| Module Name | deeplabv3p_xception65_humanseg |
|---|---|
| Category | Image segmentation |
| Network | deeplabv3p |
| Dataset | Baidu self-built dataset |
| Fine-tuning supported or not | No |
| Module Size | 162MB |
| Data indicators | - |
| Latest update date | 2021-02-26 |
-
- Sample results:


- Sample results:
-
- DeepLabv3+ model is trained by Baidu self-built dataset, which can be used for portrait segmentation.
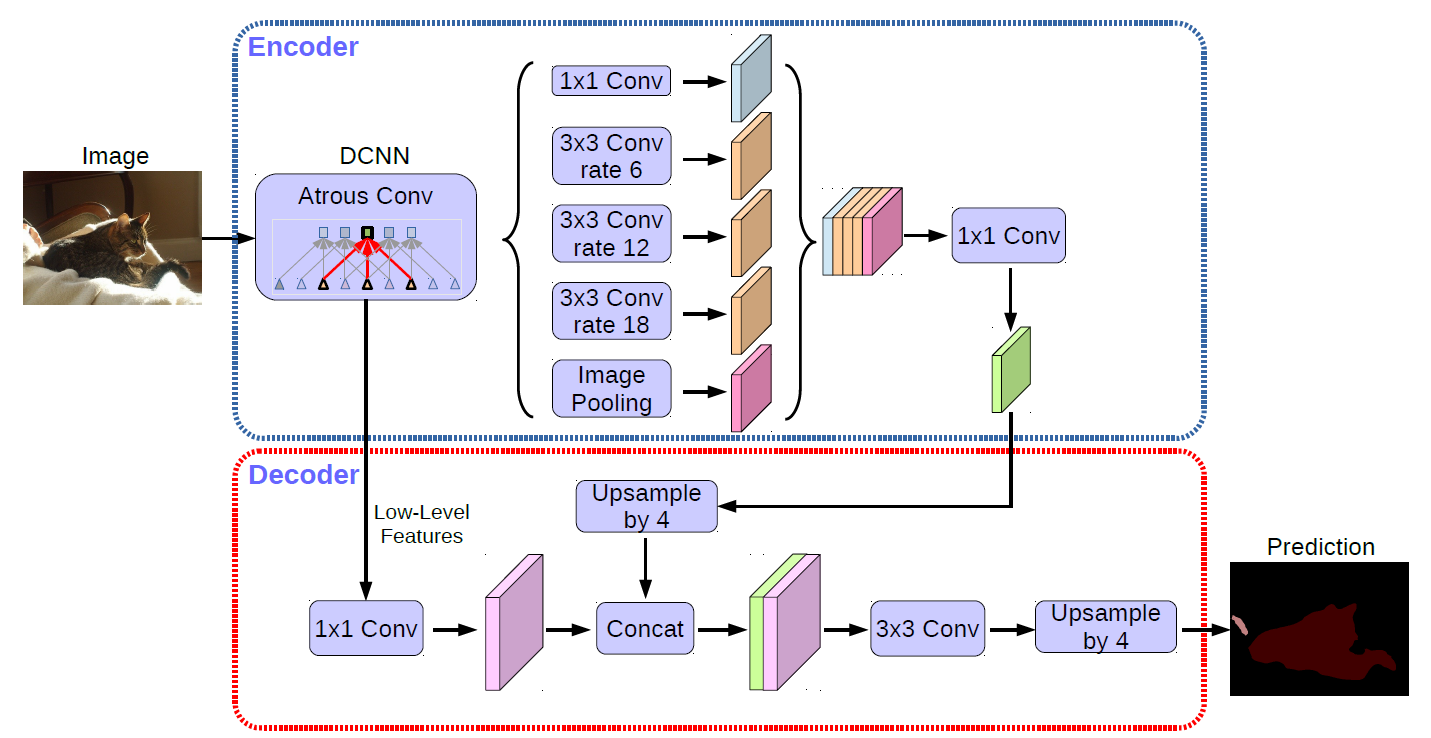
- For more information, please refer to: deeplabv3p
-
-
paddlepaddle >= 2.0.0
-
paddlehub >= 2.0.0
-
-
-
$ hub install deeplabv3p_xception65_humanseg
- In case of any problems during installation, please refer to:Windows_Quickstart | Linux_Quickstart | Mac_Quickstart
-
-
-
hub run deeplabv3p_xception65_humanseg --input_path "/PATH/TO/IMAGE" - If you want to call the Hub module through the command line, please refer to: PaddleHub Command Line Instruction
-
-
-
import paddlehub as hub import cv2 human_seg = hub.Module(name="deeplabv3p_xception65_humanseg") result = human_seg.segmentation(images=[cv2.imread('/PATH/TO/IMAGE')])
-
-
-
def segmentation(images=None, paths=None, batch_size=1, use_gpu=False, visualization=False, output_dir='humanseg_output')
-
Prediction API, generating segmentation result.
-
Parameter
- images (list[numpy.ndarray]): Image data, ndarray.shape is in the format [H, W, C], BGR.
- paths (list[str]): Image path.
- batch_size (int): Batch size.
- use_gpu (bool): Use GPU or not. set the CUDA_VISIBLE_DEVICES environment variable first if you are using GPU
- visualization (bool): Whether to save the recognition results as picture files.
- output_dir (str): Save path of images.
-
Return
- res (list[dict]): The list of recognition results, where each element is dict and each field is:
- save_path (str, optional): Save path of the result.
- data (numpy.ndarray): The result of portrait segmentation.
- res (list[dict]): The list of recognition results, where each element is dict and each field is:
-
-
def save_inference_model(dirname)
-
Save the model to the specified path.
-
Parameters
- dirname: Model save path.
-
-
-
PaddleHub Serving can deploy an online service of for human segmentation.
-
-
Run the startup command:
-
$ hub serving start -m deeplabv3p_xception65_humanseg
-
-
NOTE: If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
-
-
-
With a configured server, use the following lines of code to send the prediction request and obtain the result
-
import requests import json import cv2 import base64 import numpy as np def cv2_to_base64(image): data = cv2.imencode('.jpg', image)[1] return base64.b64encode(data.tostring()).decode('utf8') def base64_to_cv2(b64str): data = base64.b64decode(b64str.encode('utf8')) data = np.fromstring(data, np.uint8) data = cv2.imdecode(data, cv2.IMREAD_COLOR) return data org_im = cv2.imread("/PATH/TO/IMAGE") # Send an HTTP request data = {'images':[cv2_to_base64(org_im)]} headers = {"Content-type": "application/json"} url = "http://127.0.0.1:8866/predict/deeplabv3p_xception65_humanseg" r = requests.post(url=url, headers=headers, data=json.dumps(data)) mask =cv2.cvtColor(base64_to_cv2(r.json()["results"][0]['data']), cv2.COLOR_BGR2GRAY) rgba = np.concatenate((org_im, np.expand_dims(mask, axis=2)), axis=2) cv2.imwrite("segment_human_server.png", rgba)
-
-
1.0.0
First release
-
1.1.0
Improve prediction performance
-
1.1.1
Fix the bug of image value out of range
-
1.2.0
Remove fluid api
-
$ hub install deeplabv3p_xception65_humanseg==1.2.0
-