| 模型名称 | lda_news |
|---|---|
| 类别 | 文本-主题模型 |
| 网络 | LDA |
| 数据集 | 百度自建新闻领域数据集 |
| 是否支持Fine-tuning | 否 |
| 模型大小 | 19MB |
| 最新更新日期 | 2021-02-26 |
| 数据指标 | - |
-
-
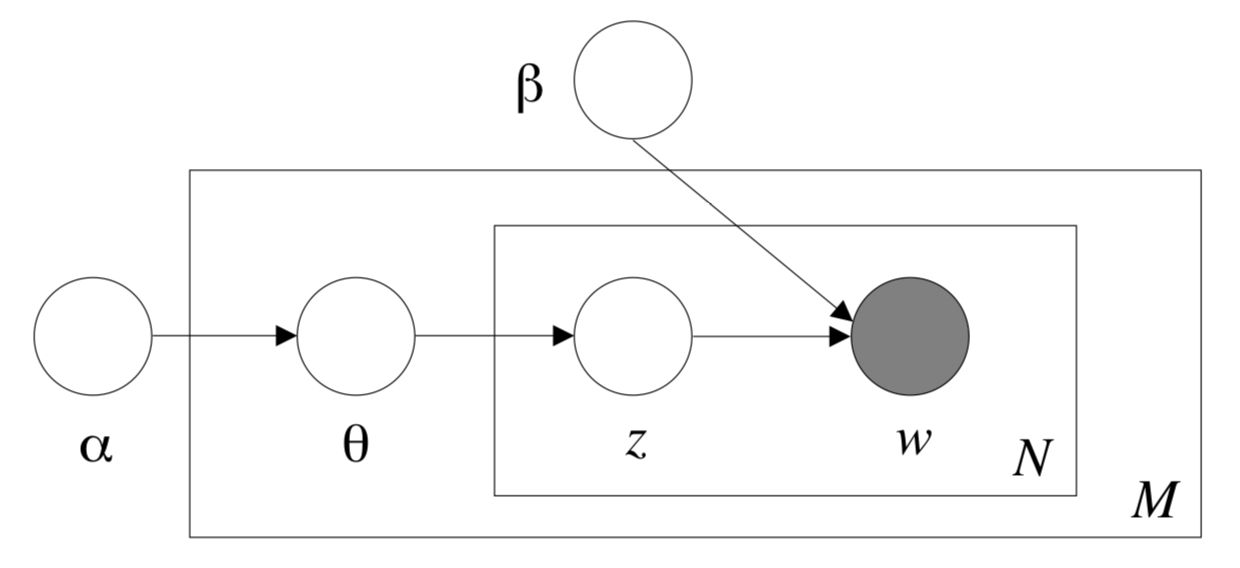
主题模型(Topic Model)是以无监督学习的方式对文档的隐含语义结构进行聚类的统计模型,其中LDA(Latent Dirichlet Allocation)算法是主题模型的一种。LDA根据对词的共现信息的分析,拟合出词-文档-主题的分布,从而将词、文本映射到一个语义空间中。
更多详情请参考LDA论文。
-
-
-
paddlepaddle >= 1.8.2
-
paddlehub >= 1.8.0 | 如何安装PaddleHub
-
-
-
$ hub install lda_news
- 如您安装时遇到问题,可参考:零基础windows安装 | 零基础Linux安装 | 零基础MacOS安装
-
import paddlehub as hub
lda_news = hub.Module(name="lda_news")
jsd, hd = lda_news.cal_doc_distance(doc_text1="今天的天气如何,适合出去游玩吗", doc_text2="感觉今天的天气不错,可以出去玩一玩了")
# jsd = 0.003109, hd = 0.0573171
lda_sim = lda_news.cal_query_doc_similarity(query='百度搜索引擎', document='百度是全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。')
# LDA similarity = 0.06826
results = lda_news.cal_doc_keywords_similarity('百度是全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。')
# [{'word': '百度', 'similarity': 0.12943492762349573},
# {'word': '信息', 'similarity': 0.06139783578769882},
# {'word': '找到', 'similarity': 0.055296603463188265},
# {'word': '搜索', 'similarity': 0.04270794098349327},
# {'word': '全球', 'similarity': 0.03773627056367886},
# {'word': '超过', 'similarity': 0.03478658388202199},
# {'word': '相关', 'similarity': 0.026295857219683725},
# {'word': '获取', 'similarity': 0.021313585287833996},
# {'word': '中文', 'similarity': 0.020187103312009513},
# {'word': '搜索引擎', 'similarity': 0.007092890537169911}]
results = lda_news.infer_doc_topic_distribution("最近有学者新出了一篇论文,关于自然语言处理的,可厉害了")
# [{'topic id': 216, 'distribution': 0.5222222222222223},
# {'topic id': 1789, 'distribution': 0.18888888888888888},
# {'topic id': 98, 'distribution': 0.1111111111111111},
# {'topic id': 805, 'distribution': 0.044444444444444446},
# {'topic id': 56, 'distribution': 0.03333333333333333}, ...]
keywords = lda_news.show_topic_keywords(topic_id=216)
# {'研究': 0.1753955534055716,
# '学术': 0.13158917246453747,
# '论文': 0.1178632702247961,
# '课题': 0.057840811145163484,
# '发表': 0.05614630212471184,
# '成果': 0.03587086607950555,
# '期刊': 0.030608728068521086,
# '科研': 0.0216061375112729,
# '学者': 0.017739360125774,
# '科学': 0.015553720885167896}-
-
cal_doc_distance(doc_text1, doc_text2)
-
用于计算两个输入文档之间的距离,包括Jensen-Shannon divergence(JS散度)、Hellinger Distance(海林格距离)。
-
参数
- doc_text1(str): 输入的第一个文档。
- doc_text2(str): 输入的第二个文档。
-
返回
- jsd(float): 两个文档之间的JS散度(Jensen-Shannon divergence)。
- hd(float): 两个文档之间的海林格距离(Hellinger Distance)。
-
-
cal_doc_keywords_similarity(document, top_k=10)
-
用于查找输入文档的前k个关键词及对应的与原文档的相似度。
-
参数
- document(str): 输入文档。
- top_k(int): 查找输入文档的前k个关键词。
-
返回
- results(list): 包含每个关键词以及对应的与原文档的相似度。其中,list的基本元素为dict,dict的key为关键词,value为对应的与原文档的相似度。
-
-
cal_query_doc_similarity(query, document)
-
用于计算短文档与长文档之间的相似度。
-
参数
-
query(str): 输入的短文档。
-
document(str): 输入的长文档。
-
返回
-
lda_sim(float): 返回短文档与长文档之间的相似度。
-
-
infer_doc_topic_distribution(document)
-
用于推理出文档的主题分布。
-
参数
- document(str): 输入文档。
-
返回
- results(list): 包含主题分布下各个主题ID和对应的概率分布。其中,list的基本元素为dict,dict的key为主题ID,value为各个主题ID对应的概率。
-
-
-
show_topic_keywords(topic_id, k=10)
-
用于展示出每个主题下对应的关键词,可配合推理主题分布的API使用。
-
参数
- topic_id(int): 主题ID。
- k(int): 需要知道对应主题的前k个关键词。
-
返回
- results(dict): 返回对应文档的前k个关键词,以及各个关键词在文档中的出现概率。
-
-
-
-
1.0.0
初始发布
-
1.0.1
修复因为return的bug导致的NoneType错误
-
1.0.2
修复由于Windows
gbk编码导致的问题