二叉树在算法里面有着比较重要的地位,很多算法题的思路都启发于二叉树算法,同时对应很多递归的思路也在二叉树中有着深刻的体现。
void traverse(TreeNode root) {
if (root == null) {
return;
}
// 前序位置
traverse(root.left);
// 中序位置
traverse(root.right);
// 后序位置
}所谓前序位置,就是刚进入一个节点(元素)的时候,后序位置就是即将离开一个节点(元素)的时候,那么进一步,你把代码写在不同位置,代码执行的时机也不同
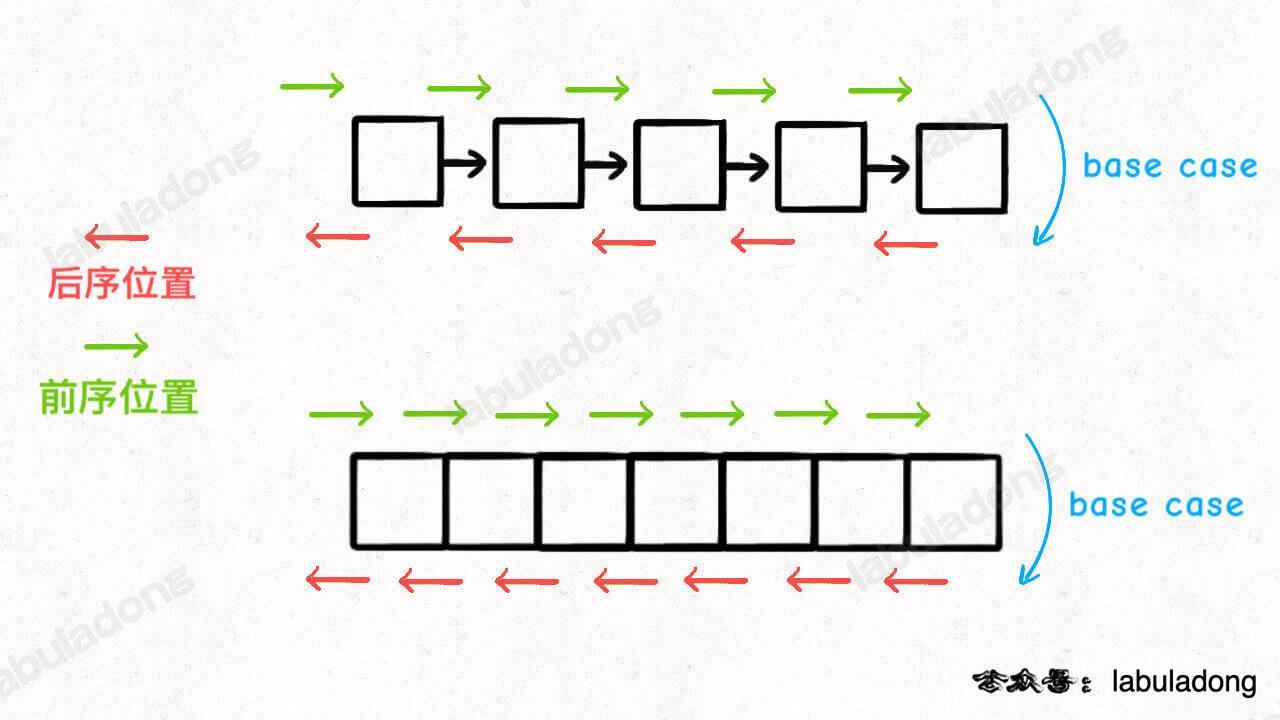
前中后序是遍历二叉树过程中处理每一个节点的三个特殊时间点,绝不仅仅是三个顺序不同的 List:
- 前序位置的代码在刚刚进入一个二叉树节点的时候执行;
- 后序位置的代码在将要离开一个二叉树节点的时候执行;
- 中序位置的代码在一个二叉树节点左子树都遍历完,即将开始遍历右子树的时候执行。
你注意本文的用词,我一直说前中后序「位置」,就是要和大家常说的前中后序「遍历」有所区别:你可以在前序位置写代码往一个 List 里面塞元素,那最后得到的就是前序遍历结果;但并不是说你就不可以写更复杂的代码做更复杂的事。
二叉树题目的递归解法可以分两类思路,
- 第一类是遍历一遍二叉树得出答案,
- 第二类是通过分解问题计算出答案,这两类思路分别对应着 回溯算法核心框架 和 动态规划核心框架。
-
1、是否可以通过遍历一遍二叉树得到答案?如果可以,用一个 traverse 函数配合外部变量来实现。
-
2、是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值。
-
3、无论使用哪一种思维模式,你都要明白二叉树的每一个节点需要做什么,需要在什么时候(前中后序)做。
前序位置的代码只能从函数参数中获取父节点传递来的数据,而后序位置的代码不仅可以获取参数数据,还可以获取到子树通过函数返回值传递回来的数据。
换句话说,一旦你发现题目和子树有关,那大概率要给函数设置合理的定义和返回值,在后序位置写代码了。