v0.12.1).(感谢@[parano](https://github.com/parano) @[cqvu](https://github.com/cqvu) @[deehrlic](https://github.com/deehrlic))的贡献与支持。【5】预训练模型总量达到[**【300】**](https://www.paddlepaddle.org.cn/hublist)个。
-- **2021.02.18**,发布v2.0.0版本,【1】模型开发调试更简单,finetune接口更加灵活易用。视觉类任务迁移学习能力全面升级,支持[图像分类](./demo/image_classification/README.md)、[图像着色](./demo/colorization/README.md)、[风格迁移](./demo/style_transfer/README.md)等多种任务;BERT、ERNIE、RoBERTa等Transformer类模型升级至动态图,支持[文本分类](./demo/text_classification/README.md)、[序列标注](./demo/sequence_labeling/README.md)的Fine-Tune能力;【2】优化服务化部署Serving能力,支持多卡预测、自动负载均衡,性能大幅度提升;【3】新增自动数据增强能力[Auto Augment](./demo/autoaug/README.md),能高效地搜索适合数据集的数据增强策略组合。【4】新增[词向量模型](./modules/text/embedding)61个,其中包含中文模型51个,英文模型10个;新增[图像分割](./modules/thirdparty/image/semantic_segmentation)模型4个、[深度模型](./modules/thirdparty/image/depth_estimation)2个、[图像生成](./modules/thirdparty/image/Image_gan/style_transfer)模型7个、[文本生成](./modules/thirdparty/text/text_generation)模型3个。【5】预训练模型总量达到[**【274】**](https://www.paddlepaddle.org.cn/hublist) 个。
-- [More](./docs/docs_ch/release.md)
+- **🔥2022.08.19:** 发布v2.3.0版本新增[文心大模型](https://wenxin.baidu.com/)和disco diffusion(dd)系列文图生成模型。
+ - 支持对[文心大模型API](https://wenxin.baidu.com/moduleApi)的调用, 包括 文图生成模型**ERNIE-ViLG**([体验Demo](https://aistudio.baidu.com/aistudio/projectdetail/4445016)), 以及支持写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等多个应用的语言模型**ERNIE 3.0 Zeus**([体验Demo](https://aistudio.baidu.com/aistudio/projectdetail/4445054))。
+ - 新增基于disco diffusion技术的文图生成dd系列模型5个,其中英文模型([体验Demo](https://aistudio.baidu.com/aistudio/projectdetail/4444984))3个,中文模型2个。欢迎点击链接在aistudio上进行体验基于**ERNIE-ViL**开发的中文文图生成模型disco_diffusion_ernievil_base([体验Demo](https://aistudio.baidu.com/aistudio/projectdetail/4444998))。
+- **2022.02.18:** 加入Huggingface,创建了PaddlePaddle的空间并上传了模型: [PaddlePaddle Huggingface](https://huggingface.co/PaddlePaddle)。
+
+- **🔥2021.12.22**,发布v2.2.0版本新增[预训练模型库官网](https://www.paddlepaddle.org.cn/hublist)。
+ - 新增100+高质量模型,涵盖对话、语音处理、语义分割、文字识别、文本处理、图像生成等多个领域,预训练模型总量达到【360+】;
+ - 新增模型[检索列表](./modules/README_ch.md),包含模型名称、网络、数据集和使用场景等信息,快速定位用户所需的模型;
+ - 模型文档排版优化,呈现数据集、指标、模型大小等更多实用信息。
+- [More](./docs/docs_ch/release.md)
## **精品模型效果展示[【更多】](./docs/docs_ch/visualization.md)[【模型库】](./modules/README_ch.md)**
+### **[文心大模型](https://www.paddlepaddle.org.cn/hubdetail?name=ernie_vilg&en_category=TextToImage)**
+- 包含大模型ERNIE-ViL、ERNIE 3.0 Zeus, 支持文图生成、写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等多个应用。
+ +
+
+
### **[图像类(212个)](./modules/README_ch.md#图像)**
- 包括图像分类、人脸检测、口罩检测、车辆检测、人脸/人体/手部关键点检测、人像分割、80+语言文本识别、图像超分/上色/动漫化等
+
diff --git a/docs/docs_ch/release.md b/docs/docs_ch/release.md
index b7e82c9d6..8eebd7202 100755
--- a/docs/docs_ch/release.md
+++ b/docs/docs_ch/release.md
@@ -1,5 +1,15 @@
# 更新历史
+## `v2.3.0`
+
+### 【1、支持文图生成新场景】
+ - 新增基于disco diffusion技术的文图生成dd系列模型5个,其中英文模型3个,中文模型2个,其中中文文图生成模型[disco_diffusion_ernievil_base](https://aistudio.baidu.com/aistudio/projectdetail/4444998)基于百度自研多模态模型**ERNIE-ViL**开发,欢迎体验。
+
+### 【2、支持文心大模型API调用】
+ - 新增对文心大模型[**ERNIE-ViLG**](https://aistudio.baidu.com/aistudio/projectdetail/4445016)的API调用,支持文图生成任务。
+ - 新增对文心大模型[**ERNIE 3.0 Zeus**](https://aistudio.baidu.com/aistudio/projectdetail/4445054)的API调用,支持写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等多个应用。
+
+
## `v2.1.0`
### 【1、版本迭代】
diff --git a/docs/docs_en/release.md b/docs/docs_en/release.md
index 407d95ca8..781ecdf65 100755
--- a/docs/docs_en/release.md
+++ b/docs/docs_en/release.md
@@ -1,5 +1,14 @@
# Release Note
+## `v2.3.0`
+
+### [1、Support text-to-image domain model]
+ - Add five text-to-image domain models based on disco diffusion, in which three models are for English and two for Chinese. Especially, Chinese text-to-image model [disco_diffusion_ernievil_base](https://aistudio.baidu.com/aistudio/projectdetail/4444998) is based on Baidu **ERNIE-ViL**,welcome to experience.
+
+### 【2、Support Wenxin large models API】
+ - Add api call for [**ERNIE-ViLG**](https://aistudio.baidu.com/aistudio/projectdetail/4445016) model, which supports text-to-image task。
+ - Add api call for [**ERNIE 3.0 Zeus**](https://aistudio.baidu.com/aistudio/projectdetail/4445054) model, which supports applications such as writing essays, summarization, couplets, question answering, writing novels and completing text.
+
## `v2.1.0`
### [ 1. Improvements]
From 31a5c90a3c5be2f57028c83a32cd14eab014b492 Mon Sep 17 00:00:00 2001
From: chenjian
+
+
+
### **[图像类(212个)](./modules/README_ch.md#图像)**
- 包括图像分类、人脸检测、口罩检测、车辆检测、人脸/人体/手部关键点检测、人像分割、80+语言文本识别、图像超分/上色/动漫化等
+
diff --git a/docs/docs_ch/release.md b/docs/docs_ch/release.md
index b7e82c9d6..8eebd7202 100755
--- a/docs/docs_ch/release.md
+++ b/docs/docs_ch/release.md
@@ -1,5 +1,15 @@
# 更新历史
+## `v2.3.0`
+
+### 【1、支持文图生成新场景】
+ - 新增基于disco diffusion技术的文图生成dd系列模型5个,其中英文模型3个,中文模型2个,其中中文文图生成模型[disco_diffusion_ernievil_base](https://aistudio.baidu.com/aistudio/projectdetail/4444998)基于百度自研多模态模型**ERNIE-ViL**开发,欢迎体验。
+
+### 【2、支持文心大模型API调用】
+ - 新增对文心大模型[**ERNIE-ViLG**](https://aistudio.baidu.com/aistudio/projectdetail/4445016)的API调用,支持文图生成任务。
+ - 新增对文心大模型[**ERNIE 3.0 Zeus**](https://aistudio.baidu.com/aistudio/projectdetail/4445054)的API调用,支持写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等多个应用。
+
+
## `v2.1.0`
### 【1、版本迭代】
diff --git a/docs/docs_en/release.md b/docs/docs_en/release.md
index 407d95ca8..781ecdf65 100755
--- a/docs/docs_en/release.md
+++ b/docs/docs_en/release.md
@@ -1,5 +1,14 @@
# Release Note
+## `v2.3.0`
+
+### [1、Support text-to-image domain model]
+ - Add five text-to-image domain models based on disco diffusion, in which three models are for English and two for Chinese. Especially, Chinese text-to-image model [disco_diffusion_ernievil_base](https://aistudio.baidu.com/aistudio/projectdetail/4444998) is based on Baidu **ERNIE-ViL**,welcome to experience.
+
+### 【2、Support Wenxin large models API】
+ - Add api call for [**ERNIE-ViLG**](https://aistudio.baidu.com/aistudio/projectdetail/4445016) model, which supports text-to-image task。
+ - Add api call for [**ERNIE 3.0 Zeus**](https://aistudio.baidu.com/aistudio/projectdetail/4445054) model, which supports applications such as writing essays, summarization, couplets, question answering, writing novels and completing text.
+
## `v2.1.0`
### [ 1. Improvements]
From 31a5c90a3c5be2f57028c83a32cd14eab014b492 Mon Sep 17 00:00:00 2001
From: chenjian  +
+# PaddleHub ERNIE-ViLG
|模型名称|ernie_vilg|
| :--- | :---: |
@@ -14,11 +17,11 @@
### 应用效果展示
- - 输入文本 "宁静的小镇" 风格 "油画"
+ - 输入文本 "戴眼镜的猫" 风格 "油画"
- 输出图像
+
+
+# PaddleHub ERNIE-ViLG
|模型名称|ernie_vilg|
| :--- | :---: |
@@ -14,11 +17,11 @@
### 应用效果展示
- - 输入文本 "宁静的小镇" 风格 "油画"
+ - 输入文本 "戴眼镜的猫" 风格 "油画"
- 输出图像
+ 
@@ -48,7 +51,7 @@
- ### 1、命令行预测
- ```shell
- $ hub run ernie_vilg --text_prompts "宁静的小镇" --output_dir ernie_vilg_out
+ $ hub run ernie_vilg --text_prompts "宁静的小镇" --style "油画" --output_dir ernie_vilg_out
```
- ### 2、预测代码示例
@@ -58,25 +61,16 @@
module = hub.Module(name="ernie_vilg")
text_prompts = ["宁静的小镇"]
- images = module.generate_image(text_prompts=text_prompts, output_dir='./ernie_vilg_out/')
+ images = module.generate_image(text_prompts=text_prompts, style='油画', output_dir='./ernie_vilg_out/')
```
- ### 3、API
- - ```python
- def __init__(ak: Optional[str]=None, sk: Optional[str]=None)
- ```
- - 初始化模块,可自定义用于申请访问文心API的ak和sk。
-
- - **参数**
- - ak:(Optional[str]): 用于申请文心api使用token的ak,可不填。
- - sk:(Optional[str]): 用于申请文心api使用token的sk,可不填。
-
- ```python
def generate_image(
text_prompts:str,
style: Optional[str] = "油画",
- topk: Optional[int] = 10,
+ topk: Optional[int] = 6,
output_dir: Optional[str] = 'ernievilg_output')
```
@@ -85,8 +79,8 @@
- **参数**
- text_prompts(str): 输入的语句,描述想要生成的图像的内容。
- - style(Optional[str]): 生成图像的风格,当前支持'油画','水彩','粉笔画','卡通','儿童画','蜡笔画'。
- - topk(Optional[int]): 保存前多少张图,最多保存10张。
+ - style(Optional[str]): 生成图像的风格,当前支持'油画','水彩','粉笔画','卡通','儿童画','蜡笔画','探索无限'。
+ - topk(Optional[int]): 保存前多少张图,最多保存6张。
- output_dir(Optional[str]): 保存输出图像的目录,默认为"ernievilg_output"。
@@ -141,3 +135,653 @@
```shell
$ hub install ernie_vilg == 1.0.0
```
+
+
+
+
+## 六、 Prompt 指南
+
+
+
+这是一份如何调整 Prompt 得到更漂亮的图片的经验性文档。我们的结果和经验都来源于[文心 ERNIE-ViLG Demo](https://wenxin.baidu.com/moduleApi/ernieVilg) 和[社区的资料](#related-work)。
+
+什么是 Prompt?Prompt 是输入到 Demo 中的文字,可以是一个实体,例如猫;也可以是一串富含想象力的文字,例如:『夕阳日落时,天边有巨大的云朵,海面波涛汹涌,风景,胶片感』。不同的 Prompt 对于生成的图像质量影响非常大。所以也就有了下面所有的 Prompt 的一些经验性技巧。
+
+|  |
+| :----------------------------------------------------------: |
+| 蒙娜丽莎,赛博朋克,宝丽来,33毫米,蒸汽波艺术 |
+
+
+
+
+## 前言
+
+Prompt 的重要性如此重要,以至于我们需要构造一个示例来进行一次说明。
+
+如下图,[文心 ERNIE-ViLG Demo](https://wenxin.baidu.com/moduleApi/ernieVilg) 中,『卡通』模式下,输入的 Prompt 为『橘猫』,以及 『卡通』模型式下『极乐迪斯科里的猫, 故障艺术』两个示例,能够看出来后者的细节更多,呈现的图片也更加的风格化。
+
+开放风格限制(本质上就是在 Prompt 中不加入风格控制词),即下图图3,得到的图片细节更多、也更加真实,同时还保留了比较强烈的风格元素。所以后面的所有内容,都将围绕着如何构造更好的 Prompt 进行资料的整理。
+
+|  |  |  |
+| :----------------------------------------------------------: | :----------------------------------------------------------: | ------------------------------------------------------------ |
+| “橘猫”(卡通) | “极乐迪斯科里的猫, 故障艺术”(卡通) | “极乐迪斯科里的猫, 故障艺术” (探索无限) |
+
+|  |
+| :----------------------------: |
+| 极乐迪斯科里的猫,故障艺术 |
+
+
+
+## 呼吁与准则
+
+机器生成图片的最终目的还是便捷地为人类创造美的作品。而技术不是十全十美的,不能保证每次生成的图像都能够尽善尽美。因此呼吁所有相关玩家,如果想分享作品,那就分享那些美感爆棚的作品!
+
+算法生成的图片难免会受到数据的影响,从而导致生成的图片是有数据偏见的。因此在分享机器生成图片到社交媒体之前,请三思当前的图片是不是含有:令人不适的、暴力的、色情的内容。如果有以上的内容请自行承担法律后果。
+
+
+
+## Prompt 的设计
+
+如何设计 Prompt,下文大概会通过4个方面来说明:[Prompt 公式](#p-eq),[Prompt 原则](#p-principle),[Prompt 主体](#p-entity)、[Prompt 修饰词](#p-modifier)。
+
+需要注意的是,这里的 Prompt 公式仅仅是个入门级别的参考,是经验的简单总结,在熟悉了 Prompt 的原理之后,可以尽情的发挥脑洞修改 Prompt。
+
+
+
+
+
+
+## Prompt 公式
+
+$$
+Prompt = [形容词] [主语] ,[细节设定], [修饰语或者艺术家]
+$$
+
+按照这个公式,我们首先构造一个形容词加主语的案例。 这里我构造的是 戴着眼镜的猫, 风格我选择的是油画风格,然后我再添加一些细节设定,这里我给的是 漂浮在宇宙中, 可以看到 ,猫猫的后面出现了很多天体。
+
+|  |  |  |
+| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
+| “戴着眼镜的猫”(油画) | “戴着眼镜的猫,漂浮在宇宙中”(油画) | “戴着眼镜的猫,漂浮在宇宙中,高更风格”(油画) |
+
+最后我们想让我们的照片风格更加有艺术性的效果, 我们选择的艺术家是高更, 可以看到图像的画风有了更强的艺术风格。
+
+
+
+
+## Prompt 设计原则
+
+### Prompt 简单原则: 清楚地陈述
+
+除了公式之外,也有一些简单的 Prompt设计原则分享给大家:即**清楚的陈述**。
+
+例如我们如果是简单的输入风景的话,往往模型不知道我们想要的风景是什么样子的(下图1)。我们要去尽量的幻想风景的样子,然后变成语言描述。 例如我想像的是日落时,海边的风景, 那我就构造了 Prompt 『夕阳日落时,阳光落在云层上,海面波光粼粼,风景』(下图2)。 进一步的,我想风格化我的图像,所以我在结尾的部分,增加了『胶片感』来让图片的色彩更加好看一些(下图3)。但是云彩的细节丢失了一些,进一步的我再增加天边巨大云朵这一个细节,让我的图片朝着我想要的样子靠的更进一步(下图4)。
+
+|  |  |  |  |
+| :------------------------: | :----------------------------------------------: | :------------------------------------------------------: | -------------------------------------------------------- |
+| “风景” | “夕阳日落时,阳光落在云层上,海面波光粼粼,风景” | “夕阳日落时,阳光落在云层上,海面波涛汹涌,风景,胶片感” | 夕阳日落时,天边有巨大的云朵,海面波涛汹涌,风景,胶片感 |
+
+
+
+
+## Prompt 主体的选择
+
+Prompt 的主体可以是千奇百怪、各种各样的。这里我挑了几个简单的容易出效果的主体示例和一些能够营造特殊氛围的氛围词来激发大家的灵感。
+
+
+
+|  |  |  |  |
+| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
+| 宇航员 | 孤岛 | 白色城堡 | 机器人 |
+|  |  |  |  |
+| 巫师 | 罗马城 | 海鸥 | 气球 |
+
+
+
+
+
+|  |  |  |
+| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
+| …日落,霓虹灯…薄雾 | …烟… | …燃烧漩涡, …烟雾和碎片 |
+|  |  |  |
+| …废墟… | 光之… | 巨大的… |
+
+
+
+
+## Prompt 修饰词
+
+如果想让生成的图片更加的艺术化、风格话,可以考虑在 Prompt 中添加艺术修饰词。艺术修饰词可以是一些美术风格(例如表现主义、抽象主义等),也可以是一些美学词汇(蒸汽波艺术、故障艺术等),也可以是一些摄影术语(80mm摄像头、浅景深等),也可以是一些绘图软件(虚幻引擎、C4D等)。
+
+按照这样的规律,我们在两个输入基准上 :
+
+> 一只猫坐在椅子上,戴着一副墨镜
+>
+> 日落时的城市天际线
+>
+
+通过构造『输入 + Prompt 修饰词』来展示不同修饰词的效果 (这里的策略参考了[资料](https://docs.google.com/document/d/11WlzjBT0xRpQhP9tFMtxzd0q6ANIdHPUBkMV-YB043U/edit))。
+
+需要注意的是,不是所有的 Prompt 对于所有的修饰词都会发生反应。所以查阅 Prompt 修饰词的过程中,会发现部分的 Prompt 修饰词只能对两个基准中的一个生效。这是很正常的,因为 Prompt 的调优是一个反复的试错的过程。接下来,大家结合如下的 Prompt 修饰词, Happy Prompting 吧!
+
+
+
+### 复古未来主义风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,复古未来主义风格 | 日落时的城市天际线,复古未来主义风格 |
+
+
+
+### 粉彩朋克风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,粉彩朋克风格 | 日落时的城市天际线,粉彩朋克风格 |
+
+### 史前遗迹风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,史前遗迹风格 | 日落时的城市天际线,史前遗迹风格 |
+
+
+
+
+### 波普艺术风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,波普艺术风格 | 日落时的城市天际线,后世界末日风格 |
+
+
+
+### 迷幻风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,迷幻风格 | 日落时的城市天际线,迷幻风格 |
+
+
+### 赛博朋克风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,赛博朋克风格 | 日落时的城市天际线,赛博朋克风格 |
+
+
+### 纸箱风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,纸箱风格 | 日落时的城市天际线,纸箱风格 |
+
+### 未来主义风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,未来主义风格 | 一只猫坐在椅子上,戴着一副墨镜,未来主义风格 |
+
+
+
+### 抽象技术风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,抽象技术风格 | 日落时的城市天际线,抽象技术风格 |
+
+
+
+
+### 海滩兔风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,海滩兔风格 | 日落时的城市天际线,海滩兔风格 |
+
+
+### 粉红公主风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,粉红公主风格 | 日落时的城市天际线,粉红公主风格 |
+
+
+### 嬉皮士风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,嬉皮士风格 | 日落时的城市天际线,嬉皮士风格 |
+
+### 幻象之城风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,幻象之城风格 | 日落时的城市天际线,幻象之城风格 |
+
+
+### 美人鱼风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,美人鱼风格 | 日落时的城市天际线,美人鱼风格 |
+
+
+### 迷宫物语风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,迷宫物语风格 | 日落时的城市天际线,迷宫物语风格 |
+
+### 仙女风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,仙女风格 | 日落时的城市天际线,仙女风格 |
+
+
+
+
+
+### Low Poly 风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜, low poly 风格 | 日落时的城市天际线, low-poly |
+
+
+
+
+### 浮世绘风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,浮世绘风格 | 日落时的城市天际线,浮世绘风格 |
+
+### 矢量心风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,矢量心风格 | 日落时的城市天际线,矢量心风格 |
+
+
+### 摩托车手风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,摩托车手风格 | 日落时的城市天际线,摩托车手风格 |
+
+
+
+### 孟菲斯公司风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,孟菲斯公司风格 | 日落时的城市天际线,孟菲斯公司风格 |
+
+
+### 泥塑风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜, 泥塑风格 | 日落时的城市天际线, 泥塑风格 |
+
+
+
+
+### 苔藓风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,苔藓风格 | 日落时的城市天际线,苔藓风格 |
+
+
+
+### 新浪潮风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,新浪潮风格 | 日落时的城市天际线,新浪潮风格 |
+
+### 嘻哈风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,嘻哈风格 | 日落时的城市天际线,嘻哈风格 |
+
+### 矢量图
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜, 矢量图 | 日落时的城市天际线, 矢量图 |
+
+### 铅笔艺术
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜, 铅笔艺术 | 日落时的城市天际线, 铅笔艺术 |
+
+
+### 女巫店风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,女巫店风格 | 日落时的城市天际线,女巫店风格 |
+
+
+
+### 4D 建模
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜, 4D 建模 | 日落时的城市天际线, 4D 建模 |
+
+
+
+### 水彩墨风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜, 水彩墨风格 | 日落时的城市天际线, 水彩墨风格 |
+
+
+
+### 酸性精灵风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,酸性精灵风格 | 日落时的城市天际线,酸性精灵风格 |
+
+
+### 海盗风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 日落时的城市天际线,海盗风格 | 一只猫坐在椅子上,戴着一副墨镜,海盗风格 |
+
+
+
+### 古埃及风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,古埃及风格 | 日落时的城市天际线,古埃及风格 |
+
+### 风帽风格
+
+
+|  |  |
+| --------------------------------------------------------- | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,风帽风格 | 日落时的城市天际线,风帽风格 |
+
+### 装饰艺术风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,装饰艺术风格 | 日落时的城市天际线,装饰艺术风格 |
+
+### 极光风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,极光风格 | 日落时的城市天际线,极光风格 |
+
+### 秋天风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 日落时的城市天际线,秋天风格 | 一只猫坐在椅子上,戴着一副墨镜,秋天风格 |
+
+### 巴洛克风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,巴洛克风格 | 日落时的城市天际线,巴洛克风格 |
+
+### 立体主义风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,立体主义风格 | 日落时的城市天际线,立体主义风格 |
+
+
+### 黑暗自然主义风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,黑暗自然主义风格 | 日落时的城市天际线,黑暗自然主义风格 |
+
+### 表现主义风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,表现主义风格 | 日落时的城市天际线,表现主义风格 |
+
+### 野兽派风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,野兽派风格 | 日落时的城市天际线,野兽派风格 |
+
+### 鬼魂风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,鬼魂风格 | 日落时的城市天际线,鬼魂风格 |
+
+### 印象主义风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,印象主义风格 | 日落时的城市天际线,印象主义风格 |
+
+### 卡瓦伊风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,卡瓦伊风格 | 日落时的城市天际线,卡瓦伊风格 |
+
+### 极简主义风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,极简主义风格 | 日落时的城市天际线,极简主义风格 |
+
+### 水井惠郎风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,水井惠郎风格 | 日落时的城市天际线,水井惠郎风格 |
+
+### 照片写实风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,照片写实风格 | 日落时的城市天际线,照片写实风格 |
+
+
+### 像素可爱风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,像素可爱风格 | 日落时的城市天际线,像素可爱风格 |
+
+
+
+### 雨天风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 日落时的城市天际线,雨天风格 | 一只猫坐在椅子上,戴着一副墨镜,雨天风格 |
+
+### 湿漉漉的风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,湿漉漉的风格 | 日落时的城市天际线,湿漉漉的风格 |
+
+
+### 维京人风格
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,维京人风格 | 日落时的城市天际线,维京人风格 |
+
+### 后印象主义
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,风格:后印象主义 | 日落时的城市天际线, 风格:后印象主义-v2 |
+
+### 素人主义
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,风格:素人主义 | 日落时的城市天际线, 风格:素人艺术 |
+
+
+
+### 碎核风格
+
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只猫坐在椅子上,戴着一副墨镜,碎核风格 | 日落时的城市天际线,碎核风格 |
+
+
+
+
+
+
+
+## Prompt 更多信息
+
+### 概念组合
+
+
+
+## ShowCase
+
+更多 ShowCase 和创意 Prompt,可以参考我的[社交账号](#关注我) 或者是 http://youpromptme.cn/#/gallery/ (建设中)
+
+### 故障艺术
+
+|  |  |  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| _时钟故障,时间故障,概念艺术,艺术站总部,pixiv趋势,cgsociety,蒸汽波艺术 | 巨大的纯白色城堡-油画,故障艺术 | Yggdrasil,世界树和地球融合在一起,故障艺术 | 在百货公司和工厂的高商业需求中,未来复古科幻幻想对象或设备的专业概念艺术,故障艺术 |
+
+
+
+### 蒸汽波艺术
+
+|  |  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 荒岛,蒸汽波艺术 | Christoph-Vacher和Kevin-sloan创作的广阔幻想景观,蒸汽波艺术 | 戴着眼镜的猫,蒸汽波艺术 |
+
+
+### 包豪斯艺术
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 一只海鸥和史蒂文·西格正在进行一场凝视比赛,绘画,包豪斯 | 梵高猫头鹰,包豪斯 |
+
+
+
+
+
+### 概念艺术
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 4k专业HDR-DnD幻想概念艺术一条由闪电制成的令人敬畏的龙,概念艺术 | 4k专业HDR-DnD奇幻概念艺术小鸡施展幻觉咒语,概念艺术 |
+
+
+
+### 像素艺术
+
+|  |  |  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+
+
+
+### 艺术家
+
+|  |  |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 萨尔瓦多·达利描绘古代文明的超现实主义梦幻油画,写实风格 | 梵高猫头鹰,蒸汽波艺术 |
+
+
+
+
+## 附录
+
+### 常见的艺术家和艺术风格整理
+
+| 艺术类型 | 艺术家 | 常用艺术风格 |
+| ---------- | ---------------------- | ---------------------- |
+| 肖像画 | 文森特·梵高 | 印象主义 |
+| 风景画 | 尼古拉斯·罗伊里奇 | 现实主义 |
+| 风俗画 | 皮埃尔-奥古斯特·雷诺阿 | 浪漫主义 |
+| 宗教绘画 | 克劳德·莫内 | 表现主义 |
+| 抽象画 | 彼得·孔查洛夫斯基 | 后印象主义 |
+| 都市风景画 | 卡米尔·毕沙罗 | 象征主义 |
+| 素描与草图 | 约翰·辛格·萨金特 | 新艺术主义 |
+| 静物 | 伦勃朗 | 巴洛克风格 |
+| 裸体画 | 马克·夏加尔 | 抽象表现主义 |
+| 插画 | 巴勃罗·毕加索 | 北欧文艺复兴 |
+| | 古斯塔夫·多雷 | 素人艺术,原始主义 |
+| | 阿尔布雷特·丢勒 | 立体主义 |
+| | 鲍里斯·库斯妥基耶夫 | 洛可可 |
+| | 埃德加·德加 | 色域绘画 |
+| | | 波普艺术 |
+| | | 文艺复兴开端 |
+| | | 文艺复兴全盛期 |
+| | | 极简主义 |
+| | | 矫饰主义,文艺复兴晚期 |
+
+
+
+### 常见的摄影风格词整理
+
+| 可以加入到 Prompt 中的摄影词 | |
+| ---------------------------- | ------------ |
+| 浅景深 | 仰拍 |
+| 负像 | 动态模糊 |
+| 微距 | 高反差 |
+| 双色版 | 中心构图 |
+| 角度 | 逆光 |
+| 三分法 | 长曝光 |
+| 抓拍 | 禅宗摄影 |
+| 软焦点 | 抽象微距镜头 |
+| 黑白 | 暗色调 |
+| 无镜反射 | 长时间曝光 |
+| 双色调 | 框架,取景 |
+| 颗粒图像 | |
+
+
+
+
+### 相关链接
+
+美学相关的词汇: https://aesthetics.fandom.com/wiki/List_of_Aesthetics
+
+DALL-E 2 的 Prompt 技巧资料:https://docs.google.com/document/d/11WlzjBT0xRpQhP9tFMtxzd0q6ANIdHPUBkMV-YB043U/edit
+
+DiscoDiffusion Prompt 技巧资料:https://docs.google.com/document/d/1l8s7uS2dGqjztYSjPpzlmXLjl5PM3IGkRWI3IiCuK7g/edit
diff --git a/modules/image/text_to_image/ernie_vilg/module.py b/modules/image/text_to_image/ernie_vilg/module.py
index dad3c9833..38ed6b9d4 100755
--- a/modules/image/text_to_image/ernie_vilg/module.py
+++ b/modules/image/text_to_image/ernie_vilg/module.py
@@ -66,13 +66,15 @@ def generate_image(self,
text_prompts,
style: Optional[str] = "油画",
topk: Optional[int] = 10,
+ visualization: Optional[bool] = True,
output_dir: Optional[str] = 'ernievilg_output'):
"""
Create image by text prompts using ErnieVilG model.
:param text_prompts: Phrase, sentence, or string of words and phrases describing what the image should look like.
- :param style: Image stype, currently supported 油画、水彩、粉笔画、卡通、儿童画、蜡笔画
+ :param style: Image stype, currently supported 油画、水彩、粉笔画、卡通、儿童画、蜡笔画、探索无限。
:param topk: Top k images to save.
+ :param visualization: Whether to save images or not.
:output_dir: Output directory
"""
if not os.path.exists(output_dir):
@@ -186,7 +188,8 @@ def generate_image(self,
for text, data in results.items():
for idx, imgdata in enumerate(data['imgUrls']):
image = Image.open(BytesIO(requests.get(imgdata['image']).content))
- image.save(os.path.join(output_dir, '{}_{}.png'.format(text, idx)))
+ if visualization:
+ image.save(os.path.join(output_dir, '{}_{}.png'.format(text, idx)))
result_images.append(image)
if idx + 1 >= topk:
break
@@ -212,6 +215,7 @@ def run_cmd(self, argvs):
results = self.generate_image(text_prompts=args.text_prompts,
style=args.style,
topk=args.topk,
+ visualization=args.visualization,
output_dir=args.output_dir)
return results
@@ -237,9 +241,10 @@ def add_module_input_arg(self):
self.arg_input_group.add_argument('--style',
type=str,
default='油画',
- choices=['油画', '水彩', '粉笔画', '卡通', '儿童画', '蜡笔画'],
+ choices=['油画', '水彩', '粉笔画', '卡通', '儿童画', '蜡笔画', '探索无限'],
help="绘画风格")
self.arg_input_group.add_argument('--topk', type=int, default=10, help="选取保存前多少张图,最多10张")
self.arg_input_group.add_argument('--ak', type=str, default=None, help="申请文心api使用token的ak")
self.arg_input_group.add_argument('--sk', type=str, default=None, help="申请文心api使用token的sk")
+ self.arg_input_group.add_argument('--visualization', type=bool, default=True, help="是否保存生成的图片")
self.arg_input_group.add_argument('--output_dir', type=str, default='ernievilg_output')
From 752bd02fd490111ca68b6b11320f9f2f78afc1ce Mon Sep 17 00:00:00 2001
From: chenjian
-### **[Computer Vision (212 models)](./modules#Image)**
+#### 👓 [Computer Vision Models](./modules#Image)
@@ -66,7 +66,7 @@ English | [简体中文](README_ch.md)
- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
-### **[Natural Language Processing (130 models)](./modules#Text)**
+#### 🎤 [Natural Language Processing Models](./modules#Text)
@@ -75,7 +75,7 @@ English | [简体中文](README_ch.md)
-### [Speech (15 models)](./modules#Audio)
+#### 🎧 [Speech Models](./modules#Audio)
- ASR speech recognition algorithm, multiple algorithms are available.
- The speech recognition effect is as follows:
 @@ -138,7 +138,7 @@ English | [简体中文](README_ch.md)
- Many thanks to CopyRight@[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech) for the pre-trained models, you can try to train your models with PaddleSpeech.
-### [Video (8 models)](./modules#Video)
+#### 📽️ [Video Models](./modules#Video)
- Short video classification trained via large-scale video datasets, supports 3000+ tag types prediction for short Form Videos.
- Many thanks to CopyRight@[PaddleVideo](https://github.com/PaddlePaddle/PaddleVideo) for the pre-trained model, you can try to train your models with PaddleVideo.
- `Example: Input a short video of swimming, the algorithm can output the result of "swimming"`
@@ -146,8 +146,8 @@ English | [简体中文](README_ch.md)
-## ===**Key Points**===
-- All the above pre-trained models are all open source and free, and the number of models is continuously updated. Welcome **⭐Star⭐** to pay attention.
+### ⭐ Thanks for Your Star ⭐
+- All the above pre-trained models are all **open source and free**, and the number of models is continuously updated. Welcome **⭐Star⭐** to pay attention.
@@ -138,7 +138,7 @@ English | [简体中文](README_ch.md)
- Many thanks to CopyRight@[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech) for the pre-trained models, you can try to train your models with PaddleSpeech.
-### [Video (8 models)](./modules#Video)
+#### 📽️ [Video Models](./modules#Video)
- Short video classification trained via large-scale video datasets, supports 3000+ tag types prediction for short Form Videos.
- Many thanks to CopyRight@[PaddleVideo](https://github.com/PaddlePaddle/PaddleVideo) for the pre-trained model, you can try to train your models with PaddleVideo.
- `Example: Input a short video of swimming, the algorithm can output the result of "swimming"`
@@ -146,8 +146,8 @@ English | [简体中文](README_ch.md)
-## ===**Key Points**===
-- All the above pre-trained models are all open source and free, and the number of models is continuously updated. Welcome **⭐Star⭐** to pay attention.
+### ⭐ Thanks for Your Star ⭐
+- All the above pre-trained models are all **open source and free**, and the number of models is continuously updated. Welcome **⭐Star⭐** to pay attention.
 ```python
!hub serving start -m lac
```
-More model description, please refer [Models List](https://www.paddlepaddle.org.cn/hublist)
+- 📣More model description, please refer [Models List](https://www.paddlepaddle.org.cn/hublist)
-More API for transfer learning, please refer [Tutorial](https://paddlehub.readthedocs.io/en/release-v2.1/transfer_learning_index.html)
+- 📣More API for transfer learning, please refer [Tutorial](https://paddlehub.readthedocs.io/en/release-v2.1/transfer_learning_index.html)
-## License
+## 📚License
The release of this project is certified by the Apache 2.0 license.
-## Contribution
+## 👨👨👧👦Contribution
```python
!hub serving start -m lac
```
-More model description, please refer [Models List](https://www.paddlepaddle.org.cn/hublist)
+- 📣More model description, please refer [Models List](https://www.paddlepaddle.org.cn/hublist)
-More API for transfer learning, please refer [Tutorial](https://paddlehub.readthedocs.io/en/release-v2.1/transfer_learning_index.html)
+- 📣More API for transfer learning, please refer [Tutorial](https://paddlehub.readthedocs.io/en/release-v2.1/transfer_learning_index.html)
-## License
+## 📚License
The release of this project is certified by the Apache 2.0 license.
-## Contribution
+## 👨👨👧👦Contribution
 @@ -155,18 +155,18 @@ English | [简体中文](README_ch.md)
-## Welcome to join PaddleHub technical group
+## 🍻Welcome to join PaddleHub technical group
-If you have any questions during the use of the model, you can join the official WeChat group to get more efficient questions and answers, and fully communicate with developers from all walks of life. We look forward to your joining.
+- If you have any questions during the use of the model, you can join the official WeChat group to get more efficient questions and answers, and fully communicate with developers from all walks of life. We look forward to your joining.
-please add WeChat above and send "Hub" to the robot, the robot will invite you to join the group automatically.
+- please add WeChat above and send "Hub" to the robot, the robot will invite you to join the group automatically.
-## QuickStart
+## ✈️QuickStart
-### The installation of required components.
+#### 🚁The installation of required components.
```python
# install paddlepaddle with gpu
# !pip install --upgrade paddlepaddle-gpu
@@ -178,7 +178,7 @@ please add WeChat above and send "Hub" to the robot, the robot will invite you t
!pip install --upgrade paddlehub
```
-### The simplest cases of Chinese word segmentation.
+#### 🛫The simplest cases of Chinese word segmentation.
```python
import paddlehub as hub
@@ -190,23 +190,23 @@ results = lac.cut(text=test_text, use_gpu=False, batch_size=1, return_tag=True)
print(results)
#{'word': ['今天', '是', '个', '好天气', '。'], 'tag': ['TIME', 'v', 'q', 'n', 'w']}
```
-### The simplest command of deploying lac service.
+#### 🛰️The simplest command of deploying lac service.
@@ -155,18 +155,18 @@ English | [简体中文](README_ch.md)
-## Welcome to join PaddleHub technical group
+## 🍻Welcome to join PaddleHub technical group
-If you have any questions during the use of the model, you can join the official WeChat group to get more efficient questions and answers, and fully communicate with developers from all walks of life. We look forward to your joining.
+- If you have any questions during the use of the model, you can join the official WeChat group to get more efficient questions and answers, and fully communicate with developers from all walks of life. We look forward to your joining.
-please add WeChat above and send "Hub" to the robot, the robot will invite you to join the group automatically.
+- please add WeChat above and send "Hub" to the robot, the robot will invite you to join the group automatically.
-## QuickStart
+## ✈️QuickStart
-### The installation of required components.
+#### 🚁The installation of required components.
```python
# install paddlepaddle with gpu
# !pip install --upgrade paddlepaddle-gpu
@@ -178,7 +178,7 @@ please add WeChat above and send "Hub" to the robot, the robot will invite you t
!pip install --upgrade paddlehub
```
-### The simplest cases of Chinese word segmentation.
+#### 🛫The simplest cases of Chinese word segmentation.
```python
import paddlehub as hub
@@ -190,23 +190,23 @@ results = lac.cut(text=test_text, use_gpu=False, batch_size=1, return_tag=True)
print(results)
#{'word': ['今天', '是', '个', '好天气', '。'], 'tag': ['TIME', 'v', 'q', 'n', 'w']}
```
-### The simplest command of deploying lac service.
+#### 🛰️The simplest command of deploying lac service.


 +
+
+
+ - 生成过程
+  +
+
+
+### 模型介绍
+
+Stable Diffusion是一种潜在扩散模型(Latent Diffusion), 属于生成类模型,这类模型通过对随机噪声进行一步步地迭代降噪并采样来获得感兴趣的图像,当前取得了令人惊艳的效果。相比于Disco Diffusion, Stable Diffusion通过在低纬度的潜在空间(lower dimensional latent space)而不是原像素空间来做迭代,极大地降低了内存和计算量的需求,并且在V100上一分钟之内即可以渲染出想要的图像,欢迎体验。
+
+更多详情请参考论文:[High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install stable_diffusion
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run stable_diffusion --text_prompts "in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation." --output_dir stable_diffusion_out
+ ```
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="stable_diffusion")
+ text_prompts = ["in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation."]
+ # 生成图像, 默认会在stable_diffusion_out目录保存图像
+ # 返回的da是一个DocumentArray对象,保存了所有的结果,包括最终结果和迭代过程的中间结果
+ # 可以通过操作DocumentArray对象对生成的图像做后处理,保存或者分析
+ # 您可以设置batch_size一次生成多张
+ da = module.generate_image(text_prompts=text_prompts, batch_size=3, output_dir='./stable_diffusion_out/')
+ # 展示所有的中间结果
+ da[0].chunks[-1].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # 将整个生成过程保存为一个动态图gif
+ da[0].chunks[-1].chunks.save_gif('stable_diffusion_out-merged-result.gif')
+ # da索引的是prompt, da[0].chunks索引的是该prompt下生成的第一张图,在batch_size不为1时能同时生成多张图
+ # 您也可以按照上述操作显示单张图,如第0张的生成过程
+ da[0].chunks[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ da[0].chunks[0].chunks.save_gif('stable_diffusion_out-image-0-result.gif')
+ ```
+
+- ### 3、API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [512, 512],
+ seed: Optional[int] = None,
+ batch_size: Optional[int] = 1,
+ output_dir: Optional[str] = 'stable_diffusion_out'):
+ ```
+
+ - 文图生成API,生成文本描述内容的图像。
+
+ - **参数**
+
+ - text_prompts(str): 输入的语句,描述想要生成的图像的内容。通常比较有效的构造方式为 "一段描述性的文字内容" + "指定艺术家的名字",如"in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation."。prompt的构造可以参考[网站](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#)。
+ - style(Optional[str]): 指定绘画的风格,如'watercolor','Chinese painting'等。当不指定时,风格完全由您所填写的prompt决定。
+ - artist(Optional[str]): 指定特定的艺术家,如Greg Rutkowsk、krenz,将会生成所指定艺术家的绘画风格。当不指定时,风格完全由您所填写的prompt决定。各种艺术家的风格可以参考[网站](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/)。
+ - width_height(Optional[List[int]]): 指定最终输出图像的宽高,宽和高都需要是64的倍数,生成的图像越大,所需要的计算时间越长。
+ - seed(Optional[int]): 随机种子,由于输入默认是随机高斯噪声,设置不同的随机种子会由不同的初始输入,从而最终生成不同的结果,可以设置该参数来获得不同的输出图像。
+ - batch_size(Optional[int]): 指定每个prompt一次生成的图像的数量。
+ - output_dir(Optional[str]): 保存输出图像的目录,默认为"stable_diffusion_out"。
+
+
+ - **返回**
+ - ra(DocumentArray): DocumentArray对象, 包含`batch_size`个Documents,其中每个Document都保存了迭代过程的所有中间结果。详细可参考[DocumentArray使用文档](https://docarray.jina.ai/fundamentals/documentarray/index.html)。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线文图生成服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+ - ```shell
+ $ hub serving start -m stable_diffusion
+ ```
+
+ - 这样就完成了一个文图生成的在线服务API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果,返回的预测结果在反序列化后即是上述接口声明中说明的DocumentArray类型,返回后对结果的操作方式和使用generate_image接口完全相同。
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ from docarray import DocumentArray
+
+ # 发送HTTP请求
+ data = {'text_prompts': 'in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation.'}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/stable_diffusion"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 获取返回结果
+ r.json()["results"]
+ da = DocumentArray.from_base64(r.json()["results"])
+ # 保存结果图
+ da[0].save_uri_to_file('stable_diffusion_out.png')
+ # 将生成过程保存为一个动态图gif
+ da[0].chunks[0].chunks.save_gif('stable_diffusion_out.gif')
+ ```
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install stable_diffusion == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/stable_diffusion/clip/README.md b/modules/image/text_to_image/stable_diffusion/clip/README.md
new file mode 100755
index 000000000..9944794f8
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/clip/README.md
@@ -0,0 +1,2 @@
+# OpenAI CLIP implemented in Paddle.
+The original implementation repo is [ranchlai/clip.paddle](https://github.com/ranchlai/clip.paddle). We use this repo here for text encoder in stable diffusion.
diff --git a/modules/image/text_to_image/stable_diffusion/clip/clip/__init__.py b/modules/image/text_to_image/stable_diffusion/clip/clip/__init__.py
new file mode 100755
index 000000000..5657b56e6
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/clip/clip/__init__.py
@@ -0,0 +1 @@
+from .utils import *
diff --git a/modules/image/text_to_image/stable_diffusion/clip/clip/layers.py b/modules/image/text_to_image/stable_diffusion/clip/clip/layers.py
new file mode 100755
index 000000000..286f35ab4
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/clip/clip/layers.py
@@ -0,0 +1,182 @@
+from typing import Optional
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn import Linear
+
+__all__ = ['ResidualAttentionBlock', 'AttentionPool2d', 'multi_head_attention_forward', 'MultiHeadAttention']
+
+
+def multi_head_attention_forward(x: Tensor,
+ num_heads: int,
+ q_proj: Linear,
+ k_proj: Linear,
+ v_proj: Linear,
+ c_proj: Linear,
+ attn_mask: Optional[Tensor] = None):
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = emb_dim // num_heads
+ scaling = float(head_dim)**-0.5
+ q = q_proj(x) # L, N, E
+ k = k_proj(x) # L, N, E
+ v = v_proj(x) # L, N, E
+ #k = k.con
+ v = v.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ k = k.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ q = q.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+
+ q = q * scaling
+ qk = paddle.bmm(q, k.transpose((0, 2, 1)))
+ if attn_mask is not None:
+ if attn_mask.ndim == 2:
+ attn_mask.unsqueeze_(0)
+ #assert str(attn_mask.dtype) == 'VarType.FP32' and attn_mask.ndim == 3
+ assert attn_mask.shape[0] == 1 and attn_mask.shape[1] == max_len and attn_mask.shape[2] == max_len
+ qk += attn_mask
+
+ qk = paddle.nn.functional.softmax(qk, axis=-1)
+ atten = paddle.bmm(qk, v)
+ atten = atten.transpose((1, 0, 2))
+ atten = atten.reshape((max_len, batch_size, emb_dim))
+ atten = c_proj(atten)
+ return atten
+
+
+class MultiHeadAttention(nn.Layer): # without attention mask
+
+ def __init__(self, emb_dim: int, num_heads: int):
+ super().__init__()
+ self.q_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.k_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.v_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.c_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.head_dim = emb_dim // num_heads
+ self.emb_dim = emb_dim
+ self.num_heads = num_heads
+ assert self.head_dim * num_heads == emb_dim, "embed_dim must be divisible by num_heads"
+ #self.scaling = float(self.head_dim) ** -0.5
+
+ def forward(self, x, attn_mask=None): # x is in shape[max_len,batch_size,emb_dim]
+
+ atten = multi_head_attention_forward(x,
+ self.num_heads,
+ self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.c_proj,
+ attn_mask=attn_mask)
+
+ return atten
+
+
+class Identity(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return x
+
+
+class Bottleneck(nn.Layer):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1):
+ super().__init__()
+
+ # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
+ self.conv1 = nn.Conv2D(inplanes, planes, 1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(planes)
+
+ self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(planes)
+
+ self.avgpool = nn.AvgPool2D(stride) if stride > 1 else Identity()
+
+ self.conv3 = nn.Conv2D(planes, planes * self.expansion, 1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(planes * self.expansion)
+
+ self.relu = nn.ReLU()
+ self.downsample = None
+ self.stride = stride
+
+ if stride > 1 or inplanes != planes * Bottleneck.expansion:
+ self.downsample = nn.Sequential(
+ ("-1", nn.AvgPool2D(stride)),
+ ("0", nn.Conv2D(inplanes, planes * self.expansion, 1, stride=1, bias_attr=False)),
+ ("1", nn.BatchNorm2D(planes * self.expansion)))
+
+ def forward(self, x):
+ identity = x
+
+ out = self.relu(self.bn1(self.conv1(x)))
+ out = self.relu(self.bn2(self.conv2(out)))
+ out = self.avgpool(out)
+ out = self.bn3(self.conv3(out))
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.relu(out)
+ return out
+
+
+class AttentionPool2d(nn.Layer):
+
+ def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
+ super().__init__()
+
+ self.positional_embedding = paddle.create_parameter((spacial_dim**2 + 1, embed_dim), dtype='float32')
+
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim, bias_attr=True)
+ self.num_heads = num_heads
+
+ self.head_dim = embed_dim // num_heads
+ assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
+
+ def forward(self, x):
+
+ x = x.reshape((x.shape[0], x.shape[1], x.shape[2] * x.shape[3])).transpose((2, 0, 1)) # NCHW -> (HW)NC
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = self.head_dim
+ x = paddle.concat([paddle.mean(x, axis=0, keepdim=True), x], axis=0)
+ x = x + paddle.unsqueeze(self.positional_embedding, 1)
+ out = multi_head_attention_forward(x, self.num_heads, self.q_proj, self.k_proj, self.v_proj, self.c_proj)
+
+ return out[0]
+
+
+class QuickGELU(nn.Layer):
+
+ def forward(self, x):
+ return x * paddle.nn.functional.sigmoid(1.702 * x)
+
+
+class ResidualAttentionBlock(nn.Layer):
+
+ def __init__(self, d_model: int, n_head: int, attn_mask=None):
+ super().__init__()
+
+ self.attn = MultiHeadAttention(d_model, n_head)
+ self.ln_1 = nn.LayerNorm(d_model)
+ self.mlp = nn.Sequential(("c_fc", nn.Linear(d_model, d_model * 4)), ("gelu", QuickGELU()),
+ ("c_proj", nn.Linear(d_model * 4, d_model)))
+ self.ln_2 = nn.LayerNorm(d_model)
+ self.attn_mask = attn_mask
+
+ def attention(self, x):
+ x = self.attn(x, self.attn_mask)
+ assert isinstance(x, paddle.Tensor) # not tuble here
+ return x
+
+ def forward(self, x):
+
+ x = x + self.attention(self.ln_1(x))
+ x = x + self.mlp(self.ln_2(x))
+ return x
diff --git a/modules/image/text_to_image/stable_diffusion/clip/clip/model.py b/modules/image/text_to_image/stable_diffusion/clip/clip/model.py
new file mode 100755
index 000000000..06affcc4b
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/clip/clip/model.py
@@ -0,0 +1,259 @@
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import nn
+
+from .layers import AttentionPool2d
+from .layers import Bottleneck
+from .layers import MultiHeadAttention
+from .layers import ResidualAttentionBlock
+
+
+class ModifiedResNet(nn.Layer):
+ """
+ A ResNet class that is similar to torchvision's but contains the following changes:
+ - There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
+ - Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
+ - The final pooling layer is a QKV attention instead of an average pool
+ """
+
+ def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
+ super().__init__()
+ self.output_dim = output_dim
+ self.input_resolution = input_resolution
+
+ # the 3-layer stem
+ self.conv1 = nn.Conv2D(3, width // 2, kernel_size=3, stride=2, padding=1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(width // 2)
+ self.conv2 = nn.Conv2D(width // 2, width // 2, kernel_size=3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(width // 2)
+ self.conv3 = nn.Conv2D(width // 2, width, kernel_size=3, padding=1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(width)
+ self.avgpool = nn.AvgPool2D(2)
+ self.relu = nn.ReLU()
+
+ # residual layers
+ self._inplanes = width # this is a *mutable* variable used during construction
+ self.layer1 = self._make_layer(width, layers[0])
+ self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
+ self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
+ self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
+
+ embed_dim = width * 32 # the ResNet feature dimension
+ self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
+
+ def _make_layer(self, planes, blocks, stride=1):
+ layers = [Bottleneck(self._inplanes, planes, stride)]
+
+ self._inplanes = planes * Bottleneck.expansion
+ for _ in range(1, blocks):
+ layers.append(Bottleneck(self._inplanes, planes))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ def stem(x):
+ for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
+ x = self.relu(bn(conv(x)))
+ x = self.avgpool(x)
+ return x
+
+ #x = x.type(self.conv1.weight.dtype)
+ x = stem(x)
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+ x = self.attnpool(x)
+
+ return x
+
+
+class Transformer(nn.Layer):
+
+ def __init__(self, width: int, layers: int, heads: int, attn_mask=None):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
+
+ def forward(self, x):
+ return self.resblocks(x)
+
+
+class VisualTransformer(nn.Layer):
+
+ def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.output_dim = output_dim
+ # used patch_size x patch_size, stride patch_size to do linear projection
+ self.conv1 = nn.Conv2D(in_channels=3,
+ out_channels=width,
+ kernel_size=patch_size,
+ stride=patch_size,
+ bias_attr=False)
+
+ # scale = width ** -0.5
+ self.class_embedding = paddle.create_parameter((width, ), 'float32')
+
+ self.positional_embedding = paddle.create_parameter(((input_resolution // patch_size)**2 + 1, width), 'float32')
+
+ self.ln_pre = nn.LayerNorm(width)
+
+ self.transformer = Transformer(width, layers, heads)
+
+ self.ln_post = nn.LayerNorm(width)
+ self.proj = paddle.create_parameter((width, output_dim), 'float32')
+
+ def forward(self, x):
+
+ x = self.conv1(x)
+ x = x.reshape((x.shape[0], x.shape[1], -1))
+ x = x.transpose((0, 2, 1))
+ x = paddle.concat([self.class_embedding + paddle.zeros((x.shape[0], 1, x.shape[-1]), dtype=x.dtype), x], axis=1)
+
+ x = x + self.positional_embedding
+ x = self.ln_pre(x)
+ x = x.transpose((1, 0, 2))
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2))
+ x = self.ln_post(x[:, 0, :])
+ if self.proj is not None:
+ x = paddle.matmul(x, self.proj)
+
+ return x
+
+
+class TextTransformer(nn.Layer):
+
+ def __init__(self, context_length: int, vocab_size: int, transformer_width: int, transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+ self.context_length = context_length
+ self.transformer = Transformer(width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+
+ self.vocab_size = vocab_size
+ self.token_embedding = nn.Embedding(vocab_size, transformer_width)
+ self.positional_embedding = paddle.create_parameter((self.context_length, transformer_width), 'float32')
+ self.ln_final = nn.LayerNorm(transformer_width)
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # mask = paddle.empty((self.context_length, self.context_length),dtype='float32')
+ # mask.fill_(float("-inf"))
+ #mask.triu_(1) # zero out the lower diagonal
+
+ mask = paddle.ones((self.context_length, self.context_length)) * float("-inf")
+ mask = paddle.triu(mask, diagonal=1)
+
+ return mask
+
+ def forward(self, text):
+ x = self.token_embedding(text) # [batch_size, n_ctx, d_model]
+ x = x + self.positional_embedding
+ x = x.transpose((1, 0, 2)) # NLD -> LND
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2)) # LND -> NLD
+ x = self.ln_final(x)
+ return x
+
+
+class CLIP(nn.Layer):
+
+ def __init__(
+ self,
+ embed_dim: int,
+ # vision
+ image_resolution: int,
+ vision_layers: Union[Tuple[int, int, int, int], int],
+ vision_width: int,
+ vision_patch_size: int,
+ # text
+ context_length: int,
+ vocab_size: int,
+ transformer_width: int,
+ transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+
+ self.context_length = context_length
+ if isinstance(vision_layers, (tuple, list)):
+ vision_heads = vision_width * 32 // 64
+ self.visual = ModifiedResNet(layers=vision_layers,
+ output_dim=embed_dim,
+ heads=vision_heads,
+ input_resolution=image_resolution,
+ width=vision_width)
+ else:
+ vision_heads = vision_width // 64
+ self.visual = VisualTransformer(input_resolution=image_resolution,
+ patch_size=vision_patch_size,
+ width=vision_width,
+ layers=vision_layers,
+ heads=vision_heads,
+ output_dim=embed_dim)
+
+ self.transformer = Transformer(width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+
+ self.vocab_size = vocab_size
+ self.token_embedding = nn.Embedding(vocab_size, transformer_width)
+ self.positional_embedding = paddle.create_parameter((self.context_length, transformer_width), 'float32')
+ self.ln_final = nn.LayerNorm(transformer_width)
+
+ self.text_projection = paddle.create_parameter((transformer_width, embed_dim), 'float32')
+ self.logit_scale = paddle.create_parameter((1, ), 'float32')
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # mask = paddle.empty((self.context_length, self.context_length),dtype='float32')
+ # mask.fill_(float("-inf"))
+ #mask.triu_(1) # zero out the lower diagonal
+
+ mask = paddle.ones((self.context_length, self.context_length)) * float("-inf")
+ mask = paddle.triu(mask, diagonal=1)
+
+ return mask
+
+ def encode_image(self, image):
+ return self.visual(image)
+
+ def encode_text(self, text):
+ x = self.token_embedding(text) # [batch_size, n_ctx, d_model]
+ x = x + self.positional_embedding
+ x = x.transpose((1, 0, 2)) # NLD -> LND
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2)) # LND -> NLD
+ x = self.ln_final(x)
+ idx = text.numpy().argmax(-1)
+ idx = list(idx)
+ x = [x[i:i + 1, int(j), :] for i, j in enumerate(idx)]
+ x = paddle.concat(x, 0)
+ x = paddle.matmul(x, self.text_projection)
+ return x
+
+ def forward(self, image, text):
+ image_features = self.encode_image(image)
+ text_features = self.encode_text(text)
+
+ # normalized features
+ image_features = image_features / image_features.norm(dim=-1, keepdim=True)
+ text_features = text_features / text_features.norm(dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_image = paddle.matmul(logit_scale * image_features, text_features.t())
+ logits_per_text = paddle.matmul(logit_scale * text_features, image_features.t())
+
+ # shape = [global_batch_size, global_batch_size]
+ return logits_per_image, logits_per_text
diff --git a/modules/image/text_to_image/stable_diffusion/clip/clip/simple_tokenizer.py b/modules/image/text_to_image/stable_diffusion/clip/clip/simple_tokenizer.py
new file mode 100755
index 000000000..4eaf82e9e
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/clip/clip/simple_tokenizer.py
@@ -0,0 +1,135 @@
+import gzip
+import html
+import os
+from functools import lru_cache
+
+import ftfy
+import regex as re
+
+
+@lru_cache()
+def default_bpe():
+ return os.path.join(os.path.dirname(os.path.abspath(__file__)), "../assets/bpe_simple_vocab_16e6.txt.gz")
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a corresponding list of unicode strings.
+ The reversible bpe codes work on unicode strings.
+ This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
+ When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
+ This is a signficant percentage of your normal, say, 32K bpe vocab.
+ To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ And avoids mapping to whitespace/control characters the bpe code barfs on.
+ """
+ bs = list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """Return set of symbol pairs in a word.
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+def basic_clean(text):
+ text = ftfy.fix_text(text)
+ text = html.unescape(html.unescape(text))
+ return text.strip()
+
+
+def whitespace_clean(text):
+ text = re.sub(r'\s+', ' ', text)
+ text = text.strip()
+ return text
+
+
+class SimpleTokenizer(object):
+
+ def __init__(self, bpe_path: str = default_bpe()):
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
+ merges = merges[1:49152 - 256 - 2 + 1]
+ merges = [tuple(merge.split()) for merge in merges]
+ vocab = list(bytes_to_unicode().values())
+ vocab = vocab + [v + '' for v in vocab]
+ for merge in merges:
+ vocab.append(''.join(merge))
+ vocab.extend(['<|startoftext|>', '<|endoftext|>'])
+ self.encoder = dict(zip(vocab, range(len(vocab))))
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.bpe_ranks = dict(zip(merges, range(len(merges))))
+ self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
+ self.pat = re.compile(
+ r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
+ re.IGNORECASE)
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token[:-1]) + (token[-1] + '', )
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token + ''
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ new_word.extend(word[i:j])
+ i = j
+ except:
+ new_word.extend(word[i:])
+ break
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = ' '.join(word)
+ self.cache[token] = word
+ return word
+
+ def encode(self, text):
+ bpe_tokens = []
+ text = whitespace_clean(basic_clean(text)).lower()
+ for token in re.findall(self.pat, text):
+ token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
+ bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
+ return bpe_tokens
+
+ def decode(self, tokens):
+ text = ''.join([self.decoder[token] for token in tokens])
+ text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('', ' ')
+ return text
diff --git a/modules/image/text_to_image/stable_diffusion/clip/clip/utils.py b/modules/image/text_to_image/stable_diffusion/clip/clip/utils.py
new file mode 100755
index 000000000..b5d417144
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/clip/clip/utils.py
@@ -0,0 +1,88 @@
+import os
+from typing import List
+from typing import Union
+
+import numpy as np
+import paddle
+from paddle.utils import download
+from paddle.vision.transforms import CenterCrop
+from paddle.vision.transforms import Compose
+from paddle.vision.transforms import Normalize
+from paddle.vision.transforms import Resize
+from paddle.vision.transforms import ToTensor
+
+from .model import CLIP
+from .model import TextTransformer
+from .simple_tokenizer import SimpleTokenizer
+
+__all__ = ['transform', 'tokenize', 'build_model']
+
+MODEL_NAMES = ['VITL14']
+
+URL = {'VITL14': os.path.join(os.path.dirname(__file__), 'pre_trained', 'vitl14_textencoder.pdparams')}
+
+MEAN, STD = (0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)
+_tokenizer = SimpleTokenizer()
+
+transform = Compose([
+ Resize(224, interpolation='bicubic'),
+ CenterCrop(224), lambda image: image.convert('RGB'),
+ ToTensor(),
+ Normalize(mean=MEAN, std=STD), lambda t: t.unsqueeze_(0)
+])
+
+
+def tokenize(texts: Union[str, List[str]], context_length: int = 77):
+ """
+ Returns the tokenized representation of given input string(s)
+
+ Parameters
+ ----------
+ texts : Union[str, List[str]]
+ An input string or a list of input strings to tokenize
+
+ context_length : int
+ The context length to use; all CLIP models use 77 as the context length
+
+ Returns
+ -------
+ A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
+ """
+ if isinstance(texts, str):
+ texts = [texts]
+
+ sot_token = _tokenizer.encoder["<|startoftext|>"]
+ eot_token = _tokenizer.encoder["<|endoftext|>"]
+ all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
+ result = paddle.zeros((len(all_tokens), context_length), dtype='int64')
+
+ for i, tokens in enumerate(all_tokens):
+ if len(tokens) > context_length:
+ raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
+ result[i, :len(tokens)] = paddle.Tensor(np.array(tokens))
+
+ return result
+
+
+def build_model(name='VITL14'):
+ assert name in MODEL_NAMES, f"model name must be one of {MODEL_NAMES}"
+ name2model = {'VITL14': build_vitl14_language_model}
+ model = name2model[name]()
+ weight = URL[name]
+ sd = paddle.load(weight)
+ state_dict = model.state_dict()
+ for key, value in sd.items():
+ if key in state_dict:
+ state_dict[key] = value
+ model.load_dict(state_dict)
+ model.eval()
+ return model
+
+
+def build_vitl14_language_model():
+ model = TextTransformer(context_length=77,
+ vocab_size=49408,
+ transformer_width=768,
+ transformer_heads=12,
+ transformer_layers=12)
+ return model
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/__init__.py b/modules/image/text_to_image/stable_diffusion/diffusers/__init__.py
new file mode 100644
index 000000000..7f41816d7
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/__init__.py
@@ -0,0 +1,20 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+__version__ = "0.2.4"
+
+from .models import AutoencoderKL, UNet2DConditionModel, UNet2DModel, VQModel
+
+from .schedulers import (DDIMScheduler, DDPMScheduler, KarrasVeScheduler, PNDMScheduler, SchedulerMixin,
+ ScoreSdeVeScheduler, LMSDiscreteScheduler)
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/configuration_utils.py b/modules/image/text_to_image/stable_diffusion/diffusers/configuration_utils.py
new file mode 100644
index 000000000..c90ebd5be
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/configuration_utils.py
@@ -0,0 +1,312 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" ConfigMixinuration base class and utilities."""
+import functools
+import inspect
+import json
+import os
+import re
+from collections import OrderedDict
+from typing import Any
+from typing import Dict
+from typing import Tuple
+from typing import Union
+
+from requests import HTTPError
+
+from paddlehub.common.logger import logger
+
+HUGGINGFACE_CO_RESOLVE_ENDPOINT = "HUGGINGFACE_CO_RESOLVE_ENDPOINT"
+DIFFUSERS_CACHE = "./caches"
+
+_re_configuration_file = re.compile(r"config\.(.*)\.json")
+
+
+class ConfigMixin:
+ r"""
+ Base class for all configuration classes. Handles a few parameters common to all models' configurations as well as
+ methods for loading/downloading/saving configurations.
+
+ """
+ config_name = "model_config.json"
+ ignore_for_config = []
+
+ def register_to_config(self, **kwargs):
+ if self.config_name is None:
+ raise NotImplementedError(f"Make sure that {self.__class__} has defined a class name `config_name`")
+ kwargs["_class_name"] = self.__class__.__name__
+ kwargs["_diffusers_version"] = "0.0.1"
+
+ for key, value in kwargs.items():
+ try:
+ setattr(self, key, value)
+ except AttributeError as err:
+ logger.error(f"Can't set {key} with value {value} for {self}")
+ raise err
+
+ if not hasattr(self, "_internal_dict"):
+ internal_dict = kwargs
+ else:
+ previous_dict = dict(self._internal_dict)
+ internal_dict = {**self._internal_dict, **kwargs}
+ logger.debug(f"Updating config from {previous_dict} to {internal_dict}")
+
+ self._internal_dict = FrozenDict(internal_dict)
+
+ def save_config(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
+ """
+ Save a configuration object to the directory `save_directory`, so that it can be re-loaded using the
+ [`~ConfigMixin.from_config`] class method.
+
+ Args:
+ save_directory (`str` or `os.PathLike`):
+ Directory where the configuration JSON file will be saved (will be created if it does not exist).
+ kwargs:
+ Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
+ """
+ if os.path.isfile(save_directory):
+ raise AssertionError(f"Provided path ({save_directory}) should be a directory, not a file")
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ # If we save using the predefined names, we can load using `from_config`
+ output_config_file = os.path.join(save_directory, self.config_name)
+
+ self.to_json_file(output_config_file)
+ logger.info(f"ConfigMixinuration saved in {output_config_file}")
+
+ @classmethod
+ def from_config(cls, pretrained_model_name_or_path: Union[str, os.PathLike], return_unused_kwargs=False, **kwargs):
+ config_dict = cls.get_config_dict(pretrained_model_name_or_path=pretrained_model_name_or_path, **kwargs)
+
+ init_dict, unused_kwargs = cls.extract_init_dict(config_dict, **kwargs)
+
+ model = cls(**init_dict)
+
+ if return_unused_kwargs:
+ return model, unused_kwargs
+ else:
+ return model
+
+ @classmethod
+ def get_config_dict(cls, pretrained_model_name_or_path: Union[str, os.PathLike],
+ **kwargs) -> Tuple[Dict[str, Any], Dict[str, Any]]:
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ revision = kwargs.pop("revision", None)
+ subfolder = kwargs.pop("subfolder", None)
+
+ user_agent = {"file_type": "config"}
+
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+
+ if cls.config_name is None:
+ raise ValueError(
+ "`self.config_name` is not defined. Note that one should not load a config from "
+ "`ConfigMixin`. Please make sure to define `config_name` in a class inheriting from `ConfigMixin`")
+
+ if os.path.isfile(pretrained_model_name_or_path):
+ config_file = pretrained_model_name_or_path
+ elif os.path.isdir(pretrained_model_name_or_path):
+ if os.path.isfile(os.path.join(pretrained_model_name_or_path, cls.config_name)):
+ # Load from a PyTorch checkpoint
+ config_file = os.path.join(pretrained_model_name_or_path, cls.config_name)
+ elif subfolder is not None and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)):
+ config_file = os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
+ else:
+ raise EnvironmentError(
+ f"Error no file named {cls.config_name} found in directory {pretrained_model_name_or_path}.")
+ else:
+ try:
+ # Load from URL or cache if already cached
+ from huggingface_hub import hf_hub_download
+ config_file = hf_hub_download(
+ pretrained_model_name_or_path,
+ filename=cls.config_name,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ user_agent=user_agent,
+ subfolder=subfolder,
+ )
+
+ except HTTPError as err:
+ raise EnvironmentError("There was a specific connection error when trying to load"
+ f" {pretrained_model_name_or_path}:\n{err}")
+ except ValueError:
+ raise EnvironmentError(
+ f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this model, couldn't find it"
+ f" in the cached files and it looks like {pretrained_model_name_or_path} is not the path to a"
+ f" directory containing a {cls.config_name} file.\nCheckout your internet connection or see how to"
+ " run the library in offline mode at"
+ " 'https://huggingface.co/docs/diffusers/installation#offline-mode'.")
+ except EnvironmentError:
+ raise EnvironmentError(
+ f"Can't load config for '{pretrained_model_name_or_path}'. If you were trying to load it from "
+ "'https://huggingface.co/models', make sure you don't have a local directory with the same name. "
+ f"Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a directory "
+ f"containing a {cls.config_name} file")
+
+ try:
+ # Load config dict
+ config_dict = cls._dict_from_json_file(config_file)
+ except (json.JSONDecodeError, UnicodeDecodeError):
+ raise EnvironmentError(f"It looks like the config file at '{config_file}' is not a valid JSON file.")
+
+ return config_dict
+
+ @classmethod
+ def extract_init_dict(cls, config_dict, **kwargs):
+ expected_keys = set(dict(inspect.signature(cls.__init__).parameters).keys())
+ expected_keys.remove("self")
+ # remove general kwargs if present in dict
+ if "kwargs" in expected_keys:
+ expected_keys.remove("kwargs")
+ # remove keys to be ignored
+ if len(cls.ignore_for_config) > 0:
+ expected_keys = expected_keys - set(cls.ignore_for_config)
+ init_dict = {}
+ for key in expected_keys:
+ if key in kwargs:
+ # overwrite key
+ init_dict[key] = kwargs.pop(key)
+ elif key in config_dict:
+ # use value from config dict
+ init_dict[key] = config_dict.pop(key)
+
+ unused_kwargs = config_dict.update(kwargs)
+
+ passed_keys = set(init_dict.keys())
+ if len(expected_keys - passed_keys) > 0:
+ logger.warning(
+ f"{expected_keys - passed_keys} was not found in config. Values will be initialized to default values.")
+
+ return init_dict, unused_kwargs
+
+ @classmethod
+ def _dict_from_json_file(cls, json_file: Union[str, os.PathLike]):
+ with open(json_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ return json.loads(text)
+
+ def __repr__(self):
+ return f"{self.__class__.__name__} {self.to_json_string()}"
+
+ @property
+ def config(self) -> Dict[str, Any]:
+ return self._internal_dict
+
+ def to_json_string(self) -> str:
+ """
+ Serializes this instance to a JSON string.
+
+ Returns:
+ `str`: String containing all the attributes that make up this configuration instance in JSON format.
+ """
+ config_dict = self._internal_dict if hasattr(self, "_internal_dict") else {}
+ return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
+
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this configuration instance's parameters will be saved.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ writer.write(self.to_json_string())
+
+
+class FrozenDict(OrderedDict):
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ for key, value in self.items():
+ setattr(self, key, value)
+
+ self.__frozen = True
+
+ def __delitem__(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``__delitem__`` on a {self.__class__.__name__} instance.")
+
+ def setdefault(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``setdefault`` on a {self.__class__.__name__} instance.")
+
+ def pop(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``pop`` on a {self.__class__.__name__} instance.")
+
+ def update(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``update`` on a {self.__class__.__name__} instance.")
+
+ def __setattr__(self, name, value):
+ if hasattr(self, "__frozen") and self.__frozen:
+ raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
+ super().__setattr__(name, value)
+
+ def __setitem__(self, name, value):
+ if hasattr(self, "__frozen") and self.__frozen:
+ raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
+ super().__setitem__(name, value)
+
+
+def register_to_config(init):
+ """
+ Decorator to apply on the init of classes inheriting from `ConfigMixin` so that all the arguments are automatically
+ sent to `self.register_for_config`. To ignore a specific argument accepted by the init but that shouldn't be
+ registered in the config, use the `ignore_for_config` class variable
+
+ Warning: Once decorated, all private arguments (beginning with an underscore) are trashed and not sent to the init!
+ """
+
+ @functools.wraps(init)
+ def inner_init(self, *args, **kwargs):
+ # Ignore private kwargs in the init.
+ init_kwargs = {k: v for k, v in kwargs.items() if not k.startswith("_")}
+ init(self, *args, **init_kwargs)
+ if not isinstance(self, ConfigMixin):
+ raise RuntimeError(
+ f"`@register_for_config` was applied to {self.__class__.__name__} init method, but this class does "
+ "not inherit from `ConfigMixin`.")
+
+ ignore = getattr(self, "ignore_for_config", [])
+ # Get positional arguments aligned with kwargs
+ new_kwargs = {}
+ signature = inspect.signature(init)
+ parameters = {
+ name: p.default
+ for i, (name, p) in enumerate(signature.parameters.items()) if i > 0 and name not in ignore
+ }
+ for arg, name in zip(args, parameters.keys()):
+ new_kwargs[name] = arg
+
+ # Then add all kwargs
+ new_kwargs.update({
+ k: init_kwargs.get(k, default)
+ for k, default in parameters.items() if k not in ignore and k not in new_kwargs
+ })
+ getattr(self, "register_to_config")(**new_kwargs)
+
+ return inner_init
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/models/README.md b/modules/image/text_to_image/stable_diffusion/diffusers/models/README.md
new file mode 100644
index 000000000..e786fe518
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/models/README.md
@@ -0,0 +1,11 @@
+# Models
+
+- Models: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to denoise a noisy input to an image. Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet
+
+## API
+
+TODO(Suraj, Patrick)
+
+## Examples
+
+TODO(Suraj, Patrick)
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/models/__init__.py b/modules/image/text_to_image/stable_diffusion/diffusers/models/__init__.py
new file mode 100644
index 000000000..f55cc88a8
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/models/__init__.py
@@ -0,0 +1,20 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .unet_2d import UNet2DModel
+from .unet_2d_condition import UNet2DConditionModel
+from .vae import AutoencoderKL
+from .vae import VQModel
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/models/attention.py b/modules/image/text_to_image/stable_diffusion/diffusers/models/attention.py
new file mode 100644
index 000000000..29d0e73a7
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/models/attention.py
@@ -0,0 +1,465 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+from inspect import isfunction
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def finfo(dtype):
+ if dtype == paddle.float32:
+ return np.finfo(np.float32)
+ if dtype == paddle.float16:
+ return np.finfo(np.float16)
+ if dtype == paddle.float64:
+ return np.finfo(np.float64)
+
+
+paddle.finfo = finfo
+
+
+class AttentionBlockNew(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other. Originally ported from here, but adapted
+ to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ Uses three q, k, v linear layers to compute attention
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_head_channels=None,
+ num_groups=32,
+ rescale_output_factor=1.0,
+ eps=1e-5,
+ ):
+ super().__init__()
+ self.channels = channels
+
+ self.num_heads = channels // num_head_channels if num_head_channels is not None else 1
+ self.num_head_size = num_head_channels
+ self.group_norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=eps)
+
+ # define q,k,v as linear layers
+ self.query = nn.Linear(channels, channels)
+ self.key = nn.Linear(channels, channels)
+ self.value = nn.Linear(channels, channels)
+
+ self.rescale_output_factor = rescale_output_factor
+ self.proj_attn = nn.Linear(channels, channels)
+
+ def transpose_for_scores(self, projection: paddle.Tensor) -> paddle.Tensor:
+ new_projection_shape = projection.shape[:-1] + [self.num_heads, -1]
+ # move heads to 2nd position (B, T, H * D) -> (B, T, H, D) -> (B, H, T, D)
+ new_projection = projection.reshape(new_projection_shape).transpose([0, 2, 1, 3])
+ return new_projection
+
+ def forward(self, hidden_states):
+ residual = hidden_states
+ batch, channel, height, width = hidden_states.shape
+
+ # norm
+ hidden_states = self.group_norm(hidden_states)
+
+ hidden_states = hidden_states.reshape([batch, channel, height * width]).transpose([0, 2, 1])
+
+ # proj to q, k, v
+ query_proj = self.query(hidden_states)
+ key_proj = self.key(hidden_states)
+ value_proj = self.value(hidden_states)
+
+ # transpose
+ query_states = self.transpose_for_scores(query_proj)
+ key_states = self.transpose_for_scores(key_proj)
+ value_states = self.transpose_for_scores(value_proj)
+
+ # get scores
+ scale = 1 / math.sqrt(math.sqrt(self.channels / self.num_heads))
+ attention_scores = paddle.matmul(query_states * scale, key_states * scale, transpose_y=True)
+ attention_probs = F.softmax(attention_scores.astype("float32"), axis=-1).astype(attention_scores.dtype)
+
+ # compute attention output
+ context_states = paddle.matmul(attention_probs, value_states)
+
+ context_states = context_states.transpose([0, 2, 1, 3])
+ new_context_states_shape = context_states.shape[:-2] + [
+ self.channels,
+ ]
+ context_states = context_states.reshape(new_context_states_shape)
+
+ # compute next hidden_states
+ hidden_states = self.proj_attn(context_states)
+ hidden_states = hidden_states.transpose([0, 2, 1]).reshape([batch, channel, height, width])
+
+ # res connect and rescale
+ hidden_states = (hidden_states + residual) / self.rescale_output_factor
+ return hidden_states
+
+ def set_weight(self, attn_layer):
+ self.group_norm.weight.set_value(attn_layer.norm.weight)
+ self.group_norm.bias.set_value(attn_layer.norm.bias)
+
+ if hasattr(attn_layer, "q"):
+ self.query.weight.set_value(attn_layer.q.weight[:, :, 0, 0])
+ self.key.weight.set_value(attn_layer.k.weight[:, :, 0, 0])
+ self.value.weight.set_value(attn_layer.v.weight[:, :, 0, 0])
+
+ self.query.bias.set_value(attn_layer.q.bias)
+ self.key.bias.set_value(attn_layer.k.bias)
+ self.value.bias.set_value(attn_layer.v.bias)
+
+ self.proj_attn.weight.set_value(attn_layer.proj_out.weight[:, :, 0, 0])
+ self.proj_attn.bias.set_value(attn_layer.proj_out.bias)
+ elif hasattr(attn_layer, "NIN_0"):
+ self.query.weight.set_value(attn_layer.NIN_0.W.t())
+ self.key.weight.set_value(attn_layer.NIN_1.W.t())
+ self.value.weight.set_value(attn_layer.NIN_2.W.t())
+
+ self.query.bias.set_value(attn_layer.NIN_0.b)
+ self.key.bias.set_value(attn_layer.NIN_1.b)
+ self.value.bias.set_value(attn_layer.NIN_2.b)
+
+ self.proj_attn.weight.set_value(attn_layer.NIN_3.W.t())
+ self.proj_attn.bias.set_value(attn_layer.NIN_3.b)
+
+ self.group_norm.weight.set_value(attn_layer.GroupNorm_0.weight)
+ self.group_norm.bias.set_value(attn_layer.GroupNorm_0.bias)
+ else:
+ qkv_weight = attn_layer.qkv.weight.reshape(
+ [self.num_heads, 3 * self.channels // self.num_heads, self.channels])
+ qkv_bias = attn_layer.qkv.bias.reshape([self.num_heads, 3 * self.channels // self.num_heads])
+
+ q_w, k_w, v_w = qkv_weight.split(self.channels // self.num_heads, axis=1)
+ q_b, k_b, v_b = qkv_bias.split(self.channels // self.num_heads, axis=1)
+
+ self.query.weight.set_value(q_w.reshape([-1, self.channels]))
+ self.key.weight.set_value(k_w.reshape([-1, self.channels]))
+ self.value.weight.set_value(v_w.reshape([-1, self.channels]))
+
+ self.query.bias.set_value(q_b.flatten())
+ self.key.bias.set_value(k_b.flatten())
+ self.value.bias.set_value(v_b.flatten())
+
+ self.proj_attn.weight.set_value(attn_layer.proj.weight[:, :, 0])
+ self.proj_attn.bias.set_value(attn_layer.proj.bias)
+
+
+class SpatialTransformer(nn.Layer):
+ """
+ Transformer block for image-like data. First, project the input (aka embedding) and reshape to b, t, d. Then apply
+ standard transformer action. Finally, reshape to image
+ """
+
+ def __init__(self, in_channels, n_heads, d_head, depth=1, dropout=0.0, context_dim=None):
+ super().__init__()
+ self.n_heads = n_heads
+ self.d_head = d_head
+ self.in_channels = in_channels
+ inner_dim = n_heads * d_head
+ self.norm = nn.GroupNorm(num_groups=32, num_channels=in_channels, epsilon=1e-6)
+
+ self.proj_in = nn.Conv2D(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
+
+ self.transformer_blocks = nn.LayerList([
+ BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
+ for d in range(depth)
+ ])
+
+ self.proj_out = nn.Conv2D(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x, context=None):
+ # note: if no context is given, cross-attention defaults to self-attention
+ b, c, h, w = x.shape
+ x_in = x
+ x = self.norm(x)
+ x = self.proj_in(x)
+ x = x.transpose([0, 2, 3, 1]).reshape([b, h * w, c])
+ for block in self.transformer_blocks:
+ x = block(x, context=context)
+ x = x.reshape([b, h, w, c]).transpose([0, 3, 1, 2])
+ x = self.proj_out(x)
+ return x + x_in
+
+ def set_weight(self, layer):
+ self.norm = layer.norm
+ self.proj_in = layer.proj_in
+ self.transformer_blocks = layer.transformer_blocks
+ self.proj_out = layer.proj_out
+
+
+class BasicTransformerBlock(nn.Layer):
+
+ def __init__(self, dim, n_heads, d_head, dropout=0.0, context_dim=None, gated_ff=True, checkpoint=True):
+ super().__init__()
+ self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head,
+ dropout=dropout) # is a self-attention
+ self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
+ self.attn2 = CrossAttention(query_dim=dim,
+ context_dim=context_dim,
+ heads=n_heads,
+ dim_head=d_head,
+ dropout=dropout) # is self-attn if context is none
+ self.norm1 = nn.LayerNorm(dim)
+ self.norm2 = nn.LayerNorm(dim)
+ self.norm3 = nn.LayerNorm(dim)
+ self.checkpoint = checkpoint
+
+ def forward(self, x, context=None):
+ x = self.attn1(self.norm1(x)) + x
+ x = self.attn2(self.norm2(x), context=context) + x
+ x = self.ff(self.norm3(x)) + x
+ return x
+
+
+class CrossAttention(nn.Layer):
+
+ def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.0):
+ super().__init__()
+ inner_dim = dim_head * heads
+ context_dim = default(context_dim, query_dim)
+
+ self.scale = dim_head**-0.5
+ self.heads = heads
+
+ self.to_q = nn.Linear(query_dim, inner_dim, bias_attr=False)
+ self.to_k = nn.Linear(context_dim, inner_dim, bias_attr=False)
+ self.to_v = nn.Linear(context_dim, inner_dim, bias_attr=False)
+
+ self.to_out = nn.Sequential(nn.Linear(inner_dim, query_dim), nn.Dropout(dropout))
+
+ def reshape_heads_to_batch_dim(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.heads
+ tensor = tensor.reshape([batch_size, seq_len, head_size, dim // head_size])
+ tensor = tensor.transpose([0, 2, 1, 3]).reshape([batch_size * head_size, seq_len, dim // head_size])
+ return tensor
+
+ def reshape_batch_dim_to_heads(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.heads
+ tensor = tensor.reshape([batch_size // head_size, head_size, seq_len, dim])
+ tensor = tensor.transpose([0, 2, 1, 3]).reshape([batch_size // head_size, seq_len, dim * head_size])
+ return tensor
+
+ def forward(self, x, context=None, mask=None):
+ batch_size, sequence_length, dim = x.shape
+
+ h = self.heads
+
+ q = self.to_q(x)
+ context = default(context, x)
+ k = self.to_k(context)
+ v = self.to_v(context)
+
+ q = self.reshape_heads_to_batch_dim(q)
+ k = self.reshape_heads_to_batch_dim(k)
+ v = self.reshape_heads_to_batch_dim(v)
+
+ sim = paddle.einsum("b i d, b j d -> b i j", q * self.scale, k)
+
+ if exists(mask):
+ mask = mask.reshape([batch_size, -1])
+ max_neg_value = -paddle.finfo(sim.dtype).max
+ mask = mask[:, None, :].repeat(h, 1, 1)
+ sim.masked_fill_(~mask, max_neg_value)
+
+ # attention, what we cannot get enough of
+ attn = F.softmax(sim, axis=-1)
+
+ out = paddle.einsum("b i j, b j d -> b i d", attn, v)
+ out = self.reshape_batch_dim_to_heads(out)
+ return self.to_out(out)
+
+
+class FeedForward(nn.Layer):
+
+ def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.0):
+ super().__init__()
+ inner_dim = int(dim * mult)
+ dim_out = default(dim_out, dim)
+ project_in = nn.Sequential(nn.Linear(dim, inner_dim), nn.GELU()) if not glu else GEGLU(dim, inner_dim)
+
+ self.net = nn.Sequential(project_in, nn.Dropout(dropout), nn.Linear(inner_dim, dim_out))
+
+ def forward(self, x):
+ return self.net(x)
+
+
+# feedforward
+class GEGLU(nn.Layer):
+
+ def __init__(self, dim_in, dim_out):
+ super().__init__()
+ self.proj = nn.Linear(dim_in, dim_out * 2)
+
+ def forward(self, x):
+ x, gate = self.proj(x).chunk(2, axis=-1)
+ return x * F.gelu(gate)
+
+
+# TODO(Patrick) - remove once all weights have been converted -> not needed anymore then
+class NIN(nn.Layer):
+
+ def __init__(self, in_dim, num_units, init_scale=0.1):
+ super().__init__()
+ self.W = self.create_parameter(shape=[in_dim, num_units], default_initializer=nn.initializer.Constant(0.))
+ self.b = self.create_parameter(shape=[
+ num_units,
+ ],
+ is_bias=True,
+ default_initializer=nn.initializer.Constant(0.))
+
+
+def exists(val):
+ return val is not None
+
+
+def default(val, d):
+ if exists(val):
+ return val
+ return d() if isfunction(d) else d
+
+
+# the main attention block that is used for all models
+class AttentionBlock(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other.
+
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_heads=1,
+ num_head_channels=None,
+ num_groups=32,
+ encoder_channels=None,
+ overwrite_qkv=False,
+ overwrite_linear=False,
+ rescale_output_factor=1.0,
+ eps=1e-5,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels is None:
+ self.num_heads = num_heads
+ else:
+ assert (channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+
+ self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=eps)
+ self.qkv = nn.Conv1D(channels, channels * 3, 1)
+ self.n_heads = self.num_heads
+ self.rescale_output_factor = rescale_output_factor
+
+ if encoder_channels is not None:
+ self.encoder_kv = nn.Conv1D(encoder_channels, channels * 2, 1)
+
+ self.proj = nn.Conv1D(channels, channels, 1)
+
+ self.overwrite_qkv = overwrite_qkv
+ self.overwrite_linear = overwrite_linear
+
+ if overwrite_qkv:
+ in_channels = channels
+ self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=1e-6)
+ self.q = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.k = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.v = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.proj_out = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ elif self.overwrite_linear:
+ num_groups = min(channels // 4, 32)
+ self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=1e-6)
+ self.NIN_0 = NIN(channels, channels)
+ self.NIN_1 = NIN(channels, channels)
+ self.NIN_2 = NIN(channels, channels)
+ self.NIN_3 = NIN(channels, channels)
+
+ self.GroupNorm_0 = nn.GroupNorm(num_groups=num_groups, num_channels=channels, epsilon=1e-6)
+ else:
+ self.proj_out = nn.Conv1D(channels, channels, 1)
+ self.set_weights(self)
+
+ self.is_overwritten = False
+
+ def set_weights(self, layer):
+ if self.overwrite_qkv:
+ qkv_weight = paddle.concat([layer.q.weight, layer.k.weight, layer.v.weight], axis=0)[:, :, :, 0]
+ qkv_bias = paddle.concat([layer.q.bias, layer.k.bias, layer.v.bias], axis=0)
+
+ self.qkv.weight.set_value(qkv_weight)
+ self.qkv.bias.set_value(qkv_bias)
+
+ proj_out = nn.Conv1D(self.channels, self.channels, 1)
+ proj_out.weight.set_value(layer.proj_out.weight[:, :, :, 0])
+ proj_out.bias.set_value(layer.proj_out.bias)
+
+ self.proj = proj_out
+ elif self.overwrite_linear:
+ self.qkv.weight.set_value(
+ paddle.concat([self.NIN_0.W.t(), self.NIN_1.W.t(), self.NIN_2.W.t()], axis=0)[:, :, None])
+ self.qkv.bias.set_value(paddle.concat([self.NIN_0.b, self.NIN_1.b, self.NIN_2.b], axis=0))
+
+ self.proj.weight.set_value(self.NIN_3.W.t()[:, :, None])
+ self.proj.bias.set_value(self.NIN_3.b)
+
+ self.norm.weight.set_value(self.GroupNorm_0.weight)
+ self.norm.bias.set_value(self.GroupNorm_0.bias)
+ else:
+ self.proj.weight.set_value(self.proj_out.weight)
+ self.proj.bias.set_value(self.proj_out.bias)
+
+ def forward(self, x, encoder_out=None):
+ if not self.is_overwritten and (self.overwrite_qkv or self.overwrite_linear):
+ self.set_weights(self)
+ self.is_overwritten = True
+
+ b, c, *spatial = x.shape
+ hid_states = self.norm(x).reshape([b, c, -1])
+
+ qkv = self.qkv(hid_states)
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.reshape([bs * self.n_heads, ch * 3, length]).split(ch, axis=1)
+
+ if encoder_out is not None:
+ encoder_kv = self.encoder_kv(encoder_out)
+ assert encoder_kv.shape[1] == self.n_heads * ch * 2
+ ek, ev = encoder_kv.reshape([bs * self.n_heads, ch * 2, -1]).split(ch, axis=1)
+ k = paddle.concat([ek, k], axis=-1)
+ v = paddle.concat([ev, v], axis=-1)
+
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
+ weight = F.softmax(weight.astype("float32"), axis=-1).astype(weight.dtype)
+
+ a = paddle.einsum("bts,bcs->bct", weight, v)
+ h = a.reshape([bs, -1, length])
+
+ h = self.proj(h)
+ h = h.reshape([b, c, *spatial])
+
+ result = x + h
+
+ result = result / self.rescale_output_factor
+
+ return result
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/models/embeddings.py b/modules/image/text_to_image/stable_diffusion/diffusers/models/embeddings.py
new file mode 100644
index 000000000..3e826193b
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/models/embeddings.py
@@ -0,0 +1,116 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def get_timestep_embedding(timesteps,
+ embedding_dim,
+ flip_sin_to_cos=False,
+ downscale_freq_shift=1,
+ scale=1,
+ max_period=10000):
+ """
+ This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
+
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
+ embeddings. :return: an [N x dim] Tensor of positional embeddings.
+ """
+ assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
+
+ half_dim = embedding_dim // 2
+ exponent = -math.log(max_period) * paddle.arange(start=0, end=half_dim, dtype="float32")
+ exponent = exponent / (half_dim - downscale_freq_shift)
+
+ emb = paddle.exp(exponent)
+ emb = timesteps[:, None].astype("float32") * emb[None, :]
+
+ # scale embeddings
+ emb = scale * emb
+
+ # concat sine and cosine embeddings
+ emb = paddle.concat([paddle.sin(emb), paddle.cos(emb)], axis=-1)
+
+ # flip sine and cosine embeddings
+ if flip_sin_to_cos:
+ emb = paddle.concat([emb[:, half_dim:], emb[:, :half_dim]], axis=-1)
+
+ # zero pad
+ if embedding_dim % 2 == 1:
+ emb = paddle.concat(emb, paddle.zeros([emb.shape[0], 1]), axis=-1)
+ return emb
+
+
+class TimestepEmbedding(nn.Layer):
+
+ def __init__(self, channel, time_embed_dim, act_fn="silu"):
+ super().__init__()
+
+ self.linear_1 = nn.Linear(channel, time_embed_dim)
+ self.act = None
+ if act_fn == "silu":
+ self.act = nn.Silu()
+ self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim)
+
+ def forward(self, sample):
+ sample = self.linear_1(sample)
+
+ if self.act is not None:
+ sample = self.act(sample)
+
+ sample = self.linear_2(sample)
+ return sample
+
+
+class Timesteps(nn.Layer):
+
+ def __init__(self, num_channels, flip_sin_to_cos, downscale_freq_shift):
+ super().__init__()
+ self.num_channels = num_channels
+ self.flip_sin_to_cos = flip_sin_to_cos
+ self.downscale_freq_shift = downscale_freq_shift
+
+ def forward(self, timesteps):
+ t_emb = get_timestep_embedding(
+ timesteps,
+ self.num_channels,
+ flip_sin_to_cos=self.flip_sin_to_cos,
+ downscale_freq_shift=self.downscale_freq_shift,
+ )
+ return t_emb
+
+
+class GaussianFourierProjection(nn.Layer):
+ """Gaussian Fourier embeddings for noise levels."""
+
+ def __init__(self, embedding_size=256, scale=1.0):
+ super().__init__()
+ self.register_buffer("weight", paddle.randn((embedding_size, )) * scale)
+
+ # to delete later
+ self.register_buffer("W", paddle.randn((embedding_size, )) * scale)
+
+ self.weight = self.W
+
+ def forward(self, x):
+ x = paddle.log(x)
+ x_proj = x[:, None] * self.weight[None, :] * 2 * np.pi
+ out = paddle.concat([paddle.sin(x_proj), paddle.cos(x_proj)], axis=-1)
+ return out
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/models/resnet.py b/modules/image/text_to_image/stable_diffusion/diffusers/models/resnet.py
new file mode 100644
index 000000000..944bc11cd
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/models/resnet.py
@@ -0,0 +1,515 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from functools import partial
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def pad_new(x, pad, mode="constant", value=0):
+ new_pad = []
+ for _ in range(x.ndim * 2 - len(pad)):
+ new_pad.append(0)
+ ndim = list(range(x.ndim - 1, 0, -1))
+ axes_start = {}
+ for i, _pad in enumerate(pad):
+ if _pad < 0:
+ new_pad.append(0)
+ zhengshu, yushu = divmod(i, 2)
+ if yushu == 0:
+ axes_start[ndim[zhengshu]] = -_pad
+ else:
+ new_pad.append(_pad)
+
+ padded = paddle.nn.functional.pad(x, new_pad, mode=mode, value=value)
+ padded_shape = paddle.shape(padded)
+ axes = []
+ starts = []
+ ends = []
+ for k, v in axes_start.items():
+ axes.append(k)
+ starts.append(v)
+ ends.append(padded_shape[k])
+ assert v < padded_shape[k]
+
+ if axes:
+ return padded.slice(axes=axes, starts=starts, ends=ends)
+ else:
+ return padded
+
+
+class Upsample2D(nn.Layer):
+ """
+ An upsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
+ applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv=False, use_conv_transpose=False, out_channels=None, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_conv_transpose = use_conv_transpose
+ self.name = name
+
+ conv = None
+ if use_conv_transpose:
+ conv = nn.Conv2DTranspose(channels, self.out_channels, 4, 2, 1)
+ elif use_conv:
+ conv = nn.Conv2D(self.channels, self.out_channels, 3, padding=1)
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if name == "conv":
+ self.conv = conv
+ else:
+ self.Conv2d_0 = conv
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.use_conv_transpose:
+ return self.conv(x)
+
+ x = F.interpolate(x, scale_factor=2.0, mode="nearest")
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if self.use_conv:
+ if self.name == "conv":
+ x = self.conv(x)
+ else:
+ x = self.Conv2d_0(x)
+
+ return x
+
+
+class Downsample2D(nn.Layer):
+ """
+ A downsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
+ applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv=False, out_channels=None, padding=1, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.padding = padding
+ stride = 2
+ self.name = name
+
+ if use_conv:
+ conv = nn.Conv2D(self.channels, self.out_channels, 3, stride=stride, padding=padding)
+ else:
+ assert self.channels == self.out_channels
+ conv = nn.AvgPool2D(kernel_size=stride, stride=stride)
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if name == "conv":
+ self.Conv2d_0 = conv
+ self.conv = conv
+ elif name == "Conv2d_0":
+ self.conv = conv
+ else:
+ self.conv = conv
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.use_conv and self.padding == 0:
+ pad = (0, 1, 0, 1)
+ x = pad_new(x, pad, mode="constant", value=0)
+
+ assert x.shape[1] == self.channels
+ x = self.conv(x)
+
+ return x
+
+
+class FirUpsample2D(nn.Layer):
+
+ def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
+ super().__init__()
+ out_channels = out_channels if out_channels else channels
+ if use_conv:
+ self.Conv2d_0 = nn.Conv2D(channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.use_conv = use_conv
+ self.fir_kernel = fir_kernel
+ self.out_channels = out_channels
+
+ def _upsample_2d(self, x, w=None, k=None, factor=2, gain=1):
+ """Fused `upsample_2d()` followed by `Conv2d()`.
+
+ Args:
+ Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
+ efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
+ order.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
+ C]`.
+ w: Weight tensor of the shape `[filterH, filterW, inChannels,
+ outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] // numGroups`.
+ k: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
+ factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H * factor, W * factor]` or `[N, H * factor, W * factor, C]`, and same datatype as
+ `x`.
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+
+ # Setup filter kernel.
+ if k is None:
+ k = [1] * factor
+
+ # setup kernel
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * (gain * (factor**2))
+
+ if self.use_conv:
+ convH = w.shape[2]
+ convW = w.shape[3]
+ inC = w.shape[1]
+
+ p = (k.shape[0] - factor) - (convW - 1)
+
+ stride = (factor, factor)
+ # Determine data dimensions.
+ stride = [1, 1, factor, factor]
+ output_shape = ((x.shape[2] - 1) * factor + convH, (x.shape[3] - 1) * factor + convW)
+ output_padding = (
+ output_shape[0] - (x.shape[2] - 1) * stride[0] - convH,
+ output_shape[1] - (x.shape[3] - 1) * stride[1] - convW,
+ )
+ assert output_padding[0] >= 0 and output_padding[1] >= 0
+ inC = w.shape[1]
+ num_groups = x.shape[1] // inC
+
+ # Transpose weights.
+ w = paddle.reshape(w, (num_groups, -1, inC, convH, convW))
+ w = w[..., ::-1, ::-1].transpose([0, 2, 1, 3, 4])
+ w = paddle.reshape(w, (num_groups * inC, -1, convH, convW))
+
+ x = F.conv2d_transpose(x, w, stride=stride, output_padding=output_padding, padding=0)
+
+ x = upfirdn2d_native(x, paddle.to_tensor(k), pad=((p + 1) // 2 + factor - 1, p // 2 + 1))
+ else:
+ p = k.shape[0] - factor
+ x = upfirdn2d_native(x, paddle.to_tensor(k), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2))
+
+ return x
+
+ def forward(self, x):
+ if self.use_conv:
+ h = self._upsample_2d(x, self.Conv2d_0.weight, k=self.fir_kernel)
+ h = h + self.Conv2d_0.bias.reshape([1, -1, 1, 1])
+ else:
+ h = self._upsample_2d(x, k=self.fir_kernel, factor=2)
+
+ return h
+
+
+class FirDownsample2D(nn.Layer):
+
+ def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
+ super().__init__()
+ out_channels = out_channels if out_channels else channels
+ if use_conv:
+ self.Conv2d_0 = nn.Conv2D(channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.fir_kernel = fir_kernel
+ self.use_conv = use_conv
+ self.out_channels = out_channels
+
+ def _downsample_2d(self, x, w=None, k=None, factor=2, gain=1):
+ """Fused `Conv2d()` followed by `downsample_2d()`.
+
+ Args:
+ Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
+ efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
+ order.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`. w: Weight tensor of the shape `[filterH,
+ filterW, inChannels, outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] //
+ numGroups`. k: FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] *
+ factor`, which corresponds to average pooling. factor: Integer downsampling factor (default: 2). gain:
+ Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H // factor, W // factor]` or `[N, H // factor, W // factor, C]`, and same
+ datatype as `x`.
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+ if k is None:
+ k = [1] * factor
+
+ # setup kernel
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * gain
+
+ if self.use_conv:
+ _, _, convH, convW = w.shape
+ p = (k.shape[0] - factor) + (convW - 1)
+ s = [factor, factor]
+ x = upfirdn2d_native(x, paddle.to_tensor(k), pad=((p + 1) // 2, p // 2))
+ x = F.conv2d(x, w, stride=s, padding=0)
+ else:
+ p = k.shape[0] - factor
+ x = upfirdn2d_native(x, paddle.to_tensor(k), down=factor, pad=((p + 1) // 2, p // 2))
+
+ return x
+
+ def forward(self, x):
+ if self.use_conv:
+ x = self._downsample_2d(x, w=self.Conv2d_0.weight, k=self.fir_kernel)
+ x = x + self.Conv2d_0.bias.reshape([1, -1, 1, 1])
+ else:
+ x = self._downsample_2d(x, k=self.fir_kernel, factor=2)
+
+ return x
+
+
+class ResnetBlock(nn.Layer):
+
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout=0.0,
+ temb_channels=512,
+ groups=32,
+ groups_out=None,
+ pre_norm=True,
+ eps=1e-6,
+ non_linearity="swish",
+ time_embedding_norm="default",
+ kernel=None,
+ output_scale_factor=1.0,
+ use_nin_shortcut=None,
+ up=False,
+ down=False,
+ ):
+ super().__init__()
+ self.pre_norm = pre_norm
+ self.pre_norm = True
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+ self.time_embedding_norm = time_embedding_norm
+ self.up = up
+ self.down = down
+ self.output_scale_factor = output_scale_factor
+
+ if groups_out is None:
+ groups_out = groups
+
+ self.norm1 = nn.GroupNorm(num_groups=groups, num_channels=in_channels, epsilon=eps)
+
+ self.conv1 = nn.Conv2D(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if temb_channels is not None:
+ self.time_emb_proj = nn.Linear(temb_channels, out_channels)
+ else:
+ self.time_emb_proj = None
+
+ self.norm2 = nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, epsilon=eps)
+ self.dropout = nn.Dropout(dropout)
+ self.conv2 = nn.Conv2D(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if non_linearity == "swish":
+ self.nonlinearity = lambda x: F.silu(x)
+ elif non_linearity == "mish":
+ self.nonlinearity = Mish()
+ elif non_linearity == "silu":
+ self.nonlinearity = nn.Silu()
+
+ self.upsample = self.downsample = None
+ if self.up:
+ if kernel == "fir":
+ fir_kernel = (1, 3, 3, 1)
+ self.upsample = lambda x: upsample_2d(x, k=fir_kernel)
+ elif kernel == "sde_vp":
+ self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
+ else:
+ self.upsample = Upsample2D(in_channels, use_conv=False)
+ elif self.down:
+ if kernel == "fir":
+ fir_kernel = (1, 3, 3, 1)
+ self.downsample = lambda x: downsample_2d(x, k=fir_kernel)
+ elif kernel == "sde_vp":
+ self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
+ else:
+ self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
+
+ self.use_nin_shortcut = self.in_channels != self.out_channels if use_nin_shortcut is None else use_nin_shortcut
+
+ self.conv_shortcut = None
+ if self.use_nin_shortcut:
+ self.conv_shortcut = nn.Conv2D(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x, temb, hey=False):
+ h = x
+
+ # make sure hidden states is in float32
+ # when running in half-precision
+ h = self.norm1(h.astype("float32")).astype(h.dtype)
+ h = self.nonlinearity(h)
+
+ if self.upsample is not None:
+ x = self.upsample(x)
+ h = self.upsample(h)
+ elif self.downsample is not None:
+ x = self.downsample(x)
+ h = self.downsample(h)
+
+ h = self.conv1(h)
+
+ if temb is not None:
+ temb = self.time_emb_proj(self.nonlinearity(temb))[:, :, None, None]
+ h = h + temb
+
+ # make sure hidden states is in float32
+ # when running in half-precision
+ h = self.norm2(h.astype("float32")).astype(h.dtype)
+ h = self.nonlinearity(h)
+
+ h = self.dropout(h)
+ h = self.conv2(h)
+
+ if self.conv_shortcut is not None:
+ x = self.conv_shortcut(x)
+
+ out = (x + h) / self.output_scale_factor
+
+ return out
+
+
+class Mish(nn.Layer):
+
+ def forward(self, x):
+ return x * F.tanh(F.softplus(x))
+
+
+def upsample_2d(x, k=None, factor=2, gain=1):
+ r"""Upsample2D a batch of 2D images with the given filter.
+
+ Args:
+ Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and upsamples each image with the given
+ filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the specified
+ `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its shape is a:
+ multiple of the upsampling factor.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
+ C]`.
+ k: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
+ factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H * factor, W * factor]`
+ """
+ assert isinstance(factor, int) and factor >= 1
+ if k is None:
+ k = [1] * factor
+
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * (gain * (factor**2))
+ p = k.shape[0] - factor
+ return upfirdn2d_native(x, paddle.to_tensor(k), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2))
+
+
+def downsample_2d(x, k=None, factor=2, gain=1):
+ r"""Downsample2D a batch of 2D images with the given filter.
+
+ Args:
+ Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and downsamples each image with the
+ given filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the
+ specified `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its
+ shape is a multiple of the downsampling factor.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
+ C]`.
+ k: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to average pooling.
+ factor: Integer downsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H // factor, W // factor]`
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+ if k is None:
+ k = [1] * factor
+
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * gain
+ p = k.shape[0] - factor
+ return upfirdn2d_native(x, paddle.to_tensor(k), down=factor, pad=((p + 1) // 2, p // 2))
+
+
+def upfirdn2d_native(input, kernel, up=1, down=1, pad=(0, 0)):
+ up_x = up_y = up
+ down_x = down_y = down
+ pad_x0 = pad_y0 = pad[0]
+ pad_x1 = pad_y1 = pad[1]
+
+ _, channel, in_h, in_w = input.shape
+ input = input.reshape([-1, in_h, in_w, 1])
+
+ _, in_h, in_w, minor = input.shape
+ kernel_h, kernel_w = kernel.shape
+
+ out = input.reshape([-1, in_h, 1, in_w, 1, minor])
+ # TODO
+ out = pad_new(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
+ out = out.reshape([-1, in_h * up_y, in_w * up_x, minor])
+
+ out = pad_new(out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)])
+ out = out[:, max(-pad_y0, 0):out.shape[1] - max(-pad_y1, 0), max(-pad_x0, 0):out.shape[2] - max(-pad_x1, 0), :, ]
+
+ out = out.transpose([0, 3, 1, 2])
+ out = out.reshape([-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1])
+ w = paddle.flip(kernel, [0, 1]).reshape([1, 1, kernel_h, kernel_w])
+ out = F.conv2d(out, w)
+ out = out.reshape(
+ [-1, minor, in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1, in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1])
+ out = out.transpose([0, 2, 3, 1])
+ out = out[:, ::down_y, ::down_x, :]
+
+ out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
+ out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
+
+ return out.reshape([-1, channel, out_h, out_w])
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/models/unet_2d.py b/modules/image/text_to_image/stable_diffusion/diffusers/models/unet_2d.py
new file mode 100644
index 000000000..11316a819
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/models/unet_2d.py
@@ -0,0 +1,206 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .embeddings import GaussianFourierProjection
+from .embeddings import TimestepEmbedding
+from .embeddings import Timesteps
+from .unet_blocks import get_down_block
+from .unet_blocks import get_up_block
+from .unet_blocks import UNetMidBlock2D
+
+
+class UNet2DModel(nn.Layer, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size=None,
+ in_channels=3,
+ out_channels=3,
+ center_input_sample=False,
+ time_embedding_type="positional",
+ freq_shift=0,
+ flip_sin_to_cos=True,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D"),
+ block_out_channels=(224, 448, 672, 896),
+ layers_per_block=2,
+ mid_block_scale_factor=1,
+ downsample_padding=1,
+ act_fn="silu",
+ attention_head_dim=8,
+ norm_num_groups=32,
+ norm_eps=1e-5,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+ time_embed_dim = block_out_channels[0] * 4
+
+ # input
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
+
+ # time
+ if time_embedding_type == "fourier":
+ self.time_proj = GaussianFourierProjection(embedding_size=block_out_channels[0], scale=16)
+ timestep_input_dim = 2 * block_out_channels[0]
+ elif time_embedding_type == "positional":
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+
+ self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+
+ self.down_blocks = nn.LayerList([])
+ self.mid_block = None
+ self.up_blocks = nn.LayerList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=attention_head_dim,
+ downsample_padding=downsample_padding,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ temb_channels=time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=attention_head_dim,
+ resnet_groups=norm_num_groups,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=time_embed_dim,
+ add_upsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=attention_head_dim,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ num_groups_out = norm_num_groups if norm_num_groups is not None else min(block_out_channels[0] // 4, 32)
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0],
+ num_groups=num_groups_out,
+ epsilon=norm_eps)
+ self.conv_act = nn.Silu()
+ self.conv_out = nn.Conv2D(block_out_channels[0], out_channels, 3, padding=1)
+
+ def forward(self, sample: paddle.Tensor, timestep: Union[paddle.Tensor, float, int]) -> Dict[str, paddle.Tensor]:
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not paddle.is_tensor(timesteps):
+ timesteps = paddle.to_tensor([timesteps], dtype="int64")
+ elif paddle.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None]
+
+ # broadcast to batch dimension
+ timesteps = paddle.broadcast_to(timesteps, [sample.shape[0]])
+
+ t_emb = self.time_proj(timesteps)
+ emb = self.time_embedding(t_emb)
+
+ # 2. pre-process
+ skip_sample = sample
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample, )
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "skip_conv"):
+ sample, res_samples, skip_sample = downsample_block(hidden_states=sample,
+ temb=emb,
+ skip_sample=skip_sample)
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ # 4. mid
+ sample = self.mid_block(sample, emb)
+
+ # 5. up
+ skip_sample = None
+ for upsample_block in self.up_blocks:
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[:-len(upsample_block.resnets)]
+
+ if hasattr(upsample_block, "skip_conv"):
+ sample, skip_sample = upsample_block(sample, res_samples, emb, skip_sample)
+ else:
+ sample = upsample_block(sample, res_samples, emb)
+
+ # 6. post-process
+ # make sure hidden states is in float32
+ # when running in half-precision
+ sample = self.conv_norm_out(sample.astype("float32")).astype(sample.dtype)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ if skip_sample is not None:
+ sample += skip_sample
+
+ if self.config.time_embedding_type == "fourier":
+ timesteps = timesteps.reshape((sample.shape[0], *([1] * len(sample.shape[1:]))))
+ sample = sample / timesteps
+
+ output = {"sample": sample}
+
+ return output
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/models/unet_2d_condition.py b/modules/image/text_to_image/stable_diffusion/diffusers/models/unet_2d_condition.py
new file mode 100644
index 000000000..897491b2f
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/models/unet_2d_condition.py
@@ -0,0 +1,206 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .embeddings import TimestepEmbedding
+from .embeddings import Timesteps
+from .unet_blocks import get_down_block
+from .unet_blocks import get_up_block
+from .unet_blocks import UNetMidBlock2DCrossAttn
+
+
+class UNet2DConditionModel(nn.Layer, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size=64,
+ in_channels=4,
+ out_channels=4,
+ center_input_sample=False,
+ flip_sin_to_cos=True,
+ freq_shift=0,
+ down_block_types=("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D"),
+ up_block_types=("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
+ block_out_channels=(320, 640, 1280, 1280),
+ layers_per_block=2,
+ downsample_padding=1,
+ mid_block_scale_factor=1,
+ act_fn="silu",
+ norm_num_groups=32,
+ norm_eps=1e-5,
+ cross_attention_dim=768,
+ attention_head_dim=8,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+ time_embed_dim = block_out_channels[0] * 4
+
+ # input
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
+
+ # time
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+
+ self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+
+ self.down_blocks = nn.LayerList([])
+ self.mid_block = None
+ self.up_blocks = nn.LayerList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim,
+ downsample_padding=downsample_padding,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2DCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift="default",
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim,
+ resnet_groups=norm_num_groups,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=time_embed_dim,
+ add_upsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0],
+ num_groups=norm_num_groups,
+ epsilon=norm_eps)
+ self.conv_act = nn.Silu()
+ self.conv_out = nn.Conv2D(block_out_channels[0], out_channels, 3, padding=1)
+
+ def forward(
+ self,
+ sample: paddle.Tensor,
+ timestep: Union[paddle.Tensor, float, int],
+ encoder_hidden_states: paddle.Tensor,
+ ) -> Dict[str, paddle.Tensor]:
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not paddle.is_tensor(timesteps):
+ timesteps = paddle.to_tensor([timesteps], dtype="int64")
+ elif paddle.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None]
+
+ # broadcast to batch dimension
+ timesteps = paddle.broadcast_to(timesteps, [sample.shape[0]])
+
+ t_emb = self.time_proj(timesteps)
+ emb = self.time_embedding(t_emb)
+
+ # 2. pre-process
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample, )
+ for downsample_block in self.down_blocks:
+
+ if hasattr(downsample_block, "attentions") and downsample_block.attentions is not None:
+ sample, res_samples = downsample_block(hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states)
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ # 4. mid
+ sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
+
+ # 5. up
+ for upsample_block in self.up_blocks:
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[:-len(upsample_block.resnets)]
+
+ if hasattr(upsample_block, "attentions") and upsample_block.attentions is not None:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ else:
+ sample = upsample_block(hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples)
+
+ # 6. post-process
+ # make sure hidden states is in float32
+ # when running in half-precision
+ sample = self.conv_norm_out(sample.astype("float32")).astype(sample.dtype)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ output = {"sample": sample}
+
+ return output
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/models/unet_blocks.py b/modules/image/text_to_image/stable_diffusion/diffusers/models/unet_blocks.py
new file mode 100644
index 000000000..684a2a43d
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/models/unet_blocks.py
@@ -0,0 +1,1428 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import paddle
+import paddle.nn as nn
+
+from .attention import AttentionBlockNew
+from .attention import SpatialTransformer
+from .resnet import Downsample2D
+from .resnet import FirDownsample2D
+from .resnet import FirUpsample2D
+from .resnet import ResnetBlock
+from .resnet import Upsample2D
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ cross_attention_dim=None,
+ downsample_padding=None,
+):
+ down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
+ if down_block_type == "DownBlock2D":
+ return DownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ )
+ elif down_block_type == "AttnDownBlock2D":
+ return AttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif down_block_type == "CrossAttnDownBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock2D")
+ return CrossAttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif down_block_type == "SkipDownBlock2D":
+ return SkipDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ )
+ elif down_block_type == "AttnSkipDownBlock2D":
+ return AttnSkipDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif down_block_type == "DownEncoderBlock2D":
+ return DownEncoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ )
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ cross_attention_dim=None,
+):
+ up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
+ if up_block_type == "UpBlock2D":
+ return UpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ elif up_block_type == "CrossAttnUpBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock2D")
+ return CrossAttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif up_block_type == "AttnUpBlock2D":
+ return AttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif up_block_type == "SkipUpBlock2D":
+ return SkipUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ elif up_block_type == "AttnSkipUpBlock2D":
+ return AttnSkipUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif up_block_type == "UpDecoderBlock2D":
+ return UpDecoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+class UNetMidBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=1.0,
+ **kwargs,
+ ):
+ super().__init__()
+
+ self.attention_type = attention_type
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ attentions.append(
+ AttentionBlockNew(
+ in_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ num_groups=resnet_groups,
+ ))
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_states=None):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ if self.attention_type == "default":
+ hidden_states = attn(hidden_states)
+ else:
+ hidden_states = attn(hidden_states, encoder_states)
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+class UNetMidBlock2DCrossAttn(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ **kwargs,
+ ):
+ super().__init__()
+
+ self.attention_type = attention_type
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ attentions.append(
+ SpatialTransformer(
+ in_channels,
+ attn_num_head_channels,
+ in_channels // attn_num_head_channels,
+ depth=1,
+ context_dim=cross_attention_dim,
+ ))
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ hidden_states = attn(hidden_states, encoder_hidden_states)
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+class AttnDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states
+
+
+class CrossAttnDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ attention_type="default",
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ SpatialTransformer(
+ out_channels,
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ depth=1,
+ context_dim=cross_attention_dim,
+ ))
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, context=encoder_hidden_states)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states
+
+
+class DownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states
+
+
+class DownEncoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb=None)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnDownEncoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ num_groups=resnet_groups,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb=None)
+ hidden_states = attn(hidden_states)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnSkipDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=np.sqrt(2.0),
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ self.attentions = nn.LayerList([])
+ self.resnets = nn.LayerList([])
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(in_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ self.attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ if add_downsample:
+ self.resnet_down = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ down=True,
+ kernel="fir",
+ )
+ self.downsamplers = nn.LayerList([FirDownsample2D(in_channels, out_channels=out_channels)])
+ self.skip_conv = nn.Conv2D(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
+ else:
+ self.resnet_down = None
+ self.downsamplers = None
+ self.skip_conv = None
+
+ def forward(self, hidden_states, temb=None, skip_sample=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ hidden_states = self.resnet_down(hidden_states, temb)
+ for downsampler in self.downsamplers:
+ skip_sample = downsampler(skip_sample)
+
+ hidden_states = self.skip_conv(skip_sample) + hidden_states
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states, skip_sample
+
+
+class SkipDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ output_scale_factor=np.sqrt(2.0),
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ self.resnets = nn.LayerList([])
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(in_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ if add_downsample:
+ self.resnet_down = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ down=True,
+ kernel="fir",
+ )
+ self.downsamplers = nn.LayerList([FirDownsample2D(in_channels, out_channels=out_channels)])
+ self.skip_conv = nn.Conv2D(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
+ else:
+ self.resnet_down = None
+ self.downsamplers = None
+ self.skip_conv = None
+
+ def forward(self, hidden_states, temb=None, skip_sample=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ hidden_states = self.resnet_down(hidden_states, temb)
+ for downsampler in self.downsamplers:
+ skip_sample = downsampler(skip_sample)
+
+ hidden_states = self.skip_conv(skip_sample) + hidden_states
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states, skip_sample
+
+
+class AttnUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attention_type="default",
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ for resnet, attn in zip(self.resnets, self.attentions):
+
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class CrossAttnUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ attention_type="default",
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ SpatialTransformer(
+ out_channels,
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ depth=1,
+ context_dim=cross_attention_dim,
+ ))
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, encoder_hidden_states=None):
+ for resnet, attn in zip(self.resnets, self.attentions):
+
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, context=encoder_hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class UpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ for resnet in self.resnets:
+
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class UpDecoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ input_channels = in_channels if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=input_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb=None)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnUpDecoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ input_channels = in_channels if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=input_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ num_groups=resnet_groups,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb=None)
+ hidden_states = attn(hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnSkipUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=np.sqrt(2.0),
+ upsample_padding=1,
+ add_upsample=True,
+ ):
+ super().__init__()
+ self.attentions = nn.LayerList([])
+ self.resnets = nn.LayerList([])
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(resnet_in_channels + res_skip_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
+ if add_upsample:
+ self.resnet_up = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ up=True,
+ kernel="fir",
+ )
+ self.skip_conv = nn.Conv2D(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ self.skip_norm = nn.GroupNorm(num_groups=min(out_channels // 4, 32),
+ num_channels=out_channels,
+ eps=resnet_eps,
+ affine=True)
+ self.act = nn.SiLU()
+ else:
+ self.resnet_up = None
+ self.skip_conv = None
+ self.skip_norm = None
+ self.act = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, skip_sample=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ hidden_states = self.attentions[0](hidden_states)
+
+ if skip_sample is not None:
+ skip_sample = self.upsampler(skip_sample)
+ else:
+ skip_sample = 0
+
+ if self.resnet_up is not None:
+ skip_sample_states = self.skip_norm(hidden_states)
+ skip_sample_states = self.act(skip_sample_states)
+ skip_sample_states = self.skip_conv(skip_sample_states)
+
+ skip_sample = skip_sample + skip_sample_states
+
+ hidden_states = self.resnet_up(hidden_states, temb)
+
+ return hidden_states, skip_sample
+
+
+class SkipUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ output_scale_factor=np.sqrt(2.0),
+ add_upsample=True,
+ upsample_padding=1,
+ ):
+ super().__init__()
+ self.resnets = nn.LayerList([])
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min((resnet_in_channels + res_skip_channels) // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
+ if add_upsample:
+ self.resnet_up = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ up=True,
+ kernel="fir",
+ )
+ self.skip_conv = nn.Conv2D(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ self.skip_norm = nn.GroupNorm(num_groups=min(out_channels // 4, 32),
+ num_channels=out_channels,
+ eps=resnet_eps,
+ affine=True)
+ self.act = nn.SiLU()
+ else:
+ self.resnet_up = None
+ self.skip_conv = None
+ self.skip_norm = None
+ self.act = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, skip_sample=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ if skip_sample is not None:
+ skip_sample = self.upsampler(skip_sample)
+ else:
+ skip_sample = 0
+
+ if self.resnet_up is not None:
+ skip_sample_states = self.skip_norm(hidden_states)
+ skip_sample_states = self.act(skip_sample_states)
+ skip_sample_states = self.skip_conv(skip_sample_states)
+
+ skip_sample = skip_sample + skip_sample_states
+
+ hidden_states = self.resnet_up(hidden_states, temb)
+
+ return hidden_states, skip_sample
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/models/vae.py b/modules/image/text_to_image/stable_diffusion/diffusers/models/vae.py
new file mode 100644
index 000000000..59e35b0fb
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/models/vae.py
@@ -0,0 +1,465 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import paddle
+import paddle.nn as nn
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .unet_blocks import get_down_block
+from .unet_blocks import get_up_block
+from .unet_blocks import UNetMidBlock2D
+
+
+class Encoder(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", ),
+ block_out_channels=(64, ),
+ layers_per_block=2,
+ act_fn="silu",
+ double_z=True,
+ ):
+ super().__init__()
+ self.layers_per_block = layers_per_block
+
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[0], kernel_size=3, stride=1, padding=1)
+
+ self.mid_block = None
+ self.down_blocks = nn.LayerList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=self.layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ add_downsample=not is_final_block,
+ resnet_eps=1e-6,
+ downsample_padding=0,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=None,
+ temb_channels=None,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ output_scale_factor=1,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=None,
+ resnet_groups=32,
+ temb_channels=None,
+ )
+
+ # out
+ num_groups_out = 32
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[-1], num_groups=num_groups_out, epsilon=1e-6)
+ self.conv_act = nn.Silu()
+
+ conv_out_channels = 2 * out_channels if double_z else out_channels
+ self.conv_out = nn.Conv2D(block_out_channels[-1], conv_out_channels, 3, padding=1)
+
+ def forward(self, x):
+ sample = x
+ sample = self.conv_in(sample)
+
+ # down
+ for down_block in self.down_blocks:
+ sample = down_block(sample)
+
+ # middle
+ sample = self.mid_block(sample)
+
+ # post-process
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class Decoder(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ up_block_types=("UpDecoderBlock2D", ),
+ block_out_channels=(64, ),
+ layers_per_block=2,
+ act_fn="silu",
+ ):
+ super().__init__()
+ self.layers_per_block = layers_per_block
+
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[-1], kernel_size=3, stride=1, padding=1)
+
+ self.mid_block = None
+ self.up_blocks = nn.LayerList([])
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ output_scale_factor=1,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=None,
+ resnet_groups=32,
+ temb_channels=None,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=self.layers_per_block + 1,
+ in_channels=prev_output_channel,
+ out_channels=output_channel,
+ prev_output_channel=None,
+ add_upsample=not is_final_block,
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=None,
+ temb_channels=None,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ num_groups_out = 32
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=num_groups_out, epsilon=1e-6)
+ self.conv_act = nn.Silu()
+ self.conv_out = nn.Conv2D(block_out_channels[0], out_channels, 3, padding=1)
+
+ def forward(self, z):
+ sample = z
+ sample = self.conv_in(sample)
+
+ # middle
+ sample = self.mid_block(sample)
+
+ # up
+ for up_block in self.up_blocks:
+ sample = up_block(sample)
+
+ # post-process
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class VectorQuantizer(nn.Layer):
+ """
+ Improved version over VectorQuantizer, can be used as a drop-in replacement. Mostly avoids costly matrix
+ multiplications and allows for post-hoc remapping of indices.
+ """
+
+ # NOTE: due to a bug the beta term was applied to the wrong term. for
+ # backwards compatibility we use the buggy version by default, but you can
+ # specify legacy=False to fix it.
+ def __init__(self, n_e, e_dim, beta, remap=None, unknown_index="random", sane_index_shape=False, legacy=True):
+ super().__init__()
+ self.n_e = n_e
+ self.e_dim = e_dim
+ self.beta = beta
+ self.legacy = legacy
+
+ self.embedding = nn.Embedding(self.n_e, self.e_dim)
+ self.embedding.weight.data.uniform_(-1.0 / self.n_e, 1.0 / self.n_e)
+
+ self.remap = remap
+ if self.remap is not None:
+ self.register_buffer("used", paddle.to_tensor(np.load(self.remap)))
+ self.re_embed = self.used.shape[0]
+ self.unknown_index = unknown_index # "random" or "extra" or integer
+ if self.unknown_index == "extra":
+ self.unknown_index = self.re_embed
+ self.re_embed = self.re_embed + 1
+ print(f"Remapping {self.n_e} indices to {self.re_embed} indices. "
+ f"Using {self.unknown_index} for unknown indices.")
+ else:
+ self.re_embed = n_e
+
+ self.sane_index_shape = sane_index_shape
+
+ def remap_to_used(self, inds):
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape([ishape[0], -1])
+ used = self.used
+ match = (inds[:, :, None] == used[None, None, ...]).astype("int64")
+ new = match.argmax(-1)
+ unknown = match.sum(2) < 1
+ if self.unknown_index == "random":
+ new[unknown] = paddle.randint(0, self.re_embed, shape=new[unknown].shape)
+ else:
+ new[unknown] = self.unknown_index
+ return new.reshape(ishape)
+
+ def unmap_to_all(self, inds):
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape([ishape[0], -1])
+ used = self.used
+ if self.re_embed > self.used.shape[0]: # extra token
+ inds[inds >= self.used.shape[0]] = 0 # simply set to zero
+ back = paddle.gather(used[None, :][inds.shape[0] * [0], :], inds, axis=1)
+ return back.reshape(ishape)
+
+ def forward(self, z):
+ # reshape z -> (batch, height, width, channel) and flatten
+ z = z.transpose([0, 2, 3, 1])
+ z_flattened = z.reshape([-1, self.e_dim])
+ # distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
+
+ d = (paddle.sum(z_flattened**2, axis=1, keepdim=True) + paddle.sum(self.embedding.weight**2, axis=1) -
+ 2 * paddle.einsum("bd,dn->bn", z_flattened, self.embedding.weight.t()))
+
+ min_encoding_indices = paddle.argmin(d, axis=1)
+ z_q = self.embedding(min_encoding_indices).reshape(z.shape)
+ perplexity = None
+ min_encodings = None
+
+ # compute loss for embedding
+ if not self.legacy:
+ loss = self.beta * paddle.mean((z_q.detach() - z)**2) + paddle.mean((z_q - z.detach())**2)
+ else:
+ loss = paddle.mean((z_q.detach() - z)**2) + self.beta * paddle.mean((z_q - z.detach())**2)
+
+ # preserve gradients
+ z_q = z + (z_q - z).detach()
+
+ # reshape back to match original input shape
+ z_q = z_q.transpose([0, 3, 1, 2])
+
+ if self.remap is not None:
+ min_encoding_indices = min_encoding_indices.reshape([z.shape[0], -1]) # add batch axis
+ min_encoding_indices = self.remap_to_used(min_encoding_indices)
+ min_encoding_indices = min_encoding_indices.reshape([-1, 1]) # flatten
+
+ if self.sane_index_shape:
+ min_encoding_indices = min_encoding_indices.reshape([z_q.shape[0], z_q.shape[2], z_q.shape[3]])
+
+ return z_q, loss, (perplexity, min_encodings, min_encoding_indices)
+
+ def get_codebook_entry(self, indices, shape):
+ # shape specifying (batch, height, width, channel)
+ if self.remap is not None:
+ indices = indices.reshape([shape[0], -1]) # add batch axis
+ indices = self.unmap_to_all(indices)
+ indices = indices.flatten() # flatten again
+
+ # get quantized latent vectors
+ z_q = self.embedding(indices)
+
+ if shape is not None:
+ z_q = z_q.reshape(shape)
+ # reshape back to match original input shape
+ z_q = z_q.transpose([0, 3, 1, 2])
+
+ return z_q
+
+
+class DiagonalGaussianDistribution(object):
+
+ def __init__(self, parameters, deterministic=False):
+ self.parameters = parameters
+ self.mean, self.logvar = paddle.chunk(parameters, 2, axis=1)
+ self.logvar = paddle.clip(self.logvar, -30.0, 20.0)
+ self.deterministic = deterministic
+ self.std = paddle.exp(0.5 * self.logvar)
+ self.var = paddle.exp(self.logvar)
+ if self.deterministic:
+ self.var = self.std = paddle.zeros_like(self.mean)
+
+ def sample(self):
+ x = self.mean + self.std * paddle.randn(self.mean.shape)
+ return x
+
+ def kl(self, other=None):
+ if self.deterministic:
+ return paddle.to_tensor([0.0])
+ else:
+ if other is None:
+ return 0.5 * paddle.sum(paddle.pow(self.mean, 2) + self.var - 1.0 - self.logvar, axis=[1, 2, 3])
+ else:
+ return 0.5 * paddle.sum(
+ paddle.pow(self.mean - other.mean, 2) / other.var + self.var / other.var - 1.0 - self.logvar +
+ other.logvar,
+ axis=[1, 2, 3],
+ )
+
+ def nll(self, sample, dims=[1, 2, 3]):
+ if self.deterministic:
+ return paddle.to_tensor([0.0])
+ logtwopi = np.log(2.0 * np.pi)
+ return 0.5 * paddle.sum(logtwopi + self.logvar + paddle.pow(sample - self.mean, 2) / self.var, axis=dims)
+
+ def mode(self):
+ return self.mean
+
+
+class VQModel(ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", ),
+ up_block_types=("UpDecoderBlock2D", ),
+ block_out_channels=(64, ),
+ layers_per_block=1,
+ act_fn="silu",
+ latent_channels=3,
+ sample_size=32,
+ num_vq_embeddings=256,
+ ):
+ super().__init__()
+
+ # pass init params to Encoder
+ self.encoder = Encoder(
+ in_channels=in_channels,
+ out_channels=latent_channels,
+ down_block_types=down_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ double_z=False,
+ )
+
+ self.quant_conv = nn.Conv2D(latent_channels, latent_channels, 1)
+ self.quantize = VectorQuantizer(num_vq_embeddings,
+ latent_channels,
+ beta=0.25,
+ remap=None,
+ sane_index_shape=False)
+ self.post_quant_conv = nn.Conv2D(latent_channels, latent_channels, 1)
+
+ # pass init params to Decoder
+ self.decoder = Decoder(
+ in_channels=latent_channels,
+ out_channels=out_channels,
+ up_block_types=up_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ )
+
+ def encode(self, x):
+ h = self.encoder(x)
+ h = self.quant_conv(h)
+ return h
+
+ def decode(self, h, force_not_quantize=False):
+ # also go through quantization layer
+ if not force_not_quantize:
+ quant, emb_loss, info = self.quantize(h)
+ else:
+ quant = h
+ quant = self.post_quant_conv(quant)
+ dec = self.decoder(quant)
+ return dec
+
+ def forward(self, sample):
+ x = sample
+ h = self.encode(x)
+ dec = self.decode(h)
+ return dec
+
+
+class AutoencoderKL(nn.Layer, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", "DownEncoderBlock2D", "DownEncoderBlock2D", "DownEncoderBlock2D"),
+ up_block_types=("UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D"),
+ block_out_channels=(128, 256, 512, 512),
+ layers_per_block=2,
+ act_fn="silu",
+ latent_channels=4,
+ sample_size=512,
+ ):
+ super().__init__()
+
+ # pass init params to Encoder
+ self.encoder = Encoder(
+ in_channels=in_channels,
+ out_channels=latent_channels,
+ down_block_types=down_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ double_z=True,
+ )
+
+ # pass init params to Decoder
+ self.decoder = Decoder(
+ in_channels=latent_channels,
+ out_channels=out_channels,
+ up_block_types=up_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ )
+
+ self.quant_conv = nn.Conv2D(2 * latent_channels, 2 * latent_channels, 1)
+ self.post_quant_conv = nn.Conv2D(latent_channels, latent_channels, 1)
+
+ def encode(self, x):
+ h = self.encoder(x)
+ moments = self.quant_conv(h)
+ posterior = DiagonalGaussianDistribution(moments)
+ return posterior
+
+ def decode(self, z):
+ z = self.post_quant_conv(z)
+ dec = self.decoder(z)
+ return dec
+
+ def forward(self, sample, sample_posterior=False):
+ x = sample
+ posterior = self.encode(x)
+ if sample_posterior:
+ z = posterior.sample()
+ else:
+ z = posterior.mode()
+ dec = self.decode(z)
+ return dec
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/schedulers/README.md b/modules/image/text_to_image/stable_diffusion/diffusers/schedulers/README.md
new file mode 100644
index 000000000..40f50f232
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/schedulers/README.md
@@ -0,0 +1,18 @@
+# Schedulers
+
+- Schedulers are the algorithms to use diffusion models in inference as well as for training. They include the noise schedules and define algorithm-specific diffusion steps.
+- Schedulers can be used interchangable between diffusion models in inference to find the preferred trade-off between speed and generation quality.
+- Schedulers are available in numpy, but can easily be transformed into Py
+
+## API
+
+- Schedulers should provide one or more `def step(...)` functions that should be called iteratively to unroll the diffusion loop during
+the forward pass.
+- Schedulers should be framework-agnostic, but provide a simple functionality to convert the scheduler into a specific framework, such as PyTorch
+with a `set_format(...)` method.
+
+## Examples
+
+- The DDPM scheduler was proposed in [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) and can be found in [scheduling_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py). An example of how to use this scheduler can be found in [pipeline_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddpm.py).
+- The DDIM scheduler was proposed in [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) and can be found in [scheduling_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py). An example of how to use this scheduler can be found in [pipeline_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddim.py).
+- The PNDM scheduler was proposed in [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778) and can be found in [scheduling_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py). An example of how to use this scheduler can be found in [pipeline_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py).
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/schedulers/__init__.py b/modules/image/text_to_image/stable_diffusion/diffusers/schedulers/__init__.py
new file mode 100644
index 000000000..cebc3e618
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/schedulers/__init__.py
@@ -0,0 +1,24 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .scheduling_ddim import DDIMScheduler
+from .scheduling_ddpm import DDPMScheduler
+from .scheduling_karras_ve import KarrasVeScheduler
+from .scheduling_lms_discrete import LMSDiscreteScheduler
+from .scheduling_pndm import PNDMScheduler
+from .scheduling_sde_ve import ScoreSdeVeScheduler
+from .scheduling_sde_vp import ScoreSdeVpScheduler
+from .scheduling_utils import SchedulerMixin
diff --git a/modules/image/text_to_image/stable_diffusion/diffusers/schedulers/scheduling_ddim.py b/modules/image/text_to_image/stable_diffusion/diffusers/schedulers/scheduling_ddim.py
new file mode 100644
index 000000000..ebe362d99
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/diffusers/schedulers/scheduling_ddim.py
@@ -0,0 +1,182 @@
+# Copyright 2022 Stanford University Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pypaddle_diffusion
+# and https://github.com/hojonathanho/diffusion
+import math
+from typing import Union
+
+import numpy as np
+import paddle
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .scheduling_utils import SchedulerMixin
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ :param num_diffusion_timesteps: the number of betas to produce. :param alpha_bar: a lambda that takes an argument t
+ from 0 to 1 and
+ produces the cumulative product of (1-beta) up to that part of the diffusion process.
+ :param max_beta: the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2)**2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return np.array(betas, dtype=np.float32)
+
+
+class DDIMScheduler(SchedulerMixin, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps=1000,
+ beta_start=0.0001,
+ beta_end=0.02,
+ beta_schedule="linear",
+ trained_betas=None,
+ timestep_values=None,
+ clip_sample=True,
+ set_alpha_to_one=True,
+ tensor_format="pd",
+ ):
+
+ if beta_schedule == "linear":
+ self.betas = np.linspace(beta_start, beta_end, num_train_timesteps, dtype=np.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = np.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=np.float32)**2
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = np.cumprod(self.alphas, axis=0)
+
+ # At every step in ddim, we are looking into the previous alphas_cumprod
+ # For the final step, there is no previous alphas_cumprod because we are already at 0
+ # `set_alpha_to_one` decides whether we set this paratemer simply to one or
+ # whether we use the final alpha of the "non-previous" one.
+ self.final_alpha_cumprod = np.array(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
+
+ # setable values
+ self.num_inference_steps = None
+ self.timesteps = np.arange(0, num_train_timesteps)[::-1].copy()
+
+ self.tensor_format = tensor_format
+ self.set_format(tensor_format=tensor_format)
+
+ def _get_variance(self, timestep, prev_timestep):
+ alpha_prod_t = self.alphas_cumprod[timestep]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
+
+ return variance
+
+ def set_timesteps(self, num_inference_steps, offset=0):
+ self.num_inference_steps = num_inference_steps
+ self.timesteps = np.arange(0, self.config.num_train_timesteps,
+ self.config.num_train_timesteps // self.num_inference_steps)[::-1].copy()
+ self.timesteps += offset
+ self.set_format(tensor_format=self.tensor_format)
+
+ def step(
+ self,
+ model_output: Union[paddle.Tensor, np.ndarray],
+ timestep: int,
+ sample: Union[paddle.Tensor, np.ndarray],
+ eta: float = 0.0,
+ use_clipped_model_output: bool = False,
+ generator=None,
+ ):
+ # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # Ideally, read DDIM paper in-detail understanding
+
+ # Notation (![]() -
- 
![]()
![]()






From f7c781b2858d537e1f2e9588431e0f4cf04c4fc3 Mon Sep 17 00:00:00 2001
From: DanielYang
![]() -
------------------------------------------------------------------------------------------
@@ -35,6 +35,8 @@ English | [简体中文](README_ch.md)
- [**More**](./docs/docs_en/release.md)
+
+
## 🌈Visualization Demo
#### 🏜️ [Text-to-Image Models](https://www.paddlepaddle.org.cn/hubdetail?name=ernie_vilg&en_category=TextToImage)
@@ -62,8 +64,6 @@ English | [简体中文](README_ch.md)
#### 🎧 [Speech Models](./modules#Audio)
-- ASR speech recognition algorithm, multiple algorithms are available.
-- The speech recognition effect is as follows:
-
------------------------------------------------------------------------------------------
@@ -35,6 +35,8 @@ English | [简体中文](README_ch.md)
- [**More**](./docs/docs_en/release.md)
+
+
## 🌈Visualization Demo
#### 🏜️ [Text-to-Image Models](https://www.paddlepaddle.org.cn/hubdetail?name=ernie_vilg&en_category=TextToImage)
@@ -62,8 +64,6 @@ English | [简体中文](README_ch.md)
#### 🎧 [Speech Models](./modules#Audio)
-- ASR speech recognition algorithm, multiple algorithms are available.
-- The speech recognition effect is as follows:
QuickStart | Tutorial | Models List | Demos
+ QuickStart | Models List | Demos
-
-- TTS speech synthesis algorithm, multiple algorithms are available.
-- Input: `Life was like a box of chocolates, you never know what you're gonna get.`
-- The synthesis effect is as follows:
@@ -90,33 +90,21 @@ English | [简体中文](README_ch.md)
@@ -429,51 +430,51 @@ English | [简体中文](README_ch.md)
|module|Network|Dataset|Introduction|Huggingface Spaces Demo|
|--|--|--|--|--|
-|[ernie_skep_sentiment_analysis](text/sentiment_analysis/ernie_skep_sentiment_analysis)|SKEP|百度自建数据集|句子级情感分析|
-|[emotion_detection_textcnn](text/sentiment_analysis/emotion_detection_textcnn)|TextCNN|百度自建数据集|对话情绪识别|
-|[senta_bilstm](text/sentiment_analysis/senta_bilstm)|BiLSTM|百度自建数据集|中文情感倾向分析| [](https://huggingface.co/spaces/PaddlePaddle/senta_bilstm)
-|[senta_bow](text/sentiment_analysis/senta_bow)|BOW|百度自建数据集|中文情感倾向分析|
-|[senta_gru](text/sentiment_analysis/senta_gru)|GRU|百度自建数据集|中文情感倾向分析|
-|[senta_lstm](text/sentiment_analysis/senta_lstm)|LSTM|百度自建数据集|中文情感倾向分析|
-|[senta_cnn](text/sentiment_analysis/senta_cnn)|CNN|百度自建数据集|中文情感倾向分析|
+|[ernie_skep_sentiment_analysis](text/sentiment_analysis/ernie_skep_sentiment_analysis)|SKEP|Baidu self built dataset|Sentence level sentiment analysis|
+|[emotion_detection_textcnn](text/sentiment_analysis/emotion_detection_textcnn)|TextCNN|Baidu self built dataset|Dialogue emotion detection|
+|[senta_bilstm](text/sentiment_analysis/senta_bilstm)|BiLSTM|Baidu self built dataset|Chinesesentiment analysis| [](https://huggingface.co/spaces/PaddlePaddle/senta_bilstm)
+|[senta_bow](text/sentiment_analysis/senta_bow)|BOW|Baidu self built dataset|Chinese sentiment analysis|
+|[senta_gru](text/sentiment_analysis/senta_gru)|GRU|Baidu self built dataset|Chinese sentiment analysis|
+|[senta_lstm](text/sentiment_analysis/senta_lstm)|LSTM|Baidu self built dataset|Chinese sentiment analysis|
+|[senta_cnn](text/sentiment_analysis/senta_cnn)|CNN|Baidu self built dataset|Chinese sentiment analysis|
- ### Syntactic Analysis
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[DDParser](text/syntactic_analysis/DDParser)|Deep Biaffine Attention|搜索query、网页文本、语音输入等数据|句法分析|
+|[DDParser](text/syntactic_analysis/DDParser)|Deep Biaffine Attention|Search query, web text, voice input and other data|Syntactic analysis|
- ### Simultaneous Translation
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[transformer_nist_wait_1](text/simultaneous_translation/stacl/transformer_nist_wait_1)|transformer|NIST 2008-中英翻译数据集|中译英-wait-1策略|
-|[transformer_nist_wait_3](text/simultaneous_translation/stacl/transformer_nist_wait_3)|transformer|NIST 2008-中英翻译数据集|中译英-wait-3策略|
-|[transformer_nist_wait_5](text/simultaneous_translation/stacl/transformer_nist_wait_5)|transformer|NIST 2008-中英翻译数据集|中译英-wait-5策略|
-|[transformer_nist_wait_7](text/simultaneous_translation/stacl/transformer_nist_wait_7)|transformer|NIST 2008-中英翻译数据集|中译英-wait-7策略|
-|[transformer_nist_wait_all](text/simultaneous_translation/stacl/transformer_nist_wait_all)|transformer|NIST 2008-中英翻译数据集|中译英-waitk=-1策略|
+|[transformer_nist_wait_1](text/simultaneous_translation/stacl/transformer_nist_wait_1)|transformer|NIST 2008|Chinese to English - wait-1|
+|[transformer_nist_wait_3](text/simultaneous_translation/stacl/transformer_nist_wait_3)|transformer|NIST 2008|Chinese to English - wait-3|
+|[transformer_nist_wait_5](text/simultaneous_translation/stacl/transformer_nist_wait_5)|transformer|NIST 2008|Chinese to English - wait-5|
+|[transformer_nist_wait_7](text/simultaneous_translation/stacl/transformer_nist_wait_7)|transformer|NIST 2008|Chinese to English - wait-7|
+|[transformer_nist_wait_all](text/simultaneous_translation/stacl/transformer_nist_wait_all)|transformer|NIST 2008|Chinese to English - waitk=-1|
- ### Lexical Analysis
|module|Network|Dataset|Introduction|Huggingface Spaces Demo|
|--|--|--|--|--|
-|[jieba_paddle](text/lexical_analysis/jieba_paddle)|BiGRU+CRF|百度自建数据集|jieba使用Paddle搭建的切词网络(双向GRU)。同时支持jieba的传统切词方法,如精确模式、全模式、搜索引擎模式等切词模式。|
-|[lac](text/lexical_analysis/lac)|BiGRU+CRF|百度自建数据集|百度自研联合的词法分析模型,能整体性地完成中文分词、词性标注、专名识别任务。在百度自建数据集上评测,LAC效果:Precision=88.0%,Recall=88.7%,F1-Score=88.4%。|[](https://huggingface.co/spaces/PaddlePaddle/lac)
+|[jieba_paddle](text/lexical_analysis/jieba_paddle)|BiGRU+CRF|Baidu self built dataset|Jieba uses Paddle to build a word segmentation network (two-way GRU). At the same time, it supports traditional word segmentation methods of jieba, such as precise mode, full mode, search engine mode, etc.|
+|[lac](text/lexical_analysis/lac)|BiGRU+CRF|Baidu self built dataset|The lexical analysis model jointly developed by Baidu can complete the tasks of Chinese word segmentation, part of speech tagging and proper name recognition as a whole. Evaluated on Baidu self built dataset, LAC effect: Precision=88.0%, Recall=88.7%, F1 Score=88.4%.|[](https://huggingface.co/spaces/PaddlePaddle/lac)
- ### Punctuation Restoration
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[auto_punc](text/punctuation_restoration/auto_punc)|Ernie-1.0|WuDaoCorpora 2.0|自动添加7种标点符号|
+|[auto_punc](text/punctuation_restoration/auto_punc)|Ernie-1.0|WuDaoCorpora 2.0|Automatically add 7 punctuation marks|
- ### Text Review
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[porn_detection_cnn](text/text_review/porn_detection_cnn)|CNN|百度自建数据集|色情检测,自动判别文本是否涉黄并给出相应的置信度,对文本中的色情描述、低俗交友、污秽文案进行识别|
-|[porn_detection_gru](text/text_review/porn_detection_gru)|GRU|百度自建数据集|色情检测,自动判别文本是否涉黄并给出相应的置信度,对文本中的色情描述、低俗交友、污秽文案进行识别|
-|[porn_detection_lstm](text/text_review/porn_detection_lstm)|LSTM|百度自建数据集|色情检测,自动判别文本是否涉黄并给出相应的置信度,对文本中的色情描述、低俗交友、污秽文案进行识别|
+|[porn_detection_cnn](text/text_review/porn_detection_cnn)|CNN|Baidu self built dataset|Pornography detection, automatically identify whether the text is pornographic and give the corresponding confidence, and identify pornographic descriptions, vulgar friends, and dirty documents in the text|
+|[porn_detection_gru](text/text_review/porn_detection_gru)|GRU|Baidu self built dataset|Pornography detection, automatically identify whether the text is pornographic and give the corresponding confidence, and identify pornographic descriptions, vulgar friends, and dirty documents in the text|
+|[porn_detection_lstm](text/text_review/porn_detection_lstm)|LSTM|Baidu self built dataset|Pornography detection, automatically identify whether the text is pornographic and give the corresponding confidence, and identify pornographic descriptions, vulgar friends, and dirty documents in the text|
## Audio
@@ -481,62 +482,62 @@ English | [简体中文](README_ch.md)
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[ge2e_fastspeech2_pwgan](audio/voice_cloning/ge2e_fastspeech2_pwgan)|FastSpeech2|AISHELL-3|中文语音克隆|
-|[lstm_tacotron2](audio/voice_cloning/lstm_tacotron2)|LSTM、Tacotron2、WaveFlow|AISHELL-3|中文语音克隆|
+|[ge2e_fastspeech2_pwgan](audio/voice_cloning/ge2e_fastspeech2_pwgan)|FastSpeech2|AISHELL-3|Chinese speech cloning|
+|[lstm_tacotron2](audio/voice_cloning/lstm_tacotron2)|LSTM、Tacotron2、WaveFlow|AISHELL-3|Chinese speech cloning|
- ### Text to Speech
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[transformer_tts_ljspeech](audio/tts/transformer_tts_ljspeech)|Transformer|LJSpeech-1.1|英文语音合成|
-|[fastspeech_ljspeech](audio/tts/fastspeech_ljspeech)|FastSpeech|LJSpeech-1.1|英文语音合成|
-|[fastspeech2_baker](audio/tts/fastspeech2_baker)|FastSpeech2|Chinese Standard Mandarin Speech Copus|中文语音合成|
-|[fastspeech2_ljspeech](audio/tts/fastspeech2_ljspeech)|FastSpeech2|LJSpeech-1.1|英文语音合成|
-|[deepvoice3_ljspeech](audio/tts/deepvoice3_ljspeech)|DeepVoice3|LJSpeech-1.1|英文语音合成|
+|[transformer_tts_ljspeech](audio/tts/transformer_tts_ljspeech)|Transformer|LJSpeech-1.1|English speech synthesis|
+|[fastspeech_ljspeech](audio/tts/fastspeech_ljspeech)|FastSpeech|LJSpeech-1.1|English speech synthesis|
+|[fastspeech2_baker](audio/tts/fastspeech2_baker)|FastSpeech2|Chinese Standard Mandarin Speech Copus|Chinese speech synthesis|
+|[fastspeech2_ljspeech](audio/tts/fastspeech2_ljspeech)|FastSpeech2|LJSpeech-1.1|English speech synthesis|
+|[deepvoice3_ljspeech](audio/tts/deepvoice3_ljspeech)|DeepVoice3|LJSpeech-1.1|English speech synthesis|
- ### Automatic Speech Recognition
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[deepspeech2_aishell](audio/asr/deepspeech2_aishell)|DeepSpeech2|AISHELL-1|中文语音识别|
-|[deepspeech2_librispeech](audio/asr/deepspeech2_librispeech)|DeepSpeech2|LibriSpeech|英文语音识别|
-|[u2_conformer_aishell](audio/asr/u2_conformer_aishell)|Conformer|AISHELL-1|中文语音识别|
-|[u2_conformer_wenetspeech](audio/asr/u2_conformer_wenetspeech)|Conformer|WenetSpeech|中文语音识别|
-|[u2_conformer_librispeech](audio/asr/u2_conformer_librispeech)|Conformer|LibriSpeech|英文语音识别|
+|[deepspeech2_aishell](audio/asr/deepspeech2_aishell)|DeepSpeech2|AISHELL-1|Chinese Speech Recognition|
+|[deepspeech2_librispeech](audio/asr/deepspeech2_librispeech)|DeepSpeech2|LibriSpeech|English Speech Recognition|
+|[u2_conformer_aishell](audio/asr/u2_conformer_aishell)|Conformer|AISHELL-1|Chinese Speech Recognition|
+|[u2_conformer_wenetspeech](audio/asr/u2_conformer_wenetspeech)|Conformer|WenetSpeech|Chinese Speech Recognition|
+|[u2_conformer_librispeech](audio/asr/u2_conformer_librispeech)|Conformer|LibriSpeech|English Speech Recognition|
- ### Audio Classification
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[panns_cnn6](audio/audio_classification/PANNs/cnn6)|PANNs|Google Audioset|主要包含4个卷积层和2个全连接层,模型参数为4.5M。经过预训练后,可以用于提取音频的embbedding,维度是512|
-|[panns_cnn14](audio/audio_classification/PANNs/cnn14)|PANNs|Google Audioset|主要包含12个卷积层和2个全连接层,模型参数为79.6M。经过预训练后,可以用于提取音频的embbedding,维度是2048|
-|[panns_cnn10](audio/audio_classification/PANNs/cnn10)|PANNs|Google Audioset|主要包含8个卷积层和2个全连接层,模型参数为4.9M。经过预训练后,可以用于提取音频的embbedding,维度是512|
+|[panns_cnn6](audio/audio_classification/PANNs/cnn6)|PANNs|Google Audioset|It mainly includes 4 convolution layers and 2 full connection layers, and the model parameter is 4.5M. After pre-training, it can be used to extract the embbedding of audio. The dimension is 512|
+|[panns_cnn14](audio/audio_classification/PANNs/cnn14)|PANNs|Google Audioset|It mainly includes 4 convolution layers and 2 full connection layers, and the model parameter is 4.5M. After pre-training, it can be used to extract the embbedding of audio. The dimension is 2048|
+|[panns_cnn10](audio/audio_classification/PANNs/cnn10)|PANNs|Google Audioset|It mainly includes 4 convolution layers and 2 full connection layers, and the model parameter is 4.5M. After pre-training, it can be used to extract the embbedding of audio. The dimension is 512|
## Video
- ### Video Classification
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[videotag_tsn_lstm](video/classification/videotag_tsn_lstm)|TSN + AttentionLSTM|百度自建数据集|大规模短视频分类打标签|
-|[tsn_kinetics400](video/classification/tsn_kinetics400)|TSN|Kinetics-400|视频分类|
-|[tsm_kinetics400](video/classification/tsm_kinetics400)|TSM|Kinetics-400|视频分类|
-|[stnet_kinetics400](video/classification/stnet_kinetics400)|StNet|Kinetics-400|视频分类|
-|[nonlocal_kinetics400](video/classification/nonlocal_kinetics400)|Non-local|Kinetics-400|视频分类|
+|[videotag_tsn_lstm](video/classification/videotag_tsn_lstm)|TSN + AttentionLSTM|Baidu self built dataset|Short-video classification|
+|[tsn_kinetics400](video/classification/tsn_kinetics400)|TSN|Kinetics-400|Video classification|
+|[tsm_kinetics400](video/classification/tsm_kinetics400)|TSM|Kinetics-400|Video classification|
+|[stnet_kinetics400](video/classification/stnet_kinetics400)|StNet|Kinetics-400|Video classification|
+|[nonlocal_kinetics400](video/classification/nonlocal_kinetics400)|Non-local|Kinetics-400|Video classification|
- ### Video Editing
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[SkyAR](video/Video_editing/SkyAR)|UNet|UNet|视频换天|
+|[SkyAR](video/Video_editing/SkyAR)|UNet|UNet|Video sky Replacement|
- ### Multiple Object tracking
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[fairmot_dla34](video/multiple_object_tracking/fairmot_dla34)|CenterNet|Caltech Pedestrian+CityPersons+CUHK-SYSU+PRW+ETHZ+MOT17|实时多目标跟踪|
-|[jde_darknet53](video/multiple_object_tracking/jde_darknet53)|YOLOv3|Caltech Pedestrian+CityPersons+CUHK-SYSU+PRW+ETHZ+MOT17|多目标跟踪-兼顾精度和速度|
+|[fairmot_dla34](video/multiple_object_tracking/fairmot_dla34)|CenterNet|Caltech Pedestrian+CityPersons+CUHK-SYSU+PRW+ETHZ+MOT17|Realtime multiple object tracking|
+|[jde_darknet53](video/multiple_object_tracking/jde_darknet53)|YOLOv3|Caltech Pedestrian+CityPersons+CUHK-SYSU+PRW+ETHZ+MOT17|object tracking with both accuracy and speed|
## Industrial Application
@@ -544,4 +545,4 @@ English | [简体中文](README_ch.md)
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[WatermeterSegmentation](image/semantic_segmentation/WatermeterSegmentation)|DeepLabV3|水表的数字表盘分割数据集|水表的数字表盘分割|
+|[WatermeterSegmentation](image/semantic_segmentation/WatermeterSegmentation)|DeepLabV3|Water meter dataset|Water meter segmentation|
From aa949a69c1d824e1e63b6278d79e6ed3fcb77dc8 Mon Sep 17 00:00:00 2001
From: chenjian
@@ -124,16 +112,9 @@ English | [简体中文](README_ch.md)
- Many thanks to CopyRight@[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech) for the pre-trained models, you can try to train your models with PaddleSpeech.
-#### 📽️ [Video Models](./modules#Video)
-- Short video classification trained via large-scale video datasets, supports 3000+ tag types prediction for short Form Videos.
-- Many thanks to CopyRight@[PaddleVideo](https://github.com/PaddlePaddle/PaddleVideo) for the pre-trained model, you can try to train your models with PaddleVideo.
-- `Example: Input a short video of swimming, the algorithm can output the result of "swimming"`
-
-
deepvoice3
- fastspeech
- transformer
+ Input Text
+ Output Audio
-
-
-
+ ![]()
- Life was like a box of chocolates, you never know what you're gonna get.
- ![]()
-
-
![]()
-
-
-### ⭐ Thanks for Your Star ⭐
-- All the above pre-trained models are all **open source and free**, and the number of models is continuously updated. Welcome **⭐Star⭐** to pay attention.
+### ⭐ Thanks for Your Star
+- All the above pre-trained models are all **open source and free**, and the number of models is continuously updated. Welcome **Star** to pay attention.
-
+
- please add WeChat above and send "Hub" to the robot, the robot will invite you to join the group automatically.
@@ -183,9 +165,7 @@ print(results)
!hub serving start -m lac
```
-- 📣More model description, please refer [Models List](https://www.paddlepaddle.org.cn/hublist)
-
-- 📣More API for transfer learning, please refer [Tutorial](https://paddlehub.readthedocs.io/en/release-v2.1/transfer_learning_index.html)
+- 📣More model description, please refer [Models List](./modules)
## 📚License
From 7cf4b9de2f5153783272f1f5d51b7d80fec2bd79 Mon Sep 17 00:00:00 2001
From: Zeyu Chen
@@ -146,7 +127,8 @@ English | [简体中文](README_ch.md)
- If you have any questions during the use of the model, you can join the official WeChat group to get more efficient questions and answers, and fully communicate with developers from all walks of life. We look forward to your joining.
+
-![]() +
+ ![]() -- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
+- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR), [PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN), [AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg), [Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
#### 🎤 [Natural Language Processing Models](./modules#Text)
From e03d11260b86a2f49f896e733d68e82edb0d9286 Mon Sep 17 00:00:00 2001
From: chenjian
-- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
+- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR), [PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN), [AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg), [Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
#### 🎤 [Natural Language Processing Models](./modules#Text)
From e03d11260b86a2f49f896e733d68e82edb0d9286 Mon Sep 17 00:00:00 2001
From: chenjian QuickStart | Models List | Demos
@@ -22,18 +22,18 @@ English | [简体中文](README_ch.md)
## ⭐Features
- **📦400+ AI Models**: Rich, high-quality AI models, including CV, NLP, Speech, Video and Cross-Modal.
-- **🧒Easy to Use**: 3 lines of code to predict the 400+ AI models
+- **🧒Easy to Use**: 3 lines of code to predict the 400+ AI models.
- **💁Model As Service**: Easy to build a service with only one line of command.
-- **💻Cross-platform**: Support Linux, Windows and MacOS
+- **💻Cross-platform**: Support Linux, Windows and MacOS.
### 💥Recent Updates
-- **🔥2022.08.19:** The v2.3.0 version is released
+- **🔥2022.08.19:** The v2.3.0 version is released 🎉
- supports [**ERNIE_ViLG**](./modules/image/text_to_image/ernie_vilg)([Hugging Face Space Demo](https://huggingface.co/spaces/PaddlePaddle/ERNIE-ViLG))
- supports [**Disco Diffusion(DD)**](./modules/image/text_to_image/disco_diffusion_clip_vitb32) and [**Stable Diffusion(SD)**](./modules/image/text_to_image/stable_diffusion)
-- **2022.02.18:** Release models to the HuggingFace PaddlePaddle Space: [PaddlePaddle Huggingface](https://huggingface.co/PaddlePaddle)
+- **2022.02.18:** Release models to HuggingFace [PaddlePaddle Space](https://huggingface.co/PaddlePaddle)
-- [**More**](./docs/docs_en/release.md)
+- For more previous release please refer to [**PaddleHub Release Note**](./docs/docs_en/release.md)
@@ -51,7 +51,7 @@ English | [简体中文](README_ch.md)
 +
+## 四、服务部署
+
+- 通过启动PaddleHub Serving,可以加载模型部署在线翻译服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m baidu_translate
+ ```
+
+ - 通过以上命令可完成一个翻译API的部署,默认端口号为8866。
+
+
+- ## 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ text = "I like panda"
+ data = {"query": text, "from_lang":'en', "to_lang":'zh'}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://127.0.0.1:8866/predict/baidu_translate"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+ - 关于PaddleHub Serving更多信息参考:[服务部署](../../../../docs/docs_ch/tutorial/serving.md)
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ - ```shell
+ $ hub install baidu_translate==1.0.0
+ ```
diff --git a/modules/text/machine_translation/baidu_translate/module.py b/modules/text/machine_translation/baidu_translate/module.py
new file mode 100644
index 000000000..f19d8f92a
--- /dev/null
+++ b/modules/text/machine_translation/baidu_translate/module.py
@@ -0,0 +1,104 @@
+import argparse
+import random
+from hashlib import md5
+from typing import Optional
+
+import requests
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+def make_md5(s, encoding='utf-8'):
+ return md5(s.encode(encoding)).hexdigest()
+
+
+@moduleinfo(name="baidu_translate",
+ version="1.0.0",
+ type="text/machine_translation",
+ summary="",
+ author="baidu-nlp",
+ author_email="paddle-dev@baidu.com")
+class BaiduTranslate:
+
+ def __init__(self, appid=None, appkey=None):
+ """
+ :param appid: appid for requesting Baidu translation service.
+ :param appkey: appkey for requesting Baidu translation service.
+ """
+ # Set your own appid/appkey.
+ if appid == None:
+ self.appid = '20201015000580007'
+ else:
+ self.appid = appid
+ if appkey is None:
+ self.appkey = 'IFJB6jBORFuMmVGDRud1'
+ else:
+ self.appkey = appkey
+ self.url = 'http://api.fanyi.baidu.com/api/trans/vip/translate'
+
+ def translate(self, query: str, from_lang: Optional[str] = "en", to_lang: Optional[int] = "zh"):
+ """
+ Create image by text prompts using ErnieVilG model.
+
+ :param query: Text to be translated.
+ :param from_lang: Source language.
+ :param to_lang: Dst language.
+
+ Return translated string.
+ """
+ # Generate salt and sign
+ salt = random.randint(32768, 65536)
+ sign = make_md5(self.appid + query + str(salt) + self.appkey)
+
+ # Build request
+ headers = {'Content-Type': 'application/x-www-form-urlencoded'}
+ payload = {'appid': self.appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}
+
+ # Send request
+ try:
+ r = requests.post(self.url, params=payload, headers=headers)
+ result = r.json()
+ except Exception as e:
+ error_msg = str(e)
+ raise RuntimeError(error_msg)
+ if 'error_code' in result:
+ raise RuntimeError(result['error_msg'])
+ return result['trans_result'][0]['dst']
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ if args.appid is not None and args.appkey is not None:
+ self.appid = args.appid
+ self.appkey = args.appkey
+ result = self.translate(args.query, args.from_lang, args.to_lang)
+ return result
+
+ @serving
+ def serving_method(self, query, from_lang, to_lang):
+ """
+ Run as a service.
+ """
+ return self.translate(query, from_lang, to_lang)
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument('--query', type=str)
+ self.arg_input_group.add_argument('--from_lang', type=str, default='en', help="源语言")
+ self.arg_input_group.add_argument('--to_lang', type=str, default='zh', help="目标语言")
+ self.arg_input_group.add_argument('--appid', type=str, default=None, help="注册得到的个人appid")
+ self.arg_input_group.add_argument('--appkey', type=str, default=None, help="注册得到的个人appkey")
From 8fd2696f9c4af91fa811def055aadf65b59129bb Mon Sep 17 00:00:00 2001
From: Zeyu Chen
+
+## 四、服务部署
+
+- 通过启动PaddleHub Serving,可以加载模型部署在线翻译服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m baidu_translate
+ ```
+
+ - 通过以上命令可完成一个翻译API的部署,默认端口号为8866。
+
+
+- ## 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ text = "I like panda"
+ data = {"query": text, "from_lang":'en', "to_lang":'zh'}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://127.0.0.1:8866/predict/baidu_translate"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+ - 关于PaddleHub Serving更多信息参考:[服务部署](../../../../docs/docs_ch/tutorial/serving.md)
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ - ```shell
+ $ hub install baidu_translate==1.0.0
+ ```
diff --git a/modules/text/machine_translation/baidu_translate/module.py b/modules/text/machine_translation/baidu_translate/module.py
new file mode 100644
index 000000000..f19d8f92a
--- /dev/null
+++ b/modules/text/machine_translation/baidu_translate/module.py
@@ -0,0 +1,104 @@
+import argparse
+import random
+from hashlib import md5
+from typing import Optional
+
+import requests
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+def make_md5(s, encoding='utf-8'):
+ return md5(s.encode(encoding)).hexdigest()
+
+
+@moduleinfo(name="baidu_translate",
+ version="1.0.0",
+ type="text/machine_translation",
+ summary="",
+ author="baidu-nlp",
+ author_email="paddle-dev@baidu.com")
+class BaiduTranslate:
+
+ def __init__(self, appid=None, appkey=None):
+ """
+ :param appid: appid for requesting Baidu translation service.
+ :param appkey: appkey for requesting Baidu translation service.
+ """
+ # Set your own appid/appkey.
+ if appid == None:
+ self.appid = '20201015000580007'
+ else:
+ self.appid = appid
+ if appkey is None:
+ self.appkey = 'IFJB6jBORFuMmVGDRud1'
+ else:
+ self.appkey = appkey
+ self.url = 'http://api.fanyi.baidu.com/api/trans/vip/translate'
+
+ def translate(self, query: str, from_lang: Optional[str] = "en", to_lang: Optional[int] = "zh"):
+ """
+ Create image by text prompts using ErnieVilG model.
+
+ :param query: Text to be translated.
+ :param from_lang: Source language.
+ :param to_lang: Dst language.
+
+ Return translated string.
+ """
+ # Generate salt and sign
+ salt = random.randint(32768, 65536)
+ sign = make_md5(self.appid + query + str(salt) + self.appkey)
+
+ # Build request
+ headers = {'Content-Type': 'application/x-www-form-urlencoded'}
+ payload = {'appid': self.appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}
+
+ # Send request
+ try:
+ r = requests.post(self.url, params=payload, headers=headers)
+ result = r.json()
+ except Exception as e:
+ error_msg = str(e)
+ raise RuntimeError(error_msg)
+ if 'error_code' in result:
+ raise RuntimeError(result['error_msg'])
+ return result['trans_result'][0]['dst']
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ if args.appid is not None and args.appkey is not None:
+ self.appid = args.appid
+ self.appkey = args.appkey
+ result = self.translate(args.query, args.from_lang, args.to_lang)
+ return result
+
+ @serving
+ def serving_method(self, query, from_lang, to_lang):
+ """
+ Run as a service.
+ """
+ return self.translate(query, from_lang, to_lang)
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument('--query', type=str)
+ self.arg_input_group.add_argument('--from_lang', type=str, default='en', help="源语言")
+ self.arg_input_group.add_argument('--to_lang', type=str, default='zh', help="目标语言")
+ self.arg_input_group.add_argument('--appid', type=str, default=None, help="注册得到的个人appid")
+ self.arg_input_group.add_argument('--appkey', type=str, default=None, help="注册得到的个人appkey")
From 8fd2696f9c4af91fa811def055aadf65b59129bb Mon Sep 17 00:00:00 2001
From: Zeyu Chen ![]() -
-
------------------------------------------------------------------------------------------
-
-
------------------------------------------------------------------------------------------
QuickStart | Models List | Demos
+ Quick Start | Model List | Demos
From bd1f20e6adb543f6894ee3bed28c721717137b92 Mon Sep 17 00:00:00 2001
From: Zeyu Chen
 ## 第6步:飞桨预训练模型探索之旅
-- 恭喜你,到这里PaddleHub在windows环境下的安装和入门案例就全部完成了,快快开启你更多的深度学习模型探索之旅吧。[【更多模型探索,跳转飞桨官网】](https://www.paddlepaddle.org.cn/hublist)
+- 恭喜你,到这里PaddleHub在linux环境下的安装和入门案例就全部完成了,快快开启你更多的深度学习模型探索之旅吧。[【更多模型探索,跳转飞桨官网】](https://www.paddlepaddle.org.cn/hublist)
From 27aa1eab93b9023a0ae9025f78d3878a82ecb54b Mon Sep 17 00:00:00 2001
From: DanielYang
## 第6步:飞桨预训练模型探索之旅
-- 恭喜你,到这里PaddleHub在windows环境下的安装和入门案例就全部完成了,快快开启你更多的深度学习模型探索之旅吧。[【更多模型探索,跳转飞桨官网】](https://www.paddlepaddle.org.cn/hublist)
+- 恭喜你,到这里PaddleHub在linux环境下的安装和入门案例就全部完成了,快快开启你更多的深度学习模型探索之旅吧。[【更多模型探索,跳转飞桨官网】](https://www.paddlepaddle.org.cn/hublist)
From 27aa1eab93b9023a0ae9025f78d3878a82ecb54b Mon Sep 17 00:00:00 2001
From: DanielYang 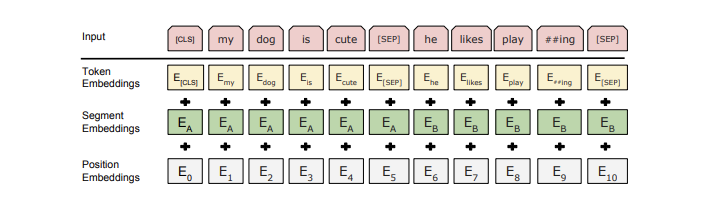
@@ -85,7 +85,7 @@ label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='rtb3',
- version='2.0.1',
+ version='2.0.2',
task='seq-cls',
load_checkpoint='/path/to/parameters',
label_map=label_map)
@@ -163,3 +163,7 @@ paddlehub >= 2.0.0
* 2.0.1
增加文本匹配任务`text-matching`
+
+* 2.0.2
+
+ 更新预训练模型调用方法
diff --git a/modules/text/language_model/rbt3/module.py b/modules/text/language_model/rbt3/module.py
index 1fdde350a..6ef8b7e03 100644
--- a/modules/text/language_model/rbt3/module.py
+++ b/modules/text/language_model/rbt3/module.py
@@ -11,17 +11,19 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-from typing import Dict
-import os
import math
+import os
+from typing import Dict
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
-
-from paddlenlp.transformers.roberta.modeling import RobertaForSequenceClassification, RobertaForTokenClassification, RobertaModel
-from paddlenlp.transformers.roberta.tokenizer import RobertaTokenizer
from paddlenlp.metrics import ChunkEvaluator
+from paddlenlp.transformers import AutoModel
+from paddlenlp.transformers import AutoModelForSequenceClassification
+from paddlenlp.transformers import AutoModelForTokenClassification
+from paddlenlp.transformers import AutoTokenizer
+
from paddlehub.module.module import moduleinfo
from paddlehub.module.nlp_module import TransformerModule
from paddlehub.utils.log import logger
@@ -29,7 +31,7 @@
@moduleinfo(
name="rbt3",
- version="2.0.1",
+ version="2.0.2",
summary="rbt3, 3-layer, 768-hidden, 12-heads, 38M parameters ",
author="ymcui",
author_email="ymcui@ir.hit.edu.cn",
@@ -42,13 +44,13 @@ class Roberta(nn.Layer):
"""
def __init__(
- self,
- task: str = None,
- load_checkpoint: str = None,
- label_map: Dict = None,
- num_classes: int = 2,
- suffix: bool = False,
- **kwargs,
+ self,
+ task: str = None,
+ load_checkpoint: str = None,
+ label_map: Dict = None,
+ num_classes: int = 2,
+ suffix: bool = False,
+ **kwargs,
):
super(Roberta, self).__init__()
if label_map:
@@ -63,23 +65,26 @@ def __init__(
"current task name 'sequence_classification' was renamed to 'seq-cls', "
"'sequence_classification' has been deprecated and will be removed in the future.", )
if task == 'seq-cls':
- self.model = RobertaForSequenceClassification.from_pretrained(
- pretrained_model_name_or_path='rbt3', num_classes=self.num_classes, **kwargs)
+ self.model = AutoModelForSequenceClassification.from_pretrained(pretrained_model_name_or_path='hfl/rbt3',
+ num_classes=self.num_classes,
+ **kwargs)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
self.metric = paddle.metric.Accuracy()
elif task == 'token-cls':
- self.model = RobertaForTokenClassification.from_pretrained(
- pretrained_model_name_or_path='rbt3', num_classes=self.num_classes, **kwargs)
+ self.model = AutoModelForTokenClassification.from_pretrained(pretrained_model_name_or_path='hfl/rbt3',
+ num_classes=self.num_classes,
+ **kwargs)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
- self.metric = ChunkEvaluator(label_list=[self.label_map[i] for i in sorted(self.label_map.keys())], suffix=suffix)
+ self.metric = ChunkEvaluator(label_list=[self.label_map[i] for i in sorted(self.label_map.keys())],
+ suffix=suffix)
elif task == 'text-matching':
- self.model = RobertaModel.from_pretrained(pretrained_model_name_or_path='rbt3', **kwargs)
+ self.model = AutoModel.from_pretrained(pretrained_model_name_or_path='hfl/rbt3', **kwargs)
self.dropout = paddle.nn.Dropout(0.1)
self.classifier = paddle.nn.Linear(self.model.config['hidden_size'] * 3, 2)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
self.metric = paddle.metric.Accuracy()
elif task is None:
- self.model = RobertaModel.from_pretrained(pretrained_model_name_or_path='rbt3', **kwargs)
+ self.model = AutoModel.from_pretrained(pretrained_model_name_or_path='hfl/rbt3', **kwargs)
else:
raise RuntimeError("Unknown task {}, task should be one in {}".format(task, self._tasks_supported))
@@ -171,4 +176,4 @@ def get_tokenizer(*args, **kwargs):
"""
Gets the tokenizer that is customized for this module.
"""
- return RobertaTokenizer.from_pretrained(pretrained_model_name_or_path='rbt3', *args, **kwargs)
+ return AutoTokenizer.from_pretrained(pretrained_model_name_or_path='hfl/rbt3', *args, **kwargs)
diff --git a/modules/text/language_model/rbtl3/README.md b/modules/text/language_model/rbtl3/README.md
index c61df18d2..8bcda2905 100644
--- a/modules/text/language_model/rbtl3/README.md
+++ b/modules/text/language_model/rbtl3/README.md
@@ -1,5 +1,5 @@
```shell
-$ hub install rbtl3==2.0.1
+$ hub install rbtl3==2.0.2
```
@@ -85,7 +85,7 @@ label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='rbtl3',
- version='2.0.1',
+ version='2.0.2',
task='seq-cls',
load_checkpoint='/path/to/parameters',
label_map=label_map)
@@ -163,3 +163,7 @@ paddlehub >= 2.0.0
* 2.0.1
增加文本匹配任务`text-matching`
+
+* 2.0.2
+
+ 更新预训练模型调用方法
diff --git a/modules/text/language_model/rbtl3/module.py b/modules/text/language_model/rbtl3/module.py
index d5789099d..bab919f10 100644
--- a/modules/text/language_model/rbtl3/module.py
+++ b/modules/text/language_model/rbtl3/module.py
@@ -11,17 +11,19 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-from typing import Dict
-import os
import math
+import os
+from typing import Dict
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
-
-from paddlenlp.transformers.roberta.modeling import RobertaForSequenceClassification, RobertaForTokenClassification, RobertaModel
-from paddlenlp.transformers.roberta.tokenizer import RobertaTokenizer
from paddlenlp.metrics import ChunkEvaluator
+from paddlenlp.transformers import AutoModel
+from paddlenlp.transformers import AutoModelForSequenceClassification
+from paddlenlp.transformers import AutoModelForTokenClassification
+from paddlenlp.transformers import AutoTokenizer
+
from paddlehub.module.module import moduleinfo
from paddlehub.module.nlp_module import TransformerModule
from paddlehub.utils.log import logger
@@ -29,7 +31,7 @@
@moduleinfo(
name="rbtl3",
- version="2.0.1",
+ version="2.0.2",
summary="rbtl3, 3-layer, 1024-hidden, 16-heads, 61M parameters ",
author="ymcui",
author_email="ymcui@ir.hit.edu.cn",
@@ -42,13 +44,13 @@ class Roberta(nn.Layer):
"""
def __init__(
- self,
- task: str = None,
- load_checkpoint: str = None,
- label_map: Dict = None,
- num_classes: int = 2,
- suffix: bool = False,
- **kwargs,
+ self,
+ task: str = None,
+ load_checkpoint: str = None,
+ label_map: Dict = None,
+ num_classes: int = 2,
+ suffix: bool = False,
+ **kwargs,
):
super(Roberta, self).__init__()
if label_map:
@@ -63,23 +65,26 @@ def __init__(
"current task name 'sequence_classification' was renamed to 'seq-cls', "
"'sequence_classification' has been deprecated and will be removed in the future.", )
if task == 'seq-cls':
- self.model = RobertaForSequenceClassification.from_pretrained(
- pretrained_model_name_or_path='rbtl3', num_classes=self.num_classes, **kwargs)
+ self.model = AutoModelForSequenceClassification.from_pretrained(pretrained_model_name_or_path='hfl/rbtl3',
+ num_classes=self.num_classes,
+ **kwargs)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
self.metric = paddle.metric.Accuracy()
elif task == 'token-cls':
- self.model = RobertaForTokenClassification.from_pretrained(
- pretrained_model_name_or_path='rbtl3', num_classes=self.num_classes, **kwargs)
+ self.model = AutoModelForTokenClassification.from_pretrained(pretrained_model_name_or_path='hfl/rbtl3',
+ num_classes=self.num_classes,
+ **kwargs)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
- self.metric = ChunkEvaluator(label_list=[self.label_map[i] for i in sorted(self.label_map.keys())], suffix=suffix)
+ self.metric = ChunkEvaluator(label_list=[self.label_map[i] for i in sorted(self.label_map.keys())],
+ suffix=suffix)
elif task == 'text-matching':
- self.model = RobertaModel.from_pretrained(pretrained_model_name_or_path='rbtl3', **kwargs)
+ self.model = AutoModel.from_pretrained(pretrained_model_name_or_path='hfl/rbtl3', **kwargs)
self.dropout = paddle.nn.Dropout(0.1)
self.classifier = paddle.nn.Linear(self.model.config['hidden_size'] * 3, 2)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
self.metric = paddle.metric.Accuracy()
elif task is None:
- self.model = RobertaModel.from_pretrained(pretrained_model_name_or_path='rbtl3', **kwargs)
+ self.model = AutoModel.from_pretrained(pretrained_model_name_or_path='hfl/rbtl3', **kwargs)
else:
raise RuntimeError("Unknown task {}, task should be one in {}".format(task, self._tasks_supported))
@@ -171,4 +176,4 @@ def get_tokenizer(*args, **kwargs):
"""
Gets the tokenizer that is customized for this module.
"""
- return RobertaTokenizer.from_pretrained(pretrained_model_name_or_path='rbtl3', *args, **kwargs)
+ return AutoTokenizer.from_pretrained(pretrained_model_name_or_path='hfl/rbtl3', *args, **kwargs)
diff --git a/modules/text/language_model/roberta-wwm-ext-large/README.md b/modules/text/language_model/roberta-wwm-ext-large/README.md
index d5c5aa592..a08e62d7f 100644
--- a/modules/text/language_model/roberta-wwm-ext-large/README.md
+++ b/modules/text/language_model/roberta-wwm-ext-large/README.md
@@ -1,6 +1,6 @@
# roberta-wwm-ext-large
|模型名称|roberta-wwm-ext-large|
-| :--- | :---: |
+| :--- | :---: |
|类别|文本-语义模型|
|网络|roberta-wwm-ext-large|
|数据集|百度自建数据集|
@@ -51,7 +51,7 @@ label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='roberta-wwm-ext-large',
- version='2.0.2',
+ version='2.0.3',
task='seq-cls',
load_checkpoint='/path/to/parameters',
label_map=label_map)
@@ -181,6 +181,10 @@ for idx, text in enumerate(data):
* 2.0.2
增加文本匹配任务`text-matching`
+
+* 2.0.3
+
+ 更新预训练模型调用方法
```shell
- $ hub install roberta-wwm-ext-large==2.0.2
+ $ hub install roberta-wwm-ext==2.0.3
```
diff --git a/modules/text/language_model/roberta-wwm-ext-large/module.py b/modules/text/language_model/roberta-wwm-ext-large/module.py
index 13efb6aea..272df4425 100644
--- a/modules/text/language_model/roberta-wwm-ext-large/module.py
+++ b/modules/text/language_model/roberta-wwm-ext-large/module.py
@@ -11,17 +11,19 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-from typing import Dict
-import os
import math
+import os
+from typing import Dict
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
-
-from paddlenlp.transformers.roberta.modeling import RobertaForSequenceClassification, RobertaForTokenClassification, RobertaModel
-from paddlenlp.transformers.roberta.tokenizer import RobertaTokenizer
from paddlenlp.metrics import ChunkEvaluator
+from paddlenlp.transformers import AutoModel
+from paddlenlp.transformers import AutoModelForSequenceClassification
+from paddlenlp.transformers import AutoModelForTokenClassification
+from paddlenlp.transformers import AutoTokenizer
+
from paddlehub.module.module import moduleinfo
from paddlehub.module.nlp_module import TransformerModule
from paddlehub.utils.log import logger
@@ -29,7 +31,7 @@
@moduleinfo(
name="roberta-wwm-ext-large",
- version="2.0.2",
+ version="2.0.3",
summary=
"chinese-roberta-wwm-ext-large, 24-layer, 1024-hidden, 16-heads, 340M parameters. The module is executed as paddle.dygraph.",
author="ymcui",
@@ -43,13 +45,13 @@ class Roberta(nn.Layer):
"""
def __init__(
- self,
- task: str = None,
- load_checkpoint: str = None,
- label_map: Dict = None,
- num_classes: int = 2,
- suffix: bool = False,
- **kwargs,
+ self,
+ task: str = None,
+ load_checkpoint: str = None,
+ label_map: Dict = None,
+ num_classes: int = 2,
+ suffix: bool = False,
+ **kwargs,
):
super(Roberta, self).__init__()
if label_map:
@@ -64,23 +66,24 @@ def __init__(
"current task name 'sequence_classification' was renamed to 'seq-cls', "
"'sequence_classification' has been deprecated and will be removed in the future.", )
if task == 'seq-cls':
- self.model = RobertaForSequenceClassification.from_pretrained(
- pretrained_model_name_or_path='roberta-wwm-ext-large', num_classes=self.num_classes, **kwargs)
+ self.model = AutoModelForSequenceClassification.from_pretrained(
+ pretrained_model_name_or_path='hfl/roberta-wwm-ext-large', num_classes=self.num_classes, **kwargs)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
self.metric = paddle.metric.Accuracy()
elif task == 'token-cls':
- self.model = RobertaForTokenClassification.from_pretrained(
- pretrained_model_name_or_path='roberta-wwm-ext-large', num_classes=self.num_classes, **kwargs)
+ self.model = AutoModelForTokenClassification.from_pretrained(
+ pretrained_model_name_or_path='hfl/roberta-wwm-ext-large', num_classes=self.num_classes, **kwargs)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
- self.metric = ChunkEvaluator(label_list=[self.label_map[i] for i in sorted(self.label_map.keys())], suffix=suffix)
+ self.metric = ChunkEvaluator(label_list=[self.label_map[i] for i in sorted(self.label_map.keys())],
+ suffix=suffix)
elif task == 'text-matching':
- self.model = RobertaModel.from_pretrained(pretrained_model_name_or_path='roberta-wwm-ext-large', **kwargs)
+ self.model = AutoModel.from_pretrained(pretrained_model_name_or_path='hfl/roberta-wwm-ext-large', **kwargs)
self.dropout = paddle.nn.Dropout(0.1)
self.classifier = paddle.nn.Linear(self.model.config['hidden_size'] * 3, 2)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
self.metric = paddle.metric.Accuracy()
elif task is None:
- self.model = RobertaModel.from_pretrained(pretrained_model_name_or_path='roberta-wwm-ext-large', **kwargs)
+ self.model = AutoModel.from_pretrained(pretrained_model_name_or_path='hfl/roberta-wwm-ext-large', **kwargs)
else:
raise RuntimeError("Unknown task {}, task should be one in {}".format(task, self._tasks_supported))
@@ -172,4 +175,4 @@ def get_tokenizer(*args, **kwargs):
"""
Gets the tokenizer that is customized for this module.
"""
- return RobertaTokenizer.from_pretrained(pretrained_model_name_or_path='roberta-wwm-ext-large', *args, **kwargs)
+ return AutoTokenizer.from_pretrained(pretrained_model_name_or_path='hfl/roberta-wwm-ext-large', *args, **kwargs)
diff --git a/modules/text/language_model/roberta-wwm-ext/README.md b/modules/text/language_model/roberta-wwm-ext/README.md
index f052628f2..7bb502237 100644
--- a/modules/text/language_model/roberta-wwm-ext/README.md
+++ b/modules/text/language_model/roberta-wwm-ext/README.md
@@ -1,6 +1,6 @@
# roberta-wwm-ext
|模型名称|roberta-wwm-ext|
-| :--- | :---: |
+| :--- | :---: |
|类别|文本-语义模型|
|网络|roberta-wwm-ext|
|数据集|百度自建数据集|
@@ -51,7 +51,7 @@ label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='roberta-wwm-ext',
- version='2.0.2',
+ version='2.0.3',
task='seq-cls',
load_checkpoint='/path/to/parameters',
label_map=label_map)
@@ -181,6 +181,10 @@ for idx, text in enumerate(data):
* 2.0.2
增加文本匹配任务`text-matching`
+
+* 2.0.3
+
+ 更新预训练模型调用方法
```shell
- $ hub install roberta-wwm-ext==2.0.2
+ $ hub install roberta-wwm-ext==2.0.3
```
diff --git a/modules/text/language_model/roberta-wwm-ext/module.py b/modules/text/language_model/roberta-wwm-ext/module.py
index 66108a239..2fe144315 100644
--- a/modules/text/language_model/roberta-wwm-ext/module.py
+++ b/modules/text/language_model/roberta-wwm-ext/module.py
@@ -11,17 +11,19 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-from typing import Dict
-import os
import math
+import os
+from typing import Dict
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
-
-from paddlenlp.transformers.roberta.modeling import RobertaForSequenceClassification, RobertaForTokenClassification, RobertaModel
-from paddlenlp.transformers.roberta.tokenizer import RobertaTokenizer
from paddlenlp.metrics import ChunkEvaluator
+from paddlenlp.transformers import AutoModel
+from paddlenlp.transformers import AutoModelForSequenceClassification
+from paddlenlp.transformers import AutoModelForTokenClassification
+from paddlenlp.transformers import AutoTokenizer
+
from paddlehub.module.module import moduleinfo
from paddlehub.module.nlp_module import TransformerModule
from paddlehub.utils.log import logger
@@ -29,7 +31,7 @@
@moduleinfo(
name="roberta-wwm-ext",
- version="2.0.2",
+ version="2.0.3",
summary=
"chinese-roberta-wwm-ext, 12-layer, 768-hidden, 12-heads, 110M parameters. The module is executed as paddle.dygraph.",
author="ymcui",
@@ -43,13 +45,13 @@ class Roberta(nn.Layer):
"""
def __init__(
- self,
- task: str = None,
- load_checkpoint: str = None,
- label_map: Dict = None,
- num_classes: int = 2,
- suffix: bool = False,
- **kwargs,
+ self,
+ task: str = None,
+ load_checkpoint: str = None,
+ label_map: Dict = None,
+ num_classes: int = 2,
+ suffix: bool = False,
+ **kwargs,
):
super(Roberta, self).__init__()
if label_map:
@@ -64,23 +66,24 @@ def __init__(
"current task name 'sequence_classification' was renamed to 'seq-cls', "
"'sequence_classification' has been deprecated and will be removed in the future.", )
if task == 'seq-cls':
- self.model = RobertaForSequenceClassification.from_pretrained(
- pretrained_model_name_or_path='roberta-wwm-ext', num_classes=self.num_classes, **kwargs)
+ self.model = AutoModelForSequenceClassification.from_pretrained(
+ pretrained_model_name_or_path='hfl/roberta-wwm-ext', num_classes=self.num_classes, **kwargs)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
self.metric = paddle.metric.Accuracy()
elif task == 'token-cls':
- self.model = RobertaForTokenClassification.from_pretrained(
- pretrained_model_name_or_path='roberta-wwm-ext', num_classes=self.num_classes, **kwargs)
+ self.model = AutoModelForTokenClassification.from_pretrained(
+ pretrained_model_name_or_path='hfl/roberta-wwm-ext', num_classes=self.num_classes, **kwargs)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
- self.metric = ChunkEvaluator(label_list=[self.label_map[i] for i in sorted(self.label_map.keys())], suffix=suffix)
+ self.metric = ChunkEvaluator(label_list=[self.label_map[i] for i in sorted(self.label_map.keys())],
+ suffix=suffix)
elif task == 'text-matching':
- self.model = RobertaModel.from_pretrained(pretrained_model_name_or_path='roberta-wwm-ext', **kwargs)
+ self.model = AutoModel.from_pretrained(pretrained_model_name_or_path='hfl/roberta-wwm-ext', **kwargs)
self.dropout = paddle.nn.Dropout(0.1)
self.classifier = paddle.nn.Linear(self.model.config['hidden_size'] * 3, 2)
self.criterion = paddle.nn.loss.CrossEntropyLoss()
self.metric = paddle.metric.Accuracy()
elif task is None:
- self.model = RobertaModel.from_pretrained(pretrained_model_name_or_path='roberta-wwm-ext', **kwargs)
+ self.model = AutoModel.from_pretrained(pretrained_model_name_or_path='hfl/roberta-wwm-ext', **kwargs)
else:
raise RuntimeError("Unknown task {}, task should be one in {}".format(task, self._tasks_supported))
@@ -172,4 +175,4 @@ def get_tokenizer(*args, **kwargs):
"""
Gets the tokenizer that is customized for this module.
"""
- return RobertaTokenizer.from_pretrained(pretrained_model_name_or_path='roberta-wwm-ext', *args, **kwargs)
+ return AutoTokenizer.from_pretrained(pretrained_model_name_or_path='hfl/roberta-wwm-ext', *args, **kwargs)
From 196f7e6739d57b5aeaf598a6cae8f396bb205d04 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 10:28:00 +0800
Subject: [PATCH 054/117] update faster_rcnn_resnet50_coco2017 (#1947)
* update faster_rcnn_resnet50_coco2017
* update unittest
* update unittest
* update unittest
* update gpu config
* update
* add clean func
* update save inference model
Co-authored-by: wuzewu
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -167,6 +161,11 @@
* 1.1.1
修复numpy数据读取问题
+
+* 1.2.0
+
+ 移除 fluid api
+
- ```shell
- $ hub install faster_rcnn_resnet50_coco2017==1.1.1
+ $ hub install faster_rcnn_resnet50_coco2017==1.2.0
```
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/README_en.md b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/README_en.md
index aaa652df6..35814624e 100644
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/README_en.md
+++ b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/README_en.md
@@ -103,19 +103,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -168,6 +162,11 @@
* 1.1.1
Fix the problem of reading numpy
+
+* 1.2.0
+
+ Remove fluid api
+
- ```shell
- $ hub install faster_rcnn_resnet50_coco2017==1.1.1
+ $ hub install faster_rcnn_resnet50_coco2017==1.2.0
```
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/bbox_assigner.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/bbox_assigner.py
deleted file mode 100644
index bcb6b42d1..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/bbox_assigner.py
+++ /dev/null
@@ -1,19 +0,0 @@
-class BBoxAssigner(object):
- def __init__(self,
- batch_size_per_im=512,
- fg_fraction=.25,
- fg_thresh=.5,
- bg_thresh_hi=.5,
- bg_thresh_lo=0.,
- bbox_reg_weights=[0.1, 0.1, 0.2, 0.2],
- class_nums=81,
- shuffle_before_sample=True):
- super(BBoxAssigner, self).__init__()
- self.batch_size_per_im = batch_size_per_im
- self.fg_fraction = fg_fraction
- self.fg_thresh = fg_thresh
- self.bg_thresh_hi = bg_thresh_hi
- self.bg_thresh_lo = bg_thresh_lo
- self.bbox_reg_weights = bbox_reg_weights
- self.class_nums = class_nums
- self.use_random = shuffle_before_sample
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/bbox_head.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/bbox_head.py
deleted file mode 100644
index 7f72bb939..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/bbox_head.py
+++ /dev/null
@@ -1,269 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from collections import OrderedDict
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.initializer import Normal, Xavier
-from paddle.fluid.regularizer import L2Decay
-from paddle.fluid.initializer import MSRA
-
-
-class MultiClassNMS(object):
- # __op__ = fluid.layers.multiclass_nms
- def __init__(self,
- score_threshold=.05,
- nms_top_k=-1,
- keep_top_k=100,
- nms_threshold=.5,
- normalized=False,
- nms_eta=1.0,
- background_label=0):
- super(MultiClassNMS, self).__init__()
- self.score_threshold = score_threshold
- self.nms_top_k = nms_top_k
- self.keep_top_k = keep_top_k
- self.nms_threshold = nms_threshold
- self.normalized = normalized
- self.nms_eta = nms_eta
- self.background_label = background_label
-
-
-class SmoothL1Loss(object):
- '''
- Smooth L1 loss
- Args:
- sigma (float): hyper param in smooth l1 loss
- '''
-
- def __init__(self, sigma=1.0):
- super(SmoothL1Loss, self).__init__()
- self.sigma = sigma
-
- def __call__(self, x, y, inside_weight=None, outside_weight=None):
- return fluid.layers.smooth_l1(
- x,
- y,
- inside_weight=inside_weight,
- outside_weight=outside_weight,
- sigma=self.sigma)
-
-
-class BoxCoder(object):
- def __init__(self,
- prior_box_var=[0.1, 0.1, 0.2, 0.2],
- code_type='decode_center_size',
- box_normalized=False,
- axis=1):
- super(BoxCoder, self).__init__()
- self.prior_box_var = prior_box_var
- self.code_type = code_type
- self.box_normalized = box_normalized
- self.axis = axis
-
-
-class TwoFCHead(object):
- """
- RCNN head with two Fully Connected layers
- Args:
- mlp_dim (int): num of filters for the fc layers
- """
-
- def __init__(self, mlp_dim=1024):
- super(TwoFCHead, self).__init__()
- self.mlp_dim = mlp_dim
-
- def __call__(self, roi_feat):
- fan = roi_feat.shape[1] * roi_feat.shape[2] * roi_feat.shape[3]
-
- fc6 = fluid.layers.fc(
- input=roi_feat,
- size=self.mlp_dim,
- act='relu',
- name='fc6',
- param_attr=ParamAttr(name='fc6_w', initializer=Xavier(fan_out=fan)),
- bias_attr=ParamAttr(
- name='fc6_b', learning_rate=2., regularizer=L2Decay(0.)))
- head_feat = fluid.layers.fc(
- input=fc6,
- size=self.mlp_dim,
- act='relu',
- name='fc7',
- param_attr=ParamAttr(name='fc7_w', initializer=Xavier()),
- bias_attr=ParamAttr(
- name='fc7_b', learning_rate=2., regularizer=L2Decay(0.)))
-
- return head_feat
-
-
-class BBoxHead(object):
- """
- RCNN bbox head
-
- Args:
- head (object): the head module instance, e.g., `ResNetC5`, `TwoFCHead`
- box_coder (object): `BoxCoder` instance
- nms (object): `MultiClassNMS` instance
- num_classes: number of output classes
- """
- __inject__ = ['head', 'box_coder', 'nms', 'bbox_loss']
- __shared__ = ['num_classes']
-
- def __init__(self,
- head,
- box_coder=BoxCoder(),
- nms=MultiClassNMS(),
- bbox_loss=SmoothL1Loss(),
- num_classes=81):
- super(BBoxHead, self).__init__()
- self.head = head
- self.num_classes = num_classes
- self.box_coder = box_coder
- self.nms = nms
- self.bbox_loss = bbox_loss
- self.head_feat = None
-
- def get_head_feat(self, input=None):
- """
- Get the bbox head feature map.
- """
-
- if input is not None:
- feat = self.head(input)
- if isinstance(feat, OrderedDict):
- feat = list(feat.values())[0]
- self.head_feat = feat
- return self.head_feat
-
- def _get_output(self, roi_feat):
- """
- Get bbox head output.
-
- Args:
- roi_feat (Variable): RoI feature from RoIExtractor.
-
- Returns:
- cls_score(Variable): Output of rpn head with shape of
- [N, num_anchors, H, W].
- bbox_pred(Variable): Output of rpn head with shape of
- [N, num_anchors * 4, H, W].
- """
- head_feat = self.get_head_feat(roi_feat)
- # when ResNetC5 output a single feature map
- if not isinstance(self.head, TwoFCHead):
- head_feat = fluid.layers.pool2d(
- head_feat, pool_type='avg', global_pooling=True)
- cls_score = fluid.layers.fc(
- input=head_feat,
- size=self.num_classes,
- act=None,
- name='cls_score',
- param_attr=ParamAttr(
- name='cls_score_w', initializer=Normal(loc=0.0, scale=0.01)),
- bias_attr=ParamAttr(
- name='cls_score_b', learning_rate=2., regularizer=L2Decay(0.)))
- bbox_pred = fluid.layers.fc(
- input=head_feat,
- size=4 * self.num_classes,
- act=None,
- name='bbox_pred',
- param_attr=ParamAttr(
- name='bbox_pred_w', initializer=Normal(loc=0.0, scale=0.001)),
- bias_attr=ParamAttr(
- name='bbox_pred_b', learning_rate=2., regularizer=L2Decay(0.)))
- return cls_score, bbox_pred
-
- def get_loss(self, roi_feat, labels_int32, bbox_targets,
- bbox_inside_weights, bbox_outside_weights):
- """
- Get bbox_head loss.
-
- Args:
- roi_feat (Variable): RoI feature from RoIExtractor.
- labels_int32(Variable): Class label of a RoI with shape [P, 1].
- P is the number of RoI.
- bbox_targets(Variable): Box label of a RoI with shape
- [P, 4 * class_nums].
- bbox_inside_weights(Variable): Indicates whether a box should
- contribute to loss. Same shape as bbox_targets.
- bbox_outside_weights(Variable): Indicates whether a box should
- contribute to loss. Same shape as bbox_targets.
-
- Return:
- Type: Dict
- loss_cls(Variable): bbox_head loss.
- loss_bbox(Variable): bbox_head loss.
- """
-
- cls_score, bbox_pred = self._get_output(roi_feat)
-
- labels_int64 = fluid.layers.cast(x=labels_int32, dtype='int64')
- labels_int64.stop_gradient = True
- loss_cls = fluid.layers.softmax_with_cross_entropy(
- logits=cls_score, label=labels_int64, numeric_stable_mode=True)
- loss_cls = fluid.layers.reduce_mean(loss_cls)
- loss_bbox = self.bbox_loss(
- x=bbox_pred,
- y=bbox_targets,
- inside_weight=bbox_inside_weights,
- outside_weight=bbox_outside_weights)
- loss_bbox = fluid.layers.reduce_mean(loss_bbox)
- return {'loss_cls': loss_cls, 'loss_bbox': loss_bbox}
-
- def get_prediction(self,
- roi_feat,
- rois,
- im_info,
- im_shape,
- return_box_score=False):
- """
- Get prediction bounding box in test stage.
-
- Args:
- roi_feat (Variable): RoI feature from RoIExtractor.
- rois (Variable): Output of generate_proposals in rpn head.
- im_info (Variable): A 2-D LoDTensor with shape [B, 3]. B is the
- number of input images, each element consists of im_height,
- im_width, im_scale.
- im_shape (Variable): Actual shape of original image with shape
- [B, 3]. B is the number of images, each element consists of
- original_height, original_width, 1
-
- Returns:
- pred_result(Variable): Prediction result with shape [N, 6]. Each
- row has 6 values: [label, confidence, xmin, ymin, xmax, ymax].
- N is the total number of prediction.
- """
- cls_score, bbox_pred = self._get_output(roi_feat)
-
- im_scale = fluid.layers.slice(im_info, [1], starts=[2], ends=[3])
- im_scale = fluid.layers.sequence_expand(im_scale, rois)
- boxes = rois / im_scale
- cls_prob = fluid.layers.softmax(cls_score, use_cudnn=False)
- bbox_pred = fluid.layers.reshape(bbox_pred, (-1, self.num_classes, 4))
- # self.box_coder
- decoded_box = fluid.layers.box_coder(
- prior_box=boxes,
- target_box=bbox_pred,
- prior_box_var=self.box_coder.prior_box_var,
- code_type=self.box_coder.code_type,
- box_normalized=self.box_coder.box_normalized,
- axis=self.box_coder.axis)
- cliped_box = fluid.layers.box_clip(input=decoded_box, im_info=im_shape)
- if return_box_score:
- return {'bbox': cliped_box, 'score': cls_prob}
- # self.nms
- pred_result = fluid.layers.multiclass_nms(
- bboxes=cliped_box,
- scores=cls_prob,
- score_threshold=self.nms.score_threshold,
- nms_top_k=self.nms.nms_top_k,
- keep_top_k=self.nms.keep_top_k,
- nms_threshold=self.nms.nms_threshold,
- normalized=self.nms.normalized,
- nms_eta=self.nms.nms_eta,
- background_label=self.nms.background_label)
- return pred_result
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/data_feed.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/data_feed.py
index e52cce168..d2fc1de7a 100644
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/data_feed.py
+++ b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/data_feed.py
@@ -4,12 +4,9 @@
from __future__ import division
import os
-from collections import OrderedDict
import cv2
import numpy as np
-from PIL import Image, ImageEnhance
-from paddle import fluid
__all__ = ['test_reader']
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py
index 7b26eab37..5161b6628 100644
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py
+++ b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py
@@ -6,40 +6,31 @@
import os
import ast
import argparse
-from collections import OrderedDict
-from functools import partial
from math import ceil
+import paddle
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
+import paddle.static
from paddlehub.module.module import moduleinfo, runnable, serving
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
-from paddlehub.io.parser import txt_parser
-from paddlehub.common.paddle_helper import add_vars_prefix
-
-from faster_rcnn_resnet50_coco2017.processor import load_label_info, postprocess, base64_to_cv2
-from faster_rcnn_resnet50_coco2017.data_feed import test_reader, padding_minibatch
-from faster_rcnn_resnet50_coco2017.resnet import ResNet, ResNetC5
-from faster_rcnn_resnet50_coco2017.rpn_head import AnchorGenerator, RPNTargetAssign, GenerateProposals, RPNHead
-from faster_rcnn_resnet50_coco2017.bbox_head import MultiClassNMS, BBoxHead, SmoothL1Loss
-from faster_rcnn_resnet50_coco2017.bbox_assigner import BBoxAssigner
-from faster_rcnn_resnet50_coco2017.roi_extractor import RoIAlign
+from paddle.inference import Config, create_predictor
+from paddlehub.utils.parser import txt_parser
+from .processor import load_label_info, postprocess, base64_to_cv2
+from .data_feed import test_reader, padding_minibatch
@moduleinfo(
name="faster_rcnn_resnet50_coco2017",
- version="1.1.1",
+ version="1.2.0",
type="cv/object_detection",
summary=
"Baidu's Faster R-CNN model for object detection with backbone ResNet50, trained with dataset COCO2017",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class FasterRCNNResNet50(hub.Module):
- def _initialize(self):
+class FasterRCNNResNet50:
+ def __init__(self):
# default pretrained model, Faster-RCNN with backbone ResNet50, shape of input tensor is [3, 800, 1333]
self.default_pretrained_model_path = os.path.join(
- self.directory, "faster_rcnn_resnet50_model")
+ self.directory, "faster_rcnn_resnet50_model", "model")
self.label_names = load_label_info(
os.path.join(self.directory, "label_file.txt"))
self._set_config()
@@ -48,10 +39,12 @@ def _set_config(self):
"""
predictor config setting
"""
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -60,236 +53,14 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
-
- def context(self,
- num_classes=81,
- trainable=True,
- pretrained=True,
- phase='train'):
- """
- Distill the Head Features, so as to perform transfer learning.
-
- Args:
- num_classes (int): number of categories
- trainable (bool): whether to set parameters trainable.
- pretrained (bool): whether to load default pretrained model.
- phase (str): optional choices are 'train' and 'predict'.
-
- Returns:
- inputs (dict): the input variables.
- outputs (dict): the output variables.
- context_prog (Program): the program to execute transfer learning.
- """
- context_prog = fluid.Program()
- startup_program = fluid.Program()
- with fluid.program_guard(context_prog, startup_program):
- with fluid.unique_name.guard():
- image = fluid.layers.data(
- name='image', shape=[-1, 3, -1, -1], dtype='float32')
- # backbone
- backbone = ResNet(
- norm_type='affine_channel',
- depth=50,
- feature_maps=4,
- freeze_at=2)
- body_feats = backbone(image)
-
- # var_prefix
- var_prefix = '@HUB_{}@'.format(self.name)
- im_info = fluid.layers.data(
- name='im_info', shape=[3], dtype='float32', lod_level=0)
- im_shape = fluid.layers.data(
- name='im_shape', shape=[3], dtype='float32', lod_level=0)
- body_feat_names = list(body_feats.keys())
- # rpn_head: RPNHead
- rpn_head = self.rpn_head()
- rois = rpn_head.get_proposals(body_feats, im_info, mode=phase)
- # train
- if phase == 'train':
- gt_bbox = fluid.layers.data(
- name='gt_bbox', shape=[4], dtype='float32', lod_level=1)
- is_crowd = fluid.layers.data(
- name='is_crowd', shape=[1], dtype='int32', lod_level=1)
- gt_class = fluid.layers.data(
- name='gt_class', shape=[1], dtype='int32', lod_level=1)
- rpn_loss = rpn_head.get_loss(im_info, gt_bbox, is_crowd)
- # bbox_assigner: BBoxAssigner
- bbox_assigner = self.bbox_assigner(num_classes)
- outs = fluid.layers.generate_proposal_labels(
- rpn_rois=rois,
- gt_classes=gt_class,
- is_crowd=is_crowd,
- gt_boxes=gt_bbox,
- im_info=im_info,
- batch_size_per_im=bbox_assigner.batch_size_per_im,
- fg_fraction=bbox_assigner.fg_fraction,
- fg_thresh=bbox_assigner.fg_thresh,
- bg_thresh_hi=bbox_assigner.bg_thresh_hi,
- bg_thresh_lo=bbox_assigner.bg_thresh_lo,
- bbox_reg_weights=bbox_assigner.bbox_reg_weights,
- class_nums=bbox_assigner.class_nums,
- use_random=bbox_assigner.use_random)
- rois = outs[0]
-
- body_feat = body_feats[body_feat_names[-1]]
- # roi_extractor: RoIAlign
- roi_extractor = self.roi_extractor()
- roi_feat = fluid.layers.roi_align(
- input=body_feat,
- rois=rois,
- pooled_height=roi_extractor.pooled_height,
- pooled_width=roi_extractor.pooled_width,
- spatial_scale=roi_extractor.spatial_scale,
- sampling_ratio=roi_extractor.sampling_ratio)
- # head_feat
- bbox_head = self.bbox_head(num_classes)
- head_feat = bbox_head.head(roi_feat)
- if isinstance(head_feat, OrderedDict):
- head_feat = list(head_feat.values())[0]
- if phase == 'train':
- inputs = {
- 'image': var_prefix + image.name,
- 'im_info': var_prefix + im_info.name,
- 'im_shape': var_prefix + im_shape.name,
- 'gt_class': var_prefix + gt_class.name,
- 'gt_bbox': var_prefix + gt_bbox.name,
- 'is_crowd': var_prefix + is_crowd.name
- }
- outputs = {
- 'head_features':
- var_prefix + head_feat.name,
- 'rpn_cls_loss':
- var_prefix + rpn_loss['rpn_cls_loss'].name,
- 'rpn_reg_loss':
- var_prefix + rpn_loss['rpn_reg_loss'].name,
- 'generate_proposal_labels':
- [var_prefix + var.name for var in outs]
- }
- elif phase == 'predict':
- pred = bbox_head.get_prediction(roi_feat, rois, im_info,
- im_shape)
- inputs = {
- 'image': var_prefix + image.name,
- 'im_info': var_prefix + im_info.name,
- 'im_shape': var_prefix + im_shape.name
- }
- outputs = {
- 'head_features': var_prefix + head_feat.name,
- 'rois': var_prefix + rois.name,
- 'bbox_out': var_prefix + pred.name
- }
- add_vars_prefix(context_prog, var_prefix)
- add_vars_prefix(startup_program, var_prefix)
-
- global_vars = context_prog.global_block().vars
- inputs = {
- key: global_vars[value]
- for key, value in inputs.items()
- }
- outputs = {
- key: global_vars[value] if not isinstance(value, list) else
- [global_vars[var] for var in value]
- for key, value in outputs.items()
- }
-
- for param in context_prog.global_block().iter_parameters():
- param.trainable = trainable
-
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- exe.run(startup_program)
- if pretrained:
-
- def _if_exist(var):
- if num_classes != 81:
- if 'bbox_pred' in var.name or 'cls_score' in var.name:
- return False
- return os.path.exists(
- os.path.join(self.default_pretrained_model_path,
- var.name))
-
- fluid.io.load_vars(
- exe,
- self.default_pretrained_model_path,
- predicate=_if_exist)
- return inputs, outputs, context_prog
-
- def rpn_head(self):
- return RPNHead(
- anchor_generator=AnchorGenerator(
- anchor_sizes=[32, 64, 128, 256, 512],
- aspect_ratios=[0.5, 1.0, 2.0],
- stride=[16.0, 16.0],
- variance=[1.0, 1.0, 1.0, 1.0]),
- rpn_target_assign=RPNTargetAssign(
- rpn_batch_size_per_im=256,
- rpn_fg_fraction=0.5,
- rpn_negative_overlap=0.3,
- rpn_positive_overlap=0.7,
- rpn_straddle_thresh=0.0),
- train_proposal=GenerateProposals(
- min_size=0.0,
- nms_thresh=0.7,
- post_nms_top_n=12000,
- pre_nms_top_n=2000),
- test_proposal=GenerateProposals(
- min_size=0.0,
- nms_thresh=0.7,
- post_nms_top_n=6000,
- pre_nms_top_n=1000))
-
- def roi_extractor(self):
- return RoIAlign(resolution=14, sampling_ratio=0, spatial_scale=0.0625)
-
- def bbox_head(self, num_classes):
- return BBoxHead(
- head=ResNetC5(depth=50, norm_type='affine_channel'),
- nms=MultiClassNMS(
- keep_top_k=100, nms_threshold=0.5, score_threshold=0.05),
- bbox_loss=SmoothL1Loss(),
- num_classes=num_classes)
-
- def bbox_assigner(self, num_classes):
- return BBoxAssigner(
- batch_size_per_im=512,
- bbox_reg_weights=[0.1, 0.1, 0.2, 0.2],
- bg_thresh_hi=0.5,
- bg_thresh_lo=0.0,
- fg_fraction=0.25,
- fg_thresh=0.5,
- class_nums=num_classes)
-
- def save_inference_model(self,
- dirname,
- model_filename=None,
- params_filename=None,
- combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
+ self.gpu_predictor = create_predictor(gpu_config)
def object_detection(self,
paths=None,
images=None,
- data=None,
use_gpu=False,
batch_size=1,
output_dir='detection_result',
@@ -326,8 +97,6 @@ def object_detection(self,
"Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
)
paths = paths if paths else list()
- if data and 'image' in data:
- paths += data['image']
all_images = list()
for yield_return in test_reader(paths, images):
@@ -347,20 +116,28 @@ def object_detection(self,
padding_image, padding_info, padding_shape = padding_minibatch(
batch_data)
- padding_image_tensor = PaddleTensor(padding_image.copy())
- padding_info_tensor = PaddleTensor(padding_info.copy())
- padding_shape_tensor = PaddleTensor(padding_shape.copy())
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+
feed_list = [
- padding_image_tensor, padding_info_tensor, padding_shape_tensor
+ padding_image, padding_info, padding_shape
]
- if use_gpu:
- data_out = self.gpu_predictor.run(feed_list)
- else:
- data_out = self.cpu_predictor.run(feed_list)
+
+ input_names = predictor.get_input_names()
+
+ for i, input_name in enumerate(input_names):
+ data = np.asarray(feed_list[i], dtype=np.float32)
+ handle = predictor.get_input_handle(input_name)
+ handle.copy_from_cpu(data)
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+
output = postprocess(
paths=paths,
images=images,
- data_out=data_out,
+ data_out=output_handle,
score_thresh=score_thresh,
label_names=self.label_names,
output_dir=output_dir,
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/name_adapter.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/name_adapter.py
deleted file mode 100644
index bebf8bdee..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/name_adapter.py
+++ /dev/null
@@ -1,61 +0,0 @@
-# coding=utf-8
-
-
-class NameAdapter(object):
- """Fix the backbones variable names for pretrained weight"""
-
- def __init__(self, model):
- super(NameAdapter, self).__init__()
- self.model = model
-
- @property
- def model_type(self):
- return getattr(self.model, '_model_type', '')
-
- @property
- def variant(self):
- return getattr(self.model, 'variant', '')
-
- def fix_conv_norm_name(self, name):
- if name == "conv1":
- bn_name = "bn_" + name
- else:
- bn_name = "bn" + name[3:]
- # the naming rule is same as pretrained weight
- if self.model_type == 'SEResNeXt':
- bn_name = name + "_bn"
- return bn_name
-
- def fix_shortcut_name(self, name):
- if self.model_type == 'SEResNeXt':
- name = 'conv' + name + '_prj'
- return name
-
- def fix_bottleneck_name(self, name):
- if self.model_type == 'SEResNeXt':
- conv_name1 = 'conv' + name + '_x1'
- conv_name2 = 'conv' + name + '_x2'
- conv_name3 = 'conv' + name + '_x3'
- shortcut_name = name
- else:
- conv_name1 = name + "_branch2a"
- conv_name2 = name + "_branch2b"
- conv_name3 = name + "_branch2c"
- shortcut_name = name + "_branch1"
- return conv_name1, conv_name2, conv_name3, shortcut_name
-
- def fix_layer_warp_name(self, stage_num, count, i):
- name = 'res' + str(stage_num)
- if count > 10 and stage_num == 4:
- if i == 0:
- conv_name = name + "a"
- else:
- conv_name = name + "b" + str(i)
- else:
- conv_name = name + chr(ord("a") + i)
- if self.model_type == 'SEResNeXt':
- conv_name = str(stage_num + 2) + '_' + str(i + 1)
- return conv_name
-
- def fix_c1_stage_name(self):
- return "res_conv1" if self.model_type == 'ResNeXt' else "conv1"
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/nonlocal_helper.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/nonlocal_helper.py
deleted file mode 100644
index 599b8dfa0..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/nonlocal_helper.py
+++ /dev/null
@@ -1,154 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import paddle.fluid as fluid
-from paddle.fluid import ParamAttr
-
-nonlocal_params = {
- "use_zero_init_conv": False,
- "conv_init_std": 0.01,
- "no_bias": True,
- "use_maxpool": False,
- "use_softmax": True,
- "use_bn": False,
- "use_scale": True, # vital for the model prformance!!!
- "use_affine": False,
- "bn_momentum": 0.9,
- "bn_epsilon": 1.0000001e-5,
- "bn_init_gamma": 0.9,
- "weight_decay_bn": 1.e-4,
-}
-
-
-def space_nonlocal(input, dim_in, dim_out, prefix, dim_inner,
- max_pool_stride=2):
- cur = input
- theta = fluid.layers.conv2d(input = cur, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr=ParamAttr(name = prefix + '_theta' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_theta' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if not nonlocal_params["no_bias"] else False, \
- name = prefix + '_theta')
- theta_shape = theta.shape
- theta_shape_op = fluid.layers.shape(theta)
- theta_shape_op.stop_gradient = True
-
- if nonlocal_params["use_maxpool"]:
- max_pool = fluid.layers.pool2d(input = cur, \
- pool_size = [max_pool_stride, max_pool_stride], \
- pool_type = 'max', \
- pool_stride = [max_pool_stride, max_pool_stride], \
- pool_padding = [0, 0], \
- name = prefix + '_pool')
- else:
- max_pool = cur
-
- phi = fluid.layers.conv2d(input = max_pool, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_phi' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_phi' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_phi')
- phi_shape = phi.shape
-
- g = fluid.layers.conv2d(input = max_pool, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_g' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0, scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_g' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_g')
- g_shape = g.shape
- # we have to use explicit batch size (to support arbitrary spacetime size)
- # e.g. (8, 1024, 4, 14, 14) => (8, 1024, 784)
- theta = fluid.layers.reshape(theta, shape=(0, 0, -1))
- theta = fluid.layers.transpose(theta, [0, 2, 1])
- phi = fluid.layers.reshape(phi, [0, 0, -1])
- theta_phi = fluid.layers.matmul(theta, phi, name=prefix + '_affinity')
- g = fluid.layers.reshape(g, [0, 0, -1])
-
- if nonlocal_params["use_softmax"]:
- if nonlocal_params["use_scale"]:
- theta_phi_sc = fluid.layers.scale(theta_phi, scale=dim_inner**-.5)
- else:
- theta_phi_sc = theta_phi
- p = fluid.layers.softmax(
- theta_phi_sc, name=prefix + '_affinity' + '_prob')
- else:
- # not clear about what is doing in xlw's code
- p = None # not implemented
- raise "Not implemented when not use softmax"
-
- # note g's axis[2] corresponds to p's axis[2]
- # e.g. g(8, 1024, 784_2) * p(8, 784_1, 784_2) => (8, 1024, 784_1)
- p = fluid.layers.transpose(p, [0, 2, 1])
- t = fluid.layers.matmul(g, p, name=prefix + '_y')
-
- # reshape back
- # e.g. (8, 1024, 784) => (8, 1024, 4, 14, 14)
- t_shape = t.shape
- t_re = fluid.layers.reshape(
- t, shape=list(theta_shape), actual_shape=theta_shape_op)
- blob_out = t_re
- blob_out = fluid.layers.conv2d(input = blob_out, num_filters = dim_out, \
- filter_size = [1, 1], stride = [1, 1], padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_out' + "_w", \
- initializer = fluid.initializer.Constant(value = 0.) \
- if nonlocal_params["use_zero_init_conv"] \
- else fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_out' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_out')
- blob_out_shape = blob_out.shape
-
- if nonlocal_params["use_bn"]:
- bn_name = prefix + "_bn"
- blob_out = fluid.layers.batch_norm(blob_out, \
- # is_test = test_mode, \
- momentum = nonlocal_params["bn_momentum"], \
- epsilon = nonlocal_params["bn_epsilon"], \
- name = bn_name, \
- param_attr = ParamAttr(name = bn_name + "_s", \
- initializer = fluid.initializer.Constant(value = nonlocal_params["bn_init_gamma"]), \
- regularizer = fluid.regularizer.L2Decay(nonlocal_params["weight_decay_bn"])), \
- bias_attr = ParamAttr(name = bn_name + "_b", \
- regularizer = fluid.regularizer.L2Decay(nonlocal_params["weight_decay_bn"])), \
- moving_mean_name = bn_name + "_rm", \
- moving_variance_name = bn_name + "_riv") # add bn
-
- if nonlocal_params["use_affine"]:
- affine_scale = fluid.layers.create_parameter(\
- shape=[blob_out_shape[1]], dtype = blob_out.dtype, \
- attr=ParamAttr(name=prefix + '_affine' + '_s'), \
- default_initializer = fluid.initializer.Constant(value = 1.))
- affine_bias = fluid.layers.create_parameter(\
- shape=[blob_out_shape[1]], dtype = blob_out.dtype, \
- attr=ParamAttr(name=prefix + '_affine' + '_b'), \
- default_initializer = fluid.initializer.Constant(value = 0.))
- blob_out = fluid.layers.affine_channel(blob_out, scale = affine_scale, \
- bias = affine_bias, name = prefix + '_affine') # add affine
-
- return blob_out
-
-
-def add_space_nonlocal(input, dim_in, dim_out, prefix, dim_inner):
- '''
- add_space_nonlocal:
- Non-local Neural Networks: see https://arxiv.org/abs/1711.07971
- '''
- conv = space_nonlocal(input, dim_in, dim_out, prefix, dim_inner)
- output = fluid.layers.elementwise_add(input, conv, name=prefix + '_sum')
- return output
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/processor.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/processor.py
index 2b3e1ce9c..fd31a14e0 100644
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/processor.py
+++ b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/processor.py
@@ -107,7 +107,7 @@ def postprocess(paths,
handle_id,
visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): the path of images.
@@ -130,9 +130,8 @@ def postprocess(paths,
confidence (float): The confidence of detection result.
save_path (str): The path to save output images.
"""
- lod_tensor = data_out[0]
- lod = lod_tensor.lod[0]
- results = lod_tensor.as_ndarray()
+ lod = data_out.lod()[0]
+ results = data_out.copy_to_cpu()
check_dir(output_dir)
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/resnet.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/resnet.py
deleted file mode 100644
index 4bd6fb61e..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/resnet.py
+++ /dev/null
@@ -1,447 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import math
-from collections import OrderedDict
-from numbers import Integral
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.framework import Variable
-from paddle.fluid.regularizer import L2Decay
-from paddle.fluid.initializer import Constant
-
-from .nonlocal_helper import add_space_nonlocal
-from .name_adapter import NameAdapter
-
-__all__ = ['ResNet', 'ResNetC5']
-
-
-class ResNet(object):
- """
- Residual Network, see https://arxiv.org/abs/1512.03385
- Args:
- depth (int): ResNet depth, should be 34, 50.
- freeze_at (int): freeze the backbone at which stage
- norm_type (str): normalization type, 'bn'/'sync_bn'/'affine_channel'
- freeze_norm (bool): freeze normalization layers
- norm_decay (float): weight decay for normalization layer weights
- variant (str): ResNet variant, supports 'a', 'b', 'c', 'd' currently
- feature_maps (list): index of stages whose feature maps are returned
- dcn_v2_stages (list): index of stages who select deformable conv v2
- nonlocal_stages (list): index of stages who select nonlocal networks
- """
- __shared__ = ['norm_type', 'freeze_norm', 'weight_prefix_name']
-
- def __init__(self,
- depth=50,
- freeze_at=0,
- norm_type='sync_bn',
- freeze_norm=False,
- norm_decay=0.,
- variant='b',
- feature_maps=[3, 4, 5],
- dcn_v2_stages=[],
- weight_prefix_name='',
- nonlocal_stages=[],
- get_prediction=False,
- class_dim=1000):
- super(ResNet, self).__init__()
-
- if isinstance(feature_maps, Integral):
- feature_maps = [feature_maps]
-
- assert depth in [34, 50], \
- "depth {} not in [34, 50]"
- assert variant in ['a', 'b', 'c', 'd'], "invalid ResNet variant"
- assert 0 <= freeze_at <= 4, "freeze_at should be 0, 1, 2, 3 or 4"
- assert len(feature_maps) > 0, "need one or more feature maps"
- assert norm_type in ['bn', 'sync_bn', 'affine_channel']
- assert not (len(nonlocal_stages)>0 and depth<50), \
- "non-local is not supported for resnet18 or resnet34"
-
- self.depth = depth
- self.freeze_at = freeze_at
- self.norm_type = norm_type
- self.norm_decay = norm_decay
- self.freeze_norm = freeze_norm
- self.variant = variant
- self._model_type = 'ResNet'
- self.feature_maps = feature_maps
- self.dcn_v2_stages = dcn_v2_stages
- self.depth_cfg = {
- 34: ([3, 4, 6, 3], self.basicblock),
- 50: ([3, 4, 6, 3], self.bottleneck),
- }
- self.stage_filters = [64, 128, 256, 512]
- self._c1_out_chan_num = 64
- self.na = NameAdapter(self)
- self.prefix_name = weight_prefix_name
-
- self.nonlocal_stages = nonlocal_stages
- self.nonlocal_mod_cfg = {
- 50: 2,
- 101: 5,
- 152: 8,
- 200: 12,
- }
- self.get_prediction = get_prediction
- self.class_dim = class_dim
-
- def _conv_offset(self,
- input,
- filter_size,
- stride,
- padding,
- act=None,
- name=None):
- out_channel = filter_size * filter_size * 3
- out = fluid.layers.conv2d(
- input,
- num_filters=out_channel,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- param_attr=ParamAttr(initializer=Constant(0.0), name=name + ".w_0"),
- bias_attr=ParamAttr(initializer=Constant(0.0), name=name + ".b_0"),
- act=act,
- name=name)
- return out
-
- def _conv_norm(self,
- input,
- num_filters,
- filter_size,
- stride=1,
- groups=1,
- act=None,
- name=None,
- dcn_v2=False):
- _name = self.prefix_name + name if self.prefix_name != '' else name
- if not dcn_v2:
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- groups=groups,
- act=None,
- param_attr=ParamAttr(name=_name + "_weights"),
- bias_attr=False,
- name=_name + '.conv2d.output.1')
- else:
- # select deformable conv"
- offset_mask = self._conv_offset(
- input=input,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- act=None,
- name=_name + "_conv_offset")
- offset_channel = filter_size**2 * 2
- mask_channel = filter_size**2
- offset, mask = fluid.layers.split(
- input=offset_mask,
- num_or_sections=[offset_channel, mask_channel],
- dim=1)
- mask = fluid.layers.sigmoid(mask)
- conv = fluid.layers.deformable_conv(
- input=input,
- offset=offset,
- mask=mask,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- groups=groups,
- deformable_groups=1,
- im2col_step=1,
- param_attr=ParamAttr(name=_name + "_weights"),
- bias_attr=False,
- name=_name + ".conv2d.output.1")
-
- bn_name = self.na.fix_conv_norm_name(name)
- bn_name = self.prefix_name + bn_name if self.prefix_name != '' else bn_name
-
- norm_lr = 0. if self.freeze_norm else 1.
- norm_decay = self.norm_decay
- pattr = ParamAttr(
- name=bn_name + '_scale',
- learning_rate=norm_lr,
- regularizer=L2Decay(norm_decay))
- battr = ParamAttr(
- name=bn_name + '_offset',
- learning_rate=norm_lr,
- regularizer=L2Decay(norm_decay))
-
- if self.norm_type in ['bn', 'sync_bn']:
- global_stats = True if self.freeze_norm else False
- out = fluid.layers.batch_norm(
- input=conv,
- act=act,
- name=bn_name + '.output.1',
- param_attr=pattr,
- bias_attr=battr,
- moving_mean_name=bn_name + '_mean',
- moving_variance_name=bn_name + '_variance',
- use_global_stats=global_stats)
- scale = fluid.framework._get_var(pattr.name)
- bias = fluid.framework._get_var(battr.name)
- elif self.norm_type == 'affine_channel':
- scale = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=pattr,
- default_initializer=fluid.initializer.Constant(1.))
- bias = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=battr,
- default_initializer=fluid.initializer.Constant(0.))
- out = fluid.layers.affine_channel(
- x=conv, scale=scale, bias=bias, act=act)
- if self.freeze_norm:
- scale.stop_gradient = True
- bias.stop_gradient = True
- return out
-
- def _shortcut(self, input, ch_out, stride, is_first, name):
- max_pooling_in_short_cut = self.variant == 'd'
- ch_in = input.shape[1]
- # the naming rule is same as pretrained weight
- name = self.na.fix_shortcut_name(name)
- std_senet = getattr(self, 'std_senet', False)
- if ch_in != ch_out or stride != 1 or (self.depth < 50 and is_first):
- if std_senet:
- if is_first:
- return self._conv_norm(input, ch_out, 1, stride, name=name)
- else:
- return self._conv_norm(input, ch_out, 3, stride, name=name)
- if max_pooling_in_short_cut and not is_first:
- input = fluid.layers.pool2d(
- input=input,
- pool_size=2,
- pool_stride=2,
- pool_padding=0,
- ceil_mode=True,
- pool_type='avg')
- return self._conv_norm(input, ch_out, 1, 1, name=name)
- return self._conv_norm(input, ch_out, 1, stride, name=name)
- else:
- return input
-
- def bottleneck(self,
- input,
- num_filters,
- stride,
- is_first,
- name,
- dcn_v2=False):
- if self.variant == 'a':
- stride1, stride2 = stride, 1
- else:
- stride1, stride2 = 1, stride
-
- # ResNeXt
- groups = getattr(self, 'groups', 1)
- group_width = getattr(self, 'group_width', -1)
- if groups == 1:
- expand = 4
- elif (groups * group_width) == 256:
- expand = 1
- else: # FIXME hard code for now, handles 32x4d, 64x4d and 32x8d
- num_filters = num_filters // 2
- expand = 2
-
- conv_name1, conv_name2, conv_name3, \
- shortcut_name = self.na.fix_bottleneck_name(name)
- std_senet = getattr(self, 'std_senet', False)
- if std_senet:
- conv_def = [[
- int(num_filters / 2), 1, stride1, 'relu', 1, conv_name1
- ], [num_filters, 3, stride2, 'relu', groups, conv_name2],
- [num_filters * expand, 1, 1, None, 1, conv_name3]]
- else:
- conv_def = [[num_filters, 1, stride1, 'relu', 1, conv_name1],
- [num_filters, 3, stride2, 'relu', groups, conv_name2],
- [num_filters * expand, 1, 1, None, 1, conv_name3]]
-
- residual = input
- for i, (c, k, s, act, g, _name) in enumerate(conv_def):
- residual = self._conv_norm(
- input=residual,
- num_filters=c,
- filter_size=k,
- stride=s,
- act=act,
- groups=g,
- name=_name,
- dcn_v2=(i == 1 and dcn_v2))
- short = self._shortcut(
- input,
- num_filters * expand,
- stride,
- is_first=is_first,
- name=shortcut_name)
- # Squeeze-and-Excitation
- if callable(getattr(self, '_squeeze_excitation', None)):
- residual = self._squeeze_excitation(
- input=residual, num_channels=num_filters, name='fc' + name)
- return fluid.layers.elementwise_add(
- x=short, y=residual, act='relu', name=name + ".add.output.5")
-
- def basicblock(self,
- input,
- num_filters,
- stride,
- is_first,
- name,
- dcn_v2=False):
- assert dcn_v2 is False, "Not implemented yet."
- conv0 = self._conv_norm(
- input=input,
- num_filters=num_filters,
- filter_size=3,
- act='relu',
- stride=stride,
- name=name + "_branch2a")
- conv1 = self._conv_norm(
- input=conv0,
- num_filters=num_filters,
- filter_size=3,
- act=None,
- name=name + "_branch2b")
- short = self._shortcut(
- input, num_filters, stride, is_first, name=name + "_branch1")
- return fluid.layers.elementwise_add(x=short, y=conv1, act='relu')
-
- def layer_warp(self, input, stage_num):
- """
- Args:
- input (Variable): input variable.
- stage_num (int): the stage number, should be 2, 3, 4, 5
-
- Returns:
- The last variable in endpoint-th stage.
- """
- assert stage_num in [2, 3, 4, 5]
-
- stages, block_func = self.depth_cfg[self.depth]
- count = stages[stage_num - 2]
-
- ch_out = self.stage_filters[stage_num - 2]
- is_first = False if stage_num != 2 else True
- dcn_v2 = True if stage_num in self.dcn_v2_stages else False
-
- nonlocal_mod = 1000
- if stage_num in self.nonlocal_stages:
- nonlocal_mod = self.nonlocal_mod_cfg[
- self.depth] if stage_num == 4 else 2
-
- # Make the layer name and parameter name consistent
- # with ImageNet pre-trained model
- conv = input
- for i in range(count):
- conv_name = self.na.fix_layer_warp_name(stage_num, count, i)
- if self.depth < 50:
- is_first = True if i == 0 and stage_num == 2 else False
- conv = block_func(
- input=conv,
- num_filters=ch_out,
- stride=2 if i == 0 and stage_num != 2 else 1,
- is_first=is_first,
- name=conv_name,
- dcn_v2=dcn_v2)
-
- # add non local model
- dim_in = conv.shape[1]
- nonlocal_name = "nonlocal_conv{}".format(stage_num)
- if i % nonlocal_mod == nonlocal_mod - 1:
- conv = add_space_nonlocal(conv, dim_in, dim_in,
- nonlocal_name + '_{}'.format(i),
- int(dim_in / 2))
- return conv
-
- def c1_stage(self, input):
- out_chan = self._c1_out_chan_num
-
- conv1_name = self.na.fix_c1_stage_name()
-
- if self.variant in ['c', 'd']:
- conv_def = [
- [out_chan // 2, 3, 2, "conv1_1"],
- [out_chan // 2, 3, 1, "conv1_2"],
- [out_chan, 3, 1, "conv1_3"],
- ]
- else:
- conv_def = [[out_chan, 7, 2, conv1_name]]
-
- for (c, k, s, _name) in conv_def:
- input = self._conv_norm(
- input=input,
- num_filters=c,
- filter_size=k,
- stride=s,
- act='relu',
- name=_name)
-
- output = fluid.layers.pool2d(
- input=input,
- pool_size=3,
- pool_stride=2,
- pool_padding=1,
- pool_type='max')
- return output
-
- def __call__(self, input):
- assert isinstance(input, Variable)
- assert not (set(self.feature_maps) - set([2, 3, 4, 5])), \
- "feature maps {} not in [2, 3, 4, 5]".format(self.feature_maps)
-
- res_endpoints = []
-
- res = input
- feature_maps = self.feature_maps
- severed_head = getattr(self, 'severed_head', False)
- if not severed_head:
- res = self.c1_stage(res)
- feature_maps = range(2, max(self.feature_maps) + 1)
-
- for i in feature_maps:
- res = self.layer_warp(res, i)
- if i in self.feature_maps:
- res_endpoints.append(res)
- if self.freeze_at >= i:
- res.stop_gradient = True
- if self.get_prediction:
- pool = fluid.layers.pool2d(
- input=res, pool_type='avg', global_pooling=True)
- stdv = 1.0 / math.sqrt(pool.shape[1] * 1.0)
-
- out = fluid.layers.fc(
- input=pool,
- size=self.class_dim,
- param_attr=fluid.param_attr.ParamAttr(
- initializer=fluid.initializer.Uniform(-stdv, stdv)))
- out = fluid.layers.softmax(out)
- return out
- return OrderedDict([('res{}_sum'.format(self.feature_maps[idx]), feat)
- for idx, feat in enumerate(res_endpoints)])
-
-
-class ResNetC5(ResNet):
- def __init__(self,
- depth=50,
- freeze_at=2,
- norm_type='affine_channel',
- freeze_norm=True,
- norm_decay=0.,
- variant='b',
- feature_maps=[5],
- weight_prefix_name=''):
- super(ResNetC5, self).__init__(depth, freeze_at, norm_type, freeze_norm,
- norm_decay, variant, feature_maps)
- self.severed_head = True
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/roi_extractor.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/roi_extractor.py
deleted file mode 100644
index 0241d1274..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/roi_extractor.py
+++ /dev/null
@@ -1,13 +0,0 @@
-# coding=utf-8
-__all__ = ['RoIAlign']
-
-
-class RoIAlign(object):
- def __init__(self, resolution=7, spatial_scale=0.0625, sampling_ratio=0):
- super(RoIAlign, self).__init__()
- if isinstance(resolution, int):
- resolution = [resolution, resolution]
- self.pooled_height = resolution[0]
- self.pooled_width = resolution[1]
- self.spatial_scale = spatial_scale
- self.sampling_ratio = sampling_ratio
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/rpn_head.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/rpn_head.py
deleted file mode 100644
index 7acdf083f..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/rpn_head.py
+++ /dev/null
@@ -1,302 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.initializer import Normal
-from paddle.fluid.regularizer import L2Decay
-
-__all__ = ['AnchorGenerator', 'RPNTargetAssign', 'GenerateProposals', 'RPNHead']
-
-
-class AnchorGenerator(object):
- # __op__ = fluid.layers.anchor_generator
- def __init__(self,
- stride=[16.0, 16.0],
- anchor_sizes=[32, 64, 128, 256, 512],
- aspect_ratios=[0.5, 1., 2.],
- variance=[1., 1., 1., 1.]):
- super(AnchorGenerator, self).__init__()
- self.anchor_sizes = anchor_sizes
- self.aspect_ratios = aspect_ratios
- self.variance = variance
- self.stride = stride
-
-
-class RPNTargetAssign(object):
- # __op__ = fluid.layers.rpn_target_assign
- def __init__(self,
- rpn_batch_size_per_im=256,
- rpn_straddle_thresh=0.,
- rpn_fg_fraction=0.5,
- rpn_positive_overlap=0.7,
- rpn_negative_overlap=0.3,
- use_random=True):
- super(RPNTargetAssign, self).__init__()
- self.rpn_batch_size_per_im = rpn_batch_size_per_im
- self.rpn_straddle_thresh = rpn_straddle_thresh
- self.rpn_fg_fraction = rpn_fg_fraction
- self.rpn_positive_overlap = rpn_positive_overlap
- self.rpn_negative_overlap = rpn_negative_overlap
- self.use_random = use_random
-
-
-class GenerateProposals(object):
- # __op__ = fluid.layers.generate_proposals
- def __init__(self,
- pre_nms_top_n=6000,
- post_nms_top_n=1000,
- nms_thresh=.5,
- min_size=.1,
- eta=1.):
- super(GenerateProposals, self).__init__()
- self.pre_nms_top_n = pre_nms_top_n
- self.post_nms_top_n = post_nms_top_n
- self.nms_thresh = nms_thresh
- self.min_size = min_size
- self.eta = eta
-
-
-class RPNHead(object):
- """
- RPN Head
-
- Args:
- anchor_generator (object): `AnchorGenerator` instance
- rpn_target_assign (object): `RPNTargetAssign` instance
- train_proposal (object): `GenerateProposals` instance for training
- test_proposal (object): `GenerateProposals` instance for testing
- num_classes (int): number of classes in rpn output
- """
- __inject__ = [
- 'anchor_generator', 'rpn_target_assign', 'train_proposal',
- 'test_proposal'
- ]
-
- def __init__(self,
- anchor_generator,
- rpn_target_assign,
- train_proposal,
- test_proposal,
- num_classes=1):
- super(RPNHead, self).__init__()
- self.anchor_generator = anchor_generator
- self.rpn_target_assign = rpn_target_assign
- self.train_proposal = train_proposal
- self.test_proposal = test_proposal
- self.num_classes = num_classes
-
- def _get_output(self, input):
- """
- Get anchor and RPN head output.
-
- Args:
- input(Variable): feature map from backbone with shape of [N, C, H, W]
-
- Returns:
- rpn_cls_score(Variable): Output of rpn head with shape of [N, num_anchors, H, W].
- rpn_bbox_pred(Variable): Output of rpn head with shape of [N, num_anchors * 4, H, W].
- """
- dim_out = input.shape[1]
- rpn_conv = fluid.layers.conv2d(
- input=input,
- num_filters=dim_out,
- filter_size=3,
- stride=1,
- padding=1,
- act='relu',
- name='conv_rpn',
- param_attr=ParamAttr(
- name="conv_rpn_w", initializer=Normal(loc=0., scale=0.01)),
- bias_attr=ParamAttr(
- name="conv_rpn_b", learning_rate=2., regularizer=L2Decay(0.)))
- # Generate anchors self.anchor_generator
- self.anchor, self.anchor_var = fluid.layers.anchor_generator(
- input=rpn_conv,
- anchor_sizes=self.anchor_generator.anchor_sizes,
- aspect_ratios=self.anchor_generator.aspect_ratios,
- variance=self.anchor_generator.variance,
- stride=self.anchor_generator.stride)
-
- num_anchor = self.anchor.shape[2]
- # Proposal classification scores
- self.rpn_cls_score = fluid.layers.conv2d(
- rpn_conv,
- num_filters=num_anchor * self.num_classes,
- filter_size=1,
- stride=1,
- padding=0,
- act=None,
- name='rpn_cls_score',
- param_attr=ParamAttr(
- name="rpn_cls_logits_w", initializer=Normal(loc=0.,
- scale=0.01)),
- bias_attr=ParamAttr(
- name="rpn_cls_logits_b",
- learning_rate=2.,
- regularizer=L2Decay(0.)))
- # Proposal bbox regression deltas
- self.rpn_bbox_pred = fluid.layers.conv2d(
- rpn_conv,
- num_filters=4 * num_anchor,
- filter_size=1,
- stride=1,
- padding=0,
- act=None,
- name='rpn_bbox_pred',
- param_attr=ParamAttr(
- name="rpn_bbox_pred_w", initializer=Normal(loc=0., scale=0.01)),
- bias_attr=ParamAttr(
- name="rpn_bbox_pred_b",
- learning_rate=2.,
- regularizer=L2Decay(0.)))
- return self.rpn_cls_score, self.rpn_bbox_pred
-
- def get_proposals(self, body_feats, im_info, mode='train'):
- """
- Get proposals according to the output of backbone.
-
- Args:
- body_feats (dict): The dictionary of feature maps from backbone.
- im_info(Variable): The information of image with shape [N, 3] with
- shape (height, width, scale).
- body_feat_names(list): A list of names of feature maps from
- backbone.
-
- Returns:
- rpn_rois(Variable): Output proposals with shape of (rois_num, 4).
- """
- # In RPN Heads, only the last feature map of backbone is used.
- # And body_feat_names[-1] represents the last level name of backbone.
- body_feat = list(body_feats.values())[-1]
- rpn_cls_score, rpn_bbox_pred = self._get_output(body_feat)
-
- if self.num_classes == 1:
- rpn_cls_prob = fluid.layers.sigmoid(
- rpn_cls_score, name='rpn_cls_prob')
- else:
- rpn_cls_score = fluid.layers.transpose(
- rpn_cls_score, perm=[0, 2, 3, 1])
- rpn_cls_score = fluid.layers.reshape(
- rpn_cls_score, shape=(0, 0, 0, -1, self.num_classes))
- rpn_cls_prob_tmp = fluid.layers.softmax(
- rpn_cls_score, use_cudnn=False, name='rpn_cls_prob')
- rpn_cls_prob_slice = fluid.layers.slice(
- rpn_cls_prob_tmp, axes=[4], starts=[1], ends=[self.num_classes])
- rpn_cls_prob, _ = fluid.layers.topk(rpn_cls_prob_slice, 1)
- rpn_cls_prob = fluid.layers.reshape(
- rpn_cls_prob, shape=(0, 0, 0, -1))
- rpn_cls_prob = fluid.layers.transpose(
- rpn_cls_prob, perm=[0, 3, 1, 2])
- prop_op = self.train_proposal if mode == 'train' else self.test_proposal
- # prop_op
- rpn_rois, rpn_roi_probs = fluid.layers.generate_proposals(
- scores=rpn_cls_prob,
- bbox_deltas=rpn_bbox_pred,
- im_info=im_info,
- anchors=self.anchor,
- variances=self.anchor_var,
- pre_nms_top_n=prop_op.pre_nms_top_n,
- post_nms_top_n=prop_op.post_nms_top_n,
- nms_thresh=prop_op.nms_thresh,
- min_size=prop_op.min_size,
- eta=prop_op.eta)
- return rpn_rois
-
- def _transform_input(self, rpn_cls_score, rpn_bbox_pred, anchor,
- anchor_var):
- rpn_cls_score = fluid.layers.transpose(rpn_cls_score, perm=[0, 2, 3, 1])
- rpn_bbox_pred = fluid.layers.transpose(rpn_bbox_pred, perm=[0, 2, 3, 1])
- anchor = fluid.layers.reshape(anchor, shape=(-1, 4))
- anchor_var = fluid.layers.reshape(anchor_var, shape=(-1, 4))
- rpn_cls_score = fluid.layers.reshape(
- x=rpn_cls_score, shape=(0, -1, self.num_classes))
- rpn_bbox_pred = fluid.layers.reshape(x=rpn_bbox_pred, shape=(0, -1, 4))
- return rpn_cls_score, rpn_bbox_pred, anchor, anchor_var
-
- def _get_loss_input(self):
- for attr in ['rpn_cls_score', 'rpn_bbox_pred', 'anchor', 'anchor_var']:
- if not getattr(self, attr, None):
- raise ValueError("self.{} should not be None,".format(attr),
- "call RPNHead.get_proposals first")
- return self._transform_input(self.rpn_cls_score, self.rpn_bbox_pred,
- self.anchor, self.anchor_var)
-
- def get_loss(self, im_info, gt_box, is_crowd, gt_label=None):
- """
- Sample proposals and Calculate rpn loss.
-
- Args:
- im_info(Variable): The information of image with shape [N, 3] with
- shape (height, width, scale).
- gt_box(Variable): The ground-truth bounding boxes with shape [M, 4].
- M is the number of groundtruth.
- is_crowd(Variable): Indicates groud-truth is crowd or not with
- shape [M, 1]. M is the number of groundtruth.
-
- Returns:
- Type: dict
- rpn_cls_loss(Variable): RPN classification loss.
- rpn_bbox_loss(Variable): RPN bounding box regression loss.
-
- """
- rpn_cls, rpn_bbox, anchor, anchor_var = self._get_loss_input()
- if self.num_classes == 1:
- # self.rpn_target_assign
- score_pred, loc_pred, score_tgt, loc_tgt, bbox_weight = \
- fluid.layers.rpn_target_assign(
- bbox_pred=rpn_bbox,
- cls_logits=rpn_cls,
- anchor_box=anchor,
- anchor_var=anchor_var,
- gt_boxes=gt_box,
- is_crowd=is_crowd,
- im_info=im_info,
- rpn_batch_size_per_im=self.rpn_target_assign.rpn_batch_size_per_im,
- rpn_straddle_thresh=self.rpn_target_assign.rpn_straddle_thresh,
- rpn_fg_fraction=self.rpn_target_assign.rpn_fg_fraction,
- rpn_positive_overlap=self.rpn_target_assign.rpn_positive_overlap,
- rpn_negative_overlap=self.rpn_target_assign.rpn_negative_overlap,
- use_random=self.rpn_target_assign.use_random)
- score_tgt = fluid.layers.cast(x=score_tgt, dtype='float32')
- score_tgt.stop_gradient = True
- rpn_cls_loss = fluid.layers.sigmoid_cross_entropy_with_logits(
- x=score_pred, label=score_tgt)
- else:
- score_pred, loc_pred, score_tgt, loc_tgt, bbox_weight = \
- self.rpn_target_assign(
- bbox_pred=rpn_bbox,
- cls_logits=rpn_cls,
- anchor_box=anchor,
- anchor_var=anchor_var,
- gt_boxes=gt_box,
- gt_labels=gt_label,
- is_crowd=is_crowd,
- num_classes=self.num_classes,
- im_info=im_info)
- labels_int64 = fluid.layers.cast(x=score_tgt, dtype='int64')
- labels_int64.stop_gradient = True
- rpn_cls_loss = fluid.layers.softmax_with_cross_entropy(
- logits=score_pred, label=labels_int64, numeric_stable_mode=True)
-
- rpn_cls_loss = fluid.layers.reduce_mean(
- rpn_cls_loss, name='loss_rpn_cls')
-
- loc_tgt = fluid.layers.cast(x=loc_tgt, dtype='float32')
- loc_tgt.stop_gradient = True
- rpn_reg_loss = fluid.layers.smooth_l1(
- x=loc_pred,
- y=loc_tgt,
- sigma=3.0,
- inside_weight=bbox_weight,
- outside_weight=bbox_weight)
- rpn_reg_loss = fluid.layers.reduce_sum(
- rpn_reg_loss, name='loss_rpn_bbox')
- score_shape = fluid.layers.shape(score_tgt)
- score_shape = fluid.layers.cast(x=score_shape, dtype='float32')
- norm = fluid.layers.reduce_prod(score_shape)
- norm.stop_gradient = True
- rpn_reg_loss = rpn_reg_loss / norm
- return {'rpn_cls_loss': rpn_cls_loss, 'rpn_reg_loss': rpn_reg_loss}
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_coco2017/test.py b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/test.py
new file mode 100644
index 000000000..d1d5d92fa
--- /dev/null
+++ b/modules/image/object_detection/faster_rcnn_resnet50_coco2017/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/68313e182f5e4ad9907e69dac9ece8fc50840d7ffbd24fa88396f009958f969a'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="faster_rcnn_resnet50_coco2017")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ cv2.error,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 3fcdd7781ed0a4ecd45f3b25b32e0e5f387f4d76 Mon Sep 17 00:00:00 2001
From: chenjian
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -167,6 +161,11 @@
* 1.0.1
修复numpy数据读取问题
+
+* 1.1.0
+
+ 移除 fluid api
+
- ```shell
- $ hub install faster_rcnn_resnet50_fpn_coco2017==1.0.1
+ $ hub install faster_rcnn_resnet50_fpn_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/README_en.md b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/README_en.md
index d90beb649..bf4c7274d 100644
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/README_en.md
+++ b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/README_en.md
@@ -101,19 +101,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -166,6 +160,11 @@
* 1.0.1
Fix the problem of reading numpy
+
+* 1.1.0
+
+ Remove fluid api
+
- ```shell
- $ hub install faster_rcnn_resnet50_fpn_coco2017==1.0.1
+ $ hub install faster_rcnn_resnet50_fpn_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/bbox_assigner.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/bbox_assigner.py
deleted file mode 100644
index d033382c4..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/bbox_assigner.py
+++ /dev/null
@@ -1,20 +0,0 @@
-class BBoxAssigner(object):
- # __op__ = fluid.layers.generate_proposal_labels
- def __init__(self,
- batch_size_per_im=512,
- fg_fraction=.25,
- fg_thresh=.5,
- bg_thresh_hi=.5,
- bg_thresh_lo=0.,
- bbox_reg_weights=[0.1, 0.1, 0.2, 0.2],
- class_nums=81,
- shuffle_before_sample=True):
- super(BBoxAssigner, self).__init__()
- self.batch_size_per_im = batch_size_per_im
- self.fg_fraction = fg_fraction
- self.fg_thresh = fg_thresh
- self.bg_thresh_hi = bg_thresh_hi
- self.bg_thresh_lo = bg_thresh_lo
- self.bbox_reg_weights = bbox_reg_weights
- self.class_nums = class_nums
- self.use_random = shuffle_before_sample
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/bbox_head.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/bbox_head.py
deleted file mode 100644
index 8080ed22f..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/bbox_head.py
+++ /dev/null
@@ -1,270 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from collections import OrderedDict
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.initializer import Normal, Xavier
-from paddle.fluid.regularizer import L2Decay
-from paddle.fluid.initializer import MSRA
-
-
-class MultiClassNMS(object):
- # __op__ = fluid.layers.multiclass_nms
- def __init__(self,
- score_threshold=.05,
- nms_top_k=-1,
- keep_top_k=100,
- nms_threshold=.5,
- normalized=False,
- nms_eta=1.0,
- background_label=0):
- super(MultiClassNMS, self).__init__()
- self.score_threshold = score_threshold
- self.nms_top_k = nms_top_k
- self.keep_top_k = keep_top_k
- self.nms_threshold = nms_threshold
- self.normalized = normalized
- self.nms_eta = nms_eta
- self.background_label = background_label
-
-
-class SmoothL1Loss(object):
- '''
- Smooth L1 loss
- Args:
- sigma (float): hyper param in smooth l1 loss
- '''
-
- def __init__(self, sigma=1.0):
- super(SmoothL1Loss, self).__init__()
- self.sigma = sigma
-
- def __call__(self, x, y, inside_weight=None, outside_weight=None):
- return fluid.layers.smooth_l1(
- x,
- y,
- inside_weight=inside_weight,
- outside_weight=outside_weight,
- sigma=self.sigma)
-
-
-class BoxCoder(object):
- def __init__(self,
- prior_box_var=[0.1, 0.1, 0.2, 0.2],
- code_type='decode_center_size',
- box_normalized=False,
- axis=1):
- super(BoxCoder, self).__init__()
- self.prior_box_var = prior_box_var
- self.code_type = code_type
- self.box_normalized = box_normalized
- self.axis = axis
-
-
-class TwoFCHead(object):
- """
- RCNN head with two Fully Connected layers
-
- Args:
- mlp_dim (int): num of filters for the fc layers
- """
-
- def __init__(self, mlp_dim=1024):
- super(TwoFCHead, self).__init__()
- self.mlp_dim = mlp_dim
-
- def __call__(self, roi_feat):
- fan = roi_feat.shape[1] * roi_feat.shape[2] * roi_feat.shape[3]
-
- fc6 = fluid.layers.fc(
- input=roi_feat,
- size=self.mlp_dim,
- act='relu',
- name='fc6',
- param_attr=ParamAttr(name='fc6_w', initializer=Xavier(fan_out=fan)),
- bias_attr=ParamAttr(
- name='fc6_b', learning_rate=2., regularizer=L2Decay(0.)))
- head_feat = fluid.layers.fc(
- input=fc6,
- size=self.mlp_dim,
- act='relu',
- name='fc7',
- param_attr=ParamAttr(name='fc7_w', initializer=Xavier()),
- bias_attr=ParamAttr(
- name='fc7_b', learning_rate=2., regularizer=L2Decay(0.)))
-
- return head_feat
-
-
-class BBoxHead(object):
- """
- RCNN bbox head
-
- Args:
- head (object): the head module instance, e.g., `ResNetC5`, `TwoFCHead`
- box_coder (object): `BoxCoder` instance
- nms (object): `MultiClassNMS` instance
- num_classes: number of output classes
- """
- __inject__ = ['head', 'box_coder', 'nms', 'bbox_loss']
- __shared__ = ['num_classes']
-
- def __init__(self,
- head,
- box_coder=BoxCoder(),
- nms=MultiClassNMS(),
- bbox_loss=SmoothL1Loss(),
- num_classes=81):
- super(BBoxHead, self).__init__()
- self.head = head
- self.num_classes = num_classes
- self.box_coder = box_coder
- self.nms = nms
- self.bbox_loss = bbox_loss
- self.head_feat = None
-
- def get_head_feat(self, input=None):
- """
- Get the bbox head feature map.
- """
-
- if input is not None:
- feat = self.head(input)
- if isinstance(feat, OrderedDict):
- feat = list(feat.values())[0]
- self.head_feat = feat
- return self.head_feat
-
- def _get_output(self, roi_feat):
- """
- Get bbox head output.
-
- Args:
- roi_feat (Variable): RoI feature from RoIExtractor.
-
- Returns:
- cls_score(Variable): Output of rpn head with shape of
- [N, num_anchors, H, W].
- bbox_pred(Variable): Output of rpn head with shape of
- [N, num_anchors * 4, H, W].
- """
- head_feat = self.get_head_feat(roi_feat)
- # when ResNetC5 output a single feature map
- if not isinstance(self.head, TwoFCHead):
- head_feat = fluid.layers.pool2d(
- head_feat, pool_type='avg', global_pooling=True)
- cls_score = fluid.layers.fc(
- input=head_feat,
- size=self.num_classes,
- act=None,
- name='cls_score',
- param_attr=ParamAttr(
- name='cls_score_w', initializer=Normal(loc=0.0, scale=0.01)),
- bias_attr=ParamAttr(
- name='cls_score_b', learning_rate=2., regularizer=L2Decay(0.)))
- bbox_pred = fluid.layers.fc(
- input=head_feat,
- size=4 * self.num_classes,
- act=None,
- name='bbox_pred',
- param_attr=ParamAttr(
- name='bbox_pred_w', initializer=Normal(loc=0.0, scale=0.001)),
- bias_attr=ParamAttr(
- name='bbox_pred_b', learning_rate=2., regularizer=L2Decay(0.)))
- return cls_score, bbox_pred
-
- def get_loss(self, roi_feat, labels_int32, bbox_targets,
- bbox_inside_weights, bbox_outside_weights):
- """
- Get bbox_head loss.
-
- Args:
- roi_feat (Variable): RoI feature from RoIExtractor.
- labels_int32(Variable): Class label of a RoI with shape [P, 1].
- P is the number of RoI.
- bbox_targets(Variable): Box label of a RoI with shape
- [P, 4 * class_nums].
- bbox_inside_weights(Variable): Indicates whether a box should
- contribute to loss. Same shape as bbox_targets.
- bbox_outside_weights(Variable): Indicates whether a box should
- contribute to loss. Same shape as bbox_targets.
-
- Return:
- Type: Dict
- loss_cls(Variable): bbox_head loss.
- loss_bbox(Variable): bbox_head loss.
- """
-
- cls_score, bbox_pred = self._get_output(roi_feat)
-
- labels_int64 = fluid.layers.cast(x=labels_int32, dtype='int64')
- labels_int64.stop_gradient = True
- loss_cls = fluid.layers.softmax_with_cross_entropy(
- logits=cls_score, label=labels_int64, numeric_stable_mode=True)
- loss_cls = fluid.layers.reduce_mean(loss_cls)
- loss_bbox = self.bbox_loss(
- x=bbox_pred,
- y=bbox_targets,
- inside_weight=bbox_inside_weights,
- outside_weight=bbox_outside_weights)
- loss_bbox = fluid.layers.reduce_mean(loss_bbox)
- return {'loss_cls': loss_cls, 'loss_bbox': loss_bbox}
-
- def get_prediction(self,
- roi_feat,
- rois,
- im_info,
- im_shape,
- return_box_score=False):
- """
- Get prediction bounding box in test stage.
-
- Args:
- roi_feat (Variable): RoI feature from RoIExtractor.
- rois (Variable): Output of generate_proposals in rpn head.
- im_info (Variable): A 2-D LoDTensor with shape [B, 3]. B is the
- number of input images, each element consists of im_height,
- im_width, im_scale.
- im_shape (Variable): Actual shape of original image with shape
- [B, 3]. B is the number of images, each element consists of
- original_height, original_width, 1
-
- Returns:
- pred_result(Variable): Prediction result with shape [N, 6]. Each
- row has 6 values: [label, confidence, xmin, ymin, xmax, ymax].
- N is the total number of prediction.
- """
- cls_score, bbox_pred = self._get_output(roi_feat)
-
- im_scale = fluid.layers.slice(im_info, [1], starts=[2], ends=[3])
- im_scale = fluid.layers.sequence_expand(im_scale, rois)
- boxes = rois / im_scale
- cls_prob = fluid.layers.softmax(cls_score, use_cudnn=False)
- bbox_pred = fluid.layers.reshape(bbox_pred, (-1, self.num_classes, 4))
- # self.box_coder
- decoded_box = fluid.layers.box_coder(
- prior_box=boxes,
- target_box=bbox_pred,
- prior_box_var=self.box_coder.prior_box_var,
- code_type=self.box_coder.code_type,
- box_normalized=self.box_coder.box_normalized,
- axis=self.box_coder.axis)
- cliped_box = fluid.layers.box_clip(input=decoded_box, im_info=im_shape)
- if return_box_score:
- return {'bbox': cliped_box, 'score': cls_prob}
- # self.nms
- pred_result = fluid.layers.multiclass_nms(
- bboxes=cliped_box,
- scores=cls_prob,
- score_threshold=self.nms.score_threshold,
- nms_top_k=self.nms.nms_top_k,
- keep_top_k=self.nms.keep_top_k,
- nms_threshold=self.nms.nms_threshold,
- normalized=self.nms.normalized,
- nms_eta=self.nms.nms_eta,
- background_label=self.nms.background_label)
- return pred_result
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/data_feed.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/data_feed.py
index b38501e5b..c9e52d54c 100644
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/data_feed.py
+++ b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/data_feed.py
@@ -4,12 +4,9 @@
from __future__ import division
import os
-from collections import OrderedDict
import cv2
import numpy as np
-from PIL import Image, ImageEnhance
-from paddle import fluid
__all__ = ['test_reader']
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/fpn.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/fpn.py
deleted file mode 100644
index bd19c712e..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/fpn.py
+++ /dev/null
@@ -1,296 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import copy
-from collections import OrderedDict
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.initializer import Xavier
-from paddle.fluid.regularizer import L2Decay
-
-__all__ = ['ConvNorm', 'FPN']
-
-
-def ConvNorm(input,
- num_filters,
- filter_size,
- stride=1,
- groups=1,
- norm_decay=0.,
- norm_type='affine_channel',
- norm_groups=32,
- dilation=1,
- lr_scale=1,
- freeze_norm=False,
- act=None,
- norm_name=None,
- initializer=None,
- name=None):
- fan = num_filters
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=((filter_size - 1) // 2) * dilation,
- dilation=dilation,
- groups=groups,
- act=None,
- param_attr=ParamAttr(
- name=name + "_weights",
- initializer=initializer,
- learning_rate=lr_scale),
- bias_attr=False,
- name=name + '.conv2d.output.1')
-
- norm_lr = 0. if freeze_norm else 1.
- pattr = ParamAttr(
- name=norm_name + '_scale',
- learning_rate=norm_lr * lr_scale,
- regularizer=L2Decay(norm_decay))
- battr = ParamAttr(
- name=norm_name + '_offset',
- learning_rate=norm_lr * lr_scale,
- regularizer=L2Decay(norm_decay))
-
- if norm_type in ['bn', 'sync_bn']:
- global_stats = True if freeze_norm else False
- out = fluid.layers.batch_norm(
- input=conv,
- act=act,
- name=norm_name + '.output.1',
- param_attr=pattr,
- bias_attr=battr,
- moving_mean_name=norm_name + '_mean',
- moving_variance_name=norm_name + '_variance',
- use_global_stats=global_stats)
- scale = fluid.framework._get_var(pattr.name)
- bias = fluid.framework._get_var(battr.name)
- elif norm_type == 'gn':
- out = fluid.layers.group_norm(
- input=conv,
- act=act,
- name=norm_name + '.output.1',
- groups=norm_groups,
- param_attr=pattr,
- bias_attr=battr)
- scale = fluid.framework._get_var(pattr.name)
- bias = fluid.framework._get_var(battr.name)
- elif norm_type == 'affine_channel':
- scale = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=pattr,
- default_initializer=fluid.initializer.Constant(1.))
- bias = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=battr,
- default_initializer=fluid.initializer.Constant(0.))
- out = fluid.layers.affine_channel(
- x=conv, scale=scale, bias=bias, act=act)
- if freeze_norm:
- scale.stop_gradient = True
- bias.stop_gradient = True
- return out
-
-
-class FPN(object):
- """
- Feature Pyramid Network, see https://arxiv.org/abs/1612.03144
-
- Args:
- num_chan (int): number of feature channels
- min_level (int): lowest level of the backbone feature map to use
- max_level (int): highest level of the backbone feature map to use
- spatial_scale (list): feature map scaling factor
- has_extra_convs (bool): whether has extral convolutions in higher levels
- norm_type (str|None): normalization type, 'bn'/'sync_bn'/'affine_channel'
- """
- __shared__ = ['norm_type', 'freeze_norm']
-
- def __init__(self,
- num_chan=256,
- min_level=2,
- max_level=6,
- spatial_scale=[1. / 32., 1. / 16., 1. / 8., 1. / 4.],
- has_extra_convs=False,
- norm_type=None,
- freeze_norm=False):
- self.freeze_norm = freeze_norm
- self.num_chan = num_chan
- self.min_level = min_level
- self.max_level = max_level
- self.spatial_scale = spatial_scale
- self.has_extra_convs = has_extra_convs
- self.norm_type = norm_type
-
- def _add_topdown_lateral(self, body_name, body_input, upper_output):
- lateral_name = 'fpn_inner_' + body_name + '_lateral'
- topdown_name = 'fpn_topdown_' + body_name
- fan = body_input.shape[1]
- if self.norm_type:
- initializer = Xavier(fan_out=fan)
- lateral = ConvNorm(
- body_input,
- self.num_chan,
- 1,
- initializer=initializer,
- norm_type=self.norm_type,
- freeze_norm=self.freeze_norm,
- name=lateral_name,
- norm_name=lateral_name)
- else:
- lateral = fluid.layers.conv2d(
- body_input,
- self.num_chan,
- 1,
- param_attr=ParamAttr(
- name=lateral_name + "_w", initializer=Xavier(fan_out=fan)),
- bias_attr=ParamAttr(
- name=lateral_name + "_b",
- learning_rate=2.,
- regularizer=L2Decay(0.)),
- name=lateral_name)
- topdown = fluid.layers.resize_nearest(
- upper_output, scale=2., name=topdown_name)
- return lateral + topdown
-
- def get_output(self, body_dict):
- """
- Add FPN onto backbone.
-
- Args:
- body_dict(OrderedDict): Dictionary of variables and each element is the
- output of backbone.
-
- Return:
- fpn_dict(OrderedDict): A dictionary represents the output of FPN with
- their name.
- spatial_scale(list): A list of multiplicative spatial scale factor.
- """
- spatial_scale = copy.deepcopy(self.spatial_scale)
- body_name_list = list(body_dict.keys())[::-1]
- num_backbone_stages = len(body_name_list)
- self.fpn_inner_output = [[] for _ in range(num_backbone_stages)]
- fpn_inner_name = 'fpn_inner_' + body_name_list[0]
- body_input = body_dict[body_name_list[0]]
- fan = body_input.shape[1]
- if self.norm_type:
- initializer = Xavier(fan_out=fan)
- self.fpn_inner_output[0] = ConvNorm(
- body_input,
- self.num_chan,
- 1,
- initializer=initializer,
- norm_type=self.norm_type,
- freeze_norm=self.freeze_norm,
- name=fpn_inner_name,
- norm_name=fpn_inner_name)
- else:
- self.fpn_inner_output[0] = fluid.layers.conv2d(
- body_input,
- self.num_chan,
- 1,
- param_attr=ParamAttr(
- name=fpn_inner_name + "_w",
- initializer=Xavier(fan_out=fan)),
- bias_attr=ParamAttr(
- name=fpn_inner_name + "_b",
- learning_rate=2.,
- regularizer=L2Decay(0.)),
- name=fpn_inner_name)
- for i in range(1, num_backbone_stages):
- body_name = body_name_list[i]
- body_input = body_dict[body_name]
- top_output = self.fpn_inner_output[i - 1]
- fpn_inner_single = self._add_topdown_lateral(
- body_name, body_input, top_output)
- self.fpn_inner_output[i] = fpn_inner_single
- fpn_dict = {}
- fpn_name_list = []
- for i in range(num_backbone_stages):
- fpn_name = 'fpn_' + body_name_list[i]
- fan = self.fpn_inner_output[i].shape[1] * 3 * 3
- if self.norm_type:
- initializer = Xavier(fan_out=fan)
- fpn_output = ConvNorm(
- self.fpn_inner_output[i],
- self.num_chan,
- 3,
- initializer=initializer,
- norm_type=self.norm_type,
- freeze_norm=self.freeze_norm,
- name=fpn_name,
- norm_name=fpn_name)
- else:
- fpn_output = fluid.layers.conv2d(
- self.fpn_inner_output[i],
- self.num_chan,
- filter_size=3,
- padding=1,
- param_attr=ParamAttr(
- name=fpn_name + "_w", initializer=Xavier(fan_out=fan)),
- bias_attr=ParamAttr(
- name=fpn_name + "_b",
- learning_rate=2.,
- regularizer=L2Decay(0.)),
- name=fpn_name)
- fpn_dict[fpn_name] = fpn_output
- fpn_name_list.append(fpn_name)
- if not self.has_extra_convs and self.max_level - self.min_level == len(
- spatial_scale):
- body_top_name = fpn_name_list[0]
- body_top_extension = fluid.layers.pool2d(
- fpn_dict[body_top_name],
- 1,
- 'max',
- pool_stride=2,
- name=body_top_name + '_subsampled_2x')
- fpn_dict[body_top_name + '_subsampled_2x'] = body_top_extension
- fpn_name_list.insert(0, body_top_name + '_subsampled_2x')
- spatial_scale.insert(0, spatial_scale[0] * 0.5)
- # Coarser FPN levels introduced for RetinaNet
- highest_backbone_level = self.min_level + len(spatial_scale) - 1
- if self.has_extra_convs and self.max_level > highest_backbone_level:
- fpn_blob = body_dict[body_name_list[0]]
- for i in range(highest_backbone_level + 1, self.max_level + 1):
- fpn_blob_in = fpn_blob
- fpn_name = 'fpn_' + str(i)
- if i > highest_backbone_level + 1:
- fpn_blob_in = fluid.layers.relu(fpn_blob)
- fan = fpn_blob_in.shape[1] * 3 * 3
- fpn_blob = fluid.layers.conv2d(
- input=fpn_blob_in,
- num_filters=self.num_chan,
- filter_size=3,
- stride=2,
- padding=1,
- param_attr=ParamAttr(
- name=fpn_name + "_w", initializer=Xavier(fan_out=fan)),
- bias_attr=ParamAttr(
- name=fpn_name + "_b",
- learning_rate=2.,
- regularizer=L2Decay(0.)),
- name=fpn_name)
- fpn_dict[fpn_name] = fpn_blob
- fpn_name_list.insert(0, fpn_name)
- spatial_scale.insert(0, spatial_scale[0] * 0.5)
- res_dict = OrderedDict([(k, fpn_dict[k]) for k in fpn_name_list])
- return res_dict, spatial_scale
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py
index b8dd5afa4..650491894 100644
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py
+++ b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py
@@ -6,41 +6,32 @@
import os
import ast
import argparse
-from collections import OrderedDict
-from functools import partial
from math import ceil
+import paddle
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
+import paddle.jit
+import paddle.static
from paddlehub.module.module import moduleinfo, runnable, serving
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
-from paddlehub.io.parser import txt_parser
-from paddlehub.common.paddle_helper import add_vars_prefix
-
-from faster_rcnn_resnet50_fpn_coco2017.processor import load_label_info, postprocess, base64_to_cv2
-from faster_rcnn_resnet50_fpn_coco2017.data_feed import test_reader, padding_minibatch
-from faster_rcnn_resnet50_fpn_coco2017.fpn import FPN
-from faster_rcnn_resnet50_fpn_coco2017.resnet import ResNet
-from faster_rcnn_resnet50_fpn_coco2017.rpn_head import AnchorGenerator, RPNTargetAssign, GenerateProposals, FPNRPNHead
-from faster_rcnn_resnet50_fpn_coco2017.bbox_head import MultiClassNMS, BBoxHead, TwoFCHead
-from faster_rcnn_resnet50_fpn_coco2017.bbox_assigner import BBoxAssigner
-from faster_rcnn_resnet50_fpn_coco2017.roi_extractor import FPNRoIAlign
+from paddle.inference import Config, create_predictor
+from paddlehub.utils.parser import txt_parser
+from .processor import load_label_info, postprocess, base64_to_cv2
+from .data_feed import test_reader, padding_minibatch
@moduleinfo(
name="faster_rcnn_resnet50_fpn_coco2017",
- version="1.0.1",
+ version="1.1.0",
type="cv/object_detection",
summary=
"Baidu's Faster-RCNN model for object detection, whose backbone is ResNet50, processed with Feature Pyramid Networks",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class FasterRCNNResNet50RPN(hub.Module):
- def _initialize(self):
+class FasterRCNNResNet50RPN:
+ def __init__(self):
# default pretrained model, Faster-RCNN with backbone ResNet50, shape of input tensor is [3, 800, 1333]
self.default_pretrained_model_path = os.path.join(
- self.directory, "faster_rcnn_resnet50_fpn_model")
+ self.directory, "faster_rcnn_resnet50_fpn_model", "model")
self.label_names = load_label_info(
os.path.join(self.directory, "label_file.txt"))
self._set_config()
@@ -49,10 +40,12 @@ def _set_config(self):
"""
predictor config setting
"""
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -61,245 +54,14 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
-
- def context(self,
- num_classes=81,
- trainable=True,
- pretrained=True,
- phase='train'):
- """
- Distill the Head Features, so as to perform transfer learning.
-
- Args:
- num_classes (int): number of categories
- trainable (bool): whether to set parameters trainable.
- pretrained (bool): whether to load default pretrained model.
- phase (str): optional choices are 'train' and 'predict'.
-
- Returns:
- inputs (dict): the input variables.
- outputs (dict): the output variables.
- context_prog (Program): the program to execute transfer learning.
- """
- context_prog = fluid.Program()
- startup_program = fluid.Program()
- with fluid.program_guard(context_prog, startup_program):
- with fluid.unique_name.guard():
- image = fluid.layers.data(
- name='image', shape=[-1, 3, -1, -1], dtype='float32')
- # backbone
- backbone = ResNet(
- norm_type='affine_channel',
- depth=50,
- feature_maps=[2, 3, 4, 5],
- freeze_at=2)
- body_feats = backbone(image)
- # fpn
- fpn = FPN(
- max_level=6,
- min_level=2,
- num_chan=256,
- spatial_scale=[0.03125, 0.0625, 0.125, 0.25])
- var_prefix = '@HUB_{}@'.format(self.name)
- im_info = fluid.layers.data(
- name='im_info', shape=[3], dtype='float32', lod_level=0)
- im_shape = fluid.layers.data(
- name='im_shape', shape=[3], dtype='float32', lod_level=0)
- body_feat_names = list(body_feats.keys())
- body_feats, spatial_scale = fpn.get_output(body_feats)
- # rpn_head: RPNHead
- rpn_head = self.rpn_head()
- rois = rpn_head.get_proposals(body_feats, im_info, mode=phase)
- # train
- if phase == 'train':
- gt_bbox = fluid.layers.data(
- name='gt_bbox', shape=[4], dtype='float32', lod_level=1)
- is_crowd = fluid.layers.data(
- name='is_crowd', shape=[1], dtype='int32', lod_level=1)
- gt_class = fluid.layers.data(
- name='gt_class', shape=[1], dtype='int32', lod_level=1)
- rpn_loss = rpn_head.get_loss(im_info, gt_bbox, is_crowd)
- # bbox_assigner: BBoxAssigner
- bbox_assigner = self.bbox_assigner(num_classes)
- outs = fluid.layers.generate_proposal_labels(
- rpn_rois=rois,
- gt_classes=gt_class,
- is_crowd=is_crowd,
- gt_boxes=gt_bbox,
- im_info=im_info,
- batch_size_per_im=bbox_assigner.batch_size_per_im,
- fg_fraction=bbox_assigner.fg_fraction,
- fg_thresh=bbox_assigner.fg_thresh,
- bg_thresh_hi=bbox_assigner.bg_thresh_hi,
- bg_thresh_lo=bbox_assigner.bg_thresh_lo,
- bbox_reg_weights=bbox_assigner.bbox_reg_weights,
- class_nums=bbox_assigner.class_nums,
- use_random=bbox_assigner.use_random)
- rois = outs[0]
-
- roi_extractor = self.roi_extractor()
- roi_feat = roi_extractor(
- head_inputs=body_feats,
- rois=rois,
- spatial_scale=spatial_scale)
- # head_feat
- bbox_head = self.bbox_head(num_classes)
- head_feat = bbox_head.head(roi_feat)
- if isinstance(head_feat, OrderedDict):
- head_feat = list(head_feat.values())[0]
- if phase == 'train':
- inputs = {
- 'image': var_prefix + image.name,
- 'im_info': var_prefix + im_info.name,
- 'im_shape': var_prefix + im_shape.name,
- 'gt_class': var_prefix + gt_class.name,
- 'gt_bbox': var_prefix + gt_bbox.name,
- 'is_crowd': var_prefix + is_crowd.name
- }
- outputs = {
- 'head_features':
- var_prefix + head_feat.name,
- 'rpn_cls_loss':
- var_prefix + rpn_loss['rpn_cls_loss'].name,
- 'rpn_reg_loss':
- var_prefix + rpn_loss['rpn_reg_loss'].name,
- 'generate_proposal_labels':
- [var_prefix + var.name for var in outs]
- }
- elif phase == 'predict':
- pred = bbox_head.get_prediction(roi_feat, rois, im_info,
- im_shape)
- inputs = {
- 'image': var_prefix + image.name,
- 'im_info': var_prefix + im_info.name,
- 'im_shape': var_prefix + im_shape.name
- }
- outputs = {
- 'head_features': var_prefix + head_feat.name,
- 'rois': var_prefix + rois.name,
- 'bbox_out': var_prefix + pred.name
- }
- add_vars_prefix(context_prog, var_prefix)
- add_vars_prefix(startup_program, var_prefix)
-
- global_vars = context_prog.global_block().vars
- inputs = {
- key: global_vars[value]
- for key, value in inputs.items()
- }
- outputs = {
- key: global_vars[value] if not isinstance(value, list) else
- [global_vars[var] for var in value]
- for key, value in outputs.items()
- }
-
- for param in context_prog.global_block().iter_parameters():
- param.trainable = trainable
-
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- exe.run(startup_program)
- if pretrained:
-
- def _if_exist(var):
- if num_classes != 81:
- if 'bbox_pred' in var.name or 'cls_score' in var.name:
- return False
- return os.path.exists(
- os.path.join(self.default_pretrained_model_path,
- var.name))
-
- fluid.io.load_vars(
- exe,
- self.default_pretrained_model_path,
- predicate=_if_exist)
- return inputs, outputs, context_prog
-
- def rpn_head(self):
- return FPNRPNHead(
- anchor_generator=AnchorGenerator(
- anchor_sizes=[32, 64, 128, 256, 512],
- aspect_ratios=[0.5, 1.0, 2.0],
- stride=[16.0, 16.0],
- variance=[1.0, 1.0, 1.0, 1.0]),
- rpn_target_assign=RPNTargetAssign(
- rpn_batch_size_per_im=256,
- rpn_fg_fraction=0.5,
- rpn_negative_overlap=0.3,
- rpn_positive_overlap=0.7,
- rpn_straddle_thresh=0.0),
- train_proposal=GenerateProposals(
- min_size=0.0,
- nms_thresh=0.7,
- post_nms_top_n=2000,
- pre_nms_top_n=2000),
- test_proposal=GenerateProposals(
- min_size=0.0,
- nms_thresh=0.7,
- post_nms_top_n=1000,
- pre_nms_top_n=1000),
- anchor_start_size=32,
- num_chan=256,
- min_level=2,
- max_level=6)
-
- def roi_extractor(self):
- return FPNRoIAlign(
- canconical_level=4,
- canonical_size=224,
- max_level=5,
- min_level=2,
- box_resolution=7,
- sampling_ratio=2)
-
- def bbox_head(self, num_classes):
- return BBoxHead(
- head=TwoFCHead(mlp_dim=1024),
- nms=MultiClassNMS(
- keep_top_k=100, nms_threshold=0.5, score_threshold=0.05),
- num_classes=num_classes)
-
- def bbox_assigner(self, num_classes):
- return BBoxAssigner(
- batch_size_per_im=512,
- bbox_reg_weights=[0.1, 0.1, 0.2, 0.2],
- bg_thresh_hi=0.5,
- bg_thresh_lo=0.0,
- fg_fraction=0.25,
- fg_thresh=0.5,
- class_nums=num_classes)
-
- def save_inference_model(self,
- dirname,
- model_filename=None,
- params_filename=None,
- combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
+ self.gpu_predictor = create_predictor(gpu_config)
def object_detection(self,
paths=None,
images=None,
- data=None,
use_gpu=False,
batch_size=1,
output_dir='detection_result',
@@ -337,8 +99,6 @@ def object_detection(self,
)
paths = paths if paths else list()
- if data and 'image' in data:
- paths += data['image']
all_images = list()
for yield_data in test_reader(paths, images):
@@ -360,29 +120,37 @@ def object_detection(self,
padding_image, padding_info, padding_shape = padding_minibatch(
batch_data, coarsest_stride=32, use_padded_im_info=True)
- padding_image_tensor = PaddleTensor(padding_image.copy())
- padding_info_tensor = PaddleTensor(padding_info.copy())
- padding_shape_tensor = PaddleTensor(padding_shape.copy())
feed_list = [
- padding_image_tensor, padding_info_tensor, padding_shape_tensor
+ padding_image, padding_info, padding_shape
]
- if use_gpu:
- data_out = self.gpu_predictor.run(feed_list)
- else:
- data_out = self.cpu_predictor.run(feed_list)
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+
+ feed_list = [
+ padding_image, padding_info, padding_shape
+ ]
+
+ input_names = predictor.get_input_names()
+
+ for i, input_name in enumerate(input_names):
+ data = np.asarray(feed_list[i], dtype=np.float32)
+ handle = predictor.get_input_handle(input_name)
+ handle.copy_from_cpu(data)
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
output = postprocess(
paths=paths,
images=images,
- data_out=data_out,
+ data_out=output_handle,
score_thresh=score_thresh,
label_names=self.label_names,
output_dir=output_dir,
handle_id=handle_id,
visualization=visualization)
res += output
-
return res
def add_module_config_arg(self):
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/name_adapter.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/name_adapter.py
deleted file mode 100644
index bebf8bdee..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/name_adapter.py
+++ /dev/null
@@ -1,61 +0,0 @@
-# coding=utf-8
-
-
-class NameAdapter(object):
- """Fix the backbones variable names for pretrained weight"""
-
- def __init__(self, model):
- super(NameAdapter, self).__init__()
- self.model = model
-
- @property
- def model_type(self):
- return getattr(self.model, '_model_type', '')
-
- @property
- def variant(self):
- return getattr(self.model, 'variant', '')
-
- def fix_conv_norm_name(self, name):
- if name == "conv1":
- bn_name = "bn_" + name
- else:
- bn_name = "bn" + name[3:]
- # the naming rule is same as pretrained weight
- if self.model_type == 'SEResNeXt':
- bn_name = name + "_bn"
- return bn_name
-
- def fix_shortcut_name(self, name):
- if self.model_type == 'SEResNeXt':
- name = 'conv' + name + '_prj'
- return name
-
- def fix_bottleneck_name(self, name):
- if self.model_type == 'SEResNeXt':
- conv_name1 = 'conv' + name + '_x1'
- conv_name2 = 'conv' + name + '_x2'
- conv_name3 = 'conv' + name + '_x3'
- shortcut_name = name
- else:
- conv_name1 = name + "_branch2a"
- conv_name2 = name + "_branch2b"
- conv_name3 = name + "_branch2c"
- shortcut_name = name + "_branch1"
- return conv_name1, conv_name2, conv_name3, shortcut_name
-
- def fix_layer_warp_name(self, stage_num, count, i):
- name = 'res' + str(stage_num)
- if count > 10 and stage_num == 4:
- if i == 0:
- conv_name = name + "a"
- else:
- conv_name = name + "b" + str(i)
- else:
- conv_name = name + chr(ord("a") + i)
- if self.model_type == 'SEResNeXt':
- conv_name = str(stage_num + 2) + '_' + str(i + 1)
- return conv_name
-
- def fix_c1_stage_name(self):
- return "res_conv1" if self.model_type == 'ResNeXt' else "conv1"
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/nonlocal_helper.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/nonlocal_helper.py
deleted file mode 100644
index 599b8dfa0..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/nonlocal_helper.py
+++ /dev/null
@@ -1,154 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import paddle.fluid as fluid
-from paddle.fluid import ParamAttr
-
-nonlocal_params = {
- "use_zero_init_conv": False,
- "conv_init_std": 0.01,
- "no_bias": True,
- "use_maxpool": False,
- "use_softmax": True,
- "use_bn": False,
- "use_scale": True, # vital for the model prformance!!!
- "use_affine": False,
- "bn_momentum": 0.9,
- "bn_epsilon": 1.0000001e-5,
- "bn_init_gamma": 0.9,
- "weight_decay_bn": 1.e-4,
-}
-
-
-def space_nonlocal(input, dim_in, dim_out, prefix, dim_inner,
- max_pool_stride=2):
- cur = input
- theta = fluid.layers.conv2d(input = cur, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr=ParamAttr(name = prefix + '_theta' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_theta' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if not nonlocal_params["no_bias"] else False, \
- name = prefix + '_theta')
- theta_shape = theta.shape
- theta_shape_op = fluid.layers.shape(theta)
- theta_shape_op.stop_gradient = True
-
- if nonlocal_params["use_maxpool"]:
- max_pool = fluid.layers.pool2d(input = cur, \
- pool_size = [max_pool_stride, max_pool_stride], \
- pool_type = 'max', \
- pool_stride = [max_pool_stride, max_pool_stride], \
- pool_padding = [0, 0], \
- name = prefix + '_pool')
- else:
- max_pool = cur
-
- phi = fluid.layers.conv2d(input = max_pool, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_phi' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_phi' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_phi')
- phi_shape = phi.shape
-
- g = fluid.layers.conv2d(input = max_pool, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_g' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0, scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_g' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_g')
- g_shape = g.shape
- # we have to use explicit batch size (to support arbitrary spacetime size)
- # e.g. (8, 1024, 4, 14, 14) => (8, 1024, 784)
- theta = fluid.layers.reshape(theta, shape=(0, 0, -1))
- theta = fluid.layers.transpose(theta, [0, 2, 1])
- phi = fluid.layers.reshape(phi, [0, 0, -1])
- theta_phi = fluid.layers.matmul(theta, phi, name=prefix + '_affinity')
- g = fluid.layers.reshape(g, [0, 0, -1])
-
- if nonlocal_params["use_softmax"]:
- if nonlocal_params["use_scale"]:
- theta_phi_sc = fluid.layers.scale(theta_phi, scale=dim_inner**-.5)
- else:
- theta_phi_sc = theta_phi
- p = fluid.layers.softmax(
- theta_phi_sc, name=prefix + '_affinity' + '_prob')
- else:
- # not clear about what is doing in xlw's code
- p = None # not implemented
- raise "Not implemented when not use softmax"
-
- # note g's axis[2] corresponds to p's axis[2]
- # e.g. g(8, 1024, 784_2) * p(8, 784_1, 784_2) => (8, 1024, 784_1)
- p = fluid.layers.transpose(p, [0, 2, 1])
- t = fluid.layers.matmul(g, p, name=prefix + '_y')
-
- # reshape back
- # e.g. (8, 1024, 784) => (8, 1024, 4, 14, 14)
- t_shape = t.shape
- t_re = fluid.layers.reshape(
- t, shape=list(theta_shape), actual_shape=theta_shape_op)
- blob_out = t_re
- blob_out = fluid.layers.conv2d(input = blob_out, num_filters = dim_out, \
- filter_size = [1, 1], stride = [1, 1], padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_out' + "_w", \
- initializer = fluid.initializer.Constant(value = 0.) \
- if nonlocal_params["use_zero_init_conv"] \
- else fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_out' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_out')
- blob_out_shape = blob_out.shape
-
- if nonlocal_params["use_bn"]:
- bn_name = prefix + "_bn"
- blob_out = fluid.layers.batch_norm(blob_out, \
- # is_test = test_mode, \
- momentum = nonlocal_params["bn_momentum"], \
- epsilon = nonlocal_params["bn_epsilon"], \
- name = bn_name, \
- param_attr = ParamAttr(name = bn_name + "_s", \
- initializer = fluid.initializer.Constant(value = nonlocal_params["bn_init_gamma"]), \
- regularizer = fluid.regularizer.L2Decay(nonlocal_params["weight_decay_bn"])), \
- bias_attr = ParamAttr(name = bn_name + "_b", \
- regularizer = fluid.regularizer.L2Decay(nonlocal_params["weight_decay_bn"])), \
- moving_mean_name = bn_name + "_rm", \
- moving_variance_name = bn_name + "_riv") # add bn
-
- if nonlocal_params["use_affine"]:
- affine_scale = fluid.layers.create_parameter(\
- shape=[blob_out_shape[1]], dtype = blob_out.dtype, \
- attr=ParamAttr(name=prefix + '_affine' + '_s'), \
- default_initializer = fluid.initializer.Constant(value = 1.))
- affine_bias = fluid.layers.create_parameter(\
- shape=[blob_out_shape[1]], dtype = blob_out.dtype, \
- attr=ParamAttr(name=prefix + '_affine' + '_b'), \
- default_initializer = fluid.initializer.Constant(value = 0.))
- blob_out = fluid.layers.affine_channel(blob_out, scale = affine_scale, \
- bias = affine_bias, name = prefix + '_affine') # add affine
-
- return blob_out
-
-
-def add_space_nonlocal(input, dim_in, dim_out, prefix, dim_inner):
- '''
- add_space_nonlocal:
- Non-local Neural Networks: see https://arxiv.org/abs/1711.07971
- '''
- conv = space_nonlocal(input, dim_in, dim_out, prefix, dim_inner)
- output = fluid.layers.elementwise_add(input, conv, name=prefix + '_sum')
- return output
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/processor.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/processor.py
index 2b3e1ce9c..f15245643 100644
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/processor.py
+++ b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/processor.py
@@ -12,7 +12,6 @@
'postprocess',
]
-
def base64_to_cv2(b64str):
data = base64.b64decode(b64str.encode('utf8'))
data = np.fromstring(data, np.uint8)
@@ -107,7 +106,7 @@ def postprocess(paths,
handle_id,
visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): the path of images.
@@ -130,9 +129,8 @@ def postprocess(paths,
confidence (float): The confidence of detection result.
save_path (str): The path to save output images.
"""
- lod_tensor = data_out[0]
- lod = lod_tensor.lod[0]
- results = lod_tensor.as_ndarray()
+ lod = data_out.lod()[0]
+ results = data_out.copy_to_cpu()
check_dir(output_dir)
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/resnet.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/resnet.py
deleted file mode 100644
index 4bd6fb61e..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/resnet.py
+++ /dev/null
@@ -1,447 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import math
-from collections import OrderedDict
-from numbers import Integral
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.framework import Variable
-from paddle.fluid.regularizer import L2Decay
-from paddle.fluid.initializer import Constant
-
-from .nonlocal_helper import add_space_nonlocal
-from .name_adapter import NameAdapter
-
-__all__ = ['ResNet', 'ResNetC5']
-
-
-class ResNet(object):
- """
- Residual Network, see https://arxiv.org/abs/1512.03385
- Args:
- depth (int): ResNet depth, should be 34, 50.
- freeze_at (int): freeze the backbone at which stage
- norm_type (str): normalization type, 'bn'/'sync_bn'/'affine_channel'
- freeze_norm (bool): freeze normalization layers
- norm_decay (float): weight decay for normalization layer weights
- variant (str): ResNet variant, supports 'a', 'b', 'c', 'd' currently
- feature_maps (list): index of stages whose feature maps are returned
- dcn_v2_stages (list): index of stages who select deformable conv v2
- nonlocal_stages (list): index of stages who select nonlocal networks
- """
- __shared__ = ['norm_type', 'freeze_norm', 'weight_prefix_name']
-
- def __init__(self,
- depth=50,
- freeze_at=0,
- norm_type='sync_bn',
- freeze_norm=False,
- norm_decay=0.,
- variant='b',
- feature_maps=[3, 4, 5],
- dcn_v2_stages=[],
- weight_prefix_name='',
- nonlocal_stages=[],
- get_prediction=False,
- class_dim=1000):
- super(ResNet, self).__init__()
-
- if isinstance(feature_maps, Integral):
- feature_maps = [feature_maps]
-
- assert depth in [34, 50], \
- "depth {} not in [34, 50]"
- assert variant in ['a', 'b', 'c', 'd'], "invalid ResNet variant"
- assert 0 <= freeze_at <= 4, "freeze_at should be 0, 1, 2, 3 or 4"
- assert len(feature_maps) > 0, "need one or more feature maps"
- assert norm_type in ['bn', 'sync_bn', 'affine_channel']
- assert not (len(nonlocal_stages)>0 and depth<50), \
- "non-local is not supported for resnet18 or resnet34"
-
- self.depth = depth
- self.freeze_at = freeze_at
- self.norm_type = norm_type
- self.norm_decay = norm_decay
- self.freeze_norm = freeze_norm
- self.variant = variant
- self._model_type = 'ResNet'
- self.feature_maps = feature_maps
- self.dcn_v2_stages = dcn_v2_stages
- self.depth_cfg = {
- 34: ([3, 4, 6, 3], self.basicblock),
- 50: ([3, 4, 6, 3], self.bottleneck),
- }
- self.stage_filters = [64, 128, 256, 512]
- self._c1_out_chan_num = 64
- self.na = NameAdapter(self)
- self.prefix_name = weight_prefix_name
-
- self.nonlocal_stages = nonlocal_stages
- self.nonlocal_mod_cfg = {
- 50: 2,
- 101: 5,
- 152: 8,
- 200: 12,
- }
- self.get_prediction = get_prediction
- self.class_dim = class_dim
-
- def _conv_offset(self,
- input,
- filter_size,
- stride,
- padding,
- act=None,
- name=None):
- out_channel = filter_size * filter_size * 3
- out = fluid.layers.conv2d(
- input,
- num_filters=out_channel,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- param_attr=ParamAttr(initializer=Constant(0.0), name=name + ".w_0"),
- bias_attr=ParamAttr(initializer=Constant(0.0), name=name + ".b_0"),
- act=act,
- name=name)
- return out
-
- def _conv_norm(self,
- input,
- num_filters,
- filter_size,
- stride=1,
- groups=1,
- act=None,
- name=None,
- dcn_v2=False):
- _name = self.prefix_name + name if self.prefix_name != '' else name
- if not dcn_v2:
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- groups=groups,
- act=None,
- param_attr=ParamAttr(name=_name + "_weights"),
- bias_attr=False,
- name=_name + '.conv2d.output.1')
- else:
- # select deformable conv"
- offset_mask = self._conv_offset(
- input=input,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- act=None,
- name=_name + "_conv_offset")
- offset_channel = filter_size**2 * 2
- mask_channel = filter_size**2
- offset, mask = fluid.layers.split(
- input=offset_mask,
- num_or_sections=[offset_channel, mask_channel],
- dim=1)
- mask = fluid.layers.sigmoid(mask)
- conv = fluid.layers.deformable_conv(
- input=input,
- offset=offset,
- mask=mask,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- groups=groups,
- deformable_groups=1,
- im2col_step=1,
- param_attr=ParamAttr(name=_name + "_weights"),
- bias_attr=False,
- name=_name + ".conv2d.output.1")
-
- bn_name = self.na.fix_conv_norm_name(name)
- bn_name = self.prefix_name + bn_name if self.prefix_name != '' else bn_name
-
- norm_lr = 0. if self.freeze_norm else 1.
- norm_decay = self.norm_decay
- pattr = ParamAttr(
- name=bn_name + '_scale',
- learning_rate=norm_lr,
- regularizer=L2Decay(norm_decay))
- battr = ParamAttr(
- name=bn_name + '_offset',
- learning_rate=norm_lr,
- regularizer=L2Decay(norm_decay))
-
- if self.norm_type in ['bn', 'sync_bn']:
- global_stats = True if self.freeze_norm else False
- out = fluid.layers.batch_norm(
- input=conv,
- act=act,
- name=bn_name + '.output.1',
- param_attr=pattr,
- bias_attr=battr,
- moving_mean_name=bn_name + '_mean',
- moving_variance_name=bn_name + '_variance',
- use_global_stats=global_stats)
- scale = fluid.framework._get_var(pattr.name)
- bias = fluid.framework._get_var(battr.name)
- elif self.norm_type == 'affine_channel':
- scale = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=pattr,
- default_initializer=fluid.initializer.Constant(1.))
- bias = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=battr,
- default_initializer=fluid.initializer.Constant(0.))
- out = fluid.layers.affine_channel(
- x=conv, scale=scale, bias=bias, act=act)
- if self.freeze_norm:
- scale.stop_gradient = True
- bias.stop_gradient = True
- return out
-
- def _shortcut(self, input, ch_out, stride, is_first, name):
- max_pooling_in_short_cut = self.variant == 'd'
- ch_in = input.shape[1]
- # the naming rule is same as pretrained weight
- name = self.na.fix_shortcut_name(name)
- std_senet = getattr(self, 'std_senet', False)
- if ch_in != ch_out or stride != 1 or (self.depth < 50 and is_first):
- if std_senet:
- if is_first:
- return self._conv_norm(input, ch_out, 1, stride, name=name)
- else:
- return self._conv_norm(input, ch_out, 3, stride, name=name)
- if max_pooling_in_short_cut and not is_first:
- input = fluid.layers.pool2d(
- input=input,
- pool_size=2,
- pool_stride=2,
- pool_padding=0,
- ceil_mode=True,
- pool_type='avg')
- return self._conv_norm(input, ch_out, 1, 1, name=name)
- return self._conv_norm(input, ch_out, 1, stride, name=name)
- else:
- return input
-
- def bottleneck(self,
- input,
- num_filters,
- stride,
- is_first,
- name,
- dcn_v2=False):
- if self.variant == 'a':
- stride1, stride2 = stride, 1
- else:
- stride1, stride2 = 1, stride
-
- # ResNeXt
- groups = getattr(self, 'groups', 1)
- group_width = getattr(self, 'group_width', -1)
- if groups == 1:
- expand = 4
- elif (groups * group_width) == 256:
- expand = 1
- else: # FIXME hard code for now, handles 32x4d, 64x4d and 32x8d
- num_filters = num_filters // 2
- expand = 2
-
- conv_name1, conv_name2, conv_name3, \
- shortcut_name = self.na.fix_bottleneck_name(name)
- std_senet = getattr(self, 'std_senet', False)
- if std_senet:
- conv_def = [[
- int(num_filters / 2), 1, stride1, 'relu', 1, conv_name1
- ], [num_filters, 3, stride2, 'relu', groups, conv_name2],
- [num_filters * expand, 1, 1, None, 1, conv_name3]]
- else:
- conv_def = [[num_filters, 1, stride1, 'relu', 1, conv_name1],
- [num_filters, 3, stride2, 'relu', groups, conv_name2],
- [num_filters * expand, 1, 1, None, 1, conv_name3]]
-
- residual = input
- for i, (c, k, s, act, g, _name) in enumerate(conv_def):
- residual = self._conv_norm(
- input=residual,
- num_filters=c,
- filter_size=k,
- stride=s,
- act=act,
- groups=g,
- name=_name,
- dcn_v2=(i == 1 and dcn_v2))
- short = self._shortcut(
- input,
- num_filters * expand,
- stride,
- is_first=is_first,
- name=shortcut_name)
- # Squeeze-and-Excitation
- if callable(getattr(self, '_squeeze_excitation', None)):
- residual = self._squeeze_excitation(
- input=residual, num_channels=num_filters, name='fc' + name)
- return fluid.layers.elementwise_add(
- x=short, y=residual, act='relu', name=name + ".add.output.5")
-
- def basicblock(self,
- input,
- num_filters,
- stride,
- is_first,
- name,
- dcn_v2=False):
- assert dcn_v2 is False, "Not implemented yet."
- conv0 = self._conv_norm(
- input=input,
- num_filters=num_filters,
- filter_size=3,
- act='relu',
- stride=stride,
- name=name + "_branch2a")
- conv1 = self._conv_norm(
- input=conv0,
- num_filters=num_filters,
- filter_size=3,
- act=None,
- name=name + "_branch2b")
- short = self._shortcut(
- input, num_filters, stride, is_first, name=name + "_branch1")
- return fluid.layers.elementwise_add(x=short, y=conv1, act='relu')
-
- def layer_warp(self, input, stage_num):
- """
- Args:
- input (Variable): input variable.
- stage_num (int): the stage number, should be 2, 3, 4, 5
-
- Returns:
- The last variable in endpoint-th stage.
- """
- assert stage_num in [2, 3, 4, 5]
-
- stages, block_func = self.depth_cfg[self.depth]
- count = stages[stage_num - 2]
-
- ch_out = self.stage_filters[stage_num - 2]
- is_first = False if stage_num != 2 else True
- dcn_v2 = True if stage_num in self.dcn_v2_stages else False
-
- nonlocal_mod = 1000
- if stage_num in self.nonlocal_stages:
- nonlocal_mod = self.nonlocal_mod_cfg[
- self.depth] if stage_num == 4 else 2
-
- # Make the layer name and parameter name consistent
- # with ImageNet pre-trained model
- conv = input
- for i in range(count):
- conv_name = self.na.fix_layer_warp_name(stage_num, count, i)
- if self.depth < 50:
- is_first = True if i == 0 and stage_num == 2 else False
- conv = block_func(
- input=conv,
- num_filters=ch_out,
- stride=2 if i == 0 and stage_num != 2 else 1,
- is_first=is_first,
- name=conv_name,
- dcn_v2=dcn_v2)
-
- # add non local model
- dim_in = conv.shape[1]
- nonlocal_name = "nonlocal_conv{}".format(stage_num)
- if i % nonlocal_mod == nonlocal_mod - 1:
- conv = add_space_nonlocal(conv, dim_in, dim_in,
- nonlocal_name + '_{}'.format(i),
- int(dim_in / 2))
- return conv
-
- def c1_stage(self, input):
- out_chan = self._c1_out_chan_num
-
- conv1_name = self.na.fix_c1_stage_name()
-
- if self.variant in ['c', 'd']:
- conv_def = [
- [out_chan // 2, 3, 2, "conv1_1"],
- [out_chan // 2, 3, 1, "conv1_2"],
- [out_chan, 3, 1, "conv1_3"],
- ]
- else:
- conv_def = [[out_chan, 7, 2, conv1_name]]
-
- for (c, k, s, _name) in conv_def:
- input = self._conv_norm(
- input=input,
- num_filters=c,
- filter_size=k,
- stride=s,
- act='relu',
- name=_name)
-
- output = fluid.layers.pool2d(
- input=input,
- pool_size=3,
- pool_stride=2,
- pool_padding=1,
- pool_type='max')
- return output
-
- def __call__(self, input):
- assert isinstance(input, Variable)
- assert not (set(self.feature_maps) - set([2, 3, 4, 5])), \
- "feature maps {} not in [2, 3, 4, 5]".format(self.feature_maps)
-
- res_endpoints = []
-
- res = input
- feature_maps = self.feature_maps
- severed_head = getattr(self, 'severed_head', False)
- if not severed_head:
- res = self.c1_stage(res)
- feature_maps = range(2, max(self.feature_maps) + 1)
-
- for i in feature_maps:
- res = self.layer_warp(res, i)
- if i in self.feature_maps:
- res_endpoints.append(res)
- if self.freeze_at >= i:
- res.stop_gradient = True
- if self.get_prediction:
- pool = fluid.layers.pool2d(
- input=res, pool_type='avg', global_pooling=True)
- stdv = 1.0 / math.sqrt(pool.shape[1] * 1.0)
-
- out = fluid.layers.fc(
- input=pool,
- size=self.class_dim,
- param_attr=fluid.param_attr.ParamAttr(
- initializer=fluid.initializer.Uniform(-stdv, stdv)))
- out = fluid.layers.softmax(out)
- return out
- return OrderedDict([('res{}_sum'.format(self.feature_maps[idx]), feat)
- for idx, feat in enumerate(res_endpoints)])
-
-
-class ResNetC5(ResNet):
- def __init__(self,
- depth=50,
- freeze_at=2,
- norm_type='affine_channel',
- freeze_norm=True,
- norm_decay=0.,
- variant='b',
- feature_maps=[5],
- weight_prefix_name=''):
- super(ResNetC5, self).__init__(depth, freeze_at, norm_type, freeze_norm,
- norm_decay, variant, feature_maps)
- self.severed_head = True
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/roi_extractor.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/roi_extractor.py
deleted file mode 100644
index 6e3398d8c..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/roi_extractor.py
+++ /dev/null
@@ -1,76 +0,0 @@
-# coding=utf-8
-import paddle.fluid as fluid
-
-__all__ = ['FPNRoIAlign']
-
-
-class FPNRoIAlign(object):
- """
- RoI align pooling for FPN feature maps
- Args:
- sampling_ratio (int): number of sampling points
- min_level (int): lowest level of FPN layer
- max_level (int): highest level of FPN layer
- canconical_level (int): the canconical FPN feature map level
- canonical_size (int): the canconical FPN feature map size
- box_resolution (int): box resolution
- mask_resolution (int): mask roi resolution
- """
-
- def __init__(self,
- sampling_ratio=0,
- min_level=2,
- max_level=5,
- canconical_level=4,
- canonical_size=224,
- box_resolution=7,
- mask_resolution=14):
- super(FPNRoIAlign, self).__init__()
- self.sampling_ratio = sampling_ratio
- self.min_level = min_level
- self.max_level = max_level
- self.canconical_level = canconical_level
- self.canonical_size = canonical_size
- self.box_resolution = box_resolution
- self.mask_resolution = mask_resolution
-
- def __call__(self, head_inputs, rois, spatial_scale, is_mask=False):
- """
- Adopt RoI align onto several level of feature maps to get RoI features.
- Distribute RoIs to different levels by area and get a list of RoI
- features by distributed RoIs and their corresponding feature maps.
-
- Returns:
- roi_feat(Variable): RoI features with shape of [M, C, R, R],
- where M is the number of RoIs and R is RoI resolution
-
- """
- k_min = self.min_level
- k_max = self.max_level
- num_roi_lvls = k_max - k_min + 1
- name_list = list(head_inputs.keys())
- input_name_list = name_list[-num_roi_lvls:]
- spatial_scale = spatial_scale[-num_roi_lvls:]
- rois_dist, restore_index = fluid.layers.distribute_fpn_proposals(
- rois, k_min, k_max, self.canconical_level, self.canonical_size)
- # rois_dist is in ascend order
- roi_out_list = []
- resolution = is_mask and self.mask_resolution or self.box_resolution
- for lvl in range(num_roi_lvls):
- name_index = num_roi_lvls - lvl - 1
- rois_input = rois_dist[lvl]
- head_input = head_inputs[input_name_list[name_index]]
- sc = spatial_scale[name_index]
- roi_out = fluid.layers.roi_align(
- input=head_input,
- rois=rois_input,
- pooled_height=resolution,
- pooled_width=resolution,
- spatial_scale=sc,
- sampling_ratio=self.sampling_ratio)
- roi_out_list.append(roi_out)
- roi_feat_shuffle = fluid.layers.concat(roi_out_list)
- roi_feat_ = fluid.layers.gather(roi_feat_shuffle, restore_index)
- roi_feat = fluid.layers.lod_reset(roi_feat_, rois)
-
- return roi_feat
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/rpn_head.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/rpn_head.py
deleted file mode 100644
index e1b69866d..000000000
--- a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/rpn_head.py
+++ /dev/null
@@ -1,533 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.initializer import Normal
-from paddle.fluid.regularizer import L2Decay
-
-__all__ = [
- 'AnchorGenerator', 'RPNTargetAssign', 'GenerateProposals', 'RPNHead',
- 'FPNRPNHead'
-]
-
-
-class AnchorGenerator(object):
- # __op__ = fluid.layers.anchor_generator
- def __init__(self,
- stride=[16.0, 16.0],
- anchor_sizes=[32, 64, 128, 256, 512],
- aspect_ratios=[0.5, 1., 2.],
- variance=[1., 1., 1., 1.]):
- super(AnchorGenerator, self).__init__()
- self.anchor_sizes = anchor_sizes
- self.aspect_ratios = aspect_ratios
- self.variance = variance
- self.stride = stride
-
-
-class RPNTargetAssign(object):
- # __op__ = fluid.layers.rpn_target_assign
- def __init__(self,
- rpn_batch_size_per_im=256,
- rpn_straddle_thresh=0.,
- rpn_fg_fraction=0.5,
- rpn_positive_overlap=0.7,
- rpn_negative_overlap=0.3,
- use_random=True):
- super(RPNTargetAssign, self).__init__()
- self.rpn_batch_size_per_im = rpn_batch_size_per_im
- self.rpn_straddle_thresh = rpn_straddle_thresh
- self.rpn_fg_fraction = rpn_fg_fraction
- self.rpn_positive_overlap = rpn_positive_overlap
- self.rpn_negative_overlap = rpn_negative_overlap
- self.use_random = use_random
-
-
-class GenerateProposals(object):
- # __op__ = fluid.layers.generate_proposals
- def __init__(self,
- pre_nms_top_n=6000,
- post_nms_top_n=1000,
- nms_thresh=.5,
- min_size=.1,
- eta=1.):
- super(GenerateProposals, self).__init__()
- self.pre_nms_top_n = pre_nms_top_n
- self.post_nms_top_n = post_nms_top_n
- self.nms_thresh = nms_thresh
- self.min_size = min_size
- self.eta = eta
-
-
-class RPNHead(object):
- """
- RPN Head
-
- Args:
- anchor_generator (object): `AnchorGenerator` instance
- rpn_target_assign (object): `RPNTargetAssign` instance
- train_proposal (object): `GenerateProposals` instance for training
- test_proposal (object): `GenerateProposals` instance for testing
- num_classes (int): number of classes in rpn output
- """
- __inject__ = [
- 'anchor_generator', 'rpn_target_assign', 'train_proposal',
- 'test_proposal'
- ]
-
- def __init__(self,
- anchor_generator,
- rpn_target_assign,
- train_proposal,
- test_proposal,
- num_classes=1):
- super(RPNHead, self).__init__()
- self.anchor_generator = anchor_generator
- self.rpn_target_assign = rpn_target_assign
- self.train_proposal = train_proposal
- self.test_proposal = test_proposal
- self.num_classes = num_classes
-
- def _get_output(self, input):
- """
- Get anchor and RPN head output.
-
- Args:
- input(Variable): feature map from backbone with shape of [N, C, H, W]
-
- Returns:
- rpn_cls_score(Variable): Output of rpn head with shape of [N, num_anchors, H, W].
- rpn_bbox_pred(Variable): Output of rpn head with shape of [N, num_anchors * 4, H, W].
- """
- dim_out = input.shape[1]
- rpn_conv = fluid.layers.conv2d(
- input=input,
- num_filters=dim_out,
- filter_size=3,
- stride=1,
- padding=1,
- act='relu',
- name='conv_rpn',
- param_attr=ParamAttr(
- name="conv_rpn_w", initializer=Normal(loc=0., scale=0.01)),
- bias_attr=ParamAttr(
- name="conv_rpn_b", learning_rate=2., regularizer=L2Decay(0.)))
- # Generate anchors self.anchor_generator
- self.anchor, self.anchor_var = fluid.layers.anchor_generator(
- input=rpn_conv,
- anchor_sizes=self.anchor_generator.anchor_sizes,
- aspect_ratios=self.anchor_generator.aspect_ratios,
- variance=self.anchor_generator.variance,
- stride=self.anchor_generator.stride)
-
- num_anchor = self.anchor.shape[2]
- # Proposal classification scores
- self.rpn_cls_score = fluid.layers.conv2d(
- rpn_conv,
- num_filters=num_anchor * self.num_classes,
- filter_size=1,
- stride=1,
- padding=0,
- act=None,
- name='rpn_cls_score',
- param_attr=ParamAttr(
- name="rpn_cls_logits_w", initializer=Normal(loc=0.,
- scale=0.01)),
- bias_attr=ParamAttr(
- name="rpn_cls_logits_b",
- learning_rate=2.,
- regularizer=L2Decay(0.)))
- # Proposal bbox regression deltas
- self.rpn_bbox_pred = fluid.layers.conv2d(
- rpn_conv,
- num_filters=4 * num_anchor,
- filter_size=1,
- stride=1,
- padding=0,
- act=None,
- name='rpn_bbox_pred',
- param_attr=ParamAttr(
- name="rpn_bbox_pred_w", initializer=Normal(loc=0., scale=0.01)),
- bias_attr=ParamAttr(
- name="rpn_bbox_pred_b",
- learning_rate=2.,
- regularizer=L2Decay(0.)))
- return self.rpn_cls_score, self.rpn_bbox_pred
-
- def get_proposals(self, body_feats, im_info, mode='train'):
- """
- Get proposals according to the output of backbone.
-
- Args:
- body_feats (dict): The dictionary of feature maps from backbone.
- im_info(Variable): The information of image with shape [N, 3] with
- shape (height, width, scale).
- body_feat_names(list): A list of names of feature maps from
- backbone.
-
- Returns:
- rpn_rois(Variable): Output proposals with shape of (rois_num, 4).
- """
- # In RPN Heads, only the last feature map of backbone is used.
- # And body_feat_names[-1] represents the last level name of backbone.
- body_feat = list(body_feats.values())[-1]
- rpn_cls_score, rpn_bbox_pred = self._get_output(body_feat)
-
- if self.num_classes == 1:
- rpn_cls_prob = fluid.layers.sigmoid(
- rpn_cls_score, name='rpn_cls_prob')
- else:
- rpn_cls_score = fluid.layers.transpose(
- rpn_cls_score, perm=[0, 2, 3, 1])
- rpn_cls_score = fluid.layers.reshape(
- rpn_cls_score, shape=(0, 0, 0, -1, self.num_classes))
- rpn_cls_prob_tmp = fluid.layers.softmax(
- rpn_cls_score, use_cudnn=False, name='rpn_cls_prob')
- rpn_cls_prob_slice = fluid.layers.slice(
- rpn_cls_prob_tmp, axes=[4], starts=[1], ends=[self.num_classes])
- rpn_cls_prob, _ = fluid.layers.topk(rpn_cls_prob_slice, 1)
- rpn_cls_prob = fluid.layers.reshape(
- rpn_cls_prob, shape=(0, 0, 0, -1))
- rpn_cls_prob = fluid.layers.transpose(
- rpn_cls_prob, perm=[0, 3, 1, 2])
- prop_op = self.train_proposal if mode == 'train' else self.test_proposal
- # prop_op
- rpn_rois, rpn_roi_probs = fluid.layers.generate_proposals(
- scores=rpn_cls_prob,
- bbox_deltas=rpn_bbox_pred,
- im_info=im_info,
- anchors=self.anchor,
- variances=self.anchor_var,
- pre_nms_top_n=prop_op.pre_nms_top_n,
- post_nms_top_n=prop_op.post_nms_top_n,
- nms_thresh=prop_op.nms_thresh,
- min_size=prop_op.min_size,
- eta=prop_op.eta)
- return rpn_rois
-
- def _transform_input(self, rpn_cls_score, rpn_bbox_pred, anchor,
- anchor_var):
- rpn_cls_score = fluid.layers.transpose(rpn_cls_score, perm=[0, 2, 3, 1])
- rpn_bbox_pred = fluid.layers.transpose(rpn_bbox_pred, perm=[0, 2, 3, 1])
- anchor = fluid.layers.reshape(anchor, shape=(-1, 4))
- anchor_var = fluid.layers.reshape(anchor_var, shape=(-1, 4))
- rpn_cls_score = fluid.layers.reshape(
- x=rpn_cls_score, shape=(0, -1, self.num_classes))
- rpn_bbox_pred = fluid.layers.reshape(x=rpn_bbox_pred, shape=(0, -1, 4))
- return rpn_cls_score, rpn_bbox_pred, anchor, anchor_var
-
- def _get_loss_input(self):
- for attr in ['rpn_cls_score', 'rpn_bbox_pred', 'anchor', 'anchor_var']:
- if not getattr(self, attr, None):
- raise ValueError("self.{} should not be None,".format(attr),
- "call RPNHead.get_proposals first")
- return self._transform_input(self.rpn_cls_score, self.rpn_bbox_pred,
- self.anchor, self.anchor_var)
-
- def get_loss(self, im_info, gt_box, is_crowd, gt_label=None):
- """
- Sample proposals and Calculate rpn loss.
-
- Args:
- im_info(Variable): The information of image with shape [N, 3] with
- shape (height, width, scale).
- gt_box(Variable): The ground-truth bounding boxes with shape [M, 4].
- M is the number of groundtruth.
- is_crowd(Variable): Indicates groud-truth is crowd or not with
- shape [M, 1]. M is the number of groundtruth.
-
- Returns:
- Type: dict
- rpn_cls_loss(Variable): RPN classification loss.
- rpn_bbox_loss(Variable): RPN bounding box regression loss.
-
- """
- rpn_cls, rpn_bbox, anchor, anchor_var = self._get_loss_input()
- if self.num_classes == 1:
- # self.rpn_target_assign
- score_pred, loc_pred, score_tgt, loc_tgt, bbox_weight = \
- fluid.layers.rpn_target_assign(
- bbox_pred=rpn_bbox,
- cls_logits=rpn_cls,
- anchor_box=anchor,
- anchor_var=anchor_var,
- gt_boxes=gt_box,
- is_crowd=is_crowd,
- im_info=im_info,
- rpn_batch_size_per_im=self.rpn_target_assign.rpn_batch_size_per_im,
- rpn_straddle_thresh=self.rpn_target_assign.rpn_straddle_thresh,
- rpn_fg_fraction=self.rpn_target_assign.rpn_fg_fraction,
- rpn_positive_overlap=self.rpn_target_assign.rpn_positive_overlap,
- rpn_negative_overlap=self.rpn_target_assign.rpn_negative_overlap,
- use_random=self.rpn_target_assign.use_random)
- score_tgt = fluid.layers.cast(x=score_tgt, dtype='float32')
- score_tgt.stop_gradient = True
- rpn_cls_loss = fluid.layers.sigmoid_cross_entropy_with_logits(
- x=score_pred, label=score_tgt)
- else:
- score_pred, loc_pred, score_tgt, loc_tgt, bbox_weight = \
- self.rpn_target_assign(
- bbox_pred=rpn_bbox,
- cls_logits=rpn_cls,
- anchor_box=anchor,
- anchor_var=anchor_var,
- gt_boxes=gt_box,
- gt_labels=gt_label,
- is_crowd=is_crowd,
- num_classes=self.num_classes,
- im_info=im_info)
- labels_int64 = fluid.layers.cast(x=score_tgt, dtype='int64')
- labels_int64.stop_gradient = True
- rpn_cls_loss = fluid.layers.softmax_with_cross_entropy(
- logits=score_pred, label=labels_int64, numeric_stable_mode=True)
-
- rpn_cls_loss = fluid.layers.reduce_mean(
- rpn_cls_loss, name='loss_rpn_cls')
-
- loc_tgt = fluid.layers.cast(x=loc_tgt, dtype='float32')
- loc_tgt.stop_gradient = True
- rpn_reg_loss = fluid.layers.smooth_l1(
- x=loc_pred,
- y=loc_tgt,
- sigma=3.0,
- inside_weight=bbox_weight,
- outside_weight=bbox_weight)
- rpn_reg_loss = fluid.layers.reduce_sum(
- rpn_reg_loss, name='loss_rpn_bbox')
- score_shape = fluid.layers.shape(score_tgt)
- score_shape = fluid.layers.cast(x=score_shape, dtype='float32')
- norm = fluid.layers.reduce_prod(score_shape)
- norm.stop_gradient = True
- rpn_reg_loss = rpn_reg_loss / norm
- return {'rpn_cls_loss': rpn_cls_loss, 'rpn_reg_loss': rpn_reg_loss}
-
-
-class FPNRPNHead(RPNHead):
- """
- RPN Head that supports FPN input
-
- Args:
- anchor_generator (object): `AnchorGenerator` instance
- rpn_target_assign (object): `RPNTargetAssign` instance
- train_proposal (object): `GenerateProposals` instance for training
- test_proposal (object): `GenerateProposals` instance for testing
- anchor_start_size (int): size of anchor at the first scale
- num_chan (int): number of FPN output channels
- min_level (int): lowest level of FPN output
- max_level (int): highest level of FPN output
- num_classes (int): number of classes in rpn output
- """
-
- def __init__(self,
- anchor_generator,
- rpn_target_assign,
- train_proposal,
- test_proposal,
- anchor_start_size=32,
- num_chan=256,
- min_level=2,
- max_level=6,
- num_classes=1):
- super(FPNRPNHead, self).__init__(anchor_generator, rpn_target_assign,
- train_proposal, test_proposal)
- self.anchor_start_size = anchor_start_size
- self.num_chan = num_chan
- self.min_level = min_level
- self.max_level = max_level
- self.num_classes = num_classes
-
- self.fpn_rpn_list = []
- self.anchors_list = []
- self.anchor_var_list = []
-
- def _get_output(self, input, feat_lvl):
- """
- Get anchor and FPN RPN head output at one level.
-
- Args:
- input(Variable): Body feature from backbone.
- feat_lvl(int): Indicate the level of rpn output corresponding
- to the level of feature map.
-
- Return:
- rpn_cls_score(Variable): Output of one level of fpn rpn head with
- shape of [N, num_anchors, H, W].
- rpn_bbox_pred(Variable): Output of one level of fpn rpn head with
- shape of [N, num_anchors * 4, H, W].
- """
- slvl = str(feat_lvl)
- conv_name = 'conv_rpn_fpn' + slvl
- cls_name = 'rpn_cls_logits_fpn' + slvl
- bbox_name = 'rpn_bbox_pred_fpn' + slvl
- conv_share_name = 'conv_rpn_fpn' + str(self.min_level)
- cls_share_name = 'rpn_cls_logits_fpn' + str(self.min_level)
- bbox_share_name = 'rpn_bbox_pred_fpn' + str(self.min_level)
-
- num_anchors = len(self.anchor_generator.aspect_ratios)
- conv_rpn_fpn = fluid.layers.conv2d(
- input=input,
- num_filters=self.num_chan,
- filter_size=3,
- padding=1,
- act='relu',
- name=conv_name,
- param_attr=ParamAttr(
- name=conv_share_name + '_w',
- initializer=Normal(loc=0., scale=0.01)),
- bias_attr=ParamAttr(
- name=conv_share_name + '_b',
- learning_rate=2.,
- regularizer=L2Decay(0.)))
-
- # self.anchor_generator
- self.anchors, self.anchor_var = fluid.layers.anchor_generator(
- input=conv_rpn_fpn,
- anchor_sizes=(self.anchor_start_size * 2.**
- (feat_lvl - self.min_level), ),
- stride=(2.**feat_lvl, 2.**feat_lvl),
- aspect_ratios=self.anchor_generator.aspect_ratios,
- variance=self.anchor_generator.variance)
-
- cls_num_filters = num_anchors * self.num_classes
- self.rpn_cls_score = fluid.layers.conv2d(
- input=conv_rpn_fpn,
- num_filters=cls_num_filters,
- filter_size=1,
- act=None,
- name=cls_name,
- param_attr=ParamAttr(
- name=cls_share_name + '_w',
- initializer=Normal(loc=0., scale=0.01)),
- bias_attr=ParamAttr(
- name=cls_share_name + '_b',
- learning_rate=2.,
- regularizer=L2Decay(0.)))
- self.rpn_bbox_pred = fluid.layers.conv2d(
- input=conv_rpn_fpn,
- num_filters=num_anchors * 4,
- filter_size=1,
- act=None,
- name=bbox_name,
- param_attr=ParamAttr(
- name=bbox_share_name + '_w',
- initializer=Normal(loc=0., scale=0.01)),
- bias_attr=ParamAttr(
- name=bbox_share_name + '_b',
- learning_rate=2.,
- regularizer=L2Decay(0.)))
- return self.rpn_cls_score, self.rpn_bbox_pred
-
- def _get_single_proposals(self, body_feat, im_info, feat_lvl, mode='train'):
- """
- Get proposals in one level according to the output of fpn rpn head
-
- Args:
- body_feat(Variable): the feature map from backone.
- im_info(Variable): The information of image with shape [N, 3] with
- format (height, width, scale).
- feat_lvl(int): Indicate the level of proposals corresponding to
- the feature maps.
-
- Returns:
- rpn_rois_fpn(Variable): Output proposals with shape of (rois_num, 4).
- rpn_roi_probs_fpn(Variable): Scores of proposals with
- shape of (rois_num, 1).
- """
-
- rpn_cls_score_fpn, rpn_bbox_pred_fpn = self._get_output(
- body_feat, feat_lvl)
-
- prop_op = self.train_proposal if mode == 'train' else self.test_proposal
- if self.num_classes == 1:
- rpn_cls_prob_fpn = fluid.layers.sigmoid(
- rpn_cls_score_fpn, name='rpn_cls_prob_fpn' + str(feat_lvl))
- else:
- rpn_cls_score_fpn = fluid.layers.transpose(
- rpn_cls_score_fpn, perm=[0, 2, 3, 1])
- rpn_cls_score_fpn = fluid.layers.reshape(
- rpn_cls_score_fpn, shape=(0, 0, 0, -1, self.num_classes))
- rpn_cls_prob_fpn = fluid.layers.softmax(
- rpn_cls_score_fpn,
- use_cudnn=False,
- name='rpn_cls_prob_fpn' + str(feat_lvl))
- rpn_cls_prob_fpn = fluid.layers.slice(
- rpn_cls_prob_fpn, axes=[4], starts=[1], ends=[self.num_classes])
- rpn_cls_prob_fpn, _ = fluid.layers.topk(rpn_cls_prob_fpn, 1)
- rpn_cls_prob_fpn = fluid.layers.reshape(
- rpn_cls_prob_fpn, shape=(0, 0, 0, -1))
- rpn_cls_prob_fpn = fluid.layers.transpose(
- rpn_cls_prob_fpn, perm=[0, 3, 1, 2])
- # prop_op
- rpn_rois_fpn, rpn_roi_prob_fpn = fluid.layers.generate_proposals(
- scores=rpn_cls_prob_fpn,
- bbox_deltas=rpn_bbox_pred_fpn,
- im_info=im_info,
- anchors=self.anchors,
- variances=self.anchor_var,
- pre_nms_top_n=prop_op.pre_nms_top_n,
- post_nms_top_n=prop_op.post_nms_top_n,
- nms_thresh=prop_op.nms_thresh,
- min_size=prop_op.min_size,
- eta=prop_op.eta)
- return rpn_rois_fpn, rpn_roi_prob_fpn
-
- def get_proposals(self, fpn_feats, im_info, mode='train'):
- """
- Get proposals in multiple levels according to the output of fpn
- rpn head
-
- Args:
- fpn_feats(dict): A dictionary represents the output feature map
- of FPN with their name.
- im_info(Variable): The information of image with shape [N, 3] with
- format (height, width, scale).
-
- Return:
- rois_list(Variable): Output proposals in shape of [rois_num, 4]
- """
- rois_list = []
- roi_probs_list = []
- fpn_feat_names = list(fpn_feats.keys())
- for lvl in range(self.min_level, self.max_level + 1):
- fpn_feat_name = fpn_feat_names[self.max_level - lvl]
- fpn_feat = fpn_feats[fpn_feat_name]
- rois_fpn, roi_probs_fpn = self._get_single_proposals(
- fpn_feat, im_info, lvl, mode)
- self.fpn_rpn_list.append((self.rpn_cls_score, self.rpn_bbox_pred))
- rois_list.append(rois_fpn)
- roi_probs_list.append(roi_probs_fpn)
- self.anchors_list.append(self.anchors)
- self.anchor_var_list.append(self.anchor_var)
- prop_op = self.train_proposal if mode == 'train' else self.test_proposal
- post_nms_top_n = prop_op.post_nms_top_n
- rois_collect = fluid.layers.collect_fpn_proposals(
- rois_list,
- roi_probs_list,
- self.min_level,
- self.max_level,
- post_nms_top_n,
- name='collect')
- return rois_collect
-
- def _get_loss_input(self):
- rpn_clses = []
- rpn_bboxes = []
- anchors = []
- anchor_vars = []
- for i in range(len(self.fpn_rpn_list)):
- single_input = self._transform_input(
- self.fpn_rpn_list[i][0], self.fpn_rpn_list[i][1],
- self.anchors_list[i], self.anchor_var_list[i])
- rpn_clses.append(single_input[0])
- rpn_bboxes.append(single_input[1])
- anchors.append(single_input[2])
- anchor_vars.append(single_input[3])
-
- rpn_cls = fluid.layers.concat(rpn_clses, axis=1)
- rpn_bbox = fluid.layers.concat(rpn_bboxes, axis=1)
- anchors = fluid.layers.concat(anchors)
- anchor_var = fluid.layers.concat(anchor_vars)
- return rpn_cls, rpn_bbox, anchors, anchor_var
diff --git a/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/test.py b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/test.py
new file mode 100644
index 000000000..0a775a4f5
--- /dev/null
+++ b/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/68313e182f5e4ad9907e69dac9ece8fc50840d7ffbd24fa88396f009958f969a'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="faster_rcnn_resnet50_fpn_coco2017")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ cv2.error,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 51427477fff7697a6dec1547158f9fb190515079 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 14:39:56 +0800
Subject: [PATCH 057/117] update ssd_vgg16_300_coco2017 (#1949)
* update ssd_vgg16_300_model
* update unittest
* update unittest
* update gpu config
* update
* add clean func
* update save inference model
Co-authored-by: chenjian  +
+
+
+ - images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ - batch\_size (int): batch 的大小;
+ - use\_gpu (bool): 是否使用 GPU;
+ - output\_dir (str): 图片的保存路径,默认设为 detection\_result;
+ - score\_thresh (float): 识别置信度的阈值;
+ - visualization (bool): 是否将识别结果保存为图片文件。
-## 第一步:启动PaddleHub Serving
+ **NOTE:** paths和images两个参数选择其一进行提供数据
-运行启动命令:
-```shell
-$ hub serving start -m ssd_vgg16_300_coco2017
-```
+ - **返回**
-这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
+ - res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
+ - data (list): 检测结果,list的每一个元素为 dict,各字段为:
+ - confidence (float): 识别的置信度
+ - label (str): 标签
+ - left (int): 边界框的左上角x坐标
+ - top (int): 边界框的左上角y坐标
+ - right (int): 边界框的右下角x坐标
+ - bottom (int): 边界框的右下角y坐标
+ - save\_path (str, optional): 识别结果的保存路径 (仅当visualization=True时存在)
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+ - ```python
+ def save_inference_model(dirname)
+ ```
+ - 将模型保存到指定路径。
-## 第二步:发送预测请求
+ - **参数**
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - dirname: 模型保存路径
-```python
-import requests
-import json
-import cv2
-import base64
+## 四、服务部署
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
+- PaddleHub Serving可以部署一个目标检测的在线服务。
+- ### 第一步:启动PaddleHub Serving
-# 发送HTTP请求
-data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/ssd_vgg16_300_coco2017"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ - 运行启动命令:
+ - ```shell
+ $ hub serving start -m ssd_vgg16_300_coco2017
+ ```
-# 打印预测结果
-print(r.json()["results"])
-```
+ - 这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
-### 依赖
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-paddlepaddle >= 1.6.2
+- ### 第二步:发送预测请求
-paddlehub >= 1.6.0
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ # 发送HTTP请求
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/ssd_vgg16_300_coco2017"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 打印预测结果
+ print(r.json()["results"])
+ ```
+
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+* 1.0.2
+
+ 修复numpy数据读取问题
+
+* 1.1.0
+
+ 移除 fluid api
+
+ - ```shell
+ $ hub install ssd_vgg16_300_coco2017==1.1.0
+ ```
diff --git a/modules/image/object_detection/ssd_vgg16_300_coco2017/README_en.md b/modules/image/object_detection/ssd_vgg16_300_coco2017/README_en.md
new file mode 100644
index 000000000..0d53ce2f7
--- /dev/null
+++ b/modules/image/object_detection/ssd_vgg16_300_coco2017/README_en.md
@@ -0,0 +1,169 @@
+# ssd_vgg16_300_coco2017
+
+|Module Name|ssd_vgg16_300_coco2017|
+| :--- | :---: |
+|Category|object detection|
+|Network|SSD|
+|Dataset|COCO2017|
+|Fine-tuning supported or not|No|
+|Module Size|139MB|
+|Latest update date|2021-03-15|
+|Data indicators|-|
+
+
+## I.Basic Information
+
+- ### Application Effect Display
+ - Sample results:
+
+
+
+ - visualization (bool): Whether to save the results as picture files;
+
+ **NOTE:** choose one parameter to provide data from paths and images
+
+ - **Return**
+
+ - res (list\[dict\]): results
+ - data (list): detection results, each element in the list is dict
+ - confidence (float): the confidence of the result
+ - label (str): label
+ - left (int): the upper left corner x coordinate of the detection box
+ - top (int): the upper left corner y coordinate of the detection box
+ - right (int): the lower right corner x coordinate of the detection box
+ - bottom (int): the lower right corner y coordinate of the detection box
+ - save\_path (str, optional): output path for saving results
+
+ - ```python
+ def save_inference_model(dirname)
+ ```
+ - Save model to specific path
+
+ - **Parameters**
+
+ - dirname: model save path
+
+
+## IV.Server Deployment
+
+- PaddleHub Serving can deploy an online service of object detection.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+ - ```shell
+ $ hub serving start -m ssd_vgg16_300_coco2017
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ # Send an HTTP request
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/ssd_vgg16_300_coco2017"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # print prediction results
+ print(r.json()["results"])
+ ```
+
+
+## V.Release Note
+
+* 1.0.0
+
+ First release
+
+* 1.0.2
+
+ Fix the problem of reading numpy
+
+* 1.1.0
+
+ Remove fluid api
+
+ - ```shell
+ $ hub install ssd_vgg16_300_coco2017==1.1.0
+ ```
diff --git a/modules/image/object_detection/ssd_vgg16_300_coco2017/data_feed.py b/modules/image/object_detection/ssd_vgg16_300_coco2017/data_feed.py
index 9fad7c95e..3d3382bb2 100644
--- a/modules/image/object_detection/ssd_vgg16_300_coco2017/data_feed.py
+++ b/modules/image/object_detection/ssd_vgg16_300_coco2017/data_feed.py
@@ -5,12 +5,10 @@
import os
import random
-from collections import OrderedDict
import cv2
import numpy as np
from PIL import Image
-from paddle import fluid
__all__ = ['reader']
diff --git a/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py b/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py
index e0083b95f..beefaf6ab 100644
--- a/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py
+++ b/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py
@@ -7,39 +7,43 @@
from functools import partial
import yaml
+import paddle
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from paddlehub.common.paddle_helper import add_vars_prefix
-from ssd_vgg16_300_coco2017.vgg import VGG
-from ssd_vgg16_300_coco2017.processor import load_label_info, postprocess, base64_to_cv2
-from ssd_vgg16_300_coco2017.data_feed import reader
+from .processor import load_label_info, postprocess, base64_to_cv2
+from .data_feed import reader
@moduleinfo(
name="ssd_vgg16_300_coco2017",
- version="1.0.1",
+ version="1.1.0",
type="cv/object_detection",
summary="SSD with backbone VGG16, trained with dataset COCO.",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class SSDVGG16(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "ssd_vgg16_300_model")
- self.label_names = load_label_info(os.path.join(self.directory, "label_file.txt"))
+class SSDVGG16:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(
+ self.directory, "ssd_vgg16_300_model", "model")
+ self.label_names = load_label_info(
+ os.path.join(self.directory, "label_file.txt"))
self.model_config = None
self._set_config()
def _set_config(self):
- # predictor config setting.
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ """
+ predictor config setting.
+ """
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
cpu_config.switch_ir_optim(False)
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -48,10 +52,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+ self.gpu_predictor = create_predictor(gpu_config)
# model config setting.
if not self.model_config:
@@ -61,73 +65,6 @@ def _set_config(self):
self.multi_box_head_config = self.model_config['MultiBoxHead']
self.output_decoder_config = self.model_config['SSDOutputDecoder']
- def context(self, trainable=True, pretrained=True, get_prediction=False):
- """
- Distill the Head Features, so as to perform transfer learning.
-
- Args:
- trainable (bool): whether to set parameters trainable.
- pretrained (bool): whether to load default pretrained model.
- get_prediction (bool): whether to get prediction.
-
- Returns:
- inputs(dict): the input variables.
- outputs(dict): the output variables.
- context_prog (Program): the program to execute transfer learning.
- """
- context_prog = fluid.Program()
- startup_program = fluid.Program()
- with fluid.program_guard(context_prog, startup_program):
- with fluid.unique_name.guard():
- # image
- image = fluid.layers.data(name='image', shape=[3, 300, 300], dtype='float32')
- # backbone
- backbone = VGG(depth=16, with_extra_blocks=True, normalizations=[20., -1, -1, -1, -1, -1])
- # body_feats
- body_feats = backbone(image)
- # im_size
- im_size = fluid.layers.data(name='im_size', shape=[2], dtype='int32')
- # var_prefix
- var_prefix = '@HUB_{}@'.format(self.name)
- # names of inputs
- inputs = {'image': var_prefix + image.name, 'im_size': var_prefix + im_size.name}
- # names of outputs
- if get_prediction:
- locs, confs, box, box_var = fluid.layers.multi_box_head(
- inputs=body_feats, image=image, num_classes=81, **self.multi_box_head_config)
- pred = fluid.layers.detection_output(
- loc=locs, scores=confs, prior_box=box, prior_box_var=box_var, **self.output_decoder_config)
- outputs = {'bbox_out': [var_prefix + pred.name]}
- else:
- outputs = {'body_features': [var_prefix + var.name for var in body_feats]}
-
- # add_vars_prefix
- add_vars_prefix(context_prog, var_prefix)
- add_vars_prefix(fluid.default_startup_program(), var_prefix)
- # inputs
- inputs = {key: context_prog.global_block().vars[value] for key, value in inputs.items()}
- outputs = {
- out_key: [context_prog.global_block().vars[varname] for varname in out_value]
- for out_key, out_value in outputs.items()
- }
- # trainable
- for param in context_prog.global_block().iter_parameters():
- param.trainable = trainable
-
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- # pretrained
- if pretrained:
-
- def _if_exist(var):
- return os.path.exists(os.path.join(self.default_pretrained_model_path, var.name))
-
- fluid.io.load_vars(exe, self.default_pretrained_model_path, predicate=_if_exist)
- else:
- exe.run(startup_program)
-
- return inputs, outputs, context_prog
-
def object_detection(self,
paths=None,
images=None,
@@ -160,47 +97,31 @@ def object_detection(self,
"""
paths = paths if paths else list()
data_reader = partial(reader, paths, images)
- batch_reader = fluid.io.batch(data_reader, batch_size=batch_size)
+ batch_reader = paddle.batch(data_reader, batch_size=batch_size)
res = []
for iter_id, feed_data in enumerate(batch_reader()):
feed_data = np.array(feed_data)
- image_tensor = PaddleTensor(np.array(list(feed_data[:, 0])).copy())
- if use_gpu:
- data_out = self.gpu_predictor.run([image_tensor])
- else:
- data_out = self.cpu_predictor.run([image_tensor])
- output = postprocess(
- paths=paths,
- images=images,
- data_out=data_out,
- score_thresh=score_thresh,
- label_names=self.label_names,
- output_dir=output_dir,
- handle_id=iter_id * batch_size,
- visualization=visualization)
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 0])))
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+
+ output = postprocess(paths=paths,
+ images=images,
+ data_out=output_handle,
+ score_thresh=score_thresh,
+ label_names=self.label_names,
+ output_dir=output_dir,
+ handle_id=iter_id * batch_size,
+ visualization=visualization)
res.extend(output)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
@@ -220,9 +141,12 @@ def run_cmd(self, argvs):
prog='hub run {}'.format(self.name),
usage='%(prog)s',
add_help=True)
- self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.arg_input_group = self.parser.add_argument_group(
+ title="Input options", description="Input data. Required")
self.arg_config_group = self.parser.add_argument_group(
- title="Config options", description="Run configuration for controlling module behavior, not required.")
+ title="Config options",
+ description=
+ "Run configuration for controlling module behavior, not required.")
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
@@ -240,17 +164,34 @@ def add_module_config_arg(self):
Add the command config options.
"""
self.arg_config_group.add_argument(
- '--use_gpu', type=ast.literal_eval, default=False, help="whether use GPU or not")
+ '--use_gpu',
+ type=ast.literal_eval,
+ default=False,
+ help="whether use GPU or not")
self.arg_config_group.add_argument(
- '--output_dir', type=str, default='detection_result', help="The directory to save output images.")
+ '--output_dir',
+ type=str,
+ default='detection_result',
+ help="The directory to save output images.")
self.arg_config_group.add_argument(
- '--visualization', type=ast.literal_eval, default=False, help="whether to save output as images.")
+ '--visualization',
+ type=ast.literal_eval,
+ default=False,
+ help="whether to save output as images.")
def add_module_input_arg(self):
"""
Add the command input options.
"""
- self.arg_input_group.add_argument('--input_path', type=str, help="path to image.")
- self.arg_input_group.add_argument('--batch_size', type=ast.literal_eval, default=1, help="batch size.")
self.arg_input_group.add_argument(
- '--score_thresh', type=ast.literal_eval, default=0.5, help="threshold for object detecion.")
+ '--input_path', type=str, help="path to image.")
+ self.arg_input_group.add_argument(
+ '--batch_size',
+ type=ast.literal_eval,
+ default=1,
+ help="batch size.")
+ self.arg_input_group.add_argument(
+ '--score_thresh',
+ type=ast.literal_eval,
+ default=0.5,
+ help="threshold for object detecion.")
diff --git a/modules/image/object_detection/ssd_vgg16_300_coco2017/processor.py b/modules/image/object_detection/ssd_vgg16_300_coco2017/processor.py
index ff4eb9fe5..9bf964540 100644
--- a/modules/image/object_detection/ssd_vgg16_300_coco2017/processor.py
+++ b/modules/image/object_detection/ssd_vgg16_300_coco2017/processor.py
@@ -85,7 +85,7 @@ def load_label_info(file_path):
def postprocess(paths, images, data_out, score_thresh, label_names, output_dir, handle_id, visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): the path of images.
@@ -108,9 +108,9 @@ def postprocess(paths, images, data_out, score_thresh, label_names, output_dir,
confidence (float): The confidence of detection result.
save_path (str): The path to save output images.
"""
- lod_tensor = data_out[0]
- lod = lod_tensor.lod[0]
- results = lod_tensor.as_ndarray()
+ lod = data_out.lod()[0]
+ results = data_out.copy_to_cpu()
+
if handle_id < len(paths):
unhandled_paths = paths[handle_id:]
unhandled_paths_num = len(unhandled_paths)
diff --git a/modules/image/object_detection/ssd_vgg16_300_coco2017/test.py b/modules/image/object_detection/ssd_vgg16_300_coco2017/test.py
new file mode 100644
index 000000000..922f3b601
--- /dev/null
+++ b/modules/image/object_detection/ssd_vgg16_300_coco2017/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/68313e182f5e4ad9907e69dac9ece8fc50840d7ffbd24fa88396f009958f969a'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="ssd_vgg16_300_coco2017")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ cv2.error,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/modules/image/object_detection/ssd_vgg16_300_coco2017/vgg.py b/modules/image/object_detection/ssd_vgg16_300_coco2017/vgg.py
deleted file mode 100644
index d950c6b55..000000000
--- a/modules/image/object_detection/ssd_vgg16_300_coco2017/vgg.py
+++ /dev/null
@@ -1,184 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-
-__all__ = ['VGG']
-
-
-class VGG(object):
- """
- VGG, see https://arxiv.org/abs/1409.1556
-
- Args:
- depth (int): the VGG net depth (16 or 19)
- normalizations (list): params list of init scale in l2 norm, skip init
- scale if param is -1.
- with_extra_blocks (bool): whether or not extra blocks should be added
- extra_block_filters (list): in each extra block, params:
- [in_channel, out_channel, padding_size, stride_size, filter_size]
- class_dim (int): number of class while classification
- """
-
- def __init__(self,
- depth=16,
- with_extra_blocks=False,
- normalizations=[20., -1, -1, -1, -1, -1],
- extra_block_filters=[[256, 512, 1, 2, 3], [128, 256, 1, 2, 3], [128, 256, 0, 1, 3],
- [128, 256, 0, 1, 3]],
- class_dim=1000):
- assert depth in [16, 19], "depth {} not in [16, 19]"
- self.depth = depth
- self.depth_cfg = {16: [2, 2, 3, 3, 3], 19: [2, 2, 4, 4, 4]}
- self.with_extra_blocks = with_extra_blocks
- self.normalizations = normalizations
- self.extra_block_filters = extra_block_filters
- self.class_dim = class_dim
-
- def __call__(self, input):
- layers = []
- layers += self._vgg_block(input)
-
- if not self.with_extra_blocks:
- return layers[-1]
-
- layers += self._add_extras_block(layers[-1])
- norm_cfg = self.normalizations
- for k, v in enumerate(layers):
- if not norm_cfg[k] == -1:
- layers[k] = self._l2_norm_scale(v, init_scale=norm_cfg[k])
-
- return layers
-
- def _vgg_block(self, input):
- nums = self.depth_cfg[self.depth]
- vgg_base = [64, 128, 256, 512, 512]
- conv = input
- res_layer = []
- layers = []
- for k, v in enumerate(vgg_base):
- conv = self._conv_block(conv, v, nums[k], name="conv{}_".format(k + 1))
- layers.append(conv)
- if self.with_extra_blocks:
- if k == 4:
- conv = self._pooling_block(conv, 3, 1, pool_padding=1)
- else:
- conv = self._pooling_block(conv, 2, 2)
- else:
- conv = self._pooling_block(conv, 2, 2)
- if not self.with_extra_blocks:
- fc_dim = 4096
- fc_name = ["fc6", "fc7", "fc8"]
- fc1 = fluid.layers.fc(
- input=conv,
- size=fc_dim,
- act='relu',
- param_attr=fluid.param_attr.ParamAttr(name=fc_name[0] + "_weights"),
- bias_attr=fluid.param_attr.ParamAttr(name=fc_name[0] + "_offset"))
- fc2 = fluid.layers.fc(
- input=fc1,
- size=fc_dim,
- act='relu',
- param_attr=fluid.param_attr.ParamAttr(name=fc_name[1] + "_weights"),
- bias_attr=fluid.param_attr.ParamAttr(name=fc_name[1] + "_offset"))
- out = fluid.layers.fc(
- input=fc2,
- size=self.class_dim,
- param_attr=fluid.param_attr.ParamAttr(name=fc_name[2] + "_weights"),
- bias_attr=fluid.param_attr.ParamAttr(name=fc_name[2] + "_offset"))
- out = fluid.layers.softmax(out)
- res_layer.append(out)
- return [out]
- else:
- fc6 = self._conv_layer(conv, 1024, 3, 1, 6, dilation=6, name="fc6")
- fc7 = self._conv_layer(fc6, 1024, 1, 1, 0, name="fc7")
- return [layers[3], fc7]
-
- def _add_extras_block(self, input):
- cfg = self.extra_block_filters
- conv = input
- layers = []
- for k, v in enumerate(cfg):
- assert len(v) == 5, "extra_block_filters size not fix"
- conv = self._extra_block(conv, v[0], v[1], v[2], v[3], v[4], name="conv{}_".format(6 + k))
- layers.append(conv)
-
- return layers
-
- def _conv_block(self, input, num_filter, groups, name=None):
- conv = input
- for i in range(groups):
- conv = self._conv_layer(
- input=conv,
- num_filters=num_filter,
- filter_size=3,
- stride=1,
- padding=1,
- act='relu',
- name=name + str(i + 1))
- return conv
-
- def _extra_block(self, input, num_filters1, num_filters2, padding_size, stride_size, filter_size, name=None):
- # 1x1 conv
- conv_1 = self._conv_layer(
- input=input, num_filters=int(num_filters1), filter_size=1, stride=1, act='relu', padding=0, name=name + "1")
-
- # 3x3 conv
- conv_2 = self._conv_layer(
- input=conv_1,
- num_filters=int(num_filters2),
- filter_size=filter_size,
- stride=stride_size,
- act='relu',
- padding=padding_size,
- name=name + "2")
- return conv_2
-
- def _conv_layer(self,
- input,
- num_filters,
- filter_size,
- stride,
- padding,
- dilation=1,
- act='relu',
- use_cudnn=True,
- name=None):
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- dilation=dilation,
- act=act,
- use_cudnn=use_cudnn,
- param_attr=ParamAttr(name=name + "_weights"),
- bias_attr=ParamAttr(name=name + "_biases") if self.with_extra_blocks else False,
- name=name + '.conv2d.output.1')
- return conv
-
- def _pooling_block(self, conv, pool_size, pool_stride, pool_padding=0, ceil_mode=True):
- pool = fluid.layers.pool2d(
- input=conv,
- pool_size=pool_size,
- pool_type='max',
- pool_stride=pool_stride,
- pool_padding=pool_padding,
- ceil_mode=ceil_mode)
- return pool
-
- def _l2_norm_scale(self, input, init_scale=1.0, channel_shared=False):
- from paddle.fluid.layer_helper import LayerHelper
- from paddle.fluid.initializer import Constant
- helper = LayerHelper("Scale")
- l2_norm = fluid.layers.l2_normalize(input, axis=1) # l2 norm along channel
- shape = [1] if channel_shared else [input.shape[1]]
- scale = helper.create_parameter(
- attr=helper.param_attr, shape=shape, dtype=input.dtype, default_initializer=Constant(init_scale))
- out = fluid.layers.elementwise_mul(
- x=l2_norm, y=scale, axis=-1 if channel_shared else 1, name="conv4_3_norm_scale")
- return out
From 0ed21a48f1cd9330209a8b436b19c87fdc4f8fa8 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 14:50:47 +0800
Subject: [PATCH 058/117] update ssd_vgg16_512_coco2017 (#1950)
* update ssd_vgg16_512_model
* update unittest
* update unittest
* update gpu config
* update
* add clean func
* update save inference model
Co-authored-by: wuzewu
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -166,6 +160,10 @@
修复numpy数据读取问题
+* 1.1.0
+
+ 移除 fluid api
+
- ```shell
- $ hub install ssd_vgg16_512_coco2017==1.0.2
+ $ hub install ssd_vgg16_512_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/ssd_vgg16_512_coco2017/README_en.md b/modules/image/object_detection/ssd_vgg16_512_coco2017/README_en.md
index 0d862abcf..38da1460c 100644
--- a/modules/image/object_detection/ssd_vgg16_512_coco2017/README_en.md
+++ b/modules/image/object_detection/ssd_vgg16_512_coco2017/README_en.md
@@ -100,19 +100,13 @@
- save\_path (str, optional): output path for saving results
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -166,6 +160,10 @@
Fix the problem of reading numpy
+* 1.1.0
+
+ 移除 fluid api
+
- ```shell
- $ hub install ssd_vgg16_512_coco2017==1.0.2
+ $ hub install ssd_vgg16_512_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/ssd_vgg16_512_coco2017/data_feed.py b/modules/image/object_detection/ssd_vgg16_512_coco2017/data_feed.py
index c1994f116..a235f9b0c 100644
--- a/modules/image/object_detection/ssd_vgg16_512_coco2017/data_feed.py
+++ b/modules/image/object_detection/ssd_vgg16_512_coco2017/data_feed.py
@@ -5,12 +5,10 @@
import os
import random
-from collections import OrderedDict
import cv2
import numpy as np
from PIL import Image
-from paddle import fluid
__all__ = ['reader']
diff --git a/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py b/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py
index 9f8e3eb64..a4e8da16e 100644
--- a/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py
+++ b/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py
@@ -7,41 +7,43 @@
from functools import partial
import yaml
+import paddle
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from paddlehub.common.paddle_helper import add_vars_prefix
-from ssd_vgg16_512_coco2017.vgg import VGG
-from ssd_vgg16_512_coco2017.processor import load_label_info, postprocess, base64_to_cv2
-from ssd_vgg16_512_coco2017.data_feed import reader
+from .processor import load_label_info, postprocess, base64_to_cv2
+from .data_feed import reader
@moduleinfo(
name="ssd_vgg16_512_coco2017",
- version="1.0.2",
+ version="1.1.0",
type="cv/object_detection",
summary="SSD with backbone VGG16, trained with dataset COCO.",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class SSDVGG16_512(hub.Module):
- def _initialize(self):
+class SSDVGG16_512:
+ def __init__(self):
self.default_pretrained_model_path = os.path.join(
- self.directory, "ssd_vgg16_512_model")
+ self.directory, "ssd_vgg16_512_model", "model")
self.label_names = load_label_info(
os.path.join(self.directory, "label_file.txt"))
self.model_config = None
self._set_config()
def _set_config(self):
- # predictor config setting.
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ """
+ predictor config setting.
+ """
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
cpu_config.switch_ir_optim(False)
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -50,10 +52,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+ self.gpu_predictor = create_predictor(gpu_config)
# model config setting.
if not self.model_config:
@@ -63,107 +65,6 @@ def _set_config(self):
self.multi_box_head_config = self.model_config['MultiBoxHead']
self.output_decoder_config = self.model_config['SSDOutputDecoder']
- def context(self, trainable=True, pretrained=True, get_prediction=False):
- """
- Distill the Head Features, so as to perform transfer learning.
-
- Args:
- trainable (bool): whether to set parameters trainable.
- pretrained (bool): whether to load default pretrained model.
- get_prediction (bool): whether to get prediction.
-
- Returns:
- inputs(dict): the input variables.
- outputs(dict): the output variables.
- context_prog (Program): the program to execute transfer learning.
- """
- context_prog = fluid.Program()
- startup_program = fluid.Program()
- with fluid.program_guard(context_prog, startup_program):
- with fluid.unique_name.guard():
- # image
- image = fluid.layers.data(
- name='image', shape=[3, 512, 512], dtype='float32')
- # backbone
- backbone = VGG(
- depth=16,
- with_extra_blocks=True,
- normalizations=[20., -1, -1, -1, -1, -1, -1],
- extra_block_filters=[[256, 512, 1, 2,
- 3], [128, 256, 1, 2, 3],
- [128, 256, 1, 2,
- 3], [128, 256, 1, 2, 3],
- [128, 256, 1, 1, 4]])
- # body_feats
- body_feats = backbone(image)
- # im_size
- im_size = fluid.layers.data(
- name='im_size', shape=[2], dtype='int32')
- # var_prefix
- var_prefix = '@HUB_{}@'.format(self.name)
- # names of inputs
- inputs = {
- 'image': var_prefix + image.name,
- 'im_size': var_prefix + im_size.name
- }
- # names of outputs
- if get_prediction:
- locs, confs, box, box_var = fluid.layers.multi_box_head(
- inputs=body_feats,
- image=image,
- num_classes=81,
- **self.multi_box_head_config)
- pred = fluid.layers.detection_output(
- loc=locs,
- scores=confs,
- prior_box=box,
- prior_box_var=box_var,
- **self.output_decoder_config)
- outputs = {'bbox_out': [var_prefix + pred.name]}
- else:
- outputs = {
- 'body_features':
- [var_prefix + var.name for var in body_feats]
- }
-
- # add_vars_prefix
- add_vars_prefix(context_prog, var_prefix)
- add_vars_prefix(fluid.default_startup_program(), var_prefix)
- # inputs
- inputs = {
- key: context_prog.global_block().vars[value]
- for key, value in inputs.items()
- }
- outputs = {
- out_key: [
- context_prog.global_block().vars[varname]
- for varname in out_value
- ]
- for out_key, out_value in outputs.items()
- }
- # trainable
- for param in context_prog.global_block().iter_parameters():
- param.trainable = trainable
-
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- # pretrained
- if pretrained:
-
- def _if_exist(var):
- return os.path.exists(
- os.path.join(self.default_pretrained_model_path,
- var.name))
-
- fluid.io.load_vars(
- exe,
- self.default_pretrained_model_path,
- predicate=_if_exist)
- else:
- exe.run(startup_program)
-
- return inputs, outputs, context_prog
-
def object_detection(self,
paths=None,
images=None,
@@ -205,51 +106,31 @@ def object_detection(self,
paths = paths if paths else list()
data_reader = partial(reader, paths, images)
- batch_reader = fluid.io.batch(data_reader, batch_size=batch_size)
+ batch_reader = paddle.batch(data_reader, batch_size=batch_size)
res = []
for iter_id, feed_data in enumerate(batch_reader()):
feed_data = np.array(feed_data)
- image_tensor = PaddleTensor(np.array(list(feed_data[:, 0])).copy())
- if use_gpu:
- data_out = self.gpu_predictor.run([image_tensor])
- else:
- data_out = self.cpu_predictor.run([image_tensor])
- output = postprocess(
- paths=paths,
- images=images,
- data_out=data_out,
- score_thresh=score_thresh,
- label_names=self.label_names,
- output_dir=output_dir,
- handle_id=iter_id * batch_size,
- visualization=visualization)
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 0])))
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+
+ output = postprocess(paths=paths,
+ images=images,
+ data_out=output_handle,
+ score_thresh=score_thresh,
+ label_names=self.label_names,
+ output_dir=output_dir,
+ handle_id=iter_id * batch_size,
+ visualization=visualization)
res.extend(output)
return res
- def save_inference_model(self,
- dirname,
- model_filename=None,
- params_filename=None,
- combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/object_detection/ssd_vgg16_512_coco2017/processor.py b/modules/image/object_detection/ssd_vgg16_512_coco2017/processor.py
index 82b2335f6..5079f50cd 100644
--- a/modules/image/object_detection/ssd_vgg16_512_coco2017/processor.py
+++ b/modules/image/object_detection/ssd_vgg16_512_coco2017/processor.py
@@ -104,7 +104,7 @@ def postprocess(paths,
handle_id,
visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): the path of images.
@@ -127,9 +127,8 @@ def postprocess(paths,
confidence (float): The confidence of detection result.
save_path (str): The path to save output images.
"""
- lod_tensor = data_out[0]
- lod = lod_tensor.lod[0]
- results = lod_tensor.as_ndarray()
+ lod = data_out.lod()[0]
+ results = data_out.copy_to_cpu()
check_dir(output_dir)
diff --git a/modules/image/object_detection/ssd_vgg16_512_coco2017/test.py b/modules/image/object_detection/ssd_vgg16_512_coco2017/test.py
new file mode 100644
index 000000000..f6c72cfb6
--- /dev/null
+++ b/modules/image/object_detection/ssd_vgg16_512_coco2017/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/68313e182f5e4ad9907e69dac9ece8fc50840d7ffbd24fa88396f009958f969a'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="ssd_vgg16_512_coco2017")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ cv2.error,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/modules/image/object_detection/ssd_vgg16_512_coco2017/vgg.py b/modules/image/object_detection/ssd_vgg16_512_coco2017/vgg.py
deleted file mode 100644
index dc760f328..000000000
--- a/modules/image/object_detection/ssd_vgg16_512_coco2017/vgg.py
+++ /dev/null
@@ -1,224 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-
-__all__ = ['VGG']
-
-
-class VGG(object):
- """
- VGG, see https://arxiv.org/abs/1409.1556
-
- Args:
- depth (int): the VGG net depth (16 or 19)
- normalizations (list): params list of init scale in l2 norm, skip init
- scale if param is -1.
- with_extra_blocks (bool): whether or not extra blocks should be added
- extra_block_filters (list): in each extra block, params:
- [in_channel, out_channel, padding_size, stride_size, filter_size]
- class_dim (int): number of class while classification
- """
-
- def __init__(self,
- depth=16,
- with_extra_blocks=False,
- normalizations=[20., -1, -1, -1, -1, -1],
- extra_block_filters=[[256, 512, 1, 2, 3], [128, 256, 1, 2, 3],
- [128, 256, 0, 1, 3], [128, 256, 0, 1, 3]],
- class_dim=1000):
- assert depth in [16, 19], "depth {} not in [16, 19]"
- self.depth = depth
- self.depth_cfg = {16: [2, 2, 3, 3, 3], 19: [2, 2, 4, 4, 4]}
- self.with_extra_blocks = with_extra_blocks
- self.normalizations = normalizations
- self.extra_block_filters = extra_block_filters
- self.class_dim = class_dim
-
- def __call__(self, input):
- layers = []
- layers += self._vgg_block(input)
-
- if not self.with_extra_blocks:
- return layers[-1]
-
- layers += self._add_extras_block(layers[-1])
- norm_cfg = self.normalizations
- for k, v in enumerate(layers):
- if not norm_cfg[k] == -1:
- layers[k] = self._l2_norm_scale(v, init_scale=norm_cfg[k])
-
- return layers
-
- def _vgg_block(self, input):
- nums = self.depth_cfg[self.depth]
- vgg_base = [64, 128, 256, 512, 512]
- conv = input
- res_layer = []
- layers = []
- for k, v in enumerate(vgg_base):
- conv = self._conv_block(
- conv, v, nums[k], name="conv{}_".format(k + 1))
- layers.append(conv)
- if self.with_extra_blocks:
- if k == 4:
- conv = self._pooling_block(conv, 3, 1, pool_padding=1)
- else:
- conv = self._pooling_block(conv, 2, 2)
- else:
- conv = self._pooling_block(conv, 2, 2)
- if not self.with_extra_blocks:
- fc_dim = 4096
- fc_name = ["fc6", "fc7", "fc8"]
- fc1 = fluid.layers.fc(
- input=conv,
- size=fc_dim,
- act='relu',
- param_attr=fluid.param_attr.ParamAttr(
- name=fc_name[0] + "_weights"),
- bias_attr=fluid.param_attr.ParamAttr(
- name=fc_name[0] + "_offset"))
- fc2 = fluid.layers.fc(
- input=fc1,
- size=fc_dim,
- act='relu',
- param_attr=fluid.param_attr.ParamAttr(
- name=fc_name[1] + "_weights"),
- bias_attr=fluid.param_attr.ParamAttr(
- name=fc_name[1] + "_offset"))
- out = fluid.layers.fc(
- input=fc2,
- size=self.class_dim,
- param_attr=fluid.param_attr.ParamAttr(
- name=fc_name[2] + "_weights"),
- bias_attr=fluid.param_attr.ParamAttr(
- name=fc_name[2] + "_offset"))
- out = fluid.layers.softmax(out)
- res_layer.append(out)
- return [out]
- else:
- fc6 = self._conv_layer(conv, 1024, 3, 1, 6, dilation=6, name="fc6")
- fc7 = self._conv_layer(fc6, 1024, 1, 1, 0, name="fc7")
- return [layers[3], fc7]
-
- def _add_extras_block(self, input):
- cfg = self.extra_block_filters
- conv = input
- layers = []
- for k, v in enumerate(cfg):
- assert len(v) == 5, "extra_block_filters size not fix"
- conv = self._extra_block(
- conv,
- v[0],
- v[1],
- v[2],
- v[3],
- v[4],
- name="conv{}_".format(6 + k))
- layers.append(conv)
-
- return layers
-
- def _conv_block(self, input, num_filter, groups, name=None):
- conv = input
- for i in range(groups):
- conv = self._conv_layer(
- input=conv,
- num_filters=num_filter,
- filter_size=3,
- stride=1,
- padding=1,
- act='relu',
- name=name + str(i + 1))
- return conv
-
- def _extra_block(self,
- input,
- num_filters1,
- num_filters2,
- padding_size,
- stride_size,
- filter_size,
- name=None):
- # 1x1 conv
- conv_1 = self._conv_layer(
- input=input,
- num_filters=int(num_filters1),
- filter_size=1,
- stride=1,
- act='relu',
- padding=0,
- name=name + "1")
-
- # 3x3 conv
- conv_2 = self._conv_layer(
- input=conv_1,
- num_filters=int(num_filters2),
- filter_size=filter_size,
- stride=stride_size,
- act='relu',
- padding=padding_size,
- name=name + "2")
- return conv_2
-
- def _conv_layer(self,
- input,
- num_filters,
- filter_size,
- stride,
- padding,
- dilation=1,
- act='relu',
- use_cudnn=True,
- name=None):
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- dilation=dilation,
- act=act,
- use_cudnn=use_cudnn,
- param_attr=ParamAttr(name=name + "_weights"),
- bias_attr=ParamAttr(
- name=name + "_biases") if self.with_extra_blocks else False,
- name=name + '.conv2d.output.1')
- return conv
-
- def _pooling_block(self,
- conv,
- pool_size,
- pool_stride,
- pool_padding=0,
- ceil_mode=True):
- pool = fluid.layers.pool2d(
- input=conv,
- pool_size=pool_size,
- pool_type='max',
- pool_stride=pool_stride,
- pool_padding=pool_padding,
- ceil_mode=ceil_mode)
- return pool
-
- def _l2_norm_scale(self, input, init_scale=1.0, channel_shared=False):
- from paddle.fluid.layer_helper import LayerHelper
- from paddle.fluid.initializer import Constant
- helper = LayerHelper("Scale")
- l2_norm = fluid.layers.l2_normalize(
- input, axis=1) # l2 norm along channel
- shape = [1] if channel_shared else [input.shape[1]]
- scale = helper.create_parameter(
- attr=helper.param_attr,
- shape=shape,
- dtype=input.dtype,
- default_initializer=Constant(init_scale))
- out = fluid.layers.elementwise_mul(
- x=l2_norm,
- y=scale,
- axis=-1 if channel_shared else 1,
- name="conv4_3_norm_scale")
- return out
From 3d3ca6579584b0aa98713857d3e95575ed455702 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:01:47 +0800
Subject: [PATCH 059/117] update yolov3_darknet53_coco2017 (#1951)
* update ssd_vgg16_512_coco2017
* update unittest
* update unittest
* update version
* update gpu config
* update
* add clean func
* update save inference model
Co-authored-by: chenjian
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -165,6 +159,9 @@
* 1.1.1
修复numpy数据读取问题
+* 1.2.0
+ 移除 fluid api
+
- ```shell
- $ hub install yolov3_darknet53_coco2017==1.1.1
+ $ hub install yolov3_darknet53_coco2017==1.2.0
```
diff --git a/modules/image/object_detection/yolov3_darknet53_coco2017/README_en.md b/modules/image/object_detection/yolov3_darknet53_coco2017/README_en.md
index b6757ff38..a50f62780 100644
--- a/modules/image/object_detection/yolov3_darknet53_coco2017/README_en.md
+++ b/modules/image/object_detection/yolov3_darknet53_coco2017/README_en.md
@@ -99,19 +99,13 @@
- save\_path (str, optional): output path for saving results
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -164,6 +158,9 @@
* 1.1.1
Fix the problem of reading numpy
+* 1.2.0
+ Remove fluid api
+
- ```shell
- $ hub install yolov3_darknet53_coco2017==1.1.1
+ $ hub install yolov3_darknet53_coco2017==1.2.0
```
diff --git a/modules/image/object_detection/yolov3_darknet53_coco2017/darknet.py b/modules/image/object_detection/yolov3_darknet53_coco2017/darknet.py
deleted file mode 100644
index fe925fb4c..000000000
--- a/modules/image/object_detection/yolov3_darknet53_coco2017/darknet.py
+++ /dev/null
@@ -1,121 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import six
-import math
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.regularizer import L2Decay
-
-__all__ = ['DarkNet']
-
-
-class DarkNet(object):
- """DarkNet, see https://pjreddie.com/darknet/yolo/
-
- Args:
- depth (int): network depth, currently only darknet 53 is supported
- norm_type (str): normalization type, 'bn' and 'sync_bn' are supported
- norm_decay (float): weight decay for normalization layer weights
- get_prediction (bool): whether to get prediction
- class_dim (int): number of class while classification
- """
-
- def __init__(self,
- depth=53,
- norm_type='sync_bn',
- norm_decay=0.,
- weight_prefix_name='',
- get_prediction=False,
- class_dim=1000):
- assert depth in [53], "unsupported depth value"
- self.depth = depth
- self.norm_type = norm_type
- self.norm_decay = norm_decay
- self.depth_cfg = {53: ([1, 2, 8, 8, 4], self.basicblock)}
- self.prefix_name = weight_prefix_name
- self.class_dim = class_dim
- self.get_prediction = get_prediction
-
- def _conv_norm(self, input, ch_out, filter_size, stride, padding, act='leaky', name=None):
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=ch_out,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- act=None,
- param_attr=ParamAttr(name=name + ".conv.weights"),
- bias_attr=False)
-
- bn_name = name + ".bn"
- bn_param_attr = ParamAttr(regularizer=L2Decay(float(self.norm_decay)), name=bn_name + '.scale')
- bn_bias_attr = ParamAttr(regularizer=L2Decay(float(self.norm_decay)), name=bn_name + '.offset')
-
- out = fluid.layers.batch_norm(
- input=conv,
- act=None,
- param_attr=bn_param_attr,
- bias_attr=bn_bias_attr,
- moving_mean_name=bn_name + '.mean',
- moving_variance_name=bn_name + '.var')
-
- # leaky relu here has `alpha` as 0.1, can not be set by
- # `act` param in fluid.layers.batch_norm above.
- if act == 'leaky':
- out = fluid.layers.leaky_relu(x=out, alpha=0.1)
-
- return out
-
- def _downsample(self, input, ch_out, filter_size=3, stride=2, padding=1, name=None):
- return self._conv_norm(input, ch_out=ch_out, filter_size=filter_size, stride=stride, padding=padding, name=name)
-
- def basicblock(self, input, ch_out, name=None):
- conv1 = self._conv_norm(input, ch_out=ch_out, filter_size=1, stride=1, padding=0, name=name + ".0")
- conv2 = self._conv_norm(conv1, ch_out=ch_out * 2, filter_size=3, stride=1, padding=1, name=name + ".1")
- out = fluid.layers.elementwise_add(x=input, y=conv2, act=None)
- return out
-
- def layer_warp(self, block_func, input, ch_out, count, name=None):
- out = block_func(input, ch_out=ch_out, name='{}.0'.format(name))
- for j in six.moves.xrange(1, count):
- out = block_func(out, ch_out=ch_out, name='{}.{}'.format(name, j))
- return out
-
- def __call__(self, input):
- """
- Get the backbone of DarkNet, that is output for the 5 stages.
- """
- stages, block_func = self.depth_cfg[self.depth]
- stages = stages[0:5]
- conv = self._conv_norm(
- input=input, ch_out=32, filter_size=3, stride=1, padding=1, name=self.prefix_name + "yolo_input")
- downsample_ = self._downsample(
- input=conv, ch_out=conv.shape[1] * 2, name=self.prefix_name + "yolo_input.downsample")
- blocks = []
- for i, stage in enumerate(stages):
- block = self.layer_warp(
- block_func=block_func,
- input=downsample_,
- ch_out=32 * 2**i,
- count=stage,
- name=self.prefix_name + "stage.{}".format(i))
- blocks.append(block)
- if i < len(stages) - 1: # do not downsaple in the last stage
- downsample_ = self._downsample(
- input=block, ch_out=block.shape[1] * 2, name=self.prefix_name + "stage.{}.downsample".format(i))
- if self.get_prediction:
- pool = fluid.layers.pool2d(input=block, pool_type='avg', global_pooling=True)
- stdv = 1.0 / math.sqrt(pool.shape[1] * 1.0)
- out = fluid.layers.fc(
- input=pool,
- size=self.class_dim,
- param_attr=ParamAttr(initializer=fluid.initializer.Uniform(-stdv, stdv), name='fc_weights'),
- bias_attr=ParamAttr(name='fc_offset'))
- out = fluid.layers.softmax(out)
- return out
- else:
- return blocks
diff --git a/modules/image/object_detection/yolov3_darknet53_coco2017/module.py b/modules/image/object_detection/yolov3_darknet53_coco2017/module.py
index 7886ef4e6..4b219bc5f 100644
--- a/modules/image/object_detection/yolov3_darknet53_coco2017/module.py
+++ b/modules/image/object_detection/yolov3_darknet53_coco2017/module.py
@@ -6,29 +6,27 @@
import os
from functools import partial
+import paddle
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle.jit
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from paddlehub.common.paddle_helper import add_vars_prefix
-from yolov3_darknet53_coco2017.darknet import DarkNet
-from yolov3_darknet53_coco2017.processor import load_label_info, postprocess, base64_to_cv2
-from yolov3_darknet53_coco2017.data_feed import reader
-from yolov3_darknet53_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
+from .processor import load_label_info, postprocess, base64_to_cv2
+from .data_feed import reader
@moduleinfo(
name="yolov3_darknet53_coco2017",
- version="1.1.1",
+ version="1.2.0",
type="CV/object_detection",
summary="Baidu's YOLOv3 model for object detection, with backbone DarkNet53, trained with dataset coco2017.",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class YOLOv3DarkNet53Coco2017(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "yolov3_darknet53_model")
+class YOLOv3DarkNet53Coco2017:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "yolov3_darknet53_model", "model")
self.label_names = load_label_info(os.path.join(self.directory, "label_file.txt"))
self._set_config()
@@ -36,11 +34,13 @@ def _set_config(self):
"""
predictor config setting.
"""
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
cpu_config.switch_ir_optim(False)
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -49,88 +49,14 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
-
- def context(self, trainable=True, pretrained=True, get_prediction=False):
- """
- Distill the Head Features, so as to perform transfer learning.
-
- Args:
- trainable (bool): whether to set parameters trainable.
- pretrained (bool): whether to load default pretrained model.
- get_prediction (bool): whether to get prediction.
-
- Returns:
- inputs(dict): the input variables.
- outputs(dict): the output variables.
- context_prog (Program): the program to execute transfer learning.
- """
- context_prog = fluid.Program()
- startup_program = fluid.Program()
- with fluid.program_guard(context_prog, startup_program):
- with fluid.unique_name.guard():
- # image
- image = fluid.layers.data(name='image', shape=[3, 608, 608], dtype='float32')
- # backbone
- backbone = DarkNet(norm_type='bn', norm_decay=0., depth=53)
- # body_feats
- body_feats = backbone(image)
- # im_size
- im_size = fluid.layers.data(name='im_size', shape=[2], dtype='int32')
- # yolo_head
- yolo_head = YOLOv3Head(num_classes=80)
- # head_features
- head_features, body_features = yolo_head._get_outputs(body_feats, is_train=trainable)
-
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- exe.run(fluid.default_startup_program())
-
- # var_prefix
- var_prefix = '@HUB_{}@'.format(self.name)
- # name of inputs
- inputs = {'image': var_prefix + image.name, 'im_size': var_prefix + im_size.name}
- # name of outputs
- if get_prediction:
- bbox_out = yolo_head.get_prediction(head_features, im_size)
- outputs = {'bbox_out': [var_prefix + bbox_out.name]}
- else:
- outputs = {
- 'head_features': [var_prefix + var.name for var in head_features],
- 'body_features': [var_prefix + var.name for var in body_features]
- }
- # add_vars_prefix
- add_vars_prefix(context_prog, var_prefix)
- add_vars_prefix(fluid.default_startup_program(), var_prefix)
- # inputs
- inputs = {key: context_prog.global_block().vars[value] for key, value in inputs.items()}
- # outputs
- outputs = {
- key: [context_prog.global_block().vars[varname] for varname in value]
- for key, value in outputs.items()
- }
- # trainable
- for param in context_prog.global_block().iter_parameters():
- param.trainable = trainable
- # pretrained
- if pretrained:
-
- def _if_exist(var):
- return os.path.exists(os.path.join(self.default_pretrained_model_path, var.name))
-
- fluid.io.load_vars(exe, self.default_pretrained_model_path, predicate=_if_exist)
- else:
- exe.run(startup_program)
-
- return inputs, outputs, context_prog
+ self.gpu_predictor = create_predictor(gpu_config)
def object_detection(self,
paths=None,
images=None,
- data=None,
batch_size=1,
use_gpu=False,
output_dir='detection_result',
@@ -168,52 +94,34 @@ def object_detection(self,
)
paths = paths if paths else list()
- if data and 'image' in data:
- paths += data['image']
-
data_reader = partial(reader, paths, images)
- batch_reader = fluid.io.batch(data_reader, batch_size=batch_size)
+ batch_reader = paddle.batch(data_reader, batch_size=batch_size)
res = []
for iter_id, feed_data in enumerate(batch_reader()):
feed_data = np.array(feed_data)
- image_tensor = PaddleTensor(np.array(list(feed_data[:, 0])))
- im_size_tensor = PaddleTensor(np.array(list(feed_data[:, 1])))
- if use_gpu:
- data_out = self.gpu_predictor.run([image_tensor, im_size_tensor])
- else:
- data_out = self.cpu_predictor.run([image_tensor, im_size_tensor])
- output = postprocess(
- paths=paths,
- images=images,
- data_out=data_out,
- score_thresh=score_thresh,
- label_names=self.label_names,
- output_dir=output_dir,
- handle_id=iter_id * batch_size,
- visualization=visualization)
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 0])))
+ input_handle = predictor.get_input_handle(input_names[1])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 1])))
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+
+ output = postprocess(paths=paths,
+ images=images,
+ data_out=output_handle,
+ score_thresh=score_thresh,
+ label_names=self.label_names,
+ output_dir=output_dir,
+ handle_id=iter_id * batch_size,
+ visualization=visualization)
res.extend(output)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/object_detection/yolov3_darknet53_coco2017/processor.py b/modules/image/object_detection/yolov3_darknet53_coco2017/processor.py
index 64049e42b..b3770fc5a 100644
--- a/modules/image/object_detection/yolov3_darknet53_coco2017/processor.py
+++ b/modules/image/object_detection/yolov3_darknet53_coco2017/processor.py
@@ -88,7 +88,7 @@ def load_label_info(file_path):
def postprocess(paths, images, data_out, score_thresh, label_names, output_dir, handle_id, visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): The paths of images.
@@ -113,9 +113,8 @@ def postprocess(paths, images, data_out, score_thresh, label_names, output_dir,
confidence (float): The confidence of detection result.
save_path (str): The path to save output images.
"""
- lod_tensor = data_out[0]
- lod = lod_tensor.lod[0]
- results = lod_tensor.as_ndarray()
+ lod = data_out.lod()[0]
+ results = data_out.copy_to_cpu()
check_dir(output_dir)
diff --git a/modules/image/object_detection/yolov3_darknet53_coco2017/test.py b/modules/image/object_detection/yolov3_darknet53_coco2017/test.py
new file mode 100644
index 000000000..af430ee3d
--- /dev/null
+++ b/modules/image/object_detection/yolov3_darknet53_coco2017/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/68313e182f5e4ad9907e69dac9ece8fc50840d7ffbd24fa88396f009958f969a'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="yolov3_darknet53_coco2017")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
\ No newline at end of file
diff --git a/modules/image/object_detection/yolov3_darknet53_coco2017/yolo_head.py b/modules/image/object_detection/yolov3_darknet53_coco2017/yolo_head.py
deleted file mode 100644
index cfe796c2e..000000000
--- a/modules/image/object_detection/yolov3_darknet53_coco2017/yolo_head.py
+++ /dev/null
@@ -1,231 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from collections import OrderedDict
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.regularizer import L2Decay
-
-__all__ = ['MultiClassNMS', 'YOLOv3Head']
-
-
-class MultiClassNMS(object):
- # __op__ = fluid.layers.multiclass_nms
- def __init__(self, background_label, keep_top_k, nms_threshold, nms_top_k, normalized, score_threshold):
- super(MultiClassNMS, self).__init__()
- self.background_label = background_label
- self.keep_top_k = keep_top_k
- self.nms_threshold = nms_threshold
- self.nms_top_k = nms_top_k
- self.normalized = normalized
- self.score_threshold = score_threshold
-
-
-class YOLOv3Head(object):
- """Head block for YOLOv3 network
-
- Args:
- norm_decay (float): weight decay for normalization layer weights
- num_classes (int): number of output classes
- ignore_thresh (float): threshold to ignore confidence loss
- label_smooth (bool): whether to use label smoothing
- anchors (list): anchors
- anchor_masks (list): anchor masks
- nms (object): an instance of `MultiClassNMS`
- """
-
- def __init__(self,
- norm_decay=0.,
- num_classes=80,
- ignore_thresh=0.7,
- label_smooth=True,
- anchors=[[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198],
- [373, 326]],
- anchor_masks=[[6, 7, 8], [3, 4, 5], [0, 1, 2]],
- nms=MultiClassNMS(
- background_label=-1,
- keep_top_k=100,
- nms_threshold=0.45,
- nms_top_k=1000,
- normalized=True,
- score_threshold=0.01),
- weight_prefix_name=''):
- self.norm_decay = norm_decay
- self.num_classes = num_classes
- self.ignore_thresh = ignore_thresh
- self.label_smooth = label_smooth
- self.anchor_masks = anchor_masks
- self._parse_anchors(anchors)
- self.nms = nms
- self.prefix_name = weight_prefix_name
-
- def _conv_bn(self, input, ch_out, filter_size, stride, padding, act='leaky', is_test=True, name=None):
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=ch_out,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- act=None,
- param_attr=ParamAttr(name=name + ".conv.weights"),
- bias_attr=False)
-
- bn_name = name + ".bn"
- bn_param_attr = ParamAttr(regularizer=L2Decay(self.norm_decay), name=bn_name + '.scale')
- bn_bias_attr = ParamAttr(regularizer=L2Decay(self.norm_decay), name=bn_name + '.offset')
- out = fluid.layers.batch_norm(
- input=conv,
- act=None,
- is_test=is_test,
- param_attr=bn_param_attr,
- bias_attr=bn_bias_attr,
- moving_mean_name=bn_name + '.mean',
- moving_variance_name=bn_name + '.var')
-
- if act == 'leaky':
- out = fluid.layers.leaky_relu(x=out, alpha=0.1)
- return out
-
- def _detection_block(self, input, channel, is_test=True, name=None):
- assert channel % 2 == 0, \
- "channel {} cannot be divided by 2 in detection block {}" \
- .format(channel, name)
-
- conv = input
- for j in range(2):
- conv = self._conv_bn(
- conv, channel, filter_size=1, stride=1, padding=0, is_test=is_test, name='{}.{}.0'.format(name, j))
- conv = self._conv_bn(
- conv, channel * 2, filter_size=3, stride=1, padding=1, is_test=is_test, name='{}.{}.1'.format(name, j))
- route = self._conv_bn(
- conv, channel, filter_size=1, stride=1, padding=0, is_test=is_test, name='{}.2'.format(name))
- tip = self._conv_bn(
- route, channel * 2, filter_size=3, stride=1, padding=1, is_test=is_test, name='{}.tip'.format(name))
- return route, tip
-
- def _upsample(self, input, scale=2, name=None):
- out = fluid.layers.resize_nearest(input=input, scale=float(scale), name=name)
- return out
-
- def _parse_anchors(self, anchors):
- """
- Check ANCHORS/ANCHOR_MASKS in config and parse mask_anchors
-
- """
- self.anchors = []
- self.mask_anchors = []
-
- assert len(anchors) > 0, "ANCHORS not set."
- assert len(self.anchor_masks) > 0, "ANCHOR_MASKS not set."
-
- for anchor in anchors:
- assert len(anchor) == 2, "anchor {} len should be 2".format(anchor)
- self.anchors.extend(anchor)
-
- anchor_num = len(anchors)
- for masks in self.anchor_masks:
- self.mask_anchors.append([])
- for mask in masks:
- assert mask < anchor_num, "anchor mask index overflow"
- self.mask_anchors[-1].extend(anchors[mask])
-
- def _get_outputs(self, input, is_train=True):
- """
- Get YOLOv3 head output
-
- Args:
- input (list): List of Variables, output of backbone stages
- is_train (bool): whether in train or test mode
-
- Returns:
- outputs (list): Variables of each output layer
- """
-
- outputs = []
-
- # get last out_layer_num blocks in reverse order
- out_layer_num = len(self.anchor_masks)
- if isinstance(input, OrderedDict):
- blocks = list(input.values())[-1:-out_layer_num - 1:-1]
- else:
- blocks = input[-1:-out_layer_num - 1:-1]
- route = None
- for i, block in enumerate(blocks):
- if i > 0: # perform concat in first 2 detection_block
- block = fluid.layers.concat(input=[route, block], axis=1)
- route, tip = self._detection_block(
- block, channel=512 // (2**i), is_test=(not is_train), name=self.prefix_name + "yolo_block.{}".format(i))
-
- # out channel number = mask_num * (5 + class_num)
- num_filters = len(self.anchor_masks[i]) * (self.num_classes + 5)
- block_out = fluid.layers.conv2d(
- input=tip,
- num_filters=num_filters,
- filter_size=1,
- stride=1,
- padding=0,
- act=None,
- param_attr=ParamAttr(name=self.prefix_name + "yolo_output.{}.conv.weights".format(i)),
- bias_attr=ParamAttr(
- regularizer=L2Decay(0.), name=self.prefix_name + "yolo_output.{}.conv.bias".format(i)))
- outputs.append(block_out)
-
- if i < len(blocks) - 1:
- # do not perform upsample in the last detection_block
- route = self._conv_bn(
- input=route,
- ch_out=256 // (2**i),
- filter_size=1,
- stride=1,
- padding=0,
- is_test=(not is_train),
- name=self.prefix_name + "yolo_transition.{}".format(i))
- # upsample
- route = self._upsample(route)
-
- return outputs, blocks
-
- def get_prediction(self, outputs, im_size):
- """
- Get prediction result of YOLOv3 network
-
- Args:
- outputs (list): list of Variables, return from _get_outputs
- im_size (Variable): Variable of size([h, w]) of each image
-
- Returns:
- pred (Variable): The prediction result after non-max suppress.
-
- """
- boxes = []
- scores = []
- downsample = 32
- for i, output in enumerate(outputs):
- box, score = fluid.layers.yolo_box(
- x=output,
- img_size=im_size,
- anchors=self.mask_anchors[i],
- class_num=self.num_classes,
- conf_thresh=self.nms.score_threshold,
- downsample_ratio=downsample,
- name=self.prefix_name + "yolo_box" + str(i))
- boxes.append(box)
- scores.append(fluid.layers.transpose(score, perm=[0, 2, 1]))
-
- downsample //= 2
-
- yolo_boxes = fluid.layers.concat(boxes, axis=1)
- yolo_scores = fluid.layers.concat(scores, axis=2)
- pred = fluid.layers.multiclass_nms(
- bboxes=yolo_boxes,
- scores=yolo_scores,
- score_threshold=self.nms.score_threshold,
- nms_top_k=self.nms.nms_top_k,
- keep_top_k=self.nms.keep_top_k,
- nms_threshold=self.nms.nms_threshold,
- background_label=self.nms.background_label,
- normalized=self.nms.normalized,
- name="multiclass_nms")
- return pred
From 199fe1f8d2b309db7bccc4125e944610af833735 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:02:56 +0800
Subject: [PATCH 060/117] update humanseg_mobile (#2001)
* update humanseg_mobile
* add clean func
* update save inference model
---
.../humanseg_mobile/README.md | 20 ++-
.../humanseg_mobile/README_en.md | 24 +--
.../humanseg_mobile/module.py | 114 +++++++-------
.../humanseg_mobile/test.py | 144 ++++++++++++++++++
4 files changed, 232 insertions(+), 70 deletions(-)
create mode 100644 modules/image/semantic_segmentation/humanseg_mobile/test.py
diff --git a/modules/image/semantic_segmentation/humanseg_mobile/README.md b/modules/image/semantic_segmentation/humanseg_mobile/README.md
index 188234ed2..3817be776 100644
--- a/modules/image/semantic_segmentation/humanseg_mobile/README.md
+++ b/modules/image/semantic_segmentation/humanseg_mobile/README.md
@@ -174,19 +174,13 @@
```python
- def save_inference_model(dirname='humanseg_mobile_model',
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- * dirname: 存在模型的目录名称
- * model\_filename: 模型文件名称,默认为\_\_model\_\_
- * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
- * combined: 是否将参数保存到统一的一个文件中
+ * dirname: 模型保存路径
## 四、服务部署
@@ -244,11 +238,21 @@
* 1.0.0
初始发布
+
* 1.1.0
新增视频人像分割接口
新增视频流人像分割接口
+
* 1.1.1
修复cudnn为8.0.4显存泄露问题
+
+* 1.2.0
+
+ 移除 Fluid API
+
+ ```shell
+ $ hub install humanseg_mobile == 1.2.0
+ ```
diff --git a/modules/image/semantic_segmentation/humanseg_mobile/README_en.md b/modules/image/semantic_segmentation/humanseg_mobile/README_en.md
index 7af902ced..0c5e849e5 100644
--- a/modules/image/semantic_segmentation/humanseg_mobile/README_en.md
+++ b/modules/image/semantic_segmentation/humanseg_mobile/README_en.md
@@ -172,10 +172,7 @@
```python
- def save_inference_model(dirname='humanseg_mobile_model',
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
@@ -183,10 +180,7 @@
- **Parameters**
- * dirname: Save path.
- * model\_filename: Model file name,defalt is \_\_model\_\_
- * params\_filename: Parameter file name,defalt is \_\_params\_\_(Only takes effect when `combined` is True)
- * combined: Whether to save the parameters to a unified file.
+ * dirname: Model save path.
@@ -244,13 +238,23 @@
- 1.0.0
- First release
+ First release
- 1.1.0
Added video portrait split interface
Added video stream portrait segmentation interface
+
* 1.1.1
- Fix the video memory leakage problem of on cudnn 8.0.4
+ Fix the video memory leakage problem of on cudnn 8.0.4
+
+* 1.2.0
+
+ Remove Fluid API
+
+ ```shell
+ $ hub install humanseg_mobile == 1.2.0
+ ```
+
diff --git a/modules/image/semantic_segmentation/humanseg_mobile/module.py b/modules/image/semantic_segmentation/humanseg_mobile/module.py
index f7ac67966..413386a45 100644
--- a/modules/image/semantic_segmentation/humanseg_mobile/module.py
+++ b/modules/image/semantic_segmentation/humanseg_mobile/module.py
@@ -19,14 +19,15 @@
import cv2
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle
+import paddle.jit
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from humanseg_mobile.processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
-from humanseg_mobile.data_feed import reader, preprocess_v
-from humanseg_mobile.optimal import postprocess_v, threshold_mask
+from .processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
+from .data_feed import reader, preprocess_v
+from .optimal import postprocess_v, threshold_mask
@moduleinfo(
@@ -35,22 +36,23 @@
author="paddlepaddle",
author_email="",
summary="HRNet_w18_samll_v1 is a semantic segmentation model.",
- version="1.1.0")
-class HRNetw18samllv1humanseg(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "humanseg_mobile_inference")
+ version="1.2.0")
+class HRNetw18samllv1humanseg:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(
+ self.directory, "humanseg_mobile_inference", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- self.model_file_path = os.path.join(self.default_pretrained_model_path, '__model__')
- self.params_file_path = os.path.join(self.default_pretrained_model_path, '__params__')
- cpu_config = AnalysisConfig(self.model_file_path, self.params_file_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
int(_places[0])
@@ -58,10 +60,14 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.model_file_path, self.params_file_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+
+ if paddle.get_cudnn_version() == 8004:
+ gpu_config.delete_pass('conv_elementwise_add_act_fuse_pass')
+ gpu_config.delete_pass('conv_elementwise_add2_act_fuse_pass')
+ self.gpu_predictor = create_predictor(gpu_config)
def segment(self,
images=None,
@@ -112,9 +118,16 @@ def segment(self,
pass
# feed batch image
batch_image = np.array([data['image'] for data in batch_data])
- batch_image = PaddleTensor(batch_image.copy())
- output = self.gpu_predictor.run([batch_image]) if use_gpu else self.cpu_predictor.run([batch_image])
- output = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(batch_image.copy())
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ output = output_handle.copy_to_cpu()
+
output = np.expand_dims(output[:, 1, :, :], axis=1)
# postprocess one by one
for i in range(len(batch_data)):
@@ -152,9 +165,16 @@ def video_stream_segment(self, frame_org, frame_id, prev_gray, prev_cfd, use_gpu
height = int(frame_org.shape[1])
disflow = cv2.DISOpticalFlow_create(cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
frame = preprocess_v(frame_org, resize_w, resize_h)
- image = PaddleTensor(np.array([frame.copy()]))
- output = self.gpu_predictor.run([image]) if use_gpu else self.cpu_predictor.run([image])
- score_map = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(frame.copy()[None, ...])
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ score_map = output_handle.copy_to_cpu()
+
frame = np.transpose(frame, axes=[1, 2, 0])
score_map = np.transpose(np.squeeze(score_map, 0), axes=[1, 2, 0])
cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
@@ -217,9 +237,16 @@ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_mobil
ret, frame_org = cap_video.read()
if ret:
frame = preprocess_v(frame_org, resize_w, resize_h)
- image = PaddleTensor(np.array([frame.copy()]))
- output = self.gpu_predictor.run([image]) if use_gpu else self.cpu_predictor.run([image])
- score_map = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(frame.copy()[None, ...])
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ score_map = output_handle.copy_to_cpu()
+
frame = np.transpose(frame, axes=[1, 2, 0])
score_map = np.transpose(np.squeeze(score_map, 0), axes=[1, 2, 0])
cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
@@ -244,9 +271,16 @@ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_mobil
ret, frame_org = cap_video.read()
if ret:
frame = preprocess_v(frame_org, resize_w, resize_h)
- image = PaddleTensor(np.array([frame.copy()]))
- output = self.gpu_predictor.run([image]) if use_gpu else self.cpu_predictor.run([image])
- score_map = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(frame.copy()[None, ...])
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ score_map = output_handle.copy_to_cpu()
+
frame = np.transpose(frame, axes=[1, 2, 0])
score_map = np.transpose(np.squeeze(score_map, 0), axes=[1, 2, 0])
cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
@@ -268,30 +302,6 @@ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_mobil
break
cap_video.release()
- def save_inference_model(self,
- dirname='humanseg_mobile_model',
- model_filename=None,
- params_filename=None,
- combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path,
- model_filename=model_filename,
- params_filename=params_filename,
- executor=exe)
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/semantic_segmentation/humanseg_mobile/test.py b/modules/image/semantic_segmentation/humanseg_mobile/test.py
new file mode 100644
index 000000000..c38977f77
--- /dev/null
+++ b/modules/image/semantic_segmentation/humanseg_mobile/test.py
@@ -0,0 +1,144 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import numpy as np
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/pg_WCHWSdT8/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjYyNDM2ODI4&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
+ img = cv2.imread('tests/test.jpg')
+ video = cv2.VideoWriter('tests/test.avi', fourcc,
+ 20.0, tuple(img.shape[:2]))
+ for i in range(40):
+ video.write(img)
+ video.release()
+ cls.module = hub.Module(name="humanseg_mobile")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('humanseg_mobile_output')
+ shutil.rmtree('humanseg_mobile_video_result')
+
+ def test_segment1(self):
+ results = self.module.segment(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment2(self):
+ results = self.module.segment(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment3(self):
+ results = self.module.segment(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment4(self):
+ results = self.module.segment(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.segment,
+ paths=['no.jpg']
+ )
+
+ def test_segment6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.segment,
+ images=['test.jpg']
+ )
+
+ def test_video_stream_segment1(self):
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=1,
+ prev_gray=None,
+ prev_cfd=None,
+ use_gpu=False
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=2,
+ prev_gray=cur_gray,
+ prev_cfd=optflow_map,
+ use_gpu=False
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+
+ def test_video_stream_segment2(self):
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=1,
+ prev_gray=None,
+ prev_cfd=None,
+ use_gpu=True
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=2,
+ prev_gray=cur_gray,
+ prev_cfd=optflow_map,
+ use_gpu=True
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+
+ def test_video_segment1(self):
+ self.module.video_segment(
+ video_path="tests/test.avi",
+ use_gpu=False
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 12a6bf9251ebaae97c1ba90660def951a600bec8 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:08:48 +0800
Subject: [PATCH 061/117] update yolov3_resnet34_coco2017 (#1953)
* update yolov3_resnet34_coco2017
* update gpu config
* update
* add clean func
* update save inference model
Co-authored-by: chenjian
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -166,6 +160,10 @@
修复numpy数据读取问题
+* 1.1.0
+
+ 移除 fluid api
+
- ```shell
- $ hub install yolov3_resnet34_coco2017==1.0.2
+ $ hub install yolov3_resnet34_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_resnet34_coco2017/README_en.md b/modules/image/object_detection/yolov3_resnet34_coco2017/README_en.md
index c10a2466f..2e1e6e5f4 100644
--- a/modules/image/object_detection/yolov3_resnet34_coco2017/README_en.md
+++ b/modules/image/object_detection/yolov3_resnet34_coco2017/README_en.md
@@ -99,19 +99,13 @@
- save\_path (str, optional): output path for saving results
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -165,6 +159,10 @@
Fix the problem of reading numpy
+* 1.1.0
+
+ Remove fluid api
+
- ```shell
- $ hub install yolov3_resnet34_coco2017==1.0.2
+ $ hub install yolov3_resnet34_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_resnet34_coco2017/module.py b/modules/image/object_detection/yolov3_resnet34_coco2017/module.py
index 5c26e52ec..2a2b8d595 100644
--- a/modules/image/object_detection/yolov3_resnet34_coco2017/module.py
+++ b/modules/image/object_detection/yolov3_resnet34_coco2017/module.py
@@ -6,31 +6,30 @@
import os
from functools import partial
+import paddle
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle.jit
+import paddle.static
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from paddlehub.common.paddle_helper import add_vars_prefix
-from yolov3_resnet34_coco2017.resnet import ResNet
-from yolov3_resnet34_coco2017.processor import load_label_info, postprocess, base64_to_cv2
-from yolov3_resnet34_coco2017.data_feed import reader
-from yolov3_resnet34_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
+from .processor import load_label_info, postprocess, base64_to_cv2
+from .data_feed import reader
@moduleinfo(
name="yolov3_resnet34_coco2017",
- version="1.0.2",
+ version="1.1.0",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection with backbone ResNet34, trained with dataset coco2017.",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class YOLOv3ResNet34Coco2017(hub.Module):
- def _initialize(self):
+class YOLOv3ResNet34Coco2017:
+ def __init__(self):
self.default_pretrained_model_path = os.path.join(
- self.directory, "yolov3_resnet34_model")
+ self.directory, "yolov3_resnet34_model", "model")
self.label_names = load_label_info(
os.path.join(self.directory, "label_file.txt"))
self._set_config()
@@ -39,11 +38,13 @@ def _set_config(self):
"""
predictor config setting.
"""
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
cpu_config.switch_ir_optim(False)
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -52,108 +53,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
-
- def context(self, trainable=True, pretrained=True, get_prediction=False):
- """
- Distill the Head Features, so as to perform transfer learning.
-
- Args:
- trainable (bool): whether to set parameters trainable.
- pretrained (bool): whether to load default pretrained model.
- get_prediction (bool): whether to get prediction.
-
- Returns:
- inputs(dict): the input variables.
- outputs(dict): the output variables.
- context_prog (Program): the program to execute transfer learning.
- """
- context_prog = fluid.Program()
- startup_program = fluid.Program()
- with fluid.program_guard(context_prog, startup_program):
- with fluid.unique_name.guard():
- # image
- image = fluid.layers.data(
- name='image', shape=[3, 608, 608], dtype='float32')
- # backbone
- backbone = ResNet(
- norm_type='bn',
- freeze_at=0,
- freeze_norm=False,
- norm_decay=0.,
- depth=34,
- feature_maps=[3, 4, 5])
- # body_feats
- body_feats = backbone(image)
- # im_size
- im_size = fluid.layers.data(
- name='im_size', shape=[2], dtype='int32')
- # yolo_head
- yolo_head = YOLOv3Head(num_classes=80)
- # head_features
- head_features, body_features = yolo_head._get_outputs(
- body_feats, is_train=trainable)
-
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- exe.run(fluid.default_startup_program())
-
- # var_prefix
- var_prefix = '@HUB_{}@'.format(self.name)
- # name of inputs
- inputs = {
- 'image': var_prefix + image.name,
- 'im_size': var_prefix + im_size.name
- }
- # name of outputs
- if get_prediction:
- bbox_out = yolo_head.get_prediction(head_features, im_size)
- outputs = {'bbox_out': [var_prefix + bbox_out.name]}
- else:
- outputs = {
- 'head_features':
- [var_prefix + var.name for var in head_features],
- 'body_features':
- [var_prefix + var.name for var in body_features]
- }
- # add_vars_prefix
- add_vars_prefix(context_prog, var_prefix)
- add_vars_prefix(fluid.default_startup_program(), var_prefix)
- # inputs
- inputs = {
- key: context_prog.global_block().vars[value]
- for key, value in inputs.items()
- }
- # outputs
- outputs = {
- key: [
- context_prog.global_block().vars[varname]
- for varname in value
- ]
- for key, value in outputs.items()
- }
- # trainable
- for param in context_prog.global_block().iter_parameters():
- param.trainable = trainable
- # pretrained
- if pretrained:
-
- def _if_exist(var):
- return os.path.exists(
- os.path.join(self.default_pretrained_model_path,
- var.name))
-
- fluid.io.load_vars(
- exe,
- self.default_pretrained_model_path,
- predicate=_if_exist)
- else:
- exe.run(startup_program)
-
- return inputs, outputs, context_prog
+ self.gpu_predictor = create_predictor(gpu_config)
def object_detection(self,
paths=None,
@@ -196,54 +99,33 @@ def object_detection(self,
paths = paths if paths else list()
data_reader = partial(reader, paths, images)
- batch_reader = fluid.io.batch(data_reader, batch_size=batch_size)
+ batch_reader = paddle.batch(data_reader, batch_size=batch_size)
res = []
for iter_id, feed_data in enumerate(batch_reader()):
feed_data = np.array(feed_data)
- image_tensor = PaddleTensor(np.array(list(feed_data[:, 0])))
- im_size_tensor = PaddleTensor(np.array(list(feed_data[:, 1])))
- if use_gpu:
- data_out = self.gpu_predictor.run(
- [image_tensor, im_size_tensor])
- else:
- data_out = self.cpu_predictor.run(
- [image_tensor, im_size_tensor])
- output = postprocess(
- paths=paths,
- images=images,
- data_out=data_out,
- score_thresh=score_thresh,
- label_names=self.label_names,
- output_dir=output_dir,
- handle_id=iter_id * batch_size,
- visualization=visualization)
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 0])))
+ input_handle = predictor.get_input_handle(input_names[1])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 1])))
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+
+ output = postprocess(paths=paths,
+ images=images,
+ data_out=output_handle,
+ score_thresh=score_thresh,
+ label_names=self.label_names,
+ output_dir=output_dir,
+ handle_id=iter_id * batch_size,
+ visualization=visualization)
res.extend(output)
return res
- def save_inference_model(self,
- dirname,
- model_filename=None,
- params_filename=None,
- combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/object_detection/yolov3_resnet34_coco2017/name_adapter.py b/modules/image/object_detection/yolov3_resnet34_coco2017/name_adapter.py
deleted file mode 100644
index bebf8bdee..000000000
--- a/modules/image/object_detection/yolov3_resnet34_coco2017/name_adapter.py
+++ /dev/null
@@ -1,61 +0,0 @@
-# coding=utf-8
-
-
-class NameAdapter(object):
- """Fix the backbones variable names for pretrained weight"""
-
- def __init__(self, model):
- super(NameAdapter, self).__init__()
- self.model = model
-
- @property
- def model_type(self):
- return getattr(self.model, '_model_type', '')
-
- @property
- def variant(self):
- return getattr(self.model, 'variant', '')
-
- def fix_conv_norm_name(self, name):
- if name == "conv1":
- bn_name = "bn_" + name
- else:
- bn_name = "bn" + name[3:]
- # the naming rule is same as pretrained weight
- if self.model_type == 'SEResNeXt':
- bn_name = name + "_bn"
- return bn_name
-
- def fix_shortcut_name(self, name):
- if self.model_type == 'SEResNeXt':
- name = 'conv' + name + '_prj'
- return name
-
- def fix_bottleneck_name(self, name):
- if self.model_type == 'SEResNeXt':
- conv_name1 = 'conv' + name + '_x1'
- conv_name2 = 'conv' + name + '_x2'
- conv_name3 = 'conv' + name + '_x3'
- shortcut_name = name
- else:
- conv_name1 = name + "_branch2a"
- conv_name2 = name + "_branch2b"
- conv_name3 = name + "_branch2c"
- shortcut_name = name + "_branch1"
- return conv_name1, conv_name2, conv_name3, shortcut_name
-
- def fix_layer_warp_name(self, stage_num, count, i):
- name = 'res' + str(stage_num)
- if count > 10 and stage_num == 4:
- if i == 0:
- conv_name = name + "a"
- else:
- conv_name = name + "b" + str(i)
- else:
- conv_name = name + chr(ord("a") + i)
- if self.model_type == 'SEResNeXt':
- conv_name = str(stage_num + 2) + '_' + str(i + 1)
- return conv_name
-
- def fix_c1_stage_name(self):
- return "res_conv1" if self.model_type == 'ResNeXt' else "conv1"
diff --git a/modules/image/object_detection/yolov3_resnet34_coco2017/nonlocal_helper.py b/modules/image/object_detection/yolov3_resnet34_coco2017/nonlocal_helper.py
deleted file mode 100644
index 599b8dfa0..000000000
--- a/modules/image/object_detection/yolov3_resnet34_coco2017/nonlocal_helper.py
+++ /dev/null
@@ -1,154 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import paddle.fluid as fluid
-from paddle.fluid import ParamAttr
-
-nonlocal_params = {
- "use_zero_init_conv": False,
- "conv_init_std": 0.01,
- "no_bias": True,
- "use_maxpool": False,
- "use_softmax": True,
- "use_bn": False,
- "use_scale": True, # vital for the model prformance!!!
- "use_affine": False,
- "bn_momentum": 0.9,
- "bn_epsilon": 1.0000001e-5,
- "bn_init_gamma": 0.9,
- "weight_decay_bn": 1.e-4,
-}
-
-
-def space_nonlocal(input, dim_in, dim_out, prefix, dim_inner,
- max_pool_stride=2):
- cur = input
- theta = fluid.layers.conv2d(input = cur, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr=ParamAttr(name = prefix + '_theta' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_theta' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if not nonlocal_params["no_bias"] else False, \
- name = prefix + '_theta')
- theta_shape = theta.shape
- theta_shape_op = fluid.layers.shape(theta)
- theta_shape_op.stop_gradient = True
-
- if nonlocal_params["use_maxpool"]:
- max_pool = fluid.layers.pool2d(input = cur, \
- pool_size = [max_pool_stride, max_pool_stride], \
- pool_type = 'max', \
- pool_stride = [max_pool_stride, max_pool_stride], \
- pool_padding = [0, 0], \
- name = prefix + '_pool')
- else:
- max_pool = cur
-
- phi = fluid.layers.conv2d(input = max_pool, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_phi' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_phi' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_phi')
- phi_shape = phi.shape
-
- g = fluid.layers.conv2d(input = max_pool, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_g' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0, scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_g' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_g')
- g_shape = g.shape
- # we have to use explicit batch size (to support arbitrary spacetime size)
- # e.g. (8, 1024, 4, 14, 14) => (8, 1024, 784)
- theta = fluid.layers.reshape(theta, shape=(0, 0, -1))
- theta = fluid.layers.transpose(theta, [0, 2, 1])
- phi = fluid.layers.reshape(phi, [0, 0, -1])
- theta_phi = fluid.layers.matmul(theta, phi, name=prefix + '_affinity')
- g = fluid.layers.reshape(g, [0, 0, -1])
-
- if nonlocal_params["use_softmax"]:
- if nonlocal_params["use_scale"]:
- theta_phi_sc = fluid.layers.scale(theta_phi, scale=dim_inner**-.5)
- else:
- theta_phi_sc = theta_phi
- p = fluid.layers.softmax(
- theta_phi_sc, name=prefix + '_affinity' + '_prob')
- else:
- # not clear about what is doing in xlw's code
- p = None # not implemented
- raise "Not implemented when not use softmax"
-
- # note g's axis[2] corresponds to p's axis[2]
- # e.g. g(8, 1024, 784_2) * p(8, 784_1, 784_2) => (8, 1024, 784_1)
- p = fluid.layers.transpose(p, [0, 2, 1])
- t = fluid.layers.matmul(g, p, name=prefix + '_y')
-
- # reshape back
- # e.g. (8, 1024, 784) => (8, 1024, 4, 14, 14)
- t_shape = t.shape
- t_re = fluid.layers.reshape(
- t, shape=list(theta_shape), actual_shape=theta_shape_op)
- blob_out = t_re
- blob_out = fluid.layers.conv2d(input = blob_out, num_filters = dim_out, \
- filter_size = [1, 1], stride = [1, 1], padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_out' + "_w", \
- initializer = fluid.initializer.Constant(value = 0.) \
- if nonlocal_params["use_zero_init_conv"] \
- else fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_out' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_out')
- blob_out_shape = blob_out.shape
-
- if nonlocal_params["use_bn"]:
- bn_name = prefix + "_bn"
- blob_out = fluid.layers.batch_norm(blob_out, \
- # is_test = test_mode, \
- momentum = nonlocal_params["bn_momentum"], \
- epsilon = nonlocal_params["bn_epsilon"], \
- name = bn_name, \
- param_attr = ParamAttr(name = bn_name + "_s", \
- initializer = fluid.initializer.Constant(value = nonlocal_params["bn_init_gamma"]), \
- regularizer = fluid.regularizer.L2Decay(nonlocal_params["weight_decay_bn"])), \
- bias_attr = ParamAttr(name = bn_name + "_b", \
- regularizer = fluid.regularizer.L2Decay(nonlocal_params["weight_decay_bn"])), \
- moving_mean_name = bn_name + "_rm", \
- moving_variance_name = bn_name + "_riv") # add bn
-
- if nonlocal_params["use_affine"]:
- affine_scale = fluid.layers.create_parameter(\
- shape=[blob_out_shape[1]], dtype = blob_out.dtype, \
- attr=ParamAttr(name=prefix + '_affine' + '_s'), \
- default_initializer = fluid.initializer.Constant(value = 1.))
- affine_bias = fluid.layers.create_parameter(\
- shape=[blob_out_shape[1]], dtype = blob_out.dtype, \
- attr=ParamAttr(name=prefix + '_affine' + '_b'), \
- default_initializer = fluid.initializer.Constant(value = 0.))
- blob_out = fluid.layers.affine_channel(blob_out, scale = affine_scale, \
- bias = affine_bias, name = prefix + '_affine') # add affine
-
- return blob_out
-
-
-def add_space_nonlocal(input, dim_in, dim_out, prefix, dim_inner):
- '''
- add_space_nonlocal:
- Non-local Neural Networks: see https://arxiv.org/abs/1711.07971
- '''
- conv = space_nonlocal(input, dim_in, dim_out, prefix, dim_inner)
- output = fluid.layers.elementwise_add(input, conv, name=prefix + '_sum')
- return output
diff --git a/modules/image/object_detection/yolov3_resnet34_coco2017/processor.py b/modules/image/object_detection/yolov3_resnet34_coco2017/processor.py
index 2f9a42d9c..aa9a61bd0 100644
--- a/modules/image/object_detection/yolov3_resnet34_coco2017/processor.py
+++ b/modules/image/object_detection/yolov3_resnet34_coco2017/processor.py
@@ -101,7 +101,7 @@ def postprocess(paths,
handle_id,
visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): The paths of images.
@@ -126,9 +126,8 @@ def postprocess(paths,
confidence (float): The confidence of detection result.
save_path (str): The path to save output images.
"""
- lod_tensor = data_out[0]
- lod = lod_tensor.lod[0]
- results = lod_tensor.as_ndarray()
+ lod = data_out.lod()[0]
+ results = data_out.copy_to_cpu()
check_dir(output_dir)
diff --git a/modules/image/object_detection/yolov3_resnet34_coco2017/resnet.py b/modules/image/object_detection/yolov3_resnet34_coco2017/resnet.py
deleted file mode 100644
index 4bd6fb61e..000000000
--- a/modules/image/object_detection/yolov3_resnet34_coco2017/resnet.py
+++ /dev/null
@@ -1,447 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import math
-from collections import OrderedDict
-from numbers import Integral
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.framework import Variable
-from paddle.fluid.regularizer import L2Decay
-from paddle.fluid.initializer import Constant
-
-from .nonlocal_helper import add_space_nonlocal
-from .name_adapter import NameAdapter
-
-__all__ = ['ResNet', 'ResNetC5']
-
-
-class ResNet(object):
- """
- Residual Network, see https://arxiv.org/abs/1512.03385
- Args:
- depth (int): ResNet depth, should be 34, 50.
- freeze_at (int): freeze the backbone at which stage
- norm_type (str): normalization type, 'bn'/'sync_bn'/'affine_channel'
- freeze_norm (bool): freeze normalization layers
- norm_decay (float): weight decay for normalization layer weights
- variant (str): ResNet variant, supports 'a', 'b', 'c', 'd' currently
- feature_maps (list): index of stages whose feature maps are returned
- dcn_v2_stages (list): index of stages who select deformable conv v2
- nonlocal_stages (list): index of stages who select nonlocal networks
- """
- __shared__ = ['norm_type', 'freeze_norm', 'weight_prefix_name']
-
- def __init__(self,
- depth=50,
- freeze_at=0,
- norm_type='sync_bn',
- freeze_norm=False,
- norm_decay=0.,
- variant='b',
- feature_maps=[3, 4, 5],
- dcn_v2_stages=[],
- weight_prefix_name='',
- nonlocal_stages=[],
- get_prediction=False,
- class_dim=1000):
- super(ResNet, self).__init__()
-
- if isinstance(feature_maps, Integral):
- feature_maps = [feature_maps]
-
- assert depth in [34, 50], \
- "depth {} not in [34, 50]"
- assert variant in ['a', 'b', 'c', 'd'], "invalid ResNet variant"
- assert 0 <= freeze_at <= 4, "freeze_at should be 0, 1, 2, 3 or 4"
- assert len(feature_maps) > 0, "need one or more feature maps"
- assert norm_type in ['bn', 'sync_bn', 'affine_channel']
- assert not (len(nonlocal_stages)>0 and depth<50), \
- "non-local is not supported for resnet18 or resnet34"
-
- self.depth = depth
- self.freeze_at = freeze_at
- self.norm_type = norm_type
- self.norm_decay = norm_decay
- self.freeze_norm = freeze_norm
- self.variant = variant
- self._model_type = 'ResNet'
- self.feature_maps = feature_maps
- self.dcn_v2_stages = dcn_v2_stages
- self.depth_cfg = {
- 34: ([3, 4, 6, 3], self.basicblock),
- 50: ([3, 4, 6, 3], self.bottleneck),
- }
- self.stage_filters = [64, 128, 256, 512]
- self._c1_out_chan_num = 64
- self.na = NameAdapter(self)
- self.prefix_name = weight_prefix_name
-
- self.nonlocal_stages = nonlocal_stages
- self.nonlocal_mod_cfg = {
- 50: 2,
- 101: 5,
- 152: 8,
- 200: 12,
- }
- self.get_prediction = get_prediction
- self.class_dim = class_dim
-
- def _conv_offset(self,
- input,
- filter_size,
- stride,
- padding,
- act=None,
- name=None):
- out_channel = filter_size * filter_size * 3
- out = fluid.layers.conv2d(
- input,
- num_filters=out_channel,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- param_attr=ParamAttr(initializer=Constant(0.0), name=name + ".w_0"),
- bias_attr=ParamAttr(initializer=Constant(0.0), name=name + ".b_0"),
- act=act,
- name=name)
- return out
-
- def _conv_norm(self,
- input,
- num_filters,
- filter_size,
- stride=1,
- groups=1,
- act=None,
- name=None,
- dcn_v2=False):
- _name = self.prefix_name + name if self.prefix_name != '' else name
- if not dcn_v2:
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- groups=groups,
- act=None,
- param_attr=ParamAttr(name=_name + "_weights"),
- bias_attr=False,
- name=_name + '.conv2d.output.1')
- else:
- # select deformable conv"
- offset_mask = self._conv_offset(
- input=input,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- act=None,
- name=_name + "_conv_offset")
- offset_channel = filter_size**2 * 2
- mask_channel = filter_size**2
- offset, mask = fluid.layers.split(
- input=offset_mask,
- num_or_sections=[offset_channel, mask_channel],
- dim=1)
- mask = fluid.layers.sigmoid(mask)
- conv = fluid.layers.deformable_conv(
- input=input,
- offset=offset,
- mask=mask,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- groups=groups,
- deformable_groups=1,
- im2col_step=1,
- param_attr=ParamAttr(name=_name + "_weights"),
- bias_attr=False,
- name=_name + ".conv2d.output.1")
-
- bn_name = self.na.fix_conv_norm_name(name)
- bn_name = self.prefix_name + bn_name if self.prefix_name != '' else bn_name
-
- norm_lr = 0. if self.freeze_norm else 1.
- norm_decay = self.norm_decay
- pattr = ParamAttr(
- name=bn_name + '_scale',
- learning_rate=norm_lr,
- regularizer=L2Decay(norm_decay))
- battr = ParamAttr(
- name=bn_name + '_offset',
- learning_rate=norm_lr,
- regularizer=L2Decay(norm_decay))
-
- if self.norm_type in ['bn', 'sync_bn']:
- global_stats = True if self.freeze_norm else False
- out = fluid.layers.batch_norm(
- input=conv,
- act=act,
- name=bn_name + '.output.1',
- param_attr=pattr,
- bias_attr=battr,
- moving_mean_name=bn_name + '_mean',
- moving_variance_name=bn_name + '_variance',
- use_global_stats=global_stats)
- scale = fluid.framework._get_var(pattr.name)
- bias = fluid.framework._get_var(battr.name)
- elif self.norm_type == 'affine_channel':
- scale = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=pattr,
- default_initializer=fluid.initializer.Constant(1.))
- bias = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=battr,
- default_initializer=fluid.initializer.Constant(0.))
- out = fluid.layers.affine_channel(
- x=conv, scale=scale, bias=bias, act=act)
- if self.freeze_norm:
- scale.stop_gradient = True
- bias.stop_gradient = True
- return out
-
- def _shortcut(self, input, ch_out, stride, is_first, name):
- max_pooling_in_short_cut = self.variant == 'd'
- ch_in = input.shape[1]
- # the naming rule is same as pretrained weight
- name = self.na.fix_shortcut_name(name)
- std_senet = getattr(self, 'std_senet', False)
- if ch_in != ch_out or stride != 1 or (self.depth < 50 and is_first):
- if std_senet:
- if is_first:
- return self._conv_norm(input, ch_out, 1, stride, name=name)
- else:
- return self._conv_norm(input, ch_out, 3, stride, name=name)
- if max_pooling_in_short_cut and not is_first:
- input = fluid.layers.pool2d(
- input=input,
- pool_size=2,
- pool_stride=2,
- pool_padding=0,
- ceil_mode=True,
- pool_type='avg')
- return self._conv_norm(input, ch_out, 1, 1, name=name)
- return self._conv_norm(input, ch_out, 1, stride, name=name)
- else:
- return input
-
- def bottleneck(self,
- input,
- num_filters,
- stride,
- is_first,
- name,
- dcn_v2=False):
- if self.variant == 'a':
- stride1, stride2 = stride, 1
- else:
- stride1, stride2 = 1, stride
-
- # ResNeXt
- groups = getattr(self, 'groups', 1)
- group_width = getattr(self, 'group_width', -1)
- if groups == 1:
- expand = 4
- elif (groups * group_width) == 256:
- expand = 1
- else: # FIXME hard code for now, handles 32x4d, 64x4d and 32x8d
- num_filters = num_filters // 2
- expand = 2
-
- conv_name1, conv_name2, conv_name3, \
- shortcut_name = self.na.fix_bottleneck_name(name)
- std_senet = getattr(self, 'std_senet', False)
- if std_senet:
- conv_def = [[
- int(num_filters / 2), 1, stride1, 'relu', 1, conv_name1
- ], [num_filters, 3, stride2, 'relu', groups, conv_name2],
- [num_filters * expand, 1, 1, None, 1, conv_name3]]
- else:
- conv_def = [[num_filters, 1, stride1, 'relu', 1, conv_name1],
- [num_filters, 3, stride2, 'relu', groups, conv_name2],
- [num_filters * expand, 1, 1, None, 1, conv_name3]]
-
- residual = input
- for i, (c, k, s, act, g, _name) in enumerate(conv_def):
- residual = self._conv_norm(
- input=residual,
- num_filters=c,
- filter_size=k,
- stride=s,
- act=act,
- groups=g,
- name=_name,
- dcn_v2=(i == 1 and dcn_v2))
- short = self._shortcut(
- input,
- num_filters * expand,
- stride,
- is_first=is_first,
- name=shortcut_name)
- # Squeeze-and-Excitation
- if callable(getattr(self, '_squeeze_excitation', None)):
- residual = self._squeeze_excitation(
- input=residual, num_channels=num_filters, name='fc' + name)
- return fluid.layers.elementwise_add(
- x=short, y=residual, act='relu', name=name + ".add.output.5")
-
- def basicblock(self,
- input,
- num_filters,
- stride,
- is_first,
- name,
- dcn_v2=False):
- assert dcn_v2 is False, "Not implemented yet."
- conv0 = self._conv_norm(
- input=input,
- num_filters=num_filters,
- filter_size=3,
- act='relu',
- stride=stride,
- name=name + "_branch2a")
- conv1 = self._conv_norm(
- input=conv0,
- num_filters=num_filters,
- filter_size=3,
- act=None,
- name=name + "_branch2b")
- short = self._shortcut(
- input, num_filters, stride, is_first, name=name + "_branch1")
- return fluid.layers.elementwise_add(x=short, y=conv1, act='relu')
-
- def layer_warp(self, input, stage_num):
- """
- Args:
- input (Variable): input variable.
- stage_num (int): the stage number, should be 2, 3, 4, 5
-
- Returns:
- The last variable in endpoint-th stage.
- """
- assert stage_num in [2, 3, 4, 5]
-
- stages, block_func = self.depth_cfg[self.depth]
- count = stages[stage_num - 2]
-
- ch_out = self.stage_filters[stage_num - 2]
- is_first = False if stage_num != 2 else True
- dcn_v2 = True if stage_num in self.dcn_v2_stages else False
-
- nonlocal_mod = 1000
- if stage_num in self.nonlocal_stages:
- nonlocal_mod = self.nonlocal_mod_cfg[
- self.depth] if stage_num == 4 else 2
-
- # Make the layer name and parameter name consistent
- # with ImageNet pre-trained model
- conv = input
- for i in range(count):
- conv_name = self.na.fix_layer_warp_name(stage_num, count, i)
- if self.depth < 50:
- is_first = True if i == 0 and stage_num == 2 else False
- conv = block_func(
- input=conv,
- num_filters=ch_out,
- stride=2 if i == 0 and stage_num != 2 else 1,
- is_first=is_first,
- name=conv_name,
- dcn_v2=dcn_v2)
-
- # add non local model
- dim_in = conv.shape[1]
- nonlocal_name = "nonlocal_conv{}".format(stage_num)
- if i % nonlocal_mod == nonlocal_mod - 1:
- conv = add_space_nonlocal(conv, dim_in, dim_in,
- nonlocal_name + '_{}'.format(i),
- int(dim_in / 2))
- return conv
-
- def c1_stage(self, input):
- out_chan = self._c1_out_chan_num
-
- conv1_name = self.na.fix_c1_stage_name()
-
- if self.variant in ['c', 'd']:
- conv_def = [
- [out_chan // 2, 3, 2, "conv1_1"],
- [out_chan // 2, 3, 1, "conv1_2"],
- [out_chan, 3, 1, "conv1_3"],
- ]
- else:
- conv_def = [[out_chan, 7, 2, conv1_name]]
-
- for (c, k, s, _name) in conv_def:
- input = self._conv_norm(
- input=input,
- num_filters=c,
- filter_size=k,
- stride=s,
- act='relu',
- name=_name)
-
- output = fluid.layers.pool2d(
- input=input,
- pool_size=3,
- pool_stride=2,
- pool_padding=1,
- pool_type='max')
- return output
-
- def __call__(self, input):
- assert isinstance(input, Variable)
- assert not (set(self.feature_maps) - set([2, 3, 4, 5])), \
- "feature maps {} not in [2, 3, 4, 5]".format(self.feature_maps)
-
- res_endpoints = []
-
- res = input
- feature_maps = self.feature_maps
- severed_head = getattr(self, 'severed_head', False)
- if not severed_head:
- res = self.c1_stage(res)
- feature_maps = range(2, max(self.feature_maps) + 1)
-
- for i in feature_maps:
- res = self.layer_warp(res, i)
- if i in self.feature_maps:
- res_endpoints.append(res)
- if self.freeze_at >= i:
- res.stop_gradient = True
- if self.get_prediction:
- pool = fluid.layers.pool2d(
- input=res, pool_type='avg', global_pooling=True)
- stdv = 1.0 / math.sqrt(pool.shape[1] * 1.0)
-
- out = fluid.layers.fc(
- input=pool,
- size=self.class_dim,
- param_attr=fluid.param_attr.ParamAttr(
- initializer=fluid.initializer.Uniform(-stdv, stdv)))
- out = fluid.layers.softmax(out)
- return out
- return OrderedDict([('res{}_sum'.format(self.feature_maps[idx]), feat)
- for idx, feat in enumerate(res_endpoints)])
-
-
-class ResNetC5(ResNet):
- def __init__(self,
- depth=50,
- freeze_at=2,
- norm_type='affine_channel',
- freeze_norm=True,
- norm_decay=0.,
- variant='b',
- feature_maps=[5],
- weight_prefix_name=''):
- super(ResNetC5, self).__init__(depth, freeze_at, norm_type, freeze_norm,
- norm_decay, variant, feature_maps)
- self.severed_head = True
diff --git a/modules/image/object_detection/yolov3_resnet34_coco2017/test.py b/modules/image/object_detection/yolov3_resnet34_coco2017/test.py
new file mode 100644
index 000000000..b84ff35d7
--- /dev/null
+++ b/modules/image/object_detection/yolov3_resnet34_coco2017/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/68313e182f5e4ad9907e69dac9ece8fc50840d7ffbd24fa88396f009958f969a'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="yolov3_resnet34_coco2017")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
\ No newline at end of file
diff --git a/modules/image/object_detection/yolov3_resnet34_coco2017/yolo_head.py b/modules/image/object_detection/yolov3_resnet34_coco2017/yolo_head.py
deleted file mode 100644
index 7428fb4c2..000000000
--- a/modules/image/object_detection/yolov3_resnet34_coco2017/yolo_head.py
+++ /dev/null
@@ -1,273 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from collections import OrderedDict
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.regularizer import L2Decay
-
-__all__ = ['MultiClassNMS', 'YOLOv3Head']
-
-
-class MultiClassNMS(object):
- # __op__ = fluid.layers.multiclass_nms
- def __init__(self, background_label, keep_top_k, nms_threshold, nms_top_k,
- normalized, score_threshold):
- super(MultiClassNMS, self).__init__()
- self.background_label = background_label
- self.keep_top_k = keep_top_k
- self.nms_threshold = nms_threshold
- self.nms_top_k = nms_top_k
- self.normalized = normalized
- self.score_threshold = score_threshold
-
-
-class YOLOv3Head(object):
- """Head block for YOLOv3 network
-
- Args:
- norm_decay (float): weight decay for normalization layer weights
- num_classes (int): number of output classes
- ignore_thresh (float): threshold to ignore confidence loss
- label_smooth (bool): whether to use label smoothing
- anchors (list): anchors
- anchor_masks (list): anchor masks
- nms (object): an instance of `MultiClassNMS`
- """
-
- def __init__(self,
- norm_decay=0.,
- num_classes=80,
- ignore_thresh=0.7,
- label_smooth=True,
- anchors=[[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
- [59, 119], [116, 90], [156, 198], [373, 326]],
- anchor_masks=[[6, 7, 8], [3, 4, 5], [0, 1, 2]],
- nms=MultiClassNMS(
- background_label=-1,
- keep_top_k=100,
- nms_threshold=0.45,
- nms_top_k=1000,
- normalized=True,
- score_threshold=0.01),
- weight_prefix_name=''):
- self.norm_decay = norm_decay
- self.num_classes = num_classes
- self.ignore_thresh = ignore_thresh
- self.label_smooth = label_smooth
- self.anchor_masks = anchor_masks
- self._parse_anchors(anchors)
- self.nms = nms
- self.prefix_name = weight_prefix_name
-
- def _conv_bn(self,
- input,
- ch_out,
- filter_size,
- stride,
- padding,
- act='leaky',
- is_test=True,
- name=None):
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=ch_out,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- act=None,
- param_attr=ParamAttr(name=name + ".conv.weights"),
- bias_attr=False)
-
- bn_name = name + ".bn"
- bn_param_attr = ParamAttr(
- regularizer=L2Decay(self.norm_decay), name=bn_name + '.scale')
- bn_bias_attr = ParamAttr(
- regularizer=L2Decay(self.norm_decay), name=bn_name + '.offset')
- out = fluid.layers.batch_norm(
- input=conv,
- act=None,
- is_test=is_test,
- param_attr=bn_param_attr,
- bias_attr=bn_bias_attr,
- moving_mean_name=bn_name + '.mean',
- moving_variance_name=bn_name + '.var')
-
- if act == 'leaky':
- out = fluid.layers.leaky_relu(x=out, alpha=0.1)
- return out
-
- def _detection_block(self, input, channel, is_test=True, name=None):
- assert channel % 2 == 0, \
- "channel {} cannot be divided by 2 in detection block {}" \
- .format(channel, name)
-
- conv = input
- for j in range(2):
- conv = self._conv_bn(
- conv,
- channel,
- filter_size=1,
- stride=1,
- padding=0,
- is_test=is_test,
- name='{}.{}.0'.format(name, j))
- conv = self._conv_bn(
- conv,
- channel * 2,
- filter_size=3,
- stride=1,
- padding=1,
- is_test=is_test,
- name='{}.{}.1'.format(name, j))
- route = self._conv_bn(
- conv,
- channel,
- filter_size=1,
- stride=1,
- padding=0,
- is_test=is_test,
- name='{}.2'.format(name))
- tip = self._conv_bn(
- route,
- channel * 2,
- filter_size=3,
- stride=1,
- padding=1,
- is_test=is_test,
- name='{}.tip'.format(name))
- return route, tip
-
- def _upsample(self, input, scale=2, name=None):
- out = fluid.layers.resize_nearest(
- input=input, scale=float(scale), name=name)
- return out
-
- def _parse_anchors(self, anchors):
- """
- Check ANCHORS/ANCHOR_MASKS in config and parse mask_anchors
-
- """
- self.anchors = []
- self.mask_anchors = []
-
- assert len(anchors) > 0, "ANCHORS not set."
- assert len(self.anchor_masks) > 0, "ANCHOR_MASKS not set."
-
- for anchor in anchors:
- assert len(anchor) == 2, "anchor {} len should be 2".format(anchor)
- self.anchors.extend(anchor)
-
- anchor_num = len(anchors)
- for masks in self.anchor_masks:
- self.mask_anchors.append([])
- for mask in masks:
- assert mask < anchor_num, "anchor mask index overflow"
- self.mask_anchors[-1].extend(anchors[mask])
-
- def _get_outputs(self, input, is_train=True):
- """
- Get YOLOv3 head output
-
- Args:
- input (list): List of Variables, output of backbone stages
- is_train (bool): whether in train or test mode
-
- Returns:
- outputs (list): Variables of each output layer
- """
-
- outputs = []
-
- # get last out_layer_num blocks in reverse order
- out_layer_num = len(self.anchor_masks)
- if isinstance(input, OrderedDict):
- blocks = list(input.values())[-1:-out_layer_num - 1:-1]
- else:
- blocks = input[-1:-out_layer_num - 1:-1]
- route = None
- for i, block in enumerate(blocks):
- if i > 0: # perform concat in first 2 detection_block
- block = fluid.layers.concat(input=[route, block], axis=1)
- route, tip = self._detection_block(
- block,
- channel=512 // (2**i),
- is_test=(not is_train),
- name=self.prefix_name + "yolo_block.{}".format(i))
-
- # out channel number = mask_num * (5 + class_num)
- num_filters = len(self.anchor_masks[i]) * (self.num_classes + 5)
- block_out = fluid.layers.conv2d(
- input=tip,
- num_filters=num_filters,
- filter_size=1,
- stride=1,
- padding=0,
- act=None,
- param_attr=ParamAttr(name=self.prefix_name +
- "yolo_output.{}.conv.weights".format(i)),
- bias_attr=ParamAttr(
- regularizer=L2Decay(0.),
- name=self.prefix_name +
- "yolo_output.{}.conv.bias".format(i)))
- outputs.append(block_out)
-
- if i < len(blocks) - 1:
- # do not perform upsample in the last detection_block
- route = self._conv_bn(
- input=route,
- ch_out=256 // (2**i),
- filter_size=1,
- stride=1,
- padding=0,
- is_test=(not is_train),
- name=self.prefix_name + "yolo_transition.{}".format(i))
- # upsample
- route = self._upsample(route)
-
- return outputs, blocks
-
- def get_prediction(self, outputs, im_size):
- """
- Get prediction result of YOLOv3 network
-
- Args:
- outputs (list): list of Variables, return from _get_outputs
- im_size (Variable): Variable of size([h, w]) of each image
-
- Returns:
- pred (Variable): The prediction result after non-max suppress.
-
- """
- boxes = []
- scores = []
- downsample = 32
- for i, output in enumerate(outputs):
- box, score = fluid.layers.yolo_box(
- x=output,
- img_size=im_size,
- anchors=self.mask_anchors[i],
- class_num=self.num_classes,
- conf_thresh=self.nms.score_threshold,
- downsample_ratio=downsample,
- name=self.prefix_name + "yolo_box" + str(i))
- boxes.append(box)
- scores.append(fluid.layers.transpose(score, perm=[0, 2, 1]))
-
- downsample //= 2
-
- yolo_boxes = fluid.layers.concat(boxes, axis=1)
- yolo_scores = fluid.layers.concat(scores, axis=2)
- pred = fluid.layers.multiclass_nms(
- bboxes=yolo_boxes,
- scores=yolo_scores,
- score_threshold=self.nms.score_threshold,
- nms_top_k=self.nms.nms_top_k,
- keep_top_k=self.nms.keep_top_k,
- nms_threshold=self.nms.nms_threshold,
- background_label=self.nms.background_label,
- normalized=self.nms.normalized,
- name="multiclass_nms")
- return pred
From 9d700dd6337c51b10c0426990343de26bdceb4e1 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:10:39 +0800
Subject: [PATCH 062/117] update yolov3_resnet50_vd_coco2017 (#1954)
* update yolov3_resnet50_vd_coco2017
* update unittest
* update gpu config
* update
* add clean func
* update save inference model
---
.../yolov3_resnet50_vd_coco2017/README.md | 17 +-
.../yolov3_resnet50_vd_coco2017/README_en.md | 16 +-
.../yolov3_resnet50_vd_coco2017/module.py | 194 ++------
.../name_adapter.py | 61 ---
.../nonlocal_helper.py | 154 ------
.../yolov3_resnet50_vd_coco2017/processor.py | 7 +-
.../yolov3_resnet50_vd_coco2017/resnet.py | 447 ------------------
.../yolov3_resnet50_vd_coco2017/test.py | 108 +++++
.../yolov3_resnet50_vd_coco2017/yolo_head.py | 273 -----------
9 files changed, 161 insertions(+), 1116 deletions(-)
delete mode 100644 modules/image/object_detection/yolov3_resnet50_vd_coco2017/name_adapter.py
delete mode 100644 modules/image/object_detection/yolov3_resnet50_vd_coco2017/nonlocal_helper.py
delete mode 100644 modules/image/object_detection/yolov3_resnet50_vd_coco2017/resnet.py
create mode 100644 modules/image/object_detection/yolov3_resnet50_vd_coco2017/test.py
delete mode 100644 modules/image/object_detection/yolov3_resnet50_vd_coco2017/yolo_head.py
diff --git a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/README.md b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/README.md
index 0ad42e87a..c481bb47c 100644
--- a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/README.md
+++ b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/README.md
@@ -100,20 +100,13 @@
- save\_path (str, optional): 识别结果的保存路径 (仅当visualization=True时存在)
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称;
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
-
+ - dirname: 模型保存路径
## 四、服务部署
@@ -166,6 +159,10 @@
修复numpy数据读取问题
+* 1.1.0
+
+ 移除 fluid api
+
- ```shell
- $ hub install yolov3_resnet50_vd_coco2017==1.0.2
+ $ hub install yolov3_resnet50_vd_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/README_en.md b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/README_en.md
index 7bb7b10ae..2f9b46bd8 100644
--- a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/README_en.md
+++ b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/README_en.md
@@ -99,19 +99,13 @@
- save\_path (str, optional): output path for saving results
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: save model path
## IV.Server Deployment
@@ -165,6 +159,10 @@
Fix the problem of reading numpy
+* 1.1.0
+
+ Remove fluid api
+
- ```shell
- $ hub install yolov3_resnet50_vd_coco2017==1.0.2
+ $ hub install yolov3_resnet50_vd_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py
index cdd037d89..7e1101dd8 100644
--- a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py
+++ b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py
@@ -6,44 +6,43 @@
import os
from functools import partial
+import paddle
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from paddlehub.common.paddle_helper import add_vars_prefix
-from yolov3_resnet50_vd_coco2017.resnet import ResNet
-from yolov3_resnet50_vd_coco2017.processor import load_label_info, postprocess, base64_to_cv2
-from yolov3_resnet50_vd_coco2017.data_feed import reader
-from yolov3_resnet50_vd_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
+from .processor import load_label_info, postprocess, base64_to_cv2
+from .data_feed import reader
@moduleinfo(
name="yolov3_resnet50_vd_coco2017",
- version="1.0.2",
+ version="1.1.0",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection with backbone ResNet50, trained with dataset coco2017.",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class YOLOv3ResNet50Coco2017(hub.Module):
- def _initialize(self):
+class YOLOv3ResNet50Coco2017:
+ def __init__(self):
self.default_pretrained_model_path = os.path.join(
- self.directory, "yolov3_resnet50_model")
+ self.directory, "yolov3_resnet50_model", "model")
self.label_names = load_label_info(
os.path.join(self.directory, "label_file.txt"))
self._set_config()
-
+
def _set_config(self):
"""
predictor config setting.
"""
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
cpu_config.switch_ir_optim(False)
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -52,110 +51,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
-
- def context(self, trainable=True, pretrained=True, get_prediction=False):
- """
- Distill the Head Features, so as to perform transfer learning.
-
- Args:
- trainable (bool): whether to set parameters trainable.
- pretrained (bool): whether to load default pretrained model.
- get_prediction (bool): whether to get prediction.
-
- Returns:
- inputs(dict): the input variables.
- outputs(dict): the output variables.
- context_prog (Program): the program to execute transfer learning.
- """
- context_prog = fluid.Program()
- startup_program = fluid.Program()
- with fluid.program_guard(context_prog, startup_program):
- with fluid.unique_name.guard():
- # image
- image = fluid.layers.data(
- name='image', shape=[3, 608, 608], dtype='float32')
- # backbone
- backbone = ResNet(
- norm_type='sync_bn',
- freeze_at=0,
- freeze_norm=False,
- norm_decay=0.,
- dcn_v2_stages=[5],
- depth=50,
- variant='d',
- feature_maps=[3, 4, 5])
- # body_feats
- body_feats = backbone(image)
- # im_size
- im_size = fluid.layers.data(
- name='im_size', shape=[2], dtype='int32')
- # yolo_head
- yolo_head = YOLOv3Head(num_classes=80)
- # head_features
- head_features, body_features = yolo_head._get_outputs(
- body_feats, is_train=trainable)
-
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- exe.run(fluid.default_startup_program())
-
- # var_prefix
- var_prefix = '@HUB_{}@'.format(self.name)
- # name of inputs
- inputs = {
- 'image': var_prefix + image.name,
- 'im_size': var_prefix + im_size.name
- }
- # name of outputs
- if get_prediction:
- bbox_out = yolo_head.get_prediction(head_features, im_size)
- outputs = {'bbox_out': [var_prefix + bbox_out.name]}
- else:
- outputs = {
- 'head_features':
- [var_prefix + var.name for var in head_features],
- 'body_features':
- [var_prefix + var.name for var in body_features]
- }
- # add_vars_prefix
- add_vars_prefix(context_prog, var_prefix)
- add_vars_prefix(fluid.default_startup_program(), var_prefix)
- # inputs
- inputs = {
- key: context_prog.global_block().vars[value]
- for key, value in inputs.items()
- }
- # outputs
- outputs = {
- key: [
- context_prog.global_block().vars[varname]
- for varname in value
- ]
- for key, value in outputs.items()
- }
- # trainable
- for param in context_prog.global_block().iter_parameters():
- param.trainable = trainable
- # pretrained
- if pretrained:
-
- def _if_exist(var):
- return os.path.exists(
- os.path.join(self.default_pretrained_model_path,
- var.name))
-
- fluid.io.load_vars(
- exe,
- self.default_pretrained_model_path,
- predicate=_if_exist)
- else:
- exe.run(startup_program)
-
- return inputs, outputs, context_prog
+ self.gpu_predictor = create_predictor(gpu_config)
def object_detection(self,
paths=None,
@@ -198,54 +97,33 @@ def object_detection(self,
paths = paths if paths else list()
data_reader = partial(reader, paths, images)
- batch_reader = fluid.io.batch(data_reader, batch_size=batch_size)
+ batch_reader = paddle.batch(data_reader, batch_size=batch_size)
res = []
for iter_id, feed_data in enumerate(batch_reader()):
feed_data = np.array(feed_data)
- image_tensor = PaddleTensor(np.array(list(feed_data[:, 0])))
- im_size_tensor = PaddleTensor(np.array(list(feed_data[:, 1])))
- if use_gpu:
- data_out = self.gpu_predictor.run(
- [image_tensor, im_size_tensor])
- else:
- data_out = self.cpu_predictor.run(
- [image_tensor, im_size_tensor])
- output = postprocess(
- paths=paths,
- images=images,
- data_out=data_out,
- score_thresh=score_thresh,
- label_names=self.label_names,
- output_dir=output_dir,
- handle_id=iter_id * batch_size,
- visualization=visualization)
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 0])))
+ input_handle = predictor.get_input_handle(input_names[1])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 1])))
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+
+ output = postprocess(paths=paths,
+ images=images,
+ data_out=output_handle,
+ score_thresh=score_thresh,
+ label_names=self.label_names,
+ output_dir=output_dir,
+ handle_id=iter_id * batch_size,
+ visualization=visualization)
res.extend(output)
return res
- def save_inference_model(self,
- dirname,
- model_filename=None,
- params_filename=None,
- combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/name_adapter.py b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/name_adapter.py
deleted file mode 100644
index bebf8bdee..000000000
--- a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/name_adapter.py
+++ /dev/null
@@ -1,61 +0,0 @@
-# coding=utf-8
-
-
-class NameAdapter(object):
- """Fix the backbones variable names for pretrained weight"""
-
- def __init__(self, model):
- super(NameAdapter, self).__init__()
- self.model = model
-
- @property
- def model_type(self):
- return getattr(self.model, '_model_type', '')
-
- @property
- def variant(self):
- return getattr(self.model, 'variant', '')
-
- def fix_conv_norm_name(self, name):
- if name == "conv1":
- bn_name = "bn_" + name
- else:
- bn_name = "bn" + name[3:]
- # the naming rule is same as pretrained weight
- if self.model_type == 'SEResNeXt':
- bn_name = name + "_bn"
- return bn_name
-
- def fix_shortcut_name(self, name):
- if self.model_type == 'SEResNeXt':
- name = 'conv' + name + '_prj'
- return name
-
- def fix_bottleneck_name(self, name):
- if self.model_type == 'SEResNeXt':
- conv_name1 = 'conv' + name + '_x1'
- conv_name2 = 'conv' + name + '_x2'
- conv_name3 = 'conv' + name + '_x3'
- shortcut_name = name
- else:
- conv_name1 = name + "_branch2a"
- conv_name2 = name + "_branch2b"
- conv_name3 = name + "_branch2c"
- shortcut_name = name + "_branch1"
- return conv_name1, conv_name2, conv_name3, shortcut_name
-
- def fix_layer_warp_name(self, stage_num, count, i):
- name = 'res' + str(stage_num)
- if count > 10 and stage_num == 4:
- if i == 0:
- conv_name = name + "a"
- else:
- conv_name = name + "b" + str(i)
- else:
- conv_name = name + chr(ord("a") + i)
- if self.model_type == 'SEResNeXt':
- conv_name = str(stage_num + 2) + '_' + str(i + 1)
- return conv_name
-
- def fix_c1_stage_name(self):
- return "res_conv1" if self.model_type == 'ResNeXt' else "conv1"
diff --git a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/nonlocal_helper.py b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/nonlocal_helper.py
deleted file mode 100644
index 599b8dfa0..000000000
--- a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/nonlocal_helper.py
+++ /dev/null
@@ -1,154 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import paddle.fluid as fluid
-from paddle.fluid import ParamAttr
-
-nonlocal_params = {
- "use_zero_init_conv": False,
- "conv_init_std": 0.01,
- "no_bias": True,
- "use_maxpool": False,
- "use_softmax": True,
- "use_bn": False,
- "use_scale": True, # vital for the model prformance!!!
- "use_affine": False,
- "bn_momentum": 0.9,
- "bn_epsilon": 1.0000001e-5,
- "bn_init_gamma": 0.9,
- "weight_decay_bn": 1.e-4,
-}
-
-
-def space_nonlocal(input, dim_in, dim_out, prefix, dim_inner,
- max_pool_stride=2):
- cur = input
- theta = fluid.layers.conv2d(input = cur, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr=ParamAttr(name = prefix + '_theta' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_theta' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if not nonlocal_params["no_bias"] else False, \
- name = prefix + '_theta')
- theta_shape = theta.shape
- theta_shape_op = fluid.layers.shape(theta)
- theta_shape_op.stop_gradient = True
-
- if nonlocal_params["use_maxpool"]:
- max_pool = fluid.layers.pool2d(input = cur, \
- pool_size = [max_pool_stride, max_pool_stride], \
- pool_type = 'max', \
- pool_stride = [max_pool_stride, max_pool_stride], \
- pool_padding = [0, 0], \
- name = prefix + '_pool')
- else:
- max_pool = cur
-
- phi = fluid.layers.conv2d(input = max_pool, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_phi' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_phi' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_phi')
- phi_shape = phi.shape
-
- g = fluid.layers.conv2d(input = max_pool, num_filters = dim_inner, \
- filter_size = [1, 1], stride = [1, 1], \
- padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_g' + "_w", \
- initializer = fluid.initializer.Normal(loc = 0.0, scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_g' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_g')
- g_shape = g.shape
- # we have to use explicit batch size (to support arbitrary spacetime size)
- # e.g. (8, 1024, 4, 14, 14) => (8, 1024, 784)
- theta = fluid.layers.reshape(theta, shape=(0, 0, -1))
- theta = fluid.layers.transpose(theta, [0, 2, 1])
- phi = fluid.layers.reshape(phi, [0, 0, -1])
- theta_phi = fluid.layers.matmul(theta, phi, name=prefix + '_affinity')
- g = fluid.layers.reshape(g, [0, 0, -1])
-
- if nonlocal_params["use_softmax"]:
- if nonlocal_params["use_scale"]:
- theta_phi_sc = fluid.layers.scale(theta_phi, scale=dim_inner**-.5)
- else:
- theta_phi_sc = theta_phi
- p = fluid.layers.softmax(
- theta_phi_sc, name=prefix + '_affinity' + '_prob')
- else:
- # not clear about what is doing in xlw's code
- p = None # not implemented
- raise "Not implemented when not use softmax"
-
- # note g's axis[2] corresponds to p's axis[2]
- # e.g. g(8, 1024, 784_2) * p(8, 784_1, 784_2) => (8, 1024, 784_1)
- p = fluid.layers.transpose(p, [0, 2, 1])
- t = fluid.layers.matmul(g, p, name=prefix + '_y')
-
- # reshape back
- # e.g. (8, 1024, 784) => (8, 1024, 4, 14, 14)
- t_shape = t.shape
- t_re = fluid.layers.reshape(
- t, shape=list(theta_shape), actual_shape=theta_shape_op)
- blob_out = t_re
- blob_out = fluid.layers.conv2d(input = blob_out, num_filters = dim_out, \
- filter_size = [1, 1], stride = [1, 1], padding = [0, 0], \
- param_attr = ParamAttr(name = prefix + '_out' + "_w", \
- initializer = fluid.initializer.Constant(value = 0.) \
- if nonlocal_params["use_zero_init_conv"] \
- else fluid.initializer.Normal(loc = 0.0,
- scale = nonlocal_params["conv_init_std"])), \
- bias_attr = ParamAttr(name = prefix + '_out' + "_b", \
- initializer = fluid.initializer.Constant(value = 0.)) \
- if (nonlocal_params["no_bias"] == 0) else False, \
- name = prefix + '_out')
- blob_out_shape = blob_out.shape
-
- if nonlocal_params["use_bn"]:
- bn_name = prefix + "_bn"
- blob_out = fluid.layers.batch_norm(blob_out, \
- # is_test = test_mode, \
- momentum = nonlocal_params["bn_momentum"], \
- epsilon = nonlocal_params["bn_epsilon"], \
- name = bn_name, \
- param_attr = ParamAttr(name = bn_name + "_s", \
- initializer = fluid.initializer.Constant(value = nonlocal_params["bn_init_gamma"]), \
- regularizer = fluid.regularizer.L2Decay(nonlocal_params["weight_decay_bn"])), \
- bias_attr = ParamAttr(name = bn_name + "_b", \
- regularizer = fluid.regularizer.L2Decay(nonlocal_params["weight_decay_bn"])), \
- moving_mean_name = bn_name + "_rm", \
- moving_variance_name = bn_name + "_riv") # add bn
-
- if nonlocal_params["use_affine"]:
- affine_scale = fluid.layers.create_parameter(\
- shape=[blob_out_shape[1]], dtype = blob_out.dtype, \
- attr=ParamAttr(name=prefix + '_affine' + '_s'), \
- default_initializer = fluid.initializer.Constant(value = 1.))
- affine_bias = fluid.layers.create_parameter(\
- shape=[blob_out_shape[1]], dtype = blob_out.dtype, \
- attr=ParamAttr(name=prefix + '_affine' + '_b'), \
- default_initializer = fluid.initializer.Constant(value = 0.))
- blob_out = fluid.layers.affine_channel(blob_out, scale = affine_scale, \
- bias = affine_bias, name = prefix + '_affine') # add affine
-
- return blob_out
-
-
-def add_space_nonlocal(input, dim_in, dim_out, prefix, dim_inner):
- '''
- add_space_nonlocal:
- Non-local Neural Networks: see https://arxiv.org/abs/1711.07971
- '''
- conv = space_nonlocal(input, dim_in, dim_out, prefix, dim_inner)
- output = fluid.layers.elementwise_add(input, conv, name=prefix + '_sum')
- return output
diff --git a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/processor.py b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/processor.py
index 1039e3e48..dd2aea11a 100644
--- a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/processor.py
+++ b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/processor.py
@@ -101,7 +101,7 @@ def postprocess(paths,
handle_id,
visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): The paths of images.
@@ -126,9 +126,8 @@ def postprocess(paths,
confidence (float): The confidence of detection result.
save_path (str): The path to save output images.
"""
- lod_tensor = data_out[0]
- lod = lod_tensor.lod[0]
- results = lod_tensor.as_ndarray()
+ lod = data_out.lod()[0]
+ results = data_out.copy_to_cpu()
check_dir(output_dir)
diff --git a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/resnet.py b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/resnet.py
deleted file mode 100644
index 4bd6fb61e..000000000
--- a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/resnet.py
+++ /dev/null
@@ -1,447 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import math
-from collections import OrderedDict
-from numbers import Integral
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.framework import Variable
-from paddle.fluid.regularizer import L2Decay
-from paddle.fluid.initializer import Constant
-
-from .nonlocal_helper import add_space_nonlocal
-from .name_adapter import NameAdapter
-
-__all__ = ['ResNet', 'ResNetC5']
-
-
-class ResNet(object):
- """
- Residual Network, see https://arxiv.org/abs/1512.03385
- Args:
- depth (int): ResNet depth, should be 34, 50.
- freeze_at (int): freeze the backbone at which stage
- norm_type (str): normalization type, 'bn'/'sync_bn'/'affine_channel'
- freeze_norm (bool): freeze normalization layers
- norm_decay (float): weight decay for normalization layer weights
- variant (str): ResNet variant, supports 'a', 'b', 'c', 'd' currently
- feature_maps (list): index of stages whose feature maps are returned
- dcn_v2_stages (list): index of stages who select deformable conv v2
- nonlocal_stages (list): index of stages who select nonlocal networks
- """
- __shared__ = ['norm_type', 'freeze_norm', 'weight_prefix_name']
-
- def __init__(self,
- depth=50,
- freeze_at=0,
- norm_type='sync_bn',
- freeze_norm=False,
- norm_decay=0.,
- variant='b',
- feature_maps=[3, 4, 5],
- dcn_v2_stages=[],
- weight_prefix_name='',
- nonlocal_stages=[],
- get_prediction=False,
- class_dim=1000):
- super(ResNet, self).__init__()
-
- if isinstance(feature_maps, Integral):
- feature_maps = [feature_maps]
-
- assert depth in [34, 50], \
- "depth {} not in [34, 50]"
- assert variant in ['a', 'b', 'c', 'd'], "invalid ResNet variant"
- assert 0 <= freeze_at <= 4, "freeze_at should be 0, 1, 2, 3 or 4"
- assert len(feature_maps) > 0, "need one or more feature maps"
- assert norm_type in ['bn', 'sync_bn', 'affine_channel']
- assert not (len(nonlocal_stages)>0 and depth<50), \
- "non-local is not supported for resnet18 or resnet34"
-
- self.depth = depth
- self.freeze_at = freeze_at
- self.norm_type = norm_type
- self.norm_decay = norm_decay
- self.freeze_norm = freeze_norm
- self.variant = variant
- self._model_type = 'ResNet'
- self.feature_maps = feature_maps
- self.dcn_v2_stages = dcn_v2_stages
- self.depth_cfg = {
- 34: ([3, 4, 6, 3], self.basicblock),
- 50: ([3, 4, 6, 3], self.bottleneck),
- }
- self.stage_filters = [64, 128, 256, 512]
- self._c1_out_chan_num = 64
- self.na = NameAdapter(self)
- self.prefix_name = weight_prefix_name
-
- self.nonlocal_stages = nonlocal_stages
- self.nonlocal_mod_cfg = {
- 50: 2,
- 101: 5,
- 152: 8,
- 200: 12,
- }
- self.get_prediction = get_prediction
- self.class_dim = class_dim
-
- def _conv_offset(self,
- input,
- filter_size,
- stride,
- padding,
- act=None,
- name=None):
- out_channel = filter_size * filter_size * 3
- out = fluid.layers.conv2d(
- input,
- num_filters=out_channel,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- param_attr=ParamAttr(initializer=Constant(0.0), name=name + ".w_0"),
- bias_attr=ParamAttr(initializer=Constant(0.0), name=name + ".b_0"),
- act=act,
- name=name)
- return out
-
- def _conv_norm(self,
- input,
- num_filters,
- filter_size,
- stride=1,
- groups=1,
- act=None,
- name=None,
- dcn_v2=False):
- _name = self.prefix_name + name if self.prefix_name != '' else name
- if not dcn_v2:
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- groups=groups,
- act=None,
- param_attr=ParamAttr(name=_name + "_weights"),
- bias_attr=False,
- name=_name + '.conv2d.output.1')
- else:
- # select deformable conv"
- offset_mask = self._conv_offset(
- input=input,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- act=None,
- name=_name + "_conv_offset")
- offset_channel = filter_size**2 * 2
- mask_channel = filter_size**2
- offset, mask = fluid.layers.split(
- input=offset_mask,
- num_or_sections=[offset_channel, mask_channel],
- dim=1)
- mask = fluid.layers.sigmoid(mask)
- conv = fluid.layers.deformable_conv(
- input=input,
- offset=offset,
- mask=mask,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- groups=groups,
- deformable_groups=1,
- im2col_step=1,
- param_attr=ParamAttr(name=_name + "_weights"),
- bias_attr=False,
- name=_name + ".conv2d.output.1")
-
- bn_name = self.na.fix_conv_norm_name(name)
- bn_name = self.prefix_name + bn_name if self.prefix_name != '' else bn_name
-
- norm_lr = 0. if self.freeze_norm else 1.
- norm_decay = self.norm_decay
- pattr = ParamAttr(
- name=bn_name + '_scale',
- learning_rate=norm_lr,
- regularizer=L2Decay(norm_decay))
- battr = ParamAttr(
- name=bn_name + '_offset',
- learning_rate=norm_lr,
- regularizer=L2Decay(norm_decay))
-
- if self.norm_type in ['bn', 'sync_bn']:
- global_stats = True if self.freeze_norm else False
- out = fluid.layers.batch_norm(
- input=conv,
- act=act,
- name=bn_name + '.output.1',
- param_attr=pattr,
- bias_attr=battr,
- moving_mean_name=bn_name + '_mean',
- moving_variance_name=bn_name + '_variance',
- use_global_stats=global_stats)
- scale = fluid.framework._get_var(pattr.name)
- bias = fluid.framework._get_var(battr.name)
- elif self.norm_type == 'affine_channel':
- scale = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=pattr,
- default_initializer=fluid.initializer.Constant(1.))
- bias = fluid.layers.create_parameter(
- shape=[conv.shape[1]],
- dtype=conv.dtype,
- attr=battr,
- default_initializer=fluid.initializer.Constant(0.))
- out = fluid.layers.affine_channel(
- x=conv, scale=scale, bias=bias, act=act)
- if self.freeze_norm:
- scale.stop_gradient = True
- bias.stop_gradient = True
- return out
-
- def _shortcut(self, input, ch_out, stride, is_first, name):
- max_pooling_in_short_cut = self.variant == 'd'
- ch_in = input.shape[1]
- # the naming rule is same as pretrained weight
- name = self.na.fix_shortcut_name(name)
- std_senet = getattr(self, 'std_senet', False)
- if ch_in != ch_out or stride != 1 or (self.depth < 50 and is_first):
- if std_senet:
- if is_first:
- return self._conv_norm(input, ch_out, 1, stride, name=name)
- else:
- return self._conv_norm(input, ch_out, 3, stride, name=name)
- if max_pooling_in_short_cut and not is_first:
- input = fluid.layers.pool2d(
- input=input,
- pool_size=2,
- pool_stride=2,
- pool_padding=0,
- ceil_mode=True,
- pool_type='avg')
- return self._conv_norm(input, ch_out, 1, 1, name=name)
- return self._conv_norm(input, ch_out, 1, stride, name=name)
- else:
- return input
-
- def bottleneck(self,
- input,
- num_filters,
- stride,
- is_first,
- name,
- dcn_v2=False):
- if self.variant == 'a':
- stride1, stride2 = stride, 1
- else:
- stride1, stride2 = 1, stride
-
- # ResNeXt
- groups = getattr(self, 'groups', 1)
- group_width = getattr(self, 'group_width', -1)
- if groups == 1:
- expand = 4
- elif (groups * group_width) == 256:
- expand = 1
- else: # FIXME hard code for now, handles 32x4d, 64x4d and 32x8d
- num_filters = num_filters // 2
- expand = 2
-
- conv_name1, conv_name2, conv_name3, \
- shortcut_name = self.na.fix_bottleneck_name(name)
- std_senet = getattr(self, 'std_senet', False)
- if std_senet:
- conv_def = [[
- int(num_filters / 2), 1, stride1, 'relu', 1, conv_name1
- ], [num_filters, 3, stride2, 'relu', groups, conv_name2],
- [num_filters * expand, 1, 1, None, 1, conv_name3]]
- else:
- conv_def = [[num_filters, 1, stride1, 'relu', 1, conv_name1],
- [num_filters, 3, stride2, 'relu', groups, conv_name2],
- [num_filters * expand, 1, 1, None, 1, conv_name3]]
-
- residual = input
- for i, (c, k, s, act, g, _name) in enumerate(conv_def):
- residual = self._conv_norm(
- input=residual,
- num_filters=c,
- filter_size=k,
- stride=s,
- act=act,
- groups=g,
- name=_name,
- dcn_v2=(i == 1 and dcn_v2))
- short = self._shortcut(
- input,
- num_filters * expand,
- stride,
- is_first=is_first,
- name=shortcut_name)
- # Squeeze-and-Excitation
- if callable(getattr(self, '_squeeze_excitation', None)):
- residual = self._squeeze_excitation(
- input=residual, num_channels=num_filters, name='fc' + name)
- return fluid.layers.elementwise_add(
- x=short, y=residual, act='relu', name=name + ".add.output.5")
-
- def basicblock(self,
- input,
- num_filters,
- stride,
- is_first,
- name,
- dcn_v2=False):
- assert dcn_v2 is False, "Not implemented yet."
- conv0 = self._conv_norm(
- input=input,
- num_filters=num_filters,
- filter_size=3,
- act='relu',
- stride=stride,
- name=name + "_branch2a")
- conv1 = self._conv_norm(
- input=conv0,
- num_filters=num_filters,
- filter_size=3,
- act=None,
- name=name + "_branch2b")
- short = self._shortcut(
- input, num_filters, stride, is_first, name=name + "_branch1")
- return fluid.layers.elementwise_add(x=short, y=conv1, act='relu')
-
- def layer_warp(self, input, stage_num):
- """
- Args:
- input (Variable): input variable.
- stage_num (int): the stage number, should be 2, 3, 4, 5
-
- Returns:
- The last variable in endpoint-th stage.
- """
- assert stage_num in [2, 3, 4, 5]
-
- stages, block_func = self.depth_cfg[self.depth]
- count = stages[stage_num - 2]
-
- ch_out = self.stage_filters[stage_num - 2]
- is_first = False if stage_num != 2 else True
- dcn_v2 = True if stage_num in self.dcn_v2_stages else False
-
- nonlocal_mod = 1000
- if stage_num in self.nonlocal_stages:
- nonlocal_mod = self.nonlocal_mod_cfg[
- self.depth] if stage_num == 4 else 2
-
- # Make the layer name and parameter name consistent
- # with ImageNet pre-trained model
- conv = input
- for i in range(count):
- conv_name = self.na.fix_layer_warp_name(stage_num, count, i)
- if self.depth < 50:
- is_first = True if i == 0 and stage_num == 2 else False
- conv = block_func(
- input=conv,
- num_filters=ch_out,
- stride=2 if i == 0 and stage_num != 2 else 1,
- is_first=is_first,
- name=conv_name,
- dcn_v2=dcn_v2)
-
- # add non local model
- dim_in = conv.shape[1]
- nonlocal_name = "nonlocal_conv{}".format(stage_num)
- if i % nonlocal_mod == nonlocal_mod - 1:
- conv = add_space_nonlocal(conv, dim_in, dim_in,
- nonlocal_name + '_{}'.format(i),
- int(dim_in / 2))
- return conv
-
- def c1_stage(self, input):
- out_chan = self._c1_out_chan_num
-
- conv1_name = self.na.fix_c1_stage_name()
-
- if self.variant in ['c', 'd']:
- conv_def = [
- [out_chan // 2, 3, 2, "conv1_1"],
- [out_chan // 2, 3, 1, "conv1_2"],
- [out_chan, 3, 1, "conv1_3"],
- ]
- else:
- conv_def = [[out_chan, 7, 2, conv1_name]]
-
- for (c, k, s, _name) in conv_def:
- input = self._conv_norm(
- input=input,
- num_filters=c,
- filter_size=k,
- stride=s,
- act='relu',
- name=_name)
-
- output = fluid.layers.pool2d(
- input=input,
- pool_size=3,
- pool_stride=2,
- pool_padding=1,
- pool_type='max')
- return output
-
- def __call__(self, input):
- assert isinstance(input, Variable)
- assert not (set(self.feature_maps) - set([2, 3, 4, 5])), \
- "feature maps {} not in [2, 3, 4, 5]".format(self.feature_maps)
-
- res_endpoints = []
-
- res = input
- feature_maps = self.feature_maps
- severed_head = getattr(self, 'severed_head', False)
- if not severed_head:
- res = self.c1_stage(res)
- feature_maps = range(2, max(self.feature_maps) + 1)
-
- for i in feature_maps:
- res = self.layer_warp(res, i)
- if i in self.feature_maps:
- res_endpoints.append(res)
- if self.freeze_at >= i:
- res.stop_gradient = True
- if self.get_prediction:
- pool = fluid.layers.pool2d(
- input=res, pool_type='avg', global_pooling=True)
- stdv = 1.0 / math.sqrt(pool.shape[1] * 1.0)
-
- out = fluid.layers.fc(
- input=pool,
- size=self.class_dim,
- param_attr=fluid.param_attr.ParamAttr(
- initializer=fluid.initializer.Uniform(-stdv, stdv)))
- out = fluid.layers.softmax(out)
- return out
- return OrderedDict([('res{}_sum'.format(self.feature_maps[idx]), feat)
- for idx, feat in enumerate(res_endpoints)])
-
-
-class ResNetC5(ResNet):
- def __init__(self,
- depth=50,
- freeze_at=2,
- norm_type='affine_channel',
- freeze_norm=True,
- norm_decay=0.,
- variant='b',
- feature_maps=[5],
- weight_prefix_name=''):
- super(ResNetC5, self).__init__(depth, freeze_at, norm_type, freeze_norm,
- norm_decay, variant, feature_maps)
- self.severed_head = True
diff --git a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/test.py b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/test.py
new file mode 100644
index 000000000..c70c92380
--- /dev/null
+++ b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/68313e182f5e4ad9907e69dac9ece8fc50840d7ffbd24fa88396f009958f969a'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="yolov3_resnet50_vd_coco2017")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
\ No newline at end of file
diff --git a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/yolo_head.py b/modules/image/object_detection/yolov3_resnet50_vd_coco2017/yolo_head.py
deleted file mode 100644
index 7428fb4c2..000000000
--- a/modules/image/object_detection/yolov3_resnet50_vd_coco2017/yolo_head.py
+++ /dev/null
@@ -1,273 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from collections import OrderedDict
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.regularizer import L2Decay
-
-__all__ = ['MultiClassNMS', 'YOLOv3Head']
-
-
-class MultiClassNMS(object):
- # __op__ = fluid.layers.multiclass_nms
- def __init__(self, background_label, keep_top_k, nms_threshold, nms_top_k,
- normalized, score_threshold):
- super(MultiClassNMS, self).__init__()
- self.background_label = background_label
- self.keep_top_k = keep_top_k
- self.nms_threshold = nms_threshold
- self.nms_top_k = nms_top_k
- self.normalized = normalized
- self.score_threshold = score_threshold
-
-
-class YOLOv3Head(object):
- """Head block for YOLOv3 network
-
- Args:
- norm_decay (float): weight decay for normalization layer weights
- num_classes (int): number of output classes
- ignore_thresh (float): threshold to ignore confidence loss
- label_smooth (bool): whether to use label smoothing
- anchors (list): anchors
- anchor_masks (list): anchor masks
- nms (object): an instance of `MultiClassNMS`
- """
-
- def __init__(self,
- norm_decay=0.,
- num_classes=80,
- ignore_thresh=0.7,
- label_smooth=True,
- anchors=[[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
- [59, 119], [116, 90], [156, 198], [373, 326]],
- anchor_masks=[[6, 7, 8], [3, 4, 5], [0, 1, 2]],
- nms=MultiClassNMS(
- background_label=-1,
- keep_top_k=100,
- nms_threshold=0.45,
- nms_top_k=1000,
- normalized=True,
- score_threshold=0.01),
- weight_prefix_name=''):
- self.norm_decay = norm_decay
- self.num_classes = num_classes
- self.ignore_thresh = ignore_thresh
- self.label_smooth = label_smooth
- self.anchor_masks = anchor_masks
- self._parse_anchors(anchors)
- self.nms = nms
- self.prefix_name = weight_prefix_name
-
- def _conv_bn(self,
- input,
- ch_out,
- filter_size,
- stride,
- padding,
- act='leaky',
- is_test=True,
- name=None):
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=ch_out,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- act=None,
- param_attr=ParamAttr(name=name + ".conv.weights"),
- bias_attr=False)
-
- bn_name = name + ".bn"
- bn_param_attr = ParamAttr(
- regularizer=L2Decay(self.norm_decay), name=bn_name + '.scale')
- bn_bias_attr = ParamAttr(
- regularizer=L2Decay(self.norm_decay), name=bn_name + '.offset')
- out = fluid.layers.batch_norm(
- input=conv,
- act=None,
- is_test=is_test,
- param_attr=bn_param_attr,
- bias_attr=bn_bias_attr,
- moving_mean_name=bn_name + '.mean',
- moving_variance_name=bn_name + '.var')
-
- if act == 'leaky':
- out = fluid.layers.leaky_relu(x=out, alpha=0.1)
- return out
-
- def _detection_block(self, input, channel, is_test=True, name=None):
- assert channel % 2 == 0, \
- "channel {} cannot be divided by 2 in detection block {}" \
- .format(channel, name)
-
- conv = input
- for j in range(2):
- conv = self._conv_bn(
- conv,
- channel,
- filter_size=1,
- stride=1,
- padding=0,
- is_test=is_test,
- name='{}.{}.0'.format(name, j))
- conv = self._conv_bn(
- conv,
- channel * 2,
- filter_size=3,
- stride=1,
- padding=1,
- is_test=is_test,
- name='{}.{}.1'.format(name, j))
- route = self._conv_bn(
- conv,
- channel,
- filter_size=1,
- stride=1,
- padding=0,
- is_test=is_test,
- name='{}.2'.format(name))
- tip = self._conv_bn(
- route,
- channel * 2,
- filter_size=3,
- stride=1,
- padding=1,
- is_test=is_test,
- name='{}.tip'.format(name))
- return route, tip
-
- def _upsample(self, input, scale=2, name=None):
- out = fluid.layers.resize_nearest(
- input=input, scale=float(scale), name=name)
- return out
-
- def _parse_anchors(self, anchors):
- """
- Check ANCHORS/ANCHOR_MASKS in config and parse mask_anchors
-
- """
- self.anchors = []
- self.mask_anchors = []
-
- assert len(anchors) > 0, "ANCHORS not set."
- assert len(self.anchor_masks) > 0, "ANCHOR_MASKS not set."
-
- for anchor in anchors:
- assert len(anchor) == 2, "anchor {} len should be 2".format(anchor)
- self.anchors.extend(anchor)
-
- anchor_num = len(anchors)
- for masks in self.anchor_masks:
- self.mask_anchors.append([])
- for mask in masks:
- assert mask < anchor_num, "anchor mask index overflow"
- self.mask_anchors[-1].extend(anchors[mask])
-
- def _get_outputs(self, input, is_train=True):
- """
- Get YOLOv3 head output
-
- Args:
- input (list): List of Variables, output of backbone stages
- is_train (bool): whether in train or test mode
-
- Returns:
- outputs (list): Variables of each output layer
- """
-
- outputs = []
-
- # get last out_layer_num blocks in reverse order
- out_layer_num = len(self.anchor_masks)
- if isinstance(input, OrderedDict):
- blocks = list(input.values())[-1:-out_layer_num - 1:-1]
- else:
- blocks = input[-1:-out_layer_num - 1:-1]
- route = None
- for i, block in enumerate(blocks):
- if i > 0: # perform concat in first 2 detection_block
- block = fluid.layers.concat(input=[route, block], axis=1)
- route, tip = self._detection_block(
- block,
- channel=512 // (2**i),
- is_test=(not is_train),
- name=self.prefix_name + "yolo_block.{}".format(i))
-
- # out channel number = mask_num * (5 + class_num)
- num_filters = len(self.anchor_masks[i]) * (self.num_classes + 5)
- block_out = fluid.layers.conv2d(
- input=tip,
- num_filters=num_filters,
- filter_size=1,
- stride=1,
- padding=0,
- act=None,
- param_attr=ParamAttr(name=self.prefix_name +
- "yolo_output.{}.conv.weights".format(i)),
- bias_attr=ParamAttr(
- regularizer=L2Decay(0.),
- name=self.prefix_name +
- "yolo_output.{}.conv.bias".format(i)))
- outputs.append(block_out)
-
- if i < len(blocks) - 1:
- # do not perform upsample in the last detection_block
- route = self._conv_bn(
- input=route,
- ch_out=256 // (2**i),
- filter_size=1,
- stride=1,
- padding=0,
- is_test=(not is_train),
- name=self.prefix_name + "yolo_transition.{}".format(i))
- # upsample
- route = self._upsample(route)
-
- return outputs, blocks
-
- def get_prediction(self, outputs, im_size):
- """
- Get prediction result of YOLOv3 network
-
- Args:
- outputs (list): list of Variables, return from _get_outputs
- im_size (Variable): Variable of size([h, w]) of each image
-
- Returns:
- pred (Variable): The prediction result after non-max suppress.
-
- """
- boxes = []
- scores = []
- downsample = 32
- for i, output in enumerate(outputs):
- box, score = fluid.layers.yolo_box(
- x=output,
- img_size=im_size,
- anchors=self.mask_anchors[i],
- class_num=self.num_classes,
- conf_thresh=self.nms.score_threshold,
- downsample_ratio=downsample,
- name=self.prefix_name + "yolo_box" + str(i))
- boxes.append(box)
- scores.append(fluid.layers.transpose(score, perm=[0, 2, 1]))
-
- downsample //= 2
-
- yolo_boxes = fluid.layers.concat(boxes, axis=1)
- yolo_scores = fluid.layers.concat(scores, axis=2)
- pred = fluid.layers.multiclass_nms(
- bboxes=yolo_boxes,
- scores=yolo_scores,
- score_threshold=self.nms.score_threshold,
- nms_top_k=self.nms.nms_top_k,
- keep_top_k=self.nms.keep_top_k,
- nms_threshold=self.nms.nms_threshold,
- background_label=self.nms.background_label,
- normalized=self.nms.normalized,
- name="multiclass_nms")
- return pred
From a1c050dff013b693720d2dc074b4358806773b5e Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:12:00 +0800
Subject: [PATCH 063/117] update ssd_mobilenet_v1_pascal (#1955)
* update ssd_mobilenet_v1_pascal
* update gpu config
* update
* add clean func
* update save inference model
---
.../ssd_mobilenet_v1_pascal/README.md | 16 ++-
.../ssd_mobilenet_v1_pascal/README_en.md | 16 ++-
.../ssd_mobilenet_v1_pascal/data_feed.py | 2 -
.../ssd_mobilenet_v1_pascal/module.py | 45 +++-----
.../ssd_mobilenet_v1_pascal/test.py | 108 ++++++++++++++++++
5 files changed, 136 insertions(+), 51 deletions(-)
create mode 100644 modules/image/object_detection/ssd_mobilenet_v1_pascal/test.py
diff --git a/modules/image/object_detection/ssd_mobilenet_v1_pascal/README.md b/modules/image/object_detection/ssd_mobilenet_v1_pascal/README.md
index 4b3ac1822..ff5b0e231 100644
--- a/modules/image/object_detection/ssd_mobilenet_v1_pascal/README.md
+++ b/modules/image/object_detection/ssd_mobilenet_v1_pascal/README.md
@@ -102,19 +102,13 @@
- save\_path (str, optional): 识别结果的保存路径 (仅当visualization=True时存在)
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称;
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -172,6 +166,10 @@
移除 fluid api
+* 1.2.0
+
+ 修复推理模型无法导出的问题
+
- ```shell
- $ hub install ssd_mobilenet_v1_pascal==1.1.3
+ $ hub install ssd_mobilenet_v1_pascal==1.2.0
```
diff --git a/modules/image/object_detection/ssd_mobilenet_v1_pascal/README_en.md b/modules/image/object_detection/ssd_mobilenet_v1_pascal/README_en.md
index 4bad42420..9876bcc03 100644
--- a/modules/image/object_detection/ssd_mobilenet_v1_pascal/README_en.md
+++ b/modules/image/object_detection/ssd_mobilenet_v1_pascal/README_en.md
@@ -101,19 +101,13 @@
- save\_path (str, optional): output path for saving results
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -171,6 +165,10 @@
Remove fluid api
+* 1.2.0
+
+ Fix bug of save_inference_model
+
- ```shell
- $ hub install ssd_mobilenet_v1_pascal==1.1.3
+ $ hub install ssd_mobilenet_v1_pascal==1.2.0
```
diff --git a/modules/image/object_detection/ssd_mobilenet_v1_pascal/data_feed.py b/modules/image/object_detection/ssd_mobilenet_v1_pascal/data_feed.py
index 42677536f..6768b03e0 100644
--- a/modules/image/object_detection/ssd_mobilenet_v1_pascal/data_feed.py
+++ b/modules/image/object_detection/ssd_mobilenet_v1_pascal/data_feed.py
@@ -5,12 +5,10 @@
import os
import random
-from collections import OrderedDict
import cv2
import numpy as np
from PIL import Image
-from paddle import fluid
__all__ = ['reader']
diff --git a/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py b/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py
index 7460115c3..a926a4402 100644
--- a/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py
+++ b/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py
@@ -8,38 +8,39 @@
import numpy as np
import paddle
+import paddle.jit
+import paddle.static
import yaml
from paddle.inference import Config
from paddle.inference import create_predictor
-from ssd_mobilenet_v1_pascal.data_feed import reader
-from ssd_mobilenet_v1_pascal.processor import base64_to_cv2
-from ssd_mobilenet_v1_pascal.processor import load_label_info
-from ssd_mobilenet_v1_pascal.processor import postprocess
+from .data_feed import reader
+from .processor import base64_to_cv2
+from .processor import load_label_info
+from .processor import postprocess
-import paddlehub as hub
-from paddlehub.common.paddle_helper import add_vars_prefix
from paddlehub.module.module import moduleinfo
from paddlehub.module.module import runnable
from paddlehub.module.module import serving
@moduleinfo(name="ssd_mobilenet_v1_pascal",
- version="1.1.3",
+ version="1.2.0",
type="cv/object_detection",
summary="SSD with backbone MobileNet_V1, trained with dataset Pasecal VOC.",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class SSDMobileNetv1(hub.Module):
-
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "ssd_mobilenet_v1_model")
+class SSDMobileNetv1:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "ssd_mobilenet_v1_model", "model")
self.label_names = load_label_info(os.path.join(self.directory, "label_file.txt"))
self.model_config = None
self._set_config()
def _set_config(self):
# predictor config setting.
- cpu_config = Config(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
cpu_config.switch_ir_optim(False)
@@ -52,7 +53,7 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = Config(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
self.gpu_predictor = create_predictor(gpu_config)
@@ -136,24 +137,6 @@ def object_detection(self,
res.extend(output)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = paddle.CPUPlace()
- exe = paddle.Executor(place)
-
- program, feeded_var_names, target_vars = paddle.static.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- paddle.static.save_inference_model(dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/object_detection/ssd_mobilenet_v1_pascal/test.py b/modules/image/object_detection/ssd_mobilenet_v1_pascal/test.py
new file mode 100644
index 000000000..c27307b8a
--- /dev/null
+++ b/modules/image/object_detection/ssd_mobilenet_v1_pascal/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/68313e182f5e4ad9907e69dac9ece8fc50840d7ffbd24fa88396f009958f969a'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="ssd_mobilenet_v1_pascal")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(200 < left < 800)
+ self.assertTrue(2500 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(3500 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ cv2.error,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From f3d7b12ca2ef769e703b39cdfd631b03107cf453 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:13:26 +0800
Subject: [PATCH 064/117] update yolov3_darknet53_pedestrian (#1956)
* update yolov3_darknet53_pedestrian
* update gpu config
* update
* add clean func
* update save inference model
Co-authored-by: chenjian
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -171,6 +165,10 @@
移除 fluid api
+* 1.1.0
+
+ 修复推理模型无法导出的问题
+
- ```shell
- $ hub install yolov3_darknet53_pedestrian==1.0.3
+ $ hub install yolov3_darknet53_pedestrian==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_darknet53_pedestrian/README_en.md b/modules/image/object_detection/yolov3_darknet53_pedestrian/README_en.md
index 09d82d391..faaf48e3c 100644
--- a/modules/image/object_detection/yolov3_darknet53_pedestrian/README_en.md
+++ b/modules/image/object_detection/yolov3_darknet53_pedestrian/README_en.md
@@ -100,19 +100,13 @@
- save\_path (str, optional): output path for saving results
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -170,6 +164,10 @@
Remove fluid api
+* 1.1.0
+
+ Fix bug of save_inference_model
+
- ```shell
- $ hub install yolov3_darknet53_pedestrian==1.0.3
+ $ hub install yolov3_darknet53_pedestrian==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py b/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py
index 5b8a4c842..7d52f1fef 100644
--- a/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py
+++ b/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py
@@ -8,30 +8,29 @@
import numpy as np
import paddle
+import paddle.jit
+import paddle.static
from paddle.inference import Config
from paddle.inference import create_predictor
-from yolov3_darknet53_pedestrian.data_feed import reader
-from yolov3_darknet53_pedestrian.processor import base64_to_cv2
-from yolov3_darknet53_pedestrian.processor import load_label_info
-from yolov3_darknet53_pedestrian.processor import postprocess
+from .data_feed import reader
+from .processor import base64_to_cv2
+from .processor import load_label_info
+from .processor import postprocess
-import paddlehub as hub
-from paddlehub.common.paddle_helper import add_vars_prefix
from paddlehub.module.module import moduleinfo
from paddlehub.module.module import runnable
from paddlehub.module.module import serving
@moduleinfo(name="yolov3_darknet53_pedestrian",
- version="1.0.3",
+ version="1.1.0",
type="CV/object_detection",
summary="Baidu's YOLOv3 model for pedestrian detection, with backbone DarkNet53.",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class YOLOv3DarkNet53Pedestrian(hub.Module):
-
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "yolov3_darknet53_pedestrian_model")
+class YOLOv3DarkNet53Pedestrian:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "yolov3_darknet53_pedestrian_model", "model")
self.label_names = load_label_info(os.path.join(self.directory, "label_file.txt"))
self._set_config()
@@ -39,7 +38,9 @@ def _set_config(self):
"""
predictor config setting.
"""
- cpu_config = Config(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
cpu_config.switch_ir_optim(False)
@@ -52,7 +53,7 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = Config(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
self.gpu_predictor = create_predictor(gpu_config)
@@ -125,24 +126,6 @@ def object_detection(self,
res.extend(output)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = paddle.CPUPlace()
- exe = paddle.Executor(place)
-
- program, feeded_var_names, target_vars = paddle.static.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- paddle.static.save_inference_model(dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/object_detection/yolov3_darknet53_pedestrian/processor.py b/modules/image/object_detection/yolov3_darknet53_pedestrian/processor.py
index 356ce0342..25390dcf8 100644
--- a/modules/image/object_detection/yolov3_darknet53_pedestrian/processor.py
+++ b/modules/image/object_detection/yolov3_darknet53_pedestrian/processor.py
@@ -89,7 +89,7 @@ def load_label_info(file_path):
def postprocess(paths, images, data_out, score_thresh, label_names, output_dir, handle_id, visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): The paths of images.
diff --git a/modules/image/object_detection/yolov3_darknet53_pedestrian/test.py b/modules/image/object_detection/yolov3_darknet53_pedestrian/test.py
new file mode 100644
index 000000000..72a015d8c
--- /dev/null
+++ b/modules/image/object_detection/yolov3_darknet53_pedestrian/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/15310014bf794c87a1e3b289d904ecae122aafe8c8fe47fd98634e79a8e4012f'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="yolov3_darknet53_pedestrian")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('yolov3_pedestrian_detect_output')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'pedestrian')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'pedestrian')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'pedestrian')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
\ No newline at end of file
From 7a847a39b1da6e6867031f52f713d92391b9729d Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:13:47 +0800
Subject: [PATCH 065/117] update yolov3_darknet53_vehicles (#1957)
* update yolov3_darknet53_vehicles
* update gpu config
* update
* add clean func
* update save inference model
---
.../yolov3_darknet53_vehicles/README.md | 16 ++-
.../yolov3_darknet53_vehicles/README_en.md | 16 ++-
.../yolov3_darknet53_vehicles/module.py | 49 +++-----
.../yolov3_darknet53_vehicles/processor.py | 2 +-
.../yolov3_darknet53_vehicles/test.py | 108 ++++++++++++++++++
5 files changed, 139 insertions(+), 52 deletions(-)
create mode 100644 modules/image/object_detection/yolov3_darknet53_vehicles/test.py
diff --git a/modules/image/object_detection/yolov3_darknet53_vehicles/README.md b/modules/image/object_detection/yolov3_darknet53_vehicles/README.md
index fdf4569de..9c42eef96 100644
--- a/modules/image/object_detection/yolov3_darknet53_vehicles/README.md
+++ b/modules/image/object_detection/yolov3_darknet53_vehicles/README.md
@@ -100,19 +100,13 @@
- save\_path (str, optional): 识别结果的保存路径 (仅当visualization=True时存在)
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称;
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -170,6 +164,10 @@
移除 fluid api
+* 1.1.0
+
+ 修复推理模型无法导出的问题
+
- ```shell
- $ hub install yolov3_darknet53_vehicles==1.0.3
+ $ hub install yolov3_darknet53_vehicles==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_darknet53_vehicles/README_en.md b/modules/image/object_detection/yolov3_darknet53_vehicles/README_en.md
index 59cb62134..d014fc3ad 100644
--- a/modules/image/object_detection/yolov3_darknet53_vehicles/README_en.md
+++ b/modules/image/object_detection/yolov3_darknet53_vehicles/README_en.md
@@ -100,19 +100,13 @@
- save\_path (str, optional): output path for saving results
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -170,6 +164,10 @@
Remove fluid api
+* 1.1.0
+
+ Fix bug of save_inference_model
+
- ```shell
- $ hub install yolov3_darknet53_vehicles==1.0.3
+ $ hub install yolov3_darknet53_vehicles==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_darknet53_vehicles/module.py b/modules/image/object_detection/yolov3_darknet53_vehicles/module.py
index b4586de5a..05ae70855 100644
--- a/modules/image/object_detection/yolov3_darknet53_vehicles/module.py
+++ b/modules/image/object_detection/yolov3_darknet53_vehicles/module.py
@@ -8,30 +8,29 @@
import numpy as np
import paddle
+import paddle.jit
+import paddle.static
from paddle.inference import Config
from paddle.inference import create_predictor
-from yolov3_darknet53_vehicles.data_feed import reader
-from yolov3_darknet53_vehicles.processor import base64_to_cv2
-from yolov3_darknet53_vehicles.processor import load_label_info
-from yolov3_darknet53_vehicles.processor import postprocess
+from .data_feed import reader
+from .processor import base64_to_cv2
+from .processor import load_label_info
+from .processor import postprocess
-import paddlehub as hub
-from paddlehub.common.paddle_helper import add_vars_prefix
from paddlehub.module.module import moduleinfo
from paddlehub.module.module import runnable
from paddlehub.module.module import serving
@moduleinfo(name="yolov3_darknet53_vehicles",
- version="1.0.3",
+ version="1.1.0",
type="CV/object_detection",
summary="Baidu's YOLOv3 model for vehicles detection, with backbone DarkNet53.",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class YOLOv3DarkNet53Vehicles(hub.Module):
-
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "yolov3_darknet53_vehicles_model")
+class YOLOv3DarkNet53Vehicles:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "yolov3_darknet53_vehicles_model", "model")
self.label_names = load_label_info(os.path.join(self.directory, "label_file.txt"))
self._set_config()
@@ -49,7 +48,9 @@ def _set_config(self):
"""
# create default cpu predictor
- cpu_config = Config(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
self.cpu_predictor = create_predictor(cpu_config)
@@ -60,7 +61,7 @@ def _set_config(self):
npu_id = self._get_device_id("FLAGS_selected_npus")
if npu_id != -1:
# use npu
- npu_config = Config(self.default_pretrained_model_path)
+ npu_config = Config(model, params)
npu_config.disable_glog_info()
npu_config.enable_npu(device_id=npu_id)
self.npu_predictor = create_predictor(npu_config)
@@ -69,7 +70,7 @@ def _set_config(self):
gpu_id = self._get_device_id("CUDA_VISIBLE_DEVICES")
if gpu_id != -1:
# use gpu
- gpu_config = Config(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=gpu_id)
self.gpu_predictor = create_predictor(gpu_config)
@@ -78,7 +79,7 @@ def _set_config(self):
xpu_id = self._get_device_id("XPU_VISIBLE_DEVICES")
if xpu_id != -1:
# use xpu
- xpu_config = Config(self.default_pretrained_model_path)
+ xpu_config = Config(model, params)
xpu_config.disable_glog_info()
xpu_config.enable_xpu(100)
self.xpu_predictor = create_predictor(xpu_config)
@@ -169,24 +170,6 @@ def object_detection(self,
res.extend(output)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = paddle.CPUPlace()
- exe = paddle.Executor(place)
-
- program, feeded_var_names, target_vars = paddle.static.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- paddle.static.save_inference_model(dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/object_detection/yolov3_darknet53_vehicles/processor.py b/modules/image/object_detection/yolov3_darknet53_vehicles/processor.py
index 5aa464e6b..95e12def7 100644
--- a/modules/image/object_detection/yolov3_darknet53_vehicles/processor.py
+++ b/modules/image/object_detection/yolov3_darknet53_vehicles/processor.py
@@ -88,7 +88,7 @@ def load_label_info(file_path):
def postprocess(paths, images, data_out, score_thresh, label_names, output_dir, handle_id, visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): The paths of images.
diff --git a/modules/image/object_detection/yolov3_darknet53_vehicles/test.py b/modules/image/object_detection/yolov3_darknet53_vehicles/test.py
new file mode 100644
index 000000000..6ab7c6e42
--- /dev/null
+++ b/modules/image/object_detection/yolov3_darknet53_vehicles/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/036990d3d8654d789c2138492155d9dd95dba2a2fc8e410ab059eea42b330f59'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="yolov3_darknet53_vehicles")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('yolov3_vehicles_detect_output')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'car')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(2000 < left < 4000)
+ self.assertTrue(4000 < right < 6000)
+ self.assertTrue(1000 < top < 3000)
+ self.assertTrue(2000 < bottom < 5000)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'car')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(2000 < left < 4000)
+ self.assertTrue(4000 < right < 6000)
+ self.assertTrue(1000 < top < 3000)
+ self.assertTrue(2000 < bottom < 5000)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'car')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(2000 < left < 4000)
+ self.assertTrue(4000 < right < 6000)
+ self.assertTrue(1000 < top < 3000)
+ self.assertTrue(2000 < bottom < 5000)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
\ No newline at end of file
From ce4efe174556048176adf55c5006883a0f25b7e8 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:14:10 +0800
Subject: [PATCH 066/117] update ultra_light_fast_generic_face_detector_1mb_640
(#1964)
* update ultra_light_fast_generic_face_detector_1mb
* add clean func
* update save inference model
---
.../README.md | 17 ++-
.../README_en.md | 16 +--
.../module.py | 41 ++----
.../test.py | 133 ++++++++++++++++++
4 files changed, 160 insertions(+), 47 deletions(-)
create mode 100644 modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/test.py
diff --git a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/README.md b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/README.md
index b7b36aa78..b015f9e77 100644
--- a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/README.md
+++ b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/README.md
@@ -102,19 +102,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称;
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -168,6 +162,11 @@
移除 fluid api
+* 1.2.0
+
+ 修复无法导出推理模型的问题
+
- ```shell
- $ hub install ultra_light_fast_generic_face_detector_1mb_640==1.1.3
+ $ hub install ultra_light_fast_generic_face_detector_1mb_640==1.2.0
```
+
diff --git a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/README_en.md b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/README_en.md
index e200bb397..473715081 100644
--- a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/README_en.md
+++ b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/README_en.md
@@ -101,19 +101,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -167,6 +161,10 @@
Remove fluid api
+* 1.2.0
+
+ Fix a bug of save_inference_model
+
- ```shell
- $ hub install ultra_light_fast_generic_face_detector_1mb_640==1.1.3
+ $ hub install ultra_light_fast_generic_face_detector_1mb_640==1.2.0
```
diff --git a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py
index 6caa32ace..ceebbfb30 100644
--- a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py
+++ b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py
@@ -8,13 +8,13 @@
import numpy as np
import paddle
+import paddle.static
from paddle.inference import Config
from paddle.inference import create_predictor
-from ultra_light_fast_generic_face_detector_1mb_640.data_feed import reader
-from ultra_light_fast_generic_face_detector_1mb_640.processor import base64_to_cv2
-from ultra_light_fast_generic_face_detector_1mb_640.processor import postprocess
+from .data_feed import reader
+from .processor import base64_to_cv2
+from .processor import postprocess
-import paddlehub as hub
from paddlehub.module.module import moduleinfo
from paddlehub.module.module import runnable
from paddlehub.module.module import serving
@@ -27,19 +27,20 @@
author_email="paddle-dev@baidu.com",
summary=
"Ultra-Light-Fast-Generic-Face-Detector-1MB is a high-performance object detection model release on https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB.",
- version="1.1.3")
-class FaceDetector640(hub.Module):
-
- def _initialize(self):
+ version="1.2.0")
+class FaceDetector640:
+ def __init__(self):
self.default_pretrained_model_path = os.path.join(self.directory,
- "ultra_light_fast_generic_face_detector_1mb_640")
+ "ultra_light_fast_generic_face_detector_1mb_640", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- cpu_config = Config(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
self.cpu_predictor = create_predictor(cpu_config)
@@ -51,29 +52,11 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = Config(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
self.gpu_predictor = create_predictor(gpu_config)
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = paddle.CPUPlace()
- exe = paddle.Executor(place)
-
- program, feeded_var_names, target_vars = paddle.static.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- paddle.static.save_inference_model(dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
def face_detection(self,
images=None,
paths=None,
diff --git a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/test.py b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/test.py
new file mode 100644
index 000000000..ecf7365fa
--- /dev/null
+++ b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/test.py
@@ -0,0 +1,133 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/7799a8ccc5f6471b9d56fb6eff94f82a08b70ca2c7594d3f99877e366c0a2619'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="ultra_light_fast_generic_face_detector_1mb_640")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('face_detector_640_predict_output')
+
+ def test_face_detection1(self):
+ results = self.module.face_detection(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection2(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection3(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection4(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.face_detection,
+ paths=['no.jpg']
+ )
+
+ def test_face_detection6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.face_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 02674b5db2e13aa1ba563d3ba9f660c27cb3c263 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:14:34 +0800
Subject: [PATCH 067/117] update ultra_light_fast_generic_face_detector_1mb_320
(#1965)
* update ultra_light_fast_generic_face_detector_1mb
* add clean func
* update save inference model
---
.../README.md | 16 +--
.../README_en.md | 16 +--
.../module.py | 40 ++----
.../test.py | 133 ++++++++++++++++++
4 files changed, 158 insertions(+), 47 deletions(-)
create mode 100644 modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/test.py
diff --git a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/README.md b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/README.md
index bb44d9c6a..c2ff5a40a 100644
--- a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/README.md
+++ b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/README.md
@@ -102,19 +102,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称;
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -168,6 +162,10 @@
移除 fluid api
+* 1.2.0
+
+ 修复无法导出推理模型的问题
+
- ```shell
- $ hub install ultra_light_fast_generic_face_detector_1mb_320==1.1.3
+ $ hub install ultra_light_fast_generic_face_detector_1mb_320==1.2.0
```
diff --git a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/README_en.md b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/README_en.md
index 2bad14e23..cadcdc2bb 100644
--- a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/README_en.md
+++ b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/README_en.md
@@ -101,19 +101,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -167,6 +161,10 @@
Remove fluid api
+* 1.2.0
+
+ Fix a bug of save_inference_model
+
- ```shell
- $ hub install ultra_light_fast_generic_face_detector_1mb_320==1.1.3
+ $ hub install ultra_light_fast_generic_face_detector_1mb_320==1.2.0
```
diff --git a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py
index 6744e3571..8e5340077 100644
--- a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py
+++ b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py
@@ -10,11 +10,10 @@
import paddle
from paddle.inference import Config
from paddle.inference import create_predictor
-from ultra_light_fast_generic_face_detector_1mb_320.data_feed import reader
-from ultra_light_fast_generic_face_detector_1mb_320.processor import base64_to_cv2
-from ultra_light_fast_generic_face_detector_1mb_320.processor import postprocess
+from .data_feed import reader
+from .processor import base64_to_cv2
+from .processor import postprocess
-import paddlehub as hub
from paddlehub.module.module import moduleinfo
from paddlehub.module.module import runnable
from paddlehub.module.module import serving
@@ -27,19 +26,20 @@
author_email="paddle-dev@baidu.com",
summary=
"Ultra-Light-Fast-Generic-Face-Detector-1MB is a high-performance object detection model release on https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB.",
- version="1.1.3")
-class FaceDetector320(hub.Module):
-
- def _initialize(self):
+ version="1.2.0")
+class FaceDetector320:
+ def __init__(self):
self.default_pretrained_model_path = os.path.join(self.directory,
- "ultra_light_fast_generic_face_detector_1mb_320")
+ "ultra_light_fast_generic_face_detector_1mb_320", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- cpu_config = Config(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
self.cpu_predictor = create_predictor(cpu_config)
@@ -51,29 +51,11 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = Config(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
self.gpu_predictor = create_predictor(gpu_config)
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = paddle.CPUPlace()
- exe = paddle.Executor(place)
-
- program, feeded_var_names, target_vars = paddle.static.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- paddle.static.save_inference_model(dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
def face_detection(self,
images=None,
paths=None,
diff --git a/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/test.py b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/test.py
new file mode 100644
index 000000000..a180acfee
--- /dev/null
+++ b/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/test.py
@@ -0,0 +1,133 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/7799a8ccc5f6471b9d56fb6eff94f82a08b70ca2c7594d3f99877e366c0a2619'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="ultra_light_fast_generic_face_detector_1mb_320")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('face_detector_320_predict_output')
+
+ def test_face_detection1(self):
+ results = self.module.face_detection(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection2(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection3(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection4(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.face_detection,
+ paths=['no.jpg']
+ )
+
+ def test_face_detection6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.face_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 931f1e7c7e60b027e641bcf897132341a6608b90 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:15:00 +0800
Subject: [PATCH 068/117] update face_landmark_localization (#1966)
* update face_landmark_localization
* fix typo
* update
* add clean func
* update save inference model
* update save inference model
Co-authored-by: chenjian
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -167,6 +161,10 @@
修复numpy数据读取问题
+* 1.1.0
+
+ 移除 fluid api
+
- ```shell
- $ hub install yolov3_mobilenet_v1_coco2017==1.0.2
+ $ hub install yolov3_mobilenet_v1_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/README_en.md b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/README_en.md
index f80472bfa..08ecd92a9 100644
--- a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/README_en.md
+++ b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/README_en.md
@@ -100,19 +100,13 @@
- save\_path (str, optional): output path for saving results
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -166,6 +160,10 @@
Fix the problem of reading numpy
+* 1.1.0
+
+ Remove fluid api
+
- ```shell
- $ hub install yolov3_mobilenet_v1_coco2017==1.0.2
+ $ hub install yolov3_mobilenet_v1_coco2017==1.1.0
```
diff --git a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/mobilenet_v1.py b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/mobilenet_v1.py
deleted file mode 100644
index 05f64c938..000000000
--- a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/mobilenet_v1.py
+++ /dev/null
@@ -1,194 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.regularizer import L2Decay
-
-__all__ = ['MobileNet']
-
-
-class MobileNet(object):
- """
- MobileNet v1, see https://arxiv.org/abs/1704.04861
-
- Args:
- norm_type (str): normalization type, 'bn' and 'sync_bn' are supported
- norm_decay (float): weight decay for normalization layer weights
- conv_group_scale (int): scaling factor for convolution groups
- with_extra_blocks (bool): if extra blocks should be added
- extra_block_filters (list): number of filter for each extra block
- """
- __shared__ = ['norm_type', 'weight_prefix_name']
-
- def __init__(self,
- norm_type='bn',
- norm_decay=0.,
- conv_group_scale=1,
- conv_learning_rate=1.0,
- with_extra_blocks=False,
- extra_block_filters=[[256, 512], [128, 256], [128, 256],
- [64, 128]],
- weight_prefix_name=''):
- self.norm_type = norm_type
- self.norm_decay = norm_decay
- self.conv_group_scale = conv_group_scale
- self.conv_learning_rate = conv_learning_rate
- self.with_extra_blocks = with_extra_blocks
- self.extra_block_filters = extra_block_filters
- self.prefix_name = weight_prefix_name
-
- def _conv_norm(self,
- input,
- filter_size,
- num_filters,
- stride,
- padding,
- num_groups=1,
- act='relu',
- use_cudnn=True,
- name=None):
- parameter_attr = ParamAttr(
- learning_rate=self.conv_learning_rate,
- initializer=fluid.initializer.MSRA(),
- name=name + "_weights")
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- groups=num_groups,
- act=None,
- use_cudnn=use_cudnn,
- param_attr=parameter_attr,
- bias_attr=False)
-
- bn_name = name + "_bn"
- norm_decay = self.norm_decay
- bn_param_attr = ParamAttr(
- regularizer=L2Decay(norm_decay), name=bn_name + '_scale')
- bn_bias_attr = ParamAttr(
- regularizer=L2Decay(norm_decay), name=bn_name + '_offset')
- return fluid.layers.batch_norm(
- input=conv,
- act=act,
- param_attr=bn_param_attr,
- bias_attr=bn_bias_attr,
- moving_mean_name=bn_name + '_mean',
- moving_variance_name=bn_name + '_variance')
-
- def depthwise_separable(self,
- input,
- num_filters1,
- num_filters2,
- num_groups,
- stride,
- scale,
- name=None):
- depthwise_conv = self._conv_norm(
- input=input,
- filter_size=3,
- num_filters=int(num_filters1 * scale),
- stride=stride,
- padding=1,
- num_groups=int(num_groups * scale),
- use_cudnn=False,
- name=name + "_dw")
-
- pointwise_conv = self._conv_norm(
- input=depthwise_conv,
- filter_size=1,
- num_filters=int(num_filters2 * scale),
- stride=1,
- padding=0,
- name=name + "_sep")
- return pointwise_conv
-
- def _extra_block(self,
- input,
- num_filters1,
- num_filters2,
- num_groups,
- stride,
- name=None):
- pointwise_conv = self._conv_norm(
- input=input,
- filter_size=1,
- num_filters=int(num_filters1),
- stride=1,
- num_groups=int(num_groups),
- padding=0,
- name=name + "_extra1")
- normal_conv = self._conv_norm(
- input=pointwise_conv,
- filter_size=3,
- num_filters=int(num_filters2),
- stride=2,
- num_groups=int(num_groups),
- padding=1,
- name=name + "_extra2")
- return normal_conv
-
- def __call__(self, input):
- scale = self.conv_group_scale
-
- blocks = []
- # input 1/1
- out = self._conv_norm(
- input, 3, int(32 * scale), 2, 1, name=self.prefix_name + "conv1")
- # 1/2
- out = self.depthwise_separable(
- out, 32, 64, 32, 1, scale, name=self.prefix_name + "conv2_1")
- out = self.depthwise_separable(
- out, 64, 128, 64, 2, scale, name=self.prefix_name + "conv2_2")
- # 1/4
- out = self.depthwise_separable(
- out, 128, 128, 128, 1, scale, name=self.prefix_name + "conv3_1")
- out = self.depthwise_separable(
- out, 128, 256, 128, 2, scale, name=self.prefix_name + "conv3_2")
- # 1/8
- blocks.append(out)
- out = self.depthwise_separable(
- out, 256, 256, 256, 1, scale, name=self.prefix_name + "conv4_1")
- out = self.depthwise_separable(
- out, 256, 512, 256, 2, scale, name=self.prefix_name + "conv4_2")
- # 1/16
- blocks.append(out)
- for i in range(5):
- out = self.depthwise_separable(
- out,
- 512,
- 512,
- 512,
- 1,
- scale,
- name=self.prefix_name + "conv5_" + str(i + 1))
- module11 = out
-
- out = self.depthwise_separable(
- out, 512, 1024, 512, 2, scale, name=self.prefix_name + "conv5_6")
- # 1/32
- out = self.depthwise_separable(
- out, 1024, 1024, 1024, 1, scale, name=self.prefix_name + "conv6")
- module13 = out
- blocks.append(out)
- if not self.with_extra_blocks:
- return blocks
-
- num_filters = self.extra_block_filters
- module14 = self._extra_block(module13, num_filters[0][0],
- num_filters[0][1], 1, 2,
- self.prefix_name + "conv7_1")
- module15 = self._extra_block(module14, num_filters[1][0],
- num_filters[1][1], 1, 2,
- self.prefix_name + "conv7_2")
- module16 = self._extra_block(module15, num_filters[2][0],
- num_filters[2][1], 1, 2,
- self.prefix_name + "conv7_3")
- module17 = self._extra_block(module16, num_filters[3][0],
- num_filters[3][1], 1, 2,
- self.prefix_name + "conv7_4")
- return module11, module13, module14, module15, module16, module17
diff --git a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py
index 98e1110a0..0a642907e 100644
--- a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py
+++ b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py
@@ -6,31 +6,29 @@
import os
from functools import partial
+import paddle
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle.jit
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from paddlehub.common.paddle_helper import add_vars_prefix
-from yolov3_mobilenet_v1_coco2017.mobilenet_v1 import MobileNet
-from yolov3_mobilenet_v1_coco2017.processor import load_label_info, postprocess, base64_to_cv2
-from yolov3_mobilenet_v1_coco2017.data_feed import reader
-from yolov3_mobilenet_v1_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
+from .processor import load_label_info, postprocess, base64_to_cv2
+from .data_feed import reader
@moduleinfo(
name="yolov3_mobilenet_v1_coco2017",
- version="1.0.2",
+ version="1.1.0",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection with backbone MobileNet_V1, trained with dataset COCO2017.",
author="paddlepaddle",
author_email="paddle-dev@baidu.com")
-class YOLOv3MobileNetV1Coco2017(hub.Module):
- def _initialize(self):
+class YOLOv3MobileNetV1Coco2017:
+ def __init__(self):
self.default_pretrained_model_path = os.path.join(
- self.directory, "yolov3_mobilenet_v1_model")
+ self.directory, "yolov3_mobilenet_v1_model", "model")
self.label_names = load_label_info(
os.path.join(self.directory, "label_file.txt"))
self._set_config()
@@ -39,11 +37,13 @@ def _set_config(self):
"""
predictor config setting.
"""
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
cpu_config.switch_ir_optim(False)
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -52,106 +52,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=500, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
-
- def context(self, trainable=True, pretrained=True, get_prediction=False):
- """
- Distill the Head Features, so as to perform transfer learning.
-
- Args:
- trainable (bool): whether to set parameters trainable.
- pretrained (bool): whether to load default pretrained model.
- get_prediction (bool): whether to get prediction.
-
- Returns:
- inputs(dict): the input variables.
- outputs(dict): the output variables.
- context_prog (Program): the program to execute transfer learning.
- """
- context_prog = fluid.Program()
- startup_program = fluid.Program()
- with fluid.program_guard(context_prog, startup_program):
- with fluid.unique_name.guard():
- # image
- image = fluid.layers.data(
- name='image', shape=[3, 608, 608], dtype='float32')
- # backbone
- backbone = MobileNet(
- norm_type='sync_bn',
- norm_decay=0.,
- conv_group_scale=1,
- with_extra_blocks=False)
- # body_feats
- body_feats = backbone(image)
- # im_size
- im_size = fluid.layers.data(
- name='im_size', shape=[2], dtype='int32')
- # yolo_head
- yolo_head = YOLOv3Head(num_classes=80)
- # head_features
- head_features, body_features = yolo_head._get_outputs(
- body_feats, is_train=trainable)
-
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- exe.run(startup_program)
-
- # var_prefix
- var_prefix = '@HUB_{}@'.format(self.name)
- # name of inputs
- inputs = {
- 'image': var_prefix + image.name,
- 'im_size': var_prefix + im_size.name
- }
- # name of outputs
- if get_prediction:
- bbox_out = yolo_head.get_prediction(head_features, im_size)
- outputs = {'bbox_out': [var_prefix + bbox_out.name]}
- else:
- outputs = {
- 'head_features':
- [var_prefix + var.name for var in head_features],
- 'body_features':
- [var_prefix + var.name for var in body_features]
- }
- # add_vars_prefix
- add_vars_prefix(context_prog, var_prefix)
- add_vars_prefix(startup_program, var_prefix)
- # inputs
- inputs = {
- key: context_prog.global_block().vars[value]
- for key, value in inputs.items()
- }
- # outputs
- outputs = {
- key: [
- context_prog.global_block().vars[varname]
- for varname in value
- ]
- for key, value in outputs.items()
- }
- # trainable
- for param in context_prog.global_block().iter_parameters():
- param.trainable = trainable
- # pretrained
- if pretrained:
-
- def _if_exist(var):
- return os.path.exists(
- os.path.join(self.default_pretrained_model_path,
- var.name))
-
- fluid.io.load_vars(
- exe,
- self.default_pretrained_model_path,
- predicate=_if_exist)
- else:
- exe.run(startup_program)
-
- return inputs, outputs, context_prog
+ self.gpu_predictor = create_predictor(gpu_config)
def object_detection(self,
paths=None,
@@ -194,54 +98,33 @@ def object_detection(self,
paths = paths if paths else list()
data_reader = partial(reader, paths, images)
- batch_reader = fluid.io.batch(data_reader, batch_size=batch_size)
+ batch_reader = paddle.batch(data_reader, batch_size=batch_size)
res = []
for iter_id, feed_data in enumerate(batch_reader()):
feed_data = np.array(feed_data)
- image_tensor = PaddleTensor(np.array(list(feed_data[:, 0])))
- im_size_tensor = PaddleTensor(np.array(list(feed_data[:, 1])))
- if use_gpu:
- data_out = self.gpu_predictor.run(
- [image_tensor, im_size_tensor])
- else:
- data_out = self.cpu_predictor.run(
- [image_tensor, im_size_tensor])
- output = postprocess(
- paths=paths,
- images=images,
- data_out=data_out,
- score_thresh=score_thresh,
- label_names=self.label_names,
- output_dir=output_dir,
- handle_id=iter_id * batch_size,
- visualization=visualization)
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 0])))
+ input_handle = predictor.get_input_handle(input_names[1])
+ input_handle.copy_from_cpu(np.array(list(feed_data[:, 1])))
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+
+ output = postprocess(paths=paths,
+ images=images,
+ data_out=output_handle,
+ score_thresh=score_thresh,
+ label_names=self.label_names,
+ output_dir=output_dir,
+ handle_id=iter_id * batch_size,
+ visualization=visualization)
res.extend(output)
return res
- def save_inference_model(self,
- dirname,
- model_filename=None,
- params_filename=None,
- combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/processor.py b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/processor.py
index 2f9a42d9c..aa9a61bd0 100644
--- a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/processor.py
+++ b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/processor.py
@@ -101,7 +101,7 @@ def postprocess(paths,
handle_id,
visualization=True):
"""
- postprocess the lod_tensor produced by fluid.Executor.run
+ postprocess the lod_tensor produced by Executor.run
Args:
paths (list[str]): The paths of images.
@@ -126,9 +126,8 @@ def postprocess(paths,
confidence (float): The confidence of detection result.
save_path (str): The path to save output images.
"""
- lod_tensor = data_out[0]
- lod = lod_tensor.lod[0]
- results = lod_tensor.as_ndarray()
+ lod = data_out.lod()[0]
+ results = data_out.copy_to_cpu()
check_dir(output_dir)
diff --git a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/test.py b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/test.py
new file mode 100644
index 000000000..ed99b6289
--- /dev/null
+++ b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/test.py
@@ -0,0 +1,108 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/68313e182f5e4ad9907e69dac9ece8fc50840d7ffbd24fa88396f009958f969a'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="yolov3_mobilenet_v1_coco2017")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_object_detection1(self):
+ results = self.module.object_detection(
+ paths=['tests/test.jpg']
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection2(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection3(self):
+ results = self.module.object_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'cat')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 1000)
+ self.assertTrue(1000 < right < 3500)
+ self.assertTrue(500 < top < 1500)
+ self.assertTrue(1000 < bottom < 4500)
+
+ def test_object_detection4(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.object_detection,
+ paths=['no.jpg']
+ )
+
+ def test_object_detection5(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.object_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
\ No newline at end of file
diff --git a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/yolo_head.py b/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/yolo_head.py
deleted file mode 100644
index 7428fb4c2..000000000
--- a/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/yolo_head.py
+++ /dev/null
@@ -1,273 +0,0 @@
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from collections import OrderedDict
-
-from paddle import fluid
-from paddle.fluid.param_attr import ParamAttr
-from paddle.fluid.regularizer import L2Decay
-
-__all__ = ['MultiClassNMS', 'YOLOv3Head']
-
-
-class MultiClassNMS(object):
- # __op__ = fluid.layers.multiclass_nms
- def __init__(self, background_label, keep_top_k, nms_threshold, nms_top_k,
- normalized, score_threshold):
- super(MultiClassNMS, self).__init__()
- self.background_label = background_label
- self.keep_top_k = keep_top_k
- self.nms_threshold = nms_threshold
- self.nms_top_k = nms_top_k
- self.normalized = normalized
- self.score_threshold = score_threshold
-
-
-class YOLOv3Head(object):
- """Head block for YOLOv3 network
-
- Args:
- norm_decay (float): weight decay for normalization layer weights
- num_classes (int): number of output classes
- ignore_thresh (float): threshold to ignore confidence loss
- label_smooth (bool): whether to use label smoothing
- anchors (list): anchors
- anchor_masks (list): anchor masks
- nms (object): an instance of `MultiClassNMS`
- """
-
- def __init__(self,
- norm_decay=0.,
- num_classes=80,
- ignore_thresh=0.7,
- label_smooth=True,
- anchors=[[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
- [59, 119], [116, 90], [156, 198], [373, 326]],
- anchor_masks=[[6, 7, 8], [3, 4, 5], [0, 1, 2]],
- nms=MultiClassNMS(
- background_label=-1,
- keep_top_k=100,
- nms_threshold=0.45,
- nms_top_k=1000,
- normalized=True,
- score_threshold=0.01),
- weight_prefix_name=''):
- self.norm_decay = norm_decay
- self.num_classes = num_classes
- self.ignore_thresh = ignore_thresh
- self.label_smooth = label_smooth
- self.anchor_masks = anchor_masks
- self._parse_anchors(anchors)
- self.nms = nms
- self.prefix_name = weight_prefix_name
-
- def _conv_bn(self,
- input,
- ch_out,
- filter_size,
- stride,
- padding,
- act='leaky',
- is_test=True,
- name=None):
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=ch_out,
- filter_size=filter_size,
- stride=stride,
- padding=padding,
- act=None,
- param_attr=ParamAttr(name=name + ".conv.weights"),
- bias_attr=False)
-
- bn_name = name + ".bn"
- bn_param_attr = ParamAttr(
- regularizer=L2Decay(self.norm_decay), name=bn_name + '.scale')
- bn_bias_attr = ParamAttr(
- regularizer=L2Decay(self.norm_decay), name=bn_name + '.offset')
- out = fluid.layers.batch_norm(
- input=conv,
- act=None,
- is_test=is_test,
- param_attr=bn_param_attr,
- bias_attr=bn_bias_attr,
- moving_mean_name=bn_name + '.mean',
- moving_variance_name=bn_name + '.var')
-
- if act == 'leaky':
- out = fluid.layers.leaky_relu(x=out, alpha=0.1)
- return out
-
- def _detection_block(self, input, channel, is_test=True, name=None):
- assert channel % 2 == 0, \
- "channel {} cannot be divided by 2 in detection block {}" \
- .format(channel, name)
-
- conv = input
- for j in range(2):
- conv = self._conv_bn(
- conv,
- channel,
- filter_size=1,
- stride=1,
- padding=0,
- is_test=is_test,
- name='{}.{}.0'.format(name, j))
- conv = self._conv_bn(
- conv,
- channel * 2,
- filter_size=3,
- stride=1,
- padding=1,
- is_test=is_test,
- name='{}.{}.1'.format(name, j))
- route = self._conv_bn(
- conv,
- channel,
- filter_size=1,
- stride=1,
- padding=0,
- is_test=is_test,
- name='{}.2'.format(name))
- tip = self._conv_bn(
- route,
- channel * 2,
- filter_size=3,
- stride=1,
- padding=1,
- is_test=is_test,
- name='{}.tip'.format(name))
- return route, tip
-
- def _upsample(self, input, scale=2, name=None):
- out = fluid.layers.resize_nearest(
- input=input, scale=float(scale), name=name)
- return out
-
- def _parse_anchors(self, anchors):
- """
- Check ANCHORS/ANCHOR_MASKS in config and parse mask_anchors
-
- """
- self.anchors = []
- self.mask_anchors = []
-
- assert len(anchors) > 0, "ANCHORS not set."
- assert len(self.anchor_masks) > 0, "ANCHOR_MASKS not set."
-
- for anchor in anchors:
- assert len(anchor) == 2, "anchor {} len should be 2".format(anchor)
- self.anchors.extend(anchor)
-
- anchor_num = len(anchors)
- for masks in self.anchor_masks:
- self.mask_anchors.append([])
- for mask in masks:
- assert mask < anchor_num, "anchor mask index overflow"
- self.mask_anchors[-1].extend(anchors[mask])
-
- def _get_outputs(self, input, is_train=True):
- """
- Get YOLOv3 head output
-
- Args:
- input (list): List of Variables, output of backbone stages
- is_train (bool): whether in train or test mode
-
- Returns:
- outputs (list): Variables of each output layer
- """
-
- outputs = []
-
- # get last out_layer_num blocks in reverse order
- out_layer_num = len(self.anchor_masks)
- if isinstance(input, OrderedDict):
- blocks = list(input.values())[-1:-out_layer_num - 1:-1]
- else:
- blocks = input[-1:-out_layer_num - 1:-1]
- route = None
- for i, block in enumerate(blocks):
- if i > 0: # perform concat in first 2 detection_block
- block = fluid.layers.concat(input=[route, block], axis=1)
- route, tip = self._detection_block(
- block,
- channel=512 // (2**i),
- is_test=(not is_train),
- name=self.prefix_name + "yolo_block.{}".format(i))
-
- # out channel number = mask_num * (5 + class_num)
- num_filters = len(self.anchor_masks[i]) * (self.num_classes + 5)
- block_out = fluid.layers.conv2d(
- input=tip,
- num_filters=num_filters,
- filter_size=1,
- stride=1,
- padding=0,
- act=None,
- param_attr=ParamAttr(name=self.prefix_name +
- "yolo_output.{}.conv.weights".format(i)),
- bias_attr=ParamAttr(
- regularizer=L2Decay(0.),
- name=self.prefix_name +
- "yolo_output.{}.conv.bias".format(i)))
- outputs.append(block_out)
-
- if i < len(blocks) - 1:
- # do not perform upsample in the last detection_block
- route = self._conv_bn(
- input=route,
- ch_out=256 // (2**i),
- filter_size=1,
- stride=1,
- padding=0,
- is_test=(not is_train),
- name=self.prefix_name + "yolo_transition.{}".format(i))
- # upsample
- route = self._upsample(route)
-
- return outputs, blocks
-
- def get_prediction(self, outputs, im_size):
- """
- Get prediction result of YOLOv3 network
-
- Args:
- outputs (list): list of Variables, return from _get_outputs
- im_size (Variable): Variable of size([h, w]) of each image
-
- Returns:
- pred (Variable): The prediction result after non-max suppress.
-
- """
- boxes = []
- scores = []
- downsample = 32
- for i, output in enumerate(outputs):
- box, score = fluid.layers.yolo_box(
- x=output,
- img_size=im_size,
- anchors=self.mask_anchors[i],
- class_num=self.num_classes,
- conf_thresh=self.nms.score_threshold,
- downsample_ratio=downsample,
- name=self.prefix_name + "yolo_box" + str(i))
- boxes.append(box)
- scores.append(fluid.layers.transpose(score, perm=[0, 2, 1]))
-
- downsample //= 2
-
- yolo_boxes = fluid.layers.concat(boxes, axis=1)
- yolo_scores = fluid.layers.concat(scores, axis=2)
- pred = fluid.layers.multiclass_nms(
- bboxes=yolo_boxes,
- scores=yolo_scores,
- score_threshold=self.nms.score_threshold,
- nms_top_k=self.nms.nms_top_k,
- keep_top_k=self.nms.keep_top_k,
- nms_threshold=self.nms.nms_threshold,
- background_label=self.nms.background_label,
- normalized=self.nms.normalized,
- name="multiclass_nms")
- return pred
From 0a26a1fabfa7f2d0a8239498f1da79e1b47a57ae Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:16:39 +0800
Subject: [PATCH 071/117] update human_pose_estimation_resnet50_mpii (#1961)
* update human_pose_estimation_resnet50_mpii
* update
* add clean func
* update save inference model
---
.../README.md | 16 +-
.../data_feed.py | 1 -
.../module.py | 61 +++----
.../pose_resnet.py | 157 ------------------
.../test.py | 83 +++++++++
5 files changed, 114 insertions(+), 204 deletions(-)
delete mode 100644 modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/pose_resnet.py
create mode 100644 modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/test.py
diff --git a/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/README.md b/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/README.md
index 7bb495224..ad3b7c7c7 100644
--- a/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/README.md
+++ b/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/README.md
@@ -89,20 +89,14 @@
- data (OrderedDict): 人体骨骼关键点的坐标。
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True):
+ def save_inference_model(dirname):
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称
- - model_filename: 模型文件名称,默认为__model__
- - params_filename: 参数文件名称,默认为__params__(仅当combined为True时生效)
- - combined: 是否将参数保存到统一的一个文件中
+ - dirname: 模型保存路径
## 四、服务部署
@@ -155,6 +149,10 @@
* 1.1.1
+* 1.2.0
+
+ 移除 fluid api
+
* ```shell
- $ hub install human_pose_estimation_resnet50_mpii==1.1.1
+ $ hub install human_pose_estimation_resnet50_mpii==1.2.0
```
diff --git a/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/data_feed.py b/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/data_feed.py
index a86e90cff..ab9d57a6c 100644
--- a/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/data_feed.py
+++ b/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/data_feed.py
@@ -5,7 +5,6 @@
import cv2
import numpy as np
-from PIL import Image
__all__ = ['reader']
diff --git a/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/module.py b/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/module.py
index 43bf5b84e..e7a8e19e6 100644
--- a/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/module.py
+++ b/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/module.py
@@ -6,15 +6,15 @@
import os
import argparse
+import paddle
+import paddle.jit
+import paddle.static
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from human_pose_estimation_resnet50_mpii.processor import base64_to_cv2, postprocess
-from human_pose_estimation_resnet50_mpii.data_feed import reader
-from human_pose_estimation_resnet50_mpii.pose_resnet import ResNet
+from .processor import base64_to_cv2, postprocess
+from .data_feed import reader
@moduleinfo(
@@ -24,20 +24,22 @@
author_email="paddle-dev@baidu.comi",
summary=
"Paddle implementation for the paper `Simple baselines for human pose estimation and tracking`, trained with the MPII dataset.",
- version="1.1.1")
-class HumanPoseEstimation(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "pose-resnet50-mpii-384x384")
+ version="1.2.0")
+class HumanPoseEstimation:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "pose-resnet50-mpii-384x384", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -46,10 +48,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+ self.gpu_predictor = create_predictor(gpu_config)
def keypoint_detection(self,
images=None,
@@ -80,7 +82,6 @@ def keypoint_detection(self,
total_num = len(all_data)
loop_num = int(np.ceil(total_num / batch_size))
-
res = list()
for iter_id in range(loop_num):
batch_data = list()
@@ -92,9 +93,14 @@ def keypoint_detection(self,
pass
# feed batch image
batch_image = np.array([data['image'] for data in batch_data])
- batch_image = PaddleTensor(batch_image.copy())
- output = self.gpu_predictor.run([batch_image]) if use_gpu else self.cpu_predictor.run([batch_image])
- output = np.expand_dims(output[0].as_ndarray(), axis=1)
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(batch_image)
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+ output = np.expand_dims(output_handle.copy_to_cpu(), axis=1)
# postprocess one by one
for i in range(len(batch_data)):
out = postprocess(
@@ -107,25 +113,6 @@ def keypoint_detection(self,
res.append(out)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/pose_resnet.py b/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/pose_resnet.py
deleted file mode 100644
index f5a7638a2..000000000
--- a/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/pose_resnet.py
+++ /dev/null
@@ -1,157 +0,0 @@
-# coding=utf-8
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import paddle.fluid as fluid
-
-__all__ = ["ResNet", "ResNet50", "ResNet101", "ResNet152"]
-
-BN_MOMENTUM = 0.9
-
-
-class ResNet():
- def __init__(self, layers=50, kps_num=16, test_mode=False):
- """
- :param layers: int, the layers number which is used here
- :param kps_num: int, the number of keypoints in accord with the dataset
- :param test_mode: bool, if True, only return output heatmaps, no loss
-
- :return: loss, output heatmaps
- """
- self.k = kps_num
- self.layers = layers
- self.test_mode = test_mode
-
- def net(self, input, target=None, target_weight=None):
- layers = self.layers
- supported_layers = [50, 101, 152]
- assert layers in supported_layers, \
- "supported layers are {} but input layer is {}".format(supported_layers, layers)
-
- if layers == 50:
- depth = [3, 4, 6, 3]
- elif layers == 101:
- depth = [3, 4, 23, 3]
- elif layers == 152:
- depth = [3, 8, 36, 3]
- num_filters = [64, 128, 256, 512]
-
- conv = self.conv_bn_layer(input=input, num_filters=64, filter_size=7, stride=2, act='relu')
- conv = fluid.layers.pool2d(input=conv, pool_size=3, pool_stride=2, pool_padding=1, pool_type='max')
-
- for block in range(len(depth)):
- for i in range(depth[block]):
- conv = self.bottleneck_block(
- input=conv, num_filters=num_filters[block], stride=2 if i == 0 and block != 0 else 1)
-
- conv = fluid.layers.conv2d_transpose(
- input=conv,
- num_filters=256,
- filter_size=4,
- padding=1,
- stride=2,
- param_attr=fluid.param_attr.ParamAttr(initializer=fluid.initializer.Normal(0., 0.001)),
- act=None,
- bias_attr=False)
- conv = fluid.layers.batch_norm(input=conv, act='relu', momentum=BN_MOMENTUM)
- conv = fluid.layers.conv2d_transpose(
- input=conv,
- num_filters=256,
- filter_size=4,
- padding=1,
- stride=2,
- param_attr=fluid.param_attr.ParamAttr(initializer=fluid.initializer.Normal(0., 0.001)),
- act=None,
- bias_attr=False)
- conv = fluid.layers.batch_norm(input=conv, act='relu', momentum=BN_MOMENTUM)
- conv = fluid.layers.conv2d_transpose(
- input=conv,
- num_filters=256,
- filter_size=4,
- padding=1,
- stride=2,
- param_attr=fluid.param_attr.ParamAttr(initializer=fluid.initializer.Normal(0., 0.001)),
- act=None,
- bias_attr=False)
- conv = fluid.layers.batch_norm(input=conv, act='relu', momentum=BN_MOMENTUM)
-
- out = fluid.layers.conv2d(
- input=conv,
- num_filters=self.k,
- filter_size=1,
- stride=1,
- padding=0,
- act=None,
- param_attr=fluid.param_attr.ParamAttr(initializer=fluid.initializer.Normal(0., 0.001)))
-
- if self.test_mode:
- return out
- else:
- loss = self.calc_loss(out, target, target_weight)
- return loss, out
-
- def conv_bn_layer(self, input, num_filters, filter_size, stride=1, groups=1, act=None):
- conv = fluid.layers.conv2d(
- input=input,
- num_filters=num_filters,
- filter_size=filter_size,
- stride=stride,
- padding=(filter_size - 1) // 2,
- groups=groups,
- param_attr=fluid.param_attr.ParamAttr(initializer=fluid.initializer.Normal(0., 0.001)),
- act=None,
- bias_attr=False)
- return fluid.layers.batch_norm(input=conv, act=act, momentum=BN_MOMENTUM)
-
- def shortcut(self, input, ch_out, stride):
- ch_in = input.shape[1]
- if ch_in != ch_out or stride != 1:
- return self.conv_bn_layer(input, ch_out, 1, stride)
- else:
- return input
-
- def calc_loss(self, heatmap, target, target_weight):
- _, c, h, w = heatmap.shape
- x = fluid.layers.reshape(heatmap, (-1, self.k, h * w))
- y = fluid.layers.reshape(target, (-1, self.k, h * w))
- w = fluid.layers.reshape(target_weight, (-1, self.k))
-
- x = fluid.layers.split(x, num_or_sections=self.k, dim=1)
- y = fluid.layers.split(y, num_or_sections=self.k, dim=1)
- w = fluid.layers.split(w, num_or_sections=self.k, dim=1)
-
- _list = []
- for idx in range(self.k):
- _tmp = fluid.layers.scale(x=x[idx] - y[idx], scale=1.)
- _tmp = _tmp * _tmp
- _tmp = fluid.layers.reduce_mean(_tmp, dim=2)
- _list.append(_tmp * w[idx])
-
- _loss = fluid.layers.concat(_list, axis=0)
- _loss = fluid.layers.reduce_mean(_loss)
- return 0.5 * _loss
-
- def bottleneck_block(self, input, num_filters, stride):
- conv0 = self.conv_bn_layer(input=input, num_filters=num_filters, filter_size=1, act='relu')
- conv1 = self.conv_bn_layer(input=conv0, num_filters=num_filters, filter_size=3, stride=stride, act='relu')
- conv2 = self.conv_bn_layer(input=conv1, num_filters=num_filters * 4, filter_size=1, act=None)
-
- short = self.shortcut(input, num_filters * 4, stride)
-
- return fluid.layers.elementwise_add(x=short, y=conv2, act='relu')
-
-
-def ResNet50():
- model = ResNet(layers=50)
- return model
-
-
-def ResNet101():
- model = ResNet(layers=101)
- return model
-
-
-def ResNet152():
- model = ResNet(layers=152)
- return model
diff --git a/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/test.py b/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/test.py
new file mode 100644
index 000000000..0878026bf
--- /dev/null
+++ b/modules/image/keypoint_detection/human_pose_estimation_resnet50_mpii/test.py
@@ -0,0 +1,83 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/7799a8ccc5f6471b9d56fb6eff94f82a08b70ca2c7594d3f99877e366c0a2619'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="human_pose_estimation_resnet50_mpii")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('output_pose')
+
+ def test_keypoint_detection1(self):
+ results = self.module.keypoint_detection(
+ paths=['tests/test.jpg']
+ )
+ kps = results[0]['data']
+ self.assertIsInstance(kps, dict)
+
+ def test_keypoint_detection2(self):
+ results = self.module.keypoint_detection(
+ images=[cv2.imread('tests/test.jpg')]
+ )
+ kps = results[0]['data']
+ self.assertIsInstance(kps, dict)
+
+ def test_keypoint_detection3(self):
+ results = self.module.keypoint_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=True
+ )
+ kps = results[0]['data']
+ self.assertIsInstance(kps, dict)
+
+ def test_keypoint_detection4(self):
+ results = self.module.keypoint_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True
+ )
+ kps = results[0]['data']
+ self.assertIsInstance(kps, dict)
+
+ def test_keypoint_detection5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.keypoint_detection,
+ paths=['no.jpg']
+ )
+
+ def test_keypoint_detection6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.keypoint_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 6b42963d62833925ffed1cdb73400e7d528a5353 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:17:18 +0800
Subject: [PATCH 072/117] update hand_pose_localization (#1967)
* update hand_pose_localization
* add clean func
---
.../hand_pose_localization/model.py | 169 ++++++++++++++----
.../hand_pose_localization/module.py | 24 ++-
.../hand_pose_localization/readme.md | 4 +-
.../hand_pose_localization/test.py | 79 ++++++++
4 files changed, 228 insertions(+), 48 deletions(-)
create mode 100644 modules/image/keypoint_detection/hand_pose_localization/test.py
diff --git a/modules/image/keypoint_detection/hand_pose_localization/model.py b/modules/image/keypoint_detection/hand_pose_localization/model.py
index ebe429716..e737c99c0 100644
--- a/modules/image/keypoint_detection/hand_pose_localization/model.py
+++ b/modules/image/keypoint_detection/hand_pose_localization/model.py
@@ -3,74 +3,167 @@
from paddle.inference import create_predictor, Config
-__all__ = ['Model']
+__all__ = ['InferenceModel']
-class Model():
+class InferenceModel:
# 初始化函数
- def __init__(self, modelpath, use_gpu=False, use_mkldnn=True, combined=True):
- # 加载模型预测器
- self.predictor = self.load_model(modelpath, use_gpu, use_mkldnn, combined)
+ def __init__(self,
+ modelpath,
+ use_gpu=False,
+ gpu_id=0,
+ use_mkldnn=False,
+ cpu_threads=1):
+ '''
+ init the inference model
+ modelpath: inference model path
+ use_gpu: use gpu or not
+ use_mkldnn: use mkldnn or not
+ '''
+ # 加载模型配置
+ self.config = self.load_config(modelpath, use_gpu, gpu_id, use_mkldnn, cpu_threads)
- # 获取模型的输入输出
- self.input_names = self.predictor.get_input_names()
- self.output_names = self.predictor.get_output_names()
- self.input_handle = self.predictor.get_input_handle(self.input_names[0])
- self.output_handle = self.predictor.get_output_handle(self.output_names[0])
+ # 打印函数
+ def __repr__(self):
+ '''
+ get the numbers and name of inputs and outputs
+ '''
+ return 'input_num: %d\ninput_names: %s\noutput_num: %d\noutput_names: %s' % (
+ self.input_num,
+ str(self.input_names),
+ self.output_num,
+ str(self.output_names)
+ )
- # 模型加载函数
- def load_model(self, modelpath, use_gpu, use_mkldnn, combined):
+ # 类调用函数
+ def __call__(self, *input_datas, batch_size=1):
+ '''
+ call function
+ '''
+ return self.forward(*input_datas, batch_size=batch_size)
+
+ # 模型参数加载函数
+ def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_threads):
+ '''
+ load the model config
+ modelpath: inference model path
+ use_gpu: use gpu or not
+ use_mkldnn: use mkldnn or not
+ '''
# 对运行位置进行配置
if use_gpu:
try:
int(os.environ.get('CUDA_VISIBLE_DEVICES'))
except Exception:
print(
- 'Error! Unable to use GPU. Please set the environment variables "CUDA_VISIBLE_DEVICES=GPU_id" to use GPU.'
- )
+ '''Error! Unable to use GPU. Please set the environment variables "CUDA_VISIBLE_DEVICES=GPU_id" to use GPU. Now switch to CPU to continue...''')
use_gpu = False
- # 加载模型参数
- if combined:
- model = os.path.join(modelpath, "__model__")
- params = os.path.join(modelpath, "__params__")
+ if os.path.isdir(modelpath):
+ if os.path.exists(os.path.join(modelpath, "__params__")):
+ # __model__ + __params__
+ model = os.path.join(modelpath, "__model__")
+ params = os.path.join(modelpath, "__params__")
+ config = Config(model, params)
+ elif os.path.exists(os.path.join(modelpath, "params")):
+ # model + params
+ model = os.path.join(modelpath, "model")
+ params = os.path.join(modelpath, "params")
+ config = Config(model, params)
+ elif os.path.exists(os.path.join(modelpath, "__model__")):
+ # __model__ + others
+ config = Config(modelpath)
+ else:
+ raise Exception(
+ "Error! Can\'t find the model in: %s. Please check your model path." % os.path.abspath(modelpath))
+ elif os.path.exists(modelpath + ".pdmodel"):
+ # *.pdmodel + *.pdiparams
+ model = modelpath + ".pdmodel"
+ params = modelpath + ".pdiparams"
config = Config(model, params)
+ elif isinstance(modelpath, Config):
+ config = modelpath
else:
- config = Config(modelpath)
+ raise Exception(
+ "Error! Can\'t find the model in: %s. Please check your model path." % os.path.abspath(modelpath))
# 设置参数
if use_gpu:
- config.enable_use_gpu(100, 0)
+ config.enable_use_gpu(100, gpu_id)
else:
config.disable_gpu()
+ config.set_cpu_math_library_num_threads(cpu_threads)
if use_mkldnn:
config.enable_mkldnn()
+
config.disable_glog_info()
- config.switch_ir_optim(True)
- config.enable_memory_optim()
- config.switch_use_feed_fetch_ops(False)
- config.switch_specify_input_names(True)
- # 通过参数加载模型预测器
- predictor = create_predictor(config)
+ # 返回配置
+ return config
- # 返回预测器
- return predictor
+ # 预测器创建函数
+ def eval(self):
+ '''
+ create the model predictor by model config
+ '''
+ # 创建预测器
+ self.predictor = create_predictor(self.config)
+
+ # 获取模型的输入输出名称
+ self.input_names = self.predictor.get_input_names()
+ self.output_names = self.predictor.get_output_names()
- # 模型预测函数
- def predict(self, input_datas):
- outputs = []
+ # 获取模型的输入输出节点数量
+ self.input_num = len(self.input_names)
+ self.output_num = len(self.output_names)
+
+ # 获取输入
+ self.input_handles = []
+ for input_name in self.input_names:
+ self.input_handles.append(
+ self.predictor.get_input_handle(input_name))
+
+ # 获取输出
+ self.output_handles = []
+ for output_name in self.output_names:
+ self.output_handles.append(
+ self.predictor.get_output_handle(output_name))
+
+ # 前向计算函数
+ def forward(self, *input_datas, batch_size=1):
+ """
+ model inference
+ batch_size: batch size
+ *input_datas: x1, x2, ..., xn
+ """
+ # 切分输入数据
+ datas_num = input_datas[0].shape[0]
+ split_num = datas_num // batch_size + \
+ 1 if datas_num % batch_size != 0 else datas_num // batch_size
+ input_datas = [np.array_split(input_data, split_num)
+ for input_data in input_datas]
# 遍历输入数据进行预测
- for input_data in input_datas:
- inputs = input_data.copy()
- self.input_handle.copy_from_cpu(inputs)
+ outputs = {}
+ for step in range(split_num):
+ for i in range(self.input_num):
+ input_data = input_datas[i][step].copy()
+ self.input_handles[i].copy_from_cpu(input_data)
+
self.predictor.run()
- output = self.output_handle.copy_to_cpu()
- outputs.append(output)
+
+ for i in range(self.output_num):
+ output = self.output_handles[i].copy_to_cpu()
+ if i in outputs:
+ outputs[i].append(output)
+ else:
+ outputs[i] = [output]
# 预测结果合并
- outputs = np.concatenate(outputs, 0)
+ for key in outputs.keys():
+ outputs[key] = np.concatenate(outputs[key], 0)
+
+ outputs = [v for v in outputs.values()]
# 返回预测结果
- return outputs
+ return tuple(outputs) if len(outputs) > 1 else outputs[0]
\ No newline at end of file
diff --git a/modules/image/keypoint_detection/hand_pose_localization/module.py b/modules/image/keypoint_detection/hand_pose_localization/module.py
index c855319f1..3176283d0 100644
--- a/modules/image/keypoint_detection/hand_pose_localization/module.py
+++ b/modules/image/keypoint_detection/hand_pose_localization/module.py
@@ -1,11 +1,11 @@
# coding=utf-8
import os
-from paddlehub import Module
+import numpy as np
from paddlehub.module.module import moduleinfo, serving
-from hand_pose_localization.model import Model
-from hand_pose_localization.processor import base64_to_cv2, Processor
+from .model import InferenceModel
+from .processor import base64_to_cv2, Processor
@moduleinfo(
@@ -14,16 +14,18 @@
author="jm12138", # 作者名称
author_email="jm12138@qq.com", # 作者邮箱
summary="hand_pose_localization", # 模型介绍
- version="1.0.2" # 版本号
+ version="1.1.0" # 版本号
)
-class Hand_Pose_Localization(Module):
+class Hand_Pose_Localization:
# 初始化函数
- def __init__(self, name=None, use_gpu=False):
+ def __init__(self, use_gpu=False):
# 设置模型路径
- self.model_path = os.path.join(self.directory, "hand_pose_localization")
+ self.model_path = os.path.join(self.directory, "hand_pose_localization", "model")
# 加载模型
- self.model = Model(modelpath=self.model_path, use_gpu=use_gpu, use_mkldnn=False, combined=True)
+ self.model = InferenceModel(modelpath=self.model_path, use_gpu=use_gpu)
+
+ self.model.eval()
# 关键点检测函数
def keypoint_detection(self, images=None, paths=None, batch_size=1, output_dir='output', visualization=False):
@@ -31,7 +33,11 @@ def keypoint_detection(self, images=None, paths=None, batch_size=1, output_dir='
processor = Processor(images, paths, batch_size, output_dir)
# 模型预测
- outputs = self.model.predict(processor.input_datas)
+ outputs = []
+ for input_data in processor.input_datas:
+ output = self.model(input_data)
+ outputs.append(output)
+ outputs = np.concatenate(outputs, 0)
# 结果后处理
results = processor.postprocess(outputs, visualization)
diff --git a/modules/image/keypoint_detection/hand_pose_localization/readme.md b/modules/image/keypoint_detection/hand_pose_localization/readme.md
index 0852a5bc0..1309f8087 100644
--- a/modules/image/keypoint_detection/hand_pose_localization/readme.md
+++ b/modules/image/keypoint_detection/hand_pose_localization/readme.md
@@ -130,8 +130,10 @@
适配paddlehub 2.0
+* 1.1.0
+
* ```shell
- $ hub install hand_pose_localization==1.0.1
+ $ hub install hand_pose_localization==1.1.0
```
diff --git a/modules/image/keypoint_detection/hand_pose_localization/test.py b/modules/image/keypoint_detection/hand_pose_localization/test.py
new file mode 100644
index 000000000..fc28e9a92
--- /dev/null
+++ b/modules/image/keypoint_detection/hand_pose_localization/test.py
@@ -0,0 +1,79 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/8UAUuP97RlY/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjYxODQxMzI1&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="hand_pose_localization")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('output')
+
+ def test_keypoint_detection1(self):
+ results = self.module.keypoint_detection(
+ paths=['tests/test.jpg'],
+ visualization=False
+ )
+ kps = results[0]
+ self.assertIsInstance(kps, list)
+
+ def test_keypoint_detection2(self):
+ results = self.module.keypoint_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ kps = results[0]
+ self.assertIsInstance(kps, list)
+
+ def test_keypoint_detection3(self):
+ results = self.module.keypoint_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=True
+ )
+ kps = results[0]
+ self.assertIsInstance(kps, list)
+
+ def test_keypoint_detection4(self):
+ self.module = hub.Module(name="hand_pose_localization", use_gpu=True)
+ results = self.module.keypoint_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ kps = results[0]
+ self.assertIsInstance(kps, list)
+
+ def test_keypoint_detection5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.keypoint_detection,
+ paths=['no.jpg']
+ )
+
+ def test_keypoint_detection6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.keypoint_detection,
+ images=['test.jpg']
+ )
+
+
+if __name__ == "__main__":
+ unittest.main()
From 16165a742fed5b37aa2a6c7c750b1950c8c29040 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:17:39 +0800
Subject: [PATCH 073/117] update pyramidbox_face_detection (#1975)
* update pyramidbox_face_detection
* update
* add clean func
* update save inference model
---
.../pyramidbox_face_detection/README.md | 17 ++-
.../pyramidbox_face_detection/README_en.md | 17 ++-
.../pyramidbox_face_detection/module.py | 60 ++++----
.../pyramidbox_face_detection/processor.py | 3 +-
.../pyramidbox_face_detection/test.py | 133 ++++++++++++++++++
5 files changed, 175 insertions(+), 55 deletions(-)
create mode 100644 modules/image/face_detection/pyramidbox_face_detection/test.py
diff --git a/modules/image/face_detection/pyramidbox_face_detection/README.md b/modules/image/face_detection/pyramidbox_face_detection/README.md
index d7c26e9b2..7a6293727 100644
--- a/modules/image/face_detection/pyramidbox_face_detection/README.md
+++ b/modules/image/face_detection/pyramidbox_face_detection/README.md
@@ -100,19 +100,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称;
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -165,6 +159,11 @@
* 1.1.0
修复numpy数据读取问题
+
+* 1.2.0
+
+ 修复无法导出推理模型的问题
+
- ```shell
- $ hub install pyramidbox_face_detection==1.1.0
+ $ hub install pyramidbox_face_detection==1.2.0
```
diff --git a/modules/image/face_detection/pyramidbox_face_detection/README_en.md b/modules/image/face_detection/pyramidbox_face_detection/README_en.md
index 5f12c1def..502437e0c 100644
--- a/modules/image/face_detection/pyramidbox_face_detection/README_en.md
+++ b/modules/image/face_detection/pyramidbox_face_detection/README_en.md
@@ -99,19 +99,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -164,6 +158,11 @@
* 1.1.0
Fix the problem of reading numpy
+
+* 1.2.0
+
+ Fix a bug of save_inference_model
+
- ```shell
- $ hub install pyramidbox_face_detection==1.1.0
+ $ hub install pyramidbox_face_detection==1.2.0
```
diff --git a/modules/image/face_detection/pyramidbox_face_detection/module.py b/modules/image/face_detection/pyramidbox_face_detection/module.py
index 8b44a11da..89fa16c43 100644
--- a/modules/image/face_detection/pyramidbox_face_detection/module.py
+++ b/modules/image/face_detection/pyramidbox_face_detection/module.py
@@ -7,13 +7,14 @@
import os
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle
+import paddle.jit
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from pyramidbox_face_detection.data_feed import reader
-from pyramidbox_face_detection.processor import postprocess, base64_to_cv2
+from .data_feed import reader
+from .processor import postprocess, base64_to_cv2
@moduleinfo(
@@ -22,20 +23,22 @@
author="baidu-vis",
author_email="",
summary="Baidu's PyramidBox model for face detection.",
- version="1.1.0")
-class PyramidBoxFaceDetection(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "pyramidbox_face_detection_widerface")
+ version="1.2.0")
+class PyramidBoxFaceDetection:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "pyramidbox_face_detection_widerface", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- cpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -44,10 +47,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+ self.gpu_predictor = create_predictor(gpu_config)
def face_detection(self,
images=None,
@@ -95,11 +98,17 @@ def face_detection(self,
# process one by one
for element in reader(images, paths):
image = np.expand_dims(element['image'], axis=0).astype('float32')
- image_tensor = PaddleTensor(image.copy())
- data_out = self.gpu_predictor.run([image_tensor]) if use_gpu else self.cpu_predictor.run([image_tensor])
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(image)
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+ output = np.expand_dims(output_handle.copy_to_cpu(), axis=1)
# print(len(data_out)) # 1
out = postprocess(
- data_out=data_out[0].as_ndarray(),
+ data_out=output_handle.copy_to_cpu(),
org_im=element['org_im'],
org_im_path=element['org_im_path'],
org_im_width=element['org_im_width'],
@@ -110,25 +119,6 @@ def face_detection(self,
res.append(out)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/face_detection/pyramidbox_face_detection/processor.py b/modules/image/face_detection/pyramidbox_face_detection/processor.py
index 0d27ee57c..3fee41e8f 100644
--- a/modules/image/face_detection/pyramidbox_face_detection/processor.py
+++ b/modules/image/face_detection/pyramidbox_face_detection/processor.py
@@ -5,12 +5,11 @@
import os
import time
-from collections import OrderedDict
import base64
import cv2
import numpy as np
-from PIL import Image, ImageDraw
+from PIL import ImageDraw
__all__ = ['base64_to_cv2', 'postprocess']
diff --git a/modules/image/face_detection/pyramidbox_face_detection/test.py b/modules/image/face_detection/pyramidbox_face_detection/test.py
new file mode 100644
index 000000000..730a31417
--- /dev/null
+++ b/modules/image/face_detection/pyramidbox_face_detection/test.py
@@ -0,0 +1,133 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/7799a8ccc5f6471b9d56fb6eff94f82a08b70ca2c7594d3f99877e366c0a2619'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="pyramidbox_face_detection")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_face_detection1(self):
+ results = self.module.face_detection(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection2(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection3(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection4(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.face_detection,
+ paths=['no.jpg']
+ )
+
+ def test_face_detection6(self):
+ self.assertRaises(
+ cv2.error,
+ self.module.face_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 497279b52a1df55a29123781359c2f27a8dd4e30 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:20:31 +0800
Subject: [PATCH 074/117] update pyramidbox_lite_mobile (#1976)
* update pyramidbox_lite_mobile
* update
* add clean func
* update save inference model
* update save inference model
---
.../pyramidbox_lite_mobile/README.md | 16 +--
.../pyramidbox_lite_mobile/README_en.md | 16 +--
.../pyramidbox_lite_mobile/module.py | 42 ++----
.../pyramidbox_lite_mobile/processor.py | 1 -
.../pyramidbox_lite_mobile/test.py | 133 ++++++++++++++++++
5 files changed, 158 insertions(+), 50 deletions(-)
create mode 100644 modules/image/face_detection/pyramidbox_lite_mobile/test.py
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile/README.md b/modules/image/face_detection/pyramidbox_lite_mobile/README.md
index b4fd8b8c8..e4f99608a 100644
--- a/modules/image/face_detection/pyramidbox_lite_mobile/README.md
+++ b/modules/image/face_detection/pyramidbox_lite_mobile/README.md
@@ -101,19 +101,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称;
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -167,6 +161,10 @@
移除 fluid api
+* 1.3.0
+
+ 修复无法导出推理模型的问题
+
- ```shell
- $ hub install pyramidbox_lite_mobile==1.2.1
+ $ hub install pyramidbox_lite_mobile==1.3.0
```
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile/README_en.md b/modules/image/face_detection/pyramidbox_lite_mobile/README_en.md
index d1439fc22..3c50825ef 100644
--- a/modules/image/face_detection/pyramidbox_lite_mobile/README_en.md
+++ b/modules/image/face_detection/pyramidbox_lite_mobile/README_en.md
@@ -100,19 +100,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -166,6 +160,10 @@
Remove fluid api
+* 1.3.0
+
+ Fix a bug of save_inference_model
+
- ```shell
- $ hub install pyramidbox_lite_mobile==1.2.1
+ $ hub install pyramidbox_lite_mobile==1.3.0
```
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile/module.py b/modules/image/face_detection/pyramidbox_lite_mobile/module.py
index 2f6e665e9..2a550bb5f 100644
--- a/modules/image/face_detection/pyramidbox_lite_mobile/module.py
+++ b/modules/image/face_detection/pyramidbox_lite_mobile/module.py
@@ -10,11 +10,10 @@
import paddle
from paddle.inference import Config
from paddle.inference import create_predictor
-from pyramidbox_lite_mobile.data_feed import reader
-from pyramidbox_lite_mobile.processor import base64_to_cv2
-from pyramidbox_lite_mobile.processor import postprocess
+from .data_feed import reader
+from .processor import base64_to_cv2
+from .processor import postprocess
-import paddlehub as hub
from paddlehub.module.module import moduleinfo
from paddlehub.module.module import runnable
from paddlehub.module.module import serving
@@ -25,11 +24,10 @@
author="baidu-vis",
author_email="",
summary="PyramidBox-Lite-Mobile is a high-performance face detection model.",
- version="1.2.1")
-class PyramidBoxLiteMobile(hub.Module):
-
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "pyramidbox_lite_mobile_face_detection")
+ version="1.3.0")
+class PyramidBoxLiteMobile:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "pyramidbox_lite_mobile_face_detection", "model")
self._set_config()
self.processor = self
@@ -37,7 +35,9 @@ def _set_config(self):
"""
predictor config setting
"""
- cpu_config = Config(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
self.cpu_predictor = create_predictor(cpu_config)
@@ -49,7 +49,7 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = Config(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
self.gpu_predictor = create_predictor(gpu_config)
@@ -125,26 +125,6 @@ def face_detection(self,
res.append(out)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = paddle.CPUPlace()
- exe = paddle.Executor(place)
-
- program, feeded_var_names, target_vars = paddle.static.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- var = program.global_block().vars['detection_output_0.tmp_1']
-
- paddle.static.save_inference_model(dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile/processor.py b/modules/image/face_detection/pyramidbox_lite_mobile/processor.py
index 5057ab5b1..2045f51c2 100644
--- a/modules/image/face_detection/pyramidbox_lite_mobile/processor.py
+++ b/modules/image/face_detection/pyramidbox_lite_mobile/processor.py
@@ -5,7 +5,6 @@
import os
import time
-from collections import OrderedDict
import base64
import cv2
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile/test.py b/modules/image/face_detection/pyramidbox_lite_mobile/test.py
new file mode 100644
index 000000000..1b06f9b7f
--- /dev/null
+++ b/modules/image/face_detection/pyramidbox_lite_mobile/test.py
@@ -0,0 +1,133 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/7799a8ccc5f6471b9d56fb6eff94f82a08b70ca2c7594d3f99877e366c0a2619'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="pyramidbox_lite_mobile")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_face_detection1(self):
+ results = self.module.face_detection(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection2(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection3(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection4(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.face_detection,
+ paths=['no.jpg']
+ )
+
+ def test_face_detection6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.face_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 2588a324ab29f067c009ee499d0354b57600c169 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:21:00 +0800
Subject: [PATCH 075/117] update pyramidbox_lite_server_mask (#1981)
* update pyramidbox_lite_server_mask
* update
* add clean func
* update save inference model
---
.../pyramidbox_lite_server_mask/README.md | 17 +--
.../pyramidbox_lite_server_mask/README_en.md | 16 +-
.../pyramidbox_lite_server_mask/data_feed.py | 20 +--
.../pyramidbox_lite_server_mask/module.py | 48 ++----
.../pyramidbox_lite_server_mask/processor.py | 1 -
.../pyramidbox_lite_server_mask/test.py | 144 ++++++++++++++++++
6 files changed, 179 insertions(+), 67 deletions(-)
create mode 100644 modules/image/face_detection/pyramidbox_lite_server_mask/test.py
diff --git a/modules/image/face_detection/pyramidbox_lite_server_mask/README.md b/modules/image/face_detection/pyramidbox_lite_server_mask/README.md
index 6f21a6ab7..744bef6cb 100644
--- a/modules/image/face_detection/pyramidbox_lite_server_mask/README.md
+++ b/modules/image/face_detection/pyramidbox_lite_server_mask/README.md
@@ -131,19 +131,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称;
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -194,7 +188,6 @@
# 将模型保存在test_program文件夹之中
pyramidbox_lite_server_mask.save_inference_model(dirname="test_program")
```
- 通过以上命令,可以获得人脸检测和口罩佩戴判断模型,分别存储在pyramidbox\_lite和mask\_detector之中。文件夹中的\_\_model\_\_是模型结构文件,\_\_params\_\_文件是权重文件。
- ### 进行模型转换
- 从paddlehub下载的是预测模型,可以使用PaddleLite提供的模型优化工具OPT对预测模型进行转换,转换之后进而可以实现在手机等端侧硬件上的部署,具体请请参考[OPT工具](https://paddle-lite.readthedocs.io/zh/latest/user_guides/model_optimize_tool.html)
@@ -212,6 +205,10 @@
移除 fluid api
+* 1.4.0
+
+ 修复无法导出推理模型的问题
+
- ```shell
- $ hub install pyramidbox_lite_server_mask==1.3.2
+ $ hub install pyramidbox_lite_server_mask==1.4.0
```
diff --git a/modules/image/face_detection/pyramidbox_lite_server_mask/README_en.md b/modules/image/face_detection/pyramidbox_lite_server_mask/README_en.md
index da5ba9e38..f4d878b4d 100644
--- a/modules/image/face_detection/pyramidbox_lite_server_mask/README_en.md
+++ b/modules/image/face_detection/pyramidbox_lite_server_mask/README_en.md
@@ -107,19 +107,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
+ - dirname: model save path
## IV.Server Deployment
@@ -189,6 +183,10 @@
Remove fluid api
+* 1.4.0
+
+ Fix a bug of save_inference_model
+
- ```shell
- $ hub install pyramidbox_lite_server_mask==1.3.2
+ $ hub install pyramidbox_lite_server_mask==1.4.0
```
diff --git a/modules/image/face_detection/pyramidbox_lite_server_mask/data_feed.py b/modules/image/face_detection/pyramidbox_lite_server_mask/data_feed.py
index 7d1316482..5068a2a14 100644
--- a/modules/image/face_detection/pyramidbox_lite_server_mask/data_feed.py
+++ b/modules/image/face_detection/pyramidbox_lite_server_mask/data_feed.py
@@ -180,17 +180,17 @@ def reader(face_detector, shrink, confs_threshold, images, paths, use_gpu,
if _s:
scale_res.append(np.array(_s))
if scale_res:
- scale_res = np.row_stack(scale_res)
- scale_res = bbox_vote(scale_res)
- keep_index = np.where(scale_res[:, 4] >= confs_threshold)[0]
- scale_res = scale_res[keep_index, :]
- for data in scale_res:
+ scale_res = np.row_stack(scale_res)
+ scale_res = bbox_vote(scale_res)
+ keep_index = np.where(scale_res[:, 4] >= confs_threshold)[0]
+ scale_res = scale_res[keep_index, :]
+ for data in scale_res:
face = {
- 'left': data[0],
- 'top': data[1],
- 'right': data[2],
- 'bottom': data[3],
- 'confidence': data[4]
+ 'left': data[0],
+ 'top': data[1],
+ 'right': data[2],
+ 'bottom': data[3],
+ 'confidence': data[4]
}
detect_faces.append(face)
else:
diff --git a/modules/image/face_detection/pyramidbox_lite_server_mask/module.py b/modules/image/face_detection/pyramidbox_lite_server_mask/module.py
index 9184fa6f6..0a7e34d37 100644
--- a/modules/image/face_detection/pyramidbox_lite_server_mask/module.py
+++ b/modules/image/face_detection/pyramidbox_lite_server_mask/module.py
@@ -10,9 +10,9 @@
import paddle
from paddle.inference import Config
from paddle.inference import create_predictor
-from pyramidbox_lite_server_mask.data_feed import reader
-from pyramidbox_lite_server_mask.processor import base64_to_cv2
-from pyramidbox_lite_server_mask.processor import postprocess
+from .data_feed import reader
+from .processor import base64_to_cv2
+from .processor import postprocess
import paddlehub as hub
from paddlehub.module.module import moduleinfo
@@ -27,15 +27,14 @@
author_email="",
summary=
"PyramidBox-Lite-Server-Mask is a high-performance face detection model used to detect whether people wear masks.",
- version="1.3.2")
-class PyramidBoxLiteServerMask(hub.Module):
-
- def _initialize(self, face_detector_module=None):
+ version="1.4.0")
+class PyramidBoxLiteServerMask:
+ def __init__(self, face_detector_module=None):
"""
Args:
face_detector_module (class): module to detect face.
"""
- self.default_pretrained_model_path = os.path.join(self.directory, "pyramidbox_lite_server_mask_model")
+ self.default_pretrained_model_path = os.path.join(self.directory, "pyramidbox_lite_server_mask_model", "model")
if face_detector_module is None:
self.face_detector = hub.Module(name='pyramidbox_lite_server')
else:
@@ -47,7 +46,9 @@ def _set_config(self):
"""
predictor config setting
"""
- cpu_config = Config(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
self.cpu_predictor = create_predictor(cpu_config)
@@ -59,7 +60,7 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = Config(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
self.gpu_predictor = create_predictor(gpu_config)
@@ -179,33 +180,6 @@ def face_detection(self,
res.append(out)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- classifier_dir = os.path.join(dirname, 'mask_detector')
- detector_dir = os.path.join(dirname, 'pyramidbox_lite')
- self._save_classifier_model(classifier_dir, model_filename, params_filename, combined)
- self._save_detector_model(detector_dir, model_filename, params_filename, combined)
-
- def _save_detector_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- self.face_detector.save_inference_model(dirname, model_filename, params_filename, combined)
-
- def _save_classifier_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = paddle.CPUPlace()
- exe = paddle.Executor(place)
-
- program, feeded_var_names, target_vars = paddle.static.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- paddle.static.save_inference_model(dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py b/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py
index 61c7be6ad..9c2268761 100644
--- a/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py
+++ b/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py
@@ -5,7 +5,6 @@
import os
import time
-from collections import OrderedDict
import base64
import cv2
diff --git a/modules/image/face_detection/pyramidbox_lite_server_mask/test.py b/modules/image/face_detection/pyramidbox_lite_server_mask/test.py
new file mode 100644
index 000000000..1ed3810e2
--- /dev/null
+++ b/modules/image/face_detection/pyramidbox_lite_server_mask/test.py
@@ -0,0 +1,144 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/iFgRcqHznqg/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MXx8ZmFjZXxlbnwwfHx8fDE2NjE5ODAyMTc&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="pyramidbox_lite_server_mask")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_face_detection1(self):
+ results = self.module.face_detection(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'NO MASK')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 2000)
+ self.assertTrue(0 < right < 2000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection2(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'NO MASK')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 2000)
+ self.assertTrue(0 < right < 2000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection3(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ bbox = results[0]['data'][0]
+
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'NO MASK')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 2000)
+ self.assertTrue(0 < right < 2000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection4(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'NO MASK')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(0 < left < 2000)
+ self.assertTrue(0 < right < 2000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.face_detection,
+ paths=['no.jpg']
+ )
+
+ def test_face_detection6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.face_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model/face_detector.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model/face_detector.pdiparams'))
+
+ self.assertTrue(os.path.exists('./inference/model/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 7a54b07f0be8dedc3ca5cd8eb37dbfc029bbceed Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:21:18 +0800
Subject: [PATCH 076/117] update falsr_b (#1988)
* update falsr_b
* add clean func
* update falsr_b
---
.../super_resolution/falsr_b/README.md | 29 +++----
.../super_resolution/falsr_b/README_en.md | 30 +++----
.../super_resolution/falsr_b/data_feed.py | 2 +-
.../super_resolution/falsr_b/module.py | 70 ++++++---------
.../super_resolution/falsr_b/test.py | 86 +++++++++++++++++++
5 files changed, 144 insertions(+), 73 deletions(-)
create mode 100644 modules/image/Image_editing/super_resolution/falsr_b/test.py
diff --git a/modules/image/Image_editing/super_resolution/falsr_b/README.md b/modules/image/Image_editing/super_resolution/falsr_b/README.md
index b74a5f894..4eb25789a 100644
--- a/modules/image/Image_editing/super_resolution/falsr_b/README.md
+++ b/modules/image/Image_editing/super_resolution/falsr_b/README.md
@@ -68,12 +68,11 @@
- ### 3、API
- ```python
- def reconstruct(self,
- images=None,
- paths=None,
- use_gpu=False,
- visualization=False,
- output_dir="falsr_b_output")
+ def reconstruct(images=None,
+ paths=None,
+ use_gpu=False,
+ visualization=False,
+ output_dir="falsr_b_output")
```
- 预测API,用于图像超分辨率。
@@ -93,21 +92,14 @@
* data (numpy.ndarray): 超分辨后图像。
- ```python
- def save_inference_model(self,
- dirname='falsr_b_save_model',
- model_filename=None,
- params_filename=None,
- combined=False)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- * dirname: 存在模型的目录名称
- * model\_filename: 模型文件名称,默认为\_\_model\_\_
- * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
- * combined: 是否将参数保存到统一的一个文件中
+ * dirname: 模型保存路径
@@ -167,4 +159,11 @@
初始发布
+* 1.1.0
+
+ 移除 fluid API
+
+ ```shell
+ $ hub install falsr_b == 1.1.0
+ ```
diff --git a/modules/image/Image_editing/super_resolution/falsr_b/README_en.md b/modules/image/Image_editing/super_resolution/falsr_b/README_en.md
index 5507b2ac6..1dbea0f77 100644
--- a/modules/image/Image_editing/super_resolution/falsr_b/README_en.md
+++ b/modules/image/Image_editing/super_resolution/falsr_b/README_en.md
@@ -71,12 +71,11 @@
- ### 3、API
- ```python
- def reconstruct(self,
- images=None,
- paths=None,
- use_gpu=False,
- visualization=False,
- output_dir="falsr_b_output")
+ def reconstruct(images=None,
+ paths=None,
+ use_gpu=False,
+ visualization=False,
+ output_dir="falsr_b_output")
```
- Prediction API.
@@ -95,21 +94,14 @@
* data (numpy.ndarray): Result of super resolution.
- ```python
- def save_inference_model(self,
- dirname='falsr_b_save_model',
- model_filename=None,
- params_filename=None,
- combined=False)
+ def save_inference_model(dirname)
```
- Save the model to the specified path.
- **Parameters**
- * dirname: Save path.
- * model\_filename: Model file name,defalt is \_\_model\_\_
- * params\_filename: Parameter file name,defalt is \_\_params\_\_(Only takes effect when `combined` is True)
- * combined: Whether to save the parameters to a unified file.
+ * dirname: Model save path.
@@ -170,4 +162,12 @@
First release
+- 1.1.0
+
+ Remove Fluid API
+
+
+ ```shell
+ $ hub install falsr_b == 1.1.0
+ ```
diff --git a/modules/image/Image_editing/super_resolution/falsr_b/data_feed.py b/modules/image/Image_editing/super_resolution/falsr_b/data_feed.py
index 8aa6514b0..c64ffa078 100644
--- a/modules/image/Image_editing/super_resolution/falsr_b/data_feed.py
+++ b/modules/image/Image_editing/super_resolution/falsr_b/data_feed.py
@@ -5,7 +5,7 @@
import cv2
import numpy as np
-from PIL import Image
+
__all__ = ['reader']
diff --git a/modules/image/Image_editing/super_resolution/falsr_b/module.py b/modules/image/Image_editing/super_resolution/falsr_b/module.py
index b5db9e5ef..73ee69a7c 100644
--- a/modules/image/Image_editing/super_resolution/falsr_b/module.py
+++ b/modules/image/Image_editing/super_resolution/falsr_b/module.py
@@ -18,13 +18,14 @@
import argparse
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle
+import paddle.jit
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from falsr_b.data_feed import reader
-from falsr_b.processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
+from .data_feed import reader
+from .processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
@moduleinfo(
@@ -33,21 +34,22 @@
author="paddlepaddle",
author_email="",
summary="falsr_b is a super resolution model.",
- version="1.0.0")
-class Falsr_B(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "falsr_b_model")
+ version="1.1.0")
+class Falsr_B:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "falsr_b_model", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- self.model_file_path = self.default_pretrained_model_path
- cpu_config = AnalysisConfig(self.model_file_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -56,10 +58,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.model_file_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+ self.gpu_predictor = create_predictor(gpu_config)
def reconstruct(self, images=None, paths=None, use_gpu=False, visualization=False, output_dir="falsr_b_output"):
"""
@@ -96,11 +98,18 @@ def reconstruct(self, images=None, paths=None, use_gpu=False, visualization=Fals
for i in range(total_num):
image_y = np.array([all_data[i]['img_y']])
image_scale_pbpr = np.array([all_data[i]['img_scale_pbpr']])
- image_y = PaddleTensor(image_y.copy())
- image_scale_pbpr = PaddleTensor(image_scale_pbpr.copy())
- output = self.gpu_predictor.run([image_y, image_scale_pbpr]) if use_gpu else self.cpu_predictor.run(
- [image_y, image_scale_pbpr])
- output = np.expand_dims(output[0].as_ndarray(), axis=1)
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(image_y.copy())
+ input_handle = predictor.get_input_handle(input_names[1])
+ input_handle.copy_from_cpu(image_scale_pbpr.copy())
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+ output = np.expand_dims(output_handle.copy_to_cpu(), axis=1)
out = postprocess(
data_out=output,
org_im=all_data[i]['org_im'],
@@ -111,29 +120,6 @@ def reconstruct(self, images=None, paths=None, use_gpu=False, visualization=Fals
res.append(out)
return res
- def save_inference_model(self,
- dirname='falsr_b_save_model',
- model_filename=None,
- params_filename=None,
- combined=False):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/Image_editing/super_resolution/falsr_b/test.py b/modules/image/Image_editing/super_resolution/falsr_b/test.py
new file mode 100644
index 000000000..f64fca235
--- /dev/null
+++ b/modules/image/Image_editing/super_resolution/falsr_b/test.py
@@ -0,0 +1,86 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import numpy as np
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/1sLIu1XKQrY/download?ixid=MnwxMjA3fDB8MXxhbGx8MTJ8fHx8fHwyfHwxNjYyMzQxNDUx&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="falsr_b")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('falsr_b_output')
+
+ def test_reconstruct1(self):
+ results = self.module.reconstruct(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct2(self):
+ results = self.module.reconstruct(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct3(self):
+ results = self.module.reconstruct(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct4(self):
+ results = self.module.reconstruct(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.reconstruct,
+ paths=['no.jpg']
+ )
+
+ def test_reconstruct6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.reconstruct,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From e6891a504ab1fba528dfda6880e361173d73f65c Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:21:45 +0800
Subject: [PATCH 077/117] update falsr_c (#1989)
* update falsr_c
* update version
* add clean func
* update falsr_c
---
.../super_resolution/falsr_c/README.md | 30 +++----
.../super_resolution/falsr_c/README_en.md | 29 +++----
.../super_resolution/falsr_c/data_feed.py | 2 +-
.../super_resolution/falsr_c/module.py | 70 ++++++---------
.../super_resolution/falsr_c/processor.py | 1 -
.../super_resolution/falsr_c/test.py | 86 +++++++++++++++++++
6 files changed, 144 insertions(+), 74 deletions(-)
create mode 100644 modules/image/Image_editing/super_resolution/falsr_c/test.py
diff --git a/modules/image/Image_editing/super_resolution/falsr_c/README.md b/modules/image/Image_editing/super_resolution/falsr_c/README.md
index 2e7d35bbe..405b73970 100644
--- a/modules/image/Image_editing/super_resolution/falsr_c/README.md
+++ b/modules/image/Image_editing/super_resolution/falsr_c/README.md
@@ -68,12 +68,11 @@
- ### 3、API
- ```python
- def reconstruct(self,
- images=None,
- paths=None,
- use_gpu=False,
- visualization=False,
- output_dir="falsr_c_output")
+ def reconstruct(images=None,
+ paths=None,
+ use_gpu=False,
+ visualization=False,
+ output_dir="falsr_c_output")
```
- 预测API,用于图像超分辨率。
@@ -93,21 +92,14 @@
* data (numpy.ndarray): 超分辨后图像。
- ```python
- def save_inference_model(self,
- dirname='falsr_c_save_model',
- model_filename=None,
- params_filename=None,
- combined=False)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- * dirname: 存在模型的目录名称
- * model\_filename: 模型文件名称,默认为\_\_model\_\_
- * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
- * combined: 是否将参数保存到统一的一个文件中
+ * dirname: 模型保存路径
@@ -166,3 +158,11 @@
初始发布
+
+* 1.1.0
+
+ 移除 fluid API
+
+ ```shell
+ $ hub install falsr_c == 1.1.0
+ ```
diff --git a/modules/image/Image_editing/super_resolution/falsr_c/README_en.md b/modules/image/Image_editing/super_resolution/falsr_c/README_en.md
index 5e651a7ea..c7e1d8a20 100644
--- a/modules/image/Image_editing/super_resolution/falsr_c/README_en.md
+++ b/modules/image/Image_editing/super_resolution/falsr_c/README_en.md
@@ -71,12 +71,11 @@
- ### 3、API
- ```python
- def reconstruct(self,
- images=None,
- paths=None,
- use_gpu=False,
- visualization=False,
- output_dir="falsr_c_output")
+ def reconstruct(images=None,
+ paths=None,
+ use_gpu=False,
+ visualization=False,
+ output_dir="falsr_c_output")
```
- Prediction API.
@@ -95,21 +94,14 @@
* data (numpy.ndarray): Result of super resolution.
- ```python
- def save_inference_model(self,
- dirname='falsr_c_save_model',
- model_filename=None,
- params_filename=None,
- combined=False)
+ def save_inference_model(dirname)
```
- Save the model to the specified path.
- **Parameters**
- * dirname: Save path.
- * model\_filename: Model file name,defalt is \_\_model\_\_
- * params\_filename: Parameter file name,defalt is \_\_params\_\_(Only takes effect when `combined` is True)
- * combined: Whether to save the parameters to a unified file.
+ * dirname: Model save path.
@@ -170,4 +162,11 @@
First release
+- 1.1.0
+ Remove Fluid API
+
+
+ ```shell
+ $ hub install falsr_c == 1.1.0
+ ```
diff --git a/modules/image/Image_editing/super_resolution/falsr_c/data_feed.py b/modules/image/Image_editing/super_resolution/falsr_c/data_feed.py
index 8aa6514b0..c64ffa078 100644
--- a/modules/image/Image_editing/super_resolution/falsr_c/data_feed.py
+++ b/modules/image/Image_editing/super_resolution/falsr_c/data_feed.py
@@ -5,7 +5,7 @@
import cv2
import numpy as np
-from PIL import Image
+
__all__ = ['reader']
diff --git a/modules/image/Image_editing/super_resolution/falsr_c/module.py b/modules/image/Image_editing/super_resolution/falsr_c/module.py
index 8a8f25997..b1d8a8a35 100644
--- a/modules/image/Image_editing/super_resolution/falsr_c/module.py
+++ b/modules/image/Image_editing/super_resolution/falsr_c/module.py
@@ -18,13 +18,14 @@
import argparse
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle
+import paddle.jit
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from falsr_c.data_feed import reader
-from falsr_c.processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
+from .data_feed import reader
+from .processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
@moduleinfo(
@@ -33,21 +34,22 @@
author="paddlepaddle",
author_email="",
summary="falsr_c is a super resolution model.",
- version="1.0.0")
-class Falsr_C(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "falsr_c_model")
+ version="1.1.0")
+class Falsr_C:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "falsr_c_model", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- self.model_file_path = self.default_pretrained_model_path
- cpu_config = AnalysisConfig(self.model_file_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -56,10 +58,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.model_file_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+ self.gpu_predictor = create_predictor(gpu_config)
def reconstruct(self, images=None, paths=None, use_gpu=False, visualization=False, output_dir="falsr_c_output"):
"""
@@ -96,11 +98,18 @@ def reconstruct(self, images=None, paths=None, use_gpu=False, visualization=Fals
for i in range(total_num):
image_y = np.array([all_data[i]['img_y']])
image_scale_pbpr = np.array([all_data[i]['img_scale_pbpr']])
- image_y = PaddleTensor(image_y.copy())
- image_scale_pbpr = PaddleTensor(image_scale_pbpr.copy())
- output = self.gpu_predictor.run([image_y, image_scale_pbpr]) if use_gpu else self.cpu_predictor.run(
- [image_y, image_scale_pbpr])
- output = np.expand_dims(output[0].as_ndarray(), axis=1)
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(image_y.copy())
+ input_handle = predictor.get_input_handle(input_names[1])
+ input_handle.copy_from_cpu(image_scale_pbpr.copy())
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+ output = np.expand_dims(output_handle.copy_to_cpu(), axis=1)
out = postprocess(
data_out=output,
org_im=all_data[i]['org_im'],
@@ -111,29 +120,6 @@ def reconstruct(self, images=None, paths=None, use_gpu=False, visualization=Fals
res.append(out)
return res
- def save_inference_model(self,
- dirname='falsr_c_save_model',
- model_filename=None,
- params_filename=None,
- combined=False):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/Image_editing/super_resolution/falsr_c/processor.py b/modules/image/Image_editing/super_resolution/falsr_c/processor.py
index fe451116a..805ada4d6 100644
--- a/modules/image/Image_editing/super_resolution/falsr_c/processor.py
+++ b/modules/image/Image_editing/super_resolution/falsr_c/processor.py
@@ -52,7 +52,6 @@ def postprocess(data_out, org_im, org_im_shape, org_im_path, output_dir, visuali
result['data'] = sr
else:
result['data'] = sr
- print("result['data'] shape", result['data'].shape)
return result
diff --git a/modules/image/Image_editing/super_resolution/falsr_c/test.py b/modules/image/Image_editing/super_resolution/falsr_c/test.py
new file mode 100644
index 000000000..ec2ef6734
--- /dev/null
+++ b/modules/image/Image_editing/super_resolution/falsr_c/test.py
@@ -0,0 +1,86 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import numpy as np
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/1sLIu1XKQrY/download?ixid=MnwxMjA3fDB8MXxhbGx8MTJ8fHx8fHwyfHwxNjYyMzQxNDUx&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="falsr_c")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('falsr_c_output')
+
+ def test_reconstruct1(self):
+ results = self.module.reconstruct(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct2(self):
+ results = self.module.reconstruct(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct3(self):
+ results = self.module.reconstruct(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct4(self):
+ results = self.module.reconstruct(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.reconstruct,
+ paths=['no.jpg']
+ )
+
+ def test_reconstruct6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.reconstruct,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 9d830b932d120ed58e54781bd77ae608856c2eb4 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:22:03 +0800
Subject: [PATCH 078/117] update dcscn (#1990)
* update dcscn
* add clean func
* update dcscn
---
.../super_resolution/dcscn/README.md | 31 +++----
.../super_resolution/dcscn/README_en.md | 32 +++----
.../super_resolution/dcscn/data_feed.py | 2 +-
.../super_resolution/dcscn/module.py | 72 +++++++---------
.../super_resolution/dcscn/test.py | 86 +++++++++++++++++++
5 files changed, 149 insertions(+), 74 deletions(-)
create mode 100644 modules/image/Image_editing/super_resolution/dcscn/test.py
diff --git a/modules/image/Image_editing/super_resolution/dcscn/README.md b/modules/image/Image_editing/super_resolution/dcscn/README.md
index 15722b2f2..da6069abe 100644
--- a/modules/image/Image_editing/super_resolution/dcscn/README.md
+++ b/modules/image/Image_editing/super_resolution/dcscn/README.md
@@ -68,12 +68,11 @@
- ### 3、API
- ```python
- def reconstruct(self,
- images=None,
- paths=None,
- use_gpu=False,
- visualization=False,
- output_dir="dcscn_output")
+ def reconstruct(images=None,
+ paths=None,
+ use_gpu=False,
+ visualization=False,
+ output_dir="dcscn_output")
```
- 预测API,用于图像超分辨率。
@@ -93,21 +92,14 @@
* data (numpy.ndarray): 超分辨后图像。
- ```python
- def save_inference_model(self,
- dirname='dcscn_save_model',
- model_filename=None,
- params_filename=None,
- combined=False)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- * dirname: 存在模型的目录名称
- * model\_filename: 模型文件名称,默认为\_\_model\_\_
- * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
- * combined: 是否将参数保存到统一的一个文件中
+ * dirname: 模型保存路径
@@ -171,3 +163,12 @@
* 1.0.0
初始发布
+
+
+* 1.1.0
+
+ 移除 fluid API
+
+ ```shell
+ $ hub install dcscn == 1.1.0
+ ```
diff --git a/modules/image/Image_editing/super_resolution/dcscn/README_en.md b/modules/image/Image_editing/super_resolution/dcscn/README_en.md
index 098d03657..427d8e6f0 100644
--- a/modules/image/Image_editing/super_resolution/dcscn/README_en.md
+++ b/modules/image/Image_editing/super_resolution/dcscn/README_en.md
@@ -70,12 +70,11 @@
- ### 3、API
- ```python
- def reconstruct(self,
- images=None,
- paths=None,
- use_gpu=False,
- visualization=False,
- output_dir="dcscn_output")
+ def reconstruct(images=None,
+ paths=None,
+ use_gpu=False,
+ visualization=False,
+ output_dir="dcscn_output")
```
- Prediction API.
@@ -94,21 +93,14 @@
* data (numpy.ndarray): Result of super resolution.
- ```python
- def save_inference_model(self,
- dirname='dcscn_save_model',
- model_filename=None,
- params_filename=None,
- combined=False)
+ def save_inference_model(dirname)
```
- Save the model to the specified path.
- **Parameters**
- * dirname: Save path.
- * model\_filename: Model file name,defalt is \_\_model\_\_
- * params\_filename: Parameter file name,defalt is \_\_params\_\_(Only takes effect when `combined` is True)
- * combined: Whether to save the parameters to a unified file.
+ * dirname: Model save path.
@@ -170,3 +162,13 @@
- 1.0.0
First release
+
+
+- 1.1.0
+
+ Remove Fluid API
+
+
+ ```shell
+ $ hub install dcscn == 1.1.0
+ ```
diff --git a/modules/image/Image_editing/super_resolution/dcscn/data_feed.py b/modules/image/Image_editing/super_resolution/dcscn/data_feed.py
index 10eeba2e6..0fad3b1ec 100644
--- a/modules/image/Image_editing/super_resolution/dcscn/data_feed.py
+++ b/modules/image/Image_editing/super_resolution/dcscn/data_feed.py
@@ -5,7 +5,7 @@
import cv2
import numpy as np
-from PIL import Image
+
__all__ = ['reader']
diff --git a/modules/image/Image_editing/super_resolution/dcscn/module.py b/modules/image/Image_editing/super_resolution/dcscn/module.py
index 96b2715bc..8f94e5854 100644
--- a/modules/image/Image_editing/super_resolution/dcscn/module.py
+++ b/modules/image/Image_editing/super_resolution/dcscn/module.py
@@ -18,13 +18,14 @@
import argparse
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle
+import paddle.jit
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from dcscn.data_feed import reader
-from dcscn.processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
+from .data_feed import reader
+from .processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
@moduleinfo(
@@ -33,21 +34,22 @@
author="paddlepaddle",
author_email="",
summary="dcscn is a super resolution model.",
- version="1.0.0")
-class Dcscn(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "dcscn_model")
+ version="1.1.0")
+class Dcscn:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "dcscn_model", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- self.model_file_path = self.default_pretrained_model_path
- cpu_config = AnalysisConfig(self.model_file_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -56,10 +58,10 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.model_file_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+ self.gpu_predictor = create_predictor(gpu_config)
def reconstruct(self, images=None, paths=None, use_gpu=False, visualization=False, output_dir="dcscn_output"):
"""
@@ -97,13 +99,20 @@ def reconstruct(self, images=None, paths=None, use_gpu=False, visualization=Fals
image_x = np.array([all_data[i]['img_x']])
image_x2 = np.array([all_data[i]['img_x2']])
dropout = np.array([0])
- image_x = PaddleTensor(image_x.copy())
- image_x2 = PaddleTensor(image_x2.copy())
- drop_out = PaddleTensor(dropout.copy())
- output = self.gpu_predictor.run([image_x, image_x2]) if use_gpu else self.cpu_predictor.run(
- [image_x, image_x2])
- output = np.expand_dims(output[0].as_ndarray(), axis=1)
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(image_x.copy())
+ input_handle = predictor.get_input_handle(input_names[1])
+ input_handle.copy_from_cpu(image_x2.copy())
+
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[0])
+
+ output = np.expand_dims(output_handle.copy_to_cpu(), axis=1)
out = postprocess(
data_out=output,
@@ -115,29 +124,6 @@ def reconstruct(self, images=None, paths=None, use_gpu=False, visualization=Fals
res.append(out)
return res
- def save_inference_model(self,
- dirname='dcscn_save_model',
- model_filename=None,
- params_filename=None,
- combined=False):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/Image_editing/super_resolution/dcscn/test.py b/modules/image/Image_editing/super_resolution/dcscn/test.py
new file mode 100644
index 000000000..525240f9a
--- /dev/null
+++ b/modules/image/Image_editing/super_resolution/dcscn/test.py
@@ -0,0 +1,86 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import numpy as np
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/1sLIu1XKQrY/download?ixid=MnwxMjA3fDB8MXxhbGx8MTJ8fHx8fHwyfHwxNjYyMzQxNDUx&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="dcscn")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('dcscn_output')
+
+ def test_reconstruct1(self):
+ results = self.module.reconstruct(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct2(self):
+ results = self.module.reconstruct(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct3(self):
+ results = self.module.reconstruct(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct4(self):
+ results = self.module.reconstruct(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_reconstruct5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.reconstruct,
+ paths=['no.jpg']
+ )
+
+ def test_reconstruct6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.reconstruct,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 0ea0f8e8757c3844a98d74013ae3708836bd6355 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:22:22 +0800
Subject: [PATCH 079/117] update user_guided_colorization (#1994)
* update user_guided_colorization
* add clean func
---
.../user_guided_colorization/README.md | 4 +
.../user_guided_colorization/README_en.md | 5 ++
.../user_guided_colorization/module.py | 2 +-
.../user_guided_colorization/test.py | 85 +++++++++++++++++++
4 files changed, 95 insertions(+), 1 deletion(-)
create mode 100644 modules/image/Image_editing/colorization/user_guided_colorization/test.py
diff --git a/modules/image/Image_editing/colorization/user_guided_colorization/README.md b/modules/image/Image_editing/colorization/user_guided_colorization/README.md
index d5d13144e..d91c4fede 100644
--- a/modules/image/Image_editing/colorization/user_guided_colorization/README.md
+++ b/modules/image/Image_editing/colorization/user_guided_colorization/README.md
@@ -201,4 +201,8 @@
初始发布
+ - ```shell
+ $ hub install user_guided_colorization==1.0.0
+ ```
+
diff --git a/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md b/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
index 8e17592c8..69a11988c 100644
--- a/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
+++ b/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
@@ -203,3 +203,8 @@
* 1.0.0
First release
+
+
+ - ```shell
+ $ hub install user_guided_colorization==1.0.0
+ ```
diff --git a/modules/image/Image_editing/colorization/user_guided_colorization/module.py b/modules/image/Image_editing/colorization/user_guided_colorization/module.py
index c74bdf8d7..8b447e892 100644
--- a/modules/image/Image_editing/colorization/user_guided_colorization/module.py
+++ b/modules/image/Image_editing/colorization/user_guided_colorization/module.py
@@ -20,7 +20,7 @@
from paddlehub.module.module import moduleinfo
import paddlehub.vision.transforms as T
from paddlehub.module.cv_module import ImageColorizeModule
-from user_guided_colorization.data_feed import ColorizePreprocess
+from .data_feed import ColorizePreprocess
@moduleinfo(
diff --git a/modules/image/Image_editing/colorization/user_guided_colorization/test.py b/modules/image/Image_editing/colorization/user_guided_colorization/test.py
new file mode 100644
index 000000000..990f25ea9
--- /dev/null
+++ b/modules/image/Image_editing/colorization/user_guided_colorization/test.py
@@ -0,0 +1,85 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import numpy as np
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/1sLIu1XKQrY/download?ixid=MnwxMjA3fDB8MXxhbGx8MTJ8fHx8fHwyfHwxNjYyMzQxNDUx&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="user_guided_colorization")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('colorization')
+
+ def test_predict1(self):
+ results = self.module.predict(
+ images=['tests/test.jpg'],
+ visualization=False
+ )
+ gray = results[0]['gray']
+ hint = results[0]['hint']
+ real = results[0]['real']
+ fake_reg = results[0]['fake_reg']
+
+ self.assertIsInstance(gray, np.ndarray)
+ self.assertIsInstance(hint, np.ndarray)
+ self.assertIsInstance(real, np.ndarray)
+ self.assertIsInstance(fake_reg, np.ndarray)
+
+ def test_predict2(self):
+ results = self.module.predict(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=False
+ )
+ gray = results[0]['gray']
+ hint = results[0]['hint']
+ real = results[0]['real']
+ fake_reg = results[0]['fake_reg']
+
+ self.assertIsInstance(gray, np.ndarray)
+ self.assertIsInstance(hint, np.ndarray)
+ self.assertIsInstance(real, np.ndarray)
+ self.assertIsInstance(fake_reg, np.ndarray)
+
+ def test_predict3(self):
+ results = self.module.predict(
+ images=[cv2.imread('tests/test.jpg')],
+ visualization=True
+ )
+ gray = results[0]['gray']
+ hint = results[0]['hint']
+ real = results[0]['real']
+ fake_reg = results[0]['fake_reg']
+
+ self.assertIsInstance(gray, np.ndarray)
+ self.assertIsInstance(hint, np.ndarray)
+ self.assertIsInstance(real, np.ndarray)
+ self.assertIsInstance(fake_reg, np.ndarray)
+
+ def test_predict4(self):
+ self.assertRaises(
+ IndexError,
+ self.module.predict,
+ images=['no.jpg'],
+ visualization=False
+ )
+
+if __name__ == "__main__":
+ unittest.main()
From 5c923528176f6b0cd8d5b5f76b97f48748d94bb8 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:22:51 +0800
Subject: [PATCH 080/117] update pyramidbox_lite_mobile_mask (#1997)
* update pyramidbox_lite_mobile_mask
* update
* add clean func
* update save inference model
---
.../pyramidbox_lite_mobile_mask/README.md | 17 +--
.../pyramidbox_lite_mobile_mask/README_en.md | 17 +--
.../pyramidbox_lite_mobile_mask/module.py | 48 ++----
.../pyramidbox_lite_mobile_mask/processor.py | 1 -
.../pyramidbox_lite_mobile_mask/test.py | 144 ++++++++++++++++++
5 files changed, 169 insertions(+), 58 deletions(-)
create mode 100644 modules/image/face_detection/pyramidbox_lite_mobile_mask/test.py
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile_mask/README.md b/modules/image/face_detection/pyramidbox_lite_mobile_mask/README.md
index 458a60e72..1e73457e3 100644
--- a/modules/image/face_detection/pyramidbox_lite_mobile_mask/README.md
+++ b/modules/image/face_detection/pyramidbox_lite_mobile_mask/README.md
@@ -131,19 +131,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- - dirname: 存在模型的目录名称;
- - model\_filename: 模型文件名称,默认为\_\_model\_\_;
- - params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);
- - combined: 是否将参数保存到统一的一个文件中。
+ - dirname: 模型保存路径
## 四、服务部署
@@ -194,7 +188,6 @@
# 将模型保存在test_program文件夹之中
pyramidbox_lite_mobile_mask.save_inference_model(dirname="test_program")
```
- 通过以上命令,可以获得人脸检测和口罩佩戴判断模型,分别存储在pyramidbox\_lite和mask\_detector之中。文件夹中的\_\_model\_\_是模型结构文件,\_\_params\_\_文件是权重文件。
- ### 进行模型转换
- 从paddlehub下载的是预测模型,可以使用PaddleLite提供的模型优化工具OPT对预测模型进行转换,转换之后进而可以实现在手机等端侧硬件上的部署,具体请请参考[OPT工具](https://paddle-lite.readthedocs.io/zh/latest/user_guides/model_optimize_tool.html)
@@ -212,6 +205,10 @@
移除 fluid api
+* 1.4.0
+
+ 修复无法导出模型的问题
+
- ```shell
- $ hub install pyramidbox_lite_mobile_mask==1.3.1
+ $ hub install pyramidbox_lite_mobile_mask==1.4.0
```
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile_mask/README_en.md b/modules/image/face_detection/pyramidbox_lite_mobile_mask/README_en.md
index f7d2ef026..abe053f18 100644
--- a/modules/image/face_detection/pyramidbox_lite_mobile_mask/README_en.md
+++ b/modules/image/face_detection/pyramidbox_lite_mobile_mask/README_en.md
@@ -107,20 +107,13 @@
- ```python
- def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- Save model to specific path
- **Parameters**
- - dirname: output dir for saving model
- - model\_filename: filename for saving model
- - params\_filename: filename for saving parameters
- - combined: whether save parameters into one file
-
+ - dirname: model save path
## IV.Server Deployment
@@ -188,6 +181,10 @@
Remove fluid api
+* 1.4.0
+
+ Fix a bug of save_inference_model
+
- ```shell
- $ hub install pyramidbox_lite_mobile_mask==1.3.1
+ $ hub install pyramidbox_lite_mobile_mask==1.4.0
```
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py b/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py
index 99a09fdd4..f548ac00b 100644
--- a/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py
+++ b/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py
@@ -10,9 +10,9 @@
import paddle
from paddle.inference import Config
from paddle.inference import create_predictor
-from pyramidbox_lite_mobile_mask.data_feed import reader
-from pyramidbox_lite_mobile_mask.processor import base64_to_cv2
-from pyramidbox_lite_mobile_mask.processor import postprocess
+from .data_feed import reader
+from .processor import base64_to_cv2
+from .processor import postprocess
import paddlehub as hub
from paddlehub.module.module import moduleinfo
@@ -27,15 +27,14 @@
author_email="",
summary=
"Pyramidbox-Lite-Mobile-Mask is a high-performance face detection model used to detect whether people wear masks.",
- version="1.3.1")
-class PyramidBoxLiteMobileMask(hub.Module):
-
- def _initialize(self, face_detector_module=None):
+ version="1.4.0")
+class PyramidBoxLiteMobileMask:
+ def __init__(self, face_detector_module=None):
"""
Args:
face_detector_module (class): module to detect face.
"""
- self.default_pretrained_model_path = os.path.join(self.directory, "pyramidbox_lite_mobile_mask_model")
+ self.default_pretrained_model_path = os.path.join(self.directory, "pyramidbox_lite_mobile_mask_model", "model")
if face_detector_module is None:
self.face_detector = hub.Module(name='pyramidbox_lite_mobile')
else:
@@ -47,7 +46,9 @@ def _set_config(self):
"""
predictor config setting
"""
- cpu_config = Config(self.default_pretrained_model_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
self.cpu_predictor = create_predictor(cpu_config)
@@ -59,7 +60,7 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = Config(self.default_pretrained_model_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
self.gpu_predictor = create_predictor(gpu_config)
@@ -180,33 +181,6 @@ def face_detection(self,
res.append(out)
return res
- def save_inference_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- classifier_dir = os.path.join(dirname, 'mask_detector')
- detector_dir = os.path.join(dirname, 'pyramidbox_lite')
- self._save_classifier_model(classifier_dir, model_filename, params_filename, combined)
- self._save_detector_model(detector_dir, model_filename, params_filename, combined)
-
- def _save_detector_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- self.face_detector.save_inference_model(dirname, model_filename, params_filename, combined)
-
- def _save_classifier_model(self, dirname, model_filename=None, params_filename=None, combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = paddle.CPUPlace()
- exe = paddle.Executor(place)
-
- program, feeded_var_names, target_vars = paddle.static.load_inference_model(
- dirname=self.default_pretrained_model_path, executor=exe)
-
- paddle.static.save_inference_model(dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py b/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py
index 4a9173f88..8605749a9 100644
--- a/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py
+++ b/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py
@@ -5,7 +5,6 @@
import os
import time
-from collections import OrderedDict
import base64
import cv2
diff --git a/modules/image/face_detection/pyramidbox_lite_mobile_mask/test.py b/modules/image/face_detection/pyramidbox_lite_mobile_mask/test.py
new file mode 100644
index 000000000..776a2ccf7
--- /dev/null
+++ b/modules/image/face_detection/pyramidbox_lite_mobile_mask/test.py
@@ -0,0 +1,144 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://ai-studio-static-online.cdn.bcebos.com/7799a8ccc5f6471b9d56fb6eff94f82a08b70ca2c7594d3f99877e366c0a2619'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="pyramidbox_lite_mobile_mask")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('detection_result')
+
+ def test_face_detection1(self):
+ results = self.module.face_detection(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'NO MASK')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection2(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'NO MASK')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection3(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ bbox = results[0]['data'][0]
+
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'NO MASK')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection4(self):
+ results = self.module.face_detection(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ bbox = results[0]['data'][0]
+
+ label = bbox['label']
+ confidence = bbox['confidence']
+ left = bbox['left']
+ right = bbox['right']
+ top = bbox['top']
+ bottom = bbox['bottom']
+
+ self.assertEqual(label, 'NO MASK')
+ self.assertTrue(confidence > 0.5)
+ self.assertTrue(1000 < left < 4000)
+ self.assertTrue(1000 < right < 4000)
+ self.assertTrue(0 < top < 2000)
+ self.assertTrue(0 < bottom < 2000)
+
+ def test_face_detection5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.face_detection,
+ paths=['no.jpg']
+ )
+
+ def test_face_detection6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.face_detection,
+ images=['test.jpg']
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model/face_detector.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model/face_detector.pdiparams'))
+
+ self.assertTrue(os.path.exists('./inference/model/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From 8873a70c51af296f65506810ae3a53da0a1d89ca Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:23:10 +0800
Subject: [PATCH 081/117] update humanseg_lite (#2000)
* update humanseg_lite
* add clean func
* update save inference model
---
.../humanseg_lite/README.md | 20 ++-
.../humanseg_lite/README_en.md | 23 +--
.../humanseg_lite/data_feed.py | 1 -
.../humanseg_lite/module.py | 115 +++++++-------
.../humanseg_lite/processor.py | 1 -
.../humanseg_lite/test.py | 145 ++++++++++++++++++
6 files changed, 231 insertions(+), 74 deletions(-)
create mode 100644 modules/image/semantic_segmentation/humanseg_lite/test.py
diff --git a/modules/image/semantic_segmentation/humanseg_lite/README.md b/modules/image/semantic_segmentation/humanseg_lite/README.md
index 67472e181..12248ce8a 100644
--- a/modules/image/semantic_segmentation/humanseg_lite/README.md
+++ b/modules/image/semantic_segmentation/humanseg_lite/README.md
@@ -170,19 +170,13 @@
```python
- def save_inference_model(dirname='humanseg_lite_model',
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- * dirname: 存在模型的目录名称
- * model\_filename: 模型文件名称,默认为\_\_model\_\_
- * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
- * combined: 是否将参数保存到统一的一个文件中
+ * dirname: 模型保存路径
## 四、服务部署
@@ -240,11 +234,21 @@
* 1.0.0
初始发布
+
* 1.1.0
新增视频人像分割接口
新增视频流人像分割接口
+
* 1.1.1
修复cudnn为8.0.4显存泄露问题
+
+* 1.2.0
+
+ 移除 Fluid API
+
+ ```shell
+ $ hub install humanseg_lite == 1.2.0
+ ```
diff --git a/modules/image/semantic_segmentation/humanseg_lite/README_en.md b/modules/image/semantic_segmentation/humanseg_lite/README_en.md
index e37ba0123..f2b45ae35 100644
--- a/modules/image/semantic_segmentation/humanseg_lite/README_en.md
+++ b/modules/image/semantic_segmentation/humanseg_lite/README_en.md
@@ -171,10 +171,7 @@
- ```python
- def save_inference_model(dirname='humanseg_lite_model',
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
@@ -182,10 +179,7 @@
- **Parameters**
- * dirname: Save path.
- * model\_filename: model file name,defalt is \_\_model\_\_
- * params\_filename: parameter file name,defalt is \_\_params\_\_(Only takes effect when `combined` is True)
- * combined: Whether to save the parameters to a unified file.
+ * dirname: Model save path.
@@ -243,13 +237,22 @@
- 1.0.0
- First release
+ First release
- 1.1.0
Added video portrait segmentation interface
Added video stream portrait segmentation interface
+
* 1.1.1
- Fix memory leakage problem of on cudnn 8.0.4
+ Fix memory leakage problem of on cudnn 8.0.4
+
+* 1.2.0
+
+ Remove Fluid API
+
+ ```shell
+ $ hub install humanseg_lite == 1.2.0
+ ```
diff --git a/modules/image/semantic_segmentation/humanseg_lite/data_feed.py b/modules/image/semantic_segmentation/humanseg_lite/data_feed.py
index 7f9033975..f7fbb0e21 100644
--- a/modules/image/semantic_segmentation/humanseg_lite/data_feed.py
+++ b/modules/image/semantic_segmentation/humanseg_lite/data_feed.py
@@ -5,7 +5,6 @@
import cv2
import numpy as np
-from PIL import Image
__all__ = ['reader', 'preprocess_v']
diff --git a/modules/image/semantic_segmentation/humanseg_lite/module.py b/modules/image/semantic_segmentation/humanseg_lite/module.py
index b8ba86858..600d4c289 100644
--- a/modules/image/semantic_segmentation/humanseg_lite/module.py
+++ b/modules/image/semantic_segmentation/humanseg_lite/module.py
@@ -19,14 +19,15 @@
import cv2
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle
+import paddle.jit
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
-from humanseg_lite.processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
-from humanseg_lite.data_feed import reader, preprocess_v
-from humanseg_lite.optimal import postprocess_v, threshold_mask
+from .processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
+from .data_feed import reader, preprocess_v
+from .optimal import postprocess_v, threshold_mask
@moduleinfo(
@@ -35,22 +36,22 @@
author="paddlepaddle",
author_email="",
summary="humanseg_lite is a semantic segmentation model.",
- version="1.1.0")
-class ShufflenetHumanSeg(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "humanseg_lite_inference")
+ version="1.2.0")
+class ShufflenetHumanSeg:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "humanseg_lite_inference", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- self.model_file_path = os.path.join(self.default_pretrained_model_path, '__model__')
- self.params_file_path = os.path.join(self.default_pretrained_model_path, '__params__')
- cpu_config = AnalysisConfig(self.model_file_path, self.params_file_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
@@ -60,10 +61,14 @@ def _set_config(self):
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.model_file_path, self.params_file_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+
+ if paddle.get_cudnn_version() == 8004:
+ gpu_config.delete_pass('conv_elementwise_add_act_fuse_pass')
+ gpu_config.delete_pass('conv_elementwise_add2_act_fuse_pass')
+ self.gpu_predictor = create_predictor(gpu_config)
def segment(self,
images=None,
@@ -116,9 +121,16 @@ def segment(self,
pass
# feed batch image
batch_image = np.array([data['image'] for data in batch_data])
- batch_image = PaddleTensor(batch_image.copy())
- output = self.gpu_predictor.run([batch_image]) if use_gpu else self.cpu_predictor.run([batch_image])
- output = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(batch_image.copy())
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ output = output_handle.copy_to_cpu()
+
output = np.expand_dims(output[:, 1, :, :], axis=1)
# postprocess one by one
for i in range(len(batch_data)):
@@ -156,9 +168,16 @@ def video_stream_segment(self, frame_org, frame_id, prev_gray, prev_cfd, use_gpu
height = int(frame_org.shape[1])
disflow = cv2.DISOpticalFlow_create(cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
frame = preprocess_v(frame_org, resize_w, resize_h)
- image = PaddleTensor(np.array([frame.copy()]))
- output = self.gpu_predictor.run([image]) if use_gpu else self.cpu_predictor.run([image])
- score_map = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(frame.copy()[None, ...])
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ score_map = output_handle.copy_to_cpu()
+
frame = np.transpose(frame, axes=[1, 2, 0])
score_map = np.transpose(np.squeeze(score_map, 0), axes=[1, 2, 0])
cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
@@ -227,9 +246,16 @@ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_lite_
ret, frame_org = cap_video.read()
if ret:
frame = preprocess_v(frame_org, resize_w, resize_h)
- image = PaddleTensor(np.array([frame.copy()]))
- output = self.gpu_predictor.run([image]) if use_gpu else self.cpu_predictor.run([image])
- score_map = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(frame.copy()[None, ...])
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ score_map = output_handle.copy_to_cpu()
+
frame = np.transpose(frame, axes=[1, 2, 0])
score_map = np.transpose(np.squeeze(score_map, 0), axes=[1, 2, 0])
cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
@@ -255,9 +281,16 @@ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_lite_
ret, frame_org = cap_video.read()
if ret:
frame = preprocess_v(frame_org, resize_w, resize_h)
- image = PaddleTensor(np.array([frame.copy()]))
- output = self.gpu_predictor.run([image]) if use_gpu else self.cpu_predictor.run([image])
- score_map = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(frame.copy()[None, ...])
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ score_map = output_handle.copy_to_cpu()
+
frame = np.transpose(frame, axes=[1, 2, 0])
score_map = np.transpose(np.squeeze(score_map, 0), axes=[1, 2, 0])
cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
@@ -279,32 +312,6 @@ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_lite_
break
cap_video.release()
- def save_inference_model(self,
- dirname='humanseg_lite_model',
- model_filename=None,
- params_filename=None,
- combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
-
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path,
- model_filename=model_filename,
- params_filename=params_filename,
- executor=exe)
-
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/semantic_segmentation/humanseg_lite/processor.py b/modules/image/semantic_segmentation/humanseg_lite/processor.py
index e4911ff4d..9cd53a841 100644
--- a/modules/image/semantic_segmentation/humanseg_lite/processor.py
+++ b/modules/image/semantic_segmentation/humanseg_lite/processor.py
@@ -50,7 +50,6 @@ def postprocess(data_out, org_im, org_im_shape, org_im_path, output_dir, visuali
result['data'] = logit
else:
result['data'] = logit
- print("result['data'] shape", result['data'].shape)
return result
diff --git a/modules/image/semantic_segmentation/humanseg_lite/test.py b/modules/image/semantic_segmentation/humanseg_lite/test.py
new file mode 100644
index 000000000..df4334693
--- /dev/null
+++ b/modules/image/semantic_segmentation/humanseg_lite/test.py
@@ -0,0 +1,145 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import numpy as np
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/pg_WCHWSdT8/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjYyNDM2ODI4&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
+ img = cv2.imread('tests/test.jpg')
+ video = cv2.VideoWriter('tests/test.avi', fourcc,
+ 20.0, tuple(img.shape[:2]))
+ for i in range(40):
+ video.write(img)
+ video.release()
+ cls.module = hub.Module(name="humanseg_lite")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('humanseg_lite_output')
+ shutil.rmtree('humanseg_lite_video_result')
+
+ def test_segment1(self):
+ results = self.module.segment(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment2(self):
+ results = self.module.segment(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment3(self):
+ results = self.module.segment(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment4(self):
+ results = self.module.segment(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.segment,
+ paths=['no.jpg']
+ )
+
+ def test_segment6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.segment,
+ images=['test.jpg']
+ )
+
+ def test_video_stream_segment1(self):
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=1,
+ prev_gray=None,
+ prev_cfd=None,
+ use_gpu=False
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=2,
+ prev_gray=cur_gray,
+ prev_cfd=optflow_map,
+ use_gpu=False
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+
+ def test_video_stream_segment2(self):
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=1,
+ prev_gray=None,
+ prev_cfd=None,
+ use_gpu=True
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=2,
+ prev_gray=cur_gray,
+ prev_cfd=optflow_map,
+ use_gpu=True
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+
+ def test_video_segment1(self):
+ self.module.video_segment(
+ video_path="tests/test.avi",
+ use_gpu=False,
+ save_dir='humanseg_lite_video_result'
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From cf5f31126a7b9b44b68666103a2c04cfb5b4b48a Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 16 Sep 2022 15:23:49 +0800
Subject: [PATCH 082/117] update humanseg_server (#2002)
* update humanseg_server
* add clean func
* update save inference model
---
.../humanseg_server/README.md | 20 ++-
.../humanseg_server/README_en.md | 23 +--
.../humanseg_server/data_feed.py | 1 -
.../humanseg_server/module.py | 109 +++++++------
.../humanseg_server/test.py | 144 ++++++++++++++++++
5 files changed, 228 insertions(+), 69 deletions(-)
create mode 100644 modules/image/semantic_segmentation/humanseg_server/test.py
diff --git a/modules/image/semantic_segmentation/humanseg_server/README.md b/modules/image/semantic_segmentation/humanseg_server/README.md
index 35e19365c..621d880e2 100644
--- a/modules/image/semantic_segmentation/humanseg_server/README.md
+++ b/modules/image/semantic_segmentation/humanseg_server/README.md
@@ -173,19 +173,13 @@
```python
- def save_inference_model(dirname='humanseg_server_model',
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
- 将模型保存到指定路径。
- **参数**
- * dirname: 存在模型的目录名称
- * model\_filename: 模型文件名称,默认为\_\_model\_\_
- * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
- * combined: 是否将参数保存到统一的一个文件中
+ * dirname: 模型保存路径
## 四、服务部署
@@ -243,11 +237,21 @@
* 1.0.0
初始发布
+
* 1.1.0
新增视频人像分割接口
新增视频流人像分割接口
+
* 1.1.1
修复cudnn为8.0.4显存泄露问题
+
+* 1.2.0
+
+ 移除 Fluid API
+
+ ```shell
+ $ hub install humanseg_server == 1.2.0
+ ```
diff --git a/modules/image/semantic_segmentation/humanseg_server/README_en.md b/modules/image/semantic_segmentation/humanseg_server/README_en.md
index 052b37e2a..303d03a30 100644
--- a/modules/image/semantic_segmentation/humanseg_server/README_en.md
+++ b/modules/image/semantic_segmentation/humanseg_server/README_en.md
@@ -170,10 +170,7 @@
```python
- def save_inference_model(dirname='humanseg_server_model',
- model_filename=None,
- params_filename=None,
- combined=True)
+ def save_inference_model(dirname)
```
@@ -181,10 +178,7 @@
- **Parameters**
- * dirname: Save path.
- * model\_filename: Model file name,defalt is \_\_model\_\_
- * params\_filename: Parameter file name,defalt is \_\_params\_\_(Only takes effect when `combined` is True)
- * combined: Whether to save the parameters to a unified file.
+ * dirname: Model save path.
@@ -242,7 +236,7 @@
- 1.0.0
- First release
+ First release
- 1.1.0
@@ -252,4 +246,13 @@
* 1.1.1
- Fix memory leakage problem of on cudnn 8.0.4
+ Fix memory leakage problem of on cudnn 8.0.4
+
+* 1.2.0
+
+ Remove Fluid API
+
+ ```shell
+ $ hub install humanseg_server == 1.2.0
+ ```
+
diff --git a/modules/image/semantic_segmentation/humanseg_server/data_feed.py b/modules/image/semantic_segmentation/humanseg_server/data_feed.py
index 85639d02d..f538db0ad 100644
--- a/modules/image/semantic_segmentation/humanseg_server/data_feed.py
+++ b/modules/image/semantic_segmentation/humanseg_server/data_feed.py
@@ -5,7 +5,6 @@
import cv2
import numpy as np
-from PIL import Image
__all__ = ['reader', 'preprocess_v']
diff --git a/modules/image/semantic_segmentation/humanseg_server/module.py b/modules/image/semantic_segmentation/humanseg_server/module.py
index f266f59ec..76e76a591 100644
--- a/modules/image/semantic_segmentation/humanseg_server/module.py
+++ b/modules/image/semantic_segmentation/humanseg_server/module.py
@@ -20,9 +20,10 @@
import cv2
import numpy as np
-import paddle.fluid as fluid
-import paddlehub as hub
-from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+import paddle
+import paddle.jit
+import paddle.static
+from paddle.inference import Config, create_predictor
from paddlehub.module.module import moduleinfo, runnable, serving
from humanseg_server.processor import postprocess, base64_to_cv2, cv2_to_base64, check_dir
@@ -36,22 +37,22 @@
author="baidu-vis",
author_email="",
summary="DeepLabv3+ is a semantic segmentation model.",
- version="1.1.0")
-class DeeplabV3pXception65HumanSeg(hub.Module):
- def _initialize(self):
- self.default_pretrained_model_path = os.path.join(self.directory, "humanseg_server_inference")
+ version="1.2.0")
+class DeeplabV3pXception65HumanSeg:
+ def __init__(self):
+ self.default_pretrained_model_path = os.path.join(self.directory, "humanseg_server_inference", "model")
self._set_config()
def _set_config(self):
"""
predictor config setting
"""
- self.model_file_path = os.path.join(self.default_pretrained_model_path, '__model__')
- self.params_file_path = os.path.join(self.default_pretrained_model_path, '__params__')
- cpu_config = AnalysisConfig(self.model_file_path, self.params_file_path)
+ model = self.default_pretrained_model_path+'.pdmodel'
+ params = self.default_pretrained_model_path+'.pdiparams'
+ cpu_config = Config(model, params)
cpu_config.disable_glog_info()
cpu_config.disable_gpu()
- self.cpu_predictor = create_paddle_predictor(cpu_config)
+ self.cpu_predictor = create_predictor(cpu_config)
try:
_places = os.environ["CUDA_VISIBLE_DEVICES"]
int(_places[0])
@@ -59,10 +60,14 @@ def _set_config(self):
except:
use_gpu = False
if use_gpu:
- gpu_config = AnalysisConfig(self.model_file_path, self.params_file_path)
+ gpu_config = Config(model, params)
gpu_config.disable_glog_info()
gpu_config.enable_use_gpu(memory_pool_init_size_mb=1000, device_id=0)
- self.gpu_predictor = create_paddle_predictor(gpu_config)
+
+ if paddle.get_cudnn_version() == 8004:
+ gpu_config.delete_pass('conv_elementwise_add_act_fuse_pass')
+ gpu_config.delete_pass('conv_elementwise_add2_act_fuse_pass')
+ self.gpu_predictor = create_predictor(gpu_config)
def segment(self,
images=None,
@@ -114,9 +119,16 @@ def segment(self,
pass
# feed batch image
batch_image = np.array([data['image'] for data in batch_data])
- batch_image = PaddleTensor(batch_image.copy())
- output = self.gpu_predictor.run([batch_image]) if use_gpu else self.cpu_predictor.run([batch_image])
- output = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(batch_image.copy())
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ output = output_handle.copy_to_cpu()
+
output = np.expand_dims(output[:, 1, :, :], axis=1)
# postprocess one by one
for i in range(len(batch_data)):
@@ -154,9 +166,16 @@ def video_stream_segment(self, frame_org, frame_id, prev_gray, prev_cfd, use_gpu
height = int(frame_org.shape[1])
disflow = cv2.DISOpticalFlow_create(cv2.DISOPTICAL_FLOW_PRESET_ULTRAFAST)
frame = preprocess_v(frame_org, resize_w, resize_h)
- image = PaddleTensor(np.array([frame.copy()]))
- output = self.gpu_predictor.run([image]) if use_gpu else self.cpu_predictor.run([image])
- score_map = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(frame.copy()[None, ...])
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ score_map = output_handle.copy_to_cpu()
+
frame = np.transpose(frame, axes=[1, 2, 0])
score_map = np.transpose(np.squeeze(score_map, 0), axes=[1, 2, 0])
cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
@@ -173,7 +192,7 @@ def video_stream_segment(self, frame_org, frame_id, prev_gray, prev_cfd, use_gpu
img_matting = cv2.resize(optflow_map, (height, width), cv2.INTER_LINEAR)
return [img_matting, cur_gray, optflow_map]
- def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_server_video'):
+ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_server_video_result'):
resize_h = 512
resize_w = 512
if not video_path:
@@ -201,9 +220,16 @@ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_serve
ret, frame_org = cap_video.read()
if ret:
frame = preprocess_v(frame_org, resize_w, resize_h)
- image = PaddleTensor(np.array([frame.copy()]))
- output = self.gpu_predictor.run([image]) if use_gpu else self.cpu_predictor.run([image])
- score_map = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(frame.copy()[None, ...])
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ score_map = output_handle.copy_to_cpu()
+
frame = np.transpose(frame, axes=[1, 2, 0])
score_map = np.transpose(np.squeeze(score_map, 0), axes=[1, 2, 0])
cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
@@ -228,9 +254,16 @@ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_serve
ret, frame_org = cap_video.read()
if ret:
frame = preprocess_v(frame_org, resize_w, resize_h)
- image = PaddleTensor(np.array([frame.copy()]))
- output = self.gpu_predictor.run([image]) if use_gpu else self.cpu_predictor.run([image])
- score_map = output[1].as_ndarray()
+
+ predictor = self.gpu_predictor if use_gpu else self.cpu_predictor
+ input_names = predictor.get_input_names()
+ input_handle = predictor.get_input_handle(input_names[0])
+ input_handle.copy_from_cpu(frame.copy()[None, ...])
+ predictor.run()
+ output_names = predictor.get_output_names()
+ output_handle = predictor.get_output_handle(output_names[1])
+ score_map = output_handle.copy_to_cpu()
+
frame = np.transpose(frame, axes=[1, 2, 0])
score_map = np.transpose(np.squeeze(score_map, 0), axes=[1, 2, 0])
cur_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
@@ -252,30 +285,6 @@ def video_segment(self, video_path=None, use_gpu=False, save_dir='humanseg_serve
break
cap_video.release()
- def save_inference_model(self,
- dirname='humanseg_server_model',
- model_filename=None,
- params_filename=None,
- combined=True):
- if combined:
- model_filename = "__model__" if not model_filename else model_filename
- params_filename = "__params__" if not params_filename else params_filename
- place = fluid.CPUPlace()
- exe = fluid.Executor(place)
- program, feeded_var_names, target_vars = fluid.io.load_inference_model(
- dirname=self.default_pretrained_model_path,
- model_filename=model_filename,
- params_filename=params_filename,
- executor=exe)
- fluid.io.save_inference_model(
- dirname=dirname,
- main_program=program,
- executor=exe,
- feeded_var_names=feeded_var_names,
- target_vars=target_vars,
- model_filename=model_filename,
- params_filename=params_filename)
-
@serving
def serving_method(self, images, **kwargs):
"""
diff --git a/modules/image/semantic_segmentation/humanseg_server/test.py b/modules/image/semantic_segmentation/humanseg_server/test.py
new file mode 100644
index 000000000..c6097abae
--- /dev/null
+++ b/modules/image/semantic_segmentation/humanseg_server/test.py
@@ -0,0 +1,144 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import requests
+import numpy as np
+import paddlehub as hub
+
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/pg_WCHWSdT8/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjYyNDM2ODI4&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
+ img = cv2.imread('tests/test.jpg')
+ video = cv2.VideoWriter('tests/test.avi', fourcc,
+ 20.0, tuple(img.shape[:2]))
+ for i in range(40):
+ video.write(img)
+ video.release()
+ cls.module = hub.Module(name="humanseg_server")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('inference')
+ shutil.rmtree('humanseg_server_output')
+ shutil.rmtree('humanseg_server_video_result')
+
+ def test_segment1(self):
+ results = self.module.segment(
+ paths=['tests/test.jpg'],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment2(self):
+ results = self.module.segment(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment3(self):
+ results = self.module.segment(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=False,
+ visualization=True
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment4(self):
+ results = self.module.segment(
+ images=[cv2.imread('tests/test.jpg')],
+ use_gpu=True,
+ visualization=False
+ )
+ self.assertIsInstance(results[0]['data'], np.ndarray)
+
+ def test_segment5(self):
+ self.assertRaises(
+ AssertionError,
+ self.module.segment,
+ paths=['no.jpg']
+ )
+
+ def test_segment6(self):
+ self.assertRaises(
+ AttributeError,
+ self.module.segment,
+ images=['test.jpg']
+ )
+
+ def test_video_stream_segment1(self):
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=1,
+ prev_gray=None,
+ prev_cfd=None,
+ use_gpu=False
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=2,
+ prev_gray=cur_gray,
+ prev_cfd=optflow_map,
+ use_gpu=False
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+
+ def test_video_stream_segment2(self):
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=1,
+ prev_gray=None,
+ prev_cfd=None,
+ use_gpu=True
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+ img_matting, cur_gray, optflow_map = self.module.video_stream_segment(
+ frame_org=cv2.imread('tests/test.jpg'),
+ frame_id=2,
+ prev_gray=cur_gray,
+ prev_cfd=optflow_map,
+ use_gpu=True
+ )
+ self.assertIsInstance(img_matting, np.ndarray)
+ self.assertIsInstance(cur_gray, np.ndarray)
+ self.assertIsInstance(optflow_map, np.ndarray)
+
+ def test_video_segment1(self):
+ self.module.video_segment(
+ video_path="tests/test.avi",
+ use_gpu=False
+ )
+
+ def test_save_inference_model(self):
+ self.module.save_inference_model('./inference/model')
+
+ self.assertTrue(os.path.exists('./inference/model.pdmodel'))
+ self.assertTrue(os.path.exists('./inference/model.pdiparams'))
+
+
+if __name__ == "__main__":
+ unittest.main()
From cfd8f7f5d4b750316d3e11d129dcb7bcea87d871 Mon Sep 17 00:00:00 2001
From: DanielYang  + - Select the version appropriate for your operating system
+ - You can enter `uname -m` at the terminal to query the instruction set used by the system
+
+ - Download method 1: Download locally, and then transfer the installation package to the Linux server
+
+ - Download method 2: directly use the Linux command line to download
+
+ - ```shell
+ # Install wget first
+ sudo apt-get install wget # Ubuntu
+ sudo yum install wget # CentOS
+ ```
+
+ - ```shell
+ # Then use wget to download from Tsinghua Source
+ # To download Anaconda3-2021.05-Linux-x86_64.sh, the download command is as follows:
+ wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.05-Linux-x86_64.sh
+
+ # If you want to download other versions, you need to change the last/last file name to the version you want to download
+ ```
+
+- To install Anaconda:
+
+ - At the command line, enter `sh Anaconda3-2021.05-Linux-x86_64.sh`
+ - If you download another version, replace the file name of the command with the file name you downloaded
+ - Just follow the installation prompts
+ - When viewing the license, you can enter q to exit
+
+- **Add conda to the environment variable**
+
+ - The environment variable is added to enable the system to recognize the conda command. If you have added conda to the environment variable path during installation, you can skip this step
+
+ - Open `~/.bashrc` in the terminal:
+
+ - ```shell
+ # Enter the following command in the terminal:
+ vim ~/.bashrc
+ ```
+
+ - Add conda as an environment variable in `~/.bashrc`:
+
+ - ```shell
+ # Press i first to enter editing mode
+ # On the first line, enter:
+ export PATH="~/anaconda3/bin:$PATH"
+ # If the installation location is customized during installation, change ~/anaconda3/bin to the bin folder under the customized installation directory
+ ```
+
+ - ```shell
+ # Modified ~/.bash_profile file should be as follows (where xxx is the user name)::
+ export PATH="~/opt/anaconda3/bin:$PATH"
+ # >>> conda initialize >>>
+ # !! Contents within this block are managed by 'conda init' !!
+ __conda_setup="$('/Users/xxx/opt/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
+ if [ $? -eq 0 ]; then
+ eval "$__conda_setup"
+ else
+ if [ -f "/Users/xxx/opt/anaconda3/etc/profile.d/conda.sh" ]; then
+ . "/Users/xxx/opt/anaconda3/etc/profile.d/conda.sh"
+ else
+ export PATH="/Users/xxx/opt/anaconda3/bin:$PATH"
+ fi
+ fi
+ unset __conda_setup
+ # <<< conda initialize <<<
+ ```
+
+ - After modification, press the `esc` key to exit editing mode, and then enter `:wq!` And enter to save the exit
+
+ - Verify that the conda command is recognized:
+
+ - Enter `source ~/.bash_profile` in the terminal to update environment variables
+ - Then enter `conda info --envs` on the terminal. If the current base environment can be displayed, conda has added an environment variable
+
+## Step 2: Create a conda environment
+
+- Create a new conda environment
+
+ - ```shell
+ # On the command line, enter the following command to create a file named paddle_env environment
+ # This is for accelerated download, use Tsinghua Source
+ conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
+ ```
+
+ - This command will create an executable environment named paddle_env with Python version 3.8. It will take a while depending on the network status
+
+ - Then the command line will output a prompt message, enter y and press Enter to continue the installation
+
+ -
+ - Select the version appropriate for your operating system
+ - You can enter `uname -m` at the terminal to query the instruction set used by the system
+
+ - Download method 1: Download locally, and then transfer the installation package to the Linux server
+
+ - Download method 2: directly use the Linux command line to download
+
+ - ```shell
+ # Install wget first
+ sudo apt-get install wget # Ubuntu
+ sudo yum install wget # CentOS
+ ```
+
+ - ```shell
+ # Then use wget to download from Tsinghua Source
+ # To download Anaconda3-2021.05-Linux-x86_64.sh, the download command is as follows:
+ wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.05-Linux-x86_64.sh
+
+ # If you want to download other versions, you need to change the last/last file name to the version you want to download
+ ```
+
+- To install Anaconda:
+
+ - At the command line, enter `sh Anaconda3-2021.05-Linux-x86_64.sh`
+ - If you download another version, replace the file name of the command with the file name you downloaded
+ - Just follow the installation prompts
+ - When viewing the license, you can enter q to exit
+
+- **Add conda to the environment variable**
+
+ - The environment variable is added to enable the system to recognize the conda command. If you have added conda to the environment variable path during installation, you can skip this step
+
+ - Open `~/.bashrc` in the terminal:
+
+ - ```shell
+ # Enter the following command in the terminal:
+ vim ~/.bashrc
+ ```
+
+ - Add conda as an environment variable in `~/.bashrc`:
+
+ - ```shell
+ # Press i first to enter editing mode
+ # On the first line, enter:
+ export PATH="~/anaconda3/bin:$PATH"
+ # If the installation location is customized during installation, change ~/anaconda3/bin to the bin folder under the customized installation directory
+ ```
+
+ - ```shell
+ # Modified ~/.bash_profile file should be as follows (where xxx is the user name)::
+ export PATH="~/opt/anaconda3/bin:$PATH"
+ # >>> conda initialize >>>
+ # !! Contents within this block are managed by 'conda init' !!
+ __conda_setup="$('/Users/xxx/opt/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
+ if [ $? -eq 0 ]; then
+ eval "$__conda_setup"
+ else
+ if [ -f "/Users/xxx/opt/anaconda3/etc/profile.d/conda.sh" ]; then
+ . "/Users/xxx/opt/anaconda3/etc/profile.d/conda.sh"
+ else
+ export PATH="/Users/xxx/opt/anaconda3/bin:$PATH"
+ fi
+ fi
+ unset __conda_setup
+ # <<< conda initialize <<<
+ ```
+
+ - After modification, press the `esc` key to exit editing mode, and then enter `:wq!` And enter to save the exit
+
+ - Verify that the conda command is recognized:
+
+ - Enter `source ~/.bash_profile` in the terminal to update environment variables
+ - Then enter `conda info --envs` on the terminal. If the current base environment can be displayed, conda has added an environment variable
+
+## Step 2: Create a conda environment
+
+- Create a new conda environment
+
+ - ```shell
+ # On the command line, enter the following command to create a file named paddle_env environment
+ # This is for accelerated download, use Tsinghua Source
+ conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
+ ```
+
+ - This command will create an executable environment named paddle_env with Python version 3.8. It will take a while depending on the network status
+
+ - Then the command line will output a prompt message, enter y and press Enter to continue the installation
+
+ -  +
+- Activate the newly created conda environment, and enter the following command on the command line:
+
+ - ```shell
+ # Activate paddle_env environment
+ conda activate paddle_env
+ ```
+
+ - The above anaconda environment and python environment have been installed
+
+## Step 3: Install the libraries required by the program
+
+- Use the pip command to install the paddle in the newly activated environment:
+
+ - ```shell
+ # On the command line, enter the following command:
+ # The CPU version is installed by default. Baidu Source is recommended when installing the paddlepaddle
+ pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+ ```
+
+- After installing the PaddlePaddle, continue to install the paddlehub in the paddle_env environment:
+
+ - ```shell
+ # On the command line, enter the following command:
+ pip install paddlehub -i https://mirror.baidu.com/pypi/simple
+ ```
+
+ - Introduction document of paddlehub: https://github.com/PaddlePaddle/PaddleHub/blob/develop/README.md
+
+ - When installing the paddlehub, other dependent libraries will be installed automatically, which may take a while
+
+## Step 4: Install the paddlehub and download the model
+
+- After installing the paddlehub, download the style migration model:
+
+ - ```shell
+ # Enter the following command on the command line
+ hub install stylepro_artistic==1.0.1
+ ```
+
+ - Description document of the model: [https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value=%7B%22scenes%22%3A%5B%22GANs%22%5D%7D](https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value={"scenes"%3A["GANs"]})
+
+ -
+
+- Activate the newly created conda environment, and enter the following command on the command line:
+
+ - ```shell
+ # Activate paddle_env environment
+ conda activate paddle_env
+ ```
+
+ - The above anaconda environment and python environment have been installed
+
+## Step 3: Install the libraries required by the program
+
+- Use the pip command to install the paddle in the newly activated environment:
+
+ - ```shell
+ # On the command line, enter the following command:
+ # The CPU version is installed by default. Baidu Source is recommended when installing the paddlepaddle
+ pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+ ```
+
+- After installing the PaddlePaddle, continue to install the paddlehub in the paddle_env environment:
+
+ - ```shell
+ # On the command line, enter the following command:
+ pip install paddlehub -i https://mirror.baidu.com/pypi/simple
+ ```
+
+ - Introduction document of paddlehub: https://github.com/PaddlePaddle/PaddleHub/blob/develop/README.md
+
+ - When installing the paddlehub, other dependent libraries will be installed automatically, which may take a while
+
+## Step 4: Install the paddlehub and download the model
+
+- After installing the paddlehub, download the style migration model:
+
+ - ```shell
+ # Enter the following command on the command line
+ hub install stylepro_artistic==1.0.1
+ ```
+
+ - Description document of the model: [https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value=%7B%22scenes%22%3A%5B%22GANs%22%5D%7D](https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value={"scenes"%3A["GANs"]})
+
+ -  +
+## Step 5: Prepare the style to migrate data and code
+
+### Prepare style migration data
+
+- Create Working Directory `style_transfer` under User Directory `~`
+
+ - ```shell
+ # Enter the following command in the terminal:
+ cd ~ # Enter the user directory
+ mkdir style_transfer # Create style_transfer folder
+ cd style_transfer # Enter style_transfer directory
+ ```
+
+- Place pictures to be converted and style pictures respectively:
+
+ - Place the picture to be converted to `~/style_transfer/pic.jpg`
+ -
+
+## Step 5: Prepare the style to migrate data and code
+
+### Prepare style migration data
+
+- Create Working Directory `style_transfer` under User Directory `~`
+
+ - ```shell
+ # Enter the following command in the terminal:
+ cd ~ # Enter the user directory
+ mkdir style_transfer # Create style_transfer folder
+ cd style_transfer # Enter style_transfer directory
+ ```
+
+- Place pictures to be converted and style pictures respectively:
+
+ - Place the picture to be converted to `~/style_transfer/pic.jpg`
+ -  + - Place style picture to `~/style_transfer/fangao.jpg`
+ -
+ - Place style picture to `~/style_transfer/fangao.jpg`
+ -  +
+### Code
+
+- Create code file:
+
+ - ```shell
+ # The following commands are executed on the command line
+ $ pwd # Check whether the current directory is style_transfer, if not, enter: cd ~/style_transfer
+ $ touch style_transfer.py # Create an empty file
+ $ vim style_transfer.py # Open code file with vim editor
+ # Enter i first to enter editing mode
+ # Copy the code into the vim editor
+ # Press esc key to exit editing mode, then enter ": wq" and enter Enter to save and exit
+ ```
+
+ - ```python
+ # Code
+ import paddlehub as hub
+ import cv2
+
+ # Relative address of the picture to be converted
+ picture = './pic.jpg'
+ # Relative address of style picture
+ style_image = './fangao.jpg'
+
+ # Create a style transfer network and load parameters
+ stylepro_artistic = hub.Module(name="stylepro_artistic")
+
+ # Read in pictures and start style conversion
+ result = stylepro_artistic.style_transfer(
+ images=[{'content': cv2.imread(picture),
+ 'styles': [cv2.imread(style_image)]}],
+ visualization=True
+ )
+ ```
+
+- Running code:
+
+ - On the command line, enter `python style_transfer.py`
+ - When the program executes, a new folder `transfer_result` will be created, and save the converted file to this directory
+ - The output pictures are as follows:
+ -
+
+## Step 6: Explore the pre training model of flying oars
+- Congratulations, the installation and introduction cases of PaddleHub in the Linux environment will be completed here. Start your more in-depth learning model exploration journey quickly.[【More model exploration, jump to the official website of PaddlePaddle】](https://www.paddlepaddle.org.cn/hublist)
+
diff --git a/docs/docs_en/get_start/mac_quickstart.md b/docs/docs_en/get_start/mac_quickstart.md
new file mode 100755
index 000000000..f6a3dd5ab
--- /dev/null
+++ b/docs/docs_en/get_start/mac_quickstart.md
@@ -0,0 +1,199 @@
+# Zero base mac installation and image style transfer
+
+## Step 1: Install Anaconda
+
+- Note: To use paddlepaddle, you need to install the Python environment first. Here we choose the Python integrated environment Anaconda toolkit
+ - Anaconda is a commonly used python package management program
+ - After installing Anaconda, you can install the python environment and the toolkit environment required by numpy
+- Anaconda Download:
+ - Link: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
+ -
+
+### Code
+
+- Create code file:
+
+ - ```shell
+ # The following commands are executed on the command line
+ $ pwd # Check whether the current directory is style_transfer, if not, enter: cd ~/style_transfer
+ $ touch style_transfer.py # Create an empty file
+ $ vim style_transfer.py # Open code file with vim editor
+ # Enter i first to enter editing mode
+ # Copy the code into the vim editor
+ # Press esc key to exit editing mode, then enter ": wq" and enter Enter to save and exit
+ ```
+
+ - ```python
+ # Code
+ import paddlehub as hub
+ import cv2
+
+ # Relative address of the picture to be converted
+ picture = './pic.jpg'
+ # Relative address of style picture
+ style_image = './fangao.jpg'
+
+ # Create a style transfer network and load parameters
+ stylepro_artistic = hub.Module(name="stylepro_artistic")
+
+ # Read in pictures and start style conversion
+ result = stylepro_artistic.style_transfer(
+ images=[{'content': cv2.imread(picture),
+ 'styles': [cv2.imread(style_image)]}],
+ visualization=True
+ )
+ ```
+
+- Running code:
+
+ - On the command line, enter `python style_transfer.py`
+ - When the program executes, a new folder `transfer_result` will be created, and save the converted file to this directory
+ - The output pictures are as follows:
+ -
+
+## Step 6: Explore the pre training model of flying oars
+- Congratulations, the installation and introduction cases of PaddleHub in the Linux environment will be completed here. Start your more in-depth learning model exploration journey quickly.[【More model exploration, jump to the official website of PaddlePaddle】](https://www.paddlepaddle.org.cn/hublist)
+
diff --git a/docs/docs_en/get_start/mac_quickstart.md b/docs/docs_en/get_start/mac_quickstart.md
new file mode 100755
index 000000000..f6a3dd5ab
--- /dev/null
+++ b/docs/docs_en/get_start/mac_quickstart.md
@@ -0,0 +1,199 @@
+# Zero base mac installation and image style transfer
+
+## Step 1: Install Anaconda
+
+- Note: To use paddlepaddle, you need to install the Python environment first. Here we choose the Python integrated environment Anaconda toolkit
+ - Anaconda is a commonly used python package management program
+ - After installing Anaconda, you can install the python environment and the toolkit environment required by numpy
+- Anaconda Download:
+ - Link: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
+ -  + - Select the lowest `Anaconda3-2021.05-MacOSX-x86_64.pkg` download
+- After downloading, double click the. pkg file to enter the graphical interface
+ - By default, the installation will take a while
+- It is recommended to install a code editor such as vscode or pycharm
+
+## Step 2: Open the terminal and create a conda environment
+
+- Open terminal
+
+ - Press the command key and the space bar at the same time, enter "terminal" in the focus search, and double-click to enter the terminal
+
+- **Add conda to the environment variable**
+
+ - The environment variable is added to enable the system to recognize the conda command
+
+ - Enter the following command to open `~/.bash_profile`:
+
+ - ```shell
+ vim ~/.bash_profile
+ ```
+
+ - In `~/.bash_profile` add conda as an environment variable:
+
+ - ```shell
+ # Press i first to enter editing mode
+ # On the first line, enter:
+ export PATH="~/opt/anaconda3/bin:$PATH"
+ # If the installation location is customized during installation, change ~/opt/anaconda3/bin to the bin folder under the customized installation directory
+ ```
+
+ - ```shell
+ # Modified ~/.bash_profile file should be as follows (where xxx is the user name):
+ export PATH="~/opt/anaconda3/bin:$PATH"
+ # >>> conda initialize >>>
+ # !! Contents within this block are managed by 'conda init' !!
+ __conda_setup="$('/Users/xxx/opt/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
+ if [ $? -eq 0 ]; then
+ eval "$__conda_setup"
+ else
+ if [ -f "/Users/xxx/opt/anaconda3/etc/profile.d/conda.sh" ]; then
+ . "/Users/xxx/opt/anaconda3/etc/profile.d/conda.sh"
+ else
+ export PATH="/Users/xxx/opt/anaconda3/bin:$PATH"
+ fi
+ fi
+ unset __conda_setup
+ # <<< conda initialize <<<
+ ```
+
+ - After modification, press the `esc` key to exit editing mode, and then enter `:wq!` And enter to save the exit
+
+ - Verify that the conda command is recognized:
+
+ - Enter `source ~/.bash_profile` to update environment variables
+ - Then enter `conda info --envs` on the terminal. If the current base environment can be displayed, conda has added an environment variable
+
+- Create a new conda environment
+
+ - ```shell
+ # On the command line, enter the following command to create a file named paddle_env environment
+ # This is for accelerated download, use Tsinghua source
+ conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
+ ```
+
+ - This command will create an executable environment named paddle_env with Python version 3.8. It will take a while depending on the network status
+
+ - Then the command line will output a prompt message, enter y and press Enter to continue the installation
+
+ -
+ - Select the lowest `Anaconda3-2021.05-MacOSX-x86_64.pkg` download
+- After downloading, double click the. pkg file to enter the graphical interface
+ - By default, the installation will take a while
+- It is recommended to install a code editor such as vscode or pycharm
+
+## Step 2: Open the terminal and create a conda environment
+
+- Open terminal
+
+ - Press the command key and the space bar at the same time, enter "terminal" in the focus search, and double-click to enter the terminal
+
+- **Add conda to the environment variable**
+
+ - The environment variable is added to enable the system to recognize the conda command
+
+ - Enter the following command to open `~/.bash_profile`:
+
+ - ```shell
+ vim ~/.bash_profile
+ ```
+
+ - In `~/.bash_profile` add conda as an environment variable:
+
+ - ```shell
+ # Press i first to enter editing mode
+ # On the first line, enter:
+ export PATH="~/opt/anaconda3/bin:$PATH"
+ # If the installation location is customized during installation, change ~/opt/anaconda3/bin to the bin folder under the customized installation directory
+ ```
+
+ - ```shell
+ # Modified ~/.bash_profile file should be as follows (where xxx is the user name):
+ export PATH="~/opt/anaconda3/bin:$PATH"
+ # >>> conda initialize >>>
+ # !! Contents within this block are managed by 'conda init' !!
+ __conda_setup="$('/Users/xxx/opt/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
+ if [ $? -eq 0 ]; then
+ eval "$__conda_setup"
+ else
+ if [ -f "/Users/xxx/opt/anaconda3/etc/profile.d/conda.sh" ]; then
+ . "/Users/xxx/opt/anaconda3/etc/profile.d/conda.sh"
+ else
+ export PATH="/Users/xxx/opt/anaconda3/bin:$PATH"
+ fi
+ fi
+ unset __conda_setup
+ # <<< conda initialize <<<
+ ```
+
+ - After modification, press the `esc` key to exit editing mode, and then enter `:wq!` And enter to save the exit
+
+ - Verify that the conda command is recognized:
+
+ - Enter `source ~/.bash_profile` to update environment variables
+ - Then enter `conda info --envs` on the terminal. If the current base environment can be displayed, conda has added an environment variable
+
+- Create a new conda environment
+
+ - ```shell
+ # On the command line, enter the following command to create a file named paddle_env environment
+ # This is for accelerated download, use Tsinghua source
+ conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
+ ```
+
+ - This command will create an executable environment named paddle_env with Python version 3.8. It will take a while depending on the network status
+
+ - Then the command line will output a prompt message, enter y and press Enter to continue the installation
+
+ -  +
+- Activate the newly created conda environment, and enter the following command on the command line:
+
+ - ```shell
+ # Activate paddle_env environment
+ conda activate paddle_env
+ # View the current python location
+ where python
+ ```
+
+ -
+
+- Activate the newly created conda environment, and enter the following command on the command line:
+
+ - ```shell
+ # Activate paddle_env environment
+ conda activate paddle_env
+ # View the current python location
+ where python
+ ```
+
+ -  +
+ - The above anaconda environment and python environment have been installed
+
+## Step 3: Install the libraries required by the program
+
+- Use the pip command to install the pad in the newly activated environment:
+
+ - ```shell
+ # Enter the following command on the command line
+ # Confirm whether the currently used pip is the pip in the paddle_env environment
+ where pip
+ # The CPU version is installed by default. Baidu Source is recommended when installing the PaddlePaddle
+ pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+ ```
+
+- After installing Paddle, continue to install the PaddleHub in the paddle_env environment:
+
+ - ```shell
+ # Enter the following command on the command line
+ pip install paddlehub -i https://mirror.baidu.com/pypi/simple
+ ```
+
+ - Introduction document of paddlehub: https://github.com/PaddlePaddle/PaddleHub/blob/develop/README.md
+
+ - When installing the paddlehub, other dependent libraries will be installed automatically, which may take a while
+
+## Step 4: Install the paddlehub and download the model
+
+- After installing the PaddleHub, download the style migration model:
+
+ - ```shell
+ # Enter the following command on the command line
+ hub install stylepro_artistic==1.0.1
+ ```
+
+ - Description document of the model: [https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value=%7B%22scenes%22%3A%5B%22GANs%22%5D%7D](https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value={"scenes"%3A["GANs"]})
+
+ -
+
+ - The above anaconda environment and python environment have been installed
+
+## Step 3: Install the libraries required by the program
+
+- Use the pip command to install the pad in the newly activated environment:
+
+ - ```shell
+ # Enter the following command on the command line
+ # Confirm whether the currently used pip is the pip in the paddle_env environment
+ where pip
+ # The CPU version is installed by default. Baidu Source is recommended when installing the PaddlePaddle
+ pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+ ```
+
+- After installing Paddle, continue to install the PaddleHub in the paddle_env environment:
+
+ - ```shell
+ # Enter the following command on the command line
+ pip install paddlehub -i https://mirror.baidu.com/pypi/simple
+ ```
+
+ - Introduction document of paddlehub: https://github.com/PaddlePaddle/PaddleHub/blob/develop/README.md
+
+ - When installing the paddlehub, other dependent libraries will be installed automatically, which may take a while
+
+## Step 4: Install the paddlehub and download the model
+
+- After installing the PaddleHub, download the style migration model:
+
+ - ```shell
+ # Enter the following command on the command line
+ hub install stylepro_artistic==1.0.1
+ ```
+
+ - Description document of the model: [https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value=%7B%22scenes%22%3A%5B%22GANs%22%5D%7D](https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value={"scenes"%3A["GANs"]})
+
+ -  +
+## Step 5: Prepare the style to migrate data and code
+
+### Prepare style migration data
+
+- Create Working Directory `style_transfer` on Desktop
+
+ - ```shell
+ # Enter the following command in the terminal:
+ cd ~/Desktop # Enter the desktop
+ mkdir style_transfer # Create style_transfer folder
+ cd style_transfer # Enter style_transfer directory
+ ```
+
+- Place pictures to be converted and style pictures respectively:
+
+ - Place the picture to be converted on the desktop `style_transfer/pic.jpg`
+ -
+
+## Step 5: Prepare the style to migrate data and code
+
+### Prepare style migration data
+
+- Create Working Directory `style_transfer` on Desktop
+
+ - ```shell
+ # Enter the following command in the terminal:
+ cd ~/Desktop # Enter the desktop
+ mkdir style_transfer # Create style_transfer folder
+ cd style_transfer # Enter style_transfer directory
+ ```
+
+- Place pictures to be converted and style pictures respectively:
+
+ - Place the picture to be converted on the desktop `style_transfer/pic.jpg`
+ -  + - Place Style Picture on Desktop `style_transfer/fangao.jpg`
+ -
+ - Place Style Picture on Desktop `style_transfer/fangao.jpg`
+ -  +
+### 代码
+
+- In `style_transfer` create code file `style_transfer.py`
+
+- Copy the following code into `style_transfer.py`
+
+ - ```python
+ import paddlehub as hub
+ import cv2
+
+ # Relative address of the picture to be converted
+ picture = './pic.jpg'
+ # Relative address of style picture
+ style_image = './fangao.jpg'
+
+ # Create a style transfer network and load parameters
+ stylepro_artistic = hub.Module(name="stylepro_artistic")
+
+ # Read in pictures and start style conversion
+ result = stylepro_artistic.style_transfer(
+ images=[{'content': cv2.imread(picture),
+ 'styles': [cv2.imread(style_image)]}],
+ visualization=True
+ )
+ ```
+
+- If there is no code editor such as vscode, you can use the command line method:
+
+ - ```shell
+ pwd # Check whether the current directory is style_transfer, if not, enter: cd ~/Desktop/style_transfer
+ touch style_transfer.py # Create an empty file
+ vim style_transfer.py # Open code file with vim editor
+ # Enter i first to enter editing mode
+ # Copy the above code into the vim editor
+ # Press esc key to exit editing mode, then enter ": wq" and enter Enter to save and exit
+ ```
+
+- Running code:
+
+ - On the command line, enter `python style_transfer.py`
+ - When the program executes, a new folder `transfer_result` will be created, and save the converted file to this directory
+ - The output pictures are as follows:
+ -
+
+### 代码
+
+- In `style_transfer` create code file `style_transfer.py`
+
+- Copy the following code into `style_transfer.py`
+
+ - ```python
+ import paddlehub as hub
+ import cv2
+
+ # Relative address of the picture to be converted
+ picture = './pic.jpg'
+ # Relative address of style picture
+ style_image = './fangao.jpg'
+
+ # Create a style transfer network and load parameters
+ stylepro_artistic = hub.Module(name="stylepro_artistic")
+
+ # Read in pictures and start style conversion
+ result = stylepro_artistic.style_transfer(
+ images=[{'content': cv2.imread(picture),
+ 'styles': [cv2.imread(style_image)]}],
+ visualization=True
+ )
+ ```
+
+- If there is no code editor such as vscode, you can use the command line method:
+
+ - ```shell
+ pwd # Check whether the current directory is style_transfer, if not, enter: cd ~/Desktop/style_transfer
+ touch style_transfer.py # Create an empty file
+ vim style_transfer.py # Open code file with vim editor
+ # Enter i first to enter editing mode
+ # Copy the above code into the vim editor
+ # Press esc key to exit editing mode, then enter ": wq" and enter Enter to save and exit
+ ```
+
+- Running code:
+
+ - On the command line, enter `python style_transfer.py`
+ - When the program executes, a new folder `transfer_result` will be created, and save the converted file to this directory
+ - The output pictures are as follows:
+ -  +
+## Step 6: Explore the pre training model of flying oars
+- Congratulations, the installation and introduction cases of PaddleHub in the Mac environment will be completed here. Start your more in-depth learning model exploration journey quickly.[【More model exploration, jump to the official website of PaddlePaddle】](https://www.paddlepaddle.org.cn/hublist)
+
+
+
+
diff --git a/docs/docs_en/get_start/windows_quickstart.md b/docs/docs_en/get_start/windows_quickstart.md
new file mode 100644
index 000000000..9f05636ec
--- /dev/null
+++ b/docs/docs_en/get_start/windows_quickstart.md
@@ -0,0 +1,151 @@
+# Zero base Windows installation and image style transfer
+
+## Step 1: Install Anaconda
+
+- Note: To use paddlepaddle, you need to install the Python environment first. Here we choose the Python integrated environment Anaconda toolkit
+ - Anaconda is a commonly used python package management program
+ - After installing Anaconda, you can install the python environment and the toolkit environment required by numpy.
+- Anaconda Download:
+ - Link: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
+ - Most win10 computers are 64 bit operating systems, choose x86_64 version; If the computer is a 32-bit operating system, select x86.exe
+ -
+
+## Step 6: Explore the pre training model of flying oars
+- Congratulations, the installation and introduction cases of PaddleHub in the Mac environment will be completed here. Start your more in-depth learning model exploration journey quickly.[【More model exploration, jump to the official website of PaddlePaddle】](https://www.paddlepaddle.org.cn/hublist)
+
+
+
+
diff --git a/docs/docs_en/get_start/windows_quickstart.md b/docs/docs_en/get_start/windows_quickstart.md
new file mode 100644
index 000000000..9f05636ec
--- /dev/null
+++ b/docs/docs_en/get_start/windows_quickstart.md
@@ -0,0 +1,151 @@
+# Zero base Windows installation and image style transfer
+
+## Step 1: Install Anaconda
+
+- Note: To use paddlepaddle, you need to install the Python environment first. Here we choose the Python integrated environment Anaconda toolkit
+ - Anaconda is a commonly used python package management program
+ - After installing Anaconda, you can install the python environment and the toolkit environment required by numpy.
+- Anaconda Download:
+ - Link: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
+ - Most win10 computers are 64 bit operating systems, choose x86_64 version; If the computer is a 32-bit operating system, select x86.exe
+ -  + - After downloading, double click the installer to enter the graphical interface
+ - The default installation location is Disk C, and it is recommended to change the installation location to Disk D:
+ -
+ - After downloading, double click the installer to enter the graphical interface
+ - The default installation location is Disk C, and it is recommended to change the installation location to Disk D:
+ -  + - Check conda to add environment variables, and ignore the warning:
+ -
+ - Check conda to add environment variables, and ignore the warning:
+ -  +
+## Step 2: Open the terminal and create a conda environment
+
+- Open Anaconda Prompt terminal
+ - Windows Start Menu -> Anaconda3 -> Anaconda Prompt
+ -
+
+## Step 2: Open the terminal and create a conda environment
+
+- Open Anaconda Prompt terminal
+ - Windows Start Menu -> Anaconda3 -> Anaconda Prompt
+ -  +
+
+- Create a new conda environment
+
+ - ```shell
+ # On the command line, enter the following command to create a file named paddle_env Env environment
+ # This is for accelerated download, use Tsinghua Source
+ conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # a shell command
+ ```
+
+ - This command will create an executable environment named paddle_env with Python version 3.8. It will take a while depending on the network status
+
+ - Then the command line will output a prompt message, enter y and press Enter to continue the installation
+
+ -
+
+
+- Create a new conda environment
+
+ - ```shell
+ # On the command line, enter the following command to create a file named paddle_env Env environment
+ # This is for accelerated download, use Tsinghua Source
+ conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # a shell command
+ ```
+
+ - This command will create an executable environment named paddle_env with Python version 3.8. It will take a while depending on the network status
+
+ - Then the command line will output a prompt message, enter y and press Enter to continue the installation
+
+ -  +
+- Activate the newly created conda environment, and enter the following command on the command line:
+
+ - ```shell
+ # Activate paddle_env environment
+ conda activate paddle_env
+ # View the current python location
+ where python
+ ```
+
+ -
+
+- Activate the newly created conda environment, and enter the following command on the command line:
+
+ - ```shell
+ # Activate paddle_env environment
+ conda activate paddle_env
+ # View the current python location
+ where python
+ ```
+
+ -  +
+ - The above anaconda environment and python environment have been installed
+
+## Step 3: The required libraries for the installer to run
+
+- Use the pip command to install the PaddlePaddle in the environment you just activated
+
+ - ```shell
+ # Enter the following command on the command line
+ # Confirm whether the currently used pip is a pad_ Pip in env environment
+ where pip
+ # The CPU version is installed by default. Baidu Source is recommended when installing the paddle
+ pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+ ```
+
+ - If you need to install the GPU version, please open the [paddle official website](https://www.paddlepaddle.org.cn/) select the appropriate version.
+
+ - Paddle official website: https://www.paddlepaddle.org.cn/
+ - Since CUDA and cudnn need to be configured before installing the GPU version, it is recommended to install the GPU version after a certain foundation
+
+- After installing the Paddle, continue to install the paddlehub in the paddle_env environment:
+
+ - ```shell
+ # Enter the following command on the command line
+ pip install paddlehub -i https://mirror.baidu.com/pypi/simple
+ ```
+
+ - Introduction document of paddlehub: https://github.com/PaddlePaddle/PaddleHub/blob/develop/README.md
+
+## Step 4: Install the paddlehub and download the model
+
+- After installing the paddlehub, download the style migration model:
+
+ - ```shell
+ # Enter the following command on the command line
+ hub install stylepro_artistic==1.0.1
+ ```
+
+ - Description document of the model: [https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value=%7B%22scenes%22%3A%5B%22GANs%22%5D%7D](https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value={"scenes"%3A["GANs"]})
+
+ -
+
+ - The above anaconda environment and python environment have been installed
+
+## Step 3: The required libraries for the installer to run
+
+- Use the pip command to install the PaddlePaddle in the environment you just activated
+
+ - ```shell
+ # Enter the following command on the command line
+ # Confirm whether the currently used pip is a pad_ Pip in env environment
+ where pip
+ # The CPU version is installed by default. Baidu Source is recommended when installing the paddle
+ pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+ ```
+
+ - If you need to install the GPU version, please open the [paddle official website](https://www.paddlepaddle.org.cn/) select the appropriate version.
+
+ - Paddle official website: https://www.paddlepaddle.org.cn/
+ - Since CUDA and cudnn need to be configured before installing the GPU version, it is recommended to install the GPU version after a certain foundation
+
+- After installing the Paddle, continue to install the paddlehub in the paddle_env environment:
+
+ - ```shell
+ # Enter the following command on the command line
+ pip install paddlehub -i https://mirror.baidu.com/pypi/simple
+ ```
+
+ - Introduction document of paddlehub: https://github.com/PaddlePaddle/PaddleHub/blob/develop/README.md
+
+## Step 4: Install the paddlehub and download the model
+
+- After installing the paddlehub, download the style migration model:
+
+ - ```shell
+ # Enter the following command on the command line
+ hub install stylepro_artistic==1.0.1
+ ```
+
+ - Description document of the model: [https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value=%7B%22scenes%22%3A%5B%22GANs%22%5D%7D](https://www.paddlepaddle.org.cn/hubsearch?filter=en_category&value={"scenes"%3A["GANs"]})
+
+ -  +
+## Step 5: Prepare the style to migrate data and code
+
+### Prepare style migration data
+
+- Switch Working Directory to `D:\style_transfer`, enter the following command on the command line
+
+ - ```shell
+ # Enter the following command on the command line
+ # Switch the current working directory to the root directory of disk D
+ D:
+ # Create style_transfer directory
+ mkdir style_transfer
+ # Switch the current directory to style_transfer directory
+ cd style_transfer
+ ```
+
+- Place pictures to be converted and style pictures respectively
+ - Place the picture to be converted to `D:\style_transfer\pic.jpg`
+ -
+
+## Step 5: Prepare the style to migrate data and code
+
+### Prepare style migration data
+
+- Switch Working Directory to `D:\style_transfer`, enter the following command on the command line
+
+ - ```shell
+ # Enter the following command on the command line
+ # Switch the current working directory to the root directory of disk D
+ D:
+ # Create style_transfer directory
+ mkdir style_transfer
+ # Switch the current directory to style_transfer directory
+ cd style_transfer
+ ```
+
+- Place pictures to be converted and style pictures respectively
+ - Place the picture to be converted to `D:\style_transfer\pic.jpg`
+ -  + - Place Style Picture to `D:\style_transfer\fangao.jpg`
+ -
+ - Place Style Picture to `D:\style_transfer\fangao.jpg`
+ -  +
+### Code
+
+- In `D:\style_transfer` create code file `style_transfer.py`
+
+ - If there is no editor such as vscode, you can use Notepad to create a txt file first, and then change the file name to `style_transfer.py`
+
+- Copy the following code into `style_transfer.py`
+
+ - ```python
+ import paddlehub as hub
+ import cv2
+
+ # The absolute address of the picture to be converted
+ picture = 'D:\\style_transfer\\pic.jpg' # Note that double backslashes are used in the code
+
+ # Absolute address of the style picture
+ style_image = 'D:\\style_transfer\\fangao.jpg'
+
+ # Create a style transfer network and load parameters
+ stylepro_artistic = hub.Module(name="stylepro_artistic")
+
+ # Read in pictures and start style conversion
+ result = stylepro_artistic.style_transfer(
+ images=[{'content': cv2.imread(picture),
+ 'styles': [cv2.imread(style_image)]}],
+ visualization=True
+ )
+ ```
+
+- Running code:
+
+ - On the command line, enter `python style_transfer.py`
+ - When the program executes, a new folder `transfer_result` will be created, and save the converted file to this directory.
+ - The output picture is as follows:
+ -
+
+### Code
+
+- In `D:\style_transfer` create code file `style_transfer.py`
+
+ - If there is no editor such as vscode, you can use Notepad to create a txt file first, and then change the file name to `style_transfer.py`
+
+- Copy the following code into `style_transfer.py`
+
+ - ```python
+ import paddlehub as hub
+ import cv2
+
+ # The absolute address of the picture to be converted
+ picture = 'D:\\style_transfer\\pic.jpg' # Note that double backslashes are used in the code
+
+ # Absolute address of the style picture
+ style_image = 'D:\\style_transfer\\fangao.jpg'
+
+ # Create a style transfer network and load parameters
+ stylepro_artistic = hub.Module(name="stylepro_artistic")
+
+ # Read in pictures and start style conversion
+ result = stylepro_artistic.style_transfer(
+ images=[{'content': cv2.imread(picture),
+ 'styles': [cv2.imread(style_image)]}],
+ visualization=True
+ )
+ ```
+
+- Running code:
+
+ - On the command line, enter `python style_transfer.py`
+ - When the program executes, a new folder `transfer_result` will be created, and save the converted file to this directory.
+ - The output picture is as follows:
+ -  +
+## Step 6: Explore the pre training model of flying oars
+- Congratulations, the installation and introduction cases of PaddleHub in the Windows environment will be completed here. Start your more in-depth learning model exploration journey quickly.[【More model exploration, jump to the official website of PaddlePaddle】](https://www.paddlepaddle.org.cn/hublist)
+
diff --git a/modules/README.md b/modules/README.md
index a6b0d265a..7b3ea3404 100644
--- a/modules/README.md
+++ b/modules/README.md
@@ -222,43 +222,44 @@ English | [简体中文](README_ch.md)
|module|Network|Dataset|Introduction|Huggingface Spaces Demo|
|--|--|--|--|--|
-|[chinese_ocr_db_crnn_mobile](image/text_recognition/chinese_ocr_db_crnn_mobile)|Differentiable Binarization+RCNN|icdar2015数据集|中文文字识别|[](https://huggingface.co/spaces/PaddlePaddle/chinese_ocr_db_crnn_mobile) |[chinese_text_detection_db_mobile](image/text_recognition/chinese_text_detection_db_mobile)|Differentiable Binarization|icdar2015数据集|中文文本检测|
-|[chinese_text_detection_db_server](image/text_recognition/chinese_text_detection_db_server)|Differentiable Binarization|icdar2015数据集|中文文本检测|
-|[chinese_ocr_db_crnn_server](image/text_recognition/chinese_ocr_db_crnn_server)|Differentiable Binarization+RCNN|icdar2015数据集|中文文字识别|[](https://huggingface.co/spaces/PaddlePaddle/chinese_ocr_db_crnn_server) |
-|[Vehicle_License_Plate_Recognition](image/text_recognition/Vehicle_License_Plate_Recognition)|-|CCPD|车牌识别|
-|[chinese_cht_ocr_db_crnn_mobile](image/text_recognition/chinese_cht_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|繁体中文文字识别|
-|[japan_ocr_db_crnn_mobile](image/text_recognition/japan_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|日文文字识别|
-|[korean_ocr_db_crnn_mobile](image/text_recognition/korean_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|韩文文字识别|
-|[german_ocr_db_crnn_mobile](image/text_recognition/german_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|德文文字识别|
-|[french_ocr_db_crnn_mobile](image/text_recognition/french_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|法文文字识别|
-|[latin_ocr_db_crnn_mobile](image/text_recognition/latin_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|拉丁文文字识别|
-|[cyrillic_ocr_db_crnn_mobile](image/text_recognition/cyrillic_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|斯拉夫文文字识别|
-|[multi_languages_ocr_db_crnn](image/text_recognition/multi_languages_ocr_db_crnn)|Differentiable Binarization+RCNN|icdar2015数据集|多语言文字识别|
-|[kannada_ocr_db_crnn_mobile](image/text_recognition/kannada_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|卡纳达文文字识别|
-|[arabic_ocr_db_crnn_mobile](image/text_recognition/arabic_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|阿拉伯文文字识别|
-|[telugu_ocr_db_crnn_mobile](image/text_recognition/telugu_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|泰卢固文文字识别|
-|[devanagari_ocr_db_crnn_mobile](image/text_recognition/devanagari_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|梵文文字识别|
-|[tamil_ocr_db_crnn_mobile](image/text_recognition/tamil_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|泰米尔文文字识别|
+|[chinese_ocr_db_crnn_mobile](image/text_recognition/chinese_ocr_db_crnn_mobile)|Differentiable Binarization+RCNN|icdar2015|Chinese text recognition|[](https://huggingface.co/spaces/PaddlePaddle/chinese_ocr_db_crnn_mobile) |
+|[chinese_text_detection_db_mobile](image/text_recognition/chinese_text_detection_db_mobile)|Differentiable Binarization|icdar2015|Chinese text Detection|
+|[chinese_text_detection_db_server](image/text_recognition/chinese_text_detection_db_server)|Differentiable Binarization|icdar2015|Chinese text Detection|
+|[chinese_ocr_db_crnn_server](image/text_recognition/chinese_ocr_db_crnn_server)|Differentiable Binarization+RCNN|icdar2015|Chinese text recognition|[](https://huggingface.co/spaces/PaddlePaddle/chinese_ocr_db_crnn_server) |
+|[Vehicle_License_Plate_Recognition](image/text_recognition/Vehicle_License_Plate_Recognition)|-|CCPD|Vehicle license plate recognition|
+|[chinese_cht_ocr_db_crnn_mobile](image/text_recognition/chinese_cht_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Traditional Chinese text Detection|
+|[japan_ocr_db_crnn_mobile](image/text_recognition/japan_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Japanese text recognition|
+|[korean_ocr_db_crnn_mobile](image/text_recognition/korean_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Korean text recognition|
+|[german_ocr_db_crnn_mobile](image/text_recognition/german_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|German text recognition|
+|[french_ocr_db_crnn_mobile](image/text_recognition/french_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|French text recognition|
+|[latin_ocr_db_crnn_mobile](image/text_recognition/latin_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Latin text recognition|
+|[cyrillic_ocr_db_crnn_mobile](image/text_recognition/cyrillic_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Cyrillic text recognition|
+|[multi_languages_ocr_db_crnn](image/text_recognition/multi_languages_ocr_db_crnn)|Differentiable Binarization+RCNN|icdar2015|Multi languages text recognition|
+|[kannada_ocr_db_crnn_mobile](image/text_recognition/kannada_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Kannada text recognition|
+|[arabic_ocr_db_crnn_mobile](image/text_recognition/arabic_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Arabic text recognition|
+|[telugu_ocr_db_crnn_mobile](image/text_recognition/telugu_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Telugu text recognition|
+|[devanagari_ocr_db_crnn_mobile](image/text_recognition/devanagari_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Devanagari text recognition|
+|[tamil_ocr_db_crnn_mobile](image/text_recognition/tamil_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Tamil text recognition|
- ### Image Editing
|module|Network|Dataset|Introduction|Huggingface Spaces Demo|
|--|--|--|--|--|
-|[realsr](image/Image_editing/super_resolution/realsr)|LP-KPN|RealSR dataset|图像/视频超分-4倍|
-|[deoldify](image/Image_editing/colorization/deoldify)|GAN|ILSVRC 2012|黑白照片/视频着色|[](https://huggingface.co/spaces/PaddlePaddle/deoldify) |
-|[photo_restoration](image/Image_editing/colorization/photo_restoration)|基于deoldify和realsr模型|-|老照片修复|
-|[user_guided_colorization](image/Image_editing/colorization/user_guided_colorization)|siggraph|ILSVRC 2012|图像着色|
-|[falsr_c](image/Image_editing/super_resolution/falsr_c)|falsr_c| DIV2k|轻量化超分-2倍|
-|[dcscn](image/Image_editing/super_resolution/dcscn)|dcscn| DIV2k|轻量化超分-2倍|
-|[falsr_a](image/Image_editing/super_resolution/falsr_a)|falsr_a| DIV2k|轻量化超分-2倍|
-|[falsr_b](image/Image_editing/super_resolution/falsr_b)|falsr_b|DIV2k|轻量化超分-2倍|
+|[realsr](image/Image_editing/super_resolution/realsr)|LP-KPN|RealSR dataset|Image / Video super-resolution|
+|[deoldify](image/Image_editing/colorization/deoldify)|GAN|ILSVRC 2012|Black-and-white image / video colorization|[](https://huggingface.co/spaces/PaddlePaddle/deoldify) |
+|[photo_restoration](image/Image_editing/colorization/photo_restoration)|deoldify + realsr|-|Old photo restoration|
+|[user_guided_colorization](image/Image_editing/colorization/user_guided_colorization)|siggraph|ILSVRC 2012|User guided colorization|
+|[falsr_c](image/Image_editing/super_resolution/falsr_c)|falsr_c| DIV2k|Lightweight super resolution - 2x|
+|[dcscn](image/Image_editing/super_resolution/dcscn)|dcscn| DIV2k|Lightweight super resolution - 2x|
+|[falsr_a](image/Image_editing/super_resolution/falsr_a)|falsr_a| DIV2k|Lightweight super resolution - 2x|
+|[falsr_b](image/Image_editing/super_resolution/falsr_b)|falsr_b|DIV2k|Lightweight super resolution - 2x|
- ### Instance Segmentation
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[solov2](image/instance_segmentation/solov2)|-|COCO2014|实例分割|
+|[solov2](image/instance_segmentation/solov2)|-|COCO2014|Instance segmentation|
- ### Object Detection
@@ -266,16 +267,16 @@ English | [简体中文](README_ch.md)
|--|--|--|--|
|[faster_rcnn_resnet50_coco2017](image/object_detection/faster_rcnn_resnet50_coco2017)|faster_rcnn|COCO2017||
|[ssd_vgg16_512_coco2017](image/object_detection/ssd_vgg16_512_coco2017)|SSD|COCO2017||
-|[faster_rcnn_resnet50_fpn_venus](image/object_detection/faster_rcnn_resnet50_fpn_venus)|faster_rcnn|百度自建数据集|大规模通用目标检测|
+|[faster_rcnn_resnet50_fpn_venus](image/object_detection/faster_rcnn_resnet50_fpn_venus)|faster_rcnn|Baidu self built dataset|Large-scale general detection|
|[ssd_vgg16_300_coco2017](image/object_detection/ssd_vgg16_300_coco2017)||||
|[yolov3_resnet34_coco2017](image/object_detection/yolov3_resnet34_coco2017)|YOLOv3|COCO2017||
-|[yolov3_darknet53_pedestrian](image/object_detection/yolov3_darknet53_pedestrian)|YOLOv3|百度自建大规模行人数据集|行人检测|
+|[yolov3_darknet53_pedestrian](image/object_detection/yolov3_darknet53_pedestrian)|YOLOv3|Baidu Self built large-scale pedestrian dataset|Pedestrian Detection|
|[yolov3_mobilenet_v1_coco2017](image/object_detection/yolov3_mobilenet_v1_coco2017)|YOLOv3|COCO2017||
|[ssd_mobilenet_v1_pascal](image/object_detection/ssd_mobilenet_v1_pascal)|SSD|PASCAL VOC||
|[faster_rcnn_resnet50_fpn_coco2017](image/object_detection/faster_rcnn_resnet50_fpn_coco2017)|faster_rcnn|COCO2017||
|[yolov3_darknet53_coco2017](image/object_detection/yolov3_darknet53_coco2017)|YOLOv3|COCO2017||
-|[yolov3_darknet53_vehicles](image/object_detection/yolov3_darknet53_vehicles)|YOLOv3|百度自建大规模车辆数据集|车辆检测|
-|[yolov3_darknet53_venus](image/object_detection/yolov3_darknet53_venus)|YOLOv3|百度自建数据集|大规模通用检测|
+|[yolov3_darknet53_vehicles](image/object_detection/yolov3_darknet53_vehicles)|YOLOv3|Baidu Self built large-scale vehicles dataset|vehicles Detection|
+|[yolov3_darknet53_venus](image/object_detection/yolov3_darknet53_venus)|YOLOv3|Baidu self built datasetset|Large-scale general detection|
|[yolov3_resnet50_vd_coco2017](image/object_detection/yolov3_resnet50_vd_coco2017)|YOLOv3|COCO2017||
- ### Depth Estimation
@@ -290,22 +291,22 @@ English | [简体中文](README_ch.md)
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[ernie_gen](text/text_generation/ernie_gen)|ERNIE-GEN|-|面向生成任务的预训练-微调框架|
-|[ernie_gen_poetry](text/text_generation/ernie_gen_poetry)|ERNIE-GEN|开源诗歌数据集|诗歌生成|
-|[ernie_gen_couplet](text/text_generation/ernie_gen_couplet)|ERNIE-GEN|开源对联数据集|对联生成|
-|[ernie_gen_lover_words](text/text_generation/ernie_gen_lover_words)|ERNIE-GEN|网络情诗、情话数据|情话生成|
-|[ernie_tiny_couplet](text/text_generation/ernie_tiny_couplet)|Eernie_tiny|开源对联数据集|对联生成|
-|[ernie_gen_acrostic_poetry](text/text_generation/ernie_gen_acrostic_poetry)|ERNIE-GEN|开源诗歌数据集|藏头诗生成|
-|[Rumor_prediction](text/text_generation/Rumor_prediction)|-|新浪微博中文谣言数据|谣言预测|
-|[plato-mini](text/text_generation/plato-mini)|Unified Transformer|十亿级别的中文对话数据|中文对话|
-|[plato2_en_large](text/text_generation/plato2_en_large)|plato2|开放域多轮数据集|超大规模生成式对话|
-|[plato2_en_base](text/text_generation/plato2_en_base)|plato2|开放域多轮数据集|超大规模生成式对话|
-|[CPM_LM](text/text_generation/CPM_LM)|GPT-2|自建数据集|中文文本生成|
-|[unified_transformer-12L-cn](text/text_generation/unified_transformer-12L-cn)|Unified Transformer|千万级别中文会话数据|人机多轮对话|
-|[unified_transformer-12L-cn-luge](text/text_generation/unified_transformer-12L-cn-luge)|Unified Transformer|千言对话数据集|人机多轮对话|
-|[reading_pictures_writing_poems](text/text_generation/reading_pictures_writing_poems)|多网络级联|-|看图写诗|
-|[GPT2_CPM_LM](text/text_generation/GPT2_CPM_LM)|||问答类文本生成|
-|[GPT2_Base_CN](text/text_generation/GPT2_Base_CN)|||问答类文本生成|
+|[ernie_gen](text/text_generation/ernie_gen)|ERNIE-GEN|-|Pre-training finetuning framework for generating tasks|
+|[ernie_gen_poetry](text/text_generation/ernie_gen_poetry)|ERNIE-GEN|Open source poetry dataset|Poetry generation|
+|[ernie_gen_couplet](text/text_generation/ernie_gen_couplet)|ERNIE-GEN|Open source couplet dataset|Couplet generation|
+|[ernie_gen_lover_words](text/text_generation/ernie_gen_lover_words)|ERNIE-GEN|Online love poems and love talk data|Love word generation|
+|[ernie_tiny_couplet](text/text_generation/ernie_tiny_couplet)|Eernie_tiny|Open source couplet dataset|Couplet generation|
+|[ernie_gen_acrostic_poetry](text/text_generation/ernie_gen_acrostic_poetry)|ERNIE-GEN|Open source poetry dataset|Acrostic poetry Generation|
+|[Rumor_prediction](text/text_generation/Rumor_prediction)|-|Sina Weibo Chinese rumor data|Rumor prediction|
+|[plato-mini](text/text_generation/plato-mini)|Unified Transformer|Billion level Chinese conversation data|Chinese dialogue|
+|[plato2_en_large](text/text_generation/plato2_en_large)|plato2|Open domain multi round dataset|Super large scale generative dialogue|
+|[plato2_en_base](text/text_generation/plato2_en_base)|plato2|Open domain multi round dataset|Super large scale generative dialogue|
+|[CPM_LM](text/text_generation/CPM_LM)|GPT-2|Self built dataset|Chinese text generation|
+|[unified_transformer-12L-cn](text/text_generation/unified_transformer-12L-cn)|Unified Transformer|Ten million level Chinese conversation data|Man machine multi round dialogue|
+|[unified_transformer-12L-cn-luge](text/text_generation/unified_transformer-12L-cn-luge)|Unified Transformer|dialogue dataset|Man machine multi round dialogue|
+|[reading_pictures_writing_poems](text/text_generation/reading_pictures_writing_poems)|Multi network cascade|-|Look at pictures and write poems|
+|[GPT2_CPM_LM](text/text_generation/GPT2_CPM_LM)|||Q&A text generation|
+|[GPT2_Base_CN](text/text_generation/GPT2_Base_CN)|||Q&A text generation|
- ### Word Embedding
@@ -316,7 +317,7 @@ English | [简体中文](README_ch.md)
|[w2v_weibo_target_word-bigram_dim300](text/embedding/w2v_weibo_target_word-bigram_dim300)|w2v|weibo||
|[w2v_baidu_encyclopedia_target_word-ngram_1-2_dim300](text/embedding/w2v_baidu_encyclopedia_target_word-ngram_1-2_dim300)|w2v|baidu_encyclopedia||
|[w2v_literature_target_word-word_dim300](text/embedding/w2v_literature_target_word-word_dim300)|w2v|literature||
-|[word2vec_skipgram](text/embedding/word2vec_skipgram)|skip-gram|百度自建数据集||
+|[word2vec_skipgram](text/embedding/word2vec_skipgram)|skip-gram|Baidu self built dataset||
|[w2v_sogou_target_word-char_dim300](text/embedding/w2v_sogou_target_word-char_dim300)|w2v|sogou||
|[w2v_weibo_target_bigram-char_dim300](text/embedding/w2v_weibo_target_bigram-char_dim300)|w2v|weibo||
|[w2v_zhihu_target_word-bigram_dim300](text/embedding/w2v_zhihu_target_word-bigram_dim300)|w2v|zhihu||
@@ -393,16 +394,16 @@ English | [简体中文](README_ch.md)
|--|--|--|--|
|[chinese_electra_small](text/language_model/chinese_electra_small)||||
|[chinese_electra_base](text/language_model/chinese_electra_base)||||
-|[roberta-wwm-ext-large](text/language_model/roberta-wwm-ext-large)|roberta-wwm-ext-large|百度自建数据集||
-|[chinese-bert-wwm-ext](text/language_model/chinese_bert_wwm_ext)|chinese-bert-wwm-ext|百度自建数据集||
-|[lda_webpage](text/language_model/lda_webpage)|LDA|百度自建网页领域数据集||
+|[roberta-wwm-ext-large](text/language_model/roberta-wwm-ext-large)|roberta-wwm-ext-large|Baidu self built dataset||
+|[chinese-bert-wwm-ext](text/language_model/chinese_bert_wwm_ext)|chinese-bert-wwm-ext|Baidu self built dataset||
+|[lda_webpage](text/language_model/lda_webpage)|LDA|Baidu Self built Web Page Domain Dataset||
|[lda_novel](text/language_model/lda_novel)||||
|[bert-base-multilingual-uncased](text/language_model/bert-base-multilingual-uncased)||||
|[rbt3](text/language_model/rbt3)||||
-|[ernie_v2_eng_base](text/language_model/ernie_v2_eng_base)|ernie_v2_eng_base|百度自建数据集||
+|[ernie_v2_eng_base](text/language_model/ernie_v2_eng_base)|ernie_v2_eng_base|Baidu self built dataset||
|[bert-base-multilingual-cased](text/language_model/bert-base-multilingual-cased)||||
|[rbtl3](text/language_model/rbtl3)||||
-|[chinese-bert-wwm](text/language_model/chinese_bert_wwm)|chinese-bert-wwm|百度自建数据集||
+|[chinese-bert-wwm](text/language_model/chinese_bert_wwm)|chinese-bert-wwm|Baidu self built dataset||
|[bert-large-uncased](text/language_model/bert-large-uncased)||||
|[slda_novel](text/language_model/slda_novel)||||
|[slda_news](text/language_model/slda_news)||||
@@ -410,16 +411,16 @@ English | [简体中文](README_ch.md)
|[slda_webpage](text/language_model/slda_webpage)||||
|[bert-base-cased](text/language_model/bert-base-cased)||||
|[slda_weibo](text/language_model/slda_weibo)||||
-|[roberta-wwm-ext](text/language_model/roberta-wwm-ext)|roberta-wwm-ext|百度自建数据集||
+|[roberta-wwm-ext](text/language_model/roberta-wwm-ext)|roberta-wwm-ext|Baidu self built dataset||
|[bert-base-uncased](text/language_model/bert-base-uncased)||||
|[electra_large](text/language_model/electra_large)||||
-|[ernie](text/language_model/ernie)|ernie-1.0|百度自建数据集||
-|[simnet_bow](text/language_model/simnet_bow)|BOW|百度自建数据集||
-|[ernie_tiny](text/language_model/ernie_tiny)|ernie_tiny|百度自建数据集||
-|[bert-base-chinese](text/language_model/bert-base-chinese)|bert-base-chinese|百度自建数据集||
-|[lda_news](text/language_model/lda_news)|LDA|百度自建新闻领域数据集||
+|[ernie](text/language_model/ernie)|ernie-1.0|Baidu self built dataset||
+|[simnet_bow](text/language_model/simnet_bow)|BOW|Baidu self built dataset||
+|[ernie_tiny](text/language_model/ernie_tiny)|ernie_tiny|Baidu self built dataset||
+|[bert-base-chinese](text/language_model/bert-base-chinese)|bert-base-chinese|Baidu self built dataset||
+|[lda_news](text/language_model/lda_news)|LDA|Baidu Self built News Field Dataset||
|[electra_base](text/language_model/electra_base)||||
-|[ernie_v2_eng_large](text/language_model/ernie_v2_eng_large)|ernie_v2_eng_large|百度自建数据集||
+|[ernie_v2_eng_large](text/language_model/ernie_v2_eng_large)|ernie_v2_eng_large|Baidu self built dataset||
|[bert-large-cased](text/language_model/bert-large-cased)||||
+
+
+## Step 6: Explore the pre training model of flying oars
+- Congratulations, the installation and introduction cases of PaddleHub in the Windows environment will be completed here. Start your more in-depth learning model exploration journey quickly.[【More model exploration, jump to the official website of PaddlePaddle】](https://www.paddlepaddle.org.cn/hublist)
+
diff --git a/modules/README.md b/modules/README.md
index a6b0d265a..7b3ea3404 100644
--- a/modules/README.md
+++ b/modules/README.md
@@ -222,43 +222,44 @@ English | [简体中文](README_ch.md)
|module|Network|Dataset|Introduction|Huggingface Spaces Demo|
|--|--|--|--|--|
-|[chinese_ocr_db_crnn_mobile](image/text_recognition/chinese_ocr_db_crnn_mobile)|Differentiable Binarization+RCNN|icdar2015数据集|中文文字识别|[](https://huggingface.co/spaces/PaddlePaddle/chinese_ocr_db_crnn_mobile) |[chinese_text_detection_db_mobile](image/text_recognition/chinese_text_detection_db_mobile)|Differentiable Binarization|icdar2015数据集|中文文本检测|
-|[chinese_text_detection_db_server](image/text_recognition/chinese_text_detection_db_server)|Differentiable Binarization|icdar2015数据集|中文文本检测|
-|[chinese_ocr_db_crnn_server](image/text_recognition/chinese_ocr_db_crnn_server)|Differentiable Binarization+RCNN|icdar2015数据集|中文文字识别|[](https://huggingface.co/spaces/PaddlePaddle/chinese_ocr_db_crnn_server) |
-|[Vehicle_License_Plate_Recognition](image/text_recognition/Vehicle_License_Plate_Recognition)|-|CCPD|车牌识别|
-|[chinese_cht_ocr_db_crnn_mobile](image/text_recognition/chinese_cht_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|繁体中文文字识别|
-|[japan_ocr_db_crnn_mobile](image/text_recognition/japan_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|日文文字识别|
-|[korean_ocr_db_crnn_mobile](image/text_recognition/korean_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|韩文文字识别|
-|[german_ocr_db_crnn_mobile](image/text_recognition/german_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|德文文字识别|
-|[french_ocr_db_crnn_mobile](image/text_recognition/french_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|法文文字识别|
-|[latin_ocr_db_crnn_mobile](image/text_recognition/latin_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|拉丁文文字识别|
-|[cyrillic_ocr_db_crnn_mobile](image/text_recognition/cyrillic_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|斯拉夫文文字识别|
-|[multi_languages_ocr_db_crnn](image/text_recognition/multi_languages_ocr_db_crnn)|Differentiable Binarization+RCNN|icdar2015数据集|多语言文字识别|
-|[kannada_ocr_db_crnn_mobile](image/text_recognition/kannada_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|卡纳达文文字识别|
-|[arabic_ocr_db_crnn_mobile](image/text_recognition/arabic_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|阿拉伯文文字识别|
-|[telugu_ocr_db_crnn_mobile](image/text_recognition/telugu_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|泰卢固文文字识别|
-|[devanagari_ocr_db_crnn_mobile](image/text_recognition/devanagari_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|梵文文字识别|
-|[tamil_ocr_db_crnn_mobile](image/text_recognition/tamil_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015数据集|泰米尔文文字识别|
+|[chinese_ocr_db_crnn_mobile](image/text_recognition/chinese_ocr_db_crnn_mobile)|Differentiable Binarization+RCNN|icdar2015|Chinese text recognition|[](https://huggingface.co/spaces/PaddlePaddle/chinese_ocr_db_crnn_mobile) |
+|[chinese_text_detection_db_mobile](image/text_recognition/chinese_text_detection_db_mobile)|Differentiable Binarization|icdar2015|Chinese text Detection|
+|[chinese_text_detection_db_server](image/text_recognition/chinese_text_detection_db_server)|Differentiable Binarization|icdar2015|Chinese text Detection|
+|[chinese_ocr_db_crnn_server](image/text_recognition/chinese_ocr_db_crnn_server)|Differentiable Binarization+RCNN|icdar2015|Chinese text recognition|[](https://huggingface.co/spaces/PaddlePaddle/chinese_ocr_db_crnn_server) |
+|[Vehicle_License_Plate_Recognition](image/text_recognition/Vehicle_License_Plate_Recognition)|-|CCPD|Vehicle license plate recognition|
+|[chinese_cht_ocr_db_crnn_mobile](image/text_recognition/chinese_cht_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Traditional Chinese text Detection|
+|[japan_ocr_db_crnn_mobile](image/text_recognition/japan_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Japanese text recognition|
+|[korean_ocr_db_crnn_mobile](image/text_recognition/korean_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Korean text recognition|
+|[german_ocr_db_crnn_mobile](image/text_recognition/german_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|German text recognition|
+|[french_ocr_db_crnn_mobile](image/text_recognition/french_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|French text recognition|
+|[latin_ocr_db_crnn_mobile](image/text_recognition/latin_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Latin text recognition|
+|[cyrillic_ocr_db_crnn_mobile](image/text_recognition/cyrillic_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Cyrillic text recognition|
+|[multi_languages_ocr_db_crnn](image/text_recognition/multi_languages_ocr_db_crnn)|Differentiable Binarization+RCNN|icdar2015|Multi languages text recognition|
+|[kannada_ocr_db_crnn_mobile](image/text_recognition/kannada_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Kannada text recognition|
+|[arabic_ocr_db_crnn_mobile](image/text_recognition/arabic_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Arabic text recognition|
+|[telugu_ocr_db_crnn_mobile](image/text_recognition/telugu_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Telugu text recognition|
+|[devanagari_ocr_db_crnn_mobile](image/text_recognition/devanagari_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Devanagari text recognition|
+|[tamil_ocr_db_crnn_mobile](image/text_recognition/tamil_ocr_db_crnn_mobile)|Differentiable Binarization+CRNN|icdar2015|Tamil text recognition|
- ### Image Editing
|module|Network|Dataset|Introduction|Huggingface Spaces Demo|
|--|--|--|--|--|
-|[realsr](image/Image_editing/super_resolution/realsr)|LP-KPN|RealSR dataset|图像/视频超分-4倍|
-|[deoldify](image/Image_editing/colorization/deoldify)|GAN|ILSVRC 2012|黑白照片/视频着色|[](https://huggingface.co/spaces/PaddlePaddle/deoldify) |
-|[photo_restoration](image/Image_editing/colorization/photo_restoration)|基于deoldify和realsr模型|-|老照片修复|
-|[user_guided_colorization](image/Image_editing/colorization/user_guided_colorization)|siggraph|ILSVRC 2012|图像着色|
-|[falsr_c](image/Image_editing/super_resolution/falsr_c)|falsr_c| DIV2k|轻量化超分-2倍|
-|[dcscn](image/Image_editing/super_resolution/dcscn)|dcscn| DIV2k|轻量化超分-2倍|
-|[falsr_a](image/Image_editing/super_resolution/falsr_a)|falsr_a| DIV2k|轻量化超分-2倍|
-|[falsr_b](image/Image_editing/super_resolution/falsr_b)|falsr_b|DIV2k|轻量化超分-2倍|
+|[realsr](image/Image_editing/super_resolution/realsr)|LP-KPN|RealSR dataset|Image / Video super-resolution|
+|[deoldify](image/Image_editing/colorization/deoldify)|GAN|ILSVRC 2012|Black-and-white image / video colorization|[](https://huggingface.co/spaces/PaddlePaddle/deoldify) |
+|[photo_restoration](image/Image_editing/colorization/photo_restoration)|deoldify + realsr|-|Old photo restoration|
+|[user_guided_colorization](image/Image_editing/colorization/user_guided_colorization)|siggraph|ILSVRC 2012|User guided colorization|
+|[falsr_c](image/Image_editing/super_resolution/falsr_c)|falsr_c| DIV2k|Lightweight super resolution - 2x|
+|[dcscn](image/Image_editing/super_resolution/dcscn)|dcscn| DIV2k|Lightweight super resolution - 2x|
+|[falsr_a](image/Image_editing/super_resolution/falsr_a)|falsr_a| DIV2k|Lightweight super resolution - 2x|
+|[falsr_b](image/Image_editing/super_resolution/falsr_b)|falsr_b|DIV2k|Lightweight super resolution - 2x|
- ### Instance Segmentation
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[solov2](image/instance_segmentation/solov2)|-|COCO2014|实例分割|
+|[solov2](image/instance_segmentation/solov2)|-|COCO2014|Instance segmentation|
- ### Object Detection
@@ -266,16 +267,16 @@ English | [简体中文](README_ch.md)
|--|--|--|--|
|[faster_rcnn_resnet50_coco2017](image/object_detection/faster_rcnn_resnet50_coco2017)|faster_rcnn|COCO2017||
|[ssd_vgg16_512_coco2017](image/object_detection/ssd_vgg16_512_coco2017)|SSD|COCO2017||
-|[faster_rcnn_resnet50_fpn_venus](image/object_detection/faster_rcnn_resnet50_fpn_venus)|faster_rcnn|百度自建数据集|大规模通用目标检测|
+|[faster_rcnn_resnet50_fpn_venus](image/object_detection/faster_rcnn_resnet50_fpn_venus)|faster_rcnn|Baidu self built dataset|Large-scale general detection|
|[ssd_vgg16_300_coco2017](image/object_detection/ssd_vgg16_300_coco2017)||||
|[yolov3_resnet34_coco2017](image/object_detection/yolov3_resnet34_coco2017)|YOLOv3|COCO2017||
-|[yolov3_darknet53_pedestrian](image/object_detection/yolov3_darknet53_pedestrian)|YOLOv3|百度自建大规模行人数据集|行人检测|
+|[yolov3_darknet53_pedestrian](image/object_detection/yolov3_darknet53_pedestrian)|YOLOv3|Baidu Self built large-scale pedestrian dataset|Pedestrian Detection|
|[yolov3_mobilenet_v1_coco2017](image/object_detection/yolov3_mobilenet_v1_coco2017)|YOLOv3|COCO2017||
|[ssd_mobilenet_v1_pascal](image/object_detection/ssd_mobilenet_v1_pascal)|SSD|PASCAL VOC||
|[faster_rcnn_resnet50_fpn_coco2017](image/object_detection/faster_rcnn_resnet50_fpn_coco2017)|faster_rcnn|COCO2017||
|[yolov3_darknet53_coco2017](image/object_detection/yolov3_darknet53_coco2017)|YOLOv3|COCO2017||
-|[yolov3_darknet53_vehicles](image/object_detection/yolov3_darknet53_vehicles)|YOLOv3|百度自建大规模车辆数据集|车辆检测|
-|[yolov3_darknet53_venus](image/object_detection/yolov3_darknet53_venus)|YOLOv3|百度自建数据集|大规模通用检测|
+|[yolov3_darknet53_vehicles](image/object_detection/yolov3_darknet53_vehicles)|YOLOv3|Baidu Self built large-scale vehicles dataset|vehicles Detection|
+|[yolov3_darknet53_venus](image/object_detection/yolov3_darknet53_venus)|YOLOv3|Baidu self built datasetset|Large-scale general detection|
|[yolov3_resnet50_vd_coco2017](image/object_detection/yolov3_resnet50_vd_coco2017)|YOLOv3|COCO2017||
- ### Depth Estimation
@@ -290,22 +291,22 @@ English | [简体中文](README_ch.md)
|module|Network|Dataset|Introduction|
|--|--|--|--|
-|[ernie_gen](text/text_generation/ernie_gen)|ERNIE-GEN|-|面向生成任务的预训练-微调框架|
-|[ernie_gen_poetry](text/text_generation/ernie_gen_poetry)|ERNIE-GEN|开源诗歌数据集|诗歌生成|
-|[ernie_gen_couplet](text/text_generation/ernie_gen_couplet)|ERNIE-GEN|开源对联数据集|对联生成|
-|[ernie_gen_lover_words](text/text_generation/ernie_gen_lover_words)|ERNIE-GEN|网络情诗、情话数据|情话生成|
-|[ernie_tiny_couplet](text/text_generation/ernie_tiny_couplet)|Eernie_tiny|开源对联数据集|对联生成|
-|[ernie_gen_acrostic_poetry](text/text_generation/ernie_gen_acrostic_poetry)|ERNIE-GEN|开源诗歌数据集|藏头诗生成|
-|[Rumor_prediction](text/text_generation/Rumor_prediction)|-|新浪微博中文谣言数据|谣言预测|
-|[plato-mini](text/text_generation/plato-mini)|Unified Transformer|十亿级别的中文对话数据|中文对话|
-|[plato2_en_large](text/text_generation/plato2_en_large)|plato2|开放域多轮数据集|超大规模生成式对话|
-|[plato2_en_base](text/text_generation/plato2_en_base)|plato2|开放域多轮数据集|超大规模生成式对话|
-|[CPM_LM](text/text_generation/CPM_LM)|GPT-2|自建数据集|中文文本生成|
-|[unified_transformer-12L-cn](text/text_generation/unified_transformer-12L-cn)|Unified Transformer|千万级别中文会话数据|人机多轮对话|
-|[unified_transformer-12L-cn-luge](text/text_generation/unified_transformer-12L-cn-luge)|Unified Transformer|千言对话数据集|人机多轮对话|
-|[reading_pictures_writing_poems](text/text_generation/reading_pictures_writing_poems)|多网络级联|-|看图写诗|
-|[GPT2_CPM_LM](text/text_generation/GPT2_CPM_LM)|||问答类文本生成|
-|[GPT2_Base_CN](text/text_generation/GPT2_Base_CN)|||问答类文本生成|
+|[ernie_gen](text/text_generation/ernie_gen)|ERNIE-GEN|-|Pre-training finetuning framework for generating tasks|
+|[ernie_gen_poetry](text/text_generation/ernie_gen_poetry)|ERNIE-GEN|Open source poetry dataset|Poetry generation|
+|[ernie_gen_couplet](text/text_generation/ernie_gen_couplet)|ERNIE-GEN|Open source couplet dataset|Couplet generation|
+|[ernie_gen_lover_words](text/text_generation/ernie_gen_lover_words)|ERNIE-GEN|Online love poems and love talk data|Love word generation|
+|[ernie_tiny_couplet](text/text_generation/ernie_tiny_couplet)|Eernie_tiny|Open source couplet dataset|Couplet generation|
+|[ernie_gen_acrostic_poetry](text/text_generation/ernie_gen_acrostic_poetry)|ERNIE-GEN|Open source poetry dataset|Acrostic poetry Generation|
+|[Rumor_prediction](text/text_generation/Rumor_prediction)|-|Sina Weibo Chinese rumor data|Rumor prediction|
+|[plato-mini](text/text_generation/plato-mini)|Unified Transformer|Billion level Chinese conversation data|Chinese dialogue|
+|[plato2_en_large](text/text_generation/plato2_en_large)|plato2|Open domain multi round dataset|Super large scale generative dialogue|
+|[plato2_en_base](text/text_generation/plato2_en_base)|plato2|Open domain multi round dataset|Super large scale generative dialogue|
+|[CPM_LM](text/text_generation/CPM_LM)|GPT-2|Self built dataset|Chinese text generation|
+|[unified_transformer-12L-cn](text/text_generation/unified_transformer-12L-cn)|Unified Transformer|Ten million level Chinese conversation data|Man machine multi round dialogue|
+|[unified_transformer-12L-cn-luge](text/text_generation/unified_transformer-12L-cn-luge)|Unified Transformer|dialogue dataset|Man machine multi round dialogue|
+|[reading_pictures_writing_poems](text/text_generation/reading_pictures_writing_poems)|Multi network cascade|-|Look at pictures and write poems|
+|[GPT2_CPM_LM](text/text_generation/GPT2_CPM_LM)|||Q&A text generation|
+|[GPT2_Base_CN](text/text_generation/GPT2_Base_CN)|||Q&A text generation|
- ### Word Embedding
@@ -316,7 +317,7 @@ English | [简体中文](README_ch.md)
|[w2v_weibo_target_word-bigram_dim300](text/embedding/w2v_weibo_target_word-bigram_dim300)|w2v|weibo||
|[w2v_baidu_encyclopedia_target_word-ngram_1-2_dim300](text/embedding/w2v_baidu_encyclopedia_target_word-ngram_1-2_dim300)|w2v|baidu_encyclopedia||
|[w2v_literature_target_word-word_dim300](text/embedding/w2v_literature_target_word-word_dim300)|w2v|literature||
-|[word2vec_skipgram](text/embedding/word2vec_skipgram)|skip-gram|百度自建数据集||
+|[word2vec_skipgram](text/embedding/word2vec_skipgram)|skip-gram|Baidu self built dataset||
|[w2v_sogou_target_word-char_dim300](text/embedding/w2v_sogou_target_word-char_dim300)|w2v|sogou||
|[w2v_weibo_target_bigram-char_dim300](text/embedding/w2v_weibo_target_bigram-char_dim300)|w2v|weibo||
|[w2v_zhihu_target_word-bigram_dim300](text/embedding/w2v_zhihu_target_word-bigram_dim300)|w2v|zhihu||
@@ -393,16 +394,16 @@ English | [简体中文](README_ch.md)
|--|--|--|--|
|[chinese_electra_small](text/language_model/chinese_electra_small)||||
|[chinese_electra_base](text/language_model/chinese_electra_base)||||
-|[roberta-wwm-ext-large](text/language_model/roberta-wwm-ext-large)|roberta-wwm-ext-large|百度自建数据集||
-|[chinese-bert-wwm-ext](text/language_model/chinese_bert_wwm_ext)|chinese-bert-wwm-ext|百度自建数据集||
-|[lda_webpage](text/language_model/lda_webpage)|LDA|百度自建网页领域数据集||
+|[roberta-wwm-ext-large](text/language_model/roberta-wwm-ext-large)|roberta-wwm-ext-large|Baidu self built dataset||
+|[chinese-bert-wwm-ext](text/language_model/chinese_bert_wwm_ext)|chinese-bert-wwm-ext|Baidu self built dataset||
+|[lda_webpage](text/language_model/lda_webpage)|LDA|Baidu Self built Web Page Domain Dataset||
|[lda_novel](text/language_model/lda_novel)||||
|[bert-base-multilingual-uncased](text/language_model/bert-base-multilingual-uncased)||||
|[rbt3](text/language_model/rbt3)||||
-|[ernie_v2_eng_base](text/language_model/ernie_v2_eng_base)|ernie_v2_eng_base|百度自建数据集||
+|[ernie_v2_eng_base](text/language_model/ernie_v2_eng_base)|ernie_v2_eng_base|Baidu self built dataset||
|[bert-base-multilingual-cased](text/language_model/bert-base-multilingual-cased)||||
|[rbtl3](text/language_model/rbtl3)||||
-|[chinese-bert-wwm](text/language_model/chinese_bert_wwm)|chinese-bert-wwm|百度自建数据集||
+|[chinese-bert-wwm](text/language_model/chinese_bert_wwm)|chinese-bert-wwm|Baidu self built dataset||
|[bert-large-uncased](text/language_model/bert-large-uncased)||||
|[slda_novel](text/language_model/slda_novel)||||
|[slda_news](text/language_model/slda_news)||||
@@ -410,16 +411,16 @@ English | [简体中文](README_ch.md)
|[slda_webpage](text/language_model/slda_webpage)||||
|[bert-base-cased](text/language_model/bert-base-cased)||||
|[slda_weibo](text/language_model/slda_weibo)||||
-|[roberta-wwm-ext](text/language_model/roberta-wwm-ext)|roberta-wwm-ext|百度自建数据集||
+|[roberta-wwm-ext](text/language_model/roberta-wwm-ext)|roberta-wwm-ext|Baidu self built dataset||
|[bert-base-uncased](text/language_model/bert-base-uncased)||||
|[electra_large](text/language_model/electra_large)||||
-|[ernie](text/language_model/ernie)|ernie-1.0|百度自建数据集||
-|[simnet_bow](text/language_model/simnet_bow)|BOW|百度自建数据集||
-|[ernie_tiny](text/language_model/ernie_tiny)|ernie_tiny|百度自建数据集||
-|[bert-base-chinese](text/language_model/bert-base-chinese)|bert-base-chinese|百度自建数据集||
-|[lda_news](text/language_model/lda_news)|LDA|百度自建新闻领域数据集||
+|[ernie](text/language_model/ernie)|ernie-1.0|Baidu self built dataset||
+|[simnet_bow](text/language_model/simnet_bow)|BOW|Baidu self built dataset||
+|[ernie_tiny](text/language_model/ernie_tiny)|ernie_tiny|Baidu self built dataset||
+|[bert-base-chinese](text/language_model/bert-base-chinese)|bert-base-chinese|Baidu self built dataset||
+|[lda_news](text/language_model/lda_news)|LDA|Baidu Self built News Field Dataset||
|[electra_base](text/language_model/electra_base)||||
-|[ernie_v2_eng_large](text/language_model/ernie_v2_eng_large)|ernie_v2_eng_large|百度自建数据集||
+|[ernie_v2_eng_large](text/language_model/ernie_v2_eng_large)|ernie_v2_eng_large|Baidu self built dataset||
|[bert-large-cased](text/language_model/bert-large-cased)||||
+
+
+ - Generating process
+
+
+
+### Module Introduction
+
+disco_diffusion_clip_rn101 is a text-to-image generation model that can generate images that match the semantics of the sentence you prompt. The model consists of two parts, one is the diffusion model, which is a generative model that reconstructs the original image from the noisy input. The other part is the multimodal pre-training model (CLIP), which can represent text and images in the same feature space, and text and images with similar semantics will be closer in this feature space. In the text image generation model, the diffusion model is responsible for generating the target image from the initial noise or the specified initial image, and CLIP is responsible for guiding the generated image to be as close as possible to the semantics of the input text. Diffusion model under the guidance of CLIP iteratively generates new images, eventually generating images of what the text describes. The CLIP model used in this module is ResNet101.
+
+For more details, please refer to [Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233) and [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
+
+## II.Installation
+
+- ### 1.Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [How to install PaddleHub](../../../../docs/docs_en/get_start/installation.rst)
+
+- ### 2.Installation
+
+ - ```shell
+ $ hub install disco_diffusion_clip_rn101
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_en/get_start/windows_quickstart.md) | [Linux_Quickstart](../../../../docs/docs_en/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_en/get_start/mac_quickstart.md)
+
+
+## III.Module API Prediction
+
+- ### 1.Command line Prediction
+
+ - ```shell
+ $ hub run disco_diffusion_clip_rn101 --text_prompts "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation." --output_dir disco_diffusion_clip_rn101_out
+ ```
+
+- ### 2.Prediction Code Example
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_clip_rn101")
+ text_prompts = ["A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."]
+ # Output images will be saved in disco_diffusion_clip_rn101_out directory.
+ # The returned da is a DocumentArray object, which contains all immediate and final results
+ # You can manipulate the DocumentArray object to do post-processing and save images
+ da = module.generate_image(text_prompts=text_prompts, output_dir='./disco_diffusion_clip_rn101_out/')
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_clip_rn101_out-result.png')
+ # Show all immediate results
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_clip_rn101_out-result.gif')
+ ```
+
+- ### 3.API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_clip_rn101_out'):
+ ```
+
+ - Image generating api, which generates an image corresponding to your prompt..
+
+ - **Parameters**
+
+ - text_prompts(str): Prompt, used to describe your image content. You can construct a prompt conforms to the format "content" + "artist/style", such as "a beautiful painting of Chinese architecture, by krenz, sunny, super wide angle, artstation.". For more details, you can refer to [website](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#).
+ - style(Optional[str]): Image style, such as "watercolor" and "Chinese painting". If not provided, style is totally up to your prompt.
+ - artist(Optional[str]): Artist name, such as Greg Rutkowsk, krenz, image style is as whose works you choose. If not provided, style is totally up to your [prompt](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/).
+ - width_height(Optional[List[int]]): The width and height of output images, should be better multiples of 64. The larger size is, the longger computation time is.
+ - seed(Optional[int]): Random seed, different seeds result in different output images.
+ - output_dir(Optional[str]): Output directory, default is "disco_diffusion_clip_rn101_out".
+
+
+ - **Return**
+ - ra(DocumentArray): DocumentArray object, including `n_batches` Documents,each document keeps all immediate results during generation, please refer to [DocumentArray tutorial](https://docarray.jina.ai/fundamentals/documentarray/index.html) for more details.
+
+## IV.Server Deployment
+
+- PaddleHub Serving can deploy an online service of text-to-image.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+ - ```shell
+ $ hub serving start -m disco_diffusion_clip_rn101
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result.
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ from docarray import DocumentArray
+
+ # Send an HTTP request
+ data = {'text_prompts': 'in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation.'}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/disco_diffusion_clip_rn101"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # Get results
+ da = DocumentArray.from_base64(r.json()["results"])
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_clip_rn101_out-result.png')
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_clip_rn101_out-result.gif')
+
+
+## V.Release Note
+
+* 1.0.0
+
+ First release
+
+ ```shell
+ $ hub install disco_diffusion_clip_rn101 == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/disco_diffusion_clip_rn50/README_en.md b/modules/image/text_to_image/disco_diffusion_clip_rn50/README_en.md
new file mode 100644
index 000000000..89f35cc3f
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_rn50/README_en.md
@@ -0,0 +1,152 @@
+# disco_diffusion_clip_rn50
+
+|Module Name|disco_diffusion_clip_rn50|
+| :--- | :---: |
+|Category|text to image|
+|Network|dd+clip ResNet50|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size|2.8GB|
+|Latest update date|2022-08-02|
+|Data indicators|-|
+
+## I.Basic Information
+
+### Application Effect Display
+
+ - Prompt "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."
+
+ - Output image
+
+
+
+ - Generating process
+
+
+
+### Module Introduction
+
+disco_diffusion_clip_rn50 is a text-to-image generation model that can generate images that match the semantics of the sentence you prompt. The model consists of two parts, one is the diffusion model, which is a generative model that reconstructs the original image from the noisy input. The other part is the multimodal pre-training model (CLIP), which can represent text and images in the same feature space, and text and images with similar semantics will be closer in this feature space. In the text image generation model, the diffusion model is responsible for generating the target image from the initial noise or the specified initial image, and CLIP is responsible for guiding the generated image to be as close as possible to the semantics of the input text. Diffusion model under the guidance of CLIP iteratively generates new images, eventually generating images of what the text describes. The CLIP model used in this module is ResNet50.
+
+For more details, please refer to [Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233) and [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
+
+## II.Installation
+
+- ### 1.Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [How to install PaddleHub](../../../../docs/docs_en/get_start/installation.rst)
+
+- ### 2.Installation
+
+ - ```shell
+ $ hub install disco_diffusion_clip_rn50
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_en/get_start/windows_quickstart.md) | [Linux_Quickstart](../../../../docs/docs_en/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_en/get_start/mac_quickstart.md)
+
+
+## III.Module API Prediction
+
+- ### 1.Command line Prediction
+
+ - ```shell
+ $ hub run disco_diffusion_clip_rn50 --text_prompts "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation." --output_dir disco_diffusion_clip_rn50_out
+ ```
+
+- ### 2.Prediction Code Example
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_clip_rn50")
+ text_prompts = ["A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."]
+ # Output images will be saved in disco_diffusion_clip_rn50_out directory.
+ # The returned da is a DocumentArray object, which contains all immediate and final results
+ # You can manipulate the DocumentArray object to do post-processing and save images
+ da = module.generate_image(text_prompts=text_prompts, output_dir='./disco_diffusion_clip_rn50_out/')
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_clip_rn50_out-result.png')
+ # Show all immediate results
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_clip_rn50_out-result.gif')
+ ```
+
+- ### 3.API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_clip_rn50_out'):
+ ```
+
+ - Image generating api, which generates an image corresponding to your prompt.
+
+ - **Parameters**
+
+ - text_prompts(str): Prompt, used to describe your image content. You can construct a prompt conforms to the format "content" + "artist/style", such as "a beautiful painting of Chinese architecture, by krenz, sunny, super wide angle, artstation.". For more details, you can refer to [website](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#).
+ - style(Optional[str]): Image style, such as "watercolor" and "Chinese painting". If not provided, style is totally up to your prompt.
+ - artist(Optional[str]): Artist name, such as Greg Rutkowsk, krenz, image style is as whose works you choose. If not provided, style is totally up to your [prompt](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/).
+ - width_height(Optional[List[int]]): The width and height of output images, should be better multiples of 64. The larger size is, the longger computation time is.
+ - seed(Optional[int]): Random seed, different seeds result in different output images.
+ - output_dir(Optional[str]): Output directory, default is "disco_diffusion_clip_rn50_out".
+
+
+ - **Return**
+ - ra(DocumentArray): DocumentArray object, including `n_batches` Documents,each document keeps all immediate results during generation, please refer to [DocumentArray tutorial](https://docarray.jina.ai/fundamentals/documentarray/index.html) for more details.
+
+## IV.Server Deployment
+
+- PaddleHub Serving can deploy an online service of text-to-image.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+ - ```shell
+ $ hub serving start -m disco_diffusion_clip_rn50
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result.
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ from docarray import DocumentArray
+
+ # Send an HTTP request
+ data = {'text_prompts': 'in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation.'}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/disco_diffusion_clip_rn50"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # Get results
+ da = DocumentArray.from_base64(r.json()["results"])
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_clip_rn50_out-result.png')
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_clip_rn50_out-result.gif')
+
+## V.Release Note
+
+* 1.0.0
+
+ First release
+
+ ```shell
+ $ hub install disco_diffusion_clip_rn50 == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/disco_diffusion_clip_vitb32/README_en.md b/modules/image/text_to_image/disco_diffusion_clip_vitb32/README_en.md
new file mode 100644
index 000000000..f53df2688
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_clip_vitb32/README_en.md
@@ -0,0 +1,153 @@
+# disco_diffusion_clip_vitb32
+
+|Module Name|disco_diffusion_clip_vitb32|
+| :--- | :---: |
+|Category|text to image|
+|Network|dd+clip ViTB32|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size|3.1GB|
+|Latest update date|2022-08-02|
+|Data indicators|-|
+
+## I.Basic Information
+
+### Application Effect Display
+
+ - Prompt "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."
+
+ - Output image
+
+
+
+ - Generating process
+
+
+
+### Module Introduction
+
+disco_diffusion_clip_vitb32 disco_diffusion_clip_rn50 is a text-to-image generation model that can generate images that match the semantics of the sentence you prompt. The model consists of two parts, one is the diffusion model, which is a generative model that reconstructs the original image from the noisy input. The other part is the multimodal pre-training model (CLIP), which can represent text and images in the same feature space, and text and images with similar semantics will be closer in this feature space. In the text image generation model, the diffusion model is responsible for generating the target image from the initial noise or the specified initial image, and CLIP is responsible for guiding the generated image to be as close as possible to the semantics of the input text. Diffusion model under the guidance of CLIP iteratively generates new images, eventually generating images of what the text describes. The CLIP model used in this module is ViTB32.
+
+For more details, please refer to [Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233) and [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
+
+## II.Installation
+
+- ### 1.Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [How to install PaddleHub](../../../../docs/docs_en/get_start/installation.rst)
+
+- ### 2.Installation
+
+ - ```shell
+ $ hub install disco_diffusion_clip_vitb32
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_en/get_start/windows_quickstart.md) | [Linux_Quickstart](../../../../docs/docs_en/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_en/get_start/mac_quickstart.md)
+
+
+## III.Module API Prediction
+
+- ### 1.Command line Prediction
+
+ - ```shell
+ $ hub run disco_diffusion_clip_vitb32 --text_prompts "A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation." --output_dir disco_diffusion_clip_vitb32_out
+ ```
+
+- ### 2.Prediction Code Example
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_clip_vitb32")
+ text_prompts = ["A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation."]
+ # Output images will be saved in disco_diffusion_clip_vitb32_out directory.
+ # The returned da is a DocumentArray object, which contains all immediate and final results
+ # You can manipulate the DocumentArray object to do post-processing and save images
+ da = module.generate_image(text_prompts=text_prompts, output_dir='./disco_diffusion_clip_vitb32_out/')
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_clip_vitb32_out-result.png')
+ # Show all immediate results
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_clip_vitb32_out-result.gif')
+ ```
+
+- ### 3.API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_clip_vitb32_out'):
+ ```
+
+ - Image generating api, which generates an image corresponding to your prompt..
+
+ - **Parameters**
+
+ - text_prompts(str): Prompt, used to describe your image content. You can construct a prompt conforms to the format "content" + "artist/style", such as "a beautiful painting of Chinese architecture, by krenz, sunny, super wide angle, artstation.". For more details, you can refer to [website](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#).
+ - style(Optional[str]): Image style, such as "watercolor" and "Chinese painting". If not provided, style is totally up to your prompt.
+ - artist(Optional[str]): Artist name, such as Greg Rutkowsk, krenz, image style is as whose works you choose. If not provided, style is totally up to your [prompt](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/).
+ - width_height(Optional[List[int]]): The width and height of output images, should be better multiples of 64. The larger size is, the longger computation time is.
+ - seed(Optional[int]): Random seed, different seeds result in different output images.
+ - output_dir(Optional[str]): Output directory, default is "disco_diffusion_clip_vitb32_out".
+
+
+ - **Return**
+ - ra(DocumentArray): DocumentArray object, including `n_batches` Documents,each document keeps all immediate results during generation, please refer to [DocumentArray tutorial](https://docarray.jina.ai/fundamentals/documentarray/index.html) for more details.
+
+## IV.Server Deployment
+
+- PaddleHub Serving can deploy an online service of text-to-image.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+ - ```shell
+ $ hub serving start -m disco_diffusion_clip_vitb32
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result.
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ from docarray import DocumentArray
+
+ # Send an HTTP request
+ data = {'text_prompts': 'in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation.'}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/disco_diffusion_clip_vitb32"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # Get results
+ da = DocumentArray.from_base64(r.json()["results"])
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_clip_vitb32_out-result.png')
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_clip_vitb32_out-result.gif')
+
+
+## V.Release Note
+
+* 1.0.0
+
+ First release
+
+ ```shell
+ $ hub install disco_diffusion_clip_vitb32 == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/README_en.md b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/README_en.md
new file mode 100644
index 000000000..79c01c523
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_cnclip_vitb16/README_en.md
@@ -0,0 +1,153 @@
+# disco_diffusion_cnclip_vitb16
+
+|Module Name|disco_diffusion_cnclip_vitb16|
+| :--- | :---: |
+|Category|text to image|
+|Network|dd+cnclip ViTB16|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size|2.9GB|
+|Latest update date|2022-08-02|
+|Data indicators|-|
+
+## I.Basic Information
+
+### Application Effect Display
+
+ - Prompt "在宁静的风景中画一幅美丽的建筑画,由Arthur Adams在artstation上所作"
+
+ - Output image
+
+
+
+ - Generating process
+
+
+
+### Module Introduction
+
+disco_diffusion_cnclip_vitb16 is a text-to-image generation model that can generate images that match the semantics of the sentence you prompt. The model consists of two parts, one is the diffusion model, which is a generative model that reconstructs the original image from the noisy input. The other part is the multimodal pre-training model (CLIP), which can represent text and images in the same feature space, and text and images with similar semantics will be closer in this feature space. In the text image generation model, the diffusion model is responsible for generating the target image from the initial noise or the specified initial image, and CLIP is responsible for guiding the generated image to be as close as possible to the semantics of the input text. Diffusion model under the guidance of CLIP iteratively generates new images, eventually generating images of what the text describes. The CLIP model used in this module is ViTB16.
+
+For more details, please refer to [Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233) and [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
+
+## II.Installation
+
+- ### 1.Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [How to install PaddleHub](../../../../docs/docs_en/get_start/installation.rst)
+
+- ### 2.Installation
+
+ - ```shell
+ $ hub install disco_diffusion_cnclip_vitb16
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_en/get_start/windows_quickstart.md) | [Linux_Quickstart](../../../../docs/docs_en/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_en/get_start/mac_quickstart.md)
+
+
+## III.Module API Prediction
+
+- ### 1.Command line Prediction
+
+ - ```shell
+ $ hub run disco_diffusion_cnclip_vitb16 --text_prompts "孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作。" --output_dir disco_diffusion_cnclip_vitb16_out
+ ```
+
+- ### 2.Prediction Code Example
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_cnclip_vitb16")
+ text_prompts = ["孤舟蓑笠翁,独钓寒江雪。"]
+ # Output images will be saved in disco_diffusion_cnclip_vitb16_out directory.
+ # The returned da is a DocumentArray object, which contains all immediate and final results
+ # You can manipulate the DocumentArray object to do post-processing and save images
+ da = module.generate_image(text_prompts=text_prompts, artist='齐白石', output_dir='./disco_diffusion_cnclip_vitb16_out/')
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_cnclip_vitb16_out-result.png')
+ # Show all immediate results
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_cnclip_vitb16_out-result.gif')
+ ```
+
+- ### 3.API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_cnclip_vitb16_out'):
+ ```
+
+ - Image generating api, which generates an image corresponding to your prompt.
+
+ - **Parameters**
+
+ - text_prompts(str): Prompt, used to describe your image content. You can construct a prompt conforms to the format "content" + "artist/style", such as "孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作". For more details, you can refer to [website](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#).
+ - style(Optional[str]): Image style, such as "watercolor" and "Chinese painting". If not provided, style is totally up to your prompt.
+ - artist(Optional[str]): Artist name, such as 齐白石,Greg Rutkowsk,image style is as whose works you choose. If not provided, style is totally up to your [prompt](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/).
+ - width_height(Optional[List[int]]): The width and height of output images, should be better multiples of 64. The larger size is, the longger computation time is.
+ - seed(Optional[int]): Random seed, different seeds result in different output images.
+ - output_dir(Optional[str]): Output directory, default is "disco_diffusion_cnclip_vitb16_out".
+
+
+ - **Return**
+ - ra(DocumentArray): DocumentArray object, including `n_batches` Documents,each document keeps all immediate results during generation, please refer to [DocumentArray tutorial](https://docarray.jina.ai/fundamentals/documentarray/index.html) for more details.
+
+## IV.Server Deployment
+
+- PaddleHub Serving can deploy an online service of text-to-image.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+ - ```shell
+ $ hub serving start -m disco_diffusion_cnclip_vitb16
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result.
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ from docarray import DocumentArray
+
+ # Send an HTTP request
+ data = {'text_prompts': '孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作'}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/disco_diffusion_cnclip_vitb16"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # Get results
+ da = DocumentArray.from_base64(r.json()["results"])
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_cnclip_vitb16_out-result.png')
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_cnclip_vitb16_out-result.gif')
+
+
+## V.Release Note
+
+* 1.0.0
+
+ First release
+
+ ```shell
+ $ hub install disco_diffusion_cnclip_vitb16 == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/disco_diffusion_ernievil_base/README_en.md b/modules/image/text_to_image/disco_diffusion_ernievil_base/README_en.md
new file mode 100644
index 000000000..041ad0ed6
--- /dev/null
+++ b/modules/image/text_to_image/disco_diffusion_ernievil_base/README_en.md
@@ -0,0 +1,154 @@
+# disco_diffusion_ernievil_base
+
+|Module Name|disco_diffusion_ernievil_base|
+| :--- | :---: |
+|Category|text to image|
+|Network|dd+ERNIE-ViL|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size|2.9GB|
+|Latest update date|2022-08-02|
+|Data indicators|-|
+
+## I.Basic Information
+
+### Application Effect Display
+
+ - Prompt "小桥流水人家"
+
+ - Output image
+
+
+
+ - Generating process
+
+
+
+
+### Module Introduction
+
+disco_diffusion_ernievil_base is a text-to-image generation model that can generate images that match the semantics of the sentence you prompt. The model consists of two parts, one is the diffusion model, which is a generative model that reconstructs the original image from the noisy input. The other part is the multimodal pre-training model (ERNIE-ViL), which can represent text and images in the same feature space, and text and images with similar semantics will be closer in this feature space. In the text image generation model, the diffusion model is responsible for generating the target image from the initial noise or the specified initial image, and ERNIE-ViL is responsible for guiding the generated image to be as close as possible to the semantics of the input text. Diffusion model under the guidance of ERNIE-ViL iteratively generates new images, eventually generating images of what the text describes. The model used in this module is ERNIE-ViL, consisting of ERNIE 3.0+ViT.
+
+For more details, please refer to [Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233)
+
+## II.Installation
+
+- ### 1.Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.2.0 | [How to install PaddleHub](../../../../docs/docs_en/get_start/installation.rst)
+
+- ### 2.Installation
+
+ - ```shell
+ $ hub install disco_diffusion_ernievil_base
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_en/get_start/windows_quickstart.md) | [Linux_Quickstart](../../../../docs/docs_en/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_en/get_start/mac_quickstart.md)
+
+
+## III.Module API Prediction
+
+- ### 1.Command line Prediction
+
+ - ```shell
+ $ hub run disco_diffusion_ernievil_base --text_prompts "孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作。" --output_dir disco_diffusion_ernievil_base_out
+ ```
+
+- ### 2.Prediction Code Example
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="disco_diffusion_ernievil_base")
+ text_prompts = ["孤舟蓑笠翁,独钓寒江雪。"]
+ # Output images will be saved in disco_diffusion_ernievil_base_out directory.
+ # The returned da is a DocumentArray object, which contains all immediate and final results
+ # You can manipulate the DocumentArray object to do post-processing and save images
+ da = module.generate_image(text_prompts=text_prompts, artist='齐白石', output_dir='./disco_diffusion_ernievil_base_out/')
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_ernievil_base_out-result.png')
+ # Show all immediate results
+ da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_ernievil_base_out-result.gif')
+ ```
+
+- ### 3.API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [1280, 768],
+ seed: Optional[int] = None,
+ output_dir: Optional[str] = 'disco_diffusion_ernievil_base_out'):
+ ```
+
+ - Image generating api, which generates an image corresponding to your prompt.
+
+ - **Parameters**
+
+ - text_prompts(str): Prompt, used to describe your image content. You can construct a prompt conforms to the format "content" + "artist/style", such as "孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作". For more details, you can refer to [website](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#).
+ - style(Optional[str]): Image style, such as "watercolor" and "Chinese painting". If not provided, style is totally up to your prompt.
+ - artist(Optional[str]): Artist name, such as 齐白石,Greg Rutkowsk,image style is as whose works you choose. If not provided, style is totally up to your [prompt](https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/).
+ - width_height(Optional[List[int]]): The width and height of output images, should be better multiples of 64. The larger size is, the longger computation time is.
+ - seed(Optional[int]): Random seed, different seeds result in different output images.
+ - output_dir(Optional[str]): Output directory, default is "disco_diffusion_ernievil_base_out".
+
+
+ - **Return**
+ - ra(DocumentArray): DocumentArray object, including `n_batches` Documents,each document keeps all immediate results during generation, please refer to [DocumentArray tutorial](https://docarray.jina.ai/fundamentals/documentarray/index.html) for more details.
+
+## IV.Server Deployment
+
+- PaddleHub Serving can deploy an online service of text-to-image.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+ - ```shell
+ $ hub serving start -m disco_diffusion_ernievil_base
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result.
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ from docarray import DocumentArray
+
+ # Send an HTTP request
+ data = {'text_prompts': '孤舟蓑笠翁,独钓寒江雪。风格如齐白石所作'}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/disco_diffusion_ernievil_base"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # Get results
+ da = DocumentArray.from_base64(r.json()["results"])
+ # Save final result image to a file
+ da[0].save_uri_to_file('disco_diffusion_ernievil_base_out-result.png')
+ # Save the generating process as a gif
+ da[0].chunks.save_gif('disco_diffusion_ernievil_base_out-result.gif')
+
+
+## V.Release Note
+
+* 1.0.0
+
+ First release
+
+ ```shell
+ $ hub install disco_diffusion_ernievil_base == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/stable_diffusion/README_en.md b/modules/image/text_to_image/stable_diffusion/README_en.md
new file mode 100644
index 000000000..b99b19a52
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion/README_en.md
@@ -0,0 +1,157 @@
+# stable_diffusion
+
+|Module Name|stable_diffusion|
+| :--- | :---: |
+|Category|text to image|
+|Network|CLIP Text Encoder+UNet+VAD|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size|4.0GB|
+|Latest update date|2022-08-26|
+|Data indicators|-|
+
+## I.Basic Information
+
+### Application Effect Display
+
+ - Prompt "in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation."
+
+ - Output image
+
+
+
+ - Generating process
+
+
+
+### Module Introduction
+
+Stable Diffusion is a latent diffusion model (Latent Diffusion), which belongs to the generative model. This kind of model obtains the images by iteratively denoising noise and sampling step by step, and currently has achieved amazing results. Compared with Disco Diffusion, Stable Diffusion iterates in a lower dimensional latent space instead of the original pixel space, which greatly reduces the memory and computational requirements. You can render the desired image within a minute on the V100, welcome to enjoy it in [aistudio](https://aistudio.baidu.com/aistudio/projectdetail/4512600).
+
+For more details, please refer to [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)
+
+## II.Installation
+
+- ### 1.Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0 | [How to install PaddleHub](../../../../docs/docs_en/get_start/installation.rst)
+
+- ### 2.Installation
+
+ - ```shell
+ $ hub install stable_diffusion
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_en/get_start/windows_quickstart.md) | [Linux_Quickstart](../../../../docs/docs_en/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_en/get_start/mac_quickstart.md)
+
+
+## III.Module API Prediction
+
+- ### 1.Command line Prediction
+
+ - ```shell
+ $ hub run stable_diffusion --text_prompts "in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation." --output_dir stable_diffusion_out
+ ```
+
+- ### 2.Prediction Code Example
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="stable_diffusion")
+ text_prompts = ["in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation."]
+ # Output images will be saved in stable_diffusion_out directory.
+ # The returned da is a DocumentArray object, which contains all immediate and final results
+ # You can manipulate the DocumentArray object to do post-processing and save images
+ # you can set batch_size parameter to generate number of batch_size images at one inference step.
+ da = module.generate_image(text_prompts=text_prompts, batch_size=3, output_dir='./stable_diffusion_out/')
+ # Show all immediate results
+ da[0].chunks[-1].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # Save the generating process as a gif
+ da[0].chunks[-1].chunks.save_gif('stable_diffusion_out-merged-result.gif')
+ da[0].chunks[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ da[0].chunks[0].chunks.save_gif('stable_diffusion_out-image-0-result.gif')
+ ```
+
+- ### 3.API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ style: Optional[str] = None,
+ artist: Optional[str] = None,
+ width_height: Optional[List[int]] = [512, 512],
+ seed: Optional[int] = None,
+ batch_size: Optional[int] = 1,
+ output_dir: Optional[str] = 'stable_diffusion_out'):
+ ```
+
+ - Image generating api, which generates an image corresponding to your prompt.
+
+ - **Parameters**
+
+ - text_prompts(str): Prompt, used to describe your image content. You can construct a prompt conforms to the format "content" + "artist/style", such as "in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation.". For more details, you can refer to [website](https://docs.google.com/document/d/1XUT2G9LmkZataHFzmuOtRXnuWBfhvXDAo8DkS--8tec/edit#).
+ - style(Optional[str]): Image style, such as "watercolor" and "Chinese painting". If not provided, style is totally up to your prompt.
+ - artist(Optional[str]): Artist name, such as Greg Rutkowsk,krenz, image style is as whose works you choose. If not provided, style is totally up to your prompt.(https://weirdwonderfulai.art/resources/disco-diffusion-70-plus-artist-studies/).
+ - width_height(Optional[List[int]]): The width and height of output images, should be better multiples of 64. The larger size is, the longger computation time is.
+ - seed(Optional[int]): Random seed, different seeds result in different output images.
+ - batch_size(Optional[int]): Number of images generated for one inference step.
+ - output_dir(Optional[str]): Output directory, default is "stable_diffusion_out".
+
+
+ - **Return**
+ - ra(DocumentArray): DocumentArray object, including `batch_size` Documents,each document keeps all immediate results during generation, please refer to [DocumentArray tutorial](https://docarray.jina.ai/fundamentals/documentarray/index.html) for more details.
+
+## IV.Server Deployment
+
+- PaddleHub Serving can deploy an online service of text-to-image.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+ - ```shell
+ $ hub serving start -m stable_diffusion
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result.
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ from docarray import DocumentArray
+
+ # Send an HTTP request
+ data = {'text_prompts': 'in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation.'}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/stable_diffusion"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # Get results
+ r.json()["results"]
+ da = DocumentArray.from_base64(r.json()["results"])
+ # Save final result image to a file
+ da[0].save_uri_to_file('stable_diffusion_out.png')
+ # Save the generating process as a gif
+ da[0].chunks[0].chunks.save_gif('stable_diffusion_out.gif')
+ ```
+
+## V.Release Note
+
+* 1.0.0
+
+ First release
+
+ ```shell
+ $ hub install stable_diffusion == 1.0.0
+ ```
From 87eca2dff7ad25fe2f7fbb8e81f0905205996595 Mon Sep 17 00:00:00 2001
From: chenjian  +
+## 四、服务部署
+
+- 通过启动PaddleHub Serving,可以加载模型部署在线语种识别服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m baidu_language_recognition
+ ```
+
+ - 通过以上命令可完成一个语种识别API的部署,默认端口号为8866。
+
+
+- ## 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ text = "I like panda"
+ data = {"query": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://127.0.0.1:8866/predict/baidu_language_recognition"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+ - 关于PaddleHub Serving更多信息参考:[服务部署](../../../../docs/docs_ch/tutorial/serving.md)
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ - ```shell
+ $ hub install baidu_language_recognition==1.0.0
+ ```
diff --git a/modules/text/machine_translation/baidu_language_recognition/module.py b/modules/text/machine_translation/baidu_language_recognition/module.py
new file mode 100644
index 000000000..e444fe05b
--- /dev/null
+++ b/modules/text/machine_translation/baidu_language_recognition/module.py
@@ -0,0 +1,100 @@
+import argparse
+import random
+from hashlib import md5
+from typing import Optional
+
+import requests
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+def make_md5(s, encoding='utf-8'):
+ return md5(s.encode(encoding)).hexdigest()
+
+
+@moduleinfo(name="baidu_language_recognition",
+ version="1.0.0",
+ type="text/machine_translation",
+ summary="",
+ author="baidu-nlp",
+ author_email="paddle-dev@baidu.com")
+class BaiduLanguageRecognition:
+
+ def __init__(self, appid=None, appkey=None):
+ """
+ :param appid: appid for requesting Baidu translation service.
+ :param appkey: appkey for requesting Baidu translation service.
+ """
+ # Set your own appid/appkey.
+ if appid == None:
+ self.appid = '20201015000580007'
+ else:
+ self.appid = appid
+ if appkey is None:
+ self.appkey = 'IFJB6jBORFuMmVGDRud1'
+ else:
+ self.appkey = appkey
+ self.url = 'https://fanyi-api.baidu.com/api/trans/vip/language'
+
+ def recognize(self, query: str):
+ """
+ Create image by text prompts using ErnieVilG model.
+
+ :param query: Text to be translated.
+
+ Return language type code.
+ """
+ # Generate salt and sign
+ salt = random.randint(32768, 65536)
+ sign = make_md5(self.appid + query + str(salt) + self.appkey)
+
+ # Build request
+ headers = {'Content-Type': 'application/x-www-form-urlencoded'}
+ payload = {'appid': self.appid, 'q': query, 'salt': salt, 'sign': sign}
+
+ # Send request
+ try:
+ r = requests.post(self.url, params=payload, headers=headers)
+ result = r.json()
+ except Exception as e:
+ error_msg = str(e)
+ raise RuntimeError(error_msg)
+ if result['error_code'] != 0:
+ raise RuntimeError(result['error_msg'])
+ return result['data']['src']
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ if args.appid is not None and args.appkey is not None:
+ self.appid = args.appid
+ self.appkey = args.appkey
+ result = self.recognize(args.query)
+ return result
+
+ @serving
+ def serving_method(self, query):
+ """
+ Run as a service.
+ """
+ return self.recognize(query)
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument('--query', type=str)
+ self.arg_input_group.add_argument('--appid', type=str, default=None, help="注册得到的个人appid")
+ self.arg_input_group.add_argument('--appkey', type=str, default=None, help="注册得到的个人appkey")
From 14ad25465300399aac0d9066fc6df55bb657e719 Mon Sep 17 00:00:00 2001
From: chenjian
+
+## 四、服务部署
+
+- 通过启动PaddleHub Serving,可以加载模型部署在线语种识别服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m baidu_language_recognition
+ ```
+
+ - 通过以上命令可完成一个语种识别API的部署,默认端口号为8866。
+
+
+- ## 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ text = "I like panda"
+ data = {"query": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://127.0.0.1:8866/predict/baidu_language_recognition"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+ - 关于PaddleHub Serving更多信息参考:[服务部署](../../../../docs/docs_ch/tutorial/serving.md)
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ - ```shell
+ $ hub install baidu_language_recognition==1.0.0
+ ```
diff --git a/modules/text/machine_translation/baidu_language_recognition/module.py b/modules/text/machine_translation/baidu_language_recognition/module.py
new file mode 100644
index 000000000..e444fe05b
--- /dev/null
+++ b/modules/text/machine_translation/baidu_language_recognition/module.py
@@ -0,0 +1,100 @@
+import argparse
+import random
+from hashlib import md5
+from typing import Optional
+
+import requests
+
+import paddlehub as hub
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+def make_md5(s, encoding='utf-8'):
+ return md5(s.encode(encoding)).hexdigest()
+
+
+@moduleinfo(name="baidu_language_recognition",
+ version="1.0.0",
+ type="text/machine_translation",
+ summary="",
+ author="baidu-nlp",
+ author_email="paddle-dev@baidu.com")
+class BaiduLanguageRecognition:
+
+ def __init__(self, appid=None, appkey=None):
+ """
+ :param appid: appid for requesting Baidu translation service.
+ :param appkey: appkey for requesting Baidu translation service.
+ """
+ # Set your own appid/appkey.
+ if appid == None:
+ self.appid = '20201015000580007'
+ else:
+ self.appid = appid
+ if appkey is None:
+ self.appkey = 'IFJB6jBORFuMmVGDRud1'
+ else:
+ self.appkey = appkey
+ self.url = 'https://fanyi-api.baidu.com/api/trans/vip/language'
+
+ def recognize(self, query: str):
+ """
+ Create image by text prompts using ErnieVilG model.
+
+ :param query: Text to be translated.
+
+ Return language type code.
+ """
+ # Generate salt and sign
+ salt = random.randint(32768, 65536)
+ sign = make_md5(self.appid + query + str(salt) + self.appkey)
+
+ # Build request
+ headers = {'Content-Type': 'application/x-www-form-urlencoded'}
+ payload = {'appid': self.appid, 'q': query, 'salt': salt, 'sign': sign}
+
+ # Send request
+ try:
+ r = requests.post(self.url, params=payload, headers=headers)
+ result = r.json()
+ except Exception as e:
+ error_msg = str(e)
+ raise RuntimeError(error_msg)
+ if result['error_code'] != 0:
+ raise RuntimeError(result['error_msg'])
+ return result['data']['src']
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.add_module_input_arg()
+ args = self.parser.parse_args(argvs)
+ if args.appid is not None and args.appkey is not None:
+ self.appid = args.appid
+ self.appkey = args.appkey
+ result = self.recognize(args.query)
+ return result
+
+ @serving
+ def serving_method(self, query):
+ """
+ Run as a service.
+ """
+ return self.recognize(query)
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument('--query', type=str)
+ self.arg_input_group.add_argument('--appid', type=str, default=None, help="注册得到的个人appid")
+ self.arg_input_group.add_argument('--appkey', type=str, default=None, help="注册得到的个人appkey")
From 14ad25465300399aac0d9066fc6df55bb657e719 Mon Sep 17 00:00:00 2001
From: chenjian 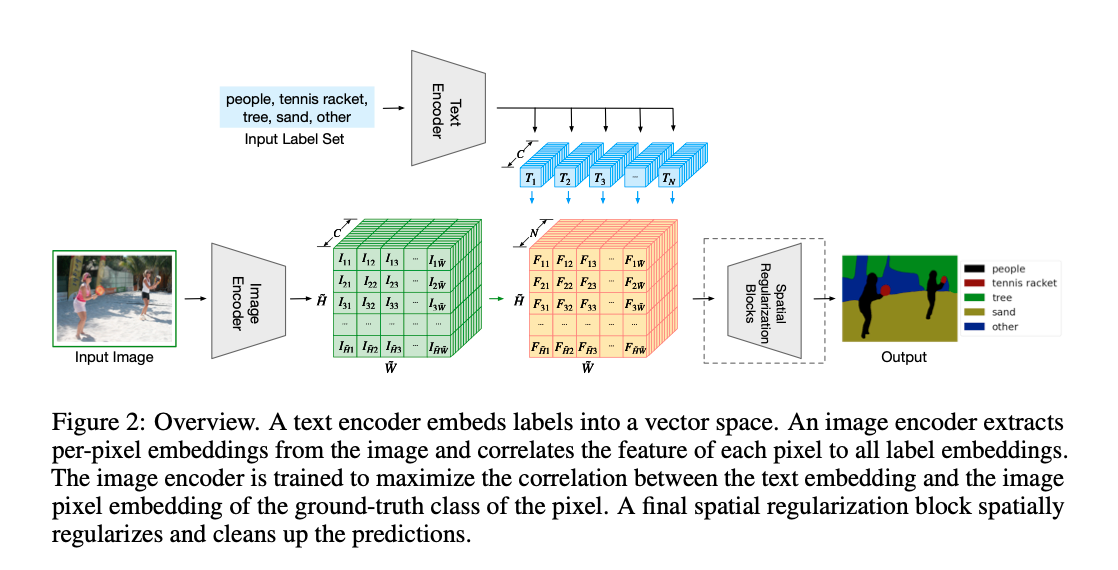
+ 
 +
+
+
+ - 输出图像
+  +
+
+
+ - 生成过程
+  +
+
+
+### 模型介绍
+
+Stable Diffusion是一种潜在扩散模型(Latent Diffusion), 属于生成类模型,这类模型通过对随机噪声进行一步步地迭代降噪并采样来获得感兴趣的图像,当前取得了令人惊艳的效果。相比于Disco Diffusion, Stable Diffusion通过在低纬度的潜在空间(lower dimensional latent space)而不是原像素空间来做迭代,极大地降低了内存和计算量的需求,并且在V100上一分钟之内即可以渲染出想要的图像,欢迎体验。该模块支持输入文本以及一个初始图像,对初始图像的内容进行改变。
+
+更多详情请参考论文:[High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install stable_diffusion_img2img
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run stable_diffusion_img2img --text_prompts "A fantasy landscape, trending on artstation" --init_image /PATH/TO/IMAGE --output_dir stable_diffusion_img2img_out
+ ```
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="stable_diffusion_img2img")
+ text_prompts = ["A fantasy landscape, trending on artstation"]
+ # 生成图像, 默认会在stable_diffusion_img2img_out目录保存图像
+ # 返回的da是一个DocumentArray对象,保存了所有的结果,包括最终结果和迭代过程的中间结果
+ # 可以通过操作DocumentArray对象对生成的图像做后处理,保存或者分析
+ # 您可以设置batch_size一次生成多张
+ da = module.generate_image(text_prompts=text_prompts, batch_size=2, output_dir='./stable_diffusion_img2img_out/')
+ # 展示所有的中间结果
+ da[0].chunks[-1].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # 将整个生成过程保存为一个动态图gif
+ da[0].chunks[-1].chunks.save_gif('stable_diffusion_img2img_out-merged-result.gif')
+ # da索引的是prompt, da[0].chunks索引的是该prompt下生成的第一张图,在batch_size不为1时能同时生成多张图
+ # 您也可以按照上述操作显示单张图,如第0张的生成过程
+ da[0].chunks[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ da[0].chunks[0].chunks.save_gif('stable_diffusion_img2img-image-0-result.gif')
+ ```
+
+- ### 3、API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ init_image,
+ strength: float = 0.8,
+ width_height: Optional[List[int]] = [512, 512],
+ seed: Optional[int] = None,
+ batch_size: Optional[int] = 1,
+ display_rate: Optional[int] = 5,
+ output_dir: Optional[str] = 'stable_diffusion_out'):
+ ```
+
+ - 文图生成API,生成文本描述内容的图像。
+
+ - **参数**
+
+ - text_prompts(str): 输入的语句,描述想要生成的图像的内容。
+ - init_image(str|numpy.ndarray|PIL.Image): 输入的初始图像。
+ - strength(float): 控制添加到输入图像的噪声强度,取值范围0到1。越接近1.0,图像变化越大。
+ - width_height(Optional[List[int]]): 指定最终输出图像的宽高,宽和高都需要是64的倍数,生成的图像越大,所需要的计算时间越长。
+ - seed(Optional[int]): 随机种子,由于输入默认是随机高斯噪声,设置不同的随机种子会由不同的初始输入,从而最终生成不同的结果,可以设置该参数来获得不同的输出图像。
+ - batch_size(Optional[int]): 指定每个prompt一次生成的图像的数量。
+ - display_rate(Optional[int]): 保存中间结果的频率,默认每5个step保存一次中间结果,如果不需要中间结果来让程序跑的更快,可以将这个值设大。
+ - output_dir(Optional[str]): 保存输出图像的目录,默认为"stable_diffusion_out"。
+
+
+ - **返回**
+ - ra(DocumentArray): DocumentArray对象, 包含`n_batches`个Documents,其中每个Document都保存了迭代过程的所有中间结果。详细可参考[DocumentArray使用文档](https://docarray.jina.ai/fundamentals/documentarray/index.html)。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线文图生成服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+ - ```shell
+ $ hub serving start -m stable_diffusion_img2img
+ ```
+
+ - 这样就完成了一个文图生成的在线服务API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果,返回的预测结果在反序列化后即是上述接口声明中说明的DocumentArray类型,返回后对结果的操作方式和使用generate_image接口完全相同。
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ from docarray import DocumentArray
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tobytes())
+
+ # 发送HTTP请求
+ data = {'text_prompts': 'A fantasy landscape, trending on artstation', 'init_image': cv2_to_base64(cv2.imread('/PATH/TO/IMAGE'))}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/stable_diffusion_img2img"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 获取返回结果
+ r.json()["results"]
+ da = DocumentArray.from_base64(r.json()["results"])
+ # 保存结果图
+ da[0].save_uri_to_file('stable_diffusion_img2img_out.png')
+ # 将生成过程保存为一个动态图gif
+ da[0].chunks[0].chunks.save_gif('stable_diffusion_img2img_out.gif')
+ ```
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install stable_diffusion_img2img == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/clip/README.md b/modules/image/text_to_image/stable_diffusion_img2img/clip/README.md
new file mode 100755
index 000000000..9944794f8
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/clip/README.md
@@ -0,0 +1,2 @@
+# OpenAI CLIP implemented in Paddle.
+The original implementation repo is [ranchlai/clip.paddle](https://github.com/ranchlai/clip.paddle). We use this repo here for text encoder in stable diffusion.
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/__init__.py b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/__init__.py
new file mode 100755
index 000000000..5657b56e6
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/__init__.py
@@ -0,0 +1 @@
+from .utils import *
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/layers.py b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/layers.py
new file mode 100755
index 000000000..286f35ab4
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/layers.py
@@ -0,0 +1,182 @@
+from typing import Optional
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn import Linear
+
+__all__ = ['ResidualAttentionBlock', 'AttentionPool2d', 'multi_head_attention_forward', 'MultiHeadAttention']
+
+
+def multi_head_attention_forward(x: Tensor,
+ num_heads: int,
+ q_proj: Linear,
+ k_proj: Linear,
+ v_proj: Linear,
+ c_proj: Linear,
+ attn_mask: Optional[Tensor] = None):
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = emb_dim // num_heads
+ scaling = float(head_dim)**-0.5
+ q = q_proj(x) # L, N, E
+ k = k_proj(x) # L, N, E
+ v = v_proj(x) # L, N, E
+ #k = k.con
+ v = v.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ k = k.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ q = q.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+
+ q = q * scaling
+ qk = paddle.bmm(q, k.transpose((0, 2, 1)))
+ if attn_mask is not None:
+ if attn_mask.ndim == 2:
+ attn_mask.unsqueeze_(0)
+ #assert str(attn_mask.dtype) == 'VarType.FP32' and attn_mask.ndim == 3
+ assert attn_mask.shape[0] == 1 and attn_mask.shape[1] == max_len and attn_mask.shape[2] == max_len
+ qk += attn_mask
+
+ qk = paddle.nn.functional.softmax(qk, axis=-1)
+ atten = paddle.bmm(qk, v)
+ atten = atten.transpose((1, 0, 2))
+ atten = atten.reshape((max_len, batch_size, emb_dim))
+ atten = c_proj(atten)
+ return atten
+
+
+class MultiHeadAttention(nn.Layer): # without attention mask
+
+ def __init__(self, emb_dim: int, num_heads: int):
+ super().__init__()
+ self.q_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.k_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.v_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.c_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.head_dim = emb_dim // num_heads
+ self.emb_dim = emb_dim
+ self.num_heads = num_heads
+ assert self.head_dim * num_heads == emb_dim, "embed_dim must be divisible by num_heads"
+ #self.scaling = float(self.head_dim) ** -0.5
+
+ def forward(self, x, attn_mask=None): # x is in shape[max_len,batch_size,emb_dim]
+
+ atten = multi_head_attention_forward(x,
+ self.num_heads,
+ self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.c_proj,
+ attn_mask=attn_mask)
+
+ return atten
+
+
+class Identity(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return x
+
+
+class Bottleneck(nn.Layer):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1):
+ super().__init__()
+
+ # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
+ self.conv1 = nn.Conv2D(inplanes, planes, 1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(planes)
+
+ self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(planes)
+
+ self.avgpool = nn.AvgPool2D(stride) if stride > 1 else Identity()
+
+ self.conv3 = nn.Conv2D(planes, planes * self.expansion, 1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(planes * self.expansion)
+
+ self.relu = nn.ReLU()
+ self.downsample = None
+ self.stride = stride
+
+ if stride > 1 or inplanes != planes * Bottleneck.expansion:
+ self.downsample = nn.Sequential(
+ ("-1", nn.AvgPool2D(stride)),
+ ("0", nn.Conv2D(inplanes, planes * self.expansion, 1, stride=1, bias_attr=False)),
+ ("1", nn.BatchNorm2D(planes * self.expansion)))
+
+ def forward(self, x):
+ identity = x
+
+ out = self.relu(self.bn1(self.conv1(x)))
+ out = self.relu(self.bn2(self.conv2(out)))
+ out = self.avgpool(out)
+ out = self.bn3(self.conv3(out))
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.relu(out)
+ return out
+
+
+class AttentionPool2d(nn.Layer):
+
+ def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
+ super().__init__()
+
+ self.positional_embedding = paddle.create_parameter((spacial_dim**2 + 1, embed_dim), dtype='float32')
+
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim, bias_attr=True)
+ self.num_heads = num_heads
+
+ self.head_dim = embed_dim // num_heads
+ assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
+
+ def forward(self, x):
+
+ x = x.reshape((x.shape[0], x.shape[1], x.shape[2] * x.shape[3])).transpose((2, 0, 1)) # NCHW -> (HW)NC
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = self.head_dim
+ x = paddle.concat([paddle.mean(x, axis=0, keepdim=True), x], axis=0)
+ x = x + paddle.unsqueeze(self.positional_embedding, 1)
+ out = multi_head_attention_forward(x, self.num_heads, self.q_proj, self.k_proj, self.v_proj, self.c_proj)
+
+ return out[0]
+
+
+class QuickGELU(nn.Layer):
+
+ def forward(self, x):
+ return x * paddle.nn.functional.sigmoid(1.702 * x)
+
+
+class ResidualAttentionBlock(nn.Layer):
+
+ def __init__(self, d_model: int, n_head: int, attn_mask=None):
+ super().__init__()
+
+ self.attn = MultiHeadAttention(d_model, n_head)
+ self.ln_1 = nn.LayerNorm(d_model)
+ self.mlp = nn.Sequential(("c_fc", nn.Linear(d_model, d_model * 4)), ("gelu", QuickGELU()),
+ ("c_proj", nn.Linear(d_model * 4, d_model)))
+ self.ln_2 = nn.LayerNorm(d_model)
+ self.attn_mask = attn_mask
+
+ def attention(self, x):
+ x = self.attn(x, self.attn_mask)
+ assert isinstance(x, paddle.Tensor) # not tuble here
+ return x
+
+ def forward(self, x):
+
+ x = x + self.attention(self.ln_1(x))
+ x = x + self.mlp(self.ln_2(x))
+ return x
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/model.py b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/model.py
new file mode 100755
index 000000000..06affcc4b
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/model.py
@@ -0,0 +1,259 @@
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import nn
+
+from .layers import AttentionPool2d
+from .layers import Bottleneck
+from .layers import MultiHeadAttention
+from .layers import ResidualAttentionBlock
+
+
+class ModifiedResNet(nn.Layer):
+ """
+ A ResNet class that is similar to torchvision's but contains the following changes:
+ - There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
+ - Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
+ - The final pooling layer is a QKV attention instead of an average pool
+ """
+
+ def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
+ super().__init__()
+ self.output_dim = output_dim
+ self.input_resolution = input_resolution
+
+ # the 3-layer stem
+ self.conv1 = nn.Conv2D(3, width // 2, kernel_size=3, stride=2, padding=1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(width // 2)
+ self.conv2 = nn.Conv2D(width // 2, width // 2, kernel_size=3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(width // 2)
+ self.conv3 = nn.Conv2D(width // 2, width, kernel_size=3, padding=1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(width)
+ self.avgpool = nn.AvgPool2D(2)
+ self.relu = nn.ReLU()
+
+ # residual layers
+ self._inplanes = width # this is a *mutable* variable used during construction
+ self.layer1 = self._make_layer(width, layers[0])
+ self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
+ self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
+ self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
+
+ embed_dim = width * 32 # the ResNet feature dimension
+ self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
+
+ def _make_layer(self, planes, blocks, stride=1):
+ layers = [Bottleneck(self._inplanes, planes, stride)]
+
+ self._inplanes = planes * Bottleneck.expansion
+ for _ in range(1, blocks):
+ layers.append(Bottleneck(self._inplanes, planes))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ def stem(x):
+ for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
+ x = self.relu(bn(conv(x)))
+ x = self.avgpool(x)
+ return x
+
+ #x = x.type(self.conv1.weight.dtype)
+ x = stem(x)
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+ x = self.attnpool(x)
+
+ return x
+
+
+class Transformer(nn.Layer):
+
+ def __init__(self, width: int, layers: int, heads: int, attn_mask=None):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
+
+ def forward(self, x):
+ return self.resblocks(x)
+
+
+class VisualTransformer(nn.Layer):
+
+ def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.output_dim = output_dim
+ # used patch_size x patch_size, stride patch_size to do linear projection
+ self.conv1 = nn.Conv2D(in_channels=3,
+ out_channels=width,
+ kernel_size=patch_size,
+ stride=patch_size,
+ bias_attr=False)
+
+ # scale = width ** -0.5
+ self.class_embedding = paddle.create_parameter((width, ), 'float32')
+
+ self.positional_embedding = paddle.create_parameter(((input_resolution // patch_size)**2 + 1, width), 'float32')
+
+ self.ln_pre = nn.LayerNorm(width)
+
+ self.transformer = Transformer(width, layers, heads)
+
+ self.ln_post = nn.LayerNorm(width)
+ self.proj = paddle.create_parameter((width, output_dim), 'float32')
+
+ def forward(self, x):
+
+ x = self.conv1(x)
+ x = x.reshape((x.shape[0], x.shape[1], -1))
+ x = x.transpose((0, 2, 1))
+ x = paddle.concat([self.class_embedding + paddle.zeros((x.shape[0], 1, x.shape[-1]), dtype=x.dtype), x], axis=1)
+
+ x = x + self.positional_embedding
+ x = self.ln_pre(x)
+ x = x.transpose((1, 0, 2))
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2))
+ x = self.ln_post(x[:, 0, :])
+ if self.proj is not None:
+ x = paddle.matmul(x, self.proj)
+
+ return x
+
+
+class TextTransformer(nn.Layer):
+
+ def __init__(self, context_length: int, vocab_size: int, transformer_width: int, transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+ self.context_length = context_length
+ self.transformer = Transformer(width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+
+ self.vocab_size = vocab_size
+ self.token_embedding = nn.Embedding(vocab_size, transformer_width)
+ self.positional_embedding = paddle.create_parameter((self.context_length, transformer_width), 'float32')
+ self.ln_final = nn.LayerNorm(transformer_width)
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # mask = paddle.empty((self.context_length, self.context_length),dtype='float32')
+ # mask.fill_(float("-inf"))
+ #mask.triu_(1) # zero out the lower diagonal
+
+ mask = paddle.ones((self.context_length, self.context_length)) * float("-inf")
+ mask = paddle.triu(mask, diagonal=1)
+
+ return mask
+
+ def forward(self, text):
+ x = self.token_embedding(text) # [batch_size, n_ctx, d_model]
+ x = x + self.positional_embedding
+ x = x.transpose((1, 0, 2)) # NLD -> LND
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2)) # LND -> NLD
+ x = self.ln_final(x)
+ return x
+
+
+class CLIP(nn.Layer):
+
+ def __init__(
+ self,
+ embed_dim: int,
+ # vision
+ image_resolution: int,
+ vision_layers: Union[Tuple[int, int, int, int], int],
+ vision_width: int,
+ vision_patch_size: int,
+ # text
+ context_length: int,
+ vocab_size: int,
+ transformer_width: int,
+ transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+
+ self.context_length = context_length
+ if isinstance(vision_layers, (tuple, list)):
+ vision_heads = vision_width * 32 // 64
+ self.visual = ModifiedResNet(layers=vision_layers,
+ output_dim=embed_dim,
+ heads=vision_heads,
+ input_resolution=image_resolution,
+ width=vision_width)
+ else:
+ vision_heads = vision_width // 64
+ self.visual = VisualTransformer(input_resolution=image_resolution,
+ patch_size=vision_patch_size,
+ width=vision_width,
+ layers=vision_layers,
+ heads=vision_heads,
+ output_dim=embed_dim)
+
+ self.transformer = Transformer(width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+
+ self.vocab_size = vocab_size
+ self.token_embedding = nn.Embedding(vocab_size, transformer_width)
+ self.positional_embedding = paddle.create_parameter((self.context_length, transformer_width), 'float32')
+ self.ln_final = nn.LayerNorm(transformer_width)
+
+ self.text_projection = paddle.create_parameter((transformer_width, embed_dim), 'float32')
+ self.logit_scale = paddle.create_parameter((1, ), 'float32')
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # mask = paddle.empty((self.context_length, self.context_length),dtype='float32')
+ # mask.fill_(float("-inf"))
+ #mask.triu_(1) # zero out the lower diagonal
+
+ mask = paddle.ones((self.context_length, self.context_length)) * float("-inf")
+ mask = paddle.triu(mask, diagonal=1)
+
+ return mask
+
+ def encode_image(self, image):
+ return self.visual(image)
+
+ def encode_text(self, text):
+ x = self.token_embedding(text) # [batch_size, n_ctx, d_model]
+ x = x + self.positional_embedding
+ x = x.transpose((1, 0, 2)) # NLD -> LND
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2)) # LND -> NLD
+ x = self.ln_final(x)
+ idx = text.numpy().argmax(-1)
+ idx = list(idx)
+ x = [x[i:i + 1, int(j), :] for i, j in enumerate(idx)]
+ x = paddle.concat(x, 0)
+ x = paddle.matmul(x, self.text_projection)
+ return x
+
+ def forward(self, image, text):
+ image_features = self.encode_image(image)
+ text_features = self.encode_text(text)
+
+ # normalized features
+ image_features = image_features / image_features.norm(dim=-1, keepdim=True)
+ text_features = text_features / text_features.norm(dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_image = paddle.matmul(logit_scale * image_features, text_features.t())
+ logits_per_text = paddle.matmul(logit_scale * text_features, image_features.t())
+
+ # shape = [global_batch_size, global_batch_size]
+ return logits_per_image, logits_per_text
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/simple_tokenizer.py b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/simple_tokenizer.py
new file mode 100755
index 000000000..4eaf82e9e
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/simple_tokenizer.py
@@ -0,0 +1,135 @@
+import gzip
+import html
+import os
+from functools import lru_cache
+
+import ftfy
+import regex as re
+
+
+@lru_cache()
+def default_bpe():
+ return os.path.join(os.path.dirname(os.path.abspath(__file__)), "../assets/bpe_simple_vocab_16e6.txt.gz")
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a corresponding list of unicode strings.
+ The reversible bpe codes work on unicode strings.
+ This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
+ When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
+ This is a signficant percentage of your normal, say, 32K bpe vocab.
+ To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ And avoids mapping to whitespace/control characters the bpe code barfs on.
+ """
+ bs = list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """Return set of symbol pairs in a word.
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+def basic_clean(text):
+ text = ftfy.fix_text(text)
+ text = html.unescape(html.unescape(text))
+ return text.strip()
+
+
+def whitespace_clean(text):
+ text = re.sub(r'\s+', ' ', text)
+ text = text.strip()
+ return text
+
+
+class SimpleTokenizer(object):
+
+ def __init__(self, bpe_path: str = default_bpe()):
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
+ merges = merges[1:49152 - 256 - 2 + 1]
+ merges = [tuple(merge.split()) for merge in merges]
+ vocab = list(bytes_to_unicode().values())
+ vocab = vocab + [v + '' for v in vocab]
+ for merge in merges:
+ vocab.append(''.join(merge))
+ vocab.extend(['<|startoftext|>', '<|endoftext|>'])
+ self.encoder = dict(zip(vocab, range(len(vocab))))
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.bpe_ranks = dict(zip(merges, range(len(merges))))
+ self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
+ self.pat = re.compile(
+ r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
+ re.IGNORECASE)
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token[:-1]) + (token[-1] + '', )
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token + ''
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ new_word.extend(word[i:j])
+ i = j
+ except:
+ new_word.extend(word[i:])
+ break
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = ' '.join(word)
+ self.cache[token] = word
+ return word
+
+ def encode(self, text):
+ bpe_tokens = []
+ text = whitespace_clean(basic_clean(text)).lower()
+ for token in re.findall(self.pat, text):
+ token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
+ bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
+ return bpe_tokens
+
+ def decode(self, tokens):
+ text = ''.join([self.decoder[token] for token in tokens])
+ text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('', ' ')
+ return text
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/utils.py b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/utils.py
new file mode 100755
index 000000000..b5d417144
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/clip/clip/utils.py
@@ -0,0 +1,88 @@
+import os
+from typing import List
+from typing import Union
+
+import numpy as np
+import paddle
+from paddle.utils import download
+from paddle.vision.transforms import CenterCrop
+from paddle.vision.transforms import Compose
+from paddle.vision.transforms import Normalize
+from paddle.vision.transforms import Resize
+from paddle.vision.transforms import ToTensor
+
+from .model import CLIP
+from .model import TextTransformer
+from .simple_tokenizer import SimpleTokenizer
+
+__all__ = ['transform', 'tokenize', 'build_model']
+
+MODEL_NAMES = ['VITL14']
+
+URL = {'VITL14': os.path.join(os.path.dirname(__file__), 'pre_trained', 'vitl14_textencoder.pdparams')}
+
+MEAN, STD = (0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)
+_tokenizer = SimpleTokenizer()
+
+transform = Compose([
+ Resize(224, interpolation='bicubic'),
+ CenterCrop(224), lambda image: image.convert('RGB'),
+ ToTensor(),
+ Normalize(mean=MEAN, std=STD), lambda t: t.unsqueeze_(0)
+])
+
+
+def tokenize(texts: Union[str, List[str]], context_length: int = 77):
+ """
+ Returns the tokenized representation of given input string(s)
+
+ Parameters
+ ----------
+ texts : Union[str, List[str]]
+ An input string or a list of input strings to tokenize
+
+ context_length : int
+ The context length to use; all CLIP models use 77 as the context length
+
+ Returns
+ -------
+ A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
+ """
+ if isinstance(texts, str):
+ texts = [texts]
+
+ sot_token = _tokenizer.encoder["<|startoftext|>"]
+ eot_token = _tokenizer.encoder["<|endoftext|>"]
+ all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
+ result = paddle.zeros((len(all_tokens), context_length), dtype='int64')
+
+ for i, tokens in enumerate(all_tokens):
+ if len(tokens) > context_length:
+ raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
+ result[i, :len(tokens)] = paddle.Tensor(np.array(tokens))
+
+ return result
+
+
+def build_model(name='VITL14'):
+ assert name in MODEL_NAMES, f"model name must be one of {MODEL_NAMES}"
+ name2model = {'VITL14': build_vitl14_language_model}
+ model = name2model[name]()
+ weight = URL[name]
+ sd = paddle.load(weight)
+ state_dict = model.state_dict()
+ for key, value in sd.items():
+ if key in state_dict:
+ state_dict[key] = value
+ model.load_dict(state_dict)
+ model.eval()
+ return model
+
+
+def build_vitl14_language_model():
+ model = TextTransformer(context_length=77,
+ vocab_size=49408,
+ transformer_width=768,
+ transformer_heads=12,
+ transformer_layers=12)
+ return model
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/__init__.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/__init__.py
new file mode 100644
index 000000000..7f41816d7
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/__init__.py
@@ -0,0 +1,20 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+__version__ = "0.2.4"
+
+from .models import AutoencoderKL, UNet2DConditionModel, UNet2DModel, VQModel
+
+from .schedulers import (DDIMScheduler, DDPMScheduler, KarrasVeScheduler, PNDMScheduler, SchedulerMixin,
+ ScoreSdeVeScheduler, LMSDiscreteScheduler)
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/configuration_utils.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/configuration_utils.py
new file mode 100644
index 000000000..c90ebd5be
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/configuration_utils.py
@@ -0,0 +1,312 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" ConfigMixinuration base class and utilities."""
+import functools
+import inspect
+import json
+import os
+import re
+from collections import OrderedDict
+from typing import Any
+from typing import Dict
+from typing import Tuple
+from typing import Union
+
+from requests import HTTPError
+
+from paddlehub.common.logger import logger
+
+HUGGINGFACE_CO_RESOLVE_ENDPOINT = "HUGGINGFACE_CO_RESOLVE_ENDPOINT"
+DIFFUSERS_CACHE = "./caches"
+
+_re_configuration_file = re.compile(r"config\.(.*)\.json")
+
+
+class ConfigMixin:
+ r"""
+ Base class for all configuration classes. Handles a few parameters common to all models' configurations as well as
+ methods for loading/downloading/saving configurations.
+
+ """
+ config_name = "model_config.json"
+ ignore_for_config = []
+
+ def register_to_config(self, **kwargs):
+ if self.config_name is None:
+ raise NotImplementedError(f"Make sure that {self.__class__} has defined a class name `config_name`")
+ kwargs["_class_name"] = self.__class__.__name__
+ kwargs["_diffusers_version"] = "0.0.1"
+
+ for key, value in kwargs.items():
+ try:
+ setattr(self, key, value)
+ except AttributeError as err:
+ logger.error(f"Can't set {key} with value {value} for {self}")
+ raise err
+
+ if not hasattr(self, "_internal_dict"):
+ internal_dict = kwargs
+ else:
+ previous_dict = dict(self._internal_dict)
+ internal_dict = {**self._internal_dict, **kwargs}
+ logger.debug(f"Updating config from {previous_dict} to {internal_dict}")
+
+ self._internal_dict = FrozenDict(internal_dict)
+
+ def save_config(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
+ """
+ Save a configuration object to the directory `save_directory`, so that it can be re-loaded using the
+ [`~ConfigMixin.from_config`] class method.
+
+ Args:
+ save_directory (`str` or `os.PathLike`):
+ Directory where the configuration JSON file will be saved (will be created if it does not exist).
+ kwargs:
+ Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
+ """
+ if os.path.isfile(save_directory):
+ raise AssertionError(f"Provided path ({save_directory}) should be a directory, not a file")
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ # If we save using the predefined names, we can load using `from_config`
+ output_config_file = os.path.join(save_directory, self.config_name)
+
+ self.to_json_file(output_config_file)
+ logger.info(f"ConfigMixinuration saved in {output_config_file}")
+
+ @classmethod
+ def from_config(cls, pretrained_model_name_or_path: Union[str, os.PathLike], return_unused_kwargs=False, **kwargs):
+ config_dict = cls.get_config_dict(pretrained_model_name_or_path=pretrained_model_name_or_path, **kwargs)
+
+ init_dict, unused_kwargs = cls.extract_init_dict(config_dict, **kwargs)
+
+ model = cls(**init_dict)
+
+ if return_unused_kwargs:
+ return model, unused_kwargs
+ else:
+ return model
+
+ @classmethod
+ def get_config_dict(cls, pretrained_model_name_or_path: Union[str, os.PathLike],
+ **kwargs) -> Tuple[Dict[str, Any], Dict[str, Any]]:
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ revision = kwargs.pop("revision", None)
+ subfolder = kwargs.pop("subfolder", None)
+
+ user_agent = {"file_type": "config"}
+
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+
+ if cls.config_name is None:
+ raise ValueError(
+ "`self.config_name` is not defined. Note that one should not load a config from "
+ "`ConfigMixin`. Please make sure to define `config_name` in a class inheriting from `ConfigMixin`")
+
+ if os.path.isfile(pretrained_model_name_or_path):
+ config_file = pretrained_model_name_or_path
+ elif os.path.isdir(pretrained_model_name_or_path):
+ if os.path.isfile(os.path.join(pretrained_model_name_or_path, cls.config_name)):
+ # Load from a PyTorch checkpoint
+ config_file = os.path.join(pretrained_model_name_or_path, cls.config_name)
+ elif subfolder is not None and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)):
+ config_file = os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
+ else:
+ raise EnvironmentError(
+ f"Error no file named {cls.config_name} found in directory {pretrained_model_name_or_path}.")
+ else:
+ try:
+ # Load from URL or cache if already cached
+ from huggingface_hub import hf_hub_download
+ config_file = hf_hub_download(
+ pretrained_model_name_or_path,
+ filename=cls.config_name,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ user_agent=user_agent,
+ subfolder=subfolder,
+ )
+
+ except HTTPError as err:
+ raise EnvironmentError("There was a specific connection error when trying to load"
+ f" {pretrained_model_name_or_path}:\n{err}")
+ except ValueError:
+ raise EnvironmentError(
+ f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this model, couldn't find it"
+ f" in the cached files and it looks like {pretrained_model_name_or_path} is not the path to a"
+ f" directory containing a {cls.config_name} file.\nCheckout your internet connection or see how to"
+ " run the library in offline mode at"
+ " 'https://huggingface.co/docs/diffusers/installation#offline-mode'.")
+ except EnvironmentError:
+ raise EnvironmentError(
+ f"Can't load config for '{pretrained_model_name_or_path}'. If you were trying to load it from "
+ "'https://huggingface.co/models', make sure you don't have a local directory with the same name. "
+ f"Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a directory "
+ f"containing a {cls.config_name} file")
+
+ try:
+ # Load config dict
+ config_dict = cls._dict_from_json_file(config_file)
+ except (json.JSONDecodeError, UnicodeDecodeError):
+ raise EnvironmentError(f"It looks like the config file at '{config_file}' is not a valid JSON file.")
+
+ return config_dict
+
+ @classmethod
+ def extract_init_dict(cls, config_dict, **kwargs):
+ expected_keys = set(dict(inspect.signature(cls.__init__).parameters).keys())
+ expected_keys.remove("self")
+ # remove general kwargs if present in dict
+ if "kwargs" in expected_keys:
+ expected_keys.remove("kwargs")
+ # remove keys to be ignored
+ if len(cls.ignore_for_config) > 0:
+ expected_keys = expected_keys - set(cls.ignore_for_config)
+ init_dict = {}
+ for key in expected_keys:
+ if key in kwargs:
+ # overwrite key
+ init_dict[key] = kwargs.pop(key)
+ elif key in config_dict:
+ # use value from config dict
+ init_dict[key] = config_dict.pop(key)
+
+ unused_kwargs = config_dict.update(kwargs)
+
+ passed_keys = set(init_dict.keys())
+ if len(expected_keys - passed_keys) > 0:
+ logger.warning(
+ f"{expected_keys - passed_keys} was not found in config. Values will be initialized to default values.")
+
+ return init_dict, unused_kwargs
+
+ @classmethod
+ def _dict_from_json_file(cls, json_file: Union[str, os.PathLike]):
+ with open(json_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ return json.loads(text)
+
+ def __repr__(self):
+ return f"{self.__class__.__name__} {self.to_json_string()}"
+
+ @property
+ def config(self) -> Dict[str, Any]:
+ return self._internal_dict
+
+ def to_json_string(self) -> str:
+ """
+ Serializes this instance to a JSON string.
+
+ Returns:
+ `str`: String containing all the attributes that make up this configuration instance in JSON format.
+ """
+ config_dict = self._internal_dict if hasattr(self, "_internal_dict") else {}
+ return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
+
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this configuration instance's parameters will be saved.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ writer.write(self.to_json_string())
+
+
+class FrozenDict(OrderedDict):
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ for key, value in self.items():
+ setattr(self, key, value)
+
+ self.__frozen = True
+
+ def __delitem__(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``__delitem__`` on a {self.__class__.__name__} instance.")
+
+ def setdefault(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``setdefault`` on a {self.__class__.__name__} instance.")
+
+ def pop(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``pop`` on a {self.__class__.__name__} instance.")
+
+ def update(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``update`` on a {self.__class__.__name__} instance.")
+
+ def __setattr__(self, name, value):
+ if hasattr(self, "__frozen") and self.__frozen:
+ raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
+ super().__setattr__(name, value)
+
+ def __setitem__(self, name, value):
+ if hasattr(self, "__frozen") and self.__frozen:
+ raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
+ super().__setitem__(name, value)
+
+
+def register_to_config(init):
+ """
+ Decorator to apply on the init of classes inheriting from `ConfigMixin` so that all the arguments are automatically
+ sent to `self.register_for_config`. To ignore a specific argument accepted by the init but that shouldn't be
+ registered in the config, use the `ignore_for_config` class variable
+
+ Warning: Once decorated, all private arguments (beginning with an underscore) are trashed and not sent to the init!
+ """
+
+ @functools.wraps(init)
+ def inner_init(self, *args, **kwargs):
+ # Ignore private kwargs in the init.
+ init_kwargs = {k: v for k, v in kwargs.items() if not k.startswith("_")}
+ init(self, *args, **init_kwargs)
+ if not isinstance(self, ConfigMixin):
+ raise RuntimeError(
+ f"`@register_for_config` was applied to {self.__class__.__name__} init method, but this class does "
+ "not inherit from `ConfigMixin`.")
+
+ ignore = getattr(self, "ignore_for_config", [])
+ # Get positional arguments aligned with kwargs
+ new_kwargs = {}
+ signature = inspect.signature(init)
+ parameters = {
+ name: p.default
+ for i, (name, p) in enumerate(signature.parameters.items()) if i > 0 and name not in ignore
+ }
+ for arg, name in zip(args, parameters.keys()):
+ new_kwargs[name] = arg
+
+ # Then add all kwargs
+ new_kwargs.update({
+ k: init_kwargs.get(k, default)
+ for k, default in parameters.items() if k not in ignore and k not in new_kwargs
+ })
+ getattr(self, "register_to_config")(**new_kwargs)
+
+ return inner_init
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/README.md b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/README.md
new file mode 100644
index 000000000..e786fe518
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/README.md
@@ -0,0 +1,11 @@
+# Models
+
+- Models: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to denoise a noisy input to an image. Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet
+
+## API
+
+TODO(Suraj, Patrick)
+
+## Examples
+
+TODO(Suraj, Patrick)
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/__init__.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/__init__.py
new file mode 100644
index 000000000..f55cc88a8
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/__init__.py
@@ -0,0 +1,20 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .unet_2d import UNet2DModel
+from .unet_2d_condition import UNet2DConditionModel
+from .vae import AutoencoderKL
+from .vae import VQModel
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/attention.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/attention.py
new file mode 100644
index 000000000..29d0e73a7
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/attention.py
@@ -0,0 +1,465 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+from inspect import isfunction
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def finfo(dtype):
+ if dtype == paddle.float32:
+ return np.finfo(np.float32)
+ if dtype == paddle.float16:
+ return np.finfo(np.float16)
+ if dtype == paddle.float64:
+ return np.finfo(np.float64)
+
+
+paddle.finfo = finfo
+
+
+class AttentionBlockNew(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other. Originally ported from here, but adapted
+ to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ Uses three q, k, v linear layers to compute attention
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_head_channels=None,
+ num_groups=32,
+ rescale_output_factor=1.0,
+ eps=1e-5,
+ ):
+ super().__init__()
+ self.channels = channels
+
+ self.num_heads = channels // num_head_channels if num_head_channels is not None else 1
+ self.num_head_size = num_head_channels
+ self.group_norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=eps)
+
+ # define q,k,v as linear layers
+ self.query = nn.Linear(channels, channels)
+ self.key = nn.Linear(channels, channels)
+ self.value = nn.Linear(channels, channels)
+
+ self.rescale_output_factor = rescale_output_factor
+ self.proj_attn = nn.Linear(channels, channels)
+
+ def transpose_for_scores(self, projection: paddle.Tensor) -> paddle.Tensor:
+ new_projection_shape = projection.shape[:-1] + [self.num_heads, -1]
+ # move heads to 2nd position (B, T, H * D) -> (B, T, H, D) -> (B, H, T, D)
+ new_projection = projection.reshape(new_projection_shape).transpose([0, 2, 1, 3])
+ return new_projection
+
+ def forward(self, hidden_states):
+ residual = hidden_states
+ batch, channel, height, width = hidden_states.shape
+
+ # norm
+ hidden_states = self.group_norm(hidden_states)
+
+ hidden_states = hidden_states.reshape([batch, channel, height * width]).transpose([0, 2, 1])
+
+ # proj to q, k, v
+ query_proj = self.query(hidden_states)
+ key_proj = self.key(hidden_states)
+ value_proj = self.value(hidden_states)
+
+ # transpose
+ query_states = self.transpose_for_scores(query_proj)
+ key_states = self.transpose_for_scores(key_proj)
+ value_states = self.transpose_for_scores(value_proj)
+
+ # get scores
+ scale = 1 / math.sqrt(math.sqrt(self.channels / self.num_heads))
+ attention_scores = paddle.matmul(query_states * scale, key_states * scale, transpose_y=True)
+ attention_probs = F.softmax(attention_scores.astype("float32"), axis=-1).astype(attention_scores.dtype)
+
+ # compute attention output
+ context_states = paddle.matmul(attention_probs, value_states)
+
+ context_states = context_states.transpose([0, 2, 1, 3])
+ new_context_states_shape = context_states.shape[:-2] + [
+ self.channels,
+ ]
+ context_states = context_states.reshape(new_context_states_shape)
+
+ # compute next hidden_states
+ hidden_states = self.proj_attn(context_states)
+ hidden_states = hidden_states.transpose([0, 2, 1]).reshape([batch, channel, height, width])
+
+ # res connect and rescale
+ hidden_states = (hidden_states + residual) / self.rescale_output_factor
+ return hidden_states
+
+ def set_weight(self, attn_layer):
+ self.group_norm.weight.set_value(attn_layer.norm.weight)
+ self.group_norm.bias.set_value(attn_layer.norm.bias)
+
+ if hasattr(attn_layer, "q"):
+ self.query.weight.set_value(attn_layer.q.weight[:, :, 0, 0])
+ self.key.weight.set_value(attn_layer.k.weight[:, :, 0, 0])
+ self.value.weight.set_value(attn_layer.v.weight[:, :, 0, 0])
+
+ self.query.bias.set_value(attn_layer.q.bias)
+ self.key.bias.set_value(attn_layer.k.bias)
+ self.value.bias.set_value(attn_layer.v.bias)
+
+ self.proj_attn.weight.set_value(attn_layer.proj_out.weight[:, :, 0, 0])
+ self.proj_attn.bias.set_value(attn_layer.proj_out.bias)
+ elif hasattr(attn_layer, "NIN_0"):
+ self.query.weight.set_value(attn_layer.NIN_0.W.t())
+ self.key.weight.set_value(attn_layer.NIN_1.W.t())
+ self.value.weight.set_value(attn_layer.NIN_2.W.t())
+
+ self.query.bias.set_value(attn_layer.NIN_0.b)
+ self.key.bias.set_value(attn_layer.NIN_1.b)
+ self.value.bias.set_value(attn_layer.NIN_2.b)
+
+ self.proj_attn.weight.set_value(attn_layer.NIN_3.W.t())
+ self.proj_attn.bias.set_value(attn_layer.NIN_3.b)
+
+ self.group_norm.weight.set_value(attn_layer.GroupNorm_0.weight)
+ self.group_norm.bias.set_value(attn_layer.GroupNorm_0.bias)
+ else:
+ qkv_weight = attn_layer.qkv.weight.reshape(
+ [self.num_heads, 3 * self.channels // self.num_heads, self.channels])
+ qkv_bias = attn_layer.qkv.bias.reshape([self.num_heads, 3 * self.channels // self.num_heads])
+
+ q_w, k_w, v_w = qkv_weight.split(self.channels // self.num_heads, axis=1)
+ q_b, k_b, v_b = qkv_bias.split(self.channels // self.num_heads, axis=1)
+
+ self.query.weight.set_value(q_w.reshape([-1, self.channels]))
+ self.key.weight.set_value(k_w.reshape([-1, self.channels]))
+ self.value.weight.set_value(v_w.reshape([-1, self.channels]))
+
+ self.query.bias.set_value(q_b.flatten())
+ self.key.bias.set_value(k_b.flatten())
+ self.value.bias.set_value(v_b.flatten())
+
+ self.proj_attn.weight.set_value(attn_layer.proj.weight[:, :, 0])
+ self.proj_attn.bias.set_value(attn_layer.proj.bias)
+
+
+class SpatialTransformer(nn.Layer):
+ """
+ Transformer block for image-like data. First, project the input (aka embedding) and reshape to b, t, d. Then apply
+ standard transformer action. Finally, reshape to image
+ """
+
+ def __init__(self, in_channels, n_heads, d_head, depth=1, dropout=0.0, context_dim=None):
+ super().__init__()
+ self.n_heads = n_heads
+ self.d_head = d_head
+ self.in_channels = in_channels
+ inner_dim = n_heads * d_head
+ self.norm = nn.GroupNorm(num_groups=32, num_channels=in_channels, epsilon=1e-6)
+
+ self.proj_in = nn.Conv2D(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
+
+ self.transformer_blocks = nn.LayerList([
+ BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
+ for d in range(depth)
+ ])
+
+ self.proj_out = nn.Conv2D(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x, context=None):
+ # note: if no context is given, cross-attention defaults to self-attention
+ b, c, h, w = x.shape
+ x_in = x
+ x = self.norm(x)
+ x = self.proj_in(x)
+ x = x.transpose([0, 2, 3, 1]).reshape([b, h * w, c])
+ for block in self.transformer_blocks:
+ x = block(x, context=context)
+ x = x.reshape([b, h, w, c]).transpose([0, 3, 1, 2])
+ x = self.proj_out(x)
+ return x + x_in
+
+ def set_weight(self, layer):
+ self.norm = layer.norm
+ self.proj_in = layer.proj_in
+ self.transformer_blocks = layer.transformer_blocks
+ self.proj_out = layer.proj_out
+
+
+class BasicTransformerBlock(nn.Layer):
+
+ def __init__(self, dim, n_heads, d_head, dropout=0.0, context_dim=None, gated_ff=True, checkpoint=True):
+ super().__init__()
+ self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head,
+ dropout=dropout) # is a self-attention
+ self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
+ self.attn2 = CrossAttention(query_dim=dim,
+ context_dim=context_dim,
+ heads=n_heads,
+ dim_head=d_head,
+ dropout=dropout) # is self-attn if context is none
+ self.norm1 = nn.LayerNorm(dim)
+ self.norm2 = nn.LayerNorm(dim)
+ self.norm3 = nn.LayerNorm(dim)
+ self.checkpoint = checkpoint
+
+ def forward(self, x, context=None):
+ x = self.attn1(self.norm1(x)) + x
+ x = self.attn2(self.norm2(x), context=context) + x
+ x = self.ff(self.norm3(x)) + x
+ return x
+
+
+class CrossAttention(nn.Layer):
+
+ def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.0):
+ super().__init__()
+ inner_dim = dim_head * heads
+ context_dim = default(context_dim, query_dim)
+
+ self.scale = dim_head**-0.5
+ self.heads = heads
+
+ self.to_q = nn.Linear(query_dim, inner_dim, bias_attr=False)
+ self.to_k = nn.Linear(context_dim, inner_dim, bias_attr=False)
+ self.to_v = nn.Linear(context_dim, inner_dim, bias_attr=False)
+
+ self.to_out = nn.Sequential(nn.Linear(inner_dim, query_dim), nn.Dropout(dropout))
+
+ def reshape_heads_to_batch_dim(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.heads
+ tensor = tensor.reshape([batch_size, seq_len, head_size, dim // head_size])
+ tensor = tensor.transpose([0, 2, 1, 3]).reshape([batch_size * head_size, seq_len, dim // head_size])
+ return tensor
+
+ def reshape_batch_dim_to_heads(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.heads
+ tensor = tensor.reshape([batch_size // head_size, head_size, seq_len, dim])
+ tensor = tensor.transpose([0, 2, 1, 3]).reshape([batch_size // head_size, seq_len, dim * head_size])
+ return tensor
+
+ def forward(self, x, context=None, mask=None):
+ batch_size, sequence_length, dim = x.shape
+
+ h = self.heads
+
+ q = self.to_q(x)
+ context = default(context, x)
+ k = self.to_k(context)
+ v = self.to_v(context)
+
+ q = self.reshape_heads_to_batch_dim(q)
+ k = self.reshape_heads_to_batch_dim(k)
+ v = self.reshape_heads_to_batch_dim(v)
+
+ sim = paddle.einsum("b i d, b j d -> b i j", q * self.scale, k)
+
+ if exists(mask):
+ mask = mask.reshape([batch_size, -1])
+ max_neg_value = -paddle.finfo(sim.dtype).max
+ mask = mask[:, None, :].repeat(h, 1, 1)
+ sim.masked_fill_(~mask, max_neg_value)
+
+ # attention, what we cannot get enough of
+ attn = F.softmax(sim, axis=-1)
+
+ out = paddle.einsum("b i j, b j d -> b i d", attn, v)
+ out = self.reshape_batch_dim_to_heads(out)
+ return self.to_out(out)
+
+
+class FeedForward(nn.Layer):
+
+ def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.0):
+ super().__init__()
+ inner_dim = int(dim * mult)
+ dim_out = default(dim_out, dim)
+ project_in = nn.Sequential(nn.Linear(dim, inner_dim), nn.GELU()) if not glu else GEGLU(dim, inner_dim)
+
+ self.net = nn.Sequential(project_in, nn.Dropout(dropout), nn.Linear(inner_dim, dim_out))
+
+ def forward(self, x):
+ return self.net(x)
+
+
+# feedforward
+class GEGLU(nn.Layer):
+
+ def __init__(self, dim_in, dim_out):
+ super().__init__()
+ self.proj = nn.Linear(dim_in, dim_out * 2)
+
+ def forward(self, x):
+ x, gate = self.proj(x).chunk(2, axis=-1)
+ return x * F.gelu(gate)
+
+
+# TODO(Patrick) - remove once all weights have been converted -> not needed anymore then
+class NIN(nn.Layer):
+
+ def __init__(self, in_dim, num_units, init_scale=0.1):
+ super().__init__()
+ self.W = self.create_parameter(shape=[in_dim, num_units], default_initializer=nn.initializer.Constant(0.))
+ self.b = self.create_parameter(shape=[
+ num_units,
+ ],
+ is_bias=True,
+ default_initializer=nn.initializer.Constant(0.))
+
+
+def exists(val):
+ return val is not None
+
+
+def default(val, d):
+ if exists(val):
+ return val
+ return d() if isfunction(d) else d
+
+
+# the main attention block that is used for all models
+class AttentionBlock(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other.
+
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_heads=1,
+ num_head_channels=None,
+ num_groups=32,
+ encoder_channels=None,
+ overwrite_qkv=False,
+ overwrite_linear=False,
+ rescale_output_factor=1.0,
+ eps=1e-5,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels is None:
+ self.num_heads = num_heads
+ else:
+ assert (channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+
+ self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=eps)
+ self.qkv = nn.Conv1D(channels, channels * 3, 1)
+ self.n_heads = self.num_heads
+ self.rescale_output_factor = rescale_output_factor
+
+ if encoder_channels is not None:
+ self.encoder_kv = nn.Conv1D(encoder_channels, channels * 2, 1)
+
+ self.proj = nn.Conv1D(channels, channels, 1)
+
+ self.overwrite_qkv = overwrite_qkv
+ self.overwrite_linear = overwrite_linear
+
+ if overwrite_qkv:
+ in_channels = channels
+ self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=1e-6)
+ self.q = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.k = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.v = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.proj_out = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ elif self.overwrite_linear:
+ num_groups = min(channels // 4, 32)
+ self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=1e-6)
+ self.NIN_0 = NIN(channels, channels)
+ self.NIN_1 = NIN(channels, channels)
+ self.NIN_2 = NIN(channels, channels)
+ self.NIN_3 = NIN(channels, channels)
+
+ self.GroupNorm_0 = nn.GroupNorm(num_groups=num_groups, num_channels=channels, epsilon=1e-6)
+ else:
+ self.proj_out = nn.Conv1D(channels, channels, 1)
+ self.set_weights(self)
+
+ self.is_overwritten = False
+
+ def set_weights(self, layer):
+ if self.overwrite_qkv:
+ qkv_weight = paddle.concat([layer.q.weight, layer.k.weight, layer.v.weight], axis=0)[:, :, :, 0]
+ qkv_bias = paddle.concat([layer.q.bias, layer.k.bias, layer.v.bias], axis=0)
+
+ self.qkv.weight.set_value(qkv_weight)
+ self.qkv.bias.set_value(qkv_bias)
+
+ proj_out = nn.Conv1D(self.channels, self.channels, 1)
+ proj_out.weight.set_value(layer.proj_out.weight[:, :, :, 0])
+ proj_out.bias.set_value(layer.proj_out.bias)
+
+ self.proj = proj_out
+ elif self.overwrite_linear:
+ self.qkv.weight.set_value(
+ paddle.concat([self.NIN_0.W.t(), self.NIN_1.W.t(), self.NIN_2.W.t()], axis=0)[:, :, None])
+ self.qkv.bias.set_value(paddle.concat([self.NIN_0.b, self.NIN_1.b, self.NIN_2.b], axis=0))
+
+ self.proj.weight.set_value(self.NIN_3.W.t()[:, :, None])
+ self.proj.bias.set_value(self.NIN_3.b)
+
+ self.norm.weight.set_value(self.GroupNorm_0.weight)
+ self.norm.bias.set_value(self.GroupNorm_0.bias)
+ else:
+ self.proj.weight.set_value(self.proj_out.weight)
+ self.proj.bias.set_value(self.proj_out.bias)
+
+ def forward(self, x, encoder_out=None):
+ if not self.is_overwritten and (self.overwrite_qkv or self.overwrite_linear):
+ self.set_weights(self)
+ self.is_overwritten = True
+
+ b, c, *spatial = x.shape
+ hid_states = self.norm(x).reshape([b, c, -1])
+
+ qkv = self.qkv(hid_states)
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.reshape([bs * self.n_heads, ch * 3, length]).split(ch, axis=1)
+
+ if encoder_out is not None:
+ encoder_kv = self.encoder_kv(encoder_out)
+ assert encoder_kv.shape[1] == self.n_heads * ch * 2
+ ek, ev = encoder_kv.reshape([bs * self.n_heads, ch * 2, -1]).split(ch, axis=1)
+ k = paddle.concat([ek, k], axis=-1)
+ v = paddle.concat([ev, v], axis=-1)
+
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
+ weight = F.softmax(weight.astype("float32"), axis=-1).astype(weight.dtype)
+
+ a = paddle.einsum("bts,bcs->bct", weight, v)
+ h = a.reshape([bs, -1, length])
+
+ h = self.proj(h)
+ h = h.reshape([b, c, *spatial])
+
+ result = x + h
+
+ result = result / self.rescale_output_factor
+
+ return result
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/embeddings.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/embeddings.py
new file mode 100644
index 000000000..3e826193b
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/embeddings.py
@@ -0,0 +1,116 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def get_timestep_embedding(timesteps,
+ embedding_dim,
+ flip_sin_to_cos=False,
+ downscale_freq_shift=1,
+ scale=1,
+ max_period=10000):
+ """
+ This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
+
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
+ embeddings. :return: an [N x dim] Tensor of positional embeddings.
+ """
+ assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
+
+ half_dim = embedding_dim // 2
+ exponent = -math.log(max_period) * paddle.arange(start=0, end=half_dim, dtype="float32")
+ exponent = exponent / (half_dim - downscale_freq_shift)
+
+ emb = paddle.exp(exponent)
+ emb = timesteps[:, None].astype("float32") * emb[None, :]
+
+ # scale embeddings
+ emb = scale * emb
+
+ # concat sine and cosine embeddings
+ emb = paddle.concat([paddle.sin(emb), paddle.cos(emb)], axis=-1)
+
+ # flip sine and cosine embeddings
+ if flip_sin_to_cos:
+ emb = paddle.concat([emb[:, half_dim:], emb[:, :half_dim]], axis=-1)
+
+ # zero pad
+ if embedding_dim % 2 == 1:
+ emb = paddle.concat(emb, paddle.zeros([emb.shape[0], 1]), axis=-1)
+ return emb
+
+
+class TimestepEmbedding(nn.Layer):
+
+ def __init__(self, channel, time_embed_dim, act_fn="silu"):
+ super().__init__()
+
+ self.linear_1 = nn.Linear(channel, time_embed_dim)
+ self.act = None
+ if act_fn == "silu":
+ self.act = nn.Silu()
+ self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim)
+
+ def forward(self, sample):
+ sample = self.linear_1(sample)
+
+ if self.act is not None:
+ sample = self.act(sample)
+
+ sample = self.linear_2(sample)
+ return sample
+
+
+class Timesteps(nn.Layer):
+
+ def __init__(self, num_channels, flip_sin_to_cos, downscale_freq_shift):
+ super().__init__()
+ self.num_channels = num_channels
+ self.flip_sin_to_cos = flip_sin_to_cos
+ self.downscale_freq_shift = downscale_freq_shift
+
+ def forward(self, timesteps):
+ t_emb = get_timestep_embedding(
+ timesteps,
+ self.num_channels,
+ flip_sin_to_cos=self.flip_sin_to_cos,
+ downscale_freq_shift=self.downscale_freq_shift,
+ )
+ return t_emb
+
+
+class GaussianFourierProjection(nn.Layer):
+ """Gaussian Fourier embeddings for noise levels."""
+
+ def __init__(self, embedding_size=256, scale=1.0):
+ super().__init__()
+ self.register_buffer("weight", paddle.randn((embedding_size, )) * scale)
+
+ # to delete later
+ self.register_buffer("W", paddle.randn((embedding_size, )) * scale)
+
+ self.weight = self.W
+
+ def forward(self, x):
+ x = paddle.log(x)
+ x_proj = x[:, None] * self.weight[None, :] * 2 * np.pi
+ out = paddle.concat([paddle.sin(x_proj), paddle.cos(x_proj)], axis=-1)
+ return out
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/resnet.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/resnet.py
new file mode 100644
index 000000000..944bc11cd
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/resnet.py
@@ -0,0 +1,515 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from functools import partial
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def pad_new(x, pad, mode="constant", value=0):
+ new_pad = []
+ for _ in range(x.ndim * 2 - len(pad)):
+ new_pad.append(0)
+ ndim = list(range(x.ndim - 1, 0, -1))
+ axes_start = {}
+ for i, _pad in enumerate(pad):
+ if _pad < 0:
+ new_pad.append(0)
+ zhengshu, yushu = divmod(i, 2)
+ if yushu == 0:
+ axes_start[ndim[zhengshu]] = -_pad
+ else:
+ new_pad.append(_pad)
+
+ padded = paddle.nn.functional.pad(x, new_pad, mode=mode, value=value)
+ padded_shape = paddle.shape(padded)
+ axes = []
+ starts = []
+ ends = []
+ for k, v in axes_start.items():
+ axes.append(k)
+ starts.append(v)
+ ends.append(padded_shape[k])
+ assert v < padded_shape[k]
+
+ if axes:
+ return padded.slice(axes=axes, starts=starts, ends=ends)
+ else:
+ return padded
+
+
+class Upsample2D(nn.Layer):
+ """
+ An upsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
+ applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv=False, use_conv_transpose=False, out_channels=None, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_conv_transpose = use_conv_transpose
+ self.name = name
+
+ conv = None
+ if use_conv_transpose:
+ conv = nn.Conv2DTranspose(channels, self.out_channels, 4, 2, 1)
+ elif use_conv:
+ conv = nn.Conv2D(self.channels, self.out_channels, 3, padding=1)
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if name == "conv":
+ self.conv = conv
+ else:
+ self.Conv2d_0 = conv
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.use_conv_transpose:
+ return self.conv(x)
+
+ x = F.interpolate(x, scale_factor=2.0, mode="nearest")
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if self.use_conv:
+ if self.name == "conv":
+ x = self.conv(x)
+ else:
+ x = self.Conv2d_0(x)
+
+ return x
+
+
+class Downsample2D(nn.Layer):
+ """
+ A downsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
+ applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv=False, out_channels=None, padding=1, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.padding = padding
+ stride = 2
+ self.name = name
+
+ if use_conv:
+ conv = nn.Conv2D(self.channels, self.out_channels, 3, stride=stride, padding=padding)
+ else:
+ assert self.channels == self.out_channels
+ conv = nn.AvgPool2D(kernel_size=stride, stride=stride)
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if name == "conv":
+ self.Conv2d_0 = conv
+ self.conv = conv
+ elif name == "Conv2d_0":
+ self.conv = conv
+ else:
+ self.conv = conv
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.use_conv and self.padding == 0:
+ pad = (0, 1, 0, 1)
+ x = pad_new(x, pad, mode="constant", value=0)
+
+ assert x.shape[1] == self.channels
+ x = self.conv(x)
+
+ return x
+
+
+class FirUpsample2D(nn.Layer):
+
+ def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
+ super().__init__()
+ out_channels = out_channels if out_channels else channels
+ if use_conv:
+ self.Conv2d_0 = nn.Conv2D(channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.use_conv = use_conv
+ self.fir_kernel = fir_kernel
+ self.out_channels = out_channels
+
+ def _upsample_2d(self, x, w=None, k=None, factor=2, gain=1):
+ """Fused `upsample_2d()` followed by `Conv2d()`.
+
+ Args:
+ Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
+ efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
+ order.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
+ C]`.
+ w: Weight tensor of the shape `[filterH, filterW, inChannels,
+ outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] // numGroups`.
+ k: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
+ factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H * factor, W * factor]` or `[N, H * factor, W * factor, C]`, and same datatype as
+ `x`.
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+
+ # Setup filter kernel.
+ if k is None:
+ k = [1] * factor
+
+ # setup kernel
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * (gain * (factor**2))
+
+ if self.use_conv:
+ convH = w.shape[2]
+ convW = w.shape[3]
+ inC = w.shape[1]
+
+ p = (k.shape[0] - factor) - (convW - 1)
+
+ stride = (factor, factor)
+ # Determine data dimensions.
+ stride = [1, 1, factor, factor]
+ output_shape = ((x.shape[2] - 1) * factor + convH, (x.shape[3] - 1) * factor + convW)
+ output_padding = (
+ output_shape[0] - (x.shape[2] - 1) * stride[0] - convH,
+ output_shape[1] - (x.shape[3] - 1) * stride[1] - convW,
+ )
+ assert output_padding[0] >= 0 and output_padding[1] >= 0
+ inC = w.shape[1]
+ num_groups = x.shape[1] // inC
+
+ # Transpose weights.
+ w = paddle.reshape(w, (num_groups, -1, inC, convH, convW))
+ w = w[..., ::-1, ::-1].transpose([0, 2, 1, 3, 4])
+ w = paddle.reshape(w, (num_groups * inC, -1, convH, convW))
+
+ x = F.conv2d_transpose(x, w, stride=stride, output_padding=output_padding, padding=0)
+
+ x = upfirdn2d_native(x, paddle.to_tensor(k), pad=((p + 1) // 2 + factor - 1, p // 2 + 1))
+ else:
+ p = k.shape[0] - factor
+ x = upfirdn2d_native(x, paddle.to_tensor(k), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2))
+
+ return x
+
+ def forward(self, x):
+ if self.use_conv:
+ h = self._upsample_2d(x, self.Conv2d_0.weight, k=self.fir_kernel)
+ h = h + self.Conv2d_0.bias.reshape([1, -1, 1, 1])
+ else:
+ h = self._upsample_2d(x, k=self.fir_kernel, factor=2)
+
+ return h
+
+
+class FirDownsample2D(nn.Layer):
+
+ def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
+ super().__init__()
+ out_channels = out_channels if out_channels else channels
+ if use_conv:
+ self.Conv2d_0 = nn.Conv2D(channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.fir_kernel = fir_kernel
+ self.use_conv = use_conv
+ self.out_channels = out_channels
+
+ def _downsample_2d(self, x, w=None, k=None, factor=2, gain=1):
+ """Fused `Conv2d()` followed by `downsample_2d()`.
+
+ Args:
+ Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
+ efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
+ order.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`. w: Weight tensor of the shape `[filterH,
+ filterW, inChannels, outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] //
+ numGroups`. k: FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] *
+ factor`, which corresponds to average pooling. factor: Integer downsampling factor (default: 2). gain:
+ Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H // factor, W // factor]` or `[N, H // factor, W // factor, C]`, and same
+ datatype as `x`.
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+ if k is None:
+ k = [1] * factor
+
+ # setup kernel
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * gain
+
+ if self.use_conv:
+ _, _, convH, convW = w.shape
+ p = (k.shape[0] - factor) + (convW - 1)
+ s = [factor, factor]
+ x = upfirdn2d_native(x, paddle.to_tensor(k), pad=((p + 1) // 2, p // 2))
+ x = F.conv2d(x, w, stride=s, padding=0)
+ else:
+ p = k.shape[0] - factor
+ x = upfirdn2d_native(x, paddle.to_tensor(k), down=factor, pad=((p + 1) // 2, p // 2))
+
+ return x
+
+ def forward(self, x):
+ if self.use_conv:
+ x = self._downsample_2d(x, w=self.Conv2d_0.weight, k=self.fir_kernel)
+ x = x + self.Conv2d_0.bias.reshape([1, -1, 1, 1])
+ else:
+ x = self._downsample_2d(x, k=self.fir_kernel, factor=2)
+
+ return x
+
+
+class ResnetBlock(nn.Layer):
+
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout=0.0,
+ temb_channels=512,
+ groups=32,
+ groups_out=None,
+ pre_norm=True,
+ eps=1e-6,
+ non_linearity="swish",
+ time_embedding_norm="default",
+ kernel=None,
+ output_scale_factor=1.0,
+ use_nin_shortcut=None,
+ up=False,
+ down=False,
+ ):
+ super().__init__()
+ self.pre_norm = pre_norm
+ self.pre_norm = True
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+ self.time_embedding_norm = time_embedding_norm
+ self.up = up
+ self.down = down
+ self.output_scale_factor = output_scale_factor
+
+ if groups_out is None:
+ groups_out = groups
+
+ self.norm1 = nn.GroupNorm(num_groups=groups, num_channels=in_channels, epsilon=eps)
+
+ self.conv1 = nn.Conv2D(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if temb_channels is not None:
+ self.time_emb_proj = nn.Linear(temb_channels, out_channels)
+ else:
+ self.time_emb_proj = None
+
+ self.norm2 = nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, epsilon=eps)
+ self.dropout = nn.Dropout(dropout)
+ self.conv2 = nn.Conv2D(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if non_linearity == "swish":
+ self.nonlinearity = lambda x: F.silu(x)
+ elif non_linearity == "mish":
+ self.nonlinearity = Mish()
+ elif non_linearity == "silu":
+ self.nonlinearity = nn.Silu()
+
+ self.upsample = self.downsample = None
+ if self.up:
+ if kernel == "fir":
+ fir_kernel = (1, 3, 3, 1)
+ self.upsample = lambda x: upsample_2d(x, k=fir_kernel)
+ elif kernel == "sde_vp":
+ self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
+ else:
+ self.upsample = Upsample2D(in_channels, use_conv=False)
+ elif self.down:
+ if kernel == "fir":
+ fir_kernel = (1, 3, 3, 1)
+ self.downsample = lambda x: downsample_2d(x, k=fir_kernel)
+ elif kernel == "sde_vp":
+ self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
+ else:
+ self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
+
+ self.use_nin_shortcut = self.in_channels != self.out_channels if use_nin_shortcut is None else use_nin_shortcut
+
+ self.conv_shortcut = None
+ if self.use_nin_shortcut:
+ self.conv_shortcut = nn.Conv2D(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x, temb, hey=False):
+ h = x
+
+ # make sure hidden states is in float32
+ # when running in half-precision
+ h = self.norm1(h.astype("float32")).astype(h.dtype)
+ h = self.nonlinearity(h)
+
+ if self.upsample is not None:
+ x = self.upsample(x)
+ h = self.upsample(h)
+ elif self.downsample is not None:
+ x = self.downsample(x)
+ h = self.downsample(h)
+
+ h = self.conv1(h)
+
+ if temb is not None:
+ temb = self.time_emb_proj(self.nonlinearity(temb))[:, :, None, None]
+ h = h + temb
+
+ # make sure hidden states is in float32
+ # when running in half-precision
+ h = self.norm2(h.astype("float32")).astype(h.dtype)
+ h = self.nonlinearity(h)
+
+ h = self.dropout(h)
+ h = self.conv2(h)
+
+ if self.conv_shortcut is not None:
+ x = self.conv_shortcut(x)
+
+ out = (x + h) / self.output_scale_factor
+
+ return out
+
+
+class Mish(nn.Layer):
+
+ def forward(self, x):
+ return x * F.tanh(F.softplus(x))
+
+
+def upsample_2d(x, k=None, factor=2, gain=1):
+ r"""Upsample2D a batch of 2D images with the given filter.
+
+ Args:
+ Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and upsamples each image with the given
+ filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the specified
+ `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its shape is a:
+ multiple of the upsampling factor.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
+ C]`.
+ k: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
+ factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H * factor, W * factor]`
+ """
+ assert isinstance(factor, int) and factor >= 1
+ if k is None:
+ k = [1] * factor
+
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * (gain * (factor**2))
+ p = k.shape[0] - factor
+ return upfirdn2d_native(x, paddle.to_tensor(k), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2))
+
+
+def downsample_2d(x, k=None, factor=2, gain=1):
+ r"""Downsample2D a batch of 2D images with the given filter.
+
+ Args:
+ Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and downsamples each image with the
+ given filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the
+ specified `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its
+ shape is a multiple of the downsampling factor.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
+ C]`.
+ k: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to average pooling.
+ factor: Integer downsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H // factor, W // factor]`
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+ if k is None:
+ k = [1] * factor
+
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * gain
+ p = k.shape[0] - factor
+ return upfirdn2d_native(x, paddle.to_tensor(k), down=factor, pad=((p + 1) // 2, p // 2))
+
+
+def upfirdn2d_native(input, kernel, up=1, down=1, pad=(0, 0)):
+ up_x = up_y = up
+ down_x = down_y = down
+ pad_x0 = pad_y0 = pad[0]
+ pad_x1 = pad_y1 = pad[1]
+
+ _, channel, in_h, in_w = input.shape
+ input = input.reshape([-1, in_h, in_w, 1])
+
+ _, in_h, in_w, minor = input.shape
+ kernel_h, kernel_w = kernel.shape
+
+ out = input.reshape([-1, in_h, 1, in_w, 1, minor])
+ # TODO
+ out = pad_new(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
+ out = out.reshape([-1, in_h * up_y, in_w * up_x, minor])
+
+ out = pad_new(out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)])
+ out = out[:, max(-pad_y0, 0):out.shape[1] - max(-pad_y1, 0), max(-pad_x0, 0):out.shape[2] - max(-pad_x1, 0), :, ]
+
+ out = out.transpose([0, 3, 1, 2])
+ out = out.reshape([-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1])
+ w = paddle.flip(kernel, [0, 1]).reshape([1, 1, kernel_h, kernel_w])
+ out = F.conv2d(out, w)
+ out = out.reshape(
+ [-1, minor, in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1, in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1])
+ out = out.transpose([0, 2, 3, 1])
+ out = out[:, ::down_y, ::down_x, :]
+
+ out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
+ out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
+
+ return out.reshape([-1, channel, out_h, out_w])
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/unet_2d.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/unet_2d.py
new file mode 100644
index 000000000..11316a819
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/unet_2d.py
@@ -0,0 +1,206 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .embeddings import GaussianFourierProjection
+from .embeddings import TimestepEmbedding
+from .embeddings import Timesteps
+from .unet_blocks import get_down_block
+from .unet_blocks import get_up_block
+from .unet_blocks import UNetMidBlock2D
+
+
+class UNet2DModel(nn.Layer, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size=None,
+ in_channels=3,
+ out_channels=3,
+ center_input_sample=False,
+ time_embedding_type="positional",
+ freq_shift=0,
+ flip_sin_to_cos=True,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D"),
+ block_out_channels=(224, 448, 672, 896),
+ layers_per_block=2,
+ mid_block_scale_factor=1,
+ downsample_padding=1,
+ act_fn="silu",
+ attention_head_dim=8,
+ norm_num_groups=32,
+ norm_eps=1e-5,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+ time_embed_dim = block_out_channels[0] * 4
+
+ # input
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
+
+ # time
+ if time_embedding_type == "fourier":
+ self.time_proj = GaussianFourierProjection(embedding_size=block_out_channels[0], scale=16)
+ timestep_input_dim = 2 * block_out_channels[0]
+ elif time_embedding_type == "positional":
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+
+ self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+
+ self.down_blocks = nn.LayerList([])
+ self.mid_block = None
+ self.up_blocks = nn.LayerList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=attention_head_dim,
+ downsample_padding=downsample_padding,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ temb_channels=time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=attention_head_dim,
+ resnet_groups=norm_num_groups,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=time_embed_dim,
+ add_upsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=attention_head_dim,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ num_groups_out = norm_num_groups if norm_num_groups is not None else min(block_out_channels[0] // 4, 32)
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0],
+ num_groups=num_groups_out,
+ epsilon=norm_eps)
+ self.conv_act = nn.Silu()
+ self.conv_out = nn.Conv2D(block_out_channels[0], out_channels, 3, padding=1)
+
+ def forward(self, sample: paddle.Tensor, timestep: Union[paddle.Tensor, float, int]) -> Dict[str, paddle.Tensor]:
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not paddle.is_tensor(timesteps):
+ timesteps = paddle.to_tensor([timesteps], dtype="int64")
+ elif paddle.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None]
+
+ # broadcast to batch dimension
+ timesteps = paddle.broadcast_to(timesteps, [sample.shape[0]])
+
+ t_emb = self.time_proj(timesteps)
+ emb = self.time_embedding(t_emb)
+
+ # 2. pre-process
+ skip_sample = sample
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample, )
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "skip_conv"):
+ sample, res_samples, skip_sample = downsample_block(hidden_states=sample,
+ temb=emb,
+ skip_sample=skip_sample)
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ # 4. mid
+ sample = self.mid_block(sample, emb)
+
+ # 5. up
+ skip_sample = None
+ for upsample_block in self.up_blocks:
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[:-len(upsample_block.resnets)]
+
+ if hasattr(upsample_block, "skip_conv"):
+ sample, skip_sample = upsample_block(sample, res_samples, emb, skip_sample)
+ else:
+ sample = upsample_block(sample, res_samples, emb)
+
+ # 6. post-process
+ # make sure hidden states is in float32
+ # when running in half-precision
+ sample = self.conv_norm_out(sample.astype("float32")).astype(sample.dtype)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ if skip_sample is not None:
+ sample += skip_sample
+
+ if self.config.time_embedding_type == "fourier":
+ timesteps = timesteps.reshape((sample.shape[0], *([1] * len(sample.shape[1:]))))
+ sample = sample / timesteps
+
+ output = {"sample": sample}
+
+ return output
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/unet_2d_condition.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/unet_2d_condition.py
new file mode 100644
index 000000000..897491b2f
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/unet_2d_condition.py
@@ -0,0 +1,206 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .embeddings import TimestepEmbedding
+from .embeddings import Timesteps
+from .unet_blocks import get_down_block
+from .unet_blocks import get_up_block
+from .unet_blocks import UNetMidBlock2DCrossAttn
+
+
+class UNet2DConditionModel(nn.Layer, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size=64,
+ in_channels=4,
+ out_channels=4,
+ center_input_sample=False,
+ flip_sin_to_cos=True,
+ freq_shift=0,
+ down_block_types=("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D"),
+ up_block_types=("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
+ block_out_channels=(320, 640, 1280, 1280),
+ layers_per_block=2,
+ downsample_padding=1,
+ mid_block_scale_factor=1,
+ act_fn="silu",
+ norm_num_groups=32,
+ norm_eps=1e-5,
+ cross_attention_dim=768,
+ attention_head_dim=8,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+ time_embed_dim = block_out_channels[0] * 4
+
+ # input
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
+
+ # time
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+
+ self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+
+ self.down_blocks = nn.LayerList([])
+ self.mid_block = None
+ self.up_blocks = nn.LayerList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim,
+ downsample_padding=downsample_padding,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2DCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift="default",
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim,
+ resnet_groups=norm_num_groups,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=time_embed_dim,
+ add_upsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0],
+ num_groups=norm_num_groups,
+ epsilon=norm_eps)
+ self.conv_act = nn.Silu()
+ self.conv_out = nn.Conv2D(block_out_channels[0], out_channels, 3, padding=1)
+
+ def forward(
+ self,
+ sample: paddle.Tensor,
+ timestep: Union[paddle.Tensor, float, int],
+ encoder_hidden_states: paddle.Tensor,
+ ) -> Dict[str, paddle.Tensor]:
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not paddle.is_tensor(timesteps):
+ timesteps = paddle.to_tensor([timesteps], dtype="int64")
+ elif paddle.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None]
+
+ # broadcast to batch dimension
+ timesteps = paddle.broadcast_to(timesteps, [sample.shape[0]])
+
+ t_emb = self.time_proj(timesteps)
+ emb = self.time_embedding(t_emb)
+
+ # 2. pre-process
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample, )
+ for downsample_block in self.down_blocks:
+
+ if hasattr(downsample_block, "attentions") and downsample_block.attentions is not None:
+ sample, res_samples = downsample_block(hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states)
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ # 4. mid
+ sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
+
+ # 5. up
+ for upsample_block in self.up_blocks:
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[:-len(upsample_block.resnets)]
+
+ if hasattr(upsample_block, "attentions") and upsample_block.attentions is not None:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ else:
+ sample = upsample_block(hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples)
+
+ # 6. post-process
+ # make sure hidden states is in float32
+ # when running in half-precision
+ sample = self.conv_norm_out(sample.astype("float32")).astype(sample.dtype)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ output = {"sample": sample}
+
+ return output
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/unet_blocks.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/unet_blocks.py
new file mode 100644
index 000000000..684a2a43d
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/unet_blocks.py
@@ -0,0 +1,1428 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import paddle
+import paddle.nn as nn
+
+from .attention import AttentionBlockNew
+from .attention import SpatialTransformer
+from .resnet import Downsample2D
+from .resnet import FirDownsample2D
+from .resnet import FirUpsample2D
+from .resnet import ResnetBlock
+from .resnet import Upsample2D
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ cross_attention_dim=None,
+ downsample_padding=None,
+):
+ down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
+ if down_block_type == "DownBlock2D":
+ return DownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ )
+ elif down_block_type == "AttnDownBlock2D":
+ return AttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif down_block_type == "CrossAttnDownBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock2D")
+ return CrossAttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif down_block_type == "SkipDownBlock2D":
+ return SkipDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ )
+ elif down_block_type == "AttnSkipDownBlock2D":
+ return AttnSkipDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif down_block_type == "DownEncoderBlock2D":
+ return DownEncoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ )
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ cross_attention_dim=None,
+):
+ up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
+ if up_block_type == "UpBlock2D":
+ return UpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ elif up_block_type == "CrossAttnUpBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock2D")
+ return CrossAttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif up_block_type == "AttnUpBlock2D":
+ return AttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif up_block_type == "SkipUpBlock2D":
+ return SkipUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ elif up_block_type == "AttnSkipUpBlock2D":
+ return AttnSkipUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif up_block_type == "UpDecoderBlock2D":
+ return UpDecoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+class UNetMidBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=1.0,
+ **kwargs,
+ ):
+ super().__init__()
+
+ self.attention_type = attention_type
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ attentions.append(
+ AttentionBlockNew(
+ in_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ num_groups=resnet_groups,
+ ))
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_states=None):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ if self.attention_type == "default":
+ hidden_states = attn(hidden_states)
+ else:
+ hidden_states = attn(hidden_states, encoder_states)
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+class UNetMidBlock2DCrossAttn(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ **kwargs,
+ ):
+ super().__init__()
+
+ self.attention_type = attention_type
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ attentions.append(
+ SpatialTransformer(
+ in_channels,
+ attn_num_head_channels,
+ in_channels // attn_num_head_channels,
+ depth=1,
+ context_dim=cross_attention_dim,
+ ))
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ hidden_states = attn(hidden_states, encoder_hidden_states)
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+class AttnDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states
+
+
+class CrossAttnDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ attention_type="default",
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ SpatialTransformer(
+ out_channels,
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ depth=1,
+ context_dim=cross_attention_dim,
+ ))
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, context=encoder_hidden_states)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states
+
+
+class DownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states
+
+
+class DownEncoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb=None)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnDownEncoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ num_groups=resnet_groups,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb=None)
+ hidden_states = attn(hidden_states)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnSkipDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=np.sqrt(2.0),
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ self.attentions = nn.LayerList([])
+ self.resnets = nn.LayerList([])
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(in_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ self.attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ if add_downsample:
+ self.resnet_down = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ down=True,
+ kernel="fir",
+ )
+ self.downsamplers = nn.LayerList([FirDownsample2D(in_channels, out_channels=out_channels)])
+ self.skip_conv = nn.Conv2D(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
+ else:
+ self.resnet_down = None
+ self.downsamplers = None
+ self.skip_conv = None
+
+ def forward(self, hidden_states, temb=None, skip_sample=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ hidden_states = self.resnet_down(hidden_states, temb)
+ for downsampler in self.downsamplers:
+ skip_sample = downsampler(skip_sample)
+
+ hidden_states = self.skip_conv(skip_sample) + hidden_states
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states, skip_sample
+
+
+class SkipDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ output_scale_factor=np.sqrt(2.0),
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ self.resnets = nn.LayerList([])
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(in_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ if add_downsample:
+ self.resnet_down = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ down=True,
+ kernel="fir",
+ )
+ self.downsamplers = nn.LayerList([FirDownsample2D(in_channels, out_channels=out_channels)])
+ self.skip_conv = nn.Conv2D(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
+ else:
+ self.resnet_down = None
+ self.downsamplers = None
+ self.skip_conv = None
+
+ def forward(self, hidden_states, temb=None, skip_sample=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ hidden_states = self.resnet_down(hidden_states, temb)
+ for downsampler in self.downsamplers:
+ skip_sample = downsampler(skip_sample)
+
+ hidden_states = self.skip_conv(skip_sample) + hidden_states
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states, skip_sample
+
+
+class AttnUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attention_type="default",
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ for resnet, attn in zip(self.resnets, self.attentions):
+
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class CrossAttnUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ attention_type="default",
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ SpatialTransformer(
+ out_channels,
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ depth=1,
+ context_dim=cross_attention_dim,
+ ))
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, encoder_hidden_states=None):
+ for resnet, attn in zip(self.resnets, self.attentions):
+
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, context=encoder_hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class UpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ for resnet in self.resnets:
+
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class UpDecoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ input_channels = in_channels if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=input_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb=None)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnUpDecoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ input_channels = in_channels if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=input_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ num_groups=resnet_groups,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb=None)
+ hidden_states = attn(hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnSkipUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=np.sqrt(2.0),
+ upsample_padding=1,
+ add_upsample=True,
+ ):
+ super().__init__()
+ self.attentions = nn.LayerList([])
+ self.resnets = nn.LayerList([])
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(resnet_in_channels + res_skip_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
+ if add_upsample:
+ self.resnet_up = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ up=True,
+ kernel="fir",
+ )
+ self.skip_conv = nn.Conv2D(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ self.skip_norm = nn.GroupNorm(num_groups=min(out_channels // 4, 32),
+ num_channels=out_channels,
+ eps=resnet_eps,
+ affine=True)
+ self.act = nn.SiLU()
+ else:
+ self.resnet_up = None
+ self.skip_conv = None
+ self.skip_norm = None
+ self.act = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, skip_sample=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ hidden_states = self.attentions[0](hidden_states)
+
+ if skip_sample is not None:
+ skip_sample = self.upsampler(skip_sample)
+ else:
+ skip_sample = 0
+
+ if self.resnet_up is not None:
+ skip_sample_states = self.skip_norm(hidden_states)
+ skip_sample_states = self.act(skip_sample_states)
+ skip_sample_states = self.skip_conv(skip_sample_states)
+
+ skip_sample = skip_sample + skip_sample_states
+
+ hidden_states = self.resnet_up(hidden_states, temb)
+
+ return hidden_states, skip_sample
+
+
+class SkipUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ output_scale_factor=np.sqrt(2.0),
+ add_upsample=True,
+ upsample_padding=1,
+ ):
+ super().__init__()
+ self.resnets = nn.LayerList([])
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min((resnet_in_channels + res_skip_channels) // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
+ if add_upsample:
+ self.resnet_up = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ up=True,
+ kernel="fir",
+ )
+ self.skip_conv = nn.Conv2D(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ self.skip_norm = nn.GroupNorm(num_groups=min(out_channels // 4, 32),
+ num_channels=out_channels,
+ eps=resnet_eps,
+ affine=True)
+ self.act = nn.SiLU()
+ else:
+ self.resnet_up = None
+ self.skip_conv = None
+ self.skip_norm = None
+ self.act = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, skip_sample=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ if skip_sample is not None:
+ skip_sample = self.upsampler(skip_sample)
+ else:
+ skip_sample = 0
+
+ if self.resnet_up is not None:
+ skip_sample_states = self.skip_norm(hidden_states)
+ skip_sample_states = self.act(skip_sample_states)
+ skip_sample_states = self.skip_conv(skip_sample_states)
+
+ skip_sample = skip_sample + skip_sample_states
+
+ hidden_states = self.resnet_up(hidden_states, temb)
+
+ return hidden_states, skip_sample
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/vae.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/vae.py
new file mode 100644
index 000000000..59e35b0fb
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/models/vae.py
@@ -0,0 +1,465 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import paddle
+import paddle.nn as nn
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .unet_blocks import get_down_block
+from .unet_blocks import get_up_block
+from .unet_blocks import UNetMidBlock2D
+
+
+class Encoder(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", ),
+ block_out_channels=(64, ),
+ layers_per_block=2,
+ act_fn="silu",
+ double_z=True,
+ ):
+ super().__init__()
+ self.layers_per_block = layers_per_block
+
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[0], kernel_size=3, stride=1, padding=1)
+
+ self.mid_block = None
+ self.down_blocks = nn.LayerList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=self.layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ add_downsample=not is_final_block,
+ resnet_eps=1e-6,
+ downsample_padding=0,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=None,
+ temb_channels=None,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ output_scale_factor=1,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=None,
+ resnet_groups=32,
+ temb_channels=None,
+ )
+
+ # out
+ num_groups_out = 32
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[-1], num_groups=num_groups_out, epsilon=1e-6)
+ self.conv_act = nn.Silu()
+
+ conv_out_channels = 2 * out_channels if double_z else out_channels
+ self.conv_out = nn.Conv2D(block_out_channels[-1], conv_out_channels, 3, padding=1)
+
+ def forward(self, x):
+ sample = x
+ sample = self.conv_in(sample)
+
+ # down
+ for down_block in self.down_blocks:
+ sample = down_block(sample)
+
+ # middle
+ sample = self.mid_block(sample)
+
+ # post-process
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class Decoder(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ up_block_types=("UpDecoderBlock2D", ),
+ block_out_channels=(64, ),
+ layers_per_block=2,
+ act_fn="silu",
+ ):
+ super().__init__()
+ self.layers_per_block = layers_per_block
+
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[-1], kernel_size=3, stride=1, padding=1)
+
+ self.mid_block = None
+ self.up_blocks = nn.LayerList([])
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ output_scale_factor=1,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=None,
+ resnet_groups=32,
+ temb_channels=None,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=self.layers_per_block + 1,
+ in_channels=prev_output_channel,
+ out_channels=output_channel,
+ prev_output_channel=None,
+ add_upsample=not is_final_block,
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=None,
+ temb_channels=None,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ num_groups_out = 32
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=num_groups_out, epsilon=1e-6)
+ self.conv_act = nn.Silu()
+ self.conv_out = nn.Conv2D(block_out_channels[0], out_channels, 3, padding=1)
+
+ def forward(self, z):
+ sample = z
+ sample = self.conv_in(sample)
+
+ # middle
+ sample = self.mid_block(sample)
+
+ # up
+ for up_block in self.up_blocks:
+ sample = up_block(sample)
+
+ # post-process
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class VectorQuantizer(nn.Layer):
+ """
+ Improved version over VectorQuantizer, can be used as a drop-in replacement. Mostly avoids costly matrix
+ multiplications and allows for post-hoc remapping of indices.
+ """
+
+ # NOTE: due to a bug the beta term was applied to the wrong term. for
+ # backwards compatibility we use the buggy version by default, but you can
+ # specify legacy=False to fix it.
+ def __init__(self, n_e, e_dim, beta, remap=None, unknown_index="random", sane_index_shape=False, legacy=True):
+ super().__init__()
+ self.n_e = n_e
+ self.e_dim = e_dim
+ self.beta = beta
+ self.legacy = legacy
+
+ self.embedding = nn.Embedding(self.n_e, self.e_dim)
+ self.embedding.weight.data.uniform_(-1.0 / self.n_e, 1.0 / self.n_e)
+
+ self.remap = remap
+ if self.remap is not None:
+ self.register_buffer("used", paddle.to_tensor(np.load(self.remap)))
+ self.re_embed = self.used.shape[0]
+ self.unknown_index = unknown_index # "random" or "extra" or integer
+ if self.unknown_index == "extra":
+ self.unknown_index = self.re_embed
+ self.re_embed = self.re_embed + 1
+ print(f"Remapping {self.n_e} indices to {self.re_embed} indices. "
+ f"Using {self.unknown_index} for unknown indices.")
+ else:
+ self.re_embed = n_e
+
+ self.sane_index_shape = sane_index_shape
+
+ def remap_to_used(self, inds):
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape([ishape[0], -1])
+ used = self.used
+ match = (inds[:, :, None] == used[None, None, ...]).astype("int64")
+ new = match.argmax(-1)
+ unknown = match.sum(2) < 1
+ if self.unknown_index == "random":
+ new[unknown] = paddle.randint(0, self.re_embed, shape=new[unknown].shape)
+ else:
+ new[unknown] = self.unknown_index
+ return new.reshape(ishape)
+
+ def unmap_to_all(self, inds):
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape([ishape[0], -1])
+ used = self.used
+ if self.re_embed > self.used.shape[0]: # extra token
+ inds[inds >= self.used.shape[0]] = 0 # simply set to zero
+ back = paddle.gather(used[None, :][inds.shape[0] * [0], :], inds, axis=1)
+ return back.reshape(ishape)
+
+ def forward(self, z):
+ # reshape z -> (batch, height, width, channel) and flatten
+ z = z.transpose([0, 2, 3, 1])
+ z_flattened = z.reshape([-1, self.e_dim])
+ # distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
+
+ d = (paddle.sum(z_flattened**2, axis=1, keepdim=True) + paddle.sum(self.embedding.weight**2, axis=1) -
+ 2 * paddle.einsum("bd,dn->bn", z_flattened, self.embedding.weight.t()))
+
+ min_encoding_indices = paddle.argmin(d, axis=1)
+ z_q = self.embedding(min_encoding_indices).reshape(z.shape)
+ perplexity = None
+ min_encodings = None
+
+ # compute loss for embedding
+ if not self.legacy:
+ loss = self.beta * paddle.mean((z_q.detach() - z)**2) + paddle.mean((z_q - z.detach())**2)
+ else:
+ loss = paddle.mean((z_q.detach() - z)**2) + self.beta * paddle.mean((z_q - z.detach())**2)
+
+ # preserve gradients
+ z_q = z + (z_q - z).detach()
+
+ # reshape back to match original input shape
+ z_q = z_q.transpose([0, 3, 1, 2])
+
+ if self.remap is not None:
+ min_encoding_indices = min_encoding_indices.reshape([z.shape[0], -1]) # add batch axis
+ min_encoding_indices = self.remap_to_used(min_encoding_indices)
+ min_encoding_indices = min_encoding_indices.reshape([-1, 1]) # flatten
+
+ if self.sane_index_shape:
+ min_encoding_indices = min_encoding_indices.reshape([z_q.shape[0], z_q.shape[2], z_q.shape[3]])
+
+ return z_q, loss, (perplexity, min_encodings, min_encoding_indices)
+
+ def get_codebook_entry(self, indices, shape):
+ # shape specifying (batch, height, width, channel)
+ if self.remap is not None:
+ indices = indices.reshape([shape[0], -1]) # add batch axis
+ indices = self.unmap_to_all(indices)
+ indices = indices.flatten() # flatten again
+
+ # get quantized latent vectors
+ z_q = self.embedding(indices)
+
+ if shape is not None:
+ z_q = z_q.reshape(shape)
+ # reshape back to match original input shape
+ z_q = z_q.transpose([0, 3, 1, 2])
+
+ return z_q
+
+
+class DiagonalGaussianDistribution(object):
+
+ def __init__(self, parameters, deterministic=False):
+ self.parameters = parameters
+ self.mean, self.logvar = paddle.chunk(parameters, 2, axis=1)
+ self.logvar = paddle.clip(self.logvar, -30.0, 20.0)
+ self.deterministic = deterministic
+ self.std = paddle.exp(0.5 * self.logvar)
+ self.var = paddle.exp(self.logvar)
+ if self.deterministic:
+ self.var = self.std = paddle.zeros_like(self.mean)
+
+ def sample(self):
+ x = self.mean + self.std * paddle.randn(self.mean.shape)
+ return x
+
+ def kl(self, other=None):
+ if self.deterministic:
+ return paddle.to_tensor([0.0])
+ else:
+ if other is None:
+ return 0.5 * paddle.sum(paddle.pow(self.mean, 2) + self.var - 1.0 - self.logvar, axis=[1, 2, 3])
+ else:
+ return 0.5 * paddle.sum(
+ paddle.pow(self.mean - other.mean, 2) / other.var + self.var / other.var - 1.0 - self.logvar +
+ other.logvar,
+ axis=[1, 2, 3],
+ )
+
+ def nll(self, sample, dims=[1, 2, 3]):
+ if self.deterministic:
+ return paddle.to_tensor([0.0])
+ logtwopi = np.log(2.0 * np.pi)
+ return 0.5 * paddle.sum(logtwopi + self.logvar + paddle.pow(sample - self.mean, 2) / self.var, axis=dims)
+
+ def mode(self):
+ return self.mean
+
+
+class VQModel(ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", ),
+ up_block_types=("UpDecoderBlock2D", ),
+ block_out_channels=(64, ),
+ layers_per_block=1,
+ act_fn="silu",
+ latent_channels=3,
+ sample_size=32,
+ num_vq_embeddings=256,
+ ):
+ super().__init__()
+
+ # pass init params to Encoder
+ self.encoder = Encoder(
+ in_channels=in_channels,
+ out_channels=latent_channels,
+ down_block_types=down_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ double_z=False,
+ )
+
+ self.quant_conv = nn.Conv2D(latent_channels, latent_channels, 1)
+ self.quantize = VectorQuantizer(num_vq_embeddings,
+ latent_channels,
+ beta=0.25,
+ remap=None,
+ sane_index_shape=False)
+ self.post_quant_conv = nn.Conv2D(latent_channels, latent_channels, 1)
+
+ # pass init params to Decoder
+ self.decoder = Decoder(
+ in_channels=latent_channels,
+ out_channels=out_channels,
+ up_block_types=up_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ )
+
+ def encode(self, x):
+ h = self.encoder(x)
+ h = self.quant_conv(h)
+ return h
+
+ def decode(self, h, force_not_quantize=False):
+ # also go through quantization layer
+ if not force_not_quantize:
+ quant, emb_loss, info = self.quantize(h)
+ else:
+ quant = h
+ quant = self.post_quant_conv(quant)
+ dec = self.decoder(quant)
+ return dec
+
+ def forward(self, sample):
+ x = sample
+ h = self.encode(x)
+ dec = self.decode(h)
+ return dec
+
+
+class AutoencoderKL(nn.Layer, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", "DownEncoderBlock2D", "DownEncoderBlock2D", "DownEncoderBlock2D"),
+ up_block_types=("UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D"),
+ block_out_channels=(128, 256, 512, 512),
+ layers_per_block=2,
+ act_fn="silu",
+ latent_channels=4,
+ sample_size=512,
+ ):
+ super().__init__()
+
+ # pass init params to Encoder
+ self.encoder = Encoder(
+ in_channels=in_channels,
+ out_channels=latent_channels,
+ down_block_types=down_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ double_z=True,
+ )
+
+ # pass init params to Decoder
+ self.decoder = Decoder(
+ in_channels=latent_channels,
+ out_channels=out_channels,
+ up_block_types=up_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ )
+
+ self.quant_conv = nn.Conv2D(2 * latent_channels, 2 * latent_channels, 1)
+ self.post_quant_conv = nn.Conv2D(latent_channels, latent_channels, 1)
+
+ def encode(self, x):
+ h = self.encoder(x)
+ moments = self.quant_conv(h)
+ posterior = DiagonalGaussianDistribution(moments)
+ return posterior
+
+ def decode(self, z):
+ z = self.post_quant_conv(z)
+ dec = self.decoder(z)
+ return dec
+
+ def forward(self, sample, sample_posterior=False):
+ x = sample
+ posterior = self.encode(x)
+ if sample_posterior:
+ z = posterior.sample()
+ else:
+ z = posterior.mode()
+ dec = self.decode(z)
+ return dec
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/schedulers/README.md b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/schedulers/README.md
new file mode 100644
index 000000000..40f50f232
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/schedulers/README.md
@@ -0,0 +1,18 @@
+# Schedulers
+
+- Schedulers are the algorithms to use diffusion models in inference as well as for training. They include the noise schedules and define algorithm-specific diffusion steps.
+- Schedulers can be used interchangable between diffusion models in inference to find the preferred trade-off between speed and generation quality.
+- Schedulers are available in numpy, but can easily be transformed into Py
+
+## API
+
+- Schedulers should provide one or more `def step(...)` functions that should be called iteratively to unroll the diffusion loop during
+the forward pass.
+- Schedulers should be framework-agnostic, but provide a simple functionality to convert the scheduler into a specific framework, such as PyTorch
+with a `set_format(...)` method.
+
+## Examples
+
+- The DDPM scheduler was proposed in [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) and can be found in [scheduling_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py). An example of how to use this scheduler can be found in [pipeline_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddpm.py).
+- The DDIM scheduler was proposed in [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) and can be found in [scheduling_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py). An example of how to use this scheduler can be found in [pipeline_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddim.py).
+- The PNDM scheduler was proposed in [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778) and can be found in [scheduling_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py). An example of how to use this scheduler can be found in [pipeline_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py).
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/schedulers/__init__.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/schedulers/__init__.py
new file mode 100644
index 000000000..cebc3e618
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/schedulers/__init__.py
@@ -0,0 +1,24 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .scheduling_ddim import DDIMScheduler
+from .scheduling_ddpm import DDPMScheduler
+from .scheduling_karras_ve import KarrasVeScheduler
+from .scheduling_lms_discrete import LMSDiscreteScheduler
+from .scheduling_pndm import PNDMScheduler
+from .scheduling_sde_ve import ScoreSdeVeScheduler
+from .scheduling_sde_vp import ScoreSdeVpScheduler
+from .scheduling_utils import SchedulerMixin
diff --git a/modules/image/text_to_image/stable_diffusion_img2img/diffusers/schedulers/scheduling_ddim.py b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/schedulers/scheduling_ddim.py
new file mode 100644
index 000000000..ebe362d99
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_img2img/diffusers/schedulers/scheduling_ddim.py
@@ -0,0 +1,182 @@
+# Copyright 2022 Stanford University Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pypaddle_diffusion
+# and https://github.com/hojonathanho/diffusion
+import math
+from typing import Union
+
+import numpy as np
+import paddle
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .scheduling_utils import SchedulerMixin
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ :param num_diffusion_timesteps: the number of betas to produce. :param alpha_bar: a lambda that takes an argument t
+ from 0 to 1 and
+ produces the cumulative product of (1-beta) up to that part of the diffusion process.
+ :param max_beta: the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2)**2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return np.array(betas, dtype=np.float32)
+
+
+class DDIMScheduler(SchedulerMixin, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps=1000,
+ beta_start=0.0001,
+ beta_end=0.02,
+ beta_schedule="linear",
+ trained_betas=None,
+ timestep_values=None,
+ clip_sample=True,
+ set_alpha_to_one=True,
+ tensor_format="pd",
+ ):
+
+ if beta_schedule == "linear":
+ self.betas = np.linspace(beta_start, beta_end, num_train_timesteps, dtype=np.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = np.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=np.float32)**2
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = np.cumprod(self.alphas, axis=0)
+
+ # At every step in ddim, we are looking into the previous alphas_cumprod
+ # For the final step, there is no previous alphas_cumprod because we are already at 0
+ # `set_alpha_to_one` decides whether we set this paratemer simply to one or
+ # whether we use the final alpha of the "non-previous" one.
+ self.final_alpha_cumprod = np.array(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
+
+ # setable values
+ self.num_inference_steps = None
+ self.timesteps = np.arange(0, num_train_timesteps)[::-1].copy()
+
+ self.tensor_format = tensor_format
+ self.set_format(tensor_format=tensor_format)
+
+ def _get_variance(self, timestep, prev_timestep):
+ alpha_prod_t = self.alphas_cumprod[timestep]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
+
+ return variance
+
+ def set_timesteps(self, num_inference_steps, offset=0):
+ self.num_inference_steps = num_inference_steps
+ self.timesteps = np.arange(0, self.config.num_train_timesteps,
+ self.config.num_train_timesteps // self.num_inference_steps)[::-1].copy()
+ self.timesteps += offset
+ self.set_format(tensor_format=self.tensor_format)
+
+ def step(
+ self,
+ model_output: Union[paddle.Tensor, np.ndarray],
+ timestep: int,
+ sample: Union[paddle.Tensor, np.ndarray],
+ eta: float = 0.0,
+ use_clipped_model_output: bool = False,
+ generator=None,
+ ):
+ # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # Ideally, read DDIM paper in-detail understanding
+
+ # Notation ( +
+
+
+ - 输入mask
+  +
+
+
+ - 输出图像
+  +
+
+
+ - 生成过程
+  +
+
+
+### 模型介绍
+
+Stable Diffusion是一种潜在扩散模型(Latent Diffusion), 属于生成类模型,这类模型通过对随机噪声进行一步步地迭代降噪并采样来获得感兴趣的图像,当前取得了令人惊艳的效果。相比于Disco Diffusion, Stable Diffusion通过在低纬度的潜在空间(lower dimensional latent space)而不是原像素空间来做迭代,极大地降低了内存和计算量的需求,并且在V100上一分钟之内即可以渲染出想要的图像,欢迎体验。该模块支持输入文本以及一张图片,一张掩码图片,对掩码部分的内容进行改变。
+
+更多详情请参考论文:[High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install stable_diffusion_inpainting
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run stable_diffusion_inpainting --text_prompts "a cat sitting on a bench" --init_image /PATH/TO/IMAGE --mask_image /PATH/TO/IMAGE --output_dir stable_diffusion_inpainting_out
+ ```
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="stable_diffusion_inpainting")
+ text_prompts = ["a cat sitting on a bench"]
+ # 生成图像, 默认会在stable_diffusion_inpainting_out目录保存图像
+ # 返回的da是一个DocumentArray对象,保存了所有的结果,包括最终结果和迭代过程的中间结果
+ # 可以通过操作DocumentArray对象对生成的图像做后处理,保存或者分析
+ # 您可以设置batch_size一次生成多张
+ da = module.generate_image(text_prompts=text_prompts, batch_size=2, output_dir='./stable_diffusion_inpainting_out/')
+ # 展示所有的中间结果
+ da[0].chunks[-1].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ # 将整个生成过程保存为一个动态图gif
+ da[0].chunks[-1].chunks.save_gif('stable_diffusion_inpainting_out-merged-result.gif')
+ # da索引的是prompt, da[0].chunks索引的是该prompt下生成的第一张图,在batch_size不为1时能同时生成多张图
+ # 您也可以按照上述操作显示单张图,如第0张的生成过程
+ da[0].chunks[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
+ da[0].chunks[0].chunks.save_gif('stable_diffusion_inpainting-image-0-result.gif')
+ ```
+
+- ### 3、API
+
+ - ```python
+ def generate_image(
+ text_prompts,
+ init_image,
+ mask_image,
+ strength: float = 0.8,
+ width_height: Optional[List[int]] = [512, 512],
+ seed: Optional[int] = None,
+ batch_size: Optional[int] = 1,
+ display_rate: Optional[int] = 5,
+ output_dir: Optional[str] = 'stable_diffusion_inpainting_out'):
+ ```
+
+ - 文图生成API,生成文本描述内容的图像。
+
+ - **参数**
+
+ - text_prompts(str): 输入的语句,描述想要生成的图像的内容。
+ - init_image(str|numpy.ndarray|PIL.Image): 输入的初始图像。
+ - mask_image(str|numpy.ndarray|PIL.Image): 输入的掩码图像。
+ - strength(float): 控制添加到输入图像的噪声强度,取值范围0到1。越接近1.0,图像变化越大。
+ - width_height(Optional[List[int]]): 指定最终输出图像的宽高,宽和高都需要是64的倍数,生成的图像越大,所需要的计算时间越长。
+ - seed(Optional[int]): 随机种子,由于输入默认是随机高斯噪声,设置不同的随机种子会由不同的初始输入,从而最终生成不同的结果,可以设置该参数来获得不同的输出图像。
+ - batch_size(Optional[int]): 指定每个prompt一次生成的图像的数量。
+ - display_rate(Optional[int]): 保存中间结果的频率,默认每5个step保存一次中间结果,如果不需要中间结果来让程序跑的更快,可以将这个值设大。
+ - output_dir(Optional[str]): 保存输出图像的目录,默认为"stable_diffusion_out"。
+
+
+ - **返回**
+ - ra(DocumentArray): DocumentArray对象, 包含`n_batches`个Documents,其中每个Document都保存了迭代过程的所有中间结果。详细可参考[DocumentArray使用文档](https://docarray.jina.ai/fundamentals/documentarray/index.html)。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线文图生成服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+ - ```shell
+ $ hub serving start -m stable_diffusion_inpainting
+ ```
+
+ - 这样就完成了一个文图生成的在线服务API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果,返回的预测结果在反序列化后即是上述接口声明中说明的DocumentArray类型,返回后对结果的操作方式和使用generate_image接口完全相同。
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ from docarray import DocumentArray
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tobytes())
+
+ # 发送HTTP请求
+ data = {'text_prompts': 'a cat sitting on a bench', 'init_image': cv2_to_base64(cv2.imread('/PATH/TO/IMAGE')),
+ 'mask_image': cv2_to_base64(cv2.imread('/PATH/TO/IMAGE')}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/stable_diffusion_inpainting"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 获取返回结果
+ r.json()["results"]
+ da = DocumentArray.from_base64(r.json()["results"])
+ # 保存结果图
+ da[0].save_uri_to_file('stable_diffusion_inpainting_out.png')
+ # 将生成过程保存为一个动态图gif
+ da[0].chunks[0].chunks.save_gif('stable_diffusion_inpainting_out.gif')
+ ```
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install stable_diffusion_inpainting == 1.0.0
+ ```
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/clip/README.md b/modules/image/text_to_image/stable_diffusion_inpainting/clip/README.md
new file mode 100755
index 000000000..9944794f8
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/clip/README.md
@@ -0,0 +1,2 @@
+# OpenAI CLIP implemented in Paddle.
+The original implementation repo is [ranchlai/clip.paddle](https://github.com/ranchlai/clip.paddle). We use this repo here for text encoder in stable diffusion.
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/__init__.py b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/__init__.py
new file mode 100755
index 000000000..5657b56e6
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/__init__.py
@@ -0,0 +1 @@
+from .utils import *
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/layers.py b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/layers.py
new file mode 100755
index 000000000..286f35ab4
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/layers.py
@@ -0,0 +1,182 @@
+from typing import Optional
+
+import paddle
+import paddle.nn as nn
+from paddle import Tensor
+from paddle.nn import functional as F
+from paddle.nn import Linear
+
+__all__ = ['ResidualAttentionBlock', 'AttentionPool2d', 'multi_head_attention_forward', 'MultiHeadAttention']
+
+
+def multi_head_attention_forward(x: Tensor,
+ num_heads: int,
+ q_proj: Linear,
+ k_proj: Linear,
+ v_proj: Linear,
+ c_proj: Linear,
+ attn_mask: Optional[Tensor] = None):
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = emb_dim // num_heads
+ scaling = float(head_dim)**-0.5
+ q = q_proj(x) # L, N, E
+ k = k_proj(x) # L, N, E
+ v = v_proj(x) # L, N, E
+ #k = k.con
+ v = v.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ k = k.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+ q = q.reshape((-1, batch_size * num_heads, head_dim)).transpose((1, 0, 2))
+
+ q = q * scaling
+ qk = paddle.bmm(q, k.transpose((0, 2, 1)))
+ if attn_mask is not None:
+ if attn_mask.ndim == 2:
+ attn_mask.unsqueeze_(0)
+ #assert str(attn_mask.dtype) == 'VarType.FP32' and attn_mask.ndim == 3
+ assert attn_mask.shape[0] == 1 and attn_mask.shape[1] == max_len and attn_mask.shape[2] == max_len
+ qk += attn_mask
+
+ qk = paddle.nn.functional.softmax(qk, axis=-1)
+ atten = paddle.bmm(qk, v)
+ atten = atten.transpose((1, 0, 2))
+ atten = atten.reshape((max_len, batch_size, emb_dim))
+ atten = c_proj(atten)
+ return atten
+
+
+class MultiHeadAttention(nn.Layer): # without attention mask
+
+ def __init__(self, emb_dim: int, num_heads: int):
+ super().__init__()
+ self.q_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.k_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.v_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.c_proj = nn.Linear(emb_dim, emb_dim, bias_attr=True)
+ self.head_dim = emb_dim // num_heads
+ self.emb_dim = emb_dim
+ self.num_heads = num_heads
+ assert self.head_dim * num_heads == emb_dim, "embed_dim must be divisible by num_heads"
+ #self.scaling = float(self.head_dim) ** -0.5
+
+ def forward(self, x, attn_mask=None): # x is in shape[max_len,batch_size,emb_dim]
+
+ atten = multi_head_attention_forward(x,
+ self.num_heads,
+ self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.c_proj,
+ attn_mask=attn_mask)
+
+ return atten
+
+
+class Identity(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return x
+
+
+class Bottleneck(nn.Layer):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1):
+ super().__init__()
+
+ # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
+ self.conv1 = nn.Conv2D(inplanes, planes, 1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(planes)
+
+ self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(planes)
+
+ self.avgpool = nn.AvgPool2D(stride) if stride > 1 else Identity()
+
+ self.conv3 = nn.Conv2D(planes, planes * self.expansion, 1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(planes * self.expansion)
+
+ self.relu = nn.ReLU()
+ self.downsample = None
+ self.stride = stride
+
+ if stride > 1 or inplanes != planes * Bottleneck.expansion:
+ self.downsample = nn.Sequential(
+ ("-1", nn.AvgPool2D(stride)),
+ ("0", nn.Conv2D(inplanes, planes * self.expansion, 1, stride=1, bias_attr=False)),
+ ("1", nn.BatchNorm2D(planes * self.expansion)))
+
+ def forward(self, x):
+ identity = x
+
+ out = self.relu(self.bn1(self.conv1(x)))
+ out = self.relu(self.bn2(self.conv2(out)))
+ out = self.avgpool(out)
+ out = self.bn3(self.conv3(out))
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.relu(out)
+ return out
+
+
+class AttentionPool2d(nn.Layer):
+
+ def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
+ super().__init__()
+
+ self.positional_embedding = paddle.create_parameter((spacial_dim**2 + 1, embed_dim), dtype='float32')
+
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias_attr=True)
+ self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim, bias_attr=True)
+ self.num_heads = num_heads
+
+ self.head_dim = embed_dim // num_heads
+ assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
+
+ def forward(self, x):
+
+ x = x.reshape((x.shape[0], x.shape[1], x.shape[2] * x.shape[3])).transpose((2, 0, 1)) # NCHW -> (HW)NC
+ max_len, batch_size, emb_dim = x.shape
+ head_dim = self.head_dim
+ x = paddle.concat([paddle.mean(x, axis=0, keepdim=True), x], axis=0)
+ x = x + paddle.unsqueeze(self.positional_embedding, 1)
+ out = multi_head_attention_forward(x, self.num_heads, self.q_proj, self.k_proj, self.v_proj, self.c_proj)
+
+ return out[0]
+
+
+class QuickGELU(nn.Layer):
+
+ def forward(self, x):
+ return x * paddle.nn.functional.sigmoid(1.702 * x)
+
+
+class ResidualAttentionBlock(nn.Layer):
+
+ def __init__(self, d_model: int, n_head: int, attn_mask=None):
+ super().__init__()
+
+ self.attn = MultiHeadAttention(d_model, n_head)
+ self.ln_1 = nn.LayerNorm(d_model)
+ self.mlp = nn.Sequential(("c_fc", nn.Linear(d_model, d_model * 4)), ("gelu", QuickGELU()),
+ ("c_proj", nn.Linear(d_model * 4, d_model)))
+ self.ln_2 = nn.LayerNorm(d_model)
+ self.attn_mask = attn_mask
+
+ def attention(self, x):
+ x = self.attn(x, self.attn_mask)
+ assert isinstance(x, paddle.Tensor) # not tuble here
+ return x
+
+ def forward(self, x):
+
+ x = x + self.attention(self.ln_1(x))
+ x = x + self.mlp(self.ln_2(x))
+ return x
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/model.py b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/model.py
new file mode 100755
index 000000000..06affcc4b
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/model.py
@@ -0,0 +1,259 @@
+from typing import Tuple
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddle import nn
+
+from .layers import AttentionPool2d
+from .layers import Bottleneck
+from .layers import MultiHeadAttention
+from .layers import ResidualAttentionBlock
+
+
+class ModifiedResNet(nn.Layer):
+ """
+ A ResNet class that is similar to torchvision's but contains the following changes:
+ - There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
+ - Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
+ - The final pooling layer is a QKV attention instead of an average pool
+ """
+
+ def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
+ super().__init__()
+ self.output_dim = output_dim
+ self.input_resolution = input_resolution
+
+ # the 3-layer stem
+ self.conv1 = nn.Conv2D(3, width // 2, kernel_size=3, stride=2, padding=1, bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(width // 2)
+ self.conv2 = nn.Conv2D(width // 2, width // 2, kernel_size=3, padding=1, bias_attr=False)
+ self.bn2 = nn.BatchNorm2D(width // 2)
+ self.conv3 = nn.Conv2D(width // 2, width, kernel_size=3, padding=1, bias_attr=False)
+ self.bn3 = nn.BatchNorm2D(width)
+ self.avgpool = nn.AvgPool2D(2)
+ self.relu = nn.ReLU()
+
+ # residual layers
+ self._inplanes = width # this is a *mutable* variable used during construction
+ self.layer1 = self._make_layer(width, layers[0])
+ self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
+ self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
+ self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
+
+ embed_dim = width * 32 # the ResNet feature dimension
+ self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
+
+ def _make_layer(self, planes, blocks, stride=1):
+ layers = [Bottleneck(self._inplanes, planes, stride)]
+
+ self._inplanes = planes * Bottleneck.expansion
+ for _ in range(1, blocks):
+ layers.append(Bottleneck(self._inplanes, planes))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ def stem(x):
+ for conv, bn in [(self.conv1, self.bn1), (self.conv2, self.bn2), (self.conv3, self.bn3)]:
+ x = self.relu(bn(conv(x)))
+ x = self.avgpool(x)
+ return x
+
+ #x = x.type(self.conv1.weight.dtype)
+ x = stem(x)
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+ x = self.attnpool(x)
+
+ return x
+
+
+class Transformer(nn.Layer):
+
+ def __init__(self, width: int, layers: int, heads: int, attn_mask=None):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
+
+ def forward(self, x):
+ return self.resblocks(x)
+
+
+class VisualTransformer(nn.Layer):
+
+ def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.output_dim = output_dim
+ # used patch_size x patch_size, stride patch_size to do linear projection
+ self.conv1 = nn.Conv2D(in_channels=3,
+ out_channels=width,
+ kernel_size=patch_size,
+ stride=patch_size,
+ bias_attr=False)
+
+ # scale = width ** -0.5
+ self.class_embedding = paddle.create_parameter((width, ), 'float32')
+
+ self.positional_embedding = paddle.create_parameter(((input_resolution // patch_size)**2 + 1, width), 'float32')
+
+ self.ln_pre = nn.LayerNorm(width)
+
+ self.transformer = Transformer(width, layers, heads)
+
+ self.ln_post = nn.LayerNorm(width)
+ self.proj = paddle.create_parameter((width, output_dim), 'float32')
+
+ def forward(self, x):
+
+ x = self.conv1(x)
+ x = x.reshape((x.shape[0], x.shape[1], -1))
+ x = x.transpose((0, 2, 1))
+ x = paddle.concat([self.class_embedding + paddle.zeros((x.shape[0], 1, x.shape[-1]), dtype=x.dtype), x], axis=1)
+
+ x = x + self.positional_embedding
+ x = self.ln_pre(x)
+ x = x.transpose((1, 0, 2))
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2))
+ x = self.ln_post(x[:, 0, :])
+ if self.proj is not None:
+ x = paddle.matmul(x, self.proj)
+
+ return x
+
+
+class TextTransformer(nn.Layer):
+
+ def __init__(self, context_length: int, vocab_size: int, transformer_width: int, transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+ self.context_length = context_length
+ self.transformer = Transformer(width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+
+ self.vocab_size = vocab_size
+ self.token_embedding = nn.Embedding(vocab_size, transformer_width)
+ self.positional_embedding = paddle.create_parameter((self.context_length, transformer_width), 'float32')
+ self.ln_final = nn.LayerNorm(transformer_width)
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # mask = paddle.empty((self.context_length, self.context_length),dtype='float32')
+ # mask.fill_(float("-inf"))
+ #mask.triu_(1) # zero out the lower diagonal
+
+ mask = paddle.ones((self.context_length, self.context_length)) * float("-inf")
+ mask = paddle.triu(mask, diagonal=1)
+
+ return mask
+
+ def forward(self, text):
+ x = self.token_embedding(text) # [batch_size, n_ctx, d_model]
+ x = x + self.positional_embedding
+ x = x.transpose((1, 0, 2)) # NLD -> LND
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2)) # LND -> NLD
+ x = self.ln_final(x)
+ return x
+
+
+class CLIP(nn.Layer):
+
+ def __init__(
+ self,
+ embed_dim: int,
+ # vision
+ image_resolution: int,
+ vision_layers: Union[Tuple[int, int, int, int], int],
+ vision_width: int,
+ vision_patch_size: int,
+ # text
+ context_length: int,
+ vocab_size: int,
+ transformer_width: int,
+ transformer_heads: int,
+ transformer_layers: int):
+ super().__init__()
+
+ self.context_length = context_length
+ if isinstance(vision_layers, (tuple, list)):
+ vision_heads = vision_width * 32 // 64
+ self.visual = ModifiedResNet(layers=vision_layers,
+ output_dim=embed_dim,
+ heads=vision_heads,
+ input_resolution=image_resolution,
+ width=vision_width)
+ else:
+ vision_heads = vision_width // 64
+ self.visual = VisualTransformer(input_resolution=image_resolution,
+ patch_size=vision_patch_size,
+ width=vision_width,
+ layers=vision_layers,
+ heads=vision_heads,
+ output_dim=embed_dim)
+
+ self.transformer = Transformer(width=transformer_width,
+ layers=transformer_layers,
+ heads=transformer_heads,
+ attn_mask=self.build_attention_mask())
+
+ self.vocab_size = vocab_size
+ self.token_embedding = nn.Embedding(vocab_size, transformer_width)
+ self.positional_embedding = paddle.create_parameter((self.context_length, transformer_width), 'float32')
+ self.ln_final = nn.LayerNorm(transformer_width)
+
+ self.text_projection = paddle.create_parameter((transformer_width, embed_dim), 'float32')
+ self.logit_scale = paddle.create_parameter((1, ), 'float32')
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # mask = paddle.empty((self.context_length, self.context_length),dtype='float32')
+ # mask.fill_(float("-inf"))
+ #mask.triu_(1) # zero out the lower diagonal
+
+ mask = paddle.ones((self.context_length, self.context_length)) * float("-inf")
+ mask = paddle.triu(mask, diagonal=1)
+
+ return mask
+
+ def encode_image(self, image):
+ return self.visual(image)
+
+ def encode_text(self, text):
+ x = self.token_embedding(text) # [batch_size, n_ctx, d_model]
+ x = x + self.positional_embedding
+ x = x.transpose((1, 0, 2)) # NLD -> LND
+ x = self.transformer(x)
+ x = x.transpose((1, 0, 2)) # LND -> NLD
+ x = self.ln_final(x)
+ idx = text.numpy().argmax(-1)
+ idx = list(idx)
+ x = [x[i:i + 1, int(j), :] for i, j in enumerate(idx)]
+ x = paddle.concat(x, 0)
+ x = paddle.matmul(x, self.text_projection)
+ return x
+
+ def forward(self, image, text):
+ image_features = self.encode_image(image)
+ text_features = self.encode_text(text)
+
+ # normalized features
+ image_features = image_features / image_features.norm(dim=-1, keepdim=True)
+ text_features = text_features / text_features.norm(dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_image = paddle.matmul(logit_scale * image_features, text_features.t())
+ logits_per_text = paddle.matmul(logit_scale * text_features, image_features.t())
+
+ # shape = [global_batch_size, global_batch_size]
+ return logits_per_image, logits_per_text
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/simple_tokenizer.py b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/simple_tokenizer.py
new file mode 100755
index 000000000..4eaf82e9e
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/simple_tokenizer.py
@@ -0,0 +1,135 @@
+import gzip
+import html
+import os
+from functools import lru_cache
+
+import ftfy
+import regex as re
+
+
+@lru_cache()
+def default_bpe():
+ return os.path.join(os.path.dirname(os.path.abspath(__file__)), "../assets/bpe_simple_vocab_16e6.txt.gz")
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a corresponding list of unicode strings.
+ The reversible bpe codes work on unicode strings.
+ This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
+ When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
+ This is a signficant percentage of your normal, say, 32K bpe vocab.
+ To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ And avoids mapping to whitespace/control characters the bpe code barfs on.
+ """
+ bs = list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """Return set of symbol pairs in a word.
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+def basic_clean(text):
+ text = ftfy.fix_text(text)
+ text = html.unescape(html.unescape(text))
+ return text.strip()
+
+
+def whitespace_clean(text):
+ text = re.sub(r'\s+', ' ', text)
+ text = text.strip()
+ return text
+
+
+class SimpleTokenizer(object):
+
+ def __init__(self, bpe_path: str = default_bpe()):
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
+ merges = merges[1:49152 - 256 - 2 + 1]
+ merges = [tuple(merge.split()) for merge in merges]
+ vocab = list(bytes_to_unicode().values())
+ vocab = vocab + [v + '' for v in vocab]
+ for merge in merges:
+ vocab.append(''.join(merge))
+ vocab.extend(['<|startoftext|>', '<|endoftext|>'])
+ self.encoder = dict(zip(vocab, range(len(vocab))))
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.bpe_ranks = dict(zip(merges, range(len(merges))))
+ self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}
+ self.pat = re.compile(
+ r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
+ re.IGNORECASE)
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token[:-1]) + (token[-1] + '', )
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token + ''
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ new_word.extend(word[i:j])
+ i = j
+ except:
+ new_word.extend(word[i:])
+ break
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = ' '.join(word)
+ self.cache[token] = word
+ return word
+
+ def encode(self, text):
+ bpe_tokens = []
+ text = whitespace_clean(basic_clean(text)).lower()
+ for token in re.findall(self.pat, text):
+ token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
+ bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
+ return bpe_tokens
+
+ def decode(self, tokens):
+ text = ''.join([self.decoder[token] for token in tokens])
+ text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('', ' ')
+ return text
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/utils.py b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/utils.py
new file mode 100755
index 000000000..b5d417144
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/clip/clip/utils.py
@@ -0,0 +1,88 @@
+import os
+from typing import List
+from typing import Union
+
+import numpy as np
+import paddle
+from paddle.utils import download
+from paddle.vision.transforms import CenterCrop
+from paddle.vision.transforms import Compose
+from paddle.vision.transforms import Normalize
+from paddle.vision.transforms import Resize
+from paddle.vision.transforms import ToTensor
+
+from .model import CLIP
+from .model import TextTransformer
+from .simple_tokenizer import SimpleTokenizer
+
+__all__ = ['transform', 'tokenize', 'build_model']
+
+MODEL_NAMES = ['VITL14']
+
+URL = {'VITL14': os.path.join(os.path.dirname(__file__), 'pre_trained', 'vitl14_textencoder.pdparams')}
+
+MEAN, STD = (0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)
+_tokenizer = SimpleTokenizer()
+
+transform = Compose([
+ Resize(224, interpolation='bicubic'),
+ CenterCrop(224), lambda image: image.convert('RGB'),
+ ToTensor(),
+ Normalize(mean=MEAN, std=STD), lambda t: t.unsqueeze_(0)
+])
+
+
+def tokenize(texts: Union[str, List[str]], context_length: int = 77):
+ """
+ Returns the tokenized representation of given input string(s)
+
+ Parameters
+ ----------
+ texts : Union[str, List[str]]
+ An input string or a list of input strings to tokenize
+
+ context_length : int
+ The context length to use; all CLIP models use 77 as the context length
+
+ Returns
+ -------
+ A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
+ """
+ if isinstance(texts, str):
+ texts = [texts]
+
+ sot_token = _tokenizer.encoder["<|startoftext|>"]
+ eot_token = _tokenizer.encoder["<|endoftext|>"]
+ all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
+ result = paddle.zeros((len(all_tokens), context_length), dtype='int64')
+
+ for i, tokens in enumerate(all_tokens):
+ if len(tokens) > context_length:
+ raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
+ result[i, :len(tokens)] = paddle.Tensor(np.array(tokens))
+
+ return result
+
+
+def build_model(name='VITL14'):
+ assert name in MODEL_NAMES, f"model name must be one of {MODEL_NAMES}"
+ name2model = {'VITL14': build_vitl14_language_model}
+ model = name2model[name]()
+ weight = URL[name]
+ sd = paddle.load(weight)
+ state_dict = model.state_dict()
+ for key, value in sd.items():
+ if key in state_dict:
+ state_dict[key] = value
+ model.load_dict(state_dict)
+ model.eval()
+ return model
+
+
+def build_vitl14_language_model():
+ model = TextTransformer(context_length=77,
+ vocab_size=49408,
+ transformer_width=768,
+ transformer_heads=12,
+ transformer_layers=12)
+ return model
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/__init__.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/__init__.py
new file mode 100644
index 000000000..7f41816d7
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/__init__.py
@@ -0,0 +1,20 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+__version__ = "0.2.4"
+
+from .models import AutoencoderKL, UNet2DConditionModel, UNet2DModel, VQModel
+
+from .schedulers import (DDIMScheduler, DDPMScheduler, KarrasVeScheduler, PNDMScheduler, SchedulerMixin,
+ ScoreSdeVeScheduler, LMSDiscreteScheduler)
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/configuration_utils.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/configuration_utils.py
new file mode 100644
index 000000000..c90ebd5be
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/configuration_utils.py
@@ -0,0 +1,312 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" ConfigMixinuration base class and utilities."""
+import functools
+import inspect
+import json
+import os
+import re
+from collections import OrderedDict
+from typing import Any
+from typing import Dict
+from typing import Tuple
+from typing import Union
+
+from requests import HTTPError
+
+from paddlehub.common.logger import logger
+
+HUGGINGFACE_CO_RESOLVE_ENDPOINT = "HUGGINGFACE_CO_RESOLVE_ENDPOINT"
+DIFFUSERS_CACHE = "./caches"
+
+_re_configuration_file = re.compile(r"config\.(.*)\.json")
+
+
+class ConfigMixin:
+ r"""
+ Base class for all configuration classes. Handles a few parameters common to all models' configurations as well as
+ methods for loading/downloading/saving configurations.
+
+ """
+ config_name = "model_config.json"
+ ignore_for_config = []
+
+ def register_to_config(self, **kwargs):
+ if self.config_name is None:
+ raise NotImplementedError(f"Make sure that {self.__class__} has defined a class name `config_name`")
+ kwargs["_class_name"] = self.__class__.__name__
+ kwargs["_diffusers_version"] = "0.0.1"
+
+ for key, value in kwargs.items():
+ try:
+ setattr(self, key, value)
+ except AttributeError as err:
+ logger.error(f"Can't set {key} with value {value} for {self}")
+ raise err
+
+ if not hasattr(self, "_internal_dict"):
+ internal_dict = kwargs
+ else:
+ previous_dict = dict(self._internal_dict)
+ internal_dict = {**self._internal_dict, **kwargs}
+ logger.debug(f"Updating config from {previous_dict} to {internal_dict}")
+
+ self._internal_dict = FrozenDict(internal_dict)
+
+ def save_config(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
+ """
+ Save a configuration object to the directory `save_directory`, so that it can be re-loaded using the
+ [`~ConfigMixin.from_config`] class method.
+
+ Args:
+ save_directory (`str` or `os.PathLike`):
+ Directory where the configuration JSON file will be saved (will be created if it does not exist).
+ kwargs:
+ Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
+ """
+ if os.path.isfile(save_directory):
+ raise AssertionError(f"Provided path ({save_directory}) should be a directory, not a file")
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ # If we save using the predefined names, we can load using `from_config`
+ output_config_file = os.path.join(save_directory, self.config_name)
+
+ self.to_json_file(output_config_file)
+ logger.info(f"ConfigMixinuration saved in {output_config_file}")
+
+ @classmethod
+ def from_config(cls, pretrained_model_name_or_path: Union[str, os.PathLike], return_unused_kwargs=False, **kwargs):
+ config_dict = cls.get_config_dict(pretrained_model_name_or_path=pretrained_model_name_or_path, **kwargs)
+
+ init_dict, unused_kwargs = cls.extract_init_dict(config_dict, **kwargs)
+
+ model = cls(**init_dict)
+
+ if return_unused_kwargs:
+ return model, unused_kwargs
+ else:
+ return model
+
+ @classmethod
+ def get_config_dict(cls, pretrained_model_name_or_path: Union[str, os.PathLike],
+ **kwargs) -> Tuple[Dict[str, Any], Dict[str, Any]]:
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ revision = kwargs.pop("revision", None)
+ subfolder = kwargs.pop("subfolder", None)
+
+ user_agent = {"file_type": "config"}
+
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+
+ if cls.config_name is None:
+ raise ValueError(
+ "`self.config_name` is not defined. Note that one should not load a config from "
+ "`ConfigMixin`. Please make sure to define `config_name` in a class inheriting from `ConfigMixin`")
+
+ if os.path.isfile(pretrained_model_name_or_path):
+ config_file = pretrained_model_name_or_path
+ elif os.path.isdir(pretrained_model_name_or_path):
+ if os.path.isfile(os.path.join(pretrained_model_name_or_path, cls.config_name)):
+ # Load from a PyTorch checkpoint
+ config_file = os.path.join(pretrained_model_name_or_path, cls.config_name)
+ elif subfolder is not None and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)):
+ config_file = os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
+ else:
+ raise EnvironmentError(
+ f"Error no file named {cls.config_name} found in directory {pretrained_model_name_or_path}.")
+ else:
+ try:
+ # Load from URL or cache if already cached
+ from huggingface_hub import hf_hub_download
+ config_file = hf_hub_download(
+ pretrained_model_name_or_path,
+ filename=cls.config_name,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ user_agent=user_agent,
+ subfolder=subfolder,
+ )
+
+ except HTTPError as err:
+ raise EnvironmentError("There was a specific connection error when trying to load"
+ f" {pretrained_model_name_or_path}:\n{err}")
+ except ValueError:
+ raise EnvironmentError(
+ f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this model, couldn't find it"
+ f" in the cached files and it looks like {pretrained_model_name_or_path} is not the path to a"
+ f" directory containing a {cls.config_name} file.\nCheckout your internet connection or see how to"
+ " run the library in offline mode at"
+ " 'https://huggingface.co/docs/diffusers/installation#offline-mode'.")
+ except EnvironmentError:
+ raise EnvironmentError(
+ f"Can't load config for '{pretrained_model_name_or_path}'. If you were trying to load it from "
+ "'https://huggingface.co/models', make sure you don't have a local directory with the same name. "
+ f"Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a directory "
+ f"containing a {cls.config_name} file")
+
+ try:
+ # Load config dict
+ config_dict = cls._dict_from_json_file(config_file)
+ except (json.JSONDecodeError, UnicodeDecodeError):
+ raise EnvironmentError(f"It looks like the config file at '{config_file}' is not a valid JSON file.")
+
+ return config_dict
+
+ @classmethod
+ def extract_init_dict(cls, config_dict, **kwargs):
+ expected_keys = set(dict(inspect.signature(cls.__init__).parameters).keys())
+ expected_keys.remove("self")
+ # remove general kwargs if present in dict
+ if "kwargs" in expected_keys:
+ expected_keys.remove("kwargs")
+ # remove keys to be ignored
+ if len(cls.ignore_for_config) > 0:
+ expected_keys = expected_keys - set(cls.ignore_for_config)
+ init_dict = {}
+ for key in expected_keys:
+ if key in kwargs:
+ # overwrite key
+ init_dict[key] = kwargs.pop(key)
+ elif key in config_dict:
+ # use value from config dict
+ init_dict[key] = config_dict.pop(key)
+
+ unused_kwargs = config_dict.update(kwargs)
+
+ passed_keys = set(init_dict.keys())
+ if len(expected_keys - passed_keys) > 0:
+ logger.warning(
+ f"{expected_keys - passed_keys} was not found in config. Values will be initialized to default values.")
+
+ return init_dict, unused_kwargs
+
+ @classmethod
+ def _dict_from_json_file(cls, json_file: Union[str, os.PathLike]):
+ with open(json_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ return json.loads(text)
+
+ def __repr__(self):
+ return f"{self.__class__.__name__} {self.to_json_string()}"
+
+ @property
+ def config(self) -> Dict[str, Any]:
+ return self._internal_dict
+
+ def to_json_string(self) -> str:
+ """
+ Serializes this instance to a JSON string.
+
+ Returns:
+ `str`: String containing all the attributes that make up this configuration instance in JSON format.
+ """
+ config_dict = self._internal_dict if hasattr(self, "_internal_dict") else {}
+ return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
+
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this configuration instance's parameters will be saved.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ writer.write(self.to_json_string())
+
+
+class FrozenDict(OrderedDict):
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ for key, value in self.items():
+ setattr(self, key, value)
+
+ self.__frozen = True
+
+ def __delitem__(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``__delitem__`` on a {self.__class__.__name__} instance.")
+
+ def setdefault(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``setdefault`` on a {self.__class__.__name__} instance.")
+
+ def pop(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``pop`` on a {self.__class__.__name__} instance.")
+
+ def update(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``update`` on a {self.__class__.__name__} instance.")
+
+ def __setattr__(self, name, value):
+ if hasattr(self, "__frozen") and self.__frozen:
+ raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
+ super().__setattr__(name, value)
+
+ def __setitem__(self, name, value):
+ if hasattr(self, "__frozen") and self.__frozen:
+ raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
+ super().__setitem__(name, value)
+
+
+def register_to_config(init):
+ """
+ Decorator to apply on the init of classes inheriting from `ConfigMixin` so that all the arguments are automatically
+ sent to `self.register_for_config`. To ignore a specific argument accepted by the init but that shouldn't be
+ registered in the config, use the `ignore_for_config` class variable
+
+ Warning: Once decorated, all private arguments (beginning with an underscore) are trashed and not sent to the init!
+ """
+
+ @functools.wraps(init)
+ def inner_init(self, *args, **kwargs):
+ # Ignore private kwargs in the init.
+ init_kwargs = {k: v for k, v in kwargs.items() if not k.startswith("_")}
+ init(self, *args, **init_kwargs)
+ if not isinstance(self, ConfigMixin):
+ raise RuntimeError(
+ f"`@register_for_config` was applied to {self.__class__.__name__} init method, but this class does "
+ "not inherit from `ConfigMixin`.")
+
+ ignore = getattr(self, "ignore_for_config", [])
+ # Get positional arguments aligned with kwargs
+ new_kwargs = {}
+ signature = inspect.signature(init)
+ parameters = {
+ name: p.default
+ for i, (name, p) in enumerate(signature.parameters.items()) if i > 0 and name not in ignore
+ }
+ for arg, name in zip(args, parameters.keys()):
+ new_kwargs[name] = arg
+
+ # Then add all kwargs
+ new_kwargs.update({
+ k: init_kwargs.get(k, default)
+ for k, default in parameters.items() if k not in ignore and k not in new_kwargs
+ })
+ getattr(self, "register_to_config")(**new_kwargs)
+
+ return inner_init
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/README.md b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/README.md
new file mode 100644
index 000000000..e786fe518
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/README.md
@@ -0,0 +1,11 @@
+# Models
+
+- Models: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to denoise a noisy input to an image. Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet
+
+## API
+
+TODO(Suraj, Patrick)
+
+## Examples
+
+TODO(Suraj, Patrick)
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/__init__.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/__init__.py
new file mode 100644
index 000000000..f55cc88a8
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/__init__.py
@@ -0,0 +1,20 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .unet_2d import UNet2DModel
+from .unet_2d_condition import UNet2DConditionModel
+from .vae import AutoencoderKL
+from .vae import VQModel
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/attention.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/attention.py
new file mode 100644
index 000000000..29d0e73a7
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/attention.py
@@ -0,0 +1,465 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+from inspect import isfunction
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def finfo(dtype):
+ if dtype == paddle.float32:
+ return np.finfo(np.float32)
+ if dtype == paddle.float16:
+ return np.finfo(np.float16)
+ if dtype == paddle.float64:
+ return np.finfo(np.float64)
+
+
+paddle.finfo = finfo
+
+
+class AttentionBlockNew(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other. Originally ported from here, but adapted
+ to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ Uses three q, k, v linear layers to compute attention
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_head_channels=None,
+ num_groups=32,
+ rescale_output_factor=1.0,
+ eps=1e-5,
+ ):
+ super().__init__()
+ self.channels = channels
+
+ self.num_heads = channels // num_head_channels if num_head_channels is not None else 1
+ self.num_head_size = num_head_channels
+ self.group_norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=eps)
+
+ # define q,k,v as linear layers
+ self.query = nn.Linear(channels, channels)
+ self.key = nn.Linear(channels, channels)
+ self.value = nn.Linear(channels, channels)
+
+ self.rescale_output_factor = rescale_output_factor
+ self.proj_attn = nn.Linear(channels, channels)
+
+ def transpose_for_scores(self, projection: paddle.Tensor) -> paddle.Tensor:
+ new_projection_shape = projection.shape[:-1] + [self.num_heads, -1]
+ # move heads to 2nd position (B, T, H * D) -> (B, T, H, D) -> (B, H, T, D)
+ new_projection = projection.reshape(new_projection_shape).transpose([0, 2, 1, 3])
+ return new_projection
+
+ def forward(self, hidden_states):
+ residual = hidden_states
+ batch, channel, height, width = hidden_states.shape
+
+ # norm
+ hidden_states = self.group_norm(hidden_states)
+
+ hidden_states = hidden_states.reshape([batch, channel, height * width]).transpose([0, 2, 1])
+
+ # proj to q, k, v
+ query_proj = self.query(hidden_states)
+ key_proj = self.key(hidden_states)
+ value_proj = self.value(hidden_states)
+
+ # transpose
+ query_states = self.transpose_for_scores(query_proj)
+ key_states = self.transpose_for_scores(key_proj)
+ value_states = self.transpose_for_scores(value_proj)
+
+ # get scores
+ scale = 1 / math.sqrt(math.sqrt(self.channels / self.num_heads))
+ attention_scores = paddle.matmul(query_states * scale, key_states * scale, transpose_y=True)
+ attention_probs = F.softmax(attention_scores.astype("float32"), axis=-1).astype(attention_scores.dtype)
+
+ # compute attention output
+ context_states = paddle.matmul(attention_probs, value_states)
+
+ context_states = context_states.transpose([0, 2, 1, 3])
+ new_context_states_shape = context_states.shape[:-2] + [
+ self.channels,
+ ]
+ context_states = context_states.reshape(new_context_states_shape)
+
+ # compute next hidden_states
+ hidden_states = self.proj_attn(context_states)
+ hidden_states = hidden_states.transpose([0, 2, 1]).reshape([batch, channel, height, width])
+
+ # res connect and rescale
+ hidden_states = (hidden_states + residual) / self.rescale_output_factor
+ return hidden_states
+
+ def set_weight(self, attn_layer):
+ self.group_norm.weight.set_value(attn_layer.norm.weight)
+ self.group_norm.bias.set_value(attn_layer.norm.bias)
+
+ if hasattr(attn_layer, "q"):
+ self.query.weight.set_value(attn_layer.q.weight[:, :, 0, 0])
+ self.key.weight.set_value(attn_layer.k.weight[:, :, 0, 0])
+ self.value.weight.set_value(attn_layer.v.weight[:, :, 0, 0])
+
+ self.query.bias.set_value(attn_layer.q.bias)
+ self.key.bias.set_value(attn_layer.k.bias)
+ self.value.bias.set_value(attn_layer.v.bias)
+
+ self.proj_attn.weight.set_value(attn_layer.proj_out.weight[:, :, 0, 0])
+ self.proj_attn.bias.set_value(attn_layer.proj_out.bias)
+ elif hasattr(attn_layer, "NIN_0"):
+ self.query.weight.set_value(attn_layer.NIN_0.W.t())
+ self.key.weight.set_value(attn_layer.NIN_1.W.t())
+ self.value.weight.set_value(attn_layer.NIN_2.W.t())
+
+ self.query.bias.set_value(attn_layer.NIN_0.b)
+ self.key.bias.set_value(attn_layer.NIN_1.b)
+ self.value.bias.set_value(attn_layer.NIN_2.b)
+
+ self.proj_attn.weight.set_value(attn_layer.NIN_3.W.t())
+ self.proj_attn.bias.set_value(attn_layer.NIN_3.b)
+
+ self.group_norm.weight.set_value(attn_layer.GroupNorm_0.weight)
+ self.group_norm.bias.set_value(attn_layer.GroupNorm_0.bias)
+ else:
+ qkv_weight = attn_layer.qkv.weight.reshape(
+ [self.num_heads, 3 * self.channels // self.num_heads, self.channels])
+ qkv_bias = attn_layer.qkv.bias.reshape([self.num_heads, 3 * self.channels // self.num_heads])
+
+ q_w, k_w, v_w = qkv_weight.split(self.channels // self.num_heads, axis=1)
+ q_b, k_b, v_b = qkv_bias.split(self.channels // self.num_heads, axis=1)
+
+ self.query.weight.set_value(q_w.reshape([-1, self.channels]))
+ self.key.weight.set_value(k_w.reshape([-1, self.channels]))
+ self.value.weight.set_value(v_w.reshape([-1, self.channels]))
+
+ self.query.bias.set_value(q_b.flatten())
+ self.key.bias.set_value(k_b.flatten())
+ self.value.bias.set_value(v_b.flatten())
+
+ self.proj_attn.weight.set_value(attn_layer.proj.weight[:, :, 0])
+ self.proj_attn.bias.set_value(attn_layer.proj.bias)
+
+
+class SpatialTransformer(nn.Layer):
+ """
+ Transformer block for image-like data. First, project the input (aka embedding) and reshape to b, t, d. Then apply
+ standard transformer action. Finally, reshape to image
+ """
+
+ def __init__(self, in_channels, n_heads, d_head, depth=1, dropout=0.0, context_dim=None):
+ super().__init__()
+ self.n_heads = n_heads
+ self.d_head = d_head
+ self.in_channels = in_channels
+ inner_dim = n_heads * d_head
+ self.norm = nn.GroupNorm(num_groups=32, num_channels=in_channels, epsilon=1e-6)
+
+ self.proj_in = nn.Conv2D(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
+
+ self.transformer_blocks = nn.LayerList([
+ BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
+ for d in range(depth)
+ ])
+
+ self.proj_out = nn.Conv2D(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x, context=None):
+ # note: if no context is given, cross-attention defaults to self-attention
+ b, c, h, w = x.shape
+ x_in = x
+ x = self.norm(x)
+ x = self.proj_in(x)
+ x = x.transpose([0, 2, 3, 1]).reshape([b, h * w, c])
+ for block in self.transformer_blocks:
+ x = block(x, context=context)
+ x = x.reshape([b, h, w, c]).transpose([0, 3, 1, 2])
+ x = self.proj_out(x)
+ return x + x_in
+
+ def set_weight(self, layer):
+ self.norm = layer.norm
+ self.proj_in = layer.proj_in
+ self.transformer_blocks = layer.transformer_blocks
+ self.proj_out = layer.proj_out
+
+
+class BasicTransformerBlock(nn.Layer):
+
+ def __init__(self, dim, n_heads, d_head, dropout=0.0, context_dim=None, gated_ff=True, checkpoint=True):
+ super().__init__()
+ self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head,
+ dropout=dropout) # is a self-attention
+ self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
+ self.attn2 = CrossAttention(query_dim=dim,
+ context_dim=context_dim,
+ heads=n_heads,
+ dim_head=d_head,
+ dropout=dropout) # is self-attn if context is none
+ self.norm1 = nn.LayerNorm(dim)
+ self.norm2 = nn.LayerNorm(dim)
+ self.norm3 = nn.LayerNorm(dim)
+ self.checkpoint = checkpoint
+
+ def forward(self, x, context=None):
+ x = self.attn1(self.norm1(x)) + x
+ x = self.attn2(self.norm2(x), context=context) + x
+ x = self.ff(self.norm3(x)) + x
+ return x
+
+
+class CrossAttention(nn.Layer):
+
+ def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.0):
+ super().__init__()
+ inner_dim = dim_head * heads
+ context_dim = default(context_dim, query_dim)
+
+ self.scale = dim_head**-0.5
+ self.heads = heads
+
+ self.to_q = nn.Linear(query_dim, inner_dim, bias_attr=False)
+ self.to_k = nn.Linear(context_dim, inner_dim, bias_attr=False)
+ self.to_v = nn.Linear(context_dim, inner_dim, bias_attr=False)
+
+ self.to_out = nn.Sequential(nn.Linear(inner_dim, query_dim), nn.Dropout(dropout))
+
+ def reshape_heads_to_batch_dim(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.heads
+ tensor = tensor.reshape([batch_size, seq_len, head_size, dim // head_size])
+ tensor = tensor.transpose([0, 2, 1, 3]).reshape([batch_size * head_size, seq_len, dim // head_size])
+ return tensor
+
+ def reshape_batch_dim_to_heads(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.heads
+ tensor = tensor.reshape([batch_size // head_size, head_size, seq_len, dim])
+ tensor = tensor.transpose([0, 2, 1, 3]).reshape([batch_size // head_size, seq_len, dim * head_size])
+ return tensor
+
+ def forward(self, x, context=None, mask=None):
+ batch_size, sequence_length, dim = x.shape
+
+ h = self.heads
+
+ q = self.to_q(x)
+ context = default(context, x)
+ k = self.to_k(context)
+ v = self.to_v(context)
+
+ q = self.reshape_heads_to_batch_dim(q)
+ k = self.reshape_heads_to_batch_dim(k)
+ v = self.reshape_heads_to_batch_dim(v)
+
+ sim = paddle.einsum("b i d, b j d -> b i j", q * self.scale, k)
+
+ if exists(mask):
+ mask = mask.reshape([batch_size, -1])
+ max_neg_value = -paddle.finfo(sim.dtype).max
+ mask = mask[:, None, :].repeat(h, 1, 1)
+ sim.masked_fill_(~mask, max_neg_value)
+
+ # attention, what we cannot get enough of
+ attn = F.softmax(sim, axis=-1)
+
+ out = paddle.einsum("b i j, b j d -> b i d", attn, v)
+ out = self.reshape_batch_dim_to_heads(out)
+ return self.to_out(out)
+
+
+class FeedForward(nn.Layer):
+
+ def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.0):
+ super().__init__()
+ inner_dim = int(dim * mult)
+ dim_out = default(dim_out, dim)
+ project_in = nn.Sequential(nn.Linear(dim, inner_dim), nn.GELU()) if not glu else GEGLU(dim, inner_dim)
+
+ self.net = nn.Sequential(project_in, nn.Dropout(dropout), nn.Linear(inner_dim, dim_out))
+
+ def forward(self, x):
+ return self.net(x)
+
+
+# feedforward
+class GEGLU(nn.Layer):
+
+ def __init__(self, dim_in, dim_out):
+ super().__init__()
+ self.proj = nn.Linear(dim_in, dim_out * 2)
+
+ def forward(self, x):
+ x, gate = self.proj(x).chunk(2, axis=-1)
+ return x * F.gelu(gate)
+
+
+# TODO(Patrick) - remove once all weights have been converted -> not needed anymore then
+class NIN(nn.Layer):
+
+ def __init__(self, in_dim, num_units, init_scale=0.1):
+ super().__init__()
+ self.W = self.create_parameter(shape=[in_dim, num_units], default_initializer=nn.initializer.Constant(0.))
+ self.b = self.create_parameter(shape=[
+ num_units,
+ ],
+ is_bias=True,
+ default_initializer=nn.initializer.Constant(0.))
+
+
+def exists(val):
+ return val is not None
+
+
+def default(val, d):
+ if exists(val):
+ return val
+ return d() if isfunction(d) else d
+
+
+# the main attention block that is used for all models
+class AttentionBlock(nn.Layer):
+ """
+ An attention block that allows spatial positions to attend to each other.
+
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_heads=1,
+ num_head_channels=None,
+ num_groups=32,
+ encoder_channels=None,
+ overwrite_qkv=False,
+ overwrite_linear=False,
+ rescale_output_factor=1.0,
+ eps=1e-5,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels is None:
+ self.num_heads = num_heads
+ else:
+ assert (channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+
+ self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=eps)
+ self.qkv = nn.Conv1D(channels, channels * 3, 1)
+ self.n_heads = self.num_heads
+ self.rescale_output_factor = rescale_output_factor
+
+ if encoder_channels is not None:
+ self.encoder_kv = nn.Conv1D(encoder_channels, channels * 2, 1)
+
+ self.proj = nn.Conv1D(channels, channels, 1)
+
+ self.overwrite_qkv = overwrite_qkv
+ self.overwrite_linear = overwrite_linear
+
+ if overwrite_qkv:
+ in_channels = channels
+ self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=1e-6)
+ self.q = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.k = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.v = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.proj_out = nn.Conv2D(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ elif self.overwrite_linear:
+ num_groups = min(channels // 4, 32)
+ self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, epsilon=1e-6)
+ self.NIN_0 = NIN(channels, channels)
+ self.NIN_1 = NIN(channels, channels)
+ self.NIN_2 = NIN(channels, channels)
+ self.NIN_3 = NIN(channels, channels)
+
+ self.GroupNorm_0 = nn.GroupNorm(num_groups=num_groups, num_channels=channels, epsilon=1e-6)
+ else:
+ self.proj_out = nn.Conv1D(channels, channels, 1)
+ self.set_weights(self)
+
+ self.is_overwritten = False
+
+ def set_weights(self, layer):
+ if self.overwrite_qkv:
+ qkv_weight = paddle.concat([layer.q.weight, layer.k.weight, layer.v.weight], axis=0)[:, :, :, 0]
+ qkv_bias = paddle.concat([layer.q.bias, layer.k.bias, layer.v.bias], axis=0)
+
+ self.qkv.weight.set_value(qkv_weight)
+ self.qkv.bias.set_value(qkv_bias)
+
+ proj_out = nn.Conv1D(self.channels, self.channels, 1)
+ proj_out.weight.set_value(layer.proj_out.weight[:, :, :, 0])
+ proj_out.bias.set_value(layer.proj_out.bias)
+
+ self.proj = proj_out
+ elif self.overwrite_linear:
+ self.qkv.weight.set_value(
+ paddle.concat([self.NIN_0.W.t(), self.NIN_1.W.t(), self.NIN_2.W.t()], axis=0)[:, :, None])
+ self.qkv.bias.set_value(paddle.concat([self.NIN_0.b, self.NIN_1.b, self.NIN_2.b], axis=0))
+
+ self.proj.weight.set_value(self.NIN_3.W.t()[:, :, None])
+ self.proj.bias.set_value(self.NIN_3.b)
+
+ self.norm.weight.set_value(self.GroupNorm_0.weight)
+ self.norm.bias.set_value(self.GroupNorm_0.bias)
+ else:
+ self.proj.weight.set_value(self.proj_out.weight)
+ self.proj.bias.set_value(self.proj_out.bias)
+
+ def forward(self, x, encoder_out=None):
+ if not self.is_overwritten and (self.overwrite_qkv or self.overwrite_linear):
+ self.set_weights(self)
+ self.is_overwritten = True
+
+ b, c, *spatial = x.shape
+ hid_states = self.norm(x).reshape([b, c, -1])
+
+ qkv = self.qkv(hid_states)
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.reshape([bs * self.n_heads, ch * 3, length]).split(ch, axis=1)
+
+ if encoder_out is not None:
+ encoder_kv = self.encoder_kv(encoder_out)
+ assert encoder_kv.shape[1] == self.n_heads * ch * 2
+ ek, ev = encoder_kv.reshape([bs * self.n_heads, ch * 2, -1]).split(ch, axis=1)
+ k = paddle.concat([ek, k], axis=-1)
+ v = paddle.concat([ev, v], axis=-1)
+
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = paddle.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
+ weight = F.softmax(weight.astype("float32"), axis=-1).astype(weight.dtype)
+
+ a = paddle.einsum("bts,bcs->bct", weight, v)
+ h = a.reshape([bs, -1, length])
+
+ h = self.proj(h)
+ h = h.reshape([b, c, *spatial])
+
+ result = x + h
+
+ result = result / self.rescale_output_factor
+
+ return result
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/embeddings.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/embeddings.py
new file mode 100644
index 000000000..3e826193b
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/embeddings.py
@@ -0,0 +1,116 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def get_timestep_embedding(timesteps,
+ embedding_dim,
+ flip_sin_to_cos=False,
+ downscale_freq_shift=1,
+ scale=1,
+ max_period=10000):
+ """
+ This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
+
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
+ embeddings. :return: an [N x dim] Tensor of positional embeddings.
+ """
+ assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
+
+ half_dim = embedding_dim // 2
+ exponent = -math.log(max_period) * paddle.arange(start=0, end=half_dim, dtype="float32")
+ exponent = exponent / (half_dim - downscale_freq_shift)
+
+ emb = paddle.exp(exponent)
+ emb = timesteps[:, None].astype("float32") * emb[None, :]
+
+ # scale embeddings
+ emb = scale * emb
+
+ # concat sine and cosine embeddings
+ emb = paddle.concat([paddle.sin(emb), paddle.cos(emb)], axis=-1)
+
+ # flip sine and cosine embeddings
+ if flip_sin_to_cos:
+ emb = paddle.concat([emb[:, half_dim:], emb[:, :half_dim]], axis=-1)
+
+ # zero pad
+ if embedding_dim % 2 == 1:
+ emb = paddle.concat(emb, paddle.zeros([emb.shape[0], 1]), axis=-1)
+ return emb
+
+
+class TimestepEmbedding(nn.Layer):
+
+ def __init__(self, channel, time_embed_dim, act_fn="silu"):
+ super().__init__()
+
+ self.linear_1 = nn.Linear(channel, time_embed_dim)
+ self.act = None
+ if act_fn == "silu":
+ self.act = nn.Silu()
+ self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim)
+
+ def forward(self, sample):
+ sample = self.linear_1(sample)
+
+ if self.act is not None:
+ sample = self.act(sample)
+
+ sample = self.linear_2(sample)
+ return sample
+
+
+class Timesteps(nn.Layer):
+
+ def __init__(self, num_channels, flip_sin_to_cos, downscale_freq_shift):
+ super().__init__()
+ self.num_channels = num_channels
+ self.flip_sin_to_cos = flip_sin_to_cos
+ self.downscale_freq_shift = downscale_freq_shift
+
+ def forward(self, timesteps):
+ t_emb = get_timestep_embedding(
+ timesteps,
+ self.num_channels,
+ flip_sin_to_cos=self.flip_sin_to_cos,
+ downscale_freq_shift=self.downscale_freq_shift,
+ )
+ return t_emb
+
+
+class GaussianFourierProjection(nn.Layer):
+ """Gaussian Fourier embeddings for noise levels."""
+
+ def __init__(self, embedding_size=256, scale=1.0):
+ super().__init__()
+ self.register_buffer("weight", paddle.randn((embedding_size, )) * scale)
+
+ # to delete later
+ self.register_buffer("W", paddle.randn((embedding_size, )) * scale)
+
+ self.weight = self.W
+
+ def forward(self, x):
+ x = paddle.log(x)
+ x_proj = x[:, None] * self.weight[None, :] * 2 * np.pi
+ out = paddle.concat([paddle.sin(x_proj), paddle.cos(x_proj)], axis=-1)
+ return out
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/resnet.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/resnet.py
new file mode 100644
index 000000000..944bc11cd
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/resnet.py
@@ -0,0 +1,515 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from functools import partial
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def pad_new(x, pad, mode="constant", value=0):
+ new_pad = []
+ for _ in range(x.ndim * 2 - len(pad)):
+ new_pad.append(0)
+ ndim = list(range(x.ndim - 1, 0, -1))
+ axes_start = {}
+ for i, _pad in enumerate(pad):
+ if _pad < 0:
+ new_pad.append(0)
+ zhengshu, yushu = divmod(i, 2)
+ if yushu == 0:
+ axes_start[ndim[zhengshu]] = -_pad
+ else:
+ new_pad.append(_pad)
+
+ padded = paddle.nn.functional.pad(x, new_pad, mode=mode, value=value)
+ padded_shape = paddle.shape(padded)
+ axes = []
+ starts = []
+ ends = []
+ for k, v in axes_start.items():
+ axes.append(k)
+ starts.append(v)
+ ends.append(padded_shape[k])
+ assert v < padded_shape[k]
+
+ if axes:
+ return padded.slice(axes=axes, starts=starts, ends=ends)
+ else:
+ return padded
+
+
+class Upsample2D(nn.Layer):
+ """
+ An upsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
+ applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv=False, use_conv_transpose=False, out_channels=None, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_conv_transpose = use_conv_transpose
+ self.name = name
+
+ conv = None
+ if use_conv_transpose:
+ conv = nn.Conv2DTranspose(channels, self.out_channels, 4, 2, 1)
+ elif use_conv:
+ conv = nn.Conv2D(self.channels, self.out_channels, 3, padding=1)
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if name == "conv":
+ self.conv = conv
+ else:
+ self.Conv2d_0 = conv
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.use_conv_transpose:
+ return self.conv(x)
+
+ x = F.interpolate(x, scale_factor=2.0, mode="nearest")
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if self.use_conv:
+ if self.name == "conv":
+ x = self.conv(x)
+ else:
+ x = self.Conv2d_0(x)
+
+ return x
+
+
+class Downsample2D(nn.Layer):
+ """
+ A downsampling layer with an optional convolution.
+
+ :param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
+ applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv=False, out_channels=None, padding=1, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.padding = padding
+ stride = 2
+ self.name = name
+
+ if use_conv:
+ conv = nn.Conv2D(self.channels, self.out_channels, 3, stride=stride, padding=padding)
+ else:
+ assert self.channels == self.out_channels
+ conv = nn.AvgPool2D(kernel_size=stride, stride=stride)
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if name == "conv":
+ self.Conv2d_0 = conv
+ self.conv = conv
+ elif name == "Conv2d_0":
+ self.conv = conv
+ else:
+ self.conv = conv
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.use_conv and self.padding == 0:
+ pad = (0, 1, 0, 1)
+ x = pad_new(x, pad, mode="constant", value=0)
+
+ assert x.shape[1] == self.channels
+ x = self.conv(x)
+
+ return x
+
+
+class FirUpsample2D(nn.Layer):
+
+ def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
+ super().__init__()
+ out_channels = out_channels if out_channels else channels
+ if use_conv:
+ self.Conv2d_0 = nn.Conv2D(channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.use_conv = use_conv
+ self.fir_kernel = fir_kernel
+ self.out_channels = out_channels
+
+ def _upsample_2d(self, x, w=None, k=None, factor=2, gain=1):
+ """Fused `upsample_2d()` followed by `Conv2d()`.
+
+ Args:
+ Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
+ efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
+ order.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
+ C]`.
+ w: Weight tensor of the shape `[filterH, filterW, inChannels,
+ outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] // numGroups`.
+ k: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
+ factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H * factor, W * factor]` or `[N, H * factor, W * factor, C]`, and same datatype as
+ `x`.
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+
+ # Setup filter kernel.
+ if k is None:
+ k = [1] * factor
+
+ # setup kernel
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * (gain * (factor**2))
+
+ if self.use_conv:
+ convH = w.shape[2]
+ convW = w.shape[3]
+ inC = w.shape[1]
+
+ p = (k.shape[0] - factor) - (convW - 1)
+
+ stride = (factor, factor)
+ # Determine data dimensions.
+ stride = [1, 1, factor, factor]
+ output_shape = ((x.shape[2] - 1) * factor + convH, (x.shape[3] - 1) * factor + convW)
+ output_padding = (
+ output_shape[0] - (x.shape[2] - 1) * stride[0] - convH,
+ output_shape[1] - (x.shape[3] - 1) * stride[1] - convW,
+ )
+ assert output_padding[0] >= 0 and output_padding[1] >= 0
+ inC = w.shape[1]
+ num_groups = x.shape[1] // inC
+
+ # Transpose weights.
+ w = paddle.reshape(w, (num_groups, -1, inC, convH, convW))
+ w = w[..., ::-1, ::-1].transpose([0, 2, 1, 3, 4])
+ w = paddle.reshape(w, (num_groups * inC, -1, convH, convW))
+
+ x = F.conv2d_transpose(x, w, stride=stride, output_padding=output_padding, padding=0)
+
+ x = upfirdn2d_native(x, paddle.to_tensor(k), pad=((p + 1) // 2 + factor - 1, p // 2 + 1))
+ else:
+ p = k.shape[0] - factor
+ x = upfirdn2d_native(x, paddle.to_tensor(k), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2))
+
+ return x
+
+ def forward(self, x):
+ if self.use_conv:
+ h = self._upsample_2d(x, self.Conv2d_0.weight, k=self.fir_kernel)
+ h = h + self.Conv2d_0.bias.reshape([1, -1, 1, 1])
+ else:
+ h = self._upsample_2d(x, k=self.fir_kernel, factor=2)
+
+ return h
+
+
+class FirDownsample2D(nn.Layer):
+
+ def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
+ super().__init__()
+ out_channels = out_channels if out_channels else channels
+ if use_conv:
+ self.Conv2d_0 = nn.Conv2D(channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.fir_kernel = fir_kernel
+ self.use_conv = use_conv
+ self.out_channels = out_channels
+
+ def _downsample_2d(self, x, w=None, k=None, factor=2, gain=1):
+ """Fused `Conv2d()` followed by `downsample_2d()`.
+
+ Args:
+ Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
+ efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
+ order.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`. w: Weight tensor of the shape `[filterH,
+ filterW, inChannels, outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] //
+ numGroups`. k: FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] *
+ factor`, which corresponds to average pooling. factor: Integer downsampling factor (default: 2). gain:
+ Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H // factor, W // factor]` or `[N, H // factor, W // factor, C]`, and same
+ datatype as `x`.
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+ if k is None:
+ k = [1] * factor
+
+ # setup kernel
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * gain
+
+ if self.use_conv:
+ _, _, convH, convW = w.shape
+ p = (k.shape[0] - factor) + (convW - 1)
+ s = [factor, factor]
+ x = upfirdn2d_native(x, paddle.to_tensor(k), pad=((p + 1) // 2, p // 2))
+ x = F.conv2d(x, w, stride=s, padding=0)
+ else:
+ p = k.shape[0] - factor
+ x = upfirdn2d_native(x, paddle.to_tensor(k), down=factor, pad=((p + 1) // 2, p // 2))
+
+ return x
+
+ def forward(self, x):
+ if self.use_conv:
+ x = self._downsample_2d(x, w=self.Conv2d_0.weight, k=self.fir_kernel)
+ x = x + self.Conv2d_0.bias.reshape([1, -1, 1, 1])
+ else:
+ x = self._downsample_2d(x, k=self.fir_kernel, factor=2)
+
+ return x
+
+
+class ResnetBlock(nn.Layer):
+
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout=0.0,
+ temb_channels=512,
+ groups=32,
+ groups_out=None,
+ pre_norm=True,
+ eps=1e-6,
+ non_linearity="swish",
+ time_embedding_norm="default",
+ kernel=None,
+ output_scale_factor=1.0,
+ use_nin_shortcut=None,
+ up=False,
+ down=False,
+ ):
+ super().__init__()
+ self.pre_norm = pre_norm
+ self.pre_norm = True
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+ self.time_embedding_norm = time_embedding_norm
+ self.up = up
+ self.down = down
+ self.output_scale_factor = output_scale_factor
+
+ if groups_out is None:
+ groups_out = groups
+
+ self.norm1 = nn.GroupNorm(num_groups=groups, num_channels=in_channels, epsilon=eps)
+
+ self.conv1 = nn.Conv2D(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if temb_channels is not None:
+ self.time_emb_proj = nn.Linear(temb_channels, out_channels)
+ else:
+ self.time_emb_proj = None
+
+ self.norm2 = nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, epsilon=eps)
+ self.dropout = nn.Dropout(dropout)
+ self.conv2 = nn.Conv2D(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if non_linearity == "swish":
+ self.nonlinearity = lambda x: F.silu(x)
+ elif non_linearity == "mish":
+ self.nonlinearity = Mish()
+ elif non_linearity == "silu":
+ self.nonlinearity = nn.Silu()
+
+ self.upsample = self.downsample = None
+ if self.up:
+ if kernel == "fir":
+ fir_kernel = (1, 3, 3, 1)
+ self.upsample = lambda x: upsample_2d(x, k=fir_kernel)
+ elif kernel == "sde_vp":
+ self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
+ else:
+ self.upsample = Upsample2D(in_channels, use_conv=False)
+ elif self.down:
+ if kernel == "fir":
+ fir_kernel = (1, 3, 3, 1)
+ self.downsample = lambda x: downsample_2d(x, k=fir_kernel)
+ elif kernel == "sde_vp":
+ self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
+ else:
+ self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
+
+ self.use_nin_shortcut = self.in_channels != self.out_channels if use_nin_shortcut is None else use_nin_shortcut
+
+ self.conv_shortcut = None
+ if self.use_nin_shortcut:
+ self.conv_shortcut = nn.Conv2D(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x, temb, hey=False):
+ h = x
+
+ # make sure hidden states is in float32
+ # when running in half-precision
+ h = self.norm1(h.astype("float32")).astype(h.dtype)
+ h = self.nonlinearity(h)
+
+ if self.upsample is not None:
+ x = self.upsample(x)
+ h = self.upsample(h)
+ elif self.downsample is not None:
+ x = self.downsample(x)
+ h = self.downsample(h)
+
+ h = self.conv1(h)
+
+ if temb is not None:
+ temb = self.time_emb_proj(self.nonlinearity(temb))[:, :, None, None]
+ h = h + temb
+
+ # make sure hidden states is in float32
+ # when running in half-precision
+ h = self.norm2(h.astype("float32")).astype(h.dtype)
+ h = self.nonlinearity(h)
+
+ h = self.dropout(h)
+ h = self.conv2(h)
+
+ if self.conv_shortcut is not None:
+ x = self.conv_shortcut(x)
+
+ out = (x + h) / self.output_scale_factor
+
+ return out
+
+
+class Mish(nn.Layer):
+
+ def forward(self, x):
+ return x * F.tanh(F.softplus(x))
+
+
+def upsample_2d(x, k=None, factor=2, gain=1):
+ r"""Upsample2D a batch of 2D images with the given filter.
+
+ Args:
+ Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and upsamples each image with the given
+ filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the specified
+ `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its shape is a:
+ multiple of the upsampling factor.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
+ C]`.
+ k: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
+ factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H * factor, W * factor]`
+ """
+ assert isinstance(factor, int) and factor >= 1
+ if k is None:
+ k = [1] * factor
+
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * (gain * (factor**2))
+ p = k.shape[0] - factor
+ return upfirdn2d_native(x, paddle.to_tensor(k), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2))
+
+
+def downsample_2d(x, k=None, factor=2, gain=1):
+ r"""Downsample2D a batch of 2D images with the given filter.
+
+ Args:
+ Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and downsamples each image with the
+ given filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the
+ specified `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its
+ shape is a multiple of the downsampling factor.
+ x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
+ C]`.
+ k: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to average pooling.
+ factor: Integer downsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ Tensor of the shape `[N, C, H // factor, W // factor]`
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+ if k is None:
+ k = [1] * factor
+
+ k = np.asarray(k, dtype=np.float32)
+ if k.ndim == 1:
+ k = np.outer(k, k)
+ k /= np.sum(k)
+
+ k = k * gain
+ p = k.shape[0] - factor
+ return upfirdn2d_native(x, paddle.to_tensor(k), down=factor, pad=((p + 1) // 2, p // 2))
+
+
+def upfirdn2d_native(input, kernel, up=1, down=1, pad=(0, 0)):
+ up_x = up_y = up
+ down_x = down_y = down
+ pad_x0 = pad_y0 = pad[0]
+ pad_x1 = pad_y1 = pad[1]
+
+ _, channel, in_h, in_w = input.shape
+ input = input.reshape([-1, in_h, in_w, 1])
+
+ _, in_h, in_w, minor = input.shape
+ kernel_h, kernel_w = kernel.shape
+
+ out = input.reshape([-1, in_h, 1, in_w, 1, minor])
+ # TODO
+ out = pad_new(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
+ out = out.reshape([-1, in_h * up_y, in_w * up_x, minor])
+
+ out = pad_new(out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)])
+ out = out[:, max(-pad_y0, 0):out.shape[1] - max(-pad_y1, 0), max(-pad_x0, 0):out.shape[2] - max(-pad_x1, 0), :, ]
+
+ out = out.transpose([0, 3, 1, 2])
+ out = out.reshape([-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1])
+ w = paddle.flip(kernel, [0, 1]).reshape([1, 1, kernel_h, kernel_w])
+ out = F.conv2d(out, w)
+ out = out.reshape(
+ [-1, minor, in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1, in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1])
+ out = out.transpose([0, 2, 3, 1])
+ out = out[:, ::down_y, ::down_x, :]
+
+ out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
+ out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
+
+ return out.reshape([-1, channel, out_h, out_w])
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/unet_2d.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/unet_2d.py
new file mode 100644
index 000000000..11316a819
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/unet_2d.py
@@ -0,0 +1,206 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .embeddings import GaussianFourierProjection
+from .embeddings import TimestepEmbedding
+from .embeddings import Timesteps
+from .unet_blocks import get_down_block
+from .unet_blocks import get_up_block
+from .unet_blocks import UNetMidBlock2D
+
+
+class UNet2DModel(nn.Layer, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size=None,
+ in_channels=3,
+ out_channels=3,
+ center_input_sample=False,
+ time_embedding_type="positional",
+ freq_shift=0,
+ flip_sin_to_cos=True,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D"),
+ block_out_channels=(224, 448, 672, 896),
+ layers_per_block=2,
+ mid_block_scale_factor=1,
+ downsample_padding=1,
+ act_fn="silu",
+ attention_head_dim=8,
+ norm_num_groups=32,
+ norm_eps=1e-5,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+ time_embed_dim = block_out_channels[0] * 4
+
+ # input
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
+
+ # time
+ if time_embedding_type == "fourier":
+ self.time_proj = GaussianFourierProjection(embedding_size=block_out_channels[0], scale=16)
+ timestep_input_dim = 2 * block_out_channels[0]
+ elif time_embedding_type == "positional":
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+
+ self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+
+ self.down_blocks = nn.LayerList([])
+ self.mid_block = None
+ self.up_blocks = nn.LayerList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=attention_head_dim,
+ downsample_padding=downsample_padding,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ temb_channels=time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=attention_head_dim,
+ resnet_groups=norm_num_groups,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=time_embed_dim,
+ add_upsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=attention_head_dim,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ num_groups_out = norm_num_groups if norm_num_groups is not None else min(block_out_channels[0] // 4, 32)
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0],
+ num_groups=num_groups_out,
+ epsilon=norm_eps)
+ self.conv_act = nn.Silu()
+ self.conv_out = nn.Conv2D(block_out_channels[0], out_channels, 3, padding=1)
+
+ def forward(self, sample: paddle.Tensor, timestep: Union[paddle.Tensor, float, int]) -> Dict[str, paddle.Tensor]:
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not paddle.is_tensor(timesteps):
+ timesteps = paddle.to_tensor([timesteps], dtype="int64")
+ elif paddle.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None]
+
+ # broadcast to batch dimension
+ timesteps = paddle.broadcast_to(timesteps, [sample.shape[0]])
+
+ t_emb = self.time_proj(timesteps)
+ emb = self.time_embedding(t_emb)
+
+ # 2. pre-process
+ skip_sample = sample
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample, )
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "skip_conv"):
+ sample, res_samples, skip_sample = downsample_block(hidden_states=sample,
+ temb=emb,
+ skip_sample=skip_sample)
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ # 4. mid
+ sample = self.mid_block(sample, emb)
+
+ # 5. up
+ skip_sample = None
+ for upsample_block in self.up_blocks:
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[:-len(upsample_block.resnets)]
+
+ if hasattr(upsample_block, "skip_conv"):
+ sample, skip_sample = upsample_block(sample, res_samples, emb, skip_sample)
+ else:
+ sample = upsample_block(sample, res_samples, emb)
+
+ # 6. post-process
+ # make sure hidden states is in float32
+ # when running in half-precision
+ sample = self.conv_norm_out(sample.astype("float32")).astype(sample.dtype)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ if skip_sample is not None:
+ sample += skip_sample
+
+ if self.config.time_embedding_type == "fourier":
+ timesteps = timesteps.reshape((sample.shape[0], *([1] * len(sample.shape[1:]))))
+ sample = sample / timesteps
+
+ output = {"sample": sample}
+
+ return output
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/unet_2d_condition.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/unet_2d_condition.py
new file mode 100644
index 000000000..897491b2f
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/unet_2d_condition.py
@@ -0,0 +1,206 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .embeddings import TimestepEmbedding
+from .embeddings import Timesteps
+from .unet_blocks import get_down_block
+from .unet_blocks import get_up_block
+from .unet_blocks import UNetMidBlock2DCrossAttn
+
+
+class UNet2DConditionModel(nn.Layer, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size=64,
+ in_channels=4,
+ out_channels=4,
+ center_input_sample=False,
+ flip_sin_to_cos=True,
+ freq_shift=0,
+ down_block_types=("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D"),
+ up_block_types=("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
+ block_out_channels=(320, 640, 1280, 1280),
+ layers_per_block=2,
+ downsample_padding=1,
+ mid_block_scale_factor=1,
+ act_fn="silu",
+ norm_num_groups=32,
+ norm_eps=1e-5,
+ cross_attention_dim=768,
+ attention_head_dim=8,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+ time_embed_dim = block_out_channels[0] * 4
+
+ # input
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
+
+ # time
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+
+ self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+
+ self.down_blocks = nn.LayerList([])
+ self.mid_block = None
+ self.up_blocks = nn.LayerList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim,
+ downsample_padding=downsample_padding,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2DCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift="default",
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim,
+ resnet_groups=norm_num_groups,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=time_embed_dim,
+ add_upsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0],
+ num_groups=norm_num_groups,
+ epsilon=norm_eps)
+ self.conv_act = nn.Silu()
+ self.conv_out = nn.Conv2D(block_out_channels[0], out_channels, 3, padding=1)
+
+ def forward(
+ self,
+ sample: paddle.Tensor,
+ timestep: Union[paddle.Tensor, float, int],
+ encoder_hidden_states: paddle.Tensor,
+ ) -> Dict[str, paddle.Tensor]:
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not paddle.is_tensor(timesteps):
+ timesteps = paddle.to_tensor([timesteps], dtype="int64")
+ elif paddle.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None]
+
+ # broadcast to batch dimension
+ timesteps = paddle.broadcast_to(timesteps, [sample.shape[0]])
+
+ t_emb = self.time_proj(timesteps)
+ emb = self.time_embedding(t_emb)
+
+ # 2. pre-process
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample, )
+ for downsample_block in self.down_blocks:
+
+ if hasattr(downsample_block, "attentions") and downsample_block.attentions is not None:
+ sample, res_samples = downsample_block(hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states)
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ # 4. mid
+ sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
+
+ # 5. up
+ for upsample_block in self.up_blocks:
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets):]
+ down_block_res_samples = down_block_res_samples[:-len(upsample_block.resnets)]
+
+ if hasattr(upsample_block, "attentions") and upsample_block.attentions is not None:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ else:
+ sample = upsample_block(hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples)
+
+ # 6. post-process
+ # make sure hidden states is in float32
+ # when running in half-precision
+ sample = self.conv_norm_out(sample.astype("float32")).astype(sample.dtype)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ output = {"sample": sample}
+
+ return output
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/unet_blocks.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/unet_blocks.py
new file mode 100644
index 000000000..684a2a43d
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/unet_blocks.py
@@ -0,0 +1,1428 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import paddle
+import paddle.nn as nn
+
+from .attention import AttentionBlockNew
+from .attention import SpatialTransformer
+from .resnet import Downsample2D
+from .resnet import FirDownsample2D
+from .resnet import FirUpsample2D
+from .resnet import ResnetBlock
+from .resnet import Upsample2D
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ cross_attention_dim=None,
+ downsample_padding=None,
+):
+ down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
+ if down_block_type == "DownBlock2D":
+ return DownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ )
+ elif down_block_type == "AttnDownBlock2D":
+ return AttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif down_block_type == "CrossAttnDownBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock2D")
+ return CrossAttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif down_block_type == "SkipDownBlock2D":
+ return SkipDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ )
+ elif down_block_type == "AttnSkipDownBlock2D":
+ return AttnSkipDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif down_block_type == "DownEncoderBlock2D":
+ return DownEncoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ )
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ cross_attention_dim=None,
+):
+ up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
+ if up_block_type == "UpBlock2D":
+ return UpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ elif up_block_type == "CrossAttnUpBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock2D")
+ return CrossAttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif up_block_type == "AttnUpBlock2D":
+ return AttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif up_block_type == "SkipUpBlock2D":
+ return SkipUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ elif up_block_type == "AttnSkipUpBlock2D":
+ return AttnSkipUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+ elif up_block_type == "UpDecoderBlock2D":
+ return UpDecoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+class UNetMidBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=1.0,
+ **kwargs,
+ ):
+ super().__init__()
+
+ self.attention_type = attention_type
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ attentions.append(
+ AttentionBlockNew(
+ in_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ num_groups=resnet_groups,
+ ))
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_states=None):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ if self.attention_type == "default":
+ hidden_states = attn(hidden_states)
+ else:
+ hidden_states = attn(hidden_states, encoder_states)
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+class UNetMidBlock2DCrossAttn(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ **kwargs,
+ ):
+ super().__init__()
+
+ self.attention_type = attention_type
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ attentions.append(
+ SpatialTransformer(
+ in_channels,
+ attn_num_head_channels,
+ in_channels // attn_num_head_channels,
+ depth=1,
+ context_dim=cross_attention_dim,
+ ))
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ hidden_states = attn(hidden_states, encoder_hidden_states)
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+class AttnDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states
+
+
+class CrossAttnDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ attention_type="default",
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ SpatialTransformer(
+ out_channels,
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ depth=1,
+ context_dim=cross_attention_dim,
+ ))
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None, encoder_hidden_states=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, context=encoder_hidden_states)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states
+
+
+class DownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states
+
+
+class DownEncoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb=None)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnDownEncoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ num_groups=resnet_groups,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.LayerList([
+ Downsample2D(in_channels,
+ use_conv=True,
+ out_channels=out_channels,
+ padding=downsample_padding,
+ name="op")
+ ])
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb=None)
+ hidden_states = attn(hidden_states)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnSkipDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=np.sqrt(2.0),
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ self.attentions = nn.LayerList([])
+ self.resnets = nn.LayerList([])
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(in_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ self.attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ if add_downsample:
+ self.resnet_down = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ down=True,
+ kernel="fir",
+ )
+ self.downsamplers = nn.LayerList([FirDownsample2D(in_channels, out_channels=out_channels)])
+ self.skip_conv = nn.Conv2D(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
+ else:
+ self.resnet_down = None
+ self.downsamplers = None
+ self.skip_conv = None
+
+ def forward(self, hidden_states, temb=None, skip_sample=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ hidden_states = self.resnet_down(hidden_states, temb)
+ for downsampler in self.downsamplers:
+ skip_sample = downsampler(skip_sample)
+
+ hidden_states = self.skip_conv(skip_sample) + hidden_states
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states, skip_sample
+
+
+class SkipDownBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ output_scale_factor=np.sqrt(2.0),
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ self.resnets = nn.LayerList([])
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(in_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ if add_downsample:
+ self.resnet_down = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ down=True,
+ kernel="fir",
+ )
+ self.downsamplers = nn.LayerList([FirDownsample2D(in_channels, out_channels=out_channels)])
+ self.skip_conv = nn.Conv2D(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
+ else:
+ self.resnet_down = None
+ self.downsamplers = None
+ self.skip_conv = None
+
+ def forward(self, hidden_states, temb=None, skip_sample=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb)
+ output_states += (hidden_states, )
+
+ if self.downsamplers is not None:
+ hidden_states = self.resnet_down(hidden_states, temb)
+ for downsampler in self.downsamplers:
+ skip_sample = downsampler(skip_sample)
+
+ hidden_states = self.skip_conv(skip_sample) + hidden_states
+
+ output_states += (hidden_states, )
+
+ return hidden_states, output_states, skip_sample
+
+
+class AttnUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attention_type="default",
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ for resnet, attn in zip(self.resnets, self.attentions):
+
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class CrossAttnUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ attention_type="default",
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ SpatialTransformer(
+ out_channels,
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ depth=1,
+ context_dim=cross_attention_dim,
+ ))
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, encoder_hidden_states=None):
+ for resnet, attn in zip(self.resnets, self.attentions):
+
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states, context=encoder_hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class UpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ for resnet in self.resnets:
+
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class UpDecoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ input_channels = in_channels if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=input_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb=None)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnUpDecoderBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ input_channels = in_channels if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock(
+ in_channels=input_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+ attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ num_groups=resnet_groups,
+ ))
+
+ self.attentions = nn.LayerList(attentions)
+ self.resnets = nn.LayerList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.LayerList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb=None)
+ hidden_states = attn(hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnSkipUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ attention_type="default",
+ output_scale_factor=np.sqrt(2.0),
+ upsample_padding=1,
+ add_upsample=True,
+ ):
+ super().__init__()
+ self.attentions = nn.LayerList([])
+ self.resnets = nn.LayerList([])
+
+ self.attention_type = attention_type
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(resnet_in_channels + res_skip_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.attentions.append(
+ AttentionBlockNew(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ ))
+
+ self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
+ if add_upsample:
+ self.resnet_up = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ up=True,
+ kernel="fir",
+ )
+ self.skip_conv = nn.Conv2D(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ self.skip_norm = nn.GroupNorm(num_groups=min(out_channels // 4, 32),
+ num_channels=out_channels,
+ eps=resnet_eps,
+ affine=True)
+ self.act = nn.SiLU()
+ else:
+ self.resnet_up = None
+ self.skip_conv = None
+ self.skip_norm = None
+ self.act = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, skip_sample=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ hidden_states = self.attentions[0](hidden_states)
+
+ if skip_sample is not None:
+ skip_sample = self.upsampler(skip_sample)
+ else:
+ skip_sample = 0
+
+ if self.resnet_up is not None:
+ skip_sample_states = self.skip_norm(hidden_states)
+ skip_sample_states = self.act(skip_sample_states)
+ skip_sample_states = self.skip_conv(skip_sample_states)
+
+ skip_sample = skip_sample + skip_sample_states
+
+ hidden_states = self.resnet_up(hidden_states, temb)
+
+ return hidden_states, skip_sample
+
+
+class SkipUpBlock2D(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ output_scale_factor=np.sqrt(2.0),
+ add_upsample=True,
+ upsample_padding=1,
+ ):
+ super().__init__()
+ self.resnets = nn.LayerList([])
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ self.resnets.append(
+ ResnetBlock(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min((resnet_in_channels + res_skip_channels) // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ ))
+
+ self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
+ if add_upsample:
+ self.resnet_up = ResnetBlock(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_nin_shortcut=True,
+ up=True,
+ kernel="fir",
+ )
+ self.skip_conv = nn.Conv2D(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ self.skip_norm = nn.GroupNorm(num_groups=min(out_channels // 4, 32),
+ num_channels=out_channels,
+ eps=resnet_eps,
+ affine=True)
+ self.act = nn.SiLU()
+ else:
+ self.resnet_up = None
+ self.skip_conv = None
+ self.skip_norm = None
+ self.act = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, skip_sample=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = paddle.concat([hidden_states, res_hidden_states], axis=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ if skip_sample is not None:
+ skip_sample = self.upsampler(skip_sample)
+ else:
+ skip_sample = 0
+
+ if self.resnet_up is not None:
+ skip_sample_states = self.skip_norm(hidden_states)
+ skip_sample_states = self.act(skip_sample_states)
+ skip_sample_states = self.skip_conv(skip_sample_states)
+
+ skip_sample = skip_sample + skip_sample_states
+
+ hidden_states = self.resnet_up(hidden_states, temb)
+
+ return hidden_states, skip_sample
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/vae.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/vae.py
new file mode 100644
index 000000000..59e35b0fb
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/models/vae.py
@@ -0,0 +1,465 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import paddle
+import paddle.nn as nn
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .unet_blocks import get_down_block
+from .unet_blocks import get_up_block
+from .unet_blocks import UNetMidBlock2D
+
+
+class Encoder(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", ),
+ block_out_channels=(64, ),
+ layers_per_block=2,
+ act_fn="silu",
+ double_z=True,
+ ):
+ super().__init__()
+ self.layers_per_block = layers_per_block
+
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[0], kernel_size=3, stride=1, padding=1)
+
+ self.mid_block = None
+ self.down_blocks = nn.LayerList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=self.layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ add_downsample=not is_final_block,
+ resnet_eps=1e-6,
+ downsample_padding=0,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=None,
+ temb_channels=None,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ output_scale_factor=1,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=None,
+ resnet_groups=32,
+ temb_channels=None,
+ )
+
+ # out
+ num_groups_out = 32
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[-1], num_groups=num_groups_out, epsilon=1e-6)
+ self.conv_act = nn.Silu()
+
+ conv_out_channels = 2 * out_channels if double_z else out_channels
+ self.conv_out = nn.Conv2D(block_out_channels[-1], conv_out_channels, 3, padding=1)
+
+ def forward(self, x):
+ sample = x
+ sample = self.conv_in(sample)
+
+ # down
+ for down_block in self.down_blocks:
+ sample = down_block(sample)
+
+ # middle
+ sample = self.mid_block(sample)
+
+ # post-process
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class Decoder(nn.Layer):
+
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ up_block_types=("UpDecoderBlock2D", ),
+ block_out_channels=(64, ),
+ layers_per_block=2,
+ act_fn="silu",
+ ):
+ super().__init__()
+ self.layers_per_block = layers_per_block
+
+ self.conv_in = nn.Conv2D(in_channels, block_out_channels[-1], kernel_size=3, stride=1, padding=1)
+
+ self.mid_block = None
+ self.up_blocks = nn.LayerList([])
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ output_scale_factor=1,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=None,
+ resnet_groups=32,
+ temb_channels=None,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=self.layers_per_block + 1,
+ in_channels=prev_output_channel,
+ out_channels=output_channel,
+ prev_output_channel=None,
+ add_upsample=not is_final_block,
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ attn_num_head_channels=None,
+ temb_channels=None,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ num_groups_out = 32
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=num_groups_out, epsilon=1e-6)
+ self.conv_act = nn.Silu()
+ self.conv_out = nn.Conv2D(block_out_channels[0], out_channels, 3, padding=1)
+
+ def forward(self, z):
+ sample = z
+ sample = self.conv_in(sample)
+
+ # middle
+ sample = self.mid_block(sample)
+
+ # up
+ for up_block in self.up_blocks:
+ sample = up_block(sample)
+
+ # post-process
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class VectorQuantizer(nn.Layer):
+ """
+ Improved version over VectorQuantizer, can be used as a drop-in replacement. Mostly avoids costly matrix
+ multiplications and allows for post-hoc remapping of indices.
+ """
+
+ # NOTE: due to a bug the beta term was applied to the wrong term. for
+ # backwards compatibility we use the buggy version by default, but you can
+ # specify legacy=False to fix it.
+ def __init__(self, n_e, e_dim, beta, remap=None, unknown_index="random", sane_index_shape=False, legacy=True):
+ super().__init__()
+ self.n_e = n_e
+ self.e_dim = e_dim
+ self.beta = beta
+ self.legacy = legacy
+
+ self.embedding = nn.Embedding(self.n_e, self.e_dim)
+ self.embedding.weight.data.uniform_(-1.0 / self.n_e, 1.0 / self.n_e)
+
+ self.remap = remap
+ if self.remap is not None:
+ self.register_buffer("used", paddle.to_tensor(np.load(self.remap)))
+ self.re_embed = self.used.shape[0]
+ self.unknown_index = unknown_index # "random" or "extra" or integer
+ if self.unknown_index == "extra":
+ self.unknown_index = self.re_embed
+ self.re_embed = self.re_embed + 1
+ print(f"Remapping {self.n_e} indices to {self.re_embed} indices. "
+ f"Using {self.unknown_index} for unknown indices.")
+ else:
+ self.re_embed = n_e
+
+ self.sane_index_shape = sane_index_shape
+
+ def remap_to_used(self, inds):
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape([ishape[0], -1])
+ used = self.used
+ match = (inds[:, :, None] == used[None, None, ...]).astype("int64")
+ new = match.argmax(-1)
+ unknown = match.sum(2) < 1
+ if self.unknown_index == "random":
+ new[unknown] = paddle.randint(0, self.re_embed, shape=new[unknown].shape)
+ else:
+ new[unknown] = self.unknown_index
+ return new.reshape(ishape)
+
+ def unmap_to_all(self, inds):
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape([ishape[0], -1])
+ used = self.used
+ if self.re_embed > self.used.shape[0]: # extra token
+ inds[inds >= self.used.shape[0]] = 0 # simply set to zero
+ back = paddle.gather(used[None, :][inds.shape[0] * [0], :], inds, axis=1)
+ return back.reshape(ishape)
+
+ def forward(self, z):
+ # reshape z -> (batch, height, width, channel) and flatten
+ z = z.transpose([0, 2, 3, 1])
+ z_flattened = z.reshape([-1, self.e_dim])
+ # distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
+
+ d = (paddle.sum(z_flattened**2, axis=1, keepdim=True) + paddle.sum(self.embedding.weight**2, axis=1) -
+ 2 * paddle.einsum("bd,dn->bn", z_flattened, self.embedding.weight.t()))
+
+ min_encoding_indices = paddle.argmin(d, axis=1)
+ z_q = self.embedding(min_encoding_indices).reshape(z.shape)
+ perplexity = None
+ min_encodings = None
+
+ # compute loss for embedding
+ if not self.legacy:
+ loss = self.beta * paddle.mean((z_q.detach() - z)**2) + paddle.mean((z_q - z.detach())**2)
+ else:
+ loss = paddle.mean((z_q.detach() - z)**2) + self.beta * paddle.mean((z_q - z.detach())**2)
+
+ # preserve gradients
+ z_q = z + (z_q - z).detach()
+
+ # reshape back to match original input shape
+ z_q = z_q.transpose([0, 3, 1, 2])
+
+ if self.remap is not None:
+ min_encoding_indices = min_encoding_indices.reshape([z.shape[0], -1]) # add batch axis
+ min_encoding_indices = self.remap_to_used(min_encoding_indices)
+ min_encoding_indices = min_encoding_indices.reshape([-1, 1]) # flatten
+
+ if self.sane_index_shape:
+ min_encoding_indices = min_encoding_indices.reshape([z_q.shape[0], z_q.shape[2], z_q.shape[3]])
+
+ return z_q, loss, (perplexity, min_encodings, min_encoding_indices)
+
+ def get_codebook_entry(self, indices, shape):
+ # shape specifying (batch, height, width, channel)
+ if self.remap is not None:
+ indices = indices.reshape([shape[0], -1]) # add batch axis
+ indices = self.unmap_to_all(indices)
+ indices = indices.flatten() # flatten again
+
+ # get quantized latent vectors
+ z_q = self.embedding(indices)
+
+ if shape is not None:
+ z_q = z_q.reshape(shape)
+ # reshape back to match original input shape
+ z_q = z_q.transpose([0, 3, 1, 2])
+
+ return z_q
+
+
+class DiagonalGaussianDistribution(object):
+
+ def __init__(self, parameters, deterministic=False):
+ self.parameters = parameters
+ self.mean, self.logvar = paddle.chunk(parameters, 2, axis=1)
+ self.logvar = paddle.clip(self.logvar, -30.0, 20.0)
+ self.deterministic = deterministic
+ self.std = paddle.exp(0.5 * self.logvar)
+ self.var = paddle.exp(self.logvar)
+ if self.deterministic:
+ self.var = self.std = paddle.zeros_like(self.mean)
+
+ def sample(self):
+ x = self.mean + self.std * paddle.randn(self.mean.shape)
+ return x
+
+ def kl(self, other=None):
+ if self.deterministic:
+ return paddle.to_tensor([0.0])
+ else:
+ if other is None:
+ return 0.5 * paddle.sum(paddle.pow(self.mean, 2) + self.var - 1.0 - self.logvar, axis=[1, 2, 3])
+ else:
+ return 0.5 * paddle.sum(
+ paddle.pow(self.mean - other.mean, 2) / other.var + self.var / other.var - 1.0 - self.logvar +
+ other.logvar,
+ axis=[1, 2, 3],
+ )
+
+ def nll(self, sample, dims=[1, 2, 3]):
+ if self.deterministic:
+ return paddle.to_tensor([0.0])
+ logtwopi = np.log(2.0 * np.pi)
+ return 0.5 * paddle.sum(logtwopi + self.logvar + paddle.pow(sample - self.mean, 2) / self.var, axis=dims)
+
+ def mode(self):
+ return self.mean
+
+
+class VQModel(ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", ),
+ up_block_types=("UpDecoderBlock2D", ),
+ block_out_channels=(64, ),
+ layers_per_block=1,
+ act_fn="silu",
+ latent_channels=3,
+ sample_size=32,
+ num_vq_embeddings=256,
+ ):
+ super().__init__()
+
+ # pass init params to Encoder
+ self.encoder = Encoder(
+ in_channels=in_channels,
+ out_channels=latent_channels,
+ down_block_types=down_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ double_z=False,
+ )
+
+ self.quant_conv = nn.Conv2D(latent_channels, latent_channels, 1)
+ self.quantize = VectorQuantizer(num_vq_embeddings,
+ latent_channels,
+ beta=0.25,
+ remap=None,
+ sane_index_shape=False)
+ self.post_quant_conv = nn.Conv2D(latent_channels, latent_channels, 1)
+
+ # pass init params to Decoder
+ self.decoder = Decoder(
+ in_channels=latent_channels,
+ out_channels=out_channels,
+ up_block_types=up_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ )
+
+ def encode(self, x):
+ h = self.encoder(x)
+ h = self.quant_conv(h)
+ return h
+
+ def decode(self, h, force_not_quantize=False):
+ # also go through quantization layer
+ if not force_not_quantize:
+ quant, emb_loss, info = self.quantize(h)
+ else:
+ quant = h
+ quant = self.post_quant_conv(quant)
+ dec = self.decoder(quant)
+ return dec
+
+ def forward(self, sample):
+ x = sample
+ h = self.encode(x)
+ dec = self.decode(h)
+ return dec
+
+
+class AutoencoderKL(nn.Layer, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", "DownEncoderBlock2D", "DownEncoderBlock2D", "DownEncoderBlock2D"),
+ up_block_types=("UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D"),
+ block_out_channels=(128, 256, 512, 512),
+ layers_per_block=2,
+ act_fn="silu",
+ latent_channels=4,
+ sample_size=512,
+ ):
+ super().__init__()
+
+ # pass init params to Encoder
+ self.encoder = Encoder(
+ in_channels=in_channels,
+ out_channels=latent_channels,
+ down_block_types=down_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ double_z=True,
+ )
+
+ # pass init params to Decoder
+ self.decoder = Decoder(
+ in_channels=latent_channels,
+ out_channels=out_channels,
+ up_block_types=up_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ )
+
+ self.quant_conv = nn.Conv2D(2 * latent_channels, 2 * latent_channels, 1)
+ self.post_quant_conv = nn.Conv2D(latent_channels, latent_channels, 1)
+
+ def encode(self, x):
+ h = self.encoder(x)
+ moments = self.quant_conv(h)
+ posterior = DiagonalGaussianDistribution(moments)
+ return posterior
+
+ def decode(self, z):
+ z = self.post_quant_conv(z)
+ dec = self.decoder(z)
+ return dec
+
+ def forward(self, sample, sample_posterior=False):
+ x = sample
+ posterior = self.encode(x)
+ if sample_posterior:
+ z = posterior.sample()
+ else:
+ z = posterior.mode()
+ dec = self.decode(z)
+ return dec
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/schedulers/README.md b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/schedulers/README.md
new file mode 100644
index 000000000..40f50f232
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/schedulers/README.md
@@ -0,0 +1,18 @@
+# Schedulers
+
+- Schedulers are the algorithms to use diffusion models in inference as well as for training. They include the noise schedules and define algorithm-specific diffusion steps.
+- Schedulers can be used interchangable between diffusion models in inference to find the preferred trade-off between speed and generation quality.
+- Schedulers are available in numpy, but can easily be transformed into Py
+
+## API
+
+- Schedulers should provide one or more `def step(...)` functions that should be called iteratively to unroll the diffusion loop during
+the forward pass.
+- Schedulers should be framework-agnostic, but provide a simple functionality to convert the scheduler into a specific framework, such as PyTorch
+with a `set_format(...)` method.
+
+## Examples
+
+- The DDPM scheduler was proposed in [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) and can be found in [scheduling_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py). An example of how to use this scheduler can be found in [pipeline_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddpm.py).
+- The DDIM scheduler was proposed in [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) and can be found in [scheduling_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py). An example of how to use this scheduler can be found in [pipeline_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddim.py).
+- The PNDM scheduler was proposed in [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778) and can be found in [scheduling_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py). An example of how to use this scheduler can be found in [pipeline_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py).
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/schedulers/__init__.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/schedulers/__init__.py
new file mode 100644
index 000000000..cebc3e618
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/schedulers/__init__.py
@@ -0,0 +1,24 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from .scheduling_ddim import DDIMScheduler
+from .scheduling_ddpm import DDPMScheduler
+from .scheduling_karras_ve import KarrasVeScheduler
+from .scheduling_lms_discrete import LMSDiscreteScheduler
+from .scheduling_pndm import PNDMScheduler
+from .scheduling_sde_ve import ScoreSdeVeScheduler
+from .scheduling_sde_vp import ScoreSdeVpScheduler
+from .scheduling_utils import SchedulerMixin
diff --git a/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/schedulers/scheduling_ddim.py b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/schedulers/scheduling_ddim.py
new file mode 100644
index 000000000..ebe362d99
--- /dev/null
+++ b/modules/image/text_to_image/stable_diffusion_inpainting/diffusers/schedulers/scheduling_ddim.py
@@ -0,0 +1,182 @@
+# Copyright 2022 Stanford University Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pypaddle_diffusion
+# and https://github.com/hojonathanho/diffusion
+import math
+from typing import Union
+
+import numpy as np
+import paddle
+
+from ..configuration_utils import ConfigMixin
+from ..configuration_utils import register_to_config
+from .scheduling_utils import SchedulerMixin
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ :param num_diffusion_timesteps: the number of betas to produce. :param alpha_bar: a lambda that takes an argument t
+ from 0 to 1 and
+ produces the cumulative product of (1-beta) up to that part of the diffusion process.
+ :param max_beta: the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2)**2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return np.array(betas, dtype=np.float32)
+
+
+class DDIMScheduler(SchedulerMixin, ConfigMixin):
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps=1000,
+ beta_start=0.0001,
+ beta_end=0.02,
+ beta_schedule="linear",
+ trained_betas=None,
+ timestep_values=None,
+ clip_sample=True,
+ set_alpha_to_one=True,
+ tensor_format="pd",
+ ):
+
+ if beta_schedule == "linear":
+ self.betas = np.linspace(beta_start, beta_end, num_train_timesteps, dtype=np.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = np.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=np.float32)**2
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = np.cumprod(self.alphas, axis=0)
+
+ # At every step in ddim, we are looking into the previous alphas_cumprod
+ # For the final step, there is no previous alphas_cumprod because we are already at 0
+ # `set_alpha_to_one` decides whether we set this paratemer simply to one or
+ # whether we use the final alpha of the "non-previous" one.
+ self.final_alpha_cumprod = np.array(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
+
+ # setable values
+ self.num_inference_steps = None
+ self.timesteps = np.arange(0, num_train_timesteps)[::-1].copy()
+
+ self.tensor_format = tensor_format
+ self.set_format(tensor_format=tensor_format)
+
+ def _get_variance(self, timestep, prev_timestep):
+ alpha_prod_t = self.alphas_cumprod[timestep]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
+
+ return variance
+
+ def set_timesteps(self, num_inference_steps, offset=0):
+ self.num_inference_steps = num_inference_steps
+ self.timesteps = np.arange(0, self.config.num_train_timesteps,
+ self.config.num_train_timesteps // self.num_inference_steps)[::-1].copy()
+ self.timesteps += offset
+ self.set_format(tensor_format=self.tensor_format)
+
+ def step(
+ self,
+ model_output: Union[paddle.Tensor, np.ndarray],
+ timestep: int,
+ sample: Union[paddle.Tensor, np.ndarray],
+ eta: float = 0.0,
+ use_clipped_model_output: bool = False,
+ generator=None,
+ ):
+ # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # Ideally, read DDIM paper in-detail understanding
+
+ # Notation (5y-UT
zJtNBMi6D+Fcbe|_CLGPkA5B?YRaIvt3uHwAGr6XUo